

INTRODUCTION
In the USA, methicillin-resistant Staphylococcus aureus (MRSA) is the most common cause of skin and soft tissue infections in patients presenting to emergency departments and is endemic in many hospitals [Reference Klevens1]. Interventions to reduce transmission include emphasizing hand hygiene, active surveillance culturing, and educating healthcare workers in the ‘culture’ of infection control. We explored options for evaluating chronologically overlapping interventions in an existing dataset [Reference Ellingson2]. The outcome of interest was the impact of specific interventions on the incidence of MRSA in each unit, where interventions might take weeks or months to become effective and might be implemented in different units at different times. This approach is also known as a step wedge design [Reference Brown and Lilford3].
METHODOLOGICAL FRAMEWORK
Segmented models may explain sudden and gradual shifts in data due to external mechanisms not accounted for by simple multiple regression models [Reference Smith4–Reference Shardell10]. Segmented modelling, a reasonable approach for evaluating interventions when data are collected over time [Reference Gillings, Makuc and Sigel11], has been used extensively for public health interventions [Reference Madden12–Reference Mol15] and for effects on MRSA rates in particular [Reference Haung16, Reference Bosso and Mauldin17]. Biglan et al. [Reference Biglan, Ary and Wagenaar18] overviewed models of the effect of community interventions using a conventional time series (autoregressive integrated moving average), and this was applied to nosocomial infections by Fernández-Pérez et al. [Reference Fernández-Pérez, Tejada and Carrasco19]. Clinical incidence of MRSA is a proxy for MRSA transmission [Reference Feng20]. We extended this idea to a model of infection rates of MRSA transmission incorporating multiple hospital units.
Approaches to answering these questions can be complicated by methodological concerns including: (1) the same intervention may be implemented at different times in units within the same facility (i.e. hospitals), (2) there may be a correlation of incidence rates across time periods; and (3) the intervention may take weeks or months to produce a measurable effect.
RESULTS
Data sources
Data were collected over 109 months at a Veterans Affairs (VA) hospital in Pittsburgh. The intervention included culturing for MRSA colonization at admission before initiation of contact precautions and hand-hygiene awareness, which were incrementally phased in. The intervention began in October 2001 (month 25) in unit A; in October 2003 (month 49) in unit B; then in July 2005 (month 70) in the remainder of the acute care units (area C). The first date for which MRSA incidence data were available for all three areas was 1 October 1999. One study objective was to quantify estimates of the changes in rates over time to allow researchers and administrators to gauge the effect of introduction of interventions introduced to individual units or hospitals.
The outcome of interest was the monthly clinical incidence of MRSA cases in each area of the hospital, a proxy for MRSA transmission or new acquisition of infection or colonization (at a clinical site). An incident case was defined as: a positive, clinical (non-surveillance) MRSA culture obtained at least 48 h after admission to an acute-care unit and, if the patient was transferred, within 48 h of transfer to another unit. Cases were excluded as ‘non-incident’ if a positive clinical culture in the previous year (including long-term care and outpatient setting) could be identified anywhere in the laboratory information system. Nasal and rectal swabs were considered surveillance cultures and thus ineligible. Clinical incidence was expressed as the number of incident cases per 1000 patient-days. The corresponding incidence rate for month i (i = 1, 2, …, 109), denoted as λi, was estimated by dividing the number of patients with incident MRSA by the patient-days for each month (Fig. 1).

Fig. 1. Observed incident MRSA cases per 1000 patient-days. (a) Unit A, (b) unit B, and (c) area C.
Pooled analysis: fixed effects
Within each unit, the number of MRSA events in any one month can be thought of as a Poisson count, with the number of patient-days being the exposure time. An interrupted time series (or segmented regression) using a generalized linear model for a Poisson distribution, by using a segmented approach [Reference Wagner8] can be fitted.
