


1. Introduction
Named entity recognition (NER) is a subfield of information extraction that searches for and extracts named entities (NEs) such as locations, person names, organizations, and numbers from texts (Tjong Kim Sang and De Meulder Reference Tjong Kim Sang and De Meulder2003). With the rapid development in the field of machine learning, recent works on NER rely significantly on machine learning methods instead of grammar-based symbolic rules, with a particular focus on neural network algorithms. Numerous studies have been conducted on NER concerning several natural languages, including Carreras et al. (Reference Carreras, Màrquez and Padró2003) for Catalan, Li and McCallum (Reference Li and McCallum2003) for Hindi, Nouvel et al. (Reference Nouvel, Antoine, Friburger and Soulet2013) and Park (Reference Park2018) for French, Benikova, Biemann, and Reznicek (Reference Benikova, Biemann and Reznicek2014); Benikova et al. (Reference Benikova, Yimam, Santhanam and Biemann2015) for German, and Ahmadi and Moradi (Reference Ahmadi and Moradi2015) for Persian. There have also been language-independent multilingual models proposed (Tjong Kim Sang and De Meulder Reference Tjong Kim Sang and De Meulder2003; Nothman et al. Reference Nothman, Ringland, Radford, Murphy and Curran2013; Hahm et al. Reference Hahm, Park, Lim, Kim, Hwang and Choi2014). However, NER for the Korean language has not been explored thoroughly in previous research. This is partially because NE detection in Korean is difficult, as the language does not utilize specific features existing in some other languages such as capitalization to emphasize NEs (Chung, Hwang, and Jang Reference Chung, Hwang and Jang2003). There have been studies and attempts on this topic, one of the examples being an hidden Markov model (HMM)-based co-trained model in which co-training boosts the performance of HMM-based NE recognition (Chung et al. Reference Chung, Hwang and Jang2003). Recently, neural methods have been applied to the NER tasks of Korean, which include Bi-long short-term memory (LSTM)-conditional random field (CRF) with masked self-attention (Jin and Yu Reference Jin and Yu2021), as well as Bidirectional Encoder Representations from Transformers (BERT) (Kim and Lee Reference Kim and Lee2020). Such approaches require annotated corpora of high quality, which are usually difficult to source for Korean.
Although gold standard corpora, such as CoNLL-03 (Tjong Kim Sang and De Meulder Reference Tjong Kim Sang and De Meulder2003), are still not available for the Korean language, it is probable that by constructing silver standard corpora with automatic approaches, both NE annotation and NER modeling can be handled decently. A silver standard NE corpus in which NE annotations are completed automatically has been constructed based on Wikipedia and DBpedia Ontology including Korean (Hahm et al. Reference Hahm, Park, Lim, Kim, Hwang and Choi2014). This high-quality corpus outperforms the manually annotated corpus. On the other hand, there have been new attempts that build a Korean NER open-source dataset based on the Korean Language Understanding Evaluation (KLUE) project (Park et al. Reference Park, Moon, Kim, Cho, Han, Park, Song, Kim, Song, Oh, Lee, Oh, Lyu, Jeong, Lee, Seo, Lee, Kim, Lee, Jang, Do, Kim, Lim, Lee, Park, Shin, Kim, Park, Oh, Ha and Cho2021). KLUE’s NER corpus is built mainly with the WIKITREE corpus,Footnote a which is a body of news articles containing several types of entities.
Due to the linguistic features of the NE in Korean, conventional eojeol-based segmentation, which makes use of whitespaces to separate phrases, does not produce ideal results in NER tasks. Most language processing systems and corpora developed for Korean use eojeol delimited by whitespaces in a sentence as the fundamental unit of text analysis in Korean. This is partially because the Sejong corpus, the most widely used corpus for Korean, employs eojeol as the basic unit. The rationale of eojeol-based processing is simply treating the words as they are in the surface form. It is necessary for a better format and a better annotation scheme for the Korean language to be adapted. In particular, a word should be split into its morphemes.
To capture the language-specific features in Korean and utilize them to boost the performances of NER models, we propose a new morpheme-based scheme for Korean NER corpora that handles NE tags on the morpheme level based on the CoNLL-U format designed for Korean, as in Park and Tyers (Reference Park and Tyers2019). We also present an algorithm that converts the conventional Korean NER corpora into the morpheme-based CoNLL-U format, which includes not only NEs but also the morpheme-level information based on the morphological segmentation. The contributions of this study for Korean NER are as follows: (1) An algorithm is implemented in this study to convert the Korean NER corpora to the proposed morpheme-based CoNLL-U format. We have investigated the best method to represent NE tags in the sentence along with their linguistic properties and therefore developed the conversion algorithm with sufficient rationales. (2) The proposed Korean NER models in the paper are distinct from other systems since our neural system is simultaneously trained for part-of-speech (POS) tagging and NER with a unified, continuous representation. This approach is beneficial as it captures complex syntactic information between NE and POS. This is only possible with a scheme that contains additional linguistic information such as POS. (3) The proposed morpheme-based scheme for NE tags provides a satisfying performance based on the automatically predicted linguistic features. Furthermore, we thoroughly investigate various POS types, including the language-specific XPOS and the universal UPOS (Petrov, Das, and McDonald Reference Petrov, Das and McDonald2012) and determine the type that has the most effect. We demonstrate and account for the fact that the proposed BERT-based system with linguistic features yields better results over those in which such linguistic features are not used.
In this paper, we summarize previous work on Korean NER in Section 3 and present a linguistic description of NEs in Korean in Section 2, focusing on the features that affect the distribution of NE tags. We further provide a methodology for representing NEs in Korean in Section 4. Subsequently, we introduce morphologically enhanced Korean NER models which utilize the predicted UPOS and XPOS features in Section 5. To evaluate the effect of the proposed method, we test the proposed morpheme-based CoNLL-U data with NE tags using three different models, namely CRF, RNN-based, and BERT-based models. We provide detailed experimental results of NER for Korean, along with an error analysis (Sections 6 and Section 7). Finally, we present the conclusion (Section 9).
2. Linguistic description of NEs in Korean
2.1. Korean linguistics redux
Korean is considered to be an agglutinative language in which functional morphemes are attached to the stem of the word as suffixes. The language possesses a subject-object-verb (SOV) word order, which means the object precedes the verb in a sentence. This is different from English grammar where the object succeeds the verb in a sentence. Examples from Park and Kim (Reference Park and Kim2023) are presented as follows.
-
(1)


Two properties of the Korean language are observed. While Korean generally follows the SOV word order (1a), scrambling may occur from time to time which shifts the order of the subject and the object. Moreover, the postpositions in Korean, such as the nominative marker -i in (1a) and (1b), follow the stems to construct words, but there are also words in Korean that take no postposition, such as the subject jon (“John”) as presented in (l11).
Another notable property of Korean is its natural segmentation, namely eojeol. An eojeol is a segmentation unit separated by space in Korean. Given that Korean is an agglutinative language, joining content and functional morphemes of words (eojeols) is very productive, and the number of their combinations is exponential. We can treat a given noun or verb as a stem (also content) followed by several functional morphemes in Korean. Some of these morphemes can, sometimes, be assigned its syntactic category. Let us consider the sentence in (2). Unggaro (“Ungaro”) is a content morpheme (a proper noun) and a postposition -ga (nominative) is a functional morpheme. They form together a single eojeol (or word) unggaro-ga (“Ungaro+nom”). The nominative case markers -ga or -i may vary depending on the previous letter – vowel or consonant. A predicate naseo-eoss-da also consists of the content morpheme naseo (“become”) and its functional morphemes, -eoss (“past”) and -da (“decl”), respectively.
-
(2)

2.2. NEs in Korean
Generally, the types of NE in Korean do not differ significantly from those in other languages. NE in Korean consists of person names (PER), locations (LOC), organizations (ORG), numbers (NUM), dates (DAT), and other miscellaneous entities. Some examples of NE in Korean are as follows:
-
• PER:
ichangdong (“Lee Chang-dong,” a South Korean film director) -
• LOC:
jeju (“Jeju Island”) -
• ORG:
seouldaehaggyo (“Seoul National University”)
While NEs can appear in any part of the sentence, they typically occur with certain distributions with regard to the postpositions that follow the NEs. Figure 1 presents the overall distribution of the postpositions after NEs, whereas Table 2 lists the percentage of the postpositional markers with respect to three types of typical NEs, namely PER, ORG, and LOC, based on NAVER’s Korean NER dataset.Footnote b For instance, a PER or an ORG is often followed by a topic marker eun/neun (JX), a subject marker -i/-ga (JKS), or an object marker -eul/-leul (JKO). As detailed in Table 2, the percentages of JX, JKS, and JKO after ORG and PER are sufficiently high for us to make this conclusion, considering that in several cases, NEs are followed by other grammatical categories (e.g., noun phrases), which takes up high percentages (58.92% for LOC, 60.13% for ORG, and 66.72% for PER). Moreover, a PER or an ORG tends to occur at the front of a sentence, which serves as its subject. Higher percentages of occurrences of JX and JKS than JKO after ORG and PER prove this characteristic. Meanwhile, a LOC is typically followed by an adverbial marker (JKB) such as -e (locative “to”), -eseo (“from”), or -(eu)ro (“to”), because the percentage of JKB after LOC is considerably higher.
Table 1. XPOS (Sejong tag set) introduced in the morpheme-based CoNLL-U data converted from NAVER’s NER corpus and its type of named entities.

