


1. Introduction
The wireless power transfer technique is proved to be the most effective solution to the charging problem as the number of the IoT devices grows drastically, since it is impossible to replace the batteries of all IoT devices [Reference Giuppi, Niotaki, Collado and Georgiadis1]. In recent years’ Consumer Electronics Show (CES), a large number of wireless power transfer products have come into consumers’ sights. There are two types of wireless power transmission products: near-field and far-field. In near-field wireless power transfer, the IoT devices, which are charged by resonant inductive coupling, have to be placed very close to the wireless transmitters (less than 5 cm) [Reference Jawad, Nordin, Gharghan, Jawad and Ismail2]. In far-field wireless power transfer, the IoT devices use the electromagnetic waves from transmitters as the power resource and the effective charging distance ranges from 50 centimeters to 1.5 meters [Reference Yedavalli, Riihonen, Wang and Rabaey3–Reference Xing, Qian and Dong5]. Compared to the near-field transmitters, the far-field wireless power transmitters can charge the IoT devices (including the mobile IoT devices) that are deployed in a larger space.
However, the far-field wireless power transfer is still in its infancy for two reasons. First, the level of power supply is very low due to the long distance between the power transmitters and the energy harvesters. In [Reference Lee, Qin, Wang and Sim6], the authors mentioned that the existing far-field RF energy harvesting technologies can only achieve nanowatts-level power transfer, which is too tiny to power up the high-power-consuming electronic devices. In [Reference Yedavalli, Riihonen, Wang and Rabaey3], the authors investigated the RF beamforming in radiative far field for wireless power transfer. The authors demonstrated that, with beamforming techniques, the level of the energy harvesting can be boosted. However, as the distance between the transceivers increases to 1.5 meters, the amount of the harvested energy is less than 5 milliwatts, which is still not ideal to power up the high-energy-consuming devices. Second, most of the existing wireless charging systems can only effectively charge stationary energy harvesters. In [Reference Nikoletseas, Raptis, Souroulagkas and Tsolovos7], a set of wireless chargers (Powercast [8]) are deployed on the square area. The Powercast transmitters can adjust the transmission strategies to optimize energy harvested at the stationary energy harvesters. In [Reference Lin, Zhou, Ma, Deng, Wang and Wu9], the Powercast wireless charger is mounted on the moving robot. Therefore, the charger is a mobile wireless charger, which can adjust the transmission patterns of the stationary sensors while moving. However, the number of the IoT devices to be charged is too small. In order to wirelessly charge multiple IoT devices, some researchers proposed using Unmanned Aerial Vehicle (UAV) to implement the wireless power transfer [Reference Yan, Chen and Yang10–Reference Yuan, Yang, Hu, Xu and Schmeink13]. The UAV is designed to plan the optimal path to charge the designated IoT devices. However, it is very inefficient to use UAV to charge the IoT devices, since UAV has very high power consumption and very short operational time. Installing the wireless power emitter on the UAV will further shorten the operational time of UAV.
In order to enhance the level of the energy harvesting and efficiency in charging a large number of energy-hungry IoT devices, in this paper, we assembled the wireless power transfer robot and applied deep reinforcement learning algorithm to optimize its performance. In the system, the wireless transmitter aims to find the optimal path for the wireless power transfer robot. The robot cruises on the path, which can charge each IoT device in the shortest time. DQN has been widely used to play the complicated games which have a large number of system states even when the environment information is not entirely available [Reference Mnih, Kavukcuoglu and Silver14]. Lately, a lot of researchers have started to implement DQN in solving the complicated wireless communication optimization problems because the systems are very complicated and environment information is time-varying and hard to capture [Reference He, Zhang and Yu15–Reference Xing, Pan and Xu18]. In particular, the researchers applied deep reinforcement learning to plan the optimal path for autodrive robots [Reference Chen, Jiang, Lv and Li19–Reference Ding, Gao and Shen22] and the robots can quickly converge to the optimal path. Henceforth, we found that DQN is a perfect match to solve our proposed optimization problem. However, those papers either only proposed the theoretical model or could not implement wireless power transfer functions. To the best of our knowledge, we are the first ones to implement the automatic far-field wireless power transfer system in the test field and invent a DQN algorithm to solve it. In our system, the entire test field is evenly quantified into the square spaces. The time is slotted with the same interval. We consider the relative location of the robot in the test field as the system state, while we define the direction to move in the next time slot. At the beginning of each time slot, the wireless power transfer robot generates the system state and takes it as the input to DQN. The DQN can generate the Q values for each possible action and the one with the maximum Q value is picked to guide robot’s move during the current time slot.
As the number of IoT devices increases and the testing field becomes more complicated, the traditional DQN cannot generate the close-loop path for the robot to cruise on, which does not satisfy the requirement of charging every regular time interval. In order to deal with this problem, area division deep reinforcement learning is proposed in this paper. At first, the algorithm divides the whole test field into several areas. In each area, DQN is utilized to calculate the optimal path. Next, the entire path is formulated with the paths of each separated area. In this way, a closed loop is guaranteed and the numerical results prove that the calculated path is also the optimal path.
2. System Model
The symbols used in this paper and the corresponding explanations are listed in Table 1.
TABLE 1: Symbols and explanations.

