


1 Introduction
This paper presents acoustic analyses of four sets of vowels in contemporary New Zealand English (NZE): dress‒fleece, kit‒nurse, strut‒start, and foot‒goose‒thought.Footnote 1 Using an apparent-time approach, with samples from three age groups (as well as female and male speakers in each group), it explores claims that there have been changes in the overlap between vowels in each set in F1-F2 formant space, i.e. in vowel quality, and investigates associated changes in other characteristics that might distinguish these vowels, namely in their relative durations and in the degree of diphthongisation of the traditionally long vowels. The remainder of this introduction presents a description of the relevant parts of the NZE vowel system and a discussion of the parameters along which the vowels in question might be distinguished. Section 2 introduces the methodology and materials used in the current analyses, the results of which are presented in Section 3. The concluding discussion in Section 4 considers again the parameters distinguishing the vowels in the four sets analysed, in light of the results of the current study.
The NZE monophthongal vowel system is illustrated in Figure 1 (from Bauer et al. Reference Bauer, Warren, Bardsley, Kennedy and Major2007). A number of developments in the pronunciation of New Zealand English (NZE) indicate that the phonemic contrast between the members of a small set of pairs in this monophthongal vowel system may be shifting towards vowel duration, and away from quality differences defined in terms of F1-F2 space. This has been suggested for the pairs dress‒fleece, strut‒start, foot‒thought, and kit‒nurse (Easton & Bauer Reference Easton and Bauer2000: 113; Bauer & Warren Reference Bauer and Warren2004: 588–589). While Figure 1 indicates complete overlap of strut and start (transcribed as /ɐ/ and /ɐː/ respectively, using the NZE transcription system suggested by Bauer & Warren Reference Bauer and Warren2004), dress (/e/) and fleece (/iː/) are shown to have minimal overlap, while foot (/ʊ/) overlaps partially with two long vowels, thought (/oː/) and goose (/ʉː/). The somewhat crowded centre of the vowel space in NZE includes the substantial overlap of kit (/ɘ/; kit is famously centralised in NZE) with nurse (/ɵː/), as well as the overlap of the latter with goose. Previous work relating to each of these sets will now be presented.
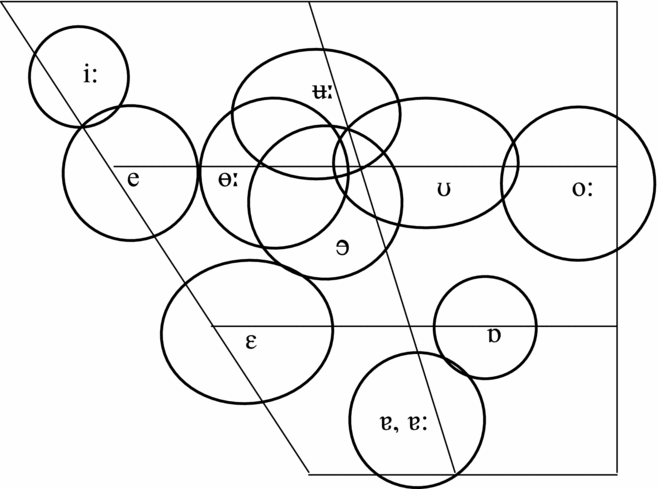
Figure 1 Approximate positions of New Zealand English short and long monophthongs (from Bauer et al. Reference Bauer, Warren, Bardsley, Kennedy and Major2007, reproduced with permission. Note that the symbols are not centroids, but labels positioned to indicate clearly the different distributions.)
In their description of NZE phonology, Bauer & Warren (Reference Bauer and Warren2004: 588) state that ‘[i]f vowels are to be paired in terms of length/tension, then in New Zealand English the dress vowel should be paired with the fleece vowel, as being the closest long vowel in terms of quality’. Note that these authors make no distinction between tension and length in their treatment of any of the vowel sets under discussion. The focus in the current paper is on the relationship between quality distinctions and durational distinctions of the vowel pairs under consideration. However, I will return in the Discussion section to a consideration of the role of tense vs. lax in the description of the NZE vowel system.
It has been noted for some time (e.g. Maclagan Reference Maclagan1982) that instead of the long/short pair of fleece and kit that is found in British English Received Pronunciation, NZE appears to have a long/short pair in fleece and dress. Given this observation and the statement above, the representation of these vowels in Figure 1 would seem very conservative. In fact, Maclagan & Hay (Reference Maclagan and Hay2007) show that there is total overlap of dress and fleece in vowel space for many younger speakers, and it is even the case for some speakers that their dress vowel is closer (higher) and/or fronter than their fleece vowel. Whether or not the lack of a quality contrast is being compensated for by a durational contrast is somewhat uncertain. On the one hand, Maclagan & Hay (Reference Maclagan, Hay, Cassidy, Cox, Mannell and Palethorpe2004) found generally higher overall fleece:dress duration ratios for younger than for older NZE speakers, suggesting a possible increasing reliance on duration to distinguish the vowels. However, more detailed analysis by Maclagan & Hay (Reference Maclagan and Hay2007) indicates that the two vowels might not in fact be reliably distinguished by length, since there is considerable overlap between the durations of dress and fleece; in particular, many speakers in their sample have fleece vowels preceding voiceless coda consonants that are not any longer than their dress vowels in the same contexts and are shorter than their dress vowels before voiced coda consonants. They also observe that for many speakers the distinction between dress and fleece now also involves the diphthongisation of fleece, with a noticeable on-glide, and that this is particularly likely when fleece is followed by a voiceless consonant, i.e. in the context where fleece is shortest and therefore most confusable with dress. Similar comments were made earlier by Easton & Bauer (Reference Easton and Bauer2000: 100), who summarised that ‘length and diphthongisation are becoming the major features distinguishing these two vowels for some speakers’. These two properties are reflected in the two transcription symbols suggested for fleece by Bauer & Warren (Reference Bauer and Warren2004), namely [iː] and [ɪɨ].
For our second vowel pair, kit and nurse, Bauer & Warren (Reference Bauer and Warren2004: 588) observe that for some NZE speakers bid and bird are distinguished only by length, and are a quantity pair for such speakers.Footnote 2 A high degree of overlap of these two vowels in the F1-F2 vowel space is also evident in the analysis presented for NZE (but not for Australian English) by Watson, Harrington & Evans (Reference Watson, Harrington and Evans1998). Bauer & Warren also note that lip-rounding for nurse is not very marked in NZE, but that the two vowels may nevertheless be distinguished on the basis of some rounding-like property. They observe that one of the speakers analysed for their study showed similar acoustic data for the nurse vowel in the words herd, from a /hVd/ word list, and word, from an impromptu remark, but had more evident rounding (as shown in video recordings) in the more formal context of the word-list recordings. The authors comment that ‘there would appear to be some other compensatory articulatory configuration that results in the rounded quality in the absence of rounded lip shape’ in many productions of nurse (Bauer & Warren Reference Bauer and Warren2004: 583).
The overlap of strut and start has been noted for some time, both in NZE and also in Australian English (in the latter as early as Bernard Reference Bernard1967). Strut and start are similar in quality to one another in a number of other varieties, such as Fijian English (Tent & Mugler Reference Tent and Mugler2004), Singapore English (Wee Reference Wee2004) and Malaysian English (Baskaran Reference Baskaran2004). However, they tend to be back vowels in these varieties and are often not distinguished by length, while in both Australian and NZ English they are fronted and there is a reliable length difference between the two. The overlap in vowel quality is reflected also in the transcription symbols suggested for both of these varieties. As indicated above, Bauer & Warren (Reference Bauer and Warren2004) in their description of NZE phonology recommend /ɐ/ and /ɐː/. The same symbols were recommended for both NZE and Australian English (AusE) by Watson et al. (Reference Watson, Harrington and Evans1998). Easton & Bauer (Reference Easton and Bauer2000) argue that strut and start are backer in AusE than in NZE, which supports Clark's (Reference Clark, Collins and Blair1989) suggestion of /![]() / and /
/ and /![]() ː/ as appropriate transcription symbols for these vowels in AusE. For NZE, Bauer & Warren (Reference Bauer and Warren2004: 588) conclude that ‘[i]f vowels are to be paired in terms of length/tension, then in New Zealand English the strut vowel should be paired with the start vowel, with which it is virtually identical in terms of formant structure, resulting in a distinction primarily of length between cut and cart’. There appears to be little evidence in the literature that either strut or start are developing a diphthongal quality. In AusE this pair has been identified as the ‘clearest example of a minimal length contrast’, since for most other vowels ‘length is correlated with a clear tendency to diphthongisation’ (Durie & Hajek Reference Durie and Hajek1995: 231).
