


Introduction
Translating basic science discoveries into demonstrated improvements in public health requires a research team from diverse backgrounds [Reference Sung, Crowley and Genel1–Reference Woolf3]. The US National Institutes of Health National Center for Advancing Translational Sciences recognized this need by establishing a strategic goal to advance translational team science by fostering innovative partnerships and diverse collaborations [4]. In the health sciences, there is significant interest in translational research and moving more quickly from single-study efficacy trials to effective, generalizable interventions in health care practice. Foundational to this body of literature is the assumption that cross-disciplinary research teams speed the process of translational research [Reference Disis and Slattery5].
Analyses of trends in scientific publications suggest that major advances in biological, physical, and social science are produced by research teams; that the work of these teams is cited more often than the work of individual researchers; and that, in the long term, the work has greater scientific impact [Reference Fortunato, Bergstrom and Börner6–Reference Uzzi, Mukherjee and Stringer9]. In addition, cross-disciplinary diversity is assumed to lead to greater innovation [Reference Larivière, Haustein and Börner10]. These observations have become the cornerstone of the translational science movement in the health sciences.
Implementing team science can be challenging. Multiple authors have noted that working in collaboration can be more expensive and labor intensive than working alone [Reference Basner, Theisz and Jensen11,Reference Hall, Stokols and Moser12]. Noted trade-offs include added time and effort to communicate with diverse collaborators, conflicts arising from different goals and assumptions, and increased start-up time with its resulting delay in productivity [Reference Cummings, Kiesler and Zadeh13–Reference Trochim, Marcus and Mâsse17]. These opportunity costs may be acceptable if the outcomes of research collaborations can accelerate knowledge or answer the complex health questions faced by today’s society.
To test the assumption that research collaboration leads to greater productivity, we need to accurately measure the characteristics of research teams and their outcomes and be able to compare results across teams [Reference Fortunato, Bergstrom and Börner6,Reference Hall, Stokols and Moser12,Reference Hall, Vogel and Stipelman15,Reference Luukkonen, Tijssen and Persson18–Reference Wooten, Rose and Ostir27]. Although different measures have so far shown that collaborations are beneficial, operational definitions of variables that may influence conclusions (construct validity) are varied, complicating interpretation of results. Despite some exceptions [Reference Hall, Stokols and Moser12,Reference Mâsse, Moser and Stokols19,Reference Oetzel, Zhou and Duran23,Reference Misra, Stokols and Cheng28], there is a lack of attention to the development and psychometric testing of reliable and valid measures of collaboration. As an initial step, it would be useful to have an overview of the current state of the science in the measurement of research collaborations. In this article, we report the results of an integrative review of the literature, looking for reliable and valid measures that describe the quality and outcomes of research collaborations.
Materials and Methods
We conducted two reviews. The first focused on measures of collaboration quality, defined as measures of interactions or processes of the team during the collaboration. The second review focused on outcomes of the collaboration (e.g., publications, citations). We used an integrative review approach. An integrative review is a specific type of review that applies a comprehensive methodology involving a combination of different approaches to summarize past research related to a particular topic, including both experimental and non-experimental studies, and reach conclusions [Reference Souza, Silva and Carvalho29,Reference Whitehead, LoBiondo-Wood and Haber30].
Our research team brainstormed keyword combinations and, based on expert opinion, agreed on final sets of keywords that were comprehensive enough to cover the topics fully but not so broad as to include non-relevant literature. For the review of collaboration quality, these keywords were “measure/measurement” combined with the following terms: community engagement, community engaged research, collaboration, community academic partnership, team science, regulatory collaboration, industry collaboration, public–private partnership (focus on research). For the review associated with collaboration outcomes, the word “outcomes” was added to the above search terms. Our intention was to include all types of research collaborations, including partnerships between academic and other community, governmental, and industry partners. The following keywords were considered, tested in preliminary searches, and eliminated by group consensus as being too broad for our purpose: consortium collaboration, public health and medicine collaboration, patient advocacy group collaboration, and coalition. Measures of collaboration related to clinical care, education, and program delivery collaborations were excluded from this review.