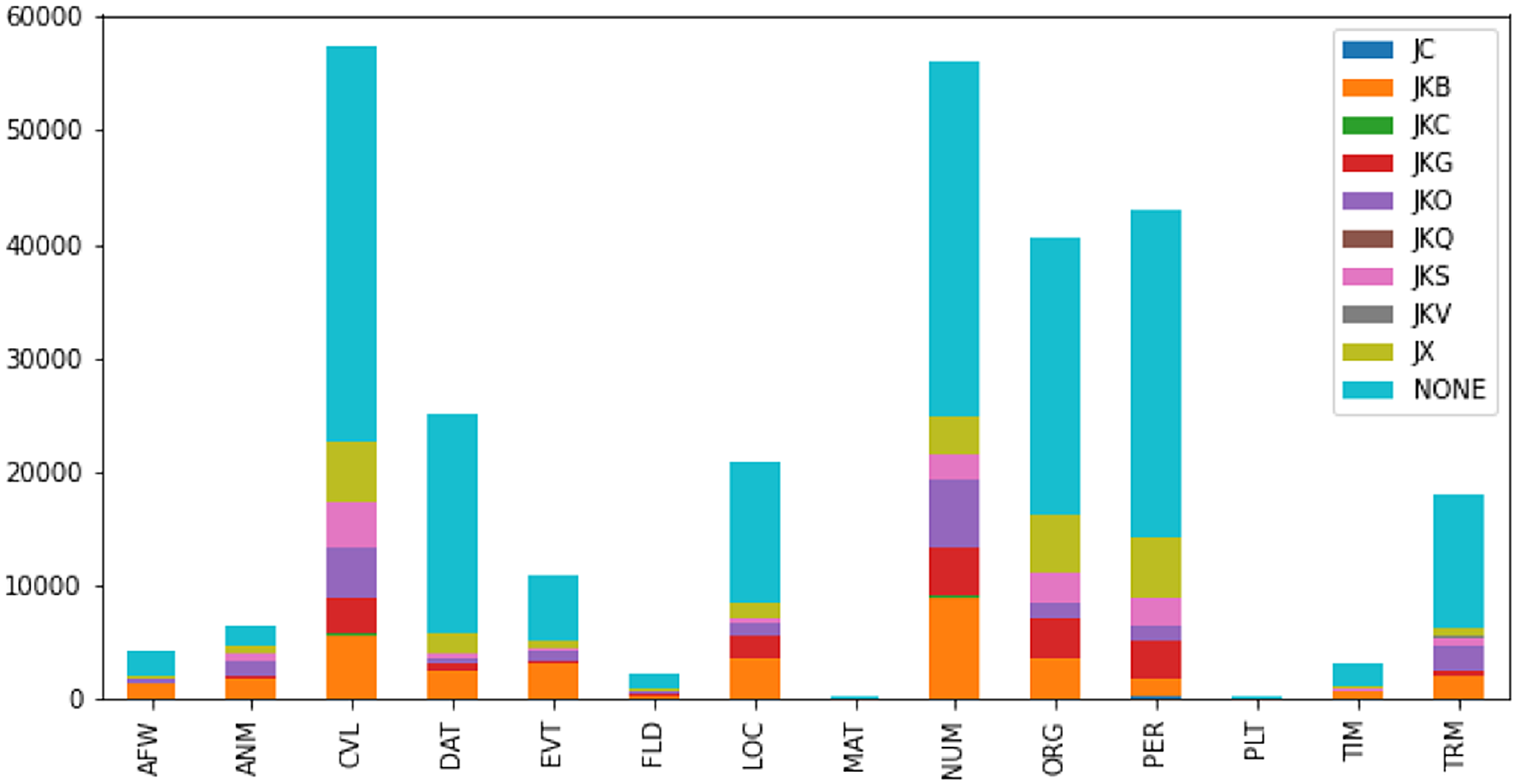
Figure 1. Distribution of each type of postposition/particle after NEs (NER data from NAVER). The terms and notations in the figure are described in Table 1.
As mentioned in Section 1, NE in the Korean language is considered to be difficult to handle compared to Latin alphabet-based languages such as English and French. This is mainly because of the linguistic features of NE in Korean. The Korean language has a unique phonetic-based writing system known as hangul, which does not differentiate lowercase and uppercase. Nor does it possess any other special forms or emphasis regarding NEs. Consequently, an NE in Korean, through its surface form, makes no difference from a non-NE word. Because the Korean writing system is only based on its phonological form owing to the lack of marking on NE, it also creates type ambiguities when it comes to NER.
Another feature of NE in Korean is that the natural segmentation of words or morphemes does not always represent NE pieces. The segmentation of Korean is based on eojeol, and each eojeol contains not only a specific phrase as a content morpheme but also postpositions or particles that are attached to the phrase as functional morphemes, which is typical in agglutinative languages. Normally, Korean NEs only consist of noun phrases and numerical digits. But under special circumstances, a particle or a postposition could be part of the NE, such as the genitive case maker -ui. Moreover, an NE in Korean does not always consist of only one eojeol. In Korean, location and organization can be decomposed into several eojeols (Yun Reference Yun2007), which implies that there is no one-to-one correspondence with respect to a Korean NE and its eojeol segment.
Table 2. Percentage (%) of occurrences of JKB/JKO/JKS/JX among all types of parts-of-speech after LOC/ORG/PER (NER data from NAVER).
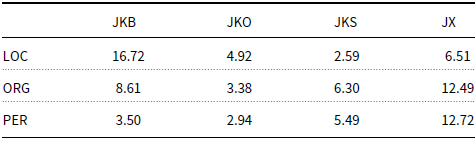

