


1. Introduction
In recent decades, the life expectancy of individuals living with HIV, particularly in industrialised countries, has increased significantly, largely due to advancements in antiretroviral therapy (ART) [Reference Bosh10, Reference Trickey, Sabin and Burkholder72]. ART has transformed HIV from a fatal disease into a manageable chronic condition, allowing many persons with HIV (PWH) to live lifespans nearly commensurate with the general population [Reference Gueler, Moser and Calmy31, Reference Marcus, Leyden and Alexeeff55, Reference Trickey, Sabin and Burkholder72]. As a result, the demographic profile of persons with diagnosed HIV (PWDH) in the United States has shifted. As shown in Figure 1, persons aged 55 and older have gone from approximately 16% of the PWDH population in 2008 to nearly 45% in 2022 [26]. Such a drastic demographic shift presents new challenges in the fight against HIV, as long-term management of chronic HIV infection will require an increasing share of resources.

Figure 1. Age distribution of the diagnosed PWH population in the United States over the years 2008 – 22.
The growing population of older PWDH requires the healthcare system to address not only the ongoing management of HIV itself, but also, increasingly, comorbidities and age-related conditions that arise as this population ages. These include cardiovascular disease, diabetes, osteoporosis, and certain cancers, which occur at higher levels, and at younger ages, among PWH as compared to the general population [Reference Bigna, Ndoadoumgue and Nansseu7, Reference Bloch, John, Smith, Rasmussen and Wright8, Reference Collins and Armstrong16, Reference Fosnacht27, Reference Nanditha, Paiero and Tafessu59, Reference Petoumenos and Worm61, Reference Rodes, Cadinanos, Esteban-Cantos, Rodríguez-Centeno and Arribas64, Reference Roomaney, van Wyk and Pillay-van Wyk65]. Older PWH also may suffer from cognitive and functional impairment [Reference Mateen and Mills56, Reference Paul, Cooley, Garcia-Egan and Ances60]. In addition, the high burden of health comorbidities leads to high levels of polypharmacy among older PWDH [Reference Smith, Letendre, Erlandson, Ma, Ellis and Farhadian69]. Finally, although ART has significantly increased overall lifespan among PWDH, ART itself is associated with health complications arising from long-term use [Reference Chawla, Wang and Patton13, Reference Guaraldi, Prakash and Moecklinghoff30, Reference Smith, Letendre, Erlandson, Ma, Ellis and Farhadian69]. As a result, healthcare providers must adapt their approaches and strategies to encompass a broader spectrum of health issues among PWH [Reference Collins and Armstrong16, Reference Kiplagat, Tran and Barber42].
Given the changing landscape of HIV care, the focus of public health strategies must also evolve. Prevention efforts now must include the mitigation of health complications associated with HIV in older adults, long-term HIV infection and long-term ART use among PWDH [Reference Collins and Armstrong16, Reference Kiplagat, Tran and Barber42], necessitating a comprehensive approach that integrates HIV care with general healthcare for chronic disease prevention and management [Reference Collins and Armstrong16, Reference Kiplagat, Tran and Barber42, Reference Petoumenos and Worm61]. Effective strategies will be crucial to maintain the health and quality of life of the ageing PWDH, ensuring that the progress made in extending life expectancy is not undermined by the rise of preventable chronic conditions, and that increased life-years are not accompanied by decreased life quality. Furthermore, despite decreases in new HIV infections and diagnoses in recent years, improved life expectancy among PWDH has led to a significant increase in the PDWH population as a whole in the United States and other high-income countries [25, Reference Puglia and Voller63], compounding ageing-related difficulties, as HIV care must be allocated across a large, and increasing, population.
To help address these challenges, the development of accurate mathematical models capable of providing reliable projections for the PWDH age structure in coming years is an important priority in HIV policy research. Such models can play a fundamental role in the planning and evaluation of intervention strategies and the allocation of valuable HIV treatment and prevention services. Recent work on this topic includes [Reference Stover and Glaubius70], which applied a compartment model for demographic projections, and [Reference Althoff, Stewart and Humes5, Reference Hyle, Kasaie and Schwamm35], which used an agent-based model to project how demographic changes in the US PWDH population may affect the burden of comorbidities. A particularly important component of these models is their ability to accurately characterise age-dependent PWDH mortality rates, and furthermore, how they may change in coming years. This arguably forms the foundation of such models, as the overall cost of HIV-related care depends most heavily on total PWDH person-years.
Given the importance of the topic, in the present work, we seek to estimate how the age-dependent mortality rates for PWDH in the US have changed in recent years in a mathematically rigorous manner, and furthermore, extrapolate from these data to project future such changes. To the authors’ knowledge, no such study has been undertaken, certainly not to describe changes in mortality at the age- and time-continuous level. To accomplish this task, we employ a data assimilation approach, in which age-discrete HIV surveillance data are integrated into a partial differential equation (PDE) model via an inverse ensemble Kalman filter (EnKF) to reconstruct the time evolution of age-dependent PWDH mortality since 2009. To project future trends in age-dependent mortality based on our reconstructions, we develop and apply a novel variant of dynamic mode decomposition (DMD), nonnegative DMD. By incorporating these data into our PDE model, we provide a forecast PWDH age structure, annual HIV diagnoses, and annual PWDH deaths in the United States over the coming years.
To reconstruct the evolution of age-dependent PWDH mortality rates in recent years, we employ the Ensemble Kalman Inversion (EKI). The EKI is an adaptation of the EnKF, a powerful tool for estimating the state of a dynamical system by iteratively refining predictions based on noisy observations. Originally introduced in the 1990s [Reference Evensen22], the EnKF has gained widespread use due to its ability to fuse model predictions with measurement data. Ensemble Kalman filtering has been employed to enhance the accuracy of solutions in diverse applications, including oceanography [Reference Evensen and Van Leeuwen23], reservoir modelling [Reference Aanonsen, Naevdal, Oliver, Reynolds and Valles1], weather forecasting [Reference Janjic, McLaughlin, Cohn and Verlaan37], milling process [Reference Schwenzer, Visconti, Ay, Bergs, Herty and Abel68], geophysical applications [Reference Keller, Franssen and Nowak39], physics [Reference Li54] and machine learning [Reference Kovachki and Stuart47, Reference Yegenoglu, Diaz, Krajsek and Herty80]. In public health, the EnKF was recently used to forecast heroin overdose deaths [Reference Böttcher, Chou and D’Orsogna11]. The EKI is a modified version of the EnKF designed for inverse problems, wherein underlying model parameters are estimated given a time-series of observations corresponding to model states [Reference Herty and Iacomini32–Reference Herty and Visconti34, Reference Schillings and Stuart66]. The EKI is attractive computationally, as it does not require the computation of derivatives of the underlying model, as well as mathematically, as it allows for provable convergence results [Reference Herty and Visconti34, Reference Schillings and Stuart66].
To project future trends from the reconstructed mortality data, we introduce a novel modification of the DMD, nonnegative DMD. DMD is a scientific machine learning (SciML) technique that extracts the most relevant dynamical structures existent in time-series data using a purely data-driven approach, with applications ranging from short-time future estimates to control, modal analysis and dimension reduction [Reference Kutz, Brunton, Brunton and Proctor48]. DMD has been deployed in a wide range of scientific and engineering applications such as biomechanics [Reference Viguerie, Grave, Barros, Lorenzo, Reali and Coutinho75], oncology [Reference Viguerie, Grave, Barros, Lorenzo, Reali and Coutinho75] epidemiology [Reference Barros, Grave, Viguerie, Reali and Coutinho6, Reference Proctor and Eckhoff62, Reference Viguerie, Barros, Grave, Reali and Coutinho74], climate modelling [Reference Kutz, Fu and Brunton49], aeroelasticity [Reference Fonzi, Brunton and Fasel24], additive manufacturing [Reference Viguerie, Barros, Grave, Reali and Coutinho74], urban mobility [Reference Alla, Balzotti, Briani and Cristiani3] and the modelling and simulation of batteries [Reference Alla, Monti and Sgura4]. The authors are not aware of any work using DMD to forecast the evolution of mortality rates, or similar quantities. In general, however, standard DMD fail to respect non-negativity when used for forecasting beyond the training period, even when the underlying training data are nonnegative [Reference Takeishi, Kawahara and Yairi71, Reference Viguerie, Barros, Grave, Reali and Coutinho74]. This makes DMD in its original formulation potentially unsuitable for forecasting nonnegative quantities, such as mortality rates, and as such must be modified accordingly.
The article is outlined as follows. In the methods section, we provide a high-level description of the mathematical model and the EnKF method. We then introduce the proposed novel variant of DMD, nonnegative DMD, discuss its numerical solution and establish some of its basic mathematical properties. We then present the results of our analyses. We first present the reconstructions of age-dependent PWDH mortality curves over previous years. We then use nonnegative DMD to obtain projections of future mortality rates, and apply these rates in our underlying PDE model in order to provide projections for age-dependent PWDH prevalence and mortality through 2030. We then provide a detailed discussion of the implications of our findings and conclude by discussing possible future directions to extend this research.
2. Methods
2.1. Mathematical model
We consider an age-structured PDE model for the population
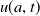 $u(a,t)$
, which gives the size of the PWDH population
$u(a,t)$
, which gives the size of the PWDH population
 $u$
aged
$u$
aged
 $a$
at a time
$a$
at a time
 $t$
. Models of this type allow for a precise description of age that is difficult to achieve with discrete age-structuring (e.g. a compartmental approach), particularly given age- and time-scales of the data do not coincide. Indeed, the surveillance data are reported annually, however, the reported age groups are 5-or 10-year ranges. The basic equations read:
$t$
. Models of this type allow for a precise description of age that is difficult to achieve with discrete age-structuring (e.g. a compartmental approach), particularly given age- and time-scales of the data do not coincide. Indeed, the surveillance data are reported annually, however, the reported age groups are 5-or 10-year ranges. The basic equations read:
 \begin{align} \begin{split} \dfrac {\partial u}{\partial t} + \dfrac {\partial u}{\partial a} &= -\mu (a,t)u + \lambda (a,t) \,\,\, \text{ for } t_0 \lt t\leq t_{end},\, 0\leq a \lt \infty , \\[5pt] u(a,0) &= u_0(a) \,\, \text{ at } t=t_0, \,\,\, u(0,t)= g(t), \end{split} \end{align}
\begin{align} \begin{split} \dfrac {\partial u}{\partial t} + \dfrac {\partial u}{\partial a} &= -\mu (a,t)u + \lambda (a,t) \,\,\, \text{ for } t_0 \lt t\leq t_{end},\, 0\leq a \lt \infty , \\[5pt] u(a,0) &= u_0(a) \,\, \text{ at } t=t_0, \,\,\, u(0,t)= g(t), \end{split} \end{align}
where
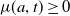 $\mu (a,t)\geq 0$
is the age- and time-dependent mortality rate,
$\mu (a,t)\geq 0$
is the age- and time-dependent mortality rate,
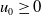 $u_0 \geq 0$
is the age-distribution of the PWDH population at the initial time, and
$u_0 \geq 0$
is the age-distribution of the PWDH population at the initial time, and
 $\lambda (a,t) \geq 0$
gives the number of new HIV diagnoses of persons aged
$\lambda (a,t) \geq 0$
gives the number of new HIV diagnoses of persons aged
 $a$
at a time
$a$
at a time
 $t$
, and is known from data.
$t$
, and is known from data.
The inflow condition
 $g(t)\geq 0$
defines new births, and may be time- and/or state-dependent in general. In the present, however, we assume
$g(t)\geq 0$
defines new births, and may be time- and/or state-dependent in general. In the present, however, we assume
 $g(t)=0$
, for several reasons. First, levels of perinatal HIV in the US are very low [Reference Lampe, Nesheim, Oladapo, Ewing, Wiener and Kourtis50]. Second, publicly available HIV surveillance data in the US does not include persons younger than 13 years of age [25]. Finally, the method of generating continuous age-distributions from discrete age-bins available from surveillance data (discussed in section 2.2), used to generate
$g(t)=0$
, for several reasons. First, levels of perinatal HIV in the US are very low [Reference Lampe, Nesheim, Oladapo, Ewing, Wiener and Kourtis50]. Second, publicly available HIV surveillance data in the US does not include persons younger than 13 years of age [25]. Finally, the method of generating continuous age-distributions from discrete age-bins available from surveillance data (discussed in section 2.2), used to generate
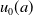 $u_0(a)$
and
$u_0(a)$
and
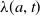 $\lambda (a,t)$
, ensures
$\lambda (a,t)$
, ensures
 $u(a,t)\gt 0$
and remains smooth for all
$u(a,t)\gt 0$
and remains smooth for all
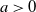 $a\gt 0$
throughout the simulation period.
$a\gt 0$
throughout the simulation period.
In practice, we solve (2.1) numerically, considering a bounded age domain
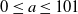 $0\leq a \leq 101$
. We employ a second-order backward differentiation (BDF2) scheme throughout the age domain, assuming physically consistent ‘ghost node’ values of
$0\leq a \leq 101$
. We employ a second-order backward differentiation (BDF2) scheme throughout the age domain, assuming physically consistent ‘ghost node’ values of
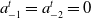 $a_{-1}^t=a_{-2}^t =0$
for all
$a_{-1}^t=a_{-2}^t =0$
for all
 $t$
. For the time discretisation, we use Heun’s method to solve the first time step, and BDF2 for the remaining time steps. Models of this type are common in many applications in the natural and social sciences, and we refer the reader to [Reference Murray and Murray57] for a presentation of these models and [Reference Li, Yang and Martcheva53] for an extensive discussion of more complex extensions.
$t$
. For the time discretisation, we use Heun’s method to solve the first time step, and BDF2 for the remaining time steps. Models of this type are common in many applications in the natural and social sciences, and we refer the reader to [Reference Murray and Murray57] for a presentation of these models and [Reference Li, Yang and Martcheva53] for an extensive discussion of more complex extensions.
Denote the domain of
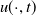 $u(\cdot ,t)$
, the set of admissible human ages, as
$u(\cdot ,t)$
, the set of admissible human ages, as
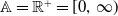 $\mathbb{A} = \mathbb{R}^+ = \lbrack 0,\,\infty )$
, endowed with a
$\mathbb{A} = \mathbb{R}^+ = \lbrack 0,\,\infty )$
, endowed with a
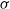 $\sigma$
-algebra
$\sigma$
-algebra
 $\mathfrak{B}$
and nonnegative measure
$\mathfrak{B}$
and nonnegative measure
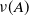 $\nu (A)$
. In the following, we use
$\nu (A)$
. In the following, we use
 $u(a,t)$
to denote a generic solution of (2.1) and provide the following positivity result:
$u(a,t)$
to denote a generic solution of (2.1) and provide the following positivity result:
Theorem 1. If
 $u_0\geq 0$
for all
$u_0\geq 0$
for all
 $a$
and
$a$
and
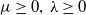 $\mu \geq 0,\, \lambda \geq 0$
for all
$\mu \geq 0,\, \lambda \geq 0$
for all
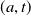 $(a,t)$
, then
$(a,t)$
, then
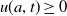 $u(a,t)\geq 0$
for all
$u(a,t)\geq 0$
for all
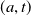 $(a,t)$
.
$(a,t)$
.
Proof. Since the age
 $a$
advances in sync with time, we can consider the characteristic curve
$a$
advances in sync with time, we can consider the characteristic curve
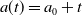 $a(t)=a_0 + t$
for some fixed
$a(t)=a_0 + t$
for some fixed
 $a_0$
, and note that
$a_0$
, and note that
 $da/dt = 1$
. Along the characteristic, we can rewrite (2.1) in terms of a function
$da/dt = 1$
. Along the characteristic, we can rewrite (2.1) in terms of a function
 $v(t)$
, depending only on
$v(t)$
, depending only on
 $t$
:
$t$
:
 \begin{equation} v(t) \, :\!= \, u(a(t), t) =u(a_0+t, t). \end{equation}
\begin{equation} v(t) \, :\!= \, u(a(t), t) =u(a_0+t, t). \end{equation}
Differentiating with respect to
 $t$
gives:
$t$
gives:
 \begin{equation} \dfrac {dv}{dt} = \dfrac {\partial u }{\partial t} + \dfrac {\partial u}{\partial a}\dfrac {d}{dt}\lbrack a_0 + t\rbrack = \dfrac {\partial u }{\partial t}(a_0+t,\,t) + \dfrac {\partial u}{\partial a}(a_0+t,\,t). \end{equation}
\begin{equation} \dfrac {dv}{dt} = \dfrac {\partial u }{\partial t} + \dfrac {\partial u}{\partial a}\dfrac {d}{dt}\lbrack a_0 + t\rbrack = \dfrac {\partial u }{\partial t}(a_0+t,\,t) + \dfrac {\partial u}{\partial a}(a_0+t,\,t). \end{equation}
where the last equation on the right hand side follows from
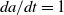 $da/dt=1$
. From (2.2), (2.3) along the characteristic (2.1) reduces to the ordinary differential equation:
$da/dt=1$
. From (2.2), (2.3) along the characteristic (2.1) reduces to the ordinary differential equation:
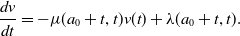 \begin{equation} \dfrac {dv}{dt}= -\mu (a_0+t,t)v(t) + \lambda (a_0+t,t). \end{equation}
\begin{equation} \dfrac {dv}{dt}= -\mu (a_0+t,t)v(t) + \lambda (a_0+t,t). \end{equation}
Re-arranging, multiplying by the integrating factor
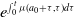 $e^{\int _0^t\mu (a_0 +\tau ,\tau )d\tau }$
, and integrating from
$e^{\int _0^t\mu (a_0 +\tau ,\tau )d\tau }$
, and integrating from
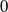 $0$
to
$0$
to
 $t$
:
$t$
:
 \begin{equation} v(t)e^{\int _0^t\mu (a_0 +\tau ,\tau )d\tau } = v(0)+\int _0^{t} \lambda (a_0+\xi ,\xi ) e^{\int _0^\xi \mu (a_0 +\tau ,\tau )d\tau }d\xi . \end{equation}
\begin{equation} v(t)e^{\int _0^t\mu (a_0 +\tau ,\tau )d\tau } = v(0)+\int _0^{t} \lambda (a_0+\xi ,\xi ) e^{\int _0^\xi \mu (a_0 +\tau ,\tau )d\tau }d\xi . \end{equation}
Recalling that
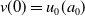 $v(0)=u_0(a_0)$
:
$v(0)=u_0(a_0)$
:
 \begin{equation} u(a_0+t,t) =e^{-\int _0^t \mu (a_0+\tau ,\tau ) d\tau }\left (u_0(a_0) + \int _0^{t} \lambda (a_0+\xi ,\xi ) e^{\int _0^\xi \mu (a_0 +\tau ,\tau )d\tau }d\xi \right ). \end{equation}
\begin{equation} u(a_0+t,t) =e^{-\int _0^t \mu (a_0+\tau ,\tau ) d\tau }\left (u_0(a_0) + \int _0^{t} \lambda (a_0+\xi ,\xi ) e^{\int _0^\xi \mu (a_0 +\tau ,\tau )d\tau }d\xi \right ). \end{equation}
From our assumptions on
 $\mu ,\,u_0,\,\lambda$
, all the terms on the right-hand side are nonnegative, and hence:
$\mu ,\,u_0,\,\lambda$
, all the terms on the right-hand side are nonnegative, and hence:
 \begin{equation} u(a_0+t,t)\geq 0 \,\,\forall t. \end{equation}
\begin{equation} u(a_0+t,t)\geq 0 \,\,\forall t. \end{equation}
Furthermore, since
 $a_0$
was arbitrary, (2.7) holds for any
$a_0$
was arbitrary, (2.7) holds for any
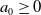 $a_0 \geq 0$
, implying:
$a_0 \geq 0$
, implying:
 \begin{equation} u(a,t)\geq 0 \,\,\, \forall (a,t), \end{equation}
\begin{equation} u(a,t)\geq 0 \,\,\, \forall (a,t), \end{equation}
as was to be shown.
2.2. Ensemble Kalman inversion
The EKI is a computational technique that extends the principles of the Kalman filter to solve inverse problems by utilising an ensemble of model realizations. By iteratively updating this ensemble with observational data, which are assumed to be affected by noise, EKI effectively estimates unknown parameters and reduces uncertainty, making it particularly suitable for high-dimensional and nonlinear inverse problems [Reference Herty, Iacomini and Visconti33, Reference Herty and Visconti34, Reference Schillings and Stuart66].
Here, we describe the EKI procedure applied in the current work. In order to do this, let us introduce the notation we will use in the following:
-
• The overline symbol
 $\overline {\,\cdot \,}$
denotes an averaged quantity.
$\overline {\,\cdot \,}$
denotes an averaged quantity. -
•
${u}(a,t)$
denotes the age-distribution of the PWDH population in time. -
•
$\boldsymbol{\mu }(a,t)$
is our unknown; in this case, it defines the time- and age-dependent mortality curve. -
•
$\Gamma$
is the matrix of the covariance of the noise, which is assumed to be known. -
•
$\mathscr{G}(\cdot )$
is our output of the total annual PWDH deaths in each age bracket, calculated from the population state
$\boldsymbol{{u}}$
and mortality curve
$\mu$
. -
•
$n_{kf}$
is the number of Kalman filtering steps. -
•
$A(\boldsymbol{\mu },\lambda ,{u})$
is the operator which advances population age distribution
$\Delta t$
units in time for a given
${\boldsymbol{\mu }}(a,t)$
and
$\lambda (a,t)$
according to the system dynamics defined by (2.1):(2.9)Note:
\begin{equation} {u}(a,t+\Delta t) = A\left (\boldsymbol{\mu }(a,t),\lambda (a,t), {u}(a,t-s\Delta t)|_{s=1}^S \right ){u}(a,t). \end{equation}
$A$
may depend on up to
$S$
additional past time steps in general, according to the time-stepping scheme employed.

