


1 Introduction
Convergence-to-the-truth theorems are a staple of Bayesian epistemology: their use in philosophy, especially in debates concerning the tenability of subjective Bayesianism, dates back to the work of Savage (Reference Savage1954) and Edwards, Lindman, and Savage (Reference Edwards, Lindman and Savage1963). In a nutshell, these results establish that, in a wide array of learning scenarios, Bayesian agents expect their future credences to align with the truth almost surely as the evidence accumulates.
Rather than seeing convergence-to-the-truth results as an asset of the Bayesian framework, a number of authors take them to be the Achilles heel of Bayesianism (see Glymour Reference Glymour1980; Earman Reference Earman1992; Kelly Reference Kelly1996; Belot Reference Belot2013). Most recently, Belot (Reference Belot2013) argued that, because of these theorems, Bayesian reasoners are plagued by a pernicious type of epistemic immodesty. By the very nature of the Bayesian framework, Bayesian agents are barred from acknowledging that, for certain learning problems, failure, rather than success, is the typical outcome of inquiry—where, crucially, the notion of typicality on which Belot’s argument relies is topological rather than measure-theoretic (or probabilistic). There are learning problems for which a Bayesian agent’s success set (the collection of data streams along which convergence to the truth occurs) is topologically atypical or “small”; yet, as a consequence of said convergence-to-the-truth results, the agent must nonetheless assign probability one to this set.Footnote 1
It is well known that measure-theoretic and topological typicality often come apart (see Oxtoby Reference Oxtoby1980). Belot’s goal is to draw attention to the fact that this dichotomy occurs in contexts that he takes to be especially problematic due to their “obvious epistemological interest” (Belot Reference Belot2013, 499, note 43): in particular, in situations in which (1) the event witnessing the coming apart of these two types of typicality is a Bayesian agent’s success set and (2) the agent’s prior is one that, in Belot’s view, otherwise displays a desirable type of open-mindedness. In such settings, the argument goes, this dichotomy is particularly alarming, because topological typicality is an objective notion—one that does not depend on any particular agent or their subjective degrees of belief—whereas the measure-theoretic notion of typicality, in this context, reflects a particular agent’s opinion and is therefore subjective. These considerations lead Belot to conclude that Bayesian agents suffer from an irrational overconfidence in their ability to be inductively successful.
This objection has received considerable attention in the literature (see Huttegger Reference Huttegger2015; Weatherson Reference Weatherson2015; Elga Reference Elga2016; Belot Reference Belot2017; Cisewski et al. Reference Cisewski, Kadane, Schervish, Seidenfeld and Stern2018; Pomatto and Sandroni Reference Pomatto and Sandroni2018; Nielsen and Stewart Reference Nielsen and Stewart2019; Gong et al. Reference Gong, Kadane, Schervish, Seidenfeld and Stern2021), and many of the available responses recommend substantial modifications of the Bayesian framework to evade Belot’s conclusion. For instance, Huttegger (Reference Huttegger2015) proposes to use metric Boolean algebras, which allow to avoid drawing distinctions between events that can only be made by infinitely many observations; Weatherson (Reference Weatherson2015) advocates passing to imprecise Bayesianism; and Elga (Reference Elga2016) and Nielsen and Stewart (Reference Nielsen and Stewart2019) suggest dropping countable additivity in favor of finite additivity.
The goal of this article is not to further examine the merits or shortcomings of Belot’s argument; rather, the aim is to shed light on how pervasive the phenomenon identified by Belot is by clarifying the conditions under which his objection does not apply—the conditions under which inductive success for a Bayesian agent is both probabilistically and topologically typical—and the conditions under which it does. To address this question, we will not depart from standard Bayesian lore: instead, comfortably situated within the Bayesian framework, we will consider a taxonomy of inductive problems, in the spirit of Kelly (Reference Kelly1996), that will help us differentiate between the learning situations in which convergence to the truth is topologically typical and those in which it is not. We will focus on a canonical convergence-to-the-truth result—Lévy’s Upward Theorem (Lévy Reference Lévy1937)—and show that, by categorizing the random variables featuring in this result (the functions used to model the inductive problems faced by Bayesian agents) in terms of their descriptive complexity and computability-theoretic strength, we can gain a deeper and sharper understanding of when topological and probabilistic typicality agree or disagree in this setting.Footnote 2
Continuity will play a crucial role in our investigation. We will show that, for several classes of random variables that are “sufficiently close” to being continuous and admit natural epistemic interpretations, convergence to the truth is indeed a topologically typical affair. We will also see, however, that, for all sufficiently complex classes of random variables, there are inductive problems for which convergence to the truth is instead topologically atypical. Even though topologically typical inductive success is guaranteed for several natural classes of inductive problems, “Bayesian orgulity”—as Belot calls it—is, in this sense at least, a pervasive phenomenon. Last, by bringing computability theory into the picture, we will identify several classes of effective inductive problems and specific topologically typical collections of data streams along which convergence to the truth is guaranteed to occur, no matter which inductive problem from those classes the agent is trying to solve. This will allow us to throw light on the kinds of properties of data streams that are conducive to topologically typical inductive learning.
2 Lévy’s Upward Theorem, typicality, and Bayesian immodesty
In keeping with much of the Bayesian epistemology literature on the topic (see Earman Reference Earman1992; Belot Reference Belot2013; Huttegger Reference Huttegger2015, Reference Huttegger2017), our discussion of Bayesian convergence to the truth will focus on the setting of infinite binary sequences—that is, the setting of Cantor space: the topological space whereby the set
 ${\{ 0,1\} ^\mathbb{N}}$
of infinite binary sequences is endowed with the topology of pointwise convergence. This is the topology generated by the collection of cylinders
${\{ 0,1\} ^\mathbb{N}}$
of infinite binary sequences is endowed with the topology of pointwise convergence. This is the topology generated by the collection of cylinders
 $\left[ \sigma \right]$
, where
$\left[ \sigma \right]$
, where
 $\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
is a finite binary string and
$\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
is a finite binary string and
 $\left[ \sigma \right] = \{ \omega \in \{ {0,1{\} ^\mathbb{N}}:{\rm{\;}}\sigma \sqsubset \omega } \}$
is the set of all sequences that begin with
$\left[ \sigma \right] = \{ \omega \in \{ {0,1{\} ^\mathbb{N}}:{\rm{\;}}\sigma \sqsubset \omega } \}$
is the set of all sequences that begin with
 $\sigma $
(“
$\sigma $
(“
 $\sigma \sqsubset \omega $
” indicates that
$\sigma \sqsubset \omega $
” indicates that
 $\sigma $
is a proper initial segment of
$\sigma $
is a proper initial segment of
 $\omega $
). Every open set in Cantor space can be expressed as a countable union of cylinders and every clopen set as a finite union of cylinders. We will think of infinite binary sequences as data streams, sequences of experimental outcomes, environments, or possible worlds. From this viewpoint, cylinders intuitively encapsulate the information available to an agent after having made finitely many observations or having performed an imprecise measurement with a certain degree of precision.
$\omega $
). Every open set in Cantor space can be expressed as a countable union of cylinders and every clopen set as a finite union of cylinders. We will think of infinite binary sequences as data streams, sequences of experimental outcomes, environments, or possible worlds. From this viewpoint, cylinders intuitively encapsulate the information available to an agent after having made finitely many observations or having performed an imprecise measurement with a certain degree of precision.
2.1 Measure-theoretic versus topological typicality
One prominent way to think about typicality—the one on which Bayesian convergence-to-the-truth theorems capitalize—is measure-theoretic. Recall that the Borel
 $\sigma $
-algebra
$\sigma $
-algebra
 $\mathfrak{B}$
on
$\mathfrak{B}$
on
 ${\{ 0,1\} ^\mathbb{N}}$
is the smallest
${\{ 0,1\} ^\mathbb{N}}$
is the smallest
 $\sigma $
-algebra containing all open sets in Cantor space. The elements of
$\sigma $
-algebra containing all open sets in Cantor space. The elements of
 $\mathfrak{B}$
are called Borel sets. A probability measure
$\mathfrak{B}$
are called Borel sets. A probability measure
 $\mu $
on
$\mu $
on
 $\mathfrak{B}$
assigns to each Borel subset of
$\mathfrak{B}$
assigns to each Borel subset of
 ${\{ 0,1\} ^\mathbb{N}}$
a value in
${\{ 0,1\} ^\mathbb{N}}$
a value in
 $\left[ {0,1} \right]$
in such a way that
$\left[ {0,1} \right]$
in such a way that
 $\mu(\{0, 1\}^\mathbb{N}) = 1$
and, for any countable collection
$\mu(\{0, 1\}^\mathbb{N}) = 1$
and, for any countable collection
 ${\{ {{\cal A}_n}\} _{n \in \mathbb{N}}}$
of pairwise disjoint Borel sets,
${\{ {{\cal A}_n}\} _{n \in \mathbb{N}}}$
of pairwise disjoint Borel sets,
 $\mu(\bigcup_{n\in\mathbb{N}}\mathcal{A}_n)=\sum_{n\in\mathbb{N}}\mu(\mathcal{A}_n)$
. Every probability measure on
$\mu(\bigcup_{n\in\mathbb{N}}\mathcal{A}_n)=\sum_{n\in\mathbb{N}}\mu(\mathcal{A}_n)$
. Every probability measure on
 $\mathfrak{B}$
can be identified with a function
$\mathfrak{B}$
can be identified with a function
 $\mu $
that maps cylinders to real numbers in
$\mu $
that maps cylinders to real numbers in
 $\left[ {0,1} \right]$
and satisfies the following two conditions: (1)
$\left[ {0,1} \right]$
and satisfies the following two conditions: (1)
 $\mu \left( {\left[ \varepsilon \right]} \right) = 1$
(where
$\mu \left( {\left[ \varepsilon \right]} \right) = 1$
(where
 $\varepsilon $
denotes the empty string) and (2)
$\varepsilon $
denotes the empty string) and (2)
 $\mu \left( {\left[ \sigma \right]} \right) = \mu \left( {\left[ {\sigma 1} \right]} \right) + \mu \left( {\left[ {\sigma 0} \right]} \right)$
for all
$\mu \left( {\left[ \sigma \right]} \right) = \mu \left( {\left[ {\sigma 1} \right]} \right) + \mu \left( {\left[ {\sigma 0} \right]} \right)$
for all
 $\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
(where
$\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
(where
 $\sigma 1$
is the string consisting of
$\sigma 1$
is the string consisting of
 $\sigma $
followed by
$\sigma $
followed by
 $1$
and
$1$
and
 $\sigma 0$
the string consisting of
$\sigma 0$
the string consisting of
 $\sigma $
followed by
$\sigma $
followed by
 $0$
). By Carathéodory’s Extension Theorem (see Williams Reference Williams1991, Theorem 1.7), any such function can in fact be uniquely extended to a full probability measure on
$0$
). By Carathéodory’s Extension Theorem (see Williams Reference Williams1991, Theorem 1.7), any such function can in fact be uniquely extended to a full probability measure on
 $\mathfrak{B}$
.
$\mathfrak{B}$
.
A probability measure of which we will often make use is the uniform measure
 $\lambda $
: the probability measure that results from tossing a fair coin infinitely many times, given by
$\lambda $
: the probability measure that results from tossing a fair coin infinitely many times, given by
 $\lambda \left( {\left[ \sigma \right]} \right) = {2^{ - \left| \sigma \right|}}$
for all
$\lambda \left( {\left[ \sigma \right]} \right) = {2^{ - \left| \sigma \right|}}$
for all
 $\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
(where
$\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
(where
 $\left| \sigma \right|$
denotes the length of
$\left| \sigma \right|$
denotes the length of
 $\sigma $
).
$\sigma $
).
Although probability measures admit various interpretations, here we will take them to represent the subjective priors of Bayesian reasoners. So, a probability measure
 $\mu $
on
$\mu $
on
 $\mathfrak{B}$
will always stand for a specific agent’s initial degrees of belief, or credences, about the events in
$\mathfrak{B}$
will always stand for a specific agent’s initial degrees of belief, or credences, about the events in
 $\mathfrak{B}$
, and it will be understood as capturing that agent’s background knowledge and inductive assumptions at the beginning of the learning process.
$\mathfrak{B}$
, and it will be understood as capturing that agent’s background knowledge and inductive assumptions at the beginning of the learning process.
Given a probability measure
 $\mu $
, a set is measure-theoretically typical relative to
$\mu $
, a set is measure-theoretically typical relative to
 $\mu $
if it has
$\mu $
if it has
 $\mu $
-measure one and is measure-theoretically atypical relative to
$\mu $
-measure one and is measure-theoretically atypical relative to
 $\mu $
if it has
$\mu $
if it has
 $\mu $
-measure zero. A
$\mu $
-measure zero. A
 $\mu $
-measure-one-set corresponds to an event of which the agent with prior
$\mu $
-measure-one-set corresponds to an event of which the agent with prior
 $\mu $
is essentially certain, whereas a
$\mu $
is essentially certain, whereas a
 $\mu $
-measure-zero set corresponds to an event that the agent considers negligible. Measure-theoretic typicality is therefore inextricably tied to the underlying prior: distinct probability measures may disagree wildly as to which sets count as measure-theoretically typical.
Footnote 3
$\mu $
-measure-zero set corresponds to an event that the agent considers negligible. Measure-theoretic typicality is therefore inextricably tied to the underlying prior: distinct probability measures may disagree wildly as to which sets count as measure-theoretically typical.
Footnote 3
Topological typicality (the type of typicality on which Belot’s criticism is grounded) is instead defined as follows. Recall that a set is nowhere dense if its closure has empty interior—intuitively, if it corresponds to a hypothesis that, no matter what evidence has been observed so far, can always be refuted by further evidence. Equivalently, a set
 ${\cal S} \subseteq {\{ 0,1\} ^\mathbb{N}}$
is nowhere dense if, for every open set
${\cal S} \subseteq {\{ 0,1\} ^\mathbb{N}}$
is nowhere dense if, for every open set
 ${\cal U} \subseteq {\{ 0,1\} ^\mathbb{N}}$
,
${\cal U} \subseteq {\{ 0,1\} ^\mathbb{N}}$
,
 ${\cal S} \cap {\cal U}$
is not dense in the subspace topology on
${\cal S} \cap {\cal U}$
is not dense in the subspace topology on
 ${\cal U}$
—where a set is dense if it has a nonempty intersection with every nonempty open set (intuitively, a dense set corresponds to a hypothesis that cannot be refuted by any finite amount of evidence). A subset of a topological space is topologically atypical if it is meager, that is, if it is expressible as a countable union of nowhere dense sets.
Footnote 4
On the other hand, a set is topologically typical if it is co-meager: if it is the complement of a meager set.
${\cal U}$
—where a set is dense if it has a nonempty intersection with every nonempty open set (intuitively, a dense set corresponds to a hypothesis that cannot be refuted by any finite amount of evidence). A subset of a topological space is topologically atypical if it is meager, that is, if it is expressible as a countable union of nowhere dense sets.
Footnote 4
On the other hand, a set is topologically typical if it is co-meager: if it is the complement of a meager set.
Measure-theoretic and topological (a)typicality have several features in common. For instance, the class of measure-zero sets and the class of meager sets are both
 $\sigma $
-ideals: measure-zero and meager sets are both closed under subsets and countable unions. However, although they both aim at capturing notions of “largeness” and “smallness,” these concepts often diverge. For a well-trodden example, consider the collection of sequences that satisfy the Strong Law of Large Numbers relative to the uniform measure
$\sigma $
-ideals: measure-zero and meager sets are both closed under subsets and countable unions. However, although they both aim at capturing notions of “largeness” and “smallness,” these concepts often diverge. For a well-trodden example, consider the collection of sequences that satisfy the Strong Law of Large Numbers relative to the uniform measure
 $\lambda $
(the set of sequences with limiting relative frequency 1/2 for
$\lambda $
(the set of sequences with limiting relative frequency 1/2 for
 $1$
): this is a set with
$1$
): this is a set with
 $\lambda $
-measure one, and yet it is also meager (see Oxtoby Reference Oxtoby1980, 85).
$\lambda $
-measure one, and yet it is also meager (see Oxtoby Reference Oxtoby1980, 85).
2.2 Lévy’s Upward Theorem
Bayesian convergence to the truth is epitomized by Lévy’s Upward Theorem (Lévy Reference Lévy1937), which establishes that, given some quantity that a Bayesian agent is trying to measure, the probability of observing a data stream that will lead the agent’s successive estimates to asymptotically align with the truth is one. In other words, a Bayesian reasoner conducting repeated experiments to gauge some quantity expects that almost every sequence of observations will bring about inductive success.
Let
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a random variable relative to some probability measure
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a random variable relative to some probability measure
 $\mu $
on
$\mu $
on
 $\mathfrak{B}$
. Think of the values of
$\mathfrak{B}$
. Think of the values of
 $f$
as quantities that the agent with prior
$f$
as quantities that the agent with prior
 $\mu $
wishes to estimate; for instance,
$\mu $
wishes to estimate; for instance,
 $f$
could record the value of some unknown physical parameter that may vary between possible worlds. The unconditional expectation of
$f$
could record the value of some unknown physical parameter that may vary between possible worlds. The unconditional expectation of
 $f$
with respect to
$f$
with respect to
 $\mu $
(the average value of
$\mu $
(the average value of
 $f$
weighted by
$f$
weighted by
 $\mu $
, given by
$\mu $
, given by
 $\int_{\{0,1\}^\mathbb{N}} f\,d\mu$
) is abbreviated as
$\int_{\{0,1\}^\mathbb{N}} f\,d\mu$
) is abbreviated as
 ${\mathbb{E}_\mu }\left[ f \right]$
. If
${\mathbb{E}_\mu }\left[ f \right]$
. If
 ${\mathbb{E}_\mu }\left[ {\left| f \right|} \right] \lt \infty $
, then
${\mathbb{E}_\mu }\left[ {\left| f \right|} \right] \lt \infty $
, then
 $f$
is integrable. For each
$f$
is integrable. For each
 $n \in \mathbb{N}$
, let
$n \in \mathbb{N}$
, let
 ${\mathfrak{F}}_n$
be the sub-
${\mathfrak{F}}_n$
be the sub-
 $\sigma $
-algebra of
$\sigma $
-algebra of
 $\mathfrak{B}$
generated by the cylinders
$\mathfrak{B}$
generated by the cylinders
 $\left[ \sigma \right]$
centered on strings
$\left[ \sigma \right]$
centered on strings
 $\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
of length
$\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
of length
 $n$
. This collection of algebras has an especially natural epistemic interpretation: each
$n$
. This collection of algebras has an especially natural epistemic interpretation: each
 ${\mathfrak{F}}_n$
intuitively captures the possible information that the agent may obtain at the
${\mathfrak{F}}_n$
intuitively captures the possible information that the agent may obtain at the
 $n$
th stage of the learning process—any string of outcomes that could result from
$n$
th stage of the learning process—any string of outcomes that could result from
 $n$
experiments. The conditional expectation
$n$
experiments. The conditional expectation
 ${\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
of
${\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
of
 $f$
given
$f$
given
 ${\mathfrak{F}}_n$
is itself a random variable that, on input
${\mathfrak{F}}_n$
is itself a random variable that, on input
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
, returns the best estimate of
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
, returns the best estimate of
 $f$
’s value, from the perspective of
$f$
’s value, from the perspective of
 $\mu $
, conditional on the first
$\mu $
, conditional on the first
 $n$
digits
$n$
digits
 $\omega\restriction n$
of
$\omega\restriction n$
of
 $\omega $
. More suggestively, when
$\omega $
. More suggestively, when
 $\omega $
is the true state of the world,
$\omega $
is the true state of the world,
 ${\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right)$
can be seen as encoding the agent’s beliefs regarding the true value of
${\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right)$
can be seen as encoding the agent’s beliefs regarding the true value of
 $f$
(namely,
$f$
(namely,
 $f\left( \omega \right)$
) after having observed the outcomes
$f\left( \omega \right)$
) after having observed the outcomes
 $\omega \restriction n$
of the first
$\omega \restriction n$
of the first
 $n$
experiments. We use throughout the following version of the conditional expectation (because it is unique only up to
$n$
experiments. We use throughout the following version of the conditional expectation (because it is unique only up to
 $\mu $
-measure zero)—though, as will become clear, this choice is immaterial for our results. For all
$\mu $
-measure zero)—though, as will become clear, this choice is immaterial for our results. For all
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
,
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
,
 $${\mathbb{E}_\mu }[{\mkern 1mu} f\mid {_n}](\omega ) = \left\{ {\frac{1}{{\mathop \mu \limits_0 ([\omega n])}}{\mkern 1mu} \int_{[\omega n]} {\mkern 1mu} f{\mkern 1mu} d\mu {\rm{ }}\begin{array}{*{20}{c}}
{{\rm{if}}\mu ([\omega n])} \\
{{\rm{otherwise}}} \\
\end{array}{\rm{ \gt }}\,0,\,{\mkern 1mu} {\rm{and }}} \right.$$
$${\mathbb{E}_\mu }[{\mkern 1mu} f\mid {_n}](\omega ) = \left\{ {\frac{1}{{\mathop \mu \limits_0 ([\omega n])}}{\mkern 1mu} \int_{[\omega n]} {\mkern 1mu} f{\mkern 1mu} d\mu {\rm{ }}\begin{array}{*{20}{c}}
{{\rm{if}}\mu ([\omega n])} \\
{{\rm{otherwise}}} \\
\end{array}{\rm{ \gt }}\,0,\,{\mkern 1mu} {\rm{and }}} \right.$$
Lévy’s Upward Theorem is the following result (see Williams Reference Williams1991, sec. 14.2):
Theorem 2.1 (Lévy’s Upward Theorem, Lévy Reference Lévy1937). Let
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be an integrable random variable. Then, for
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be an integrable random variable. Then, for
 $\mu $
-almost every
$\mu $
-almost every
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
,
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
,
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.Footnote
5
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.Footnote
5
Call the set of sequences
 $\{ \omega \in {\{ 0,1\} ^\mathbb{N}}:{\rm{\;li}}{{\rm{m}}_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)\} $
that satisfy Lévy’s Upward Theorem the success set of agent
$\{ \omega \in {\{ 0,1\} ^\mathbb{N}}:{\rm{\;li}}{{\rm{m}}_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)\} $
that satisfy Lévy’s Upward Theorem the success set of agent
 $\mu $
with respect to
$\mu $
with respect to
 $f$
and its complement the failure set. Lévy’s Upward Theorem says that, from the agent’s viewpoint, their failure set is negligible: the agent assigns probability one to the hypothesis that their beliefs will eventually converge to the truth about the value of
$f$
and its complement the failure set. Lévy’s Upward Theorem says that, from the agent’s viewpoint, their failure set is negligible: the agent assigns probability one to the hypothesis that their beliefs will eventually converge to the truth about the value of
 $f$
(i.e.,
$f$
(i.e.,
 $\mu (\{ \omega \in {\{ 0,1\} ^\mathbb{N}}:{\rm{\;li}}{{\rm{m}}_{n \to \infty }}{\mathbb{E}_\mu }[\,f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)\} ) = 1$
).
