



1. Introduction
In this study, English as a foreign language (EFL) learners’ communication strategy (CS) use was analyzed in three different environments, namely videoconferencing (VC), virtual world (VW), and face-to-face (F2F), from a psycholinguistic perspective. Specifically, the study was conducted to reveal the distribution and frequency of participants’ CS use in the three different environments and to find out whether they used any other strategies that were not included in the taxonomies presented so far in the literature. The motives for the participants’ CS use were investigated by taking Levelt’s (1989) L1 speech production model (SPM) and de Bot’s (1992) bilingual SPM as the basis and the CSs were identified accordingly. Therefore, the study was guided by the following research questions:
-
1. What CSs were used by the participants in VC, VW and F2F environments?
-
2. What is the frequency of CS use by the participants in VC, VW and F2F environments?
Even though many CS studies have been conducted from the interactionist perspective (both in computer-mediated communication [CMC] and F2F environments), as well as studies conducted F2F adopting a psycholinguistic perspective in the literature, as yet (to the best of the researchers’ knowledge) no other study has been conducted in CMC environments investigating the CS use of EFL learners from the psycholinguistic perspective. This is a critical gap because, according to the psycholinguistic perspective, understanding the underlying reasons for the use of CSs is crucial to accurately identify them. In this study, both in the F2F and CMC environments, the participants’ CS use was investigated from the psycholinguistic perspective.
2. Literature review
2.1 Theoretical perspectives
As followers of one of the two theoretical perspectives, interactionist researchers define and classify CSs only by observing the outputs of the speakers, while psycholinguist researchers take into account the cognitive processes the speakers have undertaken while using CSs and define CSs by focusing on the communicative problems underlying their use. The L1 SPM (Levelt, Reference Levelt1989) has been the most widely accepted theoretical framework among psycholinguists and has served as the foundation for numerous experimental studies (Dörnyei & Kormos, Reference Dörnyei and Kormos1998; Poulisse, Reference Poulisse, Schreuder and Weltens1993). It covers the time frame from conceptualizing the communicative intention of the speaker into a preverbal message and on to the articulation of the overt speech. In the model, there are three monitor loops (for the representation of Levelt’s model, see Dörnyei & Kormos, Reference Dörnyei and Kormos1998: 352) whose functions are to check if anything is amiss with the speaker’s outputs at various levels of the speech production process. When the speaker detects something wrong with their output after or before articulation, they could start over in coding their message, change some or all of their message or repair it. The speaker could also repair it when they cannot negotiate with their interlocutor. Since Levelt’s model was originally designed for L1 speakers, in this study it was necessary to adopt an L2 SPM. De Bot (1992) designed his L2 SPM by adapting it from Levelt’s L1 SPM; therefore, this study was based on both Levelt’s and de Bot’s SPMs. Poulisse and Bongaerts (Reference Poulisse and Bongaerts1994) claim that de Bot’s model is the only one that fully describes the L2 speech production process. In contrast to Levelt’s model, in de Bot’s model, the L2 speaker has two conceptualizers (by which the language of the message is specified) and two formulators (by which the syntactic, morphological, and phonological processes of the language to be used are determined). Since there is an interaction between the languages of an L2 speaker, the CSs such as tip-of-the-tongue phenomenon, code-switching, use of similar-sounding words and many other CSs could be explained via de Bot’s model.
As Dörnyei and Kormos (Reference Dörnyei and Kormos1998) based their study on Levelt’s L1 SPM from the psycholinguistic perspective, their CS taxonomy was adopted here. In compliance with their theoretical view, they designed a comprehensive CS taxonomy by associating the L2 communication problems and the means used to address those problems (i.e. communication strategies) with the speech production process. To properly identify and classify the CSs, Dörnyei and Scott (Reference Dörnyei and Scott1997) identified four main problem sources (resource deficit, processing time pressure, perceived deficiency in one’s own language output, perceived deficiency in the interlocutor’s performance), which Dörnyei and Kormos integrated into their taxonomy. Moreover, Dörnyei and Kormos integrated each problem-solving mechanism (PSM) into their taxonomy by matching them with the relevant speech production phase in Levelt’s model. Using Levelt’s model as the foundation, Dörnyei and Kormos aimed to investigate at what stage and why the speakers may have encountered a communicative problem during speech production, which in return led to the accurate identification and classification of communication strategies.
2.2 Previous communication strategy research
Considerable research has been conducted to investigate CS use, which can be categorized according to the context in which CSs were studied.