The form for a Poisson distribution is, for the ith unit (i = 1, 2, 3)
 $$Pr \lpar y{\rm \ cases}\rpar \equals {{{\rm e}^{ \minus \lambda _{i}} \lambda _{i}^{y} } \over {y\exclam }} \ \lpar y \equals 0\comma 1\comma 2\comma \ldots \rpar $$
$$Pr \lpar y{\rm \ cases}\rpar \equals {{{\rm e}^{ \minus \lambda _{i}} \lambda _{i}^{y} } \over {y\exclam }} \ \lpar y \equals 0\comma 1\comma 2\comma \ldots \rpar $$within each unit where a case equates to a positive microbiology culture. If the intervention occurs at time t 0, we can link the number of infections (y) to time using the following model
Model 1: ln(λ) = β0 + β1T + β2I + β3T*,
where λ = monthly incidence rate,
 $$\eqalign{\tab \hskip-1.5pt T \equals {\rm time\ in\ months\comma \ }\cr\tab \hskip-1.5pt I \equals {\rm intervention\ status} \equals \left\{ {\matrix{ 0 \tab {{\rm if} \ T \les t_{\setnum{0}} } \cr 1 \tab {{\rm if} \ T \gt t_{\setnum{0}} } \cr} } \right.}$$
$$\eqalign{\tab \hskip-1.5pt T \equals {\rm time\ in\ months\comma \ }\cr\tab \hskip-1.5pt I \equals {\rm intervention\ status} \equals \left\{ {\matrix{ 0 \tab {{\rm if} \ T \les t_{\setnum{0}} } \cr 1 \tab {{\rm if} \ T \gt t_{\setnum{0}} } \cr} } \right.}$$ $$T\ast \equals {\rm post{\hbox{-}}intervention \ time} \equals \left\{ {\matrix{ \hskip-15pt0 \tab {{\rm if} \ T \les t_{\setnum{0}} } \cr {T \minus t_{\setnum{0}} } \tab {{\rm if} \ T \gt t_{\setnum{0}} } \cr} } \right..$$
$$T\ast \equals {\rm post{\hbox{-}}intervention \ time} \equals \left\{ {\matrix{ \hskip-15pt0 \tab {{\rm if} \ T \les t_{\setnum{0}} } \cr {T \minus t_{\setnum{0}} } \tab {{\rm if} \ T \gt t_{\setnum{0}} } \cr} } \right..$$In this model, β0 represents the baseline MRSA rate; β1, the slope before the intervention at t 0; β2, the change in the rate just after t 0; β1 + β3, the slope after t 0, and β3, the change in slope after t 0. The model can be fitted using standard software, the standard error of the post-intervention slope, β1,j + β3,j for the jth hospital unit is
 $${\sc S}.{\sc E}. \lpar \hat{\beta }_{\setnum{1}\comma j} \comma \hat{\beta }_{\setnum{3}\comma j} \rpar \equals \sqrt {{\rm var} \lpar \hat{\beta }_{\setnum{1}\comma j} \rpar \plus {\rm var} \lpar \hat{\beta }_{\setnum{3}\comma j} \rpar \plus 2{\rm cov} \lpar \hat{\beta }_{\setnum{1}\comma j} \comma \hat{\beta }_{\setnum{3}\comma j} \rpar }.$$
$${\sc S}.{\sc E}. \lpar \hat{\beta }_{\setnum{1}\comma j} \comma \hat{\beta }_{\setnum{3}\comma j} \rpar \equals \sqrt {{\rm var} \lpar \hat{\beta }_{\setnum{1}\comma j} \rpar \plus {\rm var} \lpar \hat{\beta }_{\setnum{3}\comma j} \rpar \plus 2{\rm cov} \lpar \hat{\beta }_{\setnum{1}\comma j} \comma \hat{\beta }_{\setnum{3}\comma j} \rpar }.$$The quantity 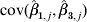 ${\rm cov} \lpar \hat{\beta }_{\setnum{1}\comma j} \comma \hat{\beta }_{\setnum{3}\comma j} \rpar $ is can be obtained from the output of statistical packages (Fig. 2). Fitting segmented Poisson regression separately for each unit in the hospital, gives, for the jth unit, parameter estimates of the coefficients:
${\rm cov} \lpar \hat{\beta }_{\setnum{1}\comma j} \comma \hat{\beta }_{\setnum{3}\comma j} \rpar $ is can be obtained from the output of statistical packages (Fig. 2). Fitting segmented Poisson regression separately for each unit in the hospital, gives, for the jth unit, parameter estimates of the coefficients: 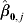 $\hat{\beta }_{\setnum{0}\comma j} $,
$\hat{\beta }_{\setnum{0}\comma j} $, 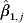 $\hat{\beta }_{\setnum{1}\comma j} $,
$\hat{\beta }_{\setnum{1}\comma j} $, 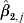 $\hat{\beta }_{\setnum{2}\comma j} $ and
$\hat{\beta }_{\setnum{2}\comma j} $ and 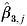 $\hat{\beta }_{\setnum{3}\comma j} $ and their associated standard errors: s.e.(
$\hat{\beta }_{\setnum{3}\comma j} $ and their associated standard errors: s.e.(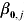 $\hat{\beta }_{\setnum{0}\comma j} $), s.e.(
$\hat{\beta }_{\setnum{0}\comma j} $), s.e.(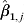 $\hat{\beta }_{\setnum{1}\comma j} $), s.e.(
$\hat{\beta }_{\setnum{1}\comma j} $), s.e.(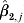 $\hat{\beta }_{\setnum{2}\comma j} $) and s.e.(
$\hat{\beta }_{\setnum{2}\comma j} $) and s.e.(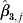 $\hat{\beta }_{\setnum{3}\comma j} $). Assuming the rate in each unit is independent of the rate in the other units, an overall estimate of β0, β1, β2 and β3 can be obtained by pooling the individual estimates [Reference DerSimonian and Laird21]. This is achieved by a weighted average of the individual unit estimates, where the weights are the inverse of the variances of the estimates from the fitted model. The variances are obtained by squaring the respective standard errors. If there are k units over which we need to pool, the estimates are obtained as:
$\hat{\beta }_{\setnum{3}\comma j} $). Assuming the rate in each unit is independent of the rate in the other units, an overall estimate of β0, β1, β2 and β3 can be obtained by pooling the individual estimates [Reference DerSimonian and Laird21]. This is achieved by a weighted average of the individual unit estimates, where the weights are the inverse of the variances of the estimates from the fitted model. The variances are obtained by squaring the respective standard errors. If there are k units over which we need to pool, the estimates are obtained as:
 $$\hat{\beta }_{\setnum{0}} \equals {{\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{0}\comma j} } \hat{\beta }_{\setnum{0}\comma j} } \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{0}\comma j} } }}\comma$$
$$\hat{\beta }_{\setnum{0}} \equals {{\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{0}\comma j} } \hat{\beta }_{\setnum{0}\comma j} } \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{0}\comma j} } }}\comma$$where 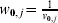 $w_{\setnum{0}\comma j} \equals {1 \over {v_{\setnum{0}\comma j} }}$ and
$w_{\setnum{0}\comma j} \equals {1 \over {v_{\setnum{0}\comma j} }}$ and 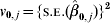 $v_{\setnum{0}\comma j} \equals \lcub {\sc S}.{\sc E}. \lpar \hat{\beta }_{\setnum{0}\comma j} \rpar \rcub ^{\setnum{2}} $ (j = 1, 2, …, k). Similarly,
$v_{\setnum{0}\comma j} \equals \lcub {\sc S}.{\sc E}. \lpar \hat{\beta }_{\setnum{0}\comma j} \rpar \rcub ^{\setnum{2}} $ (j = 1, 2, …, k). Similarly,
 $$\eqalign{\tab \hat{\beta }_{\setnum{1}} \equals {{\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{1}\comma j} } \hat{\beta }_{\setnum{1}\comma j} } \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{1}\comma j} } }}\semi \cr \tab \hat{\beta }_{\setnum{2}} \equals {{\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{2}\comma j} } \hat{\beta }_{\setnum{2}\comma j} } \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{2}\comma j} } }} \ {\rm and} \ \hat{\beta }_{\setnum{3}} \equals {{\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{3}\comma j} } \hat{\beta }_{\setnum{3}\comma j} } \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{3}\comma j} } }}.}$$
$$\eqalign{\tab \hat{\beta }_{\setnum{1}} \equals {{\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{1}\comma j} } \hat{\beta }_{\setnum{1}\comma j} } \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{1}\comma j} } }}\semi \cr \tab \hat{\beta }_{\setnum{2}} \equals {{\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{2}\comma j} } \hat{\beta }_{\setnum{2}\comma j} } \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{2}\comma j} } }} \ {\rm and} \ \hat{\beta }_{\setnum{3}} \equals {{\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{3}\comma j} } \hat{\beta }_{\setnum{3}\comma j} } \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{\setnum{3}\comma j} } }}.}$$Confidence intervals for the pooled estimates, 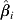 $\hat{\beta }_{i} $ (i = 0, 1, 2, 3) are constructed by noting that the variance of
$\hat{\beta }_{i} $ (i = 0, 1, 2, 3) are constructed by noting that the variance of 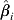 $\hat{\beta }_{i} $ is
$\hat{\beta }_{i} $ is
 $${{\rm var} \lpar \hat{\beta }_{i} \rpar \equals {1 \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{i\comma j} }}} \quad \lpar i \equals 0\comma 1\comma 2\comma 3\rpar }.$$
$${{\rm var} \lpar \hat{\beta }_{i} \rpar \equals {1 \over {\sum\limits_{j \equals \setnum{1}}^{k} {w_{i\comma j} }}} \quad \lpar i \equals 0\comma 1\comma 2\comma 3\rpar }.$$The 95% confidence interval for 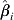 $\hat{\beta }_{i}$ is
$\hat{\beta }_{i}$ is  $\hat{\beta }_{i} \plusmn 1{\cdot}96 <$> <$> \sqrt {{\rm var} \lpar \hat{\beta }} _{i} \rpar.$ These estimates and their standard errors are based on the logarithm of the rate, and need to be exponentiated to reflect the actual rates. These rates are referred to as incidence density ratios. The estimate of the variances of these coefficients can be adjusted if there is evidence of substantial heterogeneity between the units. This adjustment for the extra variation due to heterogeneity is also referred to as a random-effects adjustment and statistical tests are available to determine whether significant heterogeneity is present. The random-effects estimate simply adds a component to each the weights w i,j reflecting this variability [Reference DerSimonian and Laird21, Reference Egger, Davey Smith and Altman22].
