


1. Introduction
Data-to-text generation (D2T) is a subfield of natural language generation (NLG) that converts nonlinguistic, structured, formal, and abstract meaning representation (MR) to a natural language sentence and is used for the generation of task-oriented dialog, question answering, machine translation, selective generation systems, and search engines. For a given MR, which is a set of meaning labels in the form of tables or dialog acts, a generator must generate readable, fluent, adequate, and diverse sentences that express all the required information contained in the MR. Early models of D2T were based on manual rules and templates (Knight and Hatzivassiloglou, Reference Knight and Hatzivassiloglou1995; Langkilde and Knight, Reference Langkilde and Knight1998; Ringger et al., Reference Ringger, Gamon, Moore, Rojas, Smets and Corston2004). Although these systems produce high-quality text, they are domain-specific so they cannot be used for other domains, are expensive to build, and have limitations in generating diverse sentences. Another trend in data-to-text approaches is corpus-based methods which learn the mapping between MR and sentences in training data (Duboue and Mckeown, Reference Duboue and Mckeown2003; Barzilay and Lee, Reference Barzilay and Lee2004; Barzilay and Lapata, Reference Barzilay and Lapata2005; Soricut and Marcu, Reference Soricut and Marcu2006; Wong and Mooney, Reference Wong and Mooney2007; Belz, Reference Belz2008; Liang, Michael, and Klein, Reference Liang, Michael and Klein2009; Lu, Ng, and Lee, Reference Lu, Ng and Lee2009; Angeli, Liang, and Klein, Reference Angeli, Liang and Klein2010; Kim and Mooney, Reference Kim and Mooney2010; Lu and Ng, Reference Lu and Ng2011; Konstas and Lapata, Reference Konstas and Lapata2012, Gyawali, Reference Gyawali2016; Gyawali, Reference Gyawali2016). These systems are relatively inexpensive and more generalizable to different domains. However, due to the lack of a mechanism to control the concept of sentences, their output is not always coherent and fluent.
Recently, systems designed to generate text are generally based on recurrent neural networks (RNN). The RNN-based D2T systems, which have an encoder–decoder structure, have been able to achieve significant results in generating descriptive text from nonlinguistic data (Wen et al., Reference Wen, Gasic, Kim, Mrksic, Su, Vandyke and Young2015a, Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2015b, Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c, Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2016; Lebret, Grangier, and Auli, Reference Lebret, Grangier and Auli2016; Mei, Bansal, and Walter, Reference Mei, Bansal and Walter2016; Nayak et al., Reference Nayak, Hakkani-Tur, Walker and Heck2017; Riou et al., Reference Riou, Jabaian, Huet and Lefèvre2017; Tran, Nguyen, and Nguyen, Reference Tran, Nguyen and Nguyen2017; Tran and Nguyen, Reference Tran and Nguyen2017; Lee, Krahmer, and Wubben, Reference Lee, Krahmer and Wubben2018; Liu et al., Reference Liu, Wang, Sha, Chang and Sui2018; Deriu and Cieliebak, Reference Deriu and Cieliebak2018; Sha et al., Reference Sha, Mou, Liu, Poupart, Li, Chang and Sui2018; Tran and Nguyen, Reference Tran and Nguyen2019; Qader, Portet, and Labbe, Reference Qader, Portet and Labbe2019; Shen et al., Reference Shen, Chang, Su, Zhou and Klakow2020). However, these systems also have limitations. One of their most important problems is the inability to express all the necessary input information in the output text (Tran and Nguyen, Reference Tran and Nguyen2019). The input MR may include meaning labels with a binary value (true, false, yes, no) or a value that cannot be expressed directly in words (none, don’t-care) and can only be identified by their concept. For example, consider a meaning label that indicates whether a hotel allows dogs to enter or not, whose value can be yes, no, none, and don’t-care. none means that information about allowing dogs in hotels is not available. This concept is expressed in sentences by the phrases such as dogs are allowed (similar when its value is yes), dogs are not allowed (similar when its value is no), or I do not know if it allows dogs. In these cases, the model should learn the relationship between these values and the words in the text and also how to express its meaning in the output. Another problem, which is related to the nature of RNN networks, is the inability to retain information about the distant past. Although LSTM is able to retain this information to some extent, the information that leads to the generation of the first words of the text is still forgotten as the output text lengthens. This causes problems like duplicate generated words, missing, and redundant meaning labels to be expressed in the output text. So far, many models have been tried to solve these deficiencies, among which models with encoder-attention-decoder structure have achieved relative but not complete success (Wen et al., Reference Wen, Gasic, Kim, Mrksic, Su, Vandyke and Young2015a, Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2015b, Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c, Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2016; Dusek and Jurcicek, Reference Dusek and Jurcicek2016; Tran et al., Reference Tran, Nguyen and Nguyen2017; Tran and Nguyen, Reference Tran and Nguyen2017, Qader et al., Reference Qader, Portet and Labbe2019; Shen et al., Reference Shen, Chang, Su, Zhou and Klakow2020; Shen et al., Reference Shen, Chang, Su, Zhou and Klakow2020).
In this paper, we have enabled the basic attention-based sequence-to-sequence model to store information leading to the generation of previous words and generate new words not only based on the current state but also on previous information. For this purpose, we use a dynamic memory network (DMN) (Kumar et al., Reference Kumar, Irsoy, Ondruska, Iyyer, Bradbury, Gulrajani, Zhong, Paulus and Socher2016). The DMN, which is introduced in 2016 for the Question and Answer (Q&A) task, has two modules for reading and writing; at each step, the memory content is updated and rewritten based on its previous value and query, and the output tokens are generated based on the content read from memory. Using this type of memory along with the sequence-to-sequence model, each output word is generated not only based on the current state but also the information and history of decisions that led to the generation of previous words. In addition, since generating words in the proposed model, unlike previous models, are done by two different levels of attention between encoder and decoder, as well as decoder and memory, the meanings of the words and their relation to the input MR are well learned and as a result, all meaning labels with binary or special values will be expressed in the output. Improving the sentence structure is another goal that was achieved by applying a postprocessing step on the proposed model outputs by using pretrained language models.
We performed experiments to evaluate the performance of the proposed model and compare it with the baseline models. These experiments are performed on datasets and evaluation metrics used by RNN-based, autoencoder-based, and transformer-based baseline models to evaluate the effect of memory usage compared to the case where there is no memory. The results of the experiments show clear improvements in the quality of the sentences, both grammatically and semantically compared to the previous models. The main contributions of our work are summarized below:
-
To reduce the flaws in the semantics of sentences generated by the attention-based sequence-to-sequence model, we proposed to use a dynamic memory module for storing the previous content vectors and decoder hidden states and then use its contents to generate new tokens.
-
To make the dynamic memory more compatible with the input MRs, we proposed two different structures of only one-slot cell and multislot cells.
The rest of the paper is organized as follows: Section 2 presents related works. Section 3 presents the proposed DM-NLG model. Datasets, experimental setups, and evaluation metrics are described in Section 4. The resulting analysis and case study are presented in Section 5. The paper is concluded in Section 6.
2. Related works
RNN-based approaches have recently demonstrated promising performance in the D2T area. In the weather forecasting and sports domain, Mei et al. (Reference Mei, Bansal and Walter2016) proposed an attention-based encoder–decoder model that used both local and global attention for content selection and generating sentences.
Wen et al. (Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c, Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2016) created a dataset containing dialog acts of four different domains: finding a restaurant, finding a hotel, buying a laptop, and buying a TV. Then, they used LSTM to generate text word by word, while checking if all information is expressed in the output by using a heuristic gate. For each input dialog act, they over-generate a number of sentences, then all generated sentences are re-ranked with the CNN ranking method and those sentences that have higher ranks are chosen as output (Wen et al., Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c). The reported results of this model show that despite the use of the control gate, a large percentage of meaning labels are still not expressed in the output. To improve this model, Wen et al. (Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2015b) used a semantically conditioned LSTM instead of a heuristic control gate. In this model, the encoded input dialog act is updated after the generation of each word to reduce the impact of the expressed meaning labels for generating the next words. They also used a backward LSTMs re-ranking method to rank the generated sentences. They also compared the results obtained from these models with an Encoder-attention-Decoder structure (Wen et al., Reference Wen, Gasic, Kim, Mrksic, Su, Vandyke and Young2015a). These results show that their proposed models for simple domains such as Restaurant and Hotel have been more successful than Laptop and TV, but still, some meaning labels remain unexpressed. After that, Riou et al. (Reference Riou, Jabaian, Huet and Lefèvre2017) proposed Combined-Context LSTM which was a combination of the approaches of Wen et al. (Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2015b) and Wen et al. (Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2016). This hybrid model simultaneously controlled unexpressed slots and slots that should be considered by the decoder at each time step. Although this model was able to use more meaning label information to generate sentences than its base models, the quality of their output sentences decreased. As the next attempt to improve the Wen et al. (Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2015b) results, Tran et al. (Reference Tran, Nguyen and Nguyen2017) suggested using an attention mechanism to represent dialog acts and then refining the input token based on this representation before sending it to the decoder. The results showed that their model was able to improve the BLEU metric by 0.01 by preventing the repetition of words or semantic defects. Further, they added a control gate on the output information of the decoder to control semantic information (Tran and Nguyen, Reference Tran and Nguyen2019). Finally, their model was able to reduce the slot error rate (SER) score value due to repetition or semantic defect of sentences by 40–50% while improving the value of BLEU by 0.01–0.02. Dusek and Jurcicek (Reference Dusek and Jurcicek2016) used a short version of the Restaurant dialog acts dataset (Wen et al., Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c), called BAGEL. They proposed a sequence-to-sequence model to generate sentences. Moreover, they re-ranked the n-best generated sentences and penalized those with repetitive words or semantic defects.
Lebret et al. (Reference Lebret, Grangier and Auli2016) generated a dataset containing Wikipedia biographies and their fact tables, called Wikibio. Then they used a neural feed-forward language model conditioned on structured data to generate the first sentence of each biography. Moreover, for sample-specific words like the name of persons, they used a copy mechanism that chooses these words from the input database to be expressed in the output sentence. Working on the same dataset, Liu et al. (Reference Liu, Wang, Sha, Chang and Sui2018) used a sequence-to-sequence structure to generate descriptive sentences from tables. The table information was encoded in the form of a field and value pairs, so their information would be present in the table representation. Also, in the decoding phase, two attention mechanisms were used, one at the word level and the other at the field level, to model the semantic relationship between the table and the generated text. After that, Sha et al. (Reference Sha, Mou, Liu, Poupart, Li, Chang and Sui2018) extended this approach to learning the order of meaning labels in the corresponding text by adding a linked matrix, so their model was able to generate a more fluent output.
