



Introduction
The term heritage language (hereafter HL), also known as “home language,” “minority language,” “community language,” “diasporic language,” or “mother tongue,” refers to a language of the immigrant community which is different from the dominant societal language (hereafter SL). HL speakers are individuals who were raised in homes where a language other than the SL was spoken, resulting in some degree of bilingualism in the HL and the SL (Benmamoun, Montrul, & Polinsky, Reference Benmamoun, Montrul and Polinsky2013; Montrul, Reference Montrul2016; Polinsky, Reference Polinsky2018a; Rothman, Reference Rothman2009; Rothman & Treffers-Daller, Reference Rothman and Treffers-Daller2014; Scontras et al., Reference Scontras, Fuchs and Polinsky2015). Typically, HL speakers are second or third-generation immigrants who grew up in immigrant families, although some other trajectories are also possible (Kupisch & Rothman, Reference Kupisch and Rothman2018).
Researchers have noted differences between HL grammars and grammars of baseline speakers, be they monolinguals or first-generation immigrant controls, that is, late acquirers of the SL (Benmamoun, Montrul, & Polinsky, Reference Benmamoun, Montrul and Polinsky2013; Montrul, Reference Montrul2016; Polinsky, Reference Polinsky2018a; Rothman, Reference Rothman2009).Footnote 1 A much-debated question has to do with the status of divergence from monolingual and immigrant controls demonstrated by HL speakers: are these differences simply a sign of processing limitations experienced by HL speakers, or do they indicate that HL grammars are different from those of the baseline speakers?
Implicit in the latter view is the conception that HL speakers’ grammars undergo internal restructuring (a) under transfer from the dominant SL (also known as cross-linguistic influence, CLI below) and/or (b) diminished input. There are multiple ways to measure the quantity and quality of input using different indices, in particular, relative exposure to the HL and the SL on a daily basis, cumulative exposure to the HL and the SL (see Armon-Lotem & Meir, Reference Armon-Lotem, Meir, De Houwer and Ortega2019), and the Age of Onset of Bilingualism (AOB). With respect to AOB, the reasoning is straightforward: an individual has a set number of hours per day when s/he is exposed to any language, therefore at the age when HL speakers become exposed to their SL on a regular basis, exposure to the HL decreases.
Within representational accounts, previous studies have explored the idea that “restructuring under transfer,” that is, CLI (direct or indirect), is linked to the pressure from the dominant SL (Cuza, Reference Cuza2013; Cuza & Frank, Reference Cuza and Frank2011; Cuza & Pérez-Tattam, Reference Cuza and Pérez-Tattam2016; Montrul & Ionin, Reference Montrul and Ionin2012; Santos & Flores, Reference Santos and Flores2016). It has been demonstrated that if grammatical features are similarly configured in the HL and the SL, their acquisition and maintenance is facilitated in the HL (Albirini & Benmamoun, Reference Albirini and Benmamoun2014; Meir & Polinsky, Reference Meir and Polinsky2021; Montrul & Ionin, Reference Montrul and Ionin2010). Conversely, if the two languages in a bilingual dyad differ in the selection and mapping of grammatical features, the HL manifests restructuring. Consider, for example, the Feature Reassembly Hypothesis (Lardiere, Reference Lardiere, Liceras, Zobl and Goodluck2008, Reference Lardiere2009) originally proposed to account for L2 acquisition, but later extended to HL development and maintenance (Meir & Janssen, Reference Meir and Janssen2021 and the studies cited therein). The Feature Reassembly Hypothesis posits that it is not only the absence/presence of the feature in L1 that determines its ease of acquisition in L2 but also the similarities and differences in feature mapping and bundling in L1 and L2. Lardiere (Reference Lardiere2009) shows that the acquisition of plural markers in L2 in English, Korean, and Chinese is linked to how the feature of plurality is bundled in these languages. Although the three languages all have plurality in their inventories, this feature selects different co-occurring features in each language, such as definiteness, specificity, and animacy. A meta-analysis investigating effects of CLI in 750 simultaneous and early sequential bilingual children (aged 4;0–10;0) in 17 unique language combinations confirmed the effects of CLI on the acquisition of morphosyntax and revealed that CLI has more effect in the direction of the SL upon the HL (Van Dijk et al., Reference Van Dijk, Van Wonderen, Koutamanis, Kootstra, Dijkstra and Unsworth2021).
Diminished input (Meir & Polinsky, Reference Meir and Polinsky2021; Montrul, Reference Montrul2016; Polinsky, Reference Polinsky2018a, Reference Polinsky2018b) has been suggested as another factor responsible for divergence. AOB allows us to operationalize diminished input for the simple reason that the introduction of the use of two languages instead of one leads to inherent changes in the quantity of input of each language. But it is not only the amount of input that is reduced for bilinguals as compared to monolinguals; the quality of input has also been argued to differ (Flores, Santos, Jesus, & Marques Reference Flores, Santos, Jesus and Marques2017; Meisel, Reference Meisel2020; Polinsky, Reference Polinsky2018a; Pires & Rothman, Reference Pires and Rothman2009; Rinke & Flores, Reference Rinke and Flores2014; Rothman, Reference Rothman2007; Tsimpli, Reference Tsimpli2014). Furthermore, differences across individual language domains (e.g., morpho-syntax, phonology, pragmatics, and lexicon) start with the AOB (Armon-Lotem et al., Reference Armon-Lotem, Rose and Altman2021; Keating, Reference Keating2022; Mikulski, Reference Mikulski2010). For example, Montrul and Sánchez-Walker (Reference Montrul and Sánchez-Walker2013) demonstrated that not only adult and child Spanish-HL speakers overlook differential object marking in their Spanish, but also that first-generation immigrants do so as well. Some researchers attribute divergences in production and comprehension of HL speakers to lack of exposure to formal registers and literacy in the HL (e.g., Pires & Rothman, Reference Pires and Rothman2009; Rothman, Reference Rothman2007). Input and the timing of acquisition of a given linguistic phenomenon have been previously suggested to be important factors not only in monolingual development but also in L2 acquisition (Tsimpli, Reference Tsimpli2014): there are early and late acquired structures, with the latter requiring more input than the former. Therefore, diminished input affects later-acquired structures, yet it is not clear to what extent structures that are acquired early by monolinguals are vulnerable and/or intact in HL acquisition.
