


1. Introduction
The development of computational models and datasets to detect various forms of offensive content online has become a very popular research topic in recent years (Fortuna and Nunes Reference Fortuna and Nunes2018; Poletto et al. Reference Poletto, Basile, Sanguinetti, Bosco and Patti2021). Research on this topic was motivated by the pressing need to create safer environments in social media platforms through strategies such as automatic content moderation (Weerasooriya et al. Reference Weerasooriya, Dutta, Ranasinghe, Zampieri, Homan and KhudaBukhsh2023). With the goal of aiding content moderation, systems are trained to recognize a variety of related phenomena such as aggression, cyberbulling, hate speech, and toxicity (Arora et al. Reference Arora, Nakov, Hardalov, Sarwar, Nayak, Dinkov, Zlatkova, Dent, Bhatawdekar, Bouchard and Augenstein2023).
A lot of research on this topic is driven by shared task competitions that provide important benchmark datasets, results, and systems to the research community. Notable examples include HatEval, OffensEval, and TSD. Organized as part of the International Workshop on Semantic Evaluation (SemEval), each of these competitions attracted hundreds of participating teams from all over the world. OffensEval is arguably the most popular shared task on this topic. Its 2019 edition focused on English and attracted 800 teams, while the 2020 was a multilingual competition with datasets in five languages and it attracted over 500 teams. The best-performing teams in these competitions developed systems using transformer-based architectures such as BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) and ELMo (Peters et al. Reference Peters, Neumann, Iyyer, Gardner, Clark, Lee and Zettlemoyer2018), which were the state-of-the-art pre-trained language models at the time.
Since the last edition of the OffensEval shared task in 2020, the field of Natural Language Processing (NLP) has undergone a revolution with the introduction of a new generation of LLMs such as GPT (Radford et al. Reference Radford, Wu, Child, Luan, Amodei and Sutskever2019), OPT (Zhang et al. Reference Zhang, Roller, Goyal, Artetxe, Chen, Chen, Dewan, Diab, Li, Lin, Mihaylov, Ott, Shleifer, Shuster, Simig, Koura, Sridhar, Wang and Zettlemoyer2022), LLaMA (Touvron et al. Reference Touvron, Martin, Stone, Albert, Almahairi, Babaei, Bashlykov, Batra, Bhargava and Bhosale2023b), LLaMA 2 (Touvron et al. Reference Touvron, Martin, Stone, Albert, Almahairi, Babaei, Bashlykov, Batra, Bhargava, Bhosale, Bikel, Blecher, Ferrer, Chen, Cucurull, Esiobu, Fernandes, Fu, Fu, Fuller, Gao, Goswami, Goyal, Hartshorn, Hosseini, Hou, Inan, Kardas, Kerkez, Khabsa, Kloumann, Korenev, Koura, Lachaux, Lavril, Lee, Liskovich, Lu, Mao, Martinet, Mihaylov, Mishra, Molybog, Nie, Poulton, Reizenstein, Rungta, Saladi, Schelten, Silva, Smith, Subramanian, Tan, Tang, Taylor, Williams, Kuan, Xu, Yan, Zarov, Zhang, Fan, Kambadur, Narang, Rodriguez, Stojnic, Edunov and Scialom2023a), PaLM (Chowdhery et al. Reference Chowdhery, Narang, Devlin, Bosma, Mishra, Roberts, Barham, Chung, Sutton, Gehrmann, Schuh, Shi, Tsvyashchenko, Maynez, Rao, Barnes, Tay, Shazeer, Prabhakaran, Reif, Du, Hutchinson, Pope, Bradbury, Austin, Isard, Gur-Ari, Yin, Duke, Levskaya, Ghemawat, Dev, Michalewski, Garcia, Misra, Robinson, Fedus, Zhou, Ippolito, Luan, Lim, Zoph, Spiridonov, Sepassi, Dohan, Agrawal, Omernick, Dai, Pillai, Pellat, Lewkowycz, Moreira, Child, Polozov, Lee, Zhou, Wang, Saeta, Diaz, Firat, Catasta, Wei, Meier-Hellstern, Eck, Dean, Petrov and Fiedel2022), BLOOM (Scao et al. Reference Scao, Fan, Akiki, Pavlick, Ilić, Hesslow, Castagné, Luccioni, Yvon, Gallé, Tow, Rush, Biderman, Webson, Ammanamanchi, Wang, Sagot, Muennighoff, del Moral, Ruwase, Bawden, Bekman, McMillan-Major, Beltagy, Nguyen, Saulnier, Tan, Suarez, Sanh, Laurençon, Jernite, Launay, Mitchell, Raffel, Gokaslan, Simhi, Soroa, Aji, Alfassy, Rogers, Nitzav, Xu, Mou, Emezue, Klamm, Leong, van Strien, Adelani, Radev, Ponferrada, Levkovizh, Kim, Natan, Toni, Dupont, Kruszewski, Pistilli, Elsahar, Benyamina, Tran, Yu, Abdulmumin, Johnson, Gonzalez-Dios, de la Rosa, Chim, Dodge, Zhu, Chang, Frohberg, Tobing, Bhattacharjee, Almubarak, Chen, Lo, Werra, Weber, Phan, allal, Tanguy, Dey, Muñoz, Masoud, Grandury, Šaško, Huang, Coavoux, Singh, Jiang, Vu, Jauhar, Ghaleb, Subramani, Kassner, Khamis, Nguyen, Espejel, de Gibert, Villegas, Henderson, Colombo, Amuok, Lhoest, Harliman, Bommasani, López, Ribeiro, Osei, Pyysalo, Nagel, Bose, Muhammad, Sharma, Longpre, Nikpoor, Silberberg, Pai, Zink, Torrent, Schick, Thrush, Danchev, Nikoulina, Laippala, Lepercq, Prabhu, Alyafeai, Talat, Raja, Heinzerling, Si, Taşar, Salesky, Mielke, Lee, Sharma, Santilli, Chaffin, Stiegler, Datta, Szczechla, Chhablani, Wang, Pandey, Strobelt, Fries, Rozen, Gao, Sutawika, Bari, Al-shaibani, Manica, Nayak, Teehan, Albanie, Shen, Ben-David, Bach, Kim, Bers, Fevry, Neeraj, Thakker, Raunak, Tang, Yong, Sun, Brody, Uri, Tojarieh, Roberts, Chung, Tae, Phang, Press, Li, Narayanan, Bourfoune, Casper, Rasley, Ryabinin, Mishra, Zhang, Shoeybi, Peyrounette, Patry, Tazi, Sanseviero, von Platen, Cornette, Lavallée, Lacroix, Rajbhandari, Gandhi, Smith, Requena, Patil, Dettmers, Baruwa, Singh, Cheveleva, Ligozat, Subramonian, Névéol, Lovering, Garrette, Tunuguntla, Reiter, Taktasheva, Voloshina, Bogdanov, Winata, Schoelkopf, Kalo, Novikova, Forde, Clive, Kasai, Kawamura, Hazan, Carpuat, Clinciu, Kim, Cheng, Serikov, Antverg, van der Wal, Zhang, Zhang, Gehrmann, Mirkin, Pais, Shavrina, Scialom, Yun, Limisiewicz, Rieser, Protasov, Mikhailov, Pruksachatkun, Belinkov, Bamberger, Kasner, Rueda, Pestana, Feizpour, Khan, Faranak, Santos, Hevia, Unldreaj, Aghagol, Abdollahi, Tammour, HajiHosseini, Behroozi, Ajibade, Saxena, Ferrandis, McDuff, Contractor, Lansky, David and Kiela2023), FLAN-T5 (Chung et al. Reference Chung, Hou, Longpre, Zoph, Tay, Fedus, Li, Wang, Dehghani and Brahma2022), etc. Such models have reached the general public with commercial tools such as ChatGPT, sparking renewed widespread interest in AI and NLP. Within the research community, LLMs have shown state-of-the-art performance for a variety of tasks, and have revolutionized the research in the field. LLMs have also given rise to the art of prompt engineering, which includes a variety of prompting techniques such as zero-shot, few-shot, chain-of-thought, etc. (Liu et al. Reference Liu, Yuan, Fu, Jiang, Hayashi and Neubig2023).