In the case of cross-domain dialog generation, Tseng et al. (Reference Tseng, Kreyssig, Budzianowski, Casanueva, Wu, Ultes and Gasic2018), used a semantically conditioned variational autoencoder architecture. This model at first encoded the input MRs and their corresponding sentences to a latent variable. Then conditioning on this latent variable, the output sentences for a given MR were generated. Tran and Nguyen (Reference Tran and Nguyen2018a) proposed a variational neural language generator that was trained adversarially by first being trained on a source domain data and then being fine-tuned on a target domain under the guidance of text similarity and domain critics. Furthermore, to deal with the low-resource domain, they integrated a variational inference into an encoder–decoder generator (Tran and Nguyen, Reference Tran and Nguyen2018b).
The E2E dataset, a large dataset in the restaurant domain, is produced in 2017 by Novikova et al. (Reference Novikova, Dusek and Rieser2017) for use in the E2E challenge (Dusek, Novikova, and Rieser, Reference Dusek, Novikova and Rieser2018). Most of the submissions in that challenge were End-to-End sequence-to-sequence models (Juraska et al., Reference Juraska, Karagiannis, Bowden and Walker2018; Gehrmann, Dai, and Elder, Reference Gehrmann, Dai and Elder2018; Zhang et al., Reference Zhang, Yang, Lin and Su2018; Gong, Reference Gong2018; Deriu and Cieliebak, Reference Deriu and Cieliebak2018) who were able to get a better result than the baseline approach by Dusek and Jurcicek (Reference Dusek and Jurcicek2016). Working on the same dataset, Qader et al. (Reference Qader, Portet and Labbe2019) proposed a combination of an NLG and an NLU sequence-to-sequence models in the form of an autoencoder structure that can learn from annotated and nonannotated data. Their model was able to achieve a result close to the winner of the E2E challenge (Juraska et al., Reference Juraska, Karagiannis, Bowden and Walker2018). Also, Shen et al. (Reference Shen, Chang, Su, Zhou and Klakow2020) proposed to automatically extract the segmental structures of texts and learn to align them with their data correspondences. More precisely, at first the input records are encoded. Then at each time step, the decoder generates tokens based on the attention weights of the input records and previously expressed records in the output sentence. For reducing hallucination, they used a constraint that all records must be used only once.
Recently, pretrained language models like GPT-2 (Radford et al., Reference Radford, Wu, Child, Luan, Amodei and Sutskever2019) are used for data-to-text in the few-shot or zero-shot settings. As for the E2E dataset (Dusek et al., Reference Dusek, Novikova and Rieser2018), Kasner and Dušek (Reference Kasner and Dušek2020) propose a few-shot approach for D2T based on iterative text editing by using LASERTAGGER (Malmi et al., Reference Malmi, Krause, Rothe, Mirylenka and Severyn2019), a sequence tagging model based on the Transformer (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) architecture with the BERT (Devlin et al., Reference Devlin, Chang, Lee and Toutanova2019) pretrained language model as the encoder and the pretrained language model GPT-2. This model first transforms data items to text using trivial templates, and then iteratively improves the resulting text by a neural model trained for the sentence fusion task. The output of the model then is filtered by a simple heuristic and re-ranked with GPT-2 language model. Peng et al. (Reference Peng, Zhu, Li, Li, Li, Zeng and Gao2020) introduce a model-based GPT-2 called semantically conditioned generative pretraining. This model is first pretrained on a large amount of publicly available dialog datasets and then fine-tuned on the target D2T dataset with few training instances. Harkous et al. (Reference Harkous, Groves and Saffari2020) introduce the DATATUNER model, an end-to-end, domain-independent data-to-text system that used GPT-2 pretrained language model and a weakly supervised semantic fidelity classifier to detect and avoid generation errors such as hallucination and omission. Chen et al. (Reference Chen, Eavani, Liu and Wang2020) proposed a few-shot learning approach that used GPT-2 with a copy mechanism. Kale and Rastogi (Reference Kale and Rastogi2020) used templates to improve the semantic correctness of the generated responses. In a zero-shot setting, at first, their model generates semantically correct but possibly incoherent responses based on the slots, with the constraint of templates, then by using T5 pretrained Text-to-Text model (Raffel et al., Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2020) as reorganizer, the generated utterances are transformed into coherent ones. Chang et al. (Reference Chang, Shen, Zhu, Demberg and Su2021) use the data augmentation methods to improve few-shot text generation results using GPT-2 language model. Lee (Reference Lee2021) presents a simple one-stage approach to generating sentences from MRs using GPT-2 language model. Juraska and Walker (Reference Juraska and Walker2021) proposed SEA-GUIDE, a semantic attention-guided decoding method for reducing semantic errors in the output text and applied it on fine-tuned T5 and BART (Lewis et al., Reference Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov and Zettlemoyer2020). This decoding method extracts interpretable information from cross-attention between encoder and decoder to infer which meaning labels are mentioned in the generated text.
The use of memory as an entity modifying (Puduppully, Dong, and Lapata, Reference Puduppully, Dong and Lapata2019) or entity tracker (Iso et al., Reference Iso, Uehara, Ishigaki, Noji, Aramaki, Kobayashi, Miyao, Okazaki and Takamura2019) in the D2T task has already been suggested. In the model proposed by Puduppully et al. (Reference Puduppully, Dong and Lapata2019), after each output token is generated by the decoder, the MR vectors of the input entities obtained by the encoder are updated using the memory module, and these updated vectors are used to select the next entity to describe in the output text. The proposed model by Iso et al. (Reference Iso, Uehara, Ishigaki, Noji, Aramaki, Kobayashi, Miyao, Okazaki and Takamura2019) uses a memory module along with the decoder, that in each time step selects the appropriate entity to be expressed in the output text, updates the encoder’s hidden state of the selected entity, and generates output tokens for describing it. However, our proposal differs from theirs in that, ours uses memory to help the decoder store the information it used to generate previous tokens. In this way, each output word is generated not only based on the current decoder state but also the information and history of decisions that led to the generation of previous words.
3. DM-NLG model
The proposed text generator in this paper is based on the sequence-to-sequence encoder–decoder architecture. The encoder part of the model, which is made by RNN, gets MR=
 $\{x_0,x_1,\ldots,x_L\}$
as input and converts it to hidden vectors. The hidden vectors of the encoder are used by the attention mechanism to produce the context vector and the final hidden state is used for initializing the hidden state of the decoder. Since the text generator must be able to express all the necessary input information in the generated output text, we propose to use dynamic memory alongside the sequence-to-sequence model. In this new model, which we named DM-NLG, the output tokens
$\{x_0,x_1,\ldots,x_L\}$
as input and converts it to hidden vectors. The hidden vectors of the encoder are used by the attention mechanism to produce the context vector and the final hidden state is used for initializing the hidden state of the decoder. Since the text generator must be able to express all the necessary input information in the generated output text, we propose to use dynamic memory alongside the sequence-to-sequence model. In this new model, which we named DM-NLG, the output tokens
 $\{w_0,w_1,\ldots,w_N\}$
are generated by the decoder based on the content of the memory cell. After generating each token, the content of the memory cell is updated. Finally, as a postprocessing stage, the generated sentences are given to a fine-tuned pretrained language model to improve their quality. The general outline of this model is shown in Figure 1.
$\{w_0,w_1,\ldots,w_N\}$
are generated by the decoder based on the content of the memory cell. After generating each token, the content of the memory cell is updated. Finally, as a postprocessing stage, the generated sentences are given to a fine-tuned pretrained language model to improve their quality. The general outline of this model is shown in Figure 1.
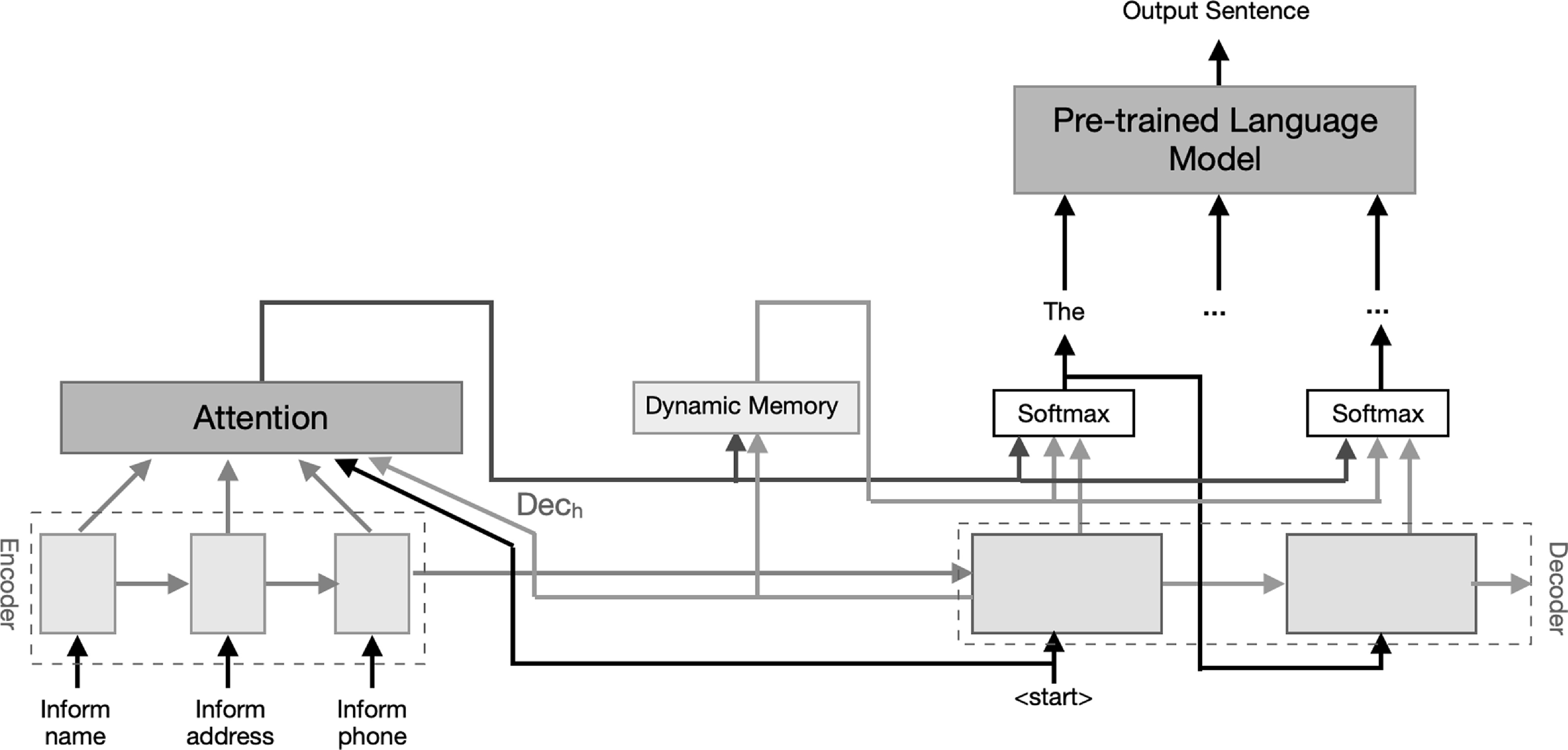
Figure 1. The block diagram of our proposed DM-NLG model. Here, the input of the encoder is an example of the restaurant dataset MRs.
