


1. Introduction
Processing of figurative languages has been one of the most challenging tasks in Natural Language Processing (NLP). Among the different types of figurative meanings, metaphor and irony have been studied extensively in NLP. The processing of metaphor and irony has been shown to make significant contributions to tasks such as semantic parsing, sentiment and emotion analysis, stance detection, etc. (Weitzel, Prati, and Aguiar Reference Weitzel, Prati and Aguiar2016; Hercig and Lenc Reference Hercig and Lenc2017; Zhang et al. Reference Zhang, Zhang, Chan and Rosso2019; Su, Wu, and Chen Reference Su, Wu and Chen2021). However, linguistic synesthesia, as one of the most productive and frequently used figurative languages, has not received much attention in computational linguistics so far.
Linguistic synesthesia is the use of words and expressions from one sensory modality to describe concepts in a different sensory modality (Ullmann Reference Ullmann1957; Williams Reference Williams1976; Shen Reference Shen1997). Examples below illustrate the usages of linguistic synesthesia in English, Mandarin, and Turkish respectively.
-
Analogue recordings sound[HEARING/target] warmer[TOUCH/source] than digital. (Strik Lievers Reference Strik Lievers2015, see p. 79)
-
 ye4se4
nong2[TASTE/source]
lv4[VISION/target]
ye4se4
nong2[TASTE/source]
lv4[VISION/target]leaf-color of intense taste green
“The color of leaves is deep green.”
(Zhao, Huang, and Long Reference Zhao, Huang and Long2018, see pp. 1178-1179)
-
yagmur-un ıslak[TOUCH/source] koku-su[SMELL/target]
rain-GEN wet scent-POSS[3SG]
“the wet smell of rain”
(Kumcu Reference Kumcu2021), see p. 247)
In the field of linguistics, Williams (Reference Williams1976) proposed a hierarchical model for linguistic synesthesia in English, as shown in Figure 1. However, Zhao et al. (Reference Zhao, Huang and Ahrens2019) found three types of directionalities of linguistic synesthesia in Mandarin Chinese, including the unidirectional, bidirectional, and biased-directional transfers between the senses, as demonstrated in Figure 2. With respect to the neuro-cognitive characteristics of linguistic synesthesia, most linguistic studies on linguistic synesthesia considered it a type of metaphor (Shen Reference Shen1997; Shen and Cohen Reference Shen and Cohen1998; Yu Reference Yu2003; Popova Reference Popova2005; Shen and Gil Reference Shen and Gil2008; Strik Lievers Reference Strik Lievers2017). However, Cacciari (Reference Cacciari2008) and Ramachandran and Hubbard (Reference Ramachandran and Hubbard2001) highlighted the neuro-biological nature of linguistic synesthesia, where linguistic synesthesia was argued to pattern with neurological synesthesia constrained by “strong anatomical constraints” (Ramachandran and Hubbard Reference Ramachandran and Hubbard2001, see p. 18).Footnote a More recently, Zhao et al. (Reference Zhao, Ahrens and Huang2022) have clarified linguistic synesthesia as a type of conceptual metaphor, where lexicalized concepts of sensory properties are involved, rather than the real-time sensory input that is processed as in neurological synesthesia. Thus, similar to metaphor, linguistic synesthesia is also one of the important vehicles, through which we can further our understanding of semantics and cognition.

Figure 1. A hierarchical model for linguistic synesthesia (Williams Reference Williams1976, see p. 463).

Figure 2. Transfer directionalities of linguistic synesthesia based on Mandarin corpus data (Zhao et al. Reference Zhao, Huang and Ahrens2019, see p. 9).
However, compared to the studies on metaphor detection which have received notable results (Turney et al. Reference Turney, Neuman, Assaf and Cohen2011; Bulat, Clark, and Shutova Reference Bulat, Clark and Shutova2017; Su, Wu, and Chen Reference Su, Wu and Chen2021), very limited research has yet been devoted to automatic linguistic synesthesia detection. Although linguistic synesthesia is similar to metaphor with conceptual mappings, linguistic synesthesia detection cannot directly apply the metaphor detection methods without significant modifications. That is, linguistic synesthesia involves conceptual mappings from one concrete sensory domain to another concrete sensory domain, while metaphor generally exhibits conceptual mappings from concrete domains to abstract domains (Zhao et al. Reference Zhao, Ahrens and Huang2022). Thus, there is a research gap in the computational analysis of linguistic synesthesia, where the task of automatic synesthesia detection has been given little attention in NLP. Jiang et al. (Reference Jiang, Zhao, Long and Wang2022)’s study is the only exception, which aimed to detect linguistic synesthesia automatically in Mandarin Chinese through a radical-based neural model. However, the study is only a pilot study, in which only radical information was incorporated. In other words, the model proposed by Jiang et al. (Reference Jiang, Zhao, Long and Wang2022) is language and writing system-dependent, which cannot be easily applied to other languages. Thus, this study proposes a neural network that leverages culturally enriched linguistic information including word segmentation and part-of-speech (POS) features, which can be generalized to other languages. Specifically, two kinds of linguistic features are utilized: the sub-lexical-level features including characters in the original text and the main semantic symbols of the characters (i.e., radicals), and the word-level features including segmented word sequences and their corresponding POS tags. Based on the extensive linguistic studies on linguistic synesthesia (Strik Lievers Reference Strik Lievers2015; Winter Reference Winter2019a; Zhao Reference Zhao2020), content words such as adjectives, verbs, nouns, and adverbs are frequently involved in linguistic synesthetic usages. In Chinese synesthesia particularly, the radical information in Chinese characters could provide important clues for determining the sensory modalities of words (Zhao, Huang, and Long Reference Zhao, Huang and Long2018 Zhao, Huang, and Ahrens Reference Zhao, Huang and Ahrens2019; Zhao, Ahrens, and Huang 2022). Thus, this study presumes that both the character information and the word information would contribute to the neural model for the detection of linguistic synesthesia.
The task of linguistic synesthesia detection conducted by this study would contribute to both computational analyses and linguistic studies of the phenomenon in the following respects. Firstly, linguistic synesthesia involves sensory words and hence crucially reports the physical world as perceived by the speaker, which thus facilitates contextualizing NLP representations in the real world. More specifically, sensory information showing great usefulness in the task of sentiment analysis, has been illustrated in Picard (Reference Picard2000), Xiang et al. (Reference Xiang, Li, Wan, Gu, Lu, Li and Huang2021), and Zolyomi and Snyder (Reference Zolyomi and Snyder2021). Thus, linguistic synesthesia encoding sensory information and showing regular patterns of sensory inputs would also show usefulness in the task of sentiment analysis. For example, Zhong et al. (Reference Zhong, Wan, Ahrens and Huang2022) illustrated that the gustatory perceptions of ![]() la4wei4 “spicy taste” and
la4wei4 “spicy taste” and ![]() ma2 “numbing” were described most frequently in terms of linguistic synesthesia using words related to hurt and irritation, which were generally unpleasant (e.g.,
ma2 “numbing” were described most frequently in terms of linguistic synesthesia using words related to hurt and irritation, which were generally unpleasant (e.g., ![]() shao1zui3 “burning the mouth (unpleasantly spicy)”). Secondly, one promising application of linguistic synesthesia detection is concerned with the clinical pre-diagnosis for neurological synesthesia. That is, studies by Rizzo (Reference Rizzo1989), Cytowic (Reference Cytowic2002), and Turner and Littlemore (Reference Turner and Littlemore2023) showed that people who could experience neurological synesthesia generally employed peculiar linguistic synesthetic descriptions (e.g., “tasting the shape”). Thirdly, most of the existing studies on linguistic synesthesia rely on the extraction of synesthetic data manually or semi-automatically, which are time-consuming (Strik Lievers Reference Strik Lievers2015; Zhao, Huang, and Ahrens Reference Zhao, Huang and Ahrens2019; Kumcu Reference Kumcu2021). The automatic methods to detect linguistic synesthesia in natural language would improve the efficiency of data collection. Last but not least, the computational models for linguistic synesthesia leveraging linguistic features could test the correlations between linguistic features and the patterns of linguistic synesthesia attested by linguistic studies, based on the extent to which a specific linguistic feature can improve the performance of the models.
shao1zui3 “burning the mouth (unpleasantly spicy)”). Secondly, one promising application of linguistic synesthesia detection is concerned with the clinical pre-diagnosis for neurological synesthesia. That is, studies by Rizzo (Reference Rizzo1989), Cytowic (Reference Cytowic2002), and Turner and Littlemore (Reference Turner and Littlemore2023) showed that people who could experience neurological synesthesia generally employed peculiar linguistic synesthetic descriptions (e.g., “tasting the shape”). Thirdly, most of the existing studies on linguistic synesthesia rely on the extraction of synesthetic data manually or semi-automatically, which are time-consuming (Strik Lievers Reference Strik Lievers2015; Zhao, Huang, and Ahrens Reference Zhao, Huang and Ahrens2019; Kumcu Reference Kumcu2021). The automatic methods to detect linguistic synesthesia in natural language would improve the efficiency of data collection. Last but not least, the computational models for linguistic synesthesia leveraging linguistic features could test the correlations between linguistic features and the patterns of linguistic synesthesia attested by linguistic studies, based on the extent to which a specific linguistic feature can improve the performance of the models.
To summarize, this study aims to fill in the gap in automatic linguistic synesthesia detection. The main contributions of our work can be summarized as follows:
-
This study proposes a neural network model that leverages culturally enriched linguistic information for linguistic synesthesia detection. As the word-level linguistic features employed are not language-specific, our model could be generalized for the detection of linguistic synesthesia in other languages.
-
We construct a Chinese synesthesia dataset with rigorous annotations.
-
Comprehensive experiments show that our model outperforms the state-of-the-art baseline models and achieves the best performance on the Chinese synesthesia dataset for the task of Chinese synesthesia detection.
-
In addition to facilitating data collection, our model shows various potential applications, such as in the sentiment analysis, the clinical pre-diagnosis of neurological synesthesia, and linguistic theories about figurative languages.
In what follows, Section 2 reviews the related work on the detection of metaphor and linguistic synesthesia. Following that, a detailed description of the dataset and linguistic features is presented in Section 3. Section 4 and Section 5 focus on the proposed methods and the experiments respectively. Section 6 summarizes the results of this study. After that, the last section presents the limitations of this study and suggests future work.
2. Related work
2.1 Metaphor detection
Studies on the processing of metaphors have developed various models to automatically detect metaphorical expressions in a sentence. These studies can be divided into three categories based on the computational methods utilized: the feature-based approach, the shallow network-based approach, and the contextualized approach.
