


1. Introduction
Generating descriptions for structured table data is an essential task for natural language generation, aiming to take table data as input to generate text that adequately and coherently describes these data (Parikh et al., Reference Parikh, Wang, Gehrmann, Faruqui, Dhingra, Yang and Das2020). It has been applied in many domains, typically including weather forecasting, question-answering systems, sports event broadcasts, and biographical writings. For example, a summary text needs to be generated in a sports event, based on real-time and detailed game data, to present to the audiences quickly.
There are some differences between table-to-text generation and the broader task of text generation (e.g., machine translation; Zhang, Xiong, and Su Reference Zhang, Xiong and Su2020) and usually need to solve two levels of problems (Wiseman, Shieber, and Rush, Reference Wiseman, Shieber and Rush2017):
-
1. Select the appropriate subset of data to describe. Unlike general text sequences, tables often contain additional information such as fields, values (linguistic and structural), and table titles. For example, when writing a biography for a person based on the data, we will firstly determine which ones to be included from a large amount of confusing and trivial information.
-
2. How to present comprehensive and precise information based on refined semantic information. In a table where only a few of the vast records are suitable for the final output, generating coherent and relevant text is the ultimate goal of this task. The second problem lies in arranging the order of them correctly. Understanding these latent semantic structures and then refining them is the foundation for the table-to-text generation.
The deep learning systems based on the neural network language models (NLM; LeCun et al., Reference LeCun, Bengio and Hinton2015) blur the boundaries between these two processes and modularly handle both subtasks through an end-to-end system (Zhang, Zhang, and Yan, Reference Zhang, Zhang and Yan2019). However, Wiseman et al. (Reference Wiseman, Shieber and Rush2017) find that although the NLM-based approaches can generate descriptions fluently, they are still not as accurate as the template-based systems in selecting the subset of records and yet have room for improvement. Current neural language models proposed to solve table-to-text generation mainly rely on the encoder–decoder structure (Sutskever, Vinyals, and Le, Reference Sutskever, Vinyals and Le2014) and attention mechanism (Bahdanau, Cho, and Bengio, Reference Bahdanau, Cho and Bengio2014). Mei et al. (Reference Mei, Bansal and Walter2016) propose a selective-generation method with an encoder–decoder-aligner structure to generate weather forecasts, using a pre-defined corrector model to correct the dependencies between the records and the text. Lebret et al. (Reference Lebret, Grangier and Auli2016) model the fields and local and global conditioning in the WikiBio dataset based on an n-gram model and improve the effect. Liu et al. (Reference Liu, Wang, Sha, Chang and Sui2018) use dual attention and a flexible copy to solve the dependencies between records and text, and finally improve the effect by about 10 points than the baseline. Puduppully et al. (Reference Puduppully, Dong and Lapata2019) improve the RotoWire dataset’s outcome by modeling the generation as content planning and surface realization. Bao et al. (Reference Bao, Tang, Duan, Yan, Zhou and Zhao2019) have made some improvements on WikiBio using the encoder–decoder structure and conditional copy mechanism for handling text alignment and rare word problems; they propose a new multi-line tabular dataset WikiTableText. These works have inspired our work. However, there are still some problems to be solved: tables often contain complex structural information, and the alignment from the attention vector would gradually diminish in generating long text, so the content of the records cannot be extracted well (Chen et al., Reference Chen, Li, Hu, Peng, Chen, Lv and Yu2020a, Reference Chen, Chen, Zha, Zhou, Zhang, Sundaresan and Wang2020d).
To this end, we propose a novel generative model based on the encoder–decoder framework and attention mechanism, SAN-T2T, using long short-term memory network (LSTM; Hochreiter and Schmidhuber, Reference Hochreiter and Schmidhuber1997) to process the complicated structure in the table. In the encoding phase, we integrate the table’s structure into its representation and add a position gate to the cell state of the LSTM unit. Then we apply the self-gated content selector to utilize its reciprocal inference (i.e., different records may determine each other’s importance in the table’s structure) and an LSTM decoder to generate the description. In the decoding phase, the semantic vector from the content selector will enhance the alignment between the output and input, and a featured copy mechanism is applied to alleviate the rare word problem.
Our contributions are as follows:
-
1. We utilize the fields’ position to enhance the decoder’s ability to extract structural information from the attention mechanism.
-
2. The gate mechanism is used to determine the importance of mutual decision-making between different fields in advance. The modified attention vector determines the amount of information that each timestep in the decoder obtains from the source sequence.
-
3. In the inference phase, the most relevant words are copied from the source sequence based solely on the attention vector to alleviate the problem of rare words.
-
4. Finally, we also experimentally compare the effect of beam search on the model’s performance.
We have performed experiments on SAN-T2T with the Bilingual Evaluation Understudy (BLEU) and recall-oriented understudy for Gisting evaluation (ROUGE) metrics. Results and attention visualizations show that SAN-T2T can precisely understand the table’s content and structure and then generate comprehensive and correct descriptive text.
2. Related work
Table-to-text generation can usually be divided into two independent modules (Wiseman et al., Reference Wiseman, Shieber and Rush2017):
-
1. Content selection (CS). Select an appropriate subset of related records to be described from the source table data. Each record has a wide range of complicated and aggregate statistics, with only a small subset of this information having a positive influence on the description, the CS component is to choose the subset which works properly.
-
2. Surface realization. Generate descriptions for these selected subsets. For the chosen records from the CS component, semantic information along with other features should be obtained precisely.
Many approaches have been proposed to solve these two problems. There are some typical methods for CS, such as Barzilay and Lapata (Reference Barzilay and Lapata2005) to build this by aligning the records and text. They treat CS as a collective classification problem and build links between entities with similar labels to consider all candidates simultaneously rather than select each item separately. Surface realization is usually regarded as obtaining semantic information from the given feature representation and then generating text. Reiter and Dale (Reference Reiter and Dale2000) use various language feature models and hand-built grammars to design text generators for surface realization. On top of this model, Reiter (Reference Reiter2007) then extended his architecture so that the input of the system was raw data rather than artificial intelligence knowledge base, and the task was divided into four stages, which were processed successively. These methods are mainly based on template rules or statistical language models to solve the alignments between text and records, while most of the recent works combine CS and surface realization in a unified end-to-end framework (Kondadadi, Howald, and Schilder, Reference Kondadadi, Howald and Schilder2013; Konstas and Lapata, Reference Konstas and Lapata2013a; Oya et al., Reference Oya, Mehdad, Carenini and Ng2014). But it can be considered as a neural extension of the Probabilistic Context-Free Grammar (PCFG) system in Konstas and Lapata (Reference Konstas and Lapata2013b), with a more powerful transition probability considering inter-segment dependence and a state-of-the-art attention-based language model as the linguistic realizer. Wiseman et al. (Reference Wiseman, Shieber and Rush2018) integrate the end-to-end model and the rules-based template system, using a hidden semi-Markov model which is suitable for fragment modeling to learn to extract and use templates, then parameterize these probabilities with a neural language model, and finally use the Viterbi algorithm to infer the hidden states and use them as the template. Jiang et al. (Reference Jiang, Chen, Zhou, Wu, Chen, Zheng and Wan2020) also integrate these two modules and propose the pipeline-assisted neural networks to conduct table-to-text generation tasks in social Internet of Things. They analyze records correlation and filter redundant records to make full use of attention and gate mechanism and to improve CS.
