




Survey experiments have become increasingly common in political science as tools to study events where real-world data are scarce or difficult to observe. Although survey experiments offer a time and cost-effective means of data generation, scholars have raised questions about their use and limitations (Hyde Reference Hyde2015; Barabas and Jerit Reference Barabas and Jerit2010). As a result, a growing stream of scholarship explores whether and how experiment design – particularly the content and structure of vignettes – affects experimental outcomes and external validity. Some research has focused on vignette format, assessing whether experiments featuring longer simulations of news articles yield different outcomes from those featuring shorter narratives (Kreps and Roblin Reference Kreps and Roblin2019). Other studies have examined whether the degree of abstraction in experiment vignettes affects outcomes (Dafoe, Zhang, and Caughey Reference Dafoe, Zhang and Caughey2018; Brutger et al. Reference Brutger, Joshua Kertzer, Tingley and Weiss2021). Still other projects analyze whether video formatting or the degree of humor affect outcomes (Young et al. Reference Young, Hall Jamieson, Poulsen and Goldring2018). These studies offer valuable insights but overlook important questions about the visual presentation of information. Does a vignette that is modeled to look like a real-world source, like a newspaper article or a politician’s Tweet, result in different levels of respondent attentiveness or produce different substantive outcomes than traditional plain text surveys?
As graphic design services and software become more readily accessible, political scientists – as well as communication and psychology scholars – have increasingly incorporated realistic depictions of newspaper articles, social media posts and misinformation, and media reports into surveys (Dill, Sagan, and Valentino Reference Dill, Sagan and Valentino2022; Smetana, Vranka, and Rosendorf Reference Smetana, Vranka and Rosendorf2023; Green-Riley, Kruszewska-Eduardo, and Fu Reference Green-Riley, Kruszewska-Eduardo and Fu2021; Bode and Vraga Reference Bode and Vraga2015). We call such depictions contextually realistic graphics. While these lifelike representations may more closely mirror real-world stimuli than the text-based scenario narratives found in most survey instruments, political scientists have yet to fully explore whether realistic graphic design affects survey outcomes. Instead, most existing research on graphics studies whether evocative imagery affects various political outcomes (Gadarian Reference Gadarian2014; Green-Riley, Kruszewska-Eduardo, and Fu Reference Green-Riley, Kruszewska-Eduardo and Fu2021). Yet, as scholars consider enhancing the realism of experimental designs, understanding whether and how treatment formatting affects outcomes becomes ever more important.
In this note, we aim to make a methodological contribution that helps political scientists navigate survey design. We field three original survey experiments that vary whether a vignette is presented as plain text or as a contextually realistic graphic – either of a presidential tweet, a leaked government document, or a newspaper article. We find that, on average, vignette format has little effect either on substantive outcomes or on retention of key details. To be sure, our experiments feature three specific contexts, limiting the generalizations we can draw from our findings. Consistency in findings across the three experiments, however, suggests that researchers need not devote the time or resources to develop contextually realistic graphics for their experiments.
Contextual realism and survey design
As survey experiments have become more common in political science, some scholars have questioned whether accurate inferences about the real world can be drawn from experiments involving text-based, hypothetical scenarios (Hyde Reference Hyde2015; Barabas and Jerit Reference Barabas and Jerit2010; Egami and Hartman Reference Egami and Hartman2022). In response, some researchers have recommended that scholars carefully craft experimental vignettes to be as realistic as possible using language and imagery that places the vignette in the proper context – in a way that approximates real-world settings (Aguinis and Bradley Reference Aguinis and Bradley2014; Alekseev, Charness, and Gneezy Reference Alekseev, Charness and Gneezy2017; McDonald Reference McDonald2020). Steiner et al. summarize the logic of contextual realism proponents, writing that “highly contextualized vignettes increase the construct validity, that is, the degree to which the vignettes measure what we intend to measure” (Steiner et al. Reference Steiner, Atzmüller and Su2017, 54).
However, a wave of recent scholarship casts doubt on whether contextual realism actually affects survey outcomes (Sauer, Auspurg, and Hinz Reference Sauer, Auspurg and Hinz2020; Shamon, Dülmer, and Giza Reference Shamon, Dülmer and Giza2019). Kreps and Roblin (Reference Kreps and Roblin2019) find that presenting vignette text as a mock news story or as plain text does not affect respondents’ opinions of support for conflict. More generally, Brutger et al. (Reference Brutger, Joshua Kertzer, Tingley and Weiss2021) conclude that respondents typically provide similar responses regardless of whether a survey features abstract or highly realistic vignettes. In short, the debate over whether contextual realism affects substantive outcomes remains unresolved.
Several elements associated with contextual realistic treatments might moderate substantive outcomes. Past research has studied variations in vignette length and framing (Kreps and Roblin Reference Kreps and Roblin2019), level of vignette detail (Brutger et al. Reference Brutger, Joshua Kertzer, Tingley and Weiss2021), and vignette specificity (Dafoe, Zhang, and Caughey Reference Dafoe, Zhang and Caughey2018), there has been less attention on a vignette’s graphic design. On one hand, an experimental treatment’s graphical realism could affect respondent engagement in ways that shape substantive outcomes. For instance, a treatment that more realistically captures real-world stimuli might more fully engage participants, bolstering their buy-in and the amount of thought they dedicate to answering questions (McDermott Reference McDermott2002). In turn, this could produce stronger treatment effects compared to plain text vignettes. Alternately, more complex realistic graphical representations could be more cognitively taxing for respondents (Skulmowski and Rey Reference Skulmowski and Rey2020), leading to decreased attentiveness and weaker treatment effects.
On the other hand, a treatment’s graphical realism might have little effect on substantive outcomes. Because graphical representation only affects whether treatments are presented in a visually realistic manner versus plain text (i.e., respondents receive identical information), there may be no difference in how respondents receive the treatment. In other words, graphical realism may not moderate treatment effects. Given the findings of recent studies on vignette format and abstraction (Kreps and Roblin Reference Kreps and Roblin2019; Brutger et al. Reference Brutger, Joshua Kertzer, Tingley and Weiss2021), we predict that there will be no difference in substantive outcomes between respondents who see a contextually realistic graphic and those who see plain text.
H 1 : The graphical realism of survey experiment vignette presentation will have no significant effect on substantive outcomes.