2.2.1 CS research in F2F environments
Most of the CS research in F2F environments has focused on either defining/classifying the CS (Dörnyei & Kormos, Reference Dörnyei and Kormos1998; Færch & Kasper, Reference Færch and Kasper1983) or on the factors affecting the CS use, such as the influence of task type (Ghout-Khenoune, Reference Ghout-Khenoune2012; Rosas, Reference Rosas2018), language proficiency level (Rosas Maldonado, Reference Rosas Maldonado2016; Ugla, Abidin & Abdullah, Reference Ugla, Abidin and Abdullah2019; Uztosun & Erten, Reference Uztosun and Erten2014), the relationship between CS use in L1 and L2 (Bialystok, Reference Bialystok, Færch and Kasper1983; Fernández Dobao, Reference Fernández Dobao2001), effect of communication context (Bialystok & Fröhlich, Reference Bialystok and Fröhlich1980), effectiveness of different types of CS (Bialystok & Fröhlich, Reference Bialystok and Fröhlich1980), as well as teachability of CSs (Bejarano, Levine, Olshtain & Steiner, Reference Bejarano, Levine, Olshtain and Steiner1997; Dörnyei, Reference Dörnyei1995; Lam, Reference Lam2006; Teng, Reference Teng2012). The effect of communicative context on CSs has also been investigated in CMC environments (Hung, Reference Hung2012; Hung & Higgins, Reference Hung and Higgins2016; Shih, Reference Shih2014; Zhao, Reference Zhao2010). Consequently, the majority of the CS studies examining the task type effect (Ghout-Khenoune, Reference Ghout-Khenoune2012; Rosas, Reference Rosas2018; Smith, Reference Smith2003) have so far concluded that open-ended, free discussion tasks promoted increased and diverse CS usage.
2.2.2 CS research in CMC environments
Even less numerous than in F2F, the majority of CS research in CMC environments have focused on text-based interaction in foreign language teaching contexts, such as Khamis (Reference Khamis2010), Kost (Reference Kost and Magnan2008), Lee (Reference Lee2001, Reference Lee2002), Omar, Embi and Yunus (Reference Omar, Embi and Yunus2012), and Smith (Reference Smith2001, Reference Smith2003). Smith (Reference Smith2003), for instance, as one of the few prominent researchers of CS use in CMC environments, focused on text-based interaction and concluded that synchronous CMC (SCMC) environments may result in differences in participants’ CS use. Some CS studies have also investigated video-based and voice-based interaction. Hung (Reference Hung2012), who comparatively analyzed the CS use of EFL learners in text-based (MSN Messenger) and video-based (Skype) interactions, showed that these two environments demanded the use of different types of CSs. However, Hung also indicated that video-based interactions are similar to F2F environments in presenting opportunities for visibility of gestures and mimics. However, it still remains unknown whether this resemblance between F2F and video-based environments has any impact on the use of CS in these two settings. Moreover, a limited number of CS studies have been conducted in VC environments (Hung, Reference Hung2012; Zhao, Reference Zhao2010) and in VWs – Chen (Reference Chen2018) in Second Life, Peterson (Reference Peterson2006) in Active Worlds and Shih (Reference Shih2014) in VEC3D. Peterson (Reference Peterson2006) compared the CS use in F2F and VW environments with the use of different types of tasks and found that mostly the participants used the same types of CSs, with differences being caused by the task type and the environments’ affordances. However, to our knowledge, there is no study in the literature that compares F2F, VC, and VW environments in terms of the EFL learners’ CS use based on audiovisual data from a psycholinguistic perspective.
3. Methods
3.1 Setting and participants
The study was conducted at the ELT department of a Turkish state university. The data were gathered from the 30 seniors (fourth and final year of study) who took the course “Materials Evaluation and Design” in the 2019–2020 fall term. The participants’ mean score on the Foreign Language Test (YDS) administered in Turkey was 86 out of 100, which corresponds to 103 points on the TOEFL IBT and C1 CEFR proficiency level, according to the Turkish student selection and placement center’s equivalency table (Türkiye Cumhuriyeti ÖSYM Başkanlığı, 2017). The background questionnaire revealed that the majority of participants were familiar with SCMC environments: 90% of them used VC tools and 86.7% used VWs prior to the study.
Neither gender nor age was examined as factors since the age range of the participants was quite narrow (from 21 to 22 years old) and because a large majority were female, making a comparison between males and females unrealistic given the relatively small sample size.
3.2 Data collection instruments
The data were collected via audio and video recordings of three opinion-exchange tasks (see Appendix E, in the supplementary material, for example task), a background and post-task questionnaire, and interviews consisting of retrospective think-aloud (RTA) protocols. In the background questionnaire, there were 34 questions (18 multiple choice, nine open ended, six demographic, and one matrix). In the post-task questionnaire, there were 16 questions (14 open ended and two multiple choice). The data obtained from the VC, VW, and F2F environments include only the audio and video chat recordings, not the text chat recordings. In order to maintain the parallel nature of the communication across the three modes, the participants in VC and VW were instructed not to make use of text chat during their communication. While the role of text chat in VC and VW modes has been examined by a number of scholars such as Hung (Reference Hung2012) and Zhao (Reference Zhao2010) in VC mode and Peterson (Reference Peterson2006) in VW mode, no other study has examined audio- and video-based interaction comparatively in VC and VW.
3.3 Data collection procedures
The data collection tools were first piloted with seven participants in the 2018–2019 spring semester. After revisions, Zoom was selected as the VC tool (Figure 1) for the main study, and Second Life was selected as the VW tool (Figure 2). For the F2F environment, a quiet room at the ELT department was used (Figure 3).