Figure 2. Various approaches of annotation for named entities (NEs): the eojeol-based approach annotates the entire word, the morpheme-based annotates only the morpheme and excludes the functional morphemes, and the syllable-based annotates syllable by syllable to exclude the functional morphemes.
Therefore, the main difficulties in Korean NEs are as follows: (1) NEs in Korean are not marked or emphasized, which requires other features from adjacent words or the entire sentence to be used; (2) in a particular eojeol segment, one needs to specify the parts of this segmentation that belong to the NE, and within several segments, one needs to determine the segments that correspond to the NE.
3. Previous work
As a sequence-labeling task, Korean NER aims at assigning tags based on the boundary of the morphemes or the eojeols (words or phrases separated by whitespaces in Korean). Thus, two major approaches, namely morpheme- and eojeol-based NER, have been proposed depending on their corresponding target boundary. The morpheme-based approach separates the word into a sequence of morphemes for detection of the NE, and accordingly, the recognized NE is the sequence of morphemes itself. The eojeol-based approach, on the other hand, uses the word (or eojeol) as the basic unit for detection of the NE, and the recognized entity may contain extra morphemes such as functional morphemes (e.g. the case marker) which should be excluded from the NE. However, this post-processing task has been ignored in the eojeol-based system. Apart from the two major approaches described above, some Korean NER datasets also adopt the syllable-based annotation approach which splits Korean texts into syllables and assigns NE tags directly on the syllables. Although the target boundaries of NER tasks between these approaches differ considerably, the statistical and neural systems for performing NER remain identical for both approaches as they both rely on the sequence-labeling algorithm. Figure 2 illustrates various annotation approaches for NEs in Korean, including eojeol, morpheme, and syllable.
The morpheme-based approach has been adopted in the publicly available Korean Information Processing System (KIPS) corpora in 2016 and 2017. The two corpora consist of 3660 and 3555 sentences, respectively, for training.Footnote c Since the extraction targets of the morpheme-based NER are NEs on the morpheme level, it requires a morphological analyzer to be used in the pre-processing step based on the input sentence. Yu and Ko (Reference Yu and Ko2016) proposed a morpheme-based NER system using a bidirectional LSTM-CRFs, in which they applied the morpheme-level Korean word embeddings to capture features for morpheme-based NEs on news corpora. Previous works such as Lee et al. (Reference Lee, Park and Kim2018) and Kim and Kim (Reference Kim and Kim2020) also used the same morpheme-based approach. In these studies, the morphological analysis model was integrated into NER. However, for the morpheme-based NER, considerable performance degradation occurs when converting eojeols into morphemes. To mitigate this performance gap between morpheme- and eojeol-based NER, Park et al. (Reference Park, Park, Jang, Choi and Kim2017a) proposed a hybrid NER model that combined eojeol- and morpheme-based NER systems. The proposed eojeol- and morpheme-based NER systems yield the best possible NER candidates based on an ensemble of both predicted results using bidirectional gated recurrent units combined with CRFs.
In the last few years, studies on Korean NER have been focusing on eojeol-based NER because such datasets have become more widely available, including NAVER’s NER corpus which was originally prepared for a Korean NER competition in 2018.Footnote d In eojeol-based Korean NER tasks, the transformer-based model has been dominant because of its outstanding performance (Min et al. Reference Min, Na, Shin and Kim2019; Kim, Oh, and Kim Reference Kim, Oh and Kim2020; You et al. Reference You, Song, Kim, Yun and Cheong2021). Various transformer-based approaches, such as adding new features including the NE dictionary in a pre-processing procedure (Kim and Kim Reference Kim and Kim2019) and adapting byte-pair encoding (BPE) and morpheme-based features simultaneously (Min et al. Reference Min, Na, Shin and Kim2019), have been proposed. Min et al. (Reference Min, Na, Shin, Kim and Kim2021) proposed a novel structure for the Korean NER system that adapts the architecture of Machine Reading Comprehension (MRC) by extracting the start and end positions of the NEs from an input sentence. Although the performance of the MRC-based NER is inferior to those using token classification methods, it shows a possibility that the NER task can be solved based on the span detection problem. Another notable approach for Korean NER is data argumentation. Cho and Kim (Reference Cho and Kim2021) achieved improvement in the performance of the Korean NER model using augmented data that replace tokens with the same NE category in the training corpus.
To avoid potential issues of the eojeol-based approach where additional morphemes that should be excluded from NEs may be included, syllable-based Korean NER corpus was proposed, such as in KLUE in 2021 (Park et al. Reference Park, Moon, Kim, Cho, Han, Park, Song, Kim, Song, Oh, Lee, Oh, Lyu, Jeong, Lee, Seo, Lee, Kim, Lee, Jang, Do, Kim, Lim, Lee, Park, Shin, Kim, Park, Oh, Ha and Cho2021). The NE tags in the corpus are annotated on the syllable level. For instance, the NE tags of the word “![]() ” (gyeongchal, “police”) are marked on the two syllables, namely
” (gyeongchal, “police”) are marked on the two syllables, namely ![]() gyeong bearing B-ORG and
gyeong bearing B-ORG and ![]() chal bearing I-ORG. Table 3 summarizes the currently available Korean NER datasets.
chal bearing I-ORG. Table 3 summarizes the currently available Korean NER datasets.
Table 3. Summary of publicly available Korean NER datasets.
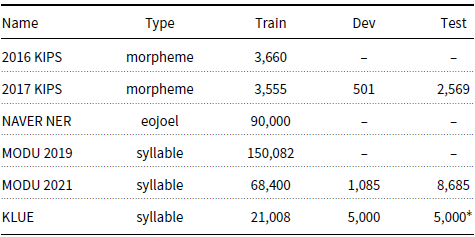
KIPS = Korean Information Processing System (DATE, LOC, ORG, PER, TIME); NAVER (14 entity labels, which we will describe in the next section); MODU (150 entity labels); KLUE = Korean Language Understanding Evaluation (KIPS’s 5 labels, and QUANTITY); *KLUE’s test dataset is only available through https://klue-benchmark.com/.
The morpheme-based approach in previous studies differs from the proposed method. In traditional morpheme-based approaches, only the sequences of morphemes are used, and there are no word boundaries displayed. This is because of the nature of the annotated KIPS corpus in which the tokens included are merely morphemes. Our proposed morpheme-based approach conforms to the current language annotation standard by using the CoNLL-U format and multiword annotation for the sequence of morphemes in a single eojeol, where morphemes and word boundaries are explicitly annotated. Limited studies have been conducted on the mechanism of efficiently annotating and recognizing NEs in Korean. To tackle this problem, an annotation scheme for the Korean corpus by adopting the CoNLL-U format, which decomposes Korean words into morphemes and reduces the ambiguity of NEs in the original segmentation, is proposed in this study. Morpheme-based segmentation for Korean has been proved beneficial. Many downstream applications for Korean language processing, such as POS tagging (Jung, Lee, and Hwang Reference Jung, Lee and Hwang2018; Park and Tyers Reference Park and Tyers2019), phrase-structure parsing (Choi, Park, and Choi Reference Choi, Park and Choi2012; Park, Hong, and Cha Reference Park, Hong and Cha2016; Kim and Park Reference Kim and Park2022), and machine translation (Park, Hong, and Cha, 2016, 2017b), are based on the morpheme-based segmentation, in which all morphemes are separated from each other. In these studies, the morpheme-based segmentation is implemented to avoid data sparsity because the number of possible words in longer segmentation granularity (such as eojeols) can be exponential given the characteristics of Korean, an agglutinative language. Since a morpheme-based dependency parsing system for Universal Dependencies with better dependency parsing results has also been developed (Chen et al. Reference Chen, Jo, Yao, Lim, Silfverberg, Tyers and Park2022), we are trying to create a consortium to develop the morphologically enhanced Universal Dependencies for other morphologically rich languages such as Basque, Finnish, French, German, Hungarian, Polish, and Swedish.
4. Representation of NEs for the Korean language
The current Universal Dependencies (Nivre et al., Reference Nivre, de Marneffe, Ginter, Goldberg, Hajic, Manning, McDonald, Petrov, Pyysalo, Silveira, Tsarfaty and Zeman2016, Reference Nivre, de Marneffe, Ginter, Hajič, Manning, Pyysalo, Schuster, Tyers and Zeman2020) for Korean uses the tokenized word-based CoNLL-U format. Addressing the NER problem using the annotation scheme of the Sejong corpus or other Korean language corpora is difficult because of the agglutinative characteristics of words in Korean.Footnote e They adopt the eojeol-based annotation scheme which cannot handle sequence-level morpheme boundaries of NEs because of the characteristics of agglutinative languages. For example, an NE emmanuel unggaro (person) without a nominative case marker instead of emmanuel unggaro-ga (“Emanuel Ungaro-nom”) should be extracted for the purpose of NER. However, this is not the case in previous work on NER for Korean.
We propose a novel approach for NEs in Korean by using morphologically separated words based on the morpheme-based CoNLL-U format of the Sejong POS tagged corpus proposed in Park and Tyers (Reference Park and Tyers2019), which has successfully obtained better results in POS tagging compared to using the word-based Sejong corpus. While Park and Tyers (Reference Park and Tyers2019) have proposed the morpheme-based annotation scheme for POS tags and conceived the idea of using their scheme on NER, they have not proposed any practical method to adopt the annotation scheme to NER tasks. As a result, existing works have not explored these aspects such as how to fit the NE tags to the morpheme-based CoNLL-U scheme and how the NEs are represented in this format. Our proposed format for NER corpora considers the linguistic characteristics of Korean NE, and it also allows the automatic conversion between the word-based format and the morpheme-based format.Footnote f Using the proposed annotation scheme in our work as demonstrated in Figure 3, we can directly handle the word boundary problem between content and functional morphemes while using any sequence labeling algorithms. For example, only peurangseu (“France”) is annotated as a NE (B-LOC) instead of peurangseu-ui (“France-gen”), and emmanuel unggaro (“Emanuel Ungaro-”) instead of emmanuel unggaro-ga (“Emanuel Ungaro-nom”) as B-PER and I-PER in Figure 3.
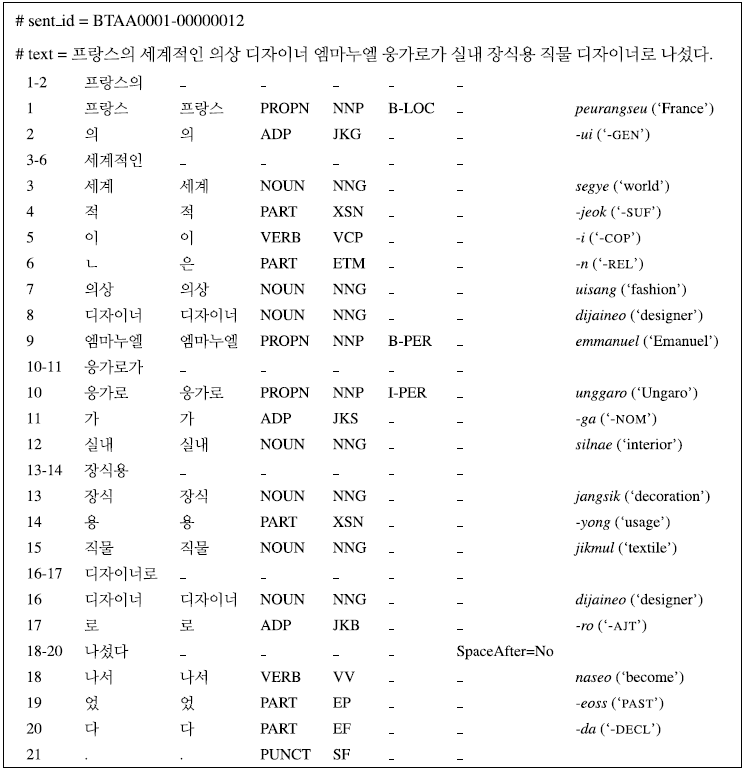
Figure 3. CoNLL-U style annotation with multiword tokens for morphological analysis and POS tagging. It can include BIO-based NER annotation where B-LOC is for a beginning word of location and I-PER for an inside word of person.
In the proposed annotation scheme, NEs are, therefore, no longer marked on the eojeol-based natural segmentation. Instead, each NE annotation corresponds to a specific set of morphemes that belong to the NE. Morphemes that do not belong to the NE are excluded from the set of the NE annotations and thus are not marked as part of the NE. As mentioned, this is achieved by adapting the CoNLL-U format as it provides morpheme-level segmentation of the Korean language. While those morphemes that do not belong to the NE are usually postpositions, determiners, and particles, this does not mean that all the postpositions, determiners, and particles are not able to be parts of the NE. An organization’s name or the name of an artifact may include postpositions or the name of an artifact may include postpositions or particles in the middle, in which case they will not be excluded. The following NE illustrates the aforementioned case:

The NE ![]() peuropesyeoneol-ui wonchik (“the principle of professional”) is the title of a book belonging to AFW (artifacts/works). Inside this NE, the genitive case marker -ui, which is a particle, remains a part of the NE. Because these exceptions can also be captured by sequence labeling, such an annotation scheme of Korean NER can provide a more detailed approach to NER tasks in which the NE annotation on eojeol-based segments can now be decomposed to morpheme-based segments, and purposeless information can be excluded from NEs to improve the performance of the machine learning process.
peuropesyeoneol-ui wonchik (“the principle of professional”) is the title of a book belonging to AFW (artifacts/works). Inside this NE, the genitive case marker -ui, which is a particle, remains a part of the NE. Because these exceptions can also be captured by sequence labeling, such an annotation scheme of Korean NER can provide a more detailed approach to NER tasks in which the NE annotation on eojeol-based segments can now be decomposed to morpheme-based segments, and purposeless information can be excluded from NEs to improve the performance of the machine learning process.
5. NER learning models
In this section, we propose our baseline and neural models that consider the state-of-the-art feature representations. NER is considered to be a classification task that classifies possible NEs from a sentence, and the previously proposed NER models are mostly trained in a supervised manner. In conventional NER systems, the maximum entropy model (Chieu and Ng Reference Chieu and Ng2003) and CRFs (McCallum and Li Reference McCallum and Li2003) are used as classifiers. Recently, neural network-based models with continuous word representations outperformed the conventional models in lots of studies (Lample et al. Reference Lample, Ballesteros, Subramanian, Kawakami and Dyer2016; Dernoncourt, Lee, and Szolovits Reference Dernoncourt, Lee and Szolovits2017; Strubell et al. Reference Strubell, Verga, Belanger and McCallum2017; Ghaddar and Langlais Reference Ghaddar and Langlais2018; Jie and Lu Reference Jie and Lu2019). In this study, we mainly present the neural network-based systems.
5.1. Baseline CRF-based model
The objective of the NER system is to predict the label sequence
 $Y=$
{
$Y=$
{
 $y_1, y_2,\ldots, y_n$
}, given the sequence of words
$y_1, y_2,\ldots, y_n$
}, given the sequence of words
 $X=$
{
$X=$
{
 $x_1, x_2,\ldots, x_n$
}, where
$x_1, x_2,\ldots, x_n$
}, where
 $n$
denotes the number of words. As we presented in Section 2,
$n$
denotes the number of words. As we presented in Section 2,
 $y$
is the gold label of the standard NEs (PER, LOC, and ORG). An advantage of CRFs compared to previous sequence labeling algorithms, such as HMMs, is that their features can be defined as per our definition. We used binary tests for feature functions by distinguishing between unigram (
$y$
is the gold label of the standard NEs (PER, LOC, and ORG). An advantage of CRFs compared to previous sequence labeling algorithms, such as HMMs, is that their features can be defined as per our definition. We used binary tests for feature functions by distinguishing between unigram (
 $f_{y,x}$
) and bigram (
$f_{y,x}$
) and bigram (
 $f_{y^{\prime},y,x}$
) features as follows:
$f_{y^{\prime},y,x}$
) features as follows:
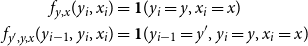 \begin{align*} f_{y,x} (y_i, x_i) & = \mathbf{1}(y_i = y, x_i = x) \\ f_{y^{\prime},y,x} (y_{i-1}, y_i, x_i) & = \mathbf{1}(y_{i-1} = y^{\prime}, y_i = y, x_i = x) \end{align*}
\begin{align*} f_{y,x} (y_i, x_i) & = \mathbf{1}(y_i = y, x_i = x) \\ f_{y^{\prime},y,x} (y_{i-1}, y_i, x_i) & = \mathbf{1}(y_{i-1} = y^{\prime}, y_i = y, x_i = x) \end{align*}
where
 $\mathbf{1}({condition})$
= 1 if the condition is satisfied and 0 otherwise. Here,
$\mathbf{1}({condition})$
= 1 if the condition is satisfied and 0 otherwise. Here,
 $({condition})$
represents the input sequence
$({condition})$
represents the input sequence
 $x$
at the current position
$x$
at the current position
 $i$
with CRF label
$i$
with CRF label
 $y$
. We used word and other linguistic information such as POS labels up to the
$y$
. We used word and other linguistic information such as POS labels up to the
 $\pm$
2-word context for each surrounding input sequence
$\pm$
2-word context for each surrounding input sequence
 $x$
and their unigram and bigram features.
$x$
and their unigram and bigram features.
5.2. RNN-based model
There have been several proposed neural systems that adapt the LSTM neural networks (Lample et al. Reference Lample, Ballesteros, Subramanian, Kawakami and Dyer2016; Strubell et al. Reference Strubell, Verga, Belanger and McCallum2017; Jie and Lu Reference Jie and Lu2019). These systems consist of three different parts. First, the word representation layer transforms the input sequence
 $X$
as a sequence of word representations. Second, the encoder layer encodes the word representation into a contextualized representation using RNN-based architectures. Third, the classification layer classifies NEs from the contextualized representation of each word.
$X$
as a sequence of word representations. Second, the encoder layer encodes the word representation into a contextualized representation using RNN-based architectures. Third, the classification layer classifies NEs from the contextualized representation of each word.
We construct our baseline neural model following Lample et al. (Reference Lample, Ballesteros, Subramanian, Kawakami and Dyer2016) by using pre-trained fastText word embedding (Bojanowski et al. Reference Bojanowski, Grave, Joulin and Mikolov2017; Grave et al. Reference Grave, Bojanowski, Gupta, Joulin and Mikolov2018) as the word representation layer and LSTM as the encoder layer. The overall structure of our baseline neural model is displayed in Figure 4.
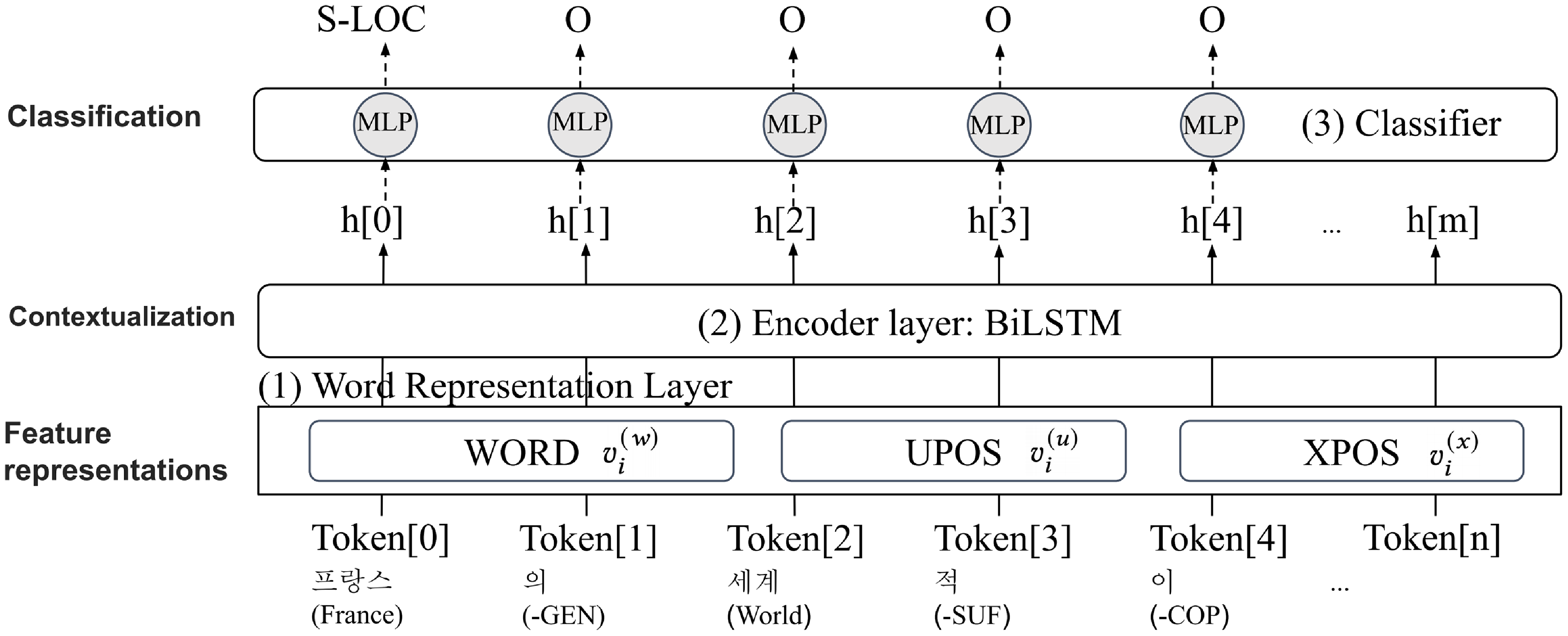
Figure 4. Overall structure of our RNN-based model.
Word representation layer. To train an NER system, the first step is to transform the words of each input sequence to the word vector for the system to learn the meaning of the words. Word2vec (Mikolov et al. Reference Mikolov, Sutskever, Chen, Corrado, Dean, Burges, Bottou, Welling, Ghahramani and Weinberger2013) and GloVe (Pennington, Socher, and Manning Reference Pennington, Socher and Manning2014) are examples of word representations. Word2Vec is based on the distributional hypothesis and generates word vectors by utilizing co-occurrence frequencies within a corpus. fastText, on the other hand, is an extension of the Word2Vec that incorporates subword information. Rather than treating each word as a discrete entity, fastText breaks words down into smaller subword units, such as character n-grams, and learns embeddings. This approach allows fastText to capture information about word morphology and handle out-of-vocabulary words more effectively than other methods.
Given an input word
 $x_i$
, we initialize word embedding
$x_i$
, we initialize word embedding
 $v^{(w)}_i$
using pre-trained fastText embeddings (Grave et al. Reference Grave, Bojanowski, Gupta, Joulin and Mikolov2018) provided by the 2018 CoNLL shared task organizer. Randomly initialized POS features, UPOS
$v^{(w)}_i$
using pre-trained fastText embeddings (Grave et al. Reference Grave, Bojanowski, Gupta, Joulin and Mikolov2018) provided by the 2018 CoNLL shared task organizer. Randomly initialized POS features, UPOS
 $v^{(u)}_i$
and XPOS
$v^{(u)}_i$
and XPOS
 $v^{(x)}_i$
are concatenated to
$v^{(x)}_i$
are concatenated to
 $v^{(w)}_i$
if available.
$v^{(w)}_i$
if available.
Encoder layer. The word embedding proposed in this study utilizes context-aware word vectors in a static environment. Therefore, in the NER domain we are using, it can be considered context-independent. For example, each word representation
 $v^{(w)}_i$
does not consider contextual words such as
$v^{(w)}_i$
does not consider contextual words such as
 $v^{(w)}_{i+1}$
and
$v^{(w)}_{i+1}$
and
 $v^{(w)}_{i-1}$
. Furthermore, since the POS features are also randomly initialized, there is an issue of not being able to determine the context. LSTMs are typically used to address the context-independent problem. The sequence of word embeddings is fed to a two-layered LSTM to transform the representation to be contextualized as follows:
$v^{(w)}_{i-1}$
. Furthermore, since the POS features are also randomly initialized, there is an issue of not being able to determine the context. LSTMs are typically used to address the context-independent problem. The sequence of word embeddings is fed to a two-layered LSTM to transform the representation to be contextualized as follows:
 \begin{eqnarray} h_i^{\text{(ner)}} = \text{BiLSTM}\left(r^{\text{(ner)}}_{0}, \left(v^{(w)}_{1},\ldots, v^{(w)}_{n}\right)\right)_{i} \end{eqnarray}
\begin{eqnarray} h_i^{\text{(ner)}} = \text{BiLSTM}\left(r^{\text{(ner)}}_{0}, \left(v^{(w)}_{1},\ldots, v^{(w)}_{n}\right)\right)_{i} \end{eqnarray}
where
 $r^{\text{(ner)}}_0$
represents the randomly initialized context vector, and
$r^{\text{(ner)}}_0$
represents the randomly initialized context vector, and
 $n$
denotes the number of word representations.
$n$
denotes the number of word representations.
Classification layer. The system consumes the contextualized vector
 $h^{\text{(ner)}}_i$
for predicting NEs using a multi-layer perceptron (MLP) classifier as follows:
$h^{\text{(ner)}}_i$
for predicting NEs using a multi-layer perceptron (MLP) classifier as follows:
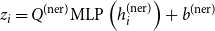 \begin{eqnarray} z_{i} = Q^{\text{(ner)}}\text{MLP}\left(h^{\text{(ner)}}_{i}\right) + b^{\text{(ner)}} \end{eqnarray}
\begin{eqnarray} z_{i} = Q^{\text{(ner)}}\text{MLP}\left(h^{\text{(ner)}}_{i}\right) + b^{\text{(ner)}} \end{eqnarray}
where MLP consists of a linear transformation with the ReLU function. The output
 $z_i$
is of size
$z_i$
is of size
 $1 \times k$
, where
$1 \times k$
, where
 $k$
denotes the number of distinct tags. We apply Softmax to convert the output,
$k$
denotes the number of distinct tags. We apply Softmax to convert the output,
 $z_i$
, to be a distribution of probability for each NE.
$z_i$
, to be a distribution of probability for each NE.
During training, the system learns parameters
 $\theta$
that maximize the probability
$\theta$
that maximize the probability
 $P(y_{i}|x_{i},\theta )$
from the training set
$P(y_{i}|x_{i},\theta )$
from the training set
 $T$
based on the conditional negative log-likelihood loss.
$T$
based on the conditional negative log-likelihood loss.
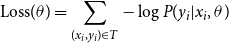 \begin{equation} \text{Loss}(\theta ) = \sum _{(x_{i},y_{i})\in T}-\log P(y_{i}|x_{i},\theta )\end{equation}
\begin{equation} \text{Loss}(\theta ) = \sum _{(x_{i},y_{i})\in T}-\log P(y_{i}|x_{i},\theta )\end{equation}
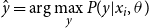 \begin{equation}\hat{y}= \arg \max _{y}P(y|x_{i},\theta ) \end{equation}
\begin{equation}\hat{y}= \arg \max _{y}P(y|x_{i},\theta ) \end{equation}
where
 $\theta$
represents all the aforementioned parameters, including
$\theta$
represents all the aforementioned parameters, including
 $Q^{\text{(ner)}}$
,
$Q^{\text{(ner)}}$
,
 $\text{MLP}^{\text{(ner)}}$
,
$\text{MLP}^{\text{(ner)}}$
,
 $b^{\text{(ner)}}$
, and
$b^{\text{(ner)}}$
, and
 $\text{BiLSTM}$
.
$\text{BiLSTM}$
.
 $(x_{i},y_{i})\in T$
denotes input data from training set
$(x_{i},y_{i})\in T$
denotes input data from training set
 $T$
, and
$T$
, and
 $y_{i}$
represents the gold label for input
$y_{i}$
represents the gold label for input
 $x_{i}$
.
$x_{i}$
.
 $\hat{y}=\arg \max _{y}P(y|x_{i},\theta )$
is a set of predicted labels.
$\hat{y}=\arg \max _{y}P(y|x_{i},\theta )$
is a set of predicted labels.
It is common to replace the MLP-based classifiers with the CRF-based classifiers because the possible combinations of NEs are not considered in MLP. Following the baseline CRF model, we also implemented CRF models on top of LSTM output
 $h$
as the input of CRF. The performance of the CRFs and MLP classifiers is investigated in Section 7.
$h$
as the input of CRF. The performance of the CRFs and MLP classifiers is investigated in Section 7.
5.3. BERT-based model
As mentioned in the previous section, the word vectors we used were trained in a static environment, which led to a lack of context information. To address this issue, a system should model the entire sentence as a source of contextual information. Consequently, the word representation method has been rapidly adjusted to adapt new embeddings trained by a masked language model (MLM). The MLM randomly masks some of the input tokens and predicts the masked word by restoring them to the original token. During the prediction stage, the MLM captures contextual information to make better predictions.
Recent studies show that BERT trained by bidirectional transformers with the MLM strategy achieved outperforming results in many NLP tasks proposed in the General Language Understanding Evaluation (GLUE) benchmark (Wang et al. Reference Wang, Singh, Michael, Hill, Levy and Bowman2018). Since then, several transformer-based models have been proposed for NLP, and they show outstanding performances over almost all NLP tasks. In this section, we propose an NER system that is based on the new annotation scheme and apply the multilingual BERT and XLM-RoBERTa models to the Korean NER task.
BERT representation layer. BERT’s tokenizer uses a WordPiece-based approach, which breaks words into subword units. For example, the word “snowing” is divided into “snow” and “##ing”. In contrast, the XLM-RoBERTa tokenizer uses a BPE-based approach (Sennrich, Haddow, and Birch Reference Sennrich, Haddow and Birch2016), which can produce more subwords than the WordPiece approach. XLM-RoBERTa uses bidirectional modeling to check context information and uses BPE when training MLM. The XLM-RoBERTa decomposes a token
 $x_i$
into a set of subwords. For example, a token
$x_i$
into a set of subwords. For example, a token ![]() silnae (“interior”) is decomposed to three subwords, namely “
silnae (“interior”) is decomposed to three subwords, namely “![]() si”, “
si”, “![]() l”, and “
l”, and “![]() nae” by the XLM-RoBERTa tokenizer. Since Korean has only a finite set of such subwords, the problems of unknown words that do not appear in the training data
nae” by the XLM-RoBERTa tokenizer. Since Korean has only a finite set of such subwords, the problems of unknown words that do not appear in the training data
 $T$
are addressed effectively. Once the BERT representation is trained by MLM using massive plain texts, the word representation and all parameters from training are stored as the pre-trained BERT. Recently, there have been several pre-trained transformer-based models in public use. Users are generally able to fine-tune the pre-trained BERT representation for their downstream tasks. We implemented our BERT-based NER systems using the pre-trained BERT models provided by Hugging Face.Footnote g In the BERT-based system, a word is tokenized and transformed into a sequence of BERT representations as
$T$
are addressed effectively. Once the BERT representation is trained by MLM using massive plain texts, the word representation and all parameters from training are stored as the pre-trained BERT. Recently, there have been several pre-trained transformer-based models in public use. Users are generally able to fine-tune the pre-trained BERT representation for their downstream tasks. We implemented our BERT-based NER systems using the pre-trained BERT models provided by Hugging Face.Footnote g In the BERT-based system, a word is tokenized and transformed into a sequence of BERT representations as
 $V^{(b)}_{i} =$
$V^{(b)}_{i} =$
 $\left\{v^{(b)}_{i,1}, v^{(b)}_{i,2},\ldots, v^{(b)}_{i,j}\right\}$
, where
$\left\{v^{(b)}_{i,1}, v^{(b)}_{i,2},\ldots, v^{(b)}_{i,j}\right\}$
, where
 $i$
and
$i$
and
 $j$
j denote the
$j$
j denote the
 $i$
-th word from the number of
$i$
-th word from the number of
 $n$
words and the number of BPE subwords of the
$n$
words and the number of BPE subwords of the
 $i$
-th word, respectively. We only take the first BPE subword for each word as the result of the BERT representations proposed in Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019). As an illustration, our system obtains embeddings for the subword “snow” in the word “snowing,” which is segmented into “snow” and “##ing” by its tokenizer. This is because BERT is a bidirectional model, and even the first BPE subword for each token contains contextual information over the sentence. Finally, the resulting word representation becomes
$i$
-th word, respectively. We only take the first BPE subword for each word as the result of the BERT representations proposed in Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019). As an illustration, our system obtains embeddings for the subword “snow” in the word “snowing,” which is segmented into “snow” and “##ing” by its tokenizer. This is because BERT is a bidirectional model, and even the first BPE subword for each token contains contextual information over the sentence. Finally, the resulting word representation becomes
 $V^{(b)} =$
$V^{(b)} =$
 $\left\{v^{(b)}_{1,1}, v^{(b)}_{2,1},\ldots, v^{(b)}_{n,1}\right\}$
. Following what has been done to the RNN-based model, we concatenate the POS embedding to
$\left\{v^{(b)}_{1,1}, v^{(b)}_{2,1},\ldots, v^{(b)}_{n,1}\right\}$
. Following what has been done to the RNN-based model, we concatenate the POS embedding to
 $v^{(b)}_{i,1}$
if available.
$v^{(b)}_{i,1}$
if available.
Classification layer. We apply the same classification layer of the RNN-based model with an identical negative log-likelihood loss for the BERT-based model.
6. Experiments
6.1. Data
The Korean NER data we introduce in this study are from NAVER, which was originally prepared for a Korean NER competition in 2018. NAVER’s data include 90,000 sentences, and each sentence consists of indices, words/phrases, and NER annotation in the BIO-like format from the first column to the following columns, respectively. However, sentences in NAVER’s data were segmented based on eojeol, which, as mentioned, is not the best way to represent Korean NEs.
We resegment all the sentences into the morpheme-based representation as described in Park and Tyers (Reference Park and Tyers2019), such that the newly segmented sentences follow the CoNLL-U format. An eoj2morph script is implemented to map the NER annotation from NAVER’s eojeol-based data to the morpheme-based data in the CoNLL-U format by pairing each character in NAVER’s data with the corresponding character in the CoNLL-U data, and removing particles and postpositions from the NEs mapped to the CoNLL-U data when necessary. The following presents an example of such conversions:

In particular, the script includes several heuristics that determine whether the morphemes in an eojeol belong to the NE the eojeol refers to. When both NAVER’s data that have eojeol-based segmentation and the corresponding NE annotation, and the data in the CoNLL-U format that only contain morphemes, UPOS (universal POS labels, Petrov et al. Reference Petrov, Das and McDonald2012), and XPOS (Sejong POS labels as language-specific POS labels) features are provided, the script first aligns each eojeol from NAVER’s data to its morphemes in the CoNLL-U data and then determines the morphemes in this eojeol that should carry the NE tag(s) of this eojeol, if any. The criteria for deciding whether the morphemes are supposed to carry the NE tags are that these morphemes should not be adpositions (prepositions and postpositions), punctuation marks, particles, determiners, or verbs. However, cases exist in which some eojeols that carry NEs only contain morphemes of the aforementioned types. In these cases, when the script does not find any morpheme that can carry the NE tag, the size of the excluding POS set above will be reduced for the given eojeol. The script will first attempt to find a verb in the eojeol to bear the NE annotation and, subsequently, will attempt to find a particle or a determiner. The excluding set keeps shrinking until a morpheme is found to carry the NE annotation of the eojeol. Finally, the script marks the morphemes that are in between two NE tags representing the same NE as part of that NE (e.g., a morpheme that is between B-LOC and I-LOC is marked as I-LOC) and assigns all other morphemes an “O” notation, where B, I, and O denote beginning, inside and outside, respectively. Because the official evaluation set is not publicly available, the converted data in the CoNLL-U format from NAVER’s training set are then divided into three subsets, namely the training, holdout, and evaluation sets, with portions of 80%, 10%, and 10%, respectively The corpus is randomly split with seed number 42 for the baseline. In addition, during evaluation of neural models, we use the seed values 41–45 and report the average and their standard deviation. Algorithm 1 describes the pseudo-code for converting data from NAVER’s eojeol-based format into the morpheme-based CoNLL-U format. Here,
 $w_i:t_i$
in
$w_i:t_i$
in
 $S_{\text{NAVER}}$
represents a word
$S_{\text{NAVER}}$
represents a word
 $w_i$
and its NE tag
$w_i$
and its NE tag
 $t_i$
(either an entity label or O).
$t_i$
(either an entity label or O).
 $w^{\prime}_{i-k} m_i \ldots m_k$
in
$w^{\prime}_{i-k} m_i \ldots m_k$
in
 $S_{\text{CoNLL-U}}$
displays a word
$S_{\text{CoNLL-U}}$
displays a word
 $w^{\prime}_{i-k}$
with its separated morphemes
$w^{\prime}_{i-k}$
with its separated morphemes
 $m_i \ldots m_k$
.
$m_i \ldots m_k$
.
Algorithm 1. Pseudo-code for converting data from NAVER’s eojeol-based format into the morpheme-based CoNLL-U format

