




1. Introduction
The significance of conversations as the fundamental medium of interaction transcends cultural boundaries (Dingemanse and Floyd Reference Dingemanse and Floyd2014). Consequently, interacting with machines and seeking information via conversational interfaces is an instinctive and familiar way for humans (Dalton et al. Reference Dalton, Fischer, Owoicho, Radlinski, Rossetto, Trippas and Zamani2022) as evidenced by the success of dialogue systems such as Apple’s SIRI,Footnote a Amazon’s Alexa,Footnote b and most recently, ChatGPT.Footnote c Moreover, dialogue-based systemsFootnote d have extensively been used for customer support (Botea et al. Reference Botea, Muise, Agarwal, Alkan, Bajgar, Daly, Kishimoto, Lastras, Marinescu, Ondrej, Pedemonte and Vodolan2019; Feigenblat et al. Reference Feigenblat, Gunasekara, Sznajder, Joshi, Konopnicki and Aharonov2021), mental health support (Kretzschmar et al. Reference Kretzschmar, Tyroll, Pavarini, Manzini and Singh2019), and counseling (Tewari et al. Reference Tewari, Chhabria, Khalsa, Chaudhary and Kanal2021; Malhotra et al. Reference Malhotra, Waheed, Srivastava, Akhtar and Chakraborty2022).
Designing practical dialogue-based systems, however, is a challenging endeavor as there are important questions that one needs to answer before embarking on developing such a system. Critical considerations include determining the types of queries the system should anticipate (e.g., chit-chat vs. informational), deciding whether to incorporate an external knowledge source, and determining the level of natural language understanding the system should support. Previous surveys in the field of dialogue-based systems have predominantly focused on examining specific system components or narrow subsets of tasks and techniques. For instance, recent surveys have delved into areas such as dialogue summarization (Tuggener et al. Reference Tuggener, Mieskes, Deriu and Cieliebak2021; Feng, Feng, and Qin Reference Feng, Feng and Qin2022a), text-to-SQL (Qin et al. Reference Qin, Hui, Wang, Yang, Li, Li, Geng, Cao, Sun, Luo, Huang and Li2022), question answering (Pandya and Bhatt Reference Pandya and Bhatt2021), dialogue management using deep learning (Chen et al. Reference Chen, Liu, Yin and Tang2017a), and reinforcement learning (Dai et al. Reference Dai, Yu, Jiang, Tang, Li and Sun2021b).
While the surveys noted above provide comprehensive insights into their respective domains, this abundance of information can make it overwhelming for both novice and experienced researchers and professionals to identify the essential components required for building their dialogue-based systems. In contrast, we adopt a broader perspective and offer a panoramic view of the various constituents comprising a dialogue-based system, elucidate the individual tasks involved in their development, and highlight the typical datasets and state-of-the-art methodologies employed for designing and evaluating these components. Consequently, the title “Dialogue Agents 101” is a deliberate choice aiming to convey that the article serves as an introductory guide or primer to the fundamental concepts and principles associated with dialogue agents. In academic settings, “101” is often used to denote introductory or basic-level courses, and here, it suggests that the article provides foundational knowledge for readers who may be new to the topic of dialogue agents. With this comprehensive survey, we aspire to assist beginners and practitioners in making well-informed decisions while developing systems for their applications. Our specific objective is to comprehensively encompass all prominent open-source textual English dialogue datasets across major dialogue tasks. That is, every dataset under consideration in our study meets four conditions: (i) it must be widely recognized within its respective field, (ii) it should incorporate a textual component in both input and output, (iii) it must be publicly accessible, and (iv) it must be designed for English.
To identify relevant material for our survey, we conducted a thorough search of the Papers With Code websiteFootnote e to identify all relevant tasks and datasets related to dialogue agents. Our goal was to gather and systematically organize different types of tasks that may be required for developing various dialogue agents and understand the methods for performing these tasks, and datasets that are typically used to train and evaluate models for these tasks. From the initial list obtained from Papers With Code, we then queried Google Scholar for publications and followed the citation threads to gather relevant literature for each task, encompassing datasets and articles proposed well before the establishment of the platforms. We emphasize that while Papers With Code functioned as our reference for locating pertinent literature, its principal values lay in pinpointing the key problem statements investigated within the domain of dialogue agents.
While delving into contemporary deep learning methods in this investigation, it is crucial to acknowledge the rich history of research in dialogue agents. Long before the advent of deep learning, researchers were actively engaged in developing computational methods to facilitate meaningful interactions between machines and humans (Weizenbaum Reference Weizenbaum1966; Bayer, Doran, and George Reference Bayer, Doran and George2001). In the nascent stages of dialogue agent development, researchers heavily relied on rule-based systems (Webb Reference Webb2000; McTear Reference McTear2021). Human experts meticulously crafted these systems, incorporating predefined rules and decision trees to interpret user inputs and generate appropriate responses. Classification tasks, such as intent detection and slot filling, often involved rule-based pattern matching (De and Kopparapu Reference De and Kopparapu2010; Ren et al. Reference Ren, Wang, Yu, Li, Zhixing Li and Zou2018) and template-based approaches (Onyshkevych Reference Onyshkevych1993; McRoy, Channarukul, and Ali Reference McRoy, Channarukul and Ali2003) to identify the user’s intention based on specific keywords or syntactic structures. Generative tasks, such as response generation, posed a significant challenge without deep learning techniques. Early approaches leveraged handcrafted templates (Weizenbaum Reference Weizenbaum1966; Chu-Carroll and Carberry Reference Chu-Carroll and Carberry1998), where responses were generated by combining predefined phrases or sentences. This method, however, lacked the flexibility to generate contextually relevant and nuanced responses, hindering the natural flow of conversations.
Table 1. Characteristic of each task based on the taxonomic characteristic of a dialogue agent. Size indicates an approximate value expressed in thousands (k). Abbreviations—DR: Dialogue Rewrite, DS: Dialogue Summary, D2S: Dialogue to Structure, QA: Question Answering, KGR: Knowledge Grounded Response, CC: Chit-chat, TOD: Task-Oriented Dialogues, ID: Intent Detection, SF: Slot Filling, DST: Dialogue State Tracking, AD: Affect Detection, CC: Chit-chat, GO: Goal Oriented, Spc: Specific, ST: Single Turn, MT: Multi Turn, U: Unimodal, M: Multimodal, Unstr: Unstructured, Str: Structured, Eng: Engaging, Inf: Informative, Instr: Instructional, Emp: Empathetic
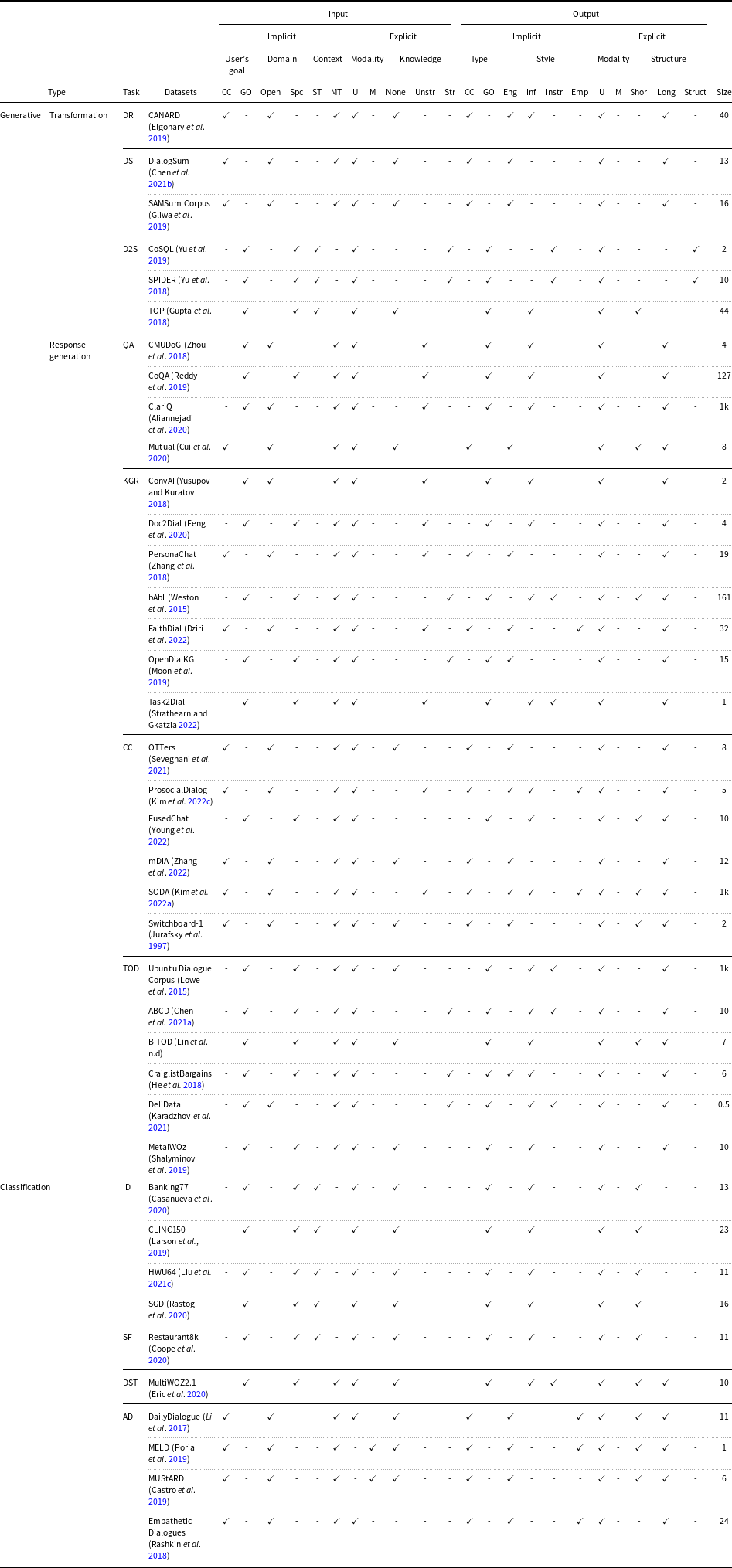
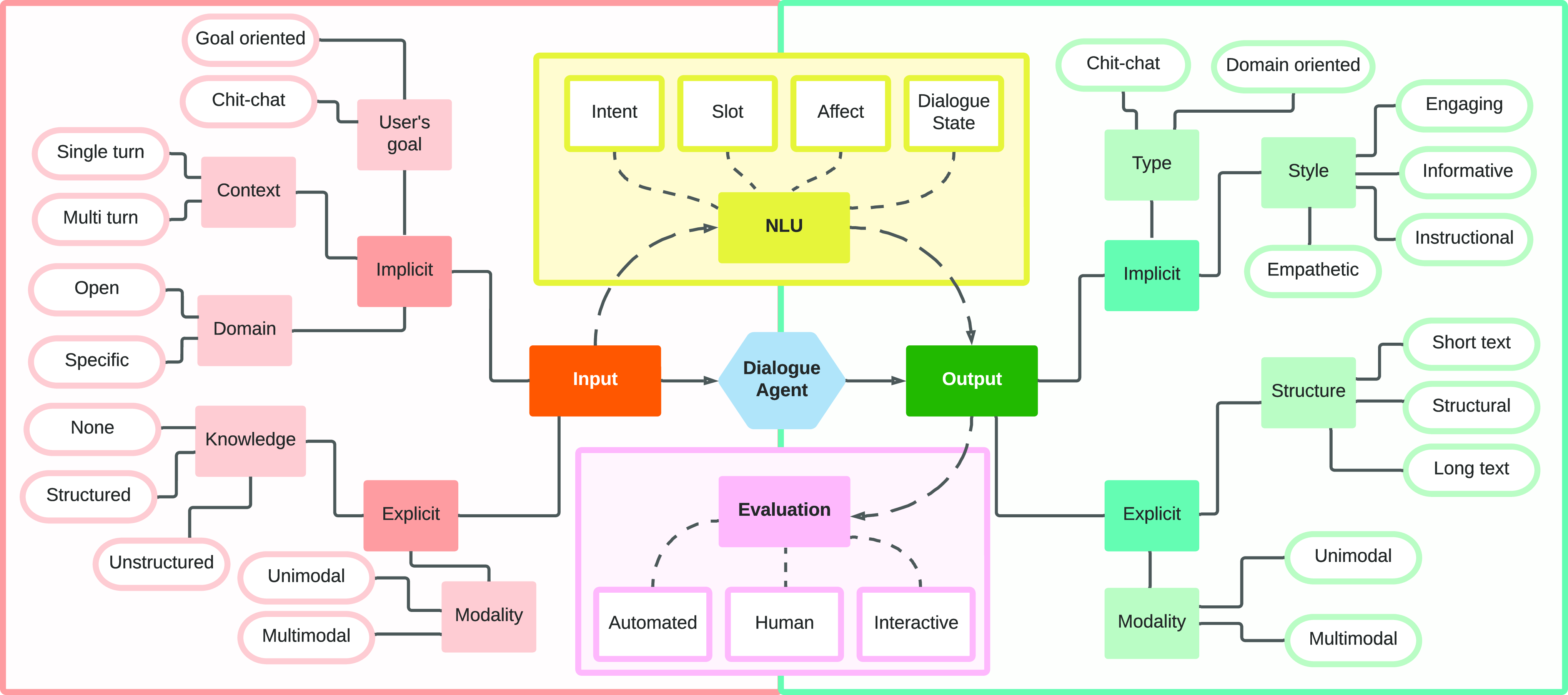
Figure 1. A taxonomic overview of a dialogue agent. The major components for designing a complete pipeline of a dialogue agent are—input(s), natural language understanding (NLU), generated output(s), and model evaluation. Each component can be further divided based on the characteristics required in the final dialogue agent.
