



Introduction
Linguistic policies are based on current paradigms in second language (L2) education that give great importance to interaction as a driving force to support second language acquisition (SLA) and L2 development. This was the case for the communicative approach (Brumfit, Reference Brumfit1985; Van Ek & Trim, Reference Van Ek and Trim1991) and for current philosophies that propose usage- and action-based perspectives on language pedagogy (e.g., Council of Europe, 2001; Tyler, Reference Tyler2010). On the other hand, SLA research has long striven to identify a link between developmental stages of acquisition proposed by the functionalist approach (Matthey & Véronique, Reference Matthey and Véronique2004) and the characteristics of interaction that foster development. Interactionist approaches to SLA, both in the anglophone (Mackey, Abbuhl, & Gass, Reference Mackey, Abbuhl, Gass, Loewen and Sato2012) and francophone (Matthey, Reference Matthey1997) literature, identified conversational dynamics that form the basis of L2 development. Over the last 30 years, a body of research has provided ample evidence that specific interactional features have a positive impact on L2 development (Mackey & Goo, Reference Mackey, Goo and Mackey2007). Much of this work focused on punctual phenomena such as negotiation of meaning and form during language-related episodes (Pica, Reference Pica1994; Swain, Reference Swain and Lantolf2000), noticing and uptake of interactional feedback (cf. Mackey & Ziegler, Reference Mackey, Ziegler, Nassaji and Kartchava2017, for review on computer-mediated communication), the presence of uptake in the learners’ turns (Lyster & Saito, Reference Lyster and Saito2010), and incidental learning (Leow & Zamora, Reference Leow, Zamora, Loewen and Sato2017).
Yet, in his recent synthesis on interactional feedback, Nassaji (Reference Nassaji2016) named several unresolved issues that deserve our attention in order to increase our understanding of how interaction and L2 development are related. Among the aspects that have received less attention, Nassaji mentioned the dynamics of interlocutors in interaction. The present article intends to explore this aspect from the theoretical perspective of alignment (Pickering & Garrod, Reference Pickering and Garrod2004). Our aim is to develop methodological tools to study alignment in computer-mediated communication (CMC) (Lamy & Hampel, Reference Lamy and Hampel2007) in ecological environments (video-based telecollaboration and text chat with a peer and a tutor). We first review studies on synchronous CMC (SCMC) and on alignment in L2 research to situate the present study. Then, we present the methodological framework of our study exploring lexical as well as structural alignment. The results for alignment in our data will be discussed in light of the theoretical and methodological implications of our work.
Synchronous CMC for Language Learning
Within the field of computer-assisted language learning (CALL), during the mid-1990s the acronym CMC appeared to cover the new possibilities of distant communication that the internet allowed (Warschauer, Reference Warschauer1997). Lamy and Hampel (Reference Lamy and Hampel2007) observed how the arrival of CMC not only boosted a change in CALL toward more communicative and less behavioristic approaches to language learning and teaching, but also resulted in a new subfield of CALL, which they named CMC for language learning. The appearance of technologies such as text chat and videoconference has established the acronym SCMC, which refers to the specific dynamics and affordances of such synchronous forms of communication (Ziegler, Reference Ziegler2016). For instance, Sotillo (Reference Sotillo2000) reported that SCMC is perceived as more similar to face-to-face interaction and is characterized by shorter turns resulting in lower linguistic complexity.
Two decades of research into CMC can be clustered into different possible configurations of use. Dooly and O'Dowd (Reference Dooly and O'Dowd2012) considered the most prominent configurations to be the following: First, CMC can be employed to enhance opportunities for language use among learners of the same class; second, productive configuration denotes “online intercultural exchange” or “telecollaboration,” which implies the use of CMC between learners in different geographical locations, usually two classes in two different nations; and third, a configuration established within Web 2.0 contexts is a possibility for learners to engage in communication on different platforms with internet users all over the world and without being restricted to a partner class (Guth & Helm, Reference Guth and Helm2010).
One major strand of research in CMC relates to task design and its impact on language learning (e.g., González-Lloret & Ortega, Reference González-Lloret and Ortega2014). The application of task-based language teaching to online environments made practitioners and researchers rethink their perspectives (Hampel, Reference Hampel2006), many of which pertain to interaction. For example, Ziegler's (Reference Ziegler2016) recent review highlights that the conversational dynamics of written SCMC present differences compared to those of face-to-face contexts, for instance, in terms of patterns of turn adjacency (cf. Loewen & Erlam, Reference Loewen and Erlam2006; Renner, Reference Renner2017) and salience (Ziegler, Reference Ziegler2018). Ziegler argued that technology should be thought of as one of the features of task design with an impact on task complexity.
Within the technological and pedagogical developments of CMC research, two strands are visible, which are inherited from the wider field of research into L2 acquisition and development: cognitive approaches and sociocultural approaches. Firth and Wagner (Reference Firth and Wagner1997) were among the first to identify the distinction between these two approaches when they started the epistemological debate, summarized by Zuengler and Miller (Reference Zuengler and Miller2006) and revisited by Hulstijn, Young, and Ortega (Reference Hulstijn, Young and Ortega2014). One of the strengths of the cognitive approach is that it aims to isolate distinct variables that may affect SLA and, through powerful quantification, allows comparisons across a wide range of contexts and overall views of the data sets explored (e.g., Mackey et al., Reference Mackey, Abbuhl, Gass, Loewen and Sato2012). Yet, this framework often restricts studies to focus on punctual phenomena in interaction, such as negotiations resulting in comprehensible input and modified output as well as noticing (Mackey & Ziegler, Reference Mackey, Ziegler, Nassaji and Kartchava2017). In contrast, sociocultural approaches (e.g., Lantolf & Thorne, Reference Lantolf and Thorne2006) usually take a more holistic stance to the phenomena observed, which typically results in in-depth case studies linking different dimensions (linguistic, sociocultural, intercultural, multimodal, etc.). Even if sociocultural studies provide conceptual tools through which they conceive data analysis and language instruction (e.g., Thorne, Reference Thorne2003), they lack power for generalization. More recently, Hulstijn et al. (Reference Hulstijn, Young and Ortega2014) argued that comprehensive research should try to transcend this debate and to link the social and the cognitive dimensions of language learning. We see ourselves in this line of research as, rather than trying to overcome the epistemological differences of these perspectives, our aim is to fruitfully draw on both of them.
In this article, we propose the theoretical framework of alignment (Pickering & Garrod, Reference Pickering and Garrod2004) as a way to study the linguistic actualization of the social dimension of language use in SCMC for language learning. As we argue, this framework allows comparisons of different contexts based on quantification and a global study of interactional dynamics, not only in relation to the more punctual dynamics identified above but also in the more pervasive use of lexical chunks and syntactic structures.