As shown in Figure 1, a mobile robot that carries two RF wireless power transmitters cruises on the calculated path to radiate the RF power to K nearby RF energy harvesters. Both the power transmitter and the RF power harvesters are equipped with one antenna. The power received at receiver k,
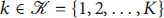 , is
, is

where p tx is the transmit power; G tx is the gain of the transmitter’s antenna; G rx is the gain of the receiver’s antenna; L is the distance between the transmitter and harvester k; η is the rectifier efficiency; λ denotes the wavelength of the transmitted signal; lp denotes the polarization loss; μ is the adjustable parameter due to Friis’s free space equation. Since the effective charging area is critical in determining the level of energy harvesting and it is the parameter to be adjusted at the transmitter, equation (1) is reexpressed using the effective area:

where S tx is the maximum effective transmit area; S rx is the effective received area; α is the angle between the transmitter and the vertical reference line.

FIGURE 1: Mobile wireless power transmitter cruises on the calculated path to charge multiple harvested energy-enabled IoT devices.
Since we consider the mobile energy harvesters in the system, the distance and effective charging area may vary over the time; we assume that the time is slotted and the position of any mobile device within one time slot is constant. In time slot n, the power harvested at receiver k can be denoted as

For a mobile energy harvester, the power harvested in different time slots is determined by the angle between the transmitter and the vertical reference line α(n) together with the distance between the transmitter and the harvester L(n) in the time slot.
In our model, the mobile transmitter is free to adjust the transmit angle α(n) and L(n) as it can move around the IoT devices. We assume that the effective charging is counted only when α(n) = 0 and L(n) < = 45 cm.
3. Problem Formulation
In this paper, the optimization problem is formulated as a Markov Decision Process (MDP) and reinforcement learning (RL) algorithm is utilized to solve the problem. Furthermore, DQN algorithm is applied to address the large number of system states.
3.1. Problem Formulation
In order to model our optimization problem as an RL problem, we define the test field consisting of same area unit square, whose side length is 30 cm. K = 8 harvested energy-enabled IoT devices are deployed in the test field, whose orders are 0, 1, 2, 3, 4, 5, 6, and 7, respectively. The map is shown in Figure 2. The system state sn at time slot n is defined as the position of a particular square where the robot is currently located at in the test field, which is specified as
 , where h is the distance between the present square and the leftmost edge, which is counted by the number of squares. v indicates the distance between the present square and the upmost edge, which is counted by the number of squares. For example, the No. 5 IoT device can be denoted as
, where h is the distance between the present square and the leftmost edge, which is counted by the number of squares. v indicates the distance between the present square and the upmost edge, which is counted by the number of squares. For example, the No. 5 IoT device can be denoted as
 . The shadow area adjacent to No. k IoT devices indicates the effective charging area for the respective IoT devices, which is denoted as effk. For example, the boundary of effective charging areas for No. 6 IoT device is highlighted in red. We define the direction of movement in a particular time slot n as the actions an. The set of possible actions A consists of 4 different
. The shadow area adjacent to No. k IoT devices indicates the effective charging area for the respective IoT devices, which is denoted as effk. For example, the boundary of effective charging areas for No. 6 IoT device is highlighted in red. We define the direction of movement in a particular time slot n as the actions an. The set of possible actions A consists of 4 different
 , where U is moving upward one unit, D is moving downward one unit, L is moving left one unit, and R is moving right one unit.
, where U is moving upward one unit, D is moving downward one unit, L is moving left one unit, and R is moving right one unit.