While we predict graphical realism will have no effect on substantive outcomes, we theorize that it might affect the retention of details about the vignette. A long tradition of pedagogical and psychology research suggests greater realism and immersion in learning result in improved memorization and retention (Joseph and Dwyer Reference Joseph and Dwyer1984; Vasu and Howe Reference Vasu and Howe1989). Although these studies offer several explanations for why realism boosts information retention, there is widespread agreement that more realistic and immersive experiences engage participants more than less immersive, traditional approaches (Chittaro and Buttussi Reference Chittaro and Buttussi2015; Di Natale et al. Reference Di Natale, Repetto, Riva and Villani2020; Hamilton et al. Reference Hamilton, McKechnie, Edgerton and Wilson2021). Moreover, the use of imagery rather than text alone is thought to engage multiple cognitive subsystems, potentially aiding with information recall (Schnotz Reference Schnotz2001). In sum, respondents presented with contextually realistic graphics are likely to spend more time examining and internalizing the information presented than respondents presented solely with text. Therefore, we predict that respondents who see a contextually realistic graphic are more likely to recall specific details of the vignette than those who see plain text.
H 2 : Survey experiment respondents are likely to demonstrate greater retention of details from an experimental vignette when the vignette is realistically presented versus presented as plain text.
To be sure, some studies suggest that immersive or graphics-intense experiences can lead to cognitive overload and stymie respondent performance (Skulmowski and Rey Reference Skulmowski and Rey2020). While this may be a risk with highly immersive and interactive experiences such as scenarios involving virtual reality, it is likely less of a risk given that our experiments do not involve the degree of immersion associated with virtual or augmented reality.
Method
To assess whether vignette format affects outcomes, we turn to three original survey experiments of hypothetical international crises that vary whether the survey instrument presents a contextually realistic graphic or plain text. We focus on crises because international relations scholars routinely use survey experiments to study public or elite preferences during international diplomatic or military confrontations (Tomz Reference Tomz2007; Tomz, Weeks, and Yarhi-Milo Reference Tomz, Weeks and Yarhi-Milo2020), but we believe the experiments should yield insights applicable to a range of substantive topics.
Our first experiment presents respondents with a hypothetical, but plausible, crisis between the United States and Iran. All respondents are told:
Over the past several months, the Iranian government has provided funding, training, and weapons to militia groups that have launched several attacks on U.S. forces and partners throughout the Middle East. Earlier this week, Iranian-backed militias attacked two oil tankers in the Red Sea that were transporting fuel to the United States and fired rockets at the U.S. Embassy in Yemen. The attacks caused significant damage to the oil tankers and the embassy and killed eight people, including one American.
Respondents are then informed that “President Biden made his first statement about the situation” by issuing a tweet. We randomly assign respondents to one of two conditions in which respondents receive either a contextually realistic graphic of the tweet (Figure 1) or a plain text description that includes identical language. The simulated tweet replicates the layout and features of an actual tweet, including details such as the date, time, retweet information, and like and comment buttons.Footnote 2 In contrast, the plain text treatment includes only the president’s statement. We then ask a series of questions about perceived credibility, crisis realism, support for the president, and several attention checks.
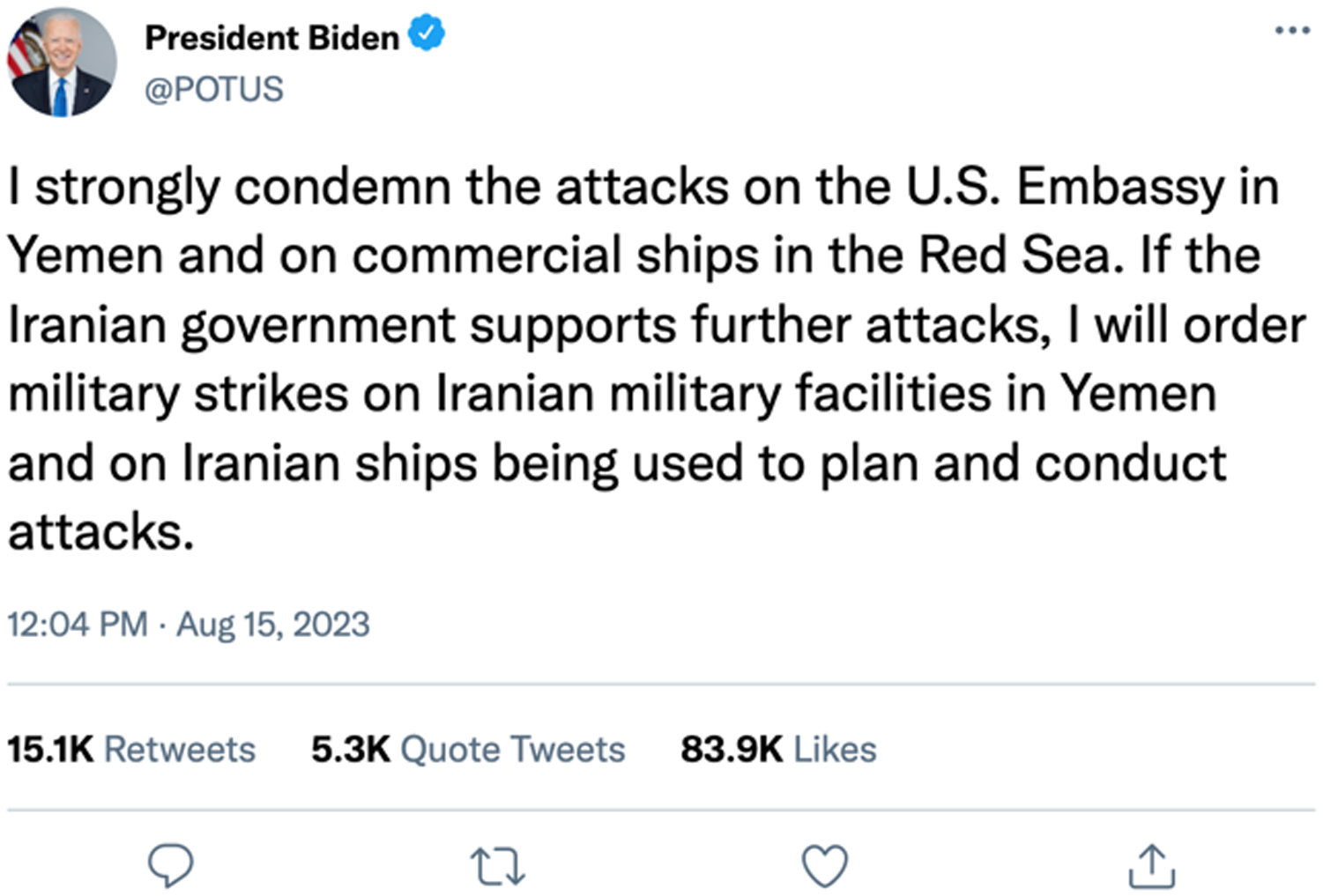
Figure 1. Contextually realistic tweet graphic treatment.
In the second experiment, we test the effect of graphical realism in a different context: a hypothetical leak of a U.S. Intelligence Community Assessment (ICA) regarding Russia and Syria. In this experiment, all respondents are told:
Last week, a document labeled as an official United States Intelligence Community Assessment began circulating on the internet. The U.S. government has neither confirmed nor denied the document’s authenticity, but the document highlights previously unknown Russian involvement in Syrian government chemical weapons attacks perpetrated against civilians in 2017.
