



Introduction
The National Institutes of Health Stroke Scale (NIHSS) and the modified Rankin Scale (mRS) are widely used to evaluate stroke severity and functional outcomes, respectively, in clinical practice and research settings.Reference Banks and Marotta1–Reference Broderick, Adeoye and Elm4 The NIHSS is the current standard for quantifying stroke-related impairments to guide treatment decisions and to determine subsequent neurological improvement and deterioration, while the 90-day mRS is the most commonly used primary outcome measure in randomized controlled trials in stroke. As such, accurate performance of these scores has become an essential competency for stroke clinicians and trial personnel.Reference Lyden2,Reference Taylor-Rowan, Wilson, Dawson and Quinn5,Reference Maguire and Attia6
In the 1980s, the NIHSS was developed as a systematic method for evaluating stroke impairmentsReference Brott, Adams and Olinger7 and rose to prominence, particularly after its use in the landmark National Institute of Neurological Disorders and Stroke alteplase trial.Reference Lyden2,Reference Goldstein, Bertels and Davis8–Reference Asplund10 The use of the NIHSS was propelled forward by validation studies and the development of a validated videotape-based training program, making this scale easily applied to many contexts and locations (e.g., multi-site trials). In the original NINDS rt-PA Stroke Trial study, raters were required to recertify 6 months after initial certification and then yearly thereafter.Reference Lyden, Brott and Tilley9,11 Yearly recertification has remained the current standard.Reference Lyden2,Reference Anderson, Klein and White12 The mRS was published in 1988 after modifications were made to the original 1957 Rankin Scale in order to increase its comprehensiveness and applicability to modern stroke practiceReference Kasner3,Reference New and Buchbinder13–Reference van Swieten, Koudstaal, Visser, Schouten and van Gijn15 Compared to the NIHSS certification and training requirements, the mRS training and certification landscape has been more heterogeneous, though mRS certification is typically required for participation in stroke trials and occasionally in clinical practice as well.Reference Quinn, Lees, Hardemark, Dawson and Walters16 Online video scenario-based certification is widely used, and yearly recertification is typically recommended, particularly for those participating in clinical trials.
To date, however, there has been little critical examination of the benefits of such training requirements. Such examination is crucial, particularly given the substantial time commitment required for mandatory training, certification and annual recertification. This systematic review sought to determine if NIHSS or mRS training, re-training, certification or recertification led to improvements in rater performance and user-reported metrics.
Methods
This review is reported following the Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA) guidelines. The protocol for this review was registered on November 8, 2023, on PROSPERO (registration number: CRD42023476934).
Search strategy
Searches (without date or language restrictions) of MEDLINE, EMBASE and Cumulated Index in Nursing and Allied Health Literature (CINAHL) databases were performed from inception until March 24, 2024. The complete search strategy is listed in the online Supplemental Material and included the following terms (and associated synonyms/mapped subject subheadings): “National Institutes of Health Stroke Scale,” “Rankin scale,” “Training,” “Certification,” “Accreditation,” “Education,” “Teaching” and “Learning.” Reference lists of the included studies were hand searched for other relevant items that were not retrieved in the original search.
Study selection
Title and abstract screening, followed by full-text review, were independently completed by two authors (DM and DK) with conflicts resolved by a third author (AG). Inclusion and exclusion criteria are reported in Table 1. Studies were included if they (1) included training or certification as an intervention, (2) reported outcomes (pre-defined outcomes of interest included in Table 2) in reference to a comparator group (i.e., control group, other intervention group or historical group or pre- vs. post-intervention comparison) and (3) included stroke clinicians or allied health professionals (including students in these fields). Outcomes of interest included measures related to reliability, accuracy, user confidence and certification/training pass rate. Any other outcomes related to effectively conducting the NIHSS or mRS scoring systems that arose during the process of screening were specified in the protocol to be included; no such additional outcomes were found.
Table 1. Inclusion and exclusion criteria

Table 2. Predefined outcomes for inclusion criteria

Studies were excluded if there was no comparator group (e.g., simply a descriptive report of NIHSS pass rate or of inter-rater reliability within a single trained group) or were not published in the English language. Published peer-reviewed conference abstracts and proceedings were included. Screening was performed using Covidence software.17
Data extraction
Given the broad inclusion criteria of this review, it was anticipated that there would be significant heterogeneity between included studies in terms of interventions, study groups and outcome measures. As such, a broad and narrative style of data extraction was pursued. We collected the following data: study design; training, certification and recertification details; participants’ health professional role; level of training or experience; outcomes; and key findings. Data extraction was completed in duplicate by two authors (DK and DM), with any conflicts resolved by consensus.
