



1. Introduction
An ongoing challenge for theories of bilingual language representation and processing is to integrate differences across the spectrum of language experiences that comprise bilingualism (Grosjean, Reference Grosjean2012) to explain cross-language interactions in healthy speakers and speakers with language disorders. To this end, research in both language experience (Anderson et al., Reference Anderson, Mak, Keyvani Chahi and Bialystok2018; Li et al., Reference Li, Zhang, Yu and Zhao2020; Luk & Esposito, Reference Luk and Esposito2020; Marian et al., Reference Marian, Blumenfeld and Kaushanskaya2007; Marte et al., Reference Marte, Carpenter, Falconer, Scimeca, Abdollahi, Peñaloza and Kiran2022) and cognate processing (Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000; White et al., Reference White, Malt and Storms2017) has shed light on the structure of the bilingual mental lexicon. Despite great progress, subsets of bilingual speakers face unique and neglected challenges, and thus relatively little remains known of the principles governing those representations and cross-language interactions. One such case is for bilingual persons with aphasia (BPWA), in which the relationship between bilingual language experience and language function is complicated by (i) diverse patterns of language impairment due to acquired brain injury (ABI; Peñaloza & Kiran, Reference Peñaloza, Kiran, Schwieter and Paradis2019) and (ii) the subsequent functional and social dynamics surrounding each language that shift from pre- to post-ABI (Centeno, Reference Centeno2009). The present study therefore investigates lexical retrieval of cognates versus noncognates in BPWA as compared to healthy bilinguals (HB) using data from the Boston Naming Test (BNT; Kaplan et al., Reference Kaplan, Goodglass and Weintraub2001; Kohnert et al., Reference Kohnert, Hernandez and Bates1998), a common standardized neuropsychological language assessment. We aim to provide insights into the factors that structure bilingual lexicons in aphasic individuals, in addition to clinically relevant findings to better inform assessment and treatment of language impairment in BPWA.
1.1 The structure of the bilingual lexicon
The Revised Hierarchical Model (RHM; Kroll & Stewart, Reference Kroll and Stewart1994) proposes that the bilingual mental lexicon is organized across three modules supporting top-down language access: first- (L1) and second-acquired language (L2) word forms, and a shared conceptual store. One remarkable feature of the RHM is its capacity to account for differences in single word production in both unbalanced and balanced bilinguals. Kroll and Stewart (Reference Kroll and Stewart1994) used a Dutch–English picture naming and translation task including cognate pairs and examined item-level naming latencies to better understand the interdependencies between the three modules. Notably, they found that naming latencies for L1 cognate items did not differ on the basis of phonological similarity to its L2 translation pair. In contrast, naming latencies for L2 cognate items differed significantly: naming latencies were longer when translation pairs were less phonologically similar, and shorter when they were more phonologically similar. This suggested that the L1-conceptual system link is stronger than L2-conceptual system link, as access to L2 word forms is mediated through the L1 module. Furthermore, they found that translation from L2 to L1 was faster than translation from L1 to L2, suggesting that the link from L2 to L1 is stronger than the link from L1 to L2, reflective of novice L2 learners initially relying on translation equivalencies in L1 as they learn L2 words. As L2 proficiency increases, the L2-conceptual system link strengthens, allowing for direct access to word meanings and thus relying less on L1 translation equivalencies (Sunderman & Kroll, Reference Sunderman and Kroll2006). Heredia (Reference Heredia1997) suggested a dynamic interplay between L1 and L2, in which language dominance, influenced by dimensions of language experience (e.g., frequency of use), explains experimental evidence from L2-dominant bilinguals. While the RHM and its subsequent developments have been able to describe word production-based representational and access asymmetries via focusing on backward (L2-L1) and forward (L1-L2) translation latencies, differences in translation latencies in HB are attenuated in cognate items despite individual-level disparities in proficiency between the two languages (de Groot, Reference de Groot1992).
Integrating empirical evidence relating but not limited to cognate performance motivated the development of new models of bilingual processing, such as the Bilingual Interactive Activation and Plus models (BIA; Dijkstra & van Heuven, Reference Dijkstra and van Heuven1998; van Heuven et al., Reference van Heuven, Dijkstra and Grainger1998; BIA+; Dijkstra & van Heuven, Reference Dijkstra and van Heuven2002). BIA/BIA+ are inspired from the monolingual Interactive Activation Model of visual word recognition (McClelland & Rumelhart, Reference McClelland and Rumelhart1981; Rumelhart & McClelland, Reference Rumelhart and McClelland1982), presenting four layers of interconnected nodes describing bottom-up processing: letter features, letters, words, and language (L1 or L2). Distinct from the RHM, the BIA model represents a unitary bilingual lexicon and asserts nonselectivity in lexical access. The BIA model contextualized neighborhood density effects within and between languages (Dijkstra & van Heuven, Reference Dijkstra and van Heuven1998; van Heuven et al., Reference van Heuven, Dijkstra and Grainger1998), orthographic priming effects (Bijeljac-Babic et al., Reference Bijeljac-Babic, Biardeau and Grainger1997), and the effects of interlingual homographs (Dijkstra et al., Reference Dijkstra, Timmermans and Schriefers2000). The BIA+ model then introduced phonological and semantic nodes, as well as complementary schemas from the Inhibitory Control Model (Green, Reference Green1998) to account for the influence of differential task demands and linguistic/non-linguistic contexts. While the BIA+ model contextualized a broader range of empirical results than its predecessor, integration of broader developmental L2 acquisition remained challenging to model without further modifications to the base architecture of the proposed representational network.