3.1. Encoder
The encoder, which is a stack of GRU units, takes the input MR. At each step of the recurrence, a meaning label
 $x_l$
of the input and hidden state
$x_l$
of the input and hidden state
 $s_{l-1}$
of the previous state is given to the GRU unit and a new hidden state
$s_{l-1}$
of the previous state is given to the GRU unit and a new hidden state
 $s_l$
is generated. This process continues until all the meaning labels of the input MR have been processed and their information stored inside the final hidden state. The formulas for this process are as follows:
$s_l$
is generated. This process continues until all the meaning labels of the input MR have been processed and their information stored inside the final hidden state. The formulas for this process are as follows:
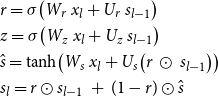 \begin{equation} \begin{aligned} &r=\sigma \!\left(W_r \ x_l+ U_r \ s_{l-1}\right)\\ &z=\sigma \!\left(W_z \ x_l+ U_z \ s_{l-1}\right)\\ &\hat{s}=\tanh \!\left(W_s \ x_l+U_s \!\left(r \ \odot \ s_{l-1}\right)\right)\\ &s_{l}=r \odot s_{l-1}\ +\ (1-r) \odot \hat{s}\\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &r=\sigma \!\left(W_r \ x_l+ U_r \ s_{l-1}\right)\\ &z=\sigma \!\left(W_z \ x_l+ U_z \ s_{l-1}\right)\\ &\hat{s}=\tanh \!\left(W_s \ x_l+U_s \!\left(r \ \odot \ s_{l-1}\right)\right)\\ &s_{l}=r \odot s_{l-1}\ +\ (1-r) \odot \hat{s}\\ \end{aligned} \end{equation}
where
 $W_r$
,
$W_r$
,
 $W_z$
,
$W_z$
,
 $W_s$
,
$W_s$
,
 $U_r$
,
$U_r$
,
 $U_z$
, and
$U_z$
, and
 $U_s$
are weight parameters that are learned during the model training process and
$U_s$
are weight parameters that are learned during the model training process and
 $\odot$
denote for the element-wise product.
$\odot$
denote for the element-wise product.
3.2. Decoder
The final hidden state of the encoder is used as the initial value for the hidden state of the decoder. The decoder, consisting of GRU units, at each step gets the generated token
 $w_{t-1}$
and hidden state
$w_{t-1}$
and hidden state
 $h_{t-1}$
of the previous step and generates the new hidden state
$h_{t-1}$
of the previous step and generates the new hidden state
 $h_t$
. The generated hidden state is used to compute a probability discrete distribution over the vocabulary and then to predict the next word:
$h_t$
. The generated hidden state is used to compute a probability discrete distribution over the vocabulary and then to predict the next word:
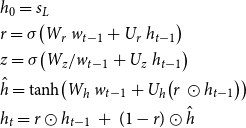 \begin{equation} \begin{aligned} &h_0=s_L\\ &r=\sigma \!\left(W_r \ w_{t-1}+ U_r\ h_{t-1} \right)\\ &z=\sigma \!\left(W_z / w_{t-1}+ U_z \ h_{t-1}\right)\\ &\hat{h}=\tanh \!\left(W_h \ w_{t-1}+U_h\! \left(r \ \odot h_{t-1}\right)\right)\\ &h_{t}=r \odot h_{t-1} \ + \ (1-r) \odot \hat{h}\\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &h_0=s_L\\ &r=\sigma \!\left(W_r \ w_{t-1}+ U_r\ h_{t-1} \right)\\ &z=\sigma \!\left(W_z / w_{t-1}+ U_z \ h_{t-1}\right)\\ &\hat{h}=\tanh \!\left(W_h \ w_{t-1}+U_h\! \left(r \ \odot h_{t-1}\right)\right)\\ &h_{t}=r \odot h_{t-1} \ + \ (1-r) \odot \hat{h}\\ \end{aligned} \end{equation}
where
 $h_0$
is the initial values of the decoder’s hidden state and
$h_0$
is the initial values of the decoder’s hidden state and
 $W_r$
,
$W_r$
,
 $W_z$
,
$W_z$
,
 $W_s$
,
$W_s$
,
 $U_r$
,
$U_r$
,
 $U_z$
, and
$U_z$
, and
 $U_s$
are weight parameters that are learned during the model training process.
$U_s$
are weight parameters that are learned during the model training process.
3.3. Attention mechanism
The output of an NLG system is a descriptive text embracing the input MR; therefore, there should be some alignment between each output text token and input labels. This alignment is modeled through the attention mechanism. Hence, at each step t, the degree of relevancy of the hidden state
 $h_t$
of the decoder to all encoder hidden states as well as previously generated token
$h_t$
of the decoder to all encoder hidden states as well as previously generated token
 $w_{t-1}$
is measured, and based on that a score is given to each hidden state of meaning labels. These scores indicate which input labels are more responsible for generating token
$w_{t-1}$
is measured, and based on that a score is given to each hidden state of meaning labels. These scores indicate which input labels are more responsible for generating token
 $w_t$
and are calculated as follows:
$w_t$
and are calculated as follows:
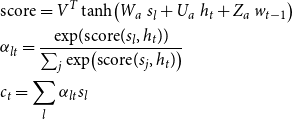 \begin{equation} \begin{aligned} &\text{score}=V^T\tanh \!\left(W_a \ s_l+U_a \ h_t + Z_a \ w_{t-1}\right)\\ &\alpha _{lt}=\frac{\exp\! ({\text{score}(s_l,h_t)})}{\sum _j \exp \!\left({\text{score}(s_j,h_t)}\right)}\\ &c_t=\sum _l{\alpha _{lt} s_l}\\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\text{score}=V^T\tanh \!\left(W_a \ s_l+U_a \ h_t + Z_a \ w_{t-1}\right)\\ &\alpha _{lt}=\frac{\exp\! ({\text{score}(s_l,h_t)})}{\sum _j \exp \!\left({\text{score}(s_j,h_t)}\right)}\\ &c_t=\sum _l{\alpha _{lt} s_l}\\ \end{aligned} \end{equation}
where
 $V$
,
$V$
,
 $W_a$
,
$W_a$
,
 $U_a$
, and
$U_a$
, and
 $Z_a$
are learning weight parameters. The context vector
$Z_a$
are learning weight parameters. The context vector
 $c_t$
, which is the weighted sum of the encoder hidden states, denotes the contribution of the input meaning labels in the production of the
$c_t$
, which is the weighted sum of the encoder hidden states, denotes the contribution of the input meaning labels in the production of the
 $w_t$
.
$w_t$
.
3.4. Dynamic memory
As mentioned before in Equations (2) and (3), both phases of generating words by the decoder and calculating attention weights by the attention mechanism are performed based on the last generated word embedding vector (
 $w_{t-1}$
) and the last hidden vector of the decoder (
$w_{t-1}$
) and the last hidden vector of the decoder (
 $h_t$
). Therefore, the only information from the past steps that affect the attention weights and word generation at current step
$h_t$
). Therefore, the only information from the past steps that affect the attention weights and word generation at current step
 $t$
is the content of the
$t$
is the content of the
 $h_t$
vector, which includes a compact representation of the sequence of words produced from step
$h_t$
vector, which includes a compact representation of the sequence of words produced from step
 $0$
to
$0$
to
 $t-1$
. On the other hand, as the generated word sequence lengthens, the weights of the initial generated words become less than the recently generated words in this representation. As a result, the information that leads to the generation of the words at the beginning of the sentence is lost, which results in the text generator to produce repetitive words or not to express part of the input meaning labels in the output text. Therefore, we propose to use dynamic memory to store the history of previous information. In this way, to generate the output word
$t-1$
. On the other hand, as the generated word sequence lengthens, the weights of the initial generated words become less than the recently generated words in this representation. As a result, the information that leads to the generation of the words at the beginning of the sentence is lost, which results in the text generator to produce repetitive words or not to express part of the input meaning labels in the output text. Therefore, we propose to use dynamic memory to store the history of previous information. In this way, to generate the output word
 $w_t$
, the content of memory that is initialized with encoder outputs, is first updated and re-written based on hidden state
$w_t$
, the content of memory that is initialized with encoder outputs, is first updated and re-written based on hidden state
 $h_t$
. The information in the updated memory is then read by the attention mechanism and used to generate the output word. In this way, all the past information that leads to generating words is always available to the decoder.
$h_t$
. The information in the updated memory is then read by the attention mechanism and used to generate the output word. In this way, all the past information that leads to generating words is always available to the decoder.
In this work, two types of dynamic memories with different sizes and initialization values are proposed. In the first case, the memory
 $M^t$
at time step
$M^t$
at time step
 $t$
consists of a slot
$t$
consists of a slot
 $m_{0}^t$
that is initialized by the last encoder’s hidden state
$m_{0}^t$
that is initialized by the last encoder’s hidden state
 $s_L$
, so contains the compressed information of the input MR. In the second case, the number of memory slots
$s_L$
, so contains the compressed information of the input MR. In the second case, the number of memory slots
 $M^t$
at time step
$M^t$
at time step
 $t$
is equal to the input meaning labels,
$t$
is equal to the input meaning labels,
 $M^t=\left\{m_0^t,m_1^t,\ldots,m_L^t\right\}$
. These slots are initialized by their hidden states generated by the encoder,
$M^t=\left\{m_0^t,m_1^t,\ldots,m_L^t\right\}$
. These slots are initialized by their hidden states generated by the encoder,
 $\{s_0,s_1,\ldots,s_L\}$
.
$\{s_0,s_1,\ldots,s_L\}$
.