The above-mentioned works all model the table-to-text task on the encoder–decoder framework, which encodes a source sequence into a fixed-length vector from which a decoder generates the target sequence. The encoder–decoder models aim to solve the problem that previous deep neural networks cannot handle most sequential problems (e.g., machine translation) because they can only be applied to solve problems which have fixed-dimensional inputs and targets. Sutskever et al. (Reference Sutskever, Vinyals and Le2014) propose the encoder–decoder model which now performs as the baseline for many sequence-to-sequence problems. They use the LSTM network to encode the input sequence, one timestep at a time, to obtain a fixed-dimensional vector representation and then use another LSTM network to extract semantic information from this vector. LSTM network doing well at learning dependencies from long-range sequences makes it the first choice for the sequence-to-sequence problems because of the considerable time lags between the inputs and outputs. Though the great advances in the encoder–decoder framework, there are several shortages either. It encodes the source sequence into a fixed-length hidden semantic vector, which leads to two problems. First, it cannot compress the full necessary information into the fixed-length hidden vector. Second, the previously hidden information will be covered due to the gates in the LSTM unit, making it harder to cope with sequential problems with long sentences, especially those much longer than the average length of the training corpus. To solve this problem, Bahdanau et al. propose the attention mechanism in 2014 which is now widely used for natural language processing (NLP) and then explore the promising applications of the encoder–decoder architecture. The attention models can automatically (soft)-align parts of the source sequence that are relevant to predicting the target sequence, without having to form these parts as a hard segment explicitly. This is done by weighing the relevance (alignment) of any entities of the input text and taking such a weight into account when predicting the result. The idea is built on the hypothesis that background features could be irrelevant regarding some objects in the foreground, but relevant to others considering the context. However, such attention approaches are not always reliable; when processing long or information-complicated sequences, the attention context representation for alignment would gradually be weakened.
Based on the previous works, the bottleneck of current models for table-to-text tasks lies in the stage of content planning (i.e., select and order salient content from the input (Gong et al., Reference Gong, Bi, Feng, Qin, Liu and Liu2020). The SAN-T2T model borrows the idea of representing hidden features through the fields and their corresponding content to describe the structured tables more accurately (Lebret et al., Reference Lebret, Grangier and Auli2016). However, the n-gram model proposed by Lebret et al. cannot effectively model the distant dependencies in the sequence. Mei et al. propose a Seq2seq model in 2016 which aligns dependencies between records and text through a pre-defined corrector and use one-hot vectors to represent features of the records, but due to the limitations of one-hot encoding, their model could not represent tables with complex structures, such as infoboxes in the WikiBio dataset. Li et al. (Reference Li, Crego and Senellart2019) present a transformer-based generation model, modify the latent representation of the record embedding, and propose two data augmentation methods. To improve performance in CS and coherent ordering, Puduppully and Lapata (Reference Puduppully and Lapata2021) propose a neural model with a macro planning stage followed by a generation stage reminiscent of traditional methods which embrace separate modules for planning and surface realization.
To address the problem of out-of-vocabulary (OOV) words appearing in the records (including some special entities, names, etc.), See et al. (Reference See, Liu and Manning2017) and Gu et al. (Reference Gu, Lu, Li and Li2016) design the copy mechanisms. When generating certain special terms, the OOV words could be copied from the source sequence to the target text. Sha et al. (Reference Sha, Mou, Liu, Poupart, Li, Chang and Sui2018) design a linking mechanism with link-based and content-based attention to model the content order, a self-adaptive gate to balance these two levels of attention, and then utilize a copy network to solve the OOV problem. Liu et al. (Reference Liu, Wang, Sha, Chang and Sui2018) extend the work of Sha et al., by using dual attention to align dependencies between records and text, and the word-level attention is focused on the alignment between the output text and input data, while field level is more concerned with that between the text and the overall structure of the table. Qin et al. (Reference Qin, Yao, Wang, Wang and Lin2018) establish the dependencies using the method of sequence labeling, regard labeling the semantics of the vocabulary as a hidden variable, and design a hidden semi-Markov model for learning and inference. Their model can learn more latent semantic information while retaining interpretability. Wiseman et al. (Reference Wiseman, Shieber and Rush2017) propose a new extractive evaluation metric and a brand new dataset RotoWire, while using joint and conditional copy mechanisms to handle the OOV problem. Later, Puduppully et al. (Reference Puduppully, Dong and Lapata2019) model the generation task as content planning and surface realization, where content planning is used to find a subset of records that keep important roles in the source data and plan a reasonable order to describe these records. Bao et al. (Reference Bao, Tang, Duan, Yan, Zhou and Zhao2019) design a model based on the encoder–decoder framework, focusing on using copy network to deal with the problem of rare words, but their models do not solve the problem that the attention mechanism cannot make good utilization of the records’ structure. To alleviate the training difficulty and consumption, Jean et al. (Reference Jean, Cho, Memisevic and Bengio2015) make use of the attention vectors to track the origins of all target words; Luong et al. (Reference Luong, Sutskever, V.Le, Vinyals and Zaremba2015) use unsupervised alignments as the word dictionary to post-process the translation and replace the unknown with the source words. Then Liu et al. (Reference Liu, Mu, Sun and Wang2020) use the pointer-generator network to handle the problem of rare words; their model can also reference the slot-value pairs data and then introduce the slot-attention mechanism and coverage mechanism to calculate the attention score using the attribute sequence and value sequence simultaneously and to alleviate the problem of assigning values to the wrong fields. A common problem with table-to-text models is that they produce text descriptions that do not conform to the tabular information, commonly known as “illusions.” To solve the “illusion,” Rebuffel et al. (Reference Rebuffel, Roberti, Soulier, Scoutheeten, Cancelliere and Gallinari2022) proposed a multi-branch-weighted decoder and a word-level labeling process. This word-level tagging process can reduce the failure of word matching process through dependency analysis, based on co-occurrence and sentence structure, while still producing correct labels in complex environments.
