



1. Introduction
Given a large corpus of phonologically transcribed words in a language, one might expect that phonemesFootnote 2 are distributed evenly within the words, but this is not the case (Diver [1979] Reference Diver, Huffman and Davis2012: 300). Many previous studies on the distribution of consonants within the word (e.g. Tobin Reference Tobin1997; Azim Reference Azim, Reid, Otheguy and Stern2002; Hameed Reference Hameed, Contini-Morava, Kirsner and Rodríguez-Bachiller2004; Dekker & De Jonge Reference Dekker and de Jonge2006; Dreer Reference Dreer2006) have found that at the beginnings of words different phonemes are favoured than at the ends of words and, importantly, provide a functional explanation for it. One pattern that emerges from analysis is the favouring of labial consonants in word-initial position in several languages, first noted by Davis ([1984] Reference Davis1987). Another pattern is the well-known phenomenon that coronal sounds are cross-linguistically more frequent than sounds made with other articulators (Blevins Reference Blevins, Stern, Otheguy, Reid and Sackler2019: 288), a favouring that is even stronger in word-final position (Tobin Reference Tobin1997; Diver [1979] Reference Diver, Huffman and Davis2012). Interestingly, the combination labial-coronal also seems to be favoured in the inventories of human languages as a sequence: statistical studies on many languages have shown a tendency to start words with a labial-vowel-coronal pattern (MacNeilage & Davis Reference MacNeilage and Davis2000). This so-called LC (labial-coronal) effect has been found in adult, but also in children’s language (MacNeilage et al. Reference MacNeilage, Davis, Kinney and Matyear1999). This paper largely corroborates these findings with lexical corpora from Spanish, English, and Dutch, and offers an explanation for the observed distributions in terms of speech perception, communicative efficiency, and the physiology of the human vocal tract.Footnote 3
Thus far, previous studies have focused on monosyllabic words or words with only one position of stress to avoid a possible influence of lexical stress on the studied distribution of consonants (Dreer Reference Dreer2006: 108), but, surprisingly enough, there has never been research into whether lexical stress is indeed a relevant factor in this distribution. Evidence from several sources suggests that it might be (e.g. Denes Reference Denes1963; J. Beckman Reference Beckman1999), and therefore this paper will have a special focus on the comparison of Spanish, English, and Dutch words with stress on either the first or the second syllable, to see if we observe different distributional patterns for these two word types. This matter will also be approached in purely functional terms.
2. Distributional problems in phonology
2.1 Functional Approaches: Explanations of the LC effect
As briefly mentioned in the introduction, cross-linguistic studies have shown a strong preference for labial (L)–vowel–coronal (C) sequences at the beginnings of words, the so-called LC effect (MacNeilage et al. Reference MacNeilage, Davis, Kinney and Matyear1999; Vallée, Rossato & Rousset Reference Vallée, Rossato, Rousset, Pellegrino, Marsico, Chitoran and Coupé2009). In a study by Rousset (Reference Rousset2004) on the lexicon of 15 languages from diverse language families, the LC effect was not only observed at the beginnings of words, but to some degree also for any consonant–vowel–consonant sequence between two consecutive syllables. As a possible explanation, MacNeilage & Davis (Reference MacNeilage and Davis2000) propose a hypothesis derived from speech motor constraints; they link consonant–vowel alternations to jaw cyclicities (or mandibular oscillation) also found in chewing, and babbling in infants’ speech. They suggest that labial consonants are easier to produce for young children than coronals, as a labial–vowel sequence may naturally result from the basic opening of the jaw, without any additional movement of the lips, and this preference is argued to persist into adulthood. The LC effect would then result from a tendency to start the word in an easy way, after which a tongue movement is added.
Nevertheless, Vilain et al. (Reference Vilain, Abry, Badin and Brosda1999) question that labials are easier to produce; they show that jaw cyclicities alone would in fact not only produce labial contact followed by a vowel, but also coronal closures inside the vocal tract, followed by a vowel. Labials are thus not obviously easier to produce than coronals.
An alternative hypothesis by Rochet-Capellan & Schwartz (Reference Rochet-Capellan and Schwartz2007) addresses a gestural overlap asymmetry when comparing LC with CL sequences in clusters. In a consonant cluster, gestural overlap occurs when the C2 onset precedes the C1 offset. Several studies (for an overview, see Sato et al. Reference Sato, Vallée, Schwartz and Rousset2007: 1467) show that this overlap is larger when the first consonant is anterior to the second consonant (as in a LC cluster) than when it is posterior (as in a CL cluster). It is argued that this may be due to the risk that the posterior consonant (coronal), when followed by an anterior one (labial), may be acoustically concealed by it: it would be rendered less salient. Rochet-Capellan & Schwartz (Reference Rochet-Capellan and Schwartz2007) extend this explanation to labial–vowel–coronal sequences, suggesting that this effect might also occur across the vowel. They argue that the apex is thus prepared for the coronal gesture during the production of the labial, whereas the inverse does not happen, because of the gestural overlap asymmetry.
The obvious problem with this is that in labial–vowel–coronal sequences there is no gestural overlap because of the intervening vowel. It is also less likely that the acoustic effect of a coronal gesture would be masked by the labial gesture, as it does not come immediately after. We argue that there must therefore be another explanation for the tendency to start words with a labial–vowel–coronal sequence.
2.2 Functional approaches: Communicative load
Davis ([1984] Reference Davis1987) and Diver ([1979] Reference Diver, Huffman and Davis2012) offer an alternative explanation. Rather than focussing on L–vowel–C sequences, they start out from the general observation that labial consonants are favoured in word-initial position in several languages and that coronal sounds are generally more frequent than sounds made with other articulators, and especially in word-final position. They argue that this can be explained with communicative load (also known as functional load); the beginnings of words have a higher communicative load than the ends and this motivates the aforementioned asymmetries in the distribution of labials and coronals.
In conversational discourse, the accumulation of speech input makes it progressively easier for the hearer to anticipate what will come next (i.e. context helps restrict the number and kind of lexical possibilities). Similarly, as an individual word is pronounced, the identification of the word becomes progressively easier from the beginning to the end (Grosjean Reference Grosjean1980). In the same vein, Nooteboom (Reference Nooteboom1981: 422) argues that word recognition can be seen as a real-time process in which acoustic information is used as it comes in; the word beginning is least predictable, and the first phonemes of a word are likely to reduce the number of word candidates that could be expected in the context. For instance, in the utterance ‘I would like to order a cup of co–’ the last word is unlikely to be any other than coffee. Therefore the word end is more redundant for word recognition, which means that initial position and final position in a word are not equal in their communicative importance or communicative load. Horowitz, White & Atwood (Reference Horowitz, White and Atwood1968) and Horowitz, Chilian & Dunnigan (Reference Horowitz, Chilian and Dunnigan1969) also present empirical evidence that word-initial position is most important for word recognition: they show that in written word recognition, word-initial word fragments (e.g. ‘rec———’ for ‘recognise’) are the best cues for recalling the complete word. Interestingly, they add that word-final fragments are better cues than word-medial fragments, but this does not reflect the linearity of spoken speech production, in which the word end is produced last, after word-initial and word-medial material (e.g. ‘recogn–’) has probably eliminated most candidates.