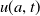


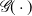





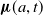
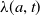


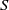
For the sake of readibility, we hereafter write
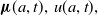 ${\boldsymbol{\mu }}(a,t),\,\boldsymbol{{u}}(a,t),\,$
and
${\boldsymbol{\mu }}(a,t),\,\boldsymbol{{u}}(a,t),\,$
and
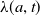 $\lambda (a,t)$
, respectively, as
$\lambda (a,t)$
, respectively, as
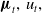 ${\boldsymbol{\mu }}_{t},\,\boldsymbol{{u}}_{t},\,$
and
${\boldsymbol{\mu }}_{t},\,\boldsymbol{{u}}_{t},\,$
and
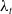 $\lambda _{t}$
, with the dependence of each quantity on age
$\lambda _{t}$
, with the dependence of each quantity on age
 $a$
understood if not explicitly denoted. We seek to use the EKI to estimate the time- and age-dependent mortality curve
$a$
understood if not explicitly denoted. We seek to use the EKI to estimate the time- and age-dependent mortality curve
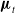 ${\boldsymbol{\mu }}_t$
, which is not observable directly, by incorporating information from the model (2.1) and surveillance data. The estimation of
${\boldsymbol{\mu }}_t$
, which is not observable directly, by incorporating information from the model (2.1) and surveillance data. The estimation of
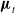 ${\boldsymbol{\mu }}_t$
relies on the current age distribution
${\boldsymbol{\mu }}_t$
relies on the current age distribution
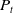 $P_t$
, calculated from the (2.1), and the age-bracketed annual mortality data
$P_t$
, calculated from the (2.1), and the age-bracketed annual mortality data
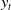 $y_t$
, available from surveillance data [26]. To ensure regularity in our estimate, we do not estimate
$y_t$
, available from surveillance data [26]. To ensure regularity in our estimate, we do not estimate
 ${\boldsymbol{\mu }}_t$
at each age individually, but compute its value at ages 1, 10, 22, 32, 42, 52, 57, 62, 67, 72, 77, 82, 95, 101. We then consider the full curve
${\boldsymbol{\mu }}_t$
at each age individually, but compute its value at ages 1, 10, 22, 32, 42, 52, 57, 62, 67, 72, 77, 82, 95, 101. We then consider the full curve
 ${\boldsymbol{\mu }}_t$
as the piecewise cubic Hermite interpolating polynomial through these points. We note that we performed a sensitivity analysis to the choice of interpolation points, and found that the effect on the overall reconstruction was not large, provided that there are sufficiently many points across all age ranges.
${\boldsymbol{\mu }}_t$
as the piecewise cubic Hermite interpolating polynomial through these points. We note that we performed a sensitivity analysis to the choice of interpolation points, and found that the effect on the overall reconstruction was not large, provided that there are sufficiently many points across all age ranges.
We begin by initialising an ensemble of mortality curves at
 ${\boldsymbol{\mu }}_{t,\,j}^1$
for
${\boldsymbol{\mu }}_{t,\,j}^1$
for
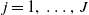 $j=1,\,\ldots ,\,J$
at
$j=1,\,\ldots ,\,J$
at
 $t=2009$
, by sampling from the distribution of the mortality rate of the general (non-PWH) population
$t=2009$
, by sampling from the distribution of the mortality rate of the general (non-PWH) population
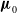 ${\boldsymbol{\mu }}_0$
. The superscript number refers to the current filter step, further clarified in the following. We assume a multivariate normal distribution with mean
${\boldsymbol{\mu }}_0$
. The superscript number refers to the current filter step, further clarified in the following. We assume a multivariate normal distribution with mean
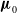 ${\boldsymbol{\mu }}_0$
and covariance
${\boldsymbol{\mu }}_0$
and covariance
 $\text{diag}({\boldsymbol{\mu }}_0^2)$
, the component-wise square.
$\text{diag}({\boldsymbol{\mu }}_0^2)$
, the component-wise square.
Similarly, we also initialise an ensemble of population age structures
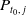 $P_{t_0,\,j}$
for
$P_{t_0,\,j}$
for
 $j=1,\,2,\,\ldots ,\,J$
at the initial time
$j=1,\,2,\,\ldots ,\,J$
at the initial time
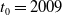 $t_0=2009$
, which serve as the initial conditions for (2.1). Each
$t_0=2009$
, which serve as the initial conditions for (2.1). Each
 $P_{t_0,\,j}$
is generated from surveillance data for the diagnosed PWDH population at year-end 2008 [26]. These data are stratified into age brackets: 13 – 24, 25 – 34, 35 – 44, 45 – 54, 55 – 59, 60 – 64, 65 – 69, 70 – 74, 75 – 79, 80 – 84 and 85 +. We define each
$P_{t_0,\,j}$
is generated from surveillance data for the diagnosed PWDH population at year-end 2008 [26]. These data are stratified into age brackets: 13 – 24, 25 – 34, 35 – 44, 45 – 54, 55 – 59, 60 – 64, 65 – 69, 70 – 74, 75 – 79, 80 – 84 and 85 +. We define each
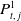 $P_{t,\,j}^1$
such that the overall number of PWDH in each age bracket is equal to the surveillance data, while the distribution of PWDH within each age bracket are defined with a uniform sample. For each calendar year
$P_{t,\,j}^1$
such that the overall number of PWDH in each age bracket is equal to the surveillance data, while the distribution of PWDH within each age bracket are defined with a uniform sample. For each calendar year
 $t_i=2009-22,\,i=1,\,2,\,\ldots$
during the simulation, we follow an identical procedure using the age-bracketed annual new HIV diagnosis data from [26] to define an ensemble
$t_i=2009-22,\,i=1,\,2,\,\ldots$
during the simulation, we follow an identical procedure using the age-bracketed annual new HIV diagnosis data from [26] to define an ensemble
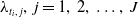 $\lambda _{t_i,\,j},\,j=1,\,2,\,\ldots ,\,J$
for new entries in the model (2.1).
$\lambda _{t_i,\,j},\,j=1,\,2,\,\ldots ,\,J$
for new entries in the model (2.1).
Algorithm 1 Algorithm with fixed number of filter steps for the model
 $\mathscr{G}$
$\mathscr{G}$

