



1. Introduction
Phonetically based sound change occurs when a subphonemic coarticulatory effect is detected and phonologized under specific conditions (Andersen Reference Andersen1973, Ohala Reference Ohala1981, Blevins Reference Blevins2004).Footnote 1 For example, contextual vowel nasalization is interpreted as contrastive when the conditioning environment, a nasal consonant, is lost. In a likely trajectory, the speaker intends to pronounce an oral vowel followed by a nasal, /Vn/, but due to coarticulation the vowel comes out as contextually nasalized, [Ṽn]. Insofar as speech is variable, the pool of possible realizations of the sequence includes one with considerable reduction of the nasal consonant, [Ṽ]. The utterance may then be interpreted as including a phonological nasal vowel, /Ṽ/. This mechanism is responsible for the emergence of nasal vowels in phonemic inventories (Ohala Reference Ohala, Kellermann and Morrissey1992).Footnote 2
Cumulative effects occur when two or more triggers exerting the same coarticulatory effect are required for phonologization; one trigger is not sufficient. In this paper, two sound changes in Kashubian are analyzed. The shared mechanism underlying the two processes involves the phonologization of contextual lengthening of vowels. Three conditions inducing phonetic lengthening must be simultaneously fulfilled to trigger phonologization: The vowel must be in a head syllable, in an open syllable, and followed by a voiced consonant. As represented in (1), phonetic lengthening occurs in (1a), where the first vowel appears in a head syllable, in an open syllable, and before a voiced consonant, marked as ‘d’, but not in (1b), where the vowel occurs in a head syllable, in an open syllable, but before a voiceless consonant, marked as ‘t’. As shown in (1a), when the final vowel is lost (due to an independent process), the additional phonetic length is phonologized. This is an instance of a cumulative effect, as all three conditions are necessary. The cumulative effect is notable for yet another reason. The necessary conditions are of a different type: The head syllable and the open syllable requirements are prosodic, while the requirement of a following voiced consonant is segmental. Cumulative effects are treated using local constraint conjunction (LCC) in Optimality Theory (OT, Smolensky Reference Smolensky1993).
The analysis is cast in the BiPhon model, a bidirectional model of phonology and phonetics (Boersma Reference Boersma1998, Reference Boersma, Benz and Mattausch2011; Boersma & Hamann Reference Boersma and Hamann2008). Bidirectionality means that both the speaking process (production) and the listening process (comprehension) are modeled. With relevance to the study of phonetically based sound change, the model uses two phonological representations (underlying and surface) and two phonetic representations (auditory and articulatory). Unlike the models advocated in, for example, Kiparsky (Reference Kiparsky1982), Lombardi (Reference Lombardi1991), and Kenstowicz (Reference Kenstowicz1994), where the relation between the phonological and phonetic representations is serial, the evaluation of representations in the BiPhon model runs in parallel. Crucially, phonology has access to phonetic detail, as phonological and phonetic representations are simultaneously available. OT constraints are used to evaluate either a single level of representation or a relation between two levels of representation. In this framework, sound change typically occurs in comprehension. It is modeled in OT using cue constraints, which map auditory categories to phonological categories.
In accounts that employ the BiPhon model, sound change occurs in comprehension, which means that such accounts are listener oriented. However, among the vast range of phonetically based approaches that can be used to model sound change are also those that are speaker oriented. For example, Jun (Reference Jun, Hayes, Kirchner and Steriade2004), Steriade (Reference Steriade1997, Reference Steriade, Hanson and Inkelas2009), Hayes & Steriade (Reference Hayes, Steriade, Hayes, Kirchner and Steriade2004), Flemming (Reference Flemming2008), and Stanton (Reference Stanton2017, Reference Stanton2018) argue that phonetic patterns are to a significant extent under the speaker’s control. The resulting context-dependent phonetic variations can lead to synchronic alternations. By extension, sound change results from synchronic pressures implemented by the speaker, which means that synchronic biases must be available to accounts of sound change. I do not take a position on the debate about listener- versus speaker-oriented approaches to sound change, as the Kashubian pattern can be successfully modeled in either of the two approaches. Instead, I focus on the pivotal tenet that phonetically based approaches share: Fine-grained phonetic information is visible to phonology. Put differently, phonological computation has access to phonetic details, including cumulative coarticulatory effects.Footnote 3
This paper is structured as follows. Section 2 provides a brief description of the Kashubian sound system. Section 3 describes the preservation and loss of jers and sheds light on the phonetic conditioning of the process. Section 4 puts forward a constraint-based analysis couched in the BiPhon model. Section 5 provides additional evidence for the proposed analysis by focusing on another change with a similar rationale: compensatory lengthening (CL). Section 6 draws a comparison between the two processes. Section 7 discusses remaining issues and alternative analyses.
2. Kashubian: Background
Kashubian, together with Polish and Polabian (the latter extinct), is classified as a Northwest Slavic or Lechitic language. This endangered language is spoken today mainly in the northwest of Poland (eastern Pomerania). According to data from the 2021 national census, the number of people in Poland who declare Kashubian as their language is 89,198 (Statistics Poland 2023). Most contemporary speakers of Kashubian are bilingual, with Polish their first or second native language.
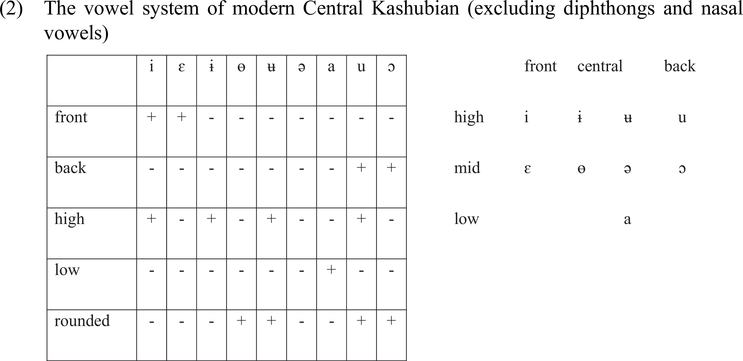
A feature table and a representation of the vowel system of Central Kashubian are given in (2). In modern Central Kashubian, vowels are not contrastive for length. To draw a distinction between central and back vowels, the feature [-back] represents front and central vowels and the feature [-front] represents central and back vowels. Descriptive sources concur that there is a great deal of dialectal, interspeaker, and intraspeaker variation in the realization of vowels (e.g. Breza & Treder Reference Breza and Treder1981: 33; Topolińska Reference Topolińska, Zeszyt, Kaszuby and Wielkopolska1982; Jocz Reference Jocz2013: 187–188). Given the attested variation of vowels, for clarity, the transcription in this paper will employ the most common variants, as given in Jocz (Reference Jocz2013).
Dialects of Central Kashubian fall into two groups regarding the stress pattern. In system I, stress is fixed on the same syllable in a paradigm, e.g. /tʃaˈrɔvɲits-a/ ‘witch’ n.sg., /tʃaˈrɔvɲits-ama/ instr.pl., /tʃaˈrɔvɲits/ g.pl. In system II, stress is word-initial, e.g. /ˈjaskuwk-a/ ‘swallow’ n.sg., /ˈjaskuwk-ama/ instr.pl. (Breza & Treder Reference Breza and Treder1981: 20–21).
The following sections discuss the preservation and loss of jers. Section 5 focuses on CL. The two processes share the basic mechanism: phonologization of phonetic length. However, they differ in their sensitivity to metrical structure.
3. Preservation and loss of jers: Data
At the outset of the analysis of the preservation and loss of jers, the necessary background and the main data are provided. Section 3.2 offers a historical account.
3.1. Background and data
I follow Bethin (Reference Bethin1998: 25–26) in assuming that quantity was phonologically relevant in Common Slavic (CS). CS is reconstructed with a nine-vowel system (plus two nasal vowels: /ę/ and /ǫ/), as shown in (3) (Lindstedt Reference Lindstedt1991, Bethin Reference Bethin1998).
In research on Slavic languages, vowels ĭ and ŭ are termed jers and are described as ultra-short vowels, /ɪ/ and /ʊ/ (Bethin Reference Bethin1998). In Late Common Slavic (LCS), jers were subject to strengthening and weakening depending on the syntagmatic context. Word-final jers and jers before a non-jer vowel were weakened, while jers in the context of another jer in the next syllable were strengthened. This generalization is termed Havlik’s Law. Following Bethin (Reference Bethin1998), Havlik’s Law can be represented as a [strong—weak] grouping of two consecutive jer syllables. Havlik’s Law is closely related to rhythmicity, which is defined as a type of prominence found in foot-sensitive contexts which creates a contrast between strong and weak syllables. The contrast may or may not involve stress (González Reference González, Miestamo and Wälchli2007). For example, LCS *šĭvĭcĭ, *šĭvĭca n.sg., g.sg. evolved into Ukrainian švec′ /ʃvets′/, ševcja /ʃewts′a/ ‘shoemaker’ (Bethin Reference Bethin1998: 105). The weak jers were eventually lost, while the strong jers were preserved and developed into non-jer vowels, usually /o/, /e/, /a/, or /ə/, depending on the dialect of Slavic (Bethin Reference Bethin1998: 104). The application of Havlik’s Law is schematized in (4) (‘ĭ’ stands for a jer, ĭ or ŭ, ‘w’ for weak and ‘s’ for strong).
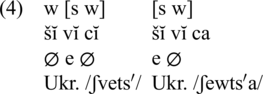
While Kashubian generally complied with Havlik’s Law, it added a condition: voicing of the intervening consonant. The data in (5) are taken from Andersen (Reference Andersen1970: 64–66), Timberlake (Reference Timberlake1988: 226–227), and Czaplicki (Reference Czaplicki2020: 112–114) (C = consonant, Y = jer, d = voiced consonant, t = voiceless consonant, # = word boundary). Transcription and modern spelling are used. Reconstructed cognates from LCS are provided in the last column. Historical jers, as visible in the LCS cognates, show up as [ɛ] ~ ∅ and [i/ɨ] ~ ∅ alternations. Modern Kashubian shows final obstruent devoicing. The loss of jers occurred at an earlier stage, that is, when voiced obstruents could appear word finally.

