



1. Introduction
Over the last five years Europe has experienced a humanitarian crisis due to the massive number of migrants seeking asylum (see stats in UNHCR, 2019). Eritrea is currently the ninth largest country of origin for refugees (The America Team For Displaced Eritreans, 2020). In Europe, more than 100,000 Eritrean people have requested asylum, and Eritrean refugees represent about 40% of Switzerland's refugee population. Despite the large number of Eritrean refugees in the world, very little is known about their language, Tigrinya, and we are not aware of any study on second language learning by Eritrean people. More generally, the vast majority of studies on L2 French learning have been conducted with speakers of European languages.
This paper aims to fill this gap in shedding some light on the way Eritrean refugees, residing in Geneva, learn French as a second language (note that the generic term ‘refugee’ is used to refer to both people with the legal status of refugee and asylum seekers). It is organized as follows. In the first part, we review the aspects of Tigrinya grammar that are relevant to this study. We then summarize research on L2 French grammar learning, focusing on the phenomena that engendered difficulties in our own study. The specificities of second language learning and assessment in refugees are then briefly discussed. In the second part of the paper, we present a study on 47 speakers of Tigrinya learning L2 French. Their lexical and grammatical competence in French is characterized by means of an online placement test (Ev@lang), a standardized sentence comprehension test, and fine analyses of semi-spontaneous oral productions. Results are discussed in regard to the impact of Tigrinya grammar properties in the process of L2 French learning, to the role of individual variables in this process, and to more applied issues related to language assessment and language teaching for refugees.
1.1. Aspects of Tigrinya grammar
Tigrinya is an ethio-semitic language spoken in Eritrea and Ethiopia, mostly in the Tigray area but also in northern and central regions of Eritrea (Bulakh, Reference Bulakh, Huehnergard and Pat-El2019; Lipiński, Reference Lipiński2001). Tigrinya is one of the nine ethnic languages officially recognized in Eritrea, along with Arabic, English, Tigre and a number of African languages (Elias, Reference Elias2014) and is spoken by approximately ten million people (Voigt, Reference Voigt and Weninger2011). In what follows we provide a sketch of Tigrinya grammar based on Bulakh (Reference Bulakh, Huehnergard and Pat-El2019), Dyer (Reference Dyer and Henderson2019), Gebregziabher (Reference Gebregziabher2013) and Kogan (Reference Kogan and Hetzron1997).
Tigrinya is a pro-drop language such that subject pronouns are either optional (1), or pronounced for emphasis.
(1) mɨs-ħaw-u bɨ-məəkina məəs'iʔ-u
with-brother-his by-car come.PF-3M.SG.S
‘He came by car with his brother.’
Tigrinya is also a verb-final language; all non-pronominal complements, including sentential ones precede the main verb.
(2) joni nɨ-ħagos səərif-u-wwo
John OM-Hagos insult.PF-3M.SG.S-3M.SG.O
‘John insulted Hagos.’
In addition, the various auxiliaries and tense/aspect particles (with the exception of the future marker, which is a prefix) follow the main (lexical) verb.
(3) wəəlləədɨ-na k'əədəəm bɨ-xəəfti yɨ-ħars-u
fathers-our long ago by-ox 3-plough.IMPF-M.PL
nəəyr-om
were-3M.PL
‘Long time ago, our fathers used to plough with oxen.’
Regarding the word order of NPs, modifying elements are positioned before nouns and, hence, demonstratives, adjectives, numerals, possessive phrases and relative clauses precede nouns.
(4) ʔɨziʔən ʕabbaj səbəjti
dem.POL.F old.F.SG woman
‘this old woman’
Tigrinya has a definite article, inflected for gender (masculine and feminine) and number (singular and plural).
(5) ʔɨt-a hagər
the-F.SG country
‘the country’
Definiteness, however, can also be expressed by means of agreement features on the noun (Tajebe, Reference Tajebe2003, p. 25, 31–35). In (6), suffix –u denotes definiteness, apart from agreement features (3rd person, masculine gender and singular number).
(6) säbɨʔay-u habitam ʔɨ yy-u
man-3M.SG rich be-3M.SG
‘The man is rich.’
Even though Tigrinya does not have indefinite articles, the numeral ħadə ‘one’, which is inflected for gender, can be used to express indefiniteness, as illustrated in (7) (Bulakh, Reference Bulakh, Huehnergard and Pat-El2019, p. 194).
(7) ħad-ə zanta
one-M story
‘a story’
Tigrinya distinguishes two gender values, masculine and feminine, marked on determiners as well as on constituents modifying nouns (see (9) and (10)). In contrast, nouns are not morphologically marked for gender, with the exception of a few suffixes (-ti and -t) that denote the feminine gender.
(8)
a. nɨgus
‘king’
b. nɨgɨs-ti
king-F
‘queen’
The gender of animate nouns is mainly determined by biological gender. The default gender is masculine when biological gender is not specified (e.g., baby; Gebregziabher, Reference Gebregziabher2013). The gender of inanimate nouns is variable, in that it can change according to semantic features such as size, power and respect (Brindle & Müller, Reference Brindle, Müller and Stefan2006; Dyer, Reference Dyer and Henderson2019). Interestingly, even animate nouns can undergo gender shift in order to express these semantic variants (Dyer, Reference Dyer and Henderson2019, pp. 5–6).
(9)
a. ʔɨz-i t'awla
this.M.SG table
‘this table’
b. ʔɨz-a t'awla
this.F.SG table
‘this (small) table’
(10)
a. ʔɨz-i sabəj
this-M.SG man
‘this man’
b. ʔɨz-a sabəj
this.F.SG man
‘this nice/dear/esteemed man’
Subject-verb agreement in Tigrinya is displayed by means of person, number, and gender affixes. The gender of the subject is morphologically marked on the verb, as distinct affixes are employed for the masculine and feminine gender – however, only for the 2nd and 3rd person.
(11) ʔɨjj-u ʔɨjj-a
is-3M.SG is-3F.SG
ʔɨjj-om ʔɨjj-ən
are-3M.PL are.3F.PL
Moreover, verbs in Tigrinya are morphologically marked for perfective and imperfective aspects, tense, and mood. Negation is displayed via a circumflex, the negative prefix -ʔay- and the negative suffix –n. Passivization in Tigrinya is marked by means of the prefix tə- (Bulakh, Reference Bulakh, Huehnergard and Pat-El2019). The same prefix, however, is used in reflexive and reciprocal constructions (Bulakh, Reference Bulakh, Huehnergard and Pat-El2019, pp. 189–191), i.e., tə-sərik'u (= he is stolen), tə-ʃəbbiru (= he is frightened), tə-rakibu (= he meets with someone, lit. he is met with each other). A passive sentence is shown in (12), where the passive verb may carry object suffixes (Kifle, Reference Kifle, Butt and King2007, p. 16).
(12) ʔɨt-omɨ tämäharo mäṣɨḥäfɨti
the-3M.PL students-PL books –PL
tä-wahib-omɨ
PASS-PERF.give-3M.PL.S
‘The students are given books.’
Additionally, pronominal objects appear as suffixes and can be attached to verbs and prepositions.
(13) tɨnəgr-ə-nni
tell-2M.SG-O.1SG
‘you tell me’
(14) mɨsʔ-u
with-3M.SG
‘with him’
In Tigrinya, the interrogative particle -do is generally suffixed to the main verb in yes/no questions, while constituent questions are obligatorily formed with wh in situ.