$\hat{\beta }_{i} \plusmn 1{\cdot}96 <$> <$> \sqrt {{\rm var} \lpar \hat{\beta }} _{i} \rpar.$ These estimates and their standard errors are based on the logarithm of the rate, and need to be exponentiated to reflect the actual rates. These rates are referred to as incidence density ratios. The estimate of the variances of these coefficients can be adjusted if there is evidence of substantial heterogeneity between the units. This adjustment for the extra variation due to heterogeneity is also referred to as a random-effects adjustment and statistical tests are available to determine whether significant heterogeneity is present. The random-effects estimate simply adds a component to each the weights w i,j reflecting this variability [Reference DerSimonian and Laird21, Reference Egger, Davey Smith and Altman22].

Fig. 2. Representation of model 1: within an individual unit. β0 = Starting baseline MRSA rate; β1 = slope of line prior to t 0; β2 = drop at t 0; β1 + β3 = slope after t 0.
Autocorrelation
As the data is a time series, any significant serial correlation (correlation between successive observations) present after the regression models have been fitted needs to be examined to determine the extent of any (first-order) serial autocorrelation in the residuals. The Durbin–Watson statistic [Reference Bhargava, Franzini and Narendranathan23], measures such correlation, and is calculated as
 $${\rm DW} \equals {{\sum\limits_{i \equals \setnum{2}}^{T} {\lcub e_{t} \minus e_{t \minus \setnum{1}} \rcub ^{\setnum{2}} } } \over {\sum\limits_{i \equals \setnum{1}}^{T} {e_{i}^{\setnum{2}} } }}\comma $$
$${\rm DW} \equals {{\sum\limits_{i \equals \setnum{2}}^{T} {\lcub e_{t} \minus e_{t \minus \setnum{1}} \rcub ^{\setnum{2}} } } \over {\sum\limits_{i \equals \setnum{1}}^{T} {e_{i}^{\setnum{2}} } }}\comma $$where the observations range from 1, …, T and e i is the ith residual from the Poisson regression model. The range of the statistic is 0–4, with values substantially less than 2 indicating (first-order) serial autocorrelation.
The data layout for the three hospital units is shown in Table 1. Table 2 shows the coefficients for each unit, the fixed- and random-effect [Reference DerSimonian and Laird21, Reference Egger, Davey Smith and Altman22] pooled estimates, and the Durbin–Watson statistic. Based on 109 observations, values of this statistic >1·58 indicate no autocorrelation at the 1% and >1·71 at the 5% levels of significance. Values <1·54, and <1·67 suggest the presence of autocorrelation at the 1% and 5% levels of significance, respectively. Critical values at the 5%, 2·5% and 1% significance levels are available online (http://www.stanford.edu/∼clint/bench/dwcrit.htm).
Table 1. Data layout for MRSA data from hospital units A and B and area C†

t 0, Time of the intervention; T, time period before the intervention (months); I, intervention time period (months); T*, time period after the intervention (months).
† Clinical incidence density rates (MRSA counts/patient days) over a period of 109 months were calculated for all units.
Table 2. Individual and pooled incidence density rates, 95% CI and P values

CI, Confidence interval.
* Durbin–Watson A: 1·90; B: 2·87; C: 1·87. Values >1·58 and 1·71 indicate no evidence of autocorrelation at the 1% and 5% levels of significance, respectively.
† Rate is the exponential of the coefficient.
‡ Adjusted for number of patient days at risk/month in each unit.
The interpretation of the pooled coefficients is as follows: At the start of data collection, compared with a rate of 0, there was a significant rate of MRSA of approximately 3/1000 in the hospital (estimated by β0). Before the intervention, the estimate of the rate (β1) was no change from the start (baseline) of data collection. The plausible rate was within the range of a 0·5% decrease and a 0·4% increase. The immediate effect of the intervention (β2) was a significant 39% decrease in the rate with a plausible effect ranging from a decrease of 55% to 14%. There was no significant reduction in clinical MRSA incidence of 1% per month of the intervention after implementation (β3). The plausible reduction ranged from 2% per month reduction to 0·3% increase. Adjustment for random effects does not substantially change the results.
Stacked analysis
Rather than fitting a separate model and pooling the estimates, we can fit a single model for all the units simultaneously to obtain estimates for pre-intervention, intervention, and post-intervention. A single model has the advantage of using the data across the units as part of the estimation procedure for each of the parameters resulting in an improvement in the efficiency of some of the estimates. In this model we concatenated the data row-wise to obtain one dataset of 327 rows.