Alignment
The theoretical framework of conversational alignment was first elaborated by the seminal article of Pickering and Garrod (Reference Pickering and Garrod2004) in relation to L1–L1 (first language to first language) interaction. Accordingly, the understanding between interlocutors in conversation is reached when their models of the situation (Zwaan & Radvansky, Reference Zwaan and Radvansky1998) are as similar as possible. In other words, interlocutors’ mental models are aligned when they share concepts of, for example, time, space, and reference of a given situation (Pickering & Garrod, Reference Pickering and Garrod2004). Alignment of situational models in the conversation is achieved mainly through the alignment of representations at linguistic levels (e.g., semantic, lexical, and syntactic), which is achieved through the mechanism of structural priming (Pickering & Ferreira, Reference Pickering and Ferreira2008). More recent accounts add dimensions of the multimodality of communication, such as posture, gestures, and laughter (Lücking, Bergmann, Kopp, & Rieser, Reference Lücking, Bergmann, Kopp and Rieser2010; Pickering & Garrod, Reference Pickering and Garrod2009) or at higher levels such as conversational alignment in storytelling (Bertrand & Espesser, Reference Bertrand and Espesser2017).
In their critical review on priming, Pickering and Ferreira (Reference Pickering and Ferreira2008) distinguished between alignment, priming, and entrainment. The term alignment refers to the overall mental phenomenon of aligning the mental representations between interlocutors. Priming refers to the activation of a mental representation on a given linguistic level. For instance, if interlocutor A utters Je suis dans un cybercafé (“I am in an internet café”), she activates the structure be + place. The actual behavior of repeating a given lexical chunk or a morphosyntactic structure is referred to as entrainment, which for some authors also includes a longitudinal dimension of repetition. In this article, following Michel and Smith (Reference Michel, Smith, Gass, Spinner and Behney2018), we use the term alignment to cover both the mental alignment as well as the linguistic behavior of entrainment that might be elicited by priming. In the end, we use alignment to refer to a repetition of a form used in earlier discourse (cf. Bock & Griffin, Reference Bock and Griffin2000). In the following, we will also review earlier work that calls the phenomenon priming.
Several characteristics of alignment have been studied over the past 15 years. Importantly, the framework of alignment rejects the dichotomy between comprehension and production: “in dialogue, production and comprehension become tightly coupled in a way that leads to the automatic alignment of linguistic representations at many levels” (Pickering & Garrod, Reference Pickering and Garrod2004, p. 2). Furthermore, alignment is considered to be an automatic, resource-free process underlying natural L1 interaction. In addition, alignment at the linguistic level “filters through” the other levels and facilitates alignment at the mental and situational levels (Pickering & Garrod, Reference Pickering and Garrod2004, 2009). Also, the competency or status assigned to the interlocutor has an influence on alignment (Foltz, Gaspers, Thiele, Stenneken, & Cimiano, Reference Foltz, Gaspers, Thiele, Stenneken and Cimiano2015). For instance, the beliefs about the interlocutor's competence or the perception of an accent considered different from one's own result in a lesser extent of lexical and syntactic alignment. Finally, research has provided mixed evidence regarding the question of whether alignment is affected by speaker identity, that is, alignment to the self versus to the interlocutor. For example, Gries (Reference Gries2005) concluded that self-priming, where prime and target are produced by the same speaker, is slightly higher than other-priming, where prime and target are uttered by different speakers. Yet, later work could not find a difference between self- and other-priming (e.g., Zawawi, Reference Zawawi2017).
Alignment in L2
Costa, Pickering, and Sorace (Reference Costa, Pickering and Sorace2008) argued that the application of the framework of alignment to L2 interaction needs some of the aforementioned characteristics to be revised. First and foremost, alignment in an L2 is not necessarily an automatic phenomenon. Costa et al. (Reference Costa, Pickering and Sorace2008) proposed several theoretical reasons to explain such a difference, which were partially confirmed by empirical studies. First, a limited proficiency level or competence in the target language by the L2 speaker might hinder alignment because unknown syntactic or lexical features as well as speech rate used by the L1 speaker might induce a high processing load, preventing automatic alignment in an L2. Second, alignment is not automatic when non-target-like forms are used in discourse. For instance, if the L2 speaker uses an incorrect form, the L1 speaker will have to consciously make the decision of whether to align or not (Costa et al., Reference Costa, Pickering and Sorace2008, p. 540) or possibly produce a recast. Recasts are particularly interesting phenomena when considered through the lens of alignment, since they provide instances of partial alignment by the L1 speaker to an L2 prime, which are strategic, that is, nonautomatic. Modified output can also have links with alignment, for instance, when an L2 speaker solicits help to build a syntactic structure for his or her sentence and then repeats the provided formulation after the L1 speaker proposed it. In this case, what has been defined as uptake (e.g., Nassaji, Reference Nassaji2016) may be interpreted as a form of strategic alignment by an L2 speaker to an L1 speaker's prime.
The characteristics of alignment inspired a strand of research in face-to-face contexts for the possible use of alignment in instructed SLA (ISLA). A decade of studies on L2-priming indeed demonstrates that alignment can be employed as a pedagogical tool to elicit avoided or infrequent structures or guide learners to more target-like versions of a structure they are acquiring (e.g., McDonough & Mackey, Reference McDonough and Mackey2006; McDonough, Reference McDonough2006; Kim & McDonough, Reference Kim and McDonough2016; Trofimovich & McDonough, Reference Trofimovich and McDonough2011). To date, many of these studies employed a scripted interactant who provided consistent primes of a certain structure (e.g., passive, question formation) to trigger its use by a language learning interlocutor. In a recent review on syntactic priming, Jackson (Reference Jackson2018) noted that the amplitude of priming—even though it is an omnipresent phenomenon—might vary substantially from one context to another and when different target structures are involved (e.g., Jackson & Ruf, Reference Jackson and Ruf2017, found long-term priming effects for temporal but not for locative phrases in L2 German). In general, Jackson called for more empirical studies, in particular, those that extend the research to naturalistic conversation and investigate languages other than English.
Recently, Dao, Trofimovich, and Kennedy (Reference Dao, Trofimovich and Kennedy2018) explored alignment in fairly natural conversation, that is, task-based face-to-face interaction, between students with various linguistic backgrounds that were enrolled at a Canadian English medium instruction university. Again, they found that different target structures varied in the extent to which they were prone to alignment, which in turn seemed to be related to the specificities of a given task. For example, a picture description task overall elicited more alignment and also generated large amounts of that + complement constructions (“it shows that the man is in the house,” p. 305). In contrast, a map task triggered frequent use of go + prepositional phrases (“the road goes to the flag,” p. 305), but participants did generally use less alignment in this task setting. For both tasks, participants aligned more to constructions they had used themselves before (alignment to self) than to constructions uttered by their interlocutor (alignment to other).
Alignment in L2 SCMC
Alignment in synchronous CMC is a relatively new area of inquiry that only a few investigations have addressed. In a series of studies, Michel and colleagues looked at alignment during text chat. On a structural level, Michel and Stiefenhöfer (Reference Michel, Stiefenhöfer, Sato and Loewen2019) studied how proficient German learners aligned to primed subjunctives in Spanish L2 and found that despite an increased creation of primed contexts and gains in accuracy of use in the experimental group, there were no significant differences in posttest scores between the primed versus control groups. Like Dao et al. (Reference Dao, Trofimovich and Kennedy2018), they found prevalent task differences; for example, alignment was stronger in an interview task than in a pro-contra discussion.