Regarding the feature-based approach, various linguistic features related to metaphorical expressions have been proposed and incorporated into (mostly) linear classifiers. The features (mainly in English) include word abstractness and concreteness (Turney et al. Reference Turney, Neuman, Assaf and Cohen2011), word imageability (Broadwell et al. Reference Broadwell, Boz, Cases, Strzalkowski, Feldman, Taylor, Shaikh, Liu, Cho and Webb2013), semantic supersenses (Tsvetkov et al. Reference Tsvetkov, Boytsov, Gershman, Nyberg and Dyer2014), and property norms (Bulat, Clark, and Shutova Reference Bulat, Clark and Shutova2017). In Mandarin Chinese, radical information and sensory information were also employed (Chen et al. Reference Chen, Long, Lu and Huang2017, Wan et al. Reference Wan, Ahrens, Chersoni, Jiang, Su, Xiang and Huang2020). However, designing features based on human knowledge is expensive, and low-frequency metaphorical features are often neglected.
With the development of neural networks, several studies proposed neural metaphor detection models using recurrent neural networks (RNNs) or convolutional neural networks (CNNs). For instance, Wu et al. (Reference Wu, Wu, Chen, Wu, Yuan and Huang2018) combined CNN and LSTM layers to utilize local and long-range contextual information to identify metaphorical details. In addition to the POS and word clustering information, Wu et al. (Reference Wu, Wu, Chen, Wu, Yuan and Huang2018) also employed text information as linguistic features. Gao et al. (Reference Gao, Choi, Choi and Zettlemoyer2018) showed that relatively standard BiLSTM models that operated on complete sentences worked well in the task of metaphor detection by formulating the task as sequence labeling or classification. These models outperform linear classification models by a significant margin and also avoid most of the feature annotation processes.
With respect to the contextualized approach, the contextualized language modeling coupled with a transformer network can encode semantic and contextual information. It can thus detect metaphors with fine-tuning training like other tasks. For instance, Su et al. (Reference Su, Wu and Chen2021) introduced a variety of linguistic features (i.e., global/local text context and POS features) into the field of computational metaphor detection by leveraging powerful pre-training language models (i.e., RoBERTa). Gong et al. (Reference Gong, Gupta, Jain and Bhat2020) applied linguistic information from external resources such as WordNet with a similar RoBERTa network. Choi et al. (Reference Choi, Lee, Choi, Park, Lee, Lee and Lee2021) proposed a metaphor-aware late interaction over the BERT (MelBERT) model, which leveraged the contextualized word representation and relevant linguistic metaphor identification theories to detect whether the target word is metaphorical.
To summarize, the different approaches for metaphor detection vary in their computational models. However, linguistic features are generally incorporated into the models, which show great contributions to the improvements of the performances of the models on the detection tasks.
2.2 Linguistic synesthesia detection
Different from extensive work on metaphor detection, there have been only several studies reported to focus on the detection of linguistic synesthesia in natural language. These studies can be classified into two categories: one is to employ semi-automatic methods, and the other is to utilize automatic methods based on neural models. Strik Lievers et al. (Reference Strik Lievers, Xu and Xu2013) and Strik Lievers and Huang (Reference Strik Lievers and Huang2016) proposed a semi-automatic approach to extract synesthetic expressions in English and Italian. The approach needed a lot of manual strategies, such as compiling a list of perception-related lexical items and manually selecting sentences that contained linguistic synesthesia. Following a similar method to Strik Lievers et al. (Reference Strik Lievers, Xu and Xu2013), Liu et al. (Reference Liu, Lievers and Huang2015) extracted linguistic synesthetic sentences for Mandarin Chinese. These semi-automatic approaches are expensive and time-consuming.
With respect to detecting linguistic synesthesia via neural networks, a recent work by Jiang et al. (Reference Jiang, Zhao, Long and Wang2022) is the first to propose the task of Chinese synesthesia detection. The study provided a family of baseline models for linguistic synesthesia detection. In addition, a radical-based neural model was proposed for linguistic synesthesia detection. However, there have been notable limitations of the work by Jiang et al. (Reference Jiang, Zhao, Long and Wang2022) in the linguistic feature selection, the data annotation, and the experiment design. From the feature engineering perspective, the study only incorporated the radical information of Chinese characters as the linguistic feature into the model. Thus, Jiang et al. (Reference Jiang, Zhao, Long and Wang2022)’s model is language and writing system-dependent and cannot be easily generalized to other languages. In addition, the orthographic information of the radical components in Chinese orthography was not utilized appropriately by Jiang et al. (Reference Jiang, Zhao, Long and Wang2022). That is, Jiang et al. (Reference Jiang, Zhao, Long and Wang2022) relied on the Xinhua dictionary which was designed for simplified Chinese characters to detect radical information, while the dataset utilized by the study contained linguistic expressions in traditional Chinese characters. In terms of the annotation process of linguistic synesthetic data by Jiang et al. (Reference Jiang, Zhao, Long and Wang2022), the annotators were not given rigorous training on how to decide linguistic synesthetic usages before the annotation, except being provided with written instructions. With respect to the experiment process, Jiang et al. (Reference Jiang, Zhao, Long and Wang2022) used the golden label of sensory word extraction as the input of sensory modality detection. However, a boundary detection model is generally used first to detect the sensory word boundary.
This study leverages culturally enriched linguistic features for the automatic detection of linguistic synesthesia. Specifically, apart from the radical information, the word segmentation and POS features are incorporated, to ensure that the proposed model could be applied to other languages. In addition, a more compatible and conventionalized conceptual orthographic system for Chinese traditional characters (i.e., HantologyFootnote b ) is utilized to detect radicals.Footnote c Furthermore, a linguist is invited to give a detailed introduction to linguistic synesthesia, to ensure that annotators have sufficient knowledge about the phenomenon before annotation. Last but not least, this study refines the experiment setting by adopting a boundary detection model for word identification (Huang et al. Reference Huang, Šimon, Hsieh and Prévot2007) rather than employing the golden labels (i.e., the sensory words annotated in the dataset) for linguistic synesthesia detection.
3. Dataset and linguistic features
3.1 Dataset
This study followed a linguistic synesthesia identification procedure proposed by Zhao (Reference Zhao2020) to construct the dataset, which is adapted as Figure 3. Although no consensus has been reached regarding the classification of human senses (Miller and Johnson-Laird Reference Miller and Johnson-Laird1976; Purves et al. Reference Purves, Augustine, Fitzpatrick, Katz, LaMantia, McNamara and Williams2001), the Aristotelian five senses (i.e., touch, taste, vision, hearing, and smell) have generally been utilized to analyze linguistic synesthesia (Strik Lievers Reference Strik Lievers2015; Zhao, Huang, and Long Reference Zhao, Huang and Long2018; Winter Reference Winter2019a; Winter Reference Winter2019b; Kumcu Reference Kumcu2021). Based on the five sensory modalities, 664 sensory words were extracted automatically from two Chinese lexical thesauri, including HIT-CIR Tongyici Cilin (Extended) (Che, Li, and Liu Reference Che, Li and Liu2010) and HowNet (Dong and Dong Reference Dong and Dong2003). In order to identify the original sensory domain of each of the 664 sensory words, the etymological origins, the earlier usages in Classic Chinese, the orthographic compositions of characters, and the comparison analyses were employed collectively. The step was conducted by a Chinese linguist. For example, the sensory adjective ![]() nong2 has two different orthographic writings in Classic Chinese: one is
nong2 has two different orthographic writings in Classic Chinese: one is ![]() with the radical denoting wine, which was used to describe the strong taste of wine; and the other is
with the radical denoting wine, which was used to describe the strong taste of wine; and the other is ![]() with the radical denoting water, which was used to describe the visual sensation of dense dew (Xu Reference Xu156; Duan Reference Duan1815). Thus, it is not easy to decide which sensory modality (i.e., taste or vision) is the original domain for the adjective
with the radical denoting water, which was used to describe the visual sensation of dense dew (Xu Reference Xu156; Duan Reference Duan1815). Thus, it is not easy to decide which sensory modality (i.e., taste or vision) is the original domain for the adjective ![]() nong2. However, the adjective
nong2. However, the adjective ![]() nong2 was used most frequently to show a comparison with the adjective
nong2 was used most frequently to show a comparison with the adjective ![]() dan4 in Classic Chinese, whose original meaning was paraphrased as “mild taste” in Chinese dictionaries (Xu Reference Xu156; Duan Reference Duan1815). Thus, the comparison analysis demonstrated that taste was the most likely to be the original sensory domain of the adjective
dan4 in Classic Chinese, whose original meaning was paraphrased as “mild taste” in Chinese dictionaries (Xu Reference Xu156; Duan Reference Duan1815). Thus, the comparison analysis demonstrated that taste was the most likely to be the original sensory domain of the adjective ![]() nong2 as well.
nong2 as well.
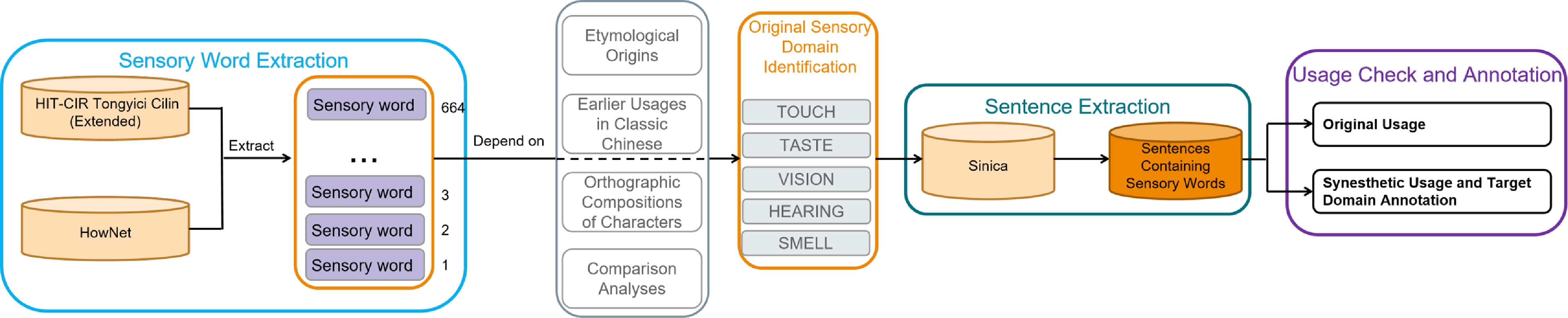
Figure 3. The procedure for dataset acquisition.
After determining the original sensory domain of the sensory words, the sentences containing the words were extracted from the Sinica corpus (Chen et al. Reference Chen, Huang, Chang and Hsu1996).Footnote
d
Three undergraduate students were trained to decide whether the usages of the sensory words were synesthetic before the annotation. Then, we asked the three annotators to manually check whether the usages of the sensory words belonged to the original sensory domains of the words: if yes, the usages were marked as original usages; if not and the usages still described sensory perceptions, the usages were marked as synesthetic usages. For the synesthetic usages, the target domains of the sensory words were also annotated. Figure 4 shows an example of annotation for linguistic synesthesia in Mandarin Chinese. Specifically, the sensory adjective ![]() bing1leng3 “cold” has its original sensory modality as touch. However, the adjective was used to describe hearing in the expression
bing1leng3 “cold” has its original sensory modality as touch. However, the adjective was used to describe hearing in the expression ![]() yi1ge4 bing1leng3 fen4nu4 de sheng1yin1 “a cold and angry voice”. Thus, the sensory word
yi1ge4 bing1leng3 fen4nu4 de sheng1yin1 “a cold and angry voice”. Thus, the sensory word ![]() bing1leng3 “cold” was marked with the linguistic synesthetic usage, and its original and target modalities were annotated as touch and hearing respectively.
bing1leng3 “cold” was marked with the linguistic synesthetic usage, and its original and target modalities were annotated as touch and hearing respectively.