Assume that (2.1) is discretised time with time step
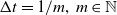 $\Delta t= 1/m,\,m\in \mathbb{N}$
, such that each year is divided into
$\Delta t= 1/m,\,m\in \mathbb{N}$
, such that each year is divided into
 $m$
time-steps. For each simulated calendar year
$m$
time-steps. For each simulated calendar year
 $t_i$
, we perform
$t_i$
, we perform
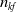 $n_{kf}$
inverse Kalman Filtering steps. The procedure is given in Algorithm (1). In a given year, we perform
$n_{kf}$
inverse Kalman Filtering steps. The procedure is given in Algorithm (1). In a given year, we perform
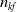 $n_{kf}$
filtering steps. At the
$n_{kf}$
filtering steps. At the
 $nn$
-th filtering step, we first advance the
$nn$
-th filtering step, we first advance the
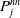 $P_j^{nn}$
following (2.1) by solving the model over
$P_j^{nn}$
following (2.1) by solving the model over
 $m$
time-steps, using
$m$
time-steps, using
 $\lambda _{t_i,\,j}$
and the mortality curve
$\lambda _{t_i,\,j}$
and the mortality curve
 ${\boldsymbol{\mu }}_{t_i,\,j}^{nn}$
. Note that we must keep a running update of the simulated age-bracketed mortality
${\boldsymbol{\mu }}_{t_i,\,j}^{nn}$
. Note that we must keep a running update of the simulated age-bracketed mortality
 $\mathscr{G}(P_j^{nn},{\boldsymbol{\mu }}_{t_i,\,j}^{nn})$
at each time step, so that an end-of-year total is available.
$\mathscr{G}(P_j^{nn},{\boldsymbol{\mu }}_{t_i,\,j}^{nn})$
at each time step, so that an end-of-year total is available.
If
 $nn$
is less than the total number of filter steps
$nn$
is less than the total number of filter steps
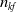 $n_{kf}$
, we use the calculated
$n_{kf}$
, we use the calculated
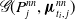 $\mathscr{G}(P_j^{nn},{\boldsymbol{\mu }}_{t_i,\,j}^{nn})$
and the surveillance mortality data
$\mathscr{G}(P_j^{nn},{\boldsymbol{\mu }}_{t_i,\,j}^{nn})$
and the surveillance mortality data
 $y_{t_i}$
to obtain the updated mortality curve
$y_{t_i}$
to obtain the updated mortality curve
 ${\boldsymbol{\mu }}_{t_i,\,j}^{nn+1}$
. We then simulate the model for the year
${\boldsymbol{\mu }}_{t_i,\,j}^{nn+1}$
. We then simulate the model for the year
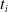 $t_i$
again, using with the updated
$t_i$
again, using with the updated
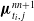 ${\boldsymbol{\mu }}_{t_i,\,j}^{nn+1}$
. If
${\boldsymbol{\mu }}_{t_i,\,j}^{nn+1}$
. If
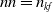 $nn=n_{kf}$
, we advance to year
$nn=n_{kf}$
, we advance to year
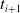 $t_{i+1}$
, setting
$t_{i+1}$
, setting
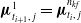 ${\boldsymbol{\mu }}_{t_{i+1},\,j}^1 = {\boldsymbol{\mu }}_{t_i,\,j}^{n_{kf}}$
and generating
${\boldsymbol{\mu }}_{t_{i+1},\,j}^1 = {\boldsymbol{\mu }}_{t_i,\,j}^{n_{kf}}$
and generating
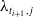 $\lambda _{t_{i+1},\,j}$
from the surveillance data for year
$\lambda _{t_{i+1},\,j}$
from the surveillance data for year
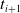 $t_{i+1}$
. Note that the solution of the EnKF procedure is given by the mean of the ensemble at the step
$t_{i+1}$
. Note that the solution of the EnKF procedure is given by the mean of the ensemble at the step
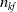 $n_{kf}$
for each year.
$n_{kf}$
for each year.
Remark. Note that, as (2.1) must be solved
 $n_{kf}$
times in each year, we must keep values of
$n_{kf}$
times in each year, we must keep values of
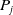 $P_j$
from the preceding year in order to repeatedly solve the first time-step of the current year. The exact number of time-step(s) to be saved depends on the specific time-stepping scheme used. As we used BDF2 in the current work, we kept the last two time-steps from the
$P_j$
from the preceding year in order to repeatedly solve the first time-step of the current year. The exact number of time-step(s) to be saved depends on the specific time-stepping scheme used. As we used BDF2 in the current work, we kept the last two time-steps from the
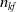 $n_{kf}$
-th filtering step of the previous year.
$n_{kf}$
-th filtering step of the previous year.
2.3. Nonnegative DMD
In the present work, we introduce a novel variant of DMD, nonnegative DMD, and use it to extrapolate the evolution of the age-dependent mortality rates (calculated using the EKI) and the age structure of new HIV diagnoses (estimated from surveillance data) through the year 2030. In the following, we will provide a brief introduction to the standard DMD algorithm, then we will introduce the nonnegative DMD algorithm, and provide some information regarding its calculation.
2.3.1. Standard DMD
In this subsection, we provide a brief description of DMD. For the purposes of simplicity and exposition, we restrict our discussion to the original formulation of DMD as proposed in [Reference Schmid67]. We remark that this is a vast topic of research, and refer the reader to [Reference Kutz, Brunton, Brunton and Proctor48] for a more comprehensive treatment of DMD. Suppose, we have time series consisting of
 $n$
snapshots:
$n$
snapshots:
 \begin{equation} \big \{{x}_i\big \}_{i=1}^n,\qquad \,{x}_i \in \mathbb{R}^m\,\,\,\,\forall i. \end{equation}
\begin{equation} \big \{{x}_i\big \}_{i=1}^n,\qquad \,{x}_i \in \mathbb{R}^m\,\,\,\,\forall i. \end{equation}
We arrange these snapshots into two
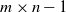 $m \times n-1$
matrices
$m \times n-1$
matrices
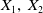 $X_1,\,X_2$
column-wise as follows:
$X_1,\,X_2$
column-wise as follows:
 \begin{align} X_1=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c}| & | & \, & | \\[5pt] {x}_1 & {x}_2 & \ldots &{x}_{n-1} \\[5pt] | & | & \, & |\end{array}\right]X_2=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} | & | & \, & | \\[5pt] {x}_2 & {x}_3 & \ldots &{x}_{n} \\[5pt] | & | & \, & | \end{array}\right]. \end{align}
\begin{align} X_1=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c}| & | & \, & | \\[5pt] {x}_1 & {x}_2 & \ldots &{x}_{n-1} \\[5pt] | & | & \, & |\end{array}\right]X_2=\left[\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} | & | & \, & | \\[5pt] {x}_2 & {x}_3 & \ldots &{x}_{n} \\[5pt] | & | & \, & | \end{array}\right]. \end{align}
DMD seeks to reconstruct the operator
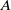 $A$
mapping
$A$
mapping
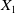 $X_1$
to
$X_1$
to
 $X_2$
, that is:
$X_2$
, that is:
 \begin{equation} A X_1 = X_2, \end{equation}
\begin{equation} A X_1 = X_2, \end{equation}
which can be obtained as [Reference Schmid67]:
 \begin{equation} A = X_2 \left (X_1\right )^{\dagger }, \end{equation}
\begin{equation} A = X_2 \left (X_1\right )^{\dagger }, \end{equation}
where
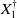 $X_1^{\dagger }$
is the Moore-Penrose pseudoinverse of
$X_1^{\dagger }$
is the Moore-Penrose pseudoinverse of
 $X_1$
(see e.g. [Reference Golub and Van Loan28]). This formulation of
$X_1$
(see e.g. [Reference Golub and Van Loan28]). This formulation of
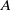 $A$
solves the minimisation problem:
$A$
solves the minimisation problem:
 \begin{equation} \mathop{\textrm{arg min}}\limits_{A} \| A X_1 - X_2 \|_{F}, \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_{A} \| A X_1 - X_2 \|_{F}, \end{equation}
with
 $\|\,\cdot \,\|_F$
denoting the Frobenius norm [Reference Kutz, Brunton, Brunton and Proctor48]. Note that, in practice,
$\|\,\cdot \,\|_F$
denoting the Frobenius norm [Reference Kutz, Brunton, Brunton and Proctor48]. Note that, in practice,
 $A$
can be large and dense, and is not typically computed directly as (2.13). Instead, algorithms which efficiently compute lower-rank approximations of
$A$
can be large and dense, and is not typically computed directly as (2.13). Instead, algorithms which efficiently compute lower-rank approximations of
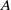 $A$
can be leveraged to avoid ever forming
$A$
can be leveraged to avoid ever forming
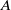 $A$
explicitly (see e.g. [Reference Kutz, Brunton, Brunton and Proctor48, Reference Schmid67, Reference Viguerie, Grave, Barros, Lorenzo, Reali and Coutinho75]).
$A$
explicitly (see e.g. [Reference Kutz, Brunton, Brunton and Proctor48, Reference Schmid67, Reference Viguerie, Grave, Barros, Lorenzo, Reali and Coutinho75]).
2.3.2. Nonnegative DMD algorithm
Being a completely data-driven algorithm, DMD, particularly when extrapolated past the training interval, will not necessarily respect the physics of the underlying systems. For example, in [Reference Alla, Monti and Sgura4], it was demonstrated that standard DMD can fail to predict periodic limit cycles. Similarly, in [Reference Viguerie, Barros, Grave, Reali and Coutinho74], it was shown that DMD, when formulated as (2.13) (or with a lower-rank approximation), will conserve the mass of a mass-conservative system (assuming the data is also mass-conservative), even projected out in time; however, other key physical properties, in particular nonnegativity, were not preserved in the extrapolations.
In the present work, we employ DMD to project two strictly nonnegative physical quantities: future HIV diagnoses and future age-dependent mortality rates among PWH. While standard DMD reliably reproduces the training data in both instances, attempting to extrapolate beyond the training interval results in negative, oscillatory reconstructions, even over short projection windows (1–2 years).
In order to guarantee
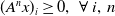 $(A^{n} {x})_i \geq 0,\,\,\forall \,i,\,n$
, assuming a nonnegative
$(A^{n} {x})_i \geq 0,\,\,\forall \,i,\,n$
, assuming a nonnegative
 $x$
, it is enough to guarantee that the matrix
$x$
, it is enough to guarantee that the matrix
 $A$
itself is nonnegative. The most obvious solution would be to find
$A$
itself is nonnegative. The most obvious solution would be to find
 $A$
as in (2.13), and then use nonnegative matrix factorisation to replace
$A$
as in (2.13), and then use nonnegative matrix factorisation to replace
 $A$
with an approximate nonnegative version
$A$
with an approximate nonnegative version
 $A\approx \widehat {A}=MN$
, that is:
$A\approx \widehat {A}=MN$
, that is:
 \begin{equation} \mathop{\textrm{arg min}}\limits_{\widehat {A}=MN} \| MN - X_2(X_1)^{\dagger } \|_F,\,\,\,M_{i,\,j}, N_{i,\,j} \geq 0\,\,\forall i,\,j. \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_{\widehat {A}=MN} \| MN - X_2(X_1)^{\dagger } \|_F,\,\,\,M_{i,\,j}, N_{i,\,j} \geq 0\,\,\forall i,\,j. \end{equation}
However, our attempts in this direction were unsuccessful, and approximations of
 $A$
obtained in this way did not provide useful forecasts; we will elaborate further later in the text.
$A$
obtained in this way did not provide useful forecasts; we will elaborate further later in the text.
As
 $\{ {x} \}_{i=1}^n \gt 0$
element-wise for all
$\{ {x} \}_{i=1}^n \gt 0$
element-wise for all
 $i$
, we also attempted to define:
$i$
, we also attempted to define:
 \begin{equation} \widetilde {X}_1=\log (X_1),\,\,\widetilde {X}_2=\log (X_2),\, \widetilde {A}=\widetilde {X}_2(\widetilde {X}_1)^{\dagger }, \end{equation}
\begin{equation} \widetilde {X}_1=\log (X_1),\,\,\widetilde {X}_2=\log (X_2),\, \widetilde {A}=\widetilde {X}_2(\widetilde {X}_1)^{\dagger }, \end{equation}
and proceeding as:
 \begin{equation} {x}_{t+1} = \exp \left (\widetilde {A}\log \left ({x}_{t}\right )\right ). \end{equation}
\begin{equation} {x}_{t+1} = \exp \left (\widetilde {A}\log \left ({x}_{t}\right )\right ). \end{equation}
Note that the logarithm and exponential functions in (2.16), (2.17) refer to the elementwise operations. While the
 ${x}_i$
${x}_i$
 ${x}_i$
obtained in this manner remained nonnegative, and accurately reconstructed the training period, extrapolation beyond the training period resulted in oscillatory, nonphysical solutions, even for just a single time-step, making this approach unsuitable for forecasting, at least for the problems studied herein.
${x}_i$
obtained in this manner remained nonnegative, and accurately reconstructed the training period, extrapolation beyond the training period resulted in oscillatory, nonphysical solutions, even for just a single time-step, making this approach unsuitable for forecasting, at least for the problems studied herein.
To understand the poor performance of the log-transform approach, note that the operator
 $\widetilde {A}$
minimises:
$\widetilde {A}$
minimises:
 \begin{equation} \sum _{i=1}^n \| \widetilde {A} \log ({x}_i) - \log ({x}_{i+1})\|_2^2, \end{equation}
\begin{equation} \sum _{i=1}^n \| \widetilde {A} \log ({x}_i) - \log ({x}_{i+1})\|_2^2, \end{equation}
which is not equivalent to minimising:
 \begin{equation} \sum _{i=1}^n \| A {x}_i - {x}_{i+1} \|_2^2 \end{equation}
\begin{equation} \sum _{i=1}^n \| A {x}_i - {x}_{i+1} \|_2^2 \end{equation}
in general. Furthermore, given the lack of specific structure on
 $\widetilde {A}$
, large complex eigenvalues are common. In log-space, these result in rotations:
$\widetilde {A}$
, large complex eigenvalues are common. In log-space, these result in rotations:
 \begin{equation} \log {x}_{i+1} = \sum _{j} \widetilde {A}_{i,\,j} \log {x}_{j}. \end{equation}
\begin{equation} \log {x}_{i+1} = \sum _{j} \widetilde {A}_{i,\,j} \log {x}_{j}. \end{equation}
However, upon exponentiation, (2.20) becomes:
 \begin{equation} {x}_{i+1} = \prod _{j} {x}_{j}^{\widetilde {A}_{i,\,j}}, \end{equation}
\begin{equation} {x}_{i+1} = \prod _{j} {x}_{j}^{\widetilde {A}_{i,\,j}}, \end{equation}
and the rotations in log-space result in spurious, nonphysical oscillations in linear space.
Instead, we formulate nonnegative DMD as the following:
Definition. Let
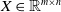 $X\in \mathbb{R}^{m\times n}$
and let
$X\in \mathbb{R}^{m\times n}$
and let
 $X_1$
,
$X_1$
,
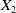 $X_2$
be snapshot matrices as defined in (2.11). We define the nonnegative DMD as the operator
$X_2$
be snapshot matrices as defined in (2.11). We define the nonnegative DMD as the operator
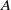 $A$
satisfying:
$A$
satisfying:
 \begin{equation} \mathop{\textrm{arg min}}\limits_A \| AX_1 - X_2\|_F,\,\,\,A_{i,\,j}\geq 0\,\,\forall i,\,j. \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_A \| AX_1 - X_2\|_F,\,\,\,A_{i,\,j}\geq 0\,\,\forall i,\,j. \end{equation}
In general, the solutions to (2.15) and (2.22) do not coincide. Let
 $A_{\textrm{LS}}\, :\!= \,X_2X_1^{\dagger}$
be the unconstrained DMD fit (2.13). Noting that:
$A_{\textrm{LS}}\, :\!= \,X_2X_1^{\dagger}$
be the unconstrained DMD fit (2.13). Noting that:
 \begin{equation} A_{LS} X_1 = X_2 \end{equation}
\begin{equation} A_{LS} X_1 = X_2 \end{equation}
and using the normal equations
 $A_{\textrm{LS}}X_1X_1^T=X_2X_1^{T}$
, we have for any
$A_{\textrm{LS}}X_1X_1^T=X_2X_1^{T}$
, we have for any
 $A$
:
$A$
:
 \begin{align} \begin{split} \|AX_1-X_2\|_F^2 &= \|(A-A_{\textrm{LS}})X_1 + (A_{\textrm{LS}}X_1-X_2)\|_F^2\\[5pt] &= \|(A-A_{\textrm{LS}})X_1\|_F^2 \\[5pt] &\qquad + 2\,\underbrace {\langle (A-A_{\textrm{LS}})X_1,\; A_{\textrm{LS}}X_1-X_2\rangle _F}_{=\,0} + \|A_{\textrm{LS}}X_1-X_2\|_F^2\\[5pt] &= \|(A-A_{\textrm{LS}})X_1\|_F^2 + \|A_{\textrm{LS}}X_1-X_2\|_F^2. \end{split} \end{align}
\begin{align} \begin{split} \|AX_1-X_2\|_F^2 &= \|(A-A_{\textrm{LS}})X_1 + (A_{\textrm{LS}}X_1-X_2)\|_F^2\\[5pt] &= \|(A-A_{\textrm{LS}})X_1\|_F^2 \\[5pt] &\qquad + 2\,\underbrace {\langle (A-A_{\textrm{LS}})X_1,\; A_{\textrm{LS}}X_1-X_2\rangle _F}_{=\,0} + \|A_{\textrm{LS}}X_1-X_2\|_F^2\\[5pt] &= \|(A-A_{\textrm{LS}})X_1\|_F^2 + \|A_{\textrm{LS}}X_1-X_2\|_F^2. \end{split} \end{align}
Note that the second term on the right-hand side above is independent of
 $A$
. Since
$A$
. Since
 $\|(A-A_{\textrm{LS}})X_1\|_F^2=\textrm{tr}\!\big ((A-A_{\textrm{LS}})X_1 X_1^T (A-A_{\textrm{LS}})^T\big )$