ː/ as appropriate transcription symbols for these vowels in AusE. For NZE, Bauer & Warren (Reference Bauer and Warren2004: 588) conclude that ‘[i]f vowels are to be paired in terms of length/tension, then in New Zealand English the strut vowel should be paired with the start vowel, with which it is virtually identical in terms of formant structure, resulting in a distinction primarily of length between cut and cart’. There appears to be little evidence in the literature that either strut or start are developing a diphthongal quality. In AusE this pair has been identified as the ‘clearest example of a minimal length contrast’, since for most other vowels ‘length is correlated with a clear tendency to diphthongisation’ (Durie & Hajek Reference Durie and Hajek1995: 231).
If we turn now to foot/thought/goose, Easton & Bauer (Reference Easton and Bauer2000: 113) observe that foot and thought overlap ‘to a considerable extent’ in the vowel space, while Bauer & Warren (Reference Bauer and Warren2004: 589) make a slightly stronger claim that any pairing of foot on the basis of length should be with thought ‘with which it is sometimes virtually identical in terms of formant structure, so that put and port may differ only in vowel length’. However, younger speakers of NZE have a more fronted foot than older speakers, so that while foot is closer in vowel space to thought for older speakers, this is not the case for younger speakers, for whom there is suggestion of overlap in acoustic space between foot and goose (Kennedy Reference Kennedy2004, Warren Reference Warren2004). Further, NZE has both conservative and innovative versions of foot – the conservative variant is back (though centralised) and slightly unrounded (Bauer & Warren Reference Bauer and Warren2004: 589 suggest [ʊ]), while the innovative form is central and unrounded (for which they suggest [ɨ]). This innovative form is found especially frequently in certain lexical items, such as ‘good’, as is reflected in the frequent spelling <gidday> for the greeting ‘good day’. It has been claimed that foot and thought are less distinct durationally for younger than older speakers, though thought is still twice as long as foot, even for those speakers with the lowest thought:foot ratio (Kennedy Reference Kennedy2004). Both long vowels in this set show evidence of diphthongisation, with an on-glide for goose and an off-glide for thought. Bauer et al. (Reference Bauer, Warren, Bardsley, Kennedy and Major2007: 101) claim that thought is ‘often diphthongised in lengthening environments’. Kennedy's (Reference Kennedy2004) small-scale study of the relationship between foot, goose and thought in NZE reports that of these three vowels only thought showed any sign of diphthongisation, reinforcing her conclusion that for younger speakers there is a greater likelihood that foot overlaps with goose than with thought. Easton & Bauer (Reference Easton and Bauer2000) had however earlier reported that their speakers show a trend towards diphthongisation for goose, supporting their claim that if there is a quantity pairing then it involves foot with thought rather than with goose.
In summary, then, while there is consensus that NZE strut and start overlap in the vowel space and are the most likely pair to be distinguished only on the basis of length (Warren Reference Warren2006), the case for the other contrasts in the sets of vowels under consideration is less clear. Dress and fleece show more extreme overlap for younger speakers, so that the depiction in Figure 1 is more appropriate for older and more conservative speakers. However, there is evidence that the two vowels are becoming distinguished for younger speakers by increasing diphthongisation of fleece (Maclagan & Hay Reference Maclagan and Hay2007). Kit and nurse have been claimed to overlap in F1-F2 space, and yet are possibly distinguished for some speakers by a rounded quality to nurse that is not found with kit (Bauer & Warren Reference Bauer and Warren2004). Foot and thought, which at one stage were looking likely to be a quantity pair, appear to be more distinct in quality for younger speakers than for older speakers, with a possible move towards foot being paired with goose (Kennedy Reference Kennedy2004, Warren Reference Warren2004). But again, diphthongisation may have a role to play here, with both thought and goose showing increasing evidence of diphthongal realisations (with off-glides and on-glides respectively) that would render them more distinct from the monophthongal short foot.
While there may be historical reasons for the treatment of NZE vowels as involving an opposition based on length or tension (reflecting the origins of the variety and the early settlement of New Zealand predominantly from southern England), recent changes in the NZE vowel system, and the observations above relating to these changes, suggest that it might be timely to revisit the nature of the vowel contrasts in this variety. With this in mind, the current paper presents acoustic analyses of tokens from the New Zealand Spoken English Database (NZSED, see Warren Reference Warren2002), considering in particular contrasts in both vowel quality and vowel duration for the four vowel sets described above. Vowel quality here includes both the position of vowels in the F1-F2 vowel space, and – where appropriate – the nature and extent of any diphthongisation. As is clear from the descriptions above, earlier analyses of these vowel sets exist and these have helped to frame the current analysis. Importantly, however, in the analyses presented below all of the vowel tokens are produced by the same groups of speakers, so that the subsequent discussion can consider the vowels as part of a single vowel system, and can consider the relevance of the treatment of vowel contrasts in this variety in terms of either length or tension.
2 Method
To confirm the patterns noted above for the four sets of potentially quantity-distinguished vowels, new analyses were carried out on data collected over the period 1999‒2002 as part of the New Zealand Spoken English Database (NZSED; Warren Reference Warren2002). The NZSED materials include recordings from three age groups (as well as from both females and males) and can therefore also be employed in an apparent-time study investigation of the extent to which NZE is moving towards quantity-based contrasts in the sets under consideration. NZSED was designed as a replication for NZE of the Australian National Database of Spoken Language (ANDOSL, see Millar et al. Reference Millar, Dermody, Harrington and Vonwiller1990) and consists of data from a number of speech tasks, including word lists where the traditionally monophthongal vowels are realised as the V in a /hVd/ sequence, and a set of 200 phonetically-rich sentences based on those developed for the SCRIBE corpus (see Vonwiller et al. Reference Vonwiller, Rogers, Cleirigh and Lewis1995).
2.1 Speakers
The speakers were from two urban centres in New Zealand (Wellington and Hamilton), three age groups (older = 46‒60 years, mid-age = 31‒45 years, and younger = 18‒30 years), and two sexes. The goal in setting up the database was to have six speakers in each of the 12 cells defined by region, age and sex. Due to circumstances to do with recruiting participants for the dialogue tasks for the NZSED corpus, i.e. for reasons not relevant to this paper, the Hamilton mid-aged female group happened to be made up of seven speakers. As there seemed to be no valid basis for choosing one of the speakers for exclusion, this group therefore contains seven speakers, and there is subsequently a total of 73 speakers in the current analysis. Regional differences are not strongly marked in New Zealand English (Gordon & Maclagan Reference Gordon and Maclagan2004), and are not explored in the current analysis.
2.2 Materials
Two sets of materials were included in the analysis. Each set involved the nine vowels discussed above: dress, fleece, kit, nurse, strut, start, foot, goose, and thought. The first set (word-list data) consisted of relevant members of the /hVd/ word list (i.e. the above vowels between the consonants /h/ and /d/ in single CVC words), and included one token of each of the vowels of interest, for each speaker. The other set (sentence data) consisted of vowels from words in sentence readings recorded by the same speakers. Eight words were selected for each vowel, all appearing in accented contexts and with the vowel in a syllable carrying primary lexical stress. The token selection resulted in a range of phonetic contexts, i.e. the preceding and following consonants could not be held constant for the different vowels. However, with each set of vowels under comparison, an attempt was made to minimise differences in terms of the immediate phonetic context and syllable structure, as well as the syllable count of the word containing the vowel. Inevitably there was some variation in how speakers phrased the sentences, which affected rhythmic structures and foot length, which has also been shown to affect duration in NZE (Warren Reference Warren, Ohala, Hasegawa, Ohala, Granville and Bailey1999). Such differences need to be borne in mind when interpreting the results reported below for vowel duration in the sentence contexts. The identical contexts of the word-list recordings therefore provide a check on durational differences between the vowels in each set. The full list of sentence contexts for the vowels analysed in this study is given in the appendix.
Phoneme-level labelling of all speech files had previously been carried out using the web-based implementation of MAUS (Kisler et al. Reference Kisler, Reichel, Schiel, Draxler, Jackl and Pörner2016), selecting New Zealand English as the analysis language. Some hand correction of the automatic alignment was necessary. All tokens (from the word list and sentence list) were accessed from the database using emuR (Winkelmann et al. Reference Winkelmann, Jaensch, Cassidy and Harrington2016).
2.3 Measuring formants and their distributions
Formant trajectories were computed using the forest function in the wrassp library in R. The wrassp library provides functionality for a range of speech signal analysis types, including formant estimation (hence forest). Forest uses linear prediction and the Split-Levinson-Algorithm to derive raw resonance frequencies and bandwidth values. The resonances are then classified using the Pisarenko frequencies (for more details, see Winkelmann Reference Winkelmann2016b). Gender-specific parameters were used for female and male speakers (i.e. an analysis window size and nominal F1 value of 12.5 ms and 560 Hz for women and 20 ms and 500 Hz for men). The resulting trajectories for the 5256 sentence tokens and 657 word-list tokens were visually inspected using the EMU-webApp (Winkelmann Reference Winkelmann2016a), and hand-corrected where necessary.