As for lexical alignment, Michel and Smith (Reference Michel, Smith, Gass, Spinner and Behney2018) studied written chat interactions between three pairs of participants using English for academic purposes during seven task-based chat sessions of 45 minutes each. Participants’ chat logs were scrutinized for overlapping multiword units of 3 to 10 words, and eye-tracking methodology examined the number and duration of their eye-gaze fixations on these lexically aligned units. Results revealed that a higher number of fixations on a lexical chunk could serve as an indication for subsequent reuse, but that roughly two thirds of the aligned units were produced without inflated attention as measured by eye-tracking methodology. The authors, therefore, concluded that most alignment in their data set was based on automatic and nonstrategic behavior. In a similar context, Michel and O'Rourke (Reference Michel and O’Rourke2019) studied lexical alignment during written SCMC by L2 learners of German alternating interaction with a peer and with a native speaker tutor. Again, only a subset of the lexically overlapping multiword units received overt attention as measured by eye-gaze data. Posttask cued interviews revealed that participants had different strategic reasons why they choose to align—or not align—to their partner. Responses suggested that both the proficiency of their partner (peer vs. tutor), as well as their own proficiency in the target language, impacted the extent to which they used their interlocutor as a model.
Finally, Kim (Reference Kimin press) compared alignment in face-to-face versus text chat conversations. While both contexts elicited alignment of stranded prepositions, the SCMC context facilitated the structure reuse to a greater degree. Kim suggested that more conscious noticing of the target structure was afforded by the specific characteristics of text chat (e.g., permanence and salience of the output; cf. Lai & Zhao, Reference Lai and Zhao2006; Ziegler, Reference Ziegler2016).
To conclude, while earlier work has provided preliminary insights into L2 alignment in written SCMC, we still have limited understanding of the exact nature of this phenomenon. In particular, it remains underexplored how the unique affordances of different SCMC contexts might influence the ways in which L2 learners align to their partners. Furthermore, there is a need to broaden the field by researching different target languages, which have not often been the subject of alignment research before. The current study aims to address these gaps by exploring the frequency and nature of alignment in different SCMC contexts.
Method and Design
The goal of the present study is to illustrate in what ways alignment is mediated by the affordances of the different settings. To this aim, we used the same methodological approach to measure lexical and structural alignment in data sets coming from two different environments (video-based vs. written L2 chat). We applied methods developed in earlier work into lexical (Michel & Smith, Reference Michel, Smith, Gass, Spinner and Behney2018) and structural (Dao et al., Reference Dao, Trofimovich and Kennedy2018) alignment to two existing data sets: free video-based conversations in French and Chinese between student teletandem pairs and task-based written chat interactions in German between language learning students and between a student and a German L1 tutor (Michel & O'Rourke, Reference Michel and O’Rourke2019). One of the aims of this study was to explore how methodological choices affect findings on alignment in these varied contexts. Our research was guided by the following overarching question:
What is the frequency and nature of lexical and structural alignment in online interactive encounters involving a language learner?
Given the different contexts and modalities our data come from, we explore the following subquestions:
1. How does the CMC environment (videoconference and text chat) affect lexical and structural alignment?
2. How does the interactional partner (language learning peer, L1 teletandem peer, and L1 tutor) affect lexical and structural alignment?
3. What structures are aligned in the different target languages (Chinese, French, and German), and how does their alignment compare across those languages?
Data Sets and Participants
Our data consist of 10 hours of online interactions of university students that are L2 users of a foreign language.
The video-based data stem from the Teletandem Dalian-Lille project (Cappellini, Reference Cappellini2016), where four French–Chinese pairs were engaged in free teletandem conversations. Two students from partner universities in France and China interacted through video chat to help each other learn their respective L1s. All eight students were female, aged 20 to 24, and had studied their target language for 3 to 4 years. Their proficiency level was B1 in Chinese for the French students and B2 in French for the Chinese students. At the time of the exchanges, all of the French students had already traveled and studied in China for long periods (one or two semesters), while none of the Chinese students had ever been to a French-speaking country. Approximately half of the time they were conversing in French, the other half in Chinese, with each of the participants taking turns in functioning as an L1 expert and L2 learner depending on the target language of a given part of the conversation. The 4 hours of video-based chat conversations provided a corpus of 26,643 words (M = 6,660, SD = 955) and 2,459 turns (M = 614, SD = 55).
The written chat data stem from eight students (half female, half male, aged 21 or 22) who were learning German at a northern university in the United Kingdom. They had all been in a German-speaking country on study abroad and had reached C1 level of the Common European Framework of Reference for Languages (CEFR) according to their recent university grades. For the present study, each of them participated in two task-based 30-minute text chat interactions (using the written modality of Skype), one with a language learning peer, one with a German-speaking tutor they were not familiar with. Task instructions asked students to discuss with each other five measures that would help to get into contact with German native speakers during study abroad (peer chat) or to advise the tutor on what five photographs (from a set of 10 given pictures) would be best to use on the study program's website (for details, see Michel & O'Rourke, Reference Michel and O’Rourke2019). The 6 hours of written chat conversations provided a corpus of 10,310 words (M = 2,578, SD = 526) and 1,096 turns (M = 274, SD = 19).
Identifying Lexical Overlap and Frequent Structures
First, oral interactions of the videoconferences were transcribed verbatim while written chat data were corrected for typos and spelling mistakes. Then, all chat conversations were coded following the same procedure for lexical as well as structural priming.
For lexical alignment we followed Michel and Smith (Reference Michel, Smith, Gass, Spinner and Behney2018) to identify N-grams of three or more words that occurred at least twice in a given conversation and showed exact lexical overlap and order of linguistic material. For example, Das ist eine sehr gute Idee would not map onto Ja, ich finde auch, dass es eine gute Idee ist, given that the exact overlap consists of only two items (gute Idee) even though lexical items are very similar throughout the two utterances. We used a free online tool that could handle Chinese, French, and German text to ensure that we would employ the same method for all conversations (https://voyant-tools.org; see Figure 1).
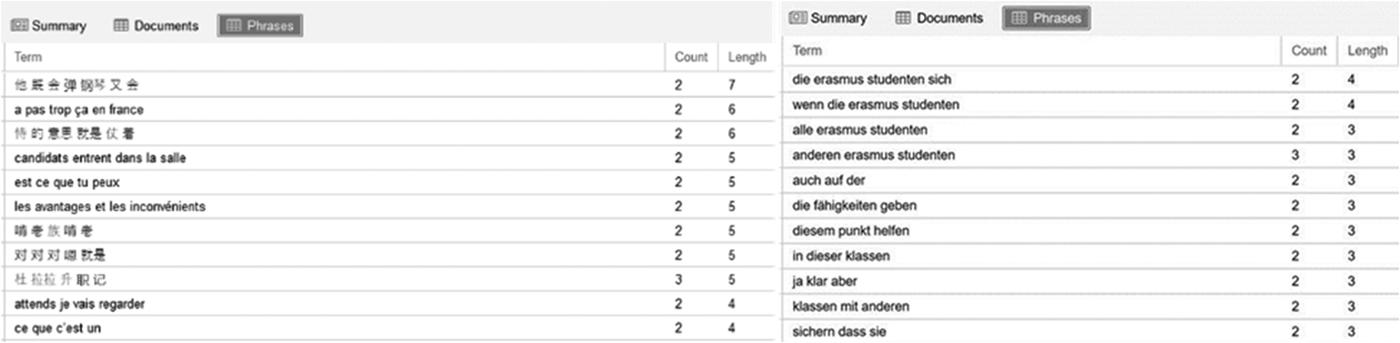
Figure 1. Screen shot of N-grams identified by the software in Chinese, French, and German. The term column refers to overlapping text; count to the frequency of an N-gram in the conversation; and length to the number of words in an N-gram.