Figure 1. A screenshot of Task 1 in Zoom

Figure 2. A screenshot of Task 2 in Second Life

Figure 3. A screenshot of Task 3 in F2F environment
The 30 participants were divided into six groups of five individuals, with each group choosing its own members. Each group completed one task per week, with each task taking place in a different environment (Task 1 in VC, Task 2 in VW, and Task 3 in F2F). In total, each group completed three tasks in three different environments (Table 1). All tasks were designed as opinion-exchange tasks so as not to add the task type effect as a variable. The content of the tasks was consistent with the “Materials Evaluation and Design” course, with each task referring to a different topic in the course syllabus and including open-ended questions to enable free exchange of opinions. In total, 18 audiovisual recordings (six per environment) were obtained from the discussion tasks. Therefore, every group spent around 45 minutes on each task and, overall, of all the six groups in three environments, 14 almost hour-long recordings were included in total. One researcher from the researcher team attended all discussion tasks as a non-participant observer (Creswell, Reference Creswell2013). To minimize the researcher’s impact, the researcher turned off video and audio in the VC, used an invisible avatar in the VW and left the F2F room with video cameras on. While Task 1 (in Zoom) was recorded using Zoom’s own recording feature, Task 2 (in Second Life EduNation III Footnote 1 ) was recorded using an external screen recording tool, Camtasia, and Task 3 (F2F) was recorded with two video cameras, one main camera and one backup camera.
Table 1. Data collection process

Total duration: 8 weeks
The post-task questionnaire investigated the participants’ perceptions toward the three environments and whether their perceptions influenced how they dealt with communication problems. Therefore, the post-task questionnaire was used to better understand the reasons behind their CS use, which in return helped to more clearly identify the CSs in the data.
During the one-to-one interviews conducted with each participant (N = 30), one researcher from the researcher team showed preselected video and audio recordings of the tasks in which the participants used CSs. The researcher then asked the participants to describe the communication problems they encountered and how they addressed them. The RTA protocol is utilized to comprehend the reasons behind the participants’ CS use in order to accurately identify the CSs. RTA protocols have been employed in numerous CS studies and are recommended for use in CS research (Dörnyei & Scott, Reference Dörnyei, Scott, Turley and Lusby1995; Færch & Kasper, Reference Færch and Kasper1983).
3.4 Data analysis methods
The video recordings of the tasks were transcribed and analyzed using the qualitative data analysis software MAXQDA 2020. The transcriptions included not just the verbal language but also the prosodic features likely to affect or change the meaning. In order to represent the verbal and nonverbal behaviors with precision, Jefferson’s (Reference Jefferson and Psathas1979) transcription conventions were used when necessary to identify the CSs clearly. To code the CSs, Dörnyei and Kormos’s (1998) taxonomy was used and when CSs not included in their taxonomy were discovered in the data, they were coded utilizing other researchers’ taxonomies (Bejarano et al., Reference Bejarano, Levine, Olshtain and Steiner1997; Chen, Reference Chen1990; Dörnyei & Scott, Reference Dörnyei, Scott, Turley and Lusby1995, Reference Dörnyei and Scott1997; Færch & Kasper, Reference Færch and Kasper1983; Smith, Reference Smith2001; Tarone, Cohen & Dumas, Reference Tarone, Cohen and Dumas1976). In addition, the CSs that were revealed in the data but did not exist in any of the aforementioned literature were also included in the codings (Appendix B). A code was assigned to each CS identified and was introduced into the MAXQDA system. The coding procedure was repeated for the data obtained from each environment (VC, VW, and F2F). Then, the frequency of CS occurrence in each environment was calculated, and the values were compared to determine if the participants’ use of CS varied between environments. To ensure the coding reliability, the CS coding taxonomy and a random sample of 20% of the data were independently coded by two experts in the field. The intercoder reliability was calculated via Cohen’s kappa statistics to be .81, indicating almost perfect agreement (Cohen, Reference Cohen1960).
For each of the communication problems that occurred in the data, several key steps were undertaken:
-
1. One of four sources for each problem was identified based on Dörnyei and Kormos (Reference Dörnyei and Kormos1998).
-
2. The strategy (or sometimes multiple strategies) used to resolve each of these problems was determined based on the taxonomies from the aforementioned literature, resulting in the identification of 67 varieties (e.g. umming and erring, restructuring, error repair, etc.) of strategies utilized (Appendix A2).
-
3. The frequency of strategies was calculated, with 8,870 instances found overall (Table 2).
Table 2. Frequency of communication strategy (CS) use in three environments


The data obtained from the open-ended questions in the background and post-task questionnaires were analyzed using the constant comparison method (Glaser & Strauss, Reference Glaser and Strauss1967), while the closed-ended questions were calculated via frequency analysis. The interview data were audio recorded and analyzed via MAXQDA after transcription.