3.4.1. Memory writing module
As mentioned before, at each step
 $t$
, the hidden vector
$t$
, the hidden vector
 $h_{t-1}$
and the previously generated word
$h_{t-1}$
and the previously generated word
 $w_{t-1}$
are given to the decoder to generate the hidden vector
$w_{t-1}$
are given to the decoder to generate the hidden vector
 $h_t$
. After that, this vector with the context vector generated by the attention mechanism is given to the writing module. The writing module, which is made of GRU units, updates, and rewrites the memory as follows:
$h_t$
. After that, this vector with the context vector generated by the attention mechanism is given to the writing module. The writing module, which is made of GRU units, updates, and rewrites the memory as follows:
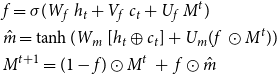 \begin{equation} \begin{aligned} &f=\sigma (W_f \ h_t+ V_f \ c_t+ U_f \ M^t)\\ &\hat{m}=\tanh (W_m \ [h_t \oplus c_t]+ U_m ( f\ \odot M^t))\\ &M^{t+1}=(1-f) \odot M^t \ + \ f \odot \hat{m}\\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &f=\sigma (W_f \ h_t+ V_f \ c_t+ U_f \ M^t)\\ &\hat{m}=\tanh (W_m \ [h_t \oplus c_t]+ U_m ( f\ \odot M^t))\\ &M^{t+1}=(1-f) \odot M^t \ + \ f \odot \hat{m}\\ \end{aligned} \end{equation}
where
 $W_f$
,
$W_f$
,
 $W_m$
,
$W_m$
,
 $V_f$
,
$V_f$
,
 $U_f$
, and
$U_f$
, and
 $U_m$
are learning weight parameters and
$U_m$
are learning weight parameters and
 $\oplus$
is the concatenation operation. If memory
$\oplus$
is the concatenation operation. If memory
 $M^t$
has multiple slots, the writing module operates recursively on
$M^t$
has multiple slots, the writing module operates recursively on
 $\left\{m_0^t,m_1^t,\ldots,m_L^t\right\}$
; Otherwise, it will act as a single GRU unit on slot
$\left\{m_0^t,m_1^t,\ldots,m_L^t\right\}$
; Otherwise, it will act as a single GRU unit on slot
 $m_{0}^t$
.
$m_{0}^t$
.
3.4.2. Memory reading module
At time step t and after the memory
 $M^t$
is updated and rewritten in
$M^t$
is updated and rewritten in
 $M^{t+1}$
, its information is read by the reading module and used to generate the next word
$M^{t+1}$
, its information is read by the reading module and used to generate the next word
 $w_{t+1}$
. The process of reading memory is done by the attention mechanism as follows:
$w_{t+1}$
. The process of reading memory is done by the attention mechanism as follows:
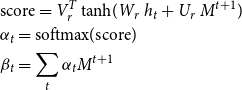 \begin{equation} \begin{aligned} &\text{score}=V_{r}^T\tanh\! (W_r \ h_t+U_r \ M^{t+1})\\ &\alpha _{t}= \text{softmax}(\text{score})\\ &\beta _t=\sum _t \alpha _{t} M^{t+1}\\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\text{score}=V_{r}^T\tanh\! (W_r \ h_t+U_r \ M^{t+1})\\ &\alpha _{t}= \text{softmax}(\text{score})\\ &\beta _t=\sum _t \alpha _{t} M^{t+1}\\ \end{aligned} \end{equation}
where
 $V_r$
,
$V_r$
,
 $W_r$
, and
$W_r$
, and
 $U_r$
are learning weight parameters. The output distribution of each token then is defined by using a softmax function as follows:
$U_r$
are learning weight parameters. The output distribution of each token then is defined by using a softmax function as follows:
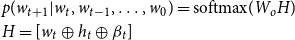 \begin{equation} \begin{aligned} &p(w_{t+1} | w_{t},w_{t-1},\ldots,w_0)=\text{softmax}(W_o H)\\ &H=[w_{t} \oplus h_t \oplus \beta _t]\\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &p(w_{t+1} | w_{t},w_{t-1},\ldots,w_0)=\text{softmax}(W_o H)\\ &H=[w_{t} \oplus h_t \oplus \beta _t]\\ \end{aligned} \end{equation}
where
 $W_o$
is the learning weight parameter.
$W_o$
is the learning weight parameter.
3.5. Training
The model is trained to minimize the negative log-likelihood cost function based on back propagation. Accordingly,
 $J(\theta )$
formulated as follows:
$J(\theta )$
formulated as follows:
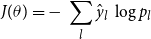 \begin{equation} \begin{aligned} &J(\theta )= -\ \sum _{l} \hat{y}_l \ \log{p_l}\\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &J(\theta )= -\ \sum _{l} \hat{y}_l \ \log{p_l}\\ \end{aligned} \end{equation}
where
 $\hat{y}_l$
is the actual word distribution,
$\hat{y}_l$
is the actual word distribution,
 $p_l$
is the predicted word distribution. For training, the ground truth token for the previous time step is used as the input of the next step; but for inference, a simple beam search is used to generate output text.
$p_l$
is the predicted word distribution. For training, the ground truth token for the previous time step is used as the input of the next step; but for inference, a simple beam search is used to generate output text.
3.6. Postprocessing
At this stage, a pretrained language model that autoregressively generates text, such as GPT-2 or Transformer-XL (Dai et al., Reference Dai, Yang, Yang, Carbonell, Le and Salakhutdinov2019), is used to improve the structural quality of the sentences produced by the decoder. For this purpose, first, the equivalent sentences for the MRs of the training data are generated by the DM-NLG model. These sentences are then used along with the ground truths as an input and output pair to fine-tune the pretrained language models, in the form of
 ${\lt}$
BOS
${\lt}$
BOS
 $\gt$
generated text
$\gt$
generated text
 $\lt$
SEP
$\lt$
SEP
 $\gt$
ground truths text
$\gt$
ground truths text
 $\lt$
EOS
$\lt$
EOS
 $\gt$
. Finally, each generated sentence at the inference time is given to the fine-tuned model as a language model, in the form of
$\gt$
. Finally, each generated sentence at the inference time is given to the fine-tuned model as a language model, in the form of
 $\lt$
BOS
$\lt$
BOS
 $\gt$
generated text
$\gt$
generated text
 $\lt$
SEP
$\lt$
SEP
 $\gt$
to generate the equivalent sentence as a continuation of the input. The impact of using each of these pretrained models in improving the quality of output sentences is discussed in the next section.
$\gt$
to generate the equivalent sentence as a continuation of the input. The impact of using each of these pretrained models in improving the quality of output sentences is discussed in the next section.
4. Experiments
To evaluate the performance of the proposed model, we conducted experiments. The used datasets, experiment settings, evaluation metrics, results of the experiments, and their analysis are described below.
4.1. Datasets
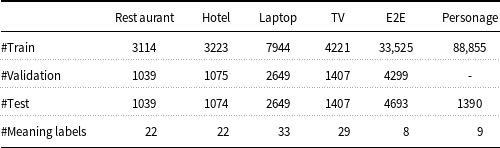
We used five publicly available datasets to examine the quality of the proposed models: finding a hotel, finding a restaurant, buying a TV, buying a laptop published by Wen et al. (Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c), the E2E challenge dataset provided by Dusek et al. (Reference Dusek, Novikova and Rieser2018) and Personage dataset published by Oraby et al. (Reference Oraby, Reed, Tandon, S., Lukin and Walker2018) which provides multiple reference outputs with various personality type (agreeable, disagreeable, conscientious, unconscientious, and extrovert) for each E2E MR. These datasets contain a set of scenarios, each containing an MR and an equivalent sentence. Details of these datasets are given in Table 1. In preprocessing, the value of meaning labels that appear exactly in the text (such as the name, address, phone, postal code, and etc.) is replaced with a specific token both in the text and in the input MR. In this way, while reducing the size of the vocabulary, the information that influences the process of generating text becomes more compact. To perform postprocessing, these values were put back into place.
Table 1. Datasets statistics.
4.2. Experimental setups
The proposed models are implemented using the TensorFlow library and trained on Google Co-laboratory with one Tesla P100-PCIE-16 GB GPU. The hidden layer size and embedding dimensions are set to 80, the batch size is set to 100, and the generators were trained with a 70% of keep dropout rate. The models were initialized with pretrained word vectors GloVe (Pennington, Socher, and Manning, Reference Pennington, Socher and Manning2014) and optimized using Adam optimizer with a learning rate of 1e-3. This process is terminated by early stopping based on the validation loss. Moreover, for every five epochs, L2-regularization with
 $\lambda =1e-5$
is added to lose values. In the inference phase, beam search with width 10 is used and for each MR, 20 candidate sentences are over-generated, then the five top sentences are selected based on their negative log-likelihood values.Footnote a For fine-tuning GPT-2 and Transformer XL as a postprocessing module, we used the gpt2 and transfo-xl-wt103 pre-trained models in the Hugging Face library (Wolf et al., Reference Wolf, Debut, Sanh, Chaumond, Delangue, Moi, Cistac, Rault, Louf, Funtowicz, Davison, Shleifer, Platen, Ma, Jernite, Plu, Xu, Le Scao, Gugger, Drame, Lhoest and Rush2020) and trained them for five epochs with a learning rate of 5e-5 and batch size 16. The output sentences are then regenerated with beam width 10 and temperature 0.9 using fine-tuned models.
$\lambda =1e-5$
is added to lose values. In the inference phase, beam search with width 10 is used and for each MR, 20 candidate sentences are over-generated, then the five top sentences are selected based on their negative log-likelihood values.Footnote a For fine-tuning GPT-2 and Transformer XL as a postprocessing module, we used the gpt2 and transfo-xl-wt103 pre-trained models in the Hugging Face library (Wolf et al., Reference Wolf, Debut, Sanh, Chaumond, Delangue, Moi, Cistac, Rault, Louf, Funtowicz, Davison, Shleifer, Platen, Ma, Jernite, Plu, Xu, Le Scao, Gugger, Drame, Lhoest and Rush2020) and trained them for five epochs with a learning rate of 5e-5 and batch size 16. The output sentences are then regenerated with beam width 10 and temperature 0.9 using fine-tuned models.
To compare the performance of the proposed DM-NLG model with the pre-trained encoder–decoder models, we fine-tuned the T5 and BART models on all five datasets. For this purpose, the t5-base and bart-base models available in the Hugging Face Library were used and trained for five epochs with a learning rate of 5e-5 and batch size 16. The output sentences are then generated using these fine-tuned models with a beam width of 10.