Quality and outcome measures were identified using both a literature review and an environmental scan. We conducted searches using the standard databases PubMed, the Comprehensive Index to Nursing and Allied Health Literature, and PsychInfo, as well as searched EMBASE, Google Scholar, Scopus, and websites recommended by members of the research team. After duplicates and articles that were not focused on a specific scale or measure of research collaboration were eliminated, team members reviewed a final list of 25 publications for the measures of collaboration quality, including 4 articles describing social network analyses, and 42 publications for measures of collaboration outcome. All publications were published prior to 2017. Figs. 1 and 2 provide flow diagrams of how articles were selected to be included in both reviews.
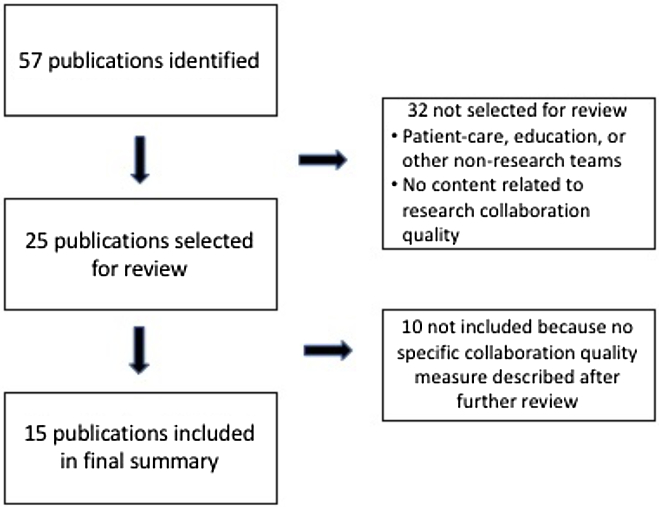
Fig. 1. Flow diagram of publications included in the final collaboration quality review.
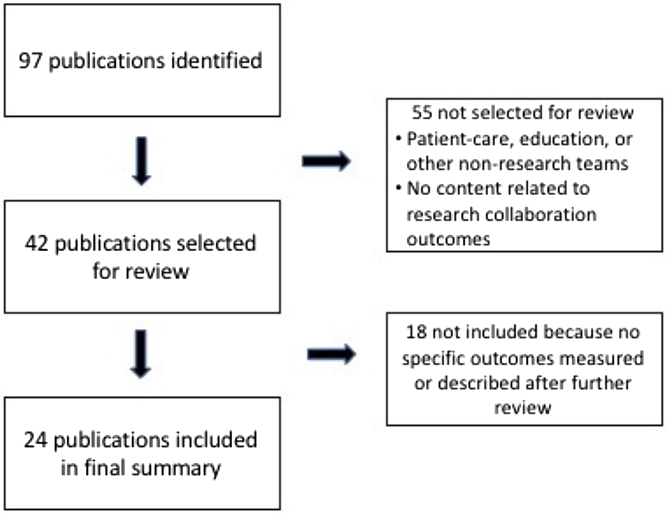
Fig. 2. Flow diagram of publications included in the final collaboration outcomes review.
At least two members of the research team reviewed each article using a standard data abstraction form that included the name of the measure/outcome; construct being measured; sample; and details about the measure, including operational definition, number of items, response options, reliability, validity, and other evidence for supporting its use. Reviewers were also asked to make a judgment as to whether the article included a measure of the collaboration quality (or outcomes or products) of the scientific/research collaborations; both reviews had a rater agreement of 99%. Differences in reviews were resolved through consensus after discussions with a third reviewer.
Results
Quality Measures
We identified 44 measures of research collaboration quality from the 15 publications included in the final summary analyses (see Fig. 1). The specifics of each measure are detailed in Table 1. Three articles were not included in Table 1 because they all used social network analysis [Reference Bian, Xie, Topaloglu and Hudson31–Reference Hughes, Peeler and Hogenesch33]. Four articles covered 80% of the measures identified [Reference Hall, Stokols and Moser12,Reference Mâsse, Moser and Stokols19,Reference Oetzel, Zhou and Duran23,Reference Huang34].