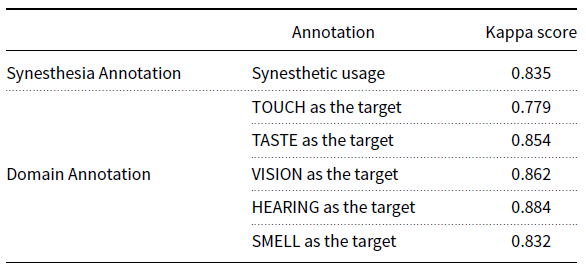
Through the annotation process, 187 sensory adjectives with both original and synesthetic usages were identified, where 7,217 synesthetic sentences were annotated. Table 1 demonstrates the inter-annotator agreements measured by the kappa scores (Fleiss Reference Fleiss1971). Our annotation has reached kappa scores of 0.779 to 0.884, which are all higher than that by Jiang et al. (Reference Jiang, Zhao, Long and Wang2022) (i.e., 0.757).
Table 1. Inter-annotator agreements for annotation of linguistic synesthesia
As original usages are generally more frequent than synesthetic usages for Mandarin sensory adjectives (Zhao, Ahrens, and Huang Reference Zhao, Ahrens and Huang2022), 7,217 original usages were randomly extracted for the 187 sensory adjectives, in accordance with the distribution of the five sensory modalities in the collected linguistic synesthetic data. Thus, both synesthetic sub-dataset and original sub-dataset were constructed, with the data distribution demonstrated in Table 2.Footnote e
Table 2. Data distribution of the five sensory modalities in synesthetic and original sub-datasets
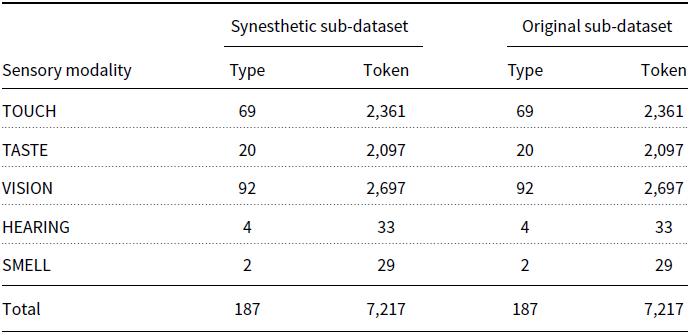
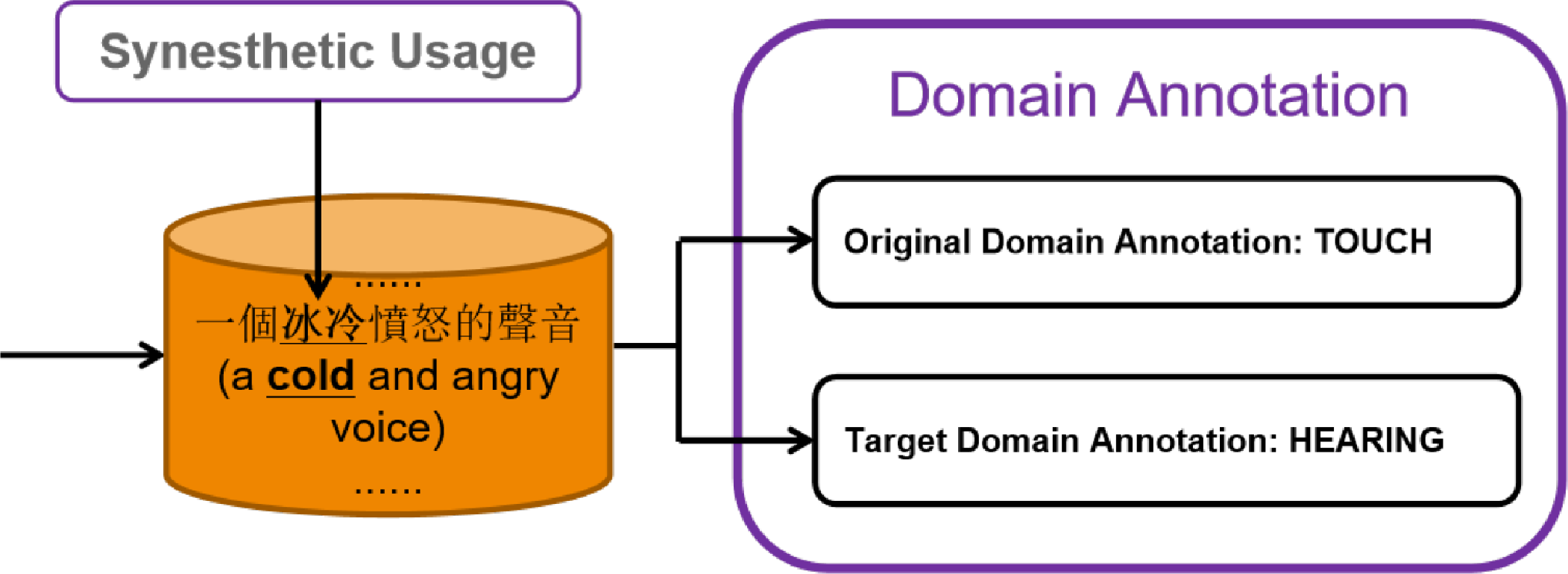
Figure 4. An example of annotation of linguistic synesthesia in Chinese.
3.2 Linguistic features
Linguistic features show significant usefulness in improving the performance of computational models for automatic metaphor detection, as reviewed above. This current study incorporates linguistic features including character information, word segmentation, and POS features into the neural network model to detect linguistic synesthesia automatically in Mandarin Chinese.
Character features. Although the character is generally regarded as an orthographic unit, it can also act as an important syntactic and semantic unit in Chinese (Xu Reference Xu2005; Ye Reference Ye2015). With respect to the NLP tasks, Chen et al. (Reference Chen, Long, Lu and Huang2017, 2019), Hou et al. (Reference Hou, Huang and Liu2019), and Chen et al. (Reference Chen, Long, Lu and Huang2021) improved the performances of the computational models by introducing the Chinese character as an independent linguistic feature on metaphor detection, register classification, and emotion classification respectively. The character is also an important linguistic feature for linguistic synesthesia detection, whose radical component provides a conventionalized clue for detecting the original sensory domain of the lexical item represented by the character. Woon and Yun (Reference Woon and Yun1987) found that over 80 percent of Chinese characters were phono-semantic compounds, where a semantic component (mostly a radical) indicated a broad category of the meaning of the character. For instance, the radical of ![]() leng3 “cold” means ice, which indicates touch as the original domain for the adjective. Similarly, the radical of
leng3 “cold” means ice, which indicates touch as the original domain for the adjective. Similarly, the radical of ![]() tian2 “sweet” is
tian2 “sweet” is ![]() denoting the tongue, through which humans experience gustatory perceptions. Thus, the original sensory domain of
denoting the tongue, through which humans experience gustatory perceptions. Thus, the original sensory domain of ![]() tian2 “sweet” is taste. In addition, there are abundant sensory words with synesthetic usages in Mandarin, which only contain one single character. Examples are such as
tian2 “sweet” is taste. In addition, there are abundant sensory words with synesthetic usages in Mandarin, which only contain one single character. Examples are such as ![]() leng3 “cold” in
leng3 “cold” in ![]() leng3 xiang1 “cold fragrance” and
leng3 xiang1 “cold fragrance” and![]() tian2 “sweet” in
tian2 “sweet” in ![]() tian2 bai2 “sweet white”.
tian2 bai2 “sweet white”.
Word segmentation features. Compounding is a productive morphological device for word formation in Mandarin Chinese (Chao Reference Chao1968; Huang and Shi Reference Huang and Shi2016). Mandarin compound adjectives can also be involved in linguistic synesthesia (Zhao Reference Zhao2020; Zhao, Ahrens, and Huang Reference Zhao, Ahrens and Huang2022). For instance, the monosyllabic visual word ![]() da4 “big” can be duplicated as one single word
da4 “big” can be duplicated as one single word ![]() da4da4 “big” to describe hearing as in
da4da4 “big” to describe hearing as in ![]() da4da4 de sheng1yin1 “a big sound”. Besides, two different monosyllabic words can be combined as a compound word used for linguistic synesthesia. For instance, the monosyllabic word
da4da4 de sheng1yin1 “a big sound”. Besides, two different monosyllabic words can be combined as a compound word used for linguistic synesthesia. For instance, the monosyllabic word ![]() tian2 “sweet” and the monosyllabic word
tian2 “sweet” and the monosyllabic word ![]() mei3 “tasty” can be compounded as a single word
mei3 “tasty” can be compounded as a single word ![]() tian2mei3 “tasty”. The compound word
tian2mei3 “tasty”. The compound word ![]() tian2mei3 “tasty” with taste as its original domain, can be used in linguistic synesthesia for vision, as in
tian2mei3 “tasty” with taste as its original domain, can be used in linguistic synesthesia for vision, as in ![]()
![]() tian2mei3 de zhang3xiang4 “a sweet appearance”. As one sub-task of this study is to detect sensory words with linguistic synesthetic usages, the word segmentation information would be of great usefulness to detect the boundary of the sensory words.
tian2mei3 de zhang3xiang4 “a sweet appearance”. As one sub-task of this study is to detect sensory words with linguistic synesthetic usages, the word segmentation information would be of great usefulness to detect the boundary of the sensory words.
POS features. Linguistic synesthesia was found to show certain patterns on syntactic structures (Strik Lievers Reference Strik Lievers2015; Zhao, Ahrens, and Huang Reference Zhao, Ahrens and Huang2022). For instance, typical synesthetic expressions in English and Italian are composed of a sensory adjective acting as the source and a noun as the target (Strik Lievers Reference Strik Lievers2015). Linguistic synesthetic expressions in Mandarin frequently exhibit the syntactic combinations of “adjective + noun” (e.g., ![]() xuan1nao4 de se4cai3 “a loud color”), “adverb + verb” (e.g.,
xuan1nao4 de se4cai3 “a loud color”), “adverb + verb” (e.g., ![]() zhong4zhong4 de shuo1 “saying in a heavy voice”), and “verb + noun” (e.g.,
zhong4zhong4 de shuo1 “saying in a heavy voice”), and “verb + noun” (e.g., ![]() wen2 dao4 hua1xiang1 “to smell the fragrance of flowers”) (Zhao Reference Zhao2020). On the contrary, function words (e.g., pronoun, preposition, conjunction, interjection, etc.) have not yet been reported to show linguistic synesthetic usages. Thus, the POS information would contribute to the computational models for linguistic synesthesia detection.
wen2 dao4 hua1xiang1 “to smell the fragrance of flowers”) (Zhao Reference Zhao2020). On the contrary, function words (e.g., pronoun, preposition, conjunction, interjection, etc.) have not yet been reported to show linguistic synesthetic usages. Thus, the POS information would contribute to the computational models for linguistic synesthesia detection.