Data synthesis
Given the diversity of interventions, study groups and outcomes, a narrative style data synthesis was used. In the review registration protocol, methods for a meta-analysis were outlined, but given the heterogeneity observed across studies, a meta-analysis was not considered to be appropriate.
Assessment of study quality and risk of bias
Risk of bias assessment of the included studies was performed using the ROBINS-I (Risk Of Bias In Non-randomized Studies - of Interventions)Reference Sterne, Hernán and Reeves18 tool for observational studies and using the CROB (Cochrane Risk of Bias)Reference Higgins, Altman and Gøtzsche19 tool for any included randomized control trial.
Results
After removal of duplicates, 4227 studies were screened, 100 of which were assessed for full-text eligibility, with 23 meeting criteria for inclusion in this review. Of the studies excluded, the majority (56/77) were excluded due to a lack of a training, certification or recertification intervention. Other reasons for exclusion included the absence of an appropriate outcome or a lack of a comparator group. The PRISMA flow diagram is shown in Figure 1.
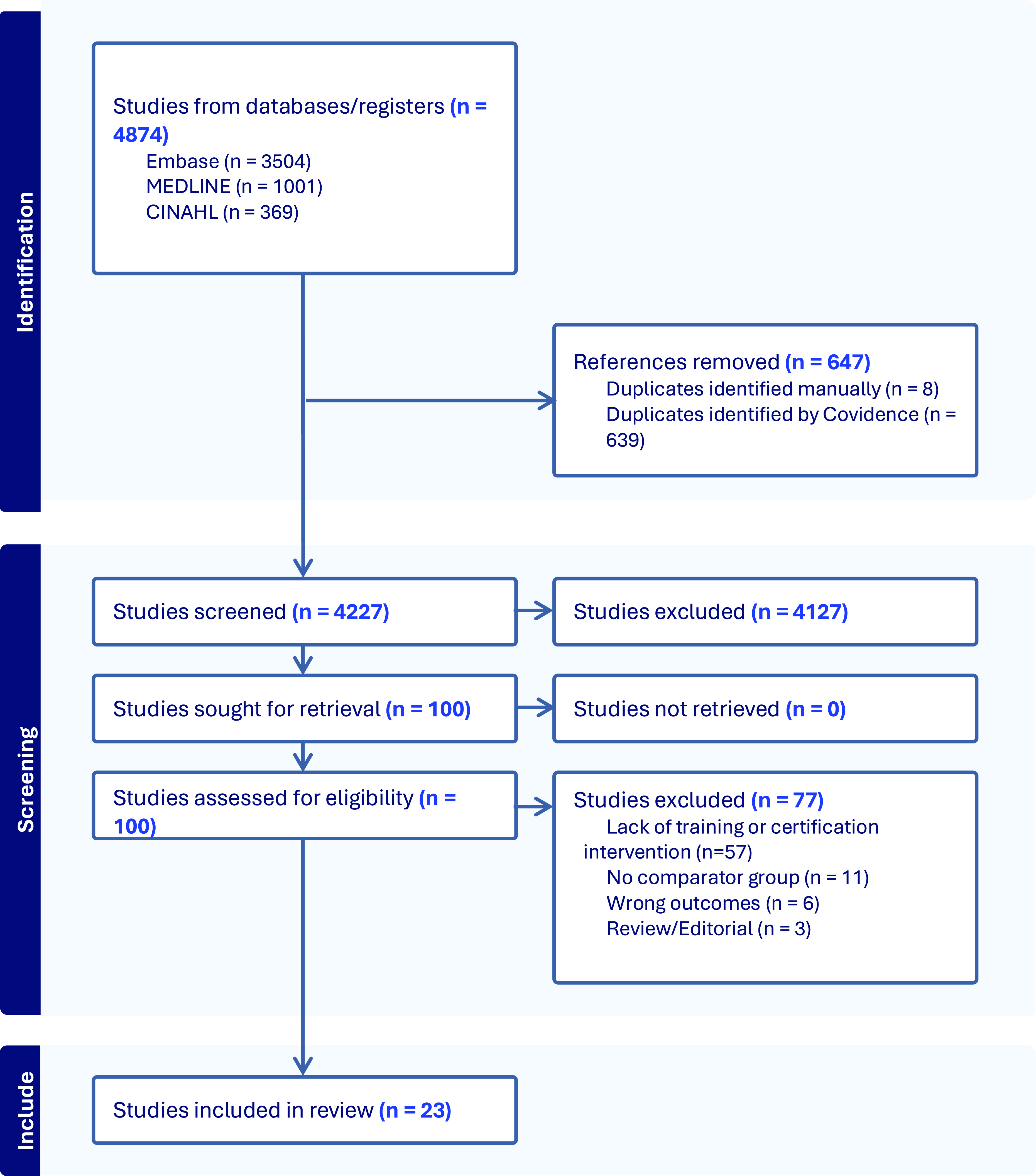
Figure 1. PRISMA diagram of the included studies.