FIGURE 2: The entire test field consists of same space unit square. K = 8 harvested energy-enabled IoT devices are deployed in the test field. The shadow area adjacent to each IoT device indicates the effective charging area for the respective IoT devices. For example, the boundary of effective charging areas for No. 6 IoT device is highlighted in red.
Given the above, the mobile wireless charging problem can be formulated as minimizing the time duration T for the robot to complete running one loop at the same time the robot has to pass through one of the effective areas of each IoT device.

Time duration for the robot to complete running one loop is defined as T. The starting position is the same as the last position, since the robot cruises in a loop. In the loop, the robot has to pass through at least one of the effective charging areas of each IoT device.
Adapting to the different positions, the agent chooses different action at each time slot. Henceforth, we can model our proposed system as a Markov chain. In the system, we use the current position to specify a particular state s. S denotes the system state set. The starting state s 0 and final state sT are the same, since the robot needs to move and return to the starting point. The MDP process can be described as the agent chooses an action a from A at a specific system state s. After that, a new system state s′ will be transit into.
 ,
,
 and
and
 , denotes the probability that system state transits from s to s′ with a.
, denotes the probability that system state transits from s to s′ with a.
The reward of the MDP is denoted as
 , which is defined for the condition that system state transits from s to state s′. The optimization problem is formulated as reaching sT in the fewest transmission time slots; henceforth, the reward has to be defined to motivate the mobile robot that does not repeatedly pass through any effective charging area of any IoT devices. Besides, the rewards at different positions are interconnected with each other, since the goal of the optimization is to pass through the effective charging areas of all the IoT devices. We assume that the optimal order to pass through all the IoT devices is defined as
, which is defined for the condition that system state transits from s to state s′. The optimization problem is formulated as reaching sT in the fewest transmission time slots; henceforth, the reward has to be defined to motivate the mobile robot that does not repeatedly pass through any effective charging area of any IoT devices. Besides, the rewards at different positions are interconnected with each other, since the goal of the optimization is to pass through the effective charging areas of all the IoT devices. We assume that the optimal order to pass through all the IoT devices is defined as
 .
.
 . Specifically, the reward function can be expressed as
. Specifically, the reward function can be expressed as

In the above equation,
 if the robot has already passed through as effective area of the
if the robot has already passed through as effective area of the
 th IoT device; and ζ denotes the unit price of the harvested energy.
th IoT device; and ζ denotes the unit price of the harvested energy.
As we have defined all the necessary elements for MDP, we can characterize the formulated problem as a stochastic shortest path search that starts at s 0 and ends at sT. At each system state s, we derive the best action
 which can generate the maximum reward. The optimal policy sets are defined as
which can generate the maximum reward. The optimal policy sets are defined as
 .
.
3.2. Optimal Path Planning with Reinforcement Learning
If the systematic dynamics obey a specific transition probability, reinforcement learning will be the perfect match to solve the optimization problems. In this section, Q-learning [Reference Barto, Bradtke and Singh23] is first introduced to solve the proposed problem. After that, to address the large states and actions sets, the DQN algorithm [Reference Mnih, Kavukcuoglu and Silver14] is utilized to determine the optimal action for each particular system state.
3.2.1. Q-Learning Method
The traditional Q-learning method is widely used to solve the dynamic optimization problem provided that the number of the system states is moderate. Corresponding to each particular system state, the best action can be determined to generate the highest reward.
Q(s, a) denotes the cost function, which uses a numerical value to describe the cost of taking action a at state s. At the beginning of the algorithm, all the cost function is zero since no action has ever been taken to generate any consequence
 . All the Q values are saved in the Q table. Only one cost function is updated in each time slot as the action is taken and the reward function is calculated. The cost function is updated as
. All the Q values are saved in the Q table. Only one cost function is updated in each time slot as the action is taken and the reward function is calculated. The cost function is updated as

where

The learning rate is defined as
 .
.
When the algorithm initializes, the Q table is empty since no exploration has been made to obtain any useful cost function to fill the Q table. Since the agent has no experience about the environment, the random action selection is implemented at the beginning of the algorithm. A threshold
 is designed to start the exploration. In each time slot, a numerical value
is designed to start the exploration. In each time slot, a numerical value
 is generated and compared with the threshold. If
is generated and compared with the threshold. If
 , action a is picked as
, action a is picked as