4. Proposed methods
There are mainly three challenges in the automatic detection of linguistic synesthesia. Firstly, the target modality of one sensory word may vary in its different contexts. For instance, the tactile adjective ![]() jian1rui4 “sharp” has its target modality as vision when used for
jian1rui4 “sharp” has its target modality as vision when used for ![]() di4xing2 “terrain” while as hearing in the context of the description of
di4xing2 “terrain” while as hearing in the context of the description of ![]() sheng1yin1 “sound”. Hence, it is necessary to capture both the sensory expressions of the sensory word and its contexts. Secondly, one sensory word may not contain a single character, as Mandarin compounds can also be used for linguistic synesthesia (see Section 3.2). Thus, it is necessary to detect the boundary of the sensory word. Thirdly, there is an association between original and synesthetic sensory modalities. For instance, taste is significantly correlated with smell, and vision is significantly associated with hearing in Mandarin synesthesia (Zhao Reference Zhao2020). It therefore makes modeling the interaction between sensory modalities necessary.
sheng1yin1 “sound”. Hence, it is necessary to capture both the sensory expressions of the sensory word and its contexts. Secondly, one sensory word may not contain a single character, as Mandarin compounds can also be used for linguistic synesthesia (see Section 3.2). Thus, it is necessary to detect the boundary of the sensory word. Thirdly, there is an association between original and synesthetic sensory modalities. For instance, taste is significantly correlated with smell, and vision is significantly associated with hearing in Mandarin synesthesia (Zhao Reference Zhao2020). It therefore makes modeling the interaction between sensory modalities necessary.
This study proposes a multi-linguistic feature-based end-to-end neural model to address the three challenges, with the overall architecture of the methods shown in Figure 5. Specifically, the linguistic features include both sub-lexical and word-level features. The sub-lexical-level feature includes characters in the original text and the main semantic symbols of the characters (i.e., radicals) obtained from an external knowledge base (i.e., Hantology). The word-level information includes segmented word sequences and their corresponding POS tags, which can be obtained directly from the Sinica corpus or by using the existing Chinese word segmentation/POS tagging system like Jieba tokenizerFootnote f or Stanford CoreNLP.Footnote g For modeling the sensory word extraction and linguistic synesthesia detection simultaneously, our model includes the following three steps:
-
Text representation: building multi-linguistic features based on the text representation and using different features to capture the relationship between sensory words and their contexts.
-
Sensory word extraction via boundary detection: extracting sensory words based on a span-based boundary detection model.
-
Joint sensory modality detection: predicting the original sensory modality of the sensory words and classifying the actual sensory modality (i.e., the synesthetic sensory modality) in the text collectively, based on the sensory words extracted in the previous steps and their contexts.
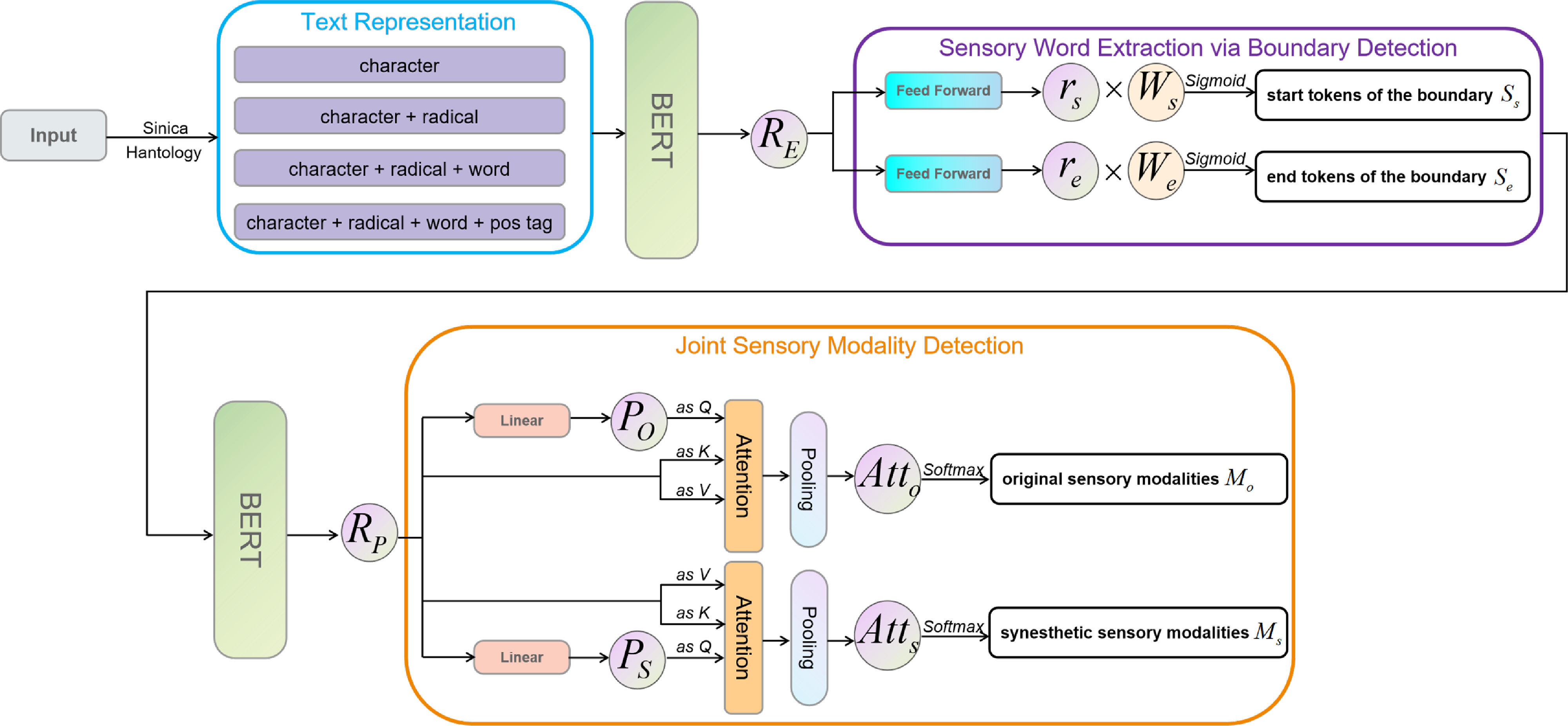
Figure 5. The architecture of our proposed methods.
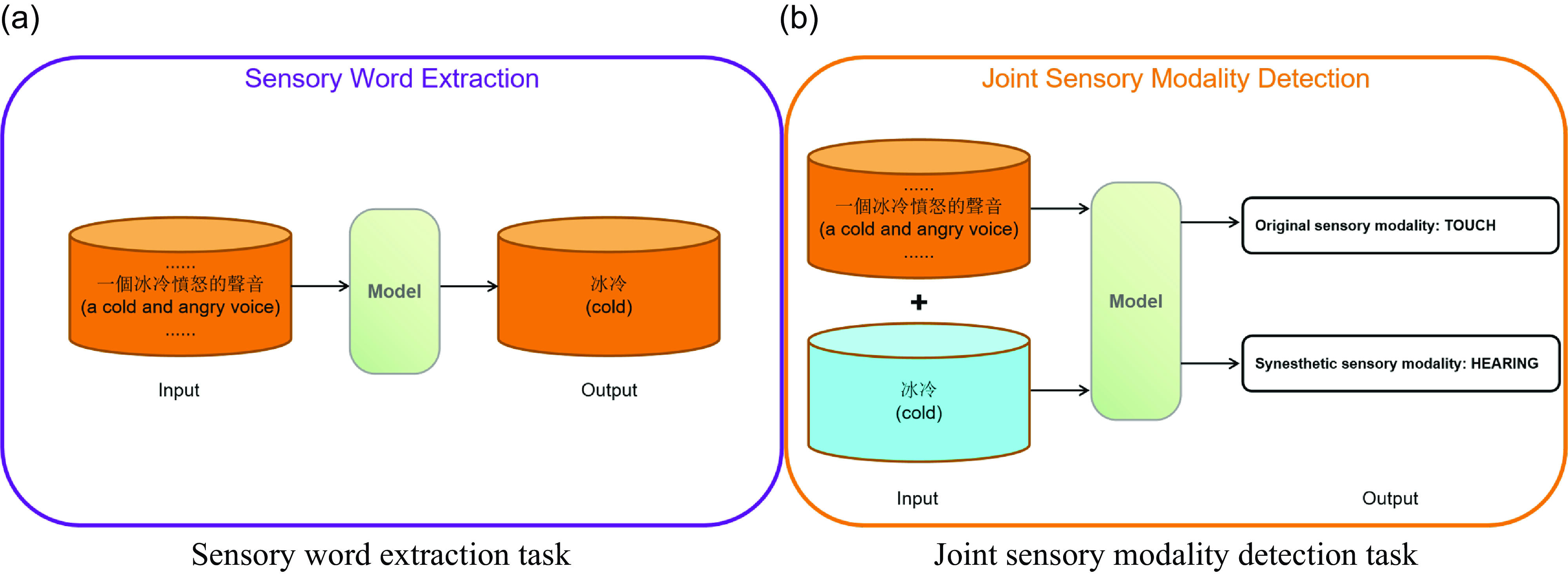
Figure 6. An example for two sub-tasks: sensory word extraction and joint sensory modality detection.
4.1 Task definition
Given a raw text of Chinese characters
 $C = \{c_1, c_2,\ldots, c_n\}$
, the desired output contains the sensory word and its related sensory modalities from both the original and target domains. Thus, the linguistic synesthesia detection task is divided into a two-part model with two sub-tasks: sensory word extraction and joint sensory modality detection (see Figure 5)
$C = \{c_1, c_2,\ldots, c_n\}$
, the desired output contains the sensory word and its related sensory modalities from both the original and target domains. Thus, the linguistic synesthesia detection task is divided into a two-part model with two sub-tasks: sensory word extraction and joint sensory modality detection (see Figure 5)
-
Sensory word extraction: its goal is to extract the sensory word in the given raw text, modeled as the sequence labeling task. As shown in the annotated example in Figure 6(a), the input of this sub-task is the raw Chinese sequence
$C$
, and the output of this sub-task is the sensory word
bing1leng3 “cold,” since the word is used in linguistic synesthesia for hearing rather than touch in the given text. -
Joint sensory modality detection: its goal is to predict the original and synesthetic sensory modalities of the previously extracted sensory word, modeled as the text classification task. As shown in the annotated example in Figure 6(b), the input consists of the raw Chinese sequence
$C$
and the extracted sensory word from the previous sub-task, and the output is the original sensory modality as touch and the synesthetic sensory modality as hearing for the word
bing1leng3 “cold.”