, problem (2.22) is the metric projection of
$\|(A-A_{\textrm{LS}})X_1\|_F^2=\textrm{tr}\!\big ((A-A_{\textrm{LS}})X_1 X_1^T (A-A_{\textrm{LS}})^T\big )$
, problem (2.22) is the metric projection of
 $A_{\textrm{LS}}$
onto the elementwise nonnegative cone
$A_{\textrm{LS}}$
onto the elementwise nonnegative cone
 $\{A:\,A\ge 0\}$
in the weighted inner product:
$\{A:\,A\ge 0\}$
in the weighted inner product:
 \begin{equation*} \langle U,V\rangle _{X_1} \; :\!= \; \textrm{tr}(U\,X_1 X_1^T\,V^T), \end{equation*}
\begin{equation*} \langle U,V\rangle _{X_1} \; :\!= \; \textrm{tr}(U\,X_1 X_1^T\,V^T), \end{equation*}
By contrast, (2.15) minimises
 \begin{equation*} \min _{M,N\ge 0}\ \|MN-A_{\textrm{LS}}\|_F^2, \end{equation*}
\begin{equation*} \min _{M,N\ge 0}\ \|MN-A_{\textrm{LS}}\|_F^2, \end{equation*}
that is, a projection of
 $A_{\textrm{LS}}$
onto the set
$A_{\textrm{LS}}$
onto the set
 \begin{equation*} \mathscr{S}_r\, :\!= \,\{MN:\; M\in \mathbb{R}_+^{m\times r},\ N\in \mathbb{R}_+^{r\times m}\}\end{equation*}
\begin{equation*} \mathscr{S}_r\, :\!= \,\{MN:\; M\in \mathbb{R}_+^{m\times r},\ N\in \mathbb{R}_+^{r\times m}\}\end{equation*}
under the standard Euclidean metric.
These two projections differ because the geometry induced by the data through
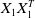 $X_1 X_1^T$
is not the Euclidean one. They coincide only in degenerate cases (e.g.
$X_1 X_1^T$
is not the Euclidean one. They coincide only in degenerate cases (e.g.
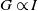 $G\propto I$
or
$G\propto I$
or
 $A_{\textrm{LS}}\ge 0$
); and, for (2.15), with
$A_{\textrm{LS}}\ge 0$
); and, for (2.15), with
 $r$
large enough to represent the same feasible
$r$
large enough to represent the same feasible
 $A$
. Practically, (2.15) fits
$A$
. Practically, (2.15) fits
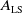 $A_{\textrm{LS}}$
in matrix space, ignoring how
$A_{\textrm{LS}}$
in matrix space, ignoring how
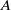 $A$
acts on
$A$
acts on
 $X_1$
, whereas (2.22) enforces nonnegativity directly on the forecasting loss
$X_1$
, whereas (2.22) enforces nonnegativity directly on the forecasting loss
 $\|AX_1-X_2\|_F$
, the quantity that matters for prediction.
$\|AX_1-X_2\|_F$
, the quantity that matters for prediction.
The computation of (2.22) is nontrivial. Note that well-known algorithms exist to solve the related matrix-vector nonnegative least squares (NNLS) problem: [Reference Lawson and Hanson52]:
 \begin{equation} \mathop{\textrm{arg min}}\limits_{{x}} \| A{x} - \boldsymbol{b} \|_2 \,\,\,x_{j}\geq 0\,\,\forall j. \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_{{x}} \| A{x} - \boldsymbol{b} \|_2 \,\,\,x_{j}\geq 0\,\,\forall j. \end{equation}
Problems related to (2.22), in which one searches for a nonnegative matrix, have been studied in [Reference Kim, Sra and Dhillon40, Reference Kim and Park41, Reference Nadisic, Cohen, Vandaele and Gillis58, Reference Van Benthem and Keenan73]. We remark that, in each of these cases, it is assumed that one has access to the matrix
 $A$
and is attempting to find
$A$
and is attempting to find
 $X_1$
, that is solving:
$X_1$
, that is solving:
 \begin{equation} \mathop{\textrm{arg min}}\limits_{X_1} \| AX_1 - X_2\|_F,\,\,\,X_{1_{i,\,j}}\geq 0\,\,\forall i,\,j. \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_{X_1} \| AX_1 - X_2\|_F,\,\,\,X_{1_{i,\,j}}\geq 0\,\,\forall i,\,j. \end{equation}
The DMD problem is the opposite, since
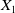 $X_1$
is known from the data and
$X_1$
is known from the data and
 $A$
is our unknown. However, recalling that
$A$
is our unknown. However, recalling that
 $\|M\|_F = \|M^T \|_F$
[Reference Golub and Van Loan28] for any matrix
$\|M\|_F = \|M^T \|_F$
[Reference Golub and Van Loan28] for any matrix
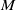 $M$
, the transposed problem:
$M$
, the transposed problem:
 \begin{equation} \mathop{\textrm{arg min}}\limits_{A^T} \|X_1^T A^T - X_2^T\|_F,\,\,\,A_{i,\,j}^T\geq 0\,\,\forall i,\,j \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_{A^T} \|X_1^T A^T - X_2^T\|_F,\,\,\,A_{i,\,j}^T\geq 0\,\,\forall i,\,j \end{equation}
is equivalent to (2.26). Note that:
 \begin{align} \begin{split} \|X_1^T A^T - X_2^T \|_F^2 &= \sum _{k=1}^{m} \|X_1^T (A_{k,1:m})^T-(X_{2\,\,k,1:(n-1)})^T\|_2^2 \end{split} \end{align}
\begin{align} \begin{split} \|X_1^T A^T - X_2^T \|_F^2 &= \sum _{k=1}^{m} \|X_1^T (A_{k,1:m})^T-(X_{2\,\,k,1:(n-1)})^T\|_2^2 \end{split} \end{align}
Let
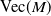 $\text{Vec}(M)$
denote the vector obtained of stacking the successive columns of a matrix
$\text{Vec}(M)$
denote the vector obtained of stacking the successive columns of a matrix
 $M$
on top of one another. Then, we can write (2.28) as:
$M$
on top of one another. Then, we can write (2.28) as:
 \begin{align} \begin{split} \|X_1^T A^T - X_2^T \|_F^2 &= \|(I \otimes X_1^T )\text{Vec}(A^T) - \text{Vec}(X_2^T)\|_2^2, \end{split} \end{align}
\begin{align} \begin{split} \|X_1^T A^T - X_2^T \|_F^2 &= \|(I \otimes X_1^T )\text{Vec}(A^T) - \text{Vec}(X_2^T)\|_2^2, \end{split} \end{align}
where
 $I$
is the identity matrix of appropriate dimension,
$I$
is the identity matrix of appropriate dimension,
 $\otimes$
denotes the Kronecker product. Note that (2.29) is a matrix-vector system. The problem (2.22) is therefore equivalent to the following matrix-vector NNLS problem:
$\otimes$
denotes the Kronecker product. Note that (2.29) is a matrix-vector system. The problem (2.22) is therefore equivalent to the following matrix-vector NNLS problem:
 \begin{equation} \mathop{\textrm{arg min}}\limits_{\text{Vec}(A^T)} \|(I \otimes X_1^T )\text{Vec}(A^T) - \text{Vec}(X_2^T)\|_2,\,\,\,\text{Vec}(A^T)_j\geq 0\,\,\forall j. \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_{\text{Vec}(A^T)} \|(I \otimes X_1^T )\text{Vec}(A^T) - \text{Vec}(X_2^T)\|_2,\,\,\,\text{Vec}(A^T)_j\geq 0\,\,\forall j. \end{equation}
Standard NNLS algorithms (see e.g. [Reference Lawson and Hanson52]) can be applied on (2.30). Converting
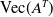 $\text{Vec}(A^T)$
back into matrix form and transposing, one obtains a solution to (2.22). For small problems, this approach is feasible, and it was used throughout the present.
$\text{Vec}(A^T)$
back into matrix form and transposing, one obtains a solution to (2.22). For small problems, this approach is feasible, and it was used throughout the present.
However, for high-dimensional data, or for datasets with many observations, the direct vectorisation approach may be untenable, due to the size of the resulting system, as the curse of dimensionality guarantees that a linear increase in the number of observations leads to quadratic increases in system size. In [Reference Nadisic, Cohen, Vandaele and Gillis58], the authors discuss several methods for solving matrix-matrix NNLS problems, including techniques that are strictly equivalent to (2.30), as well as techniques that seek sparse solutions to (2.26) directly. Note that the vectorised problem (2.30) has the structure:
 \begin{align} \mathop{\textrm{arg min}}\limits_{A} \bigg \| \left(\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} X_1^T & 0 & \ldots & 0 \\[5pt] 0 & X_1^T & \ldots & 0 \\[5pt] \vdots & \vdots & \ddots &\vdots \\[5pt] 0 & 0 & \ldots & X_1^T \end{array}\right) \left(\begin{array}{c}A_{(1,:)} \\[5pt] A_{(2,:)} \\[5pt] \vdots \\[5pt] A_{(m,:)}\end{array}\right) - \left(\begin{array}{c}X_{2\,(1,:)} \\[5pt] X_{2\,(2,:)} \\[5pt] \vdots \\[5pt] X_{2\,(m,:)}\end{array}\right)\bigg \|_2^2, \end{align}
\begin{align} \mathop{\textrm{arg min}}\limits_{A} \bigg \| \left(\begin{array}{c@{\quad}c@{\quad}c@{\quad}c} X_1^T & 0 & \ldots & 0 \\[5pt] 0 & X_1^T & \ldots & 0 \\[5pt] \vdots & \vdots & \ddots &\vdots \\[5pt] 0 & 0 & \ldots & X_1^T \end{array}\right) \left(\begin{array}{c}A_{(1,:)} \\[5pt] A_{(2,:)} \\[5pt] \vdots \\[5pt] A_{(m,:)}\end{array}\right) - \left(\begin{array}{c}X_{2\,(1,:)} \\[5pt] X_{2\,(2,:)} \\[5pt] \vdots \\[5pt] X_{2\,(m,:)}\end{array}\right)\bigg \|_2^2, \end{align}
and hence can be regarded
 $m$
independent NNLS problems:
$m$
independent NNLS problems:
 \begin{equation} \mathop{\textrm{arg min}}\limits_{A_{(k,:)}} \| X_1^T A_{(k,:)} - X_{2\,(k,:)} \|_2^2,\,A_{(k,\,j)} \geq 0\,\,\forall \,j. \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_{A_{(k,:)}} \| X_1^T A_{(k,:)} - X_{2\,(k,:)} \|_2^2,\,A_{(k,\,j)} \geq 0\,\,\forall \,j. \end{equation}
Since
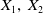 $X_1,\,X_2$
are known, and each
$X_1,\,X_2$
are known, and each
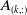 $A_{(k,:)}$
can be computed independently, (2.30) is easily parallelised. We remark that while the problems (2.30) and (2.32) are equivalent in theory, in practice, solutions to NNLS for underdetermined systems are not unique in general, and must be obtained through iterative procedures. The solutions obtained when solving the formulations (2.30) and (2.32) will, therefore, differ in practice. In the present, the authors observed that such differences were trivial; however, a comprehensive investigation of this issue was not pursued.
$A_{(k,:)}$
can be computed independently, (2.30) is easily parallelised. We remark that while the problems (2.30) and (2.32) are equivalent in theory, in practice, solutions to NNLS for underdetermined systems are not unique in general, and must be obtained through iterative procedures. The solutions obtained when solving the formulations (2.30) and (2.32) will, therefore, differ in practice. In the present, the authors observed that such differences were trivial; however, a comprehensive investigation of this issue was not pursued.
We remark that related work on a nonnegative DMD variant was pursued in [Reference Takeishi, Kawahara and Yairi71]. The formulation introduced in the present differs from [Reference Takeishi, Kawahara and Yairi71] in that we require that the approximated operator
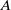 $A$
be strictly nonnegative, whereas the approach in [Reference Takeishi, Kawahara and Yairi71] requires only that the dynamic modes, or DMD eigenvectors, are nonnegative. However, as nonnegativity is not required for the corresponding DMD eigenvalues, the reconstructed DMD operator is not nonnegative in general. We note that this difference in formulation reflects the primary intended usage of each algorithm, as the approach in [Reference Takeishi, Kawahara and Yairi71] was developed principally for diagnostic purposes and dimension reduction, whereas the present algorithm is intended for usage in forecasting and extrapolation.
$A$
be strictly nonnegative, whereas the approach in [Reference Takeishi, Kawahara and Yairi71] requires only that the dynamic modes, or DMD eigenvectors, are nonnegative. However, as nonnegativity is not required for the corresponding DMD eigenvalues, the reconstructed DMD operator is not nonnegative in general. We note that this difference in formulation reflects the primary intended usage of each algorithm, as the approach in [Reference Takeishi, Kawahara and Yairi71] was developed principally for diagnostic purposes and dimension reduction, whereas the present algorithm is intended for usage in forecasting and extrapolation.
2.3.3. Application to PWDH age structure model
We use the time- and age-dependent mortality curves obtained with the EKI for the years 2009 – 22 to forecast the evolution of the PWDH population over the years 2023 – 30. For the years 2009 – 22, we solve the model (2.1), directly applying the
 $\mu (a,t)$
obtained through the EKI procedure.
$\mu (a,t)$
obtained through the EKI procedure.
To obtain mortality rates for the years 2023 – 30, we apply the nonnegative DMD algorithm outlined in section 2.3.2 defined as:
 \begin{align} {M} &= \mathop{\textrm{arg min}}\limits_{{M}} \| {M} \lbrack {\boldsymbol{\mu }}_{2009}\,{\boldsymbol{\mu }}_{2010}\,\ldots \,{\boldsymbol{\mu }}_{2018} \rbrack - \lbrack {\boldsymbol{\mu }}_{2010}\,{\boldsymbol{\mu }}_{2011}\,\ldots \,{\boldsymbol{\mu }}_{2019} \rbrack \|_F,\,\, {M} \geq 0, \end{align}
\begin{align} {M} &= \mathop{\textrm{arg min}}\limits_{{M}} \| {M} \lbrack {\boldsymbol{\mu }}_{2009}\,{\boldsymbol{\mu }}_{2010}\,\ldots \,{\boldsymbol{\mu }}_{2018} \rbrack - \lbrack {\boldsymbol{\mu }}_{2010}\,{\boldsymbol{\mu }}_{2011}\,\ldots \,{\boldsymbol{\mu }}_{2019} \rbrack \|_F,\,\, {M} \geq 0, \end{align}
where the notation
 ${M} \geq 0$
indicates that
${M} \geq 0$
indicates that
 $M$
is entry-wise nonnegative. The 2023 mortality rate is then defined as
$M$
is entry-wise nonnegative. The 2023 mortality rate is then defined as
 ${M} {\boldsymbol{\mu }}_{2022}$
, with the following years obtained by iterated multiplication by the
${M} {\boldsymbol{\mu }}_{2022}$
, with the following years obtained by iterated multiplication by the
 $M$
. We did not include the years 2020 – 22 in training the nonnegative DMD operator, as the jump in mortality rate due to COVID-19 likely represents a temporary jump in mortality, rather than a long-term trend, as indicated by preliminary 2023 mortality data returning to pre-COVID levels [Reference Ahmad, Cisewski and Anderson2].
$M$
. We did not include the years 2020 – 22 in training the nonnegative DMD operator, as the jump in mortality rate due to COVID-19 likely represents a temporary jump in mortality, rather than a long-term trend, as indicated by preliminary 2023 mortality data returning to pre-COVID levels [Reference Ahmad, Cisewski and Anderson2].
Similarly, we use nonnegative DMD to project age-structured annual new HIV diagnoses over the years 2023–30 as:
 \begin{equation} \boldsymbol{\Lambda } = \mathop{\textrm{arg min}}\limits_{\boldsymbol{\Lambda }} \| \boldsymbol{\Lambda } \lbrack \lambda _{2009}\,\lambda _{2010}\,\ldots \,\lambda _{2018} \rbrack - \lbrack \lambda _{2010}\,\lambda _{2011}\,\ldots \,\lambda _{2019} \rbrack \|_F,\,\,\boldsymbol{\Lambda }\geq 0. \end{equation}
\begin{equation} \boldsymbol{\Lambda } = \mathop{\textrm{arg min}}\limits_{\boldsymbol{\Lambda }} \| \boldsymbol{\Lambda } \lbrack \lambda _{2009}\,\lambda _{2010}\,\ldots \,\lambda _{2018} \rbrack - \lbrack \lambda _{2010}\,\lambda _{2011}\,\ldots \,\lambda _{2019} \rbrack \|_F,\,\,\boldsymbol{\Lambda }\geq 0. \end{equation}
As with mortality rates, we disregard the years 2020 – 22 in projecting HIV diagnoses, as available evidence suggests that the large drop in HIV diagnoses observed in 2020, followed by rebounds in 2021 and 2020, was primarily caused by disruption and subsequent recovery in HIV testing and diagnosis [Reference DiNenno17, Reference Viguerie, Song, Johnson, Lyles, Hernandez and Farnham78, Reference Viguerie, Song, Johnson, Lyles, Hernandez and Farnham79]. However, estimated underlying HIV incidence continued to follow the decreasing trends observed in the years immediately preceding the COVID-19 pandemic [25]. Therefore, the increases in HIV diagnoses observed in 2021 and 2022 likely reflect a recovery of diagnoses missed during 2020 due to reduced testing, rather than changes in HIV transmission. Hence, the pre-2019 trends in new HIV diagnoses are likely more reliable for informing future trends in new HIV diagnoses over the coming years.
2.3.4. Mathematical analysis
We provide a series of results that establish the key properties of nonnegative DMD. Although the results are presented in some generality, we assume some additional conditions on the underlying data, motivated by the specific problem studied in the present. Accordingly, they may not apply universally.
Letting
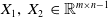 $X_1,\,X_2 \,\in \mathbb{R}^{m\times n-1}$
be as in (2.11), we assume additionally:
$X_1,\,X_2 \,\in \mathbb{R}^{m\times n-1}$
be as in (2.11), we assume additionally:
-
• Strict positivity:
(2.35)
\begin{align} {(X_1)_{i,\,j}\gt 0,\,(X_2)_{i,\,j}\gt 0\,\,\forall \,i,\,j} \end{align}
-
• Temporal regularity:
(2.36)
\begin{align} {(X_1)_{i,\,j} \lt 2 (X_2)_{i,\,j},\,\, (X_2)_{i,\,j} \lt 2(X_1)_{i,\,j}}. \end{align}