Two extra columns appear in the array of Table 3, indicator variables representing unit B (U 2) and area C (U 3), leaving unit A as the reference category. We address the columns labelled T 1*, T 2* and T 3* later. The model we fit may be represented as:
Table 3. Stacked data layout combining units

† U 2 and U 3 are indicators representing unit B and area C.
Model 2: ln(λ) = β0 + β1T + β2I + β3T* + γ1U 2 + γ2U 3,
where λ is the monthly incidence rate, T and I are as previously defined, and T* = 0 if T⩽t 0 and T*=T−t 0 for T>t 0.
For our study, t 0 = 24 if U 2 = 0 and U 3 = 0; t 0 = 48 if U 2 = 1 and U 3 = 0, and t 0 = 69 if U 2 = 0 and U 3 = 1. γ denotes the parameters relating to the effects of the individual units. The results of fitting this Poisson model (Table 4) are consistent with the pooled analysis (Table 2).
Table 4. Stacked model: incidence density rates

CI, Confidence interval.
† ln(λ) = β0 + β1T + β2I + β3T* + γ1U 2 + γ2U 3.
‡ ln(λ) = β + β1T + β2I + β3T*.
Using model 2, the contribution of the individual components to the overall estimates can be summarized as:
Unit A: U 2=U 3 = 0, T < 25: ln(λ) = β0 + β1T,
T = 25: ln(λ) = (β0 + β2 + (25β1 + β3)
T > 25: ln(λ) = (β0 + β2 − 24β3) + (β1 + β3)T.
Unit B: U 2 = 1, U 3 = 0, T < 49: ln(λ) = (β0 + γ1) + β1T,
T = 49: ln(λ) = (β0 + γ1 + β2) + (49β1 + β3)
T > 49: ln(λ) = (β0 + γ1 + β2 − 48β3) + (β1 + β3)T.
Area C: U 2 = 0, U 3 = 1, T < 70: ln(λ) = (β0 + γ2) + β1T,
T = 70: ln(λ) = (β0 + γ2 + β2) + (70β1 + β3)
T > 70: ln(λ) = (β0 + γ2 + β2 − 69β3) + (β1 + β3)T
(see Fig. 3).

Fig. 3. Representation of stacked data in model 2. ln(λ) = β0 + β1T + β2I + β3T* + γ1U 2 + γ2U 3; β1 = slope of line prior to intervention for units A, B, and area C; β2 = average drop at the intervention (drop occurs at T = 25 for unit A, T = 49 for unit B, T = 70 for area C; β1 + β3 = slope after intervention for units A, B, and area C. If β3 = 0, then the slopes are the same (β1) both before and after the intervention for all three units.
While models 1 and 2 estimate the same quantities, the estimation approaches are different. In model 2, the pre-intervention effect (β1) has simultaneous contributions from all three units until the first intervention (24 months) and from two units (unit B and area C) until the second intervention (48 months). In model 1 they are estimated separately. Similarly, for the estimation of the post-intervention effect, the contribution to β1 + β3 comes from the three units.
In a stacked analysis, the effects are adjusted for differences between units; however, this may not be feasible if (a) the number of units is large, (b) there are different durations of time series in different units, or (c) numerical instability in the model fitting or parameter estimates is observed. In these situations, a pooled analysis may be a useful option.
If the unit effects are not significant, model 2 can be simplified by omitting the variables U 2 and U 3. In this case, we revert to model 1, but with all the units pooled in one (stacked) dataset and assume no unit effect (Table 4). Differences between the unadjusted estimates in Table 4 and pooled analyses (Table 2) may arise because estimates in Table 4 use information from all units simultaneously. For the pooled analysis, the rate is a weighted sum of the intervention rates calculated separately for each unit.
These results assume no pair-wise correlation among the MRSA rates within each unit (rates from one month to the next are independent) (Tables 2 and 4). As rates are fitted over time, any correlations will be accounted for by the terms in the model(s) that involve time, T and T*. Monthly overlap of patients or seasonal effects would be unusual, but, if found, the model should be modified accordingly. Any correlation would manifest itself after the residuals have been fitted and, at most, the first-order autocorrelation would be dominant. When the size of this correlation is examined via the Durbin–Watson statistic, non-significance should be sufficient to exclude any correlation, indicating that any correlation between successive observations is negligible and accounted for by the Poisson model.
Full interaction model parameterization
The pooled analysis may be thought of as equivalent to a single model including interactions of unit with the variables of interest [intercept, time (T), intervention (I) and post-intervention time (T*)] over the units. If the number of units are few, we can incorporate the models for each unit by fitting a single model that adds to all the main effects (T, I, U i, T*) interaction terms with unit. For the stacked data, this ‘full’ model can be written as:
Model 3: ln(λ) = β0 + β1T + β2I + β3T* + γ1U 2 + γ2U 3 + δ1U 2T + δ2U 3T + δ3U 2I + δ4U 3I + δ5U 2T* + δ6U 3T*.