4.3. Evaluation metrics
Performance of the proposed model on the Restaurant, Hotel, TV, and Laptop dataset was evaluated using BLEU-4 (Papineni et al., Reference Papineni, Roukos, Ward and Zhu2002), BERTScore (Zhang et al., Reference Zhang, Kishore, Wu, Weinberger and Artzi2020), and SER metrics. SER is defined as
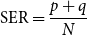 \begin{equation} \begin{aligned} &\text{SER}=\frac{p + q}{N}\\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &\text{SER}=\frac{p + q}{N}\\ \end{aligned} \end{equation}
where
 $N$
is the number of slots in the MR,
$N$
is the number of slots in the MR,
 $p$
, and
$p$
, and
 $q$
are the number of missing and redundant slots in the generated sentence (Wen et al., Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c). For the E2E and Personage datasets, BLEU-4, NIST (Martin and Przybocki, Reference Martin and Przybocki2000), METEOR (Lavie, Sagae, and Jayaraman, Reference Lavie, Sagae and Jayaraman2004), ROUGE-L (Lin, Reference Lin2004), SER, and BERTScore metrics are used.Footnote b For evaluating the diversity of generated text, Shannon Entropy is used as follows:
$q$
are the number of missing and redundant slots in the generated sentence (Wen et al., Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c). For the E2E and Personage datasets, BLEU-4, NIST (Martin and Przybocki, Reference Martin and Przybocki2000), METEOR (Lavie, Sagae, and Jayaraman, Reference Lavie, Sagae and Jayaraman2004), ROUGE-L (Lin, Reference Lin2004), SER, and BERTScore metrics are used.Footnote b For evaluating the diversity of generated text, Shannon Entropy is used as follows:
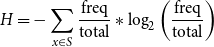 \begin{equation} \begin{aligned} &H=-\sum _{x \in S} \frac{\text{freq}}{\text{total}} * \log _2 \left(\frac{\text{freq}}{\text{total}}\right) \\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} &H=-\sum _{x \in S} \frac{\text{freq}}{\text{total}} * \log _2 \left(\frac{\text{freq}}{\text{total}}\right) \\ \end{aligned} \end{equation}
where
 $S$
is the set of unique words in all generated sentences by the model,
$S$
is the set of unique words in all generated sentences by the model,
 $freq$
is the number of times that a word occurs in all generated sentences, and
$freq$
is the number of times that a word occurs in all generated sentences, and
 $total$
is the number of words in all reference sentences (Oraby et al., Reference Oraby, Reed, Tandon, S., Lukin and Walker2018).
$total$
is the number of words in all reference sentences (Oraby et al., Reference Oraby, Reed, Tandon, S., Lukin and Walker2018).
We also ran human evaluation to evaluate the faithfulness (How many of the semantic units in the given sentence can be found/recognized in the given MR), coverage (How many of the given MRs slots values can be found/recognized in the given sentence), and fluency (whether the given sentence is clear, natural, grammatically correct, and understandable) of the generated sentences by our proposed model. For fluency, we asked the judges to evaluate the given sentence and then give it a score: 1 (with many errors and hardly understandable), 2 (with a few errors, but mostly understandable), and 3 (clear, natural, grammatically correct, completely understandable). To do this, 50 test MRs are selected randomly from each dataset. Also, as judges, 20 native English speakers (Fleiss’s
 $\kappa = 0.51$
, Krippen-dorff’s
$\kappa = 0.51$
, Krippen-dorff’s
 $\alpha = 0.59$
) are used. To avoid all bias, judges are shown one of the randomly selected MRs at a time, together with its gold sentence and the corresponding generated sentence by our model. Judges were not aware of which sentences were generated by our model.
$\alpha = 0.59$
) are used. To avoid all bias, judges are shown one of the randomly selected MRs at a time, together with its gold sentence and the corresponding generated sentence by our model. Judges were not aware of which sentences were generated by our model.
4.4. Baselines
We compared our proposed models against strong baselines including:
-
Gating-based models. HLSTM (Wen et al., Reference Wen, Gasic, Mrksic, Su, Vandyke and Young2015c) which uses a heuristic gate to ensure that all information was accurately expressed in the generated text; SCLSTM (Wen et al., Reference Wen, Gasic, Mrksic, Rojas Barahona, Su, Vandyke and Young2015b) which uses a sigmoid control gate to keep track of meaning labels in generating text; SRGRU-Context, ESRGRU-MUL, ESRGRU-INNER, and RALSTM (Tran et al., Reference Tran, Nguyen and Nguyen2017; Tran and Nguyen, Reference Tran and Nguyen2017, Reference Tran and Nguyen2019) which use different attention mechanisms for representing the input MR and then refining the input token based on this representation using a sigmoid gate.
-
Attention-based models. ENCDEC (Wen et al., Reference Wen, Gasic, Kim, Mrksic, Su, Vandyke and Young2015a) which applies the attention mechanism to an LSTM encoder–decoder; CONTEXT (Oraby et al., Reference Oraby, Reed, Tandon, S., Lukin and Walker2018) which uses a simple sequence-to-sequence with attention model; Fine-Control (Harrison et al., Reference Harrison, Reed, Oraby and Walker2019) which uses sequence-to-sequence with attention model and incorporates side constraint information into the generation process by adding additional inputs to the LSTM decoder; Seg&Align (Shen et al., Reference Shen, Chang, Su, Zhou and Klakow2020) which uses LSTM encoder-attention-decoder to first segments the text into small fragments and then learns the alignment between data and text segments.
-
Autoencoders. SCVAE (Tseng et al., Reference Tseng, Kreyssig, Budzianowski, Casanueva, Wu, Ultes and Gasic2018) which uses Conditional Variational autoencoder architecture to generate dialog sentences from semantic representations; VRALSTM and VNLG (Tran and Nguyen, Reference Tran and Nguyen2018a, Reference Tran and Nguyen2018b) which use Variational encoder–decoder based models designed to deal with low in-domain data; (Qader et al., Reference Qader, Portet and Labbe2019) work which uses two sequence-to-sequence models for understanding and generating learned jointly to compensate for the lack of annotation data.
-
Transformers. Chen et al. (Reference Chen, Eavani, Liu and Wang2020) which use the GPT-2 as generator and enabled it to switch between copying input and generating tokens; Chang et al. (Reference Chang, Shen, Zhu, Demberg and Su2021) which use data augmentation methods with GPT-2 language model; Lee (Reference Lee2021) which uses GPT-2 for generating sentences given the input MRs; SEA-GUIDE-T5-small, SEA-GUIDE-T5-based and SEA-GUIDE-BART-based (Juraska and Walker, Reference Juraska and Walker2021) which use a semantic attention-guided decoding method along beam search to reduce semantic errors in the output text.
5. Results and analysis
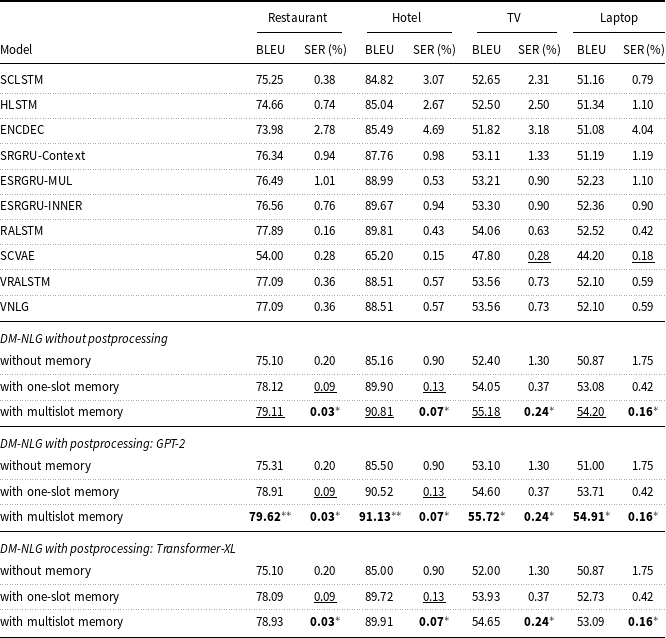
Tables 2 Footnote c, 3, 4 Footnote c, and 5 Footnote c contain the results of our proposed DM-NLG model, with and without postprocessing, along with the aforementioned baseline models on the Restaurant, Hotel, TV, Laptop, E2E, and Personage datasets. As can be seen, by adding memory to the attentional sequence-to-sequence model, SER is significantly decreased and BERTScore increased compared with attentional encoder–decoder autoencoder-based and transformer-based models indicating the improvement of the semantic and structural quality of the generated sentences by our proposed model. However, despite the fact that our proposed model has been able to get a high BERTScore and surpass all the basic models in terms of semantics and structure, its BLEU values are either less or slightly better than the baselines, except for the Personage dataset which baseline models were small and simple compared to our proposed model. This difference is due to the fact that n-gram-based metrics compare the hypothesis with a reference sentence based on its phrases, words, syntax, and length similarity. As a result, if the hypothesis sentence is completely correct in terms of semantics and structure but not similar in terms of used words and phrases, it gets a lower BLEU score.
Table 2. Performance of the baseline and the proposed DM-NLG model on Restaurant, Hotel, TV, and Laptop datasets in terms of BLEU and SER.
Measured by CIDEr and BLEU-4 (B4) scores.
 ${}^{\ast}$
and
${}^{\ast}$
and
 ${}^{\ast\ast}$
indicate statistically significant best results at p
${}^{\ast\ast}$
indicate statistically significant best results at p
 $\leq$
0.05 and p
$\leq$
0.05 and p
 $ \leq$
0.01, respectively, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
$ \leq$
0.01, respectively, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
Table 3. Performance of the proposed DM-NLG model on Restaurant, Hotel, TV, and Laptop datasets in terms of BERTScore.
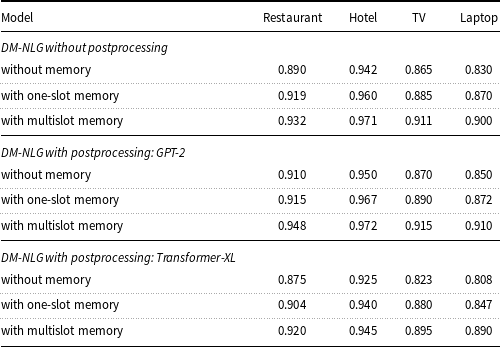
Table 4. Performance of the baseline and the proposed DM-NLG model on E2E dataset in terms of BLEU, NIST, METEOR, ROUGE-L, SER, and BERTScore.
The best and second-best models are highlighted in bold and underline face, respectively.
 ${}^{\ast}$
indicates statistically significant best results at p
${}^{\ast}$
indicates statistically significant best results at p
 $\leq$
0.05, for a paired t-test evaluation.