4.2 Text representation
In the process of building the text representation, the model uses four different text representation methods for the original text, namely “character”, “character + radical”, “character + radical + word”, and “character + radical + word + pos tag”. Among them, the radical is the part of the Chinese character that specifies the meaning category. For example, the main radical of the Chinese character ![]() chi1 “eat” is
chi1 “eat” is ![]() “mouth”. Therefore, we integrate radicals into the text representation. In addition, the word segmentation and the POS information used in this model are based on the original annotations in the Sinica corpus. Formally, given a Chinese raw text
“mouth”. Therefore, we integrate radicals into the text representation. In addition, the word segmentation and the POS information used in this model are based on the original annotations in the Sinica corpus. Formally, given a Chinese raw text
 $C$
, it contains
$C$
, it contains
 $n$
characters, i.e.,
$n$
characters, i.e.,
 $C = \{c_1, c_2, \ldots, c_n\}$
, where each character
$C = \{c_1, c_2, \ldots, c_n\}$
, where each character
 $c_i$
is an independent item. Then, the characters are mapped into the radicals respectively by looking up Hantology, i.e.,
$c_i$
is an independent item. Then, the characters are mapped into the radicals respectively by looking up Hantology, i.e.,
 $H = \{h_1, h_2, \ldots, h_m\}$
. As to the word segmentation information in the Sinica corpus, we convert the original text
$H = \{h_1, h_2, \ldots, h_m\}$
. As to the word segmentation information in the Sinica corpus, we convert the original text
 $C$
into a word sequence of
$C$
into a word sequence of
 $m$
length as
$m$
length as
 $W = \{w_1, w_2, .., w_m\}$
, and the corresponding POS sequence is
$W = \{w_1, w_2, .., w_m\}$
, and the corresponding POS sequence is
 $P = \{p_1, p_2, \ldots, p_m\}$
.
$P = \{p_1, p_2, \ldots, p_m\}$
.
Our model includes two parts, i.e., the sensory word extraction and the sensory modality detection. However, the explicit information in the sensory modality detection task contains the sensory word
 $e$
obtained from the sensory word extraction task, so the textual representations of the two parts are not the same. We thus utilize BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) to learn the representation
$e$
obtained from the sensory word extraction task, so the textual representations of the two parts are not the same. We thus utilize BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) to learn the representation
 $R_E$
for the sensory word extraction and
$R_E$
for the sensory word extraction and
 $R_P$
for the sensory modality detection, with the details as:
$R_P$
for the sensory modality detection, with the details as:
-
Character is the basic token-level information of the raw input. We use “[SEP]” token to separate the characters
$C$
and the extracted sensory word
$e$
for
$R_P$
to notify BERT that the sensory word has distinct significance when compared to other characters in the
$C$
. The text representations under the “character” feature are formulated as follows:
$R_E = \text{BERT}([CLS] C [SEP]), R_P = \text{BERT}([CLS] C [SEP] e)$
-
Character + Radical consists of token-level characters
$C$
and radical information
$H$
in the input. We use “[SEP]” to separate the characters, radical information, and the extracted sensory word. This approach enables the integration of radical information within the encoded representation, as each character is mapped to its respective radical in a one-to-one manner. The text representations under the “character + radical” feature are formulated as follows:
$R_E =\text{BERT}([CLS] C [SEP] H), R_P=\text{BERT}([CLS] C [SEP] H [SEP] e)$
-
Character + Radical + Word also incorporates word-level segmentation due to the necessity of tokenization in the Chinese language, such as word ambiguity. We also use “[SEP]” to divide different parts of the input. The text representations under the “character + radical + word” feature are formulated as follows:
$R_E =\text{BERT}([CLS] C [SEP] H [SEP] W), R_P=\text{BERT}([CLS] C [SEP] H [SEP] W [SEP] e)$
-
Character + Radical + Word + POS tag also focuses on word-level features, because sensory words are generally used as adjectives or adverbs in linguistic synesthetic usages. Similarly, we use “[SEP]” token to concatenate the different kinds of features in the encoder input. The text representations under the “character + radical + word + pos tag” feature are formulated as follows:
$R_E = \text{BERT}([CLS] C [SEP]H[SEP] W [SEP] P ), R_P = \text{BERT}([CLS] C [SEP]H[SEP] W [SEP] P$
$[SEP] e)$











Note that “[CLS]” and “[SEP]” are more than ad hoc feature-marking tokens initiated in the pre-training procedure of BERT. The token “[CLS]” (classification) is the classification result of the entire sentence, and its hidden vector is influenced by all other words in the sentence. On the other hand, the token “[SEP]” (separation) instantiates the boundary between lexical units in a sentence. Huang et al. (Reference Huang, Šimon, Hsieh and Prévot2007) proposed the boundary detection model for word segmentation, and Li et al. (Reference Li, Zhou and Huang2012) showed that boundary detection was much more efficient and required less training data than word identification. Modeling these two concepts explicitly allows us to fully leverage the contextual information in BERT. By leveraging BERT’s multi-head attention mechanism and pre-trained knowledge, each attention head learns unique patterns and relationships from various parts of the given input. This helps us to create linguistically enriched text representations that capture the deep connections between tokens and linguistic features.
4.3 Sensory word extraction via boundary detection
We then propose a boundary detection model to detect the boundary of sensory words. Therefore, the sensory word extraction is reformulated as the task of identifying the start and end indices of the sensory word (Hu et al. Reference Hu, Peng, Huang, Li and Lv2019; Wang et al. Reference Wang, Gan, Liu, Liu, Gao and Wang2019). Given a sequence
 $R_E$
from the text representation, we apply two separate feed-forward neural networks to create different representations (
$R_E$
from the text representation, we apply two separate feed-forward neural networks to create different representations (
 $r_s/r_e$
) for the start/end of the spans. A sigmoid is introduced to produce the probability of each token being selected as the start/end of the scope:
$r_s/r_e$
) for the start/end of the spans. A sigmoid is introduced to produce the probability of each token being selected as the start/end of the scope:
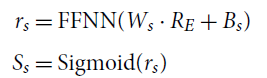 \begin{align} r_s & = \textrm{FFNN}(W_s \cdot R_E + B_s) \nonumber\\[4pt] S_s &= \textrm{Sigmoid}(r_s) \end{align}
\begin{align} r_s & = \textrm{FFNN}(W_s \cdot R_E + B_s) \nonumber\\[4pt] S_s &= \textrm{Sigmoid}(r_s) \end{align}
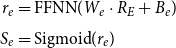 \begin{align} r_e & = \textrm{FFNN}(W_e \cdot R_E + B_e) \nonumber\\[4pt] S_e &= \textrm{Sigmoid}(r_e) \end{align}
\begin{align} r_e & = \textrm{FFNN}(W_e \cdot R_E + B_e) \nonumber\\[4pt] S_e &= \textrm{Sigmoid}(r_e) \end{align}
where
 $W_s$
,
$W_s$
,
 $W_e$
and
$W_e$
and
 $B_s$
,
$B_s$
,
 $B_e$
are weights and biases in the model parameters, and
$B_e$
are weights and biases in the model parameters, and
 $S_s$
and
$S_s$
and
 $S_e$
are the outputs of the sensory word extraction model, which are used to predict the start and end tokens of the boundary of the extracted sensory word.
$S_e$
are the outputs of the sensory word extraction model, which are used to predict the start and end tokens of the boundary of the extracted sensory word.
4.4 Joint sensory modality detection
Given the text representation
 $R_P$
and the sensory word extraction learned from the previous subsection, we propose a joint model to detect the sensory word’s original and synesthetic sensory modalities simultaneously. Specifically, we first feed
$R_P$
and the sensory word extraction learned from the previous subsection, we propose a joint model to detect the sensory word’s original and synesthetic sensory modalities simultaneously. Specifically, we first feed
 $R_P$
into two separate feed-forward neural networks and obtain two representations, i.e.,
$R_P$
into two separate feed-forward neural networks and obtain two representations, i.e.,
 $(r_o/r_a)$
for the original modality and the actual synesthetic modality, respectively:
$(r_o/r_a)$
for the original modality and the actual synesthetic modality, respectively:
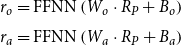 \begin{equation} \begin{aligned} r_o &= \textrm{FFNN}\left(W_o \cdot R_P + B_o\right) \\[4pt] r_a &= \textrm{FFNN}\left(W_a \cdot R_P + B_a\right) \\ \end{aligned} \end{equation}
\begin{equation} \begin{aligned} r_o &= \textrm{FFNN}\left(W_o \cdot R_P + B_o\right) \\[4pt] r_a &= \textrm{FFNN}\left(W_a \cdot R_P + B_a\right) \\ \end{aligned} \end{equation}
where
 $W_o$
,
$W_o$
,
 $W_a$
and
$W_a$
and
 $B_o$
,
$B_o$
,
 $B_a$
are weights and biases in the model parameters. We then employ distinct attention layers to capture the relationship between different sensory modalities and the original texts and leverage attention to enhance the performance of the model by emphasizing key input elements, thereby improving accuracy in our task.
$B_a$
are weights and biases in the model parameters. We then employ distinct attention layers to capture the relationship between different sensory modalities and the original texts and leverage attention to enhance the performance of the model by emphasizing key input elements, thereby improving accuracy in our task.
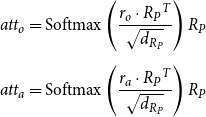 \begin{equation} \begin{aligned} att_o &= \textrm{Softmax}\left (\frac{r_o \cdot{R_P}^T}{\sqrt{d_{R_P}}}\right ) R_P \\[5pt] att_a &= \textrm{Softmax}\left (\frac{r_a \cdot{R_P}^T}{\sqrt{d_{R_P}}}\right ) R_P \end{aligned} \end{equation}
\begin{equation} \begin{aligned} att_o &= \textrm{Softmax}\left (\frac{r_o \cdot{R_P}^T}{\sqrt{d_{R_P}}}\right ) R_P \\[5pt] att_a &= \textrm{Softmax}\left (\frac{r_a \cdot{R_P}^T}{\sqrt{d_{R_P}}}\right ) R_P \end{aligned} \end{equation}
where
 $d_{R_P}$
is the dimension of the representation
$d_{R_P}$
is the dimension of the representation
 $R_P$
. After obtaining the hidden representation (
$R_P$
. After obtaining the hidden representation (
 $att_o$
/
$att_o$
/
 $att_a$
), we use two softmax layers to predict the original and synesthetic sensory modalities as follows:
$att_a$
), we use two softmax layers to predict the original and synesthetic sensory modalities as follows:
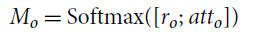 \begin{equation} M_o= \textrm{Softmax}([r_o;\, att_o]) \end{equation}
\begin{equation} M_o= \textrm{Softmax}([r_o;\, att_o]) \end{equation}
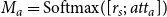 \begin{equation} M_a= \textrm{Softmax}([r_s;\, att_a]) \end{equation}
\begin{equation} M_a= \textrm{Softmax}([r_s;\, att_a]) \end{equation}
where
 $r_o$
is concatenated with
$r_o$
is concatenated with
 $att_o$
, and
$att_o$
, and
 $r_s$
is concatenated with
$r_s$
is concatenated with
 $att_a$
.
