



Nuer (ISO 6393: nus/Glottocode: nuer1246) is a Nilo-Saharan language (Nilo-Saharan, Eastern Sudanic, Nilotic, Western, Dinka-Nuer). The sound system of Nuer is of particular interest because the language has a rich inventory of vocalic and suprasegmental distinctions, including a large number of vowel phonemes, a voice quality contrast (modal versus breathy), three levels of vowel length, and a tonal inventory that interacts with the voice quality contrast.
Nuer, or Thok Nath (lit. ‘language of people’), is spoken by around 1.7 million people (Eberhard, Simons & Fennig Reference Eberhard, Simons and Fennig2021), who refer to themselves as Naath (lit. ‘people’), in the Republic of South Sudan and in the Gambella region of Ethiopia (see Figure 1). Within Nuer, three dialect clusters can be distinguished – Western, Central, and Eastern. Western Nuer is spoken to the west of the White Nile. Central Nuer is spoken on the eastern side of the White Nile in the adjacent area. Eastern Nuer is spoken elsewhere in South Sudan and in Ethiopia. The Eastern cluster includes three dialects: Lou and Nasir Jikany, both of which are spoken in South Sudan, and the Ethiopian Jikany dialect. Here I report exclusively on the South Sudanese Nuer and for most part on the system of one of the Eastern dialects - Lou Nuer, although the description of the vowel system and voice quality is based on data from speakers of Western and Lou Nuer, and the description of tone is based on the data from speakers of Lou, Nasir Jikany and Western dialects. The North Wind and the Sun story is narrated by a speaker of Nasir Jikany.
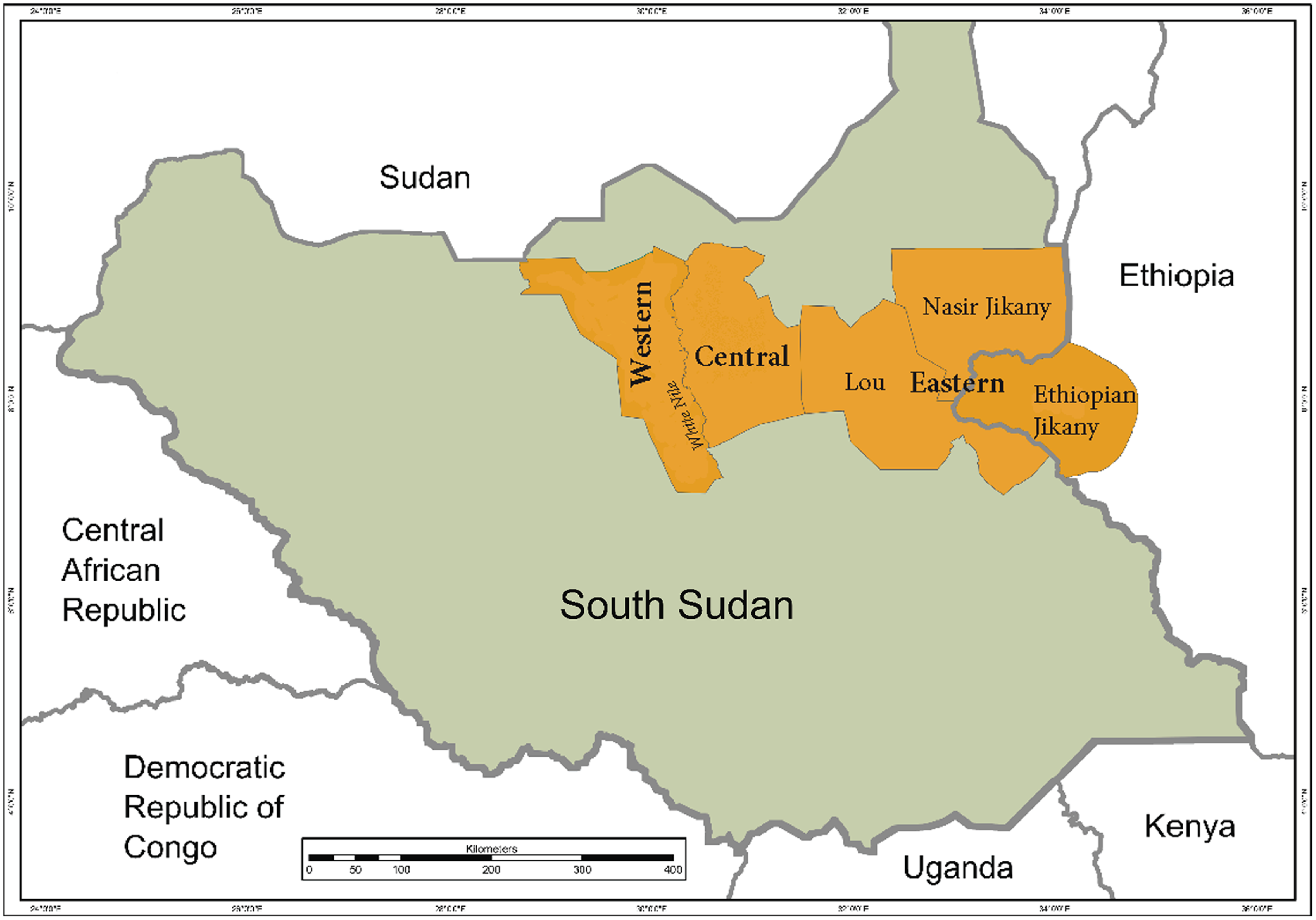
Figure 1. Map of the Nuer-speaking territories showing the distribution of the three Nuer dialect clusters – Western, Central and Eastern; and the three Eastern dialects – Lou and Nasir Jikany of South Sudan and the Ethiopian Jikany.
The audio recordings in this paper come from three speakers. All speakers lived in the Nuer-speaking area until well into their late teens. At the time of the recordings, all speakers resided in Nairobi, Kenya. They all use Nuer daily and attend Nuer-medium churches. The first speaker is Rebecca Nyawany Makwach (RNM) – a female speaker of the Lou (Eastern) dialect. Most of the recordings in this paper come from this speaker. Rebecca was in her early to mid-forties when the recordings took place (between 2016–2022). Her family comes from the Lou territory, and she grew up in the Waat town. In 2000 she came to Kenya where she has resided since. She makes frequent trips to South Sudan, usually to the country’s capital Juba. Rebecca speaks KiSwahili and English as L2. The second speaker is Jimma Kir Guicwang (JKG) – a male speaker of the Nasir Jikany (Eastern) Nuer dialect. This speaker narrated the North Wind and the Sun story, provided the Nuer orthographic version of it, and contributed the data for the study of tone. Jimma was in his mid-thirties at the time the recordings were made (2018–2020). He is originally from the Nasir town in South Sudan. At the age of six he moved to the Gambella region in Ethiopia populated by the Ethiopian Jikany Nuer speakers. Jimma came to Kenya in 2011 where he has resided since. He speaks English, Amharic and Anyuak as L2. The third speaker is a male speaker of Western Nuer dialect, Peter Gatkuoth Makun (PGM), who was twenty-nine years of age at the time of the recording (in 2018). This speaker contributed the data for the study of vowel quality, voice quality and tone. Peter is originally from the Leer community which is one of the Nuer sections that speak the Western Nuer dialect. He lived in South Sudan until 2010 when he came to Kenya to conduct his studies. He has recently returned to South Sudan for employment. Peter speaks English, KiSwahili and Arabic as L2.
The data for this study were recorded using a solid-state recorder (Marantz PMD661) and a dynamic headset-mounted microphone (Shure SM10A). When eliciting the data, between two and three repetitions were recorded as a rule in order to maximise the chances of getting good quality recordings suitable for phonetic analysis. Reported measurements were obtained by measuring only one repetition per speaker. Usually, the first repetition was measured, unless there were obvious problems (for example, the speaker hesitated, unclear formant tracks, background noise, etc.), in which case one of the subsequent repetitions was used for the measurements instead.
Consonants
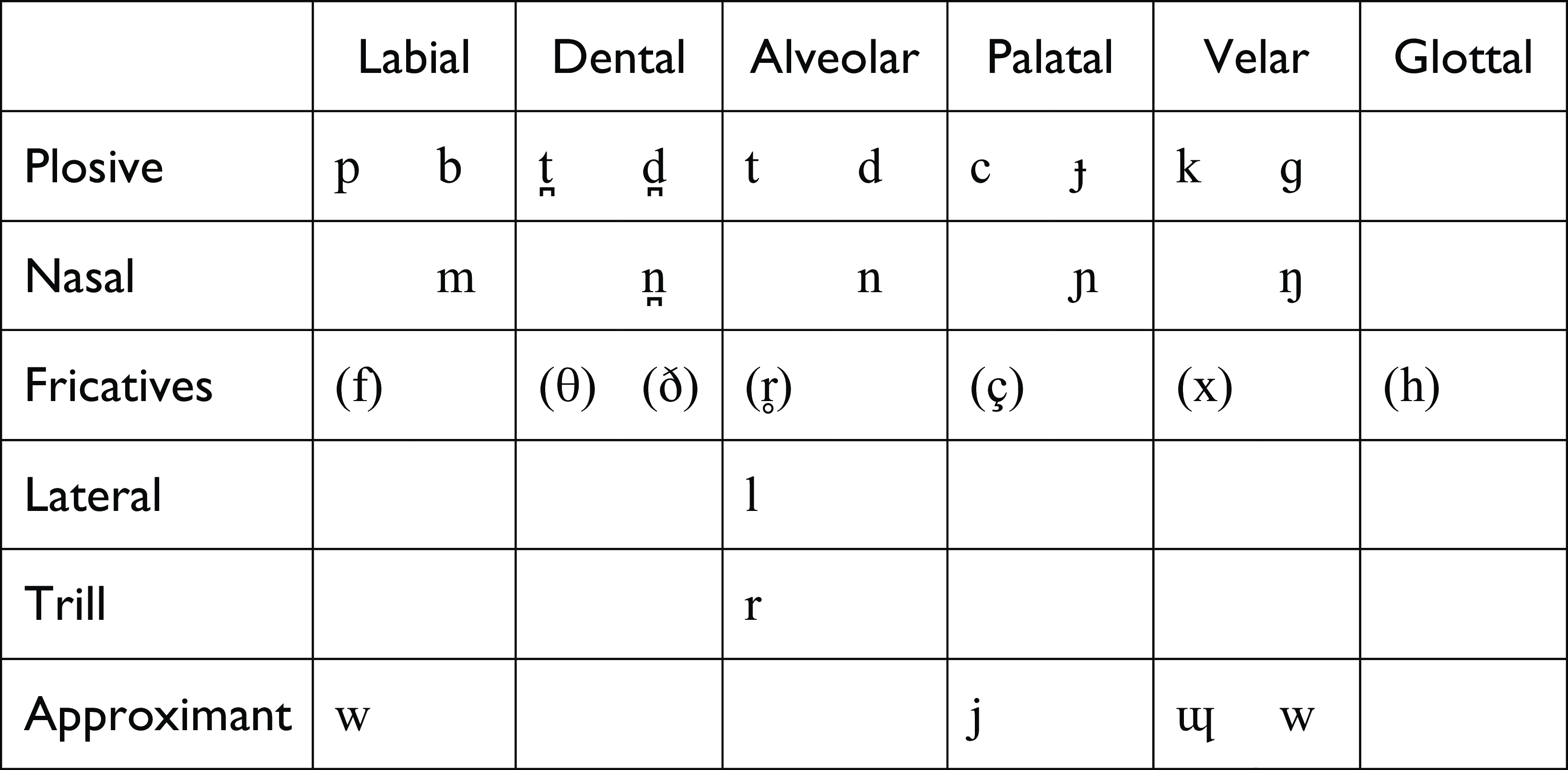
The consonantal inventory that is common to all Nuer dialects consists of twenty consonants. These include voiceless plosives, voiced plosives and nasals at five places of articulation. In addition, there are the liquids /l/ and /r/, and the three approximants /w, j, ɰ/.
Fricative phonemes, shown in the consonantal chart, are attested in the Lou and Western Nuer dialects. They appear in parenthesis to indicate that their distribution is restricted to morpheme-final position (specifically, in morphologically complex words), as will be described below. Lou Nuer has a voiceless glottal fricative phoneme. Western Nuer has voiceless fricative phonemes that occur at labial, dental, alveolar, palatal and velar places of articulation, and a voiced dental fricative phoneme (Baerman & Monich Reference Baerman and Monich2021). This paper presents the consonantal data as it occurs in the speech of a Lou Nuer speaker. As such, only one fricative phoneme will be exemplified.Footnote 1