The items in (5a) show that when the stem is monosyllabic and contains a historical jer, the jer is preserved and pronounced [ε] <e> or [i/ɨ] <é>. This generalization is exceptionless and is likely driven by a constraint against asyllabic words (Andersen Reference Andersen1970: 69). In the context of a stem-final voiced consonant (obstruent or sonorant) the penultimate jer is also preserved, as shown in (5b). However, when the stem-final consonant is a voiceless obstruent, the jer is lost, as in (5c). The processes that produced this pattern were fully regular. The counts of items given in Andersen (Reference Andersen1970) for the three conditions in (5) are 17, 27, and 38, respectively. However, the list is easily extendable. The items in (5c) can be directly compared with their Polish counterparts, which retain the historical jers in this context, e.g. /palɛts/, /dɔbɨtɛk/, /ɔtsɛt/, /rɔʐ-ɛk/, and /dɔm-ɛtʃ-ɛk/. Bearing in mind that the items on the left had a jer-ending -ĭ/-ŭ in LCS, it appears that in order to be preserved in Kashubian, a jer had to be in the strong position, thus observing Havlik’s Law, but it also had to be followed by a voiced consonant, as represented in (6) (C = consonant, V = full vowel, Y = jer, d = voiced consonant, t = voiceless consonant; based on Czaplicki Reference Czaplicki2020: 115).Footnote 5
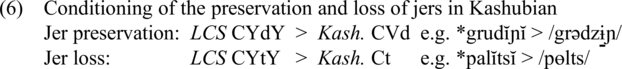
3.2. A historical account
The proposed explanation invokes phonetic duration of vowels and is based on Andersen (Reference Andersen1970), Timberlake (Reference Timberlake and Flier1983a, Reference Timberlake1988), and Czaplicki (Reference Czaplicki2020). Polish, in which the phonologization of phonetic length was less restricted than in Kashubian, is discussed first. A discussion of the Kashubian data follows. In the evolution from LCS to Polish, open syllable lengthening was sufficient for the phonologization of phonetic length, as schematized and exemplified in (7) (C stands for a consonant, either voiced or voiceless).Footnote 6 The second stage shows phonetic lengthening of the jer in the strong position due to an open syllable (indicated by parentheses). The final stage documents the loss of the conditioning context, a final jer, and phonologization of length on the preceding jer. The lengthened jer is phonologized as a full vowel, as its length can no longer be attributed to the syntagmatic context.
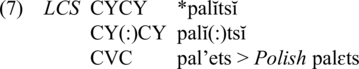
In Kashubian, the effect of open syllable lengthening was not sufficient to preserve a jer and had to be reinforced by the effect of the lengthening due to a following voiced consonant. Put differently, a jer was preserved when open syllable lengthening was enhanced by lengthening due to the voicing of the following consonant. Unlike in Polish, in Kashubian the longer duration of jers in open syllables alone was not sufficient to preserve them, as confirmed by the loss of strong jers before voiceless consonants.
In (8), the evolution of jers from LCS to Kashubian is schematized and exemplified. (8a) shows the context of a voiced consonant, marked as ‘d’, while in (8b), the context of a voiceless consonant, ‘t’, is illustrated. In (8a), the second stage shows phonetic lengthening of the jer in the strong position due to an open syllable and a following voiced consonant. The subsequent stages mirror the developments in Polish given in (7). The result is the phonologization of a full vowel before a voiced consonant. In contrast, in the context of a following voiceless consonant, schematized in (8b), open syllable lengthening was not reinforced by lengthening before a voiced consonant. In the third stage, the final jer was dropped. Since the preceding jer was not sufficiently phonetically long, it was lost, too.Footnote 7