Once overlapping N-grams (called “phrases” in the tool) were identified, they were manually searched in the original conversations and coded for alignment.
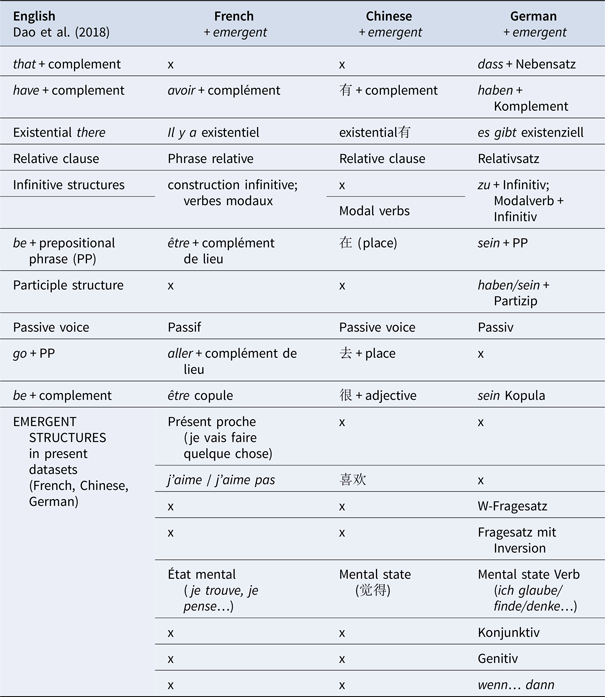
For structural alignment we followed Dao et al. (Reference Dao, Trofimovich and Kennedy2018), who looked at alignment in oral task-based conversations. We first identified frequent structures, where a structure was defined according to Goldberg's (Reference Goldberg2006) form-function-pairing “with a structural frame that is not predictable from its components” (Dao et al., Reference Dao, Trofimovich and Kennedy2018, p. 300). Using a top-down procedure, we searched for structures analyzed in Dao et al. (Reference Dao, Trofimovich and Kennedy2018) in our data and complemented this list with structures that emerged bottom-up. Following Dao et al. (Reference Dao, Trofimovich and Kennedy2018), only structures occurring five times or more within a given conversation were considered for further coding and analysis. The appendix provides an overview of the structures in the different language data sets.
Coding of Alignment
Using the same procedure, both lexical and structural alignment was then manually coded for. Working chronologically through the conversations (see Dao et al., Reference Dao, Trofimovich and Kennedy2018, for a rationale), each occurrence of an overlapping lexical or structural item was coded either as a prime or a target. A first occurrence would automatically be a prime. In accordance with the priming and alignment literature, a subsequent occurrence was coded as a target if and only if it occurred within six turns (in video-based data) or eight turns (in written data) from the prime (c.f. Bock & Griffin Reference Bock and Griffin2000; Pickering & Garrod, Reference Pickering and Garrod2004). Again, we followed Dao et al. (Reference Dao, Trofimovich and Kennedy2018) with respect to the six-turn threshold for spoken interactions. The rationale for the six-turn threshold builds on the idea that activation of a prime would decay over turns after a certain time. Given that for text chat a possible prime would remain visible on the screen, we deemed a threshold based on decay over time and turns not applicable. Instead, we counted how many turns of the chatlog would typically remain visible on the screen without scrolling. Accordingly, we adopted these eight turns as the threshold for text chat data.
If multiple instances were present within this six or eight turns from a prime, we coded them as multiple targets aligning to the same prime. If a lexical or structural item occurred beyond the threshold, it would be coded as a new prime. Any item would only be coded once; that is, if it was a target, it would not function as a prime for a following item, and vice versa.
Subsequently, all prime-target sequences were coded for alignment distinguishing alignment to self (interactant repeats themself) from alignment to interlocutor (interactant repeats partner). Any prime without a target within the threshold was coded as nonalignment.
Table 1 provides examples in French and German on how the data were coded. For French, the first turn shows two instances of the structure être + complément de lieu, the first one serving as prime for the aligned targets by the same speaker in the same turn and in Turns 3 and 4. In Turn 7, Speaker B created a target that was aligned to the same initial prime by Interlocutor A in Turn 1.
Table 1. Examples for Coding in French (structural) and German (lexical)
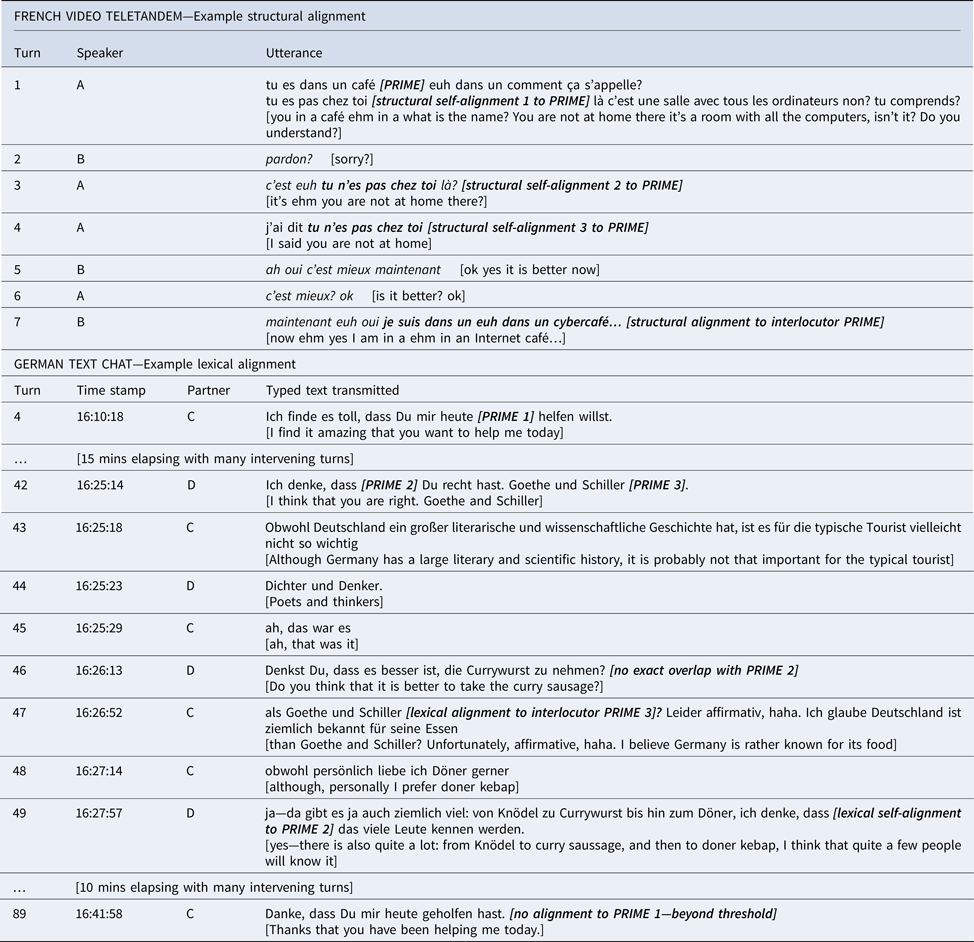
The German example shows how the written chat was coded for lexical alignment. Even though dass Du mir heute is repeated (Turns 4 and 89), it was coded as nonalignment given the large distance between the two instances. In Turn 42, there were two primes (ich denke dass and Goethe und Schiller) that were reused within eight turns: the former in Turn 49 by the same writer, hence self-alignment, and the latter as alignment to interlocutor in Turn 47 by their partner. Importantly, the phrase Denkst Du, dass in Turn 46 is not considered as a target for Prime 1, given that there is no exact overlap even though the lexical items were reused.