Tigrinya sentential complementation requires further study. Relative clauses in Tigrinya are prenominal, externally headed and introduced with the particle z(ɨ)-. The particle z(ɨ)- is a prefix and attaches to the finite verb of the relative clause (Bulakh, Reference Bulakh, Huehnergard and Pat-El2019, p. 196; Gebregziabher, Reference Gebregziabher2013, pp. 61–62).
(15) [Elsa zɨ-s'əħaf-ət-o] məs'ħaf
Elsa REL-write.PF-3F.SG-3M.SG.O book
‘a book that Elsa wrote’
(16) ʔɨta z-əʕbəj-ət-ɨnni ʔaddə-j
the.F.SG REL-bring-up.PF-3F.SG-1SG.O mother-POSS.1SG
‘my mother who brought me up’
When the relativized constituent is a possessor, a resumptive pronoun, i.e., a pronominal copy of the possessor on the possessee, is obligatory as a last resort strategy (Gebregziabher, Reference Gebregziabher2013, fn 35).
(17) [joni məs'ħaf-*(u) zɨ-fətw-o] məmhɨr
John book-his REL-like-3M.SG.O teacher
‘a teacher whose book John liked’
1.2 Learning the grammar of French as a second language
Research on the learning of L2 French grammar has for the most part been conducted on speakers of European L1s. There is extensive research on the overgeneralization of non-finite forms (RIs) in L2 French by German, English and Moroccan Arabic learners (Myles, Reference Myles2004; Prévost, Reference Prévost1997, Reference Prévost, Perez-Leroux and Roberge2003, Reference Prévost2009; Prévost & Paradis, Reference Prévost and Paradis2004; Prévost & White, Reference Prévost and White2000; Schlyter, Reference Schlyter and Martinot1997, Reference Schlyter, Dimroth and Starren2003). RIs characterize the early stages of first language acquisition (see Ferdinand, Reference Ferdinand1996 and Prévost, Reference Prévost2009 for RI in L1 French) and have been accounted for by the truncation hypothesis (Haegeman, Reference Haegeman and Clahsen1996; Rizzi, Reference Rizzi1993/1994, Reference Rizzi, Friedemann and Rizzi2000), according to which, even though all functional categories are available from the outset, not all of them are projected during the first stages of language acquisitionFootnote 1. However, the RIs produced by adult learners of French exhibit different properties from those observed in first language acquisition; namely, they are attested in main and subordinate clauses, they appear with DP and clitic subjects, and they do not predominantly have future and modal readings, as in L1 French, but they also have past readings. Hence, it is argued that RIs in L2 French are not the product of truncation but rather that they reflect problems with the instantiation of verb inflectional suffixes (see Lardiere, Reference Lardiere and Archibald2000, Reference Lardiere, Liceras, Zobl and Goodluck2008, Reference Lardiere2009; Prévost & White, Reference Prévost and White2000).
Subject clitics in L1 French also emerge early and exhibit proper clitic distribution, even though subject omission rates can be high, particularly at the early stages of L1 French (Jakubowicz, Nash, Rigaut & Gérard, Reference Jakubowicz, Nash, Rigaut and Gérard1998; Prévost, Reference Prévost2009 a.o.). In L2 French, subject clitics also appear early: more than 50% of subject clitics are reported for native speakers of Arabic (Prévost, Reference Prévost1997), Swedish (Schlyter, Reference Schlyter, Dimroth and Starren2003), and English (Prévost, Reference Prévost, Perez-Leroux and Roberge2003; but see Myles, Reference Myles2004 for divergent findings). However, subject omission is attested in some studies of L2 French; although it is rare in speakers of non-pro-drop languages like English and Swedish (Granfeldt & Schlyter, Reference Granfeldt, Schlyter, Cantone and Hinzelin2001; Prévost, Reference Prévost, Perez-Leroux and Roberge2003; Prévost & Paradis, Reference Prévost and Paradis2004; Schlyter, Reference Schlyter, Dimroth and Starren2003), it is frequent in Arabic learners, whose L1 is pro-drop (Prévost, Reference Prévost2009). Moreover, subject clitics depict typical clitic properties: they are cliticized onto the verb, they are productively doubled with an NP (NP + clitic) and they fully agree with the NP in these structures (Herschensohn, Reference Herschensohn2001; Prévost, Reference Prévost2006, Reference Prévost2009; Prévost & White, Reference Prévost and White2000; but see Granfeldt & Schlyter, Reference Granfeldt, Schlyter, Cantone and Hinzelin2001 for divergent findings).
Object clitics develop later than subject clitics in L1 French and omission rates can be high in young children (Hamann, Rizzi & Frauenfelder, Reference Hamann, Rizzi, Frauenfelder and Clahsen1996; Hamann & Belletti, Reference Hamann and Belletti2006; Jakubowicz et al., Reference Jakubowicz, Nash, Rigaut and Gérard1998; Jakubowicz & Rigaut, Reference Jakubowicz and Rigaut2000; Paradis, Reference Paradis2004 for French monolingual and French–English bilingual children; Prévost, Reference Prévost2009). However, errors regarding clitic position are infrequent (Prévost, Reference Prévost2009). Early interlanguage shows significant object clitic omission, which may be persistent even at high proficiency levels (Schlyter, Reference Schlyter, Dimroth and Starren2003; but see German, Herschensohn & Frenck-Mestre, Reference German, Herschensohn and Frenck-Mestre2015; Herschensohn & Gess, Reference Herschensohn and Gess2018). Moreover, learners tend to produce clitics in canonical complement position (Granfeldt & Schlyter, Reference Granfeldt, Schlyter, Prévost and Paradis2004; Herschensohn, Reference Herschensohn, Prévost and Paradis2004), although comprehension studies suggest that the learners are aware of the preverbal position of the clitic (Duffield, White, De Garavito, Montrul & Prévost, Reference Duffield, White, De Garavito, Montrul and Prévost2002; Grüter, Reference Grüter2006; Hoover & Dwivedi, Reference Hoover and Dwivedi1998; German et al., Reference German, Herschensohn and Frenck-Mestre2015).
Determiner omission is rarely attested even in early stages of L1 French development (Jakubowicz et al., Reference Jakubowicz, Nash, Rigaut and Gérard1998; van der Velde, Jakubowicz & Rigaut, Reference van der Velde, Jakubowicz, Rigaut and Lasser2002). In contrast, it is a prevalent error in L2 adult French, particularly with learners of article-less L1s like Japanese (Sleeman, Reference Sleeman, Cornips and Doetjes2004) and Polish (Watorek, Lenart & Trévisiol, Reference Watorek, Lenart and Trévisiol2014). Article features’ misinterpretation has also been reported (Deprez, Sleeman & Guella, Reference Deprez, Sleeman and Guella2011; Guella, Reference Guella2009; Hermas, Reference Hermas2020).
Finally, regarding the gender feature, in contrast to its early mastery in L1 French, many L2 studies have shown persistent difficulties, particularly when the learners’ L1 lacks grammatical gender (Carroll, Reference Carroll1989, Reference Carroll1999; Guillelmon & Grosjean, Reference Guillelmon and Grosjean2001; Hawkins & Franceschina, Reference Hawkins, Franceschina, Prévost and Paradis2004; Meisel, Reference Meisel2018; Surridge & Lessard, Reference Surridge and Lessard1984; Wust, Reference Wust2010). Nevertheless, gender seems to be mastered in high proficiency levels, even when the L1 does not instantiate it (Ayoun, Reference Ayoun and Ayoun2007; Bartning, Reference Bartning2000; Edmonds, Gudmestad & Metzger, Reference Edmonds, Gudmestad and Metzger2019; Prévost, Reference Prévost2009; Shimanskaya & Slabakova, Reference Shimanskaya and Slabakova2017). Most studies have indicated that the masculine gender is overused (Harley, Reference Harley1979; Bartning, Reference Bartning2000; Dewaele & Véronique, Reference Dewaele and Véronique2001; Edmonds & Gudmestad, Reference Edmonds and Gudmestad2018; Edmonds et al., Reference Edmonds, Gudmestad and Metzger2019) and that animacy, morphophonological cues as well as noun frequency affect learning (Dewaele, Reference Dewaele2015; Edmonds et al., Reference Edmonds, Gudmestad and Metzger2019; Hardison, Reference Hardison1992; Shimanskaya & Slabakova, Reference Shimanskaya and Slabakova2017; Surridge & Lessard, Reference Surridge and Lessard1984).