As computational capabilities advanced, statistical methods started gaining traction in dialogue agent development. Hidden Markov models (HMMs) (Rabiner and Juang Reference Rabiner and Juang1986) and finite-state machines (Ben-Ari and Mondada Reference Ben-Ari and Mondada2018) were applied to model the probabilistic nature of language and user interactions (Williams Reference Williams2003; Williams, Poupart, and Young Reference Williams, Poupart and Young2005). These models enabled a more dynamic and probabilistic approach to intent detection and slot filling, contributing to the improvement of dialogue system performance (Hussein and Granat Reference Hussein and Granat2002; Zhao, Meyers, and Grishman Reference Zhao, Meyers and Grishman2004). From rule-based systems and template-based approaches to early statistical models, researchers laid the groundwork for the sophisticated deep learning methodologies that dominate the contemporary landscape we aim to study in this survey. To summarize, our key contributions are as follows.
-
(1) We propose an in-depth taxonomy for different components and modules involved in building a dialogue agent (Fig. 1). We take a practitioner’s view point and develop the taxonomy in terms of features of the underlying system and discuss at length the role played by each of the features in the overall system (Section 2).
-
(2) Next, we present a comprehensive overview of different tasks and datsets in the literature and relate them to the features as identified in the proposed taxonomy (Table 1). We identify eleven broad categories of tasks related to dialogue-based systems and present a detailed overview of different methods for each task and datasets used for evaluating these tasks (Section 3). Our goal is to help the reader identify key techniques and datasets available for the tasks relevant to their applications.
-
(3) We present Unit,Footnote f a large scale unified dialogue dataset, consisting of more than 4.8M dialogues and 441 M tokens, which combine the various dialogue datasets described in Section 6. Since Unit is made from the dialogues of open-sourced datasets, it is free to use for any research purposes. This effort is motivated by the recent trends suggesting a shift toward building unified foundation models (Zhou et al. Reference Zhou, Li, Li, Yu, Liu, Wang, Zhang, Ji, Yan, Lifang, He, Peng, Li, Wu, Liu, Xie, Xiong, Pei, Yu and Sun2023a) that are pretrained on large datasets and generalize to a variety of tasks. We make Unit available to the research community with a goal to spark research efforts toward development of foundation models optimized for dialogues. We use Unit to further pretrain popular open dialogue foundation models and show how it can help improving their performance on various dialogue tasks (Section 6.1.1).
2. Designing a dialogue agent
Before developing a dialogue agent, several crucial decisions must be made to determine the appropriate architecture for the agent. Fig. 1 illustrates a comprehensive overview of these decisions, which provides a taxonomic framework for structuring the development process. A clear understanding of the end goal we aim to achieve from a dialogue agent is crucial for effective communication (Pomerantz and Fehr Reference Pomerantz and Fehr2011). For instance, questions such as “Do we want the dialogue agent to carry out goal-oriented or chit-chat conversations?” and “Does the agent need any external knowledge to answer user queries?” should be answered. Fig. 2 highlights the different type of dialogues based on the different attributes of the input and output of the system as discussed below.
2.1. Input to the system
After establishing the end goal of our dialogue agent, it is essential to determine the various factors that will inform the input to the agent (Harms et al. Reference Harms, Kucherbaev, Bozzon and Houben2019). Our contention is that the input can possess both implicit and explicit properties, depending on the task at hand.
Implicit Attributes. We classify the characteristics of the input that are not explicitly apparent from the input as implicit attributes of the input. This inherent information can be decided based on three aspects—the user’s goal (Muise et al. Reference Muise, Chakraborti, Agarwal, Bajgar, Chaudhary, Lastras-Montano, Ondrej, Vodolan and Wiecha2019), the domain of the dialogues (Budzianowski et al. Reference Budzianowski, Wen, Tseng, Casanueva, Ultes, Ramadan and Gašić2018), and the context needed to carry out the end task (Kiela and Weston Reference Kiela and Weston2019). Depending on the objective of the dialogue agent, the user could want to achieve some goal, such as making a restaurant reservation, booking an airline ticket, or resolving technical queries. For such goal-oriented dialogue agents, the input from the user is expected to differ from that received for general chit-chat (Muise et al. Reference Muise, Chakraborti, Agarwal, Bajgar, Chaudhary, Lastras-Montano, Ondrej, Vodolan and Wiecha2019). Goal-oriented dialogue agents are often designed to operate within a particular domain, while chit-chat-based agents are more versatile and are expected to handle a broader range of conversations (Zhang et al. Reference Zhang, Dinan, Urbanek, Szlam, Kiela and Weston2018). In addition to the user’s goal and the agent’s domain, the conversation context also plays a crucial role in achieving the agent’s objective (Kiela and Weston Reference Kiela and Weston2019). For example, utterance-level intent detection may not require understanding deep conversation context, while summarizing dialogues would require a complete understanding of the context (Gliwa et al. Reference Gliwa, Mochol, Biesek and Wawer2019).
Explicit Attributes. Apart from the implicit aspects of the dialogue agent’s input, various input characteristics are external in nature and should be considered while building a dialogue agent. These aspects constitute the input modality (Jovanovic and Van Leeuwen Reference Jovanovic and Van Leeuwen2018) and any additional knowledge supplied to the agent (Dinan et al. Reference Dinan, Roller, Shuster, Fan, Auli and Weston2019). Input can be unimodal, such as text or audio, or in a combination of modalities, such as an image and associated text, as in the case of visual question-answering systems (Parvaneh et al. Reference Parvaneh, Abbasnejad, Wu and Shi2019). Furthermore, additional knowledge may be required to generate appropriate responses. For example, in a chit-chat setting, the agent may need to possess commonsense knowledge (Strathearn and Gkatzia Reference Strathearn and Gkatzia2022), while in a question-answering setting, the agent may need to access relevant documents to provide accurate responses (Feng et al. Reference Feng, Wan, Gunasekara, Patel, Joshi and Lastras2020). Therefore, any explicit knowledge supplied to the dialogue agent can be structured, like a tree or a tuple, or unstructured, like a document.
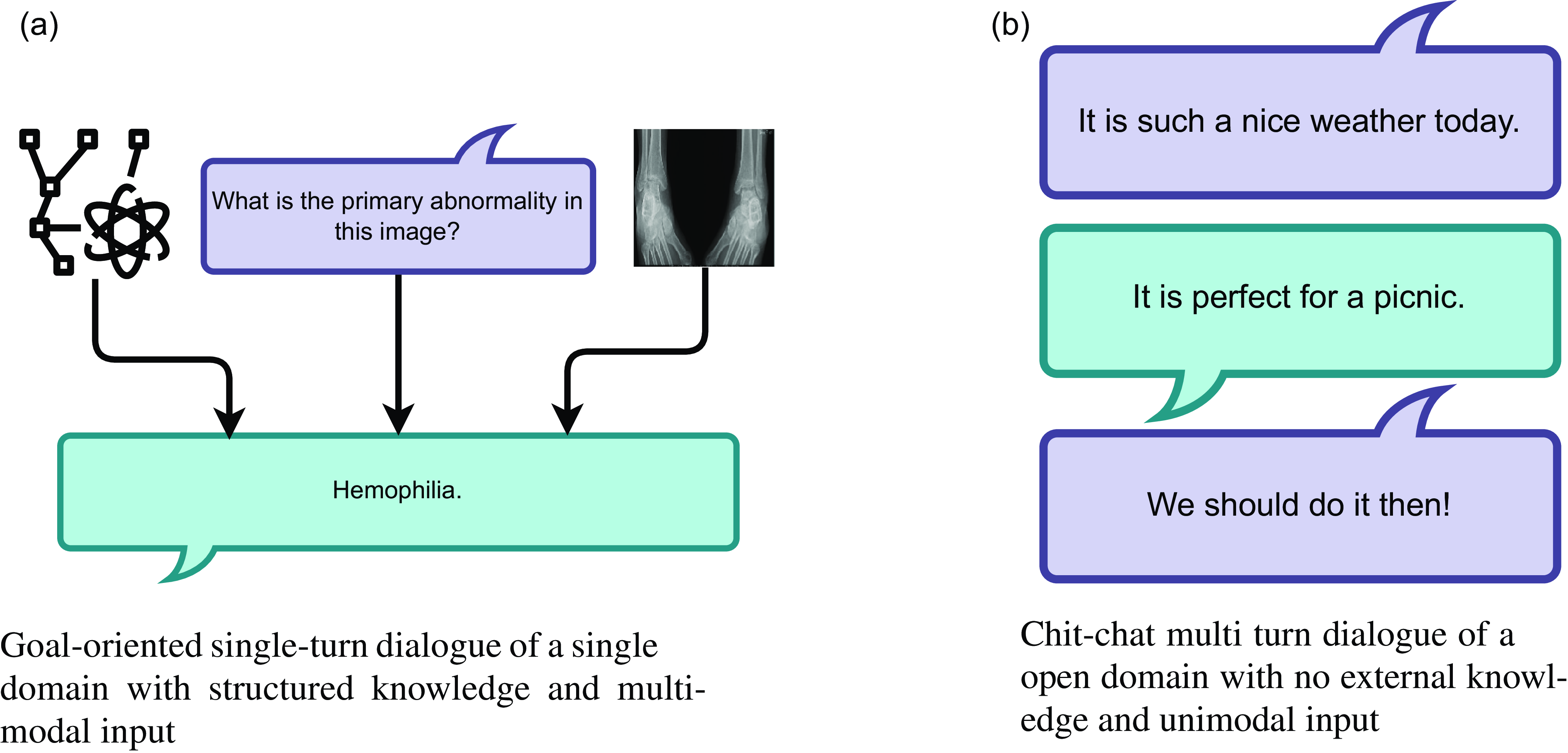
Figure 2. Dialogues highlighting different attributes of a dialogue agent input and output.
2.2. Natural language understanding
After receiving input from the user, the subsequent step involves comprehension (Liu et al. Reference Liu, Eshghi, Swietojanski and Rieser2021b). Regardless of whether the task is domain-specific or open-domain, specific attributes of the input must be identified to determine the required output. We identify four primary attributes that need to be identified from the input text—the user’s intent (Casanueva et al. Reference Casanueva, Temčinas, Gerz, Henderson and Vulić2020), any slots needed to fulfill the intent (Weld et al. Reference Weld, Huang, Long, Poon and Han2022a), affective understanding of the input (Ruusuvuori Reference Ruusuvuori2012), and the dialogue state of the input utterance (Balaraman, Sheikhalishahi, and Magnini Reference Balaraman, Sheikhalishahi and Magnini2021). While intent and slots are directly useful for a domain-specific agent to effectively complete a task, affect understanding and dialogue state tracking is also critical for a chit-chat-based agent. Affect understanding involves comprehending the user’s emotion (Poria et al. Reference Poria, Hazarika, Majumder, Naik, Cambria and Mihalcea2019), sarcasm (Castro et al. Reference Castro, Hazarika, Pérez-Rosas, Zimmermann, Mihalcea and Poria2019), and amusement (Bedi et al. Reference Bedi, Kumar, Akhtar and Chakraborty2021) in the input utterance. Furthermore, dialogue state tracking checks the type of utterance received by the agent, such as question, clarification, or guidance. Understanding these aspects is essential to determine the utterance’s underlying meaning and provide relevant responses for the task.
2.3. Output of the system
The output generated by the dialogue agent, akin to its input, possesses both implicit and explicit attributes, described below.
Implicit Attributes. Implicit attributes refer to the output’s type (Rastogi et al. Reference Rastogi, Zang, Sunkara, Gupta and Khaitan2020) and style (Su et al. Reference Su, Cai, Wang, Baker, Korhonen, Collier and Liu2020; Troiano, Velutharambath, and Klinger Reference Troiano, Velutharambath and Klinger2023), while explicit attributes pertain to its modality (Sun et al. Reference Sun, Wang, Xu, Zheng, Yang, Hu, Xu, Zhang, Geng and Jiang2022b) and structure (Yu et al. Reference Yu, Zhang, Yang, Yasunaga, Wang, Li, Ma, Li, Yao, Roman, Zhang and Radev2018). Congruent to the user’s goal in the input scenario, the type of attribute should be decided based on the end task needed to be performed by the dialogue agent. Depending on the end task of the agent, the resulting output can be informative (Feng et al. Reference Feng, Wan, Gunasekara, Patel, Joshi and Lastras2020), engaging (Zhang et al. Reference Zhang, Dinan, Urbanek, Szlam, Kiela and Weston2018), instructional (Strathearn and Gkatzia Reference Strathearn and Gkatzia2022), or empathetic (Rashkin et al. Reference Rashkin, Smith, Li and Boureau2019). For instance, a question-answering-based bot should be informative, while a cooking recipe bot should be more instructional. Both bots need not be empathetic in nature.
Explicit Attributes. While the inherent properties of the output text are critical to assess, the explicit attributes, such as modality and structure, must be considered before finalizing the dialogue agent’s architecture. Modality decides whether the required output is unimodal (such as text) or multimodal (such as text with an image). Moreover, the output can be structured differently based on the task at hand. For instance, tasks such as text-to-SQL (Yu et al. Reference Yu, Zhang, Yang, Yasunaga, Wang, Li, Ma, Li, Yao, Roman, Zhang and Radev2018) conversion require the output to adhere to a certain structure. After considering various aspects of the input, output, and understanding based on the end task, the generated output is evaluated to gauge the performance of the resultant dialogue agent (Deriu et al. Reference Deriu, Rodrigo, Otegi, Echegoyen, Rosset, Agirre and Cieliebak2021). A detailed discussion about the evaluation can be found in Section 5.