Table 1. Measures of research collaboration quality

NR, not reported; CRN, Cancer Research Network; NCI, US National Cancer Institute; TREC, Transdisciplinary Research on Energetics and Cancer; ICC, intraclass correlation coefficients; NSF, US National Science Foundation; DOE, US Department of Energy; MATRICx, Motivation Assessment for Team Readiness, Integration and Collaboration; NA, not applicable; TTURC, Transdisciplinary Tobacco Use Research Center; PI, principal investigator; PD, project director; CBPR, community-based participatory research.
a Details obtained by cross-referencing article (TREC Baseline survey) from https://www.teamsciencetoolkit.cancer.gov/Public/TSResourceMeasure.aspx?tid=2%26rid=36 [42].
b Detail obtained by cross-referencing article (NCI TREC Written Products Protocol 2006-09-27) from https://www.teamsciencetoolkit.cancer.gov/Public/TSResourceMeasure.aspx?tid=2%26rid=646 [43].
c Details obtained by cross-referencing article (TTURC Researcher Survey 2002) from https://cctst.uc.edu/sites/default/files/cis/survey-TTURC_research.pdf [44].
d Original instrument shown at http://cpr.unm.edu/research-projects/cbpr-project/index.html--scroll to 2. Quantitative Measures – “Key Informant” and “Community Engagement” survey instruments. Developmental work on measures from Oetzel et al. (2015) continues in an NIH NINR R01 (Wallerstein [PI] 2015-2020 “Engage for Equity” Study; see http://cpr.unm.edu/research-projects/cbpr-project/cbpr-e2.html).
The number of items per measure ranged from 1 to 48, with 77% having less than 10 items per measure. A few articles reported on measures that covered several domains. As shown in Table 1, we have included each domain measure separately if it was reported as an independent scale with its own individual psychometric properties.
Reliability was reported for 35 measures, not reported for four measures, and not applicable for five measures (single-item, self-reported frequency counts, or qualitative responses). Reliability measures were most frequently Cronbach’s alphas for internal consistency reliability, but also included intraclass correlation coefficients, inter-rater correlations, and, when Rasch analysis was used, person separation reliability. Test–retest reliability was never reported. Cronbach’s alpha statistics were >0.70 for 86% of the measures using that metric. Some form of validity was reported on 40 measures and typically included exploratory (n = 8) and/or confirmatory factor analysis (n = 26). Convergent or discriminant validity was evident for 38 measures but was based on study results, as interpreted by our reviewers, rather than identified by the authors as a labeled multitrait–multimethod matrix analysis of construct validity. Twelve measures had convergent or discriminant validity only, without any further exploration of validity. Face validity and content validity were reported for five measures, along with other analyses of validity.
Outcome Measures
We identified 89 outcome measures from the 24 publications included in the final summary analyses (see Fig. 2). Characteristics of each measure are detailed in Table 2. Three publications included over 44 (49%) of the measures identified [Reference Trochim, Marcus and Mâsse17,Reference Oetzel, Zhou and Duran23,Reference Philbin35]. However, only two of those [Reference Trochim, Marcus and Mâsse17,Reference Oetzel, Zhou and Duran23] included measures tested in actual studies; the remaining article [Reference Philbin35] included only recommendations for specific measures.
Table 2. Measures of research collaboration outcomes

NA, not applicable; NR, not reported; NIH, National Institutes of Health; CTSA, Clinical and Translational Science Award; NSF, National Science Foundation; ISI, Institute for Scientific Information; DOE, US Department of Energy; SCI, Science Citation Index; CV, curriculum vitae; NCI, National Cancer Institute; IF, impact factor; TTURC, Transdisciplinary Tobacco Use Research Centers; NHMFL, National High Magnetic Field Laboratory;RTI, relative team impact; TREC, Transdisciplinary Research on Energetics and Cancer; PI, principal investigator; PD, project director; CBPR, community-based participatory research.
a Details obtained by cross-referencing article (TTURC Researcher Survey 2002) from https://cctst.uc.edu/sites/default/files/cis/survey-TTURC_research.pdf [44].
b Details obtained by cross-referencing article (TREC Baseline survey) from https://www.teamsciencetoolkit.cancer.gov/Public/TSResourceMeasure.aspx?tid=2%26rid=36 [42].
c Original instrument available at http://cpr.unm.edu/research-projects/cbpr-project/index.html--scroll to 2 (Quantitative Measures – “Key Informant” and “Community Engagement” survey instruments). Developmental work on measures from Oetzel et al. (2015) continues in an NIH NINR R01 (Wallerstein [PI], 2015–2020 “Engage for Equity” study (see http://cpr.unm.edu/research-projects/cbpr-project/cbpr-e2.html).
d Details obtained by cross-referencing article (TTURC Researcher Survey 2002) from https://cctst.uc.edu/sites/default/files/cis/survey-TTURC_research.pdf [44] and from Kane and Trochim [Reference Kane and Trochim59].
e Details obtained by cross-referencing article (NCI TREC Written Products Protocol 2006-09-27) from https://www.teamsciencetoolkit.cancer.gov/Public/TSResourceMeasure.aspx?tid=2%26rid=646 [43].