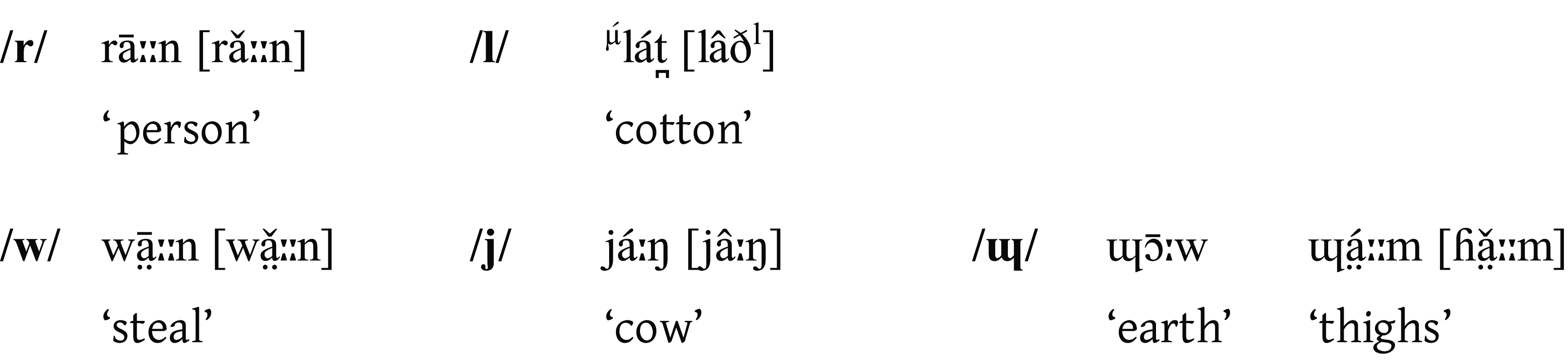
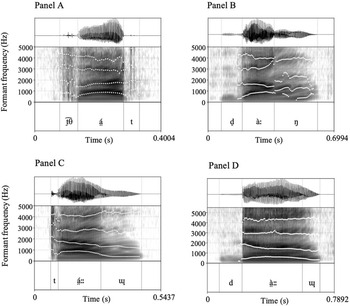
Examples above show Nuer consonants in morpheme-initial position.Footnote 3 The fricative phonemes do not occur in this context. The items that exemplify the phoneme /ɰ/ show two allophones conditioned by the vowel quality of the adjacent vowel. The phoneme /ɰ/ can be realised as a glottal fricative (either voiced [ɦ] or voiceless [h]) mostly in the context of low vowels, and as [ɰ] elsewhere. The glottal realisation is attributed to a coarticulatory effect of the maximal opening required in the production of the low vowels. In addition, /ɰ/ can also be realised as a fricative phrase initially before /ə̤/. This is evident from the examples of ɰə̤́n ‘I’ in Figure 11 and in (5a). The examples in Figure 11 show that /ɰ/ is realised as either a voiced (Panel A) or voiceless (Panel B) glottal fricative. The first example in (5a) shows that it can also be realised as a velar fricative [x]. The fricative realisation in the phrase-initial context is attributed to particularly strong prosodic strengthening condition.
Spectrograms for the labiovelar and velar approximants are presented in Figure 2. The labiovelar /w/ is exemplified in word-initial position in wā̤ːːn ‘steal’ (Panel A) and in word-final position in ɰɔ̄ːw ‘earth’ (Panel B). The velar approximant /ɰ/ is exemplified in word-initial position in ɰɔ̄ːw ‘earth’ (Panel B) and in word-final position in tá̤ːːɰ ‘plait’ (Panel C). The velar approximant has relatively high F2 and F4 compared to the labiovelar approximant. As a result, the F1 and F2 as well as F3 and F4 are closer together for /w/ than for /ɰ/. In phrase-initial position, the velar is also preceded by pre-aspiration, as is evident from the spectrogram in Panel B.
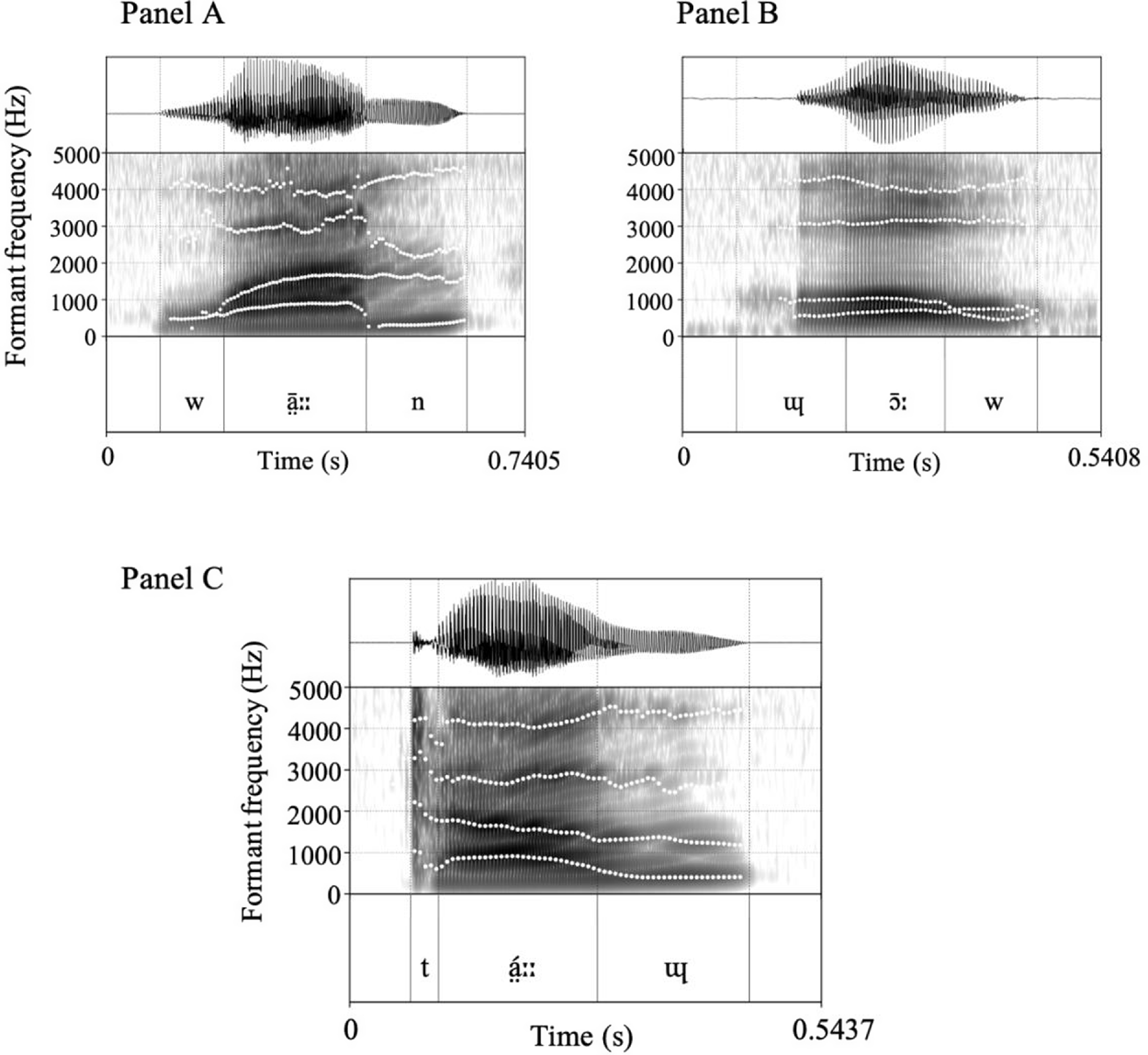
Figure 2. Spectrograms showing the labiovelar /w/ and velar /ɰ/ approximants in word-initial and word-final positions. Panel A: wā̤ːːn ‘steal’, Panel B: ɰɔ̄ːw ‘earth’, Panel C: tá̤ːːɰ ‘plait’.
Voiceless and voiced plosives contrast only in morpheme-initial position (this will be justified in the discussion of the intervocalic voicing below). The voiceless plosives are aspirated, and the voiced plosives are prevoiced.
Table 1 shows measurements of the voice onset time (VOT) for Nuer plosives. All the measured items – 430 in total – came from onsets of monosyllabic words uttered in isolation by a single speaker (RNM).
Table 1 Mean VOT and one standard deviation around the mean for voiceless and voiced plosives rounded to the nearest millisecond. Data from a single speaker (RNM).
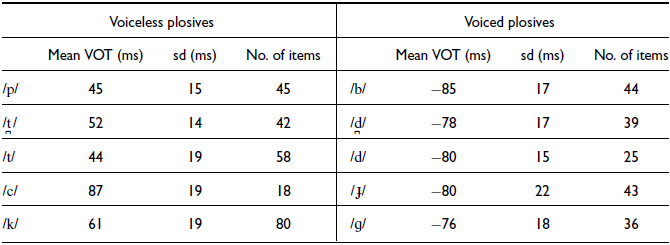
The relatively high VOT for /c/ in Table 1 is due to its variable realisation as either a fricative, an affricate or a plosive. As a fricative, it can be realised either as the alveolo-palatal or palatal. The following phonetic realisations are attested: the alveolo-palatal [ɕ] in the context of high vowels, as can be seen from the auxiliary verbs cí̤kɛ̀ in (1a); the palatal [ç], as in the word cə̤́ŋ ‘sun’ in (1a); the affricate [c͡ɕ], as in the auxiliary cɛ̀ in (1c); and a stop [c], as in the auxiliary càː in (1d).


Other plosives can also be realised as fricatives or affricates word-initially. The labial /p/ can be realised as [ɸ] or [p͡ɸ] in fluent speech, as is evident from the word pwɔ̤́ːɲdɛ̀ ‘his body’ in the two examples in (2a). The dental /t̪/ can be realised as [s], [t̪] or [t̪͡θ]. The example (2b) shows the [s] realisation in the speech of PGM. The example (2c) shows the [t̪] realisation in the speech of RNM. The affricate [t̪͡θ] realisation appears in the word t̪í̤n ‘in the middle of’ in (2d) spoken by JKG, and in the word t̪á̤t ‘cook’ in Panel A of Figure 3 spoken by RNM.