Notably, Dijkstra and Rekké (Reference Dijkstra and Rekké2010) further developed the Multilink model, which synthesizes ideas from the RHM and BIA/BIA+ models, achieving greater explanatory power by incorporating ecological and experiential facets of bilingualism, such as proficiency and L2 age of acquisition (AoA), to optimally model recognition, retrieval, and production during language processing, and particularly in special cases like interlingual homographs and cognates. For example, leveraging statistical (e.g., lexical frequency of occurrences per million) and information theoretic (e.g., Levenshtein distance) properties of words, simulations showed that unlike noncognates, cognates simultaneously coactivated two similar representations in both languages. This revealed an additional contribution to the facilitation effect of cognates – convergent spreading activation, wherein activation from two orthographic nodes would propagate to a singular semantic node resulting in earlier and stronger activation (Dijkstra et al., Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010).
Relevant to the present study focused on bilingual aphasia, a neurobiologically plausible model of language processing (Nadeau, Reference Nadeau2012) and bilingual aphasia recently proposed by Nadeau (Reference Nadeau2019) situates empirical findings within the framework of population encoding of neural representations and parallel distributed processing theory. In this model, population-encoded representations of, e.g., phonological sequences, correspond to distributed patterns of neuronal firing across various brain regions. Particular phonological sequence representations are then understood to be loci on n-dimensional manifolds of neural activity. Critically, representations and their networks are dynamically modulated by the statistical regularities of experience (e.g., lexical frequency, AoA). Moreover, they exhibit dense intra- and inter-network connectivity, variable connection strengths (i.e., synaptic strengths), and graceful degradation (i.e., fault tolerance), among other properties. As applied to bilingualism and cognates, Nadeau (Reference Nadeau2019) proposes that cognate facilitation effects arise from overlapping language-specific phonological sequences within neural networks instantiated along the pertinent cortical substrate (e.g., left-centric perisylvian acoustic-articulatory motor pathways). Although the model's most granular predictions have not been formally experimentally validated, a population encoding perspective deserves consideration given its explanatory power and applicability to bilinguals with aphasia.
In summary, a central question models of bilingual language representation and processing aim to address is how best to characterize asymmetries between languages with respect to behavioral performance, and how these asymmetries are modulated via individual-level factors, such as differential language proficiency, and item-level factors, like lexical frequency.
1.2. The cognate facilitation effect in bilingual language processing
The abovementioned models provide the context to understand the phenomenon of cognates, which are uniquely suited to examine the interdependencies present in the bilingual lexicon. Cognates are words that share semantic, orthographic, and phonological features between two or more languages. As cognates may overlap in representational space within the shared bilingual conceptual store, a cognate advantage or cognate facilitation effect is said to emerge. That is, cognates relative to noncognates are processed more efficiently across several modalities, including speech production (Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000), auditory comprehension (Blumenfeld & Marian, Reference Blumenfeld and Marian2007), and orthography (e.g., Peeters et al., Reference Peeters, Dijkstra and Grainger2013). Furthermore, there are within-cognate differences with respect to similarity that are consequential to speed and efficiency of processing. For example, Dijkstra et al. (Reference Dijkstra, Miwa, Brummelhuis, Sappelli and Baayen2010) presented HB with cognate words indexed by degree of orthographic overlap between English and Dutch. The stimuli ranged from identical cognates with perfect orthographic overlap (e.g., lamp – lamp), to partial overlap (e.g., tomato – tomaat). Their results demonstrated that cognate processing facilitation effects (indexed by reaction times; RTs) improved as a function of orthographic overlap. The authors suggested that cognate processing facilitation effects resulted from simultaneous activation of the presented stimuli's representations in both languages, thus resulting in activation of a common semantic representation.
The neurophysiological signature of cognate processing has been also examined in HB. Midgley et al. (Reference Midgley, Holcomb and Grainger2011) compared the event-related potentials (ERPs) of 42 healthy English–French bilinguals who read word lists of cognates and noncognates in two blocks, one for each language. The results showed reduced negativities in the posterior N400 component in both L1 and L2 relating specifically to cognates, reflective of easier processing (i.e., more efficient mapping of form to meaning). Of note, the authors initially hypothesized that a stronger effect would emerge when processing L2 words versus L1 words, as L2 cognates would theoretically benefit from the L1 translation pair's established link to the conceptual store. Despite some previous studies showing no cognate facilitation in L1 recognition (Gerard & Scarborough, Reference Gerard and Scarborough1989) or reporting it in highly proficient multilinguals (van Hell & Dijkstra, Reference van Hell and Dijkstra2002), Midgley et al. (Reference Midgley, Holcomb and Grainger2011) found robust cognate facilitation in L1 irrespective of proficiency.
Although L2 processing appears to benefit more robustly from cognate facilitation than L1 processing, the language-differential presence and magnitude of cognate facilitation given the asymmetric properties of bilingual language representation remain difficult to precisely predict. Therefore, considering dimensions of bilingual language experience (via, e.g., self-assessed active and passive exposure to an L2, use of an L2, and L2 proficiency; for a review, see Surrain & Luk, Reference Surrain and Luk2019) could contribute to better understanding cognate facilitation effects across different profiles of bilingualism.