One conversation each was double-coded by a linguistically trained person who also knew the target languages. Intercoder reliability was high for Chinese or French (lexical: 100%; structural: 95.9%) and German (lexical: 100%; structural: 93.0%).
Analysis
Scores correcting for text length were then computed as alignment by dividing the frequency of alignment (number of primes followed by target) by the total number of occurrences in a given conversation. Similarly, nonalignment was calculated by dividing the number of primes not followed by a target by the total number of occurrences in a given conversation. Higher alignment scores than nonalignment scores would then provide an indication of the amount of alignment taking place in the conversations. Higher nonalignment scores would suggest the absence of alignment, that is, learners using a lexical or structural item irrespective of whether it had been used before by themselves or their interlocutor.
The aim of our analysis was twofold. First, the coding process confronted us with some methodological issues, which we addressed to adapt the existing methodological tools to the characteristics of our data sets. Second, we compared scores on different variables to answer our three subquestions, and then discussed our results in light of existing the literature.
Results
In the following we present our descriptive statistics for the lexical and structural alignment found in the different data sets. We refrain from providing inferential statistics, given that the data stem from small heterogeneous samples and that the aim of this article is to showcase the outcomes of applying the same analytical tools to different CMC contexts rather than testing hypotheses. First, we provide an overview of lexical and structural alignment in our data sets, which will be used to discuss our main research question. Then, Tables 3 to 6 present results distinguishing the CMC environment and the interactional partner, which are then used to discuss our first and second subquestions. Third, we compare the alignment of structures present in the different data sets, which enables us to answer our third subquestion.
In Table 2 an overview of lexical and structural alignment is provided for each CMC and language context separately: French-Chinese videoconference and German text chat with a peer or tutor. In general, figures are much higher for structural than for lexical alignment. Comparing alignment and nonalignment at the lexical level shows higher scores for the latter in the three European languages. Yet in Chinese, the participants showed slightly higher lexical alignment than nonalignment. At the structural level, we see the reversed picture, with more alignment than nonalignment being visible for French and the two German contexts (particularly, pronounced in the tutor chat), but not for Chinese. Self-alignment seems to be more prevalent than alignment to the interlocutor, in particular, in the videoconference conversations.
Table 2. Total Number of Lexical and Structural Alignment Within and Between Speakers per Language and Context
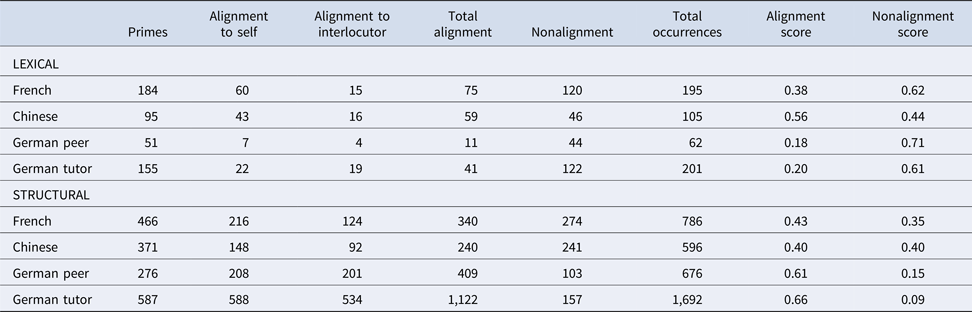
Note. French/Chinese = 4 conversations; German peer = 4 conversations; German tutor = 8 conversations; alignment score = alignment/total occurrences; nonalignment score = nonalignment/total occurrences. Numbers do not necessarily add up because one prime may be associated to more than one (self/other) target and total occurrences include primes as well as targets.