4. Results and discussion
4.1 CSs in VC, VW, and F2F environments
As shown in Table 2, the highest number of strategies used was in VC (Zoom: 3,401 times, 38.34%) followed by F2F (3,102 times, 34.97%), while the least number used was in the VW (Second Life: 2,368 times, 26.69%).
As seen in the distribution pattern across environments in Appendix A2, a wide variety of strategies were used in each of the three environments. This finding is consistent with previous studies (Hung, Reference Hung2012; Kost, Reference Kost and Magnan2008; Smith, Reference Smith2003) conducted to determine the CSs used by language learners in CMC environments.
Among the 67 strategies used, 61 were used at least once in VC, 60 in F2F and 56 in VW. Of the 67 strategies on the strategy coding list, the emojis and gestures strategy is not applicable in F2F and VC, and nonverbal strategy markers are not applicable in VW.
One of the most striking findings was that umming and erring and self-repetition strategies were the two most frequently used strategies in all three environments (Appendix A1). According to Dörnyei and Kormos (Reference Dörnyei and Kormos1998), the most frequently used strategies including these two are mainly caused by the same problem source: “processing time pressure” (VC: 1,870; VW: 1,190; F2F: 1,555). This shows that the participants needed to gain time while planning their speech or when they encountered a communication problem. Dörnyei (Reference Dörnyei1995) indicated that the most basic reason behind this problem source is that during speech production, processing time is not adequate for L2 learners. This could be because the L2 language production process is not as automatized as L1 (de Bot, Reference de Bot1992). As suggested by Uztosun and Erten (Reference Uztosun and Erten2014), even though the participants in this study were proficient English language learners, they may have had difficulties with fluency during the discussion tasks due to the limited opportunities to speak English outside of the classroom in their daily lives.
In addition, Hung (Reference Hung2012) noted that participants may experience “processing time pressure” in SCMC and F2F environments due to reasons such as feeling the need to respond to their interlocutors or plan their speech instantly. Therefore, due to these possible pressures, the speakers may have used time-gaining strategies (unfilled pauses, fillers, or self-repetition) more than any other strategy types in these environments (Appendix A1).
The reason why the participants used the strategies related to “perceived deficiencies in the interlocutor’s performance,” also known as “meaning negotiation strategies,” most infrequently (VC: 52; VW: 47; F2F: 48) is that they mostly attempted to solve their communication problems without expecting any assistance from their interlocutors. This confirms the view of the researchers (Bialystok, Reference Bialystok1990; Kellerman, Reference Kellerman, Phillipson, Kellerman, Selinker, Sharwood Smith and Swain1991; Poulisse, Reference Poulisse, Schreuder and Weltens1993) that the speaker’s role in CS use is also important and that speakers can use CSs without collaborating with their interlocutors. Stating that their findings highlighted the non-interactional aspect of CSs, Yarmohammadi and Seif (Reference Yarmohammadi and Seif1992) also encountered the same issue in their own study.
In addition, there were some factors affecting the CS use of the participants: proficiency level, task type, and the study context. Many researchers such as Ghout-Khenoune (Reference Ghout-Khenoune2012), Rosas (Reference Rosas2018), and Smith (Reference Smith2003) argue that free discussion tasks encourage a wide variety of CSs, while more guided tasks like jigsaw demand less variety of CS use. In this study, the opinion-exchange task was used, a type of free discussion task, and it was seen that the participants relied on various CS types. Consequently, it seems that opinion-exchange tasks might be influential in the participants’ wide variety of strategy use. Further, the intense use of strategies related to “processing time pressure” confirms that the participants mostly had communicative problems in terms of fluency rather than accuracy, which shows that their proficiency level in English might have been one of the factors affecting their CS use. Also supporting the probable connection between proficiency level and CS use, various researchers (e.g. Bialystok, Reference Bialystok, Færch and Kasper1983; Bialystok & Fröhlich, Reference Bialystok and Fröhlich1980; Fernández Dobao, Reference Fernández Dobao2001; Hsieh, Reference Hsieh2014; Rosas Maldonado, Reference Rosas Maldonado2016) suggest that proficient learners use more cognitively challenging strategies such as self-repair (i.e. error repair, appropriacy repair, different repair, and rephrasing repair). In addition, it was observed that the use of three different environments might have influenced the frequency and types of CS, as also found by Zhao (Reference Zhao2010). Presented below is a participant response from the post-task questionnaire that highlights the various affordances of the environments:
There is almost no use of gestures in Second Life. It was more challenging for me to solve communication problems in Second Life.
This issue carries over to facial expressions. The heads-up display (HUD) did include facial expressions such as SURPRISE, but those choices were limited. In addition, in VC and F2F, the participants could see the full nuance of facial expressions, which are simply not available in VW at this time (although virtual environments are beginning to use webcams to express the facial expressions and gestures of their users for their avatar forms). Therefore, even though, as noted in Figure 4 and also in Appendix A1, emojis and gestures was one the 10 most common CSs, some participants still did not feel that this was the case:
When I see the face of the person that is talking, I can instantly understand even the slightest communication problem and help him/her. It takes a little longer to understand this in Second Life.