$\mu (\{ \omega \in {\{ 0,1\} ^\mathbb{N}}:{\rm{\;li}}{{\rm{m}}_{n \to \infty }}{\mathbb{E}_\mu }[\,f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)\} ) = 1$
).
The philosophical literature on Lévy’s Upward Theorem generally focuses on the special case in which the integrable random variable being estimated is the indicator function
 ${{\mathbb {1}}_{\mathcal A}}$
of some Borel set
${{\mathbb {1}}_{\mathcal A}}$
of some Borel set
 ${\cal A}$
(as we shall see, this is the setting within which Belot frames his objection). This restriction corresponds to the case in which the inductive problem faced by the agent is a binary decision problem: does the true world—the observed data stream—belong to
${\cal A}$
(as we shall see, this is the setting within which Belot frames his objection). This restriction corresponds to the case in which the inductive problem faced by the agent is a binary decision problem: does the true world—the observed data stream—belong to
 ${\cal A}$
? Or, put differently, does the true world possess the property corresponding to
${\cal A}$
? Or, put differently, does the true world possess the property corresponding to
 ${\cal A}$
? In this setting, the quantity that the agent is trying to estimate is the truth value of
${\cal A}$
? In this setting, the quantity that the agent is trying to estimate is the truth value of
 ${\cal A}$
, and learning proceeds by standard Bayesian conditioning. Whenever
${\cal A}$
, and learning proceeds by standard Bayesian conditioning. Whenever
 $\mu([\omega\restriction n]) \gt 0$
, we in fact have that
$\mu([\omega\restriction n]) \gt 0$
, we in fact have that
 $${\mathbb{E}_\mu }[{\mathbb {1}_{\cal A}}|{\mathfrak{F}}_n]\left( \omega \right) = \frac{1}{{\mu ([\omega |n])}}\int_{[\omega |n]} {\mathbb {1}_{\cal A}d\mu } = \frac{{\mu ({\cal A} \cap [\omega |n])}}{{\mu ([\omega |n])}} = \mu ({\cal A}|[\omega |n]).$$
$${\mathbb{E}_\mu }[{\mathbb {1}_{\cal A}}|{\mathfrak{F}}_n]\left( \omega \right) = \frac{1}{{\mu ([\omega |n])}}\int_{[\omega |n]} {\mathbb {1}_{\cal A}d\mu } = \frac{{\mu ({\cal A} \cap [\omega |n])}}{{\mu ([\omega |n])}} = \mu ({\cal A}|[\omega |n]).$$
So, because the support
 $\text{supp}(\mu)=\{\omega\in\{0,1\}^\mathbb{N}:\, (\forall {\it{n}})\, \mu([\omega \restriction {\it n}]) \gt 0\}$
of
$\text{supp}(\mu)=\{\omega\in\{0,1\}^\mathbb{N}:\, (\forall {\it{n}})\, \mu([\omega \restriction {\it n}]) \gt 0\}$
of
 $\mu $
has
$\mu $
has
 $\mu $
-probability one, Lévy’s Upward Theorem entails that
$\mu $
-probability one, Lévy’s Upward Theorem entails that
 $\lim_{n\to\infty} \mu(\mathcal{A}\mid [\omega\restriction n]) = \mathbb {1}_\mathcal{A}(\omega)$
for
$\lim_{n\to\infty} \mu(\mathcal{A}\mid [\omega\restriction n]) = \mathbb {1}_\mathcal{A}(\omega)$
for
 $\mu $
-almost every
$\mu $
-almost every
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
. An agent with prior
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
. An agent with prior
 $\mu $
expects their beliefs, given by the preceding sequence of posterior probabilities, to converge almost surely to the truth about whether
$\mu $
expects their beliefs, given by the preceding sequence of posterior probabilities, to converge almost surely to the truth about whether
 ${\cal A}$
is the case with increasing information.
${\cal A}$
is the case with increasing information.
The almost-sure convergence to the truth achieved via Lévy’s Upward Theorem is always relative to the agent’s prior. Before performing any experiments or measurements, the agent is essentially certain that, with increasing information, their beliefs will eventually converge to the truth. Yet, there is no objective or external guarantee that this will indeed be the case. Thus Lévy’s Upward Theorem does not establish the universal reliability of Bayesian learning methods from an objective, third-person standpoint. Its epistemic significance stems from the fact that it establishes that a certain kind of skepticism about induction is impossible: if an agent is independently committed to probabilistic coherence, then, by Lévy’s Upward Theorem, that agent cannot be a skeptic about the possibility of learning from experience. The agent’s independent commitment to the Bayesian framework implies that, by their own light, their recourse to inductive reasoning is justified. As Skyrms (Reference Skyrms1984, 62) observes, from the perspective of a Bayesian agent, it is “inappropriate for you to ask the standard question, ‘Why should I believe that the real situation is not in that set of measure zero?’ The measure in question is your degree of belief. You do believe that the real situation is not in that set, with degree of belief one.”
2.3 Belot’s argument
Precisely because of its barring a certain type of skepticism about induction, Lévy’s Upward Theorem has been accused of being a drawback of the Bayesian approach, rather than serving in its favor. In particular, Belot (Reference Belot2013) argues that, because of Lévy’s Upward Theorem (and other convergence-to-the-truth results), Bayesian reasoners are forced to be epistemically immodest in an especially pernicious way. Belot’s worry is that
Bayesian convergence-to-the-truth theorems tell us that Bayesian agents are forbidden to think that there is any chance that they will be fooled in the long run, even when they know that their credence function is defined on a space that includes many [data streams] that would frustrate their desire to reach the truth. (500)
Bayesian reasoners are, in a sense, incapable of entertaining the possibility of inductive failure, and this is so even when “their desire to reach the truth” is thwarted along many data streams—in fact, on a topologically typical collection of data streams.
To make his point,Footnote 6 Belot (Reference Belot2013) considers a specific class of priors, which he calls open-minded. The notion of an open-minded prior is, by definition, always relative to a particular Borel set—more suggestively, to a particular hypothesis under consideration: given some
 ${\cal S} \in \mathfrak{B}$
,
${\cal S} \in \mathfrak{B}$
,
 $\mu $
is open-minded with respect to
$\mu $
is open-minded with respect to
 ${\cal S}$
if, no matter what string
${\cal S}$
if, no matter what string
 $\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
has been observed so far, there are always two possible distinct extensions
$\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
has been observed so far, there are always two possible distinct extensions
 $\tau ,\rho \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
of
$\tau ,\rho \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
of
 $\sigma $
(i.e.,
$\sigma $
(i.e.,
 $\sigma \sqsubset \tau $
and
$\sigma \sqsubset \tau $
and
 $\sigma \sqsubset \rho $
) such that
$\sigma \sqsubset \rho $
) such that
 $\mu ({\cal S}|\left[ \tau \right]) \ge 1/2$
and
$\mu ({\cal S}|\left[ \tau \right]) \ge 1/2$
and
 $\mu ({\cal S}|\left[ \rho \right]) \lt 1/2$
. If
$\mu ({\cal S}|\left[ \rho \right]) \lt 1/2$
. If
 $\mu $
is open-minded with respect to
$\mu $
is open-minded with respect to
 ${\cal S}$
, then no finite number of observations will ever suffice for
${\cal S}$
, then no finite number of observations will ever suffice for
 $\mu $
to settle on whether the data stream being observed belongs to
$\mu $
to settle on whether the data stream being observed belongs to
 ${\cal S}$
.
${\cal S}$
.
Now, suppose the hypothesis under consideration corresponds to a countable dense Borel set
 ${\cal D}$
(e.g.,
${\cal D}$
(e.g.,
 ${\cal D}$
could be the set of sequences that are eventually
${\cal D}$
could be the set of sequences that are eventually
 $0$
). Given a Bayesian agent with prior
$0$
). Given a Bayesian agent with prior
 $\mu $
, what do the success set and the failure set of
$\mu $
, what do the success set and the failure set of
 $\mu $
with respect to the binary estimation problem encoded by
$\mu $
with respect to the binary estimation problem encoded by
 ${\mathbb{1}_{\mathcal D}}$
look like? The answer to this question depends, of course, on the particular prior adopted by the agent. Because
${\mathbb{1}_{\mathcal D}}$
look like? The answer to this question depends, of course, on the particular prior adopted by the agent. Because
 ${\cal D}$
and its complement are both dense, any finite sequence of observations is compatible with the true data stream being in
${\cal D}$
and its complement are both dense, any finite sequence of observations is compatible with the true data stream being in
 ${\cal D}$
but also with it not being in
${\cal D}$
but also with it not being in
 ${\cal D}$
. Hence, according to Belot, in this case, it is reasonable to adopt a prior
${\cal D}$
. Hence, according to Belot, in this case, it is reasonable to adopt a prior
 $\mu $
that is open-minded with respect to
$\mu $
that is open-minded with respect to
 ${\cal D}$
. Yet, Belot shows, if
${\cal D}$
. Yet, Belot shows, if
 $\mu $
is open-minded with respect to
$\mu $
is open-minded with respect to
 ${\cal D}$
, then its failure set—the set of sequences
${\cal D}$
, then its failure set—the set of sequences
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
along which the conditional probabilities
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
along which the conditional probabilities
 $\mu(\mathcal{D}\mid[\omega\restriction n])$
fail to converge to
$\mu(\mathcal{D}\mid[\omega\restriction n])$
fail to converge to
 $\mathbb {1}{_{\cal D}}\left( \omega \right)$
in the limit—is co-meager, despite being a
$\mathbb {1}{_{\cal D}}\left( \omega \right)$
in the limit—is co-meager, despite being a
 $\mu $
-measure-zero set by Lévy’s Upward Theorem. Equivalently, the success set of
$\mu $
-measure-zero set by Lévy’s Upward Theorem. Equivalently, the success set of
 $\mu $
relative to
$\mu $
relative to
 ${\mathbb {1}_{\cal D}}$
is meager (and, so, topologically negligible), despite having probability one, according to the agent. Probabilistic and topological typicality are thus orthogonal notions in this setting.
${\mathbb {1}_{\cal D}}$
is meager (and, so, topologically negligible), despite having probability one, according to the agent. Probabilistic and topological typicality are thus orthogonal notions in this setting.
In light of these (and other analogous) observations, Belot (Reference Belot2013, 484) concludes that the Bayesian approach is irremediably flawed: the account of rationality it yields “renders a certain sort of arrogance rationally mandatory, requiring agents to be certain that they will be successful at certain tasks, even in cases where the task is so contrived as to make failure the typical outcome.”
3 Meager and co-meager success
There are several moving parts in Belot’s argument that one may call into question to avoid his conclusion. For instance, one may doubt the reasonableness of Belot’s notion of an open-minded prior or challenge the very significance of topological considerations for Bayesian epistemology (see, e.g., Huttegger Reference Huttegger2015; Cisewski et al. Reference Cisewski, Kadane, Schervish, Seidenfeld and Stern2018). Huttegger (Reference Huttegger2015, 92), for example, notes the following:
The mathematical structure of measure theory is very different from the mathematical structure of topology.… Taking all of this together suggests that topological and probabilistic concepts are fairly independent of each other, and that results about the topology of a space do not prescribe specific probability distributions for that space. From a Bayesian perspective, this makes a lot of sense. Topology is a mathematical theory of concepts like closeness and limit point, whereas probability is a mathematical theory of rational degrees of belief. The two theories have very different domains, and so there is no reason to suppose that there are any general principles connecting the two in the way required by Belot’s argument.
The question of whether topological typicality is a relevant concept when evaluating the rationality of probabilistic reasoners is a divisive one. It is, however, worth pointing out that the use of topological typicality in the setting of Bayesian convergence-to-the-truth results has some notable precedents that bear upon the long-standing debate between Bayesians and frequentists in the foundations of statistics—see, in particular, Freedman (Reference Freedman1963, Reference Freedman1965), who employs notions of topological typicality in studying the consistency of Bayes’s estimates. Regardless of whether Belot’s specific argument is ultimately successful, we take the following questions to be of independent interest: are there any ordinary learning situations where Bayesian agents (or, at the very least, certain types of Bayesian agents) are guaranteed to be inductively successful on a typical set of data streams both in the probabilistic and the topological sense? Is it possible to provide an informative classification of the learning scenarios in which these two notions of typicality are in agreement (with respect to the success sets of Bayesian agents) and of the learning scenarios in which they instead come apart, so as to be able to understand how pervasive the phenomenon Belot identified is? These are the questions that will keep us occupied in the remainder of this article.
Recall that a probability measure on
 $\mathfrak{B}$
has full support if it assigns positive probability to all cylinders. The uniform measure, for example, is a probability measure with full support, and so are all other Bernoulli measures with bias strictly less than one, as well as their mixtures. All of the learning situations identified in this article for which convergence to the truth occurs on a co-meager set will feature priors with full support. Priors with full support have a natural epistemic interpretation: they, too, correspond to a form of open-mindedness—in particular, they intuitively capture the credences of Bayesian reasoners who are open-minded with respect to the evidence, in that they do not a priori exclude any finite sequence of observations.
$\mathfrak{B}$
has full support if it assigns positive probability to all cylinders. The uniform measure, for example, is a probability measure with full support, and so are all other Bernoulli measures with bias strictly less than one, as well as their mixtures. All of the learning situations identified in this article for which convergence to the truth occurs on a co-meager set will feature priors with full support. Priors with full support have a natural epistemic interpretation: they, too, correspond to a form of open-mindedness—in particular, they intuitively capture the credences of Bayesian reasoners who are open-minded with respect to the evidence, in that they do not a priori exclude any finite sequence of observations.
Of course, the type of open-mindedness encoded by having full support is compatible with various forms of closed-mindedness. Take, for instance, the set of data streams that are eventually
 $0$
, which, as remarked earlier, is both countable and dense. According to the uniform measure
$0$
, which, as remarked earlier, is both countable and dense. According to the uniform measure
 $\lambda $
, this is a measure-zero set. Thus, though open-minded with respect to all finite sequences of observations,
$\lambda $
, this is a measure-zero set. Thus, though open-minded with respect to all finite sequences of observations,
 $\lambda $
is closed-minded with respect to the possibility of observing only finitely many
$\lambda $
is closed-minded with respect to the possibility of observing only finitely many
 $1$
s. So,
$1$
s. So,
 $\lambda $
fails to be open-minded in Belot’s sense with respect to the hypothesis encoded by this set. We take this to be a feature, rather than a bug, as no prior can be open-minded with respect to every event in
$\lambda $
fails to be open-minded in Belot’s sense with respect to the hypothesis encoded by this set. We take this to be a feature, rather than a bug, as no prior can be open-minded with respect to every event in
 $\mathfrak{B}$
. In particular, Belot’s notion of open-mindedness is just as susceptible to the charge of entailing various forms of closed-mindedness as having full support is.
$\mathfrak{B}$
. In particular, Belot’s notion of open-mindedness is just as susceptible to the charge of entailing various forms of closed-mindedness as having full support is.
Lévy’s Upward Theorem holds very generally for any integrable random variable. A crucial component of our analysis relies on classifying random variables in terms of their descriptive complexity and computational strength. This will allow us to identify well-behaved families of integrable random variables for which Lévy’s Upward Theorem can be shown to hold on a co-meager set. To this end, we need to introduce a few more definitions.
3.1 The Borel hierarchy and the arithmetical hierarchy
The events in
 $\mathfrak{B}$
can be classified in terms of their rank, or descriptive complexity, within the Borel hierarchy (see, e.g., Kechris Reference Kechris1995, sec. 11B):
$\mathfrak{B}$
can be classified in terms of their rank, or descriptive complexity, within the Borel hierarchy (see, e.g., Kechris Reference Kechris1995, sec. 11B):
Definition 3.1 (Borel hierarchy). The Borel hierarchy of subsets of Cantor space consists of the following three types of classes:
 ${\bf{\Sigma }}_\alpha ^0$
,
${\bf{\Sigma }}_\alpha ^0$
,
 ${\bf{\Pi }}_\alpha ^0$
, and
${\bf{\Pi }}_\alpha ^0$
, and
 ${\bf{\Delta }}_\alpha ^0$
, where
${\bf{\Delta }}_\alpha ^0$
, where
 $\alpha $
is a countable ordinal greater than
$\alpha $
is a countable ordinal greater than
 $0$
. Given a positive natural number
$0$
. Given a positive natural number
 $n$
,Footnote
7
a set
$n$
,Footnote
7
a set
 ${\cal S} \in \mathfrak{B}$
is in
${\cal S} \in \mathfrak{B}$
is in
-
 ${\bf{\Sigma }}_1^0$
if and only if it is open;
${\bf{\Sigma }}_1^0$
if and only if it is open; -
${\bf{\Pi }}_n^0$
if and only if its complement
$\overline{\mathcal{S}}$
is in
${\bf{\Sigma }}_n^0$
;
-
${\bf{\Sigma }}_n^0$
(
$n \gt 1$
) if and only if there is a sequence
${\{ {{\cal S}_i}\} _{i \in \mathbb{N}}}$
of
${\bf{\Pi }}_{n - 1}^0$
sets such that
$\mathcal{S}=\bigcup_{i\in \mathbb{N}}\mathcal{S}_i$
;
-
${\bf{\Delta }}_n^0$
if and only if
${\cal S}$
is in both
${\bf{\Sigma }}_n^0$
and
${\bf{\Pi }}_n^0$
.