This phenomenon is argued to affect the phonological structure of languages, and the distribution of phonemes at the beginnings and at the ends of words (Diver [1979] 2012). The beginnings of words play a more important role in word recognition (high communicative load) and, thus, in word-initial position maximum distinctiveness is favoured. Consequently, in initial position there is a relatively varied and free distribution of different phonemes and phoneme combinations. Word-final position, however, is more redundant for word recognition (low communicative load), and therefore distinctions are commonly lost, and we often observe only a subset of the full phoneme inventory (J. Beckman Reference Beckman1999: 4, 49–52; Tobin Reference Tobin, de Jonge and Tobin2011: 184). In addition to word-initial position of the word, J. Beckman (Reference Beckman1999) also mentions stressed syllables as communicatively ‘privileged’, which will be discussed in Section 6 of this paper.
Blevins (Reference Blevins, Stern, Otheguy, Reid and Sackler2019), however, does not seem to accept communicative load as an explanatory construct. She argues that explanations of sound patterns in terms of word-based communicative load are problematic, as neutralisation does not always align with information content, but also with details of phonetic realisation. As an example, she mentions the case of Yurok, where the contrast between glottalised and plain sonorants is neutralised in word-initial position, as pre-glottalisation is not always available here (p. 295). Nonetheless, one may argue that this one counterexample does not disqualify communicative load as an explanatory factor in other cases. Functional explanations are often multi-causal, and thus refer to an interplay between articulatory and communicative factors. Particular cases of word-initial neutralisation, where an articulatory factor seems to override the high communicative load of the beginning of the word, do therefore not necessarily refute communicative load as an account for the many cases of word-final neutralisation, the relatively varied distribution of contrasts at the beginnings of words cross-linguistically, the limited subset of the inventory often attested in other positions, and word-final consonant loss (Nooteboom Reference Nooteboom1981: 408; J. Beckman Reference Beckman1999: 4, 49–52; Tobin Reference Tobin, de Jonge and Tobin2011: 184). This study will show how communicative load, together with articulatory and perceptual factors, can account for the data described in this paper.
2.3 Communicative load and the favouring of labial consonants
According to Tobin (Reference Tobin1997), the greater burden on distinctiveness at the beginning of the word can account for the regularly observed favouring of labial consonants in word-initial position (e.g. Davis [1984] Reference Davis1987; Tobin Reference Tobin1997; Hameed Reference Hameed, Contini-Morava, Kirsner and Rodríguez-Bachiller2004; Dekker & De Jonge Reference Dekker and de Jonge2006; Dreer Reference Dreer2006), which is to do with a perceptual advantage of labial articulations. There is compelling evidence that visual information (lipreading) enhances speech perception (e.g. Kim, Davis & Krins Reference Kim, Davis and Krins2004; Rosenblum Reference Rosenblum2005; Buchwald, Winters & Pisoni Reference Buchwald, Winters and Pisoni2009; and quite notably, McGurk & MacDonald Reference McGurk and MacDonald1976), and not only for listeners with hearing impairments. Visual speech also facilitates comprehension for listeners with normal hearing, when acoustic information is corrupted by background noise for instance (Rosenblum Reference Rosenblum2005: 52, and references therein). In visual speech recognition, different articulatory gestures are not equally perceptible, however: bilabial and labiodental articulations are favoured due to their high visibilityFootnote 4 (e.g. Walden et al. Reference Walden, Erdman, Montgomery, Schwartz and Prosek1981; Magno Caldognetto & Zmarich Reference Magno Caldognetto and Zmarich2000). In audio-visual speech perception, then, labial consonants are communicatively more effective than other consonants; they provide an additional, visual clue. Rosenblum (Reference Rosenblum2005: 67) discusses that these advantages of visual speech could be a factor of influence in phonology, and this prediction seems to be borne out in quantitative research. According to Tobin (Reference Tobin1997), the communicative advantage of labial consonants explains the favouring of these consonants in word-initial position, where the communicative load (and the burden on distinctiveness) is highest. Note that this favouring is not phonologised; labials can appear in any position, but visual speech perception and the high communicative load of the beginning of the word are argued to be relevant factors in their favouring in word-initial position. This hypothesis will be corroborated in Sections 5 and 6 .
2.4 Communicative load and the favouring of coronal consonants
If the available articulations and articulatory combinations in the inventory of a language present different degrees of effort in production, one may expect the easier articulations to appear more often in general, but especially in word-final position. As the end of the word is more redundant for word recognition, it is predicted that the motivation for maintaining maximum distinctiveness is reduced and less effort is invested. Therefore, ease of articulation is hypothesised to be a more decisive factor in the distribution of phonemes in word-final position of words, where easier articulations should be favoured at the expense of more difficult ones (Diver [1979] 2012: 314–315).
Needless to say, that begs the question what easier articulations are. This may largely depend on the phonetic context within the word. In the case of obstruent voicing, for instance, the ease with which voicing is realised depends on the articulatory context within the word (Steriade Reference Steriade1997; Shariatmadari Reference Shariatmadari2006). But for some articulations a strong case can be made that they are more difficult to pronounce than others. /g/ is more difficult to pronounce than other voiced stops because voicing depends on air moving past the glottis. The air volume behind a velar constriction is smaller than behind constrictions made further towards the front, and it thus does not take long for the air pressure to equalise (Ohala Reference Ohala, Hardcastle and Laver1997). This is reflected in a cross-linguistic disfavouring of /g/: where gaps in obstruent inventories exist, it is often /g/ they lack (Shariatmadari Reference Shariatmadari2006). What this shows is that the difficulty or ease of an articulation is reflected in its cross-linguistic distribution (see Blasi et al. Reference Blasi, Moran, Moisik, Widmer, Dediu and Bickel2019 for another excellent example).
Let us now return to our prediction that easier articulations should appear more often in general, but especially word-finally. An observation that matches this description is the fact that coronal consonants, made with the front part of the tongue, are generally more frequent, both language-internally and cross-linguistically, than sounds produced with other articulators (Blevins Reference Blevins, Stern, Otheguy, Reid and Sackler2019), and have been shown to be favoured especially in word-final position in several languages (Tobin Reference Tobin1997; Hameed Reference Hameed, Contini-Morava, Kirsner and Rodríguez-Bachiller2004; Dreer Reference Dreer2006), and in some languages, such as Finnish and ancient Greek, only coronal consonants appear in final position (Yip Reference Yip1991: 70; Diver [1979] Reference Diver, Huffman and Davis2012: 314). The question raised by these observations is if there is something about the front part of the tongue that makes it easier to control.