Both assumptions hold for the data
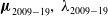 ${\boldsymbol{\mu }}_{2009-19},\,\lambda _{2009-19}$
used for (2.33), (2.34), respectively. The meaning of (2.35) is straightforward, and a similar assumption was employed in Theorem 1 in Section 2.1.1. Assumption (2.36) states that the local temporal variation at each observation point (age in the present document) must remain bounded, and should not more than double, or less than halve, from time-step to time-step (the factor of two is chosen for convenience). As DMD assumes underlying continuity in time [Reference Kutz, Brunton, Brunton and Proctor48, Reference Schmid67], (2.36) should hold for any data sufficiently well-resolved in time; in the absence of noise, it should be possible in principle, to obtain a time series satisfying (2.36) by increasing time-resolution of the measurements. However, we recognise that, in practice, time-series data is subject to limitations and (2.36) may not hold in general.
${\boldsymbol{\mu }}_{2009-19},\,\lambda _{2009-19}$
used for (2.33), (2.34), respectively. The meaning of (2.35) is straightforward, and a similar assumption was employed in Theorem 1 in Section 2.1.1. Assumption (2.36) states that the local temporal variation at each observation point (age in the present document) must remain bounded, and should not more than double, or less than halve, from time-step to time-step (the factor of two is chosen for convenience). As DMD assumes underlying continuity in time [Reference Kutz, Brunton, Brunton and Proctor48, Reference Schmid67], (2.36) should hold for any data sufficiently well-resolved in time; in the absence of noise, it should be possible in principle, to obtain a time series satisfying (2.36) by increasing time-resolution of the measurements. However, we recognise that, in practice, time-series data is subject to limitations and (2.36) may not hold in general.