In light of these recent developments, we present OffensEval 2023, an evaluation of OffensEval in the age of LLMs. We present (i) a survey of the two editions of OffensEval and related benchmark competitions and (ii) an evaluation of LLMs and fine-tuned models.
Our contributions can be summarized as follows:
1. A survey of offensive language identification benchmark competitions with a special focus on OffensEval. We discuss benchmark competitions that addressed various languages (e.g., Arabic, Danish, German) and phenomena (e.g., hate speech, toxicity).
2. An evaluation of state-of-the-art LLMs on the OffensEval 2019 and OffensEval 2020 datasets. We experiment with six LLMs and two fine-tuned BERT models on the OffensEval datasets, and we compare their performance to the best systems in the competition.
The remainder of this paper is organized as follows: Section 2 discusses popular related shared tasks such as HatEval, TRAC, and HASOC. Section 3 describes the two editions OffensEval, datasets, and previous experiments in detail. Section 4 discusses our experiments benchmarking six LLMs and two task fine-tuned BERT models on offensive language identification. Finally, Section 5 concludes this paper and presents directions for future work.
2. Related benchmark competitions
In this section, we survey some recent popular benchmark competitions on the topic. The competitions presented next have addressed different types of offensive content such as hate speech in HatEval (Basile et al. Reference Basile, Bosco, Fersini, Nozza, Patti, Pardo, Rosso and Sanguinetti2019), aggression in TRAC (Kumar et al. Reference Kumar, Ojha, Malmasi and Zampieri2018), and misogyny in MAMI (Fersini et al. Reference Fersini, Gasparini, Rizzi, Saibene, Chulvi, Rosso, Lees and Sorensen2022). While most tasks focused exclusively on offensive content, some tasks have attempted to bridge the gap between offensive content identification and other phenomena. One such example is HaHaCkaton (Meaney et al. Reference Meaney, Wilson, Chiruzzo, Lopez and Magdy2021) which provided participants with the opportunity to develop systems to model offense and humor jointly.
2.1 HatEval (SemEval-2019 task 5): multilingual detection of hate speech against immigrants and women in Twitter
HatEval (Basile et al. Reference Basile, Bosco, Fersini, Nozza, Patti, Pardo, Rosso and Sanguinetti2019) was organized as part of the 2019 edition of SemEval (the International Workshop on Semantic Evaluation). Its focus was on detecting hate speech against women and migrants, in English and Spanish. The task organizers provided an annotated dataset collected from Twitter containing 19,600 tweets: 13,000 for English and 6600 for Spanish. The dataset was annotated with respect to (1) hatefulness, (2) target, and (3) aggression. The competition received over 100 runs from 74 different teams. Half of the teams submitted systems relying on traditional machine learning approaches, while the other half submitted deep learning systems. The best systems used traditional classifiers such as SVMs (Indurthi et al. Reference Indurthi, Syed, Shrivastava, Chakravartula, Gupta and Varma2019).
2.2 TRAC: evaluating aggression identification in social media
The TRAC shared task (Kumar et al. Reference Kumar, Ojha, Malmasi and Zampieri2018) has been held as a biennial event since 2018, as part of the Workshop on Trolling, Aggression, and Cyberbullying. It focuses on aggression identification and has covered several languages. In the first iteration, TRAC had one sub-task on aggression identification, and the participants were asked to classify instances as overtly aggressive, covertly aggressive, and non-aggressive. The task organizers released a dataset of 15,000 aggression-annotated Facebook posts and comments in Hindi (in both Roman and Devanagari script) and English. A total of 130 teams registered to participate in the task, and 30 teams submitted runs. The best system used an LSTM and machine translation for data augmentation (Aroyehun and Gelbukh Reference Aroyehun and Gelbukh2018).
The 2020 edition of the TRAC shared task (Kumar et al. Reference Kumar, Ojha, Malmasi and Zampieri2020) had two sub-tasks: aggression identification (sub-task A), where the goal was to discriminate between posts labeled as overtly aggressive, covertly aggressive, and non-aggressive, and gendered aggression identification (sub-task B), which asked participants to discriminate between gendered and non-gendered posts. The shared task was organized for three languages: Bengali, Hindi, and English. The participants were provided with a dataset of approximately 5000 instances from YouTube comments in each of the languages. Approximately 1000 instances were provided per language for each sub-task for testing. The competition attracted a total of 70 teams. The best-performing system used multiple fine-tuned BERT models and bootstrap aggregation (Risch and Krestel Reference Risch and Krestel2020).
The 2022 edition of the TRAC shared task contained two different tasks from the previous iterations. In sub-task A, the primary focus remained on identifying aggression, encompassing aggression, gender bias, racial bias, religious intolerance, and casteist bias within social media content. For sub-task B, the participants were presented with a comment thread containing information about the existence of various biases and threats (such as gender bias, gendered threats, or their absence) and their discourse connections to preceding comments and the original post, categorized as attack, abetment, defense, counter-speech, or gaslighting. The participants were asked to predict the presence of aggression and bias within each comment, potentially leveraging the available contextual cues. The organizers released a dataset of 60k comments in Meitei, Bangla, and Hindi for training and testing (a total of 180k examples) from YouTube. The best system at the competition, for both tasks, used logistic regression (Kumari, Srivastav, and Suman Reference Kumari, Srivastav and Suman2022). For sub-task B, only a test set was provided containing COVID-19-related conversations, annotated with levels of aggression, offensiveness, and hate speech. The participants were asked to train their machine learning models using training data from previous TRAC editions. The primary goal of this task was to assess the adaptability and the generalizability of aggression identification systems when faced with unforeseen and unconventional scenarios. Once again, the best model used logistic regression (Kumari et al. Reference Kumari, Srivastav and Suman2022).