3. Tasks, datasets, and methods
By drawing upon the taxonomy depicted in Fig. 1 and existing literature, we identify eleven distinct tasks related to dialogue that capture all necessary characteristics of a dialogue agent. In order to construct a dialogue agent, a practitioner must be aware of these tasks, which can be classified into two primary categories—generative and classification. Specifically, the identified tasks include Dialogue Rewrite (DR) (Elgohary, Peskov, and Boyd-Graber Reference Elgohary, Peskov and Boyd-Graber2019), Dialogue Summary (DS) (Gliwa et al. Reference Gliwa, Mochol, Biesek and Wawer2019; Chen et al. Reference Chen, Liu, Chen and Zhang2021b), Dialogue to Structure (D2S) (Gupta et al. Reference Gupta, Shah, Mohit, Kumar and Lewis2018; Yu et al. Reference Yu, Zhang, Er, Li, Xue, Pang, Lin, Tan, Shi, Li, Jiang, Yasunaga, Shim, Chen, Fabbri, Li, Chen, Zhang, Dixit and Radev2019; Gupta et al. Reference Gupta, Shah, Mohit, Kumar and Lewis2018), Question Answering (QA) (Zhou, Prabhumoye, and Black Reference Zhou, Prabhumoye and Black2018; Reddy, Chen, and Manning Reference Reddy, Chen and Manning2019; Aliannejadi et al. Reference Aliannejadi, Kiseleva, Chuklin, Dalton and Burtsev2020; Cui et al. Reference Cui, Wu, Liu, Zhang and Zhou2020), Knowledge Grounded Response (KGR) (Weston et al. Reference Weston, Bordes, Chopra, Rush, van Merriënboer, Joulin and Mikolov2015; Yusupov and Kuratov Reference Yusupov and Kuratov2018; Zhang et al. Reference Zhang, Dinan, Urbanek, Szlam, Kiela and Weston2018; Moon et al. Reference Moon, Shah, Kumar and Subba2019; Feng et al. Reference Feng, Wan, Gunasekara, Patel, Joshi and Lastras2020; Dziri et al. Reference Dziri, Kamalloo, Milton, Zaiane, Yu, Ponti and Reddy2022; Strathearn and Gkatzia Reference Strathearn and Gkatzia2022), Chit-Chat (CC) (Jurafsky, Shriberg, and Biasca Reference Jurafsky, Shriberg and Biasca1997; Sevegnani et al. Reference Sevegnani, Howcroft, Konstas and Rieser2021; Young et al. Reference Young, Xing, Pandelea, Ni and Cambria2022; Kim et al. Reference Kim, Hessel, Jiang, Lu, Yu, Zhou, Bras, Alikhani, Kim, Sap and Choi2022a; Zhang et al. Reference Zhang, Shen, Chang, Ge and Chen2022; Kim et al. Reference Kim, Yu, Jiang, Lu, Khashabi, Kim, Choi and Sap2022c), and Task-Oriented Dialogues (TOD) (Lowe et al. Reference Lowe, Pow, Serban and Pineau2015; Weston et al. Reference Weston, Bordes, Chopra, Rush, van Merriënboer, Joulin and Mikolov2015; Chen et al. Reference Chen, Chen, Yang, Lin and Yu2021a; Lin et al. n.d; He et al. Reference He, Chen, Balakrishnan and Liang2018; Shalyminov et al. Reference Shalyminov, Lee, Eshghi and Lemon2019; Karadzhov, Stafford, and Vlachos Reference Karadzhov, Stafford and Vlachos2021) in the generative category and Intent Detection (ID) (Larson et al. Reference Larson, Mahendran, Peper, Clarke, Lee, Hill, Kummerfeld, Leach, Laurenzano, Tang and Mars2019; Casanueva et al. Reference Casanueva, Temčinas, Gerz, Henderson and Vulić2020; Rastogi et al. Reference Rastogi, Zang, Sunkara, Gupta and Khaitan2020; Liu et al. Reference Liu, Eshghi, Swietojanski and Rieser2021c), Slot Filling (SF) (Coope et al. Reference Coope, Farghly, Gerz, Vulić and Henderson2020), Dialogue State Tracking (DST) (Eric et al. Reference Eric, Goel, Paul, Sethi, Agarwal, Gao, Kumar, Goyal, Ku and Hakkani-Tur2020), and Affect Detection (AD) (Li et al. Reference Li, Su, Shen, Li, Cao and Niu2017; Poria et al. Reference Poria, Hazarika, Majumder, Naik, Cambria and Mihalcea2019; Castro et al. Reference Castro, Hazarika, Pérez-Rosas, Zimmermann, Mihalcea and Poria2019; Rashkin et al. Reference Rashkin, Smith, Li and Boureau2019) in the classification category. Table 1 summarizes all the datasets considered in this study for each of the mentioned tasks and illustrates the characteristics satisfied by each of these tasks from the taxonomy. As we delve into the details of each task type in the forthcoming sections, it is noteworthy to highlight a few observations obtained from the presented table.
-
In dialogue datasets featuring chit-chat conversations, an inclination toward characteristics indicative of open domain, multi-turn interactions, and the absence of external knowledge is observed. Notably, a prevalent trend emerges in the generation of similar output within such datasets. An identified gap in the existing landscape pertains to the scarcity of datasets integrating external knowledge with chit-chat dialogues. Recognizing the potential enrichment that associated knowledge, particularly commonsense (Ghosal et al. Reference Ghosal, Majumder, Gelbukh, Mihalcea and Poria2020), can bring to dialogues, it becomes a potential future research area.
-
For instances where the dataset comprises goal-oriented conversations, it is probable that the dataset is tailored to a specific domain, assisted with either structured or unstructured knowledge linked to it. Goal-oriented dialogues typically center around specific tasks like booking airline tickets, scheduling doctor appointments, or securing restaurant reservations. Notably, these “goals” can extend beyond specific tasks to encompass aspects such as the accomplishment of the goal of dialogue engagement (Gottardi et al. Reference Gottardi, Ipek, Castellucci, Hu, Vaz, Lu, Khatri, Chadha, Zhang, Sattvik, Dwivedi, Shi, Hu, Huang, Dai, Yang, Somani, Rajan, Rezac and Maarek2022). Intriguingly, such goal orientation does not necessarily confine the dialogue to a predefined domain, allowing for an open-domain context. A prospective avenue for research lies in the development of more open-domain, goal-oriented dialogue datasets that focus more on conversational goals like user engagement.
-
The chit-chat setting exhibits the predominant trend of producing extensive and engaging dialogue output (Gottardi et al. Reference Gottardi, Ipek, Castellucci, Hu, Vaz, Lu, Khatri, Chadha, Zhang, Sattvik, Dwivedi, Shi, Hu, Huang, Dai, Yang, Somani, Rajan, Rezac and Maarek2022). In contrast, the goal-oriented setting commonly yields responses characterized by informativeness, instructional clarity, and brevity (Muise et al. Reference Muise, Chakraborti, Agarwal, Bajgar, Chaudhary, Lastras-Montano, Ondrej, Vodolan and Wiecha2019). Intriguingly, datasets combining both goal-oriented and chit-chat conversations are notably sparse, despite real-world dialogues frequently encompassing a fluid interchange between these conversational types (Shuster et al. Reference Shuster, Xu, Komeili, Da, Smith, Roller, Ung, Chen, Arora, Joshua, Behrooz, Ngan, Poff, Goyal, Szlam, Boureau, Kambadur and Weston2022). The presence of such datasets could substantially enhance the research community’s capabilities and insights.
3.1. Generative dialogue tasks
Generative dialogue tasks require the handling of diverse input and output characteristics (Chen et al. Reference Chen, Liu, Yin and Tang2017b). These tasks can be classified into two distinct types—transformation and response generation. In transformation tasks, the output of the given input conversation is not the subsequent response but rather some other meaningful text, such as a dialogue summary (Gliwa et al. Reference Gliwa, Mochol, Biesek and Wawer2019). On the other hand, response generation tasks involve generating the next response in the dialogue, given an input context (Zhang et al. Reference Zhang, Sun, Galley, Chen, Brockett, Gao, Gao, Liu and Dolan2020b).
3.1.1. Transformation tasks
Dialogue Rewrite (DR). This task involves the challenging process of modifying a given conversational utterance to better fit a specific social context or conversational objective, while retaining its original meaning. To explore this task further, we turn to the CANARD dataset (Elgohary et al. Reference Elgohary, Peskov and Boyd-Graber2019). This dataset is specifically designed for rewriting context-dependent questions into self-contained questions that can be answered independently by resolving all coreferences. The objective is to ensure that the new question has the same answer as the original one. Quan et al. (Reference Quan, Xiong, Webber and Hu2019) and Martin et al. (Reference Martin, Poddar and Upasani2020) proposed the TASK and MuDoCo datasets, respectively, focusing on rewriting dialogues in a way that coreferences and ellipsis are resolved. Huang et al. (Reference Huang, Li, Zou and Zhang2021) combined sequence labeling and autoregression techniques to restore utterances without any coreferences. In contrast, Jiang et al. (Reference Jiang, Gu, Chen and Shen2023) shaped the dialogue rewrite task as sentence editing and predicted edit operations for each word in the context. Other methods also use knowledge augmentation (Ke et al. Reference Ke, Zhang, Lv, Xu, Cao, Li, Chen and Li2022), reinforcement learning (Chen et al. Reference Chen, Zhao, Fang, Fetahu, Rokhlenko and Malmasi2022b), and the copy mechanism (Quan et al. Reference Quan, Xiong, Webber and Hu2019).
Key challenges. Despite achieving a reasonable performance in the dialogue rewrite task, some challenges remain, with the major obstacle being the inclusion of new words in the ground truth annotations that are difficult to incorporate into the predicted rewrite (Liu et al. Reference Liu, Chen, Lou, Zhou and Zhang2020b). In order to mitigate this challenge, many studies have explored the methods of lexicon integration (Czarnowska et al. Reference Czarnowska, Ruder, Cotterell and Copestake2020; Lee, Cheng, and Ostendorf Reference Lee, Cheng and Ostendorf2023), open-vocabulary (Raffel et al. Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2020; Hao et al. Reference Hao, Song, Wang, Xu, Tu and Yu2021; Vu et al. Reference Vu, Barua, Lester, Cer, Iyyer and Constant2022), and context-aware encoding (Vinyals, Bengio, and Kudlur Reference Vinyals, Bengio and Kudlur2015; Xiao et al. Reference Xiao, Zhao, Zhang, Yan and Yang2020).
Dialogue summary (DS). Dialogues, despite their importance in communication, can often become lengthy and veer off-topic. This can make it challenging to extract the meaningful content from the entire conversation. To overcome this issue, the task of dialogue summarization has emerged. Dialogue summarization presents a concise account of the key topics, ideas, and arguments discussed during the conversation. There are two prominent datasets that address the challenge of dialogue summarization: the SAMSum (Gliwa et al. Reference Gliwa, Mochol, Biesek and Wawer2019) and DialogSum (Chen et al. Reference Chen, Liu, Chen and Zhang2021b) corpora consisting of dialogues and their corresponding summaries. The SAMSum dataset consists of dialogues that were curated by linguists who are fluent in English and who attempted to simulate messenger-like conversations. While DialogSum consists of face-to-face spoken dialogues covering various daily life topics such as schooling, work, and shopping. The dialogues are present in the textual format in both datasets. Other datasets such as QMSum (Zhong et al. Reference Zhong, Da, Yu, Zaidi, Mutuma, Jha, Awadallah, Celikyilmaz, Liu, Qiu and Radev2021), MediaSum (Zhu et al. Reference Zhu, Liu, Mei and Zeng2021), DiDi (Liu et al. Reference Liu, Wang, Xu, Li and Ye2019), CCCS (Favre et al. Reference Favre, Stepanov, Trione, Béchet and Riccardi2015), Telemedicine (Joshi et al. Reference Joshi, Katariya, Amatriain and Kannan2020), CRD3 (Rameshkumar and Bailey Reference Rameshkumar and Bailey2020), Television Shows (Zechner and Waibel Reference Zechner and Waibel2000), AutoMin (Nedoluzhko et al. Reference Nedoluzhko, Singh, Hledíková, Ghosal and Bojar2022), and Clinical Encounter Visits (Yim and Yetisgen Reference Yim and Yetisgen2021) are also constructed for the task of dialogue summarization. For a detailed guide on the task, we redirect the readers to the extensive survey conducted by Tuggener et al. (Reference Tuggener, Mieskes, Deriu and Cieliebak2021). Many architectures have been proposed to solve the task of dialogue summarization. Liang et al. (Reference Liang, Wu, Cui, Bai, Bian and Li2023) uses topic-aware Global-Local Centrality (GLC) to extract important context from all sub-topics. By combining global- and local-level centralities, the GLC method guides the model to capture salient context and sub-topics while generating summaries. Other studies have utilized contrastive loss (Halder, Paul, and Islam Reference Halder, Paul and Islam2022), multi-view summary generation (Chen and Yang Reference Chen and Yang2020), post-processing techniques improving the quality of summaries (Lee et al. Reference Lee, Lim, Whang, Lee, Cho, Park and Lim2021), external knowledge incorporation (Kim et al. Reference Kim, Joo, Chae, Kim, Hwang and Yeo2022b), multimodal summarization (Atri et al. Reference Atri, Pramanick, Goyal and Chakraborty2021), and methods to reduce hallucinations in generated summaries (Liu and Chen Reference Liu and Chen2021; Narayan et al. Reference Narayan, Zhao, Maynez, Simões, Nikolaev and McDonald2021; Wu et al. Reference Wu, Liu, Liu, Stenetorp and Xiong2021b).
Key challenges. With the help of pretrained language models, current methods are adept at converting the original chat into a concise summary. Nonetheless, these models still face challenges in selecting the crucial parts and tend to generate hallucinations (Feng, Feng, and Qin Reference Feng, Feng and Qin2022a). In the case of longer dialogues, the models may exhibit bias toward a specific part of the chat, such as the beginning or end, producing summaries that are not entirely satisfactory (Dey et al. Reference Dey, Chowdhury, Kumar and Chakraborty2020). Many studies explore novel attention mechanism with topic modeling (Xiao et al. Reference Xiao, Zhao, Zhang, Yan and Yang2020), reinforcement learning and differential rewards (Chen, Dodda, and Yang Reference Chen, Dodda and Yang2023; Zhang et al. Reference Zhang, Liu, Yang, Fang, Chen, Radev, Zhu, Zeng and Zhang2023; Italiani et al. Reference Italiani, Frisoni, Moro, Carbonaro and Sartori2024), and knowledge augmentation with fact-checking (Hua, Deng, and McKeown Reference Hua, Deng and McKeown2023; Hwang et al. Reference Hwang, Kim, Bae, Lee, Bang and Jung2023) to mitigate these challenges.