1.3 Cognate facilitation is moderated by bilingual language experience
Recall Midgley et al. (Reference Midgley, Holcomb and Grainger2011)'s findings which evinced more efficient processing of cognates relative to noncognates. The authors also collected self-ratings of modality-specific proficiency in L2 (e.g., comprehension, listening, and reading), the number of L2 classes the participants had taken, and whether they had ever participated in an L2 immersion program. Of their 42 participants, 18 had participated in L2 immersion programs abroad. Ultimately, they found that, of those experiential variables, only L2 immersion correlated significantly with cognate facilitation found via ERP measures. More specifically, participants with L2 immersion experience showed more cognate facilitation in L1 and less cognate facilitation in L2 relative to those who did not have an immersion experience. The authors posited that more L2 immersion led to less of a difference between L1 and L2 in speed and efficiency of lexical access, reflecting a burgeoning resemblance to L1 access as links from L2 word forms to conceptual meaning strengthen.
Likewise, language dominance is predictive of the presence and magnitude of cognate facilitation. For example, Gollan et al. (Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007) studied 29 healthy older Spanish–English bilinguals using the BNT, which contains a high number of cognates. The study divided the total sample into balanced and unbalanced bilinguals by examining the difference in BNT scores between each language and considering survey measures, including self-reported ratings of spoken proficiency and daily use of each language. The results revealed that both balanced and unbalanced bilinguals showed cognate facilitation effects in the nondominant language, but only balanced bilinguals showed significant cognate facilitation in the dominant language. While presence of cognate facilitation in the less dominant language had been previously found (Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000; van Hell & Dijkstra, Reference van Hell and Dijkstra2002), the presence of cognate facilitation in the dominant language had been less frequently reported. This led the authors to suggest that cognate facilitation in the dominant language for balanced bilinguals was present because both languages were established enough to contribute toward converging activation at shared target nodes. However, neither self-rated speaking ability nor percent of daily use in either language correlated with cognate facilitation.
Rosselli et al. (Reference Rosselli, Ardila, Jurado and Salvatierra2014) repeated this procedure with 103 healthy younger Spanish–English bilinguals, again finding asymmetric cognate facilitation such that unbalanced bilinguals showed the greatest facilitation effects when naming in their nondominant language. More recently, Robinson Anthony and Blumenfeld (Reference Robinson Anthony and Blumenfeld2019) studied cognates in 80 healthy young English–Spanish bilinguals using a battery of standardized assessments tapping receptive vocabulary and picture naming in addition to a nonlinguistic spatial Stroop task. The authors operationalized language dominance both continuously and categorically using both subjective (e.g., self-reported language proficiency and current exposure) and objective (e.g., performance on expressive and receptive language tasks) measures. Similar to Gollan et al. (Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007) and Rosselli et al. (Reference Rosselli, Ardila, Jurado and Salvatierra2014), the categorical dominance measure revealed cognate facilitation in the group-level nondominant language, whereas the continuous dominance measure showed an increase in cognate facilitation as proficiency in the target language decreased.
In summary, cognate processing as measured behaviorally and via physiological methods shows moderation by bilingual language experience across adulthood. In one case, L2 immersion resulted in less of a discrepancy in lexical access between L1 and L2 (Midgley et al., Reference Midgley, Holcomb and Grainger2011). Across three conceptually similar studies, language dominance revealed that unbalanced bilinguals showed strong cognate facilitation effects in their nondominant language in picture naming (Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007; Robinson Anthony & Blumenfeld, Reference Robinson Anthony and Blumenfeld2019; Rosselli et al., Reference Rosselli, Ardila, Jurado and Salvatierra2014). Interestingly, these effects were salient despite different measures of bilingual language experience, e.g., categorical and continuous classification schemes, objective scores on standardized assessments, and self-reported metrics. What is less known, however, is how bilingual language experience affects bilinguals whose lexical access mechanisms are impaired due to neurological damage.
1.4. Cognate facilitation in bilingual aphasia
Picture naming tests are frequently used in the diagnosis of anomia, the hallmark symptom of all aphasic syndromes. In BPWA, the presence of language impairment is often asymmetrical reflecting differences in their achieved proficiency in each language prior to their ABI (Kuzmina et al., Reference Kuzmina, Goral, Norvik and Weekes2019; Peñaloza et al., Reference Peñaloza, Barrett and Kiran2020). It is therefore essential to characterize the presence of deficits in each language in the context of individual bilingual language experience and identify cross-language interactions in language performance as they may inform both the diagnosis of impairment and prognosis. Thus, the processing of cognates is one such window into cross-language interaction in bilingual aphasia.
However, the study of cognates in BPWA has been primarily limited to single-case study designs and small groups yielding inconclusive findings. For example, based on previous accounts suggesting efficacious cognate-centered cross-language interactions in BPWA (Roberts & Deslauriers, Reference Roberts and Deslauriers1999), Kohnert (Reference Kohnert2004) studied D.J., a Spanish–English bilingual with severe non-fluent aphasia who was premorbidly highly proficient in both languages. The intervention involved two kinds of treatment: first, a two-month nonverbal skills-based cognitive therapy performed in Spanish for the first month, and English for the second month. Then, following a one-week washout period, a two-week cognate-based lexical-semantic therapy was performed in Spanish for the first week, and English for the second week. Regarding the cognate-based therapy, at pre-treatment, for cognates and noncognates in L1 and L2, accuracies were 40% and 20%, and 70% and 10%, respectively. D.J. improved on both types of words in both L1 and L2, achieving post-treatment accuracies of 80% and 70%, and 90% and 70%, respectively. However, cross-language generalization was primarily limited to cognate items: one week post treatment, L2 picture naming resulted in 70% accuracy on cognate items, but just 10% on noncognate items.