Measures were broadly classified into one of the six different categories, reflected in Table 2: (1) counts or numerical representations of products (e.g., number of publications; 38 measures); (2) quality indicators of counted products (e.g., journal impact factor; 7 measures); (3) self-reported perceptions of outcomes (e.g., perceived productivity; 32 measures); (4) peer-reviewed perceptions of outcomes (e.g., progress on the development of interventions; 5 measures); (5) qualitative descriptions of outcomes (e.g., descriptive data collected by interview; 6 measures); and (6) health indicators/outcomes (e.g., life expectancy; 1 overall measure with 60 different indicators). The number of items per measure ranged from a single count to a 99-item scale, with over 50% of the measures composed of a single count, number, or rating of a single item.
Twenty-three of the 89 measures were recommendations on measures and had no reported reliability or validity as would be expected [Reference Philbin35]. For the remaining 66 measures, only 16 reported assessments of reliability. Nine of 24 measures in the self-reported perceptions category included Cronbach’s alpha >0.70, showing internal consistency reliability. Six measures (3 of 24 in the counts of products category and 3 of 4 in the peer-reviewed category) had inter-rater agreement described; all were over 80%. One measure in the peer-reviewed category reported inter-rater reliability of r = 0.24–0.69. Of these 16 measures with reported reliability, nine had some form of validity described: confirmatory factor analysis (6 measures) and convergent validity (3 measures). Of the remaining 50 measures without reliability data, five had some type of convergent validity described and one was supported by principal component analysis. Once again, convergent validity was not formally labeled as such but was evident in terms of correlations between the measure under study and other relevant variables.
Discussion
Quality Measures
Overall, there are a relatively large number of scales, some of them robust, that have been used to measure the quality or process of research collaborations (e.g., trust, frequency of collaboration). However, many scales have not been extensively used and have been subjected to relatively little repeated psychometric study and analysis. Most have been developed in support of a particular research project rather than with the intent of becoming a standard indicator or scale for the field. Although calculated across multiple organizations, estimates of reliability and/or validity were often study specific as well. Reports of effect sizes (sensitivity or responsiveness) were rare and limited to correlations, and construct validity has not been explored beyond exploratory or confirmatory factor analyses. Given this dearth of replicated psychometric data, it is not surprising that widely accepted, standard scales have not emerged to date. Wide-scale testing of measures of collaboration is essential to establish reliability, validity, and sensitivity or responsiveness across settings and samples.
Scales developed to date have been primarily focused on group dynamics (including the quality of interpersonal interactions, trust, and communication). Although these are important factors, few measurements have been made of how well a team functions (such as leadership styles) and the degree to which the team’s work is viewed as synergistic, integrative, or otherwise more valuable than would occur in a more siloed setting. Oetzel et al.’s [Reference Oetzel, Zhou and Duran23] beginning psychometric work provides an example of some of these types of measures. This is in contrast to the numerous available (or under development) scales to measure attitudes toward collaborations and quality of collaborations that exist at specific institutions.
Despite these limitations, two sets of measures deserve note. First, those reported by Hall et al. [Reference Hall, Stokols and Moser12] and Mâsse et al. [Reference Mâsse, Moser and Stokols19] as measures of collaborations in National Cancer Institute-funded Transdisciplinary Tobacco Use Research Centers have been used more extensively than many of the other scales in this review as indicators of collaboration quality among academic partners (although relatively little additional psychometric data have been reported beyond initial publications). Second, the measures reported by Oetzel et al. [Reference Oetzel, Zhou and Duran23] are unique in that they are scales to assess research quality involving collaborations between academics and communities, agencies, and/or community-based organizations. They are also unique in representing responses from over 200 research partnerships across the USA. This review did not distinguish between partnerships (e.g., involving just two partnering organizations) and coalitions (involving multiple organizations).
Outcome Measures
Similar to measures of collaboration quality, little agreement exists as to how to best measure outcomes of research collaborations. By far, the most common type of measurement is a simple count of products over a set period of time (e.g., publications, grants, and/or patents). Interestingly, the procedures used for counting or calculating these products are rarely reported and therefore are not replicable. In addition, published reports infrequently include any type of verification of counts, leaving the reliability of such counts or calculations in question.