The current training of neural language models always requires extremely large-scale corpus, while not all tasks have sufficient-scale and high-quality datasets. Ma et al. (Reference Ma, Yang, Liu, Li, Zhou and Sun2019) extract key facts from the table through the sequence labeling model firstly and then combine these key facts as input and use a Seq2Seq model to convert them into text, which alleviates the requirement of data scale for table-to-text generation. Chen et al. (Reference Chen, Su, Yan and Wang2020c) leverage pre-training and transfer learning to address this issue, which consists of a general knowledge-grounded generation model to generate knowledge-enriched text, and a pre-trained model which can be fine-tuned on various table-to-text generation tasks. Although pre-trained models are widely used in other areas of NLP, there are some problems with using pre-trained models in the table-to-text domain. First, there is a big difference between the language input of the pre-trained model and the input of structured data. Second, table information is not a linear input like natural language (Chen et al. Reference Chen, Chen, Su, Chen and Wang2020b). Table has structured information, but the traditional pre-training model has no corresponding method to understand the structured information of table. Moreover, pre-trained models do not solve the “illusion” problem. To alleviate the above problems, Gong et al. (Reference Gong, Sun, Feng, Qin, Bi, Liu and Liu2020) proposed Table GPT, which can train the table-to-text model with few samples. In order to deal with the gap between linear sequences of natural languages and structured data tables, Gong et al. proposed a table conversion module, which used templates to transform structured tables into natural languages. In order to solve the problem of insufficient table structure information extraction, an auxiliary task of table structure reconstruction is proposed in the framework of multi-task learning.
3. Table-to-text generator
We propose a novel generative model, SAN-T2T, based on the seq2seq (Sequence-to-Sequence) learning and neural language model. In this section, we introduce the task of table-to-text generation and then reveal our major ideas on data preprocessing, field-content selective encoder, descriptive decoder, and the featured copy mechanism.
3.1. Task definition
Different from the general seq2seq models to take a sequence as input, SAN-T2T takes a table as input, which consists of an infobox of various records. We model the table-to-text generation as a language model based on the seq2seq structure. The given table T consists of
 $n$
field-value pairs and their corresponding descriptions. In the training phase, the input and output of the model are the records
$n$
field-value pairs and their corresponding descriptions. In the training phase, the input and output of the model are the records
 $r_{1:n}$
in T and the corresponding reference text
$r_{1:n}$
in T and the corresponding reference text
 $w_{1:t}$
. In the inference phase, only the input
$w_{1:t}$
. In the inference phase, only the input
 $r_{1:n}$
is given, and the output would be determined by the model. Among them,
$r_{1:n}$
is given, and the output would be determined by the model. Among them,
 $w_{1:t}$
contains t words
$w_{1:t}$
contains t words
 $\{{w_1,w_2,w_3, \dots,w_t}\}$
, and the purpose of inference is to generate
$\{{w_1,w_2,w_3, \dots,w_t}\}$
, and the purpose of inference is to generate
 $\widehat{w}_{1:t}$
that maximizes
$\widehat{w}_{1:t}$
that maximizes
 $P (w_{1:t} \mid r_{1:n} )$
.
$P (w_{1:t} \mid r_{1:n} )$
.
 \begin{equation} \widehat{w}_{1: t}=\text{argmax}_{w_{1:t}} \prod _{s=1}^{t} P\!\left (w_{s} \mid w_{0: s-1}, r_{1: n}\right ) \end{equation}
\begin{equation} \widehat{w}_{1: t}=\text{argmax}_{w_{1:t}} \prod _{s=1}^{t} P\!\left (w_{s} \mid w_{0: s-1}, r_{1: n}\right ) \end{equation}
We test the SAN-T2T model on three public datasets: WikiBio, RotoWire, and WeatherGov.
WikiBio contains 728,321 Wikipedia biographies. Each sample contains an infobox and the first paragraph of the corresponding biographical text, and each text contains 26.1 words on average.
RotoWire contains 4853 samples, which consist of human-written NBA basketball game summaries aligned with their corresponding box- and line-scores, and each summary text contains 337.1 words on average.
WeatherGov contains 29,528 samples of weather forecast records, and each sample contains 36 records of fixed length, such as temperature and wind speed, and is paired with a description text, which contains 28.7 words on average.
3.2. SAN-T2T
The neural language model SAN-T2T proposed in this paper is based on the selective attention network, which combines gate, attention, and copy mechanism for table-to-text generation. The architecture of SAN-T2T is shown in Figure 1.
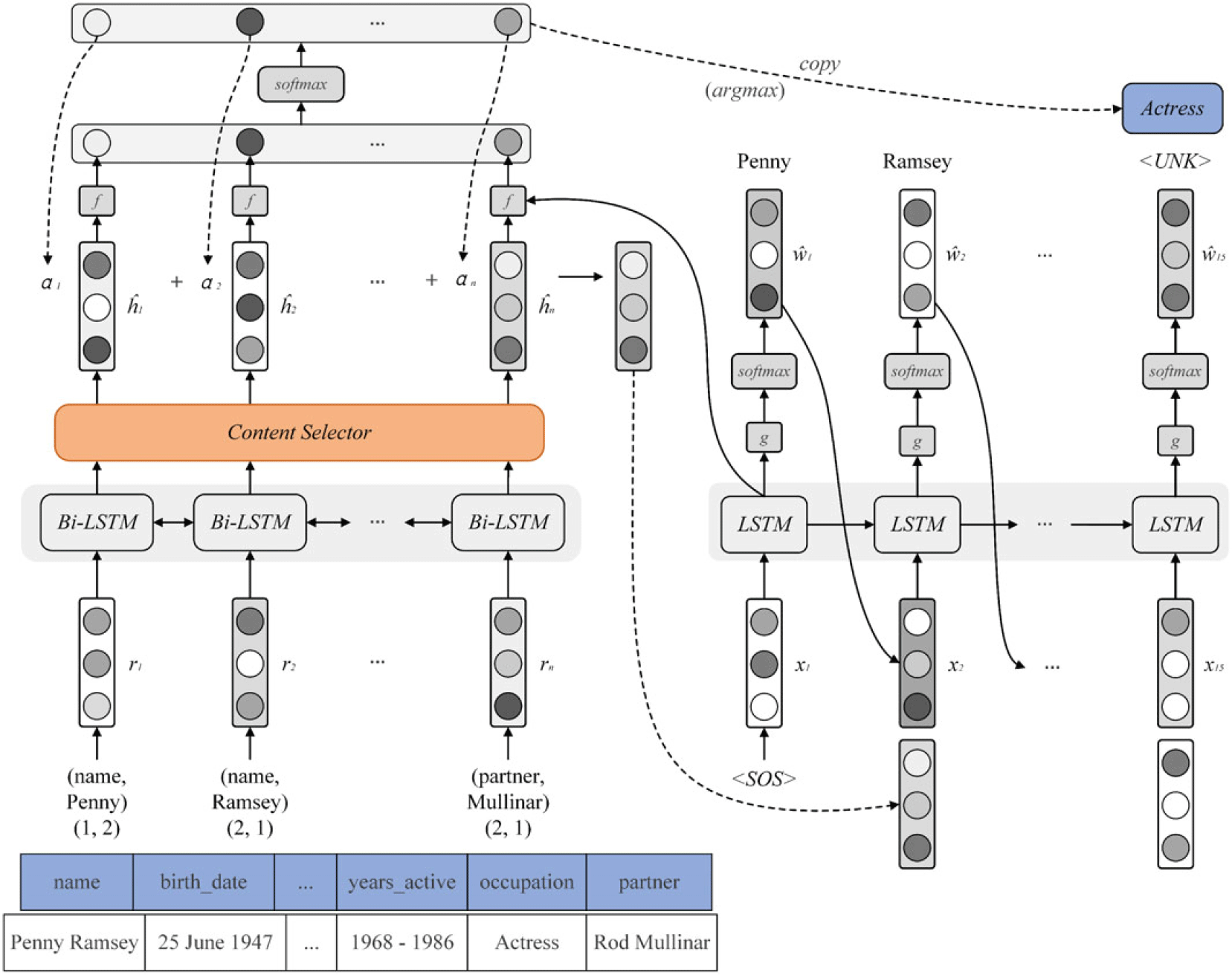
Figure 1. Architecture of SAN-T2T.
SAN-T2T could be introduced through three aspects:
-
1. Position encoding. In the preprocessing phase, we model the fields’ value and location jointly to learn semantic and structural information from the table, as shown in Section 3.3.
-
2. Field-content selective encoder. We utilize the self-gate mechanism in the encoder to determine the importance of mutual decision-making between different fields. Its architecture is shown in Figure 4. Then attention vector can obtain more information from the source sequence and refine the alignment between the records and text.
-
3. In the inference phase, a formally simple but effective copy mechanism is applied in SAN-T2T that uses attention vectors exclusively rather than training an additional layer of neural networks. This can significantly alleviate the problem of rare words while reducing the resource consumption of additional training.
3.3. Position encoding
Data records in structured tables usually contain vast field-value pairs, where values consist of sequences of words of unfixed length that correspond to the content of this field. The field values are encoded with word embedding, taking the field embedding, which is determined by the embedding vector of the field and its position in the table, as the key information to model the value. Take the WikiBio dataset as an example, Lebret et al. (Reference Lebret, Grangier and Auli2016) represent field embedding in triples:
 $ (f_w, p_w^+, p_w^- )$
, where
$ (f_w, p_w^+, p_w^- )$
, where
 $f_w$
represents word embedding of the field and
$f_w$
represents word embedding of the field and
 $p_w^+, p_w^-$
represent its forward and backward positions, respectively. Inspired by this idea, we take the fields and their appearing positions as auxiliary information for input. As shown in Figure 2, (a) represents the content of Penny Ramsey’s Wikipedia infobox, involving her birth and death information and occupation, and (b) is the corresponding preprocessed representation.
$p_w^+, p_w^-$
represent its forward and backward positions, respectively. Inspired by this idea, we take the fields and their appearing positions as auxiliary information for input. As shown in Figure 2, (a) represents the content of Penny Ramsey’s Wikipedia infobox, involving her birth and death information and occupation, and (b) is the corresponding preprocessed representation.
 $r_w=\text{concat}\{f_w, v_w\}$
represents the input, where
$r_w=\text{concat}\{f_w, v_w\}$
represents the input, where
 $v_w$
are the values corresponding to the field.
$v_w$
are the values corresponding to the field.
 $p_w=\text{concat}\{p_w^+,p_w^-\}$
is the auxiliary position information.
$p_w=\text{concat}\{p_w^+,p_w^-\}$
is the auxiliary position information.
 $r_w$
and
$r_w$
and
 $p_w$
are taken as the joint input of a certain timestep of LSTM unit.
$p_w$
are taken as the joint input of a certain timestep of LSTM unit.