2.3 HASOC: hate speech and offensive content identification in English and Indo-Aryan languages
Since 2019, the HASOC shared task (Mandl et al. Reference Mandl, Modha, Majumder, Patel, Dave, Mandlia and Patel2019) has been a regular task at FIRE (the Forum for Information Retrieval Evaluation). Its primary objective is the detection of hate speech and offensive content in English and Indo-Aryan languages. In its inaugural edition (Mandl et al. Reference Mandl, Modha, Majumder, Patel, Dave, Mandlia and Patel2019), the shared task featured two sub-tasks across three languages: English, Hindi, and German. sub-task A was a binary classification task, where the goal was to categorize content as offensive or not offensive. In sub-task B, the focus shifted to further fine-grained classification of offensive content into three categories: hate speech, offensive content, and profanity. For each language, there were 5000 training and 1000 testing examples from Twitter and Facebook. Notably, the most successful systems leveraged neural network architectures, incorporating Long Short-Term Memory (LSTM) networks and word embeddings (Wang et al. Reference Wang, Ding, Liu and Zhou2019). Several of the top-performing teams also used BERT, even though it was still emerging in NLP (Ranasinghe, Zampieri, and Hettiarachchi Reference Ranasinghe, Zampieri and Hettiarachchi2019).
The 2020 edition of the HASOC shared task (Mandl et al. Reference Mandl, Modha, Kumar and Chakravarthi2020) featured the same two sub-tasks and the same three languages as in the previous year. The organizers provided a new annotated dataset collected from Twitter, which contained 3708 English, 2373 German, and 2963 Hindi examples. The best-performing teams in that edition of the HASOC shared task used different variants of BERT (Raj, Srivastava, and Saumya Reference Raj, Srivastava and Saumya2020; Mishra, Saumya, and Kumar Reference Mishra, Saumya and Kumar2020).
The 2021 edition of the HASOC challenge had two tasks (Modha et al. Reference Modha, Mandl, Shahi, Madhu, Satapara, Ranasinghe and Zampieri2021). Task 1 contained the same two sub-tasks from the previous 2 years. However, there was a difference in the languages: German was replaced by Marathi as a new language (Mandl et al. Reference Mandl, Modha, Shahi, Madhu, Satapara, Majumder, Schäfer, Ranasinghe, Zampieri, Nandini and Jaiswal2021). The organizers provided newly annotated 3843 English instances, 4594 Hindi instances, and 1874 Marathi instances from Twitter for training. The best-performing systems again used different variants of the BERT architecture and combined it with cross-lingual transfer learning (Banerjee et al. Reference Banerjee, Sarkar, Agrawal, Saha and Das2021; Bhatia et al. Reference Bhatia, Bhotia, Agarwal, Ramesh, Gupta, Shridhar, Laumann and Dash2021; Nene et al. Reference Nene, North, Ranasinghe and Zampieri2021). The second task in 2021 focused on the identification of conversational hate speech in code-switched text, where the same message mixes different languages (Modha et al. Reference Modha, Mandl, Shahi, Madhu, Satapara, Ranasinghe and Zampieri2021). The objective of this task was to identify posts that are benign when considered in isolation, but might be judged as hate, profane, and offensive if the particular context is taken into account. The organizers provided 7000 code-switched posts in English and Hindi from Twitter. The winning team used an ensemble based on IndicBERT (Doddapaneni et al. Reference Doddapaneni, Aralikatte, Ramesh, Goyal, Khapra, Kunchukuttan and Kumar2023), Multilingual BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), and XLM-RoBERTa (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2019). In each of their model, they concatenated the conversation into the input tweet.
HASOC 2022 featured three tasks (Satapara et al. Reference Satapara, Majumder, Mandl, Modha, Madhu, Ranasinghe, Zampieri, North and Premasiri2022). Task 1 was a continuation of the 2021 task 2, where the goal was to detect hate and offensive content in conversations (Modha et al. Reference Modha, Mandl, Majumder, Satapara, Patel and Madhu2022) where the classes were hate offensive and non-hate offensive. Task 2 was a fine-grained classification of task 1, where the participants were asked to classify the hate offensive conversations from task 1 into three classes; standalone hate, contextual hate, and non-hate (Modha et al. Reference Modha, Mandl, Majumder, Satapara, Patel and Madhu2022). The participants were provided with 5200 code-mixed conversations in English, Hindi, and German, with annotations for both tasks from Twitter. The best-performing system used Google MuRIL (Khanuja et al. Reference Khanuja, Bansal, Mehtani, Khosla, Dey, Gopalan, Margam, Aggarwal, Nagipogu and Dave2021) and took the context into account (Singh and Garain Reference Singh and Garain2022). Task 3 was a continuation of 2021 task 1 (Ranasinghe et al. Reference Ranasinghe, North, Premasiri and Zampieri2022b). However, it only featured Marathi and had three sub-tasks, which followed the popular OLID taxonomy. sub-task 1 asked to detect offensive language, sub-task 2 focused on the categorization of offensive language into targeted or untargeted, and finally, the sub-task 3 looked to identify the target of the offense classifying the instances into individual target, group target and other. The participants were given 3500 annotated instances from Twitter. The best system again was based on XLM-RoBERTa (Dikshitha Vani and Bharathi Reference Dikshitha Vani and Bharathi2022).
2.4 TSD: toxic span detection
Toxic span detection was organized at the 2021 edition of SemEval (Pavlopoulos et al. Reference Pavlopoulos, Sorensen, Laugier and Androutsopoulos2021). The shared task asked to detect the text spans that contain toxic or offensive content. The participants were provided with a reannotated version of the Civil Comments dataset, with 7939 training and 2000 test instances, with toxic span annotations. TSD was the first of its kind in predicting toxicity at the span level. The shared task received 1385 valid submissions from 91 teams, with the best team modeling the problem as token labeling and span extraction. They used two systems based on BERT with a conditional random field layer at the top (Zhu et al. Reference Zhu, Lin, Zhang, Sun, Li, Lin, Dang and Xu2021).
2.5 MAMI: multimedia automatic misogyny identification
The Multimedia Automatic Misogyny Identification (MAMI) was task 5 at SemEval 2022 (Fersini et al. Reference Fersini, Gasparini, Rizzi, Saibene, Chulvi, Rosso, Lees and Sorensen2022). The task had two sub-tasks: sub-task A was a binary classification task, asking to distinguish between misogynous and non-misogynous memes, and sub-task B was a multi-label classification task to detect the type of misogyny: stereotype, shaming, objectification, and violence. The organizers provided the participants with balanced training and testing datasets with 10,000 and 5000 memes, respectively. The best-performing teams used RoBERTa and VisualBERT; many teams used ensembles combining several models (Zhang and Wang Reference Zhang and Wang2022).
2.6 HaHaCkaton: detecting and rating humor and offense
The HaHaCkathon (Meaney et al. Reference Meaney, Wilson, Chiruzzo, Lopez and Magdy2021) combined humor detection and offense language identification into a single task opening the possibly of jointly modeling two tasks that were previously addressed separately. The organizers 10,000 examples from Twitter and the Kaggle Short Jokes dataset, each annotated by 20 annotators for humor and offense. HaHaCkathon featured three sub-tasks: (1) humor detection, (2) prediction of humor and offense ratings, and (3) controversy detection (i.e., predicting whether the variance in the human humor ratings for a given example is higher than a specific threshold). The individual sub-tasks attracted between 36 and 58 submissions. In terms of approaches and performance, most teams used pre-trained language models such as BERT, ERNIE 2.0, and ALBERT and most of the best-performing teams used additional techniques, for example adversarial training.