However, provided that
 , an action is randomly selected from the action set A.
, an action is randomly selected from the action set A.
After iteratively updating the value in the Q table, the Q value converges. We can calculate the best action corresponding to each action and state by

which corresponds to finding the optimal moving direction for each system state explored during the charging process.
3.2.2. DQN Algorithm
The increase in the number of IoT devices has led to an increase in the number of system states. Suppose that Q-learning algorithm is used; a very large Q table has to be created and the convergence speed is too slow. DQN algorithm is more compatible since there is a deep neural network in the structure that can be well trained and take immediate action to determine the best action that is going to be taken.
The deep neural network in the structure has the system state as the input and the Q value for each action is defined as the output. Henceforth, the function of the neural network is to generate the cost function for particular state and action. We can describe the cost function as
 , where θ is the weight on the neuron nodes in the structure. As we collect the data when different actions are taken in different time slot, the neural network is trained to update the weight of the neural network, which can output a more precise Q value:
, where θ is the weight on the neuron nodes in the structure. As we collect the data when different actions are taken in different time slot, the neural network is trained to update the weight of the neural network, which can output a more precise Q value:

There are two identical neural networks existing in the structure of DQN [Reference Van Hasselt, Guez and Silver24]: one is called the evaluation network eval_net, and the other is called the target network target_net. Since these two deep neural networks have the same structure, multiple hidden layers are defined for each network. We use the current system state s and the next system state s′ as the input to eval_net and target_net, respectively. We use
 and
and
 to define the output of two deep neural networks eval_net and target_net. In the structure, in order to update the value of the weight of neuron nodes, we only continuously train the evaluation network eval_net. The target network is not trained. It periodically duplicates the weights of the neurons from the evaluation network (i.e.,
to define the output of two deep neural networks eval_net and target_net. In the structure, in order to update the value of the weight of neuron nodes, we only continuously train the evaluation network eval_net. The target network is not trained. It periodically duplicates the weights of the neurons from the evaluation network (i.e.,
 ). The loss function is described as follows, which is used to train eval_net:
). The loss function is described as follows, which is used to train eval_net:

We use y to represent the real Q value, which can be expressed as

We denote the learning rate as ϵ. The idea of back-propagation is utilized to update the weight of eval_net; as a result, the neural network is trained.
The experience reply method is utilized to improve the training effect, since it can effectively eliminate the correlation among the training data. Each single experience includes the system state s, the action a, and the next system state s′, together with the reward function
 . We define the experience set as
. We define the experience set as
 . In the algorithm, D individual experiences are saved and, in each training epoch, only Ds (with Ds < D) experiences are selected from D. As the training process is completed, target_net copies the weight of the neurons from the evaluation network (i.e.,
. In the algorithm, D individual experiences are saved and, in each training epoch, only Ds (with Ds < D) experiences are selected from D. As the training process is completed, target_net copies the weight of the neurons from the evaluation network (i.e.,
 ). D different experiences are generated from ep, while only Ds are picked to train the evaluation network eval_net. The total number of training iterations can be denoted as U. Both evaluation network and target network share the same structure, in which the deep neural networks have Nl hidden layers.
). D different experiences are generated from ep, while only Ds are picked to train the evaluation network eval_net. The total number of training iterations can be denoted as U. Both evaluation network and target network share the same structure, in which the deep neural networks have Nl hidden layers.
3.2.3. Dueling Double DQN
In order to leverage the performance of DQN, which can effectively select the optimal action to charge multiple harvesters in a time-varying channel conditions, we redesign the structure of the deep neural network by using Dueling Double DQN. Doubling DQN is an advanced version of DQN which can prevent the overestimating problem appearing throughout the training [Reference Van Hasselt, Guez and Silver24]. Dueling Double DQN can efficiently solve the overestimating problem throughout the training process. In the same training epochs, Dueling Double DQN is proved to outperform the original DQN in learning efficiency.
In traditional DQN, as shown in equation (12), the target network target_net is designed to derive the cost function for a particular system state. Nevertheless, because we do not update the weight of the target network target_net in each training epoch, the training error will increase while training, hence prolonging the training procedure. In Doubling DQN, both the target network target_net and the evaluation network eval_net are used to calculate the cost functions. We use evaluation network eval_net to calculate the best action for system state s′.