We also implement a syl2morph script that maps the NER annotation from syllable-based data (e.g., KLUE and MODU) to the data in the morpheme-based CoNLL-U format to further test our proposed scheme. While the eoj2morph script described above utilizes UPOS and XPOS tags to decide which morphemes in the eojeol should carry the NE tags, they are not used in syl2morph anymore, as the NE tags annotated on the syllable level already exclude the syllables that belong to the functional morphemes. Additionally, NEs are tokenized as separate eojeols at the first stage before being fed to the POS tagging model proposed by Park and Tyers (Reference Park and Tyers2019). This is because the canonical forms of Korean morphemes do not always have the same surface representations as the syllables do. Because the syl2morph script basically follows the similar principles of eoj2morph, except for the two properties (or the lack thereof) mentioned above, we simply present an example of the conversion described above:

We further provide morph2eoj and morph2syl methods which allow back-conversion from the proposed morpheme-based format to either NAVER’s eojeol-based format or the syllable-based format, respectively. The alignment algorithm for back-conversion is simpler and more straightforward given that our proposed format preserves the original eojeol segment at the top of the morphemes for each decomposed eojeol. As a result, it is not necessary to align morphemes with eojeols or syllables. Instead, only eojeol-to-eojeol or eojeol-to-syllable matching is required. The morph2eoj method assigns NE tags to the whole eojeol that contains the morphemes these NE tags belong to, given that in the original eojeol-based format, eojeols are the minimal units to bear NE tags. The morph2syl method first locates the eojeol that carries the NE tags in the same way as described above for morph2eoj. Based on the fact that NEs are tokenized as separate eojeols by syl2morph, the script assigns the NE tags to each of the syllables in the eojeol.
Back-conversions from the converted datasets in the proposed format to their original formats are performed. Both eojeol-based and syllable-based datasets turned out to be identical to the original ones after going through conversions and back-conversions using the aforementioned script, which shows the effectiveness of the proposed algorithms. Manual inspection is conducted on parts of the converted data, and no error is found. While the converted dataset may contain some errors that manual inspection fails to discover, back-conversion as a stable inspection method recovers the datasets with no discrepancy. Therefore, we consider our conversion and back-conversion algorithms to be reliable. On the other hand, no further evaluation of the conversion script is conducted, mainly because the algorithms are tailored in a way that unlike machine learning approaches, linguistic features and rules of the Korean language, which are regular and stable, are employed during the conversion process.
6.2. Experimental setup
Our feature set for baseline CRFs is described in Figure 5. We use crf++ Footnote h as the implementation of CRFs, where crf++ automatically generates a set of feature functions using the template.
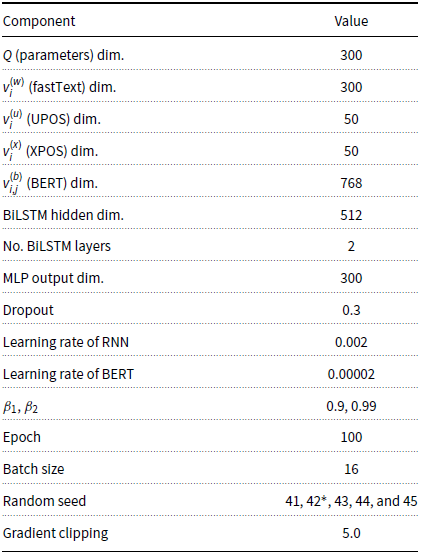
The hyperparameter settings for the neural models are listed in Table 9, Appendix A. We apply the same hyperparameter settings as in Lim et al. (Reference Lim, Park, Lee and Poibeau2018) for BiLSTM dimensions, MLP, optimizer including
 $\beta$
, and learning rate to compare our results with those in a similar environment. We set 300 dimensions for the parameters including
$\beta$
, and learning rate to compare our results with those in a similar environment. We set 300 dimensions for the parameters including
 $LSTM$
in (1),
$LSTM$
in (1),
 $Q$
, and
$Q$
, and
 $MLP$
in (2). In the training phase, we train the models over the entire training dataset as an epoch with a batch size of 16. For each epoch, we evaluate the performance on the development set and save the best-performing model within 100 epochs, with early stopping applied.
$MLP$
in (2). In the training phase, we train the models over the entire training dataset as an epoch with a batch size of 16. For each epoch, we evaluate the performance on the development set and save the best-performing model within 100 epochs, with early stopping applied.
The standard
 $F_{1}$
metric (
$F_{1}$
metric (
 $= 2 \cdot \frac{P \cdot R}{P + R}$
) is used to evaluate NER systems, where precision (
$= 2 \cdot \frac{P \cdot R}{P + R}$
) is used to evaluate NER systems, where precision (
 $P$
) and recall (
$P$
) and recall (
 $R$
) are as follows:
$R$
) are as follows:
 \begin{align*} P = \frac{\textrm{retrieved named entities} \cap \textrm{relevant named entities}}{\textrm{retrieved named entities}} \\ R = \frac{\textrm{retrieved named entities} \cap \textrm{relevant named entities}}{\textrm{relevant named entities}} \end{align*}
\begin{align*} P = \frac{\textrm{retrieved named entities} \cap \textrm{relevant named entities}}{\textrm{retrieved named entities}} \\ R = \frac{\textrm{retrieved named entities} \cap \textrm{relevant named entities}}{\textrm{relevant named entities}} \end{align*}
We evaluate our NER outputs on the official evaluation metric script provided by the organizer.Footnote i
Table 4. CRF/Neural results using different models using NAVER’s data converted into the proposed format.

fastText (Joulin et al. Reference Joulin, Grave, Bojanowski, Douze, Jégou and Mikolov2016) for LSTM+CRF word embeddings.