Dialogue to structure (D2S). Although natural language is the fundamental way humans communicate, the interaction between humans and machines often requires a more structured language such as SQL or syntactic trees. Tasks such as Text-to-SQL and Semantic Parsing seek to bridge the gap between natural language and machine-understandable forms of communication. To address this, four prominent datasets have been developed—CoSQL (Yu et al. Reference Yu, Zhang, Er, Li, Xue, Pang, Lin, Tan, Shi, Li, Jiang, Yasunaga, Shim, Chen, Fabbri, Li, Chen, Zhang, Dixit and Radev2019), SPIDER (Yu et al. Reference Yu, Zhang, Yang, Yasunaga, Wang, Li, Ma, Li, Yao, Roman, Zhang and Radev2018), and WikiSQL (Zhong, Xiong, and Socher Reference Zhong, Xiong and Socher2017) for text-to-sql, which are composed of pairs of natural language queries paired with their corresponding SQL queries, and the Task-Oriented Parsing (TOP) dataset (Gupta et al. Reference Gupta, Shah, Mohit, Kumar and Lewis2018) for semantic parsing which contains conversations that are annotated with hierarchical semantic representation for task-oriented dialogue systems. There are numerous approaches to handling these datasets, including encoder/decoder models with decoder constraints (Yin and Neubig Reference Yin and Neubig2017; Wang et al. Reference Wang, Shin, Liu, Polozov and Richardson2019b), large language models without any constraints (Suhr et al. Reference Suhr, Chang, Shaw and Lee2020; Lin, Socher, and Xiong Reference Lin, Socher and Xiong2020), final hypothesis pruning (Scholak, Schucher, and Bahdanau Reference Scholak, Schucher and Bahdanau2021), span-based extraction (Panupong Pasupat et al. Reference Panupong Pasupat, Mandyam, Shah, Lewis and Zettlemoyer2019; Meng et al. Reference Meng, Dai, Wang, Wang, Wu, Jiang and Liu2022), data augmentation (Xuan Reference Xuan2020; Lee et al. Reference Lee, Chen, Leach and Kummerfeld2022), and ensembling techniques (Einolghozati et al. Reference Einolghozati, Panupong Pasupat, Shah, Mohit, Lewis and Zettlemoyer2018).
Key challenges. Despite recent advancements in D2S type tasks, there remains a scarcity of high-quality resources related to complex queries (Lee et al. Reference Lee, Chen, Leach and Kummerfeld2022). Furthermore, the performance of D2S models tends to be suboptimal when encountering small perturbations, such as synonym substitutions or the introduction of domain-specific knowledge in the input (Qin et al. Reference Qin, Hui, Wang, Yang, Li, Li, Geng, Cao, Sun, Luo, Huang and Li2022). Existing studies explore the areas of data augmentation with resource creation to solve this challenge (Min et al. Reference Min, Yao, Xie, Wang, Zha and Zhang2020; Joshi et al. Reference Joshi, Vishwanath, Teo, Petricek, Vishwanathan, Bhagat and May2022). Enhancing robustness and handling perturbation (Jia et al. Reference Jia, Li, Zhao, Kim and Kumar2019; Yu et al. Reference Yu, Zhang, Pan, Ma, Wang and Yu2023) are other possible solutions to the challenge of brittleness in the D2S tasks. Further research in this direction could yield valuable insights.
3.1.2. Response generation
Question Answering (QA). Dialogue agents must possess the ability to ask relevant questions in order to engage the participants by introducing interesting topics via questions in general chit-chat setting (Gottardi et al. Reference Gottardi, Ipek, Castellucci, Hu, Vaz, Lu, Khatri, Chadha, Zhang, Sattvik, Dwivedi, Shi, Hu, Huang, Dai, Yang, Somani, Rajan, Rezac and Maarek2022) and provide appropriate answers to user inquiries, to remain authentic in the QA setting (Elgohary et al. Reference Elgohary, Peskov and Boyd-Graber2019). As a result, Question Answering (QA) is a crucial task for dialogue agents to perform competently. To this end, datasets such as CMUDoG (Zhou et al. Reference Zhou, Prabhumoye and Black2018), CoQA (Reddy et al. Reference Reddy, Chen and Manning2019), SQuAD (Rajpurkar et al. Reference Rajpurkar, Zhang, Lopyrev and Liang2016, 2018), ClariQ (Aliannejadi et al. Reference Aliannejadi, Kiseleva, Chuklin, Dalton and Burtsev2020), and Mutual (Reference Cui, Wu, Liu, Zhang and ZhouCui et al. 2020) are among the most notable and widely used for the purpose of training and evaluating QA systems. If external knowledge is used to answer questions, the task can be termed as knowledge-grounded question answering (Meng et al. Reference Meng, Ren, Chen, Sun, Ren, Tu and de Rijke2020). The CMUDoG, CoQA, and SQuAD datasets are examples of this category. The FIRE model (Gu et al. Reference Gu, Ling, Liu, Chen and Zhu2020) utilizes context and knowledge filters to create context- and knowledge-aware representations through global and bidirectional attention. Other methods include multitask learning (Zhou and Small Reference Zhou and Small2020), semantic parsing (Berant and Liang Reference Berant and Liang2014; Reddy, Lapata, and Steedman Reference Reddy, Lapata and Steedman2014), knowledge-based grounding (Yih et al. Reference Yih, Chang, He and Gao2015; Liang et al. Reference Liang, Berant, Le, Forbus and Lao2017), and information-retrieval based methods (Bordes et al. Reference Bordes, Usunier, Chopra and Weston2015; Dong et al. Reference Dong, Wei, Zhou and Xu2015). On the other hand, the ClariQ and Mutual datasets does not contain any external knowledge. Komeili et al. (Reference Komeili, Shuster and Weston2022) have proposed using the Internet as a source for obtaining relevant information. In contrast, Hixon et al. (Reference Hixon, Clark and Hajishirzi2015) proposes to learn domain from conversation context. Zero-shot approaches (Wang et al. Reference Wang, Tu, Rosset, Craswell, Wu and Ai2023b), adversarial pretraining (Pi et al. Reference Pi, Zhong, Gao, Duan and Lou2022), convolution networks (Liu et al. Reference Liu, Feng, Gao, Wang and Zhang2022a), and graph based methods (Ouyang, Zhang, and Zhao Reference Ouyang, Zhang and Zhao2021) are also used to solve the task of QA.
Key challenges. In the field of discourse-based question answering, which requires models to consider both deep conversation context and potential external knowledge, anaphora resolution still poses a significant challenge that necessitates further investigation (Pandya and Bhatt Reference Pandya and Bhatt2021). Additionally, capturing long dialogue context (Christmann, Roy, and Weikum Reference Christmann, Roy and Weikum2022) and preventing topical drift (Venkataram, Mattmann, and Penberthy Reference Venkataram, Mattmann and Penberthy2020) offer other research direction. Many studies explore these challenges and propose viable solutions to mitigate them (Lin et al., [n.d]; Wu et al. Reference Wu, Shen, Lan, Mao, Bai and Wu2023b). However, a reliable solution still needs more research in the field.
Knowledge-grounded response (KGR). Similar to knowledge-grounded question answering, knowledge-grounded response generation is a task that utilizes external knowledge to generate relevant responses. Some of the primary datasets related to knowledge grounding include ConvAI (Yusupov and Kuratov Reference Yusupov and Kuratov2018), Doc2Dial (Feng et al. Reference Feng, Wan, Gunasekara, Patel, Joshi and Lastras2020), PersonaChat (Zhang et al. Reference Zhang, Dinan, Urbanek, Szlam, Kiela and Weston2018), bAbI (Weston et al. Reference Weston, Bordes, Chopra, Rush, van Merriënboer, Joulin and Mikolov2015), FaithDial (Dziri et al. Reference Dziri, Kamalloo, Milton, Zaiane, Yu, Ponti and Reddy2022), OpenDialKG (Moon et al. Reference Moon, Shah, Kumar and Subba2019), and Task2Dial (Strathearn and Gkatzia Reference Strathearn and Gkatzia2022). Most methods that aim to solve the task of knowledge-grounded response generation, like knowledge-grounded QA, uses a two step approach of retrieval and generation (Zhan et al. Reference Zhan, Zhang, Chen, Ding, Bao and Lan2021; Wu et al. Reference Wu, Galley, Brockett, Zhang, Gao, Quirk, Koncel-Kedziorski, Gao, Hajishirzi, Ostendorf and Dolan2021a), graph-based approach (Wang et al. Reference Wang, Rong, Zhang, Ouyang and Xiong2020; Li et al. Reference Li, Li and Wang2021a), reinforcement learning approach (Hedayatnia et al. Reference Hedayatnia, Gopalakrishnan, Kim, Liu, Eric and Hakkani-Tur2020), and retrieval-free approaches (Xu et al. Reference Xu, Ishii, Cahyawijaya, Liu, Winata, Madotto, Su and Fung2022).
Key challenges. The current trend in knowledge-grounded response generation is to use a two-step approach of retrieval and generation, which increases the complexity of the system (Zhou et al. Reference Zhou, Gopalakrishnan, Hedayatnia, Kim, Pujara, Ren, Liu and Hakkani-Tur2022). Recently, researchers such as Xu et al. (Reference Xu, Ishii, Cahyawijaya, Liu, Winata, Madotto, Su and Fung2022) and Zhou et al. (Reference Zhou, Gopalakrishnan, Hedayatnia, Kim, Pujara, Ren, Liu and Hakkani-Tur2022) have explored ways to bypass the retrieval step and produce more efficient models. Further research in this direction can improve the efficiency of systems.
Chit-chat (CC). The primary goal of a dialogue agent is to generate responses, whether it is for chit-chat based dialogues or task-oriented dialogues. This section will specifically focus on the response generation for chit-chat agents. While there are numerous dialogue datasets available that contain chit-chat dialogues and can be used as training data, such as PersonaChat (Zhang et al. Reference Zhang, Dinan, Urbanek, Szlam, Kiela and Weston2018), MELD (Poria et al. Reference Poria, Hazarika, Majumder, Naik, Cambria and Mihalcea2019), DailyDialogue (Li et al. Reference Li, Su, Shen, Li, Cao and Niu2017), MUStARD (Castro et al. Reference Castro, Hazarika, Pérez-Rosas, Zimmermann, Mihalcea and Poria2019), and Mutual (Cui et al. Reference Cui, Wu, Liu, Zhang and Zhou2020), there are some datasets specifically curated for the task of chit-chat generation. Examples of such datasets include OTTers (Sevegnani et al. Reference Sevegnani, Howcroft, Konstas and Rieser2021), ProsocialDialog (Kim et al. Reference Kim, Yu, Jiang, Lu, Khashabi, Kim, Choi and Sap2022c), FusedChat (Young et al. Reference Young, Xing, Pandelea, Ni and Cambria2022), mDIA (Zhang et al. Reference Zhang, Shen, Chang, Ge and Chen2022), SODA (Kim et al. Reference Kim, Hessel, Jiang, Lu, Yu, Zhou, Bras, Alikhani, Kim, Sap and Choi2022a), and the Switchboard-1 corpus (Jurafsky et al. Reference Jurafsky, Shriberg and Biasca1997). Major approaches used to generate responses for chit-chat dialogue agents include the use of contrastive learning (Cai et al. Reference Cai, Chen, Song, Ding, Bao, Yan and Zhao2020, Li et al. Reference Li, Cheng, Li and Qiu2022a; Cai et al. Reference Cai, Chen, Song, Ding, Bao, Yan and Zhao2020), continual learning (Mi et al. Reference Mi, Chen, Zhao, Huang and Faltings2020; Liu and Mazumder Reference Liu and Mazumder2021; Liu et al. Reference Liu, Xu, Lei, Wang, Niu and Wu2022c), and Transformer-based methods (Cai et al. Reference Cai, Wang, Bi, Tu, Liu and Shi2019; Oluwatobi and Mueller Reference Oluwatobi and Mueller2020; Liu et al. Reference Liu, Yihong Chen, Lou, Chen, Zhou and Zhang2020a).
Key challenges. Typical challenges with chit-chat agents, such as inconsistency, unfaithfulness, and an absence of a uniform persona, persist (Liu et al. Reference Liu, Lowe, Serban, Noseworthy, Charlin and Pineau2017a). Furthermore, the ineffective management of infrequently used words is another tenacious issue (Shum et al. Reference Shum, Zheng, Kryscinski, Xiong and Socher2020). However, current advancements, such as reinforcement learning from human feedback (RLHF) (Christiano et al. Reference Christiano, Leike, Brown, Martic, Legg and Amodei2017; Stiennon et al. Reference Stiennon, Ouyang, Wu, Ziegler, Lowe, Voss, Radford, Amodei and Christiano2020), help in minimizing these issues.
Task-oriented dialogues (TOD). To generate domain-specific responses, task-oriented dialogue agents require a specialized approach. Fortunately, there are several datasets available that feature domain-oriented dialogues, including the Ubuntu Dialogue Corpus (Lowe et al. Reference Lowe, Pow, Serban and Pineau2015), ABCD (Chen et al. Reference Chen, Chen, Yang, Lin and Yu2021a), bAbI (Weston et al. Reference Weston, Bordes, Chopra, Rush, van Merriënboer, Joulin and Mikolov2015), BiTOD (Lin et al. n.d), CraiglistBargains (He et al. Reference He, Chen, Balakrishnan and Liang2018), DeliData (Karadzhov et al. Reference Karadzhov, Stafford and Vlachos2021), and MetalWOz (Shalyminov et al. Reference Shalyminov, Lee, Eshghi and Lemon2019). Generating task-oriented dialogues follows a similar approach to open domain dialogues, utilizing reinforcement learning (Liu et al. Reference Liu, Tur, Hakkani-Tur, Shah and Heck2017b; Lipton et al. Reference Lipton, Li, Gao, Li, Ahmed and Deng2018; Khandelwal Reference Khandelwal2021), graph-based methods (Yang, Zhang, and Erfani Reference Yang, Zhang and Erfani2020; Andreas et al. Andreas et al. Reference Andreas, Bufe, Burkett, Chen, Clausman, Crawford, Crim, DeLoach, Dorner, Jason, Fang, Guo, Hall, Hayes, Hill, Ho, Iwaszuk, Jha, Klein and Zotov2020; Liu et al. Reference Liu, Bai, He, Liu, Liu and Zhao2021a), and Transformer-based methods (Parvaneh et al. Reference Parvaneh, Abbasnejad, Wu and Shi2019; Chawla et al. Reference Chawla, Lucas, Gratch and May2020).