According to Diver ([1979] 2012: 314–315) the answer lies in the greater adroitness of the front part of the tongue,Footnote 5 in comparison to other articulators, which he argues makes this articulator easier to control. This is a question of anatomy: the lips and dorsum are both very limited in their movement (Ladefoged & Maddieson Reference Ladefoged and Maddieson1996).Footnote 6 The lips are attached to the maxillae and mandible, the dorsum of the tongue to the bottom of the oral cavity, whereas the tongue front is highly mobile. In addition, the front part of the tongue is situated in the middle of the vocal tract. As a consequence of its location and high mobility it can reach a high number of passive receptors, and therefore there are relatively many potential distinct articulatory gestures the front of the tongue can make, which accounts for the high frequency of coronal consonants language-internally and cross-linguistically, compared to sounds made with other articulators.
Nevertheless, Diver ([1979] 2012) equals adroitness with ease of control, and Blevins (Reference Blevins2004) argues that evidence from language acquisition research does not support the view that coronals are easier to produce. Among the first phonemes acquired by children are not only coronals, but also labials (Stemberger & Stoel-Gammon Reference Stemberger and Stoel-Gammon1991), and other studies show a near simultaneous appearance of labials, coronals, and dorsals (e.g. Sander Reference Sander1972; Grunwell Reference Grunwell1981; Smit et al. Reference Smit, Linda Hand, Bernthal and Bird1990; Vihman Reference Vihman1996; also see Williamson Reference Williamson2010).
However, it can be argued that perceptual distinctiveness plays a great role in the (near) simultaneous appearance of labials, coronals, and dorsals, and that ease of acquisition is probably not the same as articulatory ease once articulations have been acquired; similarly, it takes a child a while to learn to walk, but once acquired it becomes a routine motor skill.
If one accepts Diver’s hypothesis that in adult language a favouring of coronals (especially in word-final position) is due to ease of articulation, one should still consider that different coronal articulations are probably not equal when it comes to articulatory effort, and it is very likely that some coronals are easier to pronounce, whereas others are harder. Recent studies on the production of Catalan consonants (Recasens & Rodríguez Reference Recasens and Rodríguez2016; Recasens Reference Recasens2018) suggests that some coronals, /ʎ ɲ ʃ s r/, require a more precise tongue configuration in their production than others, /l n ɾ t d/. It is argued that there is not much variation in the production of multiple trill /r/ in Catalan, for instance, because it can only be produced as an alveolar with a lowered and backed tongue configuration: /r/ is highly restricted. In contrast, coronals /l n ɾ t d/ show much more variation in the place and manner in which they are produced (Recasens & Rodríguez Reference Recasens and Rodríguez2016), which suggests that they may not be easier to produce per se, but require less articulatory precision and are more easily adapted to their phonetic context.
The question is, then, if these findings are also applicable to other languages. Recasens & Rodríguez (Reference Recasens and Rodríguez2016: 58–59) make a general statement that coronal trills and fricatives (e.g. /r/ and /s/) need a highly precise tongue configuration which also involves the tongue body. Likewise, palatals (/ʎ ɲ ʃ/) are more restricted than non-fricative dento-alveolars, as their production involves not only the front of the tongue but constrains the whole tongue body instead, while /l n ɾ t d/ leave the tongue body freer to adjust to the phonetic context. All these consonants (save /ʃ/) are found in Spanish too, and similar results were found for English (Fowler & Brancazio Reference Fowler and Brancazio2000) and German (Hoole, Gfroerer & Tillmann Reference Hoole, Gfroerer and Tillmann1990). Unfortunately, to our knowledge there are no similar phonetic data available for Dutch yet.
3. Hypothesis
In sum, earlier research hypothesises that the high communicative load of the beginning of the word and the low communicative load of the end of the word may play a role in the distribution of labial and coronal consonants in language.
Most previous studies thus far have made a quantitative comparison between word-initial and word-final consonants, but in this study we will compare the distribution of consonants in Spanish, English, and Dutch CVCVC(V) words. This means we are analysing the initial, medial and final consonant of the word; consonant 1, 2, and 3 (henceforth C1–C2–C3), a three-way comparison. This allows us to further test the hypothesis that communicative load is a relevant factor in the distribution of phonemes: we would expect the communicative load to decrease gradually from the beginning towards the end of the word in recognition with Grosjean (Reference Grosjean1980). In other words, we would expect C1 to have the highest communicative load, C2 is expected to have a lower communicative load, and C3 the lowest.
Following earlier work in the field, the distribution of labials and coronals is hypothesised to be an observable effect of communicative load; in positions of high communicative load, labials are favoured as they are visually perceptible (which constitutes a communicative advantage), and in positions of low communicative load, coronals are favoured, as the front part of the tongue is hypothesised to be more adroit and easier to control. Recent research, however, suggests that different coronals may vary in the ease with which they are adapted to their phonetic context. This leads to the following two hypotheses:
-
I. If labial consonants are favoured where the communicative load is high, we should expect to observe the highest proportion of these consonants for C1, a lower proportion for C2, and the lowest proportion for C3.
-
II.
-
(a) If coronal consonants are favoured where the communicative load is low, we should observe the lowest proportion of coronals for C1, a higher proportion for C2, and the highest proportion for C3.
-
(b) If we corroborate the word-final favouring of coronals in our analysis, we would expect that these are easily adaptable, ‘unrestricted’ coronals /l n ɾ t d/.
-
4. Methodology
4.1 Corpora
We composed three lexical corpora consisting of Spanish CVCVCV words and English and Dutch CVCVC words, with stress on either the first or the second syllable, collected from three concise dictionaries. The corpus design is as similar and comparable as possible.
The Spanish corpus consists of CVCVCV words with stress on either the first or the second syllable (e.g. pájaro /’paxaro/ ‘bird’ and ballena /ba’ʎena/ ‘whale’), collected from a bilingual pocket dictionary (Vuyk-Bosdriesz Reference Vuyk-Bosdriesz2014). CVCVCV words with stress on the third syllable (e.g. jabalí /xaba’li/ ‘boar’) were excluded because of the negligible sample size for this word type. The corpus contains loanwords, but polymorphemic words were excluded from the corpus, as the juxtaposition of phonemes at morpheme boundaries is often morphologically motivated, and only partially controlled by phonological considerations (Diver [1979] 2012: 301). Furthermore, counting the (phonemes of the) same morpheme more than once would distort the phonological data. The final edit of the corpus was composed of 806 words; 180 with stress on the first syllable and 626 with stress on the second syllable.