As before, respondents are then randomly assigned to a contextually realistic graphic treatment (Figure 2) or a plain text treatment. The simulated graphic mimics key characteristics of an actual ICA such as the official seal and a serial number, while not including classification markings (e.g., “Top Secret”) as federal regulations govern their use.

Figure 2. Contextually realistic ICA graphic treatment.
For our third experiment, we replicate an experiment from Press et al.’s Reference Press, Sagan and Valentino2013 “Atomic Aversion” article (Press, Sagan, and Valentino Reference Press, Sagan and Valentino2013). In their original experiment, Press et al. presented respondents with vignettes styled like newspaper articles to test public attitudes toward nuclear weapons use. The experiment told respondents to consider a potential nuclear or conventional U.S. strike on an Al Qaeda nuclear lab and varied the relative effectiveness of the conventional or nuclear option. Press et al. (Reference Press, Sagan and Valentino2013, 202) find that Americans “appear to weigh the consequences of using nuclear weapons in the narrow terms of immediate military effectiveness,” rejecting the idea that the public has internalized a nuclear taboo.
In our replication, we repeat Press et al.’s original variation and include additional experimental manipulations: whether respondents see a newspaper-styled article (as in the original experiment) or plain text.Footnote 3 We present the nuclear advantage newspaper article in Figure 3. This design allows us to test the effect of graphical realism with difference-and-difference analysis by comparing the effect of the newspaper treatments among respondents who were told nuclear weapons were more effective than conventional weapons with respondents who were told nuclear weapons were equally effective. In other words, this experiment allows us to explore whether contextually realistic graphics moderate substantive outcomes in a widely cited study.Footnote 4 To assess factors that might moderate treatment, we ask respondents to directly assess cognitive load, enjoyment, and interest.

Figure 3. Long, nuclear advantage, contextually realistic treatment.
We fielded the first two experiments on a U.S. public sample of 1,511 respondents recruited using the online sampling service Lucid Theorem in June 2023. Lucid relies on quota sampling to recruit samples that align with U.S. Census demographics. Lucid samples, however, are not nationally representative across all dimensions. For instance, our sample underrepresents Hispanic Americans while overrepresenting college-educated Americans.Footnote 5 Still, Lucid samples are more representative than other online convenience samples, like Amazon’s MechanicalTurk (Coppock and McClellan Reference Coppock and McClellan2019). We fielded the third experiment on a U.S. public sample of 1,793 respondents recruited on the Prolific platform in November 2023. Recent studies suggest Prolific samples offer higher data quality (Peer et al. Reference Peer, David Rothschild, Evernden and Damer2022; Douglas, Ewell, and Brauer Reference Douglas, Ewell and Brauer2023). Still, Prolific samples are not perfectly representative. Our Prolific sample, for example, overrepresents Black Americans and underrepresents top wage earners.
Findings
Experiment 1: tweeting threats
H1: substantive outcomes
In our Twitter experiment, we measure four substantive outcomes: respondent’s perceptions of (1) crisis realism (i.e., whether a crisis involving threats made on Twitter could happen in the real world), (2) the perceived likelihood that Iranian officials will believe the threat, (3); support for the president’s handling of the threat and (4) perceived credibility of the president’s threat.Footnote 6 We use a 5-point Likert scale to measure respondent perceptions. For example, to measure credibility, we ask respondents “In your opinion, how likely or unlikely is it that the president will follow through on his threat?” on a five-point scale between “very unlikely” (1) and “very likely” (5). We run ordinary least squares regressions without (model 1) and with (model 2) demographic covariates. The average treatment effects are presented in Figure 4.Footnote 7
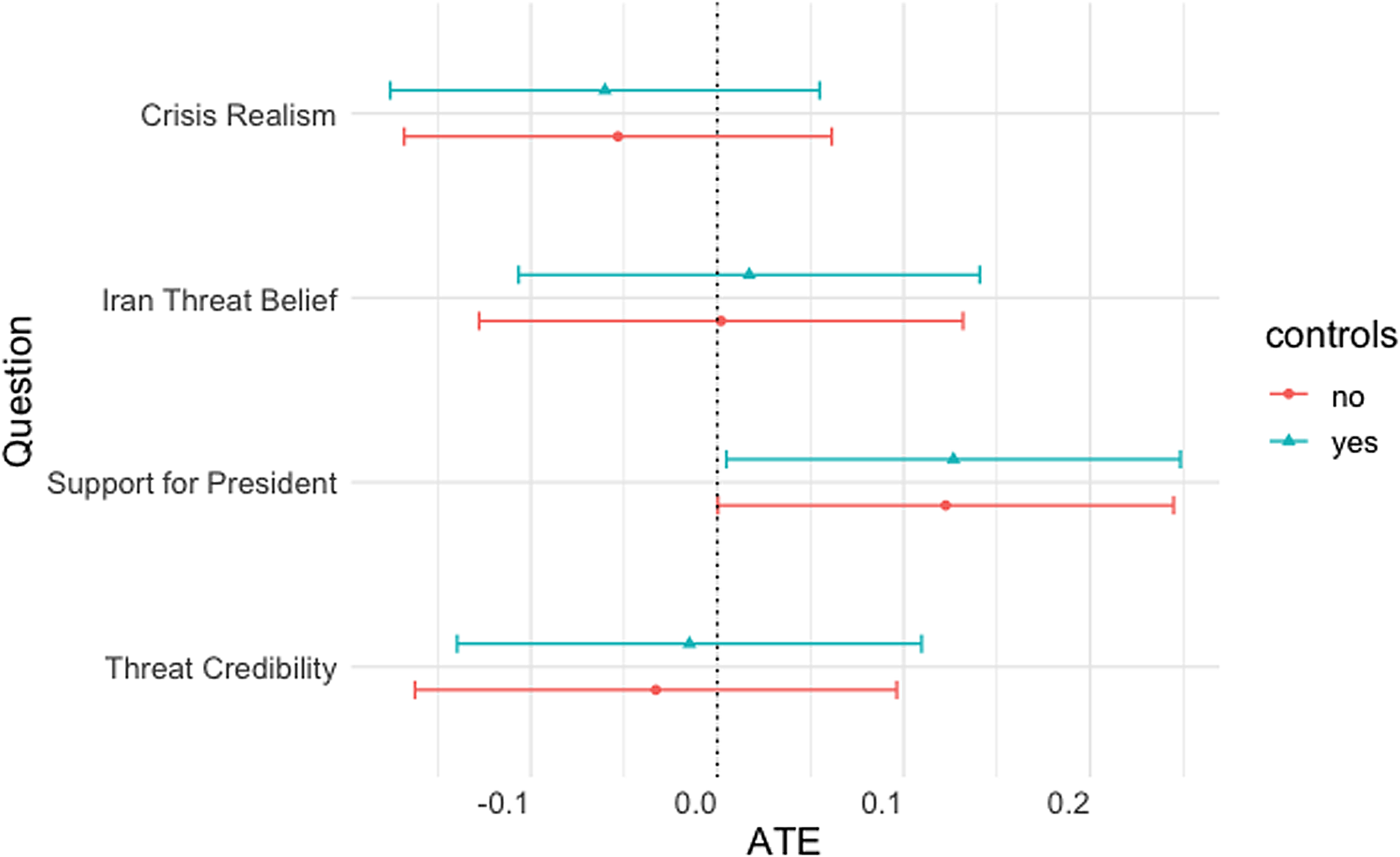
Figure 4. Average treatment effect of tweet graphic (substantive questions). Error bars represent 95% confidence intervals.