Many analyses of vowels (e.g. Watson & Harrington Reference Watson and Harrington1999) have measured formant values at points where F2 reaches a peak (for high and mid front vowels) or a trough (for high and mid back vowels) or where F1 reaches a peak (for open vowels). This approach depends on a reliable classification of vowels as front/back, open/close, etc., which is problematic for the vowel system of NZE, which has been undergoing change over recent generations, so that the ‘same’ vowel might for example be a back vowel for some speakers but a front vowel for others. An earlier comparison of different methods for measuring vowel formants, including values at single points determined by peaks or troughs in F2 or F1, values at the vowel midpoint, and values averaged over the entire vowel concluded that ‘the differences between the various methods used are, in most respects, marginal and all methods used essentially give the same outcome. When studying vowel targets, the method that is most convenient can be used’ (van Son & Pols Reference van Son and Pols1990: 1692). The approach taken in the current study was to average the formant values over the central 40% of the vowel's duration. Taking an average, rather than the formant values at a specific point, reduces the impact of local fluctuations in formant values. Taking that average over the central 40% rather than over the entire vowel reduces the impact of in- and out-transitions. Values were calculated for the first three formants, though the majority of the analyses below will present data for F1 and F2 only. F3 values were analysed in the consideration of nurse-rounding in the comparison of this vowel with kit. In addition, to measure possible diphthongisation, values for early targets (at 25% of the vowel) and late targets (at 75% of the vowel) were taken for on-glides and off-glides respectively. These targets were considered far enough into the vowel to be uninfluenced by coarticulation from the preceding or following consonants.
To reduce the impact of physiological differences between speakers on comparisons of the vowel sets under consideration, the vowel formant data were normalised. In particular, comparisons of changes over apparent time in the male and female speakers in the dataset are problematic if the impact on formants of anatomical differences in vocal tract dimensions is not taken into account. Following Flynn & Foulkes (Reference Flynn, Foulkes, Lee and Zee2011), a vowel-extrinsic, formant-intrinsic, speaker-intrinsic method was chosen as the most appropriate method for sociophonetic research. The method chosen was that developed by Watt and Fabricius (Watt & Fabricius Reference Watt and Fabricius2002, Fabricius, Watt & Johnson Reference Fabricius, Watt and Johnson2009), and implemented in the vowels package (Kendall & Thomas Reference Kendall and Thomas2015) in R. The method produces estimated centroid values S(Fn), where n = 1 or 2, based on each speaker's vowel space, which is then used to calculate normalised F1 and F2 values (shown as F1/S(F1) and F2/S(F2) in plots below).
The analysis below includes reports of Euclidean distances, either between the midpoints of two vowels or between target points within a vowel as a measure of diphthongisation. These distance measures were calculated for each speaker in the following ways. For vowel comparisons, the Euclidean distance for word-list tokens was based on midpoint formant values for the relevant /hVd/ tokens for each speaker. For the sentence data, average normalised F1 and F2 midpoint values were first calculated across the eight tokens of each vowel for each speaker, and a Euclidean distance computed from these averages. As a measure of diphthongisation, Euclidean distances were calculated between normalised F1 and F2 values for each vowel token's midpoint and the values for early or late targets, for on-glides and off-glides respectively. These Euclidean distances based on normalised F1 and F2 are reported below as distances in S units, using the Watt & Fabricius (Reference Watt and Fabricius2002) label for the estimated vowel centroid. The duration of each vowel was calculated based on transition points resulting from the hand-corrected automatic alignment of the database materials described above.
When the distributions of two vowels are compared using Euclidean distances, basing the statistical analysis on the distance between the mean normalised F1 and F2 values for each speaker reduces the overall distributional cloud for the vowel tokens, but nevertheless allows for an indicative statistical analysis of differences in the formant distributions for our speaker groups. However, Euclidean distance is a measure of distance, and not of overlap. As has been pointed out (Johnson Reference Johnson2015), measures comparing vowel distributions often fail to take into account both distance and overlap, and this can be problematic. For example, one pair of distributions might have the same distance between their centroids as another pair of distributions, but the overlap between the distributions in each pair may be considerably different. In such a case, a simple distance measure will not show that the distributions in each pair differ in their overlap (and confusability). Following Johnson (Reference Johnson2015), I report below, for each vowel comparison, values of Bhattacharyya's affinity (Bhattacharyya Reference Bhattacharyya1943), computed in R using the kerneloverlap function in the adehabitatHR library (Calenge Reference Calenge2006). Bhattacharyya's affinity is a statistical measure of the affinity between two populations and is frequently used in spatial ecology to determine overlap in the habitats of two species. It is derived from the densities of two distributions A and B at each (x, y) coordinate (for details of the calculation of Battacharyya's affinity, and a comparison of this measure with others for assessing overlap, see Fieberg & Kochanny Reference Fieberg and Kochanny2005). As pointed out by Johnson (Reference Johnson2015), Bhattacharyya's affinity is superior to the Pillai trace score (as used by Hay, Warren & Drager Reference Hay, Warren and Drager2006). In particular, if two distributions have the same centroids they will be given the same Pillai score even if the distributions differ (e.g. one distribution may be nested within the other, or they may be elliptical with different angles). This is not the case with Bhattacharyya's affinity. However, as an overlap measure, Bhattacharyya's affinity needs to be computed across two reasonably large distributions (30–50 observations, Seaman et al. Reference Seaman, Millspaugh, Kernohan, Brundige, Raedeke and Gitzen1999), which means that it would not be appropriate to calculate it separately for each of our speakers, since each has only eight tokens of each vowel in the sentence materials analysed for this study. As a result, a full statistical analysis of Bhattacharyya's affinity values is not possible. Instead, for each vowel comparison, a simple report of values will be given, derived from the sentence tokens (where there are more examples of each vowel than for the word-list tokens) broken down by each subgroup of speakers (defined by sex and age), as an indicator of the extent of overlap between the two vowels. Possible values for Bhattacharyya's affinity range from zero (no overlap) to one (total overlap).
2.4 Statistical tests
Euclidean distances (between vowels or between vowel midpoints and on- or off-glides) and durations served as dependent variables in linear mixed effects models constructed using the lme4 library in R (Bates et al. Reference Bates, Maechler, Bolker and Walker2015). Fixed effects varied depending on the analysis and will be presented with each result, but they included context (sentence vs. word lists), vowel (e.g. fleece vs. dress), speaker age and speaker sex. The random effects were speakers and, for most analyses, utterances. Utterances could not be included as a random effect when the dependent variable required averaging over utterances, e.g. in analyses that compared Euclidean distances between the centre points of two vowels in the sentence contexts, since these distances were based on the average formant values for each vowel for each speaker across the sentences, as explained above.
In each analysis, simple and interaction effects were assessed by model comparison, using the mixed function in afex (Singmann, Bolker & Westfall Reference Singmann, Bolker and Westfall2015). Significance is assessed in mixed using the chi-square distribution of a likelihood ratio test that compares models with and without the effect (or interaction) in question, i.e. they assess whether exclusion of that effect would result in a significantly weaker account for the variation present in the model. Non-significant higher-order interactions were removed, and the resulting best-fit model for each analysis provides the results reported below.
3 Results
Figures 2 and 3 show ellipse plots in normalised F1 and F2 space for the nine vowels in the /hVd/ word lists and sentence contexts respectively, based on midpoint formant data from the 12 speakers in each cell defined by age and sex, except for mid-aged females, where there are 13 (because of the extra female recorded in the Hamilton sample). Comparison of the female and male data for each age group and context shows that the normalisation procedure outlined above was effective in reducing sex-based differences in vowel space. Comparison of the ellipse sizes in Figure 3 with those in Figure 2 shows clearly the greater variation in the vowels’ realisations in the sentence contexts than in the /hVd/ context. The following subsections explore each of the four vowel contrasts in turn, and present statistical analyses of important aspects of each contrast.