In Tables 3 to 6 numbers detailing structural alignment across languages and contexts are provided. That is, for every context (e.g., French teletandem, German peer text chat) the specific aligned and nonaligned structures are listed. These figures show the totals of each structure across conversations (counted if and only if the structure was present at least five times within a conversation).
Table 3. Aligned Structures French Videoconference
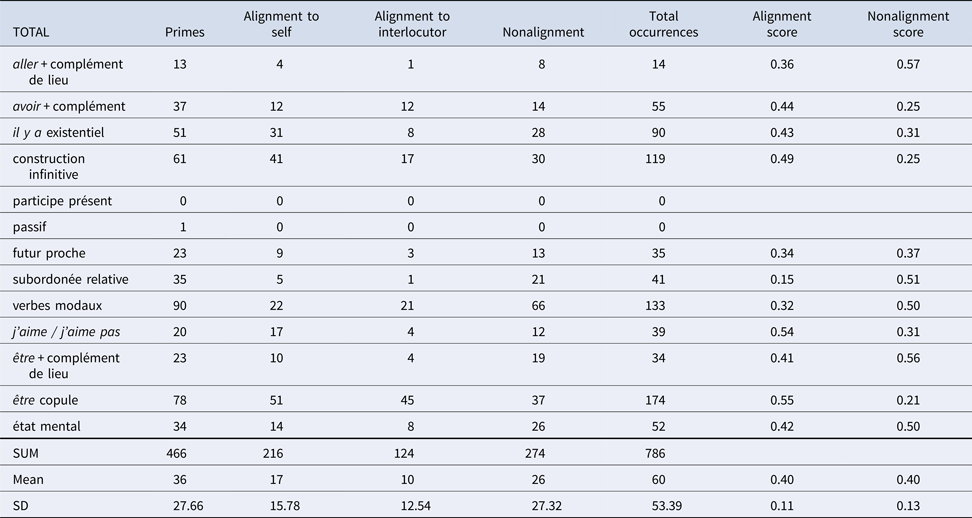
Table 4. Aligned Structures Chinese Videoconference
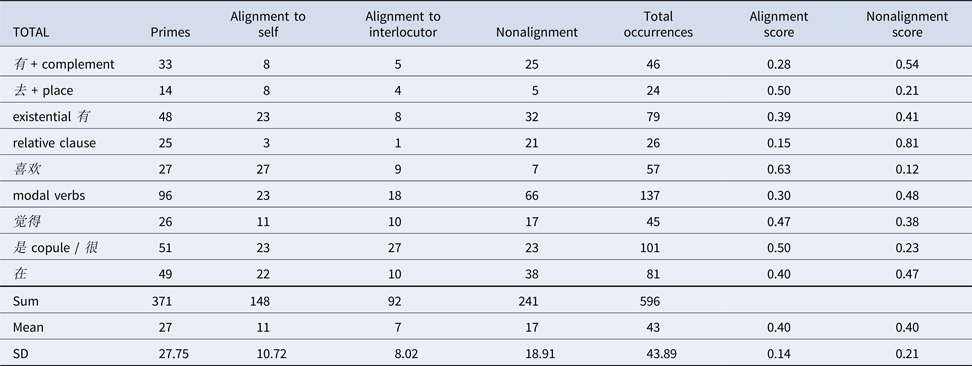
Table 5. Aligned Structures German Text Chat With Peer
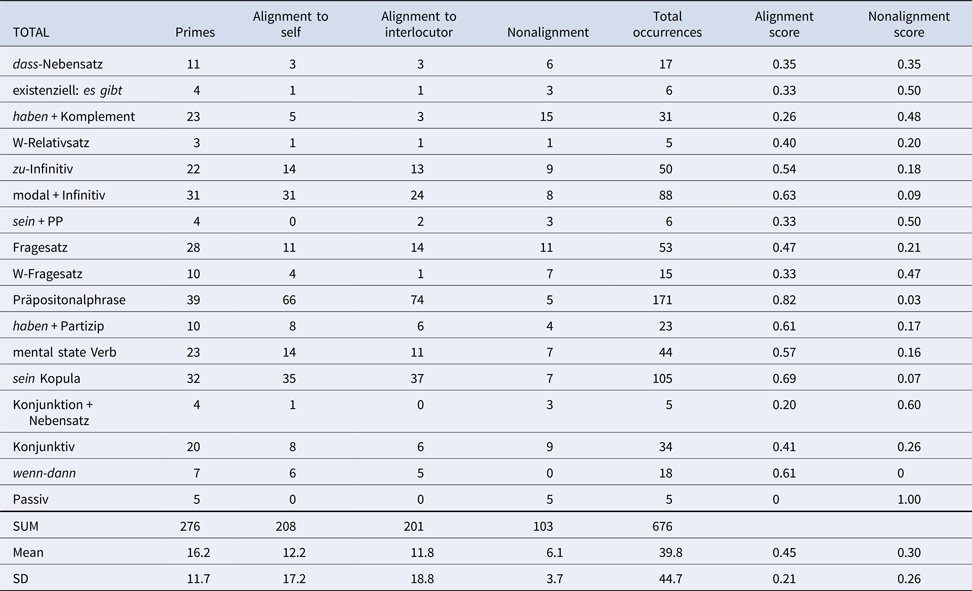
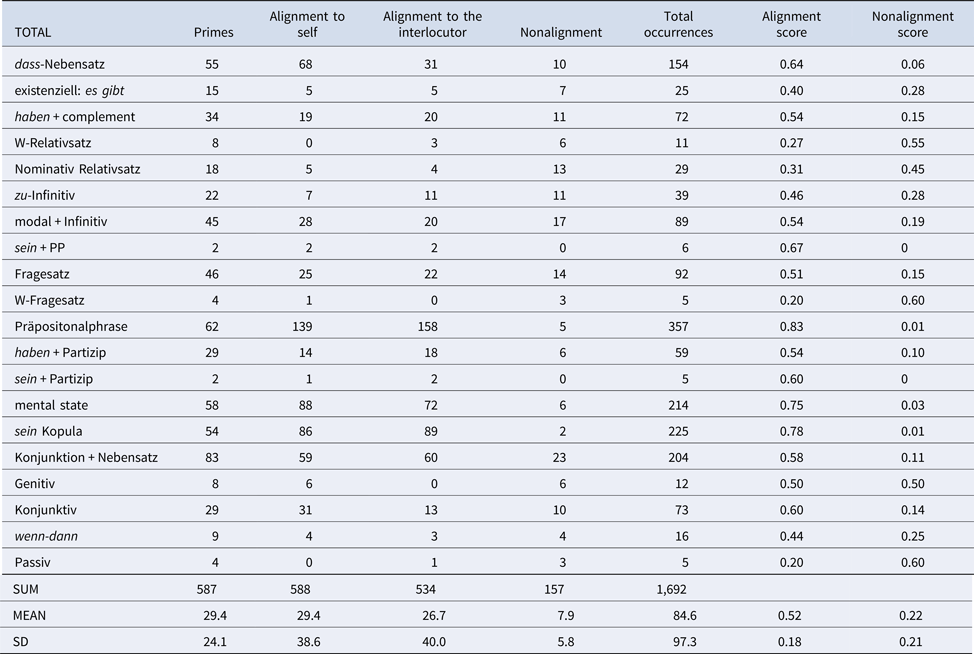
Table 6. Aligned Structures German Text Chat With Tutor
For French video tandems, highly frequent structures (e.g., copula être) seem to show more alignment than nonalignment (but see modal verbs), while less frequent forms seem to be more often nonaligned. Self-alignment mostly reveals higher figures than alignment to the interlocutor. Similarly, the Chinese video conversations show that the frequent copula constructions (很+adjective) are more often aligned than not aligned, whereas modal verbs reveal the reverse picture. With the exception of copula, all structures demonstrate more self-alignment than alignment to the interlocutor, a pattern that is particularly prominent for “existential 有” and 喜欢. Neither in French nor in Chinese do the overall means of the videoconference exchanges distinguish the (non)alignment scores.
The German text chat data provide a slightly different picture. Alignment scores for frequent structures are consistently higher than nonalignment scores, which is reflected in the mean over all structures, particularly, in the tutor chat. Exceptions are Wh-questions. In the peer chat, differences between alignment to self versus other are, if present, very small. In the tutor chat, dass + complement, mental state verbs, and subjunctive mood elicit exceptionally high numbers of self-alignment, which is mirrored in the overall means.
Finally, Table 7 relates our data to figures from Dao et al. (Reference Dao, Trofimovich and Kennedy2018) by juxtaposing specific structures that occurred in all data sets and languages: have + complement, be + prepositional phrase, and mental state verbs. Accordingly, most contexts show more alignment than nonalignment for the have-construction, with the exception of the German peer chat and Dao et al.’s (2018) map task. In contrast, prepositional phrases with be were less often aligned than aligned in the teletandem videoconference and the German peer text chat. On the other hand, mental state verbs were frequently aligned in the Chinese and German data.
Table 7. Comparing Structures Across Languages and Modalities
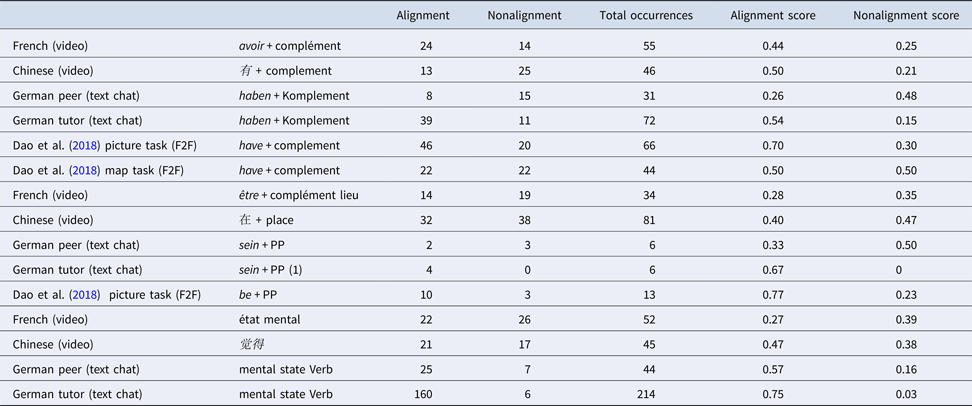
There seem to be task effects that might be stronger than context (i.e., CMC environment and status of the interlocutor) effects. That is, certain tasks did elicit certain structures more frequently (e.g., the argumentative German tasks elicited many mental state verbs), while other structures were hardly used (low numbers of be + complement in the German data) and could not therefore result in alignment. In general, it seems that alignment is most prevalent for structures that are used frequently.