The English corpus is composed of disyllabic words of a CVCVC structure, with stress on either the first or the second syllable (e.g. pígeon and cocóón), obtained from a bilingual pocket dictionary (Pieterse-Van Baars Reference Pieterse-Van Baars2004). The design of this corpus was the same as the Spanish corpus; loanwords were included, but polymorphemic words were excluded. This resulted in a corpus of 1,208 words; 1,028 with stress on the first syllable and 180 with stress on the second syllable.
The Dutch corpus was constructed in the same way: it consists of CVCVC words with stress on the first or second syllable (e.g. kikker /’kɪkəɾ/ ‘frog’ and konijn /ko’nɛɪn/ ‘rabbit’), obtained from a pronunciation dictionary (Paardekooper Reference Paardekooper1998). This third corpus is composed of a total of 717 words; 455 with stress on the first syllable and 262 with stress on the second syllable. It should be noted that /ʤ ʃ ʒ/ normally only occur in loanwords (e.g. budget /bʏ’ʤɛt/ ‘budget’, koosjer /’koʃər/ ‘kosher’, and regime /rə’ʒim/ ‘regime’).
4.2 Dictionaries as a database
The use of a dictionary as a database for phonological analysis allows for each lexical entry (and the phonemes it consists of) to be counted once, independently of its meaning.Footnote 7 The frequency of a word in discourse is largely determined by its semantic content (speakers choose meanings, not sounds), which explains why English /ð/ is ubiquitous in speech; relatively few words contain /ð/, but there is a very high demand for the word the. A lexical approach permits an evaluation of the distribution of phonemes at the word level that is largely independent of semantics (Davis [1984] Reference Davis1987). We do therefore not analyse discourse, but forms instead. What this means in practice is that we look at the structures that have arisen in the historic development of Spanish, English, and Dutch, and that every form is counted once.
4.3 Choice of the CVCVC(V) word type
The choice of the CVCVC(V) syllabic structure avoids the effects consonant clusters may have on the distribution of consonants. Nevertheless, one may argue that the CVCVCV word type in Spanish and CVCVC in English and Dutch are not entirely comparable, as C3 is an onset consonant in CVCVCV words and a coda in CVCVC, which may affect the kinds of consonants found in C3 (see Yip Reference Yip1991). The reason we did not choose to analyse English and Dutch CVCVCV words is that monomorphemic words of this structure (e.g. cínema, potáto) are exceedingly rare in these languages, in comparison with CVCVC words. Vice versa, we chose not to analyse Spanish CVCVC structures because Spanish CVCVC words with a stressed first syllable are often English or Latin loanwords (e.g. ticket ‘ticket’, bonus ‘bonus’). However, both CVCVCV and CVCVC words are suitable for a comparison between C1, C2, and C3 (CVCVC), and a comparison of words with a stressed first syllable (e.g. pígeon) and an unstressed first syllable (e.g. cocóón). Moreover, C3 finds itself at the end of the word where the communicative load is low, regardless of whether it is followed by a vowel, and, importantly, as we will see in the analysis, coronals are strongly favoured in C3 position regardless of whether it is an onset (as in the Spanish corpus) or a coda (as in the English and Dutch corpora).
5. Results
The distribution of consonants in Spanish, English, and Dutch words has been analysed, and in each analysis, a three-way comparison has been made between C1, C2, and C3. The placement of stress is not considered here yet. In Section 3, we hypothesised a gradual decrease of the communicative load as the word progresses, and we thus expect the highest proportion of labials for C1, a lower proportion for C2, and the lowest proportion for C3. For coronals, we expect a general favouring, but when comparing C1, C2, and C3, we predict the lowest proportion of coronals for C1, a higher proportion for C2, and the highest proportion for C3.
Now let us have a look at Figures 1–3, where we observe the distribution of consonants in Spanish CVCVCV words and English and Dutch CVCVC words. On the horizontal axis, C1, C2, and C3 are compared and, on the vertical axis, the proportion of labial, coronal, dorsal (and glottal) consonants in those three positions are indicated in absolute numbers. All figures show roughly the same results; at the beginning of the word we see a relatively even distribution of all consonant types, and the highest proportion of labials, but for C2 and C3 we see a clear favouring of coronals.

Figure 1 Distribution of labial, coronal, and dorsal consonants for C1, C2, and C3 in Spanish CVCVCV words (n = 806).

Figure 2 Distribution of labial, coronal, dorsal, and glottal consonants for C1, C2, and C3 in English CVCVC words (n = 1,208).

Figure 3 Distribution of labial, coronal, dorsal, and glottal consonants for C1, C2, and C3 in Dutch CVCVC words (n = 717).
In Figure 1 we see that in our Spanish corpus as many as 339 out of 806 CVCVCV words start with a labial (such as the words pájaro and ballena, in which the /p/ and the /b/ are labial), 194 words have a labial C2, and as few as 72 words have a labial C3. This evidently supports the hypothesised favouring of labials at the beginning of the word, where the communicative load is high. Importantly, we also observe a gradual decrease of the proportion of labial consonants from beginning to the end of the word (C1 ➔ C2 ➔ C3), which is explained by the decrease of communicative load as the word progresses. Very similar results were found for the English and Dutch corpora, as shown in Figures 2 and 3.
Figure 1 also shows that in our Spanish corpus, in 303 out of 806 words, the first consonant (C1) is coronal, compared to as many as 507 for C2, and the highest proportion of coronal consonants, 605, is observed for C3, where the communicative load is lowest (again, two good examples of this tendency are pájaro and ballena, where C3s /ɾ/ and the /n/ are coronal). This clearly supports the hypothesised gradual increase of the proportion of coronals from beginning to the end of the word (C1 ➔ C2 ➔ C3), with a strong favouring of coronals at the end of the word (at the expense of the proportion of labial and dorsal consonants) which we explain with the low communicative load of the end of the word. Again, the very same pattern can be observed in Figures 2 and 3, where the favouring of coronals as C3 is compelling, the proportion of labials and dorsals is minimal for C3, and the proportion of glottal /h/ is reduced to 0 at the word end.
However, the question has been raised if the distributions of all coronals are comparable. Therefore, on the left-hand side of Tables 1–3, we examine the same data as in Figures 1–3, but now we see the distribution of each separate consonant for C1, C2, and C3, subdivided into categories labial, coronal (unrestricted coronals above the dashed lines and restricted coronals below the dashed lines), dorsals, and, in the case of English and Dutch, glottals. In the centre column, the expected (average) value is calculated for each separate consonant and on the right-hand side of the table, the deviations (+ or −) from this expected value are shown for C1, C2, and C3. Three chi-square tests of independence were performed to examine the relation between position within the word and consonant categories in all three tables, and this relation was significant for all three tests: X 2 (6, N = 2,418) = 364.86, p < 0.00001 for Spanish, X 2 (8, N = 3,624) = 737.84, p < 0.00001 for English, and X 2 (8, N = 2,151) = 486.91, p < 0.00001 for Dutch.Footnote 8 Results over X 2 = 40 for individual categories show that in every corpus, the labial category was significantly favoured in C1 and disfavoured in C3 position, the unrestricted coronal category was significantly disfavoured in C1 and favoured in C3 position, but no significant results were obtained for the restricted coronal category, which supports our hypothesis.