Figure 4. Ten most frequent communication strategies in three environments
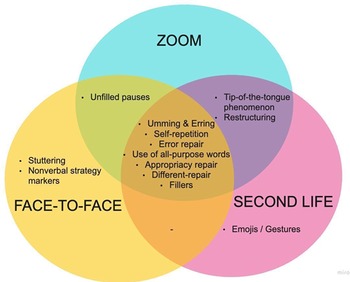
Although there are similarities in strategy use across all environments, the findings indicate there are also differences (Figure 4). Among the 10 most frequent strategies overall, seven (umming and erring, self-repetition, error repair, use of all-purpose words, appropriacy repair, different repair, fillers) were common in all three environments. However, it is noteworthy that although the participants can see each other’s faces in VC, nonverbal strategy markers were not among the top 10 frequent strategies in this environment. In addition, although stuttering strategy can be used with or without seeing each other’s faces, it is another notable finding that the stuttering strategy was among the most frequent strategies in F2F discussions, whereas it was not as prevalent in the other environments.
The frequent use of some repair strategies, such as error repair, appropriacy repair, and different repair, across all environments is likely associated with the participants’ higher proficiency level in English. As Levelt (Reference Levelt1989) indicated, to utilize repair strategies, the speaker’s monitor mechanism should be competent enough to realize that there is a communication problem waiting to be fixed so that a signal can be sent to the conceptualizer. In this way, the conceptualizer could start over the speech production process to fix the communication problem. Therefore, as Rosas Maldonado (Reference Rosas Maldonado2016) notes, repair strategies are more cognitively challenging and proficient learners employ these strategies more, so it is no surprise that the participants in this study used repair strategies so frequently. As a result, the findings are consistent with others (Bialystok, Reference Bialystok, Færch and Kasper1983; Bialystok & Fröhlich Reference Bialystok and Fröhlich1980; Fernández Dobao, Reference Fernández Dobao2001; Hsieh, Reference Hsieh2014), revealing that language proficiency level has an effect on the types of strategies employed. In line with our findings, studies conducted in CMC environments (Hung, Reference Hung2012; Kost, Reference Kost and Magnan2008; Lee, Reference Lee2001, Reference Lee2002) also showed that repair strategies were frequently used. Consequently, it seems that not just F2F but also CMC environments encouraged the use of repair strategies. As Jepson (Reference Jepson2005) revealed, speaking encourages more negotiation and repair moves, which is one of the affordances of the two CMC environments in this study. This explains why the participants frequently used the repair strategies in CMC environments as well. It is important that these three environments encourage the use of repair strategies because according to Swain’s (Reference Swain, Gass and Madden1985) output hypothesis, for the learners to produce meaningful output, they need to be able to monitor their production, realize their errors, and revise their output by repairing it.
Also, it is essential to discuss the strategies whose use varied across environments to determine the impact of the environments on strategy use. Strategies that differed across environments include indirect appeal for help, unfilled pauses, responding, nonverbal strategy markers, emojis and gestures, framing, giving assistance, lexical retrieval/word search, unasked-for help, and stuttering strategies. Most of the differences originated from the various affordances of the environments. In VW, for instance, participants are represented by avatars; therefore, their use of gestures and facial expression is limited compared to VC and F2F. Unlike in F2F or VC, where gestures may be more “automatic” in nature, participants in VW were required to click a button on their HUD, and were limited to 12 emojis and six gestures, such as hand up, nod, clap, LOL, and woo! (Figure 2).
Unfilled pauses were used less frequently in VW because it was observed that in some cases, whenever a participant used an unfilled pause, other participants assumed their interlocutor was having a technical problem and took the turn. The fact that in VW the speakers favored umming and erring strategy (605 times) more intensely than unfilled pauses (63 times) may support this. Smith (Reference Smith2001) also found that in a text-based CMC environment where participants cannot see each other as well, they showed intolerance toward unfilled pauses and preferred to use fillers instead. Another important finding was related to indirect appeal for help strategy. Even though the participants could see each other in VC as well as in F2F discussions, they used this strategy much less frequently in VC. Although gestures and facial expressions are visible in VC, it is hard for the participants to figure out who the speaker is making eye contact with and from which member specifically they are asking for indirect help. As nonverbal cues are crucial for the interlocutor to understand the signals of the speaker’s indirect request for help, this might explain why the participants used this strategy less frequently.
4.2 New strategies found in this study
This study uncovered 10 new strategies (Appendix B) that did not previously exist in the literature: stuttering, lexical retrieval/word search, unasked-for help, insertion, lexical substitution, managing the turns, phonological code-switching, recap of previous turns, use of synonyms, and lexical wavering. Although only one of these (stuttering) was included in the top 10 strategies, each of them still had an impact during the group discussions. Below, each strategy is defined, along with the cause of the communication problem, and how the strategy may be inserted into Dörnyei and Kormos’s (1998) taxonomy. Transcription samples for each strategy are given in Appendix C, and the strategy table along with definitions, problem sources, PSMs and example sentences from the data are given in Appendix B.