This model has 12 parameters and, via the interactions, the effects in each unit are modelled separately. The interaction effects δ1, …, δ6 are obtained by multiplying, in the stacked dataset, the U 2 and U 3 columns by T, I, and T*, respectively (Table 5).
Table 5. Full parameterized interaction model: Poisson and logistic regression†

RR, Rate ratio; CI, confidence interval; OR, odds ratio.
† Wald test for testing H 0: δ5 = δ6 = 0 (second order) interaction term P = 0·10.
‡ Rate = exp(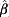 ${\hat{\beta }}$) where ${\hat{\beta }}$ is the estimated regression coefficient of the variable listed in column 1, for example, for the variable I, the rate = 0·7367 = exp(${\hat{\beta }}$) where ${\hat{\beta }}$ = ln (0·7367) = −0·3056.
${\hat{\beta }}$) where ${\hat{\beta }}$ is the estimated regression coefficient of the variable listed in column 1, for example, for the variable I, the rate = 0·7367 = exp(${\hat{\beta }}$) where ${\hat{\beta }}$ = ln (0·7367) = −0·3056.
As with the previous models, we can determine the effects for the individual units:
Unit A: U 2=U 3 = 0,
T < 25: ln(λ) = β0 + β1T
T = 25: ln(λ) = (β0 + β2) + (25β1 + β3)
T > 25: ln(λ) = (β0 + β2 − 24β3) + (β1 + β3)T.
Unit B: U 2 = 1, U 3 = 0,
T < 49: ln(λ) = (β0 + γ1) + (β1 + δ1)T
T = 49: ln(λ) = (β0 + β2 + γ1 + δ3) + 49(β1 + δ1) + (β3 + δ5)
T > 49: ln(λ) = (β0 + β2 + γ1 + δ3) − 48(β3 + δ5) + (β1 + β3 + δ1 + δ5)T.
Area C: U 2 = 0, U 3 = 1,
T < 70: ln(λ) = ( β0 + γ2)+ (β1 + δ2)T
T = 70: ln(λ) = (β0 + β2+ γ2 + δ4) + 70(β1 + δ2) + (β3 + δ6)
T > 70: ln(λ) = (β0 + β2 + γ2 + δ4) − 69(β3 + δ6) + (β1 + β3 + δ2 + δ6)T.
The effects (in terms of ‘rates’) for the individual units are obtained by exponentiating the sum of the appropriate coefficients in the model. The effects for the reference unit (unit A) are determined from the coefficients β0, β1, β2, and β3. The effects for the various components for the other units are obtained by exponentiating the sum of coefficients involving appropriate γ's and δ's in addition to β's in the model. For example, the (immediate) intervention effect for unit B is obtained by adding the estimates for β2 and δ3 and then exponentiating the result. For this dataset, we have: 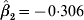 ${\hat{\beta }_{\setnum{2}} \equals \minus 0{\cdot}306}$ (=ln 0·7367 from Table 5) and
${\hat{\beta }_{\setnum{2}} \equals \minus 0{\cdot}306}$ (=ln 0·7367 from Table 5) and 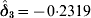 ${\hat{\delta }_{\setnum{3}} \equals \minus 0{\cdot}2319}$ (=ln 0·7931 from Table 5) yielding an estimate of the intervention effect in unit B as exp(−0·5371) = 0·5844. This result can also be obtained as the product of the rates: 0·7367∗0·7931.
${\hat{\delta }_{\setnum{3}} \equals \minus 0{\cdot}2319}$ (=ln 0·7931 from Table 5) yielding an estimate of the intervention effect in unit B as exp(−0·5371) = 0·5844. This result can also be obtained as the product of the rates: 0·7367∗0·7931.
The advantage of model 3 is that it allows testing for equality of effects for the different components (T, I, T*) by testing δ1 = δ2 = 0, δ3 = δ4 = 0, and δ5 = δ6 = 0, respectively. We first test δ5 = δ6 = 0. The term T* is the interaction of T and I (with an offset of 24, 48, or 69 months, depending on the unit). Therefore, U 2T* and U 3T* are second (or higher)-order interaction terms, and the convention is to test whether these are significant before performing tests for the first (lower)-order interaction. If we accept H 0: δ5 = δ6 = 0, then the tests H 0: δ1 = δ2 = 0 and H 0: δ3 = δ4 = 0 can be performed. For this test, P = 0·30, and we can proceed to test the interaction effects for T and I, i.e. U 2T, U 3T, U 2I, and U 3I. The tests of H 0: δ3 = δ4 = 0 and H 0: δ1 = δ2 = 0 yield P = 0·23 and P = 0·70, respectively, and so model 2 is preferred to model 3.