For instance, the
 ${\bf{\Pi }}_1^0$
sets are the closed sets, the
${\bf{\Pi }}_1^0$
sets are the closed sets, the
 ${\bf{\Delta }}_1^0$
sets are the clopen sets, the
${\bf{\Delta }}_1^0$
sets are the clopen sets, the
 ${\bf{\Sigma }}_2^0$
sets are countable unions of closed sets, and the
${\bf{\Sigma }}_2^0$
sets are countable unions of closed sets, and the
 ${\bf{\Pi }}_2^0$
sets are countable intersections of open sets.
${\bf{\Pi }}_2^0$
sets are countable intersections of open sets.
The Borel hierarchy has an effective counterpart called the arithmetical hierarchy, which allows to classify certain Borel sets in terms of their arithmetical complexity (see, e.g., Soare Reference Soare2016, chap. 14; Downey and Hirschfeldt Reference Downey and Hirschfeldt2010, sec. 2.19):
Definition 3.2 (Arithmetical hierarchy). The arithmetical hierarchy of subsets of Cantor space consists of the following three types of classes:
 $\Sigma _n^0$
,
$\Sigma _n^0$
,
 $\Pi _n^0$
, and
$\Pi _n^0$
, and
 $\Delta _n^0$
, where
$\Delta _n^0$
, where
 $n$
is a positive natural number. A set
$n$
is a positive natural number. A set
 ${\cal S} \in \mathfrak{B}$
is in
${\cal S} \in \mathfrak{B}$
is in
-
$\Sigma _1^0$
if and only if it is effectively open (i.e., if there is a computably enumerable set
$S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
such that
$\mathcal{S}= [S]=\bigcup_{\sigma\in S}[\sigma]$
);
-
$\Pi _n^0$
if and only if its complement
${\overline{\cal{S}}}$
is in
$\Sigma _n^0$
;
-
$\Sigma _n^0$
(
$n \gt 1$
) if and only if there is a computable sequence
${\{ {{\cal S}_i}\} _{i \in \mathbb{N}}}$
of
$\Pi _{n - 1}^0$
sets
Footnote 8
such that
$\mathcal{S}=\bigcup_{i\in \mathbb{N}}\mathcal{S}_i$
;
-
$\Delta _n^0$
if and only if
${\cal S}$
is in both
$\Sigma _n^0$
and
$\Pi _n^0$
.







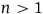







For instance, the
 $\Pi _1^0$
sets are the effectively closed sets, the
$\Pi _1^0$
sets are the effectively closed sets, the
 $\Delta _1^0$
sets are the (effectively) clopen sets, the
$\Delta _1^0$
sets are the (effectively) clopen sets, the
 $\Sigma _2^0$
sets are effective countable unions of effectively closed sets, and the
$\Sigma _2^0$
sets are effective countable unions of effectively closed sets, and the
 $\Pi _2^0$
sets are effective countable intersections of effectively open sets. A set with a classification within the arithmetical hierarchy is said to be arithmetical (or arithmetically definable).
$\Pi _2^0$
sets are effective countable intersections of effectively open sets. A set with a classification within the arithmetical hierarchy is said to be arithmetical (or arithmetically definable).
The levels of the arithmetical hierarchy can also be characterized in terms of the complexity of the formulas in the language of first-order arithmetic that define the sets belonging to those levels (hence the name “arithmetical hierarchy”). A set
 ${\cal S} \in \mathfrak{B}$
is in
${\cal S} \in \mathfrak{B}$
is in
 ${\rm{\Sigma }}_n^0$
if and only if it is definable by a
${\rm{\Sigma }}_n^0$
if and only if it is definable by a
 ${\rm{\Sigma }}_n^0$
formula, namely, if
${\rm{\Sigma }}_n^0$
formula, namely, if
 $\mathcal{S} = \{\omega\in \{0,1\}^\mathbb{N}:\, (\exists k_1)(\forall k_2) ... (Q k_n)\, R(\omega \restriction k_1, \omega \restriction k_2, ..., \omega \restriction k_n)\}$
for some computable relation
$\mathcal{S} = \{\omega\in \{0,1\}^\mathbb{N}:\, (\exists k_1)(\forall k_2) ... (Q k_n)\, R(\omega \restriction k_1, \omega \restriction k_2, ..., \omega \restriction k_n)\}$
for some computable relation
 $R$
, with
$R$
, with
 $Q = \exists $
if
$Q = \exists $
if
 $n$
is odd and
$n$
is odd and
 $Q = \forall $
if
$Q = \forall $
if
 $n$
is even. On the other hand, a set
$n$
is even. On the other hand, a set
 ${\cal S} \in \mathfrak{B}$
is in
${\cal S} \in \mathfrak{B}$
is in
 ${\rm{\Pi }}_n^0$
if and only if it is definable by a
${\rm{\Pi }}_n^0$
if and only if it is definable by a
 ${\rm{\Pi }}_n^0$
formula, namely, if there is a computable relation
${\rm{\Pi }}_n^0$
formula, namely, if there is a computable relation
 $R$
such that
$R$
such that
 $\mathcal{S} = \{\omega\in\{0,1\}^\mathbb{N}:\, (\forall k_1)(\exists k_2) ... (Q k_n)\, R(\omega\restriction k_1, \omega\restriction k_2, ..., \omega\restriction k_n)\}$
, with
$\mathcal{S} = \{\omega\in\{0,1\}^\mathbb{N}:\, (\forall k_1)(\exists k_2) ... (Q k_n)\, R(\omega\restriction k_1, \omega\restriction k_2, ..., \omega\restriction k_n)\}$
, with
 $Q = \forall $
if
$Q = \forall $
if
 $n$
is odd and
$n$
is odd and
 $Q = \exists $
if
$Q = \exists $
if
 $n$
is even.
$n$
is even.
3.2 Algorithmic randomness and effective genericity
As notions of “largeness” go, having measure one and being co-meager are rather coarse-grained. There are many sets that, while measure-theoretically or topologically (a)typical, seem to intuitively differ in “size.” For instance, the concept of Hausdorff dimension, which is a generalization of the uniform measure, was introduced to formalize the intuition that certain subsets of a metric space differ in size, even though, from the viewpoint of the uniform measure, they all have measure zero. In what follows, we will consider some more refined notions of typicality whose definitions rely on the machinery of computability theory. These notions of effective typicality allow one to make more fine-grained distinctions between intuitively “large” sets. Here we will use them to provide a more detailed analysis of the collections of data streams along which convergence to the truth holds for several classes of inductive problems.
Let us start with algorithmic randomness: a branch of computability theory that offers an account of effective measure-theoretic typicality (see Nies Reference Nies2009; Downey and Hirschfeldt Reference Downey and Hirschfeldt2010). According to algorithmic randomness, given a probability measure
 $\mu $
fixed in the background, a sequence is random relative to
$\mu $
fixed in the background, a sequence is random relative to
 $\mu $
if it is a representative outcome of
$\mu $
if it is a representative outcome of
 $\mu $
. One naive idea is that an outcome is representative of
$\mu $
. One naive idea is that an outcome is representative of
 $\mu $
if it satisfies every property that, according to
$\mu $
if it satisfies every property that, according to
 $\mu $
, “most” sequences possess, that is, if it belongs to all
$\mu $
, “most” sequences possess, that is, if it belongs to all
 $\mu $
-measure-one sets. Given that being representative in this sense is not possible in general,
Footnote 9
algorithmic randomness instead identifies representativeness—and, so, randomness—with membership in certain countable collections of
$\mu $
-measure-one sets. Given that being representative in this sense is not possible in general,
Footnote 9
algorithmic randomness instead identifies representativeness—and, so, randomness—with membership in certain countable collections of
 $\mu $
-measure-one sets: more precisely,
$\mu $
-measure-one sets: more precisely,
 $\mu $
-measure-one sets of a certain arithmetical complexity that correspond to natural statistical laws (such as the set of sequences that satisfy the Strong Law of Large Numbers relative to
$\mu $
-measure-one sets of a certain arithmetical complexity that correspond to natural statistical laws (such as the set of sequences that satisfy the Strong Law of Large Numbers relative to
 $\mu $
). In a nutshell, given such a countable collection of arithmetically definable properties that hold with
$\mu $
). In a nutshell, given such a countable collection of arithmetically definable properties that hold with
 $\mu $
-measure one (of arithmetically definable statistical laws), a sequence is algorithmically
$\mu $
-measure one (of arithmetically definable statistical laws), a sequence is algorithmically
 $\mu $
-random relative to that collection if and only if it possesses all of the corresponding properties (if and only if it satisfies all of the corresponding statistical laws).
$\mu $
-random relative to that collection if and only if it possesses all of the corresponding properties (if and only if it satisfies all of the corresponding statistical laws).
The field of algorithmic randomness is teeming with notions of differing logical strength, each determined by the particular family of measure-one arithmetically definable properties a sequence must satisfy to count as random. In what follows, we focus on two such notions.
Arguably, the simplest algorithmic randomness notion is Kurtz randomness (Kurtz Reference Kurtz1981):
Definition 3.3 (Kurtz randomness). Let
 $\mu $
be a probability measure.
Footnote
10
A sequence
$\mu $
be a probability measure.
Footnote
10
A sequence
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
 $\mu $
-Kurtz random if and only if
$\mu $
-Kurtz random if and only if
 $\omega $
belongs to all
$\omega $
belongs to all
 $\Sigma _1^0$
sets of
$\Sigma _1^0$
sets of
 $\mu $
-measure one.
$\mu $
-measure one.
In other words, to qualify as
 $\mu $
-Kurtz random, a sequence has to possess all the properties that correspond to
$\mu $
-Kurtz random, a sequence has to possess all the properties that correspond to
 $\mu $
-measure-theoretically typical effectively open subsets of Cantor space (such as the property of having at least one prime-numbered
$\mu $
-measure-theoretically typical effectively open subsets of Cantor space (such as the property of having at least one prime-numbered
 $0$
entry when
$0$
entry when
 $\mu $
is a nontrivial Bernoulli measure). Given that there are only countably many
$\mu $
is a nontrivial Bernoulli measure). Given that there are only countably many
 ${\rm{\Sigma }}_1^0$
sets, there are only countably many of them that have
${\rm{\Sigma }}_1^0$
sets, there are only countably many of them that have
 $\mu $
-measure one. Hence, for every
$\mu $
-measure one. Hence, for every
 $\mu $
, the collection of
$\mu $
, the collection of
 $\mu $
-Kurtz random sequences is itself a
$\mu $
-Kurtz random sequences is itself a
 $\mu $
-measure-one set.
$\mu $
-measure-one set.
Another fundamental algorithmic randomness notion is Martin-Löf randomness (Martin-Löf Reference Martin-Löf1966), which can easily be seen to entail Kurtz randomness:
Definition 3.4 (Martin-Löf randomness). Let
 $\mu $
be a probability measure. A
$\mu $
be a probability measure. A
 $\mu $
-Martin-Löf test is a computable sequence
$\mu $
-Martin-Löf test is a computable sequence
 ${\{ {{\cal U}_n}\} _{n \in \mathbb{N}}}$
of
${\{ {{\cal U}_n}\} _{n \in \mathbb{N}}}$
of
 $\Sigma _1^0$
sets with
$\Sigma _1^0$
sets with
 $\mu \left( {{{\cal U}_n}} \right) \le {2^{ - n}}$
for all
$\mu \left( {{{\cal U}_n}} \right) \le {2^{ - n}}$
for all
 $n \in \mathbb{N}$
. A sequence
$n \in \mathbb{N}$
. A sequence
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
 $\mu $
-Martin-Löf random if and only if, for all
$\mu $
-Martin-Löf random if and only if, for all
 $\mu $
-Martin-Löf tests
$\mu $
-Martin-Löf tests
 ${\{ {{\cal U}_n}\} _{n \in \mathbb{N}}}$
,
${\{ {{\cal U}_n}\} _{n \in \mathbb{N}}}$
,
 $\omega\ \notin\bigcap_{n\in\mathbb{N}}\mathcal{U}_n$
.
$\omega\ \notin\bigcap_{n\in\mathbb{N}}\mathcal{U}_n$
.
The requirement that, for a
 $\mu $
-Martin-Löf test
$\mu $
-Martin-Löf test
 ${\{ {{\cal U}_n}\} _{n \in \mathbb{N}}}$
,
${\{ {{\cal U}_n}\} _{n \in \mathbb{N}}}$
,
 $\mu \left( {{{\cal U}_n}} \right) \le {2^{ - n}}$
for all
$\mu \left( {{{\cal U}_n}} \right) \le {2^{ - n}}$
for all
 $n \in \mathbb{N}$
ensures that
$n \in \mathbb{N}$
ensures that
 $\bigcap_{n\in\mathbb{N}}\mathcal{U}_n$
is a set of effective
$\bigcap_{n\in\mathbb{N}}\mathcal{U}_n$
is a set of effective
 $\mu $
-measure zero: it is a
$\mu $
-measure zero: it is a
 $\mu $
-measure-zero set whose measure can be approximated at a computable rate (
$\mu $
-measure-zero set whose measure can be approximated at a computable rate (
 ${2^{ - n}}$
) using the measures of the components
${2^{ - n}}$
) using the measures of the components
 ${{\cal U}_n}$
of the test. And because the intersection of a computable sequence of
${{\cal U}_n}$
of the test. And because the intersection of a computable sequence of
 ${\rm{\Sigma }}_1^0$
sets is a
${\rm{\Sigma }}_1^0$
sets is a
 ${\rm{\Pi }}_2^0$
set, a sequence
${\rm{\Pi }}_2^0$
set, a sequence
 $\omega\in\{0, 1\}^\mathbb{N}$
is
$\omega\in\{0, 1\}^\mathbb{N}$
is
 $\mu $
-Martin-Löf random if and only if it does not possess any
$\mu $
-Martin-Löf random if and only if it does not possess any
 ${\rm{\Pi }}_2^0$
properties of effective
${\rm{\Pi }}_2^0$
properties of effective
 $\mu $
-measure zero—equivalently, if and only if it possesses all
$\mu $
-measure zero—equivalently, if and only if it possesses all
 ${\rm{\Sigma }}_2^0$
properties of effective
${\rm{\Sigma }}_2^0$
properties of effective
 $\mu $
-measure one. Once again, seeing that there are only countably many
$\mu $
-measure one. Once again, seeing that there are only countably many
 ${\rm{\Sigma }}_2^0$
properties of (effective)
${\rm{\Sigma }}_2^0$
properties of (effective)
 $\mu $
-measure one, the collection of
$\mu $
-measure one, the collection of
 $\mu $
-Martin-Löf random sequences is itself a
$\mu $
-Martin-Löf random sequences is itself a
 $\mu $
-measure-one set.
$\mu $
-measure-one set.
Since
 $\mu $
-Martin-Löf randomness entails
$\mu $
-Martin-Löf randomness entails
 $\mu $
-Kurtz randomness, while the reverse implication does not hold in general,
$\mu $
-Kurtz randomness, while the reverse implication does not hold in general,
 $\mu $
-Martin-Löf randomness yields a more fine-grained notion of measure-theoretic typicality than
$\mu $
-Martin-Löf randomness yields a more fine-grained notion of measure-theoretic typicality than
 $\mu $
-Kurtz randomness does; in turn,
$\mu $
-Kurtz randomness does; in turn,
 $\mu $
-Kurtz randomness provides a more fine-grained notion of measure-theoretic typicality than simply having
$\mu $
-Kurtz randomness provides a more fine-grained notion of measure-theoretic typicality than simply having
 $\mu $
-measure one.
$\mu $
-measure one.
The second family of effective typicality notions that will be relevant for our discussion falls under the umbrella of effective genericity: a theory of effective topological typicality (see Downey and Hirschfeldt Reference Downey and Hirschfeldt2010, sec. 2.24). Just as algorithmic randomness is defined in terms of membership in every measure-one set from some prespecified countable collection of sets, effective genericity essentially amounts to membership in every co-meager set from some prespecified countable collection of sets. Although there are many notions of effective genericity in the literature, here we only consider the
 $n$
-genericity hierarchy: a linearly ordered family of canonical genericity notions. We begin by defining
$n$
-genericity hierarchy: a linearly ordered family of canonical genericity notions. We begin by defining
 $1$
-genericity (the first level of the hierarchy) and discuss the rest of the hierarchy in the last section of the article.
$1$
-genericity (the first level of the hierarchy) and discuss the rest of the hierarchy in the last section of the article.
Given
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
and
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
and
 $S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
,
$S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
,
 $\omega $
is said to meet
$\omega $
is said to meet
 $S$
if
$S$
if
 ${\omega\in[S]=\bigcup_{\sigma\in S}[\sigma]}$
. A set
${\omega\in[S]=\bigcup_{\sigma\in S}[\sigma]}$
. A set
 $S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
is dense along
$S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
is dense along
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
if
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
if
 $\omega $
is in the closure of
$\omega $
is in the closure of
 $\left[ S \right]$
—in other words, if, for every
$\left[ S \right]$
—in other words, if, for every
 $n \in \mathbb{N}$
, there is some
$n \in \mathbb{N}$
, there is some
 $\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
$\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
 $\omega\restriction n\sqsubseteq \sigma$
such that
$\omega\restriction n\sqsubseteq \sigma$
such that
 $\left[ \sigma \right] \subseteq \left[ S \right]$
.
Footnote 11
Then,
$\left[ \sigma \right] \subseteq \left[ S \right]$
.
Footnote 11
Then,
 $1$
-genericity is defined as follows:
$1$
-genericity is defined as follows:
Definition 3.5 (
 $1$
-Genericity). A sequence
$1$
-Genericity). A sequence
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
 $1$
-generic if and only if
$1$
-generic if and only if
 $\omega $
meets every computably enumerable set
$\omega $
meets every computably enumerable set
 $S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
that is dense along
$S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
that is dense along
 $\omega $
.
$\omega $
.
Equivalently, a sequence is
 $1$
-generic if and only if it is not on the boundary of any
$1$
-generic if and only if it is not on the boundary of any
 ${\rm{\Sigma }}_1^0$
set. Intuitively, a
${\rm{\Sigma }}_1^0$
set. Intuitively, a
 $1$
-generic sequence
$1$
-generic sequence
 $\omega $
is such that, for any
$\omega $
is such that, for any
 ${\rm{\Sigma }}_1^0$
hypothesis
${\rm{\Sigma }}_1^0$
hypothesis
 ${\cal S}$
, if no imprecise measurement of
${\cal S}$
, if no imprecise measurement of
 $\omega $
can rule
$\omega $
can rule
 ${\cal S}$
out, then
${\cal S}$
out, then
 $\omega $
is in
$\omega $
is in
 ${\cal S}$
(and, so, satisfies the hypothesis).
${\cal S}$
(and, so, satisfies the hypothesis).
It is not difficult to see that every
 $1$
-generic sequence belongs to every dense
$1$
-generic sequence belongs to every dense
 ${\rm{\Sigma }}_1^0$
set and that every such set is co-meager. Moreover, the following well-known facts will be important for our discussion (see Kurtz Reference Kurtz1981; Nies Reference Nies2009; Downey and Hirschfeldt Reference Downey and Hirschfeldt2010).
${\rm{\Sigma }}_1^0$
set and that every such set is co-meager. Moreover, the following well-known facts will be important for our discussion (see Kurtz Reference Kurtz1981; Nies Reference Nies2009; Downey and Hirschfeldt Reference Downey and Hirschfeldt2010).