Although the theoretical framework of this study was mainly driven by the psycholinguistic perspective, CSs that enhanced communication were also included among the strategies found in this study in addition to the CSs that were discussed based on the problem sources introduced by Dörnyei and Kormos (Reference Dörnyei and Kormos1998). Although it is certainly the case that many studies that have focused on communication problems are both important and informative, strategies to enhance communication have often been ignored. However, as often shown by interactionist researchers, speakers do not always use CSs because they have a communication problem, but just to enhance communication and “act as better communicators” (Bejarano et al., Reference Bejarano, Levine, Olshtain and Steiner1997: 205).
4.2.1 Stuttering strategy
The stuttering strategy was the most frequent strategy (5.12%) not found in other studies and was utilized by the participants via involuntarily repeating the first one or more phones or syllables of that word until it was pronounced properly (Appendix C1).
Since the stuttering strategy activates “Phonological PSMs,” this strategy was associated with the problem source “L2 resource deficits.” The reason for this association is that in their framework, Dörnyei and Kormos (Reference Dörnyei and Kormos1998) indicated that the “Phonological PSMs” are activated to address one of the four problem sources, “L2 resource deficits.” According to Dörnyei and Kormos (Reference Dörnyei and Kormos1998), “phonological PSMs help overcome difficulties in the phonological encoding and articulatory phases caused by the lack of phonological knowledge of a word or connected speech” (p. 357). We positioned the stuttering strategy in the “phonological retrieval” subclass of phonological PSM (Appendix D1), because “phonological retrieval” is the mechanism used when the speaker tries to retrieve a lexeme, while attempting to reach the phonological information of that lexeme (Dörnyei & Kormos, Reference Dörnyei and Kormos1998).
The stuttering strategy is in the same subclass and shows similarities with the strategy of the tip-of-the-tongue phenomenon (Appendix D1). This phenomenon occurs “in an attempt to retrieve and articulate a lexical item, saying a series of incomplete or wrong forms or structures before reaching the optimal form” (Dörnyei & Kormos, Reference Dörnyei and Kormos1998: 361). In the stuttering strategy, however, there is no incomplete or wrong repetition of the forms or structures. The first phones or syllables of a word are repeated correctly and the repetition continues until the speaker manages to utter the whole word, as shown below in a participant utterance highlighted in yellow:
Participant: So is there anyone to contribute to the qu- que- question?
4.2.2 Lexical retrieval/word search strategy
Lexical retrieval/word search strategy was used when the speaker could not retrieve the word they planned to use in their message or had trouble articulating it due to a lack of L2 resources. The speaker who is in search of a word can use unfilled pauses, fillers and/or nonverbal strategy markers, or a direct/indirect appeal for help. In their utterance starting with “we can print the …”, the participant made use of body language and fillers right after their use of the article the, which signaled a word search (Appendix C2). During the retrospective protocols, the participant confirmed that this strategy arose from a lack of L2 resources:
Participant: What I’m trying to say here is that “rather than watching the input from a video uhhh … let’s print … out,” whatever it is I still don’t know ahaha. The reason I am doing this is because I am trying to find the word there.
This strategy’s problem source was defined as “L2 resource deficits” and, within Dörnyei and Kormos’s (1998) taxonomy, it was associated with the Lexical PSM (Appendix D2). Here, the strategy “word search” was associated with Lexical PSMs under the subclass, lexical retrieval/word search. Among the Phonological PSMs, although there is a “Phonological retrieval” subclass to classify the CSs used by the speaker when there is a problem with the pronunciation of a word, among the Lexical PSMs there is no such subclass under the name of “Lexical retrieval.” With the support of the data obtained from this study, the addition was necessary. It was seen that aside from the cases where the participants could not access the word simply because of its pronunciation, there were also cases where they could not retrieve the word at all. For this reason, the participants made an effort to retrieve the word via pausing, using body language or asking for help until it was accessible.
4.2.3 Unasked-for help strategy
Although there is a strategy called giving assistance in the literature, the unasked-for help strategy is different because giving assistance is used if the speaker requests help. However, the unasked-for help strategy is used by the interlocutor when the speaker has difficulty in expressing themselves in L2, even though the speaker does not request indirect or direct assistance. In some cases, even without noticing any problem, when the speaker pauses or speaks slowly, the interlocutor takes the opportunity to help the speaker.
To help participant A say the suitable word, participant B uttered the word field, when he/she heard participant A use the filler uhh (Appendix C3). The square brackets indicate the overlap in a conversation; accordingly, participant B spoke the word “[field]” when participant A said “[I’d say]”; therefore, participant B was late because participant A already came up with the word field. This shows that participant A did not intend to ask for help in the first place and used the filler uhh there to give themselves time to retrieve the word field. During the RTA protocol, by asking the speakers whether they were waiting for help at a specific moment, the researchers were able to determine this strategy. A participant’s use of this strategy highlighted in yellow is as follows:
Participant A: I’m also like, I started to teach uhh children in at weekends in a language center. Uhh but since I’m so, you know, new in this uhh field [I’d say]–
Participant B: [field].