Figure 5. CRF feature template example for word and pos.
7. Results
We focus on the following aspects of our results: (1) whether the conversion of Korean NE corpora into the proposed morpheme-based CoNLL-U format is more beneficial compared to the previously proposed eojeol-based and syllable-based styles, (2) the effect of multilingual transformer-based models, and (3) the impact of the additional POS features on Korean NER. The outputs of the models trained using the proposed morpheme-based data are converted back to their original format, either eojeol-based or syllable-based, before evaluation. Subsequently, all reported results are calculated in their original format for fair comparisons, given the fact that the numbers of tokens in different formats vary for the same sentence. Nevertheless, it is worth noting that all experiments using the morpheme-based CoNLL-U data are both trained and predicted in this proposed format before conducting back-conversion.
7.1. Intrinsic results on various types of models
We compare the intrinsic results generated by different types of models. By saying “intrinsic,” it implies that the results in this subsection differ owing to the ways and approaches of learning from the training data. We compare the performances of the baseline CRFs and our proposed neural models, and we also investigate the variations when our models use additional features in the data.
Table 4 summarizes the evaluation results on the test data based on the proposed machine learning models in Section 5. Comparing the transformer-based models with LSTM + crf, we found that both multilingual BERT-based models (bert-multi, xlm-roberta) outperformed LSTM + crf. The comparison reveals a clear trend: the word representation method is the most effective for the NER tasks adopting our proposed scheme. For the LSTM + crf model, we initialized its word representation,
 $v_{i}^{w}$
, with a fastText word embedding (Joulin et al. Reference Joulin, Grave, Bojanowski, Douze, Jégou and Mikolov2016). However, once we initialized word representation using BERT, we observed performance improvements up to 3.4 points with the identical neural network structure as shown in Table 4. Meanwhile, there are two notable observations in our experiment. The first observation is that the CRF classifier exhibits slightly better performance than the MLP classifier, with an improvement of 0.23, for xlm-roberta. However, the improvement through the use of the CRF classifier is relatively marginal compared with the reported results of English NER (Ghaddar and Langlais Reference Ghaddar and Langlais2018). Moreover, when comparing the multilingual models (bert-multilingual and xlm-roberta) to the monolingual model (klue-roberta), we found that klue-roberta outperforms both bert-multilingual and xlm-roberta. This is because klue-roberta is trained solely on Korean texts and utilizes better tokenizers for the Korean language (Park et al. Reference Park, Moon, Kim, Cho, Han, Park, Song, Kim, Song, Oh, Lee, Oh, Lyu, Jeong, Lee, Seo, Lee, Kim, Lee, Jang, Do, Kim, Lim, Lee, Park, Shin, Kim, Park, Oh, Ha and Cho2021).
$v_{i}^{w}$
, with a fastText word embedding (Joulin et al. Reference Joulin, Grave, Bojanowski, Douze, Jégou and Mikolov2016). However, once we initialized word representation using BERT, we observed performance improvements up to 3.4 points with the identical neural network structure as shown in Table 4. Meanwhile, there are two notable observations in our experiment. The first observation is that the CRF classifier exhibits slightly better performance than the MLP classifier, with an improvement of 0.23, for xlm-roberta. However, the improvement through the use of the CRF classifier is relatively marginal compared with the reported results of English NER (Ghaddar and Langlais Reference Ghaddar and Langlais2018). Moreover, when comparing the multilingual models (bert-multilingual and xlm-roberta) to the monolingual model (klue-roberta), we found that klue-roberta outperforms both bert-multilingual and xlm-roberta. This is because klue-roberta is trained solely on Korean texts and utilizes better tokenizers for the Korean language (Park et al. Reference Park, Moon, Kim, Cho, Han, Park, Song, Kim, Song, Oh, Lee, Oh, Lyu, Jeong, Lee, Seo, Lee, Kim, Lee, Jang, Do, Kim, Lim, Lee, Park, Shin, Kim, Park, Oh, Ha and Cho2021).
Table 5 details results using various sets of features. We use incremental words, UPOS, and XPOS, for the input sequence
 $x$
and their unigram and bigram features for CRFs. Both LSTM and XLM-RoBERTa achieve their best F
$x$
and their unigram and bigram features for CRFs. Both LSTM and XLM-RoBERTa achieve their best F
 $_{1}$
score when only the +UPOS feature is attached.
$_{1}$
score when only the +UPOS feature is attached.
Table 5. CRF/Neural results using the various sets of features using NAVER’s data converted into the proposed format.

7.2. Extrinsic results on different types of data
This subsection examines the extrinsic results given different types of data, whereas the previous subsection focuses on the differences in various models given only the morpheme-based CoNLL-U data. In this subsection, the performances of our models trained on the datasets either in the proposed format or in their original formats, and in either the BIO tagging format or the BIOES tagging format, are investigated.
Table 6. CRF/Neural result comparison between the proposed CoNLL-U format versus NAVER’s eojeol-based format using NAVER’s data where POS features are not applied.

As described in Table 6, both the baseline CRF-based model and the BERT-based model achieve higher F
 $_{1}$
scores when the proposed CoNLL-U data are used, in contrast with NAVER’s eojeol-based data. The testing data are organized in a way that the total number of tokens for evaluations remains the same, implying that the F
$_{1}$
scores when the proposed CoNLL-U data are used, in contrast with NAVER’s eojeol-based data. The testing data are organized in a way that the total number of tokens for evaluations remains the same, implying that the F
 $_{1}$
scores generated by conlleval are fair for both groups. This is realized by converting the model output of the morpheme-based CoNLL-U data back into NAVER’s original eojeol-based format such that they have the same number of tokens. The morpheme-based CoNLL-U format outperforms the eojeol-based format under the CRFs, whereas the CoNLL-U format still outperformed the eojeol-based format by over 1% using the BERT-based model.
$_{1}$
scores generated by conlleval are fair for both groups. This is realized by converting the model output of the morpheme-based CoNLL-U data back into NAVER’s original eojeol-based format such that they have the same number of tokens. The morpheme-based CoNLL-U format outperforms the eojeol-based format under the CRFs, whereas the CoNLL-U format still outperformed the eojeol-based format by over 1% using the BERT-based model.
Table 7 presents the comparative results on two types of tagging formats where the models do not use additional POS features. Previous studies show that the BIOES annotation scheme yields superior results for several datasets if the size of datasets is enough to disambiguate more number of labels (Ratinov and Roth Reference Ratinov and Roth2009). Both the baseline CRF and neural models achieve higher F
 $_{1}$
scores than that of the BIOES tagging format when the BIO tagging format is used, which has two more types of labels – E as endings and S as single entity elements. Our result reveals that adding more target labels to the training data degrades model prediction (14 labels
$_{1}$
scores than that of the BIOES tagging format when the BIO tagging format is used, which has two more types of labels – E as endings and S as single entity elements. Our result reveals that adding more target labels to the training data degrades model prediction (14 labels
 $\times$
2 for E and S). Accordingly, we observe that in this specific case, adding the two additional labels mentioned increases the difficulty of predictions.
$\times$
2 for E and S). Accordingly, we observe that in this specific case, adding the two additional labels mentioned increases the difficulty of predictions.
Table 8 compares the results of the proposed morpheme-based CoNLL-U data and the syllable-based data. We use the xlm-roberta+crf model and only use word features for the experiments. Similar to the previous experiments, we back-convert the model output of the morpheme-based data back to the syllable-based format for fair comparisons. The results are consistent that for all four datasets, we observe performance improvement ranging from 3.12 to 4.31 points when the CoNLL-U format is adopted.
The performance difference between syllable-based NER results and morpheme-based NER results is mainly due to the fact that the xlm-roberta+crf model we used employs a subword-based tokenizer with larger units, rather than a syllable-based tokenizer. Therefore, one needs to use a BERT model with a syllable-based tokenizer for fair comparisons, if the goal is to only compare the performance between the morpheme-based format and the syllable-based format. However, this makes it difficult to conduct a fair performance evaluation in our study, because the evaluation we intended is based on BERT models trained in different environments when morpheme-based, eojeol-based, or syllable-based data are given. Since subword-based tokenizers are widely employed in a lot of pre-trained models, our proposed format would benefit the syllable-based Korean NER corpora in a way that not only language models using syllable-based tokenizers can take them as the input, but those using BPE tokenizers or other types of subword-based tokenizers can also be trained on these syllable-based corpora once converted.
Table 7. CRF/Neural result comparison between BIO versus BIOES annotations using NAVER’s data converted into the proposed format where POS features are not applied.

Table 8. Result comparison between the proposed CoNLL-U format and the syllable-based format using MODU (19 21), KLUE, and ETRI datasets where POS features are not applied.

Model: XLM-ROBERTA+CRF.
7.3. POS features and NER results
Additional POS features help detect better B-
 $*$
tag sets. Comparing the XLM-RoBERTa models trained with and without the UPOS tags, we observe an average performance improvement of 0.25% when the UPOS feature is applied to the XLM-RoBERTa model. However, if we only focus on the entities named B-
$*$
tag sets. Comparing the XLM-RoBERTa models trained with and without the UPOS tags, we observe an average performance improvement of 0.25% when the UPOS feature is applied to the XLM-RoBERTa model. However, if we only focus on the entities named B-
 $*$
, the performance improvement increases by 0.38. We hypothesize that POS features in the NER system play a role of evidence in tagging decision-making for the start of its entities across tokens. For example, a sentence in (3a) exhibits unknown words such as the names of a location:
$*$
, the performance improvement increases by 0.38. We hypothesize that POS features in the NER system play a role of evidence in tagging decision-making for the start of its entities across tokens. For example, a sentence in (3a) exhibits unknown words such as the names of a location: ![]() haleukiu-wa donbaseu (“Kharkiv and Donbas”).
haleukiu-wa donbaseu (“Kharkiv and Donbas”).
(3)

The NER system suffers from inadequate information, but when the system has POS information (proper noun, PROPN in UPOS and NNP in XPOS) as in (3a), it can probably make better decisions.