Working-memory limitations constitute another factor which has been proposed to account for production and comprehension differences between bilinguals and monolinguals. This factor affects performance but ostensibly does not affect grammatical representations. The Shallow Structure Hypothesis (Clahsen & Felser, Reference Clahsen and Felser2006) is a representative model in this regard. According to this hypothesis, originally formulated for L2, even highly proficient L2 speakers tend to have problems building or manipulating abstract syntactic representations in real time and are guided more strongly than native speakers by semantic, pragmatic, probabilistic, or surface-level information. Specifically, it has been shown that L2 learners exhibit problems with non-local dependencies, while for local dependencies (e.g., gender agreement within the noun phrase or subject-verb (SV) agreement), they can achieve native-like processing (Clahsen & Felser, Reference Clahsen and Felser2018). Several studies addressed the sensitivity to agreement/concord violations in continuous and discontinuous dependencies (where the agreeing word was separated from the word it agreed with) in L2 speakers as compared to monolingual L1 speakers (see Foote, Reference Foote2011; Keating, Reference Keating2009)). Keating (Reference Keating2009) manipulated the distance between the agreeing noun and adjective and demonstrated that the sensitivity to gender concord violations in English-dominant L2-Spanish speakers was affected by the distance between the nouns and the adjective. At the same time, Keating showed that L2 speakers had acquired the functional feature [gender]. Therefore, L2 speakers can develop target-like grammatical representations, yet divergences in the processing performance (as compared to monolingual L1 speakers) are due to working-memory limitations. The Shallow Structure Hypothesis can also be applied to HL speakers, who are likely to face similar memory limitations (see Ivanova-Sullivan, Reference Ivanova-Sullivan2014; Sekerina & Brooks, Reference Sekerina and Brooks2006). However, a recent eye-tracking experiment investigating morphosyntactic processing during reading among HL-Spanish speakers with different AOBs (0–3, 4–6, 7–10 years) showed that HL speakers were sensitive to violations of noun–adjective gender agreement regardless of their AOB and noun–adjective proximity (adjacent vs. non-adjacent) (Keating, Reference Keating2022).
This short overview points to three mechanisms that can account for differences observed in HL speakers as compared to monolingual and first-generation immigrant controls: cross-linguistic influence (CLI), diminished input, and processing limitations. The relative contribution of these three factors is still poorly understood. Our study seeks to evaluate these three mechanisms in application to morphological processing by HL-Russian speakers who are dominant in SL-Hebrew.
We investigate processing in the comprehension of constructions where the grammatical features of a noun are matched on related constituents. In particular, we examine the comprehension of noun phrases where the number and case of the head noun are matched on modifying adjectives and the comprehension of subject-verb combinations where the person and number features of the subject are matched on the agreeing verb. Some researchers propose that feature-matching in a noun phrase and in a clause are subject to different syntactic operations: concord in the former, and agreement proper in the latter (e.g., Norris, Reference Norris2014, Reference Norris2019). Concord is the dependency between a head and its modifier matching for features of gender, number, case, or definiteness. Agreement proper is the dependency between a probing head and argument in its local (c-command) domain, for example, subject-verb agreement in gender, number, or person. While establishing empirical evidence in support of the difference between concord and agreement is beyond the scope of this study, we expect that our results may have a potential bearing on the understanding of these two syntactic operations.
The remainder of this paper is structured as follows. In “Grammatical phenomena,” we introduce the grammatical phenomena explored in this study and present a comparison between Russian and Hebrew with respect to these phenomena. “The current study” gives a detailed description of our experiments, whose results are presented in “Results.” The discussion of the results is given in “Discussion,” and “Limitations and future studies” addresses potential limitations of this study and directions for future work.
Grammatical phenomena
Nominal concord and SV agreement in Russian and in Hebrew
Russian and Hebrew are both languages with rich morphology, albeit of different kinds. In what follows, we discuss similarities and differences in the realization and mapping of case, grammatical gender, number, and person in the two languages.
All Russian nouns, adjectives, numerals, pronouns, and demonstratives must bear a case inflection (Bailyn, Reference Bailyn2012). In adjectival phrases, the noun and the adjective show obligatory concord in number, gender, and case, as shown in Table 1.
Table 1. Nominal morphology in Russian and Hebrew

In contrast to Russian, Hebrew does not use case inflections to mark cases. The accusative case is marked by the particle et in front of definite noun phrases, and there is no case matching between the head noun and its modifying adjective. Prepositional phrases correspond to what is expressed by case forms in case-rich languages such as Russian, Latin, or German. Since Hebrew and Russian differ in the use of case forms, case concord in the HL-Russian is a good candidate for attrition or simplification under the influence of the dominant SL-Hebrew.
Both Russian and Hebrew have number and gender concord, with distinct inflections in the singular and plural (see Table 1). Russian has a three-way gender system: MASC, FEM, and NEUT. Gender assignment is partially predictable based on the declension class of the noun: most nouns ending in a non-palatal consonant are masculine, the majority of nouns ending in –a are feminine, and nouns ending in –o/–e are neuter. Nouns ending in a palatalized consonant can be either feminine or masculine (Ceitlin, Reference Ceitlin, Bondarenko and Shubik2005; Corbett Reference Corbett1991, Reference Corbett2007; Mitrofanova et al., Reference Mitrofanova, Rodina, Urek and Westergaard2018). Gender assignment is complicated by the mobile character of Russian stress; unstressed vowels undergo reduction, which, among other things, can blur the distinction between feminine and neuter nouns.
Hebrew has a two-gender class system (MASC and FEM). There is a tendency for nouns ending with –t and –a to be feminine and others, usually ending with a consonant, to be masculine. Hebrew also has definiteness concord, which does not exist in Russian.
Both languages distinguish singular and plural (we leave the dual number aside, as it is not as regular and plays no role in this study). The morphological encoding of number intersects with gender categorization in complex ways, but for our purposes, it is sufficient that both Russian and Hebrew mark plural via inflectional endings.
In the category of person, both languages distinguish participant (1 and 2) and non-participant (3) persons, in the singular and plural. There are no clusivity distinctions and no dual number in person.
Both Russian and Hebrew map person, number, and gender onto verbal inflection, but the arrangement of these features is different (see Table 2). In Hebrew, all three features are mapped onto verbal inflections in the past and future tenses, while in Russian, gender and number are marked in the past tense, and number and person are marked in the non-past (Bailyn, Reference Bailyn2012).
Table 2. Verbal agreement in Russian and Hebrew
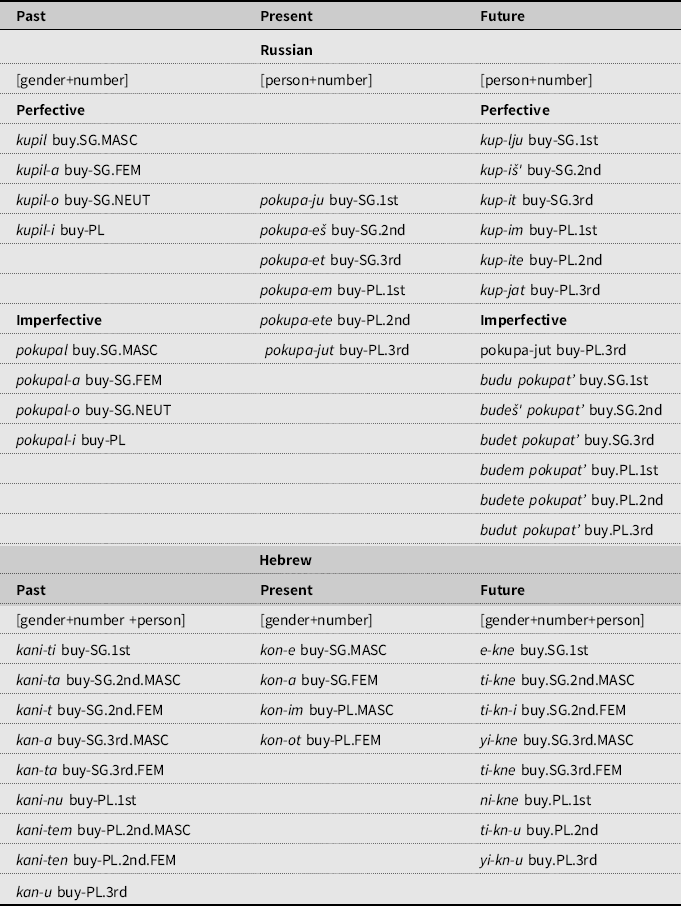
Monolingual Russian-speaking children demonstrate early acquisition of number and case oppositions in nouns. For example, nominal morphological categories appear around age 1;9, starting with NOM and ACC oppositions (e.g., Babyonyshev, Reference Babyonyshev1993; Ceitlin, Reference Ceitlin2009; Gvozdev, Reference Gvozdev1961; Protassova & Voeikova, Reference Protassova, Voeikova, Savickiene and Dressler2007). Verbal morphological categories appear between 1;10 and 2;0 (Gvozdev, Reference Gvozdev1961), and the inflectional paradigm is acquired by Russian monolinguals around 2;6 (Gagarina et al., Reference Gagarina, Armon-Lotem, Gupol, Caunt-Nulton, Kulatilake and Woo2007; Gagarina & Voeikova, Reference Gagarina, Voeikova, Stephany and Voeikova2009). Thus, the transparent and productive patterns of the rich nominal and verbal morphology of the Russian language are acquired rather early. Nevertheless, the rich nominal morphology is reported to be vulnerable in child and adult HL-Russian acquisition (e.g., Rodina et al., Reference Rodina, Kupisch, Meir, Mitrofanova, Urek and Westergaard2020; Meir et al., Reference Meir, Otwinowska, Ringblom, Karpava and La Morgia2021; and studies cited therein).