4. Preservation and loss of jers: A formal analysis
The proposed analysis is based on the assumption that (i) phonological constraints must have access to phonetic detail, and (ii) phonology is sensitive to cumulative phonetic effects. The analysis is couched in the BiPhon model. At the outset, we focus on the architecture of the BiPhon model, representing cumulative effects and vowel duration. Then, an analysis of the Kashubian data is laid out.
4.1. The BiPhon model
The proposed formal analysis of the phonologization of phonetic effects relies on the assumption that non-contrastive phonetic, including coarticulatory, effects are visible to phonology, as argued in Jun (Reference Jun1995), Boersma (Reference Boersma1998), Steriade (Reference Steriade1997, Reference Steriade, Hanson and Inkelas2009), and Lionnet (Reference Lionnet2016), among others. Coarticulatory effects are part of the phonetic knowledge of a language user (Kingston & Diehl Reference Kingston and Diehl1994). Phonetic knowledge is defined by Hayes & Steriade (Reference Hayes, Steriade, Hayes, Kirchner and Steriade2004: 1) as ‘the speaker’s partial understanding of the conditions under which speech is produced and perceived’. On this view, phonetic knowledge, such as the fact that vowels tend to be longer before voiced than before voiceless consonants, is available to phonological computation (see Steriade Reference Steriade1997 and Jun Reference Jun2002 for similar claims).
I use the BiPhon model, a bidirectional six-level model of phonology and phonetics (Boersma Reference Boersma1998, Reference Boersma2007, Reference Boersma, Benz and Mattausch2011; Boersma & Hamann Reference Boersma and Hamann2008). The BiPhon model provides tools useful for capturing and explaining the mechanisms of phonetically based change. The model is bidirectional in the sense that it represents both the speaking process (production) and the listening process (comprehension). With relevance to sound change, listener-oriented effects tend to emerge from learning algorithms for the comprehension direction (Boersma & Hamann Reference Boersma, Hamann, Calabrese and Wetzels2009).
Figure 1 presents the part of the model of the phonological grammar relevant for modeling phonetically based sound change (Boersma Reference Boersma1998, Reference Boersma2007, Reference Boersma, Benz and Mattausch2011; Apoussidou Reference Apoussidou2007). It contains two phonological representations and two phonetic representations, all connected to each other.Footnote 9 As already mentioned, the model is bidirectional. In production, the speaker moves down the levels shown in Figure 1, while in comprehension the listener moves up the levels, starting from the Auditory Form (AudF). During processing, both in production and comprehension, a number of intermediate representations are visited. OT constraints are used to evaluate either a single level of representation (structural and articulatory constraints) or a relation between two levels of representation (faithfulness, cue, and sensorimotor constraints). Bidirectionality pertains to constraints: The set of constraints for the speaker and the listener is the same.
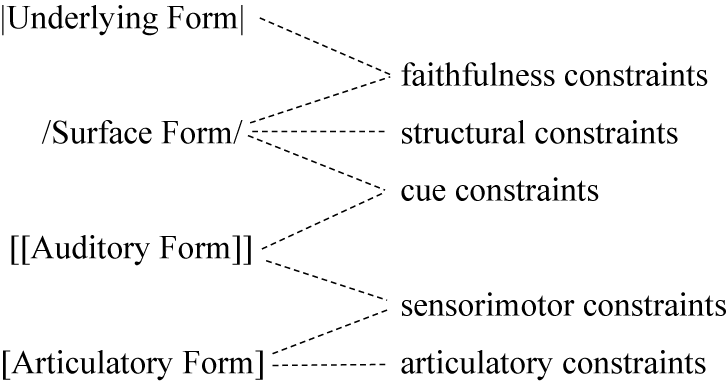
Figure 1. Phonological processing in the BiPhon model (Boersma Reference Boersma, Benz and Mattausch2011).
In this paper, we mainly refer to constraints evaluating three levels: the Underlying Form (UF), Surface Form (SF), and AudF. Following Boersma (Reference Boersma, Benz and Mattausch2011), the UF is a sequence of pieces of phonological material copied from the lexicon, with discernible morpheme structure. The SF is a treelike structure of abstract phonological elements, such as features, segments, syllables, and feet. The AudF is ‘a sequence of events on auditory continua such as pitch, noise, spectral peaks and valleys, and silences, their durations, and their relations such as simultaneity and order’ (Boersma Reference Boersma, Benz and Mattausch2011: 9). The Articulatory Form is a sequence of gestures by articulatory muscles.Footnote 10
An implementation of this model will be provided in the following sections. The main contribution of the analysis of the Kashubian data is the fact that it deals with contextual effects that are simultaneously driven by the segmental and prosodic contexts. Phonetic lengthening reaches the threshold of phonologization only when three conditions are met: The target vowel appears (i) in the head syllable of a foot, (ii) in an open syllable, and (iii) before a voiced consonant. The effect of phonetic lengthening is cumulative in the sense that meeting only one or two of the conditions is not sufficient to have an effect on phonology. Such combined segmental and prosodic effects have not been treated in the BiPhon model so far to my knowledge.Footnote 11 This cumulative effect will be derived using LCC.
4.2. Cumulative effects in phonology
The proposed analysis requires reference to the cumulative effect of three types of phonetic lengthening: head syllable lengthening, open syllable lengthening, and lengthening before a voiced consonant. There is evidence for the effect of each of the conditions. A head syllable in a metrical foot tends to be more prominent than a non-head syllable (Hayes Reference Hayes1995, Lieberman & Prince Reference Liberman and Prince1977). There is instrumental evidence that domain heads tend to be phonetically longer than non-heads (see White Reference White2014 and references therein). Such evidence has been used to support rhythmical approaches to speech timing, which propose that segment duration is related to metrical structure throughout the utterance (e.g. stress-delimited feet) (Couper-Kuhlen Reference Couper-Kuhlen1993). Further, vowels in open syllables tend to be longer than vowels in closed syllables (Maddieson Reference Maddieson and Fromkin1985, Rietveld & Frauenfelder Reference Rietveld and Frauenfelder1987). V1 is longer in CV1CV2 than in CV1C, all else being equal. In addition, vowels are longer before voiced consonants than before voiceless consonants (see Kluender, Diehl & Wright Reference Kluender, Diehl and Wright1988, House & Fairbanks Reference House and Fairbanks1953, Peterson & Lehiste Reference Peterson and Lehiste1960, Tauberer & Evanini Reference Tauberer and Evanini2009 on various dialects of English; Esposito Reference Esposito2002 on Italian; Campos-Astorkiza Reference Campos-Astorkiza2007 on Lithuanian long and short vowels; and Coretta Reference Coretta2019 on Polish and Italian). The effect of consonant voicing on the duration of the preceding vowel has been found in, for example, English, German, French, Spanish, Hindi, Russian, Italian, Arabic, Korean, and Polish (see Maddieson & Gandour Reference Maddieson and Gandour1976 for an overview). Such evidence can be extrapolated to phonetic length in LCS. Jers were the longest in head syllables, open syllables, and before voiced consonants. They were shorter in open syllables and before voiceless consonants, YdY > YtY (‘>’ = ‘longer than’). They were also shorter in closed syllables than in open syllables, all else being equal, YdY > Yd. Finally, they were shorter in non-head syllables than in head syllables of a foot, (YdY) > (YdY).
In a common trajectory of sound change, a subphonemic coarticulatory effect is detected and phonologized under specific conditions. For example, contextual vowel nasalization is interpreted as contrastive when the conditioning environment, a nasal consonant, is lost (Ohala Reference Ohala, Kellermann and Morrissey1992). Less common is a type of change that requires two or more triggers to be simultaneously present. The occurrence of one of the triggers is insufficient to effectuate the change. Lionnet (Reference Lionnet2016) dubs this change ‘subphonemic teamwork’ and defines it as ‘a type of multiple-trigger process which obtains when two segments exerting the same coarticulatory effect on a target segment trigger a categorical assimilation only if they ‘team up’ and add their coarticulatory strengths in order to pass the threshold necessary for that process to occur’ (2016: 3).
Classic OT, which relies on strict constraint domination, encounters problems treating cumulative effects. In past research, cumulative effects have been given formal accounts that invoke LCC (Smolensky Reference Smolensky1993, Reference Smolensky1995) and weighted constraints in Harmonic Grammar (Legendre, Miyata & Smolensky Reference Legendre, Miyata and Smolensky1990, Smolensky & Legendre Reference Smolensky and Legendre2006). More recently, Lionnet (Reference Lionnet2016) argued for the use of subfeatural representations to derive cumulative effects. For the purposes of the current analysis, I employ LCC, though each of the three theoretical frameworks mentioned above could in principle be used.Footnote 12 In an LCC account of cumulative effects, the two or three markedness constraints that drive an effect are ranked below the relevant faithfulness constraint(s). However, the conjunction of these constraints is ranked higher than the relevant faithfulness constraint. In other words, LCC allows for two or more weak markedness constraints to gang up to overcome strong faithfulness (Lionnet Reference Lionnet2016: 3). This ranking ensures that the effect is not generated unless all the necessary triggers are present. In the current analysis, local conjunction will be applied to three types of phonetic lengthening: head syllable in a foot, open syllable, and before a voiced consonant. Phonological length is derived only when all of them exert an effect on a single vowel (and the conditioning context is lost).
4.3. Representation of vowel duration
As represented in (9), vowels are longest in the cumulative context, that is, in the head syllable of a foot, in an open syllable, and before a voiced consonant. They are shorter when only one or two of the lengthening conditions are present. They are shortest in a non-head syllable of a foot, in a closed syllable, and before a voiceless consonant. Feet are marked by parentheses. The head syllable is foot-initial. The proposed analysis rests on the distinction between the cumulative context and all the other contexts (as indicated by the dotted line). The former context will be called the cumulative context, while the latter will be termed the elsewhere or the shortening context.