Proposition 3.6
The set of
 $1$
-generic sequences is co-meager.
$1$
-generic sequences is co-meager.
Proposition 3.7
Let
 $\mu $
be a probability measure with full support. If
$\mu $
be a probability measure with full support. If
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
 $1$
-generic, then
$1$
-generic, then
 $\omega $
is
$\omega $
is
 $\mu $
-Kurtz random.
Footnote
12
$\mu $
-Kurtz random.
Footnote
12
When
 $\mu $
is a probability measure with full support, the set of
$\mu $
is a probability measure with full support, the set of
 $\mu $
-Kurtz random sequences is thus itself a co-meager set. So, both
$\mu $
-Kurtz random sequences is thus itself a co-meager set. So, both
 $1$
-genericity and
$1$
-genericity and
 $\mu $
-Kurtz randomness provide more fine-grained notions of topological typicality than simply being co-meager.
$\mu $
-Kurtz randomness provide more fine-grained notions of topological typicality than simply being co-meager.
3.3 Continuous functions
With these taxonomic tools at our disposal, we are ready to consider some specific families of inductive problems for which Bayesian convergence to the truth is not susceptible to Belot’s charge of epistemic immodesty.
One way to achieve co-meager success is, of course, to be inductively successful no matter what data stream is observed, that is, for convergence to the truth to occur everywhere, not just almost everywhere according to the agent’s prior. So, an immediate question is whether there are any ordinary learning situations in which convergence to the truth can be achieved everywhere. In what follows, we highlight one such class of learning situations that will guide the rest of our discussion.
One simple type of inductive problem consists in estimating a continuous quantity. Quantities of this kind are naturally modeled in terms of continuous random variables. First, recall that the standard topology on
 $\mathbb{R}$
is the topology generated by the open intervals, namely, by sets of the form
$\mathbb{R}$
is the topology generated by the open intervals, namely, by sets of the form
 $\left( {a,b} \right) = \{ r \in \mathbb{R}:a,b \in \mathbb{R}\;{\rm{and\;}}a \lt r \lt b\} $
. Earlier, we introduced the Borel hierarchy of subsets of
$\left( {a,b} \right) = \{ r \in \mathbb{R}:a,b \in \mathbb{R}\;{\rm{and\;}}a \lt r \lt b\} $
. Earlier, we introduced the Borel hierarchy of subsets of
 ${\{ 0,1\} ^\mathbb{N}}$
(Definition 3.1). The very same taxonomy in terms of
${\{ 0,1\} ^\mathbb{N}}$
(Definition 3.1). The very same taxonomy in terms of
 ${\bf{\Sigma }}_n^0,{\bf{\Pi }}_n^0$
, and
${\bf{\Sigma }}_n^0,{\bf{\Pi }}_n^0$
, and
 ${\bf{\Delta }}_n^0$
sets also applies to the Borel subsets of
${\bf{\Delta }}_n^0$
sets also applies to the Borel subsets of
 $\mathbb{R}$
, where the Borel subsets of
$\mathbb{R}$
, where the Borel subsets of
 $\mathbb{R}$
are the elements of the Borel
$\mathbb{R}$
are the elements of the Borel
 $\sigma $
-algebra on
$\sigma $
-algebra on
 $\mathbb{R}$
: the smallest
$\mathbb{R}$
: the smallest
 $\sigma $
-algebra containing all open intervals. Continuous functions from
$\sigma $
-algebra containing all open intervals. Continuous functions from
 ${\{ 0,1\} ^\mathbb{N}}$
to
${\{ 0,1\} ^\mathbb{N}}$
to
 $\mathbb{R}$
are defined as follows:
$\mathbb{R}$
are defined as follows:
Definition 3.8
(Continuous function). A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is continuous if and only if, for every open (
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is continuous if and only if, for every open (
 ${\bf\Sigma} _1^0$
) subset
${\bf\Sigma} _1^0$
) subset
 ${\cal U}$
of
${\cal U}$
of
 $\mathbb{R}$
,
$\mathbb{R}$
,
 ${f^{ - 1}}\left( {\cal U} \right) = \{ \omega \in \{ {0,1{\} ^\mathbb{N}}:f\left( \omega \right) \in {\cal U}} \}$
is an open (
${f^{ - 1}}\left( {\cal U} \right) = \{ \omega \in \{ {0,1{\} ^\mathbb{N}}:f\left( \omega \right) \in {\cal U}} \}$
is an open (
 ${\bf\Sigma} _1^0$
) subset of
${\bf\Sigma} _1^0$
) subset of
 ${\{ 0,1\} ^\mathbb{N}}$
.
${\{ 0,1\} ^\mathbb{N}}$
.
Suppose an experiment is being conducted that involves measuring some real-valued physical parameter, such as the temperature at a given location or the concentration of some substance in a fluid. Such a learning situation may be modeled via the function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
that maps each sequence in
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
that maps each sequence in
 ${\{ 0,1\} ^\mathbb{N}}$
to the real number in
${\{ 0,1\} ^\mathbb{N}}$
to the real number in
 $\left[ {0,1} \right]$
of which that sequence is the binary expansion. Let the true parameter be given by
$\left[ {0,1} \right]$
of which that sequence is the binary expansion. Let the true parameter be given by
 $f\left( \omega \right)$
. Then, at each finite stage
$f\left( \omega \right)$
. Then, at each finite stage
 $n$
of the learning process, the observed data
$n$
of the learning process, the observed data
 $\omega\restriction n$
provides an approximation of
$\omega\restriction n$
provides an approximation of
 $f\left( \omega \right)$
. The map
$f\left( \omega \right)$
. The map
 $f$
is a continuous function. For another simple example of a continuous function, let
$f$
is a continuous function. For another simple example of a continuous function, let
 ${\cal U}$
be a clopen subset of
${\cal U}$
be a clopen subset of
 ${\{ 0,1\} ^\mathbb{N}}$
and take its indicator function
${\{ 0,1\} ^\mathbb{N}}$
and take its indicator function
 ${\mathbb{1}_\mathcal{U}}$
. Intuitively,
${\mathbb{1}_\mathcal{U}}$
. Intuitively,
 ${\mathbb{1}_\mathcal{U}}$
represents a binary decision problem that can be settled with a finite amount of data (such as the question of whether the first
${\mathbb{1}_\mathcal{U}}$
represents a binary decision problem that can be settled with a finite amount of data (such as the question of whether the first
 $n$
patients from a given sample all recovered after being treated for a certain disease).
$n$
patients from a given sample all recovered after being treated for a certain disease).
The following observation is entirely straightforward, but it is a useful starting point. First, note that, because Cantor space is compact, Footnote 13 every continuous function on it is bounded both below and above; Footnote 14 hence, every continuous random variable on Cantor space is integrable. When the quantity to be estimated is a continuous random variable, it is easy to see that Lévy’s Upward Theorem holds for every sequence in the support of the agent’s prior. So, when the agent’s prior has full support, Lévy’s Upward Theorem holds everywhere.
Proposition 3.9
Let
 $\mu $
be a probability measure and
$\mu $
be a probability measure and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a continuous random variable. Then, for all
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a continuous random variable. Then, for all
 $\omega \in supp\left( \mu \right)$
,
$\omega \in supp\left( \mu \right)$
,
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
. When
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
. When
 $\mu $
has full support,
$\mu $
has full support,
 $supp\left( \mu \right) = {\{ 0,1\} ^\mathbb{N}}$
, and so
$supp\left( \mu \right) = {\{ 0,1\} ^\mathbb{N}}$
, and so
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
for all
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
for all
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
.
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
.
Proof. Let
 $\omega \in {\rm{supp}}\left( \mu \right)$
. Then, for all
$\omega \in {\rm{supp}}\left( \mu \right)$
. Then, for all
 $n \in \mathbb{N}$
,
$n \in \mathbb{N}$
,
 $\mathbb{E}_\mu[f\mid {\mathfrak{F}}_n](\omega)={\int_{[\omega\restriction n]} f\, d\mu} /{\mu([ \omega\restriction n])}$
. Let
$\mathbb{E}_\mu[f\mid {\mathfrak{F}}_n](\omega)={\int_{[\omega\restriction n]} f\, d\mu} /{\mu([ \omega\restriction n])}$
. Let
 $\epsilon \gt 0$
. By continuity, there is
$\epsilon \gt 0$
. By continuity, there is
 $m \in \mathbb{N}$
such that, for all
$m \in \mathbb{N}$
such that, for all
 $\alpha\in[\omega\restriction m]$
,
$\alpha\in[\omega\restriction m]$
,
 $\left| {f\left( \omega \right) - f\left( \alpha \right)} \right| \lt \epsilon $
. Hence, for all
$\left| {f\left( \omega \right) - f\left( \alpha \right)} \right| \lt \epsilon $
. Hence, for all
 $n \ge m$
,
$n \ge m$
,
 $\Bigg|{\frac{\int_{[\omega\restriction n]} f\,d\mu} \over {\mu([\omega\restriction n])}} - f(\omega)\Bigg| \leq {\frac{\int_{[\omega\restriction n]} |f - f(\omega)|\,d\mu} \over {\mu([\omega\restriction n])}} \lt {\frac{\int_{[\omega\restriction n]} \epsilon\,d\mu} \over {\mu([\omega\restriction n])}} = \epsilon,$
$\Bigg|{\frac{\int_{[\omega\restriction n]} f\,d\mu} \over {\mu([\omega\restriction n])}} - f(\omega)\Bigg| \leq {\frac{\int_{[\omega\restriction n]} |f - f(\omega)|\,d\mu} \over {\mu([\omega\restriction n])}} \lt {\frac{\int_{[\omega\restriction n]} \epsilon\,d\mu} \over {\mu([\omega\restriction n])}} = \epsilon,$
where the first inequality holds because
 $f\left( \omega \right)$
is a constant. This establishes the claim.
$f\left( \omega \right)$
is a constant. This establishes the claim.
When the agent’s prior
 $\mu $
does not have full support, convergence to the truth is not guaranteed to happen on a co-meager set. To see this, let
$\mu $
does not have full support, convergence to the truth is not guaranteed to happen on a co-meager set. To see this, let
 $\mu $
be the probability measure that results from first flipping a coin that lands heads with probability one and then flipping a fair coin forever after.
Footnote 15
Take the indicator function
$\mu $
be the probability measure that results from first flipping a coin that lands heads with probability one and then flipping a fair coin forever after.
Footnote 15
Take the indicator function
 ${\mathbb{1}_{\left[ 0 \right]}}$
of the cylinder
${\mathbb{1}_{\left[ 0 \right]}}$
of the cylinder
 $\left[ 0 \right]$
, which, as noted earlier, is continuous. Lévy’s Upward Theorem fails everywhere on
$\left[ 0 \right]$
, which, as noted earlier, is continuous. Lévy’s Upward Theorem fails everywhere on
 $\left[ 0 \right]$
, so the success set of
$\left[ 0 \right]$
, so the success set of
 $\mu $
with respect to
$\mu $
with respect to
 ${\mathbb{1}_{\left[ 0 \right]}}$
is not co-meager, as the cylinder
${\mathbb{1}_{\left[ 0 \right]}}$
is not co-meager, as the cylinder
 $\left[ 1 \right]$
is not co-meager.
$\left[ 1 \right]$
is not co-meager.
3.4 Baire class
$n$
functions

Continuity, though natural, is a strong condition. What we will consider next is a family of functions that, relying on the classifications afforded by the Borel hierarchy, provides a broad generalization of the class of continuous functions:
Definition 3.10
(Baire class
 $n$
function). Let
$n$
function). Let
 $n \in \mathbb{N}$
. A function
$n \in \mathbb{N}$
. A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is of Baire class
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is of Baire class
 $n$
if and only if, for every
$n$
if and only if, for every
 ${\bf\Sigma} _1^0$
subset
${\bf\Sigma} _1^0$
subset
 ${\cal U}$
of
${\cal U}$
of
 $\mathbb{R}$
,
$\mathbb{R}$
,
 ${f^{ - 1}}\left( {\cal U} \right)$
is a
${f^{ - 1}}\left( {\cal U} \right)$
is a
 ${\bf\Sigma} _{n + 1}^0$
subset of
${\bf\Sigma} _{n + 1}^0$
subset of
 ${\{ 0,1\} ^\mathbb{N}}$
.
${\{ 0,1\} ^\mathbb{N}}$
.
Clearly the collection of Baire class
 $0$
functions coincides with the collection of continuous functions. Moreover, for each
$0$
functions coincides with the collection of continuous functions. Moreover, for each
 $n \in \mathbb{N}$
, every Baire class
$n \in \mathbb{N}$
, every Baire class
 $n$
function is also a Baire class
$n$
function is also a Baire class
 $\left( {n + 1} \right)$
function (while the converse does not hold).
$\left( {n + 1} \right)$
function (while the converse does not hold).
For each
 $n \ge 1$
, the indicator functions of the
$n \ge 1$
, the indicator functions of the
 ${\bf{\Delta }}_n^0$
,
${\bf{\Delta }}_n^0$
,
 ${\bf{\Sigma }}_n^0$
,
${\bf{\Sigma }}_n^0$
,
 ${\bf{\Pi }}_n^0$
, and
${\bf{\Pi }}_n^0$
, and
 ${\bf{\Delta }}_{n + 1}^0$
subsets of Cantor space are straightforward examples of Baire class
${\bf{\Delta }}_{n + 1}^0$
subsets of Cantor space are straightforward examples of Baire class
 $n$
functions. These functions have natural epistemic interpretations. For instance, the indicator functions of
$n$
functions. These functions have natural epistemic interpretations. For instance, the indicator functions of
 ${\bf{\Sigma }}_1^0$
sets intuitively capture binary decision problems membership in which can be verified with a finite amount of data, while the indicator functions of
${\bf{\Sigma }}_1^0$
sets intuitively capture binary decision problems membership in which can be verified with a finite amount of data, while the indicator functions of
 ${\bf{\Pi }}_1^0$
sets intuitively capture binary decision problems membership in which can be refuted with a finite amount of data. Similarly, the indicator functions of
${\bf{\Pi }}_1^0$
sets intuitively capture binary decision problems membership in which can be refuted with a finite amount of data. Similarly, the indicator functions of
 ${\bf{\Sigma }}_2^0$
sets correspond to binary decision problems membership in which can be verified in the limit, the indicator functions of
${\bf{\Sigma }}_2^0$
sets correspond to binary decision problems membership in which can be verified in the limit, the indicator functions of
 ${\bf{\Pi }}_2^0$
sets correspond to binary decision problems membership in which can be refuted in the limit, and the indicator functions of
${\bf{\Pi }}_2^0$
sets correspond to binary decision problems membership in which can be refuted in the limit, and the indicator functions of
 ${\bf{\Delta }}_2^0$
sets correspond to binary decision problems membership in which can be decided in the limit.
Footnote 16
${\bf{\Delta }}_2^0$
sets correspond to binary decision problems membership in which can be decided in the limit.
Footnote 16
Another family of functions that are of Baire class
 $1$
(in addition to the indicator functions of
$1$
(in addition to the indicator functions of
 ${\bf{\Delta }}_1^0$
,
${\bf{\Delta }}_1^0$
,
 ${\bf{\Sigma }}_1^0$
,
${\bf{\Sigma }}_1^0$
,
 ${\bf{\Pi }}_1^0$
, and
${\bf{\Pi }}_1^0$
, and
 ${\bf{\Delta }}_2^0$
sets) is the class of semicontinuous functions, which includes the lower semicontinuous and the upper semicontinuous functions:
${\bf{\Delta }}_2^0$
sets) is the class of semicontinuous functions, which includes the lower semicontinuous and the upper semicontinuous functions:
Definition 3.11
(Lower and upper semicontinuous functions). A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is lower semicontinuous if and only if all sets of the form
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is lower semicontinuous if and only if all sets of the form
 ${f^{ - 1}}\left( {\left( {a, + \infty } \right)} \right) = \{ \omega \in {\{ 0,1\} ^\mathbb{N}}:\;f\left( \omega \right) \gt a\} $
are
${f^{ - 1}}\left( {\left( {a, + \infty } \right)} \right) = \{ \omega \in {\{ 0,1\} ^\mathbb{N}}:\;f\left( \omega \right) \gt a\} $
are
 ${\bf\Sigma} _1^0$
. A function
${\bf\Sigma} _1^0$
. A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is upper semicontinuous if and only if all sets of the form
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is upper semicontinuous if and only if all sets of the form
 ${f^{ - 1}}\left( {\left( { - \infty ,b} \right)} \right) = \{ \omega \in {\{ 0,1\} ^\mathbb{N}}:\;f\left( \omega \right) \lt b\} $
are
${f^{ - 1}}\left( {\left( { - \infty ,b} \right)} \right) = \{ \omega \in {\{ 0,1\} ^\mathbb{N}}:\;f\left( \omega \right) \lt b\} $
are
 ${\bf\Sigma} _1^0$
.
${\bf\Sigma} _1^0$
.
Semicontinuity is a weaker form of continutiy, and it is not difficult to see that a function is continuous if and only if it is both lower semicontinuous and upper semicontinuous. The collection of lower semicontinuous functions includes the indicator functions of
 ${\bf{\Sigma }}_1^0$
sets, while the collection of upper semicontinuous functions includes the indicator functions of
${\bf{\Sigma }}_1^0$
sets, while the collection of upper semicontinuous functions includes the indicator functions of
 ${\bf{\Pi }}_1^0$
sets. For another simple example of a lower semicontinuous function (and, so, of a Baire class
${\bf{\Pi }}_1^0$
sets. For another simple example of a lower semicontinuous function (and, so, of a Baire class
 $1$
function), let
$1$
function), let
 $f$
be given by
$f$
be given by
 $f\left( \omega \right) = 1$
if
$f\left( \omega \right) = 1$
if
 $\omega $
’s prime-numbered entries feature a
$\omega $
’s prime-numbered entries feature a
 $1$
infinitely often and
$1$
infinitely often and
 $f\left( \omega \right) = 1 - {2^{ - n}}$
if
$f\left( \omega \right) = 1 - {2^{ - n}}$
if
 $\omega $
has exactly
$\omega $
has exactly
 $n \in \mathbb{N}$
prime-numbered entries featuring a
$n \in \mathbb{N}$
prime-numbered entries featuring a
 $1$
(basically, for any
$1$
(basically, for any
 $\omega $
,
$\omega $
,
 $f$
is a normalized function that counts the number of
$f$
is a normalized function that counts the number of
 $1$
s in
$1$
s in
 $\omega $
that occur at prime-numbered positions). For one last example, take a bounded function
$\omega $
that occur at prime-numbered positions). For one last example, take a bounded function
 $c:{\{ 0,1\} ^{ \lt \mathbb{N}}} \to \mathbb{R}$
recording the daily values of some stock market share. Then, the function
$c:{\{ 0,1\} ^{ \lt \mathbb{N}}} \to \mathbb{R}$
recording the daily values of some stock market share. Then, the function
 $f$
given by
$f$
given by
 $f(\omega) = \sup_{n,m \in\mathbb{N}}|c(\omega\restriction n) - c({\omega\restriction m})|$
, which tracks the greatest spread between this share’s values over its history, is lower semicontinuous. Similarly, the function
$f(\omega) = \sup_{n,m \in\mathbb{N}}|c(\omega\restriction n) - c({\omega\restriction m})|$
, which tracks the greatest spread between this share’s values over its history, is lower semicontinuous. Similarly, the function
 $g$
given by
$g$
given by
 $g(\omega) = \inf_{n,m\in\mathbb{N}}|c(\omega\restriction n) - c({\omega\restriction m})|$
, which tracks the lowest spread between the share’s values over its history, is upper semicontinuous.
$g(\omega) = \inf_{n,m\in\mathbb{N}}|c(\omega\restriction n) - c({\omega\restriction m})|$
, which tracks the lowest spread between the share’s values over its history, is upper semicontinuous.