The learning of a new language is also influenced by a number of individual variables such as multilingualism, length of exposure to the L2, age, age of onset and education level. Previous research has highlighted the positive impact of bi/multilingualism on the learning of various aspects of the new language including phonotactics (Kuo & Anderson, Reference Kuo and Anderson2012), vocabulary (Bialystok, Reference Bialystok2001; Kaushanskaya, Reference Kaushanskaya2012) and grammar (Nation & McLaughlin, Reference Nation and McLaughlin1986). Research on multilingual learners has explored the locus of crosslinguistic influences between the new language and those already known (Hammarberg, Reference Hammarberg, Cenoz, Hufeisen and Jessner2001; de Bot & Jaensch, Reference de Bot and Jaensch2015; Leung, Reference Leung2005; Rothman, Reference Rothman2015 a.o.). It has been suggested that, when learning a third language, both the first and the second languages influence the new interlanguage: grammatical properties may be transferred from the first but also the second language(s) (Leung, Reference Leung2005; Rothman, Reference Rothman2015), while the typological proximity among the speaker's known languages may affect the transfer patterns observed in L3 (Rothman, Reference Rothman2011). Length of exposure to the L2 positively correlates with L2 performance, even though this effect is more robust in child than adult learners (Hyltenstam & Abrahamsson, Reference Hyltenstam, Abrahamsson, Hyltenstam and Fraurud2003 for adult learners; Unsworth, Reference Unsworth2016 for child learners). Age effects have been extensively investigated in L2 acquisition studies, which have mainly focused on the debate about the role of a biologically based critical period (Birdsong, Reference Birdsong2018; DeKeyser & Larson-Hall, Reference DeKeyser, Larson-Hall, Kroll and de Groot2005; Hakuta, Bialystok & Wiley, Reference Hakuta, Bialystok and Wiley2003; Hyltenstam & Abrahamsson, Reference Hyltenstam, Abrahamsson, Hyltenstam and Fraurud2003; Johnson & Newport, Reference Johnson and Newport1989, a.o.). Although there is little consensus about what age constitutes a critical turning point, accumulated evidence shows that learning a second language becomes compromised with age (Birdsong, Reference Birdsong2018; Hartshorne, Tenenbaum & Pinker, Reference Hartshorne, Tenenbaum and Pinker2018). Some studies have also shown that high proficiency in the L2 is often achieved by learners with higher education levels (Studenska, Reference Studenska2011; Young-Scholten, Reference Young-Scholten2013).
1.3 Refugees’ learning of the host country language
Refugees constitute a population which is understudied in the field of L2 acquisition, even though their social profile and second language learning settings are very different from those attested in other groups of L2 learners. Refugees are a vulnerable group with traumatized experiences and often low education and interrupted schooling. Moreover, they have fewer opportunities to use the host language, as compared to other second language learners, as they are often confined in hotspots or refugee shelters, in which they mainly interact with other refugees (Dalziel & Piazzoli, Reference Dalziel and Piazzoli2019; Paradis, Soto-Corominas, Chen & Gottardo, Reference Paradis, Soto-Corominas, Chen and Gottardo2020).
Nevertheless, learning the language of the host country is of crucial importance for refugees, be it for providing them with the necessary skills to access employment, services and education, for building social cohesion (Dalziel & Piazzoli, Reference Dalziel and Piazzoli2019; Li, Reference Li, Gold and Nawyn2013), or getting residency permits. The crucial role that language level plays in European countries’ policies highlights the importance of developing valid certification procedures. The relevance of language assessment by means of CEFR (Common European Framework of Reference for Languages, Council of Europe, 2001) as well as testing procedures have been questioned (Maurer & Puren, Reference Maurer and Puren2019; McNamara, Reference McNamara2005; Saville, Reference Saville2009; Shohamy & McNamara, Reference Shohamy and McNamara2009 for thorough discussions), and very few studies have actually explored the validity of CEFR in L2 French (but see Forsberg & Bartning, Reference Forsberg, Bartning, Bartning, Martin and Vedder2010; Prodeau, Lopez & Véronique, Reference Prodeau, Lopez and Véronique2012). To our knowledge, none has been conducted on refugees.
1.4 Aims of the study
The primary goal of the study is to provide a characterization of the lexical and grammatical competence in L2 French of refugee Tigrinya speakers, and assess their difficulties in regard to specificities of Tigrinya grammar. To do so, we collected language measures in a sample of 47 Eritrean refugees on two language tests and proceeded to a fine analysis of their semi-spontaneous oral productions. The first language test consists of two subtests of the online placement test Ev@lang (assessing oral comprehension, grammar and vocabulary), allowing us to globally situate participants’ language level within the CEFR. The second test is a standardized sentence comprehension test developed in Geneva (TICSf, Test Informatisé de Compréhension Syntaxique en français), allowing us to assess participants’ level of difficulty with different syntactic phenomena (active, negative, passive, prepositional, relatives) and compare their gradient of difficulty with that of adult native French speakers. Semi-spontaneous productions were analyzed through both general indexes (Type Token Ratio, Mean Length of Utterance, mean number of verbs, proportion of subordinate clauses) and finer indexes of grammatical errors (subject omission, determiner omission, root infinitives, phenomena related to subject and object clitics, word order and agreement). The second goal of the study was to study the influence, on these language measures, of individual variables that have been shown to affect L2 learning, i.e., age, age of onset, multilingualism, level of education, and length of residence in the host country. Finally, the study also aimed to provide a preliminary evaluation of the validity of Ev@lang, a new on-line adaptive test (it adapts in real time to user performance) to assess language in refugees (https://www.evalang.fr/). Scores to the test were correlated to the language measures obtained from corpus analyses and to the TICSf in order to determine their degree of convergence, and the overall testing procedure was assessed.
2. Empirical study of Tigrinya learners of L2 French
2.1 Method
Participants
A total of 47 participants took part in the study, 27 women and 20 men. All of them were forced migrants from Eritrea living in Geneva; some with a refugee permit, others in the asylum process. They were between 19 and 54 years old (Mean = 30;7, SD = 9;5). All were literate, and the information obtained for 34 of them with respect to the number of years of education in Eritrea shows a range between 0 and 13 years of school education (Mean = 8;2, SD = 4;1).
Considering their language skills, all participants had Tigrinya as their first language and most of them (39 over 47) were bilingual, speaking, independently of French, either 2 languages (N=19), 3 languages (N = 14), or more than 3 languages (N = 6, see Table 1). The additional languages were English (N = 26), Amharic (N = 14), Arabic (N = 11), Italian (N = 5), Tigre (N = 4), Hebrew (N = 1), and German (N = 1). None of the participants had learned French before coming to Geneva. They had been living in Geneva and thus been exposed to French between 1 and 19 years (Mean = 5;5, SD = 3;8), and they were between 16 and 50 years old when they started to be exposed to French (Mean = 27;7, SD = 7;8). Twenty-seven of them had received intensive L2 French classes from the State institution Hospice Général (half a day, 4 days per week over a variable number of months). The remaining 20 participants had learned French through associations. Most of them (N = 36) had more than 400 hours of teaching, while a small subset had less than 200 hours (N = 7). Recruitment was based on the experimenters’ short evaluation before testing: participants had to be able to describe a familiar situation in simple terms. A summary of participants’ characteristics is presented in Table 1.
