



1. Introduction
L’aphasie est une pathologie consécutive à une lésion cérébrale qui affecte la communication et le langage, tant sur le plan de l’expression qu’en compréhension. Elle peut se manifester à l’oral ou à l’écrit. Le terme « aphasie » regroupe en réalité différents tableaux cliniques qui peuvent être classés, conformément à la littérature classique, en deux catégories principales : celles résultant d’un déficit antérieur – les aphasies dites non-fluentes –, et celles induites par un déficit postérieur – les aphasies dites fluentes (Ardila, Reference Ardila2010, Reference Ardila2014; Blumstein, Reference Blumstein, Hickok and Small2016). L’aphasie survient le plus souvent à la suite d’un accident vasculaire cérébral, c’est-à-dire un AVC ischémique ou hémorragique, un traumatisme, ou encore dans le cadre d’une maladie neurodégénérative (aphasie primaire progressive). Elle engendre une altération des processus cognitifs. Sur le plan langagier, tous les niveaux linguistiques sont susceptibles d’être atteints. En production orale, on observe assez fréquemment, quel que soit le tableau clinique, un trouble qui engendre la réalisation d’erreurs affectant la forme sonore des mots, i.e. la dimension infra-lexicale. Il s’agit du trouble phonético-phonologique, qui induit, entre autres, des erreurs qui se manifestent à l’oral sous la forme de distorsions phonétiques, de paraphasies, de paragraphies à l’écrit ainsi que de paralexies en lecture. Ce trouble peut se révéler extrêmement handicapant pour les locuteurs et la rééducation par les orthophonistes est très complexe par manque de compréhension fine des niveaux d’altérations du langage. Dans les faits, la nature des erreurs qui affectent la forme sonore des mots est double. Deux origines à ces difficultés linguistiques ont ainsi été répertoriées dans la littérature:
-
(i) une origine phonétique, c’est-à-dire un trouble phonétique qui engendre des difficultés sur le plan articulatoire et provoque des troubles de la planification motrice des unités (i.e. des représentations phonologiques) et de leurs conversions sur le plan phonétique.
-
(ii) une origine phonologique, c’est-à-dire un trouble phonologique qui émane d’un déficit d’accès à la sélection des représentations phonologiques sous-jacentes, des informations contenues dans le système phonologique. Outre les difficultés d’accès aux représentations phonologiques, le déficit peut aussi provenir d’une atteinte des représentations elles-mêmes (Butterworth, Reference Butterworth1992; Romani et al., Reference Romani, Galluzzi and Olson2011a/b).
Autrement dit, le trouble résulte : soit d’une atteinte d’un dysfonctionnement de l’interface entre l’accès à la représentation, la planification et la programmation des unités phonologiques sur le plan linéaire en vue de leur réalisation motrice sur le plan phonétique, soit d’une atteinte des représentations phonologiques (Romani et al., Reference Romani, Galluzzi and Olson2011a/b). Ainsi, si un segment – une consonne vélaire – n’est jamais réalisé, quelle que soit sa position, cela provient d’une difficulté articulatoire. La représentation de cette catégorie de consonne (élément vélarité/dorsalité) peut être préservée, mais la conversion de cette unité en gestes sur le plan moteur ne peut s’effectuer. La forme et les gestes articulatoires ne sont pas récupérables. Dans le cas du trouble phonologique, deux cas de figure existent : (1) la représentation est stockée et préservée, et même consultée pour atteindre la cible attendue. Toutefois, elle ne peut être sélectionnée. Le problème se situe dans l’accès au choix des unités. (2) la représentation phonologique est erronée. La consonne vélaire pourra être produite dans certains contextes et pas dans d’autres. Classiquement, le trouble phonétique est attribué aux aphasies liées à une ou plusieurs lésion(s) antérieure(s), dites aphasies non-fluentes, tandis que le trouble phonologique correspond bien souvent aux aphasies liées à une ou plusieurs lésion(s) postérieure(s), dites aphasies fluentes. Néanmoins, il s’avère bien difficile dans la pratique de distinguer l’origine de ces troubles puisqu’ils peuvent se traduire par des réalisations identiques. Du reste, il n’est pas rare d’observer chez certains locuteurs une cooccurrence des erreurs phonétiques et phonologiques. De nombreux auteurs plaident désormais en faveur de cette coexistence de troubles « mixtes » (Goldrick et Blumstein, Reference Goldrick and Blumstein2006; Laganaro, Reference Laganaro, Séron and Van der Linden2014, Reference Laganaro2015). Ainsi, un locuteur atteint d'une aphasie de type non-fluent avec un déficit de la programmation motrice peut également être atteint d’un déficit phonologique associé. En raison de cela, de nombreuses études avancent l’idée qu’il existe un continuum entre les processus phonologiques et phonétiques dans la production des énoncés (Buckingham et Buckingham, Reference Buckingham and Buckingham2015; Marczyck et Baqué, Reference Marczyck and Baqué2015; Laganaro, Reference Laganaro, Séron and Van der Linden2014, Reference Laganaro2015). En somme, il existerait, dans l’aphasie, deux origines distinctes possibles pour un trouble, mais une continuité constante entre encodage phonologique et encodage phonétique (Buckingham et Christman, Reference Buckingham, Christman, Stemmer and Whitaker2008).
En neuropsychologie, dans la plupart des modèles de production verbale, les représentations lexicales sont composées d’une pléthore d’informations de différentes natures : phonologique, morphologique, sémantique ou encore syntaxique, etc. Dans le cas des informations phonologiques, les locuteurs génèrent des formes phonologiques de mots à partir de composants sublexicaux au lieu de les récupérer sous formes d’unité lexicale (Meyer et Belke, Reference Meyer, Belke and Gareth Gaskell2007). Ces formes phonologiques comprennent des caractéristiques segmentales et métriques. Néanmoins, les modèles proposés dans la littérature sont en désaccord sur deux points distincts. Tout d’abord, l’ensemble des chercheurs ne s’accordent pas sur la manière dont les informations phonologiques circulent. Certains adoptent une architecture connexionniste comme Dell et al. (Reference Dell, Schwartz, Martin, Saffran and Gagnon1997, Reference Dell, Chang and Griffin1999), d’autres proposent une architecture de type sérielle et discrète, tels Levelt (Reference Levelt1989) et Roelofs (Reference Roelofs1997) alors que d’autres encore postulent que l’information circule selon une architecture en cascade (Caramazza, Reference Caramazza1997). Le deuxième point de désaccord concerne quant à lui le lien, l’ancrage et le stockage entre les informations sur le matériel segmental et la structure métrique et syllabique, à savoir quelles sont les informations qui sont stockées et comment (Dell, Reference Dell1986, Dell et al. (Reference Dell, Schwartz, Martin, Saffran and Gagnon1997, Reference Dell, Chang and Griffin1999), Levelt et Wheeldon, Reference Levelt and Wheeldon1994, Levelt et al. Reference Levelt, Roelofs and Meyer1999). Finalement, si plusieurs propositions sont formulées, il reste difficile de bien comprendre quelle est la nature des informations stockées, comment elles le sont et comment ces informations sont interconnectées. Une des approches permettant d’étudier le fonctionnement de l’encodage phonologique en production est l’observation des erreurs phonologiques réalisées par les personnes atteintes d’une aphasie. Ainsi, à partir de l’analyse des paraphasies phonémiques, Butterworth (Reference Butterworth1992) propose que le matériel lié aux segments est stocké et que les processus faisant intervenir la syllabe sont réalisés via un calcul lors de la conversion des unités phonologiques sur le plan articulatoire. Pour le reste, il explique qu’il existe a minima un stockage des représentations syllabiques de la forme par défaut CVCV qui justifie que les locuteurs avec aphasie réalisent, du fait de la complexité syllabique, des omissions et épenthèses qui visent à restaurer une structure CVCV par défaut. Il indique aussi que la présence d’erreurs « mixtes » permet de montrer qu’il n’y a pas de distinction claire entre les plans phonétique et phonologique. Pour certains auteurs (Den Ouden et Bastiaanse (Reference Den Ouden, Bastiaanse, van de Weijer, van Heuven and van der Hulst2003), Den Ouden (Reference Den Ouden, Botma, Kula and Nasukawa2011), Romani et al. (Reference Romani, Galluzzi and Olson2011a/b)), les erreurs phonologiques sont corrélées à la complexité syllabique. De fait, selon Den Ouden, les items de structure CV sont moins chutés que ceux comportant une structure consonantique double de type hétérosyllabique ou tautosyllabique. À partir de locuteurs italophones atteints d’aphasie, Romani et al. (Reference Romani, Galluzzi and Olson2011a/b) révèlent que les consonnes les plus souvent touchées par les erreurs sont en position faible et que les segments qui subissent des substitutions le sont en fonction des positions syllabiques qu’ils occupent. En conséquence, les informations syllabiques sont stockées dans les représentations et l’accès à ces dernières est déficitaire dans ce cas. Ces résultats questionnent le fonctionnement et l’ancrage des représentations syllabiques dans les modèles proposés. Footnote 1
D’un autre côté, il convient de retenir que dans l’aphasie, les tableaux cliniques sont variés et ont fait l’objet d’une classification rigoureuse, recensés par la littérature. Il est rare qu’un locuteur présentant ce type de handicap coche l’ensemble des cases d’un tableau clinique (Ardila, Reference Ardila2010, Reference Ardila2014; Blumstein, Reference Blumstein, Hickok and Small2016). Plus encore, la probabilité de trouver deux locuteurs ayant un profil clinique identique est faible. En effet, les caractéristiques et le profil clinique sont propres à chaque locuteur et dépendent de nombreux facteurs. Aussi, la théorie ne reflète pas toujours la réalité du terrain clinique et l’aphasie est plurielle, tout comme l’est chaque rééducation (Sainson, Reference Sainson2018).