2.7 EDOS (SemEval-2023 task 10): explainable detection of online sexism
EDOS (Kirk et al. Reference Kirk, Yin, Vidgen and Röttger2023) was organized as part of SemEval-2023 with the goal of detecting sexist online posts and explaining them. The task had three sub-tasks: sub-task A was a binary classification task where the participants needed to distinguish between sexist and non-sexist content. Sub-task B was a fine-grained classification task that disaggregates sexist content into four conceptually and analytically distinct categories: (i) threats, plans to harm & incitement, (ii) derogation, (iii) animosity, and (iv) prejudiced discussion. Finally, sub-task C disaggregates each category of sexism into eleven fine-grained sexism vectors such as threats of harm, descriptive attacks, and systemic discrimination against women as a group or as an individual (Kirk et al. Reference Kirk, Yin, Vidgen and Röttger2023). The participants of the EDOS shared task were provided with a dataset of 20,000 annotated social media comments from Reddit and Gab. Additionally, the organizers provided one million unannotated social media comments. A total of 128 teams participated in the competition. The top team uses transformer-based architectures and further improved their results using continued pre-training on the unannotated dataset and multitask learning (Zhou Reference Zhou2023).
2.8 DeTox: toxic comment classification at GermEval
The 2021 edition of GermEval (a series of shared task evaluation campaigns that focus on NLP for German) included a shared task that focused on identifying toxic, engaging, and fact-claiming comments in German (Risch et al. Reference Risch, Stoll, Wilms and Wiegand2021). The task included three sub-tasks: sub-task 1 was a binary classification problem (toxic vs. non-toxic), sub-task 2 was also a binary classification problem, asking to distinguish between engaging and non-engaging comments. sub-task 3 was also a binary classification problem, asking to distinguish between fact-claiming and non-fact-claiming comments. The participants were provided with 3244 and 1092 manually annotated training and testing instances, extracted from Facebook comments. The competition received a submission from 32 teams across the three sub-tasks. The best-performing teams used traditional classifiers combined with some form of pre-trained deep learning models such as BERT and XLM-RoBERTa (Bornheim, Grieger, and Bialonski Reference Bornheim, Grieger and Bialonski2021; Morgan, Ranasinghe, and Zampieri Reference Morgan, Ranasinghe and Zampieri2021).
2.9 DETOXIS: detection of toxicity in comments in Spanish at IberLeF
IberLeF 2021 was a workshop organized to evaluate systems in Spanish and other Iberian languages, on various NLP tasks. The competition included a general shared task to detect harmful content, with specific tasks related to offensive language detection in Spanish and Mexican Spanish and toxicity detection in Spanish comments (Taulé et al. Reference Taulé, Ariza, Nofre, Amigó and Rosso2021). The offensive language detection task was further divided in four sub-tasks: sub-task 1 was a multiclass classification problem for generic Spanish where the participants have to classify comments into five different categories; “Offensive and target is a person,” “Offensive and target is a group of people,” “Offensive and target is different from a person or a group,” “Non-offensive, but with expletive language” and “Non-offensive.” Sub-task 2 was also a multiclass classification problem with the previous categories, however, meta-data for the post was given, such as author genre. Sub-task 3 was a binary classification problem for Mexican Spanish where the participants must classify tweets as offensive or non-offensive. Sub-task 4 was a binary classification problem with the same tweets as sub-task 3, but the participants were provided with the meta-data for each tweet, such as date, retweet count, and author followers count. Sub-tasks 1 and 2 had a combined 16,710 training, 100 development, and 13,606 testing instances, while sub-tasks 3 and 4 had a combined 5060 training and 2183 testing instances. All of the instances were based on Twitter. Most of the top systems used some pre-trained transformer-based models such as multilingual BERT, BETO and XLM-RoBERTa (Plaza-del Arco, Molina-González, and Alfonso Reference Plaza-del Arco, Molina-González and Alfonso2021).
The toxicity detection task focused on detecting toxicity in Spanish news comments. The task was further divided into two sub-tasks: sub-task 1 was a binary classification task to distinguish between toxic and non-toxic comments, while sub-task 2 was about assigning a toxicity score for the comment, ranging from 0 (not toxic) to 3 (very toxic). The participants were provided with 3463 comments for training and 896 comments for testing their models. All of the instances were based on news media comments. The best-performing teams for both sub-tasks used BETO (the Spanish version of BERT model) (Plaza-del Arco et al. Reference Plaza-del Arco, Molina-González and Alfonso2021).
3. OffensEval
The evaluation presented in this paper focuses on the shared task on Identifying and Categorizing Offensive Language in Social Media (OffensEval). The task has been organized at SemEval-2019 including English data and at SemEval-2020 including data in English and other four languages, namely Arabic, Danish, Greek, and Turkish. The task has been influential as it was the first to model offensive language identification considering the type and target of offensive posts. OffensEval was based on the three levels of the Offensive Language Identification Dataset (OLID) taxonomy (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019a) which has since become a de facto standard for general offensive language taxonomy. OLID’s hierarchical annotation model was developed with the goal of serving as a general-purpose model for multiple sub-tasks (e.g., hate speech, cyberbulling, etc.) as described next.
3.1 The OLID taxonomy
Introduced in (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019a), the OLID taxonomy is a labeling schema that classifies each example for offensiveness using the following three-level hierarchy.
• A: Offensive Language Detection
• B: Categorization of Offensive Language
• C: Offensive Language Target Identification
The original OLID dataset was created for English and the taxonomy has been widely adopted for several languages (Pitenis, Zampieri, and Ranasinghe Reference Pitenis, Zampieri and Ranasinghe2020a; Gaikwad et al. Reference Gaikwad, Ranasinghe, Zampieri and Homan2021; Ranasinghe et al. Reference Ranasinghe, Anuradha, Premasiri, Silva, Hettiarachchi, Uyangodage and Zampieri2022a). The popularity of OLID is due to the flexibility provided by its hierarchical annotation model that considers multiple types of offensive content in a single taxonomy. For example, targeted insults to a group are often hate speech whereas targeted insults to an individual are often cyberbulling. The hierarchical structure of OLID allows mapping OLID level A (offensive vs. non-offensive) to labels in various other related datasets annotated with respect to hate speech, aggression, etc. as demonstrated in (Ranasinghe and Zampieri Reference Ranasinghe and Zampieri2020, Reference Ranasinghe and Zampieri2021).
We present some examples retrieved from the original OLID dataset with their respective labels in Table 1. Further details about each level of the taxonomy are described next.
Table 1. Several tweets from the original OLID dataset, with their labels for each level of the annotation model (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019a)

3.1.1 Level A: offensive language detection
In this level, annotators are asked to annotate each instance with respect to the presence of any form of offensive content by answering the question “Is the text offensive?” The following two labels are included in level A:
• OFF Inappropriate language, insults, or threats.