Table 1 Distribution of individual consonants for C1, C2, and C3 in Spanish CVCVCV words (N = 806).Footnote 9

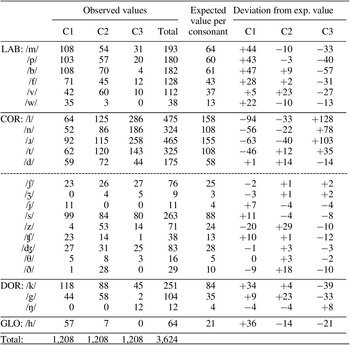
Table 2 Distribution of individual consonants for C1, C2, and C3 in English CVCVC words (n = 1,208).

Table 3 Distribution of individual consonants for C1, C2, and C3 in Dutch CVCVC words (N = 717).

When we look at the data in more detail, on the right-hand side of Tables 1–3 we observe that indeed all labials are favoured in position C1, and the distributions of practically all labials see a gradual decrease from the beginning to the end of the word.Footnote 10 The distributions of labials in our corpora can thus be concluded to be comparable. Additionally, when we look at C1 on the left-hand side of Tables 1–3, we observe that in every corpus, three out of the fourFootnote 11 most common C1s are labials; /p/, /b/, and /m/. Again, these findings are explained by the favouring of highly visible articulations at the beginning of the word.
The distributions of coronal consonants in Tables 1–3 are less uniform; some distributions show an increase from the beginning to the end of the word, some do not, and in line with our hypothesis, this difference largely coincides with the distinction between unrestricted coronals /l n ɾ (ɹ) t d/Footnote 12 above the dashed lines, and the more restricted coronals below the dashed lines. On the left-hand side of Table 1 we see that in Spanish, as expected, the four most common C3s are unrestricted coronals /l n ɾ t/. Also, on the right-hand side of Table 1 we observe that unrestricted coronals in our Spanish corpus are uniformly favoured in C3, and we see a gradual increase of the proportion of these coronals from the beginning to the end of the word. Below the dashed line, however, restricted coronals /s/, /ʧ/ and multiple trill /r/ clearly show the reverse pattern, as their distribution decreases from C1 to C3, and /θ/ also seems to show a slight decrease from C1 to C3.
However, interestingly enough /ʎ/ and /ɲ/ pattern with the unrestricted coronals even though they are restricted: their distribution shows an increase from C1 to C3. This observation can be explained by the fact that these consonants developed from earlier /l:/ and /n:/ or clusters containing /l/ and /n/ (Alarcos Llorach Reference Alarcos Llorach1974: 253), and in that sense the distribution of /ʎ/ and /ɲ/ still reflects an old favouring.
Tables 2 and 3 do not show patterns that run counter to our hypothesis in this way. We observe that only the distribution of unrestricted /l n ɾ (ɹ) t/ shows a gradual increase from the beginning to the end of the word, and at the left-hand side of Tables 2 and 3, we see that /l n ɾ (ɹ) t/ are the most common C3s. Different to the results in Spanish, however, the proportion of /d/ is relatively low for C3 in English words and drops to 0 in Dutch. This can be explained with the well-known general disfavouring (and non-occurrence in Dutch) of voiced stops in word-final position (Steriade Reference Steriade1997), which is a consequence of the fact that C3 is a coda consonant in the English and the Dutch corpus. Needless to say, the same explanation is applicable to voiced stop /b/ in English and Dutch C3 position, and voiced stop /g/ in English.
Below the dashed lines of Tables 2 and 3, the distributions of restricted coronals do not show an increase from C1 to C3; their distribution either decreases, remains more or less the same, or seems (mostly) restricted to one of the three positions, such as /z/. That is outside of the scope of this paper, however.
In sum, the distributions of labial consonants in our corpora are comparable, all labials are favoured at the beginning of the word, and the favouring of this category in C1 position is statistically significant, which supports the hypothesis that highly visible consonants are favoured at the beginning of the word where the communicative load is high. The distributions of coronals are not homogeneous, however: only the distributions of unrestricted coronals (or coronals historically derived from one) increase from C1 to C3, and only unrestricted coronals are significantly favoured in C3 position. This supports the hypothesis that easier consonants should be favoured at the end of the word where the communicative load is low. Note that the favouring of coronals we observed in Figures 1–3 is thus actually a favouring of a subset of coronals, which means that Diver ([1979] 2012) overgeneralised his findings when stating that (all) coronals are favoured at the ends of words.
Also note that in spite of the fact that C3 is an onset in Spanish CVCVCV words and a coda in English and Dutch CVCVC words, the data in all three corpora show the same general distributional patterns.
6. Results: lexical stress
The analyses presented in Figures 1–6 show that the position within the word is a relevant factor in the distribution of labial consonants and unrestricted coronals, which is explained with the decrease of communicative load from the beginning to the end of the word. The position of stress is not considered in these analyses, but as our Spanish, English, and Dutch corpora consist of words with stress on the first or on the second syllable, we can analyse these two word types separately. If we observe different distributional patterns for words with stress on the first and the second syllable, it would suggest that the placement of stress is a relevant factor in the distribution of consonants too.
But how could stress be a relevant factor in the distribution of consonants? We will show how stress plays a role in word recognition in Spanish, English, and Dutch, and argue that it could therefore be a relevant factor in communicative load and consequently in the distribution of labial consonants and unrestricted coronals too.
6.1 Lexical stress and word recognition
Stress is not found in the word-level phonology of all languages and there is considerable variation regarding its functions and realisation (Cutler Reference Cutler2005: 270; Ortega-Llebaria, Gu & Fan Reference Ortega-Llebaria, Gu and Fan2013) in languages that do have stress (for extensive reviews, see M. Beckman Reference Beckman1986; Cutler Reference Cutler2005). Spanish, English, and Dutch are stress languages in which every lexical word has one stressed syllable, which supposedly has a distinctive function in these languages. Words such as término ‘term’, termíno ‘I finish’, and terminó ‘he/she finished’ in Spanish, may differ solely in the position of the stress. Therefore, stress is considered phonologically contrastive (Hualde Reference Hualde2005: 220).