Study characteristics
Tables 3–6 summarize the characteristics of the included studies. In total, 23 studies were included, of which 10 (43%)Reference Gill, Rasmussen, Garg, Ray, McCoyd and Ruland20–Reference You, Song and Park29 were conference abstracts. Publication dates ranged from 1997 to 2023, with 16 of 23 (70%)Reference Anderson, Klein and White12,Reference Gill, Rasmussen, Garg, Ray, McCoyd and Ruland20–Reference Wendell, Reznik and Lindquist28,Reference Dancer, Brown and Yanase30–Reference Pożarowszczyk, Kurkowska-Jastrzębska, Sarzyńska-Długosz, Nowak and Karliński35 being published after 2014. The majority were observational studies (18/23, 78%),Reference Goldstein, Bertels and Davis8,Reference Anderson, Klein and White12,Reference Gill, Rasmussen, Garg, Ray, McCoyd and Ruland20–Reference You, Song and Park29,Reference McLoughlin, Olive and Lightbody33,Reference Josephson, Hills and Johnston36–Reference Schmülling, Grond, Rudolf and Kiencke39 with 5 (21%)Reference Dancer, Brown and Yanase30–Reference Koka, Suppan, Cottet, Carrera, Stuby and Suppan32,Reference Suppan, Stuby and Carrera34,Reference Chiu, Cheng and Sun40 being randomized controlled trials (Table 3). Overall, there was a wide range of the number of participants in included studies, spanning from 4 (39) to 1,313,733.Reference Anderson, Klein and White12
Table 3. Included studies related primarily to initial NIHSS training
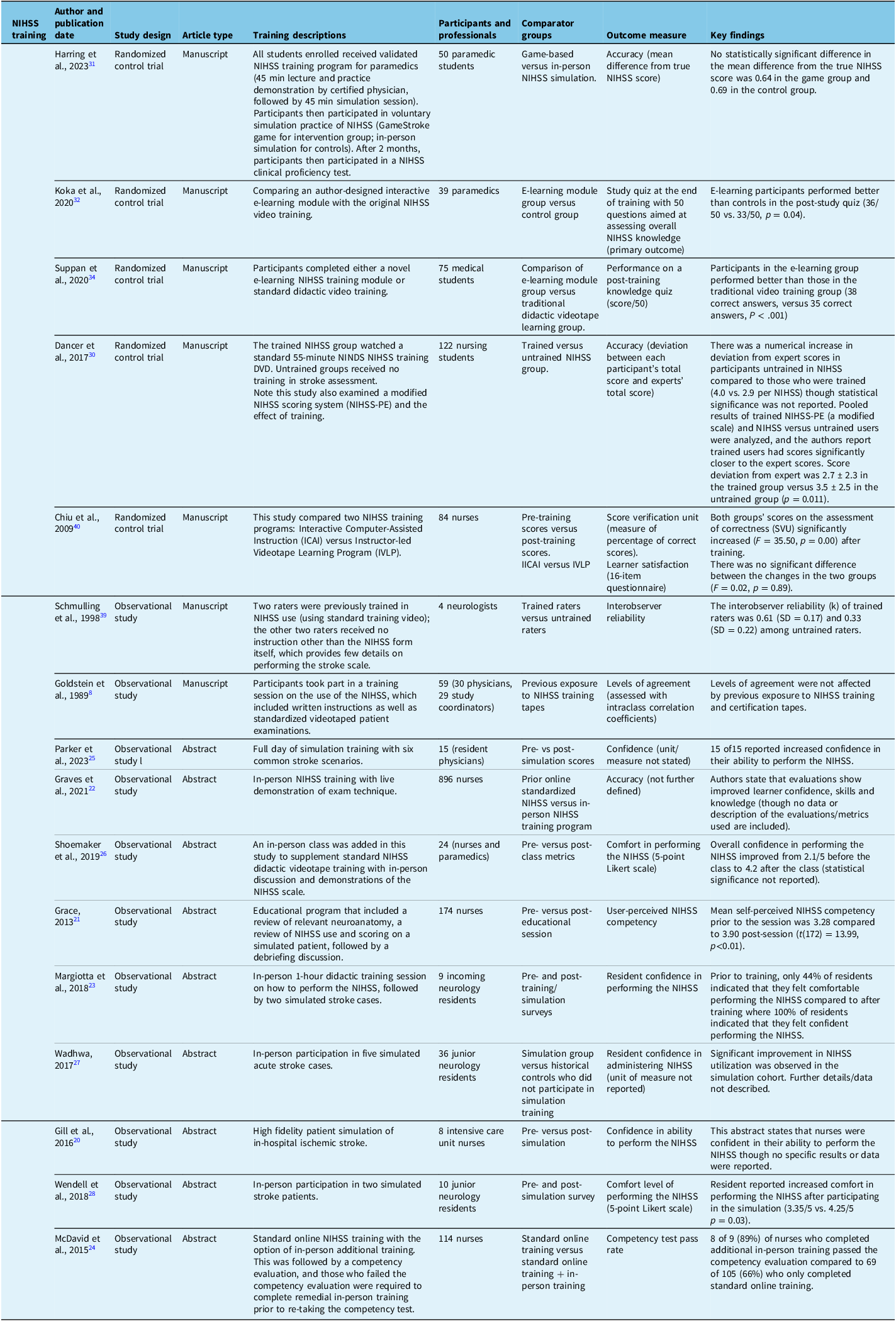
NIHSS = National Institutes of Health Stroke Scale; NINDS = National Institute of Neurological Disorders and Stroke.