In contrast, Kurland and Falcon (Reference Kurland and Falcon2011) reported the case of G.L.P., a Spanish–English bilingual woman with severe non-fluent aphasia. G.L.P. was premorbidly highly proficient in Spanish and exhibited “good” speaking and reading skills in English. She completed three phases of treatment, one in each language and a final one in both languages. Unlike D.J., increased naming accuracy was found in noncognates rather than cognates. The authors suggested that rather than facilitate, cognate items appeared to interfere with lexical retrieval of target items, positing that damage to specific regions including the basal ganglia may have contributed to the reported effect.
In another study examining picture naming in 15 balanced French–English BPWA and 15 balanced French–English HB, Roberts and Deslauriers (Reference Roberts and Deslauriers1999) examined naming accuracy of cognate items and their translation pairs, and whether the items were named accurately in both L1 and L2, either L1 or L2, or neither. The authors found that most BPWA (i) named both the cognate and its translation pair accurately and (ii) showed a significant difference between cognate and noncognate accuracy in L2 but not L1. Additionally, perhaps foreshadowing Kurland and Falcon's (Reference Kurland and Falcon2011) findings, for the subset of items that were only named accurately in L1, noncognate items were named accurately more often than cognate items.
Finally, Van der Linden et al. (Reference Van der Linden, Verreyt, De Letter, Hemelsoet, Mariën, Santens, Stevens, Szmalec and Duyck2018) examined various bilingual combinations (Dutch–French, Dutch–English, and French–Dutch) and compared the performance of 15 BPWA and 19 HB on a lexical decision task (i.e., recognition of words versus nonwords) using 30 cognates – 14 of which were identical – and 30 noncognates. 7 BPWA showed differential language impairment (i.e., one language showing greater recovery than the other), while 8 showed parallel language impairment (i.e., both languages showing similar recovery). Notably, the two aphasia groups were composed of balanced bilinguals per self-reported pre-onset proficiency. While all three groups showed higher identification accuracy for cognates relative to noncognates, the size of cognate facilitation did not differ across groups. Furthermore, RTs differed such that the BPWA group with differential language impairment showed a greater cognate facilitation (i.e., comparatively reduced latencies) than both the HB group and the BPWA group with parallel impairment.
In brief, cognate processing in BPWA is relatively understudied. While single-case studies show great utility in providing detailed descriptions of individual performance, their results are difficult to generalize and thus may generate conflicting conclusions (e.g., Kohnert, Reference Kohnert2004; Kurland & Falcon, Reference Kurland and Falcon2011). Furthermore, group-level data examining cognates in BPWA is limited. Despite evidence paralleling what has been found in one case study (Roberts & Deslauriers, Reference Roberts and Deslauriers1999), as well as evidence to support the belief that certain BPWA may show even greater cognate facilitation relative to HB (Van der Linden et al., Reference Van der Linden, Verreyt, De Letter, Hemelsoet, Mariën, Santens, Stevens, Szmalec and Duyck2018), more evidence is needed to explicate the dynamics of cognate access in bilingual aphasia.
1.5. The present study
As reviewed here, the study of cognates can facilitate our understanding of structural lexical-semantic interdependencies between languages (Kohnert, Reference Kohnert2009). Cognates have theoretical and clinical value to bilingual aphasia research, not only in probing the preserved structure and functionality of L1 and L2 processing, but also in relation to maximizing treatment efficacy. We therefore aim to elucidate lexical access in picture naming for cognates and noncognates in BPWA as compared to HB and examine the influence of bilingual language experience on naming performance using the Boston Naming Test (Kaplan et al., Reference Kaplan, Goodglass and Weintraub2001; Kohnert et al., Reference Kohnert, Hernandez and Bates1998), a standardized neuropsychological test widely used in research and clinical settings. Characterization of naming performance in the BNT may shed light on the intactness of cross-linguistic transfer mechanisms in BPWA which can potentially inform language intervention approaches.
This work builds on the rich corpus of data relating to bilingual language experience and cognate facilitation in HB to examine the cognate facilitation effect in BPWA. We thus focused on the following questions in this study:
(i) How do BPWA compare to HB in picture naming performance on cognate and noncognate items on the BNT in their L1 and L2? We hypothesized that HB would show better naming accuracy on a set of cognates and noncognates relative to BPWA secondary to post-ABI language impairment resulting in difficulty with lexical retrieval. Furthermore, we expected that both groups would show superior naming accuracy on cognates relative to noncognates. Finally, as both groups are relatively L1-dominant bilinguals, we expected language (L1/L2) to be associated with naming performance.
(ii) How do BPWA compare to HB in cognate facilitation effect on picture naming in L1 and L2? We hypothesized that we would see no significant difference in cognate facilitation – operationalized as accuracy on cognate items minus noncognate items – between BPWA and HB given the relatively similar bilingual language profiles of each group (e.g., Van der Linden et al., Reference Van der Linden, Verreyt, De Letter, Hemelsoet, Mariën, Santens, Stevens, Szmalec and Duyck2018). We expected differences in cognate facilitation by language, i.e., cognate facilitation would favor L2 given the relative L1-dominance of both groups.