Key challenges. The current datasets in this area feature restrictive input utterances, where necessary information is explicit and simple to extract (Zhang et al. Reference Zhang, Takanobu, Zhu, Huang and Zhu2020c). Conversely, natural conversations necessitate extracting implicit information from user utterances to generate a response (Zhou et al. Reference Zhou, Gopalakrishnan, Hedayatnia, Kim, Pujara, Ren, Liu and Hakkani-Tur2022). A few studies explore advanced attention mechanisms (Qu et al. Reference Qu, Yang, Wang and Hu2024), interactive learning (Yang et al. Reference Yang, Huang, Lau and Erfani2022) and dialogue augmentation (Liu et al. Reference Liu, Maynez, Simões and Narayan2022b) to capture implicit contextual information from the text. Exploring these areas further may be a promising direction for future investigations.
3.2. Classification tasks
Fig. 1 shows that dialogue classification encompasses additional tasks, including intent detection, slot filling, dialogue state tracking, and affect detection. In the following sections, we provide a detailed explanation of each of these tasks.
Intent detection (ID). Identifying the user’s objectives in a conversation is crucial, particularly in goal-oriented dialogues. Intent detection aims to achieve this objective by analyzing text and inferring its intent, which can then be categorized into predefined groups. Given its importance, there has been significant research into intent detection, with several datasets proposed for this task, such as the DialoGLUE (Mehri, Eric, and Hakkani-Tur Reference Mehri, Eric and Hakkani-Tur2020), benchmark’s Banking77 (Casanueva et al., Reference Casanueva, Temčinas, Gerz, Henderson and Vulić2020), CLINC150 (Larson et al., Reference Larson, Mahendran, Peper, Clarke, Lee, Hill, Kummerfeld, Leach, Laurenzano, Tang and Mars2019), HWU64 (Liu et al. Reference Liu, Eshghi, Swietojanski and Rieser2021c), and the Schema-Guided Dialogue (SGD) Dataset (Rastogi et al. Reference Rastogi, Zang, Sunkara, Gupta and Khaitan2020). Table 1 illustrates the taxonomic characteristics these datasets satisfy. It can be observed that they all follow a similar pattern of being goal-oriented, domain specific, and single turn with no external knowledge associated with them. The DialoGLUE leaderboardFootnote g indicates that a model called SAPCE2.0 gives exceptional performance across all intent detection tasks. In addition, other approaches include utilizing contrastive conversational finetuning (Vulić et al., Reference Vulić, Casanueva, Spithourakis, Mondal, Wen and Budzianowski2022), dual sentence encoders (Casanueva et al. Reference Casanueva, Temčinas, Gerz, Henderson and Vulić2020), and incorporating commonsense knowledge (Siddique et al. Reference Siddique, Jamour, Xu and Hristidis2021).
Key challenges. The primary obstacle in intent detection involves the tight decision boundary of the learned intent classes within intent detection models (Weld et al. Reference Weld, Huang, Long, Poon and Han2022b). Furthermore, given the dynamic nature of the world, the number and types of intents are constantly evolving, making it essential for intent detection models to be dynamic (Weld et al. Reference Weld, Huang, Long, Poon and Han2022a). Recent developments have explored ensemble learning (Zhou et al. Reference Zhou, Yang, Wang and Qiu2023b) along with Bayesian approaches (Zhang, Yang, and Liang 2019; Aftab et al. Reference Aftab, Gautam, Hawkins, Alexander and Habli2021) to mitigate the said challenge. Further, learning paradigms such as incremental learning (Hrycyk, Zarcone, and Hahn Reference Hrycyk, Zarcone and Hahn2021; Paul, Sorokin, and Gaspers Reference Paul, Sorokin and Gaspers2022) and meta-learning (Li and Zhang Reference Li and Zhang2021; Liu et al. Reference Liu, Zhao, Zhang, Zhang, Sun, Yu and Zhang2022d) also prove to be beneficial in this field. However, a detailed future investigation in this domain is needed.
Slot filling (SF). To effectively achieve a specific intent, a dialogue agent must possess all the necessary information required for task completion. These crucial pieces of information are commonly referred to as slots. It is worth noting that intent detection and slot filling often go hand in hand. As a result, the SGD dataset described in Section 3.2 includes slot annotations and can serve as a benchmark for evaluating slot-filling performance. Additionally, the Restaurant8k (Coope et al. Reference Coope, Farghly, Gerz, Vulić and Henderson2020) dataset is another prominent dataset in the domain of slot filling. Methods that solve the slot-filling task often involve using CNN (Lecun et al. Reference Lecun, Bottou, Bengio and Haffner1998) and CRF (Ma and Hovy Reference Ma and Hovy2016; Lample et al. Reference Lample, Ballesteros, Subramanian, Kawakami and Dyer2016) layers. Coope et al. (Reference Coope, Farghly, Gerz, Vulić and Henderson2020) give impressive performance on the Restaurant8k dataset by utilizing the ConveRT (Henderson et al. Reference Henderson, Casanueva, Mrkšić, Su, Wen and Vulić2020) method to obtain utterance representation. Many other studies explore the problem of slot filling as a stand-alone task (Louvan and Magnini Reference Lucas, Boberg, Traum, Artstein, Gratch, Gainer, Johnson, Leuski and Nakano2018, 2019). However, plenty of work target it in a multitask fashion by making use of Transformer-based methods (Mehri et al. Reference Mehri, Eric and Hakkani-Tur2020), graphical approach (Wu et al. Reference Wu, Harris, Zhao and Ling2023a), GRUs (Cho et al. Reference Cho, van Merriënboer, Gulcehre, Bahdanau, Bougares, Schwenk and Bengio2014), and MLB fusion layers (Bhasin et al. Reference Bhasin, Natarajan, Mathur and Mangla2020).
Key challenges. Contemporary slot-filling techniques concentrate on slots as independent entities and overlook their correlation (Louvan and Magnini Reference Louvan and Magnini2020). Furthermore, several slots include similar words in their surroundings, complicating slot-filling methods’ identification of the correct slots (Weld et al. Reference Weld, Huang, Long, Poon and Han2022a). In order to mitigate these challenges, a few studies have proposed the use of joint inference (Tang, Ji, and Zhou Reference Tang, Ji and Zhou2020), latent variable models (Wu et al. Reference Wu, Wang, Gao, Qi and Li2019; Wakabayashi, Takeuchi, and Nakano Reference Wakabayashi, Takeuchi and Nakano2022), and incorporating external knowledge (Wang et al. Reference Wang, He, Fan, Zhou and Tu2019a; He et al. Reference He, Xu, Wu, Wang and Chen2021). Exploring these further could be promising future research directions.
Dialogue State Tracking (DST) Dialogue state tracking (DST) involves identifying, during each turn of a conversation, the complete depiction of the user’s objectives at that moment in the dialogue. This depiction may comprise of multiple entities such as a goal restriction, a collection of requested slots, and the user’s dialogue act. The major database used for benchmarking the DST task is the MultiWOZ2.1 dataset (Eric et al. Reference Eric, Goel, Paul, Sethi, Agarwal, Gao, Kumar, Goyal, Ku and Hakkani-Tur2020). The TripPy+SaCLog model (Dai et al. Reference Dai, Li, Li, Sun, Huang, Si and Zhu2021a) achieved remarkable performance on this dataset. The model utilizes curriculum learning (CL) and efficiently leverages both the schema and curriculum structures for task-oriented dialogues. Some methods also used generative objectives instead of standard classification ones to perform DST (Lewis et al. Reference Lewis, Liu, Goyal, Ghazvininejad, Mohamed, Levy, Stoyanov and Zettlemoyer2020; Peng et al. Reference Peng, Li, Li, Shayandeh, Liden and Gao2021; Aghajanyan et al. Reference Aghajanyan, Gupta, Shrivastava, Chen, Zettlemoyer and Gupta2021).
Key challenges. Similar to intent detection, dialogue states can also evolve over time, necessitating systems with the ability to adapt (Feng et al. Reference Feng, Lipani, Ye, Zhang and Yilmaz2022b). While some studies have explored zero-shot settings for learning dialogue states (Balaraman et al. Reference Balaraman, Sheikhalishahi and Magnini2021), additional research in this area could be appreciated.
Affect Detection (AD). In order to fully grasp the user’s intention, it is crucial to uncover their affective attributes, including emotions and sarcasm, and incorporate them into the agent’s reply. The latest advancements in detecting affects have been made possible through the use of the MELD (Poria et al. Reference Poria, Hazarika, Majumder, Naik, Cambria and Mihalcea2019), DailyDialogue (Li et al. Reference Li, Su, Shen, Li, Cao and Niu2017), MUStARD (Castro et al. Reference Castro, Hazarika, Pérez-Rosas, Zimmermann, Mihalcea and Poria2019), and Empathetic Dialogues (Rashkin et al. Reference Rashkin, Smith, Li and Boureau2019) datasets for Emotion Recognition in Conversation (ERC), sarcasm detection, and empathetic response generation. Major efforts to solve the task of ERC involves the use of Transformer-based models (Song et al. Reference Song, Huang, Xue and Hu2022; Hu et al. Reference Hu, Lin, Zhao, Lu, Wu and Li2022; Zhao, Zhao, and Qin Reference Zhao, Zhao and Qin2022), graphical methods (Ghosal et al. Reference Ghosal, Majumder, Poria, Chhaya and Gelbukh2019; Shen et al. Reference Shen, Wu, Yang and Quan2021), and commonsense incorporation (Ghosal et al. Reference Ghosal, Majumder, Gelbukh, Mihalcea and Poria2020). For sarcasm detection too, Transformer-based methods are the most popular ones (Babanejad et al. Reference Babanejad, Davoudi, An and Papagelis2020; Zhang, Chen, and ying Li 2021; Desai, Chakraborty, and Akhtar Reference Desai, Chakraborty and Akhtar2021; Bedi et al. Reference Bedi, Kumar, Akhtar and Chakraborty2021; Bharti et al. Reference Bharti, Gupta, Shukla, Hatamleh, Tarazi and Nuagah2022). Empathetic response generation is often handled by using sequence-to-sequence encoder–decoder architecture (Rashkin et al. Reference Rashkin, Smith, Li and Boureau2018; Shin et al. Reference Shin, Xu, Madotto and Fung2019; Xie and Pu Reference Xie and Pu2021).
Key challenges. Although affect detection remains as a critical topic, merely accommodating detection may not suffice to generate appropriate responses (Pereira, Moniz, and Carvalho Reference Pereira, Moniz and Carvalho2022). Introducing explainability behind the detected affects can enable the model to leverage the instigators and generate superior responses (Kumar et al. Reference Kumar, Kulkarni, Akhtar and Chakraborty2022a). Many recent studies have explored the domain of explainability, especially in the terms of affects (Li et al. Reference Li, Li, Pandelea, Ge, Zhu and Cambria2023; An et al. Reference An, Ding, Li and Xia2023; Kumar et al. Reference Kumar, Mondai, Akhtar and Chakraborty2023b). Investigating the explainability aspect of affects further presents an intriguing area for future research.
4. Pretraining objectives for dialogue agents
In the ever-growing landscape of large language models (LLMs), which have gained widespread popularity for their adeptness in acquiring knowledge through intelligent pretraining objectives, it becomes crucial to identify the most optimal pretraining objective that elevates LLMs’ performance. Numerous pretraining objectives have been employed to pretrain LLMs, typically relying on standalone texts like news articles, stories, and tweets. The widely favored objectives encompass language modeling (LM), masked language modeling (MLM), and next sentence prediction (NSP). Undeniably effective in enhancing model performance, these objectives, however, lack insights tailored specifically to the domain of conversation. Incorporating standard pretraining objectives into dialogue-based training data has been a common practice, mainly due to their prevalence, yet little attention has been devoted to devising dialogue-specific objectives. Thus, a notable research gap exists in this domain. Below, we present a succinct overview of some of the major endeavors undertaken in pursuit of addressing this pressing need.
LM stands as the most common pretraining objective, serving as the foundational framework for many advanced systems. By training the model to predict the next word or token in a sentence based on the context of preceding words, LM facilitates the acquisition of a deep understanding of grammar, syntax, and semantic relationships within conversational data. Prominent dialogue agents like GPT (Radford et al. Reference Radford, Narasimhan, Salimans and Ilya2018), Meena (Kulshreshtha et al. Reference Kulshreshtha, De Freitas Adiwardana, So, Nemade, Hall, Fiedel, Le, Thoppilan, Luong, Lu and Yang2020), LaMDA (Thoppilan et al. Reference Thoppilan, De Freitas, Hall, Shazeer, Kulshreshtha, Cheng, Jin, Bos, Baker, Du, Li, Lee, Zheng, Ghafouri, Menegali, Huang, Krikun, Lepikhin, Qin and Le2022), and DialoGPT (Zhang et al. Reference Zhang, Sun, Galley, Chen, Brockett, Gao, Gao, Liu and Dolan2020b) have embraced the LM objective as their primary pretraining approach, owing to its effectiveness in capturing language patterns. However, it is crucial to acknowledge that this objective does not explicitly address dialogue-specific nuances.