Split constructions
Russian has split constructions, where a single constituent can be broken into two discontinuous parts, enabling us to test agreement/concord phenomena within local and non-local dependencies. For example, a noun phrase can be separated from its modifiers; the fronted sub-constituent is typically interpreted as a (contrastive) topic, and the remnant is interpreted as contrastive focus, cf. (1b).
(1)


Split noun phrases are frequent in colloquial Russian (Pereltsvaig, Reference Pereltsvaig2008; Zemskaja, Reference Zemskaja1973) but are often considered substandard, especially in written registers. As examples (1b, 1c) show, the relative order of the discontinuous parts can correspond to the default order in adjacent structures (1b) or could be inverted (1c); see Pereltsvaig (Reference Pereltsvaig2008) for a discussion. In the experiment in this study, we only used default-order splits, as in (1b).
In addition to split noun phrases, the relatively free word order of Russian allows for a separation between the subject and the predicate, with intervening material being an adverbial or a PP expression. Unlike the noun phrases in (1), the subject and predicate do not form a constituent, but in both types of splits, the features of one segment (head noun, subject) have to be matched against the features of the other segment (modifier, verbal predicate) over the intervening lexical material. Such intervening material imposes an additional working-memory load (Sekerina, Reference Sekerina1997; Sekerina & Trueswell, Reference Sekerina and Trueswell2011). In her discussion of splits, Sekerina proposes a one-split-per-clause constraint as splitting imposes “an unwanted, though not quite intolerable, burden on the human sentence processor” (Sekerina, Reference Sekerina1997, p. 294).
Going forward, we will refer to all the constructions with intervening lexical material as split constructions; we recognize their structural differences, but the processing load in the matching of features across intervening lexical material is consistent. This is what matters for our purposes. On the assumption that the processing of split constructions is associated with an extra working-memory load, we can test processing differences in HL speakers as compared to monolingual and first-generation immigrant controls. If the two groups differ only in the processing of split constructions, but not in the non-split constructions, the difference could be attributed to working-memory limitations.
Turning to Hebrew, split noun phrases were attested in Biblical Hebrew (Kaajan, Reference Kaajan2019), but in Modern Hebrew they are very infrequent (Fanselow & Féry, Reference Fanselow and Féry2006; Kaajan, Reference Kaajan2019).
As for subject-verb sequences, linear discontinuity is allowed between the head noun of the subject and the agreeing verb in Hebrew, as in (2) or (3).
(2) ha-šoter divech ki meχonit mištara me-ha-degem ha-yafe ve-ha-χadiš be-yoter nigneva be-šaa χameš lifnot boker.
DEF-policeman reported that car police from-DEF-model DEF-nice and-DEF-new in-most stolen in-hour five towards morning.
“The policeman reported that a police car of the nicest and most recent model had been stolen at five o’clock in the morning.”
(Deutsch, Reference Deutsch1998, p. 582)
(3) toχniyot šel politikayim be-zman bχirot lo yugduru be-tikšoret “toχniyot”… plans of politicians in-time elections NEG defined in-mass-media “plans”…. “Plans of politicians will not be defined as “plans” in mass media during the times of elections…”
On the assumption that similarities between the SL and the HL play a role in the relative maintenance of the HL, we may expect that HL-Russian speakers would be more accepting of discontinuous subject-verb sequences than of discontinuous noun phrases.
The current study
Research questions
In this study, we compared Monolingual controls (MonoControl) and three groups of Russian-Hebrew bilinguals with different AOBs: Immigrant Controls (IMMControl), that is, Russian-Hebrew bilinguals with the AOB after age 13; bilinguals with the AOB between 5 and 13 (BL-Late); and bilinguals with the AOB before the age of 5 (BL-Early). The latter group represents HL speakers in the conventional sense of the term, while BL-Late can be identified as 1.5 generation speakers. The relevance of IMMControl stems from the fact that their language typically serves as input for HL speakers (BL-Early) and may also influence BL-Late. As shown by previous work on immigrant varieties, immigrant controls might themselves differ from the monolingual controls quantitatively and/or qualitatively (Dubinina & Polinsky, Reference Dubinina, Polinsky, Moser and Polinsky2013; Montrul, Reference Montrul2016). The inclusion of the BL-Late group also allows us to determine whether AOB might affect the acquisition of early-acquired categories in the HL.
The study addresses the following research questions:
-
(a) Is there an effect of diminished input (as indexed by AOB) on the morphosyntax of Russian agreement and concord as evident in the differences across the four groups of participants (MonoControl, IMMControl, BL-Late, BL-Early)?
-
(b) Do the factors of CLI or working-memory limitations affect mechanisms of feature-matching in person, number, and gender?
The null hypothesis is that there will be no difference in the sensitivity to ungrammaticality, which serves as an index of morphosyntactic integration across different conditions and groups.
Under the diminished input hypothesis, we expect HL speakers with earlier AOBs to show lower sensitivity to ungrammaticalities compared to HL speakers with later AOBs.
Under the CLI hypothesis, we expect an asymmetry across different phenomena under investigation. Specifically, we expect better performance on the features similarly configured in the HL and the SL, that is, on number adjective-noun concord and personal SV agreement (where Russian and Hebrew align) compared to case concord, where Russian and Hebrew differ.
Under the working-memory-limitation hypothesis, we expect the stimuli with discontinuous (split) constructions, that is, constructions in which the agreeing elements are separated by an intervening phrase, to impose an extra working-memory load on bilingual speakers (or a subset thereof), thereby lowering their performance as compared to non-split constructions. No such effects are expected for the stimuli with adjacent agreeing elements.