$att_a$
.
 $M_o$
and
$M_o$
and
 $M_a$
are the outputs of the sub-task, corresponding to the predicted original modality and the predicted actual synesthetic modality, respectively.
$M_a$
are the outputs of the sub-task, corresponding to the predicted original modality and the predicted actual synesthetic modality, respectively.
An example is shown in Table 3, to illustrate how linguistic features are represented and contribute to the detection of linguistic synesthesia. Specifically, the radical ![]() “ear” of the character
“ear” of the character ![]() sheng1 “sound” is closely related to hearing, while the radical
sheng1 “sound” is closely related to hearing, while the radical ![]() “metal generally used for making weapons in ancient China” suggests touch as the most relevant sensory modality. The inconsistency of the sensory modalities (hearing vs. touch) within a sentence indicates a high likelihood of linguistic synesthetic usages. In addition, the word segmentation helps our model to identify the two characters
“metal generally used for making weapons in ancient China” suggests touch as the most relevant sensory modality. The inconsistency of the sensory modalities (hearing vs. touch) within a sentence indicates a high likelihood of linguistic synesthetic usages. In addition, the word segmentation helps our model to identify the two characters ![]() dun4dun4 “blunt” as a word, rather than the single character
dun4dun4 “blunt” as a word, rather than the single character ![]() dun4 “blunt”. Besides, the POS information is employed to detect
dun4 “blunt”. Besides, the POS information is employed to detect ![]() dun4dun4 “blunt” as the synesthetic word, as the sensory adjective involves linguistic synesthesia most frequently. Based on the comprehensive linguistic information of the character, radical, word segmentation, and POS features, the sensory word
dun4dun4 “blunt” as the synesthetic word, as the sensory adjective involves linguistic synesthesia most frequently. Based on the comprehensive linguistic information of the character, radical, word segmentation, and POS features, the sensory word ![]() dun4dun4 “blunt” with linguistic synesthetic usages is identified, whose original domain as touch and target domain as hearing are detected jointly, as shown in Figure 7.
dun4dun4 “blunt” with linguistic synesthetic usages is identified, whose original domain as touch and target domain as hearing are detected jointly, as shown in Figure 7.
Table 3. An example for representation of linguistic featuresFootnote h

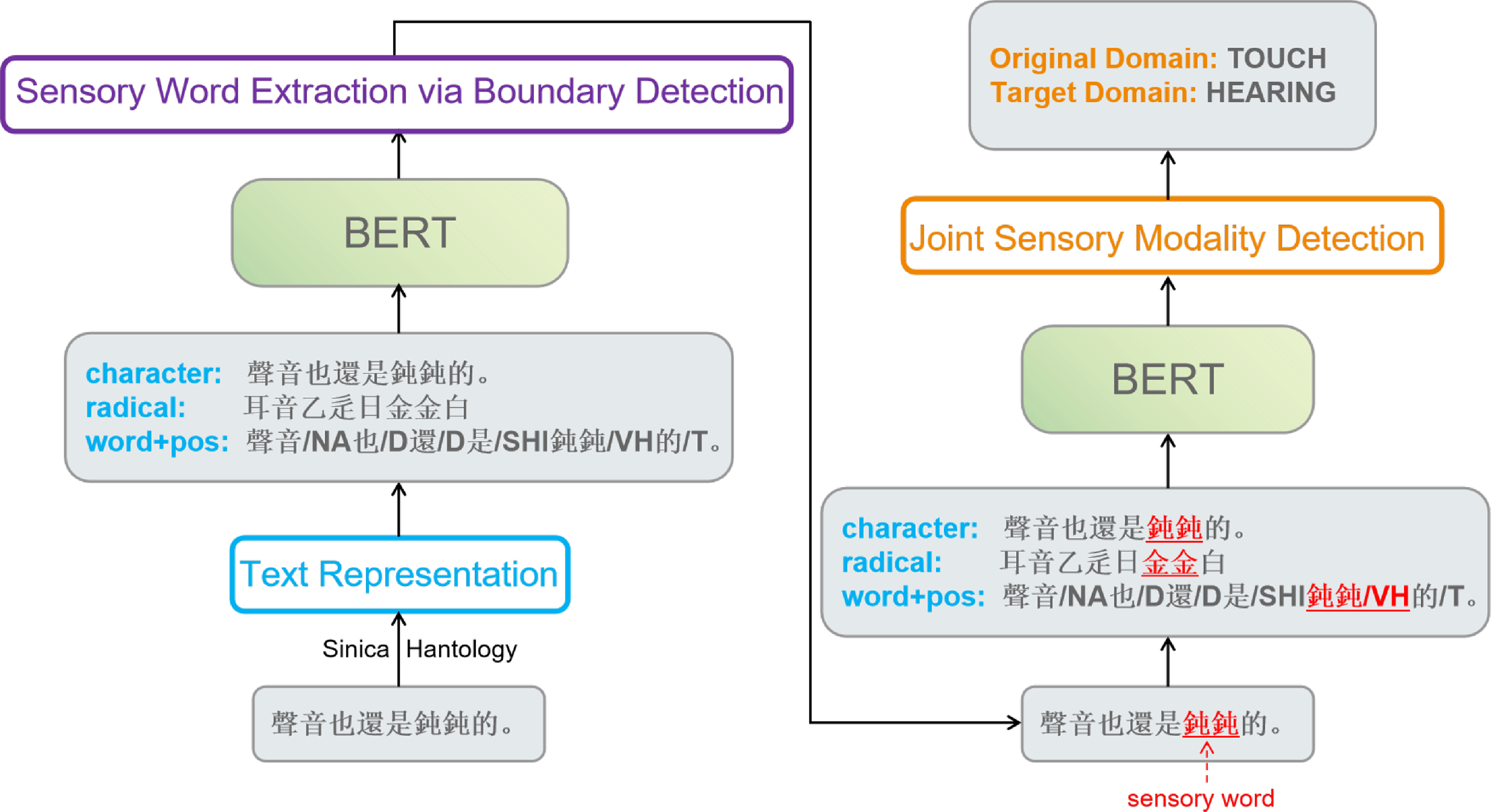
Figure 7. An example of linguistic synesthesia detection.
4.5 Training
We train the sensory modality detection with the sensory word extraction in a unified architecture.
Loss of the sensory word extraction. We minimize the negative log-likelihood loss to train the sensory word extraction model, and parameters are updated during the training process. In particular, the loss is the sum of two parts: the start token loss and the end token loss,
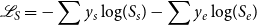 \begin{equation} \mathscr{L}_S=-\sum y_{s}\log\!({S_s})-\sum y_{e}\log\!({S_e}) \end{equation}
\begin{equation} \mathscr{L}_S=-\sum y_{s}\log\!({S_s})-\sum y_{e}\log\!({S_e}) \end{equation}
where
 $y_{s}$
and
$y_{s}$
and
 $y_{e}$
are the ground truth start and end positions for the sensory word extraction model.
$y_{e}$
are the ground truth start and end positions for the sensory word extraction model.
Loss of the sensory modality detection. Our training objective of the sensory modality detection is to minimize the cross-entropy loss with a
 $l2$
-regularization term,
$l2$
-regularization term,
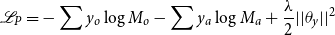 \begin{equation} \begin{split} \mathscr{L}_P=-\sum y_o\log{M_o} -\sum y_a\log{M_a}+\frac{\lambda }{2}||\theta _y||^2 \end{split} \end{equation}
\begin{equation} \begin{split} \mathscr{L}_P=-\sum y_o\log{M_o} -\sum y_a\log{M_a}+\frac{\lambda }{2}||\theta _y||^2 \end{split} \end{equation}
where
 $y_o$
and
$y_o$
and
 $y_a$
are the pre-defined labels for the original and actual sensory modalities, respectively. And
$y_a$
are the pre-defined labels for the original and actual sensory modalities, respectively. And
 $\lambda$
is a parameter for
$\lambda$
is a parameter for
 $l2$
-regularization.
$l2$
-regularization.
Therefore, the final loss is demonstrated as:
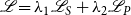 \begin{equation} \mathscr{L} = \lambda _1\mathscr{L}_S +\lambda _2\mathscr{L}_P \end{equation}
\begin{equation} \mathscr{L} = \lambda _1\mathscr{L}_S +\lambda _2\mathscr{L}_P \end{equation}
where
 $\lambda _1$
and
$\lambda _1$
and
 $\lambda _2$
are the trainable weight parameters, and
$\lambda _2$
are the trainable weight parameters, and
 $\lambda _1+\lambda _2=1$
.
$\lambda _1+\lambda _2=1$
.
5. Experiments
5.1 Experiment settings
One challenge in linguistic synesthesia detection is to find a large-scale dataset that includes rich linguistic synesthetic usages. Based on our collected Mandarin synesthesia dataset, the extraction and detection tasks both have 11,484 sentences in the training set, 1,460 sentences in the testing set, and 1,456 sentences in the development set (roughly following the 8:1:1 ratio). We have double-checked that there is no overlap between the testing dataset used in the sensory word extraction task and the testing dataset in the sensory modality detection task. In addition, the sensory words in the training set did not appear in the testing set.
This study used the BERT-base-Chinese as our pre-trained model. The optimizer chosen is Adam (Kingma and Ba Reference Kingma and Ba2015), and the parameters of BERT and other models are optimized separately. Besides, this study utilized a lower learning rate of 1e-5 with a training batch size of 16. For LSTM-based baselines, we used the 50-dimensional character embeddings, which were pre-trained on Chinese Giga-Word using Skip-gram word2vec (Mikolov et al. Reference Mikolov, Chen, Corrado and Dean2013) and fine-tuned during the model training. All experiments were conducted on a single NVIDIA GeForce RTX 1080 Ti (11 GB memory). It is important to note that different from Jiang et al. (Reference Jiang, Zhao, Long and Wang2022) using the golden data of the sensory word for linguistic synesthesia detection, this study considered the pipeline setting and used the prediction results of sensory word extraction for linguistic synesthesia detection. The selected evaluation metrics (i.e., Precision, Recall, F1 score) were calculated via the scikit-learn and SeqEvalFootnote i packages.
5.2 Baseline selection
The task of sensory word extraction aims to extract the perception-related word from a sentence. Generally speaking, it can be considered a sequence labeling task. On the other hand, linguistic synesthesia detection aims to detect the original and synesthetic sensory modalities of the given sensory word. Therefore, this task can be separated into two sub-tasks: original sensory modality detection and synesthetic sensory modality detection. These two sub-tasks can be considered two text classification tasks.
Firstly, our work chooses the following baselines for both the sensory word extraction task and the sensory modality detection task:
-
E2EB-iLSTM: a relatively standard end-to-end BiLSTM model for detecting the metaphorical use of words in context proposed by Gao et al. (Reference Gao, Choi, Choi and Zettlemoyer2018).
-
MelBERT: originally developed for the metaphor detection task, namely the metaphor-aware late interaction over BERT (i.e., MelBERT) (Choi et al. Reference Choi, Lee, Choi, Park, Lee, Lee and Lee2021). The model leveraged the contextualized word representation and linguistic features to detect whether the target word is metaphorical.