Néanmoins, les paraphasies phonologiques et les erreurs phonétiques sont fréquentes et se manifestent dans presque toutes les formes d’aphasies. Elles font pour cela l'objet de recherches approfondies. La majorité des travaux qui s’y consacre se concentre sur les erreurs d’origine phonétique et principalement sur le phonème, ainsi que sur les traits distinctifsFootnote 2 et leurs réalisations (Marczyk et Baqué, Reference Marczyck and Baqué2015; Verhaegen et al., Reference Verhaegen, Delvaux, Fagniart, Huet, Piccaluga and Harmegnies2020, Reference Verhaegen, Delvaux, Huet, Fagniart, Piccaluga and Harmegnies2018, Reference Verhaegen, Delvaux, Huet, Fagniart, Piccaluga and Harmegnies2016). Il est admis que certains phonèmes ou certains traits distinctifs posent des difficultés indéniables aux locuteurs. Pour autant, peu d’études prennent en compte ces erreurs dans une dimension phonologique, c’est-à-dire au regard de l’environnement contextuel, par exemple via les structures syllabiques des mots au sein desquelles les phonèmes sont agencés. Or, l’hypothèse soutenue dans cette étude est que le rôle des structures syllabiques est tout aussi important. C’est ce qui a été mis en exergue dans certains travaux ces dernières décennies (Béland, Reference Béland1985; Buchwald, Reference Buchwald2009, Reference Buchwald2017; Buchwald et al., Reference Buchwald, Gagnon and Miozzo2017; Nespoulous et Wilshire, Reference Wilshire and Nespoulous2003; Prince, Reference Prince2016). Dans ce sens, une étude de Buchwald (Reference Buchwald2017: 490) expose que la position au sein de la syllabe (coda ou attaque par exemple) et le fait qu’un segment consonantique (i.e. un phonème) apparaisse ou non précédé d’une autre consonne (formant alors une séquence consonantique) sont des facteurs qui ont une influence certaine sur la production orale et les réalisations des locuteurs (cf. voir aussi Buchwald et Miozzo, Reference Buchwald and Miozzo2012). Ces facteurs phonologiques renvoient à la notion de complexité phonologique et à ce qu’elle revêt.
Dans ce contexte, la présente recherche s’inscrit dans une approche par contraintes et stratégies de réparation, abrégée TCSR (voir Nespoulous et Moreau, Reference Nespoulous, Moreau and Lebrun1997; Paradis, Reference Paradis1988), ainsi que dans le cadre de la phonologie du gouvernement (Kaye et Lowenstamm, Reference Kaye, Lowenstamm and Belletti1981; Kaye et al., Reference Kaye, Lowenstamm and Vergnaud1990) et plus récemment dans le modèle CV (Scheer, Reference Scheer2004, Reference Scheer2015). Dans ces approches, il existe une forte relation entre les éléments, les segments, leurs positions et les syllabes au sein de la chaîne parlée. Dans cette vision, les relations étroites qu’entretiennent les segments et les syllabes se font par le biais de relation de gouvernement et de licenciement et les segments revêtent divers degrés de complexité selon les éléments qu’ils comportent, tout comme les syllabes. Aux principes universels s’ajoutent pour chaque langue des paramètres qui correspondent aux contraintes de bonnes formations. Ainsi, une séquence CV, qui est universelle, est moins complexe qu’une séquence consonantique de type CCV, elle-même moins complexe qu’une séquence CCCV (Kaye et Lowenstamm, Reference Kaye, Lowenstamm and Belletti1981). L’existence et la constitution de ces dernières dépendent des paramètres propres à chaque langue ; une langue comme le français admet les séquences ternaires CCV et la théorie doit en rendre compte. Pour le cas de l’aphasie, les erreurs de type omission, métathèse, insertion et substitutions sont considérées comme des stratégies de réparation engendrées pour modifier un contexte qui n’est pas réalisable dans sa forme cible (soit parce que la forme phonologique n’est pas accessible, soit parce qu’elle est erronée).
Dans cette étude, les termes syllabiques suivants seront utilisés : séquences consonantiques hétérosyllabiques (coda+attaque) comprenant traditionnellement un segment en position faible, i.e. gouverné, et un segment en position forte et séquences tautosyllabiques (de type attaque branchante) avec un segment gouverneur, en position forte, suivi d’un segment en position faible. Également, nous admettons l’existence de noyau vide (Kaye, Reference Kaye1990), c’est-à-dire des positions nucléiques non-interprétées phonétiquement quand elles sont gouvernéesFootnote 3 mais qui existent dans les représentations. À partir de cette approche, il sera possible de rendre compte des erreurs phonologiques. En outre, de telles données empiriques sur l’aphasie sont rarement analysées à l’aide de ces modèles ; pourtant, elles éprouvent ces derniers (Forest, Reference Forest2005). Nous montrerons comment nos résultats ouvrent la voie à de nouvelles perspectives sur la complexité phonologique.
La présente étude tire son originalité du fait qu’elle se concentrera sur une définition du trouble phonético-phonologique à travers le prisme de la notion de complexité phonologique chez des locuteurs francophones atteints d’aphasie. L’observation des erreurs réalisées permettra de revenir sur les contextes phonologiques qui jouent un rôle potentiel sur les erreurs. Autrement dit, l’étude tiendra compte à la fois de la nature intrinsèque des phonèmes étudiés et de leur comportement au sein de leur environnement syllabique dans la chaîne. Par ailleurs, étant donné que les séquences généralement examinées dans les travaux précédents sont de la forme CV ou CVCV, les structures consonantiques binaires seront plus particulièrement examinées, ces dernières étant plus rarement observées. Trois contextes supplémentaires seront pris en compte : la longueur (items bi vs trisyllabiques), le type de structures syllabiques (hétérosyllabique vs tautosyllabique) et la position de ces séquences dans les items (initiale vs médiane).
Pour cela, l’étude se concentrera sur le trouble phonético-phonologique dans l’aphasie consécutive à une lésion vasculaire en phase aiguë chez des locuteurs francophones, basée sur un corpus de données empiriques récolté à cet effet.
La première section de cet article sera dévolue à la présentation des travaux théoriques et des données empiriques issues de l’aphasie dans plusieurs langues qui abordent les questions liées aux erreurs sur les plans phonétique et phonologique dans la production de la parole. Une deuxième section présentera la méthodologie propre à notre étude expérimentale et la population étudiée. Une troisième section sera consacrée aux résultats. Enfin, la dernière section portera sur les analyses et les questionnements soulevés par les données et la manière dont nous pouvons rendre compte des phénomènes étudiés. Cette recherche vise à accroître les connaissances sur la nature des déficits phonologiques et les contextes favorisant les erreurs. Des explications aux mécanismes déclenchés par l’aphasie dans ce contexte précis seront proposées.
2. Contexte Théorique
Les personnes atteintes d’une aphasie (PwAFootnote 4 ) avec un déficit phonologique produisent des paraphasies phonologiques qui portent sur le contenu segmental et/ou les structures syllabiques. Plusieurs recherches sur les corpus concernant les PwA en témoignent et ce dans plusieurs langues parmi lesquelles le français, l’espagnol, l’italien, le portugais brésilien et le néerlandais (Den Ouden, Reference Den Ouden, Botma, Kula and Nasukawa2011; Den Ouden et Bastiaanse, Reference Den Ouden, Bastiaanse, van de Weijer, van Heuven and van der Hulst2003; Durand et Prince, Reference Durand, Prince, Astesano and Jucla2015; Laganaro, Reference Laganaro2005, Reference Laganaro, Séron and Van der Linden2014, Reference Laganaro2015; Nespoulous et al., Reference Nespoulous, Baqué, Rosas, Marczyck and Estrada2013; Prince, Reference Prince2017; Romani et al., Reference Romani, Galluzzi and Olson2011a/b, Reference Romani, Galuzzi, Guariglia and Goslin2017). Le niveau syllabique n’a cependant été considéré que tardivement par les modèles neuropsycholinguistiques et de nombreuses questions restent aujourd’hui en suspens – notamment concernant les niveaux de traitement et les représentations – ; pourtant, son rôle est fondamental (Butterworth, Reference Butterworth1992; Buckingham et Buckingham, Reference Buckingham and Buckingham2015; Ferrand, Reference Ferrand and Fayol2002; Goldrick et Goldstein, Reference Browman and Goldstein1986; Den Ouden et Bastiaanse, Reference Den Ouden, Bastiaanse, van de Weijer, van Heuven and van der Hulst2003; Levelt et al. Reference Levelt, Roelofs and Meyer1999).
Dans le cas d’un déficit phonologique et/ou phonétique, et dans le contexte d’une apraxie de la parole, les paraphasies et les erreurs phonétiques les plus fréquemment observées à partir de données empiriques sont : l’omission (d’un membre consonantique, vocalique, ou bien la réduction d’une séquence consonantique, d’une syllabe), l’épenthèse (insertion) consonantique ou vocalique et la substitution (l’assimilation ou l’harmonie consonantique) (Blumstein, Reference Blumstein1973, Reference Blumstein, Bell and Hooper1978; Den Ouden, Reference Den Ouden, Botma, Kula and Nasukawa2011; Den Ouden et Bastiaanse, Reference Den Ouden, Bastiaanse, van de Weijer, van Heuven and van der Hulst2003; Nespoulous et Moreau, Reference Nespoulous, Moreau, Visch-Brink and Bastiaanse1998; Prince, Reference Prince2016). D’autres erreurs, plus rares, sont également répertoriées comme la métathèse – qui correspond à une inversion de deux segments – la reduplication d’un segment au sein de la chaîne, ou encore le déplacement d’un segment au sein d’une autre position de la chaîne (shifting). Le type d’erreur est corrélé au contexte et à la nature des segments.
Les exemples ci-dessous illustrent ces cas:

Dès les premières observations auprès des PwA, Blumstein (Reference Blumstein1973) a souligné que les substitutions et les omissions correspondent aux erreurs les plus fréquentes, tandis que les métathèses, les épenthèses, les déplacements et les autres erreurs se manifestent moins systématiquement et de manière plus hétéroclite, notamment chez les locuteurs ayant une lésion postérieure. Nombreux sont les travaux qui confirment ce point, à l’instar de Baqué (Reference Baqué2004), Marczyk et Baqué (Reference Marczyck and Baqué2015) pour l’espagnol ; Béland (Reference Béland1985), Moreau (Reference Moreau1993), Nespoulous et Moreau (Reference Nespoulous, Moreau, Visch-Brink and Bastiaanse1998) et Prince (Reference Prince2016) pour le français ; Den Ouden (Reference Den Ouden, Botma, Kula and Nasukawa2011) pour le néerlandais et enfin Romani et al. (Reference Romani, Galluzzi and Olson2011a/b, Reference Romani, Galuzzi, Guariglia and Goslin2017) pour l’italien. Plus encore, lorsque les PwA (avec déficit antérieur et postérieur) réalisent des substitutions, ces dernières sont principalement consonantiques et portent soit sur le mode, le lieu d’articulation et/ou le voisement. Les fricatives et les liquides posent généralement plus de difficultés que les occlusives. Les auteurs observent une tendance à substituer les segments fricatifs en segments occlusifs et, parfois, les liquides sont réalisées en glides. La liquide [R] est fréquemment prononcée [l], comme dans l’item : guitare /ɡitaʁ/ › [ɡital] (exemple tiré de Laganaro et Zimmermann, Reference Laganaro and Zimmermann2010: 9). Les occlusives voisées engendrent plus souvent des erreurs que celles non-voisées. Si la tendance à l’assourdissement est clairement démontrée chez les locuteurs atteints d’une apraxie de la parole, ce peut être aussi le cas chez les locuteurs avec aphasie à déficit phonologique sans apraxie associée (Marczyk et Baqué, Reference Marczyck and Baqué2015; Nespoulous et Moreau, Reference Nespoulous, Moreau, Visch-Brink and Bastiaanse1998; Nespoulous et al., Reference Nespoulous, Baqué, Rosas, Marczyck and Estrada2013).
Par conséquent, de nos jours, de nombreux travaux étudient les mécanismes d’erreur au niveau du phonème et des traits distinctifs et attestent l’importance du niveau phonémique dans la distribution des erreurs. Néanmoins, et comme signalé ci-dessus, peu d’études traitent des erreurs d’un point de vue phonologique en étudiant l’environnement syllabique dans le cadre de l’aphasie.
Traditionnellement, deux variables sont principalement associées à la réalisation d’erreurs consécutives à un trouble phonologique : « la fréquence » et la « complexité phonologique ». Néanmoins, l’impact de ces deux variables sur les productions des locuteurs reste pour le moins flou. D’une part, certaines études sur le français indiquent que la fréquence lexicale affecte la réalisation des erreurs (Nespoulous et Wilshire, Reference Wilshire and Nespoulous2003), alors que d’autres indiquent que c’est la fréquence syllabique qui joue un rôle prépondérant (Laganaro, Reference Laganaro2005, Reference Laganaro2008). Un mot ou une séquence plus fréquente posera ainsi moins de difficulté qu’un mot ou une séquence plus rare (Laganaro, Reference Laganaro, Séron and Van der Linden2014). Il apparaît toutefois que les syllabes les plus fréquentes traitées dans ces travaux sont également les moins complexes du système phonologique, i.e. les séquences CV et CVCV. En cela, les tâches de dénomination, de répétition et de lecture lors desquelles les participants sont testés ne prennent pas toujours en compte la variété et la complexité des unités phonologiques de leur langue maternelle, tels que les différents types de structures syllabiques, par exemple les CCVCC. En conséquence, la fréquence syllabique pourrait n’être qu’un artefact de la complexité.
D’autre part, la « complexité phonologique » n’est pas réellement définie et peut recouvrir une multitude de variables selon les auteurs et les disciplines. Le parallèle qui est fait est bien souvent celui de la marque, au sens jakobsonien ([1941]Reference Jakobson1969) et troubetzkoyen (Reference Troubetzkoy[1939]1969), où ce qui est moins complexe correspond à ce qui est le moins marqué et inversement. De ce fait, le phonème [p] est considéré comme moins marqué que le phonème [b], car il est dépourvu d’une valeur qui marque par contraste avec [b] – cette valeur étant le trait de voisement.Footnote 5 Toutefois, la « complexité phonologique » renvoie à bien plus qu’une simple question de valeur de « marque » qui fait référence uniquement à l’articulation (en termes de propriétés articulatoires). En effet, si [p] est moins complexe et qu’il est de fait moins marqué d’un point de vue articulatoire ou acoustique, c’est aussi parce qu’il est moins marqué qu’il est moins complexe. Afin de sortir de cette circularité, et parce que marque et articulation sont souvent confondues, il appartient aux phonologues de définir à quoi correspond la marque et à quoi correspond la notion de complexité (Berent, Reference Berent2018; Glaudert, Reference Glaudert2014; Hume, Reference Hume and van Oostendorp2011; Rice, Reference Rice2007).
À ce jour, et grâce aux études en acquisition phonologique et à celles en psycholinguistique, il est possible d’appréhender la notion de complexité phonologique à travers plusieurs éléments : la structure syllabique d’un mot, la longueur (nombre de syllabes), la position d’un son ou d’une syllabe dans le mot (initiale, médiane ou finale) ou encore les segments consonantiques et vocaliques et leurs agencements au sein des syllabes, attaque, coda ou noyau (Durand et Prince, Reference Durand, Prince, Astesano and Jucla2015; Romani et Galluzzi, Reference Romani and Galluzzi2005; Romani et al., Reference Romani, Galluzzi and Olson2011a/b; inter alia). Ainsi, la complexité phonologique peut s’interpréter comme un ensemble de propriétés servant à composer les représentations phonologiques. Certains auteurs tels que Romani et al. (Reference Romani, Galluzzi and Olson2011a/b), Verhaegen et al. (Reference Verhaegen, Delvaux, Fagniart, Huet, Piccaluga and Harmegnies2020, Reference Verhaegen, Delvaux, Huet, Fagniart, Piccaluga and Harmegnies2018) pour l’italien et le français font mention d’un effet de longueur au sein des productions de plusieurs locuteurs aphasiques étudiés. En d’autres mots, les items les plus longs, par exemple les trisyllabiques, engendrent plus d’erreurs que les items bisyllabiques, notamment chez les locuteurs avec apraxie de la parole. Les connaissances actuelles ne permettent pas de préciser réellement si les différentes structures impliquées à l’intérieur même de ces syllabes jouent également un rôle dans les erreurs produites lors d’une aphasie. Par exemple, qu’en est-il des séquences consonantiques complexes ? Ce sont le plus souvent les items de structures CV(CV) et CVC qui sont examinés, plus rarement les structures comportant des séquences consonantiques binaires. Enfin, d’autres types de séquences, par exemple les séquences consonantiques ternaires, sont bien souvent laissés-pour-compte.
Outre la nature de certains segments, structurellement complexes, et à l’instar des recherches de Buchwald (Reference Buchwald2017), les résultats d’autres travaux mettent en avant un effet de complexité positionnelle où les segments en position de coda sont plus souvent supprimés que ceux en position attaque dans les paraphasies. Ainsi, la liquide [R] est omise dans presque tous les cas dans des séquences tautosyllabiques (de type occlusive+R) et hétérosyllabiques [R+occlusive]. En phonologie du gouvernement, cela s’explique par la nature de ces positions qui sont des positions phonologiquement faibles, donc sujettes à la suppressionFootnote 6 . Dans une séquence [s+occlusive], c’est [s] qui sera élidée pour des raisons identiques (résultats similaires mis en avant en français dans Prince, Reference Prince2016). Ainsi, [R] comme [s] pourront être élidées dans ces contextes mais pas en position intervocalique par exemple. La suppression n’est donc pas toujours le résultat d’une complexité segmentale. Pour Buchwald (Reference Buchwald2017) et Miozzo et Buchwald (Reference Miozzo and Buchwald2013), la composition de la séquence syllabique affecte la précision de réalisation de chacun des segments qui apparaissent au sein des séquences consonantiques. Autrement dit, si la réalisation ou la suppression d’un phonème peut différer selon qu’il se trouve en position intervocalique ou bien s’il existe au sein d’une séquence consonantique, elle peut aussi varier selon la nature de la séquence consonantique (hétérosyllabique ou tautosyllabique). Per se, il serait préférable de comparer les performances pour différents segments en prenant en compte ces facteurs et l’environnement syllabique qui les inclutFootnote 7 .
En somme, le rôle des structures syllabiques et de l’environnement contextuel en production orale dans l’aphasie est à préciser. Cela se ressent aussi dans les tests d’évaluation clinique en orthophonie. Lors de la rééducation, le clinicien travaille principalement sur les traits qui composent des phonèmes et sur le niveau phonémique. À titre d’exemple, il peut faire réaliser des tâches impliquant des exercices de paires minimales ou d’appariements de phonèmes. Il peut également se concentrer sur la longueur des mots par l’intermédiaire d’exercices sur la conscience phonologique. En revanche, lors de d’évaluation clinique, un faible contrôle de la complexité syllabique est observé. Les items sélectionnés dans les tâches de production dont la dénomination, la répétition et la lecture à haute voix (LHV) reposent principalement sur des critères comme la longueur et la fréquence. Les critères syllabiques sont moins contrôlés à l’exception de la batterie d’évaluation clinique des dysarthries de Auzou et Rolland-Monnoury (Reference Auzou and Rolland-Monnoury2019). Pourtant, il n’existe pas à notre connaissance de travaux qui attestent que les critères de structures syllabiques n’influencent pas de manière importante la production des mots lors d’un trouble phonologique. En outre, si l’on sait que la syllabe est une unité fondamentale dans la perception et qu’elle y joue un rôle majeur, il est probable que cela soit également le cas en production orale.