• NOT Neither offensive nor profane. The following example is not offensive: @USER you are also the king of taste
3.1.2 Level B: categorization of offensive language
In this level, only offensive instances labeled in level A as OFF are included. Annotators are asked to label each offensive instance as either targeted or untargeted by answering the question “Is the offensive text targeted?” The following two labels are included in level B:
• TIN Targeted insult or threat towards a group or an individual.
• UNT Untargeted profanity or swearing. The following example includes profanity (bullshit) that is not targeted to anyone: @USER What insanely ridiculous bullshit.
3.1.3 Level C: offensive language target identification
In this level, only targeted offensive instances labeled in level A as OFF and in level B as TIN are included. Annotators are asked to label each targeted offensive instance with respect to its target by answering the question “What is the target of the offensive?” The following three labels are included in level C:
• IND The target is an individual explicitly or implicitly mentioned in the conversation. The following example is targeted towards an individual, that: @USER Anyone care what that dirtbag says?
• GRP Hate speech targeting a group of people based on ethnicity, gender, sexual orientation, religion, or other common characteristic. The following example is targeted towards a group liberals: Poor sad liberals. No hope for them.
• OTH Targets that does not fall into the previous categories, for example organizations, events, and issues. The following example is targeted towards an organization, NFL: LMAO….YOU SUCK NFL
3.2 OffensEval 2019
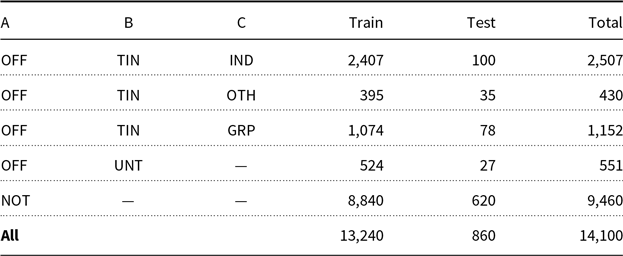
OffensEval 2019 (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019b) at SemEval received a very positive response from the community. The shared task attracted about 800 participating teams making it the largest ever SemEval task until that point. OLID, the official dataset for this task, featured 14,100 instances retrieved from Twitter divided into training and testing sets. We present a breakdown of the instances in OLID and their label distribution in Table 2.
Table 2. Distribution of label combinations in OLID (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019b)
Two factors have contributed to OffensEval’s popularity (i) the growing popularity of deep learning models and the introduction of large general pre-trained transfer models, most notably BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019), just months before the competition and (ii) the use of the OLID taxonomy (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019a). Prior to OLID, previous work on detecting offensive language focused on detecting specific types of offensive content such as hate speech, profanity, and cyberbullying. As described earlier in this section, the OLID taxonomy approached offensive content using a single annotation scheme allowing multiple types of offensive content to be modeled in a single taxonomy. This, in our opinion, helped attracting participants interested in different offensive and abusive language phenomena.
OffensEval 2019 featured three sub-tasks each representing one level of the OLID taxonomy. The organizers provided three baselines to the participants, namely a CNN model, a BiLSTM model, and an SVM model described in (Zampieri et al. Reference Zampieri, Malmasi, Nakov, Rosenthal, Farra and Kumar2019a). The best baseline was a CNN model that achieved 0.800 F1 score for sub-task A, 0.690 for sub-task B, and 0.470. The CNN baseline model would be ranked 10th among all entries in sub-tasks A and B but only 48th in sub-task C. We present the top-10 results of each sub-task along with the strongest baseline in Table 3.
Table 3. F1-Macro for the top-10 teams for all three sub-tasks. The best baseline model (CNN) is also presented
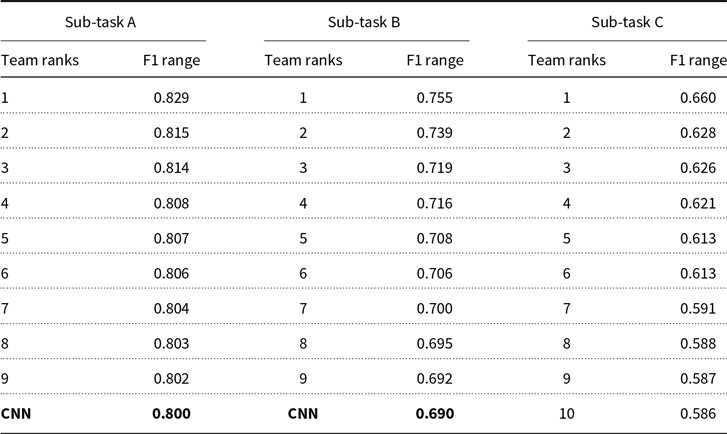
Sub-task A, where participants were asked to label each instance as either offensive or not offensive, was the most popular sub-task with 104 submissions. The best performance in this sub-task was obtained by (Liu, Li, and Zou Reference Liu, Li and Zou2019) who used a BERT model achieving 0.829 F1 score. Sub-task B, where participants were asked to label each instance as either targeted or untargeted, received 76 submissions. The best system in sub-task B by (Nikolov and Radivchev Reference Nikolov and Radivchev2019) also used a BERT model achieving 0.755 F1 score. Finally, sub-task C, where participants trained models to identify one of the three target labels (IND, GRP, OTH), received 65 submissions. The best system in sub-task C by (Han, Liu, and Wu Reference Han, Liu and Wu2019) used a deep learning approach based on bidirectional recurrent layers with gated recurrent units achieved 0.660 F1 score.
To illustrate the variety of approaches used in OffensEval 2019, we present a breakdown of all approaches used for sub-task A in Figure 1.
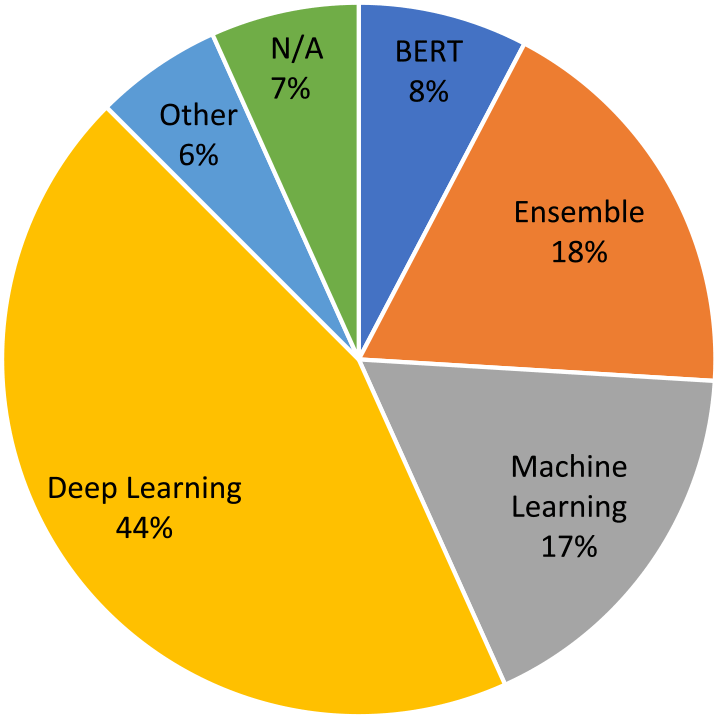
Figure 1. Pie chart adapted from (Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020) showing the models used in sub-task A. “N/A” indicates that the system did not have a description. Under machine learning, we included all approaches based on traditional classifiers such as SVMs and Naive Bayes. Under deep learning, we included approaches based on neural architectures available at that time except BERT.