Then, the following models are developed by this study as baselines only for the task of sensory word extraction:
-
BiLSTM + CRF: as BiLSTM + CRF (Lample et al. Reference Lample, Ballesteros, Subramanian, Kawakami and Dyer2016) is widely used in many sequence labeling tasks, we adopt it as an essential baseline for sensory word extraction. In particular, we apply a bidirectional LSTM (Schuster and Paliwal Reference Schuster and Paliwal1997) as the textual encoder and the conditional random fields (CRF) (Lafferty, McCallum, and Pereira Reference Lafferty, McCallum and Pereira2001) as the decoder.
-
BERT + CRF: instead of training a model from scratch, we also adopt the framework of fine-tuning a pre-trained language model on a downstream task (Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018). In this framework, we adopt BERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) as the textual encoder and use CRF as the decoder.
-
BERT + MRC: it is the same pre-training and fine-tuning model as BERT + CRF. Instead of CRF as the decoder, we formulate it as a machine reading comprehension (MRC) task (Chen and Wu Reference Chen and Wu2020). Specifically, we first utilize the original raw text as the input passage to the BERT encoder. Then, we follow Li et al. (Reference Li, Feng, Meng, Han, Wu and Li2020) to employ two separate feed-forward layers over the text representation to generate distinct representations for the start and end of the spans. This allows our model to effectively identify and locate the relevant spans of the sensory word.
In addition, for sensory modality detection, we select several state-of-the-art models in metaphor detection, aspect-based sentiment analysis, and other related text classification tasks:
-
SR-BiLSTM: similar to the standard LSTM model struggling to detect the important part for metaphor detection, SR-BiLSTM (Sensory-Related BiLSTM) is implemented by our study based on a minor modification of the TD-LSTM model originally designed for aspect-based sentiment analysis (Tang et al. Reference Tang, Qin, Feng and Liu2016). The baseline model uses an attention mechanism that can capture the critical part of a sentence in response to a sensory word (Wang et al. Reference Wang, Huang, Zhu and Zhao2016) and a bidirectional LSTM (Schuster and Paliwal Reference Schuster and Paliwal1997) as the encoder of the sensory word and the content of the sentence. Then, SR-BiLSTM employs an attention mechanism to explore the connection between the sensory word and the content.
-
PF-BERT: due to the importance of the context of the sensory word in linguistic synesthesia detection, we model the preceding and the following contexts surrounding the sensory word. Therefore, contexts in both directions can be used as feature representations for synesthesia detection. In particular, we build a baseline model called PF-BERT (Preceding and Following BERT), which uses two BERT neural networks (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) to model the preceding and the following contexts respectively.
-
MrBERT: the metaphor-relation BERT model (MrBERT) explicitly models the relationship between a verb and its grammatical, sentential, and semantic contexts (Song et al. Reference Song, Zhou, Fu, Liu and Liu2021). The model is employed to frame sensory modality detection as a relation extraction task, which enables modeling the synesthetic relation between a sensory word and its context components and uses the relation representation for determining linguistic synesthesia of the word.
The baseline models mentioned above can be roughly divided into two groups based on the type of encoder they use: LSTM-based models and BERT-based models. The primary difference between LSTM-based and BERT-based models lies in the design and learning technique. LSTM is a traditional neural network for sequential data that focuses on short-term dependencies. BERT, on the other hand, is a trending and powerful large language model that has been pre-trained on a large amount of data and knowledge, allowing it to capture long-term dependencies and complex contextual information. Furthermore, the models only for extraction tasks can also be roughly categorized into the CRF-based model and the MRC-based model in terms of the type of decoder they utilize. After obtaining the text representation from the encoder, the CRF-based model will calculate the conditional probabilities of the output sequence, taking into account label dependencies. In contrast, the MRC-based model will focus on detecting the span boundary of the required output, aiming to identify the relevant answer within the given passage.
5.3 Results and discussion
This section presents the results of experiments for both the task of sensory word extraction and the task of joint sensory modality detection. After that, we show an analysis of factors that contribute to the performance of our model.Footnote j
5.3.1 Sensory word extraction
As shown in Table 4, the transformer-based models outperform the LSTM-based models for sensory word extraction. Specifically, our models and the three selected BERT-based baselines achieve more than 3 points higher than the LSTM-based models in the F1 score. These results show the effectiveness of BERT-based models for learning the sentence representation for sensory word extraction, regardless of whether the decoder is CRF or MRC. On the other hand, comparing the results of the BiLSTM+CRF model with the BERT + CRF model reveals that contextual information is quite useful in CRF-based extraction tasks. In addition, compared to the BERT + CRF model, the BERT + MRC model performs better, which shows that the boundary detection-based model is more effective than the traditional sequence labeling model. Thirdly, our proposed model achieves a state-of-the-art result (with the F1 score of 81.1) and outperforms other baseline models significantly (p < 0.05).
Table 4. The results of sensory word extraction
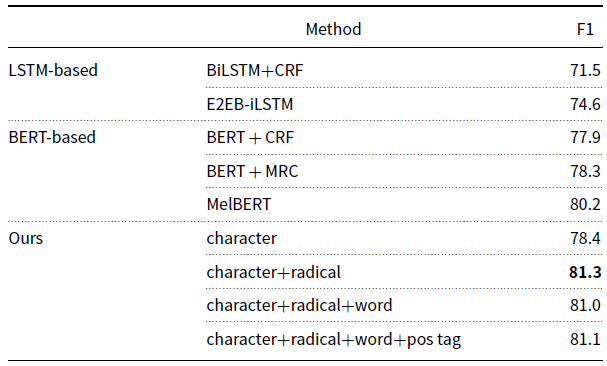
In terms of the four different linguistic features leveraged, the usage of Hantology contributes to the task of sensory word extraction significantly, resulting in a 2.9 percent improvement over the character-only model. However, adding the word segmentation and POS tagging features into the radical-incorporated model does not show an improvement in the performance of the model. These results prove that the task of sensory word extraction is sensitive to the sub-lexical-level knowledge that specifies the semantic and cognitive category of what is denoted by the character. These results also echo the work by Chen et al. (Reference Chen, Long, Lu and Huang2017), which leveraged the radical information for the classification of ontological categories to improve the performance of the neural model for metaphor detection.
The results that character and radical features play a crucial role in the task of sensory word extraction have two important implications for the research on linguistic synesthesia. One is that linguistic synesthesia is the most likely to be involved in the monosyllable word composed of one character. In fact, Chen et al. (Reference Chen, Zhao, Long, Lu and Huang2019)’s experimental study and Zhao (Reference Zhao2020)’s corpus-based study also found a great numerical advantage of monosyllabic words (i.e., the word containing one character) with linguistic synesthetic usages over compounding words (i.e., the word containing more than one character). Thus, with respect to the sensory word extraction task for linguistic synesthesia, the character boundary and the word boundary overlap in most cases. That may be the reason why adding the word segmentation information does not improve the performance of the model which has already incorporated the character information for sensory word extraction. The other implication for studying linguistic synesthesia is that radical components of Chinese characters conceptualize comprehensive and systematic sensory information that may imply a culturally grounded conceptualization of semantics and cognition. For example, radicals denoting instruments (e.g., ![]() ) are generally related to touch (e.g.,
) are generally related to touch (e.g., ![]() ), radicals denoting the tongue (e.g.,
), radicals denoting the tongue (e.g., ![]() ) are generally related to taste (e.g.,
) are generally related to taste (e.g., ![]() ), radicals denoting the nose (e.g.,
), radicals denoting the nose (e.g., ![]() ) are generally related to smell (e.g.,
) are generally related to smell (e.g., ![]() ), radicals denoting the light (e.g.,
), radicals denoting the light (e.g., ![]() ) are generally related to vision (e.g.,
) are generally related to vision (e.g., ![]() ), and radicals denoting the mouth (e.g.,
), and radicals denoting the mouth (e.g., ![]() ) are generally related to hearing (e.g.,
) are generally related to hearing (e.g., ![]() ).Footnote
k
).Footnote
k
5.3.2 Sensory modality detection
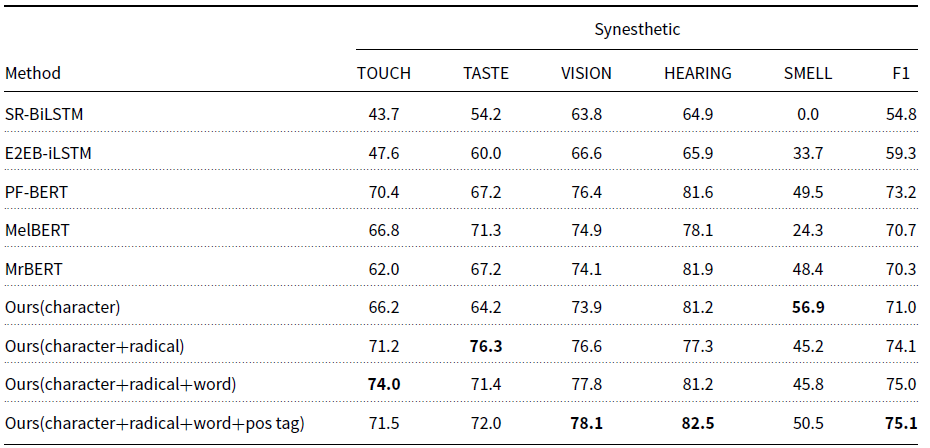
In terms of the task of sensory modality detection, our proposed model is compared with several classification baseline models in Tables 5 and 6, where SR-BiLSTM, E2EB-iLSTM, PF-BERT, MelBERT, and MrBERT are all state-of-the-art models for metaphor detection.
Table 5. The results of original modality detection, with F1 (weighted F1) calculated by taking the mean of all per-class F1 scores while considering the weight of each class
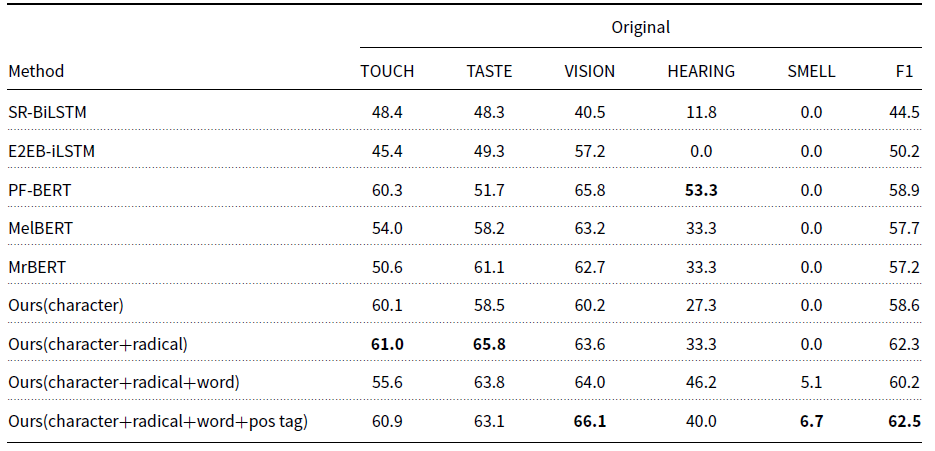
Table 6. The results of synesthetic modality detection, with F1 (weighted F1) calculated by taking the mean of all per-class F1 scores while considering the weight of each class
Based on the results in Tables 5 and 6, we find that:
-
The performances of detection of the synesthetic modalities largely surpass those of detection of the original modalities in all the models.