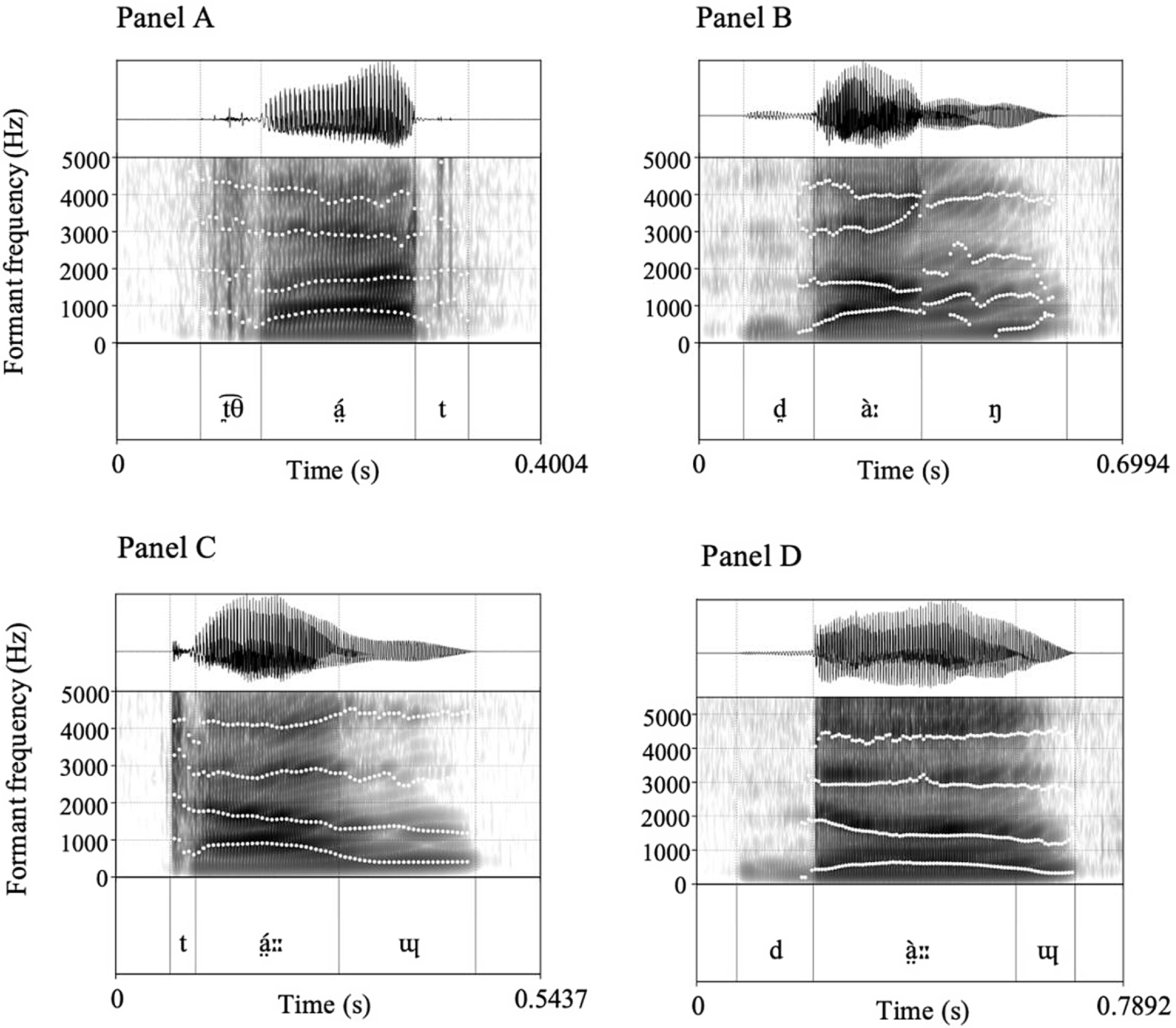
Figure 3. Spectrograms showing the dental plosives /t̪/ and /d̪/ (Panels A, B) and alveolar plosives /t/ and /d/ (Panels C, D) in word-initial position. Panel A: t̪á̤t ‘cook’, Panel B: d̪àːŋ ‘loft bed’, Panel C: tá̤ːːɰ ‘plait’, Panel D: dá̤ːːɰ ‘separate’. The annotation tier shows phonetic transcription.
Figure 3 shows spectrograms for the dental and alveolar stops in word-initial position. The alveolar plosives (Panels C, D) are characterised by the relatively higher F2 at the point of the transition into the vowel compared to the dentals (Panels A, B).
The palatal /ɟ/ can be realised as [ɟ͡ʑ], as in (3a). The velar /k/ can be realised as [k͡x] in fluent speech, as is evident from kò̤ɔ̤lí̤ (glossed as wrap-PL) ‘wrapping’ in (3b). The alveolar /d/, is typically realised as a stop [d], as can be seen from the 3sg possessive suffix in the word μ́ bì̤ː-dɛ̀ ‘his cloth’ in (3c). In fast speech it can be additionally realised as either an affricate [d͡ʑ] or a tap [ɾ], as in the two renditions of the same word in (3b).


In the majority of Nuer dialects, the phoneme /ɰ/ can occur only morpheme-initially. In Lou Nuer as well as in the Western Nuer it can additionally occur morpheme-finally. In their investigation of Western Nuer, Monich & Baerman (Reference Monich, Baerman, Clem, Jenks and Sande2019) attribute the occurrence of this phoneme (as well as the fricative phonemes) morpheme-finally to consonantal lenition as a function of morphology. Consonantal lenition is also the likely source of the phoneme /h/ in Lou Nuer. This phoneme occurs only morpheme-finally (and more specifically, in certain morphological contexts). The morpheme-final /ɰ/ and /h/ in Lou Nuer both originate from /k/ which is found in the corresponding lexical items in the non-leniting Nuer dialects.Footnote 5 At least in Lou Nuer, the contrast between /k/ - /ɰ/ - /h/ is phonemic in morpheme-final position, as is evident from the examples in (4).

Voicing in plosives is not contrastive in morpheme-final position. The examples of the verb ‘catch’ in (5) show that plosives are voiced when followed by a vowel (5a) or a sonorant (5b), and voiceless before another plosive (5c) or in the pre-pausal position (5d) where they are often unreleased. There is no good reason to assume that the morpheme-final plosives are either voiced or voiceless underlyingly. Here I make an arbitrary decision to represent them as voiceless underlyingly, and subject to voicing when followed by a vowel or a sonorant consonant.

The voicing alternation is morphologically conditioned. Specifically, the status of the consonant as either morpheme-initial versus final is important here. Example (6) shows that /k/ occurs in the intervocalic position in syllable onsets in the words ɟɛ́ːk-ɛ̀ and té̤t-nì̤-kə̤́. Despite the phonologically identical environments, the intervocalic voicing occurs only in the morpheme-final position, but not suffix-initially.

In fast speech there are also apparent exceptions to this generalisation, as is evident from the realisation of /k/ in the preposition kɛ̀ as either [ɡ] in (1a) or [ɰ] in (2d).
The behaviour of the dental plosive in the pre-pausal context provides another exception to the voicing generalisation. It can be realised as a voiced fricative [ð] when preceded by the short low vowel. This is shown by the example for ‘cotton’ in (7a). Furthermore, the voiced fricative can have a lateral release [ðl], as can be seen in another rendition of ‘cotton’ given under the consonantal chart. Compare this to the voiceless realisation with the nasal release when the dental plosive follows a high vowel in (7b). Voicing does not occur in the pre-pausal context when the preceding low vowel is overlong, as is seen from the example for ‘plaster’ ɲā̤ːːt̪ [ɲā̤ːːθ] under the consonantal chart.


In addition, the following realisations have been attested in morpheme-final position: the dental plosive is realised as a voiced fricative [ð] intervocalically and as voiceless fricatives [θ] or [s] pre-pausally, as seen from the three repetitions of the word mə̤̄ːːt̪ ‘slowly’ in (3c); and the alveolar plosive can be realised as an affricate [t͡ɕ] pre-pausally, as in the example pá̤t ‘clap’ under the consonantal chart.
Utterance and morpheme boundaries condition the realisation of the phoneme /r/. It tends to be realised as a trill utterance-initially or utterance-finally, i.e. under particularly strong prosodic strengthening conditions, although it can also be realised as a trill phrase-medially, as in the word ráːr ‘outside’ in (8a), and even at a morpheme boundary, as in the word tárɡjáw in (1d) which literally translates as ‘shield turner’, consisting of tár ‘turn inside out’ and ɡjáw ‘shield’. Saying that, the medial context usually renders the realisation of the phoneme as a tap [ɾ], as can be seen from the word tárɡjáw in (1a). In addition, the voiceless realisation [r̥] is attested morpheme-finally at the utterance boundary, as can be seen from the word ráːr in (8b).

Consonantal clusters are rare in Nuer. They mostly occur when suffixal morphology is added to stems that end in a consonant. Both the stem-final and suffix-initial consonants are realised in such cases (e.g. in (5c)), with the exception of identical or homorganic consonants which do not geminate but are realised as a singleton consonant instead.Footnote 6 Other than at the morpheme boundaries, consonantal clusters can occur in fluent speech through deletion of the intervening vowels, as is exemplified by the realisation of bì̤ rāːm-ɔ̀ in (8a).
Vowel quality and voice quality
Nuer vowels contrast in terms of vowel quality and voice quality. Overall, there are twenty-two vowel phonemes in Nuer – fourteen monophthongs /i, i̤, e, e̤, ɛ, ə̤, a, a̤, ɔ, ɔ̤, ɵ, ɵ̤, o, ṳ/ and eight diphthongs /ie, i̤e̤, ea, e̤a̤, oɔ, o̤ɔ̤, ɔa, ɔ̤a̤/. Here I transcribe the vowels on the basis of their phonetic properties. In the recent literature on the South Sudanese Nuer dialects (Baerman, Monich & Reid Reference Baerman, Monich and Reid2019; Reid Reference Reid2019; Bond et al. Reference Bond, Reid, Monich and Baerman2020; Monich Reference Monich2020; Baerman & Monich Reference Baerman and Monich2021) these vowels are represented as /ɪ, i̤, e, e̤, ɛ, ʌ̤, a, a̤, ɔ, ɔ̤, o, o̤, ʊ, ṳ, ɪe, i̤e̤, ɛa, e̤a̤(ɛ̤a̤), ʊɔ, ṳɔ̤, ɔa, ɔ̤a̤/ based on their behaviour in morphophonology. Somewhat different vowel inventories are proposed for the Ethiopian Jikany Nuer (Faust & Grossman Reference Faust and Grossman2015; Faust Reference Faust2017; Gjersøe Reference Gjersøe2019), most notably, the diphthongs /ea, e̤a̤(ɛ̤a̤)/ are not reported for this dialect.
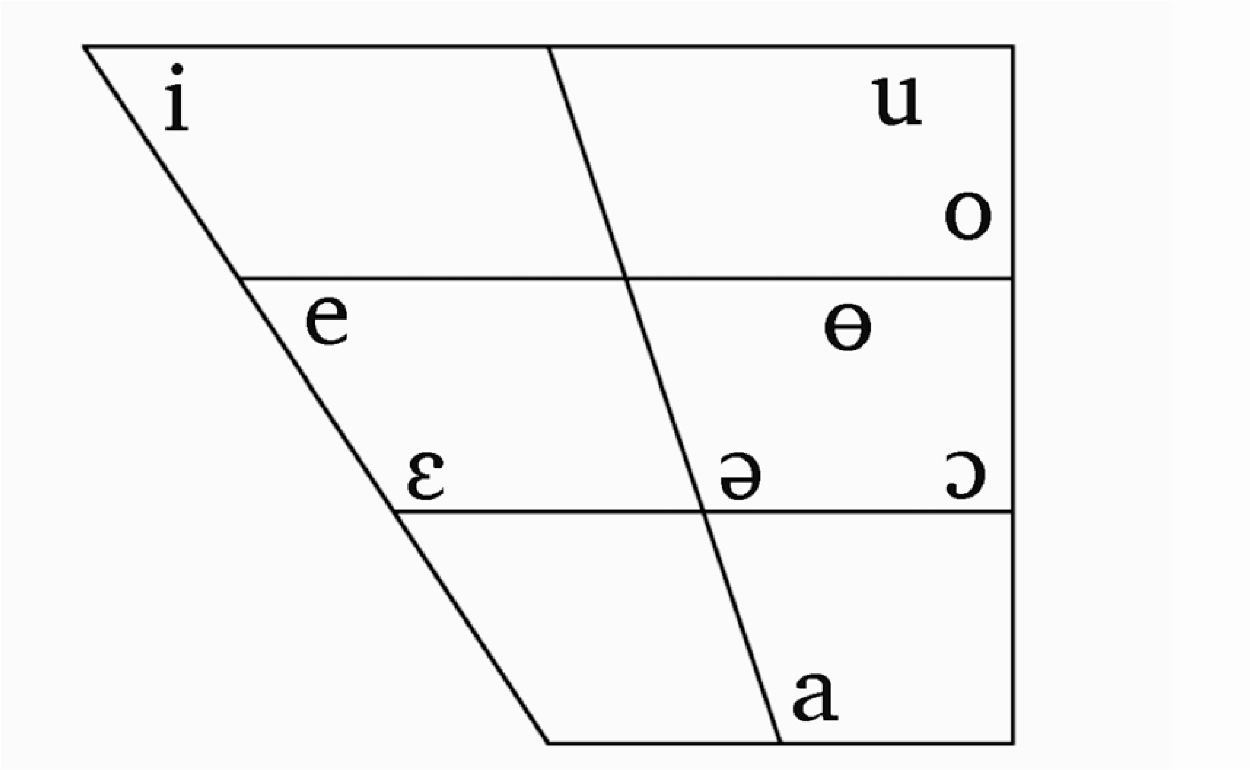
The combinations of backness and height are shown in the Nuer vowel quadrilateral. Note that the symbol used to transcribe the phonetically central vowel [a̠] throughout this document is /a/.
The voice quality contrast is binary: vowels are either modal or breathy. The monophthongs and diphthongs are split into two equal sets of eleven phonemes: the modal vowels /i, e, ɛ, a, ɔ, ɵ, o, ie, ea, oɔ, ɔa/ and the breathy vowels /i̤, e̤, ə̤, a̤, ɔ̤, ɵ̤, ṳ, i̤e̤, e̤a̤, o̤ɔ̤, ɔ̤a̤/. Voice quality contrast does not occur for all vowel qualities. For example, the vowel /ɛ/ does not have a breathy counterpart, and the phoneme /ə̤/ does not have a modal counterpart. Because the vowel quality and voice quality are not symmetrical, both contrasts are treated together in this section.
The Nuer vowel phonemes are exemplified in (9). The breathy schwa /ə̤/ phoneme is a full vowel which, just like all other Nuer vowels, appears in three levels of vowel length. In addition, a schwa can occur as a result of vowel reduction (for example, in fast speech). The sentence in (1b) exemplifies this for a short suffix /-ɔ/ in rāːm-ɔ̀ and for the copula ɛ̀.