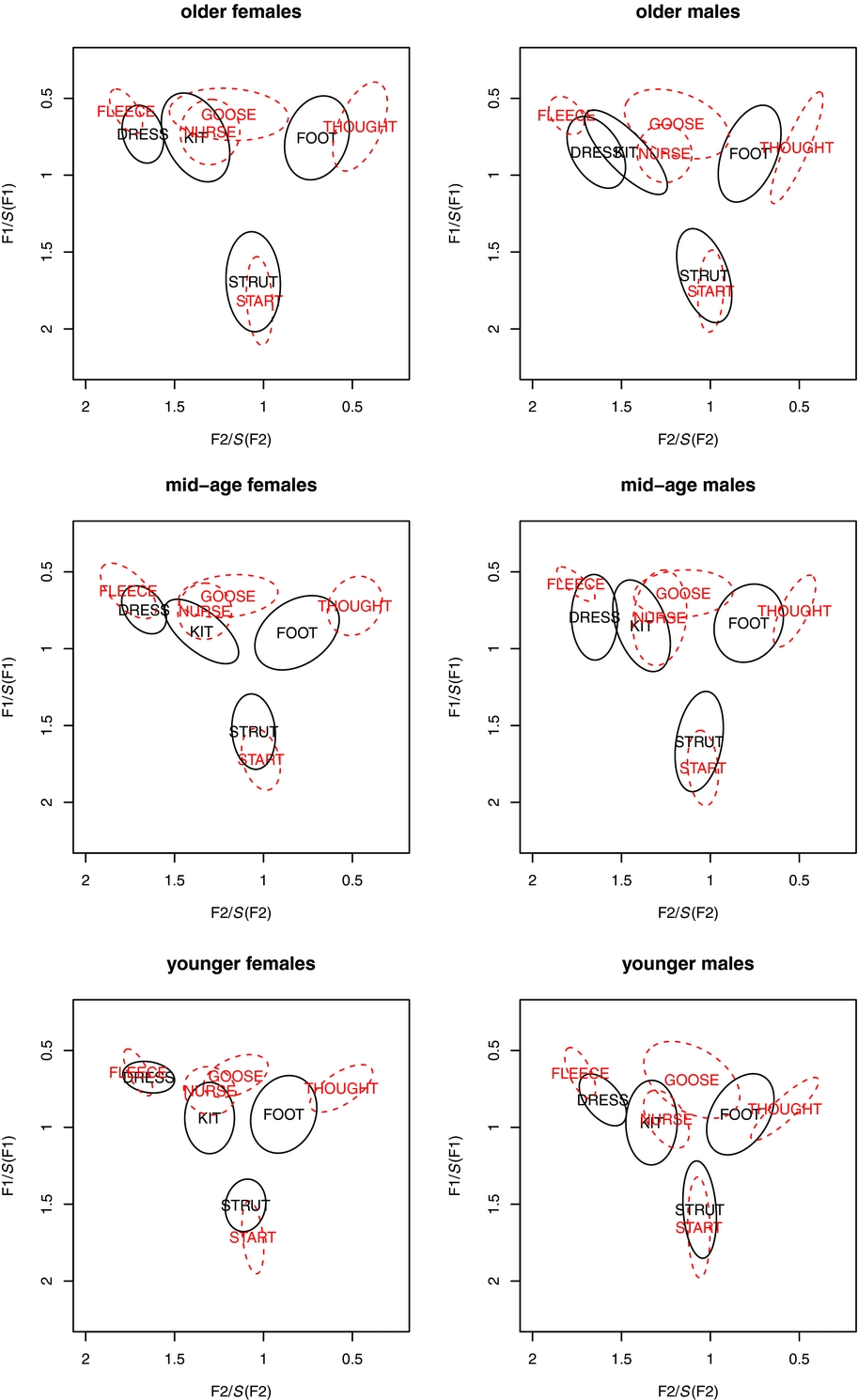
Figure 2 Normalised F1-F2 plots for vowel midpoints for the nine vowels of interest, from /hVd/ contexts, one token per speaker. Left hand panels show female speakers and right hand panels show male speakers. The top row is for older speakers, the middle row for mid-age speakers and the bottom row for younger speakers. Long vowels are shown in red with dotted ellipses.
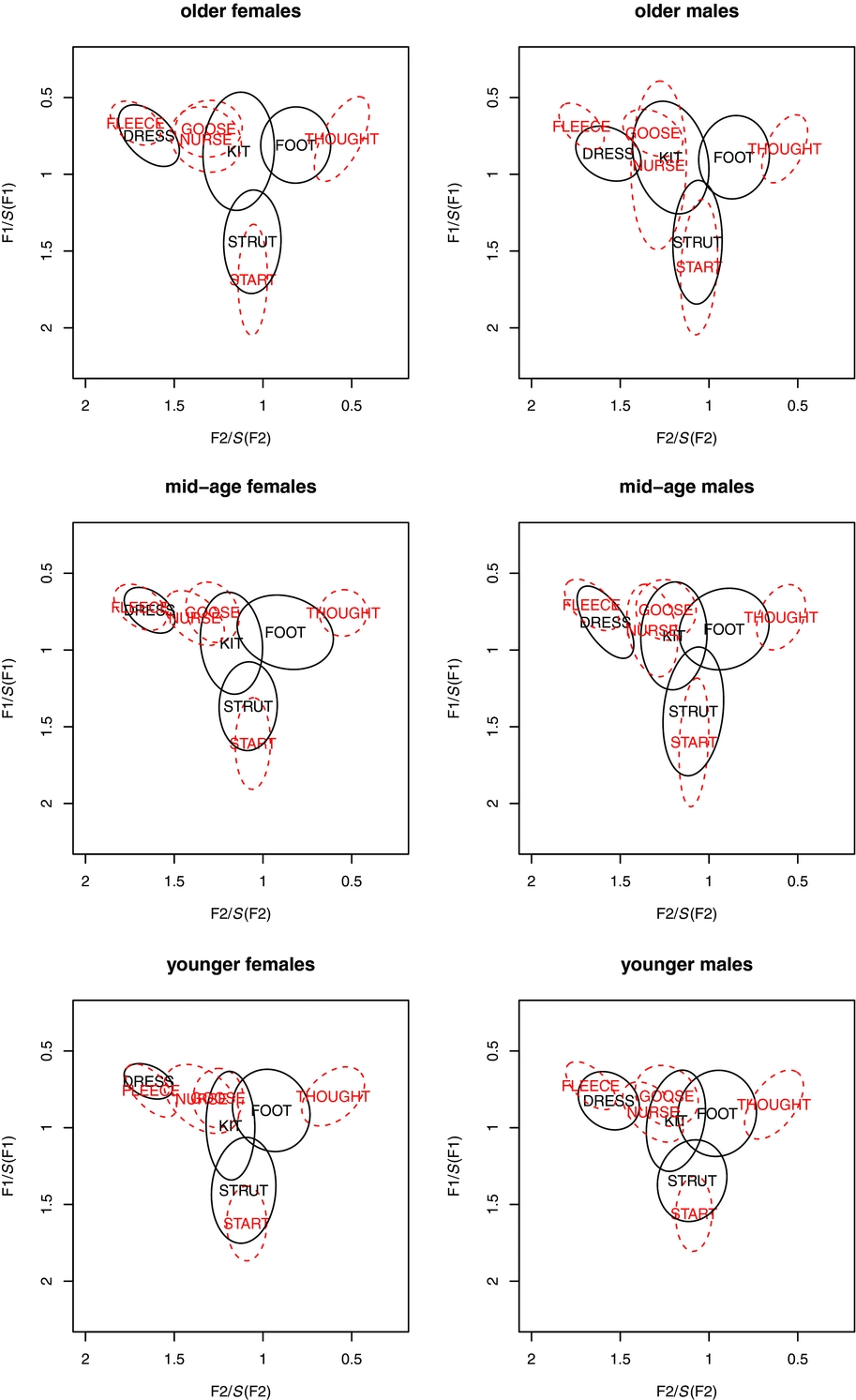
Figure 3 Normalised F1-F2 plots for vowel midpoints for the nine vowels of interest from sentence contexts, for eight accented tokens per vowel for each speaker. Left hand panels show female speakers and right hand panels show male speakers. The top row is for older speakers, the middle row for mid-age speakers and the bottom row for younger speakers. Long vowels are shown in red with dotted ellipses.
3.1 dress‒fleece
The ellipse plots in Figures 2 and 3 show considerable overlap in normalised F1-F2 space for dress and fleece in both types of context. There is also evidence of change-in-progress, i.e. the dress-raising documented by Maclagan & Hay (Reference Maclagan, Hay, Cassidy, Cox, Mannell and Palethorpe2004, Reference Maclagan and Hay2007). That is, the distribution for dress moves up in the vowel space to overlap increasingly with that for fleece as we move from older to mid-age to younger. In addition, the overlap appears to be more advanced for women in each age group than for men, suggesting that women are leading the change, as noted also by Maclagan & Hay.