-
Our proposed model outperforms other baseline models significantly (p < 0.05) and reaches acceptable results in both the original modality detection and the synesthetic modality detection. The results indicate that leveraging linguistic features and joint learning is effective in linguistic synesthesia detection. With respect to the four features leveraged, the model containing all the features (i.e., “character + radical + word + pos tag”) achieves the best performances in the detection for both original modalities and synesthetic modalities.
-
It is hard for the models to predict hearing and smell, especially for the detection of original sensory modalities.
-
Notably, Jiang et al. (Reference Jiang, Zhao, Long and Wang2022)’s work reported higher performances in both original modality detection and synesthetic modality detection. The improvements can be attributed to their use of golden standard annotations for the initial phase of the sensory word extraction task, which involves identifying the boundaries of words that evoke sensory experiences. The approach inadvertently enhanced the perceived accuracy of results in both original modality detection and synesthetic modality detection. Our model is designed as a sequential process aimed at automatically detecting and interpreting sensory-related words, such as those pertaining to taste or smell. The first step is to determine the boundaries of these sensory words. Subsequently, we ascertain the specific sense they relate to. In line with best practices for pipeline models, our model should not have access to the correct answers for the initial step during its operation, as the accurate label of the first task should not influence the prediction of the second task.
The result that the performances of the models for the detection of synesthetic modalities are better than those for the detection of original modalities may be caused by several factors. Firstly, detecting the original sensory modality mainly relies on the semantics of the sensory word, where the radical information makes a great contribution to the proposed model. However, the synesthetic sensory modality can be inferred from both the sensory word and the context. As demonstrated in Table 3, an inconsistency in the sensory modalities in a sentence can suggest a linguistic synesthetic usage, where an adjective generally shows the source modality and a noun the target modality. In addition, there are directional patterns between the five sensory modalities for linguistic synesthesia, as shown in Figure 2. That is, the probability of each sensory modality being used for another sensory modality is different. Zhao (Reference Zhao2020)’ corpus-based study showed that 84.9 percent of tactile adjectives were used for vision, 76.2 percent of gustatory adjectives for smell, and 87.9 percent of visual adjectives for hearing, while a very limited number of auditory and olfactory adjectives were used for other sensory modalities. Thus, the target synesthetic modality can also be inferred from the original sensory modality. With respect to hearing and smell, as they are the most likely to act as the target domain in linguistic synesthesia, the performances of our proposed model for detecting hearing and smell as the synesthetic target modality are improved drastically, as shown in Table 6.
5.3.3 Analysis of factors
Table 7 presents an analysis of the number of data from one original modality to one synesthetic modality. In particular, the sensory modalities of hearing and smell have very limited numbers of linguistic synesthetic data. However, the sparse data on hearing and smell mirrors the crucial characteristic of human cognition that hearing and smell are hardly used as the target domains of linguistic synesthesia cross-linguistically (Strik Lievers Reference Strik Lievers2015; Zhao Reference Zhao2020).
Table 7. The results of our proposed model with the sub-set of testing data with respect to the original modality, where “(Num.)” means the number of data from one original modality to one synesthetic modality
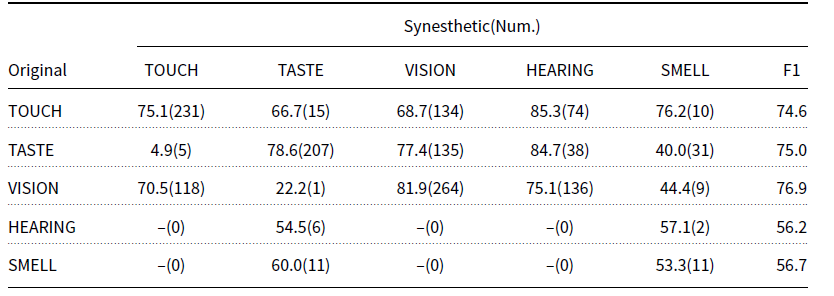
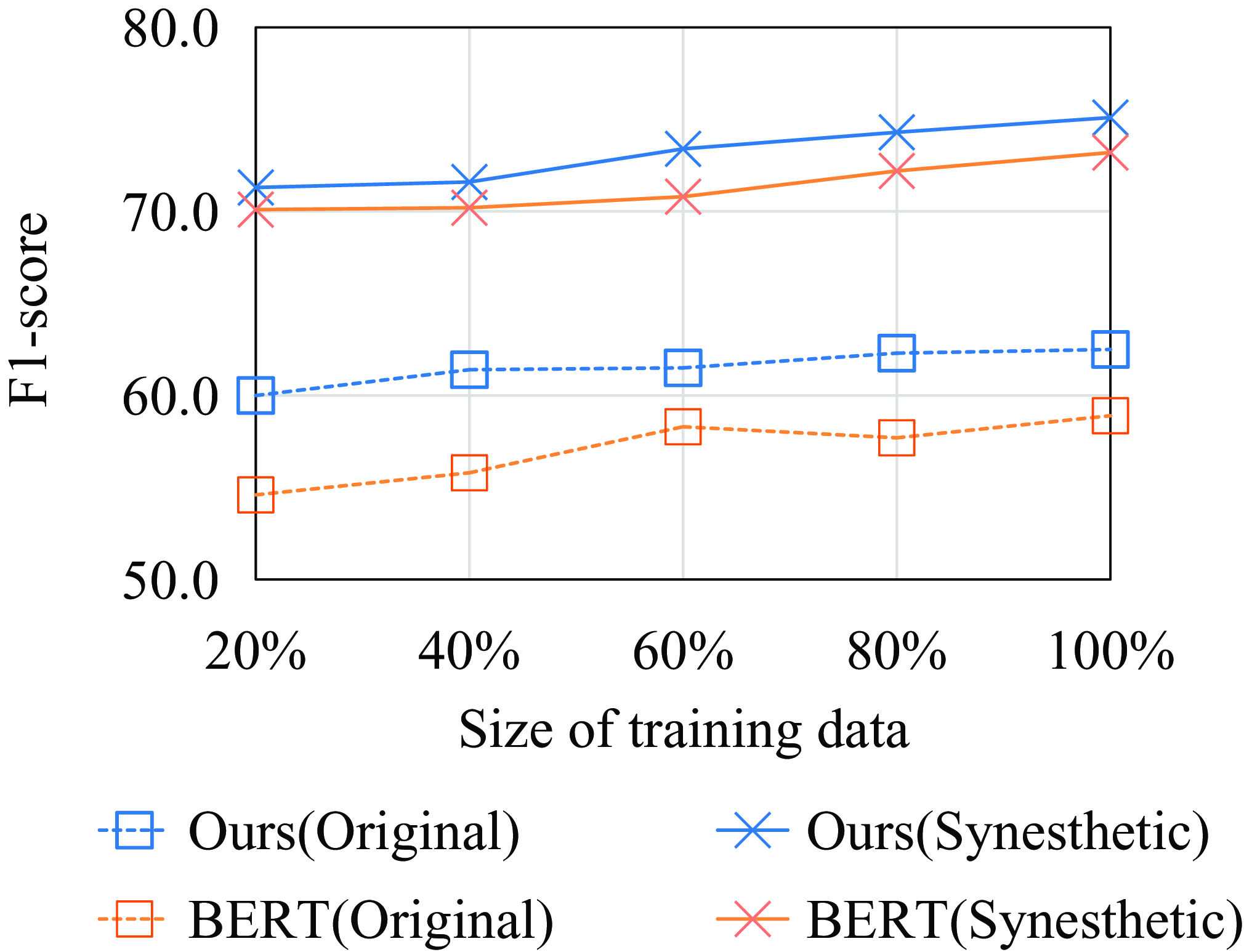
Figure 8. Influence of the size of the training data.
As sensory labeling and synesthesia labeling are usually expensive, we would like to test whether our model can still reach a reasonable performance with less data. Figure 8 shows the impact of the size of the training data on the performance of our model. Thus, our model is generally stable regardless of the size of the training data and the modality. This suggests that the linguistic features leveraged by this study contribute to a more robust model in linguistic synesthesia detection. In addition, the performances of both the BERT model and our proposed model increase with the size of the training data, which is in line with the general text classification models.
6. Conclusion
This study refines the NLP task called Chinese synesthesia detection proposed by Jiang et al. (Reference Jiang, Zhao, Long and Wang2022). In particular, we construct a large-scale manually annotated Chinese synesthesia dataset, which will be released in the open resource platform of OSF. Based on the dataset, we incorporate culturally enriched linguistic features (i.e., character and radical information, word segmentation information, and POS tagging features) into a neural network model to detect linguistic synesthesia automatically. In terms of identifying the boundary of sensory words and jointly detecting the original and synesthetic sensory modalities of the words, our proposed model achieves state-of-the-art results on the dataset for linguistic synesthesia detection through extensive experiments. Furthermore, this study shows several linguistic features that are useful in the detection of linguistic synesthesia. That is, except for the radical information that is dependent on the Chinese writing system, the word segmentation and POS features could also be incorporated for the detection of linguistic synesthesia in other languages. Thus, our proposed model would be applied to the detection of linguistic synesthesia in other languages.
7. Limitations and future work
One of the limitations of this study is that our proposed model performs poorly with the subsets of the testing data for hearing and smell due to the data sparsity. Our future work will investigate how to integrate few-shot learning or data-augmenting methods in these two sparse data categories for linguistic synesthesia detection.
Secondly, the model, leveraging non-language-specific linguistic features, can detect linguistic synesthesia in various languages. However, evaluating it solely on Chinese may limit its generalizability due to its reliance on sensory-rich Chinese characters. This reliance could hinder its applicability across different languages, especially if key linguistic features are missing or inaccurately annotated. Future research should explore techniques like data augmentation or few-shot learning within a large language modeling framework to address limited annotated resources. This could enhance the model’s versatility for application in diverse linguistic contexts.
Thirdly, our model is specifically designed for transformers based on the encoder structure and is not suitable for the encoder-decoder architecture of transformers, such as T5 (Raffel et al. Reference Raffel, Shazeer, Roberts, Lee, Narang, Matena, Zhou, Li and Liu2020), GPT (Radford et al. Reference Radford, Narasimhan, Salimans and Sutskever2018), etc. A potential limitation of our approach is that it is currently incompatible with these types of models, which may limit its applicability in scenarios where encoder-decoder models are preferred for their generative capabilities. Moving forward, a significant area for future work will be to explore strategies for integrating the model with the decoder component of these architectures and expanding the range of models that can benefit from the enrichment of sensory information.
















 Open access
Open access