The following is a classical result due to Baire (see Kechris Reference Kechris1995, Theorem 24.14; Oxtoby Reference Oxtoby1980, Theorem 7.3) that will help us shed light on Lévy’s Upward Theorem in the context of Baire class
 $1$
functions:
$1$
functions:
Theorem 3.12
(Baire). Let
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a function of Baire class
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a function of Baire class
 $1$
. The points of discontinuity of
$1$
. The points of discontinuity of
 $f$
form a meager
$f$
form a meager
 ${\bf\Sigma} _2^0$
set—equivalently, the points of continuity of
${\bf\Sigma} _2^0$
set—equivalently, the points of continuity of
 $f$
form a co-meager
$f$
form a co-meager
 ${\bf\Pi} _2^0$
set.
${\bf\Pi} _2^0$
set.
With Theorem 3.12 at hand, the following can easily be seen to hold:
Corollary 3.13
Let
 $\mu $
be a probability measure with full support and
$\mu $
be a probability measure with full support and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a Baire class
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a Baire class
 $1$
integrable random variable. Then, the collection of all
$1$
integrable random variable. Then, the collection of all
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
with
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
with
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
is co-meager.
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
is co-meager.
Proof. Let
 $\omega $
be a point of continuity of
$\omega $
be a point of continuity of
 $f$
. Because
$f$
. Because
 $\mu $
has full support,
$\mu $
has full support,
 $\mathbb{E}_\mu[f\mid{\mathfrak{F}}_n](\omega)={\int_{[\omega\restriction n]}f\, d\mu}/{\mu([ \omega\restriction n])}$
for all
$\mathbb{E}_\mu[f\mid{\mathfrak{F}}_n](\omega)={\int_{[\omega\restriction n]}f\, d\mu}/{\mu([ \omega\restriction n])}$
for all
 $n \in \mathbb{N}$
. By the very same argument used in the proof of Proposition 3.9,
$n \in \mathbb{N}$
. By the very same argument used in the proof of Proposition 3.9,
 ${\rm{li}}{{\rm{m}}_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
. So, the set of points of continuity of
${\rm{li}}{{\rm{m}}_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
. So, the set of points of continuity of
 $f$
is a subset of the set of sequences along which Lévy’s Upward Theorem holds. By Theorem 3.12, the former set is co-meager. Hence, so is the set of sequences along which Lévy’s Upward Theorem holds.
$f$
is a subset of the set of sequences along which Lévy’s Upward Theorem holds. By Theorem 3.12, the former set is co-meager. Hence, so is the set of sequences along which Lévy’s Upward Theorem holds.
When the underlying prior
 $\mu $
has full support, the success set of
$\mu $
has full support, the success set of
 $\mu $
relative to a Baire class
$\mu $
relative to a Baire class
 $1$
integrable random variable is a co-meager set. We thus have another class of inductive problems relative to which convergence to the truth is not only probabilistically typical but also topologically typical.
$1$
integrable random variable is a co-meager set. We thus have another class of inductive problems relative to which convergence to the truth is not only probabilistically typical but also topologically typical.
There are priors that do not have full support for which Corollary 3.13 does not hold. By virtue of being continuous, the indicator function
 ${\mathbb{1}_{\left[ 0 \right]}}$
of
${\mathbb{1}_{\left[ 0 \right]}}$
of
 $\left[ 0 \right]$
is also of Baire class
$\left[ 0 \right]$
is also of Baire class
 $1$
, and we have already mentioned an example of a probability measure that does not have full support whose success set with respect to
$1$
, and we have already mentioned an example of a probability measure that does not have full support whose success set with respect to
 ${\mathbb{1}_{\left[ 0 \right]}}$
fails to be co-meager.
${\mathbb{1}_{\left[ 0 \right]}}$
fails to be co-meager.
For
 $n \ge 2$
, it is not in general true that the points of discontinuity of a Baire class
$n \ge 2$
, it is not in general true that the points of discontinuity of a Baire class
 $n$
function form a meager set. Consider once again the set of all sequences that are eventually
$n$
function form a meager set. Consider once again the set of all sequences that are eventually
 $0$
, that is, the set
$0$
, that is, the set
 ${\cal Z} = \{ \omega \in {\{ 0,1\} ^\mathbb{N}}:{\rm{\;}}\left( {\exists n} \right)(\forall m \gt n){\rm{\;}}\omega \left( m \right) = 0\} $
. The indicator function
${\cal Z} = \{ \omega \in {\{ 0,1\} ^\mathbb{N}}:{\rm{\;}}\left( {\exists n} \right)(\forall m \gt n){\rm{\;}}\omega \left( m \right) = 0\} $
. The indicator function
 ${\mathbb{1}_{\cal Z}}$
of this set is of Baire class
${\mathbb{1}_{\cal Z}}$
of this set is of Baire class
 $2$
, yet
$2$
, yet
 ${\mathbb{1}_{\cal Z}}$
is discontinuous everywhere. Hence, the points of continuity of
${\mathbb{1}_{\cal Z}}$
is discontinuous everywhere. Hence, the points of continuity of
 ${\mathbb{1}_{\cal Z}}$
not only fail to form a co-meager set; they form a meager set (because this set is empty).
${\mathbb{1}_{\cal Z}}$
not only fail to form a co-meager set; they form a meager set (because this set is empty).
Of course, this remark does not preclude the possibility that an analogue of Corollary 3.13 may hold for Baire class
 $n$
integrable random variables in general. The following proposition establishes that Corollary 3.13 does not generalize:
$n$
integrable random variables in general. The following proposition establishes that Corollary 3.13 does not generalize:
Proposition 3.14
Let
 $\mu $
be a computable probability measure with full support.
Footnote
17
For each
$\mu $
be a computable probability measure with full support.
Footnote
17
For each
 $n \ge 2$
, there is a Baire class
$n \ge 2$
, there is a Baire class
 $n$
integrable random variable
$n$
integrable random variable
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
such that the collection of all
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
such that the collection of all
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
with
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
with
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
is meager.
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
is meager.
Proof. Let
 $\mu{-MLR}$
denote the set of
$\mu{-MLR}$
denote the set of
 $\mu $
-Martin-Löf random sequences (Definition 3.4). The computability of
$\mu $
-Martin-Löf random sequences (Definition 3.4). The computability of
 $\mu $
ensures the existence of a universal
$\mu $
ensures the existence of a universal
 $\mu $
-Martin-Löf test: a
$\mu $
-Martin-Löf test: a
 $\mu $
-Martin-Löf test
$\mu $
-Martin-Löf test
 ${\{ {{\cal V}_n}\} _{n \in \mathbb{N}}}$
such that, to determine whether a sequence is
${\{ {{\cal V}_n}\} _{n \in \mathbb{N}}}$
such that, to determine whether a sequence is
 $\mu $
-Martin-Löf random, it suffices to check whether that sequence belongs to
$\mu $
-Martin-Löf random, it suffices to check whether that sequence belongs to
 $\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
(if it does, then the sequence is not
$\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
(if it does, then the sequence is not
 $\mu $
-Martin-Löf random; if it does not, then it is) (see Downey and Hirschfeldt Reference Downey and Hirschfeldt2010, Theorem 6.2.5). Then,
$\mu $
-Martin-Löf random; if it does not, then it is) (see Downey and Hirschfeldt Reference Downey and Hirschfeldt2010, Theorem 6.2.5). Then,
 $\mu\textsf{-MLR}= \overline{\bigcap_{n\in\mathbb{N}}\mathcal{V}_n}$
. Because
$\mu\textsf{-MLR}= \overline{\bigcap_{n\in\mathbb{N}}\mathcal{V}_n}$
. Because
 $\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
is a
$\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
is a
 ${\rm{\Pi }}_2^0$
set,
${\rm{\Pi }}_2^0$
set,
 $\mu\textsf{-MLR}$
is a
$\mu\textsf{-MLR}$
is a
 ${\Sigma }_2^0$
set. A fortiori,
${\Sigma }_2^0$
set. A fortiori,
 $\mu\textsf{-MLR}$
is in
$\mu\textsf{-MLR}$
is in
 ${\bf{\Sigma }}_2^0$
. The set
${\bf{\Sigma }}_2^0$
. The set
 $\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
is also dense. For, suppose not. Then, there is some
$\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
is also dense. For, suppose not. Then, there is some
 $\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
$\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
 $\big(\bigcap_{n\in\mathbb{N}}\mathcal{V}_n\big)\cap[\sigma]=\emptyset$
. Hence,
$\big(\bigcap_{n\in\mathbb{N}}\mathcal{V}_n\big)\cap[\sigma]=\emptyset$
. Hence,
 $\left[ \sigma \right] \subseteq \mu\textsf{-MLR}$
. Take a computable sequence in
$\left[ \sigma \right] \subseteq \mu\textsf{-MLR}$
. Take a computable sequence in
 $\left[ \sigma \right]$
that is not a
$\left[ \sigma \right]$
that is not a
 $\mu $
-atom. We can find such a sequence as follows. Because
$\mu $
-atom. We can find such a sequence as follows. Because
 $\mu $
is computable, we can computably find
$\mu $
is computable, we can computably find
 ${\tau _1} \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
${\tau _1} \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
 $\mu \left( {\left[ {\sigma {\tau _1}} \right]} \right) \lt {{1} \over {2}}$
by dovetailing through the cylinders contained in
$\mu \left( {\left[ {\sigma {\tau _1}} \right]} \right) \lt {{1} \over {2}}$
by dovetailing through the cylinders contained in
 $\left[ \sigma \right]$
, approximating their respective measures from above. And, given
$\left[ \sigma \right]$
, approximating their respective measures from above. And, given
 ${\tau _1},...,{\tau _n} \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
${\tau _1},...,{\tau _n} \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
 $\mu \left( {\left[ {\sigma {\tau _1}...{\tau _n}} \right]} \right) \lt {2^{ - n}}$
, we can computably find
$\mu \left( {\left[ {\sigma {\tau _1}...{\tau _n}} \right]} \right) \lt {2^{ - n}}$
, we can computably find
 ${\tau _{n + 1}} \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
${\tau _{n + 1}} \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
with
 $\mu \left( {\left[ {\sigma {\tau _1}...{\tau _{n + 1}}} \right]} \right) \lt {2^{ - \left( {n + 1} \right)}}$
by following the same procedure inside
$\mu \left( {\left[ {\sigma {\tau _1}...{\tau _{n + 1}}} \right]} \right) \lt {2^{ - \left( {n + 1} \right)}}$
by following the same procedure inside
 $\left[ {\sigma {\tau _1}...{\tau _n}} \right]$
. Then,
$\left[ {\sigma {\tau _1}...{\tau _n}} \right]$
. Then,
 $\omega = \sigma {\tau _1}{\tau _2}...$
is a computable sequence with
$\omega = \sigma {\tau _1}{\tau _2}...$
is a computable sequence with
 $\mu \left( {\left\{ \omega \right\}} \right) = 0$
. Since the only way for a computable sequence to be
$\mu \left( {\left\{ \omega \right\}} \right) = 0$
. Since the only way for a computable sequence to be
 $\mu $
-Martin-Löf random is to be a
$\mu $
-Martin-Löf random is to be a
 $\mu $
-atom,
$\mu $
-atom,
 $\omega $
is not
$\omega $
is not
 $\mu $
-Martin-Löf random. But this contradicts the fact that
$\mu $
-Martin-Löf random. But this contradicts the fact that
 $\left[ \sigma \right] \subseteq \mu\textsf{-MLR}$
. Hence,
$\left[ \sigma \right] \subseteq \mu\textsf{-MLR}$
. Hence,
 $\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
is indeed dense. Clearly
$\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
is indeed dense. Clearly
 $\mu\textsf{-MLR} = \bigcup_{n\in\mathbb{N}} \overline{\mathcal{V}_n}$
, where each set
$\mu\textsf{-MLR} = \bigcup_{n\in\mathbb{N}} \overline{\mathcal{V}_n}$
, where each set
 $\overline {{{\cal V}_n}} $
is
$\overline {{{\cal V}_n}} $
is
 ${\rm{\Pi }}_1^0$
and, so, closed. By the density of
${\rm{\Pi }}_1^0$
and, so, closed. By the density of
 $\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
, no
$\bigcap_{n\in\mathbb{N}}\mathcal{V}_n$
, no
 $\overline {{{\cal V}_n}} $
contains any nonempty open sets. Therefore each
$\overline {{{\cal V}_n}} $
contains any nonempty open sets. Therefore each
 $\overline {{{\cal V}_n}} $
is such that its closure has empty interior; that is, each
$\overline {{{\cal V}_n}} $
is such that its closure has empty interior; that is, each
 $\overline {{{\cal V}_n}} $
is nowhere dense. Hence
$\overline {{{\cal V}_n}} $
is nowhere dense. Hence
 $\mu\textsf{-MLR}$
is meager. The indicator function
$\mu\textsf{-MLR}$
is meager. The indicator function
 ${\mathbb{1}_{\mu\textsf{-MLR}}}$
of
${\mathbb{1}_{\mu\textsf{-MLR}}}$
of
 $\mu\textsf{-MLR}$
is a Baire class
$\mu\textsf{-MLR}$
is a Baire class
 $2$
integrable random variable. And because
$2$
integrable random variable. And because
 $\mu \left( {\mu\textsf{-MLR}} \right) = 1$
and
$\mu \left( {\mu\textsf{-MLR}} \right) = 1$
and
 $\mu $
has full support, the set of sequences
$\mu $
has full support, the set of sequences
 $\alpha \in {\{ 0,1\} ^\mathbb{N}}$
with
$\alpha \in {\{ 0,1\} ^\mathbb{N}}$
with
 ${\rm{li}}{{\rm{m}}_{n \to \infty }}{\mathbb{E}_\mu }[{\mathbb{1}_{\mu\textsf{-MLR}}}|{\mathfrak{F}}_n]\left( \alpha \right) = {\mathbb{1}_{\mu\textsf{-MLR}}}\left( \alpha \right)$
coincides with
${\rm{li}}{{\rm{m}}_{n \to \infty }}{\mathbb{E}_\mu }[{\mathbb{1}_{\mu\textsf{-MLR}}}|{\mathfrak{F}}_n]\left( \alpha \right) = {\mathbb{1}_{\mu\textsf{-MLR}}}\left( \alpha \right)$
coincides with
 $\mu{-MLR}$
. Therefore the set of sequences along which Lévy’s Upward Theorem holds for
$\mu{-MLR}$
. Therefore the set of sequences along which Lévy’s Upward Theorem holds for
 ${\mathbb{1}_{\mu\textsf{-MLR}}}$
is meager. For
${\mathbb{1}_{\mu\textsf{-MLR}}}$
is meager. For
 $n \gt 2$
, we can then reason as follows.
Footnote 18
The notion of
$n \gt 2$
, we can then reason as follows.
Footnote 18
The notion of
 $\mu $
-Kurtz randomness (Definition 3.3) can be generalized to arbitrary levels of the arithmetical hierarchy: for any
$\mu $
-Kurtz randomness (Definition 3.3) can be generalized to arbitrary levels of the arithmetical hierarchy: for any
 $n \ge 1$
, a sequence is
$n \ge 1$
, a sequence is
 $\mu $
-weakly
$\mu $
-weakly
 $n$
-random if and only if it belongs to every
$n$
-random if and only if it belongs to every
 ${\rm{\Sigma }}_n^0$
set of
${\rm{\Sigma }}_n^0$
set of
 $\mu $
-measure one (so,
$\mu $
-measure one (so,
 $\mu $
-Kurtz randomness coincides with
$\mu $
-Kurtz randomness coincides with
 $\mu $
-weak
$\mu $
-weak
 $1$
-randomness). The set of
$1$
-randomness). The set of
 $\mu $
-weakly
$\mu $
-weakly
 $n$
-random sequences is in
$n$
-random sequences is in
 ${\bf{\Pi }}_{n + 1}^0$
and has
${\bf{\Pi }}_{n + 1}^0$
and has
 $\mu $
-measure one. Moreover,
$\mu $
-measure one. Moreover,
 $\mu $
-weak
$\mu $
-weak
 $\left( {n + 1} \right)$
-randomness entails
$\left( {n + 1} \right)$
-randomness entails
 $\mu $
-weak
$\mu $
-weak
 $n$
-randomness, and
$n$
-randomness, and
 $\mu $
-weak
$\mu $
-weak
 $2$
-randomness entails
$2$
-randomness entails
 $\mu $
-Martin-Löf randomness (see Downey and Hirschfeldt Reference Downey and Hirschfeldt2010, sec. 7.2). Hence, for each
$\mu $
-Martin-Löf randomness (see Downey and Hirschfeldt Reference Downey and Hirschfeldt2010, sec. 7.2). Hence, for each
 $n \gt 2$
, by the same argument used for
$n \gt 2$
, by the same argument used for
 ${\mathbb{1}_{\mu\textsf{-MLR}}}$
, the indicator function of the set of
${\mathbb{1}_{\mu\textsf{-MLR}}}$
, the indicator function of the set of
 $\mu $
-weakly
$\mu $
-weakly
 $\left( {n - 1} \right)$
-random sequences is an example of a Baire class
$\left( {n - 1} \right)$
-random sequences is an example of a Baire class
 $n$
integrable random variable for which convergence to the truth occurs on a meager set.
$n$
integrable random variable for which convergence to the truth occurs on a meager set.
Proposition 3.9 and Corollary 3.13 circumscribe the reach of Belot’s objection: they establish that, at least for relatively simple inductive problems, convergence to the truth is topologically typical, in addition to being probabilistically typical. Proposition 3.14 pulls in the opposite direction. Not only does it show that, for more complex classes of inductive problems, co-meager success is not always achievable, but it also reveals that the dichotomy problematized by Belot is perhaps more pervasive than one might have initially thought. Past the level of Baire class
 $1$
integrable random variables, co-meager failure can easily be found at every level of the Borel hierarchy.
$1$
integrable random variables, co-meager failure can easily be found at every level of the Borel hierarchy.
3.5 Computable and almost everywhere computable functions
Though well behaved, all of the functions considered so far were allowed to be arbitrarily computationally complex. We will now concentrate on effective functions—functions whose values are in some sense calculable or approximable—and provide several examples of effective random variables for which convergence to the truth is topologically typical.
The very same taxonomy we discussed in the context of the arithmetical hierarchy of subsets of Cantor space also applies to the arithmetical subsets of
 $\mathbb{R}$
. Here the
$\mathbb{R}$
. Here the
 ${\rm{\Sigma }}_1^0$
sets are those that can be expressed as a computably enumerable union of open intervals with rational endpoints, while the other levels of the hierarchy are defined in the same way as in the Cantor space setting. Computable functions from
${\rm{\Sigma }}_1^0$
sets are those that can be expressed as a computably enumerable union of open intervals with rational endpoints, while the other levels of the hierarchy are defined in the same way as in the Cantor space setting. Computable functions from
 ${\{ 0,1\} ^\mathbb{N}}$
to
${\{ 0,1\} ^\mathbb{N}}$
to
 $\mathbb{R}$
are defined as follows:
$\mathbb{R}$
are defined as follows:
Definition 3.15
(Computable function). A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is computable if and only if, for every
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is computable if and only if, for every
 $\Sigma _1^0$
subset
$\Sigma _1^0$
subset
 ${\cal U}$
of
${\cal U}$
of
 $\mathbb{R}$
,
$\mathbb{R}$
,
 ${f^{ - 1}}\left( {\cal U} \right)$
is a
${f^{ - 1}}\left( {\cal U} \right)$
is a
 $\Sigma _1^0$
subset of
$\Sigma _1^0$
subset of
 ${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
 ${\cal U}$
.Footnote
19
${\cal U}$
.Footnote
19
It is not difficult to see that the computable functions are precisely those functions whose values can be computably approximated to any degree of precision (via a computable sequence of rational-valued step functions) (see, e.g., Li and Vitányi Reference Li and Vitányi2019, 35–36).