Moving toward dialogue-specific objectives, one can employ the response selection and ranking methodology (Mehri et al. Reference Mehri, Razumovskaia, Zhao and Eskenazi2019; Shalyminov et al. Reference Shalyminov, Sordoni, Atkinson and Schulz2020; He et al. Reference He, Dai, Yang, Sun, Huang, Si and Li2022), in which the model undergoes training to prioritize and rank a given set of candidate responses based on their appropriateness with respect to an input utterance. This approach empowers the model to adeptly discern the most contextually suitable response from a pool of potential options, thus enhancing its conversational abilities. Another widely recognized strategy involves utterance permutation within a dialogue (Weizenbaum Reference Weizenbaum1966; Zhang and Zhao Reference Zhang and Zhao2021; Chen et al. Reference Chen, Bao, Chen, Liu, Da, Chen, Wu, Zhu, Dong, Ge, Miao, Lou and Yu2022a), granting the LLM a valuable opportunity to efficiently grasp the nuances of the dialogue context. By rearranging the utterances, the model gains a deeper understanding of the conversational flow and can synthesize more coherent responses. Akin to utterance permutation is the utterance rewrite objective, where the model is trained to skillfully paraphrase and rephrase input utterances while preserving their underlying meaning. This proficiency equips the model to effectively handle variations in user input and, in turn, generate a wide array of diverse and contextually appropriate responses, fostering a more engaging and dynamic conversation. Parallel to LM, the area of context-to-text generation has also garnered attention in the domain of dialogue-specific pretraining (Mehri et al. Reference Mehri, Razumovskaia, Zhao and Eskenazi2019; Chapuis et al. Reference Chapuis, Colombo, Manica, Labeau and Clavel2020; Yu et al. Reference Yu, Zhang, Polozov, Meek and Awadallah2021). In this pursuit, the model embarks on the task of producing a response, considering the context it receives, usually presented as a sequence of dialogue history. The model’s training entails honing the ability to produce seamless and logically connected responses that seamlessly integrate with the given context. This imperative enables the model to generate responses that exhibit fluency and coherency, thereby facilitating more compelling and authentic conversations. Moreover, the existing literature indicates a notable upswing in the adoption of hybrid methodologies (Mehri et al. Reference Mehri, Razumovskaia, Zhao and Eskenazi2019; Zhang and Zhao Reference Zhang and Zhao2021; He et al. Reference He, Dai, Yang, Sun, Huang, Si and Li2022; Li, Zhang, and Zhao Reference Li, Zhang and Zhao2022b), wherein multiple pretraining objectives are harmoniously merged to target the principal objective of the LLM. A compelling example of this lies in the work of Xu and Zhao (Reference Xu and Zhao2021), who introduced three innovative pretraining strategies - insertion, deletion, and replacement—designed to imbue dialogue-like features into plain text.
Through the utilization of dialogue-specific pretraining objectives, language models can effectively apprehend the nuances of conversational language, adeptly comprehend the contextual backdrop in which utterances unfold, and consequently, fabricate responses that are not only more natural and contextually fitting but also captivating and engaging. Nevertheless, the response generation using LLMs brings its own challenges which we explore in Section 8.
5. Evaluating dialoguebased systems
The last step for any dialogue agent is to evaluate the generated responses quantitatively or qualitatively. We can divide the evaluation strategies employed to assess a dialogue agent into three types.
-
Automatic evaluation uses metrics like ROUGE (Lin Reference Lin2004) and BLEU (Papineni et al. Reference Papineni, Roukos, Ward and Zhu2002) to evaluate the response syntactically via the use of n-gram overlap and metrics like METEOR (Banerjee and Lavie Reference Banerjee and Lavie2005) and BERTscore (Zhang et al. Reference Zhang, Kishore, Wu, Weinberger and Artzi2020a) to capture semantic similarity.
-
Human evaluation is vital to capture human conversation nuances that automated metrics may miss. Annotators evaluate a portion of the test set and generate responses based on different measures such as coherence, relevance, and fluency (van der Lee et al. Reference Lee, Lim, Whang, Lee, Cho, Park and Lim2021; Schuff et al. Reference Schuff, Vanderlyn, Adel and Vu2023). However, human evaluation can be expensive, time consuming, and may not be easily replicable.Footnote h Interactive evaluation is gaining relevance as a result.
-
Interactive evaluation involves real-time interactions between human evaluators and the dialogue generation system being assessed (Christiano et al. Reference Christiano, Leike, Brown, Martic, Legg and Amodei2017; Stiennon et al. Reference Stiennon, Ouyang, Wu, Ziegler, Lowe, Voss, Radford, Amodei and Christiano2020). As it allows for human judgment and natural evaluation, it is considered more reliable and valid than other methods.
Key challenges. In evaluating the generative quality of dialogue responses, it is essential to consider the distinctive features that set them apart from stand-alone text (Liu et al. Reference Liu, Lowe, Serban, Noseworthy, Charlin and Pineau2017a). To this end, numerous studies in linguistics have examined the idiosyncrasies of dialogue, with Gricean Maxim’s Cooperative principle (Grice Reference Grice1975, Reference Grice1989) being a prominent theory. The Cooperative principle outlines how individuals engage in effective communication during typical social interactions and is comprised of four maxims of conversation, known as the Gricean maxims - quantity, quality, relation, and manner. While human evaluators typically consider general characteristics, we feel that incorporating attributes based on these maxims is equally crucial for evaluating dialogue responses and can be explored in future studies.
6. Unit: unified dialogue dataset
Conversational AI involves several tasks that capture various characteristics of a dialogue agent. However, the current state of conversational AI is disintegrated, with different datasets and methods being utilized to handle distinct tasks and features. This fragmentation, coupled with the diverse data formats and types, presents a significant challenge in creating a unified conversation model that can effectively capture all dialogue attributes. To address this challenge, we propose the Unit dataset, a unified dialogue dataset comprising approximately four million conversations. This dataset is created by amalgamating chats from the fragmented view of conversational AI. Specifically, we consider the
 $39$
datasets listed in Table 1 and extract natural language conversations from each of them. Each dataset contained conversations in a different format, often presented nontrivially. We created separate scripts to extract dialogues from each dataset so that other researchers can utilize the complete data as a whole. An overview of how Unit is constructed can be found in Fig. 3. Unit is designed to provide a comprehensive and unified resource for conversational AI research. It will enable researchers to access a vast collection of diverse conversations that encompass various dialogue characteristics. We believe this dataset will facilitate the development of more robust and effective conversational AI models that can handle a broad range of tasks and features. We summarize the statistics of Unit in Table 2 and show the distribution of speakers and utterances in Fig. 4. Fig. 5 illustrates the dataset size distribution in Unit.
$39$
datasets listed in Table 1 and extract natural language conversations from each of them. Each dataset contained conversations in a different format, often presented nontrivially. We created separate scripts to extract dialogues from each dataset so that other researchers can utilize the complete data as a whole. An overview of how Unit is constructed can be found in Fig. 3. Unit is designed to provide a comprehensive and unified resource for conversational AI research. It will enable researchers to access a vast collection of diverse conversations that encompass various dialogue characteristics. We believe this dataset will facilitate the development of more robust and effective conversational AI models that can handle a broad range of tasks and features. We summarize the statistics of Unit in Table 2 and show the distribution of speakers and utterances in Fig. 4. Fig. 5 illustrates the dataset size distribution in Unit.
Table 2. Statistics of the Unit dataset: Unified Dialogue Dataset. Abbreviations: Dlgs: Dialogues, Utts: Utterances

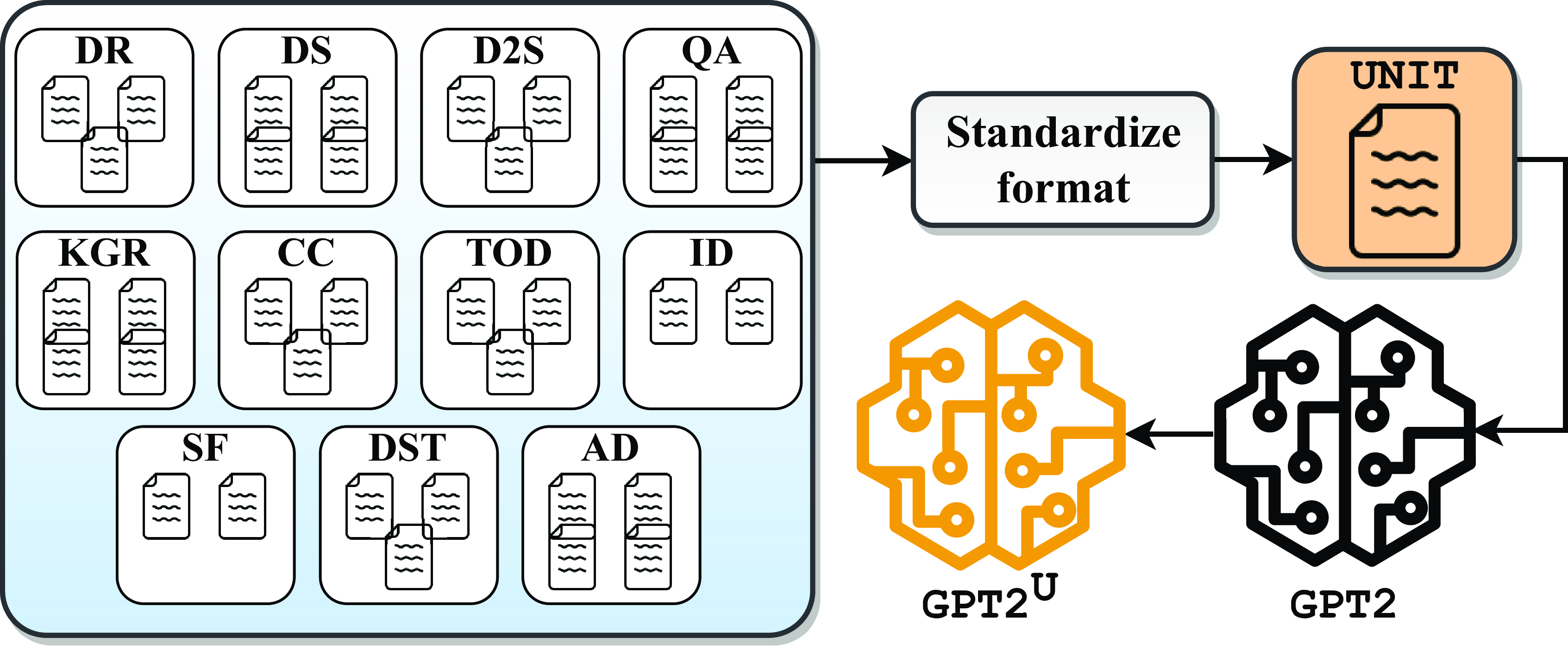
Figure 3. All
 $39$
datasets from distinct tasks are standardized and combined into a single conversational dataset called Unit. Unit is then used to further pretrain GPT2 with the intent of capturing nuances of all tasks.
$39$
datasets from distinct tasks are standardized and combined into a single conversational dataset called Unit. Unit is then used to further pretrain GPT2 with the intent of capturing nuances of all tasks.
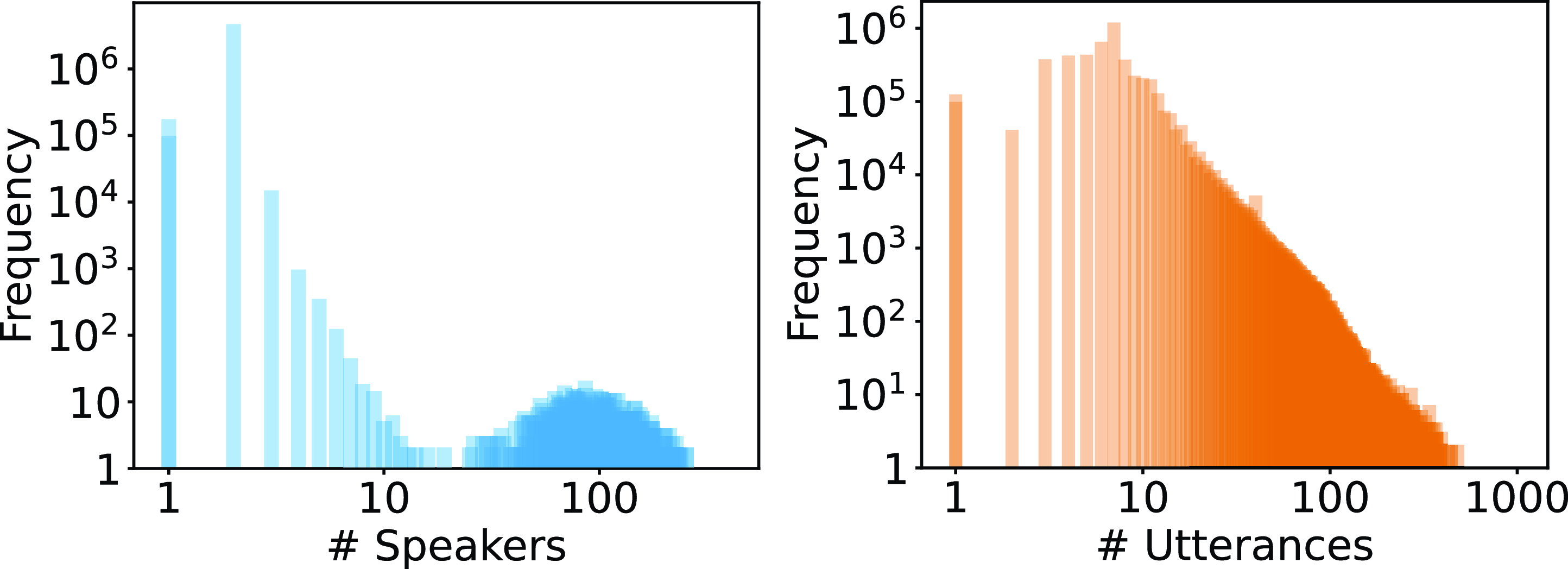
Figure 4. Log–log distribution of the number of speakers and number of utterances per dialogue in Unit. Maximum number of dialogues contain
 $2$
(
$2$
(
 $10$
) speakers (utterances) while the maximum number of speakers (utterances) in a dialogue are
$10$
) speakers (utterances) while the maximum number of speakers (utterances) in a dialogue are
 $260$
(
$260$
(
 $527$
).
$527$
).