$\leq$
0.05, for a paired t-test evaluation.
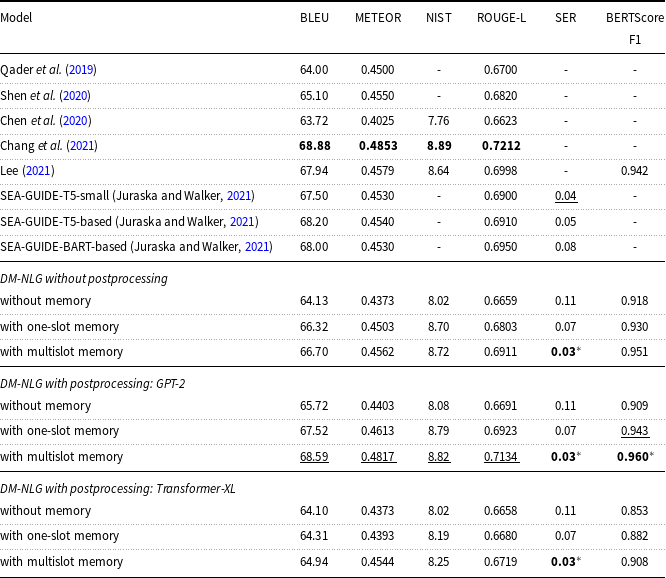
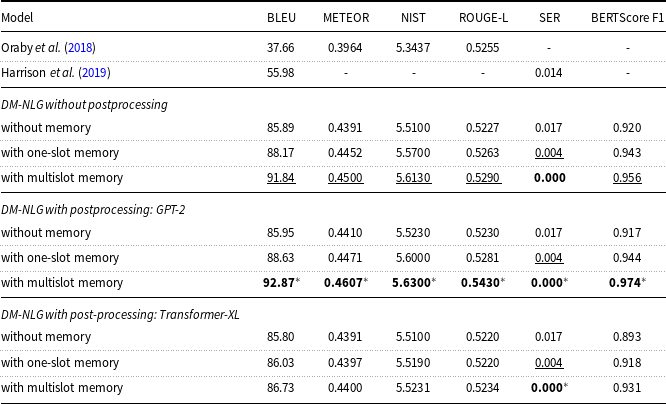
Table 5. Performance of the baseline and the proposed DM-NLG model on Personage dataset in terms of BLEU, NIST, METEOR, ROUGE-L, SER, and BERTScore.
 ${}^{\ast}$
indicates statistically significant best results at p
${}^{\ast}$
indicates statistically significant best results at p
 $\leq$
0.01, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
$\leq$
0.01, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
Based on Tables 2–5, using the GPT model as a booster of the quality of the generated sentences leads to a slight improvement in the value of the BERTScore evaluation metric. However, the Transformer-XL model reduces the quality of the output sentences, as it focuses more on learning the long dependencies between words and sentence segments, and given the number of model parameters (approximately twice as many as the GPT-2) and length of training sentences (30–40 tokens), the model tends to shorten sentences by expressing existing meaning labels only. It should be noted that since the generated sentences by DM-NLG are used as training data to fine-tune the GPT and the Transformer-XL models if there is any semantic error due to missing or redundant meaning labels expressed in these sentences, this error will also appear in the output sentences of the GPT and Transformer-XL and does not change the SER. Examples of the sentences generated by the decoder part of the DM-NLG and then regenerated by GPT and Transformer-XL are shown in Table 6. Moreover, the performance of the DM-NLG model without adding memory is close to other attention-based encoder–decoder models; but with the addition of memory to the model, the BERTScore metric improves and the SER decreases significantly. As mentioned earlier, the DM-NLG model with one-slot memory is initialized with the final hidden state of the encoder, which contains a compressed representation of the whole input MR. As a result, the decoder is aware of the history of previous alignments when generating the hidden state for the next token, resulting in a further reduction in the SER and improvement in BERTScore. When the information of each input meaning label is stored in different memory slots, the history of previous alignments is kept separately. Hence, the weights are more evenly distributed between the labels when reading memory, resulting in further reduction of SER and BERTScore improvement compared to the case where there is only one slot.
Table 6. Examples of generated sentences by DM-NLG with multislot memory and improved by GPT and Transformer-XL for given MRs from the Restaurant and Hotel datasets.

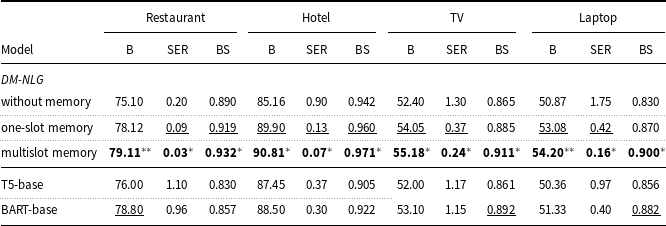
Table 7. Evaluation results on Restaurant, Hotel, TV and Laptop datasets, for proposed DM-NLG model, without postprocessing, compared to pretrained encoder–decoder transformer-based models, in terms of BLEU (B), SER, and BERTScore-F1 (BS).
 ${}^{\ast}$
and
${}^{\ast}$
and
 ${}^{\ast\ast}$
indicate statistically significant best results at p
${}^{\ast\ast}$
indicate statistically significant best results at p
 $\leq$
0.05 and p
$\leq$
0.05 and p
 $ \leq$
0.01, respectively, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
$ \leq$
0.01, respectively, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
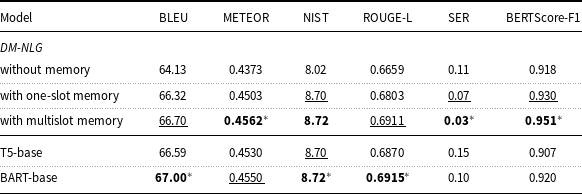
Table 8. Evaluation results on E2E dataset, for proposed DM-NLG model, without postprocessing, compared to pretrained encoder–decoder transformer-based models, in terms of BLEU, NIST, METEOR, ROUGE-L, SER, and BERTScore-F1.
 ${}^{\ast}$
indicates statistically significant best results at p
${}^{\ast}$
indicates statistically significant best results at p
 $\leq$
0.05, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
$\leq$
0.05, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
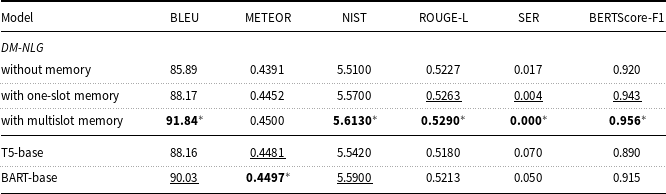
Table 9. Evaluation results on Personage dataset, for proposed DM-NLG model, without postprocessing, compared to pretrained encoder–decoder transformer-based models, in terms of BLEU, NIST, METEOR, ROUGE-L, SER, and BERTScore-F1.
 ${}^{\ast}$
indicates statistically significant best results at p
${}^{\ast}$
indicates statistically significant best results at p
 $\leq$
0.05, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
$\leq$
0.05, for a paired t-test evaluation. The best and second-best models are highlighted in bold and underline face, respectively.
Tables 7–9 show the results obtained by comparing the performance of the transformer-based encoder–decoder models with the proposed DM-NLG model without the postprocessing step. For this purpose, we fine-tuned the T5-base and BART-base models on the training dataset and examined the quality of sentences generated by these models by automated evaluation metrics. As can be seen, for the proposed model, the values of SER are less and the values of BERTScore are higher than the fine-tuned models indicating that the proposed model is well able to control the flow of input MRs information at the output text. This is why, although transformer-based models are trained on large volumes of text and then fine-tuned on training data, the values obtained for n-gram-based evaluation metrics are also close to each other. Therefore, it can be concluded that the proposed model has a good ability to generate text from structured data, especially despite having a smaller number of trainable parameters.
Table 10. Performance of our proposed model on six datasets in terms of Shannon Text Entropy.
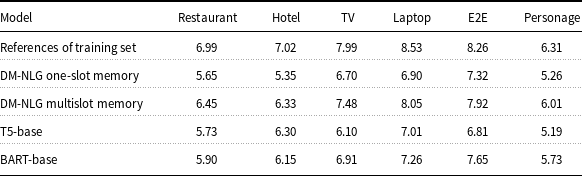
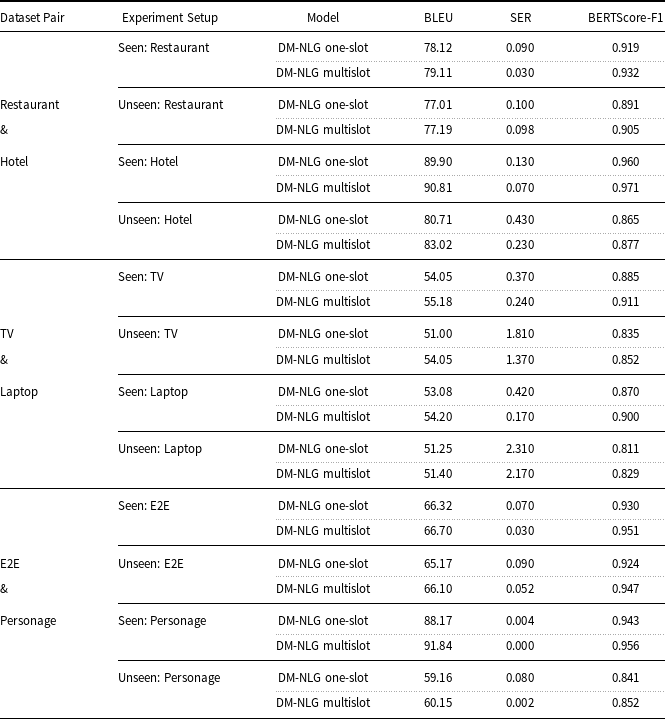
Table 11. Performance of proposed models without postprocessing on seen and unseen data. in terms of BLEU, SER, and BERTScore.
For all datasets, we evaluated the amount of variation in the training set, and also in the output generated text by the proposed model and fine-tuned BART and T5 using entropy (Equation 9), where the larger entropy value indicates a larger amount of linguistic variation in the generated outputs. The results are shown in Table 10. It is noticed that the highest entropy value is related to the training sets, and none of the models are able to match their variability. However, the small difference between the entropy value of the generated and training sentences for the different datasets shows the ability of the proposed model to produce texts with appropriate variations.
