

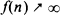 as
as  .
.Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Agrawal, R.
1992.
Adaptive control of i.i.d. processes and Markov chains on a compact control set.
p.
2752.
Agrawal, Rajeev
1995.
Sample mean based index policies byO(logn) regret for the multi-armed bandit problem.
Advances in Applied Probability,
Vol. 27,
Issue. 4,
p.
1054.
Duncan, T. E.
Pasik-Duncan, B.
and
Stettner, L.
1998.
Discretized Maximum Likelihood and Almost Optimal Adaptive Control of Ergodic Markov Models.
SIAM Journal on Control and Optimization,
Vol. 36,
Issue. 2,
p.
422.