(iii) How do BPWA compare to HB in the factors that modulate L1 and L2 naming accuracy? We examined two kinds of potential factors that would influence naming performance in HB and BPWA. First, item-level factors, including lexical frequency, degree of phoneme/grapheme overlap between BNT items and their translation pairs. Second, individual-level factors, including bilingual language experience specific to each group in each language (i.e., L1 and L2), and overall language impairment in each language for BPWA. First, for BPWA, we expected that overall language impairment in both L1 and L2 would be associated with naming performance. Additionally, we expected the degree of phoneme/grapheme overlap to relate to naming performance in both groups. Likewise, in both groups, we expected lexical frequency and language experience in the target language (i.e., high L1 experience when naming in L1) and nontarget language (i.e., high L2 experience when naming in L1) to impact naming performance. Finally, we predicted that language experience in the nontarget language would pair with overlap such that greater language experience in the nontarget language (e.g., naming in L2 with high L1 experience) would moderate the impact of overlap (Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007; Midgley et al., Reference Midgley, Holcomb and Grainger2011; Robinson Anthony & Blumenfeld, Reference Robinson Anthony and Blumenfeld2019; Rosselli et al., Reference Rosselli, Ardila, Jurado and Salvatierra2014).
(iv) How do BPWA compare to HB in the factors contributing to cognate facilitation in picture naming? We examined language experience in L1 and L2 in both HB and BPWA and L1 and L2 impairment in BPWA as potential factors that modulate the extent of cognate facilitation realized on picture naming in these groups. For BPWA, we expected language impairment to be associated with cognate facilitation. For both HB and BPWA, we hypothesized that language experience from both languages would relate to cognate facilitation, as greater experience in each language would contribute to stronger converging activation toward a singular semantic node from simultaneously coactivated representations (Djikstra et al., 2010; Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007). Alternatively, this effect could be achieved via overlapping, e.g., semantic-phonologic sequence knowledge in L1 and L2 (Nadeau, Reference Nadeau2019).
2. Materials and methods
2.1. Participants
Participants were 40 Spanish–English BPWA (18 females; mean age = 51.94 ± 16.28; mean number of years of education = 13.95 ± 3.12; mean L2 AoA = 10.80 ± 8.85), and 31 Spanish–English HB (24 females; mean age = 43.09 ± 15.59; mean number of years of education = 17.53 ± 4.66; mean L2 AoA = 13.77 ± 12.00). While the BPWA represent the group of interest for the present study, the HB served as the group of reference to make appropriate inferences regarding the cognate processing abilities in BPWA in the presence of language breakdown. The data of the two groups were retrieved retrospectively from a participant database in the Aphasia Research Laboratory at Boston University. Thirty-five BPWA and 27 HB reported Spanish as their L1 – hence, both groups consisted of primarily L1 Spanish speakers. While the two groups differed in age (t(65.9) = 2.33, p = .023) and number of years of education (t(49.8) = −3.69, p < .001) at testing, they were comparable on their L2 AoA (t(53.4) = −1.16, p = .252). Finally, both BPWA (t(51.6) = 3.37, p = .001) and HB (t(39.2) = 4.10, p < .001) showed L1-dominance per their Language Ability Ratings (see Section 2.2 and Table 1).
Table 1. Comparison of Language Use Questionnaire metrics for bilingual persons with aphasia and healthy bilinguals
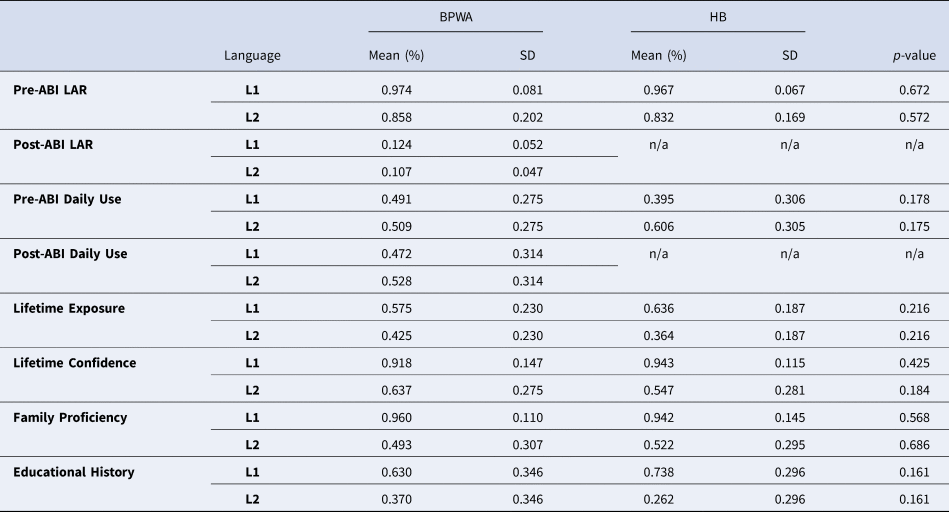
Scores are expressed as percentages of time (exposure, use, and education history in L1 and L2), confidence in L1 and L2, and family and self-rated proficiency in L1 and L2.
BPWA = bilingual persons with aphasia; HB = healthy bilingual; L1 = first-acquired language; L2 = second-acquired language; SD = standard deviation; LAR = language ability rating; ABI = acquired brain injury; n/a = not assessed (only relevant for BPWA). One data point was missing for the following BPWA metrics: L1 Pre-ABI LAR; L1 Post-ABI LAR; L2 Post-ABI LAR; L1 Post-ABI Daily Use; L2 Post-ABI Daily Use. HB had no missing data.