We find general support for H 1 .Footnote 8 Our results reveal no causal effects for three of our variables – threat credibility, the likelihood Iranian officials believe the threat, and crisis realism. However, we do have an unexpected result: respondents in the Tweet graphic treatment are more likely to express support for the president’s handling of the crisis than respondents in the plain text treatment.
Substantively, the effect size is small but noticeable given the relatively weak treatment manipulation. However, given that our analysis for this experiment includes regressions for four substantive variables and four attention check/timing variables, it would not be surprising to find at least one statistically significant result simply through chance.Footnote 9 To assess whether this unexpected finding was replicable, we repeated the experiment on a different 1,206 respondent Lucid sample. While the coefficient for presidential support remains positive, we find no statistically significant causal effect (p = 0.26), suggesting the initial finding occurred by chance.Footnote 10
H2: information retention
In addition to substantive outcomes, we examine whether contextually realistic graphics affect respondents’ attentiveness and information retention. To do this, our survey instrument tracks the time respondents spend reading the treatment and includes three attention check (AC) questions that ask respondents to recall details of the crisis scenario: the sea in which the oil tankers were attacked (“sea check”), the country supporting the militias (“support check”), and the target of the militia attacks (“target check”). Surprisingly, we find no support for H 2 : there are no statistically significant differences between the graphically realistic tweet and the plain text treatment for our attention check questions and for the time spent reading the treatment.Footnote 11 The average treatment effect for all AC questions is shown in Figure 5. Put differently, more realistic treatments do not appear to enhance information retention.
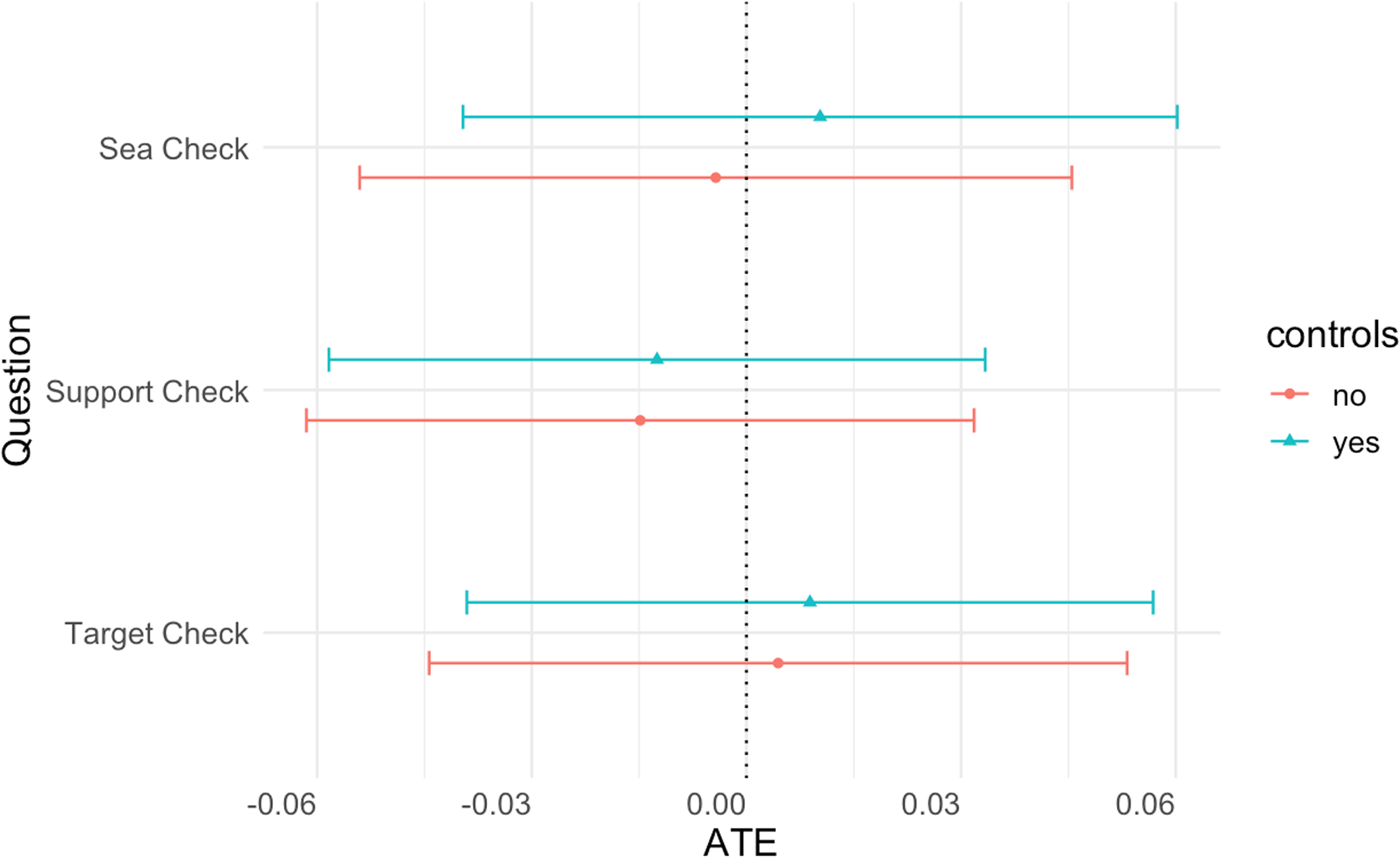
Figure 5. Average treatment effect of tweet graphic (AC questions). Error bars represent 95% confidence intervals.
Experiment 2: leaked intelligence
H1: Substantive Outcomes
We measure four substantive outcomes in our leaked intelligence experiment: (1) crisis realism (i.e., whether a similar leak could happen in the real world), (2) document authenticity (i.e., whether the document is an actual intelligence document), (3) international perceptions (i.e., whether the international community will believe Russia exported chemical weapons), and (4) credibility of the document contents (i.e., whether Russia supplied chemical weapons).Footnote 12 As before, we use a five-point Likert scale and run regression models. Figure 6 displays the average treatment effects.Footnote 13

Figure 6. Average treatment effect of intelligence graphic (substantive questions). Error bars represent 95% confidence intervals.