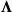
Proof. We provide a result for Problem (2.33), and note that an identical argument applies to (2.34). We prove contrapositive of the theorem statement, and show that if
 $M$
is a matrix containing only zeroes, it cannot be a solution of (2.33). For ease of notation, let:
$M$
is a matrix containing only zeroes, it cannot be a solution of (2.33). For ease of notation, let:
 \begin{equation} \widehat {{\boldsymbol{\mu }}}_{2009-18} = \lbrack {\boldsymbol{\mu }}_{2009}\,{\boldsymbol{\mu }}_{2010}\,\ldots \,{\boldsymbol{\mu }}_{2018} \rbrack ,\, \qquad \widehat {{\boldsymbol{\mu }}}_{2010-19}= \lbrack {\boldsymbol{\mu }}_{2010}\,{\boldsymbol{\mu }}_{2011}\,\ldots \,{\boldsymbol{\mu }}_{2019} \rbrack , \end{equation}
\begin{equation} \widehat {{\boldsymbol{\mu }}}_{2009-18} = \lbrack {\boldsymbol{\mu }}_{2009}\,{\boldsymbol{\mu }}_{2010}\,\ldots \,{\boldsymbol{\mu }}_{2018} \rbrack ,\, \qquad \widehat {{\boldsymbol{\mu }}}_{2010-19}= \lbrack {\boldsymbol{\mu }}_{2010}\,{\boldsymbol{\mu }}_{2011}\,\ldots \,{\boldsymbol{\mu }}_{2019} \rbrack , \end{equation}
and proceed by contradiction. Denote as
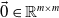 $\vec {0} \in \mathbb{R}^{m\times m}$
the
$\vec {0} \in \mathbb{R}^{m\times m}$
the
 $m \times m$
matrix whose entries are identically zero, and suppose that
$m \times m$
matrix whose entries are identically zero, and suppose that
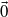 $\vec {0}$
solves (2.33). Then:
$\vec {0}$
solves (2.33). Then:
 \begin{equation} \| \vec {0} \widehat {{\boldsymbol{\mu }}}_{2009-18} - \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F = \| \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F \leq \| \boldsymbol{A} \widehat {{\boldsymbol{\mu }}}_{2009-18} - \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F \, \forall \boldsymbol{A}\geq 0. \end{equation}
\begin{equation} \| \vec {0} \widehat {{\boldsymbol{\mu }}}_{2009-18} - \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F = \| \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F \leq \| \boldsymbol{A} \widehat {{\boldsymbol{\mu }}}_{2009-18} - \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F \, \forall \boldsymbol{A}\geq 0. \end{equation}
Let
 $\boldsymbol{I}$
be the
$\boldsymbol{I}$
be the
 $m\times m$
identity matrix. Clearly
$m\times m$
identity matrix. Clearly
 $\boldsymbol{I}\geq 0$
. Observe that:
$\boldsymbol{I}\geq 0$
. Observe that:
 \begin{equation} \| \boldsymbol{I} \widehat {{\boldsymbol{\mu }}}_{2009-18} - \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F = \| \widehat {{\boldsymbol{\mu }}}_{2009-18} - \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F. \end{equation}
\begin{equation} \| \boldsymbol{I} \widehat {{\boldsymbol{\mu }}}_{2009-18} - \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F = \| \widehat {{\boldsymbol{\mu }}}_{2009-18} - \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F. \end{equation}
Squaring the right-hand side of (2.39) and applying the definition of the Frobenius norm gives:
 \begin{align} \begin{split} \sum _{j=2009}^{2018} \| {\boldsymbol{\mu }}_{j} - {\boldsymbol{\mu }}_{j+1} \|_2^2 &= \sum _{j=2009}^{2018} \sum _{i=1}^m (\mu _{i,\,j} - \mu _{i,\,j+1})^2 \\[5pt] &= \sum _{j=2009}^{2018} \sum _{i=1}^m \mu _{i,\,j}^2 + \mu _{i,\,j+1}^2 - 2\mu _{i,\,j}\mu _{i,\,j+1} \\[5pt] &\lt \sum _{j=2009}^{2018} \sum _{i=1}^m 2 \mu _{i,\,j}\mu _{i,\,j+1} + \mu _{i,\,j+1}^2 - 2\mu _{i,\,j}\mu _{i,\,j+1} \\[5pt] &= \sum _{j=2009}^{2018} \sum _{i=1}^m \mu _{i,\,j+1}^2 \\[5pt] &= \| \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F^2, \end{split} \end{align}
\begin{align} \begin{split} \sum _{j=2009}^{2018} \| {\boldsymbol{\mu }}_{j} - {\boldsymbol{\mu }}_{j+1} \|_2^2 &= \sum _{j=2009}^{2018} \sum _{i=1}^m (\mu _{i,\,j} - \mu _{i,\,j+1})^2 \\[5pt] &= \sum _{j=2009}^{2018} \sum _{i=1}^m \mu _{i,\,j}^2 + \mu _{i,\,j+1}^2 - 2\mu _{i,\,j}\mu _{i,\,j+1} \\[5pt] &\lt \sum _{j=2009}^{2018} \sum _{i=1}^m 2 \mu _{i,\,j}\mu _{i,\,j+1} + \mu _{i,\,j+1}^2 - 2\mu _{i,\,j}\mu _{i,\,j+1} \\[5pt] &= \sum _{j=2009}^{2018} \sum _{i=1}^m \mu _{i,\,j+1}^2 \\[5pt] &= \| \widehat {{\boldsymbol{\mu }}}_{2010-19} \|_F^2, \end{split} \end{align}
where the third line follows from the temporal regularity assumption (2.36). From (2.40), it follows that:
 \begin{equation} \| \boldsymbol{I} {\boldsymbol{\mu }}_{2009-18} - {\boldsymbol{\mu }}_{2010-19} \|_F \lt \| {\boldsymbol{\mu }}_{2010-19} \|_F = \| \vec {0}\, {\boldsymbol{\mu }}_{2009-18} - {\boldsymbol{\mu }}_{2010-19} \|_F, \end{equation}
\begin{equation} \| \boldsymbol{I} {\boldsymbol{\mu }}_{2009-18} - {\boldsymbol{\mu }}_{2010-19} \|_F \lt \| {\boldsymbol{\mu }}_{2010-19} \|_F = \| \vec {0}\, {\boldsymbol{\mu }}_{2009-18} - {\boldsymbol{\mu }}_{2010-19} \|_F, \end{equation}
contradicting (2.38), implying that the zero matrix cannot be a solution of (2.34), as was to be shown.
Interpretation in terms of the Perron-Frobenius operator. In this portion of the article, we provide an interpretation of nonnegative DMD in terms of the Perron-Frobenius (P-F) operator. We note that numerical methods for the P-F operator have been studied in other settings [Reference Bollt and Santitissadeekorn9, Reference Ding, Du and Li18, Reference Klus, Koltai and Schütte44, Reference Klus and Schütte46]. DMD is generally interpreted as a numerical approximation of the Koopman operator, the adjoint of the P-F operator [Reference Brunton, Budisic, Kaiser and Kutz12, Reference Kutz, Brunton, Brunton and Proctor48]. Roughly speaking, the Koopman operator acts on functions of the system state (commonly called observables), while the P-F operator acts on densities of the system state.
Since the P-F and Koopman operators are adjoint, one can use either to describe a given dynamical system [Reference Lasota and Mackey51]. Nonetheless, the literature on the numerical approximation of the two operators is somewhat distinct. Literature on the approximation of the P-F operator tends to focus on Ulam’s method and its variants [Reference Bollt and Santitissadeekorn9, Reference Ding, Du and Li18, Reference Ding and Li19, Reference Ermann and Shepelyansky21, Reference Junge and Koltai38, Reference Klus, Koltai and Schütte44], while the approximation of the Koopman operator focuses on DMD and its variants [Reference Alla, Monti and Sgura4, Reference Brunton, Budisic, Kaiser and Kutz12, Reference Colbrook, Ayton and Szőke15, Reference Kutz, Brunton, Brunton and Proctor48, Reference Proctor and Eckhoff62]. Note that this statement is only a broad, general characterisation, and several works discuss the approximation of both operators [Reference Klus43–Reference Klus, Nüske and Koltai45] and/or hybrid-type approaches incorporating aspects of both DMD and Ulam’s method [Reference Colbrook14, Reference Goswami, Thackray and Paley29].
In the following, we describe why, in the context of the present work, and problem (2.33) in particular, the P-F operator provides a natural interpretation. We remark that a full description of the P-F and Koopman operators is beyond the scope of the current work, and we recommend that the reader consult [Reference Klus43] for a comprehensive discussion of the numerical approximation of the P-F and Koopman operators, and [Reference Lasota and Mackey51] for the underlying theory. We note that this description is not, nor is intended to be, fully rigorous. Rather, it is intended as an intuitive explanation for the nonnegative DMD formulation used herein, and how it differs from other common DMD approaches within the context of Koopman/P-F theory.
Consider a measure space defined by the three-tuple
 $\mathcal{M}\, :\!= \,(\mathbb{A},\mathfrak{B}, \nu )$
where
$\mathcal{M}\, :\!= \,(\mathbb{A},\mathfrak{B}, \nu )$
where
 $\mathbb{A}=\mathbb{R}^+ = \lbrack 0,\,\infty )$
, the nonnegative real numbers, is the space of possible ages,
$\mathbb{A}=\mathbb{R}^+ = \lbrack 0,\,\infty )$
, the nonnegative real numbers, is the space of possible ages,
 $\mathfrak{B}$
is a
$\mathfrak{B}$
is a
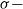 $\sigma -$
algebra on
$\sigma -$
algebra on
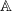 $\mathbb{A}$
and
$\mathbb{A}$
and
 $\nu$
the Lebesgue measure. Let
$\nu$
the Lebesgue measure. Let
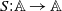 $S:\mathbb{A}\to \mathbb{A}$
be a measurable mapping which advances the age of the population. For simplicity and without the loss of generality, we assume
$S:\mathbb{A}\to \mathbb{A}$
be a measurable mapping which advances the age of the population. For simplicity and without the loss of generality, we assume
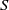 $S$
advances age forward one unit; hence,
$S$
advances age forward one unit; hence,
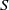 $S$
moves a member of the population aged
$S$
moves a member of the population aged
 $a$
to age
$a$
to age
 $a+1$
. For simplicity, we disregard new entries
$a+1$
. For simplicity, we disregard new entries
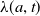 $\lambda (a,t)$
for the moment.
$\lambda (a,t)$
for the moment.
Let
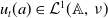 $u_t(a) \in \mathcal{L}^1(\mathbb{A},\,\nu )$
describe the population distribution at time
$u_t(a) \in \mathcal{L}^1(\mathbb{A},\,\nu )$
describe the population distribution at time
 $t$
, with an initial datum
$t$
, with an initial datum
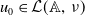 $u_0\in \mathcal{L}(\mathbb{A},\,\nu )$
assumed known. We define the support of
$u_0\in \mathcal{L}(\mathbb{A},\,\nu )$
assumed known. We define the support of
 $u_t$
as:
$u_t$
as:
 \begin{equation} \text{supp} (u_t)\, :\!= \, \{ a\in \mathbb{A} | u_t(a)\neq 0\}. \end{equation}
\begin{equation} \text{supp} (u_t)\, :\!= \, \{ a\in \mathbb{A} | u_t(a)\neq 0\}. \end{equation}
Since human lifespans are finite, we may assume:
 \begin{equation} \nu ( \text{supp} (u_t))\lt \infty . \end{equation}
\begin{equation} \nu ( \text{supp} (u_t))\lt \infty . \end{equation}
at all
 $t$
.
$t$
.
Since
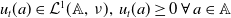 $u_t(a) \in \mathcal{L}^1(\mathbb{A},\,\nu ),\,u_t(a)\geq 0 \,\forall \,a\in \mathbb{A}$
, we may also define the population measure
$u_t(a) \in \mathcal{L}^1(\mathbb{A},\,\nu ),\,u_t(a)\geq 0 \,\forall \,a\in \mathbb{A}$
, we may also define the population measure
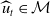 $\widehat {u}_t\in \mathcal{M}$
:
$\widehat {u}_t\in \mathcal{M}$
:
 \begin{equation} \widehat {u}_t(X) = \int _X u_t(a) da, \,\,\,X\in \mathfrak{B}. \end{equation}
\begin{equation} \widehat {u}_t(X) = \int _X u_t(a) da, \,\,\,X\in \mathfrak{B}. \end{equation}
Define the three-tuple
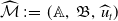 $\widehat {\mathcal{M}}\, :\!= \, (\mathbb{A},\,\mathfrak{B},\,\widehat {u}_t)$
and let
$\widehat {\mathcal{M}}\, :\!= \, (\mathbb{A},\,\mathfrak{B},\,\widehat {u}_t)$
and let
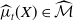 $\widehat {\mu }_t(X) \in \widehat {\mathcal{M}}$
be the mortality measure at a time
$\widehat {\mu }_t(X) \in \widehat {\mathcal{M}}$
be the mortality measure at a time
 $t$
, measuring the number of deaths in the age-set
$t$
, measuring the number of deaths in the age-set
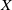 $X$
of the population
$X$
of the population
 $u$
at time
$u$
at time
 $t$
. Clearly, if
$t$
. Clearly, if
 $\widehat {u}_t(X)=0$
for some
$\widehat {u}_t(X)=0$
for some
 $X\in \mathfrak{B}$
, then
$X\in \mathfrak{B}$
, then
 $\widehat {\mu }_t(X)=0$
and hence, by the Radon-Nikodym theorem [Reference Lasota and Mackey51], there exists a density function
$\widehat {\mu }_t(X)=0$
and hence, by the Radon-Nikodym theorem [Reference Lasota and Mackey51], there exists a density function
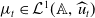 $\mu _t \in \mathcal{L}^1(\mathbb{A},\,\widehat {u}_t)$
such that:
$\mu _t \in \mathcal{L}^1(\mathbb{A},\,\widehat {u}_t)$
such that:
 \begin{equation} \widehat {\mu }_t(X) = \int _X \mu _t(a) \widehat {u}_t(da) = \int _X \mu _t(a) u_t(a) da, \,\,\,X\in \mathfrak{B}. \end{equation}
\begin{equation} \widehat {\mu }_t(X) = \int _X \mu _t(a) \widehat {u}_t(da) = \int _X \mu _t(a) u_t(a) da, \,\,\,X\in \mathfrak{B}. \end{equation}
We note that the algorithm 1 reconstructs discrete represenations
 ${\boldsymbol{\mu }}_t$
of the density
${\boldsymbol{\mu }}_t$
of the density
 $\mu _t(a)$
above, and not of the measure
$\mu _t(a)$
above, and not of the measure
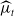 $\widehat {\mu }_t$
. From the Riesz Representation Theorem [Reference Lasota and Mackey51], there is a linear operator
$\widehat {\mu }_t$
. From the Riesz Representation Theorem [Reference Lasota and Mackey51], there is a linear operator
 $\psi _t(u)$
on the dual space of
$\psi _t(u)$
on the dual space of
 $\mathcal{L}^1(\mathbb{A},\nu )$
such that for any
$\mathcal{L}^1(\mathbb{A},\nu )$
such that for any
 $u\in \mathcal{L}^1(\mathbb{A},\nu )$
:
$u\in \mathcal{L}^1(\mathbb{A},\nu )$
:
 \begin{equation} \psi _t(u) \, :\!= \, \int _0^\infty u(a) \widehat {\mu }_t(da) = \int _0^\infty u(a) \mu _t(a) da = (u,\,\mu _t)= \widehat {\mu }_t(\mathbb{A}), \end{equation}
\begin{equation} \psi _t(u) \, :\!= \, \int _0^\infty u(a) \widehat {\mu }_t(da) = \int _0^\infty u(a) \mu _t(a) da = (u,\,\mu _t)= \widehat {\mu }_t(\mathbb{A}), \end{equation}
where
 $(\cdot ,\,\cdot )$
indicates the scalar product.
$(\cdot ,\,\cdot )$
indicates the scalar product.
We now recall that our nonnegative DMD operator
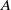 $A$
is recovered as the solution of:
$A$
is recovered as the solution of:
 \begin{equation} \mathop{\textrm{arg min}}\limits_{A^T} \|X_1^T A^T - X_2^T\|_F,\,\,\,A_{i,\,j}^T\geq 0\,\,\forall i,\,j. \end{equation}
\begin{equation} \mathop{\textrm{arg min}}\limits_{A^T} \|X_1^T A^T - X_2^T\|_F,\,\,\,A_{i,\,j}^T\geq 0\,\,\forall i,\,j. \end{equation}
For the sake of concreteness, suppose we are considering the mortality rate-recovery problem (2.33). Then, the matrices
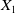 $X_1$
and
$X_1$
and
 $X_2$
have the structures:
$X_2$
have the structures:
 \begin{align} X_1^T = \left(\begin{matrix} {\boldsymbol{\mu }}_{2009}^T\\[5pt]{\boldsymbol{\mu }}_{2010}^T \\[5pt] \vdots \\[5pt]{\boldsymbol{\mu }}_{2018}^T \end{matrix}\right), \qquad X_2^T = \left(\begin{matrix} {\boldsymbol{\mu }}_{2010}^T \\[5pt]{\boldsymbol{\mu }}_{2011}^T \\[5pt]\vdots\\[5pt] {\boldsymbol{\mu }}_{2019}^T \end{matrix}\right). \end{align}
\begin{align} X_1^T = \left(\begin{matrix} {\boldsymbol{\mu }}_{2009}^T\\[5pt]{\boldsymbol{\mu }}_{2010}^T \\[5pt] \vdots \\[5pt]{\boldsymbol{\mu }}_{2018}^T \end{matrix}\right), \qquad X_2^T = \left(\begin{matrix} {\boldsymbol{\mu }}_{2010}^T \\[5pt]{\boldsymbol{\mu }}_{2011}^T \\[5pt]\vdots\\[5pt] {\boldsymbol{\mu }}_{2019}^T \end{matrix}\right). \end{align}
Heuristically, we may regard the discrete expression
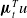 ${\boldsymbol{\mu }}_{t}^T u$
as an analogue of:
${\boldsymbol{\mu }}_{t}^T u$
as an analogue of:
 \begin{equation} {\boldsymbol{\mu }}_t^T u \approx \int _0^\infty u(a) \widehat {\mu }_t(da) = (u,\,\mu _t)= \psi _t(u). \end{equation}
\begin{equation} {\boldsymbol{\mu }}_t^T u \approx \int _0^\infty u(a) \widehat {\mu }_t(da) = (u,\,\mu _t)= \psi _t(u). \end{equation}
Following a similar intuition as used in (2.49), we note that the expression:
 \begin{equation} (A X_1 )^T u = X_2^Tu \end{equation}
\begin{equation} (A X_1 )^T u = X_2^Tu \end{equation}
is a discrete analogue of:
 \begin{equation} (u,\,A\mu _t) = (u,\,\mu _{t+1}) \end{equation}
\begin{equation} (u,\,A\mu _t) = (u,\,\mu _{t+1}) \end{equation}
which, together with (2.46):
 \begin{equation} \psi _{t+1}(u)= (u,\mu _{t+1}) = (u,A\mu _t) = (A^* u ,\mu _t) =\psi _{t}(A^* u ) = A\psi _t (u). \end{equation}
\begin{equation} \psi _{t+1}(u)= (u,\mu _{t+1}) = (u,A\mu _t) = (A^* u ,\mu _t) =\psi _{t}(A^* u ) = A\psi _t (u). \end{equation}
Consequently, the nonnegative DMD operator can be interpreted as an approximation of the Perron-Frobenius operator applied to the mortality measures
 $\widehat {\mu }_t$
(or their related densities concerning the population measure), thereby evolving them over time [Reference Lasota and Mackey51]. By employing NNLS to compute
$\widehat {\mu }_t$
(or their related densities concerning the population measure), thereby evolving them over time [Reference Lasota and Mackey51]. By employing NNLS to compute
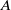 $A$
, we ensure that the projected
$A$
, we ensure that the projected
 $\mu _t$
remain on the positive cone and in
$\mu _t$
remain on the positive cone and in
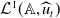 $\mathcal{L}^1(\mathbb{A},\widehat {u}_t)$
for every
$\mathcal{L}^1(\mathbb{A},\widehat {u}_t)$
for every
 $t$
. In other words, nonnegative DMD guarantees that densities are transformed into densities, as desired.
$t$
. In other words, nonnegative DMD guarantees that densities are transformed into densities, as desired.
3. Results
3.1. Reconstruction of age-dependent PWDH mortality curves, 2009 – 22
By applying the Kalman Inversion procedure outlined in the previous section, we observe a strong agreement with the data in Figure 2. This figure illustrates the age distribution of mortality for each year, juxtaposing real data (top panel) with simulated mortality (bottom panel). The simulated and observed mortality are in agreement both qualitatively and quantitatively. We provide the full numerical comparison against surveillance data, each year and age bracket, in Table A1 in an appendix at the end of the main text.