Figure 2. The wiki infobox of Penny Ramsey and the preprocessed representation.
3.4. Field-content selective encoder
The field-content selective encoder contains the field encoder and content selector. The field encoder is designed to encode the records with LSTM network and to get the semantic and structural features of the records. Then the content selector controls the amount of information to be flowed to the decoder, through the gated content-selection algorithm.
3.4.1. Field encoder
The purpose of the field encoder is to encode each input record
 $r_i$
. LSTM is suitable for processing and predicting related events with long intervals and lags in time series. But unidirectional LSTM can only predict the next output from the previous states. Therefore, we use an improved bi-directional LSTM to enable it to learn the complex structure and long dependencies of the field-value pairs. Following the design in Graves et al. (Reference Graves, Mohamed and Hinton2013), the structure used in SAN-T2T at each timestep is shown in Figure 3 and defined as:
$r_i$
. LSTM is suitable for processing and predicting related events with long intervals and lags in time series. But unidirectional LSTM can only predict the next output from the previous states. Therefore, we use an improved bi-directional LSTM to enable it to learn the complex structure and long dependencies of the field-value pairs. Following the design in Graves et al. (Reference Graves, Mohamed and Hinton2013), the structure used in SAN-T2T at each timestep is shown in Figure 3 and defined as:
 \begin{equation} h_t, c_t=\text{biLSTM}\left (r_t, h_{t-1}\right ) \end{equation}
\begin{equation} h_t, c_t=\text{biLSTM}\left (r_t, h_{t-1}\right ) \end{equation}
where
 $r_t=\text{concat}\{f_t,v_t\}$
is the input at timestep
$r_t=\text{concat}\{f_t,v_t\}$
is the input at timestep
 $t$
, and
$t$
, and
 $c_{t}$
and
$c_{t}$
and
 $h_{t}$
are the cell state and hidden state at
$h_{t}$
are the cell state and hidden state at
 $t$
, respectively. LSTM can reserve essential information through the cell states and hidden states.
$t$
, respectively. LSTM can reserve essential information through the cell states and hidden states.
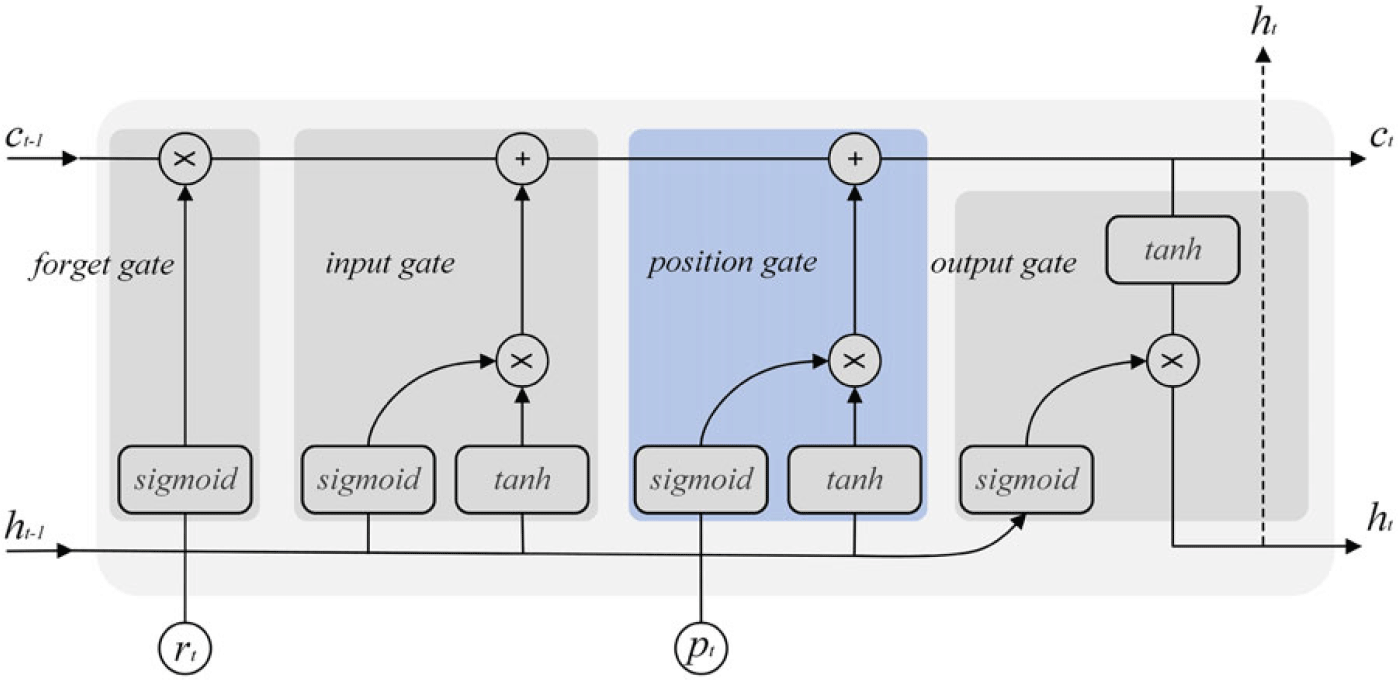
Figure 3. The structure of LSTM unit.
As we mentioned above, in order to learn more about the structure of the table, we take
 $p_t=\text{concat}\{p_t^+, p_t^-\}$
as the joint input of LSTM. The new cell states and hidden states are calculated as:
$p_t=\text{concat}\{p_t^+, p_t^-\}$
as the joint input of LSTM. The new cell states and hidden states are calculated as:
 \begin{equation} \left (\begin{array}{c} \varphi _{t} \\ \omega _{t} \end{array}\right )=\left (\begin{array}{c} \text{sigmoid} \\ \text{tanh} \end{array}\right )\left (W_{p} p_{t}+b_{p}\right ) \end{equation}
\begin{equation} \left (\begin{array}{c} \varphi _{t} \\ \omega _{t} \end{array}\right )=\left (\begin{array}{c} \text{sigmoid} \\ \text{tanh} \end{array}\right )\left (W_{p} p_{t}+b_{p}\right ) \end{equation}
 \begin{equation} \acute{c}_{t}=f_{t} \odot c_{t-1}+i_{t} \odot \widetilde{c}_{t}+\varphi _{t} \odot \omega _{t} \end{equation}
\begin{equation} \acute{c}_{t}=f_{t} \odot c_{t-1}+i_{t} \odot \widetilde{c}_{t}+\varphi _{t} \odot \omega _{t} \end{equation}
where
 $W_p \in \mathbb{R}^{2n \times 2d_p}$
,
$W_p \in \mathbb{R}^{2n \times 2d_p}$
,
 $b_p \in \mathbb{R}^{2n}$
are the weight matrix and bias.
$b_p \in \mathbb{R}^{2n}$
are the weight matrix and bias.
 $\varphi _{t} \in (0, 1 )^n$
determines the amount of structural information to be stored in
$\varphi _{t} \in (0, 1 )^n$
determines the amount of structural information to be stored in
 $c_t$
, and
$c_t$
, and
 $\omega _{t} \in (\!-\!1, 1 )^n$
retains all the structural information at the current timestep.
$\omega _{t} \in (\!-\!1, 1 )^n$
retains all the structural information at the current timestep.
 $f_t$
,
$f_t$
,
 $i_t$
, and
$i_t$
, and
 $\tilde{c}_{t}$
are obtained from the forget gate and input gate. We believe that the improved LSTM can not only learn the hidden semantic information of the long sequence but also preserve its structural information for the field-value pairs, while the structure information keeps a very important role in the decision-making of the attention mechanism in the decoder.
$\tilde{c}_{t}$
are obtained from the forget gate and input gate. We believe that the improved LSTM can not only learn the hidden semantic information of the long sequence but also preserve its structural information for the field-value pairs, while the structure information keeps a very important role in the decision-making of the attention mechanism in the decoder.
Algorithm 1. Gated Content-Selection Algorithm