Diphthongs can be realised as monophthongs under various conditions (Reid Reference Reid2019: 69–75). The resulting monophthong usually corresponds to the second component of the diphthong. This is particularly true of the diphthongs /oɔ, o̤ɔ̤/ preceded by labial consonants, as is shown by the realisation of pò̤ɔ̤t as [pɔ̤̀d] in (1c). Short diphthongs can be realised as monophthongs in fast speech, as is evident from the realisation of kò̤ɔ̤l-í̤ as [k͡xɔ̤̀lí̤] in (3b).
The remainder of this section deals separately with the monophthongs and diphthongs, respectively.
Monophthongs
An instrumental analysis of Nuer monophthongs was carried out to investigate vowel quality and voice quality. The data for the study came from two Nuer speakers: RNM – a female speaker of the Lou (Eastern) Nuer dialect, and PGM – a male speaker of the Western Nuer dialect.
The data set is exemplified by selected examples in (10). The full data set, supplemented by audio recordings, is available in the Appendix. All items were embedded in carrier sentences where the target word occurred in phrase-medial position. All vowels came from the verb stems shown in bold. Many of the items were near-minimal pairs. Note that in all examples, the High toneme with modal vowels is realised as a falling contour (as per section on tone); the preposition /ɛ/ is often realised as [ə] here and throughout the paper (as per section on vowel and voice quality).