The latest research proves that the training error can be dramatically reduced using the Doubling DQN structure [Reference Van Hasselt, Guez and Silver24].
In traditional DQN, we only define the cost function Q value as the output of the deep neural network. The Dueling DQN is invented to speed up the convergence of the deep neural network by designing 2 individual streams of the output for the deep neural network. We use the output value
 to represent the first stream of the neural network. It denotes the cost function for a specific system state. We name the second stream of the output as advantage output
to represent the first stream of the neural network. It denotes the cost function for a specific system state. We name the second stream of the output as advantage output
 , which is utilized to illustrate the advantage of using a specific action to a system state [Reference Wang, Schaul, Hessel, Van Hasselt, Lanctot and De Freitas25]. We define α and β as the parameters to correlate the output of two streams and the neural network. The cost function can be denoted as
, which is utilized to illustrate the advantage of using a specific action to a system state [Reference Wang, Schaul, Hessel, Van Hasselt, Lanctot and De Freitas25]. We define α and β as the parameters to correlate the output of two streams and the neural network. The cost function can be denoted as

The latest research proves that Dueling DQN can speeds up the training procedure by efficiently annihilating the additional freedom while training the deep neural network [Reference Wang, Schaul, Hessel, Van Hasselt, Lanctot and De Freitas25].
3.3. Area Division Deep Reinforcement Learning
In this paper, the optimization problem can be seen as calculating the optimal close-loop path which generates the maximum accumulated reward. However, the traditional DQN shows the difficulty converging to the optimal path because of the complicated experimental field. In order to leverage the performance of traditional DQN, we invent an AD-DQN in this paper. At first, the experimental field is divided into multiple separate parts. DQN is run on each part individually to obtain the optimal path for the robot, respectively. Finally, the entire close-loop path is formulated using the path on each part. In area division, the whole area is defined as W. The whole area is divided at multiple specific locations.
 .
.
The criterion to pick pi is finding the squares, which exist in more than one effective charging area of the IoT devices.

For each pi, we define
 . We define set
. We define set
 . In the clockwise direction, we find that the IoT device oi has the shortest distance to pi, and then add both oi and the effective charging area of oi to Ni. The new area can be expressed as
. In the clockwise direction, we find that the IoT device oi has the shortest distance to pi, and then add both oi and the effective charging area of oi to Ni. The new area can be expressed as