Figure 4. Architecture of the gated content selector.
3.4.2. Content selector with gate mechanism
For the different records in the table, we believe that the context of each record is important in determining the others. For example, if a person is a football player, then the other relevant records, such as his playing position and the team he is playing for, etc., should also appear in the description. Puduppully et al. take these into consideration and apply the CS gating mechanism to obtain the new representation in the encoder. We borrow this idea to better capture the latent dependency as Figure 1, replacing the output of the encoder with that of the content selector so that more accurate semantic information can be obtained for a specific record in the decoder. The details are as Algorithm 1, and Figure 4 illustrates the architecture of the content selector. We apply the output of the encoder’s LSTM layer to do a self-gate adaption and control the amount of information that flowed to the following decoder component through the sigmoid function. So the input to the decoder will be covered by the content selector’s result. Similar to the attention mechanism, we first calculate the importance score of each record
 $\alpha _{i,j}$
, which will be used later to get the dependency vector
$\alpha _{i,j}$
, which will be used later to get the dependency vector
 $d_i$
of this record, and then obtain the new encoder output
$d_i$
of this record, and then obtain the new encoder output
 $\acute{h}_i$
through the content-selection gate.
$\acute{h}_i$
through the content-selection gate.
 \begin{equation} \alpha _{i, j}=\text{softmax}\!\left (h_i W_r h_j\right ) \end{equation}
\begin{equation} \alpha _{i, j}=\text{softmax}\!\left (h_i W_r h_j\right ) \end{equation}
 \begin{equation} d_i=\sum _j\alpha _{i, j} h_j \end{equation}
\begin{equation} d_i=\sum _j\alpha _{i, j} h_j \end{equation}
 \begin{equation} \tilde{d}_i=\text{sigmoid}\!\left (\!W_d\text{concat}\{h_i, d_i\} \ + \ b_d\right ) \end{equation}
\begin{equation} \tilde{d}_i=\text{sigmoid}\!\left (\!W_d\text{concat}\{h_i, d_i\} \ + \ b_d\right ) \end{equation}
 \begin{equation} \acute{h}_i=\tilde{d}_i \odot h_i \end{equation}
\begin{equation} \acute{h}_i=\tilde{d}_i \odot h_i \end{equation}
where
 $W_r \in \mathbb{R}^{n \times n}$
,
$W_r \in \mathbb{R}^{n \times n}$
,
 $W_d \in \mathbb{R}^{n \times 2n}$
, and
$W_d \in \mathbb{R}^{n \times 2n}$
, and
 $b_d \in \mathbb{R}^n$
are the learnable weight matrix and bias. The
$b_d \in \mathbb{R}^n$
are the learnable weight matrix and bias. The
 $\acute{d}_i \in (0, 1 )^n$
controls the amount of information that can be obtained from the field-content selective encoder at each timestep in the decoder.
$\acute{d}_i \in (0, 1 )^n$
controls the amount of information that can be obtained from the field-content selective encoder at each timestep in the decoder.
3.5. Descriptive decoder
We mainly use LSTM network in the decoder to learn the semantic information of the context. In the training phase, the encoded word embedding
 $x_t$
at each timestep, the context vector
$x_t$
at each timestep, the context vector
 $z_t$
obtained from the selective encoder, and the previous hidden state
$z_t$
obtained from the selective encoder, and the previous hidden state
 $s_{t-1}$
are used as input and then output the conditional probability distribution
$s_{t-1}$
are used as input and then output the conditional probability distribution
 $P_t$
of the next word
$P_t$
of the next word
 $P (w_t \mid w_{0:t-1}, r_{1:n} )$
.
$P (w_t \mid w_{0:t-1}, r_{1:n} )$
.
A standard unidirectional and single-layer LSTM network is used in the decoder, and the context vector
 $z_t$
of each timestep is calculated through the attention mechanism as Bahdanau et al. (Reference Bahdanau, Cho and Bengio2014):
$z_t$
of each timestep is calculated through the attention mechanism as Bahdanau et al. (Reference Bahdanau, Cho and Bengio2014):
 \begin{equation} e_{t, j}=\frac{s_{t-1} \odot \acute{h}_{j}}{\sqrt{d_{n}}} \end{equation}
\begin{equation} e_{t, j}=\frac{s_{t-1} \odot \acute{h}_{j}}{\sqrt{d_{n}}} \end{equation}
 \begin{equation} \alpha _{t, j}=\frac{\text{exp} \!\left (e_{t, j}\right )}{\sum _{j}\text{exp} \!\left (e_{t, j}\right )} \end{equation}
\begin{equation} \alpha _{t, j}=\frac{\text{exp} \!\left (e_{t, j}\right )}{\sum _{j}\text{exp} \!\left (e_{t, j}\right )} \end{equation}
 \begin{equation} z_t=\sum _j\alpha _{t, j}\acute{h}_j \end{equation}
\begin{equation} z_t=\sum _j\alpha _{t, j}\acute{h}_j \end{equation}
where
 $s_t$
,
$s_t$
,
 $c_t$
are the hidden state and cell state output by the LSTM network.
$c_t$
are the hidden state and cell state output by the LSTM network.
We integrate the embedding vector of the target sequence word and context vector as input to the LSTM unit and then do the softmax function to calculate each word’s generating probability:
 \begin{equation} \acute{x}_t=\text{concat}\{x_t, z_t\} \end{equation}
\begin{equation} \acute{x}_t=\text{concat}\{x_t, z_t\} \end{equation}
 \begin{equation} s_t, c_t=\text{LSTM}\left (\acute{x}_t, s_{t-1}\right ) \end{equation}
\begin{equation} s_t, c_t=\text{LSTM}\left (\acute{x}_t, s_{t-1}\right ) \end{equation}
 \begin{equation} P\!\left (w_t \mid w_{0:t-1}, r_{1:n}\right )=\text{softmax}\left (W_s s_t + b_s\right ) \end{equation}
\begin{equation} P\!\left (w_t \mid w_{0:t-1}, r_{1:n}\right )=\text{softmax}\left (W_s s_t + b_s\right ) \end{equation}
 \begin{equation} \widehat{w}_{t}=\text{argmax}_{w_{t}}P\left (w_{t} \mid w_{0: t-1}, r_{1: n}\right ) \end{equation}
\begin{equation} \widehat{w}_{t}=\text{argmax}_{w_{t}}P\left (w_{t} \mid w_{0: t-1}, r_{1: n}\right ) \end{equation}
where
 $W_s \in \mathbb{R}^{d_{out} \times n}$
and
$W_s \in \mathbb{R}^{d_{out} \times n}$
and
 $b_s \in \mathbb{R}^{d_{out}}$
are the weight matrix and bias.
$b_s \in \mathbb{R}^{d_{out}}$
are the weight matrix and bias.
 $\widehat{w}_{t}$
is the word to be generated at timestep
$\widehat{w}_{t}$
is the word to be generated at timestep
 $t$
.
$t$
.
Since the records in some specific datasets (e.g., WeatherGov) are fixed-length rather than variable-length key-value pairs, and there exists no reciprocal location between different records, it does not make much sense to encode each record with the field encoder, respectively. To ensure that the model can still learn the dependency between the output text and records through the content selector without implementing the field encoding, we apply the method proposed by Mei et al. (Reference Mei, Bansal and Walter2016), using the regularization-term-added cross entropy as the loss function:
 \begin{equation} \text{Loss}=-\sum _{j=1}^t \log \frac{\text{exp} \!\left (y\left [w_{j}\right ]\right )}{\sum _{j}\text{exp} (y[j])}+\left (\sum _{j=1}^{n} cs_{j}-\gamma \right )^{2}+\left (1-\max \!\left (c s_{j}\right )\right ) \end{equation}
\begin{equation} \text{Loss}=-\sum _{j=1}^t \log \frac{\text{exp} \!\left (y\left [w_{j}\right ]\right )}{\sum _{j}\text{exp} (y[j])}+\left (\sum _{j=1}^{n} cs_{j}-\gamma \right )^{2}+\left (1-\max \!\left (c s_{j}\right )\right ) \end{equation}
where
 $cs_j \in (0, 1 )$
is the context vector obtained by content selector, which is calculated by the
$cs_j \in (0, 1 )$
is the context vector obtained by content selector, which is calculated by the
 $\it \textit{sigmoid}$
function, and represents the probability of each record being selected; the prunable parameter
$\it \textit{sigmoid}$
function, and represents the probability of each record being selected; the prunable parameter
 $\gamma$
can force the model to depend on the specific number of records.
$\gamma$
can force the model to depend on the specific number of records.
 $ (\sum _{j=1}^{n} cs_{j}-\gamma )^{2}$
enables the model to correct its weight based on the content selector and the context vector of the selected record through gradient descent, while
$ (\sum _{j=1}^{n} cs_{j}-\gamma )^{2}$
enables the model to correct its weight based on the content selector and the context vector of the selected record through gradient descent, while
 $ (1-\max\!(c s_{j} ) )$
can ensure that the content selector has selected at least one record.
$ (1-\max\!(c s_{j} ) )$
can ensure that the content selector has selected at least one record.
3.6. Inference model with copy mechanism
In the training phase, the records
 $r_{1:n}$
and reference text
$r_{1:n}$
and reference text
 $w_{1:t}$
are both taken as inputs into the encoder and decoder, respectively, been trained to maximize the likelihood of generating the real text
$w_{1:t}$
are both taken as inputs into the encoder and decoder, respectively, been trained to maximize the likelihood of generating the real text
 $\widehat{w}_{1:t}$
. However, in the inference phase, text is generated by finding the words with the largest posterior probability predicted by the trained model. In other words, the subsequent words are generated sequentially from the first word.
$\widehat{w}_{1:t}$
. However, in the inference phase, text is generated by finding the words with the largest posterior probability predicted by the trained model. In other words, the subsequent words are generated sequentially from the first word.
We also apply beam search to improve the model performance. The strategy is that the model will find a string of generated words that approximately maximizes the conditional probability given the previous states, so it will generate the text from begin-to-end and keep a fixed number (i.e., beam width) of candidates with the highest log-probability at each timestep.
Meanwhile, to alleviate the problem of rare words, a flexible copy mechanism is used to copy OOV words to the output text from the source sequence. This is done by replacing the <unk > character in the output with the most relevant word in the table, which is the field pointed to by the attention vector with
 $\it \textit{argmax}$
function. Experiments have proved that the copy mechanism we used can greatly improve the performance of the model without increasing additional consumption. As shown in Fig. 1, the model actually outputs <unk> when generating “actress,” but by pointing to the most relevant field “occupation” in the table via the attention vector
$\it \textit{argmax}$
function. Experiments have proved that the copy mechanism we used can greatly improve the performance of the model without increasing additional consumption. As shown in Fig. 1, the model actually outputs <unk> when generating “actress,” but by pointing to the most relevant field “occupation” in the table via the attention vector
 $\alpha$
, the <unk> is replaced with its value “actress” accordingly.
$\alpha$
, the <unk> is replaced with its value “actress” accordingly.
The specific algorithms of beam search and copy mechanism are as follows:
 \begin{equation} w_{s}^{\beta }=k\text{argmax}_{w_{s},{\beta }} P\left (w_{s} \mid r_{1: n}, w_{1}^{\beta }, \ldots, w_{s-1}^{\beta }\right ) \cdot \prod _{i=1}^{s-1} P\left (w_{i}^{\beta } \mid r_{1: n}, w_{1}^{\beta }, \ldots, w_{i-1}^{\beta }\right ) \end{equation}
\begin{equation} w_{s}^{\beta }=k\text{argmax}_{w_{s},{\beta }} P\left (w_{s} \mid r_{1: n}, w_{1}^{\beta }, \ldots, w_{s-1}^{\beta }\right ) \cdot \prod _{i=1}^{s-1} P\left (w_{i}^{\beta } \mid r_{1: n}, w_{1}^{\beta }, \ldots, w_{i-1}^{\beta }\right ) \end{equation}
 \begin{equation} \widehat{w}_s=\text{argmax}\left (z_s\right )\text{if} \, w_s = \lt unk\gt \end{equation}
\begin{equation} \widehat{w}_s=\text{argmax}\left (z_s\right )\text{if} \, w_s = \lt unk\gt \end{equation}
where
 $w_{s}^{\beta }$
indicates the words in beam
$w_{s}^{\beta }$
indicates the words in beam
 $\beta$
at timestep
$\beta$
at timestep
 $s$
, and
$s$
, and
 $k\text{argmax}$
is the
$k\text{argmax}$
is the
 $\text{argmax}$
function extended to topk scale. When inferencing text, these
$\text{argmax}$
function extended to topk scale. When inferencing text, these
 $k$
words with the highest probability are inputs to the next timestep in turn, until the length of the text exceeds the pre-defined max_length.
$k$
words with the highest probability are inputs to the next timestep in turn, until the length of the text exceeds the pre-defined max_length.
 $z_s$
is the context vector given above. Replace
$z_s$
is the context vector given above. Replace
 $w_s$
with
$w_s$
with
 $\widehat{w}_s$
when the model generates <unk> characters at a certain timestep.
$\widehat{w}_s$
when the model generates <unk> characters at a certain timestep.
4. Experiments and analysis
We firstly introduce the prerequisite in this section (i.e., datasets, evaluation metrics, and experiment setups) and then compare SAN-T2T with several baselines and SOTAs. At last, we assess the case studies and attention visualization to reveal SAN-T2T’s performance.
4.1. Datasets and evaluation metrics
In this section, we introduce the datasets we used and the evaluation metrics of the experiment.
4.1.1. Datasets
We used WikiBio (Lebret et al., Reference Lebret, Grangier and Auli2016) as the benchmark dataset, and RotoWire (Wiseman et al., Reference Wiseman, Shieber and Rush2017) and WeatherGov (Liang, Jordan, and Klein, Reference Liang, Jordan and Klein2009) as supplementary datasets to verify the generalization of SAN-T2T. WikiBio contains 728,321 samples from Wikipedia, using the first paragraph of each article as the description of the corresponding infobox, as shown in Table 1. RotoWire contains 4853 samples, which are NBA basketball game summaries aligned with their corresponding box- and line-scores. WeatherGov contains 29,528 samples, each of which has 36 records of fixed length and is paired with a description text. We split WeatherGov dataset according to the proportion of training (80%), development (10%), and test (10%).
Table 1. The Wikipedia infobox of Frederick Parker–Rhodes