Table 4. Included studies related primarily to initial National Institutes of Health Stroke Scale (NIHSS) certification
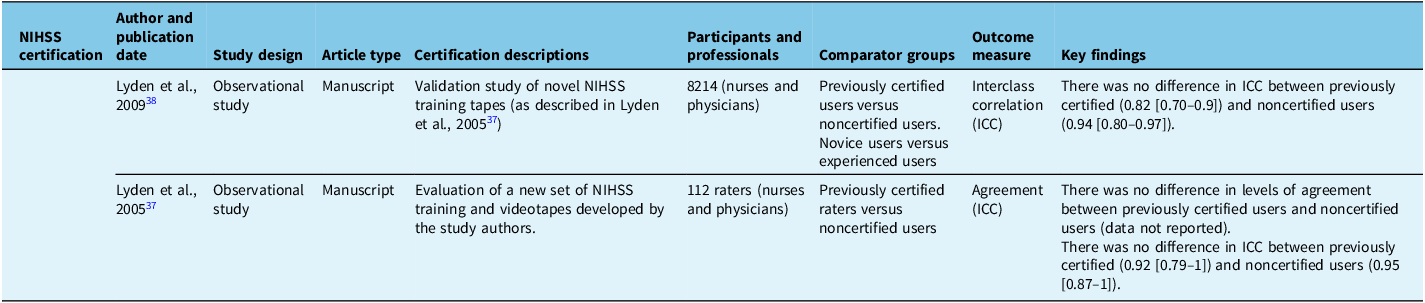
Table 5. Included studies related primarily to repeat National Institutes of Health Stroke Scale (NIHSS) training or certification
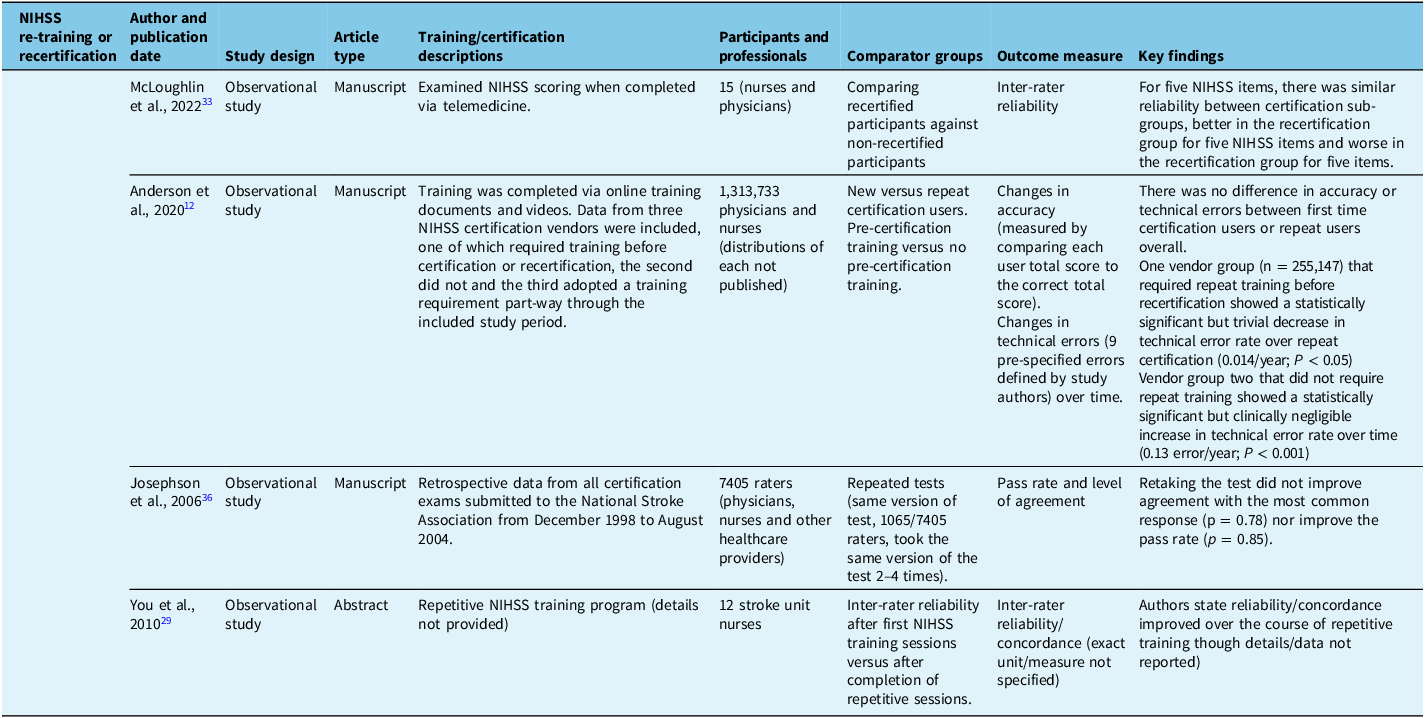
Table 6. Included studies related primarily to modified Rankin Scale training or certification

Seven of 23 (30%)Reference Margiotta, Wilhour, D’Ambrosio, Pineda and Rincon23,Reference Parker, Asher, Arnold, Hindley and Hardern25,Reference Wadhwa, Katyal and Singh27,Reference Wendell, Reznik and Lindquist28,Reference Suppan, Stuby and Carrera34,Reference Pożarowszczyk, Kurkowska-Jastrzębska, Sarzyńska-Długosz, Nowak and Karliński35,Reference Schmülling, Grond, Rudolf and Kiencke39 studies included exclusively physicians as participants, of which 5 of 8 (63%)Reference Margiotta, Wilhour, D’Ambrosio, Pineda and Rincon23,Reference Parker, Asher, Arnold, Hindley and Hardern25,Reference Wadhwa, Katyal and Singh27,Reference Wendell, Reznik and Lindquist28,Reference Suppan, Stuby and Carrera34 included only physicians in training (residents or medical students). An additional 6 of 23 (26%)Reference Goldstein, Bertels and Davis8,Reference Anderson, Klein and White12,Reference McLoughlin, Olive and Lightbody33,Reference Josephson, Hills and Johnston36–Reference Lyden, Raman, Liu, Emr, Warren and Marler38 studies included physicians as well as other health professionals. Seven of 23 (30%)Reference Gill, Rasmussen, Garg, Ray, McCoyd and Ruland20–Reference Graves, Jones and Bragg22,Reference McDavid, Bellamy and Thompson24,Reference You, Song and Park29,Reference Dancer, Brown and Yanase30,Reference Chiu, Cheng and Sun40 studies included only nurses (or nursing students), 2 of 23 (9%)Reference Harring, Røislien and Larsen31,Reference Koka, Suppan, Cottet, Carrera, Stuby and Suppan32 included paramedics (or paramedic students) and 1 of 23 (4%)Reference Shoemaker26 included both paramedics and nurses.
Risk of bias assessment