The data added up to 151 items across the two speakers. Seventy-four items came from RNM and seventy-seven items from PGM. An item stands for an individual word; no repetitions were used in this study. Each phoneme occurred in between seven to fifteen items across the two speakers. Each speaker uttered between three to eight items for each vowel.
The data was analysed using Praat software (Boersma & Weenink Reference Boersma and Weenink2005). Vowel onsets and offsets were segmented in line with the segmentation guidelines in Turk, Nakai & Sugahara (Reference Turk, Nakai, Sugahara, Sudho, Lenertová, Meyer, Pappert, Augurzky, Mleinek, Richter and Schließer2006) with one divergence: the burst phase of the voiceless stops was not included into the vowel portion.
In order to investigate the vowel quality contrast, the acoustic measurements of F1 and F2 were obtained and analysed. For the voice quality study, measurements of the energy distribution across the frequency range were obtained and analysed. I report the procedures and findings in turn, starting with the vowel quality study.
In processing the data for the vowel quality study, a Praat script (Remijsen Reference Remijsen2015) was used to measure the first two formants (F1 and F2) of the target vowels at the temporal mid point. The formants for each file were also checked manually. R (R Core Team 2021) was used to process the data and the package phonR (McCloy Reference McCloy2016a,b) was used to plot the vowel charts. The measurements were z-transformed by speaker (Lobanov Reference Lobanov1971) to normalise for between-speaker variation.
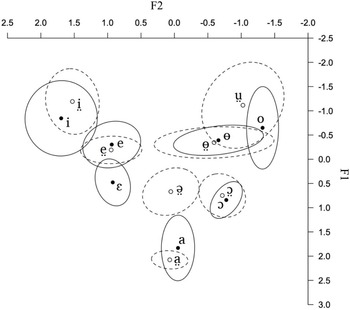
Figure 4 shows that there is a considerable overlap in the phonetic vowel quality between some of the vowel phonemes, as seen from the standard deviations. This is especially true for the pairs of vowels that differ with respect to voice quality (e.g. /e/ and /e̤/; /i/ and /i̤/, etc.). Vowels with the same voice quality do not tend to overlap in their formants. The exceptions are the vowels /o/ and /ɵ/, /i/ and /e/, /e/ and /ɛ/, and /ṳ/ and /ɵ̤/, all of which show some overlap in the formants, as is evident by considering their ellipses. These vowel pairs can sometimes be difficult to tell apart (at least for a non-native speaker).
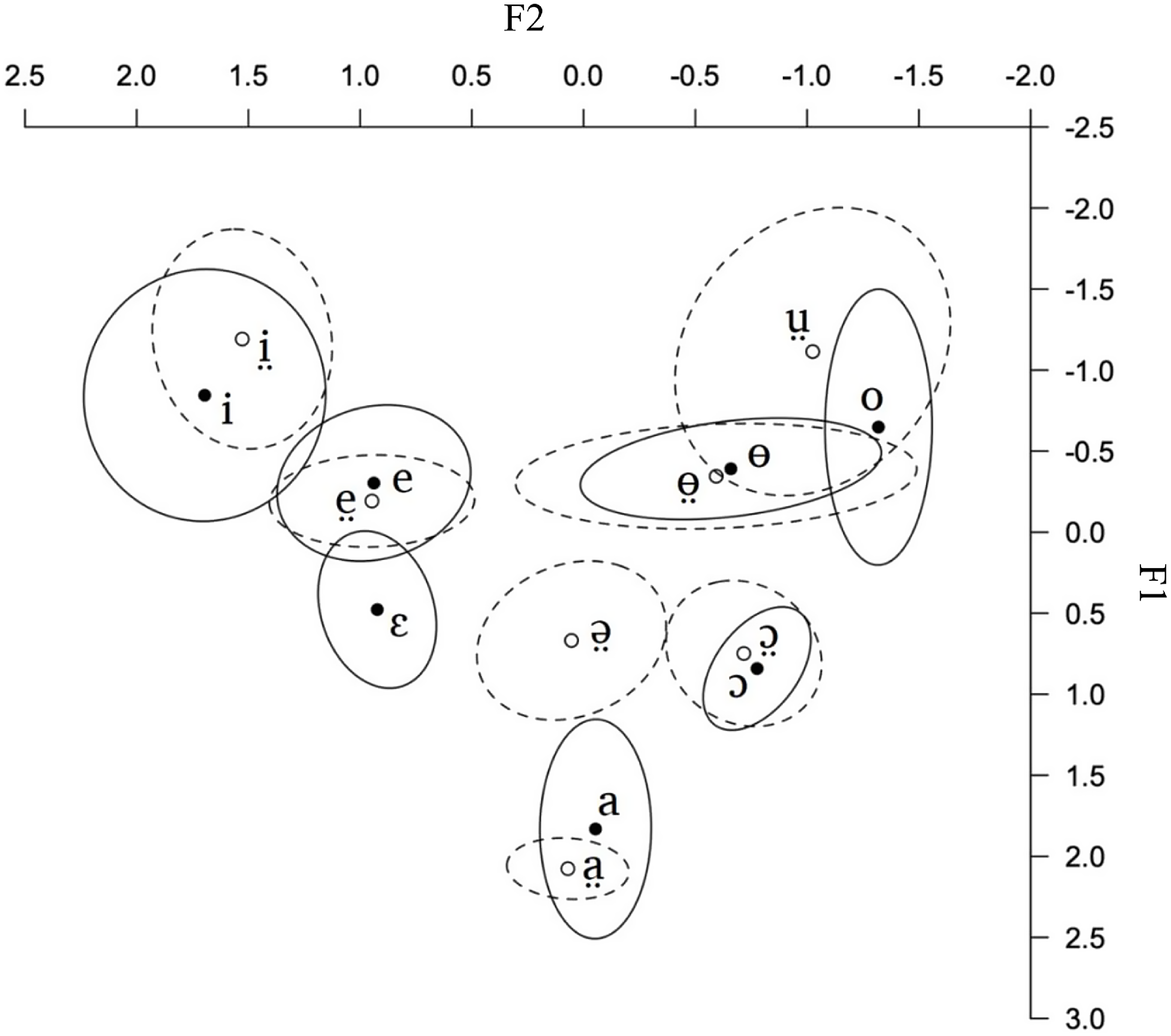
Figure 4. z-transformed F1 and F2 values for the fourteen Nuer monophthong vowel phonemes: means (dots) and one standard deviation around the mean (ellipses). Breathy vowels are marked by empty dots and interrupted line ellipses. Modal vowels are marked by filled dots and solid line ellipses. The data come from two speakers: a female speaker RNM (Lou, Eastern Nuer) and a male speaker PGM (Western Nuer).
For the voice quality study, a range of measurements of energy distribution across the frequency range were made. Here I report the results for two of them: Cepstral Peak Prominence (CPP) and Spectral Emphasis (SE) (Traunmüller & Eriksson Reference Traunmüller and Eriksson2000).
The CPP measure – a measure of dysphonia – measures the difference in the amplitude between the harmonic and inharmonic components of the source spectrum (Garellek Reference Garellek2019: 84). This measure is employed to differentiate between the modal and non-modal voice qualities since the breathy and creaky phonation types are expected to have a smaller difference between harmonic and inharmonic components than the modal phonation. Thus, the CPP measure is expected to be higher with modal vowels than with breathy and creaky vowels.
The SE measure was chosen over other spectral tilt measures (e.g. H1–H2, H2–H4, etc.) on the basis of the linear discriminant analysis (Garellek Reference Garellek2020) according to which the SE measure has the highest correlation (r = –1.2) out of all measures used (of which the next highest were H1*–A2* r = 0.26, and H2*–H4* r = 0.09). The SE measure was also shown to be the most reliable spectral tilt measure for another West Nilotic language, Shilluk (Remijsen, Ayoker & Mills Reference Remijsen, Ayoker and Mills2011).
The SE reflects the relative contribution of the energy in the high frequency band (above 1.5 times the fundamental frequency) to the overall intensity (Traunmüller & Eriksson Reference Traunmüller and Eriksson2000; Remijsen et al. Reference Remijsen, Ayoker and Mills2011). It is expected that the non-breathy vowels will have more energy in the higher frequency band than the breathy vowels, and thus we expect higher values for the non-breathy vowels and lower values for the breathy vowels according to this measure.
In sum, the CPP measure indicates the contrast between the modal and non-modal phonation types; the SE measure indicates the contrast between breathy and non-breathy phonation types. Taken together, these measures can be used to disambiguate modal and creaky voice qualities.
The measurements for the voice quality study were made using Praat scripts. CPP was measured by a script provided as part of Praatsauce (Kirby Reference Kirby2018), which is based on the suite of scripts by Mills (Reference Mills2010). The SE measure was calculated using an implementation of a procedure within the same suite of scripts by Mills (Reference Mills2010). The measurements were taken from the middle of the segmented vowel portion.
The measurements were analysed and graphically represented in R (R Core Team 2021) using the tidyverse package (Wickham et al. Reference Wickham and Mara Averick2019). In order to normalise for between-speaker variation, the measurements were z-transformed. For the CPP measure, the non-normalised results were used.
The results for the CPP measure are shown in Figure 5. The means for the perceptually breathy vowels are consistently lower than for the corresponding modal vowels. At the same time, there is a lot of overlap in the standard deviations for all of the vowel pairs, suggesting the absence of contrast according to this measure. Because CPP differentiates between the modal and non-modal phonation types, the absence of contrast in Figure 5 may indicate that there are no phonetically modal vowels in Nuer. Alternatively, the breathy tokens might not be very noisy (i.e. more ‘slack’), and this could make them look similar to modal vowels in terms of their noise profile.
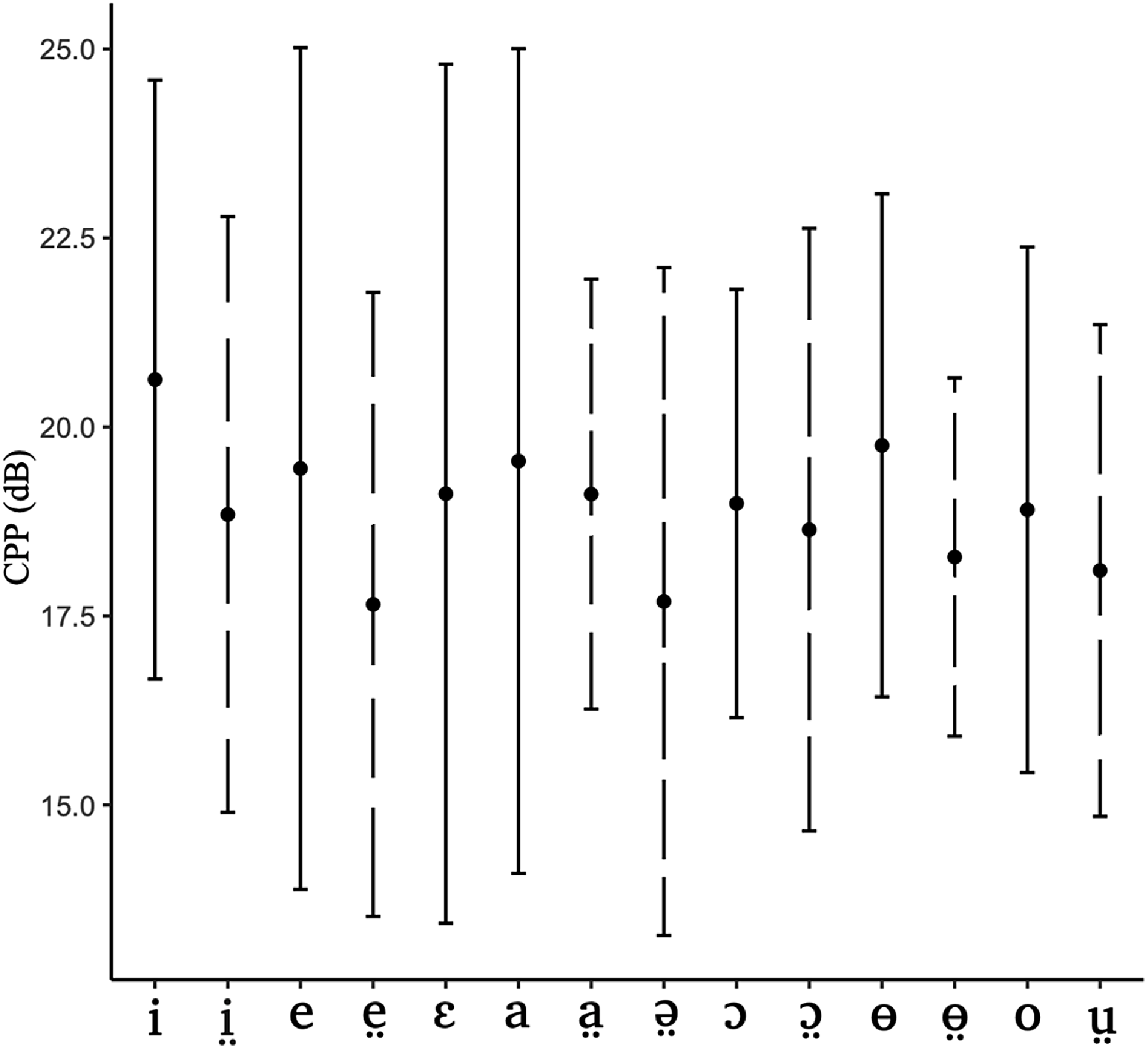
Figure 5. Cepstral Peak Prominence (CPP) measure (a measure of harmonics-to-noise ratio) showing results for the fourteen Nuer monophthong vowel phonemes: means (dots) and one standard deviation around the mean (wickers). Solid line – modal vowels, dashed line – breathy vowels. The data come from two speakers: a female speaker RNM (Lou, Eastern Nuer) and a male speaker PGM (Western Nuer).
Figure 6 shows the means and standard deviations for the SE measure. The vowels /i, e, ɛ, a, ɔ, ɵ, o/ have higher means than the vowels /i̤, e̤, ə̤, a̤, ɔ̤, ɵ̤, ṳ/. This supports the perceived voice quality contrast between the two vowel sets, with the latter set being more breathy than the former set.
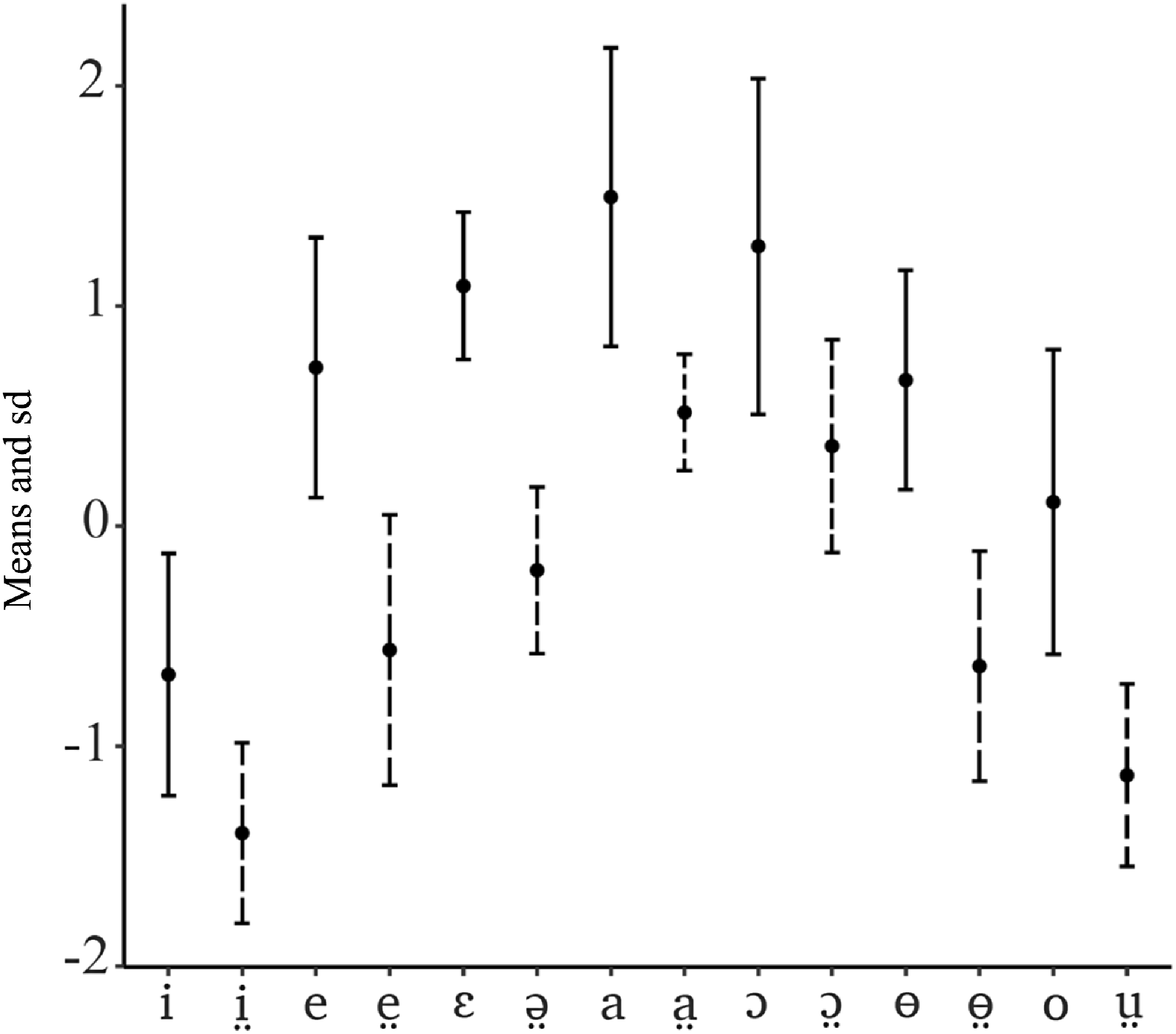
Figure 6. z-transformed spectral emphasis values (dB) showing results for the fourteen Nuer monophthong vowel phonemes: means (dots) and one standard deviation around the mean (wickers). Solid line – modal vowels, dashed line – breathy vowels. The data come from two speakers: a female speaker RNM (Lou, Eastern Nuer) and a male speaker PGM (Western Nuer).
With the exception of the two vowel pairs (/i/ and /i̤/, and /ɔ/ and /ɔ̤/) for which some overlap in the standard deviations is found, the vowel pairs with the same vowel quality do not show any overlap. This constitutes the evidence that the voice quality contrast in Nuer is categorical.
A configuration where (i) the noise component in the spectra is about the same as with the breathy phonation (as is evident by the CPP results), and (ii) the energy in the higher frequency band is greater than with the breathy phonation (as is evident by SE) is indicative of the creaky phonation type (Garellek Reference Garellek2019: 90). Therefore, I conclude that, on the basis of the data from two Nuer speakers, the vowels that fall into the modal category in Nuer are phonetically creaky.Footnote 7
Diphthongs
The eight Nuer diphthongs /ie, i̤e̤, ea, e̤a̤, oɔ, o̤ɔ̤, ɔa, ɔ̤a̤/ are all opening diphthongs, with the second element of a diphthong being more open than the first element. Both components of any given diphthong are of roughly equal duration and have the same voice quality.
Nuer diphthongs were measured to study vowel quality. The data was obtained from a single speaker RNM who speaks the Lou (Eastern) Nuer dialect. For each diphthong, seven different words (items) were recorded. The total number of items for all diphthongs was thus fifty-six. The recording and segmentation procedure for diphthongs was the same as for the monophthongs (described above). A Praat script (Remijsen Reference Remijsen2015) was used to measure the first two formants (F1 and F2). The values for F1 and F2 of a diphthong were obtained at 25 per cent and at 75 per cent into the vowel following the procedure outlined in Reid (Reference Reid2010: 60–62). The results were processed and represented in R (R Core Team 2021) using the R package tidyverse (Wickham et al. Reference Wickham and Mara Averick2019) following the procedure outlined in Stanley (Reference Stanley2018).
Figure 7 presents mean diphthong trajectories for the eight Nuer diphthongs together with the means for the Nuer monophthongs. Because the data for diphthongs come from the speaker RNM, the means for the monophthongs plotted in Figure 7 are the non-normalised values for this speaker alone.
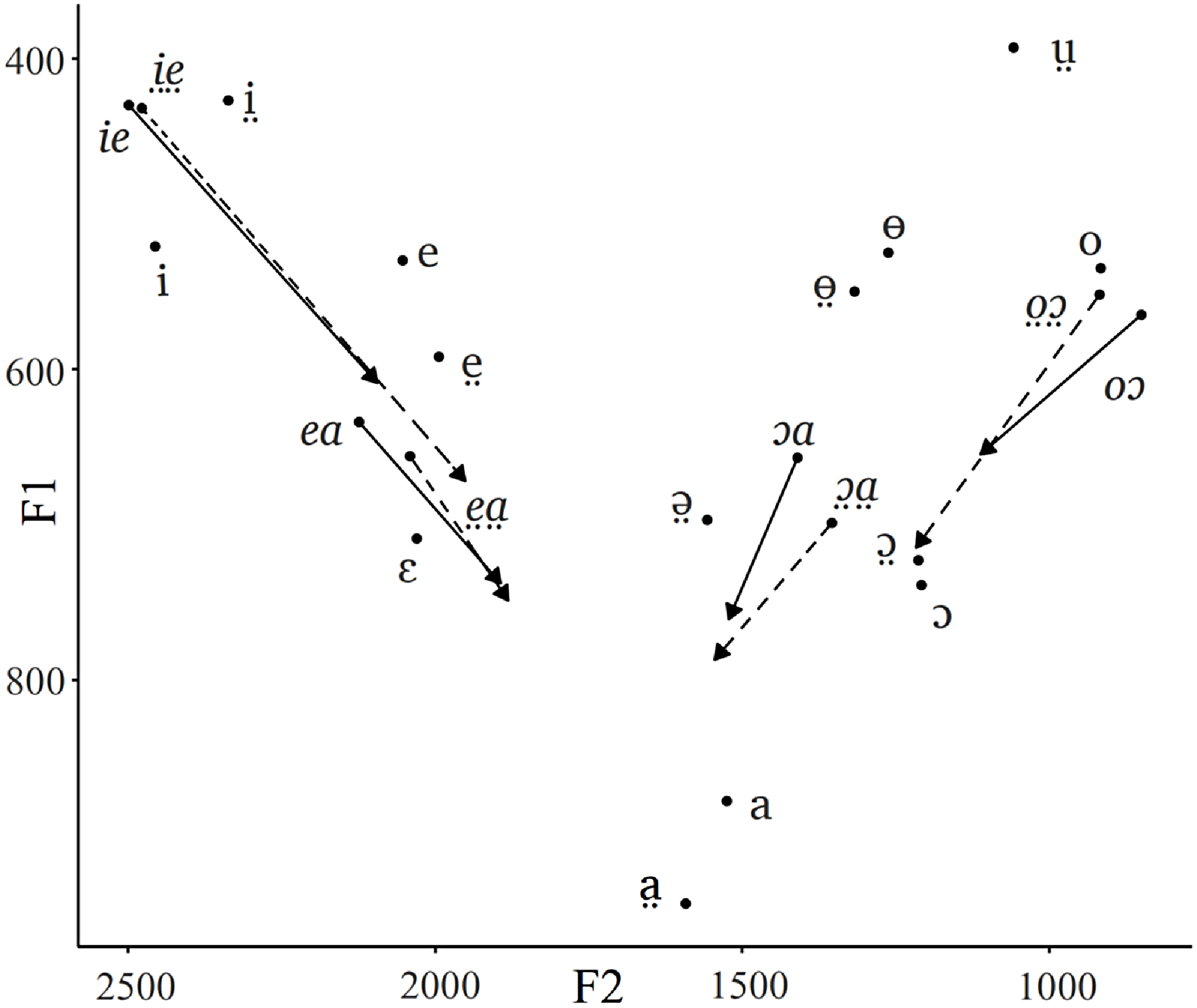
Figure 7. Formant trajectories of the Nuer diphthongs. Data from a female speaker RNM (Lou, Eastern Nuer). Diphthongs (in italics) are shown as trajectories with means corresponding to the first component represented as dots, and means corresponding to the second component as arrow heads. Solid line – modal diphthongs, dashed line – breathy diphthongs. The non-normalised means for the monophthongs for RNM are presented as dots for reference and signposted with the non-italicised vowel graphemes.
Figure 7 shows that some of the diphthongs start and end around the mean points for the corresponding monophthongs, whilst others do not. Specifically, the diphthongs that end in the low vowels have higher F1 than the monophthongs /a, a̤/. In addition, the first components of the diphthongs /ɔa/ and /ɔ̤a̤/ are more centralised than the monophthongs /ɔ, ɔ̤/.
The modal and breathy diphthongs /oɔ/ and /o̤ɔ̤/ have the same vowel quality. In particular, the formants of the first component correspond to the formants of the monophthong /o/. I represent these diphthongs uniformly as containing the high-mid vowel, in spite of the fact that there is no corresponding breathy monophthong */o̤/ in the language.
The transcription of the diphthongs that start or end in the front mid vowels requires some justification. Figure 4, which presents means and standard deviations around the mean for the Nuer monophthongs, shows that there is some overlap in the formants of the monophthongs /e̤/, /e/ and /ɛ/. The four Nuer diphthongs containing the mid front vowel /ie, i̤e̤/ and /ea, e̤a̤/ start and end, respectively, within the range of that overlap. For the sake of uniformity, I represent them as containing the vowels /e/ and /e̤/ notwithstanding the fact that the modal /e/ monophthong has a somewhat higher F1 mean.
The above observations show that, unlike the monophthongs, the diphthongs involve only three levels of height – high, mid and low.
Vowel length
The Nuer vowels come in three degrees of vowel length: short (e.g. /i/, /ie/), long (e.g. /iː/, /ieː/) and overlong (e.g. /iːː/, /ieːː/).Footnote 8 This contrast is phonemic in Nuer and the distinction is found in monophthongs (11) and diphthongs (12) alike. The two components of the diphthongs are roughly of equal duration.