BPWA were at least 6 months post-onset (mean MPO = 49.74 ± 83.53). See Supplementary Table 1 for more information regarding lesion characteristics, aphasia subtype, and aphasia severity. All participants gave written informed consent for standardized language testing per procedures approved by the Ethical Committee of Boston University and the University of Texas at Austin. All participants completed standardized language testing in each respective language on separate days with assessment language counterbalanced across days to mitigate unintended cross-language effects.
2.2. Assessment of bilingual language experience
All participants completed the Language Use Questionnaire (LUQ), previously validated in healthy bilinguals in a variety of L1 and L2 combinations (Kastenbaum et al., Reference Kastenbaum, Bedore, Peña, Sheng, Mavis, Sebastian-Vaytadden, Rangamani, Vallila-Rohter and Kiran2019). The LUQ measures various aspects of bilingual language experience including the L2 Age of Acquisition (AoA), and for each language, separately: Language Ability Rating (LAR); Daily Use; Family Proficiency; Educational History; Lifetime Exposure; and Lifetime Confidence. For BPWA, the LUQ distinguishes between pre- and post-ABI LAR and Daily Use scores, reflective of impairment-induced changes in language dynamics.
Per the LUQ, L2 AoA is the self-reported age of L2 learning onset. L2 AoA was 0 for simultaneous bilinguals. LAR is a self-reported five-point rating scale of language fluency, with 1 representing non-fluent and 5 representing native-level fluency. The final average score is computed across a variety of situations and modalities (e.g., speaking and listening in casual and formal situations, and reading and writing) in each language. Daily Use measured the languages participants and their conversational partners used in their daily life on an hourly basis for weekdays and weekends, independently. Daily Use was then calculated as a percentage of overall time participants spent using each language. Family Proficiency measured the participant's ratings on their mother, father, and siblings’ proficiency in each language in 25% increments, from not confident (0%) to strong confident (100%), which were then averaged for an overall Family Proficiency score. Educational History measured the degree to which each language was implicated in formal educational settings, was spoken by peers, and was preferred for speaking by each participant across all educational levels. An overall average percentage of Educational History was then calculated. Lifetime Exposure measured the percentage of time, in 25% increments, that participants heard, spoke, and read each language, or self-reported over the course of their life, measured in three-year intervals (e.g., 0 to 3, 3 to 6, etc.) and a final interval for age 30 and up. Likewise, Lifetime Confidence measured self-reported confidence, in 25% increments, in hearing, speaking, and reading each language over the course of their life, measured in three-year intervals (i.e., 0 to 3), and a final interval for 30 and up. BPWA had two additional Lifetime Exposure and Lifetime Confidence intervals: from age 30 until age of ABI onset, and from ABI onset to the date of LUQ administration, to account for changes pre- and post-ABI. For both Lifetime Exposure and Lifetime Confidence, final percentages for both HB and BPWA were computed as an average across the age intervals and were weighted by the participants’ age. BPWA completed the LUQ with the aid of a research assistant or a caregiver. See Table 1 for participant LUQ data and comparisons between BPWA and HB, demonstrating similar bilingual language experience profiles between groups.
2.3. Western Aphasia Battery-Revised
Only BPWA completed the Western Aphasia Battery-Revised (WAB-R; Kertesz, Reference Kertesz2007) to assess aphasia severity in their L1 and L2. The WAB-R is a core outcome measure of language impairment in aphasia (Wallace et al., Reference Wallace, Worrall, Rose, Le Dorze, Breitenstein, Hilari, Babbitt, Bose, Brady, Cherney, Copland, Cruice, Enderby, Hersh, Howe, Kelly, Kiran, Laska, Marshall and Webster2019) which comprehensively evaluates receptive and expressive linguistic skills. More specifically, the WAB-R considers several dimensions of functional language, such as fluency of speech (e.g., effortful or effortless speech), verbal and written comprehension, and repetition ability, to distinguish aphasic syndromic subtypes. Subtypes per performance on these dimensions can then be subdivided into either fluent or non-fluent subtypes. Examples of fluent subtypes include anomic (i.e., intact comprehension and repetition ability), Wernicke (i.e., impaired comprehension and repetition ability), and conduction (i.e., intact comprehension, impaired repetition ability), while examples of non-fluent subtypes include Broca (i.e., intact comprehension, impaired repetition ability) and global (i.e., impaired comprehension and repetition ability). A WAB-R Aphasia Quotient (AQ) score was computed for each language which served as a measure of overall language impairment. Scores range from 0 to 100. Severity classifications are as follows: very severe (0-25); severe (26-50); moderate (51-75); and ≥76 (mild). See Supplementary Table 1 for participant data and Table 3 for group-level data.
2.4. The Boston Naming Test
All participants completed the Boston Naming Test (Kaplan et al., Reference Kaplan, Goodglass and Weintraub2001; Kohnert et al., Reference Kohnert, Hernandez and Bates1998) in both languages. Naming trials were administered according to standardized instructions except that participants were asked to name all 60 items regardless of performance (i.e., assessment otherwise is discontinued upon six consecutive errors).