We also entertain the idea that working-memory load and CLI might have a cumulative effect on the processing of speakers with different AOBs; therefore, if CLI is at play for the processing of split constructions, an asymmetry is expected between verbal agreement and nominal concord constructions for bilinguals (but not for monolingual controls). The reason for such an asymmetry is as follows: as we indicated in “Grammatical phenomena,” subject-verb separation is possible in both languages, while split noun phrases are found only in Russian, but not in Hebrew. We can therefore expect an extra processing load for the nominal constructions as compared to the verbal ones, and we expect no decreased sensitivity to the stimuli with adjacent agreeing elements (i.e., non-split constructions). In order to test this prediction, our analysis will include three-way interactions (i.e., group, phenomenon, and working-memory load).
Participants
A total of 119 adult participants were recruited for the current study (Table 3). All the participants have spoken Russian from birth and have acquired the language in a naturalistic setting. The participants were divided into four groups (consider the classification by Remennick & Prashizky, Reference Remennick and Prashizky2022):
-
1) Monolingual Russian-speaking participants (MonoControl) Footnote 2 were Russian speakers from the Russian Federation, Belarus, Ukraine, Kazakhstan, and Estonia; all reported Russian to be their mother tongue and the language of their everyday communication;
-
2) Immigrant Controls (IMMControl), that is, Russian-Hebrew bilinguals with AOB after the age of 13, corresponding to first-generation immigrants;
-
3) Late Russian-Hebrew bilinguals (BL-Late) with AOB between 5 and 13; this group corresponds to the 1.5 immigrant generation;
-
4) Early Russian-Hebrew bilinguals (BL-Early) with AOB before the age of 5, representing HL speakers of Russian.
Table 3. Demographic information on the participants of the current study
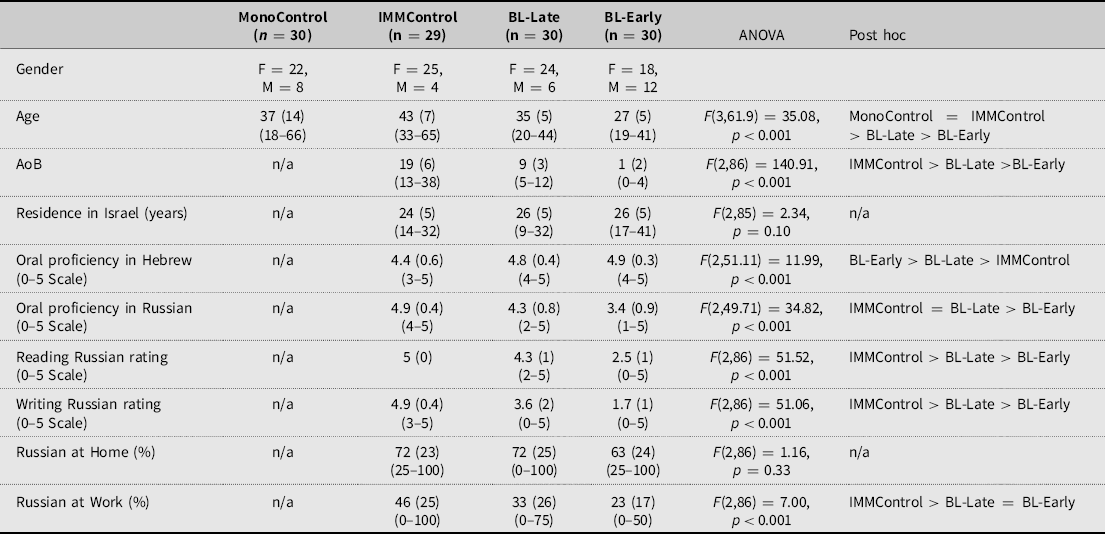
By including 1st and 1.5-generation immigrants in our speaker pool, we are able to arrive at a more fine-grained analysis of AOB effects on morphosyntactic maintenance in language contact situations.
Based on the collected questionnaire data, there were significant group differences with respect to age of the participants reflecting differences in AOBs. The bilingual groups were not different with respect to their length of residency in Israel: all participants have been living in Israel on average for over 20 years. There were significant differences for self-rated proficiency in Russian and in Hebrew. As expected, participants in the IMMControl group scored the highest in Russian, yet the lowest in Hebrew. The reverse picture was observed for the participants in the BL-Early groups: low ratings in the HL and high ratings in the SL. In the BL-Early group, participants provided low ratings for their reading and writing skills, reflecting generally well-documented characteristics of HL speakers.
Materials
The materials, data, and analysis script for this study can be retrieved from https://osf.io/3cr9f/
Procedure
The study was approved by Institutional Review Board of Bar Ilan University, Israel. Monolingual participants were recruited by word of mouth via personal social media networks. It was crucial to find Russian-speaking monolingual participants not only residing in Russia but also in different countries with Russian-speaking populations (e.g., Belarus, Ukraine, Estonia), since the families of Russian-Hebrew bilinguals immigrated to Israel from different parts of the former Soviet Union. After signing a written consent form, all participants were assigned a unique identification code and asked to fill in the background questionnaire via a Google Form and complete the offline auditory grammaticality judgment task (GJT) described below.
Background measures
Background questionnaires provide valuable data on language history and language practice in bilingual speakers, including HL speakers (Kaushanskaya et al., Reference Kaushanskaya, Blumenfeld and Marian2020; Macbeth et al., Reference Macbeth, Atagi, Montag, Bruni and Chiarello2022). In the current study, the background questionnaire (Meir & Polinsky, Reference Meir and Polinsky2021) elicited information on participants’ age, gender, country of birth, and age of immigration (if they were not born in Israel). Then, participants were asked to rate their literacy skills (reading and writing proficiency) in the HL-Russian and in the SL-Hebrew. Finally, they were asked about their HL-Russian use during different stages of their lives, and about their use of HL-Russian at home and at work. Because most HL speakers have limited literacy skills in their HL, the proposed study was an audio task, and the participants filled out the background questionnaire in SL-Hebrew.
Auditory offline grammaticality judgment task (GJT): morphosyntactic integration
The task developed in the current study is based on the previous GJT task of Meir and Polinsky (Reference Meir and Polinsky2021). There is a considerable controversy around the use of GJTs to measure morphosyntactic competence in monolingual and bilingual speakers (Orfitelli & Polinsky, Reference Orfitelli, Polinsky, Kopotev, Lyashevskaya and Mustajoki2017; Polinsky, Reference Polinsky2018a) due to “yes-bias” previously noted for HL speakers (Polinsky, Reference Polinsky2018a, but see Romano, Reference Romano2022). However, notable advantages of this methodology have been previously outlined (for more details on the validity of the task, especially for GJTs using auditory stimuli, see (Schütze, Reference Schütze1996).
We tested sensitivity to (un)grammaticality in adjective-noun concord and subject-verb agreement. The matching features include number and accusative case in the noun phrase and person in the subject-verb agreement. As discussed in “Grammatical phenomena,” the choice of number, case, and person features was not accidental, as we aimed to explore the effect of cross-linguistic influence from SL-Hebrew on HL-Russian: both Russian and Hebrew have person agreement and show number concord, yet with respect to case concord, the two languages differ. Russian has case concord, while Hebrew does not. In all the conditions, the agreeing elements appeared in two contexts: non-split, where the words matching in features as adjacent, and split, where a prepositional phrase intervenes between the target words (see Table 4). The manipulation for split vs. non-split constructions was aimed at testing working-memory limitations across the four groups of speakers.