In line with H 1 , we find no significant casual effects for three of our variables: crisis realism, international perception, and credibility. However, we surprisingly find a strong negative causal effect of the treatment on perceptions of the document’s authenticity. Respondents who received the graphic treatment were more likely to doubt the authenticity of the leaked report (p < 0.05). To assess this finding, we reran a nearly identical experiment on a different Lucid sample.Footnote 14 As in our original experiment, we find a strong negative relationship between the graphical treatment and perceived authenticity (p < 0.01).Footnote 15
We suspect that this negative relationship might result from our decision to omit classification markings from the graphical depiction of the leaked document, potentially hindering our efforts to produce an authentic-looking document. The formatting of intelligence documents may have been particularly salient to respondents since a large real-world intelligence leak occurred just prior to our survey fielding.Footnote 16 Regardless of the specific markings, participants might also simply be expressing skepticism that an internet survey would show them a picture of an actual leaked document. Importantly, this lack of perceived authenticity did not affect our other substantive dependent variables.
H2: information retention
As in the Twitter experiment, we asked respondents three attention check questions and measured the time respondents spent reading the treatment.Footnote 17 Specifically, we ask: what entity wrote the intelligence report (“Intel Check”), what country supplied the weapons (“Supplied Check”), and where the chemical weapons were used (“Used Check”).
Figure 7 shows the average treatment effect of the intelligence graphic on our three attention check questions. We find little support for H 2 for most of our results; however, we do find a positive effect of the graphical treatment on the attention check about the state supplying chemical weapons.Footnote 18 We find that respondents in the graphical realism treatment are more likely to correctly identify Russia as the supplier of chemical weapons. One difference between our leaked document graphic treatment and the plain text control is that “Russia” appears in large, bolded letters in the leaked document graphic. To test whether the font size drives effects, we repeated the experiment on a different sample, but changing the supplying country from Russia to North Korea. We were unable to replicate a statistically significant result.Footnote 19 We also found no statistically significant difference in time spent reading the plain text and graphical realism treatments.
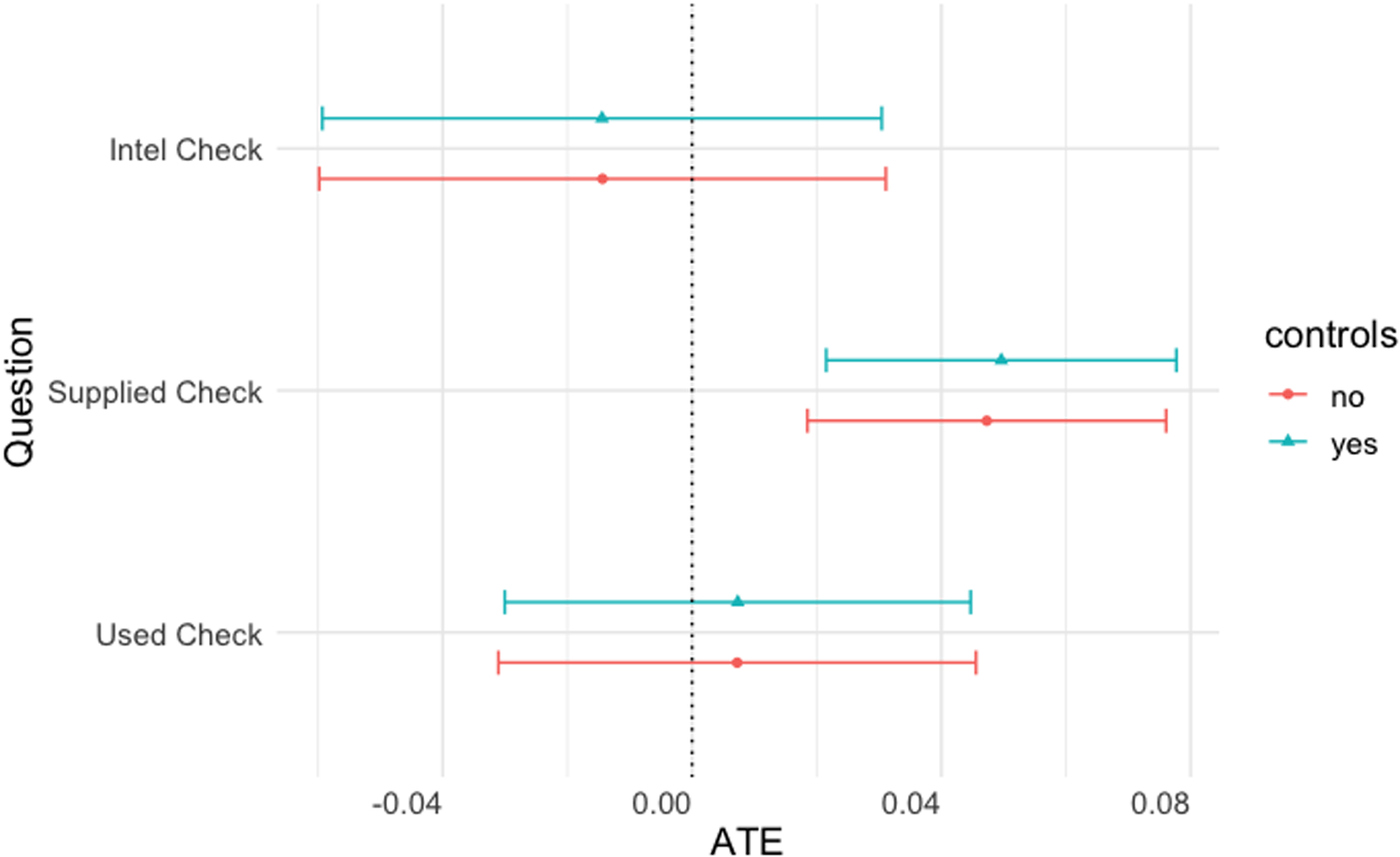
Figure 7. Average treatment effect of intelligence graphic (AC questions). Error bars represent 95% confidence intervals.
Experiment 3: atomic aversion
H1: substantive outcomes
We measure three substantive nuclear outcomes in the atomic aversion experiment, copied exactly from Press et al’s original study: (1) preferred choice between the two options (a four-point scale ranging from strong conventional preference to strong nuclear preference); (2) approval for using conventional weapons (a six-point scale); and (3) approval for using nuclear weapons (a six-point scale).Footnote 20 We measure Press et al.’s original outcome variables in order to examine whether graphical realism moderates the findings from the original experiment.
We replicate Press et al’s original findings. Greater military effectiveness for the nuclear strike option leads to sharply higher approval for nuclear use, declined support for the conventional strike, and stronger preference for the nuclear option.Footnote 21 Given our focus on graphical realism, we do not display these nuclear results graphically; we plot only the effect of graphical realism.