For each speaker, Euclidean distances were calculated between the (average) midpoint values of their fleece and dress vowels in normalised F1-F2 space, derived as explained above. If a speaker's token for dress was higher (had a lower F1) than their token for fleece, then the Euclidean distance was expressed as a negative value.Footnote 3 Out of the total sample of 73 speakers, this was true of 9 speakers (7 female and 2 male; 7 younger and 2 mid-age) in the /hVd/ set and of 17 (16 female and one male; 10 younger and 7 mid-age) in the sentence set.
Linear mixed effects models were constructed with Euclidean distance as the dependent variable, with context (words vs. sentences), sex (female vs. male) and age (older, mid-age, younger) as fixed effects, and with speaker as a random effect. All interactions of fixed effects were explored. The best-fit model showed significant simple effects of context (χ2(1) = 33.71, p < .0001), sex (χ2(1) = 33.70, p < .0001) and age (χ2(2) = 21.31, p < .0001). There were no interaction effects. Unsurprisingly, the distances for word-list data were significantly greater than those for sentence data (means of 0.188 and 0.103 S units respectively). This is because articulation is typically more careful in /hVd/ contexts. The effects for sex and age are shown in Figure 4. The smaller average Euclidean distance for females (0.076 S units) than for males (0.217 S units) reflects the differences evident in Figures 2 and 3. For age, the distance between the vowels is smaller for younger speaker groups (0.211 vs. 0.145 vs. 0.079 S units for older, mid-age and younger respectively). The Euclidean distance value for each age group was significantly different from those of the others. That is, inspection of the initial model, in which ‘older’ was the intercept value for age, showed that both mid-age and younger groups differed from the older group (t = –2.35 and –4.84 respectively). When the analysis was re-run with ‘mid-age’ as the intercept value, the younger group was also significantly different from the mid-age group (t = –2.54).

Figure 4 Euclidean distance between dress and fleece by speaker sex and age (means and standard errors).
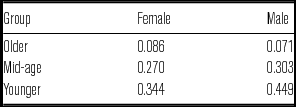
Together with the ellipse plots in Figures 2 and 3, this analysis of Euclidean distance by age between dress and fleece indicates that these two vowels are becoming increasingly similar in terms of vowel quality. This is supported in the Bhattacharyya's affinity values for this pair of vowels in the sentence data, shown in Table 1. In particular, the values are higher for mid-age and younger speakers than for older speakers and for females than for males, mirroring the results for Euclidean distance in Figure 4. The overlap values are lower for the younger speakers than for the mid-age speakers because some of the dress tokens for the younger speakers are higher than their fleece tokens, i.e. there is greater separation, but in the opposite direction to that for the older speakers.
Table 1 Bhattacharyya's affinity values for dress and fleece in the sentence tokens (possible values range from zero (no overlap) to one (total overlap)).

As noted in the Introduction, two additional means of distinguishing the vowels are through their duration and through the diphthongisation of the fleece vowel (Easton & Bauer Reference Easton and Bauer2000; Maclagan & Hay Reference Maclagan, Hay, Cassidy, Cox, Mannell and Palethorpe2004, Reference Maclagan and Hay2007). Linear mixed effects models for duration as the dependent variable were run with the fixed effects of context (sentences vs. words), vowel (dress vs. fleece), sex, and age, and with speaker and utterance as random effects. The best-fit model returned significant simple effects of vowel (χ2(1) = 257.63, p < .0001) and age (χ2(2) = 10.20, p < .01) and significant two-way interactions of context with age (χ2(2) = 6.46, p < .05) and with sex (χ2(1) = 6.13, p < .05). Fleece durations were significantly longer than dress durations (165 vs. 116 ms). The age effect reflects shorter vowel durations (averaged across vowels and contexts) for younger speakers (129 ms) than for mid-age (143 ms) and older speakers (149 ms), and is probably indicative of differences in the approach to the recording situation. The interaction of age with context arises because the difference between the contexts was greater for younger speakers (sentences: 120 ms, words: 201 ms) than for mid-age speakers (sentences: 136 ms, words: 202 ms) and older speakers (sentences: 141 ms, words: 213 ms). In particular, vowels in the sentence context are shorter as age drops. The context-by-sex interaction reflects a greater context effect for the females (sentences: 132 ms, words: 210 ms) than for the males (sentences: 133ms, words: 200 ms). The absence in this analysis specifically of interaction effects involving the identity of the vowel together with the other factors shows that the difference in the lengths of fleece and dress does not vary significantly by speaker sex or age.Footnote 4
Following Maclagan & Hay (Reference Maclagan and Hay2007), the measure of diphthongisation of fleece is the Euclidean distance between early and midpoint targets, as defined above. The mean value of this measure across all speakers and contexts was 0.134 S units. Linear mixed effects models considered context, age and sex, together with their interactions, as fixed effects, with speakers and utterances as random effects. The only significant effect in the best-fit model was age (χ2(2) = 9.60, p < .01). The younger and mid-age speakers exhibited significantly more diphthongisation than the older speakers (0.137 and 0.148 S units vs. 0.117 S units; t = 2.57 and t = 3.11 respectively), but the younger and mid-age speakers did not differ from one another (t = 1.15, p = .25).
Maclagan & Hay (Reference Maclagan and Hay2007) observe that diphthongisation of fleece is more likely as other differences between dress and fleece reduce in significance (which would include the unreliable difference that they note between dress and fleece durations). They found a negative correlation between the extent of diphthongisation of fleece and the Euclidean distance of fleece from dress, which is significant when the analysis is restricted to the younger speakers in their sample (20‒30 years; they had two age groups, the other speakers being in the range 45‒60 years). An analysis of average Euclidean dress‒fleece distances and average fleece diphthongisation from the sentence data in the current study (see Figure 5) also shows a significant negative correlation, but in this case over all three age groups (Spearman's rho = –0.47, p < .001). When the direction of the dress‒fleece Euclidean distance is ignored (i.e. absolute values are used, as was done by Maclagan & Hay, rather than using negative values for cases where dress is higher than fleece), then the strength of the correlation is lowered, but is still significant (Spearman's rho = –0.37, p < .01).

Figure 5 Euclidean distance between dress and fleece by average fleece diphthongisation. Points represent data in the sentence context for individual speakers and the line is a nonparametric smoother fit (loess).
In summary, the current apparent-time analysis confirms Maclagan & Hay's findings of an increasing overlap in vowel space of fleece and dress, accompanied by increasing diphthongisation of fleece.
3.2 kit‒nurse
The ellipse plots in Figures 2 and 3 above show that the overlap of kit and nurse in F1-F2 space varies by speaker group. The trend, though, is for increasing centralisation of kit over subsequent generations, and this appears to be more advanced for the female speakers (for earlier evidence of this change see also Bauer Reference Bauer1979, Reference Bauer1986; Bell Reference Bell1997). Accordingly, for the analyses below, the Euclidean distance between kit and nurse was assigned a negative value if kit was closer than nurse, and as positive value if kit was more open than nurse.
Linear mixed effects regression models were built, with average Euclidean distance as the dependent variable, with context, sex and age as fixed effects, and with speakers as random effects. The best-fit model included significant simple effects of context (χ2(1) = 3.75, p = .05), sex (χ2(1) = 20.23, p < .0001) and age (χ2(2) = 16.87, p < .001). These effects are shown in Figure 6.

Figure 6 Euclidean distance between kit and nurse by context, sex, and age (means and standard errors).
The vowels are more distinct in the sentence contexts than in the word-list context. This is primarily because the kit vowel has its more conservative and closer realisation in the word lists. Likewise, Euclidean distances are significantly smaller for the males and for older speakers, i.e. for groups associated with more conservative speech patterns.
Table 2 presents the Bhattacharyya's affinity measures for these two vowels in the sentence data, broken down by age and sex. The values in the table confirm the greater overlap for males than for females, as well as for older speakers.
Table 2 Bhattacharyya's affinity values for kit and nurse in the sentence tokens (possible values range from zero (no overlap) to one (total overlap)).

The data reported above, based on normalised F1 and F2 values, show that kit and nurse are more distinct for women and for younger speakers. However, it was noted in the Introduction that NZE nurse typically has a rounded quality (sometimes in the absence of visible lip-rounding). Because of rounding effects, F2 might be lower in nurse than would be expected for a given tongue position, meaning that F2 is an underestimate of the degree of fronting, and that nurse is actually fronter than would appear from Figures 2 and 3 (see also Watson et al. Reference Watson, Harrington and Evans1998: 194). If there is this rounded quality to nurse, then we would also expect lower F3 values than would be found for kit. F3 values for items from the sentence contexts (normalised to Bark values, because the Watt & Fabricius (Reference Watt and Fabricius2002) normalisation procedure outlined above only normalises F1 and F2) were entered into a mixed effects regression model, with vowel (kit vs. nurse), sex and age as fixed effects, and speakers and utterances as random effects. The best-fit model showed simple effects of sex (χ2(1) = 99.49, p < .0001), age (χ2(2) = 7.85, p < .05) and vowel (χ2(1) = 3.95, p = .05). Despite the Bark normalisation, females had higher F3 than males (15.16 vs. 14.23). Older speakers had lower F3 than mid-age or younger speakers (14.56 vs. 14.77 and 14.77 respectively). Importantly, F3 values are significantly lower for nurse (14.55 Bark vs. 14.85 Bark), and there were no interactions of vowel with either sex or age. This absence of interactions shows that the kit‒nurse difference in F3 is constant across speaker groups. It is probably safe to assume F2 values are also lower because of rounding and that nurse is therefore fronter than the F2 analysis seems to suggest. The qualities of kit and nurse may be more different than indicated by either the ellipse plots or the Bhattacharyya's affinity values.