Table 4. Stimuli examples for adjectival concord (in case and number) and SV agreement (in person)
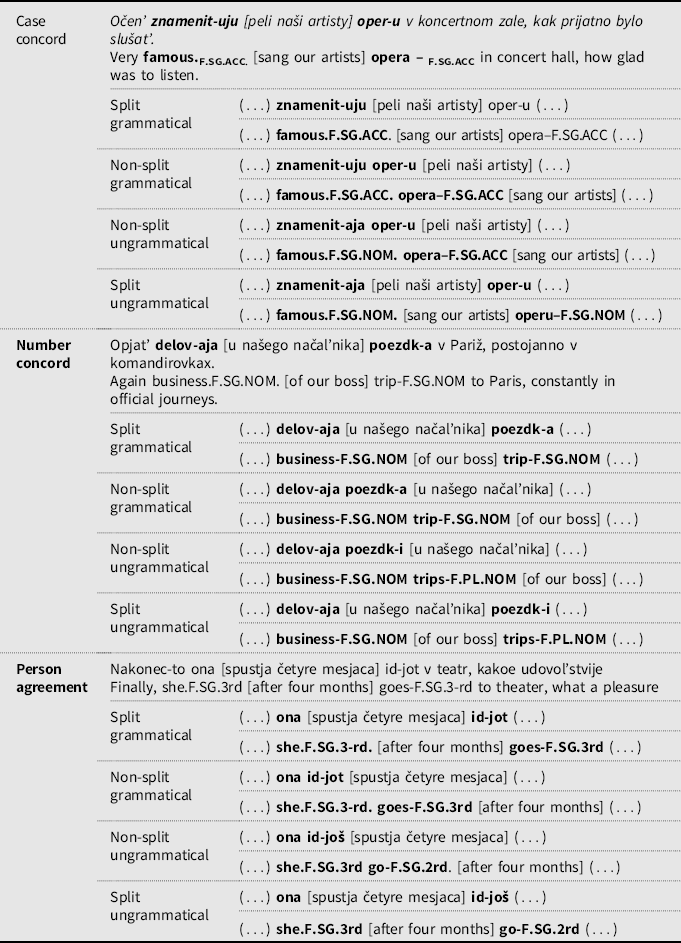
As mentioned in “Grammatical phenomena,” we used only those split constructions where the relative order of the discontinuous parts corresponds to the default order in adjacent structures. In our split and non-split stimuli, a modifying adjective precedes the head noun, and the subject precedes the agreeing verb. All sentences appeared in their grammatical and ungrammatical versions. The total number of sentences was 384. The intervening prepositional phrase was 6–11 syllable long. There were no differences between the three conditions with respect to the length of the intervening phrase (case manipulation: M = 8.31 MIN-MAX: 6–10; number manipulation: M = 8.48 MIN-MAX: 7–10; person manipulation: M = 8.49 MIN-MAX: 5–11) as determined by a one-way ANOVA (F(2,93)= 0.45, p = 0.69). The length of the pauses in each sentence between the target and the intervening phrase was kept constant. The selection of the lexicon for the sentences was based on frequency lists and dictionaries, in order to minimize the involvement of the lexicon. See Supplementary Materials for the stimulus list for the GJT.
We recorded only grammatical sentences (split and non-split), which were then cut and normalized in the Audacity program. Ungrammatical sentences were derived from the grammatical ones through cross-splicing using Audacity (see https://www.audacityteam.org/). Subsequently, all sentences were divided into 4 lists, creating a Latin-square design, with participants being exposed to only one version of the sentence. Thus, each list included 96 sentences. These four lists were hosted on the PCIbex platform (https://www.pcibex.net/; see Zehr & Schwarz, Reference Zehr and Schwarz2018 for details). The instructions for the participants were provided in written format in both languages (Russian and Hebrew) and were as follows: “Listen to the sentence and decide whether the sentence is grammatically correct or not, by choosing one of the buttons: ‘correct’ or ‘incorrect’.”
Results
Figure 1 presents the results of the auditory GJT data per group per task manipulation (e.g., Condition, Grammaticality, and Split). Due to the binary nature of the data (Correct/Incorrect), we analyzed the results using a mixed-effects binomial regression with Group (4 levels: MonoControl, IMMControl, BL-Late, BL-Early), Condition (3 levels: Number Concord, Case Concord, and Person agreement), Grammaticality (2 levels: YES (i.e., grammatical), NO (ungrammatical)), Split (2 levels (Split, Non-Split) as fixed factors. The binomial regression models were performed using the lme4 package (Bates et al., Reference Bates, Maechler, Bolker, Walker, Christensen, Singmann, Dai, Scheipl, Grothendieck and Green2009). The models were built by adding random and fixed variables in a step-by-step procedure, starting with an intercept-only baseline model. The null models included both by-subject random intercepts and by-stimulus random intercepts. Then, we built the model starting with Group and added Condition, Grammaticality, and Split as fixed factors. We introduced backward difference coding contrasts for Group and Helmert contrasts for Condition to compare the differences between the conditions. The variables and/or the interactions of the variables were retained in the model only if they significantly improved the fit of the model, resulting in a reduced AIC value. We also included two-way, three-way, and four-way interactions as fixed variables. The comparison of the models was carried out using one-way ANOVAs; a p-value which was higher than .05 indicated that the variable and/or the interaction did not improve the goodness of the fit; therefore, it was not included in the subsequent model. The interactions were followed up using the emmeans package (Lenth et al., Reference Lenth, Singmann, Love, Buerkner and Herve2019). The plots were generated using the ggplot2 package (Wickham et al., Reference Wickham, Chang and Wickham2016) and the ggpubr package (Kassambara & Kassambara, Reference Kassambara and Kassambara2020).
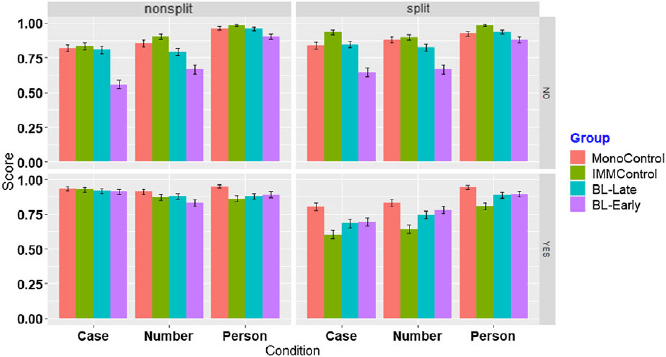
Figure 1. Observed accuracy scores per group per condition per grammaticality per split.
The analysis was conducted using R (R Core Team, 2008). The final minimal adequate model performed significantly better than the minimal baseline model (Table 5). The formula was as follows: Score ∼ (1 | Participant) + (1 | Item) + Group + Condition + Split + Grammaticality + Group:Split + Group:Grammaticality + Split:Grammaticality + Group:Condition + Condition:Grammaticality + Condition:Split + Group:Split:Grammaticality + Group:Condition:Grammaticality + Group:Condition:Split + Condition:Split:Grammaticality + Group:Condition:Split:Grammaticality.