Apart from numerical fitting problems, such comprehensive (stacked) models have the drawback of using the statistical analyses to guide the questions and the interpretation of the clinical mechanisms. A more prudent approach is to use the data or model to address prespecified hypotheses. As the number of parameters increases, so does the potential for type I errors. Nevertheless, in this instance, the fully parameterized model suggests model 2 is a satisfactory representation of the data.
Assessing model accuracy and potential correlations
An important consideration in fitting any if the proposed models is the assurance that the data are adequately represented by a Poisson model. While numerous approaches exist to assess the adequacy of the Poisson fit, two methods can readily provide a guide as to whether the fitted models are appropriate. The deviance (D) from the model fit is a quantity derived from the model likelihood and has an (asymptotic) χ2 distribution with (n−p) degrees of freedom (n being the number of observations in the model and p the number of parameters fitted, including the constant). If Pr(D > χn−p2 > 0·05 we conclude that there is insufficient evidence to reject the hypothesis that the Poisson model is adequate. A second quantity which can be calculated is the dispersion which, in the case of a Poisson model measures the relationship between the mean and the variance of the model, i.e. var(Y i) = σ2E(Y i). As the mean and the variance for the Poisson model are equal, a dispersion value greatly different from unity will indicate inadequacy of the Poisson model assumption. Of the different methods used for estimating the dispersion parameter, that based on Pearson residuals is the more common. Most computer packages provide estimates of the deviance and dispersion in their output. In our dataset, there was no evidence, based on the deviance that the Poisson model was inadequate for all models fitted. The maximum value of the dispersion parameter was <1·15 for all models suggesting that, for this dataset, the Poisson assumption was appropriate.
We can also obtain an estimate of the correlation between the different units to examine the impact of the intervention in the different units. This can be achieved by fitting the model ln(λ) = β0 + β1T + β2I + β3T* and treating the unit variables U 1, U 2, U 3 as repeated measures in a generalised estimating equations (GEE) model with a Poisson link and compound-symmetric correlation structure [Reference Hardin and Hilbe24]. For our data, the magnitude of this correlation was 0·009 indicating independence within and across units. This analysis is not appropriate in models 2 and 3 as unit effects are being formally estimated.
Poisson or logistic regression?
If the rates are low, the odds ratio will estimate the relative risk, and fitting a logistic regression may be just as useful and less complicated. For our data, a ‘success’ is a MRSA case, the number of successes is the number of cases in a month, and the exposure time is the total number of patients at risk in each month. The data structure is identical to that of the stacked data in Table 3. The model is fitted to the number of cases each month out of the total exposure time (patient-days) in each month (Table 5). There is no appreciable difference between the coefficients and 95% confidence intervals in the Poisson and logistic models. While logistic regression provides estimates of the odds ratio, a binomial model with a log-link (rather than logistic-link) will yield relative risks as opposed to odds ratios. However, these models are still the subject of research and can suffer from numerical instability when being fitted and yield expected probabilities greater than unity [Reference Marschner and Gillett25].
Long-term follow-up
If the post-intervention series is measured over a long period (e.g. ⩾60 months), the model for a single reduction in the slope after the intervention may not be the most appropriate choice over the whole series (Fig. 4).

Fig. 4. Representation of a model with a post-intervention threshold. ln(λ) = β0 + β1T + β2I +β3T* + β4T†.