Discussion
Our data provide evidence of lexical and structural alignment in all data sets, and therefore, we consider our methodology to allow for comparisons of alignment across languages and CMC environments. However, running the same apparatus of analysis on different data sets also created challenges at different levels for the adaptation to different CMC environments (videoconference vs. text chat) and different languages. Given that the theoretical framework of alignment aims at providing a description for any kind of interaction, we find it important to address these challenges in order to build an apparatus enabling comparison across languages and across media of communication. In the following discussion, we will address each of our three research questions while also focusing on the methodological implications of our study and, when relevant, of possible hypotheses to be tested on wider corpora of analysis.
The CMC Environment
Our first research question asked how the CMC environment (videoconference and text chat) affects lexical and structural alignment. Given the larger amount of verbal interaction in videoconference than in text chat (26,6k words vs. 10.3k words), in our data we could have expected a larger number of instances of alignment in the videoconference conversation. This was the case for lexical alignment (.38 and .56 alignment scores in videoconference vs. .18 and .20 in text chat), but a larger number of instances of structural alignment were present in text chat than in videoconference (.61 and .66 alignment scores vs. .43 and .40). Similar tendencies are visible for the alignment scores, where they are higher in videoconference for lexical alignment and in text chat for structural alignment. These findings confirm Kim (Reference Kimin press) who yielded more structural alignment in written SCMC than oral contexts, attributing these to the heightened salience in text chat (Lai & Zhao, Reference Lai and Zhao2006; Michel & Smith, Reference Michel, Smith, Gass, Spinner and Behney2018).
An alternative explanation could be related to task effects (González-Lloret & Ortega, Reference González-Lloret and Ortega2014). The text chat conversations in our study were elicited through pedagogic argumentative tasks—which might trigger the use of specific structures—while the video-based interactions consisted of free conversations. This might explain the findings regarding lexical alignment: Hence, the more volatile nature of spoken interaction in videoconferences presumably leads participants to build interaction cohesion by repeating their own or their partners’ chunks of words.
On a methodological level, we faced three main challenges related to the different affordances of the two CMC environments. First, it was difficult to adapt the text chat framework developed by Michel and Smith (Reference Michel, Smith, Gass, Spinner and Behney2018) to study lexical alignment in videoconference. In fact, the spoken nature of data results in a large number of disfluencies, a well-documented phenomenon in oral interaction (Pallaud, Rauzy, & Blache, Reference Pallaud, Rauzy and Blache2013). Disfluencies typically include self-repairs and repetitions of syntagma. Automatic analyses of N-grams therefore needs to distinguish between genuine lexical entrainment and these phenomena. A future direction in this sense would be to use National Language Processing (NLP) tools such as SPPAS (Bigi, Reference Bigi2015) or Marsatag (Laboratoire Parole et Langage, 2013) to automatically detect disfluencies and discard them in the study of lexical and structural alignment.
The second issue we encountered is the multimodality of CMC and especially of videoconferences, where the multimodality typical of spoken interaction (verbal, prosody, gestures, mimics, etc.), is often complemented by written interactions through the use of text chat (Develotte, Kern, & Lamy, Reference Develotte, Kern and Lamy2011). In our data, this resulted in instances of bimodal alignment, both alignment to self and to the interlocutor, especially during meaning-oriented language-related episodes. For example, when a French student explained that she worked in an art gallery in Shanghai, the Chinese student didn't understand. The French student subsequently wrote gallerie d'art in the text chat, which was subsequently repeated orally by the Chinese student. This episode was coded as containing a prime, a self-alignment (text chat), and an alignment to interlocutor.
The third challenge that remains to be addressed in this area is the production of multimodal turns (e.g., a turn that began verbally and completed gesturally) and the possible combinations of verbal and nonverbal alignment (Lücking et al., Reference Lücking, Bergmann, Kopp and Rieser2010) in L2 interaction.
The operationalization of the concept of turn is also linked to the chronological approach we adopted from Dao et al. (Reference Dao, Trofimovich and Kennedy2018). In the chronological approach, priming is defined as the short-term activation of a mental representation at a linguistic level in reaction to use in earlier discourse. After activation decays (e.g., after six turns), a repetition of the form would not qualify as alignment. However, in our view this rule needs to be reconsidered for data presenting narrative conversational sequences, where turns may be longer than other types of interaction (in our corpus, up to 2 minutes). Also in light of theories seeing alignment as a form of implicit learning (cf. review Pickering & Ferreira, Reference Pickering and Ferreira2008), this six-turn threshold might be in need of revision.
There have been earlier attempts to address this issue. For example, Zawawi (Reference Zawawi2017) coded for distance between primes and targets and statistically determined whether the likelihood of alignment depended on that distance. Zawawi's results showed that distance was on average larger in L1–L1 conversations than L2–L2 conversations, which could be linked to processing limitations in L1 versus L2. Yet, in neither data set could a relationship be established between distance and primed production. More work in this area is needed to substantiate these findings.
Alternatively, one could follow Bigi et al. (Reference Bigi, Bertrand and Guardiola2010), who stated that a meaningful repetition could be distinguished from a random one based on the frequency of use of its elements by one interlocutor throughout the conversation. In our case, a repetition of a construction (N-gram or structure) that is used only twice during a conversation would be as meaningful as alignment in two subsequent turns. The frequency of the items aligned (a given N-gram or structure) would therefore play a role in identification of alignment.
Finally, we propose a way to handle long turns, by considering the average of words per turn and the maximum length of a turn. In our corpus, the longest turn contains 240 words over 2 minutes and 18 seconds in a conversation where the average of words per turn is 47. For this given conversation, the longest distance for coding alignment would then be 240/47 = 5.1 turns. To the best of our knowledge, none of these approaches have been used in earlier work, and we consider them worth exploring.
Interactional Partners
The second research question asked how the interactional partner (language learning peer, L1 teletandem peer, or L1 tutor) might affect lexical and structural alignment. We found only limited differences in our data. Earlier work both in L1 and L2 shows that the status of the interlocutor has an influence on alignment. In particular, Michel and O'Rourke (Reference Michel and O’Rourke2019) noted that students had a tendency to focus more on text chat productions by an L1 tutor than those of a peer, which also resulted in more lexical alignment. We therefore expected more alignment to the interlocutor between teletandem participants, where one partner holds L1 status, than between L2 peers chatting in German. The results of the present study do not support this hypothesis. For example, even though for lexical alignment the alignment scores of teletandem interactions were higher than those of peers learning German, they were also higher than those in the tutor chat, which contradicts what we would expect from the literature (Michel & O'Rourke, Reference Michel and O’Rourke2019). Moreover, for structural alignment, scores were higher for peers learning German than for teletandem interactions.