Lexical frequency and cognate status are two important characteristics of the structure of the BNT relevant to the present study. First, items on the original English version of the BNT are graded by difficulty such that the progression throughout the test reflects increasing difficulty, going from high frequency items that are more easily named (item 7: comb) to low frequency items that are more difficult to name (item 59: protractor; Kohnert et al., Reference Kohnert, Hernandez and Bates1998). However, words do not necessarily share the same lexical frequency cross-linguistically (Sanfeliu & Fernandez, Reference Sanfeliu and Fernandez1996), which has been shown to affect the Spanish version of the BNT as it does not replicate the pattern of easy-to-difficult item progression (Kohnert et al., Reference Kohnert, Hernandez and Bates1998).
Second, it is estimated that nearly half of the BNT pictures are Spanish–English cognates (Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007; Rosselli et al., Reference Rosselli, Ardila, Jurado and Salvatierra2014), depending on definitions of cognate status which may vary across studies. Also, cognates and noncognates on the BNT are not matched by lexical frequency, making it difficult to assess these two variables in the full set of test items.
Consequently, and for comparison purposes with previous research, we used the cognate classification of BNT items reported in Gollan et al. (Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007) and Rosselli et al. (Reference Rosselli, Ardila, Jurado and Salvatierra2014). In addition, following the procedure in Gollan et al. (Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007), we selected the same 22 cognates (mean item number = 34.4 ± 14.7) and 22 noncognates (mean item number = 34.3 ± 17.2) matched for item number (t(41.01) = .018, p < .001).
2.5. Data preparation and analysis
To evaluate the facilitative effect of cognates in BPWA relative to the HB which served as a group of reference in the present study, we defined cognates both categorically (cognate or noncognate per Gollan et al., (Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007)'s classification; see Supplementary Table 2) and continuously, measured in degree of overlap between cognates and their translation pairs. We followed prior research (Higby et al., Reference Higby, Donnelly, Yoon and Obler2020) to calculate the degree of overlap between both cognate and noncognate pairs as a function of normalized Levenshtein distance. Levenshtein distance is a similarity rating that compares the difference between two strings by calculating the number of insertions, deletions, and substitutions required for the two inputs to match (Schepens et al., Reference Schepens, Dijkstra and Grootjen2012). As Levenshtein distance in shorter words is inherently limited (e.g., two three-letter words would produce a max rating of 3), we normalized the Levenshtein distance per Schepens et al. (Reference Schepens, Dijkstra and Grootjen2012)'s procedure by subtracting the quotient of distance (i.e., the minimum number of insertions, deletions, and substitutions) over length (i.e., the maximum number of characters between the two inputs) from 1. Furthermore, to capture phonetic information, in the case of words with poor grapheme-phoneme correspondence, e.g., accordion – acordeón, we removed one ‘c’ in accordion as the English ‘cc’ and Spanish ‘c’ are pronounced the same (e.g., Higby et al., Reference Higby, Donnelly, Yoon and Obler2020). This measure (hereafter referred to as “phoneme/grapheme overlap”) was significantly greater for cognate items (mean = .508 ± .129) relative to noncognate items (mean = .108 ± .080; t(35.004) = 12.354, p < .001).
Next, as we sought to understand the potential variation between naming in one language versus the other, as well as variation within groups, we produced models for naming in L1 and L2 in each group to address question (iii). Unlike Gollan et al. (Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007), we fit L1 and L2 naming models using log-transformed lexical frequency (hereafter referred to as “lexical frequency”) instead of item difficulty given Kohnert et al. (Reference Kohnert, Hernandez and Bates1998)'s findings that Spanish BNT items are not graded in difficulty like English BNT items. Lexical frequency values were retrieved from the EsPal (Duchon et al., Reference Duchon, Perea, Sebastián-Gallés, Martí and Carreiras2013), SUBTLEX-ESP (Cuetos et al., Reference Cuetos, Glez-Nosti, Barbón and Brysbaert2011), SUBTLEXUS (Brysbaert & New, Reference Brysbaert and New2009), and CLEARPOND (Marian et al., Reference Marian, Bartolotti, Chabal and Shook2012) databases. We were unable to retrieve lexical frequency values for the following compound word items: silla de ruedas, caballo de mar, and rollo de papel.
The remaining items were matched for lexical frequency (t(78.824) = −.180, p = .857) between Spanish (mean = 3.59; SD = 6.07) and English (mean = 3.36; SD = 5.16). Both cognate lexical frequency (t(41.43) = .083, p = .934) and noncognate lexical frequency (t(28.251) = .533, p = .598) between Spanish (cognates: mean = 4.63 ± 7.69; noncognates: mean = 2.38 ± 3.16) and English (cognates: mean = 4.18 ± 6.84; noncognates: mean = 1.92; ± 1.86) were matched. Lexical frequency of English cognates to English noncognates (t(24.111) = 1.914, p = .067) and lexical frequency of Spanish cognates to Spanish noncognates (t(28.76) = 1.266, p = .215) were also matched. Finally, we note that lexical frequency is significantly different (t(54.132) = 2.252, p = .028) between cognates overall (mean = 4.72 ± 7.19) and noncognates overall (mean = 2.12 ± 2.52).
To address how BPWA and HB compared in cognate facilitation in picture naming in L1 versus L2 (question ii), as well as the bilingual language experience associated with cognate facilitation (question iv), we first computed cognate facilitation for BPWA and HB as the mean accuracy on cognate items minus the mean accuracy on noncognate items per the binary classification, resulting in a cognate facilitation effect of .106 (skewness = .594, kurtosis = 2.667) for BPWA, and .222 (skewness = −.07, kurtosis = 2.478) for HB.