Next, we find the IoT device having the shortest distance to the IoT device oi that is just added to set Ni, and then add both the new IoT device and the effective charging area of it to Ni. Iteratively, we find that all the IoT devices besides the ones in
 are included in one Ni. Finally, classify all the rest squares to the nearest Ni.
are included in one Ni. Finally, classify all the rest squares to the nearest Ni.
 .
.
In each area, the DQN is run to determine the optimal path for the robot. In each area, the starting point is the same as the position of pi; the end point is one of the effective charging squares of the furthest IoT device from the starting point in the same area. After the optimal path is calculated for each individual area, the close-loop optimal path for the entire area can be synthesized. The algorithm is shown in Algorithm 1.
-
(i) Define
 . Among E, find all the area division points pi by
. Among E, find all the area division points pi by
-
(ii) The number of area divison points is defined as
. -
(iii)
. The number of the area to be divided is
. -
(iv)
. -
(v)
: -
(vi)
.
. -
(vii)
-
(viii)
-
(ix) In the clockwise direction, find the the IoT devices, that has the shortest distance to r1. The order of the IoT device is:
.
is updated as:
.
. -
(x) else
-
(xi) In the counterclockwise direction, find the the IoT devices, that has the shortest distance to r2. The order of the IoT device is:
. Ni is updated as:
.
. -
(xii) en d
-
(xiii) en dw hile
-
(xiv) en d
-
(xv)
: -
(xvi) Define set
-
(xvii)
-
(xviii) en d
-
(xix)
: -
(xx)
: -
(xxi) The starting point is defined as pi. The end point is defined as
. -
(xxii) The weight of the neuron nodes θ are randomly generated for the eval_net and the weights are copied by
. u = 1. D = d = 1. -
(xxiii)
.
. -
(xxiv) A probability is generated as a numerical parameter
. -
(xxv)
-
(xxvi)
-
(xxvii) else
-
(xxviii) Randomly choose the action from action set A.
-
(xxix) en d
-
(xxx)
-
(xxxi) The state transit into s′ after taking the action. d = d + 1.
. Suppose D keeps unchanged if it goes over the experience pool’s limitation, d = 1; otherwise,
.
.
. After enough data has been collected in experience pool, eval_net is trained using D of Ds experiences. Minimize the loss function Loss(θ) using Back-propagation. target_net copies the weight from eval_net periodically. -
(xxxii) en dw hile
-
(xxxiii) en dw hile
-
(xxxiv) The optimal path of the entire test field is synthesized with the optimal path in each
.




































4. Experimental Results
The implementation of the proposed wireless power transfer system is shown in Figure 3.

FIGURE 3: Flowchart of wireless power transfer implementation.
In the test field, 8 harvested energy-enabled IoT devices are placed as Figure 2 indicates. The top view of the test field can be seen as a 2D map. Henceforth, the map is modeled and inputted into the computer. Then the AD-DQN algorithm is implemented in computer using Python and the optimal charging path can be derived. At the same time, a wireless power transfer robot is assembled. Two Powercast RF power transmitters TX91501 [8] are mounted on two sides of the Raspberry Pi [26] enabled intelligent driving robot. Each transmitter is powered by 5 V power bank and continuously emits 3 Watts RF power. The infrared patrol module is installed on the robot to implement the autodrive on the test field; henceforth, the robot can automatically cruise on along the path and continuously charge the multiple IoT devices, as shown in Figure 1. To the best of our knowledge, we are the first ones to implement the automatic wireless power transfer system in the test field and invent AD-DQN algorithm to design the optimal path for the wireless power transfer robot. Since we are the first ones to design and implement the mobile far-field wireless power transfer system, there is no hardware reference design we can refer to and use for validation. So the validation of our work is done in the software aspect. But referring to the flowchart, our mobile wireless power transfer system can be replicated.
For the software, we use TensorFlow 0.13.1 together with Python 3.8 in Jupyter Notebook 5.6.0 as the software simulation environment to train the AD-DQN. The number of hidden layers is 4 and each hidden layer owns 100 nodes. The learning rate is less than 0.1. The mini-batch size is 10. The learning frequency is 5. The training starting step is 200. The experience pool is greater than 20000. The exploration interval is 0.001. The target network replacement interval is greater than 100. Reward decay is 0.99.
First, different reward functions are tested for the optimal one. Reward one reward1 is defined using equation (5). The unit price is defined as
 . Reward two reward2 is defined as
. Reward two reward2 is defined as

where
 . Reward three reward3 is defined with equation (5); however,
. Reward three reward3 is defined with equation (5); however,
 . Two factors are observed for the performance of different rewards, which are average reward during the training and average time consumption during the training.
. Two factors are observed for the performance of different rewards, which are average reward during the training and average time consumption during the training.
Based on the procedures of AD-DQN in Algorithm 1, the experimental field is divided into two areas along the only shared effective charging area for both device 2 and device 3. In area I, IoT devices 2, 3, 4, 5, and 6 are included, while in area II, IoT devices 0, 1, 2, 6, and 7 are included.
In area I, the performances of three different rewards are compared in Figures 4 and 5.

FIGURE 4: The average rewards of reward1, reward2, and reward3 versus the training episodes in area I of the experimental field.