À partir de l’ensemble des travaux évoqués, il convient de retenir que les difficultés proviennent soit de la nature du segment – son lieu, son mode d’articulation ou le voisement –, soit de la structure de la syllabe, soit enfin de la position du segment au sein de la syllabe. Il arrive aussi que les trois suscitent simultanément des difficultés. L’ensemble de ces études indique ainsi une interaction entre segments, syllabes et positions, mais pas seulement. D’autres auteurs rapportent que les locuteurs atteints d’une aphasie non-fluente avec un déficit antérieur ont tendance à réaliser des simplifications des structures linguistiques contrairement aux aphasies postérieures fluentes (Blumstein, Reference Blumstein1973, Reference Blumstein, Bell and Hooper1978; Marczyck et Baqué, Reference Marczyck and Baqué2015). Dans ce dernier cas, les erreurs générées sont plus hétéroclites et ne résultent pas toujours en une simplification Footnote 8 de la structure linguistique.
Dans cet article, nous tenterons d’appréhender la notion de complexité phonologique en tant qu’élément déterminant des erreurs produites dans l’aphasie. L’hypothèse émise est que les différentes variables qui composent cette complexité phonologique jouent tout autant un rôle dans la nature des erreurs que la fréquence lexicale.
En outre, le contexte phonologique dans lequel les segments consonantiques et vocaliques sont réalisés n’est pas toujours considéré lors de la conception et du design des tâches et des stimuli. Comme nous l’avons précédemment expliqué, de nombreuses études traitent des erreurs phonétiques ou infra-phonémiques (phonèmes ou traits), mais n’intègrent que trop peu la variété des environnements contextuel et métrique dans lequel se trouvent ces derniers (Nespoulous et al., Reference Nespoulous, Baqué, Rosas, Marczyck and Estrada2013; Verhaegen et al., Reference Verhaegen, Delvaux, Fagniart, Huet, Piccaluga and Harmegnies2020, Reference Verhaegen, Delvaux, Huet, Fagniart, Piccaluga and Harmegnies2016). Par conséquent, cette étude tâchera de s’intéresser aux erreurs phonologiques réalisées au sein des séquences consonantiques et au sein de consonnes en position intervocalique chez des locuteurs aphasiques francophones afin de dégager le rôle potentiel que jouent les différentes variables énoncées précédemment.
II. Objectifs et Hypothèses
Question de recherche
Conformément au cadre phonologique adopté, le rôle du contexte syllabique dans les erreurs réalisées sera questionné, en particulier celui des syllabes comportant des séquences consonantiques. De plus, les consonnes au sein de séquences consonantiques seront examinées de façon à vérifier si elles sont sujettes à plus d’erreurs que les consonnes en position intervocalique.
En outre, l’un des objectifs de cette étude est également de révéler si la structure des syllabes, selon sa complexité (Kaye et Lowenstamm, Reference Kaye, Lowenstamm and Belletti1981), est un facteur qui influence les erreurs.
Plus encore, il s’agira d’évaluer si le type de séquence consonantique engendre différents types d’erreurs (Buchwald, Reference Buchwald2017; Miozzo et Buchwald, Reference Miozzo and Buchwald2013). En effet, conformément à la TCSR et au modèle CV, la suppression est une opération phonologique visant à réduire la complexité qu’engendre une structure. Dans l’aphasie, le paramètre « séquence consonantique » du français est inopérant et une séquence consonantique CCV sera réduite à une séquence CV via l’omission. Dans les séquences hétérosyllabiques, la consonne /s/ dans les séquences s+consonne, de même que R dans les séquences R+consonne, seront plus souvent touchées, toutes deux en position de coda.
Ces différents résultats seront enfin croisés avec d’autres facteurs de la complexité phonologique : la longueur des mots (items bi et trisyllabiques), le type de séquences consonantiques (hétérosyllabique vs tautosyllabique) et la nature des segments composant la séquence et la position (initiale ou médiane).Footnote 9
Hypothèses
L’hypothèse émise dans cette recherche est que les consonnes au sein des séquences consonantiques (i.e. en position faible et gouvernée) sont plus fréquemment touchées par les erreurs que les consonnes en position intervocalique en français. En effet, elles constituent des contextes phonologiquement plus complexes à traiter que des contextes CVCV.
Si les résultats confirment cette première hypothèse, cela amènera à une seconde hypothèse selon laquelle la nature des séquences consonantiques elle-même est susceptible d’influencer des erreurs différentes. Par exemple, les erreurs réalisées dans les séquences tautosyllabiques type TR (attaque-attaque) seront différentes des erreurs produites dans le cas des séquences hétérosyllabiques (coda-attaque) (voir entre autres Kaye, Reference Kaye1990; Scheer, Reference Scheer2004, Reference Scheer2015, pour une discussion sur les processus phonologiques selon la structure syllabique).
III. Méthodologie
3.1. Participants
Huit locuteurs francophones monolingues atteints d’une aphasie consécutive à un AVC ont participé à cette expérience. Il s’agit de sept hommes et d’une femme dont l’âge est compris entre 21 et 83 ans avec une Mage = 49,1 ans. L’expérience a été menée auprès de participants au sein d’une unité neurovasculaire de CHU (France).Footnote 10 Tous les locuteurs présentaient une aphasie caractérisée par un déficit phonologique. L’ensemble des locuteurs sont droitiers et ont subi un accident vasculaire cérébral au sein de l’hémisphère gauche. Ils ont été enregistrés entre J + 2 et J + 31 post-onset. À partir des épreuves de la batterie MT-86 et de la BETL (Tranet Godefroy, Reference Tran and Godefroy2015), et au regard de leurs lésions et de leurs symptômes, deux locuteurs présentent une aphasie de conduction similaire et cinq locuteurs présentent un tableau clinique de type antérieur, non-fluent. Des épreuves supplémentaires (sous-épreuves du MT-86/BDAE dénomination d’images, description d’images, répétition mots/phrases, lecture, examen de la fluence lexicale, évaluation des fonctions exécutives) ont été réalisées par une orthophoniste auprès des locuteurs dans le but de recueillir des informations sur leur profil cognitif et linguistique (Table 1).
Table 1. Population des locuteurs avec aphasie et données de l’examen orthophonique. LO : langage oral ; DO : dénomination orale ; CO/CE : communication orale, écrite ; LHV : lecture à haute voix ; AoS : apraxie de la parole, + : altération légère, ++ : altération sévère
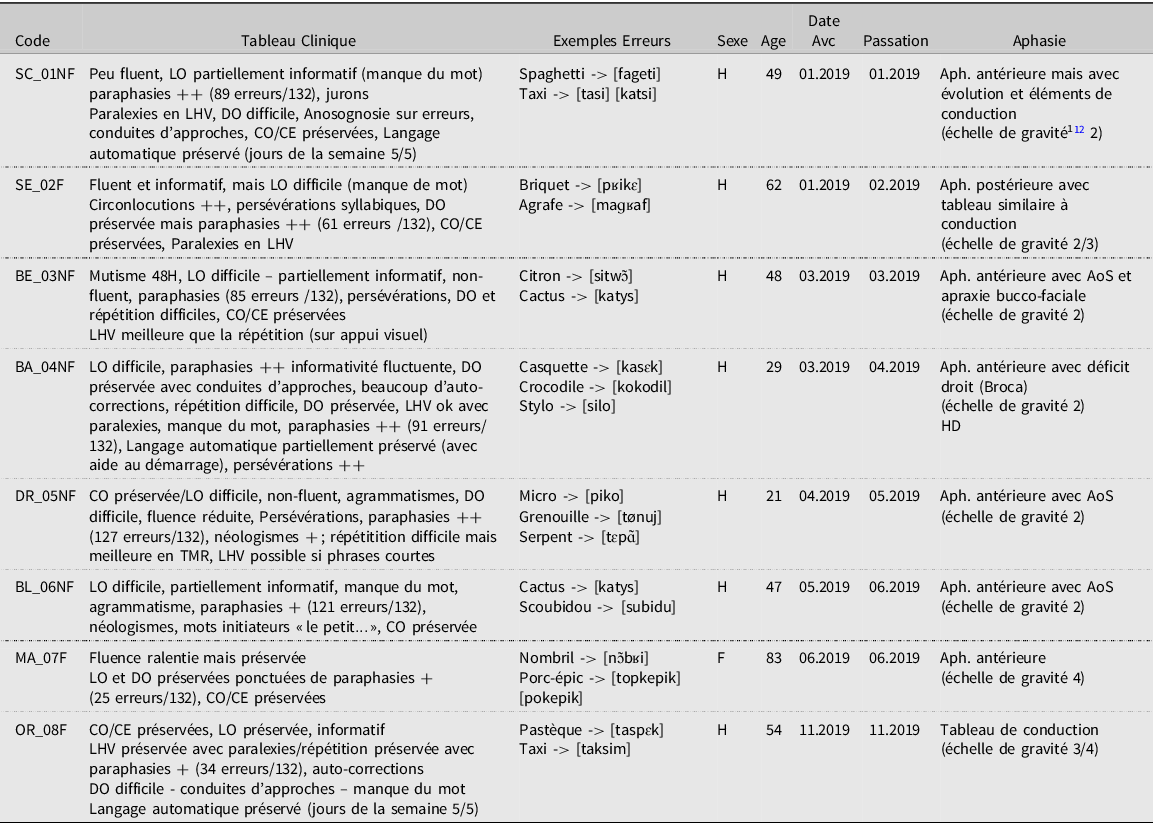
Les performances des participants ont été comparées à celles de vingt participants francophones contrôles, appariés en âge (entre 32 et 67 ans, Mage=54,3ans), sexe (12 F, 7H) et CSP. Les scores de réussite atteignent 100% pour l’ensemble de la population contrôle.
3.2. Stimuli
Les participants ont accompli deux tâches pour cette expérience : la répétition d’items et la tâche de lecture. Au total, 66 items devaient être réalisés deux fois, une pour chacune des tâches. Les mêmes items ont été appariés dans les différentes tâches de façon à observer si la nature de la tâche avait un impact sur les erreurs phonologiques de chaque patient (Laganaro, Reference Laganaro, Séron and Van der Linden2014, Reference Laganaro2015).
Pour la sélection de ces 66 items, plusieurs variables ont été retenues dans la présente étude : la longueur des mots (items bisyllabiques vs trisyllabiques), la position des séquences consonantiques (positions initiale et médiane), le type de séquences consonantiques (hétérosyllabique vs tautosyllabique) et les positions syllabiques (attaque ou coda).Footnote 11 La fréquence lexicale des mots a été récupérée sur la base de données « lexique.org » (New et al. Reference New, Pallier, Ferrand and Matos2001) et concerne spécifiquement la catégorie « freq.lem.films » qui s’approche au plus près de la production orale (qui correspond à la fréquence du lemme selon le corpus de sous-titres/par million d’occurrences). Les items ont été ensuite divisés en 4 quartiles renvoyant à 4 catégories de fréquence (très rare, rare, fréquent, très fréquent).
Trente-trois items français bisyllabiques et 33 items trisyllabiques contenant plusieurs séquences ont été choisis. Ils comportent des séquences consonantiques en positions initiale et médiane et des consonnes isolées. Ainsi, 24 mots comportent des séquences consonantiques en position initiale, composés de séquences tautosyllabiques, telles que les séquences TR (obstruante-liquide), et hétérosyllabiques, telles que les séquences s+obstruante. Quarante items contiennent des séquences consonantiques en position médiane, constitués de séquences tautosyllabiques, telles que les séquences TR, et hétérosyllabiques, telles que les séquences s+obstruante, et les séquences RT ou TT composées d’une liquide et d’une obstruante ou bien de deux obstruantes. À titre d’exemple, les items tels que : « moustache » [mustaʃ], « stylo » [stilo], « coccinelle » [koksinɛl] et « citron » [sitʁɔ̃] ont été sélectionnés (Table 2).
Table 2. Liste des items réalisés en lecture et en répétition