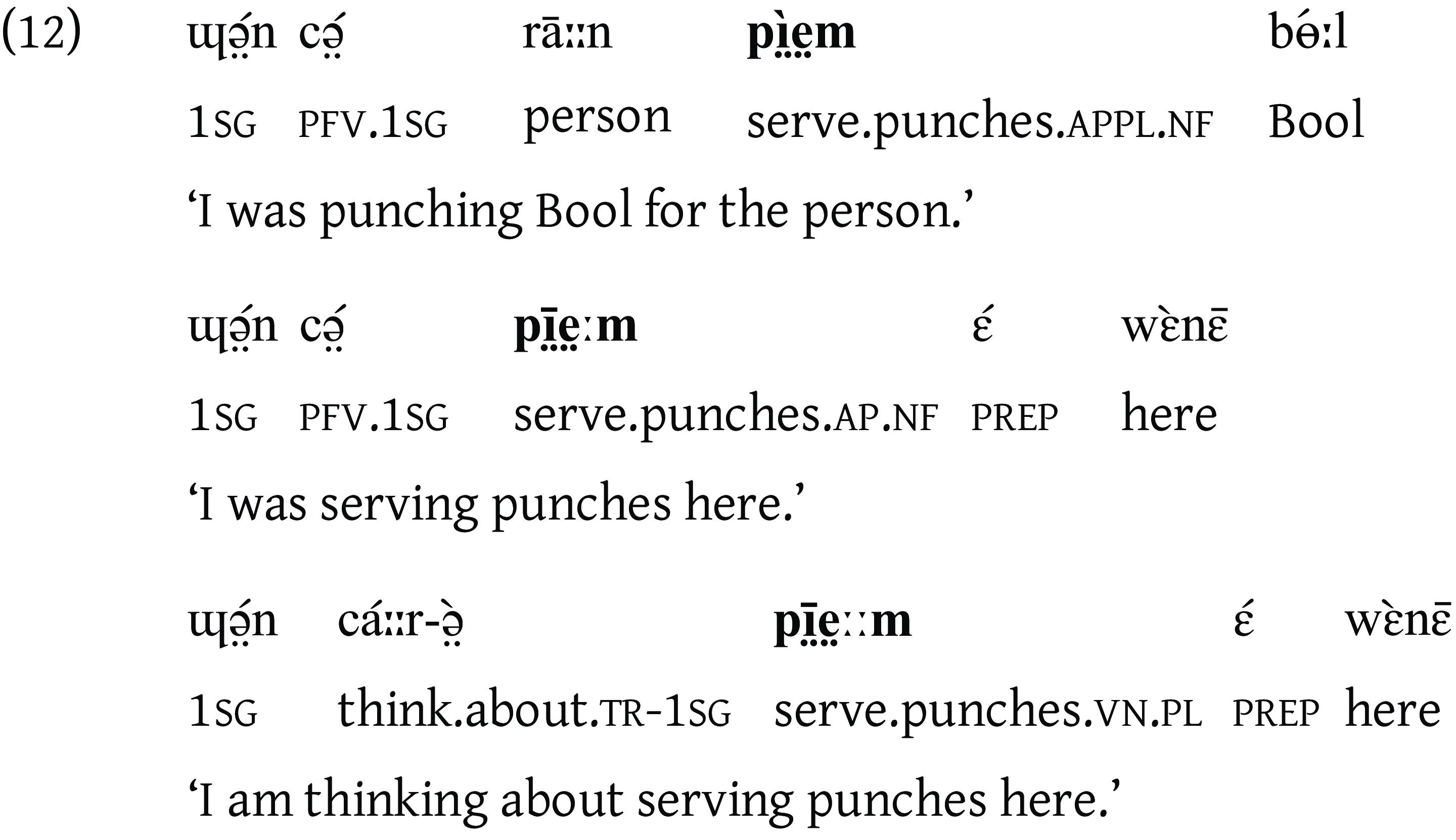
The durations of the monophthongs and diphthongs were subject to an instrumental study. The dataset came from RNM (Lou, Eastern Nuer). It was recorded, segmented and processed using the same procedure as in the study of vowel quality. Vowel durations were obtained from the stem syllables of disyllabic (stem+suffix) finite verbs, presented in bold in (13). All the words occurred in sentence-medial context. The measured data included both monophthongs and diphthongs.