As before, we find no effect on substantive outcomes for the realistic graphic treatment. In Figure 8, we show the average treatment effect for the realistic graphic treatment across all three substantive outcomes.
In addition to the standard regression, we run a difference-in-difference (DiD) analysis. In our DiD analysis, we consider whether graphical realism moderates the effects of the nuclear advantage variable on the three outcome variables outlined above. This allows us to test whether Press et al.’s original experiment would have found different results if the researchers had used plain text treatments rather than mock newspaper articles.
We divide respondents into two groups, those in the graphical realism treatments and those in the newspaper treatments. This is the first difference. We then run regressions to determine the difference between treatments where nuclear weapons have an advantage and treatments where the nuclear and conventional options have equal effectiveness (the second difference). The DiD analysis finds a null result. Figure 9 displays the difference between the estimate of the nuclear advantage coefficient between the realistic graphic treatment groups and the plain text treatment groups for all three nuclear outcomes. A positive value means that respondents in the newspaper treatment groups were more influenced by the nuclear advantage variable. A negative value would mean the plain text treatment groups were more influenced by the nuclear advantage variable. The differences are small and not statistically significant.Footnote 22
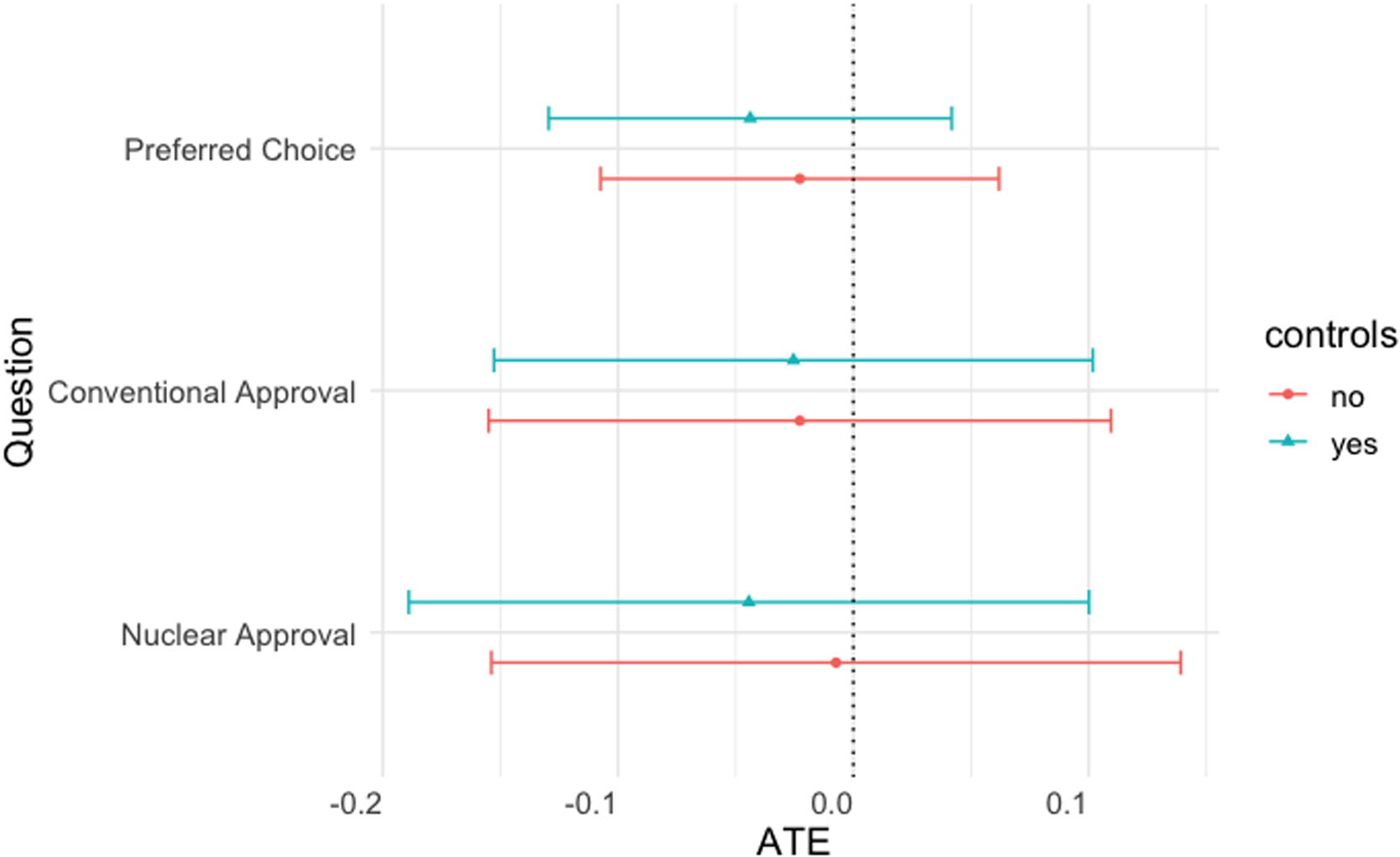
Figure 8. Average treatment effect of newspaper graphic (substantive questions). Error bars represent 95% confidence intervals.