3.3. Procédure
Après l’anamnèse réalisée par les professionnels de santé et le diagnostic posé par l’orthophoniste, deux épreuves complémentaires, lecture et répétition, ont été réalisées. Pour la tâche de lecture, les items ont été lu un à un sur une tablette électronique, dans un ordre aléatoire. Pour la tâche de répétition, les items ont été générés à partir d’une voix naturelle et manipulés à partir d’un programme sous PRAAT (Boersma et Weenink, Reference Boersma and Weenink2021). Ici aussi, les participants sont invités à répéter les items dans un ordre aléatoire lors de chacune des passations. Les premières réalisations d’items ont été prises en compte pour les participants. L’ensemble des deux tâches dure environ vingt minutes et pouvait être effectué en deux fois selon les conditions de santé et de fatigabilité des participants.
L’intégralité de ces passations a été accomplie et enregistrée par une investigatrice à l’aide d’un TASCAM DR-100. Ces dernières ont ensuite été transcrites sous PRAAT (Boersma et Weenink, Reference Boersma and Weenink2021) par deux, voire trois locuteurs francophones en parallèle, puis comparées et vérifiées. Les transcriptions de chaque item ont fait l’objet d’un consensus. En cas de désaccord entre les transcripteurs, les productions ont été écartées du set de données. Les résultats ont ensuite été analysés sous le logiciel R (R Core team, 2020).
IV. Résultats
Les résultats de cette étude seront présentés en trois temps. Tout d’abord, les résultats généraux seront exposés. Au regard des études précédentes, l’impact potentiel de la fréquence lexicale et de la nature de la tâche (répétition et lecture) sur la production des mots (réussite, échec, erreurs) sera vérifié. Dans un deuxième temps, en se focalisant sur les erreurs réalisées, il sera étudié plus précisément si, comme suggéré ci-dessus, les consonnes au sein de séquences consonantiques posent davantage de difficultés. Par la suite, la nature des séquences sera analysée afin de vérifier si elle implique différentes erreurs. L’influence de quatre autres facteurs (longueur, position de la séquence consonantique, type de séquence, nature des segments qui la compose) sur les erreurs prononcées par les locuteurs sera également examinée.
4.1 Résultats généraux
4.1.1 La production des mots
La base de données est composée de 1448 observations qui ont été divisées en trois grandes catégories selon la production des items par les huit locuteurs :
-
— Correct : le mot a été produit sans qu’aucune erreur soit remarquée,
-
— Échec : le mot n’a pas été prononcé ou il a été réalisé avec plus de quatre erreurs,
-
— Erreur : le mot a été produit avec une à quatre erreurs.
Les résultats montrent que les participants ont prononcé 55,18% d’erreurs et que dans 15,54% des cas, les items n’ont pas pu être réalisés (« échec ») (Table 3). La production des items sans erreur a été remarquée dans 29,28% (« correct ») des items prononcés.
Table 3. Pourcentages de la production des mots pour chaque locuteur. Les locuteurs se terminant par un ’NF’ indiquent des locuteurs non-fluents tandis que ceux terminant par un ’F’ désignent des locuteurs fluents

