

No CrossRef data available.
Article contents
A blind definition of shape
Published online by Cambridge University Press: 15 August 2002
Abstract
In this note, we propose a general definition of shape which isboth compatible with the one proposed in phenomenology(gestaltism) and with a computer vision implementation. We reversethe usual order in Computer Vision. We do not define “shaperecognition" as a task which requires a “model" pattern which issearched in all images of a certain kind. We give instead a“blind" definition of shapes relying only on invariance and repetition arguments.Given a set of images $\cal I$ 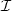 , we call shape of this set anyspatial pattern which can be found at several locations of someimage, or in several different images of $\cal I$ . (This meansthat the shapes of a set of images are defined without any a priori assumption or knowledge.) The definition is powerful whenit is invariant and we prove that the following invariancerequirements can be matched in theory and in practice: localcontrast invariance, robustness to blur, noise and sampling,affine deformations. We display experiments with single images and image pairs. In eachcase,we display the detected shapes. Surprisingly enough, but in accordancewith Gestalt theory,the repetition of shapes is so frequent in human environment, that manyshapes can even be learnedfrom single images.
, we call shape of this set anyspatial pattern which can be found at several locations of someimage, or in several different images of $\cal I$ . (This meansthat the shapes of a set of images are defined without any a priori assumption or knowledge.) The definition is powerful whenit is invariant and we prove that the following invariancerequirements can be matched in theory and in practice: localcontrast invariance, robustness to blur, noise and sampling,affine deformations. We display experiments with single images and image pairs. In eachcase,we display the detected shapes. Surprisingly enough, but in accordancewith Gestalt theory,the repetition of shapes is so frequent in human environment, that manyshapes can even be learnedfrom single images.
Information
- Type
- Research Article
- Information
- ESAIM: Control, Optimisation and Calculus of Variations , Volume 8: A tribute to JL Lions , 2002 , pp. 863 - 872
- Copyright
- © EDP Sciences, SMAI, 2002
References
S. Abbasi and F. Mokhtarian, Retrieval of similar shapes under affine transformation, in Proc. International Conference on Visual Information Systems. Amsterdam, The Netherlands (1999) 566-574.
Alvarez, L., Guichard, F., Lions, P.-L. and Morel, J.M., Axioms and fundamental equations of image processing: Multiscale analysis and P.D.E.
Arch. Rational Mech. Anal.
16 (1993) 200-257.
S. Angenent, G. Sapiro and A. Tannenbaum, On the affine heat flow for nonconvex curves. J. Amer. Math. Soc. (1998).
Brown, L.G., A survey of image registration techniques.
ACM Comput. Surveys
24 (1992) 325-376.
CrossRef
Caselles, V., Coll, B. and Morel, J.M., Topographic maps and local contrast changes in natural images.
Int. J. Comput. Vision
33 (1999) 5-27.
CrossRef
V. Caselles, B. Coll and J.M. Morel, Geometry and color in natural images. J. Math. Imaging Vision (2002).
T. Cohignac, C. Lopez and J.M. Morel, Integral and local affine invariant parameter and application to shape recognition, in ICPR94 (1994) A164-A168.
A. Desolneux, L. Moisan and J.M. Morel, Edge detection by Helmholtz principle. J. Math. Imaging Vision (to appear).
F. Dibos, From the projective group to the registration group: A new model. Preprint (2000).
R.O. Duda and P.E. Hart, Pattern Classification and Scene Analysis. Wiley (1973).
Dudek, G. and Tsotsos, J.K., Shape representation and recognition from multiscale curvature.
CVIU
2 (1997) 170-189.
O. Faugeras and R. Keriven, Some recent results on the projective evolution of 2d curves, in Proc. IEEE International Conference on Image Processing. Washington DC (1995) 13-16.
F. Guichard and J.M. Morel, Image iterative smoothing and P.D.E.'s (in preparation).
R.K. Hu, Visual pattern recognition by moments invariants. IEEE Trans. Inform. Theor. (1962) 179-187.
G. Kanizsa, Organization in vision: Essays on gestalt perception, in Praeger (1979).
Krzyzak, A., Leung, S.Y. and Suen, C.Y., Reconstruction of two-dimensional patterns from Fourier descriptors.
MVA
2 (1989) 123-140.
C.C. Lin and R. Chellappa, Classification of partial 2-d shapes using fourier descriptors, in CVPR86 (1986) 344-350.
J.L. Lisani, Comparaison automatique d'images par leurs formes, Ph.D. Dissertation. Université Paris-Dauphine (2001).
J.L. Lisani, L. Moisan, P. Monasse and J.M. Morel, Planar shapes in digital images. MAMS (submitted).
J.L. Lisani, P. Monasse and L. Rudin, Fast shape extraction and applications. PAMI (submitted).
Marr, D. and Hildreth, E.C., Theory of edge detection.
Proc. Roy. Soc. London Ser. A
207 (1980) 187-217.
CrossRef
G. Matheron, Random Sets and Integral Geometry. John Wiley, NY (1975).
W. Metzger, Gesetze des Sehens. Waldemar Kramer (1975).
Moisan, L., Affine plane curve evolution: A fully consistent scheme.
IEEE Trans. Image Process.
7 (1998) 411-420.
CrossRef
Mokhtarian, F. and Mackworth, A.K., A theory of multiscale, curvature-based shape representation for planar curves.
PAMI
14 (1992) 789-805.
CrossRef
P. Monasse, Contrast invariant image registration, in Proc. of International Conference on Acoustics, Speech and Signal Process., Vol. 6. Phoenix, Arizona (1999) 3221-3224.
Monasse, P. and Guichard, F., Fast computation of a contrast-invariant image representation.
IEEE Trans. Image Processing
9 (2000) 860-872.
CrossRef
Okutomi, M. and Kanade, T., A locally adaptive window for signal matching.
Int. J. Computer Vision
7 (1992) 143-162.
CrossRef
Persoon, E. and Shape di, K.S. Fuscrimination using fourier descriptors.
SMC
7 (1977) 170-179.
T.H. Reiss, Recognizing Planar Objects Using Invariant Image Features. Springer Verlag, Lecture Notes in Comput. Sci. 676
(1993).
Rucklidge, W.J., Efficiently locating objects using the Hausdorff distance.
Int. J. Computer Vision
24 (1997) 251-270.
CrossRef
Sapiro, G. and Tannenbaum, A., Affine invariant scale-space.
Int. J. Computer Vision
11 (1993) 25-44.
CrossRef
J. Serra, Image Analysis and Mathematical Morphology. Academic Press, New York (1982).
C.H. Teh and Chin R, On image analysis by the method of moments. IEEE Trans. Pattern Anal. Machine Intelligence 10
(1998).