According to Levelt’s (1989) framework, when a problem originated from the deficiencies in the interlocutor’s speech, the speaker activates meaning negotiation mechanisms. Therefore, we associated the unasked-for help strategy with the problem source “perceived deficiencies in the interlocutor’s performance” since the current strategy is used when the speaker thinks the interlocutor has encountered a problem in their speech production and gets involved to deal with the problem.
4.2.4 Insertion
When using the insertion strategy, the speaker interrupts their speech and shares an additional piece of information that comes to mind at that moment related to the subject in order to express themselves better and/or to facilitate the listeners’ understanding, then continues from where they interrupted their speech. The speaker can insert this additional information when they are in the middle of a sentence or between sentences. For example, the participant used the insertion strategy via adding subject-related information between two sentences (Appendix C4). The information added by the participant, which is highlighted in yellow below, is semantically linked to their original message and contains an expression describing the situation they were talking about:
Participant: Even if they’re able to speak like I’m talking about a good situation here, even if they are able to speak and understand, it’s just mechanical, not natural.
Since the insertion strategy is used by the speaker to enhance communication and make themselves clear without the presence of any communicative problems, it was not associated with Dörnyei and Kormos’s (1998) taxonomy. In this respect, the insertion strategy has similarities with Bejarano et al.’s (Reference Bejarano, Levine, Olshtain and Steiner1997) “Social interaction strategies,” which help speakers to communicate more effectively during conversations and are very important to ensure a consistent flow in intra-group interaction.
4.2.5 Lexical substitution
When using the lexical substitution strategy, because the speaker has linguistic difficulties with the word they are currently saying or retrieves a more appropriate alternative, they interrupt their speech and continue with the more appropriate one or the synonym of it that they are more linguistically confident about. This is not a repair strategy, as the speaker’s reason for using this strategy is not based on any wrong or incomplete use. For example, even though the word education is compatible with the context of the sentence, the participant preferred to continue with another contextually suitable word, learning (Appendix C5).
This strategy was associated with the “L2 resource deficits,” which activates Lexical PSM. In Dörnyei and Kormos’s (1998) taxonomy, “content reduction,” “substitution” and “substitution plus” strategies were used to solve lexical problems. Accordingly, the lexical substitution strategy was placed under “substitution strategies” (Appendix D4). As a pioneer in the field, Poulisse (Reference Poulisse, Schreuder and Weltens1993) indicated that no speaker would change the target word for no reason. Based on this statement, it was concluded that lexical substitution strategy must be related to a deficit in L2 resources.
4.2.6 Managing the turns
For the sake of effective conversation flow, the speaker uses the managing the turns strategy to give their interlocutor an opportunity to complete their unfinished turn that was interrupted before. For example, participant A prompted participant B to complete their utterance by saying “what were you saying?” and “you were also never in the top 10?” (Appendix C6). As this strategy is also used to facilitate communication, it was associated with Bejarano et al.’s (Reference Bejarano, Levine, Olshtain and Steiner1997) “social interaction strategies.”
4.2.7 Phonological code-switching
The phonological code-switching strategy is utilized when the speaker is actually speaking in L2 but uses a specific L2 word in a sentence with that word’s L1 or L3 pronunciation. This strategy can be seen as a phonological version of the code-switching strategy. As seen in Appendix B, participants used English words such as prototype and anonym with their Turkish pronunciation in the English sentence. The use of this strategy could be explained via L1-L2 interference, which takes place during the formulator phase of L2 speech production (de Bot, Reference de Bot1992) and is caused by the lack of proficiency in determining the phonological label of the target word. This strategy is associated with the problem source “L2 resource deficits” just like the code-switching strategy. However, in order to cope with the problem, since code-switching requires changing the whole word, it activates “Lexical PSMs” while phonological code-switching activates “Phonological PSMs” because it only requires a change in the pronunciation of the word (Appendix D5).
4.2.8 Recap of previous turns
Recap of previous turns is used to summarize what has been said about the subject that has been discussed up to that point. There is a strategy called interpretive summary in Dörnyei and Kormos’s (1998) taxonomy, which is “an extended paraphrase of the interlocutor’s message to check that the speaker has understood correctly” (p. 375). However, as the recap of previous turns strategy does not arise from a communication problem but is just used to facilitate communication, it was not associated with Dörnyei and Kormos’s taxonomy (Appendix C7).
During the retrospective protocol, about Example 7, the participant’s statement below was helpful in clearly specifying this strategy:
Researcher: What was the purpose of your sentence here?
Participant: After my group mates expressed their opinions, I wanted to summarize what was said. Because there was silence. Instead of moving on to what comes next directly, it was like a small summary like “aha so you mean this,” I mean to sum up the discussion about that question.
Researcher: So your purpose there was not to actually see whether you understood what was said correctly? You have already understood and just wanted to summarize the subject.
Participant: Yes.