The duration of vowels in LCS is quantified using the scales in (10). In (10a), vowels in the cumulative lengthening context (head syllable, open syllable, and before a voiced consonant, YdY) are shown, while (10b) presents vowels in the elsewhere context (YtY, Yd, Yt, VtV, etc.).Footnote 13 In the cumulative lengthening context, vowels are one unit longer than the corresponding vowels in the elsewhere context. The scales use units of duration and are sufficient for our purposes. Based on the fact that jers showed a distinct behavior from the other vowels, it is assumed that they were shorter than the other vowels (see Bethin Reference Bethin1998 for a similar claim).Footnote 14
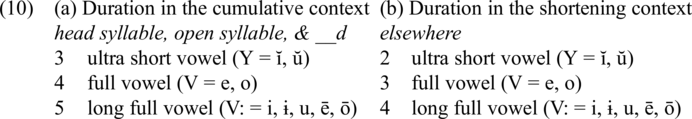
4.4. Computation in the BiPhon model
Change in the BiPhon model typically occurs during the transmission from the speaker to the listener. Production and perception are involved. The SF is subject to structural constraints, including those deriving metrical and prosodic structure. The SF is mapped onto the AudF using constraints that regulate coarticulation effects and constraints on segment duration. This is summarized in (11) below, where the effects of production and perception are shown on the example of the development /CYdY/ > /CVd/ in Kashubian. Metrical feet are indicated by parentheses. Both phonological and phonetic (auditory) categories are referred to, which accords with the assumption that the speaker draws on their phonetic knowledge. The SF invokes phonological categories (d = voiced consonant, t = voiceless consonant, C = consonant, Y = jer, V = full vowel, V: = long full vowel), which correspond to scalar phonetic (auditory) categories in the AudF, based on the speaker’s phonetic knowledge. Specifically, the speaker knows that a jer (Y) corresponds to a vowel with duration [2] (Vd=2) outside of the cumulative context in auditory terms. The AudF crucially adds knowledge of contextual realization, including contextual lengthening effects. Specifically, the penultimate jer has been lengthened in the cumulative context and corresponds to Vd=3, a vowel with duration [3]. The final jer, on the other hand, has been shortened and comes out as a vowel with duration [1] due to a process that reduced ‘unprotected’ jers (i.e. those that appear outside of the cumulative context).
In perception, the vowel with duration [1] is reinterpreted as an acoustic consonant release. The penultimate jer, now in the shortening context due to vowel loss, is reinterpreted as a full vowel. In the proposed analysis, cue constraints are responsible for mapping phonological categories to auditory categories in production. In perception, the same cue constraints map auditory categories to phonological categories. The bidirectionality of the model makes it possible to derive a change in which phonetic length is reinterpreted as phonological by the listener.Footnote 15 In the following sections, we look at the necessary constraints.

4.5. Structural constraints
Metrical structure is generated by structural constraints, which evaluate the SF. The analysis rests on the claim that sequences of jers form binary feet. Such jer feet are weaker than feet containing full vowels. The proposal that two consecutive jers form a dedicated foot is based on a well-documented perceptual bias. When short auditory events are presented to listeners in a rapid sequence, those that are similar to each other tend to be grouped together. Bregman & Campbell’s (Reference Bregman and Campbell1971) experimental study found that the sequential order of short similar auditory events is difficult to judge. Such results provide evidence for auditory grouping, which is consistent with the more general principles of perceptual grouping in human cognition (Wagemans et al. Reference Wagemans, Elder, Kubovy, Palmer, Peterson, Singh and der Heydt2012). Two consecutive jers are likely subject to auditory grouping, as they share properties that set them apart from the other vowels of LCS: They are ultra-short, high, and possibly lax. A foot specifically devoted to jers is also supported by the different behavior of jers vis-à-vis full vowels. This is elaborated in Section 5.3.Footnote 16
Based on the evidence from Havlik’s Law and the universal principles of auditory grouping, it is proposed that LCS shows a preference for parsing two consecutive jer syllables as a jer foot. Jer feet may only contain jers. This preference is enforced by the constraints Parse-Jer and Jer-Ft in (12) and (13). All-Ft-Right makes sure that parsing into feet occurs from right to left (McCarthy & Prince Reference McCarthy, Prince, Booij and van Marle1993). Ft-Bin excludes degenerate feet, that is, those that contain a single syllable. Parse-Syl is a generic constraint in relation to Parse-Jer mandating that all syllables be parsed (Prince & Smolensky 1993/Reference Prince and Smolensky2004).

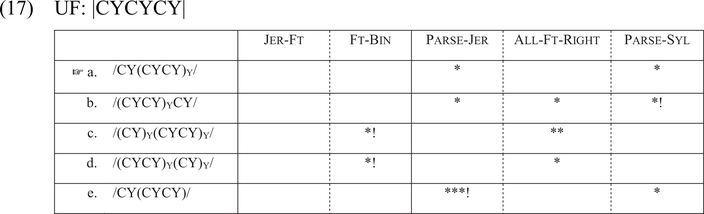
The tableaux in (17) and (18) illustrate how jer feet are generated. The evaluation in (17) deals with a word with three consecutive jers, such as LCS *šĭvĭcĭ > Ukr. švec′ /ʃvets′/ ‘shoemaker’ n.sg. Jer feet are marked with the subscript ‘Y’. Candidate (a) is optimal, as it parses two jer syllables at the right edge of the word into a jer foot. Candidate (b) loses, as it skips the final syllable. Candidates (c) and (d) contain degenerate feet, penalized by Ft-Bin. Candidate (e) incurs additional violations of Parse-Jer, as it fails to parse jer syllables into jer feet. This tableau shows that Ft-Bin must be ranked over Parse-Jer.
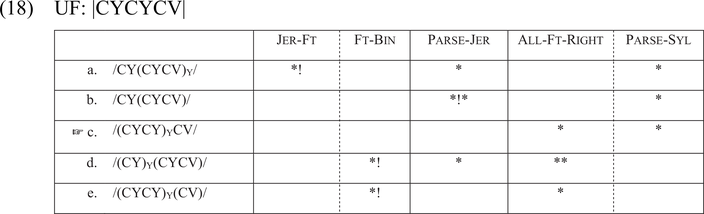
The evaluation in (18) analyzes a word with two jers followed by a full vowel, such as LCS *šĭvĭca > Ukr. ševcja /ʃewts′a/ g.sg. Candidate (a) loses, as it parses a full vowel into a jer foot and thus incurs a fatal violation of Jer-Ft. Candidate (b) fails to parse two jers into a jer foot. Candidates (d) and (e) contain degenerate feet and fatally violate Ft-Bin. Candidate (c) wins, as it parses two consecutive jers into a jer foot. This evaluation shows that Parse-Jer must dominate All-Ft-Right. Only jers can be parsed into jer feet, even if this means that a final syllable at the right edge will be left unparsed.
The proposed ranking of the constraints given in (19) ensures that two consecutive jers are parsed into a jer foot and that parsing proceeds from the right edge of the word.
In accordance with Havlik’s Law, jer feet are trochaic, that is, they have initial prominence: [s w]. The assumption is that the relative phonetic duration of vowels in a foot should reflect their prominence relations. A longer vowel is more prominent than a shorter vowel (the length-to-prominence principle, which is analogous to the familiar weight-to-stress principle). Final prominence, [w s], is incompatible with a syllabic trochee, as the second jer is longer and therefore more prominent than the first jer. RhType=T (Kager Reference Kager1999: 172) is formulated in (20) in relation to jer feet and penalizes jer feet with final prominence (iambs). Specifically, it prohibits jer feet in which the second jer is longer than the first jer. Jer feet with equal prominence, e.g. [w w], are not targeted.Footnote 17 The data indicate that jer feet could not have final prominence (in accordance with Havlik’s Law), which implies that Jer-RhType=T was undominated. It is omitted from the evaluations below.
4.6. Cue constraints
Cue constraints map SF to AudF in production. The same constraints are used in perception to map AudF to SF. The feet generated by the metrical constraints outlined in the previous section are subject to contextual lengthening of constituent jers. The constraints in (21), (22), and (23) require vowel lengthening in the specified contexts: in the head syllable in a jer foot, in an open syllable, and before a voiced consonant, respectively.Footnote 18 Constraint (23) reflects the observation that vowel duration is inversely correlated with the duration of a following consonant due to constraints establishing a preferred rhyme duration. The duration of the compound VC remains similar across different Cs, as voiceless consonants tend to be longer than corresponding voiced consonants (Flemming Reference Flemming2001). In the proposed analysis, I use Jer/HS&OS&_d-Longer, which is a shorthand for the LCC of Jer/HS-Longer & Jer/OS-Longer & Jer/_d-Longer. The locally conjoined constraint is violated when a jer (i) in a head syllable of a jer foot, (ii) in an open syllable, and (iii) before a voiced consonant fails to be lengthened by [1] unit. The constraint is mute when only one or two of these two conditions are met.Footnote 19