Of the included observational studies, 10 of 18 (56%) were deemed to have a critical risk of bias. The 10 included abstracts in this review were the same 10 deemed to have a critical risk of bias. Three of 18 (17%)Reference Anderson, Klein and White12,Reference Lyden, Raman and Liu37,Reference Lyden, Raman, Liu, Emr, Warren and Marler38 observational studies were deemed to have moderate risk of bias, and 5 of 18 (28%)Reference Goldstein, Bertels and Davis8,Reference McLoughlin, Olive and Lightbody33,Reference Pożarowszczyk, Kurkowska-Jastrzębska, Sarzyńska-Długosz, Nowak and Karliński35,Reference Josephson, Hills and Johnston36,Reference Schmülling, Grond, Rudolf and Kiencke39 were rated as serious risk of bias. Of the five included randomized control, three of five (60%) were rated as having high risk of bias,Reference Harring, Røislien and Larsen31,Reference Suppan, Stuby and Carrera34,Reference Chiu, Cheng and Sun40 and two of five (40%) were rated as having some concern for bias.Reference Dancer, Brown and Yanase30,Reference Koka, Suppan, Cottet, Carrera, Stuby and Suppan32 A summary graphic of the risk of bias assessment is included in the supplemental online Supplemental Material (Supplemental Figures 1 and 2)
Study findings
Twenty-two of 23 included studies were related to the NIHSS, with just one included mRS study.Reference Pożarowszczyk, Kurkowska-Jastrzębska, Sarzyńska-Długosz, Nowak and Karliński35 Twelve of 23 studies examined the effect of training compared to no training (i.e., no formal instruction or exposure to training tapes and simply access to the standard NIHSS or mRS scoring form that contains limited instructions). Of these training studies, threeReference Dancer, Brown and Yanase30,Reference Pożarowszczyk, Kurkowska-Jastrzębska, Sarzyńska-Długosz, Nowak and Karliński35,Reference Schmülling, Grond, Rudolf and Kiencke39 examined performance among different groups of participants (trained or untrained), and the other nine used historical controls (i.e., the same participant group before and after a training intervention). Two of the three studies examining different cohorts of participants who were trained or untrained reported numerical differences in outcomes between trained and untrained users, but statistical tests were not reported in either.