Table 1. Participants’ characteristics.

Participants were recruited for the most part from the Cafés Solidaires at the Faculté de Psychologie et des Sciences de l'Education of the University of Geneva, as well as from foyers and various associations in town. They were paid 25 CHF.
2.2. Materials and procedure
Ev@lang
This test contains three independent units: Oral comprehension, Grammar & Vocabulary, and Written comprehension; in the current study, only the first two units were used. Each unit contains three sections with 4, 4, and 3 to 6 questions respectively, the number of questions in the third section depending on performance in the first two. The level of success in the first section determines the difficulty of the second (amount of information to deal with, utterance length and response modality) as well as the time allocated to answer. Questions are randomly selected from the Ev@lang database of questions following specific procedures (all unavailable to the public). Questions from the Oral comprehension test unit can either involve (i) an audio text of a few tens of seconds (usually dialogues) followed by a written comprehension question with multiple choice answers, or (ii) the presentation of a picture or an audio sentence and a multiple-choice question involving 4 possible descriptions provided as audio sentences. Questions from the Grammar & Vocabulary test unit are presented in the written format and bear on a grammatical or a lexical component of the language. The test is computerized and is realized online, and a score for each unit, ranging between 0 and 14, is automatically generated. The test starts with an explanatory video, followed with a training phase involving questions similar to those of the test. Each session starts with the Oral comprehension unit (maximum 14 minutes) followed by the Grammar & Vocabulary unit (maximum 7 minutes). Given the uncertainty with respect to the validity of the test for our population, we parameterized the test so that the results were not displayed on the user's screen, but available to us on the Ev@lang management tool.
Test Informatisé de Compréhension Syntaxique en français (TICSf)
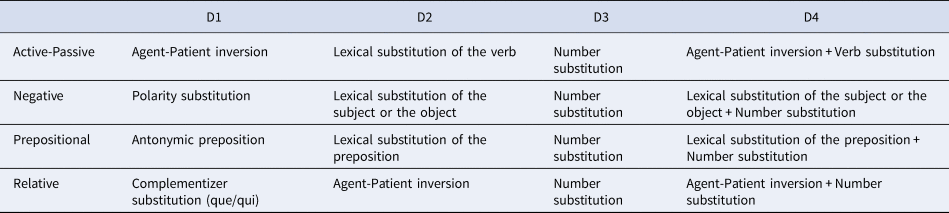
This test of sentence comprehension was designed in Geneva to assess grammar skills in French-speaking aphasic adults (Python, Bischof, Probst & Laganaro, Reference Python, Bischof, Probst and Laganaro2012). The test was standardized on a population of native French speakers ranging from 19 to 88 years old. It contains two subtests assessing lexical and syntactic comprehension. Only the latter was administered here. Syntactic comprehension is assessed through a sentence-picture matching task. Fifty declarative sentences are distributed in 5 categories of structures with 10 items each and referred to as: Active reversible, Negative, Passive reversible, Prepositional (i.e., containing a preposition), Relatives (subject, object and adjunct relatives). For each sentence, participants need to select one of four pictures or an image situated in the middle of the four pictures and containing the word ‘Other’, which is the correct response if none of the pictures correctly illustrates the target sentence. The four pictures either illustrate the target image and 3 distractors, or four distractors if the correct response is the middle image ‘Other’. The distractors are of different types, depending on the structure of the target sentence (inversion of thematic roles, inversion of polarity, lexical substitution, number feature substitution or a combination of two errors, see Table 2). The test is computerized. Before the test starts, images illustrating the nouns involved in the test sentences are presented together with the nouns, to make sure that they are known. Two training items are provided. Test sentences are presented orally, and could be listened to twice. Participants click on the picture to select their answer. Correct answers are scored 1, incorrect answers 0.
Table 2. Distractor types used in the Test Informatisé de Compréhension Syntaxique en français (TICSf), as a function of sentence structure.
Semi-controlled speech corpora
Participants were asked to describe a short story illustrated by a board of 16 drawings in the format of a comic book (see Figure S1, Supplementary Materials). The story and illustrations were inspired by materials from the data basis of OrthoEdition (https://www.orthoedition.com/) that provides materials for speech therapy. It was modified with the aim of reducing cultural biases in the scenario, and enriched to involve frequent lexical elements. Story description was favored over fully spontaneous speech in order to ensure maximal comparability among participants. Participants had a few minutes to look at the board, and were then asked to describe each image in sequential order. Productions were recorded and transcribed using the CHAT coding from the Child Language Data Exchange System (CHILDES) Talkbank program (https://childes.talkbank.org/; MacWhinney, Reference MacWhinney2000). Transcripts were checked by at least one additional coder, and two for the few cases where disagreement persisted (either related to the auditory input, or to the coding itself). Corpora were analyzed both for general indexes and for finer linguistic measures. Mean Length of Utterance and Type Token Ratio (corrected for content words only) were calculated using the Computerized Language ANalysis program (CLAN) from CHILDES. We also explored more specifically the phenomena that are known to be problematic in L2 French learning, i.e., subject omission, word order (Verb-Subject, Subject-Object-Verb), determiner omission, root infinitives, and agreement errors. Each was quantified with respect to its own obligatory context (see Results section).
Scoring and data analyses
Performance in each task was quantified by various indexes that are described in the Results section. Regression analyses were conducted to assess the influence, on L2 French indexes, of 6 individual variables: Age, Number of years of education in their home country, Number of languages spoken, Age of onset in the learning of French (AoO), Number of years of residence in Switzerland, and whether they had attended State French classes. Analyses involved multiple linear regression models or multiple logistic regression models when the dependent variable involved percentages or proportions (fitting a quasi-binomial distribution allowing for overdispersion). Model selection was done by means of a backward stepwise algorithm based on AIC for linear regressions, and of likelihood ratio tests comparing the likelihood of the data under the full model against that of reduced models in the case of logistic regressions. To assess differences between conditions when relevant, paired comparisons were conducted using the non-parametric Wilcoxon signed rank test with continuity correction. Finally, the relationships between the different language measures were explored by means of Pearson correlations. All analyses were conducted in R (R Core Team, 2012).
2.3 Results
Ev@lang
Scores to Ev@lang Grammar & Lexicon (GL) and Ev@lang Oral Comprehension (OC) ranged between 1 and 5, corresponding to levels A1 not reached and B2 respectively, the vast majority being between A1 and A2 (see Table 3). A significant positive correlation was found between the two subtests (r(45) = .64, p < .001).
Table 3. Distribution of participants according to their language level (CEFR) reached in Ev@lang Grammar & Lexicon and Ev@lang Oral Comprehension.