The introduction of his biography reads: “Arthur Frederick Parker–Rhodes (21 November 1914–2 March 1987) was an English linguist, plant pathologist, computer scientist, mathematician, mystic, and mycologist.”
4.1.2. Evaluation metrics
BLEU, an auxiliary tool for bilingual translation quality evaluation, is often used to evaluate the quality of text generation models. The core idea is to determine the similarity between two sentences and then evaluate precision and fluency of the candidate texts through different n-grams. Since BLEU only calculates the precision of the candidate texts without considering recall, ROUGE is proposed to solve this problem, and it evaluates the quality of the generated texts through paying more attention to different n-grams’ recall.
We assessed the model on table-to-text generation with BLEU-4 (Papineni et al., Reference Papineni, Roukos, Ward and Zhu2002) and ROUGE-4 (Lin, Reference Lin2004), and the standard scripts provided by the NLTK-3.5 and ROUGE-1.5.5 are used to calculate BLEU and ROUGE scores.
For RotoWire, we also assessed the model with the metrics from Wiseman et al. Let
 $\widehat{y}$
represents the reference summary and
$\widehat{y}$
represents the reference summary and
 $y$
the model output. Relation generation (RG) evaluates the precision and count of relations extracted from
$y$
the model output. Relation generation (RG) evaluates the precision and count of relations extracted from
 $y$
that also appear in records
$y$
that also appear in records
 $r$
. CS evaluates the precision and recall of relations extracted from
$r$
. CS evaluates the precision and recall of relations extracted from
 $y$
that are also extracted from
$y$
that are also extracted from
 $\widehat{y}$
. Content ordering evaluates the normalized Damerau–Levenshtein distance between the sequences of relations extracted from
$\widehat{y}$
. Content ordering evaluates the normalized Damerau–Levenshtein distance between the sequences of relations extracted from
 $y$
and
$y$
and
 $\widehat{y}$
.
$\widehat{y}$
.
4.2. Experiment setup
For WikiBio,Footnote a we select the most frequent 20,000 words in the training set to build the vocabulary, and the others will be encoded with <unk>. In the encoder, the value embedding and its corresponding field and position embedding are used as input. The largest position number is limited to 30, that is, fields with lengths longer than 30 will be truncated. <sos> and <eos> are added at the start and end of the target text, respectively. Records exceeding the pre-defined length 100 will be truncated and insufficient ones will be padded with <pad>. We also tried different beam widths to verify the influence of beam search on the model.
Set the dimension of field embedding to 50, word embedding to 400, and position embedding to 5. Hidden layer size is 500, and batch size is 32. We also restrict the generated sentence by the max_length of 60 to avoid redundant or time-consuming generation. For the Transformer model, the hidden units of the multi-head component and the feed-forward layer are both 512, with 8 heads and 6 encoder/decoder layers.
For RotoWire, we use similar settings as WikiBio without implementing position encoding. Set the dimension of field embedding to 30, word embedding to 300. max_length is 700, and max_field is 770.
For WeatherGov, in the encoder, we only need to set the embedding vector of words in the table as input. The word embedding dimension is 300, and hidden layer size is 500. For cross entropy loss,
 $\gamma =4$
is used to set the regularization term, and we also have experimented on the influence of different
$\gamma =4$
is used to set the regularization term, and we also have experimented on the influence of different
 $\gamma$
on the model.
$\gamma$
on the model.
Adam optimizer is used to perform gradient descent, the initial learning rate is 0.0003, and the gradient clipping value is 5.0.
4.3. Results and analysis
As shown in Table 2, SAN-T2T is compared with several previous works, including KN, Template KN (Heafield et al., Reference Heafield, Pouzyrevsky, Clark and Koehn2013), NLM, Table NLM (Lebret et al., Reference Lebret, Grangier and Auli2016), Table2Seq-Single (Bao et al., Reference Bao, Tang, Duan, Yan, Zhou and Zhao2019), Structure-aware Seq2Seq (Liu et al., Reference Liu, Wang, Sha, Chang and Sui2018), and Two-level model (Cao, Gong, and Zhang, Reference Cao, Gong and Zhang2019). Meanwhile, we provide a vanilla Seq2Seq model (without position encoding and content selector compared to SAN-T2T) and a Transformer model (Vaswani et al., Reference Vaswani, Shazeer, Parmar, Uszkoreit, Jones, Gomez, Kaiser and Polosukhin2017) to conduct an ablation study.
Table 2. Results on WikiBio (test set)