The five RCTs included four studies of different training approaches (game-based vs. in-person,Reference Harring, Røislien and Larsen31 e-learning vs. original video trainingReference Koka, Suppan, Cottet, Carrera, Stuby and Suppan32,Reference Suppan, Stuby and Carrera34 and computer-assisted instruction vs. instructor-led video learning).Reference Chiu, Cheng and Sun40 Only one study randomized participants to training versus no trainingReference Dancer, Brown and Yanase30 and examined NIHSS score performance. This 2017 studyReference Dancer, Brown and Yanase30 focused on nursing students. The authors reported a numerical deviation from expert scores that was greater in the untrained group (4.0 vs. 2.9 per NIHSS score) though confidence intervals and statistical analyses were not reported. Of note, Dancer et al. (2017)Reference Dancer, Brown and Yanase30 reported a statistically significant increase in deviation from expert scores in untrained participants versus trained when a pooled analysis of both NIHSS and a modified NIHSS scale (NIHSS-PE [Plain English]) was completed and the authors report trained users had scores significantly closer to the expert scores (score deviation from expert was 2.7 ± 2.3 in the trained group vs. 3.5 ± 2.5 in the untrained group [p = 0.011]). An observational study compared trained versus untrained NIHSS ratersReference Schmülling, Grond, Rudolf and Kiencke39 but reported a numerical difference in agreement among trained raters compared to untrained raters, in only four participants.Reference Schmülling, Grond, Rudolf and Kiencke39
The only mRS study compared groups of trained versus untrained ratersReference Pożarowszczyk, Kurkowska-Jastrzębska, Sarzyńska-Długosz, Nowak and Karliński35 and showed no statistical difference between pairs of trained raters or a trained rater paired with an untrained rater.Reference Pożarowszczyk, Kurkowska-Jastrzębska, Sarzyńska-Długosz, Nowak and Karliński35
NineReference Grace21–Reference Margiotta, Wilhour, D’Ambrosio, Pineda and Rincon23,Reference Parker, Asher, Arnold, Hindley and Hardern25–Reference You, Song and Park29,Reference Chiu, Cheng and Sun40 studies examined historical cohorts by comparing pre-training versus post-training scores, eightReference Grace21–Reference Margiotta, Wilhour, D’Ambrosio, Pineda and Rincon23,Reference Parker, Asher, Arnold, Hindley and Hardern25–Reference You, Song and Park29 of which were conference abstracts that generally commented on participant confidence measures pre- and post-training. Five studies Reference Grace21,Reference Margiotta, Wilhour, D’Ambrosio, Pineda and Rincon23,Reference Parker, Asher, Arnold, Hindley and Hardern25,Reference Shoemaker26,Reference Wendell, Reznik and Lindquist28 (all abstracts) reported numerical or statistically significant increases in participant (usually resident physicians) confidence in performing the NIHSS. The only full-length manuscript analyzing pre- and post-test scores was by Chiu et al. (2009)Reference Chiu, Cheng and Sun40 and was designed to compare two NIHSS training methods among a group of nurses (computer assisted vs. instructor led), although the authors do report a significant increase in score verification unit (a surrogate of accuracy) after training in both groups.