TICSf
The mean score to the TICSf is 23.3 (SD = 8.3) corresponding to 46.5% of correct responses, with individual scores ranging between 14% and 84% (see Table 4 for mean percentages per condition). Performance was significantly better in Negative sentences compared to Actives (V = 907, p < .001) and Prepositional sentences (V = 876, p < .001). Actives and Prepositional did not differ (V = 385, p = .741), but were both better than Passives (Actives vs. Passives: V = 39.5, p < .001; Prepositional vs. Passives: V = 40.5, p < .001) and Passives scored higher than Relatives (V = 244, p = .042). The gradient observed is: Negatives > Actives = Prepositional > Passives > Relatives. Qualitative analysis of the error types revealed that 43.4% of the errors occurred on Distractor D1 (inversion of the agent and the patient for Active, Passive and Relatives sentences, the addition/omission of the negative particle for Negative sentences, and the erroneous preposition for Prepositional sentences), 29.1% on D3 (number feature substitution), 19% on D2 (lexical unit substitution), 7.1% on Others and 1.4% on D4. For Active sentences, 76.6% of the errors occurred on D1 and D3, and 24% on D2 and Other. For Negatives, 67.7% of the errors were on D1 and D3, 28.3% on D2 or Other. For Passives, 56.8% were on D1, 25.4% on D3, 13% on D2. For Prepositional phrases, 80.6% of the errors were on D1 and D3, while 18.9% were on D2 and Others. Finally, Relatives showed 43% errors on D1, 31.1% on D2 and 14.6% on D3.
Table 4. Percentage of answers (Correct, Distractors D1, D2, D3, D4, Other) according to sentence structure and distractor type in the TICSf. Standard deviations for Correct responses are in parentheses.

Corpus analysis
A total of 2997 utterances were produced (M = 64, SD = 27), among which 2146 were sentences, representing about 70% of the utterances (M = 45, SD = 21). Lexical diversity was estimated by the Type Token Ratio corrected (TTRc) obtained by dividing the number of different content words (noun, verb, adjective, adverb, excluding interjections and onomatopoeias) by the total number of content words among all utterances. It ranges between 0.25 and 0.67 (M = 0.44, SD = 0.09). The Mean Length of Utterance (MLU) was calculated by dividing the total number of words (excluding interjections and onomatopoeias) by the total number of utterances. MLU ranges between 3.1 and 12.4 (M = 6.15, SD = 2.03). The mean number of verbs was obtained by dividing the total number of verbs (including auxiliaries) by the total number of sentences; it ranges between 1 and 2.46 (M = 1.48, SD = 0.33). The proportion of subordinate clauses, estimated by dividing the number of subordinate clauses (complement and relative clauses) by the total number of sentences, ranges between 0 and .54 (M = 0.23, SD = 0.12). A strong correlation was found between the three grammatical indexes: between MLU and Mean number of verbs (r(45) = .784, p < .001), between MLU and subordinates (r(45) = .648, p < .001), and between mean number of verbs and Subordinates (r(45) = .695, p < .001). TTRc did not correlate with MLU (r(45) = .145, p = .33) nor with Subordinates (r(45) = .175, p = .239). However, a significant correlation was found between TTRc and the mean number of verbs (r(45) = .348, p = .017).
Finer analyses of the major grammatical phenomena of L2 French were then conducted on the 2146 sentences. In terms of structural complexity, complement clauses were produced in 20.8% of the sentences, while 2.8% of the sentences contained a relative clause, which was nearly always a subject relative. A total of 117 sentences (5.4%) had a missing subject. Most of them were root subject drops (75%), while the remaining ones were embedded in interrogatives or complement clauses, as illustrated in (18). A substantial number of subject clitics (1328) were produced, with few agreement errors regarding the φ-features of the clitic's local referent (4%). Most of those errors (98%) were gender errors, of which 70% consisted in producing the masculine clitic in place of the feminine. Subject doubling represents 14% of the sentences involving a subject. Instances of subject doubling were fully grammatical, consisting in left or right subject dislocations of the noun phrase combined with a cliticized subject, as illustrated in (19).
(18)
a. *___ cherche la chapeau
looks-for the.F.SG hat
‘(S)he is looking for the hat.’
b. *comment ___ s'appelle?
how OCL.3SG-call.3SG
‘How is it called?’
c. *par exemple quand ___ regarde bon film
for example when ___ watches good.MSG film
‘For example, when (s)he is watching a good film.’
(19) le chapeau il est tombé dans le lac
the.M.SG hat it.M is fallen in the.M.SG lake
‘The hat fell into the lake.’
At the verb level, 175 sentences (8.2%) contained a root infinitive verb. Among them, 3.4% had a missing subject. When a subject was produced with an infinitive verb, it was a clitic in 59% of the cases, a phenomenon which was widely distributed among speakers (35 out of the 47 produced at least one subject clitic in a root infinitive). As illustrated in (20), all persons and numbers were represented in those clitics, although 70% of them were 3rd person singular. Infinitives were also used with auxiliaries in 16% of the cases (être, to be, or avoir, to have), which was always correctly inflected as illustrated in (21). Most of the auxiliaries (90%) were produced in conjunction with a subject clitic. Finally, 9% of the root infinitives also contained an object clitic, sometimes in conjunction with a subject clitic, as illustrated in (22).
(20)
a. *je partir
I leave.INF
‘I leave.’
b. *et tu oublier
and you forget.INF
‘And you forget.’
c. *monsieur avec madame il discuter
sir with lady he discuss.INF
‘The man is having a conversation with the lady.’
d. *vous prendre le chapeau pour
you.2PL take.INF the.M.SG hat for
la madame
the.F.SG lady
‘You take the hat for the lady.’
(21)
a. *ils ont prendre le chapeau
they have.3PL take.INF the.M.SG hat
b. *elle est lire un livre
she is read.INF a.M.SG book
(22)
a. monsieur le prendre le chapeau.
sir OCL.M.SG catch.INF the.M.SG hat
‘The man, he catches the hat.’
b. elle l’ aider beaucoup, oui
she OCL.M.SG help.INF very, yes
‘Yes, she helps him a lot.’
In contrast to the massive use of infinitive verbs in the context where an inflected verb was expected (root infinitives), only 10 instances (produced by 10 different speakers) of the opposite error consisting of the erroneous production of an inflected verb in the context where an infinitive verb was expected were observed, as illustrated in (23).
(23)
a. *après il monte la chaise pour trouve
then he climb.3SG the.F.SG chair for find.3SG
le chapeau
the.M.SG hat
‘Then he climbs onto the chair in order to find the hat.’
b. *il ose pas prend
he dare.3SG NEG take.3SG
‘He does not dare to take.’
Sentences with the erroneous preverbal positioning of a nominal verb complement (SOV), as illustrated in (24), were produced in 1.5% of the total number of sentences by 14 participants. This order represents between 1.5% and 13.5% of the sentences for these participants. Very few sentences showed verb-subject inversion (1.1% of sentences involving a subject), as illustrated in (25).
(24) *monsieur le chapeau donne
sir the.M.SG hat give.3SG
‘The man gives the hat.’
(25) *après sort le dame
then go-out.3SG the.MSG lady
‘Then the lady goes out.’
A total of 119 object clitics were produced, a number which is significantly lower than subject clitics (1328). Both accusative and dative object clitics were produced. About 15% of them were erroneously produced, consisting for the most part in case substitutions (accusative in place of dative and vice-versa, (26a) and (26b) respectively), as well as a few position errors in which the pronoun is produced postverbally (after the main verb or between the auxiliary and the past participle, as illustrated in (26c) and (26d)).
(26)
a *il l’ indiquait que la
he OCL.SG indicate.IMP.PAST.3SG that the.F.SG
casquette elle est passée par là
cap is passed.F.SG from there
‘He pointed out to her that the cap went past by there.’
b. *il voulait lui aider un peu
he want.IMP.PAST.3SG IOCL.SG help.INF a little
‘He wanted to help her a little bit.’
c. *elle a pris et donné lui
she has taken and given IOCL.SG
‘She took (it) and gave (it) to him.’
d. *il a lui dit aussi
he has IOCL.SG said also
‘Also, he told her.’