To derive reduction of jers, we need a constraint that decreases the duration of jers. Jer red, given in (24), is violated when a jer has duration [2] or longer in AudF. In other words, input jers should have their duration decreased by [1] in AudF. This constraint reflects a cross-linguistic tendency for short vowels to be reduced and eventually deleted in prosodically weak positions (due to their decreased perceptibility) in the processes of syncope, e.g. Latin cálidum > Italian caldo ‘hot’, or apocope, e.g. Old English lufu /luvu/ > Modern English love /lʌv/.
The cue constraints shown in (25) map auditory categories onto abstract phonological units and vice versa. As explained in Section 4.1, phonetic knowledge is available to phonological computation. For example, based on their experience with the language, a speaker knows that a vowel of duration [4] corresponds to a long full vowel (V:) and a vowel of duration [2] corresponds to a jer. The duration values necessary for the cue constraints accord with the scale in (10b), which applies in the shortening context (i.e. outside of the cumulative context). /ə/ stands for a very short vowel. The cue constraints are used both in production and perception, which means that they are used bidirectionally.
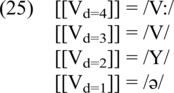
We also need to encode a pressure that effectuates the loss of reduced jers. The constraint in (26) coerces the interpretation of vocalic intervals of duration [1] (vowels of subminimal duration) as the acoustic release burst of a preceding consonant. This mechanism of vowel loss is the mirror image of the well-documented mechanism of vowel intrusion. When two consonants in a cluster are produced with a low degree of gestural overlap, an acoustic release that occurs between them can have some vocalic properties. Vowel intrusion occurs when the phasing of existing articulatory gestures produces a vowel-like percept (Hall Reference Hall2006: 406). The motivation for vowel intrusion is perceptual. The acoustic cues of consonants (especially their place cues) in clusters as well as in word-final position are relatively impoverished (Jun Reference Jun1995). An acoustic release of the first consonant in a CC cluster, especially a release that has vocalic characteristics, improves the recoverability of place cues of both consonants (Jun Reference Jun1995, Silverman Reference Silverman1995). This vocalic interval can then be interpreted by the listener as an underlying vowel (Browman & Goldstein Reference Browman, Goldstein, Docherty and Ladd1992, Hall Reference Hall2006).Footnote 20 Given that listener-oriented change is to a large extent non-deterministic (Blevins Reference Blevins2004), the reverse can also occur: A vocalic interval after a consonant can be interpreted as a property of the consonant, i.e. its acoustic release burst, as long as the vowel is very short (Boersma & Hamann Reference Boersma, Hamann, Calabrese and Wetzels2009). The reinterpretation may occur between consonants as well as in word-final positions. In fact, as a result of the reanalysis, onset consonants are phonologized as coda consonants (see below). This is indicated in the pertinent constraint in (26) by ‘.’. The constraint is consistent with the assumption that a speaker has access to phonetic knowledge obtained through experience with the language: Acoustic releases of consonants may be accompanied by short vocalic intervals.
It is argued that the loss of jers was set in motion by changes in the ranking of constraints regulating syllable structure. Prior to the loss of jers, LCS did not allow codas (Bethin Reference Bethin1998).Footnote 21 The loss of jers made codas abundant in the language. Prohibition of codas is expressed in OT by ranking high the structural constraint *Coda. In the present analysis, this change in syllable structure preference is captured by the demotion of *Coda by the listener. *Coda is ranked high in the grammar of the speaker. It is demoted in the grammar of the listener. Specifically, only with *Coda ranked below [[CVd=1]] = /[C.]/ can onset consonants be reanalyzed as coda consonants. In other words, reinterpretation of jers as consonant releases was induced by changes in syllable structure in LCS.
4.7. A constraint-based analysis
An overview of the analysis is shown in (27). We focus on the final two syllables in words of minimally three syllables and consider the stage when jers were lost. Three contextual conditions are derived. When a jer precedes a voiced consonant, it is phonologized as a full vowel, (27a). When a jer precedes a voiceless consonant, it is lost, (27b). Similarly, when a jer is followed by a full vowel, the jer is lost, (27c).

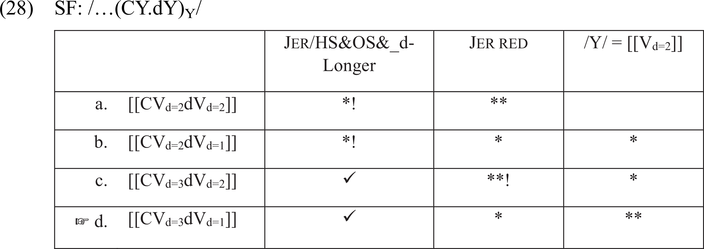
The analysis is based on the premise that although production and perception employ the same constraints, the mapping of SF to AudF in production involves cue constraints, while in perception the mapping of AudF to SF involves cue as well as structural constraints. That is, in perception both cue and structural constraints are used to derive an SF. This difference follows from the architecture of the BiPhon model, as was shown in Figure 1. Consider the sequence /CYdY/, where the second consonant is voiced. The metrical structure in SF is derived by the structural constraints discussed in the previous section. In the evaluation in (28), the SF contains two jers, whose duration equals [2]. In the SF, syllable boundaries are marked with a dot. For clarity, satisfaction of the cumulative constraint is marked with ‘✓’. Candidates (a) and (b) fail the evaluation, as they do not show the effect of lengthening of the first jer in the cumulative context and thus violate Jer/HS&OS&_d-Longer. Candidate (c), which lengthens the first jer and retains the duration of the final jer, fatally incurs two violations of Jer red. Candidate (d) is the most harmonic, as it lengthens the first jer and reduces the final jer, thus satisfying Jer/HS&OS&_d-Longer and violating Jer red only once.Footnote 22 The ranking of Jer/HS&OS&_d-Longer over /Y/ = [[Vd=2]] makes sure that cumulative lengthening is favored over faithful realization of jers. Jers outside of the cumulative context are reduced.Footnote 23
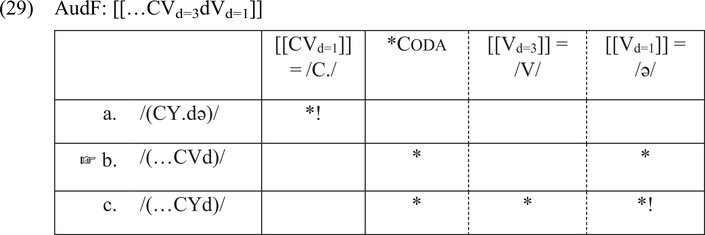
In perception, the AudF [[CVd=3dVd=1]] is phonologized as /CVd/. In (29), the syllable structure of the candidates depends on the presence of the final vowel. If the final vowel is retained, as in candidate (a), the preceding vowel is in an open syllable. If, on the other hand, it is lost, as in candidates (b) and (c), the preceding vowel is in a closed syllable. In all likelihood, constraints pertaining to jers do not emerge in the listener’s grammar, as jers are reanalyzed either as consonant releases or full vowels. Jer/HS&OS&_d-Longer and Jer red are not included in the evaluation. Candidate (a) incurs a fatal violation of [[CVd=1]] = /C./, as a short vocalic interval is phonologized as a vowel. Of the two remaining candidates, both of which fail to phonologize a short vocalic interval as a vowel (violating [[Vd=1]] = /ə/), candidate (b) is the most harmonic, because it phonologizes a vowel with duration [3] in a shortening context as a full vowel and thus respects [[Vd=3]] = /V/. It should be noted that the optimal candidate incurs a violation of *Coda, but the constraint is low ranked.Footnote 24
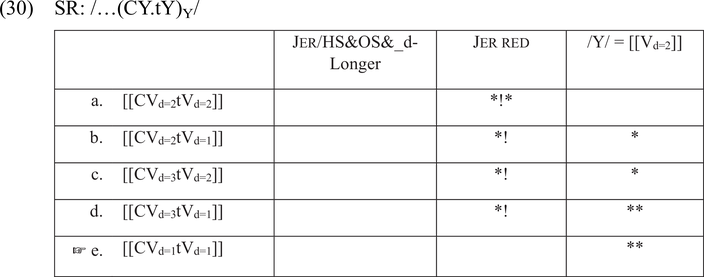
Consider the mapping of SR /CYtY/ to AudF [[CVd=1tVd=1]] in (30). We expect that the penultimate jer will be lost in this context: in a strong position, followed by a voiceless consonant. Since Jer/HS&OS&_d-Longer is inapplicable, the jer in a strong position is not shielded from reduction, as shown in (30). High-ranked Jer red targets all the candidates with unreduced jers. Candidate (e), which shows reduction of both jers, comes out victorious.
In the mapping from AudF to SR in perception, the output of (30), [[CVd=1tVd=1]], generates /Ct/. Short vowels are interpreted as consonant releases, as mandated by [[CVd=1]] = /C./, ranked over *Coda.