The UPOS tag set benefits Korean NER. Because syntactic-relevant tasks such as dependency parsing for Korean have mainly applied XPOS tag sets, we assumed the XPOS tags are more important than UPOS tags. However, results in Table 5 demonstrate that applying the UPOS feature gives marginally better results than using the XPOS feature. We consider this to be due to the predicted POS tags. Since the UPOS set contains 17 labels whereas the XPOS set (Sejong POS tag set) has 46 labels for Korean, the current prediction model is more accurate in tagging UPOS labels than tagging XPOS labels. As a result, a more reliable UPOS feature provided by the tagging model also turns out to be more helpful in NER, compared with the XPOS feature.
7.4. Comparison between XLM-RoBERTa and BERT
We reported that XLM-RoBERTa outperforms the multilingual BERT model in Table 4. The differences between the two language models are discerned from Figure 6, which displays the confusion matrix between the predicted and true labels for both BERT and XLM-RoBERTa. XLM-RoBERTa tends to exhibit superior results in finding the “I-
 $*$
” typed entities, with +0.7% of the average score. Moreover, we observed that the XLM-RoBERTa model exhibits fewer false predictions of b-mat and i-plt as o than the BERT model. It was difficult to explain the exact factors leading to the clear performance differences between BERT and XLM-RoBERTa. However, given the size of the training models where BERT and XLM are 641 MB and 1.2 GB, respectively, we assume that the model size might have contributed to the performance differences. However, it seemed that the method of tokenizing and word dictionaries had a larger impact than the model size because the size of the monolingual KLUE-RoBERTa model is 110 MB which is much smaller.
$*$
” typed entities, with +0.7% of the average score. Moreover, we observed that the XLM-RoBERTa model exhibits fewer false predictions of b-mat and i-plt as o than the BERT model. It was difficult to explain the exact factors leading to the clear performance differences between BERT and XLM-RoBERTa. However, given the size of the training models where BERT and XLM are 641 MB and 1.2 GB, respectively, we assume that the model size might have contributed to the performance differences. However, it seemed that the method of tokenizing and word dictionaries had a larger impact than the model size because the size of the monolingual KLUE-RoBERTa model is 110 MB which is much smaller.
8. Discussion
In this section, we discuss how the proposed scheme differs from the previously adopted schemes that represent NEs in Korean corpora. As described previously in Figure 2, previous studies proposed other annotation formats for Korean NER, including eojeol-based, morpheme-based, and syllable-based approaches. We demonstrate how different annotation formats look like in Korean corpora in Figure 7, which also includes our proposed format.
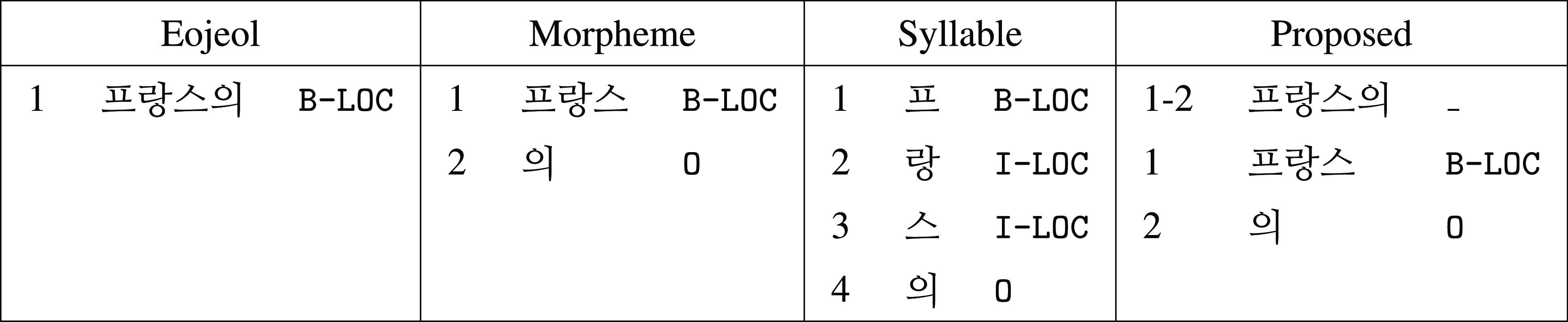
Figure 7. Various approaches of annotation for NEs in Korean.
8.1. Comparison with the eojeol-based format
The eojeol-based format, as adopted in NAVER’s dataset, considers eojeols as the tokens to which NE tags are assigned. The format preserves the natural segmentation of the Korean language and is commonly used in other Korean processing tasks such as dependency parsing (Choi et al. Reference Choi, Han, Han and Kwon1994; McDonald et al. Reference McDonald, Nivre, Quirmbach-Brundage, Goldberg, Das, Ganchev, Hall, Petrov, Zhang, Täckström, Bedini, Bertomeu Castelló and Lee2013; Chun et al. Reference Chun, Han, Hwang and Choi2018). On the other hand, taking eojeols as the basic units for NER analyses has an inevitable defect. Korean is an agglutinative language in which functional morphemes, which are not parts of the NE, are attached to the eojeol as well. As a result, it is impossible to exclude what does not belong to the NE from the token that bears the NE. Our proposed format has two advantages compared to the eojeol-based format. While the functional morphemes cannot be excluded from the NE annotation, a morpheme-based format deals with this problem properly, as the tokens are no longer eojeols, but morphemes instead. Consequently, the NE tags are assigned to the morphemes that are not functional. Moreover, since our proposed format keeps the eojeol representation on the top of its morphemes, the information on the natural segmentation of the sentence is still preserved. The advantages of the proposed scheme are testified through experiments, and the results presented in Table 6, Section 7.2 show that the format in which functional morphemes are excluded from NE labels improves the performance of the NER models trained on the same set of sentences but in different formats.
8.2. Comparison with the previous morpheme-based format
Previous studies on Korean NER attempted to employ morpheme-based annotation formats to tackle the problem of Korean’s natural segmentation which is not able to exclude functional morphemes. As discussed in Section 3, the KIPS corpora consider morphemes to be the basic units for NER analyses, and therefore the NE tags are assigned to only those morphemes that belong to the NE. While the morpheme-based format adopted in the KIPS corpora seems to be able to solve the problem the eojeol-based format has, it also introduces new problems. The information on the natural segmentation (i.e., eojeols) has been completely lost, and it is no longer possible to tell which morphemes belong to which eojeol. This poses challenges both for human researchers to understand the corpora and for the conversion from the morpheme-based format back to the eojeol-based format. Not being able to observe the word boundaries and how the morphemes constitute eojeols makes it hard for linguists and computer scientists to understand the language documented in the corpora. Moreover, since there is no information that suggests which morphemes should form an eojeol, the script is not able to recover the corresponding eojeol-based representation with NE tags. Our proposed format preserves all the eojeols in the dataset and clearly states which morphemes belong to the eojeols through indices, as illustrated in Figure 7. Conversions back to the eojeol-based format have been made possible because of the eojeol-level representations, which the morph2eoj script can refer to. Meanwhile, the proposed format is much more human-readable and presents linguistically richer information, which benefits the language documentation of Korean as well.
8.3. Comparison with the syllable-based format
Another annotation format that deals with the defect of the eojeol-based format, in which functional morphemes cannot be excluded, is the syllable-based format. Given that any syllable in Korean is never separated or shared by two morphemes or eojeols, marking the NE tags on those syllables which do not belong to functional morphemes solves the problem as well. However, there are some potential issues when adopting this straightforward approach. The major problem here is that most, if not all, linguistic properties are lost when the sentences are decomposed into syllables, as a syllable is an even smaller unit than a morpheme which is the smallest constituent that can bear meaning. Moreover, it is impossible to assign POS tags to the syllable-based data, which have been proven helpful for Korean NER using morpheme-based data as presented in Table 5. It is also not ideal to train a model which does not employ a syllable-level tokenizer using syllable-based corpora as discussed in Section 7.2, whereas many transformer-based models adopt BPE tokenization. Our proposed format addresses the above issues by preserving linguistic information and properties in the smallest units possible, namely morphemes. POS tags can therefore be assigned to each token as long as it carries meaning. We also provide a script that performs conversion from the syllable-based dataset into a morpheme-based dataset, such that a model using a subword-based tokenizer can fully utilize syllable-based corpora as additional data for further training.
9. Conclusion
In this study, we leverage the morpheme-based CoNLL-U format based on Park and Tyers (Reference Park and Tyers2019) and propose a new scheme that is compatible with Korean NER corpora. Compared with the conventional eojeol-based format in which the real pieces of NEs are not distinguished from the postpositions or particles inside the eojeol, the proposed CoNLL-U format represents NEs on the morpheme-based level such that NE annotations are assigned to the exact segments representing the entities. The results of both the CRF models and the neural models reveal that our morpheme-based format outperforms both the eojeol-based format and the syllable-based format currently adopted by various Korean NER corpora. We also examine the performance of the above formats using various additional features and tagging formats (BIO and BIOES). Meanwhile, this paper also investigates the linguistic features of the Korean language that are related to NER. This includes the distribution of postpositions and particles after NEs, the writing system of Korean, and the eojeol-based segmentation of Korean. The linguistic features we stated further justify the annotation scheme that we propose. Finally, we confirm the functionality of our NER models, and the results obtained reveal the differences among all these models, where the XLM-RoBERTa model outperformed other types of models in our study. The results of the study validate the feasibility of the proposed approach to the recognition of NEs in Korean, which is justified to be appropriate linguistically. The proposed method of recognizing NEs can be used in several real-world applications such as text summarization, document search and retrieval, and machine translation.
Acknowledgements
This research was supported by Basic Science Research Program through the National Research Foundation of Korea (NRF) funded by the Ministry of Education (2021R1F1A1063474) to KyungTae Lim.
Appendix A. Hyperparameters of the Neural Models
Table 9. Hyperparameters.
* For the baseline system.



















 Open access
Open access