Significant determiner omission was found, as 346 of the 1699 nouns (20%) were missing a determiner (27a). Among the determiners produced, 203 (15%) contained a substitution error. Most substitutions (162) were gender errors, 60% of which consisted of producing the feminine determiner where a masculine determiner was expected (27b). Interestingly, 24% of the gender errors occurred on animate nouns with semantic gender. Other substitutions included erroneous partitives in place of the definite article (27c) and erroneous elisions (27d).
(27)
a. *elle a ___ chapeau
she has hat
‘She has a hat.’
b. *après c'est trouvé dans la lac
then it is found in the.F.SG lake
‘Then it is found in the lake.’
c. *la femme s’ asseoir sur dossier
the.FSG lady CL.3SG sit.INF on bench
et lire de journal
and read.INF PART newspaper
‘The lady sits on a bench and reads a newspaper.’
d. *sur le arbre
on the.MSG tree
‘on the tree’
A total of 652 prepositions were produced, with a few errors of positioning after the noun phrase as illustrated in (28). Negative sentences were produced in 258 instances, nearly always correctly with the negative particle ‘pas’ positioned after the inflected verb (29a), between the auxiliary and the past participle, but before the infinitive verb (whenever it is a root infinitive or not), as shown in (29b).
(28)
a. *aller le chapeau avec
go.INF the.M.SG hat with
b. *trouver le chapeau pour
find.INF the.M.SG hat for
(29)
a. s’ il tombe pas dans l'eau il peut
if he falls NEG in the-water he can.3SG
venir ici
come.INF here
‘If it does not fall into the water, it may pass by here.’
b. *non c'est pas prendre
no it-is NEG tak.INF
Finally, a few gender agreement errors are noted on the adjective and the past participle, for the most part due to masculine as default. A low rate of subject-verb number agreement errors was found, but very few plural subjects were produced.
Effect of individual variables on linguistic indexes
Results of the backward stepwise multiple linear regressions conducted on the two Ev@lang scores indicated that the best fit model to account for Ev@lang GL performance involved AoO, Age, Number of languages, years of education and years in Switzerland, although the model did not reach significance level (F(5, 27) = 1.77, p = .152, Adjusted R2 = .108). The best model accounting for performance in Ev@lang OC involved AoO, Age and years of education and reached significance level (F(3, 29) = 2.84, p = .051, Adjusted R2 = .147). A significant effect of AoO was found indicating that the younger they are exposed to French, the better their performance in Ev@lang OC (t(31) = -2.21, p = .05), but no significant effect of Age and years of education. The backward stepwise multiple linear regression conducted on TICSf scores selected as best fit the model involving number of languages (F(1, 31) = 4.05, p = .05, Adjusted R2 = .087), indicating that increasing the number of languages contributes to increase TICSf scores (t(31) = 2.01, p = .05).
Backward multiple linear regressions conducted on TTRc showed that the best fit model involves number of languages and State French classes, although the model fails to reach significance level (F(2, 30) = 2.17, p = .132, Adjusted R2 = .068). The best model for MLU involves the number of languages spoken, Age and AoO (F(3, 29) = 4.28, p = .013, Adjusted R2 = .235), showing that MLU significantly increases with the number of languages spoken (t(29) = 2.50, p = .018) and Age (t(29) = 2.39, p = .023), and significantly decreases with increased AoO (t(29) = -2.31, p = .029). Mean number of verbs per sentence was best fitted with a model that includes the number of languages, Age and AoO (F(3, 29) = 3.56, p = .026, Adjusted R2 = .194), indicating a significant positive link with the number of languages (t(29) = 2.58, p = .015) while Age and AoO did not reach significance level. The best fit model for the proportion of subordinate clauses includes the number of languages, showing that the rate of subordinate clauses increases with the number of languages (t(31) = 2.23, p = .033).
GLM models estimating the role of individual variables on the indexes of the finer corpus analysis showed that the best fit model for subject omission contains as only predictor the number of years of education, which predicts the rate of subject omission (t(31) = 2.21, p = .035). Root infinitives are best accounted for by a model involving the number of languages, which contributes to significantly reducing their rate (t(31) = -2.39, p = .023). The best model accounting for the production of SOV sentences involves the number of languages, indicating that SOV sentences significantly decrease as the number of languages increases (t(30) = -2.43, p = .021). The best model accounting for determiner omission involves the number of languages and French State classes: determiner omission significantly decreases with the number of languages spoken (t(29) = -2.71, p = .011), and with having attended French classes (t(29) = -2.21, p = .035). Results are summarized in Table 5.
Table 5. Summary of the effects of individual variables on L2 French language indexes.

Relationships between Ev@lang and language measures
Performance in the two Ev@lang tests correlates with the TICSf (Ev@lGL and TICSf: r(45) = .563, p < .001, Ev@lCO and TICSf: r(45) = .519, p = .001). They also show strong correlations with the more naturalistic spontaneous speech data (TTRc, MLU, Mean number of verbs, Subordinates). Ev@lGL significantly correlates with TTRc (r(45) = .568, p < .001), MLU (r(45) = .43, p = .003), Mean number of verbs (r(45) = .563, p < .001), and Subordinates (r(45) = .379, p = .009). Ev@lOC significantly correlates with TTRc (r(45) = .408, p = .004), MLU (r(45) = .53, p < .001), Mean number of verbs (r(45) = .597, p < .001), and Subordinates (r(45) = .49, p = .001).
3. Discussion
We reported a thorough exploration of L2 French language skills of 47 native speakers of Tigrinya situated around A1-A2 levels. The results bring new insight in regard to the specific characteristics of Tigrinya speakers learning L2 French, the effect of individual variables on L2 learning, and the more applied issues of language assessment and language teaching in refugees. We discuss the three in turn.
3.1 Performance on French grammatical properties by Tigrinya speakers
Fine corpus analyses revealed a pattern of similarities and differences from the literature on L2 French learning. In line with the literature, we found that Tigrinya learners produced root infinitives in about 10% of their sentences (Myles, Reference Myles2004; Prévost, Reference Prévost, Perez-Leroux and Roberge2003, Reference Prévost2009; Prévost & Paradis, Reference Prévost and Paradis2004; Prévost & White, Reference Prévost and White2000; Schlyter, Reference Schlyter and Martinot1997, Reference Schlyter, Dimroth and Starren2003). Although this rate is lower than that reported in some studies (e.g., Myles, Reference Myles2004, on English learners of French), important variation is commonly found, even in learners of similar proficiency levels (from 5% to more than 25% in English learners, Prévost, Reference Prévost2009). Our observations show that root infinitives are rarely produced with missing subjects, massively produced with clitic subjects, and are attested together with inflected auxiliaries (Prévost, Reference Prévost, Perez-Leroux and Roberge2003, Reference Prévost2009; Prévost & Paradis, Reference Prévost and Paradis2004; Prévost & White, Reference Prévost and White2000). These specificities of root infinitives in L2 learners contrast with those reported in children, in which RIs are commonly produced with missing subjects, and rarely with subject clitics and auxiliaries. Those differences have been argued to attest to different underlying mechanisms in children and L2 learners: while root infinitives in children would result from a truncation mechanism (Haegeman, Reference Haegeman and Clahsen1996; Rizzi, Reference Rizzi1993/1994, Reference Rizzi, Friedemann and Rizzi2000), their finite properties in L2 learners’ productions suggest that they rather reflect difficulties in mapping abstract morphosyntactic features with overt morphology (Lardiere, Reference Lardiere and Archibald2000, Reference Lardiere, Liceras, Zobl and Goodluck2008, Reference Lardiere2009; Prévost & White, Reference Prévost and White2000).