BERT had been recently introduced and it was among the first models to employ a transformer-based architecture and pre-trained contextual embeddings. At the time of OffensEval 2019, BERT had quickly become very popular in NLP due to its high performance in many tasks and the possibility of being used as an off-the-shelf the model. Despite its growing popularity at that time, as depicted in Figure 1, we can see that only 8% of the teams (about 12 teams) approached sub-task A using a BERT model. However, among the top-10 teams in the sub-task, seven used BERT including the best submission (Liu et al. Reference Liu, Li and Zou2019) which confirmed BERT as the state-of-the-art model for this task in 2019.
3.3 OffensEval 2020
Building on the success of OffensEval 2019, a second edition of OffensEval was organized in 2020. The organizers, created and publicly released the Semi-Supervised Offensive Language Identification Dataset (SOLID) (Rosenthal et al. Reference Rosenthal, Atanasova, Karadzhov, Zampieri and Nakov2021), a large-scale offensive language identification dataset containing nine million English tweets with labels attributed using a semi-supervised method with OLID as a seed dataset. The creators of SOLID employed democratic co-training (Zhou and Goldman Reference Zhou and Goldman2004), a semi-supervised technique used to create large datasets with noisy labels when provided with a set of diverse models each trained in a supervised way. Four models with different inductive biases were used with the goal of decreasing each individual model’s bias, namely PMI (Turney and Littman Reference Turney and Littman2003), FastText (Bojanowski et al. Reference Bojanowski, Grave, Joulin and Mikolov2017), LSTM (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997), and BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019). Participants were provided with the dataset instances, an average prediction confidence scores by all models for each label, and the standard deviation between them. The idea behind this approach was to discourage participants from only using predictions from a specific model. The inclusion of confident scores instead of discrete labels by annotators combined with the large size of the dataset allowed participants to filter out weak data points and experiment with different thresholds when selecting instances for training.
While OffensEval 2019 was a monolingual shared task featuring only English data, OffensEval 2020 was a multilingual competition that introduced datasets in English and four other languages: Arabic (Mubarak et al. Reference Mubarak, Rashed, Darwish, Samih and Abdelali2020), Danish (Sigurbergsson and Derczynski Reference Sigurbergsson and Derczynski2020), Greek (Pitenis, Zampieri, and Ranasinghe Reference Pitenis, Zampieri and Ranasinghe2020b), and Turkish (Çöltekin Reference Çöltekin2020). Five different tracks were organized in OffensEval 2020, one for each language. All datasets have been annotated according to the OLID taxonomy in levels A, B, and C. While annotation was available in the three levels, only the English track featured sub-tasks A, B, and C as in OffensEval 2019. The Arabic, Danish, Greek, and Turkish tracks featured only sub-task A. The instances in the five datasets and their label distribution for sub-task A are presented in Table 4.
Table 4. Data statistics for OffensEval 2020 sub-task A from Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin(2020)

The availability of datasets in various languages annotated according to the same taxonomy opened the possibility for cross-lingual training and analysis. In Table 5, we present examples from the five OffensEval 2020 datasets along with their labels in A, B, and C.
Table 5. Annotated examples for all sub-tasks and languages adapted from Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin(2020)

A total of 528 teams signed up to participate in OffensEval 2020 and a total of 145 teams submitted official runs to the competition. Participation varied across languages. The English track attracted 87 submissions to sub-task A while the Greek track attracted 37 teams. In Table 6, we present the results of the top-10 systems in the English track for sub-tasks A, B, and C.
Table 6. Results for the top-10 teams in English sub-task A ordered by macro-averaged F1
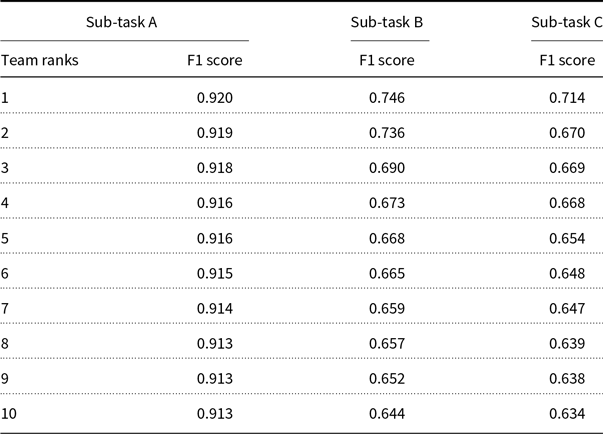
In OffensEval 2020, we have observed that pre-trained language models based on transformer architectures had become the dominant paradigm in NLP. The clear majority of teams used pre-trained transformer models such as BERT, XLM-RoBERTa, and their variations. The top-10 teams used BERT, RoBERTa, or XLM-RoBERTa, often part of ensembles that also included CNNs and LSTMs (Hochreiter and Schmidhuber Reference Hochreiter and Schmidhuber1997). The best submission in sub-task A by (Wiedemann, Yimam, and Biemann Reference Wiedemann, Yimam and Biemann2020) achieved 0.9204 F1 score using a RoBERTa-large model fine-tuned on the SOLID dataset and the second best submission by (Wang et al. Reference Wang, Liu, Ouyang and Sun2020) use an ensemble of ALBERT models.
In addition to the English results discussed in this section, OffensEval 2020 featured the aforementioned Arabic, Danish, Greek, and Turkish tracks. Due to the limited availability of LLMs that are trained for languages other than English, we were able to include only Arabic, Greek, and Turkish in the evaluation presented in Section 4 leaving Danish out. For Arabic, Danish, and Greek, only one model, Flan-T5, was available. The unavailability of suitable models unfortunately did not allow us to perform a thorough evaluation of LLM performance for these languages. For this reason, we discuss the results on these languages only in Section 4. We refer to the OffensEval 2020 report (Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020) where the interested reader can find more information about these language tracks.
4. Benchmarking LLMs for offensive language online
In this section, we carry out an evaluation of different models on the OffensEval 2019 and OffensEval 2020 test sets. We selected six popular open-source models of the latest generation of LLMs developed between 2022 and 2023. We also use two task fined-tuned BERT models that have proven to achieve competitive performance in this task. We present all models, baselines, prompting strategies, and the results obtained by the tested models compared to the best entries at OffensEval.