The boldface values show the highest values in the corresponding column.
According to Table 2, we observe that neural NLM always surpasses the statistical ones, even the vanilla Seq2Seq model can achieve better results than Table NLM, and content selector significantly improves the baselines. The Transformer model based solely on attention mechanisms achieves competitive performance, having the ability that generates buffered positional encoding using sine or cosine functions according to the length of the fields (i.e., no need for additional training). Then, according to the case studies on WikiBio, although SAN-T2T often generates short texts accurately and fluently, there is still large room for improvement for long text generation (e.g., occasionally missing information that counts), which causes the low performance. Transformer performs better through replacing the chain-like forms in LSTM structure in SAN-T2T, no need to worry about exploding gradient when generating longer texts. To learn more information on this impact, we also did experiments on samples with different reference-text-length (we split WikiBio’s test set into five subsets with different lengths, less than 10, between 10 and 20, between 20 and 30, between 30 and 40, and more than 40). As shown in Table 3, samples with text length between 10 and 30 fit the best, and samples with text length more than 40 the worst (samples with less than 10 tokens fit badly on BLEU score, for BLEU metric only calculates precision of the candidate texts without considering recall, and the high score on ROUGE verifies this).
Table 3. Effects of text length on WikiBio (test set)

The boldface values show the highest values in the corresponding column.
Table 4. Effects of different beam width on WikiBio

The boldface values show the highest values in the corresponding column.
Table 4 shows the impact of beam search. The BLEU score degrades as the beam width increases. The reason lies in the search strategy. Increasing the beam width makes the model generates texts that are disproportionately based on those early and non-greedy decisions, typically including words with relatively low probability followed by words with quite high conditional probability, leading to an overall higher probability sentence but lower precision. For example, when the
 $k$
words in a certain timestep contain the character <eos>, then its subsequent posterior words would likely remain <eos> (i.e., the sentence length will be shortened, for <eos> will be ignored), making the sentence holding a quite high probability but badly poor performance. Increasing the beam width will also significantly reduce the inference speed (about three times slower when setting beam width to 5 in our experiments).
$k$
words in a certain timestep contain the character <eos>, then its subsequent posterior words would likely remain <eos> (i.e., the sentence length will be shortened, for <eos> will be ignored), making the sentence holding a quite high probability but badly poor performance. Increasing the beam width will also significantly reduce the inference speed (about three times slower when setting beam width to 5 in our experiments).
Results also show that the application of copy mechanism can significantly improve the model (the group with copy exceed those without copy about 5 points), and it does not need additional training because there is no need for the redundant copy-network like Gu et al. (Reference Gu, Lu, Li and Li2016) to determine whether words need to be copied at current timestep, for the copied words only come from the attention vector.
After finishing works on WikiBio, we also did experiments on RotoWire and WeatherGov to verify SAN-T2T’s generalization. Table 5 compares SAN-T2T with TEMPL (template system), WS-2017 (Wiseman et al., Reference Wiseman, Shieber and Rush2017), NCP + CC (Puduppully et al., Reference Puduppully, Dong and Lapata2019), Hierarchical-k (Rebuffel et al., Reference Rebuffel, Soulier, Scoutheeten and Gallinari2019), and DATA-TRANS (Li et al., Reference Li, Crego and Senellart2019) on RotoWire. The model DATA-TRANS is the state of the art of RotoWire, which has a Transformer-based model that learns CS and summary generation jointly, and uses two data augmentation methods synthetic data generation and training data selection. The template system has the highest RG precision, for it’s faithful to the infoboxes by design. SAN-T2T is worse than the comparison models, and the reason lies in its weak ability to generate long text and reserve information, which has already been discussed in WikiBio’s results.
Table 5. Results on RotoWire (test set)

Columns indicate relation generation (RG) count (#) and precision (P%), content selection (CS), precision (P%) and recall (R%), count ordering (CO) in normalized Damerau–Levenshtein distance (DLD%), and BLEU. These metrics are described in Section 4.1. The boldface values show the highest values in the corresponding column.
Table 6 compares SAN-T2T with KL (Konstas and Lapata, Reference Konstas and Lapata2013a), MBW (Mei et al., Reference Mei, Bansal and Walter2016), and Two-level model (Cao et al., Reference Cao, Gong and Zhang2019) on WeatherGov. There is no need to apply copy mechanism because its vocabulary size is small and each sample has 36 records of fixed length, but it could also be concluded that beam search has little improvements, which is consistent with Mei et al. (Reference Mei, Bansal and Walter2016).
Table 6. Results on WeatherGov (test set)

The boldface values show the highest values in the corresponding column.
For the experiments on WeatherGov, results in Table 7 show the effect of different
 $\gamma$
on the model. BLEU score reaches the highest when
$\gamma$
on the model. BLEU score reaches the highest when
 $\gamma =4$
. After analyzing the original dataset, it can be seen that the most records number aligned by the reference text of all samples is 4, and the role of
$\gamma =4$
. After analyzing the original dataset, it can be seen that the most records number aligned by the reference text of all samples is 4, and the role of
 $\gamma$
is to constrain the number of records that the model aligns. Therefore, the best result at
$\gamma$
is to constrain the number of records that the model aligns. Therefore, the best result at
 $\gamma =4$
is in line with expectations.
$\gamma =4$
is in line with expectations.
Table 7. Effects of different
 $\gamma$
on WeatherGov
$\gamma$
on WeatherGov