4.2.9 Use of synonyms
The speaker uses this strategy to emphasize the word they use by repeating its synonym right after it. As seen in Appendix B, the words real and quick were succeeded by the words actual and fast, respectively, for the purpose of emphasis. Since this strategy does not originate from a communication problem but is used for enhancing communication and laying stress on the message, it was not positioned in Dörnyei and Kormos’s (1998) taxonomy.
4.2.10 Lexical wavering
Due to L2 resource deficits or accidentally retrieving another word by mistake, the lexical wavering strategy causes the speaker to experience a hesitation between the improperly articulated word and the original target word until they can come up with the target word. Therefore, this strategy was associated with “L2 resource deficits” and positioned under “Lexical PSMs” (Appendix D6). For example, the participant experienced lexical wavering between the prepositions for and in until the appropriate preposition for the given context was chosen (Appendix C8). Instead of correcting the unintentionally uttered word via error repair strategy, the speaker’s experiencing the hesitation between the target word and the wrong word indicates the L2 resource deficit of the speaker.
5. Limitations
As the findings of this study are limited to two SCMC tools (Second Life and Zoom), it is unclear whether similar results might be seen within other SCMC environments. To better understand the CS use in these environments, data should be obtained from other VC environments and VWs. Also, the RTA protocols that took place during the semi-structured interviews were conducted after all the tasks were completed in order to avoid bias. This situation meant some participants occasionally failed to remember the reasons for the communication problems they experienced when watching the preselected parts of the discussion tasks. Although this was not encountered frequently, to collect more precise data from the participants, the retrospective protocols could be conducted right after each task is completed.
Another limitation of this study is the sample size and participant demographics. Since this was a convenience sample, it was not possible to have a 50-50 breakdown between males and females, and the ages of the participants were also very similar. Future studies with a larger sample size and including a more diverse pool of participants might give additional insights into some of this study’s findings. One additional possible limitation connects to the way in which the data were collected for the study. In the F2F setting, a camera was recording the participants, while in Zoom, one researcher from the research team was “present” with camera and audio off (Figure 1), and in the VW, the researcher was present in avatar form, albeit invisible. This could potentially lead to the observer’s paradox, but in all cases, it was clear that the participants quickly ignored the camera/observer as they did not refer to the researcher or turn toward her, and their interaction was totally focused on their peers.
6. Conclusion
This study investigated the types and the frequency of CS use by EFL learners in VC, VW, and F2F environments. The strategies in Dörnyei and Kormos’s (1998) taxonomy as well as other researchers’ taxonomies were revealed in the data. In addition, 10 new strategies were found that did not exist in the literature. Therefore, it can be said that a wide variety of strategies were used and the types of the CSs used in the CMC and F2F environments mostly coincided except for a few such as emojis and gestures and nonverbal strategy markers. As a result, although the frequency of the use of some strategies varied across environments, all three environments encouraged the use of a variety of strategy types, and their use helped participants in resolving their communicative problems. Further, the most frequent strategies used in this study were caused by the same problem source (“processing time pressure” and “perceived deficiency in one’s own language output”), which was a prominent finding. In addition, it was seen that strategy use could have been affected by factors such as the environment, the language proficiency level, and the task type. The limits of gestures and facial expressions in VW, technical problems such as lagging in VC, and the physical proximity in F2F were observed as reasons behind the environment effect on CS use. Further research on other VC environments and VWs could expand on the variety of CS use and determine clearly the impact of the similar environment affordances. Furthermore, the study could be replicated with the use of different types of tasks and with less proficient EFL learners to better reveal the variety of CS use in CMC environments from a broader perspective. As CSs are essential for meaningful interaction to occur, it is of the utmost importance that instructors train their students on the affordances of the environments in which they will interact and design tasks that promote output and encourage students to exchange opinions.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/S0958344022000210
Ethical statement and competing interests
The authors declare no conflict of interest. This work is the authors’ own original work. Institutional requirements were followed in data collection procedures, and informed consent was obtained from all participants. All sources used are appropriately cited in the article.
About the authors
Nazlı Ceren Cirit-Işıklıgil holds a PhD from the program of foreign language teaching at Ankara University. Her research interests include computer-assisted language learning, CMC, virtual worlds and language learning (VWLL), and communication strategies in online environments.
Randall W. Sadler is an associate professor of linguistics at the University of Illinois at Urbana-Champaign, where he teaches courses on computer-mediated communication and language learning, VWLL, and the teaching of L2 reading and writing. He has published widely in these areas in journals, chapters, and books.
Elif Arıca-Akkök is an associate professor of linguistics at Ankara University, Turkey. Her research interests include cognitive linguistics, lexical semantics, and conceptual metaphor theory, and teaching figurative language and foreign language teaching. She has written several chapters in books about her research topics and published articles in national and international journals.
Author ORCIDs
Nazlı Ceren Cirit-Işıklıgil, https://orcid.org/0000-0001-7422-2026
Randall W. Sadler, https://orcid.org/0000-0001-7743-7049
Elif Arıca-Akkök, https://orcid.org/0000-0002-5805-711X







 Open access
Open access