No studies examined the effect of initial certification though sevenReference Goldstein, Bertels and Davis8,Reference You, Song and Park29,Reference McLoughlin, Olive and Lightbody33,Reference Josephson, Hills and Johnston36–Reference Lyden, Raman, Liu, Emr, Warren and Marler38 studies examined the effect of re-training or recertification. The largest of these was published by Anderson et al. (2020),Reference Anderson, Klein and White12 which included results of 1,313,733 unique NIHSS certification tests. In this study, no difference was observed in accuracy or error rate between first-time certification users compared to users completing repeat certification. The study did show a small but statistically significant (0.014/year, P < 0.05 [confidence interval not reported]) decrease in error rate from one year to the next for groups that required repeat online training prior to each repeat certification exam. On the other hand, there was a similar small (0.013/year, P < 0.001 [confidence interval not reported]) but statistically significant increase in error rate, compared to prior performance, among a group that did not require repeat training prior to recertification. Note that this study compared results within groups (i.e., customers of different NIHSS training vendors) and with historical controls within these groups rather than statistically comparing between trained versus untrained groups. The remaining sixReference Goldstein, Bertels and Davis8,Reference You, Song and Park29,Reference McLoughlin, Olive and Lightbody33,Reference Josephson, Hills and Johnston36–Reference Lyden, Raman, Liu, Emr, Warren and Marler38 included studies found no significant change in reliability or agreement measures with repeat training and/or repeat certification. For example, a study by Lyden et al. (2009),Reference Lyden, Raman, Liu, Emr, Warren and Marler38 which included 2416 previously certified NIHSS raters and 1414 uncertified raters undergoing online certification/recertification with required pre-training, showed no statistical difference in reliability between previously certified and first-time certification users.
Five studiesReference McDavid, Bellamy and Thompson24,Reference Shoemaker26,Reference Harring, Røislien and Larsen31,Reference Koka, Suppan, Cottet, Carrera, Stuby and Suppan32,Reference Chiu, Cheng and Sun40 examined differences between types of training, which included current standard training, novel computer-assisted methods and instructor-led in-person training. Two of fiveReference Koka, Suppan, Cottet, Carrera, Stuby and Suppan32,Reference Chiu, Cheng and Sun40 found statistically significant benefit in the novel computer module/e-learning groups compared to in-person or traditional online methods. Specifically, Koka et al. (2020)Reference Koka, Suppan, Cottet, Carrera, Stuby and Suppan32 report that e-learning participants performed better than controls on a post-study quiz (36/50 vs. 33/50 correct, p = 0.04), and Chiu et al. (2009)Reference Chiu, Cheng and Sun40 report an increase in the percentage of correct scores (p = <0.01) after their novel e-learning training. One of fiveReference Harring, Røislien and Larsen31 studies showed no difference between a computer module group and instructor-led group, and two of fiveReference McDavid, Bellamy and Thompson24,Reference Shoemaker26 reported improved NIHSS skills with the addition of in-person training. Specifically, a conference abstract by McDavid et al. (2015)Reference McDavid, Bellamy and Thompson24 reported an increased pass rate on competency evaluation (89% in face-to-face training group vs. 68% in the online group), although the sample size was small and statistical analysis was not reported. A conference abstract by Shoemaker et al. (2019)Reference Shoemaker26 reported an increase in user confidence after in-person training from 2.1 to 4.2 on a 5-point Likert scale, although again, statistical analysis was not reported.
Discussion
The results of this review highlight the limited and heterogeneous evidence for current NIHSS and mRS training and certification practices. Of the 12 included studies examining NIHSS training, only 2 studies showed an increase in accuracy of NIHSS scoring after training, and a single study showed a very small decrease in year-to-year error rate after re-training. The remaining studies, which included large observation studies, did not show improvement in accuracy or reliability of NIHSS scores with training. No included studies demonstrated a benefit of NIHSS certification or recertification. A number of studies reported subjective improvements in user confidence after training although these were limited to conference abstracts judged to be at critical risk of bias. Only one mRS study met our criteria, and this showed no significant difference in agreement between pairs of certified raters and pairs of certified versus noncertified raters.
Several of the larger studiesReference Anderson, Klein and White12,Reference Josephson, Hills and Johnston36–Reference Lyden, Raman, Liu, Emr, Warren and Marler38 included in this review pooled results of multiple healthcare providers (largely physicians and nurses) though it is important to consider that different healthcare provider groups (physicians, nurses, pre-hospital providers) likely have different experience with the NIHSS in daily practice and may benefit from different training and certification standards. Given that the only studies showing improvement in NIHSS accuracy were those including only nurses or nursing students, this may suggest some benefit to NIHSS training among these groups. Studies that included physicians only were largely conference abstracts and generally commented on confidence in performing the NIHSS scale. For physicians in training, who constituted the majority of the physicians included in these studies, there seems to be a signal that training may increase user confidence in scale performance although interpretation of these results is limited by the high risk of bias among these reports.