Il apparaît également que les locuteurs fluents (SE6, MA7 et OR8) ont prononcé un plus grand nombre de réalisations correctes et moins d’échecs que les locuteurs atteints d’une aphasie non-fluente. Ainsi, on peut considérer que le type d’aphasie, fluente ou non fluente, peut jouer un rôle dans la qualité de la production des mots (échec, correctement produit ou produit avec erreur).Footnote 13
Une série du test X2 d’indépendance a été effectuée sur les différents facteurs étudiés afin d’examiner leur influence sur la production des mots. Les variables manipulées dans les tests de X2 correspondent aux valeurs de : « production des mots » d’un côté et chacune des valeurs des variables étudiées de l’autre : « tâche », « fréquence », « longueur », « type de CC » et « position de CC ». Ces éléments sont repris pour chacune des figures ci-dessous.
En ce qui concerne l’analyse des pourcentages de l’impact de la nature de la tâche sur la production des mots, les résultats révèlent que la tâche impacte peu la performance des locuteurs (Figure 1). En effet il n’existe pas de relation significative entre la production des mots et la nature de la tâche selon le test de X2, X2(2) = 3.30, p = .192. Autrement dit, la réalisation correcte ou non des mots ne dépend pas de la tâche demandée : lecture ou répétition.

Figure 1. Pourcentages de l’impact de la tâche sur la production des mots.
Si l’on s’attarde sur l’influence de la fréquence des mots sur la production, les résultats montrent une légère augmentation des réalisations correctes et une diminution d’échec des mots lorsque ces derniers sont plus fréquents (Figure 2). Toutefois, les pourcentages des quatre catégories de fréquence semblent relativement stables concernant les productions avec des erreurs. Ces résultats suggèrent que la fréquence lexicale influence peu la production des mots par les participants. Cette constatation est également appuyée par le test de X2 qui indique que la fréquence lexicale et la production des mots sont indépendantes, X2(6) = 10.45, p = .107.

Figure 2. Pourcentages de l’impact de la fréquence sur la production des mots.
Contrairement aux deux précédents facteurs étudiés, le nombre de syllabes, c’est-à-dire la longueur de l’item, bisyllabique ou trisyllabique, joue un rôle dans la production des mots. Selon le test de X2, les deux variables sont dépendantes, X2(2) = 7.68, p = .021. En effet, les participants ont une meilleure performance pour les mots bisyllabiques en comparaison des mots trisyllabiques, avec un nombre plus important de mots correctement réalisés et moins d’échecs (Figure 3).

Figure 3. Pourcentages de l’impact du nombre de syllabes sur la production des mots.
Ce résultat confirme les travaux précédents (notamment Verhaegen et al., Reference Verhaegen, Delvaux, Huet, Fagniart, Piccaluga and Harmegnies2016, Reference Verhaegen, Delvaux, Huet, Fagniart, Piccaluga and Harmegnies2018, Reference Verhaegen, Delvaux, Fagniart, Huet, Piccaluga and Harmegnies2020) et montre que le traitement d’un item plus long représente un coût cognitif supplémentaire qui entraîne des erreurs.
En ce qui concerne les deux derniers facteurs, le type de séquences consonantiques et la position de la séquence consonantique, les analyses ne révèlent qu’aucun de ces deux facteurs n’influence la performance des participants, basés sur la production des mots (« correct », « échec » et « erreur »). Les pourcentages restent, de ce fait, relativement stables pour les trois catégories (Figures 4a et 4b). Le test de X2 confirme cette constatation et met en évidence que la production des mots est indépendante de ces facteurs, X2(8) = 7.73, p = .461 et X2(2) = .87, p = .646, respectivement pour le type et la position de séquence consonantique.

Figure 4. (4a et 4b) Pourcentages de l’impact de la position (figure à gauche) et du type (figure à droite) de la séquence consonantique (CC) sur la production des mots.
Ici, il est à remarquer que ni la position initiale ou médiane ni le type de séquences consonantiques ne semblent avoir une quelconque influence sur la production des mots. Pourtant, nous le verrons dans la section suivante, ces variables jouent un rôle plus important lorsque le type d’erreur est observé.
Afin de répondre aux hypothèses formulées, seuls les items réalisés avec des erreurs pour chacun des huit participants seront examinés.
4.1.2 Les types d’erreurs
Pour rappel, 55,18 % des réalisations rentrent dans la catégorie des erreurs (Table 3). Les locuteurs ont produit au total 799 erreurs, que nous proposons de répartir en cinq catégories : substitutions, omissions, insertions, réductions de séquence consonantique et métathèses (Table 4). L’observation des erreurs pour chaque locuteur indique que les participants ont réalisé principalement des erreurs de substitutions. Il s’agit des erreurs les plus fréquentes chez l’ensemble des locuteurs, à l’exception du locuteur BE3NF. Les erreurs d’omission arrivent, quant à elles, en deuxième position, suivies des erreurs d’insertion et de réduction de la séquence consonantique. La métathèse est l’erreur la moins courante, représentant seulement 5,26 % de l’ensemble des erreurs réalisées. Ces résultats sont similaires à ceux des études présentées dans la section théorique pour le français, le néerlandais ou encore l’italien (Blumstein, Reference Blumstein1973; Den Ouden, Reference Den Ouden, Botma, Kula and Nasukawa2011; Moreau, Reference Moreau1993; Romani et al., Reference Romani, Galuzzi, Guariglia and Goslin2017, inter alia).
Table 4. Pourcentages des types d’erreurs produites par les locuteurs