Table 5. The final adequate model for the GJT performance
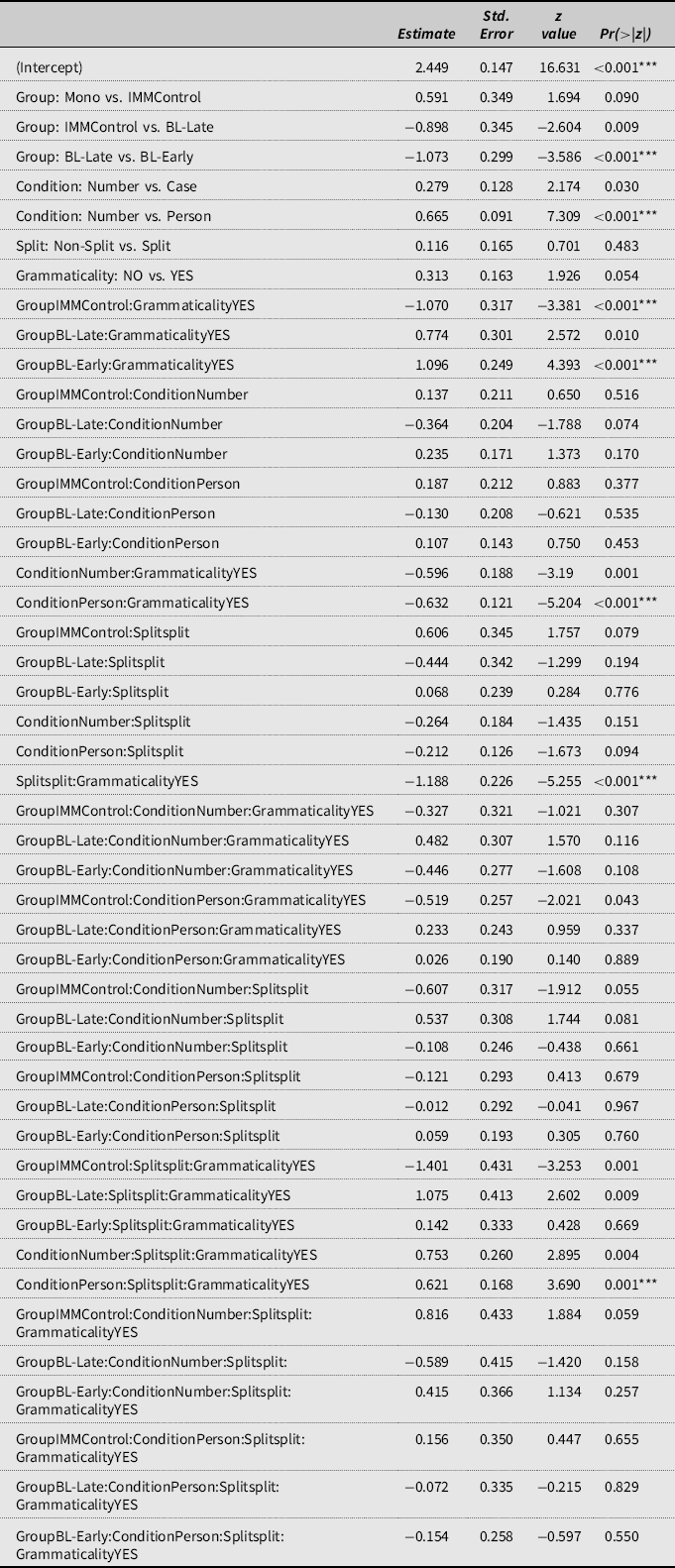
Note: Signif. codes: “***”0.001.
Figure 2 presents the visualization of fixed simple effects. The model presented in Table 5 yielded a significant effect of Group, with BL-Early scoring significantly lower than MonoControl. There was a significant effect of Condition indicating no differences between the nominal concord conditions (Case and Number), yet significant differences between adjectival concord and SV agreement. The effect of Split was not significant. The fixed effect of Grammaticality reached significance. The results also demonstrated that there were significant two-way and four-way interactions. The final model accounted for 38% (Pseudo-R2 (fixed effects) = 0.17; Pseudo-R² (total) = 0.38) of the variation in the total 11424 observations over 119 participants.
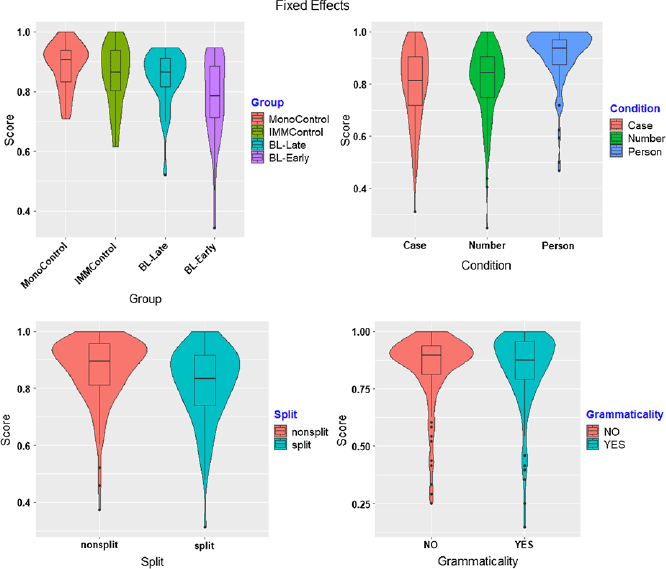
Figure 2. Visualization of GJT performance per fixed effects (Group, grammaticality, condition, and split).
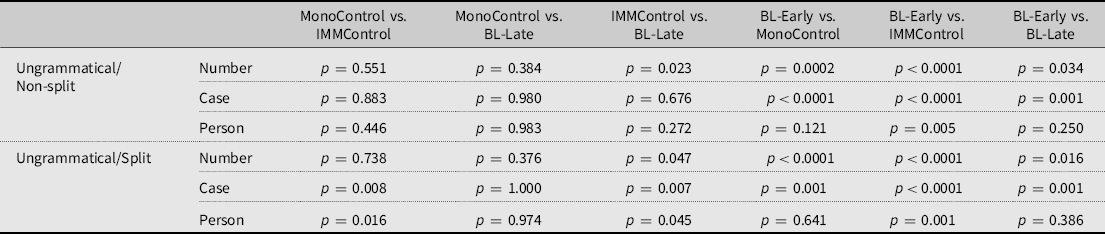
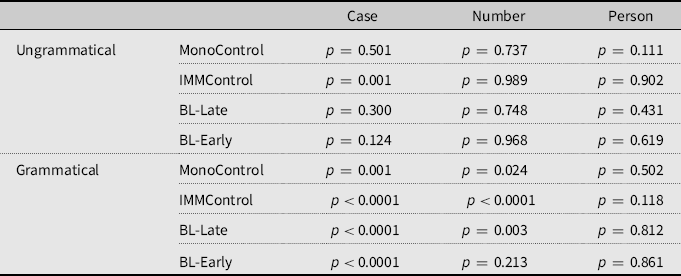
Since the results indicated a significant four-way interaction (see Table 5), we used emmeans functions in R with Tukey methods for multiple comparisons to identify the sources of this four-way GroupIMMControl*ConditionNumber*Splitsplit*:GrammaticalityYES interaction, which significantly improved the fit of the model. First, we compared the groups across the three conditions (Case concord, Number concord, and Person agreement) per Split within grammatical and ungrammatical sentences. In grammatical sentences, none of the pairwise comparisons reached significance, while there were Group differences in ungrammatical sentences (see Table 6). The BL-Early group scored significantly lower than the MonoControl on the two concord conditions (Case and Number), yet on Person agreement, they were on par with MonoControls in ungrammatical sentences in split and non-split conditions. IMMControls and BL-Late patterned with MonoControls in all non-split conditions.