Finally, consider the context where a jer is followed by a full vowel: /CYdV/. In this case, the jer is lost. How do we account for it? The jer cannot form a jer foot, as it is not followed by another jer. This is enforced by the undominated constraint Jer-Ft. Instead, it forms a regular foot together with the following vowel. As shown in the tableau in (32), Jer/HS&OS&_d-Longer is mute in non-jer feet and, as a result, the jer fails to be lengthened. Candidate (b), which shows reduction of the jer, comes out as optimal.
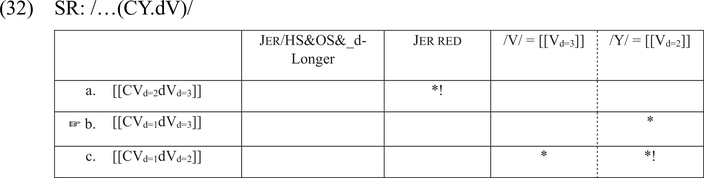
In perception, the output of (32), [[CVd=1dVd=3]], generates /CdV/. The penultimate vowel is very short, so it is interpreted as the release of a consonant.Footnote 25

5. Compensatory lengthening
This section deals with the effects of CL in Kashubian. Vowels are phonologically lengthened before voiced consonants when the final jer is lost. The proposed synchronic account relies on the phonologization of cumulative phonetic length. However, the constraints that are employed to regulate lengthening of full vowels, though similar in grounding, are distinct from the constraints that were proposed for the analysis of the preservation and loss of jers in Section 4. We begin with an overview of the process. A discussion of the Kashubian data is followed by a constraint-based analysis.
5.1. Background and data
CL is traditionally defined as lengthening of a vowel due to the loss of a jer in the next syllable. In LCS, jers, /ɪ/ and /ʊ/, were lost. This loss caused the preceding vowel to lengthen in many dialects. Reflexes of LCS CL have been identified in a number of Slavic languages, including Serbo-Croatian, Slovak, Czech, Polish, Upper Sorbian, Slovenian, and Ukrainian (Timberlake Reference Timberlake and Flier1983a, Reference Timberlake, Markov and Worth1983b, Reference Timberlake1988). The words transcribed in (34) illustrate Upper Sorbian CL (Timberlake Reference Timberlake, Markov and Worth1983b: 222, Kavitskaya Reference Kavitskaya2002: 119). Reflexes of CL are found in the nominative singular.

The necessary conditions for CL varied from language to language and included the quality of the intervening consonant, accent, jer position (internal vs. final), and the quality of the target and trigger vowels (Timberlake Reference Timberlake and Flier1983a, Reference Timberlake, Markov and Worth1983b, Reference Timberlake1988).
In Old Polish, CL was additionally conditioned by the quality of the following consonant. CL occurred before sonorants and voiced obstruents, as shown in (35a), where /ɔ/ and a nasal vowel are illustrated.Footnote 26 A voiceless obstruent failed to trigger CL under the same prosodic conditions, as exemplified in (35b) (Kavitskaya Reference Kavitskaya2002: 125).

Kashubian differs from Polish in that it shows a wider range of vowels that underwent CL: /ɔ e a i u ɔ̃/, as illustrated in (36a–f). Each case in (36) provides modern pronunciation, modern spelling, and the corresponding historical vowel alternations that resulted from CL. Modern Kashubian has lost phonemic length, but the earlier length distinctions show up as distinctions in vowel quality. The items with voiceless consonants in (36g) fail to show reflexes of CL.Footnote 27 The data have been drawn from Timberlake (Reference Timberlake and Flier1983a: 215) and Ramułt (Reference Ramułt2017).

The data in (36) show that CL in Kashubian applied to vowels /ɔ e a i u ɔ̃/ before voiced obstruents and sonorants. CL did not apply before voiceless consonants, as shown in (36g). This restriction is consistent with the evidence given in Section 4.2 that vowels tend to be longer before voiced consonants than before voiceless consonants. Phonologization of length, as a result of CL, is likely to occur when the vowel is phonetically longer. Reflexes of CL are thus expected to be more common before voiced consonants than before voiceless consonants, all else being equal.
5.2. A historical account
The account draws on Timberlake (Reference Timberlake and Flier1983a, Reference Timberlake, Markov and Worth1983b, Reference Timberlake1988) and Kavitskaya (Reference Kavitskaya2002: 125–126) and proposes that the factor conditioning CL in Kashubian was phonetic lengthening due to an open syllable and a following voiced consonant. In (37a), we consider the evolution of LCS /CVdY/ in Kashubian (V = full vowel, V: = long full vowel, Y = jer, d = voiced consonant, t = voiceless consonant). The full vowel V was phonetically lengthened in an open syllable and before a voiced consonant. When the final jer was lost, the phonetic lengthening of the preceding vowel was phonologized, as it could not be attributed to an open syllable. While modern Kashubian shows the effects of final obstruent devoicing, CL applied at a stage when final obstruents were contrastive for voice. In contrast, CL did not apply before a voiceless consonant, as shown in (37b). The vowel was not sufficiently lengthened in the context of a voiceless consonant. Therefore, the loss of the final jer in the third stage had no effect on the phonological length of the preceding vowel.

5.3. A constraint-based analysis
The analysis of CL pivots on the locally conjoined constraint V/OS&_d-Longer. Crucially, the constraints enforcing lengthening are formulated with reference to full vowels, in accordance with the evidence presented in Section 4.5 indicating that jers show a distinct behavior from full vowels. Specifically, evidence indicates that, unlike the preservation of jers, CL was not conditioned by metrical structure. It applied both in penultimate and antepenultimate syllables, as illustrated in (38a) and (38b). In (38c), CL did not occur, as the following jer was preserved. Neither did CL apply in (38d), where the relevant vowel was followed by a voiceless consonant (data taken from Andersen Reference Andersen1970: 64–66; Timberlake Reference Timberlake and Flier1983a: 218; Timberlake Reference Timberlake1988: 226–227; Czaplicki Reference Czaplicki2020: 112–114). The examples in (38a), (38b), and (38c) show that the necessary conditions for CL were the context of a following voiced consonant and the loss of a following jer. Metrical structure did not play an important role. While the vowel undergoing CL in the word in (38a), as well as those in (36), formed a foot together with the next jer syllable, the vowel subject to CL in the words exemplified in (38b) was not footed together with the following syllable. Yet, CL occurred in both cases. Additional evidence that CL and the preservation of jers may be governed by different constraints comes from Polish, in which the two processes were not uniform with respect to the voicing effect. Voicing of the following consonant was a necessary condition for CL to occur but played no role in the preservation of jers, e.g. *stolŭ → /stuw/ ‘table’ vs. *nosŭ → /nɔs/ ‘nose’, and *palĭtsĭ → /palɛts/ ‘finger’.