Every open set in the standard topology on the reals can be expressed as a (countable) union of
 ${\rm{\Sigma }}_1^0$
sets. Moreover, every
${\rm{\Sigma }}_1^0$
sets. Moreover, every
 ${\rm{\Sigma }}_1^0$
subset of Cantor space is open. Therefore every computable function is continuous. Consequently, Proposition 3.9 holds for computable random variables as well. And when
${\rm{\Sigma }}_1^0$
subset of Cantor space is open. Therefore every computable function is continuous. Consequently, Proposition 3.9 holds for computable random variables as well. And when
 $\mu $
has full support, the set of sequences along which Lévy’s Upward Theorem holds is co-meager. So, a Bayesian agent with a prior with full support trying to estimate a computable quantity is guaranteed to be inductively successful on a topologically typical collection of data streams (in fact, along every data stream).
$\mu $
has full support, the set of sequences along which Lévy’s Upward Theorem holds is co-meager. So, a Bayesian agent with a prior with full support trying to estimate a computable quantity is guaranteed to be inductively successful on a topologically typical collection of data streams (in fact, along every data stream).
Much like its classical counterpart—the concept of a continuous function—the notion of a computable function is rather demanding. The following example, taken from Ackerman, Freer, and Roy (Reference Ackerman, Freer and Roy2019), nicely illustrates this point. Let
 $\theta \in \left[ {0,1} \right]$
. A
$\theta \in \left[ {0,1} \right]$
. A
 $\left\{ {0,1} \right\}$
-valued random variable
$\left\{ {0,1} \right\}$
-valued random variable
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
relative to a probability measure
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
relative to a probability measure
 $\mu $
is a
$\mu $
is a
 $\theta $
-Bernoulli random variable if
$\theta $
-Bernoulli random variable if
 $\mu (\{ \omega \in \{ {0,1{\} ^\mathbb{N}}:{\rm{\;}}f\left( \omega \right) = 1} \}) = \theta $
(i.e., if the probability that
$\mu (\{ \omega \in \{ {0,1{\} ^\mathbb{N}}:{\rm{\;}}f\left( \omega \right) = 1} \}) = \theta $
(i.e., if the probability that
 $f$
takes value
$f$
takes value
 $1$
is
$1$
is
 $\theta $
). Ackerman, Freer, and Roy show that, for any
$\theta $
). Ackerman, Freer, and Roy show that, for any
 $\theta \in \left[ {0,1} \right]$
that is not a dyadic rational, every
$\theta \in \left[ {0,1} \right]$
that is not a dyadic rational, every
 $\theta $
-Bernoulli random variable fails to be continuous and, as a result, is not computable in the sense of Definition 3.15. At the same time, for any computable
$\theta $
-Bernoulli random variable fails to be continuous and, as a result, is not computable in the sense of Definition 3.15. At the same time, for any computable
 $\theta \in \left[ {0,1} \right]$
, there are many
$\theta \in \left[ {0,1} \right]$
, there are many
 $\theta $
-Bernoulli random variables that, though not computable, are “very close” to being computable. The following, more permissive notion—almost everywhere computability—is thus generally regarded as the more natural one on which to focus in the context of (computable) probability theory (see Hoyrup Reference Hoyrup2008; Hoyrup and Rojas Reference Hoyrup and Rojas2009; Ackerman, Freer, and Roy Reference Ackerman, Freer and Roy2019).Footnote
20
$\theta $
-Bernoulli random variables that, though not computable, are “very close” to being computable. The following, more permissive notion—almost everywhere computability—is thus generally regarded as the more natural one on which to focus in the context of (computable) probability theory (see Hoyrup Reference Hoyrup2008; Hoyrup and Rojas Reference Hoyrup and Rojas2009; Ackerman, Freer, and Roy Reference Ackerman, Freer and Roy2019).Footnote
20
Definition 3.16
(Almost everywhere computable function). Let
 $\mu $
be a probability measure. A partial function
$\mu $
be a probability measure. A partial function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is
 $\mu $
-almost everywhere computable if and only if it is computable on a
$\mu $
-almost everywhere computable if and only if it is computable on a
 $\Pi _2^0$
subset of
$\Pi _2^0$
subset of
 ${\{ 0,1\} ^\mathbb{N}}$
of
${\{ 0,1\} ^\mathbb{N}}$
of
 $\mu $
-measure one, namely, if there is a
$\mu $
-measure one, namely, if there is a
 $\Pi _2^0$
set
$\Pi _2^0$
set
 ${\cal D} \subseteq {\{ 0,1\} ^\mathbb{N}}$
with
${\cal D} \subseteq {\{ 0,1\} ^\mathbb{N}}$
with
 $\mu \left( {\cal D} \right) = 1$
such that
$\mu \left( {\cal D} \right) = 1$
such that
 $f$
is defined on every
$f$
is defined on every
 $\omega \in {\cal D}$
and, for every
$\omega \in {\cal D}$
and, for every
 $\Sigma _1^0$
subset
$\Sigma _1^0$
subset
 ${\cal U}$
of
${\cal U}$
of
 $\mathbb{R}$
,
$\mathbb{R}$
,
 ${f^{ - 1}}\left( {\cal U} \right) \cap {\cal D} = {\cal U}{\rm{'}} \cap {\cal D}$
, where
${f^{ - 1}}\left( {\cal U} \right) \cap {\cal D} = {\cal U}{\rm{'}} \cap {\cal D}$
, where
 ${\cal U}{\rm{'}}$
is a
${\cal U}{\rm{'}}$
is a
 $\Sigma _1^0$
subset of
$\Sigma _1^0$
subset of
 ${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
 ${\cal U}$
.Footnote
21
${\cal U}$
.Footnote
21
The argument from the proof of Proposition 3.9 can once again be employed to establish the following fact (because almost everywhere computable random variables are integrable):
Proposition 3.17
Let
 $\mu $
be a probability measure and
$\mu $
be a probability measure and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a
 $\mu $
-almost everywhere computable random variable, with
$\mu $
-almost everywhere computable random variable, with
 ${\cal D}$
the
${\cal D}$
the
 $\Pi _2^0$
set of
$\Pi _2^0$
set of
 $\mu $
-measure one on which
$\mu $
-measure one on which
 $f$
is computable. Then, for all
$f$
is computable. Then, for all
 $\omega \in supp\left( \mu \right) \cap {\cal D}$
,
$\omega \in supp\left( \mu \right) \cap {\cal D}$
,
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.
Proof. Let
 ${\omega \in {\rm{supp}}\left( \mu \right) \cap {\cal D}}$
. Then, for all
${\omega \in {\rm{supp}}\left( \mu \right) \cap {\cal D}}$
. Then, for all
 $n \in \mathbb{N}$
,
$n \in \mathbb{N}$
,
 $\small{\mathbb{E}_\mu[\,f\mid{\mathfrak{F}}_n](\omega)={\mathop \smallint \nolimits_{[\omega\restriction n]}f\,d\mu}/{\mu([\omega\restriction n])}}$
. Let
$\small{\mathbb{E}_\mu[\,f\mid{\mathfrak{F}}_n](\omega)={\mathop \smallint \nolimits_{[\omega\restriction n]}f\,d\mu}/{\mu([\omega\restriction n])}}$
. Let
 ${\epsilon} \gt 0$
. Because
${\epsilon} \gt 0$
. Because
 $f$
is computable on
$f$
is computable on
 ${\cal D}$
,
${\cal D}$
,
 $f$
is continuous on
$f$
is continuous on
 ${\cal D}$
. Hence, there is
${\cal D}$
. Hence, there is
 $m \in \mathbb{N}$
such that, for all
$m \in \mathbb{N}$
such that, for all
 $\alpha \in {\cal D}$
, if
$\alpha \in {\cal D}$
, if
 $\alpha\in[\omega\restriction m]$
, then
$\alpha\in[\omega\restriction m]$
, then
 $\left| {f\left( \omega \right) - f\left( \alpha \right)} \right| \lt {\epsilon} $
. Therefore, for all
$\left| {f\left( \omega \right) - f\left( \alpha \right)} \right| \lt {\epsilon} $
. Therefore, for all
 $n \ge m$
,
$n \ge m$
,
 $${\left| {{\frac{{\mathop \smallint \nolimits_{\left[ {\omega \restriction n} \right]} f{\rm{\;}}d\mu }} \over {{\mu \left( {\left[ {\omega \restriction n} \right]} \right)}}} - f\left( \omega \right)} \right|} { \le {\frac{{\mathop \smallint \nolimits_{\left[ {\omega \restriction n} \right]} \left| {f - f\left( \omega \right)} \right|{\rm{\;}}d\mu }} \over {{\mu \left( {\left[ {\omega \restriction n} \right]} \right)}}}} { = {\frac{{\mathop \smallint \nolimits_{\left[ {\omega \restriction n} \right] \cap {\cal D}} \left| {f - f\left( \omega \right)} \right|{\rm{\;}}d\mu }} \over {{\mu \left( {\left[ {\omega \restriction n} \right]} \right)}}}} { \lt {\frac{{\mathop \smallint \nolimits_{\left[ {\omega \restriction n} \right] \cap {\cal D}} \epsilon {\rm{\;}}d\mu }} \over {{\mu \left( {\left[ {\omega \restriction n} \right]} \right)}}}} { = \epsilon ,}$$
$${\left| {{\frac{{\mathop \smallint \nolimits_{\left[ {\omega \restriction n} \right]} f{\rm{\;}}d\mu }} \over {{\mu \left( {\left[ {\omega \restriction n} \right]} \right)}}} - f\left( \omega \right)} \right|} { \le {\frac{{\mathop \smallint \nolimits_{\left[ {\omega \restriction n} \right]} \left| {f - f\left( \omega \right)} \right|{\rm{\;}}d\mu }} \over {{\mu \left( {\left[ {\omega \restriction n} \right]} \right)}}}} { = {\frac{{\mathop \smallint \nolimits_{\left[ {\omega \restriction n} \right] \cap {\cal D}} \left| {f - f\left( \omega \right)} \right|{\rm{\;}}d\mu }} \over {{\mu \left( {\left[ {\omega \restriction n} \right]} \right)}}}} { \lt {\frac{{\mathop \smallint \nolimits_{\left[ {\omega \restriction n} \right] \cap {\cal D}} \epsilon {\rm{\;}}d\mu }} \over {{\mu \left( {\left[ {\omega \restriction n} \right]} \right)}}}} { = \epsilon ,}$$
where both identities follow from the fact that
 $\mu \left( {\cal D} \right) = 1$
. This establishes the claim.
$\mu \left( {\cal D} \right) = 1$
. This establishes the claim.
For any probability measure
 $\mu $
with full support, the
$\mu $
with full support, the
 ${\rm{\Pi }}_2^0$
collection of sequences over which a
${\rm{\Pi }}_2^0$
collection of sequences over which a
 $\mu $
-almost everywhere computable function is computable is co-meager:
$\mu $
-almost everywhere computable function is computable is co-meager:
Proposition 3.18
Let
 $\mu $
be a probability measure with full support and
$\mu $
be a probability measure with full support and
 ${\cal D} \subseteq {\{ 0,1\} ^\mathbb{N}}$
a
${\cal D} \subseteq {\{ 0,1\} ^\mathbb{N}}$
a
 $\Pi _2^0$
set of
$\Pi _2^0$
set of
 $\mu $
-measure one. Then,
$\mu $
-measure one. Then,
 ${\cal D}$
is co-meager.
${\cal D}$
is co-meager.
Proof. Let
 ${\{ {{\cal D}_n}\} _{n \in \mathbb{N}}}$
be a computable sequence of
${\{ {{\cal D}_n}\} _{n \in \mathbb{N}}}$
be a computable sequence of
 ${\rm{\Sigma }}_1^0$
sets with
${\rm{\Sigma }}_1^0$
sets with
 $\mathcal{D} = \bigcap_{n\in\mathbb{N}}\mathcal{D}_n$
. Then,
$\mathcal{D} = \bigcap_{n\in\mathbb{N}}\mathcal{D}_n$
. Then,
 $\mu \left( {{{\cal D}_n}} \right) = 1$
for all
$\mu \left( {{{\cal D}_n}} \right) = 1$
for all
 $n \in \mathbb{N}$
, and so each
$n \in \mathbb{N}$
, and so each
 ${{\cal D}_n}$
is dense. For, suppose not. Then, there is some
${{\cal D}_n}$
is dense. For, suppose not. Then, there is some
 $n \in \mathbb{N}$
and
$n \in \mathbb{N}$
and
 $\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
such that
$\sigma \in {\{ 0,1\} ^{ \lt \mathbb{N}}}$
such that
 ${{\cal D}_n} \cap \left[ \sigma \right] = \emptyset $
. Because
${{\cal D}_n} \cap \left[ \sigma \right] = \emptyset $
. Because
 $\mu \left( {\left[ \sigma \right]} \right) \gt 0$
,
$\mu \left( {\left[ \sigma \right]} \right) \gt 0$
,
 $\mu \left( {{{\cal D}_n}} \right) \le 1 - \mu \left( {\left[ \sigma \right]} \right) \lt 1$
, which yields a contradiction. Let
$\mu \left( {{{\cal D}_n}} \right) \le 1 - \mu \left( {\left[ \sigma \right]} \right) \lt 1$
, which yields a contradiction. Let
 ${\cal U} \subseteq {\{ 0,1\} ^\mathbb{N}}$
be an arbitrary open set. Because each
${\cal U} \subseteq {\{ 0,1\} ^\mathbb{N}}$
be an arbitrary open set. Because each
 ${{\cal D}_n}$
is dense,
${{\cal D}_n}$
is dense,
 ${{\cal D}_n} \cap {\cal U} \ne \emptyset $
for all
${{\cal D}_n} \cap {\cal U} \ne \emptyset $
for all
 $n$
. Moreover, given that each
$n$
. Moreover, given that each
 ${{\cal D}_n}$
is open, each set
${{\cal D}_n}$
is open, each set
 ${{\cal D}_n} \cap {\cal U}$
is open in the subspace topology on
${{\cal D}_n} \cap {\cal U}$
is open in the subspace topology on
 ${\cal U}$
. For all
${\cal U}$
. For all
 $n$
, given that
$n$
, given that
 $\left( {\overline {{{\cal D}_n}} \cap {\cal U}} \right) \cap \left( {{{\cal D}_n} \cap {\cal U}} \right) = \emptyset $
,
$\left( {\overline {{{\cal D}_n}} \cap {\cal U}} \right) \cap \left( {{{\cal D}_n} \cap {\cal U}} \right) = \emptyset $
,
 $\overline {{{\cal D}_n}} \cap {\cal U}$
is not dense in
$\overline {{{\cal D}_n}} \cap {\cal U}$
is not dense in
 ${\cal U}$
. Hence, each
${\cal U}$
. Hence, each
 $\overline {{{\cal D}_n}} $
is nowhere dense. Therefore
$\overline {{{\cal D}_n}} $
is nowhere dense. Therefore
 $\overline{\mathcal{D}}= \bigcup_{n\in\mathbb{N}}\overline{\mathcal{D}_n}$
is meager and
$\overline{\mathcal{D}}= \bigcup_{n\in\mathbb{N}}\overline{\mathcal{D}_n}$
is meager and
 ${\cal D}$
is co-meager.
${\cal D}$
is co-meager.
Propositions 3.17 and 3.18 entail the following:
Corollary 3.19
Let
 $\mu $
be a probability measure with full support and
$\mu $
be a probability measure with full support and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a
 $\mu $
-almost everywhere computable random variable. Then, the collection of all
$\mu $
-almost everywhere computable random variable. Then, the collection of all
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
with
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
with
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
is co-meager.
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
is co-meager.
Hence, a Bayesian reasoner whose prior has full support has a co-meager success set for any random variable whose values are computably approximable.
3.6 Randomness and genericity at work
Though in and of themselves significant, convergence to the truth with probability one and convergence to the truth on a co-meager set remain somewhat elusive notions. In its classical form, Lévy’s Upward Theorem is silent as to which data streams belong to the probability-one set of sequences along which convergence to the truth provably occurs. And, more generally, proving that convergence to the truth happens with probability one or on a co-meager set provides little information about the composition of the success set. It also does not tell us how the composition of this set varies depending on the particular quantity the agent is trying to estimate, nor does it indicate whether the data streams that ensure eventual convergence to the truth share any property that might explain their conduciveness to learning—that is, any significant property that sets them apart from the data streams along which learning fails. In what follows, we address these worries from the vantage point of computability theory. In particular, we will see that the theories of algorithmic randomness and effective genericity can be put to use to identify specific topologically typical collections of data streams along which convergence to the truth in the sense of Lévy’s Upward Theorem is achieved for several classes of effective random variables.
We begin by having a second look at the class of almost everywhere computable random variables.
Recall the definition of
 $\mu $
-Kurtz randomness (Definition 3.3). Given
$\mu $
-Kurtz randomness (Definition 3.3). Given
 $\mu $
, let
$\mu $
, let
 $\mu\textsf{-KR}$
denote the set of
$\mu\textsf{-KR}$
denote the set of
 $\mu $
-Kurtz random sequences.
$\mu $
-Kurtz random sequences.
Proposition 3.20
Let
 $\mu $
be a probability measure and
$\mu $
be a probability measure and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a
 $\mu $
-almost everywhere computable function, with
$\mu $
-almost everywhere computable function, with
 ${\cal D}$
the
${\cal D}$
the
 $\mu $
-measure-one
$\mu $
-measure-one
 $\Pi _2^0$
set on which
$\Pi _2^0$
set on which
 $f$
is computable. Then,
$f$
is computable. Then,
 $\mu\textsf{-KR} \subseteq supp\left( \mu \right) \cap {\cal D}$
.
$\mu\textsf{-KR} \subseteq supp\left( \mu \right) \cap {\cal D}$
.
Proof. Let
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
. First, suppose that
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
. First, suppose that
 $\mu([\omega\restriction n])=0$
for some
$\mu([\omega\restriction n])=0$
for some
 $n \in \mathbb{N}$
. Then, there is a
$n \in \mathbb{N}$
. Then, there is a
 ${\rm{\Pi }}_1^0$
set of
${\rm{\Pi }}_1^0$
set of
 $\mu $
-measure zero,
$\mu $
-measure zero,
 $[\omega\restriction n]$
, to which
$[\omega\restriction n]$
, to which
 $\omega $
belongs, which entails that
$\omega $
belongs, which entails that
 $\omega\ \notin \mu\textsf{-KR}$
. Now, suppose that
$\omega\ \notin \mu\textsf{-KR}$
. Now, suppose that
 $\omega \in \overline {\cal D}$
. Because
$\omega \in \overline {\cal D}$
. Because
 $\overline {\cal D}$
is a
$\overline {\cal D}$
is a
 ${\rm{\Sigma }}_2^0$
set of
${\rm{\Sigma }}_2^0$
set of
 $\mu $
-measure zero,
$\mu $
-measure zero,
 $\overline{\mathcal{D}}= \bigcup_{n\in\mathbb{N}}{\mathcal{A}_n}$
, where each
$\overline{\mathcal{D}}= \bigcup_{n\in\mathbb{N}}{\mathcal{A}_n}$
, where each
 ${{\cal A}_n}$
is in
${{\cal A}_n}$
is in
 ${\rm{\Pi }}_1^0$
and has
${\rm{\Pi }}_1^0$
and has
 $\mu $
-measure zero. Therefore, there is once again a
$\mu $
-measure zero. Therefore, there is once again a
 ${\rm{\Pi }}_1^0$
set of
${\rm{\Pi }}_1^0$
set of
 $\mu $
-measure zero to which
$\mu $
-measure zero to which
 $\omega $
belongs. Hence
$\omega $
belongs. Hence
 $\omega\ \notin \mu\textsf{-KR}$
.
$\omega\ \notin \mu\textsf{-KR}$
.
By combining Proposition 3.20 with Proposition 3.17, we can immediately conclude that, for any
 $\mu $
-almost everywhere computable random variable (and, a fortiori, any computable random variable), observing a
$\mu $
-almost everywhere computable random variable (and, a fortiori, any computable random variable), observing a
 $\mu $
-Kurtz random data stream is a sufficient condition for converging to the truth in the limit:
$\mu $
-Kurtz random data stream is a sufficient condition for converging to the truth in the limit:
Corollary 3.21
Let
 $\mu $
be a probability measure and
$\mu $
be a probability measure and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
a
 $\mu $
-almost everywhere computable random variable. Then, for all
$\mu $
-almost everywhere computable random variable. Then, for all
 $\omega \in \mu\textsf{-KR}$
,
$\omega \in \mu\textsf{-KR}$
,
 $li{m_{n \to \infty }}\mathbb{E}_\mu[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.