4.1 LLMs
Falcon-7B-Instruct (Penedo et al. Reference Penedo, Malartic, Hesslow, Cojocaru, Cappelli, Alobeidli, Pannier, Almazrouei and Launay2023), henceforth Falcon, is a decoder-only model fine-tuned with instruct and chat datasets. This model was adapted from GPT-3 (Brown et al. Reference Brown, Mann, Ryder, Subbiah, Kaplan, Dhariwal, Neelakantan, Shyam, Sastry and Askell2020) model, with differences in the positional embeddings, attention, and decoder-block components. The base model Falcon-7B, on which this model was fine-tuned on, outperforms other open-source LLM models like MPT-7B and RedPajama, among others. The limitation of this model is that it was mostly trained on English data, and hence, it does not perform well on other languages.
RedPajama-INCITE-7B-Instruct (Computer Reference Computer2023), henceforth RedPajama, is an open-source LLM, based on the RedPajama-INCITE-7B-Base model and fine-tuned for few-shot applications. The model was trained only for English.
MPT-7B-Instruct (Team Reference Team2023), henceforth MPT, is a model fine-tuned on the base MPT-7B model. The model uses a modified decoder-only architecture, with the standard transformer been modified using the FlashAttention (Dao et al. Reference Dao, Fu, Ermon, Rudra and Ré2022), Attention with Linear Biases (AliBi) (Press, Smith, and Lewis Reference Press, Smith and Lewis2021) instead of positional embeddings, and it also does not use biases. Similar to the Falcon model, this model was trained using only the English data.
Llama-2-7B-Chat (Touvron et al. Reference Touvron, Martin, Stone, Albert, Almahairi, Babaei, Bashlykov, Batra, Bhargava and Bhosale2023b), henceforth Llama 2, is an auto-regressive language model with optimized transformer architecture. This model was optimized for dialogue use case. The model was trained using publicly available online data. The model outperforms most other open-source chat models and has a performance similar to models like ChatGPT. This model, however, works best only for English.
T0-3B (Sanh et al. Reference Sanh, Webson, Raffel, Bach, Sutawika, Alyafeai, Chaffin, Stiegler, Scao, Raja, Dey, Bari, Xu, Thakker, Sharma, Szczechla, Kim, Chhablani, Nayak, Datta, Chang, Jiang, Wang, Manica, Shen, Yong, Pandey, Bawden, Wang, Neeraj, Rozen, Sharma, Santilli, Fevry, Fries, Teehan, Biderman, Gao, Bers, Wolf and Rush2021), henceforth T0, is a encoder-decoder-based model trained on several tasks using prompts. This model is based on the T5 model. The model was trained with a standard language model and using datasets for several NLP task. Similar to the other language models, this model also does not support non-English text.
Flan-T5-large (Chung et al. Reference Chung, Hou, Longpre, Zoph, Tay, Fedus, Li, Wang, Dehghani and Brahma2022), henceforth Flan-T5, is a language model based on the T5 (Raffel et al. Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2020) model, which is a Text-to-Text transformer model. This model was fine-tuned for better zero-shot and few-shot learning for over 1000 different tasks. The model is one of the few LLM with support for languages other than English.
4.2 Task-specific BERT models
hateBERT (Caselli et al. Reference Caselli, Basile, Mitrović and Granitzer2021) is a BERT-based model, trained using the Reddit comments dataset, containing about one million posts from communities banned for being offensive and abusive. It is a monolingual model specifically trained using data in English. The model outperforms the general pre-trained language models on offensive language detection datasets.
fBERT (Sarkar et al. Reference Sarkar, Zampieri, Ranasinghe and Ororbia2021) is an offensive language detection BERT-based model, retrained using the SOLID dataset. The model was trained using about 1.4 million offensive language post from social media platform. The model has more domain-specific offensive language features, and it outperforms the general BERT model on offensive language datasets.
4.3 Zero-shot prompting
Zero-shot prompting is an approach where we do not provide any examples for the inputs and outputs. This approach is especially useful when we do not have labeled data for the classes. The model must make predictions based on the prior knowledge without knowing much about the new classes. The following prompt was used for our evaluations.
Comments containing any form of non-acceptable language (profanity) or a targeted offense, which can be veiled or direct are offensive comments. This includes insults, threats, and posts containing profane language or swear words. Comments that do not contain offense or profanity are not offensive.
Question: In one word, is the following comment offensive or not? They should just shut up
Answer: The comment is
As seen in the above example, the initial part of the prompt is a summary of the task. This is not always required, and we can directly ask the question and get the answer from the LLM. Depending on the specific requirements of the models, it is required to add special tokens to the prompt. For example, the Llama 2 model requires special tokens like “[INST], [/INST],” and “<<SYS>>,<</SYS>>,” to indicate model instructions.
4.4 Zero-shot learning
Zero-shot learning approach is based on the latent embedding approach, where the input and the labels are embedded into a latent representation, using an existing model (Veeranna et al. Reference Veeranna, Nam, Mencıa and Fürnkranz2016). This approach is commonly used with the sentence embedding models. We evaluate the hateBERT and fBERT models using this approach. For a given input instance, the embedding vector for the input is obtained from the last four layers of the model. Similarly, the embedding vector for all the labels is generated. The cosine similarity between the embeddings of the input and each of the label embeddings is calculated. The input is assigned a label with which it has the highest cosine similarity.
4.5 Baselines
For OffensEval 2019, the top three systems for sub-task A were used as baseline. The best-performing team at OffensEval 2019 preprocessed the training dataset which was then used to fine-tune a pre-trained BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) model (Liu et al. Reference Liu, Li and Zou2019). The model was only fine-tuned for two epochs. The second placed team also used a BERT model, but they used pre-trained GloVe vectors (Pennington, Socher, and Manning Reference Pennington, Socher and Manning2014) while also addressing the class imbalance (Nikolov and Radivchev Reference Nikolov and Radivchev2019). The third placed team also fine-tuned a pre-trained BERT model, but they used different hyperparameters (Zhu, Tian, and Kübler Reference Zhu, Tian and Kübler2019).
The OffensEval 2020 included five languages: English, Arabic, Greek, Turkish, and Danish. For the English track, the best-performing team fine-tuned four different ALBERT (Lan et al. Reference Lan, Chen, Goodman, Gimpel, Sharma and Soricut2020) models (Wiedemann et al. Reference Wiedemann, Yimam and Biemann2020) and used the ensemble of these fine-tuned models for prediction. The second best team (Wang et al. Reference Wang, Liu, Ouyang and Sun2020) also used an ensemble approach, where they first fine-tuned two multilingual XLM-RoBERTa models, XLM-RoBERTa-base, and XLM-RoBERTa-large (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2019). In comparison, the third placed team fine-tuned only one multilingual XLM-RoBERTa model (Dadu and Pant Reference Dadu and Pant2020).