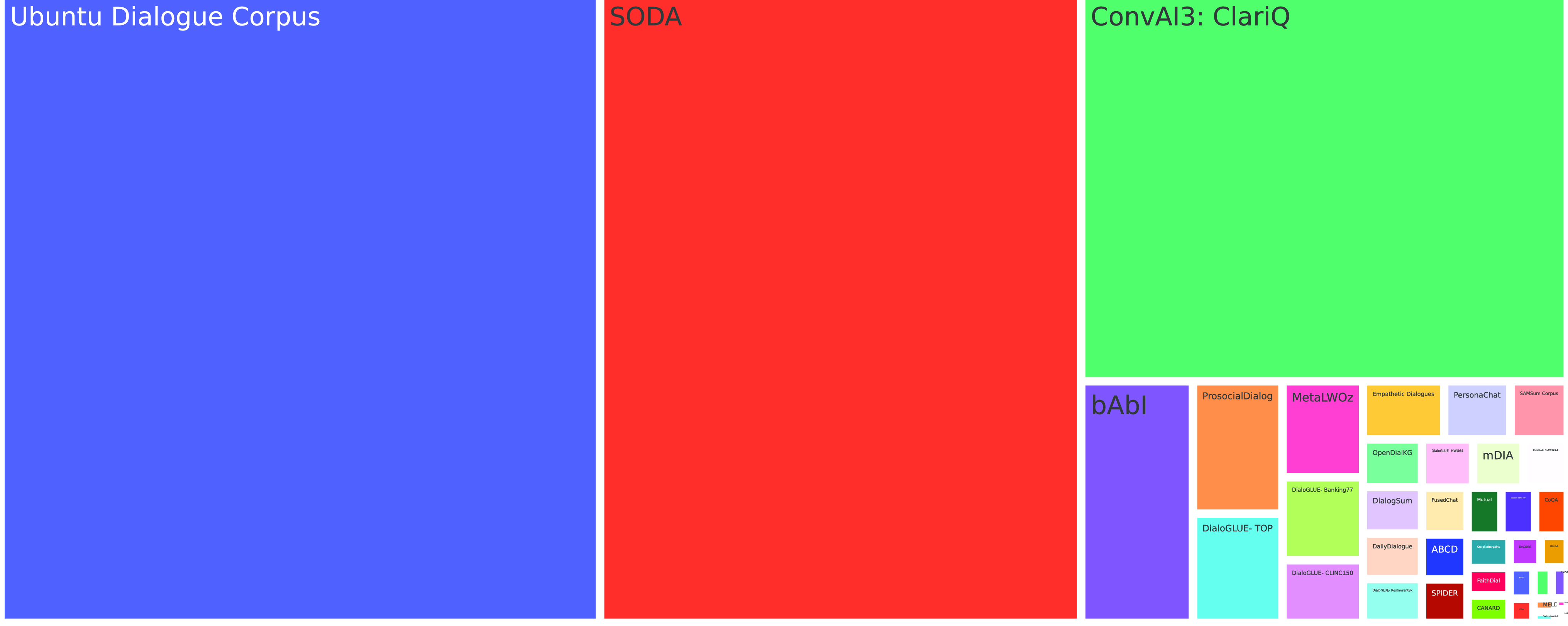
Figure 5. Distribution of sizes of different datasets in Unit. Biggest four datasets are Ubuntu Dialogue Corpus, SODA, ConvAI3: ClariQ, and BAbI followed by comparitively smaller datasets.
6.1. Unit for foundation model training
To investigate whether Unit can serve as a suitable datset for a dialogue foundation model, we use following six major open foundation models.
-
(1) GPT-2 (Radford et al. Reference Radford, Wu, Child, Luan, Amodei and Ilya2019): GPT-2 is a language model based on Transformers and has 1.5 billion parameters. It was trained on a vast dataset consisting of 8 million web pages on the language modeling objective. Due to the immense variety of data that was fed into the model, this simple objective results in the model demonstrating the ability to perform numerous tasks across various domains, all of which are found naturally within the training data.
-
(2) FLAN-T5 (Chung et al. Reference Chung, Hou, Longpre, Zoph, Tay, Fedus, Li, Wang, Dehghani, Brahma, Webson, Gu, Dai, Suzgun, Chen, Chowdhery, Castro-Ros, Pellat, Robinson and Wei2022): FLAN T5 scales T5 (Raffel et al. Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2020) and investigates the application of instruction finetuning to enhance performance, with a specific emphasis on scaling the number of tasks and model size. Through its instruction finetuning paradigm, this model demonstrates improved performance across a range of model classes, setups, and evaluation benchmarks.
-
(3) BLOOM (Scao et al. Reference Scao, Fan, Akiki, Pavlick, Ilić, Hesslow, Castagné, Luccioni, Yvon, Matthias, Tow, Rush, Biderman, Webson, Ammanamanchi, Wang, Sagot, Muennighoff, Villanova del Moral and Wolf2022): BLOOM is a language model with 176 billion parameters. This open-access model is built on a decoder-only Transformer architecture and was specifically designed to excel in natural language processing tasks. The model was trained using the ROOTS corpus (Laurençon et al. Reference Laurençon, Saulnier, Wang, Akiki, del Moral, Scao, Von Werra, Mou, Ponferrada and Huu2022), which includes hundreds of sources across 46 natural languages and 13 programming languages.
-
(4) DialoGPT (Zhang et al. Reference Zhang, Sun, Galley, Chen, Brockett, Gao, Gao, Liu and Dolan2020b): DialoGPT is a neural conversational response generation model trained on social media data consisting of 147 million conversation-like exchanges extracted from Reddit comment chains spanning over a period from 2005 through 2017. Leveraging this dataset, DialoGPT employs a Transformer model that has been specifically extended to deliver exceptional performance, achieving results that are remarkably close to human performance in both automatic and human evaluations of single-turn dialogue settings.
-
(5) BlenderBot (Roller et al. Reference Roller, Dinan, Goyal, Da, Williamson, Liu, Xu, Ott, Eric Michael Smith and Weston2021): BlenderBot is a conversational AI model that adopts a unique approach to training, eschewing the traditional emphasis on model size and data scaling in favor of a more nuanced focus on conversation-specific characteristics. Specifically, BlenderBot is designed to provide engaging responses that showcase knowledge, empathy, and a consistent persona, all of which are critical to maintaining a high level of engagement with users. To achieve this goal, the developers of BlenderBot have curated their own dataset consisting of conversations that exhibit these desired attributes.
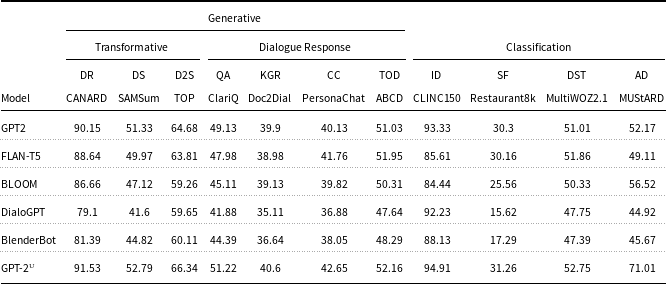
Table 3. Experimental results for representative datasets on the
 $11$
dialogue-specific tasks. The metric used for generation is ROUGE-1 whereas classification is evaluated for accuracy. For abbreviations, please refer to Table 1
$11$
dialogue-specific tasks. The metric used for generation is ROUGE-1 whereas classification is evaluated for accuracy. For abbreviations, please refer to Table 1
6.1.1. Experimental setup
In Section 3, we outlined
 $11$
distinct tasks specific to dialogue. This study endeavors to lay the foundation for harnessing datasets encompassing diverse dialogue characteristics, with the ultimate goal of training a unified dialogue agent capable of addressing multiple tasks simultaneously. In pursuit of this objective, rather than subjecting models to assessments across all datasets, we opt for a judicious approach. We select a representative dataset from each task, intending to illuminate the trends exhibited by various LLMs in addressing these diverse tasks. Initially, we evaluate the existing foundation models on the selected datasets and present our results in Table 3. It is important to highlight that our approach involves utilizing the pretrained iteration of GPT-2 and subsequently subjecting it to “further pretraining” via the causal LM objective on Unit to yield the final model, GPT-2
$11$
distinct tasks specific to dialogue. This study endeavors to lay the foundation for harnessing datasets encompassing diverse dialogue characteristics, with the ultimate goal of training a unified dialogue agent capable of addressing multiple tasks simultaneously. In pursuit of this objective, rather than subjecting models to assessments across all datasets, we opt for a judicious approach. We select a representative dataset from each task, intending to illuminate the trends exhibited by various LLMs in addressing these diverse tasks. Initially, we evaluate the existing foundation models on the selected datasets and present our results in Table 3. It is important to highlight that our approach involves utilizing the pretrained iteration of GPT-2 and subsequently subjecting it to “further pretraining” via the causal LM objective on Unit to yield the final model, GPT-2
 $^{\textrm{U}}$
. Subsequent to this, when evaluating the models—including GPT-2
$^{\textrm{U}}$
. Subsequent to this, when evaluating the models—including GPT-2
 $^{\textrm{U}}$
and others—across various tasks, we fine-tune these models specifically for each task. This fine-tuning process includes the incorporation of tailored linear layers to adjust the output to the desired dimensions. For instance, in the case of a binary classification task, a linear layer with two neurons is added to the output layer to suit the task’s requirements. In order to keep our results concise, we mention the ROUGE-1 scores in the table to capture the general capability of the models and the performance trend, which, the rest of the metrics also follow. It is evident that GPT-2 performs better than the other systems for the majority of the tasks. Therefore, we further pretrain GPT-2 using Unit to get GPT-2
$^{\textrm{U}}$
and others—across various tasks, we fine-tune these models specifically for each task. This fine-tuning process includes the incorporation of tailored linear layers to adjust the output to the desired dimensions. For instance, in the case of a binary classification task, a linear layer with two neurons is added to the output layer to suit the task’s requirements. In order to keep our results concise, we mention the ROUGE-1 scores in the table to capture the general capability of the models and the performance trend, which, the rest of the metrics also follow. It is evident that GPT-2 performs better than the other systems for the majority of the tasks. Therefore, we further pretrain GPT-2 using Unit to get GPT-2
 $^{\textrm{U}}$
. The resultant model is then evaluated on the same benchmarks as the other foundation models; the last row of Table 3 shows its performance. GPT-2
$^{\textrm{U}}$
. The resultant model is then evaluated on the same benchmarks as the other foundation models; the last row of Table 3 shows its performance. GPT-2
 $^{\textrm{U}}$
outperforms all existing foundation models including GPT-2 for almost all dialogue-specific task. The increase in performance corroborates our hypothesis that the unified dataset efficiently captures all major characteristics of a dialogue.
$^{\textrm{U}}$
outperforms all existing foundation models including GPT-2 for almost all dialogue-specific task. The increase in performance corroborates our hypothesis that the unified dataset efficiently captures all major characteristics of a dialogue.
6.1.2. Qualitative analysis
While the results for the classification tasks are straightforward, we conduct a detailed analysis of the generative outcomes in this section. Recognizing the limitations of automatic metrics in fully capturing the performance of a generative system, as discussed in Section 5, we undertake a human evaluation of predictions generated by the top comparative system, GPT-2 and GPT-2
 $^{\textrm{U}}$
. A panel of
$^{\textrm{U}}$
. A panel of
 $25$
human evaluators,Footnote
i
proficient in English linguistics and aged between 25 and 30 years, are enlisted for this task. Their assignment involves assessing a randomly chosen set of
$25$
human evaluators,Footnote
i
proficient in English linguistics and aged between 25 and 30 years, are enlisted for this task. Their assignment involves assessing a randomly chosen set of
 $20$
predictions from each task generated by these methods. The evaluators assign ratings ranging from
$20$
predictions from each task generated by these methods. The evaluators assign ratings ranging from
 $1$
to
$1$
to
 $5$
, considering key human evaluation metrics such as fluency, relevance, and coherence. The dimensions of evaluation are explained as follows:
$5$
, considering key human evaluation metrics such as fluency, relevance, and coherence. The dimensions of evaluation are explained as follows:
-
Fluency evaluates the naturalness and readability of the generated text, focusing on grammar, syntax, and language flow. Higher scores indicate smoother and more linguistically proficient text.
-
Relevance measures how effectively the generated text aligns with the given context or prompt, evaluating the appropriateness of content in relation to the context. Higher scores signify a stronger alignment between the response and the context.
-
Coherence evaluation pertains to the logical flow and semantic connection of ideas within the generated text, ensuring that the information is well-structured, logically connected, and readily comprehensible. Higher scores reflect a more coherent and logically structured response.
Table 4 presents the average ratings across all obtained responses. The results indicate a preference for GPT-2
 $^{\textrm{U}}$
by our annotators across all metrics, highlighting its superiority.
$^{\textrm{U}}$
by our annotators across all metrics, highlighting its superiority.
Table 4. Results of human evaluation for the representative tasks

7. Major takeaways: a summary
This section extensively highlights the notable revelations acquired from a thorough examination of open-source dialogue datasets, tasks, and methodologies. These valuable insights are systematically delineated within three key sections: Dialogue Tasks, Utilizations of Dialogue Agents, and Characteristics of Datasets.
Dialogue Tasks. Within the confines of this comprehensive survey, we have delved into a discourse encompassing the most prevalent and versatile dialogue tasks, capturing the fundamental characteristics that define effective conversational systems. Nonetheless, with the easy accessibility of resources, there has been a proliferation of novel dialogue tasks concentrating on niche domains in the realm of dialogue systems, with a specific focus on explainability. An example of this evolution can be found in the work of Ghosal et al. (Reference Ghosal, Hong, Shen, Majumder, Mihalcea and Poria2021), who have ventured into the realm of the dialogue explanation task. Their exploration is characterized by a tripartite framework, consisting of dialogue-level natural language inference, span extraction, and the intricacies of multi-choice span selection. Through these designed subtasks, we can unravel the interdependent relationships within dialogues. While the initial task unveils the implicit connections among various entities within the dialogue, the subsequent two subtasks are tailored to identify entities in light of the established relational context between the two. Research in the domain of affect explainability is also on the rise. For instance, emotion causing extraction in conversations (Xia and Ding Reference Xia and Ding2019; Poria et al. Reference Poria, Majumder, Hazarika, Ghosal, Bhardwaj, Jian, Hong, Ghosh, Roy, Niyati, Gelbukh and Mihalcea2021) aims to extract a span from an input utterance, which is responsible to the emotion elicited by the speaker in that utterance. Similarly, emotion flip reasoning (Kumar et al. 2022c, 2023a) tries to uncover the responsible utterances from a dialogue context that are responsible for a speaker’s emotion shift. Apart from emotions, sarcasm explanation (Kumar et al. Reference Kumar, Kulkarni, Akhtar and Chakraborty2022a,b) is also a recent task that has come into focus. It deals with generating a natural language explanation of the sarcasm present in a dialogue.