$li{m_{n \to \infty }}\mathbb{E}_\mu[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.
When
 $\mu $
has full support, the set
$\mu $
has full support, the set
 $\mu\textsf{-KR}$
is co-meager. Hence, when the agent’s prior has full support, there is a precisely identifiable collection of data streams—one that is typical both probabilistically and topologically—membership in which guarantees convergence to the truth for any inductive problem that can be modeled as a
$\mu\textsf{-KR}$
is co-meager. Hence, when the agent’s prior has full support, there is a precisely identifiable collection of data streams—one that is typical both probabilistically and topologically—membership in which guarantees convergence to the truth for any inductive problem that can be modeled as a
 $\mu $
-almost everywhere computable random variable.
$\mu $
-almost everywhere computable random variable.
Just as the computable functions are the effective analogue of the continuous functions, Baire class
 $n$
functions can be naturally effectivized as follows:
$n$
functions can be naturally effectivized as follows:
Definition 3.22
(Effective Baire class
 $n$
function). Let
$n$
function). Let
 $n \in \mathbb{N}$
. A function
$n \in \mathbb{N}$
. A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is of effective Baire class
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is of effective Baire class
 $n$
if and only if, for every
$n$
if and only if, for every
 $\Sigma _1^0$
subset
$\Sigma _1^0$
subset
 ${\cal U}$
of
${\cal U}$
of
 $\mathbb{R}$
,
$\mathbb{R}$
,
 ${f^{ - 1}}\left( {\cal U} \right)$
is a
${f^{ - 1}}\left( {\cal U} \right)$
is a
 $\Sigma _{n + 1}^0$
subset of
$\Sigma _{n + 1}^0$
subset of
 ${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
 ${\cal U}$
.
${\cal U}$
.
For each
 $n \ge 1$
, the indicator functions of
$n \ge 1$
, the indicator functions of
 ${\rm{\Delta }}_n^0$
,
${\rm{\Delta }}_n^0$
,
 ${\rm{\Sigma }}_n^0$
,
${\rm{\Sigma }}_n^0$
,
 ${\rm{\Pi }}_n^0$
, and
${\rm{\Pi }}_n^0$
, and
 ${\rm{\Delta }}_{n + 1}^0$
sets are simple examples of effective Baire class
${\rm{\Delta }}_{n + 1}^0$
sets are simple examples of effective Baire class
 $n$
functions (this, of course, is the effective counterpart of the fact that the indicator functions of
$n$
functions (this, of course, is the effective counterpart of the fact that the indicator functions of
 ${\bf{\Delta }}_n^0$
,
${\bf{\Delta }}_n^0$
,
 ${\bf{\Sigma }}_n^0$
,
${\bf{\Sigma }}_n^0$
,
 ${\bf{\Pi }}_n^0$
, and
${\bf{\Pi }}_n^0$
, and
 ${\bf{\Delta }}_{n + 1}^0$
sets are Baire class
${\bf{\Delta }}_{n + 1}^0$
sets are Baire class
 $n$
functions in the classical setting). For instance, the indicator functions of
$n$
functions in the classical setting). For instance, the indicator functions of
 ${\rm{\Sigma }}_1^0$
sets, which intuitively correspond to binary decision problems that can be effectively verified with a finite amount of data, and the indicator functions of
${\rm{\Sigma }}_1^0$
sets, which intuitively correspond to binary decision problems that can be effectively verified with a finite amount of data, and the indicator functions of
 ${\rm{\Pi }}_1^0$
sets, which correspond to binary decision problems that can be effectively refuted with a finite amount of data, are all effective Baire class
${\rm{\Pi }}_1^0$
sets, which correspond to binary decision problems that can be effectively refuted with a finite amount of data, are all effective Baire class
 $1$
functions. For the first level of the hierarchy, another natural example is the collection of semicomputable functions:
$1$
functions. For the first level of the hierarchy, another natural example is the collection of semicomputable functions:
Definition 3.23
(Lower and upper semicomputable functions). A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is lower semicomputable if and only if all sets of the form
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is lower semicomputable if and only if all sets of the form
 ${f^{ - 1}}\left( {\left( {a, + \infty } \right)} \right)$
, with
${f^{ - 1}}\left( {\left( {a, + \infty } \right)} \right)$
, with
 $a \in \mathbb{Q}$
, are
$a \in \mathbb{Q}$
, are
 $\Sigma _1^0$
, uniformly in
$\Sigma _1^0$
, uniformly in
 $a$
. A function
$a$
. A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is upper semicomputable if and only if all sets of the form
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is upper semicomputable if and only if all sets of the form
 ${f^{ - 1}}\left( {\left( { - \infty ,b} \right)} \right)$
, with
${f^{ - 1}}\left( {\left( { - \infty ,b} \right)} \right)$
, with
 $b \in \mathbb{Q}$
, are
$b \in \mathbb{Q}$
, are
 $\Sigma _1^0$
, uniformly in
$\Sigma _1^0$
, uniformly in
 $b$
.
$b$
.
Semicomputability is the effective analogue of semicontinuity: a function is computable if and only if it is both lower semicomputable and upper semicomputable. The lower semicomputable functions are those whose values can be computably approximated from below, whereas the upper semicomputable functions are those whose values can be computably approximated from above (see Li and Vitányi Reference Li and Vitányi2019, 35–36). The collection of lower semicomputable functions includes the indicator functions of
 ${\rm{\Sigma }}_1^0$
sets, while the collection of upper semicomputable functions includes the indicator functions of
${\rm{\Sigma }}_1^0$
sets, while the collection of upper semicomputable functions includes the indicator functions of
 ${\rm{\Pi }}_1^0$
sets.
${\rm{\Pi }}_1^0$
sets.
Given that every effective Baire class
 $1$
function is a Baire class
$1$
function is a Baire class
 $1$
function in the classical sense, Theorem 3.12 and Corollary 3.13 also apply to effective Baire class
$1$
function in the classical sense, Theorem 3.12 and Corollary 3.13 also apply to effective Baire class
 $1$
integrable random variables: when the agent’s prior has full support and the quantity to be estimated is an effective Baire class
$1$
integrable random variables: when the agent’s prior has full support and the quantity to be estimated is an effective Baire class
 $1$
integrable random variable, Lévy’s Upward Theorem holds on a co-meager set of data streams.
$1$
integrable random variable, Lévy’s Upward Theorem holds on a co-meager set of data streams.
But, as with the almost everywhere computable functions, adding effectivity into the mix allows us to go beyond the mere observation that we can attain co-meager success. For effective Baire class
 $1$
functions,
$1$
functions,
 $1$
-genericity (Definition 3.28) can be used to provide a more in-depth analysis of convergence to the truth via the following effectivization of Theorem 3.12:
$1$
-genericity (Definition 3.28) can be used to provide a more in-depth analysis of convergence to the truth via the following effectivization of Theorem 3.12:
Theorem 3.24
(Kuyper and Terwijn Reference Kuyper and Terwijn2014). Let
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a function of effective Baire class
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a function of effective Baire class
 $1$
. Then,
$1$
. Then,
 $f$
is continuous at every
$f$
is continuous at every
 $1$
-generic sequence.
$1$
-generic sequence.
It then immediately follows that, for any agent whose prior has full support, observing a
 $1$
-generic data stream is conducive to learning no matter which effective Baire class
$1$
-generic data stream is conducive to learning no matter which effective Baire class
 $1$
integrable random variable that agent is trying to estimate:
$1$
integrable random variable that agent is trying to estimate:
Corollary 3.25
Let
 $\mu $
be a probability measure with full support and
$\mu $
be a probability measure with full support and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
an effective Baire class
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
an effective Baire class
 $1$
integrable random variable. Then, for every
$1$
integrable random variable. Then, for every
 $1$
-generic
$1$
-generic
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
,
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
,
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.
Because the collection of
 $1$
-generic sequences is co-meager, Corollary 3.25 allows one to pinpoint a single co-meager collection of data streams that guarantee convergence to the truth for all inductive problems that can be modeled as effective Baire class
$1$
-generic sequences is co-meager, Corollary 3.25 allows one to pinpoint a single co-meager collection of data streams that guarantee convergence to the truth for all inductive problems that can be modeled as effective Baire class
 $1$
integrable random variables.
$1$
integrable random variables.
3.7
${\emptyset ^{\left( k \right)}}$
-Computable functions and
${\emptyset ^{\left( k \right)}}$
-effective Baire class
$n$
functions



We conclude our discussion of co-meager convergence to the truth with a more technical note: by considering two collections of functions that rely on oracle computation—the
 ${\emptyset ^{\left( k \right)}}$
-computable functions and the
${\emptyset ^{\left( k \right)}}$
-computable functions and the
 ${\emptyset ^{\left( k \right)}}$
-effective Baire class
${\emptyset ^{\left( k \right)}}$
-effective Baire class
 $n$
functions.
$n$
functions.
The arithmetical hierarchy can be relativized to sequences
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
(taken to represent the indicator function of a set of natural numbers) by letting the relation
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
(taken to represent the indicator function of a set of natural numbers) by letting the relation
 $R$
be
$R$
be
 $\omega $
-computable (i.e., computable with oracle
$\omega $
-computable (i.e., computable with oracle
 $\omega $
). In this way, one obtains the notions of
$\omega $
). In this way, one obtains the notions of
 ${\rm{\Sigma }}_n^{0,\omega }$
,
${\rm{\Sigma }}_n^{0,\omega }$
,
 ${\rm{\Pi }}_n^{0,\omega }$
, and
${\rm{\Pi }}_n^{0,\omega }$
, and
 ${\rm{\Delta }}_n^{0,\omega }$
sets. From the perspective of computability theory, an especially useful collection of oracles is the class of Turing jumps of the empty set
${\rm{\Delta }}_n^{0,\omega }$
sets. From the perspective of computability theory, an especially useful collection of oracles is the class of Turing jumps of the empty set
 $\emptyset $
. The zeroth jump
$\emptyset $
. The zeroth jump
 ${\emptyset ^{\left( 0 \right)}}$
of
${\emptyset ^{\left( 0 \right)}}$
of
 $\emptyset $
is simply
$\emptyset $
is simply
 $\emptyset $
itself, which of course does not provide any additional computational power. The first jump
$\emptyset $
itself, which of course does not provide any additional computational power. The first jump
 ${\emptyset ^{\left( 1 \right)}}$
of
${\emptyset ^{\left( 1 \right)}}$
of
 $\emptyset $
is the halting set, namely, the set
$\emptyset $
is the halting set, namely, the set
 $\left\{ {n \in \mathbb{N}:{\varphi _n}\left( n \right) \downarrow } \right\}$
of all natural numbers
$\left\{ {n \in \mathbb{N}:{\varphi _n}\left( n \right) \downarrow } \right\}$
of all natural numbers
 $n$
such that the
$n$
such that the
 $n$
th partial computable function
$n$
th partial computable function
 ${\varphi _n}$
(equivalently,
${\varphi _n}$
(equivalently,
 $\varphi _n^{{\emptyset ^{\left( 0 \right)}}}$
) is defined on
$\varphi _n^{{\emptyset ^{\left( 0 \right)}}}$
) is defined on
 $n$
(the Turing machine computing
$n$
(the Turing machine computing
 ${\varphi _n}$
halts on input
${\varphi _n}$
halts on input
 $n$
). For
$n$
). For
 $k \gt 1$
, the
$k \gt 1$
, the
 $k$
th jump
$k$
th jump
 ${\emptyset ^{\left( k \right)}}$
of
${\emptyset ^{\left( k \right)}}$
of
 $\emptyset $
is the halting set relativized to
$\emptyset $
is the halting set relativized to
 ${\emptyset ^{\left( {k - 1} \right)}}$
, that is, the set
${\emptyset ^{\left( {k - 1} \right)}}$
, that is, the set
 $\{ {n \in \mathbb{N}:\varphi _n^{{\emptyset ^{\left( {k - 1} \right)}}}\left( n \right) \downarrow } \}$
of all natural numbers
$\{ {n \in \mathbb{N}:\varphi _n^{{\emptyset ^{\left( {k - 1} \right)}}}\left( n \right) \downarrow } \}$
of all natural numbers
 $n$
such that the
$n$
such that the
 $n$
th
$n$
th
 ${\emptyset ^{\left( {k - 1} \right)}}$
-partial computable function
${\emptyset ^{\left( {k - 1} \right)}}$
-partial computable function
 $\varphi _n^{{\emptyset ^{\left( {k - 1} \right)}}}$
is defined on
$\varphi _n^{{\emptyset ^{\left( {k - 1} \right)}}}$
is defined on
 $n$
. Using sets of the form
$n$
. Using sets of the form
 ${\emptyset ^{\left( k \right)}}$
(or, rather, the infinite sequences corresponding to these sets) as oracles, one obtains the classes
${\emptyset ^{\left( k \right)}}$
(or, rather, the infinite sequences corresponding to these sets) as oracles, one obtains the classes
 ${\rm{\Sigma }}_n^{0,{\emptyset ^{\left( k \right)}}}$
,
${\rm{\Sigma }}_n^{0,{\emptyset ^{\left( k \right)}}}$
,
 ${\rm{\Pi }}_n^{0,{\emptyset ^{\left( k \right)}}}$
, and
${\rm{\Pi }}_n^{0,{\emptyset ^{\left( k \right)}}}$
, and
 ${\rm{\Delta }}_n^{0,{\emptyset ^{\left( k \right)}}}$
. For instance, a set
${\rm{\Delta }}_n^{0,{\emptyset ^{\left( k \right)}}}$
. For instance, a set
 ${\cal S}$
is
${\cal S}$
is
 ${\rm{\Sigma }}_1^{0,{\emptyset ^{\left( k \right)}}}$
if and only if there is a
${\rm{\Sigma }}_1^{0,{\emptyset ^{\left( k \right)}}}$
if and only if there is a
 ${\rm{\Sigma }}_{k + 1}^0$
set
${\rm{\Sigma }}_{k + 1}^0$
set
 $S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
—namely, a set of strings
$S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
—namely, a set of strings
 $S$
that is computably enumerable relative to the
$S$
that is computably enumerable relative to the
 $k$
th jump
$k$
th jump
 ${\emptyset ^{\left( k \right)}}$
of
${\emptyset ^{\left( k \right)}}$
of
 $\emptyset $
—such that
$\emptyset $
—such that
 ${\cal S} = \left[ S \right]$
(see Soare Reference Soare2016, chaps. 3 and 4).
${\cal S} = \left[ S \right]$
(see Soare Reference Soare2016, chaps. 3 and 4).
The notion of a
 ${\emptyset ^{\left( k \right)}}$
-computable function is defined as follows:
${\emptyset ^{\left( k \right)}}$
-computable function is defined as follows:
Definition 3.26
(
 ${\emptyset ^{\left( k \right)}}$
-Computable function). Let
${\emptyset ^{\left( k \right)}}$
-Computable function). Let
 $k \in \mathbb{N}$
. A function
$k \in \mathbb{N}$
. A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is
 ${\emptyset ^{\left( k \right)}}$
-computable if and only if, for every
${\emptyset ^{\left( k \right)}}$
-computable if and only if, for every
 $\Sigma _1^0$
subset
$\Sigma _1^0$
subset
 ${\cal U}$
of
${\cal U}$
of
 $\mathbb{R}$
,
$\mathbb{R}$
,
 ${f^{ - 1}}\left( {\cal U} \right)$
is a
${f^{ - 1}}\left( {\cal U} \right)$
is a
 $\Sigma _1^{0,{\emptyset ^{\left( k \right)}}}$
subset of
$\Sigma _1^{0,{\emptyset ^{\left( k \right)}}}$
subset of
 ${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
 ${\cal U}$
.
${\cal U}$
.
The indicator functions of
 ${\rm{\Delta }}_1^{0,{\emptyset ^{\left( k \right)}}}$
sets are simple instances of
${\rm{\Delta }}_1^{0,{\emptyset ^{\left( k \right)}}}$
sets are simple instances of
 ${\emptyset ^{\left( k \right)}}$
-computable functions. For
${\emptyset ^{\left( k \right)}}$
-computable functions. For
 $k \ge 1$
, functions of this type can be thought of as binary decision problems that are not in themselves decidable but become decidable having access to the background information encapsulated by
$k \ge 1$
, functions of this type can be thought of as binary decision problems that are not in themselves decidable but become decidable having access to the background information encapsulated by
 ${\emptyset ^{\left( k \right)}}$
(or any other problem of the same complexity). More generally, a
${\emptyset ^{\left( k \right)}}$
(or any other problem of the same complexity). More generally, a
 ${\emptyset ^{\left( k \right)}}$
-computable function is one whose values can be computably approximated to any degree of precision with background information
${\emptyset ^{\left( k \right)}}$
-computable function is one whose values can be computably approximated to any degree of precision with background information
 ${\emptyset ^{\left( k \right)}}$
.
${\emptyset ^{\left( k \right)}}$
.
Crucially, for all
 $k \in \mathbb{N}$
, the
$k \in \mathbb{N}$
, the
 ${\rm{\Sigma }}_1^{0,{\emptyset ^{\left( k \right)}}}$
subsets of
${\rm{\Sigma }}_1^{0,{\emptyset ^{\left( k \right)}}}$
subsets of
 ${\{ 0,1\} ^\mathbb{N}}$
are open. Hence, just like the computable functions, the
${\{ 0,1\} ^\mathbb{N}}$
are open. Hence, just like the computable functions, the
 ${\emptyset ^{\left( k \right)}}$
-computable functions are continuous. By Proposition 3.9, the set of data streams that satisfy Lévy’s Upward Theorem relative to a
${\emptyset ^{\left( k \right)}}$
-computable functions are continuous. By Proposition 3.9, the set of data streams that satisfy Lévy’s Upward Theorem relative to a
 ${\emptyset ^{\left( k \right)}}$
-computable random variable is thus co-meager, as long as the agent’s prior has full support. And because, for any probability measure
${\emptyset ^{\left( k \right)}}$
-computable random variable is thus co-meager, as long as the agent’s prior has full support. And because, for any probability measure
 $\mu $
, every
$\mu $
, every
 $\mu $
-Kurtz random sequence is in the support of
$\mu $
-Kurtz random sequence is in the support of
 $\mu $
, observing a
$\mu $
, observing a
 $\mu $
-Kurtz random data stream suffices to converge to the truth for any
$\mu $
-Kurtz random data stream suffices to converge to the truth for any
 ${\emptyset ^{\left( k \right)}}$
-computable random variable. So, the collection of
${\emptyset ^{\left( k \right)}}$
-computable random variable. So, the collection of
 $\mu $
-Kurtz random sequences once again provides a crisp example of a set of data streams along which convergence to the truth is guaranteed to occur.
$\mu $
-Kurtz random sequences once again provides a crisp example of a set of data streams along which convergence to the truth is guaranteed to occur.
A
 ${\emptyset ^{\left( k \right)}}$
-effective Baire class
${\emptyset ^{\left( k \right)}}$
-effective Baire class
 $n$
function is instead defined as follows:
$n$
function is instead defined as follows:
Definition 3.27
(
 ${\emptyset ^{\left( k \right)}}$
-Effective Baire class
${\emptyset ^{\left( k \right)}}$
-Effective Baire class
 $n$
function). Let
$n$
function). Let
 $k,n \in \mathbb{N}$
. A function
$k,n \in \mathbb{N}$
. A function
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is of
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
is of
 ${\emptyset ^{\left( k \right)}}$
-effective Baire class
${\emptyset ^{\left( k \right)}}$
-effective Baire class
 $n$
if and only if, for every
$n$
if and only if, for every
 $\Sigma _1^0$
subset
$\Sigma _1^0$
subset
 ${\cal U}$
of
${\cal U}$
of
 $\mathbb{R}$
,
$\mathbb{R}$
,
 ${f^{ - 1}}\left( {\cal U} \right)$
is a
${f^{ - 1}}\left( {\cal U} \right)$
is a
 $\Sigma _{n + 1}^{0,{\emptyset ^{\left( k \right)}}}$
subset of
$\Sigma _{n + 1}^{0,{\emptyset ^{\left( k \right)}}}$
subset of
 ${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
${\{ 0,1\} ^\mathbb{N}}$
, uniformly in a code for
 ${\cal U}$
.