Dans le détail, si ces erreurs sont observées selon le contexte, il est à noter que ces dernières ne résultent pas du hasard.
4.2 Répartition des erreurs : séquences consonantiques vs. hors séquences consonantiques
Si l’on observe la répartition des erreurs sur les segments, il est à remarquer que les erreurs qui concernent les voyelles représentent 21 % de l’ensemble des erreurs, contre 79 % pour les consonnes. Ce pourcentage laisse à penser que les voyelles posent bien moins de difficultés aux PwA que les consonnes. Plus précisément, sur les 799 erreurs observées, 380 impliquent les séquences consonantiques, c’est-à-dire les consonnes précédées ou suivies d’une autre consonne, ce qui représente 47,56 % de la totalité des erreurs. Les erreurs concernant les consonnes qui ne se situent pas au sein de séquences consonantiques représentent 31,44 % de la totalité des erreurs.
Ces chiffres confirment la première hypothèse émise selon laquelle les séquences consonantiques posent davantage de difficultés aux locuteurs avec aphasie que les consonnes en position intervocalique ou les voyelles. Cette constatation est attendue puisque la réalisation de ces dernières est plus complexe que celle des voyelles (Kent et Read, Reference Kent and Read1996).
Les erreurs réalisées uniquement sur les séquences consonantiques sont réparties selon chaque locuteur dans la table 5. Contrairement aux résultats sur l’ensemble des erreurs, l’erreur la plus fréquente dans les séquences consonantiques est l’omission et non la substitution. Cette dernière reste tout de même fréquente et est placée en deuxième position. Une autre forme d’omission, la réduction de CC, consiste en la transformation des deux segments consonantiques de la séquence en une tierce consonne ; par exemple, dans l’item biscotte /biskɔt/ réalisé [bitɔt], [sk] devient alors [t]. En ce sens, l’on peut y voir à la fois un cas d’omission et de substitution. En cela, et pour les erreurs portant sur les consonnes des séquences consonantiques, l’omission et la réduction de CC correspondent à plus de 55,27 % des erreurs.
Table 5. Pourcentages des types d’erreurs produites par les locuteurs au sein des séquences consonantiques

L’examen des pourcentages d’erreurs au sein des séquences consonantiques versus hors séquences consonantiques fait apparaître une différence entre les deux contextes. En effet, les erreurs réalisées sur les consonnes hors séquences consonantiques, c’est-à-dire en position intervocalique, sont principalement des erreurs de substitution (60,14 %), suivie par les insertions (25,78 %), consonantique ou vocalique. La substitution renvoie à une modification segmentale, par exemple la substitution d’un phonème voisé par un phonème non-voisé. L’insertion concerne l’ajout d’un segment. Selon le cadre syllabique adopté, l’on pourra considérer que l’insertion consonantique concerne le remplissage d’une position consonantique vide dans la représentation sous-jacenteFootnote 14 pour restaurer une structure initiale de type CV, dans ce cas-là, le plus souvent en position d’attaqueFootnote 15 : agrafe /agʁaf/ réalisé [kaʁdaf] avec un [k] initial.
Les erreurs d’omission et de métathèse sont respectivement de 12,41 % et de 1,19 % hors séquences consonantiques (Table 6).
Table 6. Pourcentages des types d’erreurs produites par les locuteurs hors séquences consonantiques

L’insertion, quant à elle, est la moins fréquente dans les erreurs à l’intérieur des séquences consonantiques (7,37 %). Elle est employée pour remplir une position vocalique vide, telle que dans l’item cactus réalisé /kakətys/ au lieu de la forme cible [kaktys], venant ainsi briser la séquence consonantique. Toutefois, et pour des raisons de simplification contextuelle, l’omission de l’un des membres de la séquence consonantique lui est préférée.
La répartition des erreurs tient compte du contexte syllabique : les consonnes en position intervocalique, VCV, sont différemment traitées des consonnes suivies ou précédées d’une autre consonne (au sein d’une séquence consonantique, VCCV). Par conséquent, les résultats confirment que la complexité syllabique semble jouer un rôle important dans le type d’erreurs. La différence quant aux types d’erreur pourrait s’expliquer par la tendance à transformer les séquences consonantiques en structure CV simple via l’omission ou la réduction de séquence (la somme des deux dépassant les 55 %). En dehors des séquences consonantiques, la très forte domination des substitutions consonantiques semble indiquer que le phonème pose davantage problème que la syllabe.Footnote 16 Des résultats identiques concernant les occurrences de types d’erreurs sont formulés à partir de données de locuteurs fluents et non-fluents notamment dans les travaux de Béland (Reference Béland1985), Den Ouden et Bastiaanse (Reference Den Ouden, Bastiaanse, van de Weijer, van Heuven and van der Hulst2003), Marczyck et Baqué (Reference Marczyck and Baqué2015) et Romani et al. (Reference Romani, Galluzzi and Olson2011a/b).
4.3 Facteurs de complexité et types d’erreurs
4.3.1 Nature des séquences consonantiques et type d’erreurs
Parce que la répartition des erreurs indique que les séquences consonantiques sont plus difficiles à traiter par les locuteurs aphasiques et posent davantage de difficultés, nous nous interrogeons sur le lien entre la nature des séquences consonantiques et les types d’erreurs réalisés. Pour rappel, les séquences consonantiques sont examinées à travers quatre structures dans cet article : les séquences hétérosyllabiques (RT, TT et sT où R renvoie aux liquides et T aux obstruantes, /s/ renvoie à la consonne [s]) et les séquences tautosyllabiques (désormais TR). Ces dernières correspondent aux structures consonantiques binaires existantes en français.Footnote 17 La table 7 illustre le pourcentage d’erreurs propre à chacun des quatre types de séquences sur le total des erreurs au sein des séquences consonantiques pour l’ensemble des participants.
Table 7. Pourcentages des types d’erreurs selon le type de CC sur les erreurs de CC uniquement (en %)

On peut y voir que les deux erreurs majoritairement réalisées sont la substitution consonantique et l’omission. Selon les résultats obtenus ci-dessus, la séquence tautosyllabique TR génère le plus d’erreurs, suivie par la séquence s+obstruante(sT), puis par la séquence RT (Table 7). Il est également à remarquer que la réduction de séquence consonantique (CC) se produit principalement au sein des séquences TR à hauteur de 13 % et que la métathèse est réalisée quasiment exclusivement au sein des séquences sT (7 % contre 1 % partout ailleurs). Les séquences TR sont aussi les plus touchées par les erreurs de substitution. Les mots comportant des séquences consonantiques de type TT sont ceux réalisés avec le moins d’erreurs. Les erreurs de métathèse portent principalement sur les mots contenant des séquences consonantiques de type sT comme dans l’item escalier/ɛskalje/ produit [ɛksalje]. D’après les résultats, il apparaît que le type d’erreur, lorsqu’il porte sur une séquence consonantique, dépend de la nature de la séquence consonantique.
Dans la section suivante, les autres facteurs de complexité susceptibles de jouer un rôle sur le type d’erreur réalisé seront observés : la longueur selon le type de séquence consonantique et la position initiale ou médiane.
4.3.2 La longueur et type de CC
Pour rappel (4.1, Figure 3), les locuteurs ont réalisé de meilleures performances en production de mot dans les contextes bisyllabiques et plus d’erreurs dans les contextes trisyllabiques, à l’instar des résultats de précédentes études. Les items trisyllabiques ont été plus fréquemment échoués que ceux composés de deux syllabes.
Il convient de retenir que si la production des mots est liée à la longueur des mots (Figure 3), le type d’erreur réalisé dépend également du nombre de syllabe (X2(4) = 13.78, p >. 001). Ainsi, la substitution est plus fréquente en contexte trisyllabique tandis que l’insertion prévaut dans les items bisyllabiques (Figure 5). À notre connaissance, il n’existe pas de travaux sur ce point. Ce résultat assez original doit faire l’objet d’une nouvelle étude et d’une réflexion approfondie afin de comprendre la nature de ce lien.

Figure 5. Répartition des erreurs selon la longueur des items.
Si l’on observe la nature de la séquence consonantique, il est à noter que le taux d’erreur est plus important dans les séquences TR (Table 8). Ces dernières semblent être plus problématiques pour les locuteurs que les séquences hétérosyllabiques.
Table 8. Taux d’erreurs (en %) selon la longueur et le type de séquence consonantique

4.3.3 Position des séquences consonantiques
Les types d’erreurs dépendent également de la position des séquences consonantiques. En effet, la majorité des erreurs produites à l’intérieur des séquences consonantiques ont été réalisées quand celles-ci se trouvent en position médiane.
Au contraire, les séquences consonantiques en position initiale sont plus souvent correctement réalisées, le taux d’erreur étant toujours inférieur pour ces dernières, qu’importe la nature de l’erreur (Figure 6). Cette dépendance est significative, avec X2(4) = 10.22, p>.05, et cela pourrait peut-être s’expliquer par la structure des séquences.