Such stress-based distinctions are rather common in Spanish verb conjugations. In English and Dutch, however, minimal pairs that are only distinguished by the position of stress are much rarer. Vowels in unstressed syllables are often reduced to a schwa (Ortega-Llebaria, Gu & Fan Reference Ortega-Llebaria, Gu and Fan2013), which means that in many pairs, such as cóntract and contráct in English (of which the former is traditionally seen as a noun and the latter as a verb), there is an additional phonological distinction: the first vowel of contráct is pronounced /ǝ/, rather than /ɒ/ (M. Beckman Reference Beckman1986: 28). In most instances in which the unstressed vowel is not reduced or centralised, the minimal pair consists of two words of related meaning, such as ímport (noun) and impórt (verb) (Jensen Reference Jensen1993: 77), a distinction of little relevance, as it can be deduced from the context as well (Martinet Reference Martinet1965: 149; M. Beckman Reference Beckman1986: 37). The same could be said of the Dutch minimal pair vóórnaam ‘first name’, and voornáám ‘prominent’ (Cutler & Van Donselaar Reference Cutler and van Donselaar2001), in which the difference in meaning can easily be deduced from the context too.
Therefore, the differentiation of minimal stress pairs may not be the main function of lexical stress in these languages (Martinet Reference Martinet1965: 149; M. Beckman Reference Beckman1986: 23–24). Instead, there may be other ways in which stress is useful in word recognition. Studies on lexical stress in English, Dutch, and Spanish (e.g. Cutler & Clifton Reference Cutler, Clifton, Bouma and Bouwhuis1984; Van Heuven Reference Van Heuven1984, Reference Van Heuven1985, Reference Van Heuven1988; Van Leyden & Van Heuven Reference Van Leyden and van Heuven1996; Soto-Faraco, Sebastián-Gallés & Cutler Reference Soto-Faraco, Sebastián-Gallés and Cutler2001) suggest that stress information may facilitate word identification in the following way:
As speech input activates word candidates [in the mind], only those candidates which match the structure signalled by the input in stress as well as in segmental structure would become active. Words with non-matching stress or mismatching segments would not come into consideration. (Cutler Reference Cutler2005: 276)
If listeners take account of stress, it can help to reduce the number of word candidates. This means that lexical stress could play a substantial role in word recognition even in languages where the number of minimal stress pairs is very limited (Cutler Reference Cutler2005: 276), as is the case in English and Dutch.
This phenomenon has been tested in several priming studies. In a study by Soto-Faraco et al. (Reference Soto-Faraco, Sebastián-Gallés and Cutler2001), native speakers of Castilian Spanish heard neutral sentences ending with a word fragment that matched one potential word and differed from a second option in one phoneme or in the position of the stress, in such a way that the fragment princí– (with stress on the second syllable), matched the first two syllables of the word princípio ‘beginning’ and differed only in stress from the first two syllables of príncipe ‘prince’. Subsequently, the participants were subjected to a word recognition task: their lexical decision response time to visually presented words (e.g. ‘PRINCIPIO’, ‘PRÍNCIPE’ or a nonsense word) was measured as a function of whether the prime activated the target word or its competitor. The matching words were always more readily identified than the mismatching words, clearly indicating the activation of the matching word. The same results were found in a replication of Soto-Faraco et al.’s (Reference Soto-Faraco, Sebastián-Gallés and Cutler2001) stress comparison in Dutch (Van Donselaar, Koster & Cutler Reference Van Donselaar, Koster and Cutler2005), in which the word fragment octo–, for instance, would match either óctopus or október based on stress placement. In English, however, a directly analogous experiment was impossible. Unstressed syllables in English often contain a reduced vowel, and thus there are effectively no disyllabic fragment pairs that only differ in stress, such as octopus – oktober in Dutch. The vowel in the second syllable of English octopus is reduced and therefore different from the second syllable of October (Cutler Reference Cutler2005: 278). Therefore, Cooper, Cutler & Wales (Reference Cooper, Cutler and Wales2002) carried out a partially comparable priming experiment, again using disyllabic word fragments (e.g. ádmi– and admi–), in which the contrast had to be made between words with primary stress on the first or the third syllable (e.g. ádmiral and admirátion). Results from this experiment indicated that stress information facilitates word recognition in English too.
Empirical evidence from these studies proves that stress information from the first two syllables of a word facilitates word recognition, but experiments using monosyllabic primes show that stress information from only the first syllable facilitates word recognition as well. Cooper et al. (Reference Cooper, Cutler and Wales2002) showed that after hearing a monosyllabic stress-matching prime, participants recognised target words faster than after a stress-mismatch, indicating that stress information from word-initial stressed prime mús–, for example, facilitated the recognition of the word músic, and not the word muséum. Similar results were found for Dutch by Van Heuven (Reference Van Heuven1988). Quite surprisingly, however, there has been no analogous experiment for Spanish as yet, which means there are still opportunities for further research. The most obvious possibility would be to carry out a replication of the priming experiment in Soto-Faraco et al. (Reference Soto-Faraco, Sebastián-Gallés and Cutler2001), in which the disyllabic primes are replaced by monosyllabic ones (e.g. prín– and prin–). We suspect such an experiment would yield the same results as in English and Dutch.
In summary, stress information facilitates word recognition in Spanish, English, and Dutch. There is empirical evidence showing that in English and Dutch, this happens from the first syllable on, and we suspect that in Spanish it does too.
6.2 Lexical stress and communicative load
If lexical stress plays a substantial role in word recognition, it could also be a relevant factor in communicative load. The rationale behind this is simple. First, according to the described theory, stress information inhibits word candidates in Spanish, English, and Dutch; a word-initial stressed syllable inhibits all word candidates starting with an unstressed syllable (even if the syllable is otherwise identical) and vice versa. Second, the more candidates are inhibited the more predictable the rest of the word becomes. If in a language the vast majority of words starts with a stressed syllable, that would mean that a word-initial unstressed syllable is less common and much more distinctive than a word-initial stressed syllable. A word-initial unstressed syllable would inhibit more word candidates, making the rest of the word more predictable, which results in a lower communicative load. This could be the case for Spanish, English, and Dutch. In Spanish discourse 75.5% of all lexical words start with a stressed syllable (Van Soeren Reference Van Soeren2017), and in English discourse 87.6% of all lexical words start with a stressed syllable (Cutler & Carter Reference Cutler and Carter1987). No such token frequency is available for Dutch discourse yet (further research needed, see Section 8), but according to Van Leyden & Van Heuven (Reference Van Leyden and van Heuven1996: 169), stress is generally on the initial syllable in Dutch as well.
This means that in these three languages a word-initial unstressed syllable inhibits more word candidates than a word-initial stressed syllable. A word-initial unstressed syllable is thus expected to be followed by a more substantial decrease of communicative load than a word-initial stressed syllable.Footnote 13 If this is the case, it should be reflected in the distribution of labial consonants and unrestricted coronals. After a word-initial unstressed syllable we should observe lower proportions of labials and higher proportions of unrestricted coronals than after a word-initial stressed syllable.