Durations of kit and nurse were compared in mixed effects models that included vowel, context, sex and age as fixed effects and speaker and utterance as random effects. The best-fit model returned significant simple effects of vowel (χ2(1) = 24.41, p < .0001), context (χ2(1) = 24.46, p < .0001) and sex (χ2(1) = 12.11, p < .0005), as well as interactions of vowel with each of context (χ2(1) = 11.16, p < .001), sex (χ2(1) = 30.76, p < .0001) and age (χ2(2) = 43.86, p < .0001). There were no other significant effects. The interactions are plotted in Figure 7. Durations are longer in the word-list context and the difference between kit and nurse is also greater in that context, reflecting the more deliberate style of word-list reading. Females have a greater difference between nurse and kit than males, while the difference diminishes with decreasing age. The pattern for sex does not reflect any compensatory relationship between the durational contrast and Euclidean distance, since for both measures the females show a greater difference than the males. The age pattern, however, suggests that as Euclidean distance gets larger, so the durational contrast reduces. That is, the younger speakers, for whom the vowels are more distinct in vowel space as kit centralises, appear to rely less on the durational contrast between the two vowels. To examine this relationship, a correlation test was carried out between the ratios of average nurse:kit durations and the Euclidean distance for each speaker in each context. While this test returned a negative correlation (Spearman's rho = –0.15), this was not significant (p = .07).

Figure 7 Average durations (in milliseconds) of kit and nurse by context, speaker sex and age (means and standard errors).
While previous studies of NZE have not noted any diphthongisation of the nurse vowel, an off-glide has been noted for rural white Southern US English (Thomas Reference Thomas2004), for older non-rhotic as well as rhotic speakers. As a measure of nurse diphthongisation, Euclidean distances were calculated from the normalised values at the midpoint of the vowel to the later target as described earlier. The mean value of this measure across all speakers and contexts was 0.061 S units, which is considerably lower than the mean on-glide value for fleece, reported above, of 0.134 S units. Linear mixed effects modelling with context, speaker sex and age as fixed effects and speakers and utterances as random effects returned a best-fit model with the single significant effect of context (χ2(2) = 5.85, p < .05). Diphthongisation was greater in the sentence contexts than in the word-list context, presumably reflecting more careful speech in the word list. Importantly, diphthongisation shows no evidence of change across speaker age or sex.
In summary, while kit and nurse show considerable overlap in F1-F2 space for all speaker groups and in both contexts, the two vowels are still distinguished by rounding of nurse, as well as by vowel duration. Because of nurse-rounding, it would seem that there is little likelihood that this pair of vowels will become distinguished solely on the basis of quantity.
3.3 strut‒start
The ellipse plots in Figures 2 and 3 show considerable overlap for the strut and start vowels for all age groups and for both female and male speakers. Linear mixed effects regression models for Euclidean distances, with context, speaker sex and age as fixed effects, and speakers as random effects, produced a best-fit model with context as the sole significant effect (χ2(2) = 45.10, p < .0001). strut and start were further apart in the sentence contexts than in the word-list contexts. Comparison of Figures 2 and 3 indicates that this is because of greater centralisation of strut in the sentence contexts, i.e. undershoot that affects the short vowel more than the long vowel. Indeed, comparisons of Euclidean distances between each speaker's word-list tokens and the average of their sentence tokens show a greater context effect for strut (mean distance: 0.203 S units) than for start (mean distance: 0.148 S units), which was statistically significant (paired-samples t-test: t(72) = 3.24, p < .005). It remains an open question as to whether the perceptual system compensates for undershoot in connected speech contexts to the extent that these vowels overlap perceptually more than they do acoustically (Verbrugge et al. Reference Verbrugge, Strange, Shankweiler and Edman1976, Verbrugge & Shankweiler Reference Verbrugge and Shankweiler1977).
Importantly, the analysis of strut‒start Euclidean distances showed effects neither of speaker sex nor of age, nor any interactions involving these two factors. However, the Bhattacharyya's affinity values for these vowels in the sentence data (Table 3) exhibit tendencies towards greater overlap for male than for female speakers and for older than younger speakers, despite the absence of any significant effects involving sex or age in the modelling of Euclidean distance reported above. Scrutiny of Figure 3 suggests that this is because of greater centralisation of strut for younger speakers and for females.
Table 3 Bhattacharyya's affinity values for strut and start in the sentence tokens (possible values range from zero (no overlap) to one (total overlap)).

Linear mixed effects modelling of start and strut durations returned a best-fit model with vowel (χ2(1) = 42.39, p < .0001), context (χ2(1) = 25.58, p < .0001) and age (χ2(2) = 10.29, p < .01) as simple effects, along with interactions of vowel with context (χ2(1) = 9.63, p < .01) and with age (χ2(2) = 52.97, p < .0001). Figure 8 shows these interactions. The interaction of vowel with context is similar to that observed for kit and nurse (Figure 7), i.e. the durational difference was considerably larger in the word-list context. The simple effect of context reflects the longer overall durations in the word-list context, and that for vowel reflects the longer durations for start than for strut. The interaction of vowel with age is due to shorter durations of the start vowel for younger speakers, reflecting perhaps a less formal style of reading, which has a more marked impact on the longer vowel. It is clear though that the durational difference between strut and start is maintained across all age groups.

Figure 8 Average durations (in milliseconds) of strut and start by context and age (means and standard errors).
What is interesting is the finding that any apparent-time change in the durational difference between the two vowels is in the opposite direction to what would be predicted if a quantity contrast was replacing a quality contrast. However, note that there was no age effect in the analysis of Euclidean distance, suggesting (as the ellipse plots in Figures 2 and 3 also indicate) that the quality overlap is established already for our older speakers, and that the patterns of durational difference are incidental to the vowel contrast. In addition, a test of the relationship between start:strut duration ratios and start‒strut Euclidean distance showed that these were not correlated (Spearman's rho = 0.030, p = .72).
Inspection of the average formant tracks for each vowel in each context, and by speaker sex and age, showed no evidence of diphthongisation. The F1 trajectories were in all cases bowed, with higher values in the central portion of the vowel, but this is to be expected given the need for the tongue to move from a fairly close position for most consonant contexts to the open position for the vowel.
To summarise, strut and start show a high degree of overlap in F1-F2 space, a consistently significant durational difference, any variation in which does not appear related to quality differences, and no evidence of diphthongisation. This appears to be a clear quantity pair in NZE.
3.4 foot‒goose‒thought
In this section, comparisons are made of foot first with thought and then with goose. In the Introduction it was reported that for some speakers foot and thought might constitute a quantity pair (Bauer & Warren Reference Bauer and Warren2004: 589). While this may be the case for individual speakers, the ellipse plots in Figures 2 and 3 indicate that it is not generally true across the speaker groups analysed here. Linear mixed effects modelling of foot‒thought Euclidean distances with context, sex and age as fixed effects and speakers as a random effect returned a best-fit model in which context (χ2(1) = 93.95, p < .0001) and age (χ2(2) = 6.56, p < .05) were significant simple effects, and age interacted significantly with sex (χ2(2) = 7.47, p < .05). The effect of context was that the word-list recordings had a greater Euclidean distance between foot and thought than the sentence recordings. The interaction effect of age and sex, shown in Figure 9, is that while mid-age and younger female speakers have a greater Euclidean distance between these two vowels than older females, there is no age effect for the male speakers. The women in the sample are clearly also carrying the simple age effect returned in the statistical analysis. The values for Bhattacharyya's affinity (Table 4) show a similar pattern to that found for Euclidean distances.

Figure 9 Euclidean distance between foot and thought by speaker sex and age (means and standard errors).
Table 4 Bhattacharyya's affinity values for foot and thought in the sentence tokens (possible values range from zero (no overlap) to one (total overlap)).