H2: information retention
We include three attention check questions and, as before, measure the time respondents spent reading the treatments. We ask respondents to correctly identify the affiliation of the scientist quoted in the vignette (“scientist check”); the affiliation of the fictional report’s author (“author check”); and the country in which the terrorist lab is located (“country check”). As before, we find little support for H 2 (Figure 10). We do, however, find that respondents shown the graphical realism treatment spend far less time, about thirty-four seconds less time, reading the treatment than respondents in the plain text treatment.Footnote 23
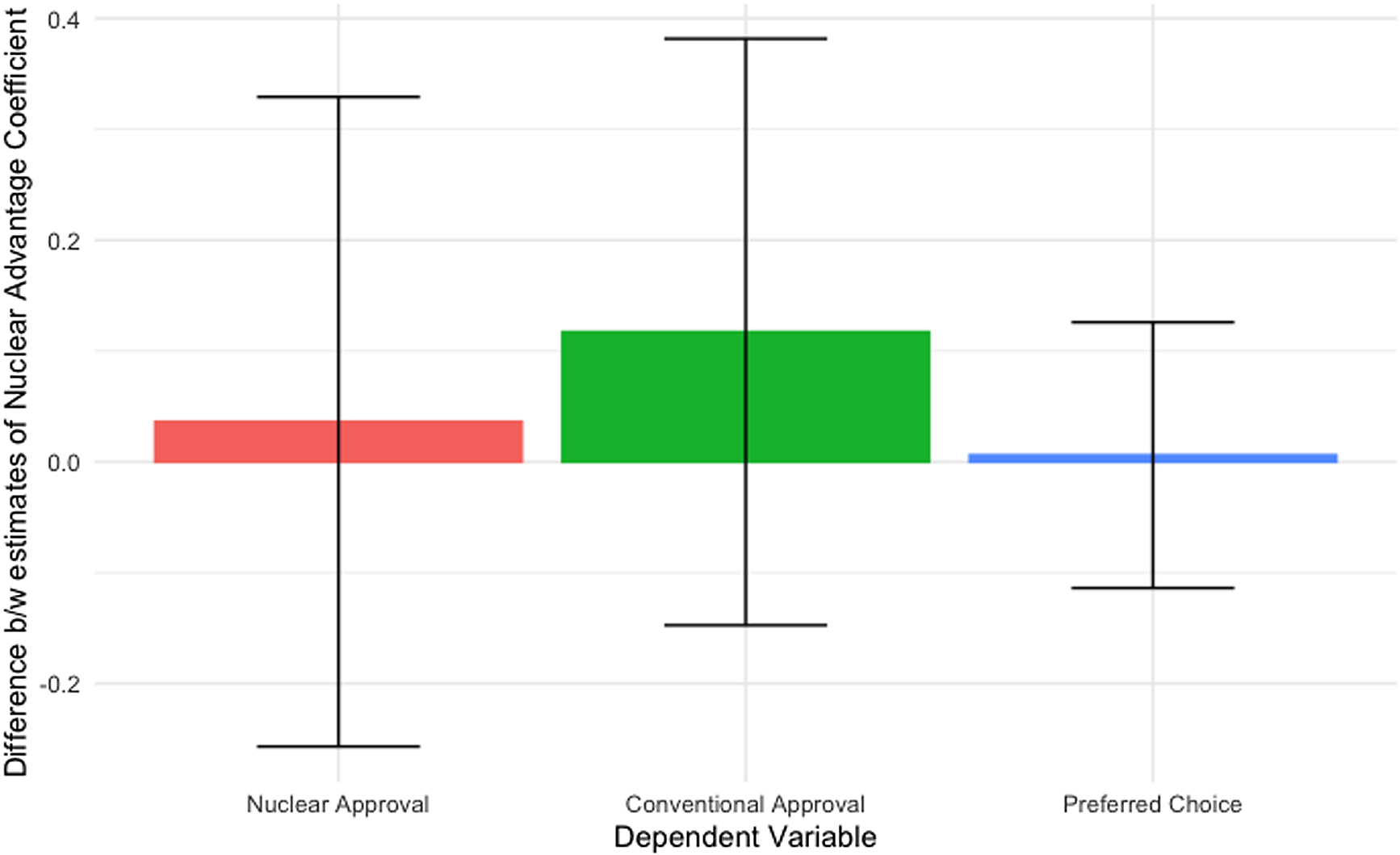
Figure 9. DiD – newspaper vs. plain text effect on nuclear advantage.
To gain insight into whether graphical realism affects respondent engagement, we asked about their experience taking the survey experiment. We include three measures: cognitive load, enjoyment, and interest. To study cognitive load, we ask, “Compared to an average news article, how difficult or easy did you find the fictitious news article to read?” To collect data on enjoyment, we ask “How much did you like or dislike reading the fictitious news article?” Finally, to explore interest, we ask, “If you heard about this incident in real life, how likely or unlikely would you be to seek out more information about the proposed strike?” We find null results for graphical realism across all experiential variables, shown in Figure 11.Footnote 24
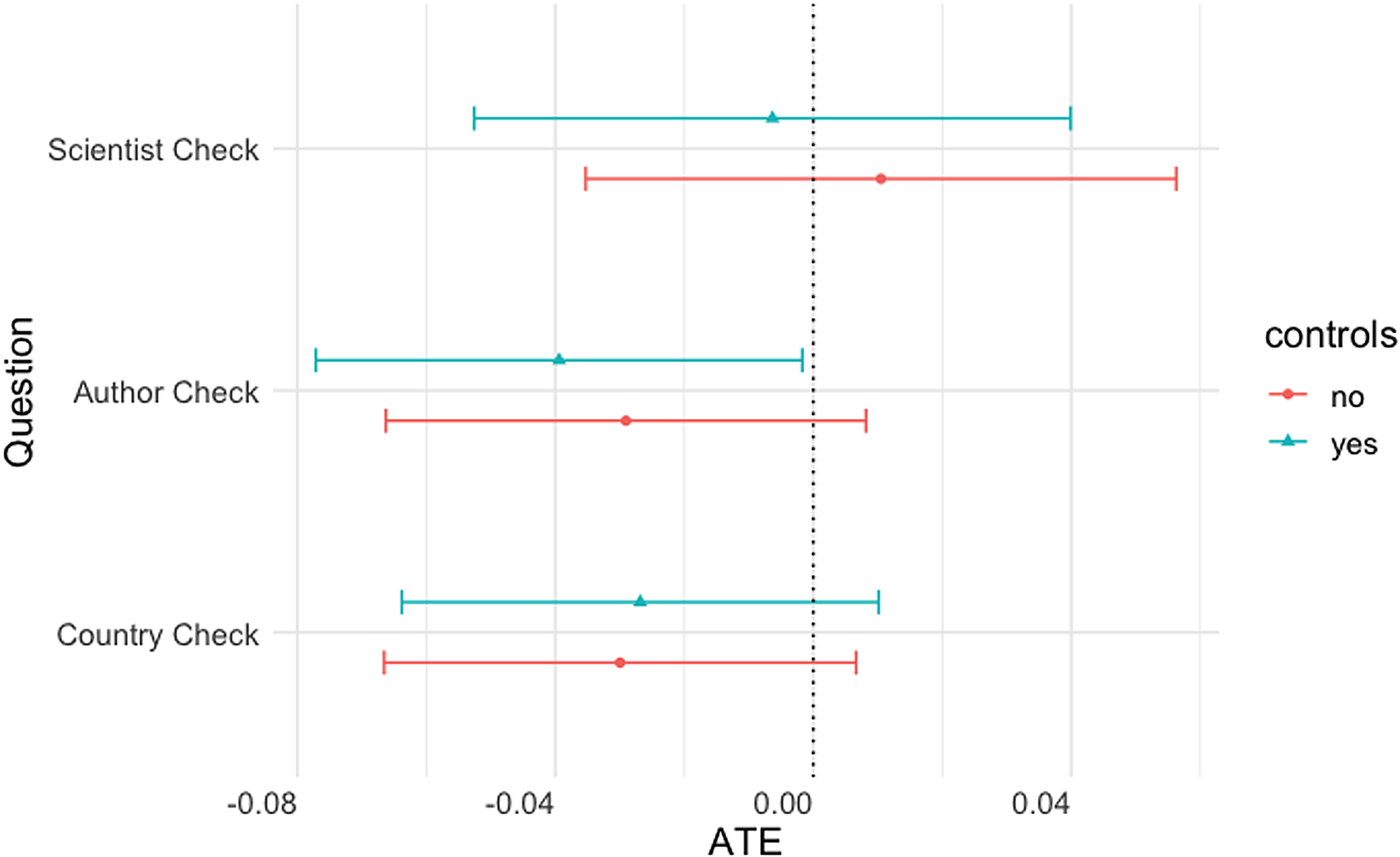
Figure 10. Average treatment effect of newspaper graphic (AC questions).