Two remarks. First, we expect similar analytical results for Spanish, English, and Dutch, as in all three of these languages the majority of words starts with a stressed syllable. Second, in this section we are analysing the distribution of labials and unrestricted coronals, not all coronals, as the results in Section 5 show that it is actually this specific subset of coronals that is favoured at the word end, and which significantly increases as the hypothesised communicative load decreases. Nevertheless, as /d/ patterns differently in Tables 2 and 3 due to the disfavouring of voiced plosives in word-final position in Dutch and English, we will exclude it from the analysis and only examine the distribution of unrestricted coronals /l n ɾ (ɹ) t/.
6.3 Hypothesis
In Sections 6.4 and 6.5, the distribution of labial consonants and unrestricted coronals /l n ɾ (ɹ) t/ will be analysed for C1, C2, and C3 of Spanish CVCVCV words and English and Dutch CVCVC words, respectively. As mentioned previously, in these analyses words with stress on the first syllable will be compared to words with stress on the second syllable. Generally, for each of these analyses, we expect a decrease of the communicative load as the word progresses, and consequently we should observe a decrease of the proportion of labials and an increase of the proportion of /l n ɾ (ɹ) t/ as the word progresses, in line with Figures 1, 2 and 3; according to our analytical position, a high proportion of labial consonants is an observable effect of high communicative load and a high proportion of unrestricted coronals is an observable effect of low communicative load.
However, according to our reasoning in Section 6.2, a word-initial unstressed syllable eliminates most word candidates in Spanish, English, and Dutch, and therefore a word-initial unstressed syllable is expected to be followed by a more substantial decline of communicative load than a word-initial stressed syllable in these languages. Consequently, after a word-initial unstressed syllable we expect to observe lower proportions of labial consonants and higher proportions of /l n ɾ (ɹ) t/ than after a word-initial stressed syllable.
6.4 Distribution of labials: Stress on the first or second syllable
Figures 4–6 show the distribution of labial consonants in position C1, C2, and C3 of Spanish, English, and Dutch words with stress on the first syllable (e.g. Sp. pájaro, En. pígeon, Du. kíkker), represented by the dark bars, and for words with stress on the second syllable (e.g. Sp. balléna, En. cocóón, Du. koníjn), represented by the light bars. For Figures 4–6, the same data were used as for Figures 1–3, the differences being that we now only observe the distribution of labials, and that the data for words with stress on the first and on the second syllable are shown separately here. Just like in the previous figures, C1, C2, and, C3 are compared on the horizontal axis, but on the vertical axis the proportion of labials is now shown in percentages. An additional feature of Figures 4–6 which previous figures did not have are the dark line connecting the three dark bars, and the light line connecting the light bars. These lines serve to visualise the decrease of the proportion of labials from C1 to C2 to C3 for both word types.

Figure 4 Distribution of labial consonants for C1, C2, and C3 in Spanish CVCVCV words (N = 806) with stress on the first syllable (dark) or stress on the second syllable (light). Significance: C1: p = 0.251, C2: p < 0.001, C3: p = 0.386.

Figure 5 Distribution of labial consonants for C1, C2, and C3 in English CVCVC words (N = 1,208) with stress on the first syllable (dark) or stress on the second syllable (light). Significance: C1: p = 0.219, C2: p < 0.05, C3: p = 0.403.

Figure 6 Distribution of labial consonants for C1, C2 and C3 in Dutch CVCVC words (N = 717) with stress on the first syllable (dark) or stress on the second syllable (light). Significance: C1: p = 0.653, C2: p < 0.05, C3: p = 0.995.
In Figures 4–6 we clearly observe that the position of stress in the word is a relevant factor in the distribution of labial consonants in Spanish, English, and Dutch words, that all three tables show the same distributional pattern, and that the results seem to support our hypotheses.
Let us first focus on what words with stress on the first or the second syllable have in common; in every figure we observe a decrease of the proportion of labial consonants from the beginning to the end of the word for both word types, with high percentages of labials in position C1 and the lowest percentages of labials in position C3. This is accounted for by the high communicative load of the beginning of the word and the low communicative load of the end of the word.
Nevertheless, Figures 4–6 also show an important difference between words with a stressed and an unstressed first syllable: after a stressed first syllable (dark bars), the percentage of labials only slightly decreases between position C1 and C2, whereas after an unstressed first syllable (light bars), the percentage of labials decreases sharply. If we argue that high proportions of labials are an effect of high communicative load, these results suggest a more substantial decline of the communicative load after an unstressed first syllable, compared to the decline of the communicative load after a stressed first syllable, in line with the hypothesis. This is accounted for by the rationale that an unstressed first syllable eliminates more word candidates than a stressed first syllable.
For each figure, three 2 × 2 chi-square tests of independence were performed to examine the relation between word type (stress on first or second syllable) and the absolute proportion of labials (versus other consonants) in the three possible positions (C1, C2, and C3). For each figure, the relation between the two variables was only significant for C2, as stated in the figure footers. This suggests that the communicative load is equally high at the beginning of the word and equally low at the end of the word for both word types, but that the communicative load decreases earlier on in the word if the first syllable is unstressed.
6.5 Distribution of coronals /l n ɾ (ɹ) t/: Stress on the first or second syllable
Figures 7–9 show the distribution of coronals /l n ɾ (ɹ) t/ in Spanish, English, and Dutch words, respectively, in which the stress is either on the first or the second syllable. The distributional patterns that we observe seem to be the mirror image of the patterns in Figures 4–6, and seem to support our hypothesis. For all three languages, we observe an overall increase of the proportion of coronals /l n ɾ (ɹ) t/ from the beginning to the end of the word regardless of the position of stress, in line with the communicative load hypothesis. What we also observe in all figures is that after a stressed first syllable (dark bars), the percentage of coronals /l n ɾ (ɹ) t/ only slightly increases between position C1 and C2, and that after an unstressed first syllable (light bars), the percentage of coronals increases sharply. Following the reasoning that a high proportion of unrestricted coronals is an observable effect of low communicative load, these results again indicate a more substantial decline of the communicative load after an unstressed first syllable, and only a slight decline of the communicative load after a stressed first syllable.

Figure 7 Distribution of coronals /l n ɾ t/ for C1, C2, and C3 in Spanish CVCVCV words (N = 806) with stress on the first syllable (dark) or stress on the second syllable (light). Significance: C1: p < 0.001, C2: p < 0.05, C3: p = 0.158.

Figure 8 Distribution of coronals /l n ɹ t/ for C1, C2, and C3 in English CVCVC words (N = 1,208) with stress on the first syllable (dark) or stress on the second syllable (light). Significance: C1: p < 0.01, C2: p < 0.001, C3: p < 0.001.

Figure 9 Distribution of coronals /l n ɾ t/ for C1, C2, and C3 in Dutch CVCVC words (N = 717) with stress on the first syllable (dark) or stress on the second syllable (light). Significance: C1: p = 0.89, C2: p < 0.001, C3: p = 0.602.