${\cal U}$
.
The indicator functions of
 ${\rm{\Delta }}_n^{0,{\emptyset ^{\left( k \right)}}}$
,
${\rm{\Delta }}_n^{0,{\emptyset ^{\left( k \right)}}}$
,
 ${\rm{\Sigma }}_n^{0,{\emptyset ^{\left( k \right)}}}$
,
${\rm{\Sigma }}_n^{0,{\emptyset ^{\left( k \right)}}}$
,
 ${\rm{\Pi }}_n^{0,{\emptyset ^{\left( k \right)}}}$
, and
${\rm{\Pi }}_n^{0,{\emptyset ^{\left( k \right)}}}$
, and
 ${\rm{\Delta }}_{n + 1}^{0,{\emptyset ^{\left( k \right)}}}$
sets are all of
${\rm{\Delta }}_{n + 1}^{0,{\emptyset ^{\left( k \right)}}}$
sets are all of
 ${\emptyset ^{\left( k \right)}}$
-effective Baire class
${\emptyset ^{\left( k \right)}}$
-effective Baire class
 $n$
. For instance, the indicator functions of
$n$
. For instance, the indicator functions of
 ${\rm{\Sigma }}_1^{0,{\emptyset ^{\left( k \right)}}}$
sets, which correspond to binary decision problems that can be effectively verified having access to
${\rm{\Sigma }}_1^{0,{\emptyset ^{\left( k \right)}}}$
sets, which correspond to binary decision problems that can be effectively verified having access to
 ${\emptyset ^{\left( k \right)}}$
, are all of
${\emptyset ^{\left( k \right)}}$
, are all of
 ${\emptyset ^{\left( k \right)}}$
-effective Baire class
${\emptyset ^{\left( k \right)}}$
-effective Baire class
 $1$
, whereas the indicator functions of
$1$
, whereas the indicator functions of
 ${\rm{\Sigma }}_2^{0,{\emptyset ^{\left( k \right)}}}$
sets, which correspond to binary decision problems that can be effectively verified in the limit having access to
${\rm{\Sigma }}_2^{0,{\emptyset ^{\left( k \right)}}}$
sets, which correspond to binary decision problems that can be effectively verified in the limit having access to
 ${\emptyset ^{\left( k \right)}}$
, are all of
${\emptyset ^{\left( k \right)}}$
, are all of
 ${\emptyset ^{\left( k \right)}}$
-effective Baire class
${\emptyset ^{\left( k \right)}}$
-effective Baire class
 $2$
.
$2$
.
Once again, because every
 ${\emptyset ^{\left( k \right)}}$
-effective Baire class
${\emptyset ^{\left( k \right)}}$
-effective Baire class
 $1$
function
$1$
function
 $f$
is a Baire class
$f$
is a Baire class
 $1$
function, Theorem 3.12 and Corollary 3.13 both apply: the points of continuity of
$1$
function, Theorem 3.12 and Corollary 3.13 both apply: the points of continuity of
 $f$
form a co-meager
$f$
form a co-meager
 ${\bf{\Pi }}_2^0$
set, and, for any prior with full support, the collection of data streams along which Lévy’s Upward Theorem holds with respect to
${\bf{\Pi }}_2^0$
set, and, for any prior with full support, the collection of data streams along which Lévy’s Upward Theorem holds with respect to
 $f$
(when
$f$
(when
 $f$
is an integrable random variable) is co-meager. As with effective Baire class
$f$
is an integrable random variable) is co-meager. As with effective Baire class
 $1$
functions, we can, however, say more.
$1$
functions, we can, however, say more.
First, note that the notion of
 $1$
-genericity introduced earlier can be generalized as follows to any positive natural number:
$1$
-genericity introduced earlier can be generalized as follows to any positive natural number:
Definition 3.28
(
 $n$
-Genericity). Let
$n$
-Genericity). Let
 $n \ge 1$
. A sequence
$n \ge 1$
. A sequence
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
is
 $n$
-generic if and only if
$n$
-generic if and only if
 $\omega $
meets every
$\omega $
meets every
 $\Sigma _n^0$
set
$\Sigma _n^0$
set
 $S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
that is dense along
$S \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
that is dense along
 $\omega $
.
$\omega $
.
For every
 $n \ge 1$
,
$n \ge 1$
,
 $\left( {n + 1} \right)$
-genericity entails
$\left( {n + 1} \right)$
-genericity entails
 $n$
-genericity, but the reverse implication does not hold. Moreover, the fact that the set of
$n$
-genericity, but the reverse implication does not hold. Moreover, the fact that the set of
 $1$
-generic sequences is topologically typical generalizes to the entire hierarchy (see Kurtz Reference Kurtz1981; Nies Reference Nies2009; Downey and Hirschfeldt Reference Downey and Hirschfeldt2010):
$1$
-generic sequences is topologically typical generalizes to the entire hierarchy (see Kurtz Reference Kurtz1981; Nies Reference Nies2009; Downey and Hirschfeldt Reference Downey and Hirschfeldt2010):
Proposition 3.29
Let
 $n \ge 1$
. The set of
$n \ge 1$
. The set of
 $n$
-generic sequences is co-meager.
$n$
-generic sequences is co-meager.
The following is proven analogously to Theorem 3.24:
Theorem 3.30
Let
 $k \ge 1$
and
$k \ge 1$
and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a function of
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a function of
 ${\emptyset ^{\left( {k - 1} \right)}}$
-effective Baire class
${\emptyset ^{\left( {k - 1} \right)}}$
-effective Baire class
 $1$
. Then,
$1$
. Then,
 $f$
is continuous at every
$f$
is continuous at every
 $k$
-generic sequence.
$k$
-generic sequence.
Proof. Let
 ${{\cal S}_0},{{\cal S}_1},{{\cal S}_2},...$
be a fixed effective enumeration of the
${{\cal S}_0},{{\cal S}_1},{{\cal S}_2},...$
be a fixed effective enumeration of the
 ${\rm{\Sigma }}_1^0$
subsets of
${\rm{\Sigma }}_1^0$
subsets of
 $\mathbb{R}$
. Recall that
$\mathbb{R}$
. Recall that
 $f$
being discontinuous at
$f$
being discontinuous at
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
means that there is an open subset
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
means that there is an open subset
 ${\cal O}$
of
${\cal O}$
of
 $\mathbb{R}$
with
$\mathbb{R}$
with
 $f\left( \omega \right) \in {\cal O}$
, but, for all open
$f\left( \omega \right) \in {\cal O}$
, but, for all open
 ${\cal U} \subseteq {f^{ - 1}}\left( {\cal O} \right)$
,
${\cal U} \subseteq {f^{ - 1}}\left( {\cal O} \right)$
,
 $\omega\ \notin \,\,{\cal U}$
. In other words,
$\omega\ \notin \,\,{\cal U}$
. In other words,
 $\omega \in {f^{ - 1}}\left( {\cal O} \right)$
, but
$\omega \in {f^{ - 1}}\left( {\cal O} \right)$
, but
 $\omega\ \notin \,\,{\rm{Int}}\left( {{f^{ - 1}}\left( {\cal O} \right)} \right)$
. Every open set is a union of
$\omega\ \notin \,\,{\rm{Int}}\left( {{f^{ - 1}}\left( {\cal O} \right)} \right)$
. Every open set is a union of
 ${\rm{\Sigma }}_1^0$
sets, so
${\rm{\Sigma }}_1^0$
sets, so
 ${\{\omega\in\{0,1\}^\mathbb{N}:\, f\ {\rm is\ discontinuous\ at\ }\omega\}=\bigcup_{n\in\mathbb{N}}\big(\,{f^{-1}(\mathcal{S}_n)\setminus \text{Int}(\,{{\it{f}}^{-1}(\mathcal{S}_{\it n}))}}\big)}$
. Let
${\{\omega\in\{0,1\}^\mathbb{N}:\, f\ {\rm is\ discontinuous\ at\ }\omega\}=\bigcup_{n\in\mathbb{N}}\big(\,{f^{-1}(\mathcal{S}_n)\setminus \text{Int}(\,{{\it{f}}^{-1}(\mathcal{S}_{\it n}))}}\big)}$
. Let
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
be such that
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
be such that
 $f$
is discontinuous at
$f$
is discontinuous at
 $\omega $
. Then, there is
$\omega $
. Then, there is
 $m \in \mathbb{N}$
with
$m \in \mathbb{N}$
with
 $\omega \in {f^{ - 1}}\left( {{{\cal S}_m}} \right)\backslash {\rm{Int}}\left( {{f^{ - 1}}\left( {{{\cal S}_m}} \right)} \right)$
. Given that
$\omega \in {f^{ - 1}}\left( {{{\cal S}_m}} \right)\backslash {\rm{Int}}\left( {{f^{ - 1}}\left( {{{\cal S}_m}} \right)} \right)$
. Given that
 $f$
is of
$f$
is of
 ${\emptyset ^{\left( {k - 1} \right)}}$
-effective Baire class
${\emptyset ^{\left( {k - 1} \right)}}$
-effective Baire class
 $1$
, by definition,
$1$
, by definition,
 ${f^{ - 1}}\left( {{{\cal S}_m}} \right)$
is a
${f^{ - 1}}\left( {{{\cal S}_m}} \right)$
is a
 ${\rm{\Sigma }}_2^{0,{\emptyset ^{\left( {k - 1} \right)}}}$
subset of
${\rm{\Sigma }}_2^{0,{\emptyset ^{\left( {k - 1} \right)}}}$
subset of
 ${\{ 0,1\} ^\mathbb{N}}$
. Hence
${\{ 0,1\} ^\mathbb{N}}$
. Hence
 $f^{-1}(\mathcal{S}_m)=\bigcup_{i\in\mathbb{N}}\mathcal{C}_i$
, where each
$f^{-1}(\mathcal{S}_m)=\bigcup_{i\in\mathbb{N}}\mathcal{C}_i$
, where each
 ${{\cal C}_i}$
is a
${{\cal C}_i}$
is a
 ${\rm{\Pi }}_1^{0,{\emptyset ^{\left( {k - 1} \right)}}}$
set. So,
${\rm{\Pi }}_1^{0,{\emptyset ^{\left( {k - 1} \right)}}}$
set. So,
 ${f^{ - 1}}({{\cal S}_m}) \setminus {\rm{Int}}({\mkern 1mu} {f^{ - 1}}({{\cal S}_m})) = { \cup _{i \in }}{{\cal C}_i} \setminus {\rm{Int}}({ \cup _{i \in }}{{\cal C}_i}) \subseteq { \cup _{i \in }}({{\cal C}_i}\backslash {\rm{Int(}}{{\cal C}_i}{\rm{))}}$
. Thus there is
${f^{ - 1}}({{\cal S}_m}) \setminus {\rm{Int}}({\mkern 1mu} {f^{ - 1}}({{\cal S}_m})) = { \cup _{i \in }}{{\cal C}_i} \setminus {\rm{Int}}({ \cup _{i \in }}{{\cal C}_i}) \subseteq { \cup _{i \in }}({{\cal C}_i}\backslash {\rm{Int(}}{{\cal C}_i}{\rm{))}}$
. Thus there is
 $j \in \mathbb{N}$
with
$j \in \mathbb{N}$
with
 $\omega \in {{\cal C}_j}\backslash {\rm{Int}}\left( {{{\cal C}_j}} \right)$
, which means that
$\omega \in {{\cal C}_j}\backslash {\rm{Int}}\left( {{{\cal C}_j}} \right)$
, which means that
 $\omega \in {{\cal C}_j} \cap {\rm{Cl}}\left( {\overline {{{\cal C}_{j}}} } \right)$
. Because
$\omega \in {{\cal C}_j} \cap {\rm{Cl}}\left( {\overline {{{\cal C}_{j}}} } \right)$
. Because
 $\overline {{{\cal C}_j}} $
is a
$\overline {{{\cal C}_j}} $
is a
 ${\rm{\Sigma }}_1^{0,{\emptyset ^{\left( {k - 1} \right)}}}$
set,
${\rm{\Sigma }}_1^{0,{\emptyset ^{\left( {k - 1} \right)}}}$
set,
 $\overline {{{\cal C}_j}} = \left[ C \right]$
for some
$\overline {{{\cal C}_j}} = \left[ C \right]$
for some
 ${\rm{\Sigma }}_k^0$
set
${\rm{\Sigma }}_k^0$
set
 $C \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
. And because
$C \subseteq {\{ 0,1\} ^{ \lt \mathbb{N}}}$
. And because
 $\omega \in {\rm{Cl}}\left( {\left[ C \right]} \right)$
,
$\omega \in {\rm{Cl}}\left( {\left[ C \right]} \right)$
,
 $C$
is dense along
$C$
is dense along
 $\omega $
. However,
$\omega $
. However,
 $\omega $
does not meet
$\omega $
does not meet
 $C$
, as
$C$
, as
 $\omega \,\notin \,\left[ C \right] = \overline {{{\cal C}_j}} $
. Therefore
$\omega \,\notin \,\left[ C \right] = \overline {{{\cal C}_j}} $
. Therefore
 $\omega $
is not
$\omega $
is not
 $k$
-generic.
$k$
-generic.
Theorem 3.30 entails that, for any Bayesian reasoner whose prior has full support, observing a
 $k$
-generic data stream leads to inductive success for any inductive problem corresponding to a
$k$
-generic data stream leads to inductive success for any inductive problem corresponding to a
 ${\emptyset ^{\left( {{k} - 1} \right)}}$
-effective Baire class
${\emptyset ^{\left( {{k} - 1} \right)}}$
-effective Baire class
 $1$
integrable random variable:
$1$
integrable random variable:
Corollary 3.31
Let
 $k \ge 1$
,
$k \ge 1$
,
 $\mu $
be a probability measure with full support, and
$\mu $
be a probability measure with full support, and
 $f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a
$f:{\{ 0,1\} ^\mathbb{N}} \to \mathbb{R}$
be a
 ${\emptyset ^{\left( {k - 1} \right)}}$
-effective Baire class
${\emptyset ^{\left( {k - 1} \right)}}$
-effective Baire class
 $1$
integrable random variable. Then, for every
$1$
integrable random variable. Then, for every
 $k$
-generic
$k$
-generic
 $\omega \in {\{ 0,1\} ^\mathbb{N}}$
,
$\omega \in {\{ 0,1\} ^\mathbb{N}}$
,
 $li{m_{n \to \infty }}{\mathbb{E}_\mu }[\,f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.
$li{m_{n \to \infty }}{\mathbb{E}_\mu }[\,f|{\mathfrak{F}}_n]\left( \omega \right) = f\left( \omega \right)$
.
As noted earlier, the set of
 $k$
-generic sequences is co-meager. Hence Corollary 3.31 reveals that, for priors with full support, we can once again single out a specific co-meager collection of data streams along which convergence to the truth happens for all
$k$
-generic sequences is co-meager. Hence Corollary 3.31 reveals that, for priors with full support, we can once again single out a specific co-meager collection of data streams along which convergence to the truth happens for all
 ${\emptyset ^{\left( {k - 1} \right)}}$
-effective Baire class
${\emptyset ^{\left( {k - 1} \right)}}$
-effective Baire class
 $1$
integrable random variables.
$1$
integrable random variables.
4 Conclusion
According to Belot (Reference Belot2013), Bayesian learners are unavoidably epistemically orgulous: the Bayesian framework, with its convergence-to-the-truth results, compels them to be confident in their ability to be inductively successful even when there are co-meager many data streams along which learning, as a matter of fact, fails.
In this article, we set out to elucidate how pervasive the issue Belot identified is. We suggested using descriptive set theory and computability theory to classify the inductive problems (random variables) faced by Bayesian agents in terms of their complexity. Then, relying on this taxonomy, we provided an analysis of the conditions under which inductive success is both probabilistically and topologically typical and the conditions under which these two notions of typicality instead come apart.
We showed that there are several classes of random variables admitting natural epistemic interpretations for which the dichotomy Belot highlights does not arise: for the inductive problems in these classes, Lévy’s Upward Theorem holds both with probability one (relative to the agent’s prior) and on a co-meager set of data streams. Specifically, the collections of inductive problems for which we established that success is topologically typical, in addition to being probabilistically typical, are the classes of random variables listed in Figure 1.

Figure 1. Classes of random variables for which convergence to the truth occurs on a co-meager set.
The random variables for which we proved that convergence to the truth happens on a co-meager set correspond to natural but relatively simple inductive problems (they include, for instance, all binary decision problems that can be verified or refuted with a finite amount of data and all binary decision problems that can be decided in the limit). For more complex families of inductive problems (in fact, for the entire hierarchy of Baire class
 $n$
integrable random variables starting at level
$n$
integrable random variables starting at level
 $2$
), we showed that there are problems for which convergence to the truth happens only on a meager set. Hence, the proposed taxonomy may also be leveraged to add to Belot’s negative results and reveal that “Bayesian orgulity” is, relative to this classification at least, a pervasive phenomenon.
$2$
), we showed that there are problems for which convergence to the truth happens only on a meager set. Hence, the proposed taxonomy may also be leveraged to add to Belot’s negative results and reveal that “Bayesian orgulity” is, relative to this classification at least, a pervasive phenomenon.
Classical notions of measure-theoretic and topological typicality can be used to prove that convergence to the truth happens along the “vast majority” of data streams, but they convey little information as to what kind of data streams are conducive to inductive learning, depending on the particular inductive problem at hand. We saw that, in the effective setting, it is possible to get a much crisper understanding of the success sets of Bayesian agents. In particular, we showed that the theories of algorithmic randomness and effective genericity (which are theories of effective measure-theoretic typicality and effective topological typicality, respectively) can be employed to single out specific co-meager collections of data streams along which Lévy’s Upward Theorem holds, no matter which inductive problem from the classes of effective random variables listed in Figure 1 the agent is trying to solve.
Our findings, while preliminary, evince that the taxonomy of inductive problems afforded by descriptive set theory and computability theory is a promising lens through which to probe Bayesian convergence-to-the-truth theorems. In particular, they suggest that, by further analyzing the inductive problems Bayesian learners face in terms of their complexity, we may be able to come to understand the full reach of Belot’s objection. Moreover, quite aside from Belot’s concerns, the approach adopted in this article also offers a natural framework within which to investigate the following general question: how does the complexity of a Bayesian learner’s success set, understood in either topological or computability-theoretic terms, vary as a function of the complexity of the inductive problem faced by the learner?
Acknowledgments
I am especially indebted to Krzysztof Mierzewski for his extensive and insightful comments on various iterations of this article. I am also grateful to the two anonymous referees for their valuable suggestions and to Gordon Belot, Kevin Dorst, Simon Huttegger, Kevin Kelly, Teddy Seidenfeld, Sean Walsh, Snow Zhang, and Kevin Zollman for many illuminating questions and discussions. Last, I thank the participants at the Logic Seminar at Peking University, the Formal Rationality Forum, the Logic and Philosophy of Science Group at the University of Toronto, and the session “What’s New in Formal Epistemology?” at the 17th Congress on Logic, Methodology, and Philosophy of Science and Technology for their helpful questions.



















































































































































 Open access
Open access