The constraints enforcing contextual lengthening of full vowels are given in (39) and (40). The analysis employs the local conjunction of the two constraints, V/OS&_d-Longer. Given that constraints are bidirectional, in perception the conjoined constraint requires that a vowel with duration [4] be mapped onto a full vowel if it appears in the cumulative context.

The remaining constraints used in the analysis of CL are the same as the ones used in the analysis of the preservation and loss of jers. CL is expected when the first vowel is full, the second vowel is a jer and the intervening consonant is voiced, /CV.dY/ → /CV:d/. Cumulative phonetic length (due to an open syllable and voicing of the following consonant) is phonologized when the conditioning context, the final jer, is lost. We focus on longer sequences of vowels to show an interaction of the constraints applicable to full vowels and jers. An overview of the analysis is given in (41). As shown in (41a), a full vowel undergoes CL as long as it stands before a voiced consonant and the jer in the next syllable is lost. In contrast, the full vowel in (41b) does not undergo CL, as the jer in the next syllable is preserved. So, even though the full vowel is followed by a voiced consonant and is phonetically longer, it is phonologized as short. Finally, in (41c), a full vowel stands before a voiceless consonant, so even though the following jer is lost, it remains short both phonetically and phonologically.
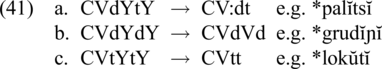
The evaluation in (42) shows the mapping of the SR /CV(dYtY)Y/ to an AudF in production. The analysis mirrors the analysis of the preservation and loss of jers in Section 4.7. The difference between full vowels and jers is that full vowels need not appear as the head syllable in a foot to undergo cumulative lengthening. Jer/HS&OS&_d-Longer is inapplicable, as neither of the two jers is in the cumulative context. V/OS&_d-Longer makes sure that the full vowel is lengthened in the cumulative context. Jer red, violated by candidate (b) twice, enforces jer reduction. Candidate (c), with a phonetically lengthened full vowel and both jers reduced, is the most harmonic.
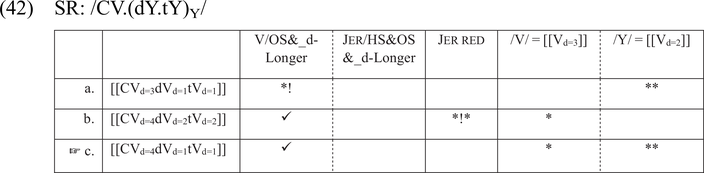
In perception, the AudF [[CVd=4dVd=1tVd=1]] is mapped onto /CV:dt/, with CL. Both vowels of subminimal duration are lost, which is enforced by [[CVd=1]] = /C./. In candidates (b) and (c) the full vowel of duration [4] is outside of the cumulative context (it is in a closed syllable), so it is phonologized as long V: thanks to [[Vd=4]] = /V:/.

The input /CV(dYdY)Y/ is phonologized by the listener as /(CVdVd)/, without CL. As shown in (44), in production, both the full vowel and the penultimate jer are in the cumulative context, so they are phonetically lengthened, which is enforced by the high-ranked V/OS&_d-Longer and Jer/HS&OS&_d-Longer. The final jer is not similarly protected, so it is reduced. Candidate (d), with phonetic lengthening of the full vowel and the penultimate jer, is the most harmonic.
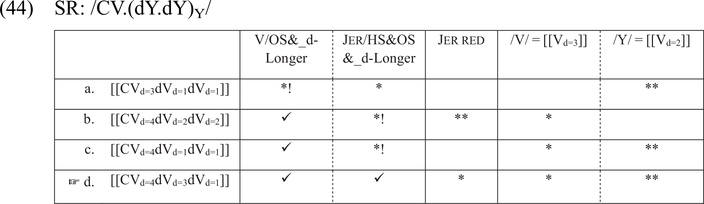
In perception, shown in (45), candidate (c), with a short full vowel, is optimal, as the vowel with duration [4] remains in the cumulative context (the following jer is preserved). The vowel is therefore mapped onto a full vowel with no effect of phonological lengthening. In candidate (b), the vowel with duration [4] in the cumulative context corresponds to a long vowel, which is penalized by V/OS&_d-Longer. Candidate (a) fatally phonologizes a subminimal vowel, which is penalized by [[CVd=1]] = /C./.

Finally, the input /CV(tYtY)Y/ is phonologized as /CVtt/, as the full vowel stands before a voiceless consonant, so the context for CL is not met. For that reason, in production V/OS&_d-Longer is mute, as visible in (46). Candidate (a) with no phonetic lengthening is the most harmonic, as it maps the full vowel onto a vowel with duration [3] (coerced by /V/ = [[Vd=3]]).
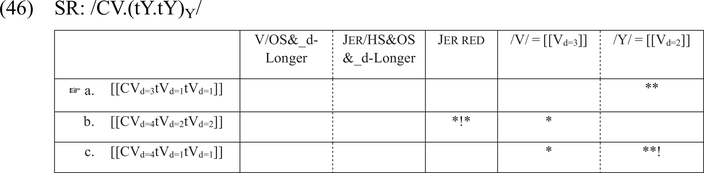
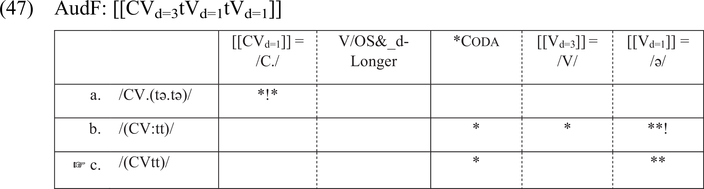
In the mapping from AudF to SF in (47), [[CVd=3tVd=1tVd=1]] is phonologized as /CVtt/. A vowel with duration [3] is mapped onto a short full vowel.
The rankings of the relevant constraints in the speaker’s and listener’s grammars are given in (48) and (49), respectively. Bidirectionality means that the constraints are used in production and perception. The main difference between the two grammars lies in the different ranking of *Coda with respect to /C./ = [[CVd=1]]. The rankings derive phonologization of cumulative phonetic length and loss of jers.
Longer sequences of vowels showed less predictable behavior, because other considerations came into play. For example, jers that appeared in antepenultimate or root-initial positions were variably preserved before voiceless consonants, e.g. *domŭtʃĭkŭ > /dɔmətʃk/ ~ /dumtʃk/ ‘house’ dimin. (Timberlake Reference Timberlake1988: 228). Plausible explanations for the variable preservation of such jers involve reference to additional structural considerations, e.g. a constraint against three-consonant clusters, and to morphological factors, e.g. morpheme-specific and paradigm uniformity constraints. This is beyond the scope of this paper.
6. Summary
This constraint-based analysis of CL is fully consistent with and provides additional evidence for the analysis of the preservation of jers. However, an important difference between jers and full vowels has been identified. While jers and full vowels are similar in that phonetic lengthening applies to them in the cumulative context: in an open syllable and before a voiced consonant, the two types of vowels show a difference in the context of the application of lengthening. It turns out that jers are lengthened when they appear in the first syllable of a foot dedicated specifically to jers. The lengthening of full vowels is not similarly metrically restricted. It suffices that they appear in an open syllable and before a voiced consonant. Thus, although the phonetic motivation for lengthening is similar for all vowels, lengthening of jers additionally required that they be part of a specific metrical structure: a foot composed entirely of jers.
The outcomes of the two processes (jer preservation and CL) in terms of vowel duration are summarized in (50). Jers in the shortening context were lost. Those jers that were phonologically lengthened in the cumulative context (recall that phonological lengthening was also conditioned by the loss of a jer in the next syllable) are identical in duration to full vowels in the shortening context. The prediction that the reflexes of such jers merged with full vowels is indeed borne out: They merged with /ɛ/, e.g. /wɛsɛw/ òseł ‘donkey’.Footnote 29 There is no qualitative or quantitative distinction between the reflexes of phonologically lengthened jers and short full vowels in modern Kashubian, cf. /wɛsɛw/ òseł ‘donkey’ and /xlɛb-a/ chleba ‘bread’ g.sg.Footnote 30 Finally, the full vowels that were phonologically lengthened through CL merged with existing long vowels.