Figure 6. Impact (en %) de la position de la séquence consonantique dans le mot sur le type d’erreur au sein des séquences consonantiques.
En effet, les séquences hétérosyllabiques sont principalement rencontrées en position médiane, TT, RT et sT et les séquences tautosyllabiques en position initiale (Figure 7). Dès lors, les difficultés seraient davantage induites par le type de structure que la position. En position initiale, les séquences de type TR posent moins de difficulté que les séquences hétérosyllabiques en position médiane, de type sT, RT et TT. Ce résultat semble prouver que les séquences hétérosyllabiques sont phonologiquement plus complexes que les séquences tautosyllabiques.

Figure 7. Pourcentages de l’impact du type de séquences sur le type d’erreur.
4.3.4. Nature des segments consonantiques et complexité positionnelle
Un intérêt particulier a été porté aux omissions puisqu’elles sont les erreurs les plus fréquentes touchant les séquences consonantiques. Le plan segmental peut être touché sans que la structure syllabique ne soit atteinte.
En guise d’ouverture, nous avons observé le rapport entre la nature des segments consonantiques et leur position phonologique attaque ou coda, selon le type de séquence consonantique. Il existe 138 erreurs d’omission touchant principalement le phonème /ʁ/ (67 occurrences). Les phonèmes /k/ et /s/ viennent en deuxième position, suivis par le /t/. Les segments /s/, /t/ et /k/ sont omis dans les séquences TT lorsqu’elles sont en position de coda, mais pas dans une séquence TR où elles sont en position d’attaque. De même, /s/ est touché dans les séquences sT. Le reste des consonnes est très peu omis (entre une et cinq erreurs seulement). En outre, les erreurs d’omission de consonnes hors séquences consonantiques sont beaucoup moins fréquentes (34 omissions) et sont étendues sur 12 consonnes (entre 2 et 5 occurrences pour chacune). En d’autres termes, ce n’est pas tant la nature de la consonne en elle-même qui est le plus souvent problématique, mais plutôt la position syllabique qu’elle occupe dans la chaîne, à savoir celle d’attaque ou bien de coda. Ainsi, si les omissions concernent principalement les consonnes au sein des séquences consonantiques, c’est en réalité la position de coda, c’est-à-dire la position faible par excellence (Scheer, Reference Scheer2015) qui est touchée dans les séquences RT et la position d’attaque double dans les séquences TR. Il en va de même pour la consonne /s/ : c’est en position faible dans les séquences sT qu’elle est principalement touchée. C’est la raison pour laquelle nous observons bien moins d’erreurs d’omission de consonnes hors séquences consonantiques, ces dernières étant en position intervocalique, c’est-à-dire en position forte (Scheer, Reference Scheer2015).
Discussion
Dans cette recherche portant sur les réalisations de huit locuteurs francophones atteints d’une aphasie, nous nous sommes interrogés sur la notion de complexité phonologique et sur les contextes susceptibles d’influencer la réalisation des erreurs au sein des mots tels que la longueur des items, la présence d’une séquence consonantique dans la structure syllabique, la position des séquences consonantiques, ou encore la nature consonantique des séquences.
Il a été montré dans la section 4.2 de cet article que les environnements comportant des séquences consonantiques génèrent un plus grand nombre d’erreurs que les environnements où les consonnes se situent en position intervocalique. L’hypothèse de départ est confirmée : les séquences consonantiques constituent des environnements syllabiques phonologiquement plus complexes au sein desquels les erreurs sont réalisées plus fréquemment qu’au sein de syllabes avec des consonnes en position intervocalique. Il a été observé que les erreurs générées et leurs natures dépendent également d’autres facteurs tels que la longueur des mots ou la position des séquences consonantiques au sein des mots : position initiale ou médiane. En observant de plus près les données, le type de séquence consonantique, TR, RT, sT et TT, impacte la nature des erreurs, ces dernières différant selon les séquences consonantiques.
Pour ces raisons, nous avons proposé que l’ensemble de ces contextes est englobé sous la terminologie « complexité phonologique ». De nombreuses variables entrent en jeu lorsque des erreurs sont produites dans le cas d’un déficit phonologique. Ces erreurs ne sont pas aléatoires et dépendent de conditions phonologiques, telles que celles étudiées dans cette recherche.
Cette étude rend compte du fait que la complexité de la syllabe joue clairement un rôle dans la nature des erreurs produites. Il apparaît que plus la complexité est grande, plus les erreurs sont importantes. Outre les questions liées au rôle de la fréquence étudiées dans diverses recherches, les résultats de ce travail sont conformes à d’autres études qui présentent des patterns d’erreurs similaires chez des locuteurs francophones (Nespoulous et Moreau, Reference Nespoulous, Moreau, Visch-Brink and Bastiaanse1998; Moreau, Reference Moreau1993). Des erreurs similaires sont également évoquées dans des travaux illustrant les données de locuteurs italophones et anglophones (Buchwald, Reference Buchwald2017; Den Ouden, Reference Den Ouden, Botma, Kula and Nasukawa2011; Romani et al. Reference Romani, Galluzzi and Olson2011a, Reference Romani, Galluzzi, Bureca and Olson2011b). L’omission et la substitution restent les deux erreurs majoritaires et les contextes avec séquences consonantiques sont plus fréquemment touchés, notamment la position de coda. Cette recherche montre que les omissions sont préférées aux substitutions dans les contextes de séquences consonantiques et que la position faible est omise. Cela confirme l’idée selon laquelle la syllabe universelle de type CV est au cœur des représentations phonologiques et qu’autour d’elle, gravitent des éléments pré et post-consonantiques (en fonction des paramètres et des contraintes phonologiques des langues), créant ainsi des structures plus ou moins complexes qui peuvent être atteintes dans le cas de certains types d'aphasies.
Conformément aux résultats de Butterworth (Reference Butterworth1992), les erreurs réalisées par les locuteurs et les analyses de ces résultats vont en faveur d’une représentation sous-jacente stockée par défaut de la forme CVCV. Dès lors, si un déficit de l’accès aux représentations phonologiques existe, cela conduit à la réalisation des erreurs de type omission, épenthèse, métathèse, etc. visant à restaurer la structure CVCV par défaut. Selon le cadre phonologique établi précédent – la TCSR et la phonologie du gouvernement –, lors d’un déficit phonologique, les structures des mots deviennent inaccessibles, ce qui conduit les PwA à développer des stratégies de réparation. Ces stratégies de réparation reflètent l’organisation des unités phonologiques et leurs analyses mettent en évidence le rôle du niveau syllabique et les structures syllabiques et phonémiques.
Les résultats présentés dans cet article confirment l’idée d’un stockage et d’un accès aux représentations syllabiques. Nous suggérons que les modèles de la production verbale (tels que celui de Levelt et al. Reference Levelt, Roelofs and Meyer1999 ou encore de Caramazza, Reference Caramazza1997) pourraient considérer alors une étape supplémentaire de traitement, outre l’accès au lexique et à l’activation des niveaux phonémique et sémantique liés, pour intégrer ces processus de complexité phonologique. Nous adoptons la position de Romani et al. (Reference Romani, Galluzzi and Olson2011a/b) pour l’intégration d’une composante syllabique au sein du traitement lexico-phonologique.
Conclusion
Cette première analyse du corpus semble confirmer que les séquences consonantiques posent des problèmes spécifiques aux PwA. Le type d’erreurs réalisé sur ces séquences consonantiques semble être lié à différents facteurs dont la longueur du mot, le type de séquence ou encore la nature des segments. La position de la séquence, initiale ou médiane, pourrait n’influencer qu’indirectement le type d’erreur qui serait avant tout déterminé par la structure, hétérosyllabique ou tautosyllabique. L’ensemble de ces facteurs est englobé sous la terminologie « complexité phonologique ». En ce sens les erreurs serviraient à réduire le « coût » cognitif qu’engendre le traitement phonologique des structures complexes. L’étude des erreurs des PwA – considérées comme des stratégies de réparation – offre de riches perspectives pour l’étude de l’interaction entre les niveaux phonologiques et phonétiques et la définition de la complexité phonologique.
Les résultats de cette étude indiquent qu’il faut prendre davantage en compte le niveau syllabique dans les tests cliniques d’évaluation de la production du niveau phonologique, car évaluer et mieux cerner son rôle revient à mieux prendre en charge ces erreurs lors de la prise en charge en rééducation orthophonique.
Conflits d’intérêt
Néant.
















 Open access
Open access