Euclidean distances between foot and goose were tested in modelling with the same structure as that reported for foot and thought. The best-fit model showed significant simple effects of context (χ2(1) = 7.55, p < .01) and age (χ2(2) = 23.73, p < .0001). The foot‒goose distance was greater for word-list recordings than for sentence recordings. The same was reported above for foot‒thought, and these two effects reflect a general pattern of a more spread vowel space for the word-list context (see Figures 2 and 3). The age effect results from a closing of the distance between foot and goose as we move from older (0.499 S units) to mid-age (0.429) to younger speakers (0.345) (all comparisons significant with |t| > 2 and p < .05). This is reflected also in the pattern of Bhattacharyya's affinity for this pair in the sentence data (Table 5), which shows greater foot‒goose overlap with decreasing age. These findings are compatible with the increasing fronting of foot reported elsewhere (Kennedy Reference Kennedy2004, Warren Reference Warren2004).
Table 5 Bhattacharyya's affinity values for foot and goose in the sentence tokens (possible values range from zero (no overlap) to one (total overlap)).
These F1-F2 data for foot, thought and goose show little evidence of overlap of foot with either of the longer vowels, while supporting the claim of increasing fronting of foot towards goose. This claim is also supported by a Bayesian classification of the foot vowel. Using normalised F1 and F2 values, Gaussian models for thought and goose were built for each speaker group (i.e. age by sex grouping), using the train function in emuR (emuR 2016), and each foot vowel token was then classified (using emuR's classify function) as thought or goose using the model for the relevant speaker group. Logistic mixed effects regression of the classification data, with age and sex as predictors and speaker as a random effect, showed a significant simple effect of age (χ2(2) = 8.04, p < .05) but no other significant effects. The age effect reflects an increasing shift in categorisation of foot as goose as we move from older to mid-age to younger speakers.
Linear mixed effects regression modelling of vowel durations, with vowel (foot, goose, thought), context, speaker sex and age as fixed effects and speakers and utterances as random effects returned a best-fit model in which there were significant simple effects for vowel (χ2(2) = 156.05, p < .0001) and context (χ2(1) = 29.58, p < .0001), as well as interactions of context with vowel (χ2(2) = 17.69, p < .0001), with sex (χ2(1) = 17.00, p < .0001), and with age (χ2(4) = 73.91, p < .0001), and of vowel with age (χ2(2) = 7.85, p < .05). The overall simple effect of context was that durations were longer in the word-list context than in the sentence context. The interaction of context with vowel arose because the context effect was stronger for the longer vowels (goose and thought). The interaction of context with sex resulted from a stronger effect of context for the female speakers, and the interaction of context with age arose because the younger speakers showed a stronger effect (largely through greater vowel length reduction in the sentence context) than the mid-age and older speakers. The remaining interaction, of vowel with age, is illustrated in Figure 10. While there is some reduction in the length of both goose and thought with decreasing age, the differences between foot and both of these vowels are consistently present, and there is no clear support for Kennedy's claim that foot‒thought duration differences are less evident for younger speakers (Kennedy Reference Kennedy2004).

Figure 10 Durations of foot, goose and thought by age (means and standard errors).
It has been noted (Easton & Bauer Reference Easton and Bauer2000, Bauer et al. Reference Bauer, Warren, Bardsley, Kennedy and Major2007) that both of the longer vowels in this set are prone to diphthongisation, with an off-glide for thought and an on-glide for goose. The average Euclidean distance from the midpoint of thought to the later measurement point (0.75 duration) for that vowel is 0.137 S units, while that from the early measurement point (0.25 duration) to the midpoint of goose is 0.110 S units. Recall that the on-glides for fleece averaged 0.134 S units.
Linear mixed effects modelling of thought off-glides and goose on-glides as dependent variables included context, speaker sex and age as fixed effects and speakers and utterances as random effects. The best-fit model for goose on-glides returned no significant effects at all, that is, goose on-glides appear stable across the contexts and speaker groups examined here. However, the best-fit model for thought off-glides returned a significant simple effect for age (χ2(2) = 6.11, p < .05), but no other effects. The diphthongisation of thought increases as age decreases (older: 0.124; mid-age: 0.134; younger: 0.153; the difference between older and younger was significant with t = –2.44, p < .05, but mid-age differed significantly from neither of the other groups). Interestingly, average thought diphthongisation is positively correlated with average Euclidean distance between foot and thought (Spearman's rho = 0.187, p < .05). That is, diphthongisation of thought is clearly not a result of any increasing overlap in vowel space with foot, since it increases as thought and foot become more separate.
4 Discussion
The acoustic analysis above of four sets of vowel comparisons in word-list and sentence materials sampled from NZSED has investigated the possibility that a number of vowel contrasts in NZE are moving towards a quantity distinction. Claims for such a development were earlier made (e.g. Bauer & Warren Reference Bauer and Warren2004, and other authors discussed in the Introduction above) for dress and fleece, kit and nurse, strut and start, and foot and thought. One of the advantages afforded by the use of the NZSED recordings is that we can consider all of these vowel contrasts for the same set of speakers, including comparisons of female and male speakers and with age-grading showing possible changes in apparent time.
The Euclidean distance measures (normalised) for the vowel comparisons showed two significant effects for speaker sex. Females had a smaller distance between dress and fleece than males, but a greater distance between kit and nurse. Although these results appear to point in contradictory directions, they both reflect more advanced innovation in the female speech. That is, the dress‒fleece difference results from the more advanced raising of dress into fleece-space for females, and the kit‒nurse difference arises because the centralisation of kit, a widely reported feature of NZE, is more advanced for females. The same explanation can be put forward for the contrasting trends in age effects on Euclidean distances – dress and fleece are significantly closer for younger than for mid-age and for mid-age than for older speakers (Figure 4), while kit and nurse are further apart for younger and mid-age than for older speakers (Figure 6). That is, younger speakers are more advanced in terms of dress raising and kit centralisation than older speakers.
In neither of these vowel contrasts is there strong evidence that a difference in Euclidean distances is compensated for by a difference in durational contrasts. Importantly, the analysis of dress and fleece revealed that the durational patterning of the vowels did not change significantly in response to any other factors (as shown by the absence of interactions of vowel identity with the other factors in the analysis of duration). While there was a suggestion that nurse:kit duration ratios decrease as Euclidean distance increases when we move from older to mid-age and then to younger speakers, these measures were not significantly correlated. What is more, such apparent-time changes in the nurse:kit duration ratio would indicate a move away from a quantity contrast, with younger speakers having smaller durational differences, rather than towards one. Other aspects of the analyses did suggest some alternative compensatory measures. In particular, the analysis of dress and fleece returned a significant correlation of the overlap of these vowels in vowel space with the diphthongisation of fleece.
As noted in the Introduction, the long-short distinction between members of NZE vowel pairs has often been conflated with the tense-lax distinction (e.g. by Bauer & Warren Reference Bauer and Warren2004). This would appear to place the NZE vowel system closer to a British English RP system, where vowel distinctions have traditionally been indicated in terms of both quality/peripherality and length (e.g. transcriptions that distinguish between /iː/ and /ɪ/), than to a General American system, where vowel length is not generally considered to be distinctive and is therefore not marked in most transcription systems (thus /i/ and /ɪ/). In phonological theory, the usefulness of the tense-lax distinction in the description of English has been the subject of much debate (see summaries in e.g. Durand Reference Durand, Carr, Durand and Ewen2005, Kwon Reference Kwon2011). While the distinction may remain useful for descriptions of phonotactic behaviour (e.g. to distinguish vowels that may occur in open syllables from those that may not), it is not clear that the correlation of tense-lax with long-short is helpful in the description of the NZE vowel system. For instance, Labov (Reference Labov1994: 285), in his description of the short front vowel shift in NZE, argues that the short front vowels in NZE should in fact be treated as tense. These NZE short front vowels have undergone a chain shift in which trap and dress have raised, and kit has retracted (Bauer Reference Bauer1979, Reference Bauer1986; Bell Reference Bell1997; Trudgill, Gordon & Lewis Reference Trudgill, Gordon and Lewis1998; Watson & Harrington Reference Watson and Harrington1999; Gordon et al. Reference Gordon, Campbell, Hay, Maclagan, Sudbury and Trudgill2004; Langstrof Reference Langstrof2006). As Labov (Reference Labov1994: 138) notes, this shift provides an exception to two of his general principles governing chain-shifts in vowels, since in such shifts short (i.e. lax) front vowels are expected to fall rather than rise (Principle II), and back vowels are expected to move to the front rather than vice versa (Principle III). If the NZE short front vowels are accordingly regarded as tense, then the tense-lax distinction for front vowels in NZE collapses.