Table 2 and Figure 8 present the descriptive statistics for duration of short, long and overlong monophthongs and diphthongs. The means and the standard deviations are well separated for the vowels of the same type, i.e. comparing separately the durations of monophthongs and that of diphthongs. Diphthongs are on average longer than the monophthongs of the corresponding vowel length, so that shorter diphthongs are about as long as the longer monophthongs.
Table 2 Summary of duration measurements. Nuer monophthongs and diphthongs as spoken by RNM – a female speaker of Lou (Eastern) Nuer dialect.
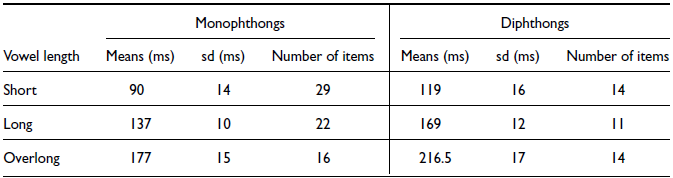
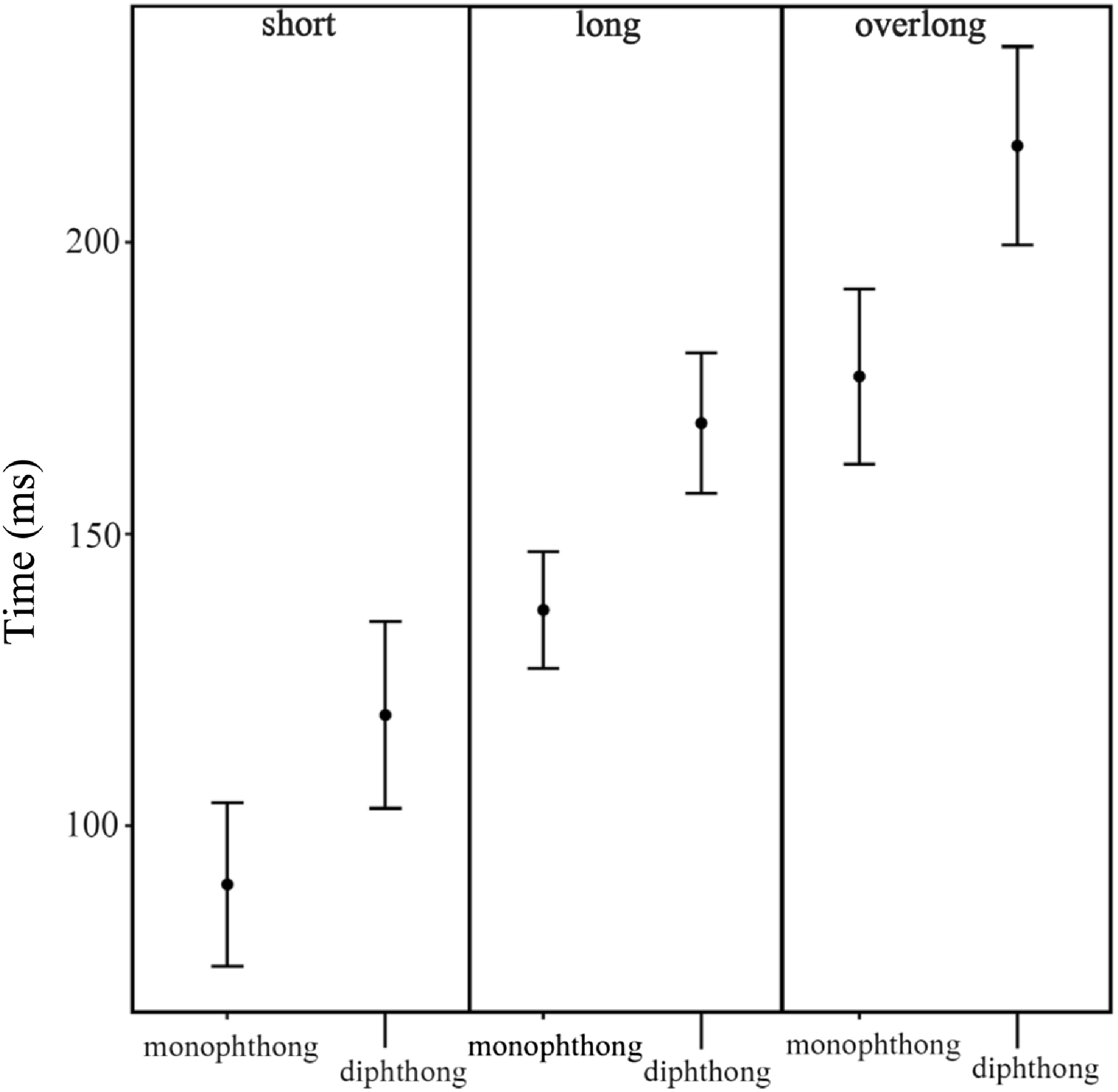
Figure 8. Duration measurements showing means and standard deviations (one sd around the mean) for short, long and overlong monophthongs and diphthongs in Nuer. Data came from stem syllables of disyllabic verbs in phrase-medial context uttered by RNM – a female speaker of Lou (Eastern) Nuer dialect.
Vowel durations can vary as a function of vowel quality with the high vowels having shorter durations than the non-high vowels (e.g. the vowel /i/ in the stem syllable of ‘taste’ in (13a) is 81 ms and the vowel /a/ in the stem syllable of ‘unite’ in (13a) is 104 ms).
Vowel durations can also vary as a function of context. Vowels are longer in phrase-final position (or in words uttered in isolation) than in phrase-medial position due to phrase-final lengthening (Reid Reference Reid2019: 49).
Tone
Nuer is a tonal language. Word-level stress is not attested in Nuer.
There are three tonemes in the South Sudanese Nuer dialects: High, Mid and Low (Reid Reference Reid2019).Footnote 9 The tonemes have a variety of phonetic realisations as a function of syllable properties. The realisation of the tonemes is primarily conditioned by the voice quality of the vowel and, to a lesser extent, by vowel length (Reid Reference Reid2019; Monich Reference Monich2020).
With respect to voice quality, the realisation of the High and the Mid tonemes appears to serve as one of the perceptual cues of the phonation contrast. This is exemplified in Figure 9 which shows the realisation of the three tonemes on the modal (Panel A) and breathy (Panel B) vowels. The data set for Figure 9 came from a near-minimal set for tone. The tonemes occur in the initial syllables of disyllabic verbs embedded into carrier sentences. The data come from a speaker RNM (Lou, Eastern Nuer); each sentence was uttered once. The f0 from the initial syllable was measured and time-normalised using a Praat script (Remijsen Reference Remijsen2004), and plotted in R (R Core Team 2021) using the package tidyverse (Wickham et al. Reference Wickham and Mara Averick2019).
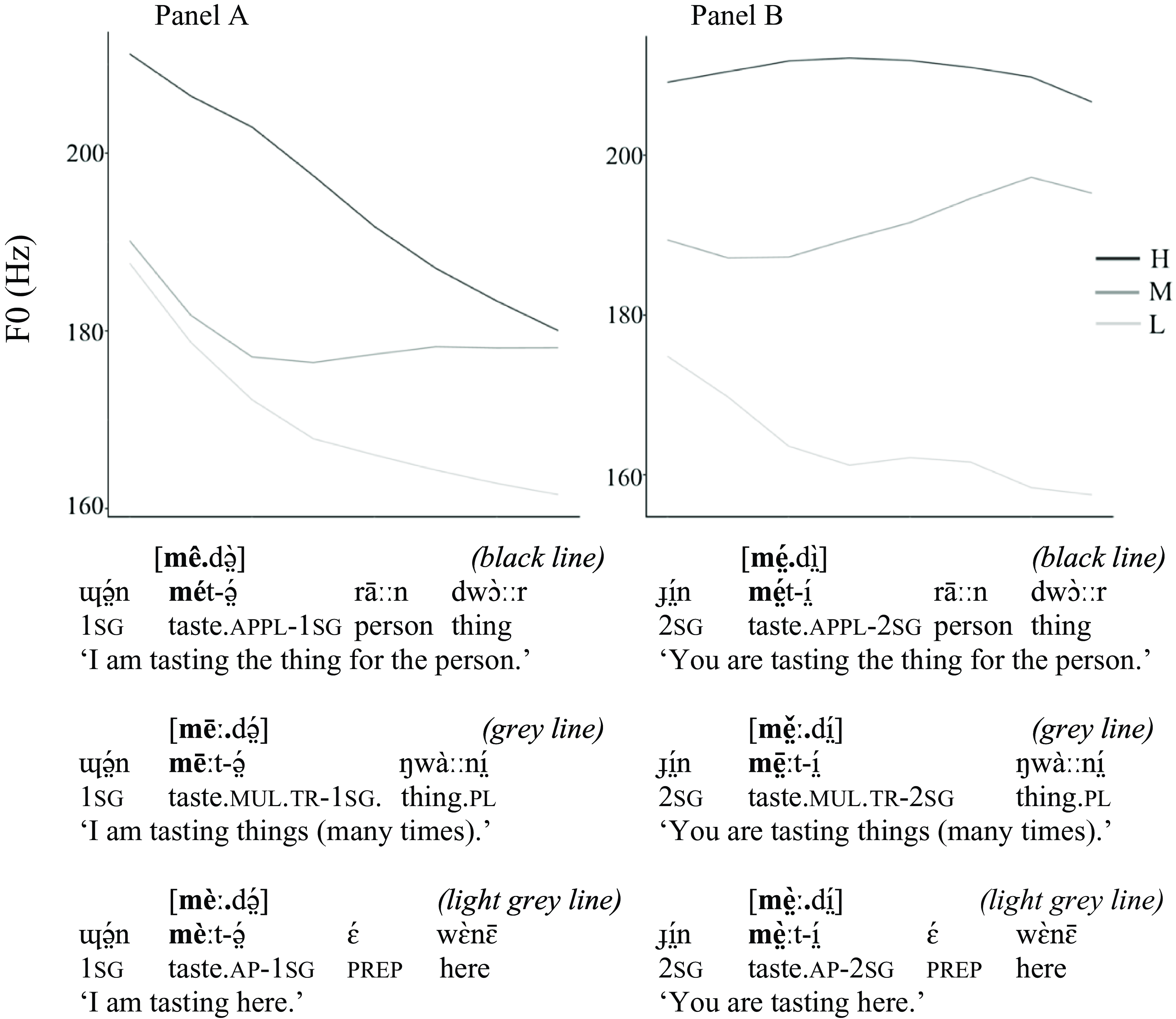
Figure 9. Normalised f0 patterns in syllables with modal vowels (Panel A) and breathy vowels (Panel B). High – black line; Mid – grey line; Low – light grey line.
Figure 9 shows that the High toneme (black lines) is realised with a falling trajectory in a syllable with the modal vowel (Panel A) and as level high in a syllable with the breathy vowel (Panel B). The Mid toneme (grey lines) is realised as mid level with the modal vowel (Panel A) and as a rise with the breathy vowel (Panel B). The Low toneme (light grey lines) has a uniform low level realisation with both phonation categories, although the f0 is relatively higher with the modal vowel (Panel A) than with the breathy vowel (Panel B).Footnote 10
The difference in the realisation of the High and Mid tonemes over vowels that differ in phonation type is akin to the contrast observed in the voice register languages (e.g. Henderson Reference Henderson1952; Huffman Reference Huffman1976; Wayland Reference Wayland1997; Tạ, Brunelle & Nguyễn Reference Tạ, Brunelle and Quý Nguyễn2019; Brunelle & Kirby Reference Brunelle and Kirby2016). There is, however, an important difference: the breathy phonation in Nuer is associated with the relatively higher pitch compared to the modal phonation. This is the opposite of what occurs in the voice register languages where the breathy phonation is associated with the relatively lower pitch than the modal phonation.
Within the same voice quality category, the Nuer tonemes can have a nearly identical f0 height in certain contexts, which often makes it difficult to tell them apart (at least for a non-native speaker). This is true of the Mid and Low tonemes in syllables with modal vowels and of the Mid and High tonemes in syllables with breathy vowels. The contrast in f0 height between the Mid and Low tonemes with the modal vowels is often small. Reid (Reference Reid2019: 143–144) reports a 15Hz difference between the levels of the Mid and the Low tonemes. The overlap in the realisations of the Mid and the High tonemes in syllables with breathy vowels is illustrated in Figure 10 where the target Mid is represented by a dashed line and the target High is represented by a solid line. As with the previous examples, the data comes from disyllabic words (verb stem+suffix); both sentences were uttered once by three speakers of Nuer: a speaker of the Lou dialect RNM, a speaker of the Western dialect PGM, and a speaker of the Nasir Jikany dialect JKG. The target tone occurs in the first syllable to the left of the vertical line, and the second syllable occurs after the vertical line. Figure 10 shows that the two tonemes in the first syllable (before the vertical line) start off and end at about the same f0 level. The main difference is in the alignment: the Mid tone (dashed line) is realised as a rise, and the High tone (solid line) is level high for most of the portion of the syllable. The underlying High tone in the suffixes (after the vertical line), however, is saliently different: it is level high after the Mid (dashed line), and it has a falling f0 after the High (solid line).Footnote 11 In this case, the difference in the f0 alignment in the first syllable is less salient than the difference in the suffix. As such, tone in the suffix can be used as a diagnostic of the tone in the stem syllable.
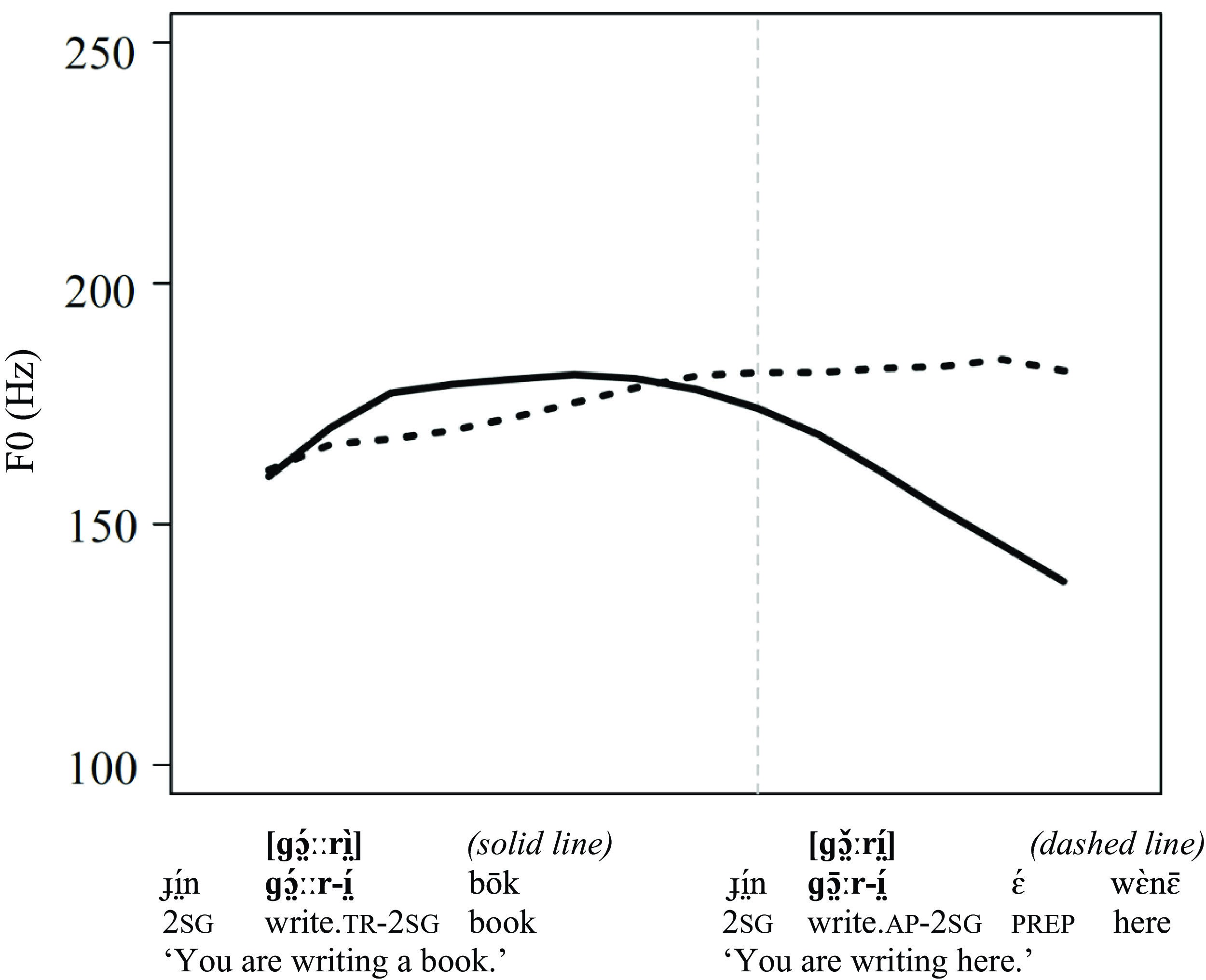
Figure 10. The normalised f0 tracks showing the realisation of the High and Mid tonemes in stems of dissyllabic words. The target syllable (verb stem) occurs before the vertical line. High stem – solid line, Mid stem – dashed line. Data from three speakers: a female speaker RNM (Lou, Eastern Nuer) and two male speakers PGM (Western Nuer) and JKG (Nasir Jikany, Eastern Nuer). Each sentence was uttered once.
Vowel length can also be a factor that affects the realisation of the tonemes. For example, the realisation of the Mid and High tonemes over breathy vowels can differ depending on vowel length. The rising realisation tends to occur more frequently with long and overlong vowels than with short vowels. With short modal vowels, the High toneme can have a level high realisation in addition to a more-common falling realisation. These observations are especially relevant in instances where short vowels are preceded and followed by plosives. The sensitivity of contours to vowel length is likely to be due to timing pressure. With short vowels there is less time for a contour to get realised compared to longer vowels.
Table 3 provides a summary of the realisations of the three Nuer tonemes in different syllable-internal environments, taking into account voice quality and vowel length. The data is based on the realisation of tone in the first syllable of dissyllabic verbs embedded into the carrier phrase, like that presented in e.g. Figure 10.
Table 3 Variation in the realisation of the tonemes as a function of voice quality and vowel length in stem syllables of disyllabic verbs, where the stem vowel is preceded and followed by a plosive.
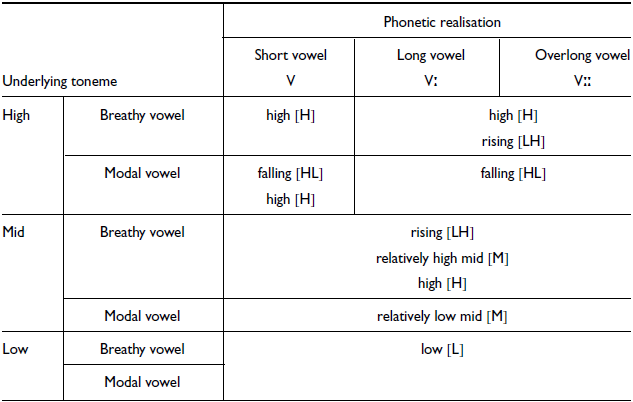
The realisation of the three tonemes can further vary as a function of neighbouring tone and presence/absence of phrasal boundaries, see Gjersøe (Reference Gjersøe2019), Reid (Reference Reid2019), and Monich (Reference Monich2020) for details.
Register expansion
Certain constructions in Nuer have a higher declination reset. Figure 11 exemplifies the negative (Panel A) and the declarative (Panel B) sentences. These sentences have identical segmental shape but differ in terms of f0. The f0 over the negative auxiliary verb in Panel A is around 63Hz higher than it is over the perfective auxiliary in Panel B. The effect is also observed on the following noun. It is realised with the higher f0 in Panel A than in Panel B. (The phonetic transcription for the noun in Panel A of Figure 11 shows it as mid toned [dwɔ̄ːːr] despite its f0 being relatively high. This is to contrast it with the realisation of the underlying High toneme which, in this context, would have f0 as high or higher than the f0 on the preceding auxiliary). The overall impression is that the negated sentence has higher f0 than the declarative sentence. This phenomenon has been referred to as ‘tone raising’ by Koang Nyang (Reference Koang Nyang2013: 64) and as ‘register expansion’ by Gjersøe (Reference Gjersøe2019: 46).