Figure 2. The comparison of surveillance (top) and simulated (bottom) mortality.

Figure 3. Annual probability of mortality at a given age, in time. Note the consistent decrease in time, punctuated by increases in the upper age ranges in 2020–22 caused by the COVID-19 pandemic.

Figure 4. Mortality curves by age for several years, plotted side-by-side. The left panel shows mortality probability over the entire age range; the right panel focuses more closely on the important 40–80 age range.
In Figure 3, we depict the annual mortality rate per age class over time. The colour scale ranges from
 $0.005$
(dark blue) to
$0.005$
(dark blue) to
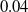 $0.04$
(red). This visualisation indicates a trend of decreasing annual mortality, evidenced by the expanding blue regions from 2010 to 2022. However, we note that at the beginning of the COVID-19 pandemic (2020), this trend slows somewhat, and mortality rates increases slightly. The red and yellow regions, which correspond to mortality rates at older ages, also show a strong diminishing trend in time until the beginning of the COVID-19 pandemic. The results suggest that the COVID-19 pandemic caused mortality rates across the 55 + age cohorts over the years 2020–21 to revert approximately to their approximate 2013 levels [26, Reference Viguerie, Song, Bosh, Lyles and Farnham77].
$0.04$
(red). This visualisation indicates a trend of decreasing annual mortality, evidenced by the expanding blue regions from 2010 to 2022. However, we note that at the beginning of the COVID-19 pandemic (2020), this trend slows somewhat, and mortality rates increases slightly. The red and yellow regions, which correspond to mortality rates at older ages, also show a strong diminishing trend in time until the beginning of the COVID-19 pandemic. The results suggest that the COVID-19 pandemic caused mortality rates across the 55 + age cohorts over the years 2020–21 to revert approximately to their approximate 2013 levels [26, Reference Viguerie, Song, Bosh, Lyles and Farnham77].
In Figure 4, we depict several age-dependent mortality curves for individual years, over the entire age range (left panel), and focusing on the important 40 – 80 age range (right panel). Mortality decreases throughout the entire age range; however, as noted previously, these trends reverse in 2020, and mortality rates over the years 2020–21 increase among the 55 + cohort to levels similar to 2013–16. The 2022 rates show the effects of COVID subsiding among the 55 + cohort, with mortality rates consistent with levels observed during the years 2016 – 19 among PWDH aged 55–75, and at their lowest rates ever for PWDH aged 75 +. However, we note that, even during the peak years of COVID-19 in 2020–21, mortality among older PWDH was still lower than 2010 levels, which suggests that the effects driving the decreases in mortality risk among PWDH over the past 15 years were more significant, on net, than the effects of the COVID-19 pandemic on PWDH mortality.
3.2. Nonnegative DMD forecasting validation
In this subsection, we provide a brief study comparing the suitability of nonnegative DMD in forecasting the evolution of age-dependent PWDH mortality.
3.2.1. Test setup
We consider the reconstructed age-dependent mortality rates used in the main text. We use the reconstructed years 2009–16 as training data, and then compare the forecasts with the reconstructed data over the window 2017–19. We compare the following forecasting algorithms:
-
(1) Standard DMD, defined as (2.13) in the main text;
-
(2) Nonnegative matrix factorisation DMD, defined as (2.15) in the main text;
-
(3) Nonnegative DMD, defined as (2.22) in the main text;
-
(4) Log-exp DMD, defined as (2.16), (2.17) in the main text;
-
(5) Naive approach, which simply uses the reconstructed age-dependent mortality for the year 2016 for each subsequent year 2017 – 19.
We evaluate each forecasting method by comparing the relative
 $L^2$
error of the forecasted mortality curve
$L^2$
error of the forecasted mortality curve
 ${\boldsymbol{\mu }}_{j}^F$
to the reconstructed curve
${\boldsymbol{\mu }}_{j}^F$
to the reconstructed curve
 ${\boldsymbol{\mu }}_j$
for each year
${\boldsymbol{\mu }}_j$
for each year
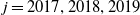 $j=2017, 2018, 2019$
.
$j=2017, 2018, 2019$
.
3.2.2. Numerical results
In figure 5, we plot the forecasts for each method, for each year, over the period 2017 – 19. As expected, the NNMF DMD (2.15) produces noisy, nonphysical extrapolations. Standard DMD (2.13) shows oscillatory behaviour and poor accuracy. The log-exp DMD approach (2.16) provides more accurate forecasts than standard or NNMF DMD; however, by 2019, oscillations appear, degrading forecasting accuracy. In contrast, nonnegative DMD (2.22) produces stable forecasts over the entire time period. In Table 1, we report the relative
 $L^2$
error for each forecasting method, for each year, which confirm that nonnegative DMD provides more accurate forecasts.
$L^2$
error for each forecasting method, for each year, which confirm that nonnegative DMD provides more accurate forecasts.

Figure 5. Comparison of data-driven forecasts against surveillance reconstructions, 2017–19 (left-to-right). We observe that nonnegative DMD provides the most consistently accurate, and stable reconstructions.
Table 1. Comparison of
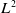 $L^2$
error for age-dependent mortality rates for different algorithms (trained through 2016; forecast 2017 – 19)
$L^2$
error for age-dependent mortality rates for different algorithms (trained through 2016; forecast 2017 – 19)

In Figure 6, we show the 10-year forecast for different DMD variants, as well as the naive approach. While data are not available to evaluate accuracy, we observe that the nonnegative DMD (2.22) is notably more plausible compared to the alternative approaches. Both standard DMD (2.13) and the log-exp DMD (2.16) exhibit nonphysical, implausible oscillations. The NNMF-based approach (2.15) is no longer visible due to the oscillations and blowup. Hence, we confirm that nonnegative DMD (2.22), in addition to being more accurate over short time horizons, is also robust over longer time horizons.

Figure 6. Comparison of the different mortality forecasting approaches over a 10-year time horizon. We observe that nonnegative DMD produces less oscillatory forecasts when projected over longer timeframes. In contrast, standard DMD and log-exp approaches are prone to nonphysical oscillation.

Figure 7. Projection of age-dependent mortality through 2030. The maximum eigenvector is the asymptotic limit of the projected future age-dependent PWDH mortality.
3.3. Forecasting PWDH mortality, new diagnoses and PWDH population age-structure, 2023-30
3.3.1. Future PWDH mortality
In order to forecast the evolution of the mortality rate per age-class, we employ the nonnegative DMD as described in Section 2.3.3. In Figure 7, we depict the annual age-dependent probability of mortality for the years 2022, 2024, 2026, 2028 and 2030. The nonnegative DMD algorithm forecasts mortality rates to continue decreasing substantially in the 40 – 55 age range, with annual mortality projected to decrease 15.6% in this age group from 2022 to 2030. Among PWDH aged 55 – 75, we also project future decreases in mortality, however, these are comparatively modest, decreasing approximately 7.5% from 2022 to 2030. For PWDH aged 75 to 90, mortality is projected to decrease approximately 15.6% from 2022 to 2030.
Analysing the spectrum of
 $M$
, we find that it has a unique maximum eigenvalue
$M$
, we find that it has a unique maximum eigenvalue
 $\xi _1 = \rho ({M})= 1$
(consistent with the interpretation of
$\xi _1 = \rho ({M})= 1$
(consistent with the interpretation of
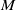 $M$
as an approximation of the P-F operator [Reference Klus43, Reference Lasota and Mackey51]), with second-largest eigenvalue
$M$
as an approximation of the P-F operator [Reference Klus43, Reference Lasota and Mackey51]), with second-largest eigenvalue
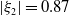 $|\xi _2|=0.87$
. We denote the corresponding eigenvectors as
$|\xi _2|=0.87$
. We denote the corresponding eigenvectors as
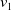 ${v}_1$
and
${v}_1$
and
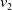 ${v}_2$
, respectively, and express
${v}_2$
, respectively, and express
 ${\boldsymbol{\mu }}_{2022}$
as a linear combination of the eigenvectors
${\boldsymbol{\mu }}_{2022}$
as a linear combination of the eigenvectors
 ${v}_i$
of
${v}_i$
of
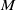 $M$
:
$M$
:
 \begin{equation} {\boldsymbol{\mu }}_{2022}=\sum _i a_i {v}_i. \end{equation}
\begin{equation} {\boldsymbol{\mu }}_{2022}=\sum _i a_i {v}_i. \end{equation}
Observe that:
 \begin{equation} \lim _{k\to \infty } {M}^k{\boldsymbol{\mu }}_{2022} = 1^k a_1 {v}_1 + 0.87^k a_2 {v}_2 + \sum _{i\geq 3} \xi _i^k a_i {v}_i = a_1 {v}_1, \end{equation}
\begin{equation} \lim _{k\to \infty } {M}^k{\boldsymbol{\mu }}_{2022} = 1^k a_1 {v}_1 + 0.87^k a_2 {v}_2 + \sum _{i\geq 3} \xi _i^k a_i {v}_i = a_1 {v}_1, \end{equation}
since
 $|\xi _i| \leq .8909 \lt 1,\,\forall i\geq 3$
.
$|\xi _i| \leq .8909 \lt 1,\,\forall i\geq 3$
.
The eigenvector
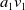 $a_1 {v}_1$
of
$a_1 {v}_1$
of
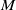 $M$
corresponding to
$M$
corresponding to
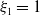 $\xi _1=1$
thus gives a long-term projection for the asymptotic age-dependent PWDH mortality rate, with age-dependent PWDH mortality converging to
$\xi _1=1$
thus gives a long-term projection for the asymptotic age-dependent PWDH mortality rate, with age-dependent PWDH mortality converging to
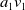 $a_1{v}_1$
like
$a_1{v}_1$
like
 $.87^t$
. We plot this eigenvector as ‘Max eigenvector’ in Figure 7. As the figure shows, beyond 2030, mortality among PWDH is projected to decrease significantly among PWDH aged 35 – 55 older than 80, and moderately among PWDH aged 60 – 80. We note that these forecasts are based on pre-2019 trends in PWDH mortality and hence cannot account for any changes beyond those pre-existing trends. As such, these forecasts, especially the asymptotic limit, should be interpreted with caution.
$.87^t$
. We plot this eigenvector as ‘Max eigenvector’ in Figure 7. As the figure shows, beyond 2030, mortality among PWDH is projected to decrease significantly among PWDH aged 35 – 55 older than 80, and moderately among PWDH aged 60 – 80. We note that these forecasts are based on pre-2019 trends in PWDH mortality and hence cannot account for any changes beyond those pre-existing trends. As such, these forecasts, especially the asymptotic limit, should be interpreted with caution.
Remark. As
 $M$
is nonnegative, if it is additionally irreducible, then we can guarantee that
$M$
is nonnegative, if it is additionally irreducible, then we can guarantee that
 ${v}_1$
has strictly positive entries from the Perron-Frobenius theorem. However, establishing irreducibility for a general
${v}_1$
has strictly positive entries from the Perron-Frobenius theorem. However, establishing irreducibility for a general
 $M$
is difficult, given the lack of a closed-form expression. Nonetheless, our experiments over an ensemble of
$M$
is difficult, given the lack of a closed-form expression. Nonetheless, our experiments over an ensemble of
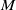 $M$
consistently showed that
$M$
consistently showed that
 $M$
has a unique maximum eigenvalue of 1, with a strictly positive corresponding eigenvector (we note that the spectral gap varied across the different
$M$
has a unique maximum eigenvalue of 1, with a strictly positive corresponding eigenvector (we note that the spectral gap varied across the different
 $M$
).
$M$
).
3.3.2. Future HIV diagnoses
To forecast future new HIV diagnoses by age, we employed the nonnegative DMD algorithm on the age-depdendent diagnosis data as in (2.34). These data were defined using NCHHSTP surveillance data [26]. New HIV diagnoses are projected to decrease at approximately 3% per year, declining to approximately 28,000 new diagnoses in 2030. Furthermore, the age structure of new HIV diagnoses is not projected to show significant change in the coming years. We depict both the number and percentage of new HIV diagnoses by age group in Figure 8.