The mechanism of listener-oriented change falls out from the architecture of the BiPhon model. The same cue constraints play a role in production and perception. However, in perception they interact with structural constraints. Put differently, perception is not regulated by cue constraints alone. Structural constraints are also relevant (Boersma & Hamann Reference Boersma, Hamann, Calabrese and Wetzels2009). Specifically, the low-ranking of *Coda in the grammar of the listener facilitates the interpretations of short vocalic intervals as consonant releases in perception. If *Coda had been ranked high, such a reinterpretation would not have been possible (the loss of jers creates codas on a massive scale). So the loss of jers was induced by the demotion of *Coda in the listener’s grammar. In other words, changes in syllable structure were the catalyst for the reinterpretation of short vowels as consonant releases, not the other way round.
7. General discussion
7.1. Why OT constraints?
Formalization of the analysis in terms of rankable OT constraints offers a way to systematically represent an interaction of various pressures, including perceptual biases, language-specific structural patterns, faithfulness to the input, and articulatory constraints. In addition, ranked OT constraints provide useful tools in representing differences in the relative importance of various forces in different languages. The predictions of such analyses can be verified computationally. For example, Boersma & Hamann (Reference Boersma and Hamann2008) and Boersma (Reference Boersma, Fanselow, Féry, Vogel and Schlesewsky2006) present the results of computer simulations of auditory dispersion and prototype effects using OT constraints in the BiPhon model. In fact, a constraint-based decision mechanism like OT or Harmonic Grammar (Smolensky & Legendre Reference Smolensky and Legendre2006) may well reflect neural processing in general (Boersma Reference Boersma2003).
7.2. Language-specific phonetics and phonology
The analysis is consistent with the well-supported finding that phonetics, like phonology, is language specific, rather than universal and automatic. For example, phonetic vowel duration is a strong cue to the voicing of the following obstruent in English but a weak cue in Polish and Czech (Keating Reference Keating and Fromkin1985). The differences in phonetic realization may be responsible for divergent developments in related languages. Specifically, the reason why the voicing of the following consonant played a role in the preservation of jers in Kashubian but not in Polish may have been that the effect of phonetic lengthening before voiced consonants was stronger in Kashubian than in Polish. Hence, the cumulative context for the phonologization of length includes three conjuncts in Kashubian (head syllable, open syllable, and a following voiced consonant) but two in Polish (head syllable and open syllable). There is compelling evidence that such phonetic patterns must be language specific.
The analysis is also consistent with the assumption that phonology is language specific. Ultra-short vowels (jers) showed a preference to form their own feet in LCS, a tendency in part based on the universal grouping principles but not necessarily found in other languages. No claims are made as to the universality of the structural constraints used in this analysis. In fact, there is accumulating evidence that certain distributional patterns are not optimizing and must be categorized as phonologically arbitrary and language specific (Paster Reference Paster2006, Czaplicki Reference Czaplicki2013, Reference Czaplicki2019, Reference Czaplicki2024). Likewise, there is evidence suggesting that features are arbitrary and language specific, as opposed to universal or innate (Boersma & Hamann Reference Boersma and Hamann2008, Mielke Reference Mielke2008).
7.3. Distinct constraints for jers and full vowels
What is the reason behind formulating separate constraints for jers? As already mentioned, jers differed in their behavior from other vowels. First, they were subject to Havlik’s Law in various dialects LCS. In Polish, they were strengthened in the position preceding other jers. The jers that failed to be strengthened, that is, those that stood before full vowels and word-finally, were lost. Full vowels were not similarly affected in this context. Second, in some Slavic languages the context of jer preservation was disconnected from the context of analogous processes applying to full vowels. For example, in Polish, jer preservation applied in the context stated in Havlik’s Law, while CL applied to full vowels before voiced consonants in open syllables. Such evidence is consistent with the assumption that jers formed metrical feet of their own and that the processes that applied to them were (partly) independent of those that applied to full vowels.
7.4. An alternative analysis: Subfeatural representations of phonetic effects
Lionnet (Reference Lionnet2016) offers a different account of cumulative effects. He argues that phonetic effects should have subfeatural representations. Specifically, phonetic lengthening should be encoded in phonological representations. Cumulative effects are derived when two or more lengthening contexts co-occur on a single vowel. Lionnet (Reference Lionnet2016) argues that subfeatural representations are capable of capturing the fact that phonetic lengthening is also found outside of cumulative contexts. The present analysis focuses on those instances of phonetic lengthening that have an impact on phonology (i.e. cumulative contexts in Kashubian), as such patterns are detected by the listener and can induce change (when structural constraints allow it). In other words, this analysis capitalizes on the finding that not all phonetic variation leads to listener-induced change.
7.5. An alternative analysis: Vowel lengthening as contrast displacement
Flemming (Reference Flemming2008) discusses the pattern of vowel lengthening in Friulian, where an underlying voicing contrast is realized as a vowel length contrast in word-final position (Baroni & Vanelli Reference Baroni, Vanelli and Repetti2000). Word-final obstruents are devoiced, but the underlying contrast is preserved thanks to the lengthening of the preceding vowel before devoiced obstruents. The voicing contrast is thus preserved as a difference in vowel duration. Flemming (Reference Flemming2008) analyzes the Friulian pattern as contrast displacement or transformation, i.e. exaggeration of vowel duration differences in the absence of closure voicing for oral stops. However, an analysis along these lines is problematic. In Friulian, lengthening took place before all voiced consonants, including stops and sonorants (Loporcaro Reference Loporcaro2015). While an analysis invoking contrast displacement is feasible for final voiced stops, it is problematic for sonorants. In contrast to oral stops, whose identification depends on release burst and consonant-to-vowel formant transitions, sonorants have internal phonetic cues (formant transitions) and are not devoiced in final position, so their identification relies less on transitional cues (Jun Reference Jun, Hayes, Kirchner and Steriade2004: 61–63). Therefore, the loss of the following vowel is not as detrimental for the perceptibility of sonorants as it is for the perceptibility of stops. The Kashubian pattern under discussion, which also involves lengthening before all voiced consonants, is similarly difficult to account for by invoking the mechanism of contrast displacement. The present analysis using cumulative lengthening offers a uniform explanation: Vowels are phonologized as long when three (or two) lengthening contexts coincide. There is independent evidence that each of the contexts involved may cause phonetic lengthening.Footnote 31
8. Conclusion
This paper has discussed two changes in Kashubian that involve reanalysis of phonetic duration as phonological length. Jers were preserved when they were phonetically long; otherwise, they were lost. Similarly, in CL, phonetically long vowels were reinterpreted as phonologically long. In the two changes, the phonetic conditions that were responsible for phonological lengthening were elucidated. Vowels in head syllables, in open syllables, and before voiced consonants are longer than vowels in non-head syllables, in closed syllables, and before voiceless consonants. An additional requirement was identified for jer preservation. The lengthened jer had to be footed together with the following jer. No similar requirement was identified for full vowels.
It has been shown that phonological constraints must be allowed to access fine-grained phonetic information. The analysis has invoked the mechanism of LCC to treat the cumulative effect of prosodic and segmental context on the phonologization of phonetic length. The local conjunction of the contexts inducing phonetic lengthening is necessary to trigger the phonologization of length. In addition, it has been demonstrated that reinterpretation of phonetic cues is conditioned on changes in the ranking of structural constraints (demotion of *Coda). This paper contributes to the typology of processes analyzed using the phonetically grounded models, as it provides evidence of alternations that are conditioned on the cumulative effects of the prosodic and segmental context on vowel duration.
Acknowledgments
I would like to thank my Kashubian consultants Ana Cupa, Dr. Joanna Ginter, Lucyna Łagòda, and Dr. Dark Majkòwsczi for their help with the Kashubian data discussed in this paper. I also thank the editor Marc van Oostendorp and three anonymous reviewers for their thorough and helpful comments, which have significantly improved the paper. All remaining errors are mine.
Competing interests
The author declares none.


 Open access
Open access