Table 6. Group comparisons per condition (number concord, case concord, and person agreement)
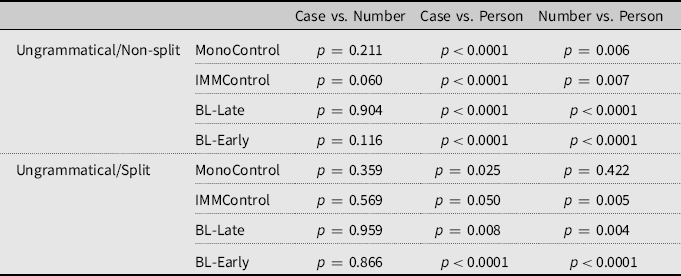
Subsequently, we ran emmeans functions in R using the Tukey method for multiple comparisons in order to determine the effect of Condition across the three Groups in grammatical and ungrammatical sentences in sentences with split and non-split manipulations. For all the groups, there were no differences between the two concord conditions (Case and Number), yet there were significant differences between adjectival concord and SV person agreement (Table 7).
Table 7. Condition comparisons (case concord vs. number concord; case concord vs. person SV agreement; number concord vs. person SV agreement) per group per grammaticality per splitFootnote 3
Finally, we ran emmens functions using the Tukey method for multiple comparisons to determine whether an additional working-memory load affected grammaticality judgments across the four groups by comparing split versus non-split conditions (see Table 8). The effect of working-memory load for identifying ungrammaticalities was not significant in any group for any condition, suggesting that the intervening phrase between the two agreeing elements did not lower the accuracy of grammaticality judgment. In grammatical sentences, participants in the MonoControl, IMMControl, and BL-Late groups judged sentences with split conditions as erroneous, presumably due to stylistic/register considerations. Such rejections of grammatical sentences with split constructions were not observed in the BL-Early group, possibly due to their lower sensitivity to register/stylistic variations.
Table 8. Split vs. non-split condition per condition per group
Discussion
Using an offline auditory GJT, we investigated feature-matching mechanisms by Russian-Hebrew bilinguals of various ages of AOBs with the ultimate goal to understand which factors influence the grammar of adult bilingual speakers. The feature-matching conditions included adjectival concord in number and case, as well as person agreement between the subject and predicate. We compared monolingual controls (MonoControl) and three groups of Russian-Hebrew bilinguals with different AOBs: Immigrant Controls, that is, Russian-Hebrew bilinguals with AOB after the age of 13 (IMMControl); bilinguals with AOB between 5–13 (BL-Late); and bilinguals with AOB before the age of 5 (BL-Early).
We considered the following core questions: (a) Are there differences in the morphosyntactic comprehension of Russian agreement and concord across the four groups of participants (MonoControls, IMMControl, BL-Late, BL-Early), and if yes, do they reflect the effect of diminished input (as indexed by AOB)? (b) Do the factors of CLI and working-memory limitations influence the processing of Russian agreement and concord?
Starting with the effects of CLI, higher sensitivity to number concord and person agreement violations, in contrast to case concord, was predicted to reflect CLI because Russian and Hebrew differ in the grammar of case. Our results showed no evidence for the CLI hypothesis, as no difference was found for number concord as compared to case concord and person agreement on the verb. The lack of CLI is surprising given that previous studies report pressure from the dominant SL as one of the potential mechanisms shaping HL grammars in child bilinguals (see a meta-analysis by Van Dijk et al., Reference Van Dijk, Van Wonderen, Koutamanis, Kootstra, Dijkstra and Unsworth2021) and adult HL speakers (Albirini & Benmamoun, Reference Albirini and Benmamoun2014; Montrul & Ionin, Reference Montrul and Ionin2010). At the same time, other researchers have argued against the CLI account in HLc (e.g., Rodina et al., Reference Rodina, Kupisch, Meir, Mitrofanova, Urek and Westergaard2020). Given the discrepancy in the findings, more studies are needed to understand the mechanisms of CLI in adult HLs. Moreover, it is imperative to carry out a meta-analysis evaluating the effect of CLI in adult HL grammars (along the lines of Van Dijk et al., Reference Van Dijk, Van Wonderen, Koutamanis, Kootstra, Dijkstra and Unsworth2021).
Contrary to our predictions for the effects of CLI, our study uncovered a significant difference between feature-matching in nominal and verbal paradigms. Our findings demonstrate that person agreement is very stable in all the groups, even in HL speakers (the BL-Early group). At the same time, HL speakers showed lower sensitivity to ungrammaticality in case and number concord. Previous research on HL morphology pointed in this direction, reporting that the nominal domain is more susceptible to change than the verbal domain (Benmamoun et al., Reference Benmamoun, Montrul and Polinsky2013; Polinsky, Reference Polinsky2018a). As mentioned in “Introduction,” some researchers have proposed that feature-matching in a noun phrase and in a clause are subject to different syntactic operations: concord in the former and agreement proper in the latter (Norris, Reference Norris2014, Reference Norris2019). Our findings may indicate that agreement operations might be intact in HL speakers, while concord might be more vulnerable. However, the features implicated in the agreement and concord in this study were also different: person in the verbal agreement, and case/number in the nominal domain. Thus, an alternative explanation may have to do with the strength of different grammatical features that need to be matched; the person feature is inherently indexical, which can contribute to its salience and maintenance in heritage grammars (Polinsky, Reference Polinsky2018a; Polinsky & Scontras, Reference Polinsky and Scontras2020). To adjudicate between these explanations, future research is needed, particularly on conditions where the same feature (e.g., number and/or gender) can be manipulated.
Turning to the effect of AOB, which indexes diminished input, we predicted that HL speakers with earlier AOBs would be less accurate compared to bilingual speakers with later AOBs. Our findings demonstrate a robust effect of AOB on the acquisition/maintenance of morphology in bilingual speakers. According to our results, the Immigrant Control group, whose age of acquisition of SL-Hebrew was later than 13 years, mostly performed as the monolingual controls.