FIGURE 5: The average time consumption achieved by reward1, reward2, and reward3 versus the training episodes in area I of the experimental field.
In area II, the performances of three different rewards are compared in Figures 6 and 7.

FIGURE 6: The average rewards of reward1, reward2, and reward3 versus the training episodes in area II of the experimental field.

FIGURE 7: The average time consumption achieved by reward1, reward2, and reward3 versus the training episodes in area II of the experimental field.
From Figures 4 and 5, we can observe that reward1 is optimal. Since all three rewards perform similarly on the time consumption, reward1 is the highest reward among all, which means that reward1 can effectively charge most of the IoT devices compared with the other two rewards.
From Figures 6 and 7, we can observe that reward3 performs best on the time consumption to complete one episode; however, reward1 is much more average reward than reward3. That can be explained as follows: compared with reward1, reward3 can only effectively charge fewer number of the IoT devices.
Overall, reward1 has optimal performance in both areas I and II; henceforth, reward1 is used to define the reward for AD-DQN.
In Figures 8 and 9, the performances of four different algorithms are compared. The random action selection randomly selects the action in the experimental test field. Same as AD-DQN, reward1 is used as the reward of Q-learning and DQN.

FIGURE 8: The effective charging rate of random action selection, Q-learning, DQN, and AD-DQN versus the total number of IoT devices.

FIGURE 9: The average time consumption of random action selection, Q-learning, DQN, and AD-DQN versus the total number of IoT devices.
We define the successful charging rate as the number of IoT devices that can be successfully charged in one complete charging episode over the total number of the IoT devices. From Figure 8, we can observe that random action selection has the worst successful charging rate. That can be explained as follows: random action selection never converges to either suboptimal or optimal path. Q-learning has a better performance than random action selection; however, it is outperformed by the other two algorithms, since Q-learning can only deal with the simple reinforcement learning model. DQN performs better than Q-learning and random action selection; however, it is outperformed by the AD-DQN, since the rewards for different states are defined as interconnected; even the reward decay is 0.99; DQN still cannot learn the optimal solution. When the total number of the IoT devices decreases, both DQN and AD-DQN perform the same since the decrease of the number of the IoT devices degrades the interconnections between different system states. From Figure 9, we can observe that, compared with the other algorithms, AD-DQN is not the one consuming the least time slots to complete one charging episode; however, AD-DQN is still the optimal algorithm, since all the other algorithms cannot achieve 100% effective charging rate; hence they consume fewer time slots to complete one charging episode.
In Figure 10, the optimal path determined by AD-DQN is shown as the bold black line. The arrows on the path show the direction of the robot to move as we assume that the robot is regulated to cruise on the path in the counterclockwise direction. In this way, the robot can continuously charge all the IoT devices. The experimental demonstration is shown in Figure 1.

FIGURE 10: The optimal path determined by AD-DQN. Bold black line indicates the path for the wireless power transfer robot.
5. Conclusions
In this paper, we invent a novel deep reinforcement learning algorithm AD-DQN to determine the optimal path for the mobile wireless power transfer robot to dynamically charge the harvesting energy-enabled IoT devices. The invented algorithm can intelligently divide a large area into multiple subareas and implement the individual DQN in each area, finally synthesizing the entire path for the robot. Compared with the state of the art, the proposed algorithm can effectively charge all the IoT devices on the experimental field. The whole system can be used in a lot of application scenarios, like charging IoT devices in the dangerous area and charging medical devices.
Data Availability
The data used to support the findings of this study are available from the corresponding author upon request.
Conflicts of Interest
The authors declare that they have no conflicts of interest.
Authors’ Contributions
Yuan Xing designed the proposed wireless power transfer system, formulated the optimization problem, and proposed the innovative reinforcement learning algorithm. Riley Young, Giaolong Nguyen, and Maxwell Lefebvre designed, built, and tested the wireless power transfer robot on the wireless power transfer test field. Tianchi Zhao optimized the performance of the proposed deep reinforcement learning algorithm. Haowen Pan implemented the comparison on the system performance between the proposed algorithm and the state of the art. Liang Dong provided the theoretical support for far-field RF power transfer technique.
Acknowledgments
This work was supported by WiSys Technology Foundation under Spark Grant.












 Open access
Open access