If, after MRSA incidence rates decrease to some threshold then cease to decrease, a linear representation of the total post-intervention experience would underestimate the effect of the intervention. In this instance, the model would be of the form:
Model 4: ln(λ) = β0 + β1T + β2I + β3T* + β4T†,
 $${\rm where\ \lambda \equals monthly\ incidence\ rate} \equals \left\{ {\matrix{ 0 \tab {\hskip2pt{\rm if} \ T\les t_{\setnum{0}} } \cr 1 \tab {\hskip2pt {\rm if} \ T \gt t_{\setnum{0}} } \cr} } \right.$$
$${\rm where\ \lambda \equals monthly\ incidence\ rate} \equals \left\{ {\matrix{ 0 \tab {\hskip2pt{\rm if} \ T\les t_{\setnum{0}} } \cr 1 \tab {\hskip2pt {\rm if} \ T \gt t_{\setnum{0}} } \cr} } \right.$$T = time in months, I = intervention status,
 $$T\ast \equals {\rm post}{\hbox{-}}{\rm intervention \ time} \equals \left\{ {\matrix{\hskip-16pt 0 \tab {\hskip-12pt{\rm if} \ T \les t_{\setnum{0}} } \cr {T \minus t_{\setnum{0}} } \tab {\hskip4pt{\rm if} \ T\gt t_{\setnum{0}} \les t_{\setnum{1}} } \cr \hskip-15pt0 \tab {\hskip-12pt{\rm if} \ T\gt t_{\setnum{1}} } \cr} } \right.$$
$$T\ast \equals {\rm post}{\hbox{-}}{\rm intervention \ time} \equals \left\{ {\matrix{\hskip-16pt 0 \tab {\hskip-12pt{\rm if} \ T \les t_{\setnum{0}} } \cr {T \minus t_{\setnum{0}} } \tab {\hskip4pt{\rm if} \ T\gt t_{\setnum{0}} \les t_{\setnum{1}} } \cr \hskip-15pt0 \tab {\hskip-12pt{\rm if} \ T\gt t_{\setnum{1}} } \cr} } \right.$$ $$\eqalign{\tab T\dagger \equals {\rm long \ term \ post{\hbox{-}}intervention \ time} \equals \cr\tab\quad\left\{ {\matrix{ \hskip-14pt0 \tab {\hskip-9pt{\rm if} \T \les t_{\setnum{1}} } \cr {T \minus t_{\setnum{1}} } \tab {{\rm if} \ T\gt t_{\setnum{1}} } \cr} } \right.}$$
$$\eqalign{\tab T\dagger \equals {\rm long \ term \ post{\hbox{-}}intervention \ time} \equals \cr\tab\quad\left\{ {\matrix{ \hskip-14pt0 \tab {\hskip-9pt{\rm if} \T \les t_{\setnum{1}} } \cr {T \minus t_{\setnum{1}} } \tab {{\rm if} \ T\gt t_{\setnum{1}} } \cr} } \right.}$$In this model, β0 represents the baseline MRSA rate; β1 is the slope of line before the intervention (t 0); β2 is the change in the MRSA rate just after t 0; β1 + β3 is the slope after t 0, and β3 is the change in slope of line after t 0 but before t 1, a predetermined time after which it is assumed that the rate has attained a threshold and is stable. Similarly, β4 is the change in slope of the line after t 1 and β1 + β4 is the slope after t 1.
DISCUSSION
In setting up an interrupted time-series model, we considered individual units in separate models, and used a single model allowing for statistical adjustment for each unit. Modelling individual units provides individual estimates, and so allows for evaluation of local practices and health policies. To estimate overall effects, individual estimates can be pooled, with modification to account for heterogeneity among the units. The key assumption in obtaining overall effects is the independence of the effects in individual units. Using a random-effects adjustment when pooling estimates is analogous to fitting a multilevel model, since both approaches assume the estimates are themselves drawn from a normal distribution with some mean and variance. A drawback of the pooled approach is that as the number of individual units increases, so does the number of parameters requiring estimation and then combination; when this happens, overdispersion may arise. If there are many hospitals, the random-effects component can be modified to adjust for possible heterogeneity across the hospitals by pooling across the units within each hospital using the fixed-effects approach and then using the random-effects adjustment to pool the effects over all the hospitals.
The second approach is to consider all the data simultaneously in a stacked model. This has the advantage of explaining all intervention effects in a single model. If population-level information (such as state or regional health policy information) is available, a multilevel approach may allow inclusion of information available at different levels of the hierarchy. Such models can be complex, requiring care in interpreting the coefficients. The stacked approach can also allow for random effects across different units or different hospitals (or both) in a mixed model. Such models allow extra variability due to a unit's effect to be included in the analysis. This may also be achieved in the pooled approach.
If there is good evidence of overflow into other months (i.e. patients who stay in wards for a long time and thus are at risk over a number of months), a different modelling strategy will be required, for example taking a longer period (say, 3 months) to minimize the effect of such overflow, or assuming a particular correlation structure as part of the model.
Any residual serial correlation from the fitted model can be examined via the Durbin–Watson statistic. If this statistic suggests significant autocorrelation, either extra terms related to time (some form of autoregressive model) may need to be investigated, or some form of differencing to reduce the serial correlation should be considered. The question that remains is whether these should be incorporated in the analysis of all the units or just the units exhibiting the serial correlation. If there is evidence of strong seasonal effect(s) and/or high autocorrelation present, then the modelling approach along the lines described by Fernández-Pérez et al. [Reference Fernández-Pérez, Tejada and Carrasco19] may be more appropriate.
CONCLUSION
We developed a model to examine the immediate and longer-term effects of a MRSA intervention programme in different units of the same hospital. Where feasible, a model adjusting for the unit effect should be fitted, or if there is strong evidence of heterogeneity between the units, an analysis incorporating a random effect for units may be appropriate.
DECLARATION OF INTEREST
None.