Figure 11. Register expansion exemplified in the negated sentence in Panel A compared to the segmentally identical declarative sentence in Panel B. Annotation tiers from top down: phonetic, phonemic, gloss, translation.
Syllable structure
The segmental templates attested in Nuer are given in (14). Example (14a) presents the syllable structure in content words. The syllables invariably consist of an initial consonant which can be followed by one of the two glides /j/ or /w/. The vowel can be short, long or overlong and there is usually a final consonant. The syllable structure of suffixes and function words is presented in (14b). These can have an obligatory short vowel, as well as optional initial and final consonants between which there can be either a short or a long vowel.

If a monosyllabic content word has an open syllable, the vowel is minimally long. Thus, the minimal shape of a Nuer content word can be either CVː, as in (15a) or CVC, as in (15b). The maximal shape of a monosyllabic content word is C(w/j)VːːC, as in (15c). Monosyllabic function words, by contrast, often have short vowels, as in (16a–b), and never overlong vowels. Thus, their minimal shape is V and the maximal shape is CVːC, as in (16c).

The North Wind and the Sun
(The story was narrated by JKG – a speaker of Jikany Nasir (Eastern Nuer) dialect. The Nuer orthography was provided by the same speaker.)
1.

2.

3.

4.

5.

6.

7.

8.

9.

10.

11.

12.

13.

14.

Acknowledgements
This work was made possible through funding from the Leverhulme Trust grant RPG-2020-040 (‘Suprasegmentals in three West Nilotic languages’) and from the Arts & Humanities Research Council (UK) grant AH/L011824/1 (‘Morphological Complexity in Nuer’). Their support is gratefully acknowledged. I am indebted to my Nuer consultants in East Africa without whom none of this would have been possible. Special thanks go to Rebecca Nyawany Makwach who is the main speaker for this study and who assisted with the data collection for this paper; to Jimma Kir Guicwang who narrated ‘The North Wind and the Sun’ story and provided the Nuer orthographic version for it; and to the hive mind of the Facebook Nuer Lexicon group for helpful explanations about Nuer words. I am grateful to Bert Remijsen who commented extensively on the drafts of this paper, to Matthew Baerman for his comments on the orthographic representation of the NW&S story, two reviewers – Siri Gjersøe and Irina Monich, and the editors of the IPA illustrations – Marc Garellek and Marija Tabain, for their comments on the paper. I am thankful to André Radtke for his assistance with the sound files.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0025100323000191.
Appendix
Vowel and voice quality dataset
Data from two South Sudanese speakers of Nuer: a female speaker RNM (Lou, Eastern Nuer) and a male speaker PGM (Leer, Western Nuer).
Filename disambiguation: RNM_1_01.wav
speaker innitials_example number_repetition number.wav
All examples show phonemic transcription. Brackets signal optionality. Suffixes -ə̤́ and -Ì̤́ are the first and second subject agreement suffixes, respectively.




(Note that both word orders are possible because the Patient argument is inanimate. When both the Patient and the Beneficiary are animate, the Beneficiary occurs close to the verb, followed by the Patient, see examples A46–A47).








Abbreviations and special symbols
1,2,3 = first, second, third person; A2 = harmonic most boosted by the second format (F2); AP = antipassive; APPL = applicative; C = consonant; COLL = colloquial; COMP = comparative; CONJ = conjunction; COP = copula; DEM = demonstrative; DIST = distal; f0 = fundamental frequency; F1 = first formant; F2 = second formant; F3 = third formant; F4 = fourth formant; FIN = finite; FOC = focus; FC = floating constituent; FUT = future; H1 = first harmonic; H2 = second harmonic; H4 = fourth harmonic; H1*–H2* = first harmonic minus second harmonic where harmonic amplitudes have been corrected for effects of formants and bandwidths; HAB = habitual; IMPER = imperative; INCL = inclusive; IN = intransitive; MED = medial; MUL = multiplicative; NEG = present negative; NF = non-finite; OBJ = object; OBL = oblique; PASS = passive; PFV = perfective; PL = plural; POSS = possessive; PREP = preposition; PROX = proximal; PST = past; REL = relative; SE = spectral emphasis measure; sd = standard deviation; SG = singular; TR = transitive base paradigm; V = vowel; VN = verbal noun; VOT = voice onset time; (μ́) = floating constituent consisting of a mora and High tone; ɔ, ɔa = short vowel; ɔː, ɔaː = long vowel; ɔːː, ɔaːː = overlong vowel; á = High tone; à = Low tone; ā - Mid tone; [â] = falling contour tone; [ǎ] = rising contour tone; (.) = syllable boundary.















 Open access
Open access