As Maclagan & Hay point out (Reference Maclagan and Hay2007: 20), a treatment of the NZE short front vowels as tense may also help to account for the linkage between the movement of dress and the realisation of fleece, since this treatment would place the two in the same subsystem of vowels. From their analysis of two age groups (20‒30 years and 45‒60 years), Maclagan & Hay (Reference Maclagan and Hay2007: 12) concluded that fleece is diphthongising in response to the raising of dress, by moving out of the monophthongal system via some process such as Labov's Upper Exit Principle (Labov Reference Labov1994: 281). Note though that while the analysis of NZED data presented above revealed significant differences between each age group in the overlap of dress and fleece, the younger and mid-age groups did not differ from one another in the extent of fleece diphthongisation, yet both had greater fleece diphthongisation than the older group. If the diphthongisation of fleece is equally strong for the younger and mid-age groups, but the overlap of dress and fleece distinguishes between these two groups, then this suggests that the diphthongisation of fleece might be occurring in advance of the overlap of the two vowels. So the current data suggest that fleece might in fact be making way for dress-raising, rather than responding to it. However, regardless of whether fleece-diphthongisation is a precursor to or consequence of dress-raising, both Maclagan & Hay (Reference Maclagan and Hay2007) and the current analysis place the two vowels in the same subsystem.
A similar breakdown of the traditional distinction of subsets on the basis of tension or length is suggested by Gordon et al. (Reference Gordon, Campbell, Hay, Maclagan, Sudbury and Trudgill2004: 206–207) in a tentative proposal that sees movement of start as the catalyst, historically, for the raising of the short front vowels in NZE. The suggestion is that as start fronted, trap raised, leading to a chain reaction that also involved dress and kit. Given the current overlap of start and strut, and the relatively open and front position of strut in data that Gordon et al. present for speakers born between 1870 and 1889 (their Figure 6.5), it is possible that strut has also been involved in this chain shift. Start and strut present a pair for which overlap in vowel quality has long been noted in NZE, and the only pair for which a revision of the transcription system (Bauer et al. Reference Bauer, Warren, Bardsley, Kennedy and Major2007) suggested the same basic symbols, with the addition of the length mark for start. In the data above it is the clearest case where quantity is the sole point of distinction, and for which there is also no indication of diphthongisation for either vowel. Interestingly, the analysis above suggests that the quantity distinction may be reducing. However, since start is still at least twice the length of strut for even the youngest speakers, it would be premature to predict a complete merger of these two vowels. In addition, this reduction in the quantity distinction is not found in the word-list data but only in the sentence recordings, where there are lexical and contextual cues to the identity of the words containing these vowels. Other research has been exploring the consequences of the vowel changes discussed in this paper for lexical access (Warren Reference Warren2006).
Finally, the comparison of foot with thought and goose supports earlier observations that foot is fronting and becoming more similar to goose than to thought. Thus the Euclidean distance between foot and thought increases and that between foot and goose decreases as we move from older to younger speakers. In neither case does there appear to have been any compensatory adjustment of vowel durations or diphthongisation. Foot remains consistently shorter than either thought or goose. The fact that diphthongisation of thought is positively correlated with foot‒thought distance indicates that the relationship between these two measures is not compensatory. At the same time, the pattern for goose does not indicate that it is diphthongising any more strongly as foot approaches its vowel space.
In summary, although a shift to a length-based contrast has been suggested for multiple vowel oppositions in NZE, this is only clearly supported in the current analysis for the strut‒start pair. For the other sets under consideration, there has either been a further move of one of the vowels out of the space of the other (i.e. a continuing process of centralisation sees kit moving away from the territory of nurse, and fronting has moved foot away from thought), or diphthongisation appears to be moving the longer vowel out of the monophthongal subset (as is most clearly the case with fleece, although diphthongal realisations of thought and goose are also prevalent).
Acknowledgments
The author wishes to thank the editor Amalia Arvaniti and three anonymous reviewers for their insightful and constructive comments on earlier drafts of this paper.
Appendix. Tokens taken from sentence recordings
The word containing the target vowel is in bold and the target vowel itself is underlined. Note that the NZ English of the samples is non-rhotic.
Dress
S001: The price range is smaller than any of us expected
S023: I'll hedge my bets and take no risks
S038: You ought to brush your teeth before you go to bed
S084: The coach swerved to the left in an attempt to avoid the blind pedestrian
S092: Compared with the previous guests she appeared coy and demure
S169: Cath opened the larder door to fetch the iceberg lettuce and a chunk of cheddar
S189: I can't pretend to know the exact answer but I can make an educated guess
S194: It's obvious that the student was amply rewarded for his endeavours
Fleece
S038: You ought to brush your teeth before you go to bed
S059: Pete couldn't bear to show us his scar so soon after the accident
S072: Everyone talks of the birds and the bees but they never mention wasps
S129: The yacht capsized in the choppy seas but all the crew swam to safety
S170: The babe was starting to teethe but her favourite toy appeared to soothe her
S173: The topic of Jeff's thesis is beginning to annoy me
S179: You always manage to besiege me with other people's blasted problems
S187: I'll never know whether it was the alcohol or the lack of sleep that gave me blurred vision
Kit
S010: It is futile to offer any further resistance
S023: I'll hedge my bets and take no risks
S037: The bath plug is missing so you'll have to take a shower
S103: The plaintiff felt thwarted because the judge didn't revoke his decision
S135: Some pop stars just mouth the words because they can't sing
S140: He clenched his fist and hammered it against the wall with a resounding smack of authority
S187: I'll never know whether it was the alcohol or the lack of sleep that gave me blurred vision
S188: I'm intrigued that social values can change so quickly
Nurse
S006: John could lend him the latest draft of his work
S017: It was important to be perfect since there were no prompts
S053: There'll be big trouble if you dare to touch that surface
S056: Doctor Philips raised a number of moot points about the Professor's abridged article in the recent journal
S113: Mary and Elizabeth both aim to be company directors by the age of thirty
S125: Dad wanted us to leave the surfboard in the boat until our return
S162: The Cuthbert family live by the village church
S197: The pretty manageress treated all her shop assistants like dirt
Strut
S011: They launched into battle with all the forces they could muster
S035: It's a shame that architects design for themselves and not for the general public
S070: They were still frisked by Customs though they had nothing to declare
S103: The plaintiff felt thwarted because the judge didn't revoke his decision
S111: Those texts you mention were discussed in depth by the brethren last Sunday
S133: I'm obliged to tell you that most women loathe their husbands
S142: You should eat less of that fudge cake if it really is aggravating your sore tooth
S162: The Cuthbert family live by the village church
Start
S002: They asked if I wanted to come along on the barge trip
S054: Tom says that ancient Saabs are far more stylish than British Leyland Triumphs
S068: He remembered he needed a passport to get a visa stamp for France
S090: We were plunged into darkness as the clouds engulfed the moon
S101: We'll need to put the poodle back on the leash when we leave the park
S151: He caught a glimpse of what looked like a badger in the marsh
S168: I feel too lethargic to wash up tonight
S177: The ivy wound its way grotesquely round the neck of the gargoyle
Foot
S021: Thank goodness it's Friday and time to go home
S031: It's difficult to choose between two such equally good alternatives
S064: We'd be hard pushed to catch the bus to Newcastle tonight
S102: The Olympic torch shines as a symbol of hope which has pushed aside the barriers of race
S115: Cobwebs slowly find their way into every nook and cranny
S136: The toddler stamped his foot in annoyance and gouged a large hole in his parents' table out of spite
S184: The Websters are going to see “Puss in Boots” just after Christmas
S186: I'm well aware that raw vegetables contain more vitamins than cooked ones
Goose
S028: The mud squelched loudly and he realised that his suede boots were doomed
S079: The food varies from place to place but the price remains fairly constant
S083: We really will need to defrost the fridge now that the strawberries have oozed out all over the place
S142: You should eat less of that fudge cake if it really is aggravating your sore tooth
S146: This is the eighth week that parsnip soup has been served at this hotel
S181: Cinderella waltzed through the night while poor Buttons mooched aimlessly about the house
S184: The Websters are going to see “Puss in Boots” just after Christmas
S198: I wish I lived a little bit nearer to the supermarket
Thought
S019: We have proof that the regime wields sufficient power in the North to exploit the entire population
S034: When forced to make a choice, Sarah chose ping-pong as her favourite game
S089: The questionnaire about “King Lear” was short and to the point
S097: It seems as if Susan does all the chores for this household
S098: I want each person here to give George their report by Thursday afternoon
S102: The Olympic torch shines as a symbol of hope which has pushed aside the barriers of race
S155: The archbishop has resolved not to disclose the details of the bitter divorce
S175: Her wealth's certain to buy her not only a Porsche but also considerable popularity