Taken together, the results of this review highlight important deficiencies of the evidence behind current NIHSS training and certification practices. At the very least, it seems reasonable to revisit current annual recertification requirements for the NIHSS and mRS for clinicians practicing in stroke. For example, in the study by Anderson et al. (2020),Reference Anderson, Klein and White12 which had the largest sample size included in this review, the authors suggested that NIHSS mastery for physicians and nurses is stable over time, that repeat training and certification lead to no clinically significant differences and that the required interval for recertification should be lengthened.Reference Anderson, Klein and White12 Based on the current review, there is little evidence to support recertification at all. A first certification may be reasonable to increase user confidence. Such an approach has been adopted by the Clinical Dementia Rating Scale,Reference Morris41 which requires initial certification though no mandatory recertification; additionally, other scales that are recognized as clinical standards (e.g., the Glasgow Coma Scale) do not require mandatory training or certification.
Limitations of this review include the heterogeneity and generally high risk of bias of the included studies. Yet, it is precisely because of a lack of high-quality evidence that certification standards must be questioned. We opted to be comprehensive in the types of studies we included in order to provide as complete a picture as we could of the available evidence in this space.
Finally, it is worth noting that medicine is rampant with resource-intensive practices with little evidence for their use.Reference Feldman42 It is important for health and research professionals to critically examine current practices and standards in order to seek evidence that justifies the current practice or, in the absence of this, seriously reconsider the practice in question. Revising the current training and certification practices has the potential to improve clinical trial efficacy and reduce investigator burden. In this case, however, while there is a lack of evidence for current NIHSS and mRS training regimens, this does not necessarily mean that these practices are ineffective; however, it does underscore the need for higher-quality data to continue justifying the current practices as well as to seek possible evidence-based alternative practices. Questioning the current requirements seems reasonable, and effort should be made to achieve professional consensus on more efficient and rational strategies that maintain the validity of these scales. Pending higher quality evidence, it is important for professional stroke organizations and trial steering committees to be transparent about their proposed approaches to NIHSS and mRS certification and their rationale in published statements, in order to promote consistency across sites in national and, ideally, international trials. Such concerted approaches would also help provide reassurance and a united front to regulatory bodies and clinical trial sponsors as opposed to a haphazard approach of individual sites refusing to pursue recertification.
Conclusions
The results of this review highlight the sparsity and heterogeneity of studies examining whether NIHSS or mRS training, re-training, certification or recertification improves the reliability and accuracy of ratings or other user metrics. In the case of the NIHSS, there is some evidence to suggest a lack of benefit of the current training and certification regimen in terms of accuracy and reliability of the ratings. For the mRS, more work is clearly needed to quantify the effects of training and/or certification in general. Overall, there is an absence of evidence to support current NIHSS and mRS certification practices; at the very least, recertification requirements should be reconsidered pending the provision of robust evidence.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/cjn.2025.10111
Data availability statement
Data is available upon request.
Acknowledgments
None.
Author contributions
D.M. was responsible for primary manuscript writing, methodology development, study screening and data extraction.
D.K. was responsible for manuscript writing, study screening and data extraction.
R.H.S. provided a review of the initial manuscript and subsequent writing and edits.
S.B.C. provided a review of the initial manuscript and subsequent writing and edits.
A.G. provided oversight of the entire project as well as manuscript development.
Funding statement
No funding to declare.
Competing interests
D.M. reports no competing interests.
D.K. reports no competing interests.
R.H.S. reports salary support by the Department of Medicine (Sunnybrook HSC, University of Toronto); grants by Bastable-Potts Chair in Stroke Research, CIHR, NIH and Ontario Brain Institute; participation in an advisory board for Hoffman LaRoche Inc.; and stock options with FollowMD Inc.
S.B.C. reports grants from the Canadian Institute of Health Research during the conduct of the DOUBT study and grants from the Heart and Stroke Foundation of Canada, Genome Canada and Boehringer Ingelheim outside the submitted work
A.G. reports membership in editorial boards of Neurology, Neurology: Clinical Practice, and Stroke; research support from the Canadian Institutes of Health Research, Alberta Innovates, Campus Alberta Neurosciences, Government of Canada – INOVAIT Program, Government of Canada – New Frontiers in Research Fund, Microvention, Alzheimer Society of Canada, Alzheimer Society of Alberta and Northwest Territories, Heart and Stroke Foundation of Canada, Panmure House, Brain Canada, MSI Foundation and the France-Canada Research Fund; payment or honoraria for lectures, presentations or educational events from Alexion, Biogen and Servier Canada; and stock or stock options in SnapDx Inc. and Collavidence Inc. (Let’s Get Proof).
Ethical statement
Systemic review – ethics and informed consent not required.










 Open access
Open access