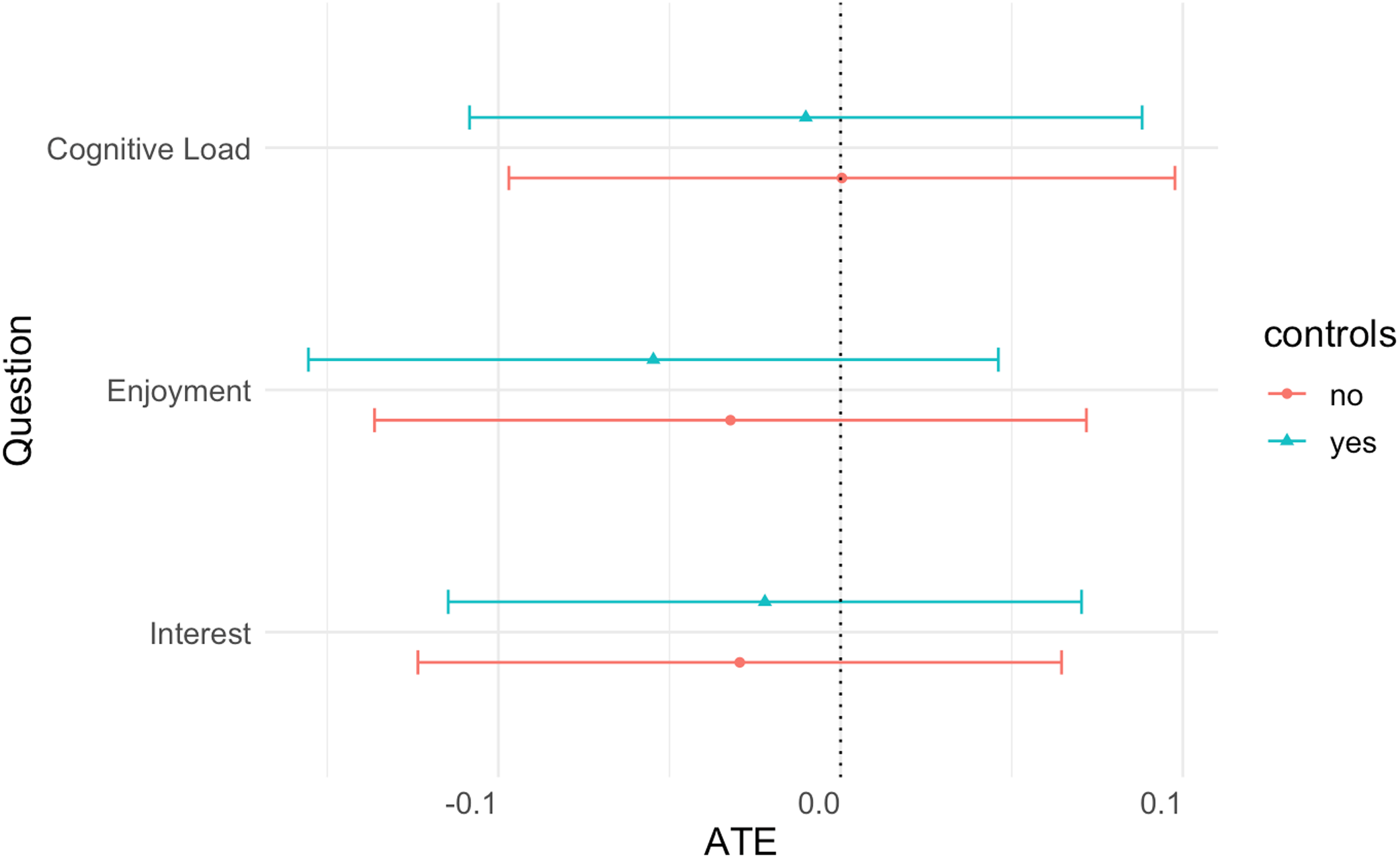
Figure 11. Average treatment effect of newspaper graphic (experiential questions).
Implications and pathways for future research
Randomized control trials are the gold standard for generating internally valid results, leading to increased survey experiment use among political scientists. The dramatic reduction in cost and expanded reach of survey platforms is a boon for the profession, but one that calls for increased study of survey experiments themselves. Our findings contribute to that line of study while also suggesting avenues for future research to help develop best practices.
In this research note, we study whether contextually realistic graphics in survey experiment treatments yield results that differ from plain text vignettes. Our results show that varying between contextually realistic graphics and plain text has little effect on substantive outcomes or on respondents’ information retention. Few of our dependent variables showed a statistically significant average treatment effect, and those that did were generally not replicable in follow-up experiments. Given the large number of tests we run, it is also unsurprising that at least a few of them would show significant results given the multiple comparison problem.
Our findings suggest political scientists gain little from using contextually realistic graphics in lieu of plain text treatments. If, however, political scientists decide to incorporate graphical realism, they should conduct thorough pretests to ensure their graphics are sufficiently realistic. Indeed, respondents consistently rated our graphically realistic intelligence document as less authentic than a plain text description. While we are unable to conclude with certainty why our leaked report was seen as less authentic, it seems plausible that it did not sufficiently resemble leaked documents that respondents had previously seen.
Future work could examine whether elites respond differently to treatments with contextually realistic graphics differently than members of the public, contributing to the burgeoning body of work on elite samples (Dietrich, Hardt, and Swedlund Reference Dietrich, Hardt and Swedlund2021; Chu and Recchia Reference Chu and Recchia2022; Kertzer and Renshon Reference Kertzer and Renshon2022). Future work could also explore whether using contextually realistic graphics affects studies outside of international relations. For example, scholars of comparative or American politics might assess whether presenting information as plain text or as a mock newspaper article or social media post influences substantive outcomes. In sum, this research note does not represent the final word, but instead suggests important areas for further inquiry.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/XPS.2024.10
Data availability
The data, code, and any additional materials required to replicate all analyses in this article are available at the Journal of Experimental Political Science Dataverse within the Harvard Dataverse Network, at: https://doi.org/10.7910/DVN/KTAJ9N.
Funding
The authors declare none.
Competing interests
The authors declare none.
Ethics statement
The experimental research in this paper was approved by the MIT IRB (The Committee on the Use of Humans as Experimental Subjects), Protocol Number E-4634. The authors affirm that the research adheres to APSA’s Principles and Guidance for Human Subjects Research. Appendix A details subject recruitment in more detail.














 Open access
Open access