Our participants produced less than 6% of subject drops. Interestingly, this low rate of subject drops is similar to that found in L2 French learners whose native language has obligatory subjects – namely, English and Swedish (Prévost, Reference Prévost, Perez-Leroux and Roberge2003; Schlyter, Reference Schlyter, Dimroth and Starren2003) – and it is lower than that found in speakers of Arabic, a pro-drop language like Tigrinya (Prévost, Reference Prévost2009). However, considerable inter-individual variation has been reported in these studies (e.g., 12% - 33% in the study on Arabic speakers), which is also the case in Tigrinya speakers (0% - 23%; 10 participants produced none, 10 produced more than 10%). Proficiency in French grammar may be partly responsible for this variability, as we found that subject drop decreases as various grammar indexes increase (negative correlations with Mean number of verbs: r(45) = -.404, p = .005; TICSf: r(45) = -.364, p = .012; MLU: r(45) = -.309, p = .034). In any case, before interpreting further our finding that Tigrinya speakers produced overall few subject drops, additional comparative data is needed on speakers of a non-pro-drop L1 with the same corpus elicitation protocol. Interestingly, Tigrinya learners, in line with Arabic speakers of French, dropped subjects in the root of the sentence, but also in intermediate positions (subordinates, questions). Again, this finding diverges from what has been reported in L1 acquisition by children of non-null subject languages, where null subjects only affect root clauses and very rarely subordinate clauses (Prévost, Reference Prévost2009). This further supports the claim that, in contrast to children acquiring their L1, subject omission is not the result of truncation.
Tigrinya learners produced a high rate of subject clitics, which appear to have the status of proper clitics since they are productively used and commonly appear together with a DP. Furthermore, the first singular clitic je was always correctly elided in front of verbs beginning with a vowel (j'ai), indicating the proper cliticisation of the pronominal form onto the verb. Object clitics were much less frequently produced than subject clitics. A small sample of errors were observed, consisting in case substitutions (accusative/dative) and positioning errors (with respect to the auxiliary and the main verb). Nevertheless, a bigger sample would be needed to be able to draw conclusions.
We found that in a small subset of sentences, participants produced preverbal complements, in line with the word order of Tigrinya. The low number of erroneous verb final structures may be related to the non-harmonic word order of Tigrinya, in which, even though verb complements are preverbal, complements of prepositions are positioned after the head.
Determiner omission is attested at a rate of 20% in our corpus and is the most frequent error made by our Tigrinya learners, even though Tigrinya instantiates determiners. Some studies have also reported determiner drop in learners whose L1 has determiners, at beginner levels (20% in Swedish learners, Granfeldt, Reference Granfeldt2003; up to 90% in English learners, Gess & Herschensohn, Reference Gess, Herschensohn, Camps and Wiltshire2001). The relatively high rate of determiner drop may be attributed to the distribution of determiners in French and Tigrinya. Definiteness in French is expressed by means of definite articles while in Tigrinya definiteness is denoted either via definite determiners or via agreement nominal features. Therefore, Tigrinya learners of French need to reassemble the definiteness feature so that it is only incorporated onto the definite article, a process that may result in their optional use (Lardiere, Reference Lardiere, Liceras, Zobl and Goodluck2008, Reference Lardiere2009).
When determiners are produced, we observed nearly 20% errors, for the most part gender errors. As discussed in section 1.2, the acquisition of gender is challenging in L2 French. Nevertheless, our data depart from the literature in two respects: a high rate of agreement errors with animate nouns, and the overuse of the feminine rather than the masculine. Interestingly, both divergences are related to the way gender agreement is encoded in Tigrinya (Brindle & Müller, Reference Brindle, Müller and Stefan2006; Dyer, Reference Dyer and Henderson2019). First, most nouns in Tigrinya, even those referring to animate entities, have flexible gender based on semantic evaluation. For example, a biologically male entity may be combined with a feminine determiner to express the feature [+status], as illustrated in (10a) and (10b). The flexibility of semantic gender may thus explain why Tigrinya speakers make gender errors with animate nouns, despite the presence of a clear semantic cue to gender. The second interesting aspect of Tigrinya grammar is that, even though most nouns can undergo gender shift, some cannot; those nouns that have a fixed gender are all feminine (Dyer, Reference Dyer and Henderson2019). Given that gender is fixed in French, the overuse of the feminine in L2 French could thus be due to transfer from the fact that, whereas feminine nouns in Tigrinya have a fixed gender, masculine nouns can occasionally shift to feminine.
Results of the standardized TICSf test show that, although L2 learners’ performance was overall lower than that of the native speakers, it replicates the major findings. First, as for L1 French speakers, we found higher performance in Negative sentences as compared to all other structures, and lower performance in Relatives as compared to all structures. Second, the distribution of the various error types that we observed also largely followed that of L1 French speakers: errors mostly concerned the assignment of thematic roles to the subject and the object in transitive sentences (in Actives, Passives, Relatives) as well as number substitutions (plural for singular or conversely). Our L2 French learners nevertheless appear to differ from L1 speakers in making one particular type of error on Relatives (D2) consisting in mistakenly interpreting the object of the relative verb as the subject of the main verb, following a local attachment strategy (Le chien qui porte le garçon a un collier; ‘The dog that carries the boy has a necklace’ while the picture selected represented the boy with a necklace). Although this finding should be investigated in depth, it is in line with the hypothesis that L2 learners tend to perform a shallow processing of sentence structure (Clahsen & Felser, Reference Clahsen and Felser2006, Reference Clahsen and Felser2018). Third, although regression analyses showed that age fails to significantly predict performance in the TICSf, the two measures actually correlate negatively (r(45) = -.301, p = .04), which is in line with the age effect reported on French natives by Python et al. (Reference Python, Bischof, Probst and Laganaro2012). Finally, our data bring new evidence that has not been so far explored in native speakers: multilingualism predicts performance in the TICSf, an effect that extends more largely to other language measures as discussed in the following section.
In sum, regarding the mechanisms involved in SLA, the production data reported here, and more specifically the properties of RIs and subject clitics (see the discussion above), imply that our learners’ inaccuracies are attributed to problems with the overt morphological marking of morphosyntactic features rather than with the instantiation of functional categories, as suggested by previous work on L2 French (Prévost, Reference Prévost2009, a.o.) and a number of L2 acquisition theories (Lardiere, Reference Lardiere, Liceras, Zobl and Goodluck2008, Reference Lardiere2009; Prévost & White, Reference Prévost and White2000; Slabakova, Reference Slabakova2008). The nominal domain appears to be more vulnerable than the verbal domain, since determiner omission and gender errors are relatively high. Whether those difficulties are due to the different gender realization patterns in French and Tigrinya remains an open question.
3.2 Role of individual variables in second language learning
Overall, L2 French language skills were found to be largely independent of the number of years of residence in Switzerland, the number of years of education, or whether participants had attended French classes from Hospice General. Length of residence did not affect any of the language indexes. An increased level of education contributed to increase subject omissions, while having attended State classes contributed to reduce determiner omissions. Age was found to affect MLU, while age of onset affected both MLU and Ev@lang CO. Our results show that MLU increases with age; although this finding is in line with classical reports in L1 acquisition (Hoff, Reference Hoff2014), research on age effects on MLU in adults and ageing shows mixed effects (see Kemper & Sumner, Reference Kemper and Sumner2001; Nippold, Cramond & Hayward-Mayhew, Reference Nippold, Cramond and Hayward-Mayhew2014). In contrast, both MLU and Ev@lang CO increase as age of onset decreases, showing that learners exposed to French at a younger age tend to produce longer sentences and have better oral comprehension scores. This is in line with the various reports showing that age of onset has a significant impact on L2 grammar proficiency (Birdsong, Reference Birdsong2018; Johnson & Newport, Reference Johnson and Newport1989).