It is worth noting that the current study investigated early-acquired phenomena. Case concord, number concord, and person agreement are known to be acquired around age 3 (for nominal morphology: Babyonyshev, Reference Babyonyshev1993; Ceitlin, Reference Ceitlin2009; Gvozdev, Reference Gvozdev1961; Protassova & Voeikova, Reference Protassova, Voeikova, Savickiene and Dressler2007; for verbal morphology: Gagarina et al., Reference Gagarina, Armon-Lotem, Gupol, Caunt-Nulton, Kulatilake and Woo2007; Gagarina & Voeikova, Reference Gagarina, Voeikova, Stephany and Voeikova2009; Voeikova, 2008). It is therefore not surprising that bilinguals with AOB between 5 and 13 showed a clear mastery of these phenomena. Similar findings were also reported by Meir and Polinsky (Reference Meir and Polinsky2021), who showed that bilinguals with AOBs between 5 and 13 performed on par with Immigrant Controls (i.e., those bilinguals who have acquired SL after the age of 13) on number concord within adjectival phrases, yet showed lower sensitivity to mismatches in numerical expressions, which are acquired later by Russian-speaking monolinguals (Gagarina & Voeikova, Reference Gagarina, Voeikova, Stephany and Voeikova2009; Gvozdev, Reference Gvozdev1961, on number acquisition). Thus, the current study confirms that the timing of acquisition of a given linguistic phenomenon is a key factor in HL development. Previously, the timing of acquisition has been shown to play an important role in monolingual child L2 acquisition (Tsimpli, Reference Tsimpli2014).
Despite the early acquisition of agreement and concord, we found that bilinguals with the earlier AOB (before age 5) were less accurate in detecting ungrammaticalities in agreement and concord compared to the other three groups. This suggests that in addition to the effects of input, the overall amount of exposure to a grammatical structure plays an important role in the shaping of HL grammars.
Finally, turning to the debate on the role of working-memory limitations in the processing of grammatical phenomena, we expected HL speakers (and possibly other bilinguals, albeit to a lesser extent) to be less sensitive to ungrammaticalities in split (non-local) phrases as compared to continuous (local) phrases. Our findings did not confirm this hypothesis. HL speakers were not additionally disadvantaged on split constructions, thereby demonstrating no effect of the increased processing load imposed by the intervening material. Split constructions are common in colloquial speech. In that regard, it is symptomatic that the non-HL groups with prior exposure to schooling and standard language found split noun phrases such as (1b) above less acceptable. Taken at face value, our findings do not support the Shallow Processing Hypothesis (Clahsen & Felser, Reference Clahsen and Felser2006) for HL speakers, as HL speakers in this study—similarly to monolingual and bilingual controls—were sensitive to ungrammaticalities regardless of the distance between the agreeing elements. However, it may well be that the intervening phrases used here were not heavy enough to challenge working memory. If so, a greater distance between the agreeing elements might play a role for HL speakers similarly to L2 speakers.
We also considered the possibility that both working-memory load and CLI might interact during grammatical processing: we predicted that if CLI is at play in the processing of split constructions, we expected an asymmetry between verbal split and nominal split constructions, with the former being acceptable in both languages and the latter being acceptable only in Russian. Thus, we expected an extra processing load for nominal constructions as compared to verbal ones and no decreased sensitivity to ungrammaticalities with adjacent agreeing elements (i.e., non-split constructions). The hypothesis of the dual effect of CLI and working memory was not confirmed; we found no asymmetry between the processing of spit and non-split constructions in the ungrammatical sentences, as participants in all groups were equally sensitive to violations in nominal and verbal domains across split and non-split constructions. Therefore, an asymmetry between split nominal and verbal phrases cannot be attributed to the influence of Hebrew.
To summarize, our predictions regarding the effects of CLI and working-memory limitations were not confirmed in this study, whereas the effect of input as indexed by AoB was robust. Furthermore, we found a discrepancy in the strength of different grammatical features required to be matched: the person feature in subject-verb agreement seems to be more resilient compared to grammatical features participating in nominal concord. One should keep in mind that the investigated phenomena are acquired early by monolingual Russian-speaking children. Thus, how can we explain the asymmetry between person matching vs. case and number matching? We provided two alternative explanations. On the one hand, concord and agreement operations might be structured and processed differently (see Norris, Reference Norris2014, Reference Norris2019), regardless of the features that are matched. On the other hand, the features themselves may have different status in grammar; in particular, the person feature is inherently indexical and therefore is accessed and processed differently from number or gender. To tease apart these explanations, future research is needed where the same feature (e.g., number and/or gender) is manipulated within nominal concord and subject-verb agreement. In addition, following the suggestion by an anonymous reviewer, the phonological properties of the targeted inflections and their salience should be taken into consideration. In the current study, verbal inflections consisted of multiple phonemes involving both vowels and consonants (4a, b), whereas the targeted inflections encoding number and case consisted of mainly vowels, (5a, b):
(4)

(5)

Note also that gender concord in Russian is only present in the singular; in (5b), the gender of the head noun does not matter. This too may contribute to the relative instability of gender as compared to person or number.
Limitations and Future Studies
Although we uncovered novel findings on the effects of AOB, CLI, and working-memory constraints, the study is not without limitations. We relied on the data from the GJT tapping into the sensitivity to ungrammaticalities in case and number concord and in person agreement. We suggest that future studies should also look into the naturalistic data and compare accuracy performance for the same phenomena. Research relying on online methodologies is needed to investigate behavioral and neural signatures of grammatical violation in HL speakers, as compared to monolingual controls and other bilinguals with various AOB of the dominant language (for more details on new methodologies in HL research, see Bayram et al., Reference Bayram, Jason, Pisa, Slabakova, Montrul and Polinsky2021). In addition, future studies should make an attempt to triangulate data from multiple tasks. For example, we manipulated the working-memory load by using non-split and split constructions, yet future studies can include separate indices of working memory to evaluate how individual differences in working-memory capacity affect processing of split and non-split constructions. Furthermore, as discussed above, future studies should focus on processing of concord and agreement operations of the same feature, for example, gender and/or number. Finally, the acoustic status of infections should be also further investigated.
Conclusions
Our study aimed to evaluate effects of cross-linguistic influence, diminished input (as indexed by AOB), and working memory on feature-matching in Russian. We investigated the comprehension of grammatical and ungrammatical sentences with number concord, case concord, and person agreement. For these purposes, we examined HL-Russian in contact with SL-Hebrew. Both languages (HL and SL) are morphologically rich; both languages show number concord and person agreement, yet only Russian has case concord. We also evaluated the effects of working memory by comparing structures where the segments matching in features were either adjacent (non-split) or separated by intervening lexical material (split). Our results showed no effect of cross-linguistic influence and no effect of working memory. However, we observed a robust effect of AOB, in that HL speakers, that is, speakers who are exposed to their SL before the age of 5. While these speakers experienced difficulties in noticing the ungrammaticality in case and number concord, they did not differ from monolingual and first-generation immigrant controls in person agreement. This difference can be attributed either to the different strengths of features that have to be matched (the person feature, being inherently indexical, is better maintained in bilingual grammars) or to structural differences between the clausal and nominal domain. Future work where the same features are manipulated in both domains is needed to tease these explanations apart; since only gender and number are matched in both domains, such work should concentrate on those features.
Replication package
All research materials, data, and analysis code are available on OSF: https://osf.io/3cr9f/
Acknowledgements
The authors would like to thank all the participants of the study for their cooperation. The authors also wish to thank all reviewers for their highly valuable and constructive feedback and suggestions for improvement.
Financial support
This study was supported by the Israel Science Foundation (ISF), grant number 552/21 “Towards understanding heritage language development: The case of child and adult heritage Russian in Israel and the USA” to Natalia Meir.
Competing interests
Natalia Meir, one of the co-authors of the article, currently serves as an Associate Editor for Applied Psycholinguistics and played no role in the editorial process for this manuscript.











 Open access
Open access