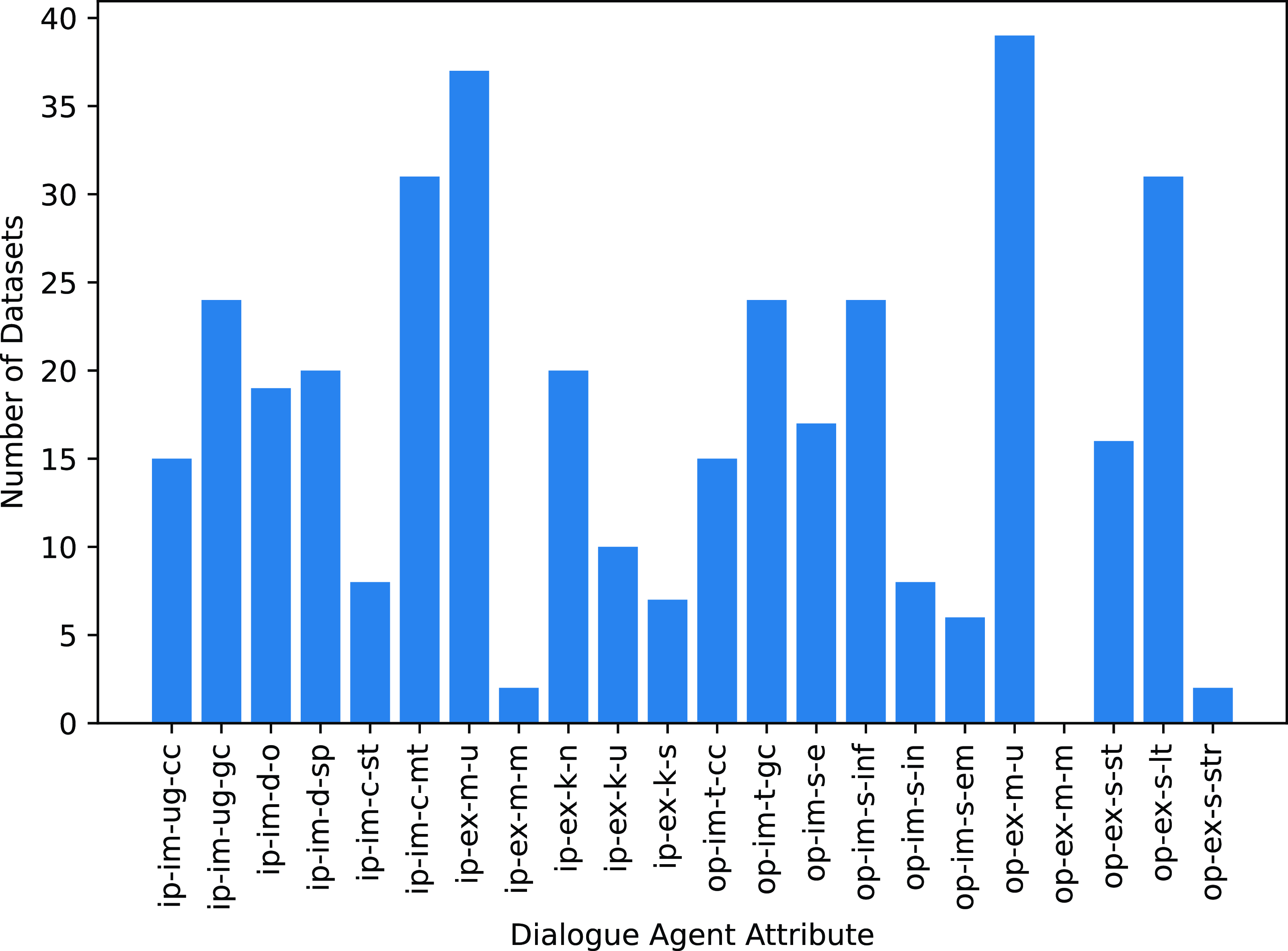
Figure 6. Distribution of datasets covering the specific dialogue attributes. Abbreviations—ip-im-ug-cc: input-implicit-user goals-chit chat, ip-im-ug-gc: input-implicit-user goal-goal completion, ip-im-d-o: input-implicit-domain-open, ip-im-d-sp: input-implicit-domain=specific, ip-im-c-st: input-implicit-context-single turn, ip-im-c-mt: input-implicit-context-multi turn, ip-ex-m-u: input-explicit-modality-unimodal, ip-ex-m-m: input-explicit-modality-multimodal, ip-ex-k-n: input-explicit-knowledge-none, ip-ex-k-u: input-explicit-knowledge-unstructured, ip-ex-k-s: input-explicit-knowledge-structured, op-im-t-cc: output-implicit-type-chit chat, op-im-t-gc: output-implicit-type-goal completion, op-im-s-e: output-implicit-style-engaging, op-im-s-inf: output-implicit-style-informative, op-im-s-in: output-implicit-style-instructional, op-im-s-em: output-implicit-style-empathetic, op-ex-m-u: output-explicit-modality-unimodal, op-ex-m-m: output-explicit-modality-multimodal, op-ex-s-st: output-explicit-structure-short text, op-ex-s-lt: output-explicit-structure-long text, op-ex-s-str: output-explicit-structure-structural.
Dialogue agent applications. Beyond the realm of novel tasks that have been introduced to enhance the capabilities of conversational agents, the scope of dialogue agents has dramatically expanded, encompassing a plethora of emerging domains. A notable illustration of this evolving landscape is evident in the realm of mental health, where recent strides have propelled dialogue agents into a pivotal role (Campillos-Llanos et al. Reference Campillos-Llanos, Thomas, Bilinski, Zweigenbaum and Rosset2020; Srivastava et al. Reference Sun, Wang, Xu, Zheng, Yang, Hu, Xu, Zhang, Geng and Jiang2022, 2023). This dynamic transformation underscores the profound versatility that dialogue agents bring to the table. Yet, the influence of dialogue agents is not confined solely to mental health; they have also forged an impactful presence in diverse domains such as education (Baker et al. Reference Baker, Mills, McDonald and Wang2023; Wang et al. Reference Wang, Kang, AbuHussein and Collen2023a), storytelling (Sun et al. Reference Sun, Ni, Feng, Ray, Lee and Asadipour2022a; Gao et al. Reference Gao, Borges, Oh, Bayazit, Kanno, Wakaki, Mitsufuji and Bosselut2023), language acquisition (Bear and Chen Reference Bear and Chen2023; Ericsson, Hashemi, and Lundin Reference Ericsson, Hashemi and Lundin2023), and companionship (Shikha et al. Reference Shikha, Naidu, Choudhury and Kayarvizhy2022; Leo-Liu Reference Leo-Liu2023).
Dataset attributes. Within the scope of this comprehensive survey, our efforts revolve around acquiring the prominent tasks along with their open-source datasets. Notably, these datasets exhibit a certain lack of uniformity in capturing the full spectrum of attributes inherent to a robust dialogue agent (c.f. Table 1). This phenomenon is illustrated in Fig. 6, which highlights the dataset distribution within unit shedding light on the prevalence of specific dialogue attributes. Upon observing this distribution, a discernible pattern emerges, highlighting the nascent stage of multimodality integration within mainstream dialogue tasks. An active focus toward bringing multimodality to the dialogue domain can profoundly influence the capabilities of dialogue agents. Another interesting trend that can be observed from Fig. 6 is the predominance of multiturn datasets and long textual outputs. While this emerging trend serves to highlight the present direction in the design of dialogue datasets, a judicious examination of the existing distribution underscores a compelling necessity: the need to curate a more diverse range of dialogue datasets. These datasets should encompass structured knowledge or facilitate the generation of responses imbued with empathy. The meticulous expansion in this curated direction would undeniably enhance the landscape of training and application for dialogue agents.
8. Conclusions and future research
This survey outlined the essential traits that a dialogue agent should possess through a comprehensive taxonomy. Major dialogue-specific tasks and their respective open-domain datasets and techniques were provided to enable the integration of these traits. To enhance efficiency and task correlation, a unified dataset of extracted conversations was proposed. We evaluated the results of experiments conducted using established foundational models and presented a concise evaluation. Although the unit pretrained model outperforms existing models, there are still many challenges that need to be addressed. Furthermore, recent advancements such as LaMDA (Thoppilan et al. Reference Thoppilan, De Freitas, Hall, Shazeer, Kulshreshtha, Cheng, Jin, Bos, Baker, Du, Li, Lee, Zheng, Ghafouri, Menegali, Huang, Krikun, Lepikhin, Qin and Le2022), ChatGPT,Footnote j Sparrow (Glaese et al. Reference Glaese, McAleese, Trȩbacz, Aslanides, Firoiu, Ewalds, Rauh, Weidinger, Chadwick, Thacker, Campbell-Gillingham, Uesato, Huang, Comanescu, Yang, See, Dathathri, Greig, Chen and Irving2022), Baize (Xu et al. Reference Xu, Guo, Duan and McAuley2023), and LLaMA (Touvron et al. Reference Touvron, Lavril, Izacard, Martinet, Lachaux, Lacroix, Rozière, Goyal, Hambro, Azhar, Rodriguez, Joulin, Grave and Lample2023) are efforts toward building foundation models capable of performing multiple tasks. While models like ChatGPT are a breakthrough in NLP, the research in conversational AI is far from complete with following key challenges. We dwell on the remaining challenges in NLP that need attention for further research.
Hallucincations, Veracity, and Correctness. Large language model-based systems are notorious for hallucinations and producing incorrect output. Further, the paradigm of RLHF (Christiano et al. Reference Christiano, Leike, Brown, Martic, Legg and Amodei2017; Stiennon et al. Reference Stiennon, Ouyang, Wu, Ziegler, Lowe, Voss, Radford, Amodei and Christiano2020) that has led to greater accuracy of models like ChatGPT also leads to verbose and ambiguous responses as agents prefer lengthy and loquacious responses. To improve the performance of goal-oriented dialogues, future research should prioritize the development of methods that reduce hallucination and produce accurate, concise responses.
Ability for Logical Reasoning. Popular models often struggle to answer queries that involve spatial, temporal, physical, or psychological reasoning (Borji Reference Borji2023). For example, if we ask ChatGPT a question such as “The trophy didn’t fit in the suitcase; it was too small. What was too small?” (Levesque, Davis, and Morgenstern Reference Levesque, Davis and Morgenstern2012), it may erroneously identify the trophy as being too small. However, reasoning capabilities such as these are essential for dialogue agents to fulfill user requests effectively.
Affect understanding. Failure to interpret emotions, humor and sarcasm nuances (Kocoń et al., Reference Kocoń, Cichecki, Kaszyca, Kochanek, Szydło, Baran, Bielaniewicz, Gruza, Janz, Kanclerz, Kocoń, Koptyra, Mieleszczenko-Kowszewicz, Miłkowski, Oleksy, Piasecki, Radliński, Wojtasik, Woźniak and Kazienko2023) can lead to inadequate responses in chit-chat conversations is a need for further investigation into the development of models that can better handle these linguistic features.
Bias. LLMs learn from vast datasets, making them susceptible to biases (Luo, Puett, and Smith Reference Luo, Puett and Smith2023). For instance, if the model is asked to complete “The Latino man worked as a…” prompt, it may suggest professions like construction worker or nurse. Yet, when prompted with “The Caucasian man worked as a…," the model suggests a software developer or doctor.
Other challenges. Significant challenges, such as the inability of models to trace the source of generated responses (attribution), demand for extensive computing resources that damage the environment,Footnote k NLP research being proprietary and focused on the English language. These challenges need consideration in future NLP research.
Ethical considerations. The deployment of dialogue agents, powered by advanced artificial intelligence and natural language processing, raises significant ethical concerns in various domains (Artstein and Silver Reference Artstein and Silver2016; Henderson et al. Reference Henderson, Sinha, Angelard-Gontier, Ke, Fried, Lowe and Pineau2018). One major ethical issue is the potential for biased behavior, where dialogue agents may inadvertently perpetuate or amplify existing societal biases present in their training data (Lucas et al. Reference Lucas, Boberg, Traum, Artstein, Gratch, Gainer, Johnson, Leuski and Nakano2018). Transparency and accountability are also critical concerns, as users often lack visibility into the decision-making processes of these systems (Hepenstal et al. Reference Hepenstal, Kodagoda, Zhang, Paudyal and Wong2019). Additionally, issues related to user privacy and data security emerge, as dialogue agents may handle sensitive information during interactions (Srivastava et al. Reference Srivastava, Suresh, Lord, Akhtar and Chakraborty2022). Striking the right balance between personalization and intrusion poses another ethical dilemma (Zhang et al. Reference Zhang, Dinan, Urbanek, Szlam, Kiela and Weston2018). Ensuring that dialogue agents respect cultural sensitivities and adhere to ethical standards in content generation is essential for fostering positive and responsible interactions. Ethical considerations surrounding the responsible development, deployment, and monitoring of dialogue agents are vital to build trust and safeguard users from potential harm in the evolving landscape of conversational AI.
Competing interests
Shivani Kumar is pursuing her PhD at Indraprastha Institute of Information Technology Delhi. Sumit Bhatia and Milan Aggarwal are employed at Adobe. Tanmoy Chakraborty is employed at Indian Institute of Technology Delhi.

















 Open access
Open access