For Figures 7–9 we also performed three 2 × 2 chi-square tests of independence, this time to examine the relation between word type and the absolute proportion of unrestricted coronals /l n ɾ (ɹ) t/ in C1, C2, and C3 position. As stated in the footers, the relation between the two variables was significant for C2 in every one of these figures, just like in Figures 4–6. Nevertheless, it is worth mentioning that in Figure 7, we also get a statistically significant result for C1, and in Figure 8, we see a significant difference in all three positions. This is a result that we did not expect under the current hypothesis, and it means that for Spanish and English words with stress on the first syllable the proportion of /l n ɾ (ɹ) t/ is significantly higher at the beginning of the word than for words with an unstressed first syllable, suggesting the communicative load is higher at the beginning of the word if it starts with an unstressed syllable. However, the results found for these languages in Figures 4 and 5 suggest otherwise.
6.6 Discussion of our data
To our knowledge, this is the first published analysis that shows distributional patterns for labial consonants and unrestricted coronals /l n ɾ (ɹ) t/ with stress as an explanatory factor. Needless to say, it is remarkable that we should see the same distributional pattern for labials for three separate languages in Figures 4–6, and the mirror image of the same distributional pattern in Figures 7–9. The hypothesis formulated in Section 6.3 seems to be supported by our analysis, but should be regarded as a tentative hypothesis that needs to be further elaborated and tested.
It is probably worth noting a working hypothesis that we abandoned as it could not account for our data. One might expect, in recognition with J. Beckman (Reference Beckman1999), that stressed syllables have a higher communicative load than unstressed syllables, just like the beginnings of words have a higher communicative load than the ends. Stressed syllables are argued to be more salient in discourse and perceptually more prominent than unstressed syllables, leading J. Beckman (Reference Beckman1999) to state stressed syllables as privileged positions. In her data, but also in Denes (Reference Denes1963) stressed syllables show a more varied distribution of vowels. Nevertheless, if stressed syllables indeed have a higher communicative load than unstressed syllables, we would expect to observe a higher proportion of labial consonants and a lower proportion of coronals /l n ɾ (ɹ) t/ for stressed syllables, in comparison to unstressed syllables. For instance, this would mean a higher proportion of labials for C2 in words of which the second syllable is stressed, and a lower proportion of labials for C2 if the second syllable is unstressed. In Figures 4–9 we observe that the reverse is true.
7. Conclusion
We have observed two recurrent sound patterns in three languages; the statistically significant favouring of labial consonants at the beginning of the word and unrestricted coronals at the end of the word in Spanish, English, and Dutch. The results are explained with functional factors known independently from analysis; the physiology of the vocal tract, human speech perception, and communicative efficiency. We argued that the beginning of the word has a higher communicative load than the more predictable end. Therefore, visually more salient consonants, labials, are favoured where the communicative load is high, due to their communicative advantage, and consonants that lend themselves better for easy coarticulation, unrestricted coronals (not all coronals, as Diver ([1979] 2012) suggests), are favoured where the communicative load is lessened and ease of articulation is argued to be a more important factor (Tobin Reference Tobin1997). It should be noted that we have accounted for our data without making reference to formal phonology-internal constraints as is customary in generative phonology.
The analyses in Section 6 seem to support the additional hypothesis proposed in Section s 6.2 and 6.3 that in addition to phonetic information, stress information contributes to the decrease of communicative load within the word as well. If this hypothesis were entirely ungrounded, we would expect the distribution of labials consonants and unrestricted coronals in C1, C2, and C3 to be the same for words with stress on the first or the second syllable. However, in all of our analyses we have observed that after an unstressed first syllable, there is a stronger decrease of the proportion of labials and a stronger increase of the proportion of unrestricted coronals than after a stressed first syllable, which is argued to be the effect of a greater decrease of the communicative load. This is accounted for by the fact that in Spanish, English, and Dutch, the majority of words in discourse start with a stressed syllable, which means that a word-initial unstressed syllable inhibits more word candidates than a word-initial stressed syllable.
8. Further research
We have analysed data from three separate languages to show that our findings might be a cross-linguistic pattern. However, one may argue that analysing both English and Dutch does not necessarily make a stronger case, as these are two closely related languages which share a substantial amount of vocabulary. Therefore, we invite other researchers to conduct a follow-up study with corpora from other languages, preferably from language families other than Romance or Germanic.
Aside from that, the explanation of the results in Section 6 is based on the idea that stress information from the first syllable is used by the hearer for word recognition. There is empirical evidence supporting this claim for Dutch and English (Van Heuven Reference Van Heuven1988; Cooper et al. Reference Cooper, Cutler and Wales2002), but not for Spanish. Given the fact that the analyses of Spanish CVCVCV words in our research show the same distributional patterns as the analyses of English and Dutch CVCVC words, we suspect that stress information from the first syllable facilitates word recognition in Spanish as well, but further research is needed to support this assumption. Our suggestion would be an adjusted replication of the priming experiment in Soto-Faraco et al. (Reference Soto-Faraco, Sebastián-Gallés and Cutler2001). In their experiment, stress information from the first two syllables of a word (e.g. princí– or prínci–) was shown to facilitate word recognition in Spanish (e.g. prínci– facilitates the recognition of príncipe). In a similar experiment, the disyllabic primes used by Soto-Faraco et al. (Reference Soto-Faraco, Sebastián-Gallés and Cutler2001) could be replaced by monosyllabic primes (e.g. prin– or prín–). We suspect such an experiment would show that stress information from the first syllable facilitates word recognition in Spanish as well.
Another missing piece of evidence is the precise proportion of words with stress on the first syllable in Dutch discourse. In Spanish discourse about 75% of all lexical words start with a stressed syllable (Van Soeren Reference Van Soeren2017), and in English discourse about 85% of all lexical words start with a stressed syllable (Cutler & Carter Reference Cutler and Carter1987), but further research is needed to find a token frequency for Dutch discourse.
Another opportunity for further investigation is in the realm of ease of articulation research. In this paper we have argued that ease of articulation is a relevant factor in the distribution of consonants at the end of the word, and although we know that some coronals are adjusted more easily to their phonetic context than others (e.g. Recasens & Rodríguez Reference Recasens and Rodríguez2016; Recasens Reference Recasens2018), to our knowledge, little is known about the relative articulatory effort involved in individual consonants. ArtiSynth biomechanical modelling (Lloyd, Stavness & Fels Reference Lloyd, Stavness, Fels and Payan2012) could be used to measure this, however, which has already led to ground-breaking results in historical phonology (Blasi et al. Reference Blasi, Moran, Moisik, Widmer, Dediu and Bickel2019).












 Open access
Open access