A reason could be that the interlocutor affected alignment to a smaller extent than the SCMC environment. The latter overruled the former in our results. Another explanation might be that proficiency had a stronger impact here. Hence, in our data sets, the text chat participants were at a higher level of the target language, German, than the Chinese-French teletandem partners. Drawing on the interview accounts reported by Michel and O'Rourke (Reference Michel and O’Rourke2019), the text chat participants might align less because they felt that at C1 level they should be able to use their own language—indicating a strategic choice not to align to their partner. In contrast, the French–Chinese partners, being at lower levels of target language proficiency, might happily reuse their interlocutor's language, in particular, lexical choices. It must be noted, however, that most of the time these participants aligned to themselves, which might again be related of the still developing repertoire in the target language. That is, participants might not have had another option than to reuse the same forms over and again, because only those were available in their L2 (Costa et al., Reference Costa, Pickering and Sorace2008).
Alignment Across Languages
The third research question was interested in how alignment of different structures compares across the different languages (Chinese, French, and German). This question did not allow for a straightforward answer because distinguishing between lexical and structural alignment provided both possibilities and challenges for comparison across languages.
As for lexical alignment, due to the presence of N-grams in all languages, it appears to be the easiest way to compare across data sets and languages. The challenges of the study of lexical alignment come from the operationalization of the concept and the tools we used. In fact, in this study lexical alignment was coded only for exact lexical overlap of three or more words. Taking a broader view on alignment and including lemma alignment rather than exact overlap will help to gain a more precise picture of this phenomenon. A lemma-based approach would not only allow to deal with changes in inflectional morphology, but it would also pave the way to handle the activation of lexical representations resulting in different word orders (cf. Bigi et al., 2010). Similarly, exploring alignment of single words would provide useful insights (Wang & Wang, 2015). The fact that we looked for exact lexical overlap of at least triplets may be the reason why our study showed that, generally speaking, lexical alignment was not that frequent.
In contrast, structural alignment was more pervasive in our data sets (2,111 instances of structural alignment vs. 186 instances of lexical alignment). However, comparisons of structural alignment provided more challenges and raised more issues than lexical alignment. The first challenge when comparing across languages is the fact that different languages do not always share the same structures. This point is fairly clear when a structure simply does not exist in a language, as, for instance, the infinitive structures in Mandarin Chinese. It was more difficult for structures that exist in slightly different manners. For example, in our data sets there was asymmetry between copular use of be in German and French versus how copula are rendered in Mandarin Chinese, a language in which the equivalent of an adverb can take the function of a copula (usually rendered with 很). For instance, in the sentence 这里比教冷 (it's rather cold in here), the adverb 比教 (rather) takes the role of the verb “be” in English. For these cases, we think that comparison across languages of those kinds of structures is not that useful.
In our study, we restrained our comparison to structures that are present across all the languages involved (Table 7). The general trend is that for more frequent structures (have + complement) alignment scores seem higher—albeit most of it is self-alignment. It might be that students used a structure frequently that they had acquired and were comfortable using (cf. McDonough, Reference McDonough and Mackey2006), while they would not align to their interlocutor for structures they did not know themselves or tended to avoid (cf. Costa et al., Reference Costa, Pickering and Sorace2008; Michel & Stiefenhöfer, Reference Michel, Stiefenhöfer, Sato and Loewen2019). Finally, it seems that alignment scores were generally higher when the task naturally elicited those structures, replicating Dao et al. (Reference Dao, Trofimovich and Kennedy2018).
Conclusions and Practical Implications
Our study demonstrates that lexical and structural alignment are both present and observable in different SCMC data sets. Given that we analyze small and heterogeneous corpora, the results of the present study are to be taken as providing venues to build future hypotheses and a methodological framework. We identified different variables that will need to be examined in future studies: the CMC environment, the status of interlocutors, the difference between lexical and structural alignment, and target structures naturally elicited by specific tasks, among others.
On a methodological level, the apparatus we adapted from the literature proved to be a useful tool to examine this phenomenon across data sets. However, some adaptations will be necessary for future studies. The first one is about the spoken nature of language in video chat conversations. This resulted in disfluencies, which need to be distinguished from genuine self-alignment. Spoken corpora therefore need to be prepared before coding alignment, and NLP tools are a precious help for this. Spoken language also resulted in long turns, and we discussed possible ways to deal with these turns depending on the theoretical position one takes on alignment. The second adaptation depends on the multimodality of video chat, which not only resulted in instances of bimodal alignment (i.e., a speaker aligning to something the interlocutor wrote in the chatbox) but also allowed bimodal turns, for example, turns that begin orally and finish gesturally. Analyses of alignment in video chat conversations need to take this into account. The third adaptation we suggest concerns both written and video communication and pertains to the coding of lexical alignment. We would recommend taking a lemma-based approach rather than working with exact overlap of N-grams. Similarly, we propose establishing distance between primes and targets using data-driven approaches rather than setting an arbitrary, threshold. Finally, we noted how, in order to compare structural alignment across languages, it can be useful to restrict to precise structures that are present in all languages and that emerge from the data.
To conclude, we would like to argue that developing research within the framework of alignment has two main strengths. First, we think that this framework is a way to go beyond the cognitive-sociocultural debate (Hulstijn et al., Reference Hulstijn, Young and Ortega2014) and instead draw on the strengths of both fields of research. On the one hand, following Pickering and Garrod (Reference Pickering and Garrod2004), alignment builds on cognitive conceptualizations that link linguistic realizations (i.e., entrainment) to cognitive dimensions (i.e., aligned situational models) of dialogue. On the other hand, Coste and Cavalli (Reference Coste and Cavalli2015) stressed how learning a foreign language is a process of social mobility and socialization where one adopts the norms of the social groups one projects oneself in. This social process includes adaptation to linguistic norms, that is, rules of grammar as well as formulaic language and common ways of saying things (Kecskes, Reference Kecskes2014; see also Lewis & Peters, Reference Lewis, Peters, Spänkuch, Dittmann, Seeliger-Mächler, Peters and Buschmann-Göbels2019, who observed this in e-tandem conversations). In our view, lexical and structural alignment, as we described them in this article, are the conversational dynamics that support the acquisition of these elements. Therefore, they can be seen as a trace of the socialization process of foreign language learners.
The second strength of research into alignment is related to its nature as a highly frequent and pervasive phenomenon. As such, it can be a powerful tool for instructed SLA (cf. Trofimovich & McDonough, Reference Trofimovich and McDonough2011). To conclude, with our approach we aimed to open a new avenue to look at interaction taking a more dynamic and pervasive perspective, which will further our understanding of how the different conversational phenomena interact with each other in supporting L2 acquisition and development.
Author ORCIDs
Marije Michel, 0000-0003-1426-4771; Marco Cappellini, 0000-0002-2086-061X.
Acknowledgments
We thank Marije Roorda and Meng Zhang for their help with coding and proofreading, and the editors and anonymous reviewers for their feedback on earlier versions of this paper. This project was supported by the Groningen University Faculty of Arts Writing Up grant awarded to the first author.
Appendix
Structures coded for in the different datasets









 Open access
Open access