The major predictor of L2 French language skills is the number of languages spoken by our participants, which was found to have an impact specifically on grammatical indexes, contributing to increase performance in the TICSf, the mean length of utterance, the mean number of verbs per sentence and the rate of subordinate clauses, and contributing to decrease the rate of determiner omission, root infinitives, and SOV sentences. Importantly, these effects do not reduce to effects of school education, as the two factors are fully independent (r(45) = -0.095 p = .524). The study of how bilingualism and multilingualism affect cognition has for the most part focused on non-verbal components of cognition. Although beneficial effects of bilingualism tend to be more salient in children (Adesope, Lavin, Thompson & Ungerleider, Reference Adesope, Lavin, Thompson and Ungerleider2010), significant effects were also reported in adults showing that bilinguals have a higher ability to adapt to ongoing changes and process information efficiently and adaptively (Bialystok, Craik & Luk, Reference Bialystok, Craik and Luk2012 but see Paap & Greenberg, Reference Paap and Greenberg2013). With respect to language skills, bilingualism was shown to increase metalinguistic awareness (Bialystok, Reference Bialystok2001) and, with respect to grammar processing, to confer an advantage in the processing of complex syntactic structures (Galambos & Hakuta, Reference Galambos and Hakuta1988; Kidd, Chan & Chiu, Reference Kidd, Chan and Chiu2015). A few studies also reported advantages of bilingualism on the learning of a new language (Bialystok, Reference Bialystok2001; Kaushanskaya, Reference Kaushanskaya2012; Kuo & Anderson, Reference Kuo and Anderson2012; Nation & McLaughlin, Reference Nation and McLaughlin1986). Our finding that the number of languages spoken by our participants predicts various aspects of their grammatical skills in L2 French provides naturalistic evidence further supporting the positive impact of multilingualism on language learning. In line with the structural sensitivity theory (Kuo & Anderson, Reference Kuo and Anderson2010), we suggest that having access to more than one language allows multilingual speakers to orient to parameters along which languages vary, which may facilitate the process of detecting structural patterns of the new language grammar. A positive influence of the second language onto the third has also been highlighted by a number of studies on L3 acquisition, some of which make specific predictions regarding the transfer patterns from the L1 and the L2 (see Rothman, Reference Rothman2011, Reference Rothman2015 a.o.). A detailed crosslinguistic comparison between French and the other languages known by our learners and an exploration of the role of typological proximity lie beyond the scope of this paper, firstly because English is spoken, to some extent, by most of our participants and secondly because we do not have systematic data on their proficiency level in the other languages.
3.3 Refugees’ learning of the host country language
Our study has implications for two applied issues related to refugees’ learning of the host country language: the issue of language assessment, and the issue of teaching methods. We discuss them in turns. Our protocol involved the Ev@lang placement test, which has the advantage of being done at home, within less than an hour, and at minimal cost. Our data reveal interesting evidence in regard to both the validity of the language measure and the validity of the testing procedure to assess L2 French in Eritrean refugees. First, we found that the two subtests strongly correlate with one another, which attests to the internal consistency of the test. Second, consistency was also found across tests, as both subtests were found to correlate with the TICSf, a sentence comprehension test developed within the field of neuropsychology to assess grammar skills. Third, comparison between performance in the two subtests and the natural language measures obtained from the corpora also showed strong correlations. The two subtests slightly differed with respect to the involvement of the lexical and grammatical components: while the strongest correlation was found with the lexical measure of type token ratio for Ev@lang GL, the strongest correlations for Ev@lang OC were found with grammatical measures – namely, mean length of utterance and mean rate of subordinates. In sum, the profile of correlations found between the two Ev@lang subtests and a variety of independent language measures provides preliminary evidence that Ev@lang may be a valid tool to assess language skills in refugee learners.
Nevertheless, we need to add some proviso in regard to the validity of the testing procedure. Ev@lang was conceived as a test that can be realized from home, without supervision. However, our experience has shown that it is necessary to guide refugee candidates throughout the whole testing session as some of them are unfamiliar with computers, and more generally unfamiliar with testing procedures themselves. The time constraint may be an additional obstacle due to the stress that it imposes on a population that is often subject to anxiety, especially in relation to language assessment. Also, it is important to point out that none of the three subtests of Ev@lang allows assessing language production or communication skills, although these are considered as key in many European countries’ assessment protocols for refugees.
Our finding that properties of L1 may transfer onto the learning of L2 French aligns with many studies conducted in non-refugee populations (see 1.2). Interestingly, the vast majority of those studies have interpreted empirical evidence for transfer in terms of negative transfer (Rothman & Slabakova, Reference Rothman and Slabakova2018), which had critical consequences on L2 teaching practices. Indeed, teaching methods advocated in Europe and the USA since the fifties virtually all rely on the principle that L2 should be taught in isolation from L1. It is argued that isolating the L2 will reduce the impact of negative transfers (Maurer & Puren, Reference Maurer and Puren2019) and the risk of ‘mixing languages’ (Paradowski & Bator, Reference Paradowski and Bator2016). Teachers are encouraged to avoid the L1 by using pictures, context, miming or paraphrases, in an attempt to promote direct ‘form-meaning’ connections without mediation through L1. We suggest that inviting the native languages in the classroom, through a systematic protocol of languages’ comparison, may be beneficial to L2 teaching, and particularly to refugee learners. At the cognitive level, it may facilitate grammar learning through the enhancement of positive transfer. At the emotional level, it may play a significant role in valorizing those languages and the cultures they are associated with, with a positive impact in terms of well-being in the classroom (Capstick & Delaney, Reference Capstick and Delaney2016; Cummins & Early, Reference Cummins and Early2011; Seligman, Reference Seligman2011). Moreover, it would promote multilingualism and multiculturalism, which have been argued to be of crucial importance to language teaching programs for refugees (Tran, Reference Tran2000; Warriner, Reference Warriner2007). We believe that such a hypothesis deserves being investigated empirically in future applied research in the field of language teaching practices.
4. Conclusion
We reported observations from Eritrean native speakers of Tigrinya learning French on a variety of measures, bringing interesting novel pieces of knowledge. Corpus analyses replicate the major difficulties reported in the literature on L2 French, but also highlight two specificities of our population departing from that literature. The first one is the low rate of subject drop, despite Tigrinya being pro-drop. The second one is the high rate of gender errors with animate nouns as well as the overuse of the feminine gender. Although we have no explanation as to the former, the latter can be accounted for by specificities of Tigrinya grammar in regard to gender. An important finding is that, whereas increased age of onset tends to penalize L2 learning, multilingualism boosts it, contributing specifically to grammar learning by enhancing indexes of grammatical complexity and reducing grammar errors. Finally, performance in the Ev@lang placement test correlates with a variety of corpus measures as well as with a test of grammar comprehension standardized for native French speakers. This finding provides preliminary evidence of the validity of the test to assess French language skills in refugee learners.
Supplementary Material
For supplementary material accompanying this paper, visit https://doi.org/10.1017/S1366728921001048
Figure S1 shows the board of 16 drawings in the format of a comic book used to elicit the semi-spontaneous speech corpora.
Acknowledgements
The authors thank Charlotte Rivière for her illustration of the story used to elicit spontaneous speech, and Pauline Combey, Nina Lauricella, Charlotte Rivière and Solange Vilpert for their contribution to data collection. We also thank Gioia Cacchioli for her insight and fieldwork on Tigrinya grammar. The research was funded by the Réseau thématique Langage et Communication from the University of Geneva, granted to J. Franck.







 Open access
Open access