The second most common type of measure is the use of self-reported scales to quantify the researchers’ perceptions of collaboration outcomes. These include measures of perceived productivity or progress, changes in relationships with partners, increased capacity, and sustainability. Few of these measures, with the exception of the psychometric works of Hall et al. [Reference Hall, Stokols and Moser12] and Oetzel et al. [Reference Oetzel, Zhou and Duran23], have documented reliability and validity. In general, despite a relatively large number of scales, most of these were not developed for the purpose of becoming standard indicators or measures and most have had little psychometric study or replication.
Efforts to measure the quality of counted products, such as consideration of citation percentiles, journal impact factors, or field performance indicators, offer important alternatives in the quantity versus quality debate and actually may be useful for evaluating the long-term scientific impact of collaborative outcomes. Likewise, peer-reviewed ratings of outcomes based on reviews of proposals or progress reports could provide more neutral and standardized measures of collaboration impact. Both of these categories of measures are used infrequently but could have significant influence if applied more widely in the evaluation of collaborative work. However, further work on a reliable rating’s scale for use in peer review is needed before it is able to provide comparable results across studies.
Recommendations
Remarkably, the results of this review, which defines research collaborations to include different types of collaborative partnerships, are very similar to reviews of measures of community coalitions [Reference Granner and Sharpe60] and community-based participatory research [Reference Sandoval, Lucero and Oetzel61] conducted 15 and 7 years ago, respectively. Both of those studies concluded that there are few reliable and valid measures. In the intervening years, some progress has been made as noted [see Refs. 12, 19, 23 as examples]. Based on this observation and our findings in this study, we offer six recommendations to advance the field of team science: (1) We must pay careful attention and devote resources to the development and psychometric testing of measures of research collaboration quality and outcomes that can be replicated and broadly applied. Measures listed in this review with solid initial reliability and validity indicators provide reasonable starting points for continued development; however, measures of other constructs will also be necessary. (2) To establish validity for use in different populations and settings, designed measures should be tested across various research partner and stakeholder relationships (e.g., academia, industry, government, patient, community, and advocacy groups). (3) When evaluating outcomes, it is critical that we focus on both the quality and quantity of products and the use of rating scales for peer review. (4) The sensitivity and responsiveness of measures to interventions should be evaluated as an additional psychometric property. (5) Publications reporting on assessments of collaborations should include a clear description of the measures used; the reliability, validity, and sensitivity or responsiveness of the measures; and a statement on their generalizability. (6) Reports incorporating the use of narrowly applicable measures should include a justification for not using a more broadly applicable measure.
Conclusions
Although a few studies have conducted exemplary psychometric analyses of some measures of both collaboration quality and outcomes, most existing measures are not well-defined; do not have well-documented reliability, validity, or sensitivity or responsiveness (quality measures); and have not been replicated. Construct validity, in particular, requires further exploration. Most of the reported measures were developed for a single project and were not tested across projects or types of teams. Published articles do not use consistent measures and often do not provide operational definitions of the measures that were used. As a result of all of these factors, it is difficult to compare the characteristics and impact of research collaborations across studies.
Team science and the study of research collaborations are becoming better and more rigorous fields of inquiry; however, to truly understand the reasons that some teams succeed and others fail, and to develop effective interventions to facilitate team effectiveness, accurate and precise measurements of the characteristics and the outcomes of the collaborations are needed to further translational science and the concomitant improvements in public health.
Acknowledgements
This work was supported by the National Center for Advancing Translational Sciences, National Institutes of Health, Grant numbers: UL1 TR001449 (BBT), UL1 TR000430 (DM), UL1 TR002389 (DM), UL1 TR002377 (JBB), UL1 TR000439 (EAB), UL1 TR002489 (GD), UL1 TR001453 (NSH), UL1 TR002366 (KSK), UL1 TR001866 (RGK), UL1 TR003096 (KL), UL1 TR000128 (JS), and U24 TR002269 (University of Rochester Center for Leading Innovation and Collaboration Coordinating Center for the Clinical and Translational Science Awards Program).
Disclosures
The authors have no conflicts of interest to declare.
Disclaimer
The views expressed in this article are the responsibility of the authors and do not necessarily represent the position of the National Center for Advancing Translational Sciences, the National Institutes of Health, or the US Department of Health and Human Services.





 Open access
Open access