To evaluate the performance of the proposed model on unseen data, we designed an experiment in which the DM-NLG model is trained on one data set and tested on another. Due to the shared meaning labels between the Hotel and Restaurant datasets, TV, and Laptop datasets, as well as E2E and Personage datasets, we performed this test individually on these sets of data, so that in each set one was used as training data and the other as test data. The performance comparisons are shown in Table 11. As observed, for all sets of data, the BLEU and BERTScore decreased and SER is increased, respectively. These differences are larger when the Hotel and Laptop domains are used as unseen datasets due to the different distributions of unshared meaning labels in the test scenarios of each one. Both E2E and Personage datasets have the same meaning labels. The Personage dataset only has one additional personality tag that specifies the style of the sentences. When E2E and Personage are used as training and test sets, respectively, the trained model does not have the ability to mimic the personality style of sentences. As a result, the value of the BLEU and BERTScore is greatly reduced although SER has not changed much. Conversely, when Personage is used as training data, the model can generate descriptive sentences well for E2E datasets input MRs, and therefore, the BLEU and BERTScore decrease slightly. These results prove that our proposed model also can adapt to a new, unseen dataset.
Table 12. Results of Human Evaluations on five used datasets in terms of Faithfulness, Coverage, and Fluency (rating out of 3).
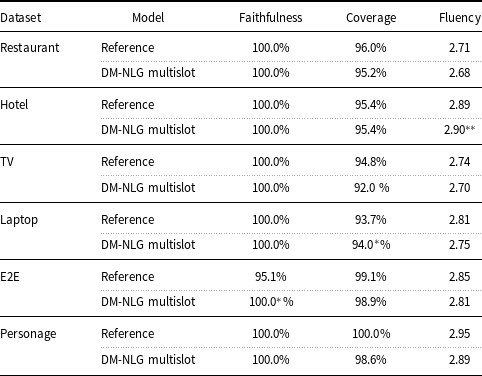
References are the golden truth sentences in each dataset.
 ${}^{\ast}$
and
${}^{\ast}$
and
 ${}^{\ast\ast}$
indicate statistically significant best results at p
${}^{\ast\ast}$
indicate statistically significant best results at p
 $\leq$
0.05, and p
$\leq$
0.05, and p
 $\leq$
0.01, for a paired t-test and ANOVA evaluation, respectively.
$\leq$
0.01, for a paired t-test and ANOVA evaluation, respectively.
Table 13. Comparison of the generated sentences from the Laptop dataset for the DM-NLG model without postprocessing and baselines.
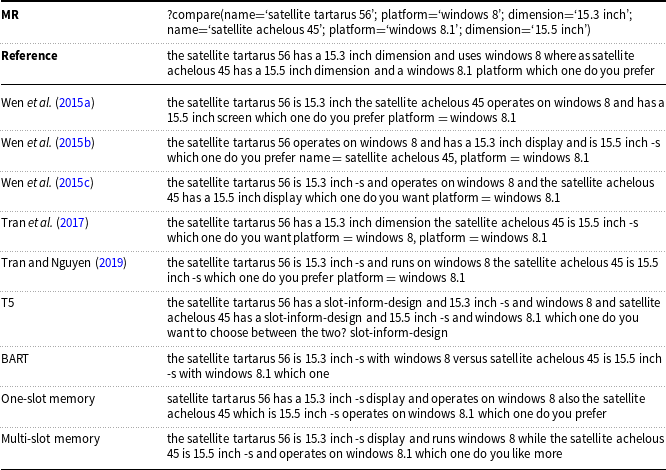
The missed and redundant meaning labels for each generated sentence are shown in red and orange, respectively.
As subjective evaluations, we compared the output generated by our best-performing model, DM-NLG multislot along with postprocessing, with its gold reference. Table 12 shows the scores of each human evaluation metric for each dataset. The sentences generated by our model received high scores from the judges for all human evaluation metrics. It should be noted that, in the E2E dataset, there is a slot called food, which specifies what kind of food is served in the restaurant (Chinese, English, French, Indian, Italian, Japanese, and Fast Food). But for some MRs, instead of expressing types of foods, names of foods, like "wines and cheeses,” "cheeses, fruits and wines,” "snacks, wine and coffee,” "fish and chips,” and "pasta,” are mentioned in the reference sentences. Considering that the nationality of the food cannot be determined with certainty based on its name, the judges have considered such cases as a missing slot. For this reason, this data set has not received a full score for the coverage and faithfulness factors. Moreover, the scores of fluency of the proposed model are lower compared to the reference sentences (about 0.1 units), which is an acceptable difference considering that the reference sentences are written by humans. Examples of input MRs and sentences generated by our proposed model are given in Tables 13–15.
Table 14. Comparison of the generated sentences from the E2E dataset for the DM-NLG model without postprocessing and baselines.
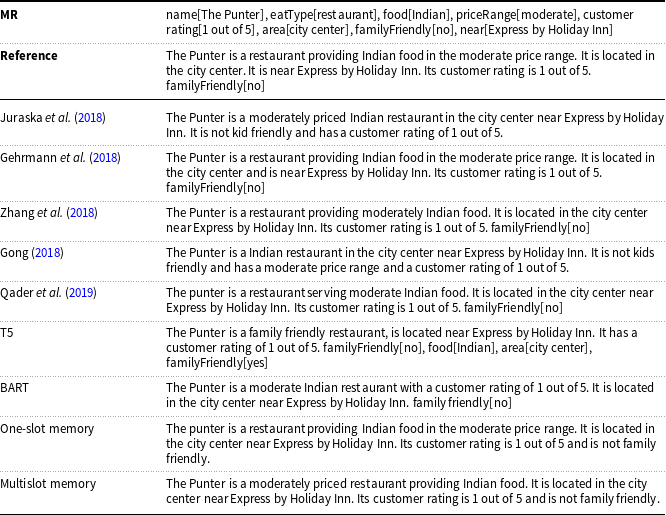
The missed and redundant meaning labels for each generated sentence are shown in red and orange, respectively.
Table 15. Comparison of the generated sentences from the Personage dataset for the DM-NLG multislot model without postprocessing and baselines.
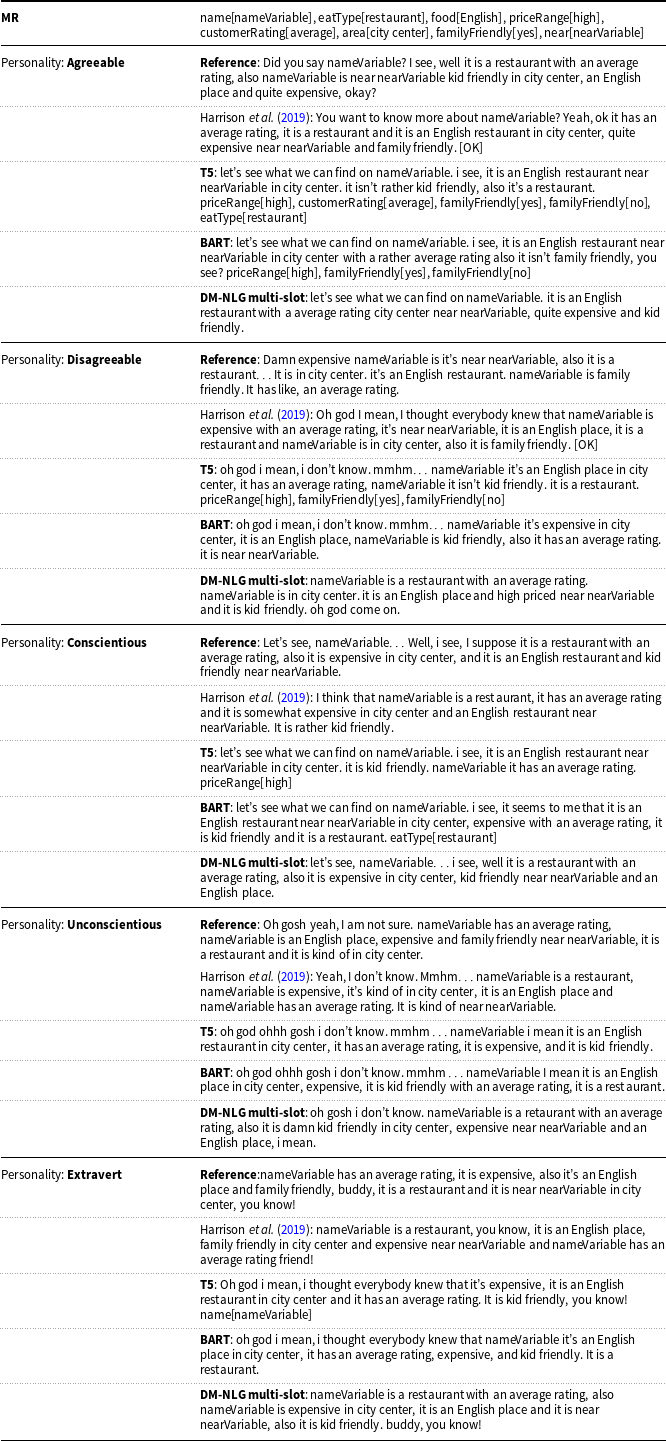
The missed, redundant, and duplicated meaning labels for each generated sentence are shown in red, orange, and blue, receptively.
6. Case study and visualization
As an intuitive way to show the performance of the DM-NLG model, Tables 13–15 show samples of generated texts for certain MRs from the Laptop, E2E, and Personage datasets by our model without doing postprocessing. The input MR selected from the Laptop domain relates to the comparison of two different models of laptops, so it includes duplicate labels. The model should be able to express all these labels in the output sentence in a way that the concept of comparison is clearly recognizable in the generated sentence. As shown in Table 13, considering the concept of comparison, it can be said that text generated by our proposed model is close to the reference text by producing words such as “also” and “while.” The input MR selected from the E2E dataset has a label with a binary value, so the model should be able to express this concept in the output sentence. The output generated by our model successfully expressed all labels. Finally, the input MR selected from the Personage dataset also has a label with a binary value, but the main task is generating sentences that describe the input MRs with different types of personality. As can be seen in Table 15, our proposed model is able to produce the equivalent text of each personality label correctly.
The heat map in Figure 2 shows the average value of the forget gate of the memory writing module (Equation 4) and attention weights (Equation 3) for a sentence from the Laptop dataset generated by the DM-NLG one-slot model. The horizontal and vertical axes show the generated sentence and the input MR, respectively. The darker color reveals a higher value while the lighter part has a lower value. Figure 2 shows that, at the beginning of the word generation process based on the input MR, the value of the forgetting gate is smaller, meaning that the contents of the memory are changing. As it gets closer to the end of the sentence while expressing all the meaning labels in it, the value of the forget gate becomes larger, meaning that the contents of the memory no longer change. The attention weights assigned to the input labels after generating each word in the output also reflect the desirable effect of memory usage.