The boldface values show the highest values in the corresponding column.
4.4. Case study
Three randomly selected samples from WikiBio, WeatherGov, and RotoWire and their descriptions are presented below. We will analyze the strengths as well as the remaining weaknesses of SAN-T2T for these cases.
Analysis of the texts generated for Alonzo Cushing in Tables 8 and 9 shows that SAN-T2T can learn more semantic information and even correct reasoning about that are not included in the input: “u.s. military’s highest decoration” does not appear in the input, but the knowledge learned from other samples (the medal of honor = u.s. military’s highest decoration) completes this information. When applying copy mechanism for the model, the copied word “battery” not only alleviates the problem of rare words but also makes up for some missing information: the ignored field commands appear as “an artillery officer” in the reference text, while SAN-T2T (without copying) outputs “actions at the battle of <unk>.”
Table 8. The Wikipedia infobox of Alonzo H. Cushing

Table 9. The generated descriptions for Alonzo H. Cushing

Table 10. Human Evaluation on WikiBio (test set)

The boldface values show the highest values in the corresponding column.
Human evaluation: For more intuitiveness, we perform human evaluation based on the sentences’ fluency (natural and grammatical) and semantic faithfulness (supported by the records). We defined three levels of fluency as: fluent, mostly fluent, and not fluent, and the same for semantic faithfulness. Three annotators are asked to evaluate on 100 randomly selected samples from the generated and reference sentences. Specifically, we asked participants questions about RG, syntax, coherence, and brevity to estimate the output of the model. Inter-rater agreement follows Fleiss’ kappa (Fleiss, Reference Fleiss1971). For fluency, kappa score
 $k$
= 0.251 (annotators assign decisions on the same 20 samples with the three categories), for semantic faithfulness,
$k$
= 0.251 (annotators assign decisions on the same 20 samples with the three categories), for semantic faithfulness,
 $k$
= 0.334. Results are shown in Table 10. The reference texts achieve the highest fluency and faithfulness, and there is a considerable gap between the SAN-T2T outputs and the human-written sentences, mainly because SAN-T2T’s weakness to generate long texts, often outputting repetitive sentences, and sometimes learning what should be wrong from other samples. Beam search has the ability to improve SAN-T2T’s performance on all of the four measures; the top-
$k$
= 0.334. Results are shown in Table 10. The reference texts achieve the highest fluency and faithfulness, and there is a considerable gap between the SAN-T2T outputs and the human-written sentences, mainly because SAN-T2T’s weakness to generate long texts, often outputting repetitive sentences, and sometimes learning what should be wrong from other samples. Beam search has the ability to improve SAN-T2T’s performance on all of the four measures; the top-
 $k$
strategy alleviates the disadvantage that greedy search cannot get the global optimum (although with the side effect of requiring much more inference time). SAN-T2T performs almost as well as Transformer. It is also structurally lighter than the previous best model, Transformer, with fewer parameters and faster computing speed. SAN-T2T with Beam Search performs better than Transformer, and the use of Beam Search increases the variety generated by SAN-T2T. Compared to greedy strategy sampling, Beam Search prevents SAN-T2T from failing at one step and then failing at all, resulting in better performance than Transformer.
$k$
strategy alleviates the disadvantage that greedy search cannot get the global optimum (although with the side effect of requiring much more inference time). SAN-T2T performs almost as well as Transformer. It is also structurally lighter than the previous best model, Transformer, with fewer parameters and faster computing speed. SAN-T2T with Beam Search performs better than Transformer, and the use of Beam Search increases the variety generated by SAN-T2T. Compared to greedy strategy sampling, Beam Search prevents SAN-T2T from failing at one step and then failing at all, resulting in better performance than Transformer.
Tables 11 and 12 are texts generated from the weather data of Northfield on 2009-02-08-1 in WeatherGov.Footnote b It can be seen that the text output by SAN-T2T is already very consistent with the reference, but there are still some factual errors (mainly numerical): the approximate range of temperature and wind speed has been increased (but still very close). We believe that this is because the semantic discrimination between different words encoded with one-hot is diminished, so the model’s ability to recognize different numerical tokens weaken. However, due to the large number of numerical inputs in WeatherGov, it is necessary to encode with one-hot rather than word embedding. We encode the numerical tokens to binary-array representation, which is proposed by Mei et al.
Table 11. Weather data for Northfield, Minnesota on 2009-08-1

Table 12. The generated descriptions for Northfield, Minnesota on 2009-08-1

Table 13. The box score and line score for Clippers - Bucks in 2014-21-20

The definition of table headers could be found at https://github.com/harvardnlp/boxscore-data.
Table 14. The generated descriptions for Clippers - Bucks

Tables 13 and 14 are the source records and generated texts from the game between Clippers and Bucks in RotoWire. SAN-T2T performs not well, missing some important information of the source records compared with the reference text. Erroneous includes the city of Bucks (which should be Milwaukee), the percentage of the three-pointers made by Bucks (which should be 33), and wrong inferences (the Bucks lost three straight games, and need to fight against Clippers on Monday). As the text gets longer, the generation quality degrades, that is, generating repetitive sentences, which further impairs the model’s performance.

Figure 5. An example of visualization for the attention. The image above is the attention from Seq2Seq model, while the below one is from SAN-T2T. The vertical axis represents the text generated by the model, while the horizontal represents the fields’ value. -lrb- and -rrb- indicate brackets (). Deeper colors depict a higher attention score.
4.5. Attention visualization
Figure 5 shows an example of a heat-map of the attention vector based on the text generated for John Uzzell Edwards. The sub-figure above comes from the vanilla Seq2Seq model, while the below from SAN-T2T. Both have applied the copy mechanism. The reference text of this sample is “john uzzell edwards (10 October 1934–5 March 2014) was a welsh painter," which consists of the SAN-T2T model. Decisive information is: {nationality: welsh}, {field: painting}, {movement: pure painting}, {awards: granada arts fellowship}. It can be seen that Seq2Seq model generates some duplicate contents (i.e., “pure and pure” aligns to the movement field) and has lost some critical information (e.g., “welsh painter” has been missed, while generating the sentence “pure artist”). However, SAN-T2T generates descriptions that are consistent with the reference text. The fields name, birth_date, death_date, occupation and other information are all obtained from the correct fields. For example, “john uzzell edwards” and “welsh Painter” are from the name field and “welsh pure painting,” respectively. This suggests that the enhanced attention mechanism can model the relationship between records through the content selector and can accurately map the alignment between the generated text and the fields.
5. Conclusion and future work
We propose a novel Seq2Seq model that further enhances the attention mechanism and conduct experiments on table-to-text generation. The model SAN-T2T is mainly composed of a field-content selective encoder and a decoder with the attention mechanism. To utilize structure in the tables, an additional gate is added to the LSTM cell in the encoder to integrate position information. Besides, the application of beam search and copy mechanism further improves the performance of SAN-T2T. Attention visualization and comparison with baselines show that SAN-T2T is far superior to these models.
Work of this research has some practical implications. First, the fact that neural language models always have better performance than statistical methods implies that the automated table-to-text generator can be designed by neural networks rather than hand-built feature engineering with statistical approaches. Second, using multi-layered features rather than simplex fields gets better results in table-to-text tasks. Third, it is possible to apply the selective attention network or its variant to other NLP tasks such as information extraction and text generation. We will research for this possibility in the future and focus on how to improve the ability of the neural language models to correctly understand the records in the tables and learn the other latent information (e.g., multi-level location. We only apply local addressing in SAN-T2T, which represents inner-record information. However, inter-record relevance within the tables is also significant, and it would be challenging to explore these information sources). SAN-T2T’s weakness to generate long texts affects its performance; we will also explore the possibility of solving this length issue in the future (adapting Transformer-based models to solve the gradient-exploding problem will be a possible direction).
Acknowledgments
We would like to thank the reviewers for their comments in advance to help us improve the quality of this paper.
Financial support
This work was supported by the National Natural Science Foundation of China under Grant 62072255.
Declaration of competing interest
The authors declare none.






















 Open access
Open access