For the Arabic track, the first placed team used the AraBERT model (Antoun, Baly, and Hajj Reference Antoun, Baly and Hajj2020) to encode the tweets, and a sigmoid classifier was then trained using the encoded tweets (Alami et al. Reference Alami, Ouatik El Alaoui, Benlahbib and En-nahnahi2020). The second placed team (Hassan et al. Reference Hassan, Samih, Mubarak and Abdelali2020) used an ensemble of SVM, CNN-BiLSTM, and multilingual BERT models. Each of these models used different features, with character and word level n-grams along with the word embeddings used as the features for the SVM model, whereas the CNN-BiLSTM model used character and word embeddings. The third best team (Wang et al. Reference Wang, Liu, Ouyang and Sun2020) used an ensemble of the XLM-RoBERTa-base and XLM-RoBERTa-large models (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2019).
The first placed team for the Greek track fine-tuned a pre-trained mBERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) model, but they also used the embeddings of a domain-specific vocabulary generated using the WordPiece algorithm to fine-tune and pre-train the model (Ahn et al. Reference Ahn, Sun, Park and Seo2020). The second placed team (Wang et al. Reference Wang, Liu, Ouyang and Sun2020) used an ensemble of the XLM-RoBERTa-base and XLM-RoBERTa-large model (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2019), while the third best team used a monolingual BERT model (Socha Reference Socha2020).
As for the Turkish track, the first placed team (Wang et al. Reference Wang, Liu, Ouyang and Sun2020) used an ensemble of the XLM-RoBERTa-base and XLM-RoBERTa-large model (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2019), the second best team (Ozdemir and Yeniterzi Reference Ozdemir and Yeniterzi2020) used an ensemble of CNN-LSTM, BiLSTM-Attention, and BERT models, with pre-trained word embeddings for tweets generated using the BERTurk, a BERT model for Turkish. The third placed team (Safaya, Abdullatif, and Yuret Reference Safaya, Abdullatif and Yuret2020) combined the BERTurk model with the CNN model.
4.6 OffensEval 2019 results
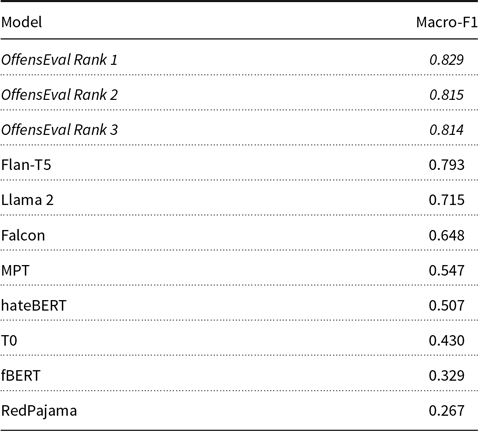
We present all evaluation results in Table 7. We observed that performance varied widely between all models tested ranging from 0.793 F1 score obtained by Flan-T5 to 0.267 obtained by RedPajama. A surprising outcome of this evaluation is the low performance of the task fine-tuned models which did not obtain competitive performance compared to the top-3 teams at OffensEval or even some of the LLMs. Flan-T5 was the only model that achieved competitive performance close to the 0.800 F1 score obtained by the competition’s CNN baseline model. All in all, all models tested were outperformed by the best three systems of the competition.
Table 7. Macro-F1 scores for the OffensEval 2019 test set. Baseline results displayed in italics
4.7 OffensEval 2020 results
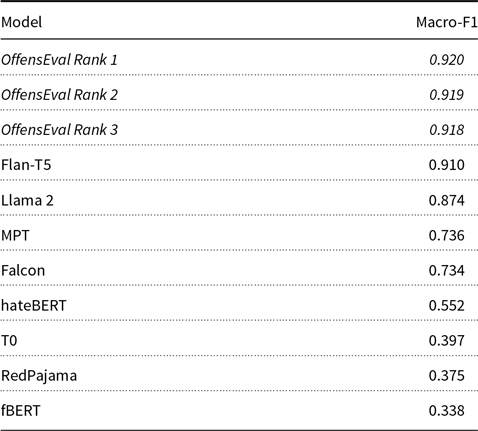
We present the results on the OffensEval 2020 dataset in Table 8. For OffensEval 2020 also, all the LLMs with the zero-shot prompting approach could not outperform the best three systems. Flan-T5, however, comes very close to the top teams in the competition with a 0.910 macro-F1 score. Llama 2 also follows closely with 0.874 macro-F1 score. The rest of the models do not perform well, falling behind 0.750 macro-F1 score.
Table 8. Macro-F1 scores for the OffensEval 2020 English test set. Baseline results are displayed in italics
Language coverage is one of the known bottlenecks of LLMs. Most LLMs tested in this study do not support non-English languages. The only model that supports some of the OffensEval 2020 languages is Flan-T5-large. The results for Arabic, Greek, and Turkish are shown in Table 9.
Table 9. Macro-F1 scores for the OffensEval 2020 Arabic, Greek, and Turkish test sets. Baseline results are displayed in italics
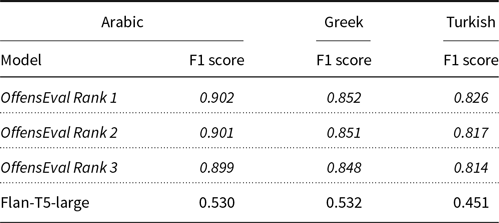
The results show that the Flan-T5-large model does not outperform the top three systems in any of the three languages. Furthermore, it should be noted that in English the gap between Flan-T5-large and the third placed system is only 0.01 macro-F1 score. However, in all these three languages, Flan-T5-large has a larger gap with the third place system, suggesting that the model is weaker in detecting offensive language in non-English languages. Most possibly, this is due to the training data limitation in non-English languages in Flan-T5-large.
5. Conclusion and future work
This paper presented a survey and evaluation of offensive language identification benchmark competitions with a focus on OffensEval. We used zero-shot prompting on six state-of-the-art LLMs and zero-shot learning on two task fine-tuned BERT models and compared their performance to the best entries submitted to OffensEval 2019 and 2020 for Arabic, English, Greek, and Turkish. Our results indicate that while some new LLMs such as Flan-T5 achieve competitive results, all LLMs tested achieved lower performance than the best three systems in those competitions which were based on more well-established transformer-based models such as BERT and ELMo. This suggests that while LLMs have been achieving impressive performance on a variety of tasks, particularly in those that involve next-word prediction and text generation, their zero-shot performance on this task is still not up to the same standard as transformer models trained on in-domain data.
Given the relatively recent introduction of the latest generation of LLMs, there are several avenues we would like to explore in the future that will help us better understand the performance of these models on offensive language identification. One of the most promising future directions is to evaluate possible data contamination in LLMs (Golchin and Surdeanu Reference Golchin and Surdeanu2023). Unfortunately, most LLM developers provide very limited information on the data these models are trained on. Therefore, it is currently not possible to know how benchmark datasets are used in the training of these models and whether shared task test sets are used in the training stage. Further investigation is required to determine the extent of data contamination in LLMs.
Finally, an obvious limitation of this study is the limited support by LLMs for languages other than English. We were able to prompt Flan-T5 for Arabic, Greek, and Turkish but Danish, which was also included in OffensEval, was not supported by any of the models. As new models are released every month and developers work to include more languages in them, we would like to replicate this study on all OffensEval languages using more LLMs in the future.











 Open access
Open access