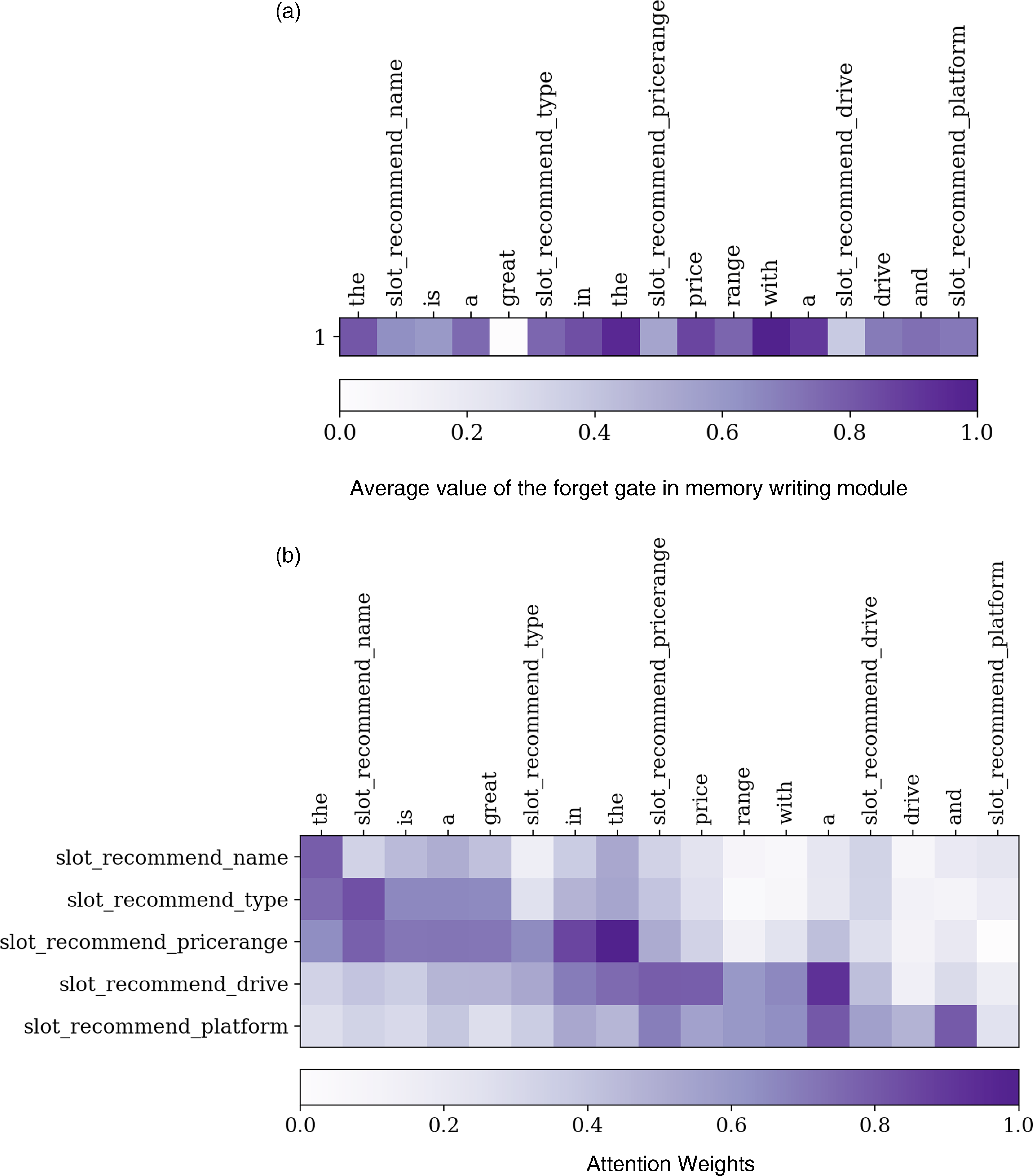
Figure 2. The change of the forget gate value of memory writing module (a) and the attention weights (b) for DM-NLG one-slot model after generating each word of the generated text for a given MR from the Laptop dataset.
The average value of the forgetting gate of the memory writing module, attention weights of the memory reading module (Equation 5), and attention weights for a sentence from the Laptop dataset generated by the DM-NLG multislot model are shown in Figure 3. Here too, the horizontal and vertical axes show the generated sentence and the input MR, respectively. In this model, for each memory cell, the value of the forget gate of writing modules changes according to its corresponding meaning labels expressed in the text. As can be seen in Figure 3a, the contents of memory slots corresponding to the name, type, and price range labels that appear at the beginning and middle of the text change more than the drive and platform labels that are expressed at the end of the sentence. Also, the uniform value of the forgetting gate from the middle of the sentence indicates that the change in the content of memory slots is balanced based on their previous step value and the new information. Furthermore, as observed in Figure 3b, at the beginning of the output generation, the weights that the memory reading module assigns to each slot have a nonuniform distribution, which indicates that some memory slots have more attention weights. But in the end, when the memory changes very slightly, these weights are evenly distributed, indicating that the contents of each memory slot corresponding to each meaning label are read in a balanced way. Weights calculated to the attention mechanism also show the same favorable effect on memory usage.
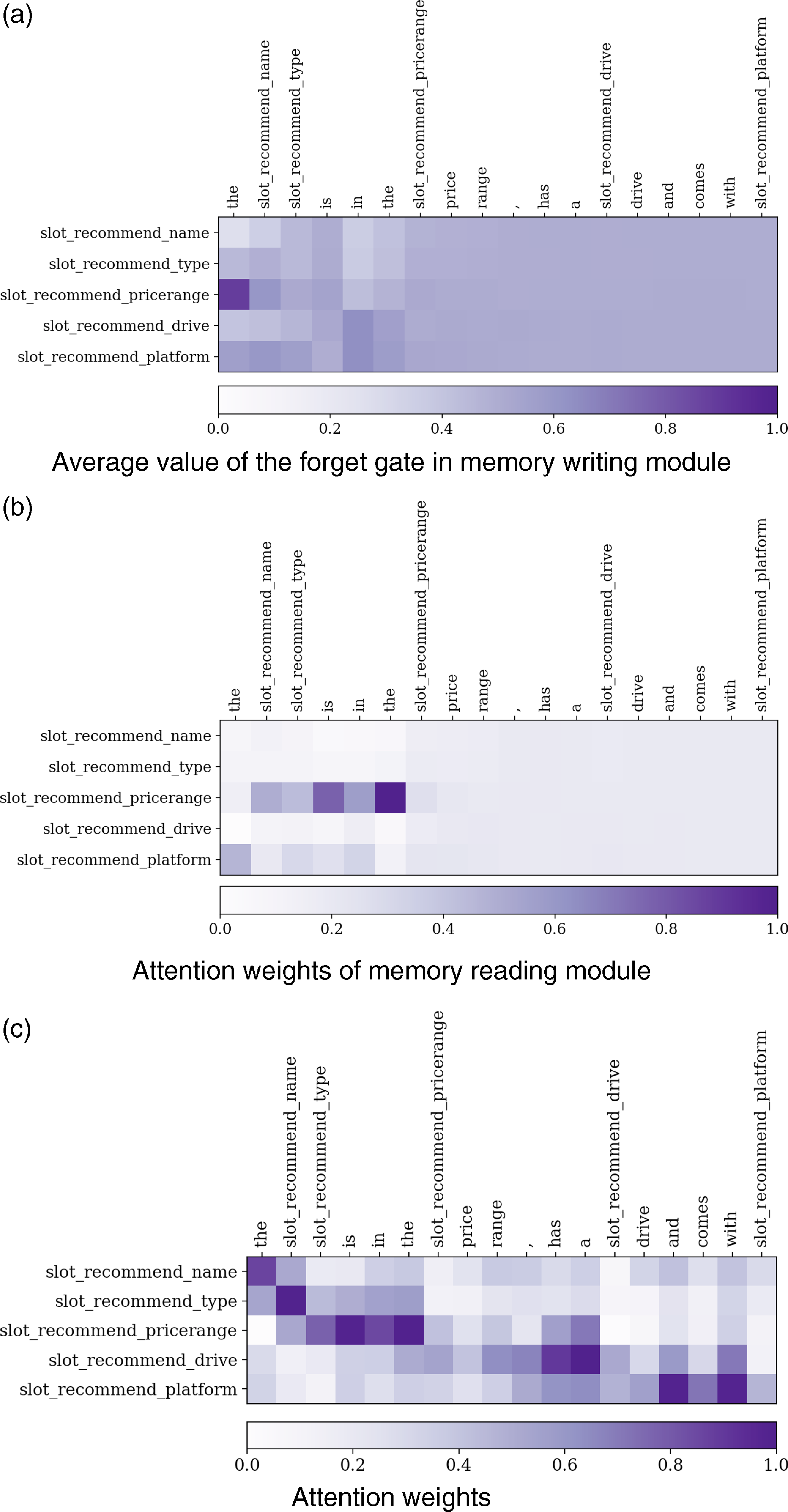
Figure 3. The change of the forget gate value in memory writing module (a), attention weights of memory reading module (b), and the attention weights (c) for DM-NLG multislot model after generating each word of the generated text for a given MR from the Laptop dataset.
7. Conclusion
In this paper, we presented our DM-NLG model to improve the performance of basic models based on the sequence-to-sequence structure in order to fully express the input information at the output. This model uses a dynamic memory that is initialized with the encoded input MR. The content of memory is rewritten and read based on the decoder’s hidden state of each generated word; in this way, the memory at any time step contains the history of information used to produce previous words, and this will prevent the generation of sentences with duplicate words or incomplete information. In this work, we considered two types of memories. In the first case, the memory has only one slot, which is initialized by the last encoder mode vector. In the second case, the number of memory slots is equal to the number of input meaning labels, and each slot is initialized by the hidden state of the encoder for its equivalent label. To improve the generated sentences quality by the decoder of DM-NLG, we used the pretrained language models which are first fine-tuned using training sentences and the generated training sentences by the DM-NLG model. Then each generated sentence for test data is regenerated by these fine-tuned models. To evaluate the performance of the proposed model versus the baseline models, we performed experiments on known datasets in the field of D2T. The subjective and objective metrics used for evaluation confirmed the superior performance of our proposed model. Also to compare the performance of the model in the case where we do not use memory versus the case where we use memory with one or more slots, we performed an experiment and its result showed that the quality of generated text will be better when multislot memory is used.



















 Open access
Open access