Figure 8. Projection of age-dependent HIV diagnoses through 2030. We project a slight decrease in overall diagnoses, with approximately 28,000 new HIV diagnoses in 2030 (compared to 34,500 in 2023).
3.3.3. PWDH population age structure, 2023–30
Using projected PWDH mortality (2.33) and projected new HIV diagnoses (2.34), we solve the system (2.1) through year-end 2030 to project the evolution of the PWDH age-structure over the years 2023-30.
The total PWDH population is projected to grow over the simulation period, increasing to 1,160,000 by the end of 2030. As a whole, the PWDH population is also projected to age significantly and rapidly in the coming years. At year-end 2024, an estimated 42.5% of PWDH were 55 and older, 19.4% 65 and older and 4.2% 75 and older. By year-end 2030, we project the percentage of PWDH over 55 to increase to 47.% and those over 65 to 26.1%. The percentage of PWDH over 75 is projected to more than double over a five year span, reaching 8.5%, by the end of 2030. This information is depicted in Figure 9.

Figure 9. Projection of the PWDH age structure in the United States through 2030. We observe a gradual ageing of the PWDH population. By 2030, 48.6% of the PWDH population is projected to be over 55 and 27.4% over 65.
We remark, however, that not all age groups are projected to increase uniformly. As discussed in the previous subsections, future PWDH mortality rates are projected to decrease, however, such decreases are vary heavily with age. Conversely, while new HIV diagnoses are expected to decrease, the projected age distribution does not show significant change. By 2030, this results in the formation of a bimodal-like population PWDH age distribtution, in which there are fewer PWDH approximately aged 50 compared to either age 40 and age 60 (Figure 10).

Figure 10. Evolution of the PWDH population age structure over the years 2012–2030. By year-end 2030, we see a bimodal distribution forming, with more PWDH around age 40 and age 60, as compared to PWDH around age 50.
4. Discussion
In the present work, we have examined age-dependent data on PWDH in the United States to better understand how the developments over the previous 15 years have changed the age structure of the PWDH population in the United States and, furthermore, what implications these changes may have going forward. Starting with a simple age-structured population model, we used an EnKF Inversion, together with discrete age-structured HIV surveillance data, to reconstruct age-dependent PWDH mortality over the years 2008–22. We found that, due to the widespread availability of effective ART, mortality has declined significantly among PWDH since 2008, particularly among PWDH aged 40–80 years. While this trend reversed somewhat among PWDH aged 55 and older in 2021–22 due to the COVID-19 pandemic, data from 2022 suggest that COVID effects have subsided, likely signalling a return to pre-COVID trends.
We then developed a novel variant of DMD, nonnegative DMD, to develop projections of future changes in PWDH mortality and diagnoses. Projections of future PWDH mortality rates suggest that PWDH mortality will continue to decrease in the coming years, with the largest decreases expected among PWDH aged 40–55 and those older than 80. While mortality rates are expected to decrease among other age groups as well, smaller decreases are projected. We note that these projections assume a continuation of pre-existing trends, and cannot account for major changes in the coming years, such as medical breakthroughs.
Our projections of future HIV diagnoses suggest a slow, but notable, decrease in annual HIV diagnoses going forward, with around 28,000 diagnoses projected in 2030. Interestingly, our methods did not indicate a major change in the age structure of new HIV diagnoses, which has remained largely static in recent years, and is projected to remain so.
Applying our reconstructed and projected mortality and diagnosis data to our core PWDH age model, we then projected the age structure of the PWDH population over the coming years. Our simulations suggest that the PWDH population will age significantly. By 2030, the percentage of PWDH aged 55 years and older is expected to increase significantly (from 40% to 47.4%). Furthermore, these increases are more dramatic for older age groups; the percentage of PWDH aged 65 and older is expected to increase to 26.1% by 2030, and the portion of those aged 75 years and older is expected to more than double by 2030.
We note that the analysis is subject to several important limitations. As previously mentioned, the projections of future changes in PWDH mortality and diagnoses assume continuation of pre-existing trends. It is possible that new medical technologies may alter the landscape of HIV prevention and care significantly. This is particularly important for new HIV diagnoses, as improvements such as rapid expansion of pre-exposure prophylaxis (PrEP) coverage or increased levels of viral suppression (e.g. due to long-acting injectable ART [Reference Viguerie, O’Shea and Johnston76]), may result in fewer new HIV diagnoses than projected [Reference Eisinger and Fauci20]. Furthermore, new HIV diagnoses were modelled as a linear source term, and any dependence on the PWDH age structure is assumed to be captured implicitly via any trends present in the data. However, the relationship between new the quantity and age distribution of new HIV diagnoses and the current PWDH population state may be more complex, and future modelling efforts should seek to better explore and define this relationship.
Crucially, the current analysis represents only a first step towards developing comprehensive models for ageing in the PWDH population. Future extensions should include other aspects of HIV prevention and care. For example, beyond biological age, time since acquiring HIV infection and time on ART may also be important factors in determining risk for certain comorbidities. Other extensions, including demographic stratification, may be similarly significant.
The techniques used for data-driven mortality forecasting used herein, while effective capturing the relevant dynamics, are not particularly interpretable, limiting their usefulness outside of forecasting. In reality, distinct processes underlie these dynamics: ART uptake/adherence, stigma/social determinants of health, as well as all the same trends driving increased longevity in the general population. Techniques such as those shown in [Reference Ichinaga, Brunton, Aravkin and Kutz36] may potentially be used to identify and distinguish the different processes underlying these dynamics. Such information is crucial for model-informed intervention planning.
On the mathematical end, further analysis of nonnegative DMD is necessary. In the present work, we introduced the basics of the method and provided some elementary results for the current problem, as well as some intuitive arguments. Given the application-oriented nature of the current work, we elected to leave further exploration to future research. However, it is important to properly formalise how nonnegative DMD fits within the larger family of DMD methods. More rigorous analysis is necessary to establish when certain conditions observed in the current analysis, such as the existence of a limiting eigenvector with an associated simple eigenvalue of 1, can be expected to hold. Finally, developing more sophisticated and efficient computational approaches for nonnegative DMD, particularly those that exploit its parallelizability, are important for extending its application to larger-scale problems.
Our analysis highlights the urgent need to prepare for the ageing population of PWDH. Current data suggest that PWDH are more vulnerable to ageing-related comorbidities, requiring that the healthcare system be properly equipped to handle the potential rapid increase in such health conditions. Furthermore, in the case of preventable age-related comorbidities, the current analysis also emphasises the need to develop and implement prevention programmes to help reduce potential burden on the healthcare system as much as possible. Urgency is necessary, as model projections show that the portion of PWDH aged 75 and older will more than double over a five-year span. Beyond HIV care, using mathematical models to account for ageing populations is an important direction for research in public health, and its importance is likely to increase in importance in the coming years.
Acknowledgments
The authors would like to acknowledge Stefan Klus, Matthew Colbrook, Nicolas Nadisic, Siobhan O‘Connor, Paul G. Farnham, Dr. John Brooks, and Ruiguang Song for their helpful input and advice. The authors are the members of the INDAM GNCS (Italian National Group of Scientific Calculus).
Funding statement
E. Iacomini is partially supported by the Italian Research Center on High-Performance Computing, Big Data and Quantum Computing (ICSC) funded by MUR Missione 4-Next Generation EU (NGEU) [Spoke 1 ‘Future HPC & Big Data’].
Competing interest
The authors declare none.
Appendix A. Full quantitative comparison with surveillance data
Table A1. PWDH deaths by age bracket: surveillance vs simulation (2009–2022)

Appendix B. The Ensemble Kalman Inversion
The Ensemble Kalman Inversion (EKI) is a derivative-free iterative algorithm designed for solving inverse problems. It originates from the Ensemble Kalman Filter (EnKF), widely used in data assimilation, but is adapted to estimate parameters rather than states. The key idea is to evolve an ensemble of candidate solutions toward the minimiser of a least-squares functional by updating them with information from the data misfit.
A typical inverse problem in finite dimension reads as:
 \begin{equation} y=\mathscr{G}(u)+\eta \end{equation}
\begin{equation} y=\mathscr{G}(u)+\eta \end{equation}
where
 $\mathscr{G}$
is the (possible nonlinear) forward operator between the finite dimensional spaces
$\mathscr{G}$
is the (possible nonlinear) forward operator between the finite dimensional spaces
 $X={\mathbb{R}}^d$
and
$X={\mathbb{R}}^d$
and
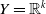 $Y={\mathbb{R}}^k$
with
$Y={\mathbb{R}}^k$
with
 $d,k\in \mathbb{N}$
,
$d,k\in \mathbb{N}$
,
 $u \in X$
is the unknown parameter,
$u \in X$
is the unknown parameter,
 $y\in Y$
is the observation and
$y\in Y$
is the observation and
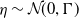 $\eta \sim \mathcal{N}(0,\Gamma )$
is the observational noise where
$\eta \sim \mathcal{N}(0,\Gamma )$
is the observational noise where
 $\Gamma$
is a known covariance measurements, the observation and the mathematical model
$\Gamma$
is a known covariance measurements, the observation and the mathematical model
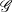 $\mathscr{G}$
, we are interested in finding the corresponding control
$\mathscr{G}$
, we are interested in finding the corresponding control
 $u$
. The EKI aims to solve a least–square formulation of the inverse problem and produces
$u$
. The EKI aims to solve a least–square formulation of the inverse problem and produces
 $u^*$
such that
$u^*$
such that
 \begin{equation} u^*=argmin_{u \in X} \frac {1}{2} \lvert \lvert \Gamma ^{-\frac {1}{2}} (y-\mathscr{G}(u))\rvert \rvert ^2 \end{equation}
\begin{equation} u^*=argmin_{u \in X} \frac {1}{2} \lvert \lvert \Gamma ^{-\frac {1}{2}} (y-\mathscr{G}(u))\rvert \rvert ^2 \end{equation}
through a sequentially update of each member of an ensemble
 $k=1,\ldots ,K$
of elements
$k=1,\ldots ,K$
of elements
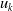 $u_k$
in the space
$u_k$
in the space
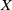 $X$
by means of the Kalman update formula, using the knowledge of the model
$X$
by means of the Kalman update formula, using the knowledge of the model
 $\mathscr{G}$
and given observational data
$\mathscr{G}$
and given observational data
 $y$
. The method is gradient free and even for small number of ensembles
$y$
. The method is gradient free and even for small number of ensembles
 $K$
satisfactory results have been reported. Assume a fixed value of
$K$
satisfactory results have been reported. Assume a fixed value of
 ${\lambda } \in \Lambda$
. The EnKF samples
${\lambda } \in \Lambda$
. The EnKF samples
 $J\gt 0$
initial values
$J\gt 0$
initial values
 $u^{j,0}({\lambda } ) \in X$
and advances those according to the following equations. For a convergence analysis and stability properties we refer e.g. to [67]. Denote by
$u^{j,0}({\lambda } ) \in X$
and advances those according to the following equations. For a convergence analysis and stability properties we refer e.g. to [67]. Denote by
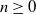 $n\ge 0$
the iteration index and
$n\ge 0$
the iteration index and
 $\Delta t \gt 0$
an artificial time step. We indicate the set of ensembles by
$\Delta t \gt 0$
an artificial time step. We indicate the set of ensembles by
 $U^n({\lambda } )=\{u^n \}_{j=1}^J$
. The set is propagated according to
$U^n({\lambda } )=\{u^n \}_{j=1}^J$
. The set is propagated according to
 \begin{equation} u_j^{n+1}=u_j^{n}+ C(U^n)\left ( D(U^n) + \frac {1}{\Delta t} \Gamma ^{-1} \right )^{-1}\left [ y_j^{n+1} -\mathscr{G}(u^{n}) \right ] \end{equation}
\begin{equation} u_j^{n+1}=u_j^{n}+ C(U^n)\left ( D(U^n) + \frac {1}{\Delta t} \Gamma ^{-1} \right )^{-1}\left [ y_j^{n+1} -\mathscr{G}(u^{n}) \right ] \end{equation}
where
 $C(U^n)$
and
$C(U^n)$
and
 $D(U^n)$
are the covariance matrices depending on the ensemble set
$D(U^n)$
are the covariance matrices depending on the ensemble set
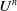 $U^n$
at the iteration
$U^n$
at the iteration
 $n$
and on
$n$
and on
 $\mathscr{G}(U^n)$
:
$\mathscr{G}(U^n)$
:
 \begin{align} C(U^n)=& \frac {1}{J}\sum _{j=1}^J(u_j^{n}-\bar {U}^n)\otimes (\mathscr{G}(u_j^{n} )-\bar {\mathscr{G}}),\\[-6pt]\nonumber \end{align}
\begin{align} C(U^n)=& \frac {1}{J}\sum _{j=1}^J(u_j^{n}-\bar {U}^n)\otimes (\mathscr{G}(u_j^{n} )-\bar {\mathscr{G}}),\\[-6pt]\nonumber \end{align}
 \begin{align} D(U^n)=& \frac {1}{J}\sum _{j=1}^J \left [\mathscr{G}(u_j^n)- \bar {\mathscr{G}}\right ]\otimes \left [\mathscr{G}(u_j^n)- \bar {\mathscr{G}}\right ],\\[-6pt]\nonumber \end{align}
\begin{align} D(U^n)=& \frac {1}{J}\sum _{j=1}^J \left [\mathscr{G}(u_j^n)- \bar {\mathscr{G}}\right ]\otimes \left [\mathscr{G}(u_j^n)- \bar {\mathscr{G}}\right ],\\[-6pt]\nonumber \end{align}
 \begin{align} \bar {U}^n&\, :\!= \,\frac {1}{J}\sum _{k=1}^J u_j^{n}, \; \bar {\mathscr{G}}\, :\!= \,\frac {1}{J}\sum _{k=1}^J \mathscr{G}(u_j^{n}). \end{align}
\begin{align} \bar {U}^n&\, :\!= \,\frac {1}{J}\sum _{k=1}^J u_j^{n}, \; \bar {\mathscr{G}}\, :\!= \,\frac {1}{J}\sum _{k=1}^J \mathscr{G}(u_j^{n}). \end{align}
Convergence results can be found in [Reference Schmid67, Reference Herty and Visconti34, Reference Herty, Iacomini and Visconti33] and the reference therein.
















 Open access
Open access