Finally, to quantify the individual differences in bilingual language experience for questions (iii) and (iv), we first performed principal component analyses (PCA) on the L1 and L2 LUQ metrics of BPWA and HB, as done in our previous work (Carpenter et al., Reference Carpenter, Peñaloza, Rao and Kiran2021; Kastenbaum et al., Reference Kastenbaum, Bedore, Peña, Sheng, Mavis, Sebastian-Vaytadden, Rangamani, Vallila-Rohter and Kiran2019; Peñaloza et al., Reference Peñaloza, Barrett and Kiran2020). We retained components per the Kaiser-Guttman criteria (eigenvalue > 1.0) and used a varimax rotation on solutions with more than one component. Component loadings for BPWA are from a larger sample (N = 85), including all 40 BPWA in this report, whereas component loadings for HB reflect those of the 31 HB included in this study (PCA procedures have been described in detail elsewhere; Marte et al., Reference Marte, Carpenter, Falconer, Scimeca, Abdollahi, Peñaloza and Kiran2022). Results of these analyses are shown in Table 2.
Table 2. Results of the principal component analysis conducted on L1 and L2 for healthy bilinguals and bilingual persons with aphasia

Component loadings exceeding .60 are marked in bold. L1 = first-acquired language; L2 = second-acquired language; AoA = L2 age of acquisition; Pre-ABI = pre-acquired brain injury; post-ABI = post-acquired brain injury; LAR = language ability ratings; PC = principal component; RC = rotated component; LUQ = Language Use Questionnaire. Table retrieved from Marte and Carpenter et al. (Reference Marte, Carpenter, Falconer, Scimeca, Abdollahi, Peñaloza and Kiran2022).
For question (i), we constructed a generalized linear mixed model using the ‘lme4’ package (Bates et al., Reference Bates, Mächler, Bolker and Walker2015) and R Statistical Software (R Core Team, 2021). The dependent variable was a binary variable corresponding to accuracy across the 44 BNT items in both L1 and L2. We included the following categorically-coded fixed effects: group (HB/BPWA), language (English/Spanish), cognate status (cognate/noncognate), and all two-way interactions. We included random intercepts for participant and item.
For question (ii), we first carried out paired t-tests between cognate and noncognate accuracy in each language for each group, and then performed effect size calculations to quantify facilitation in L1 and L2. Next, we carried out an ANOVA with cognate facilitation as the dependent variable and categorically-coded group (HB/BPWA) and language (L1/L2) as independent variables. For both models referenced in questions (i) and (ii), we performed post-hoc comparisons with a Bonferroni correction using the ‘stats’ package (R Core Team, 2021) and the p.adjust() function in R, multiplying the resultant vectors of p-values by the number of comparisons made in each model.
For question (iii), we again used generalized linear mixed modeling. The dependent variables of interest were binary variables corresponding to accuracy in L1 and L2 on BNT items. Independent variables included bilingual language experience components, lexical frequency, phoneme/grapheme overlap, and all possible two-way interactions. For BPWA, we controlled for overall language impairment by including their WAB-R AQ scores in the language examined (i.e., L1 WAB-R AQ in the L1 naming model). We carried out backward stepwise regression analyses using the step() function from the ‘lmerTest’ package (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017) in R.
For question (iv), we used a multiple linear regression analysis for each group using cognate facilitation effect (i.e., accuracy on cognate items minus accuracy on noncognate items) as the dependent variable, and bilingual language experience components derived from the LUQ as independent variables. We included all possible two-way interactions between these variables in both regression models to examine potential synergistic and antagonistic effects of bilingual language experience on cognate facilitation. For BPWA, we included their WAB-R AQ scores in each language. We then performed backward stepwise selection using the ‘MASS’ (Venables & Ripley, Reference Venables and Ripley2002) package in R.
Finally, goodness-of-fit was assessed using residual diagnostics following the procedure outlined in the ‘DHARMa’ package (Hartig & Lohse, Reference Hartig and Lohse2022) in R. All mixed models referenced showed non-significant results across dispersion, outlier, and Kolmogorov-Smirnov tests.
3. Results
3.1. Naming performance of cognates and noncognates in HB and BPWA
To address question (i) regarding group-level comparisons in picture naming performance on cognate and noncognate items across L1 and L2 on the BNT, a logistic mixed effects model comprised of the following categorical fixed effects: group (HB/BPWA); language (English/Spanish); cognate status (cognate/noncognate), and all two-way interactions, was fit to accuracy.
The resulting model revealed group (HB; p = .015), cognate status (p = .036), and a group (HB) × cognate status (cognate) interaction as significant (p < .001). All other fixed effects were not significant (all p ≥ .412). Notably, the results were not influenced by language. Post-hoc comparisons revealed that HB outperformed BPWA in naming of both cognates and noncognates (both p < .001), and that both HB (p < .001) and BPWA (p = .007) were more likely to name cognates than noncognates. See Tables 3 and 4 for further detail on between-group naming comparisons and model details, and see Figure 1 for visualization of cognate and noncognate naming across both groups in L1 and L2. In summary, performance in cognate naming exceeded that of noncognate naming performance across both groups in both languages despite significant differences in naming accuracy between the two groups favoring HB, with no apparent distinction between languages.
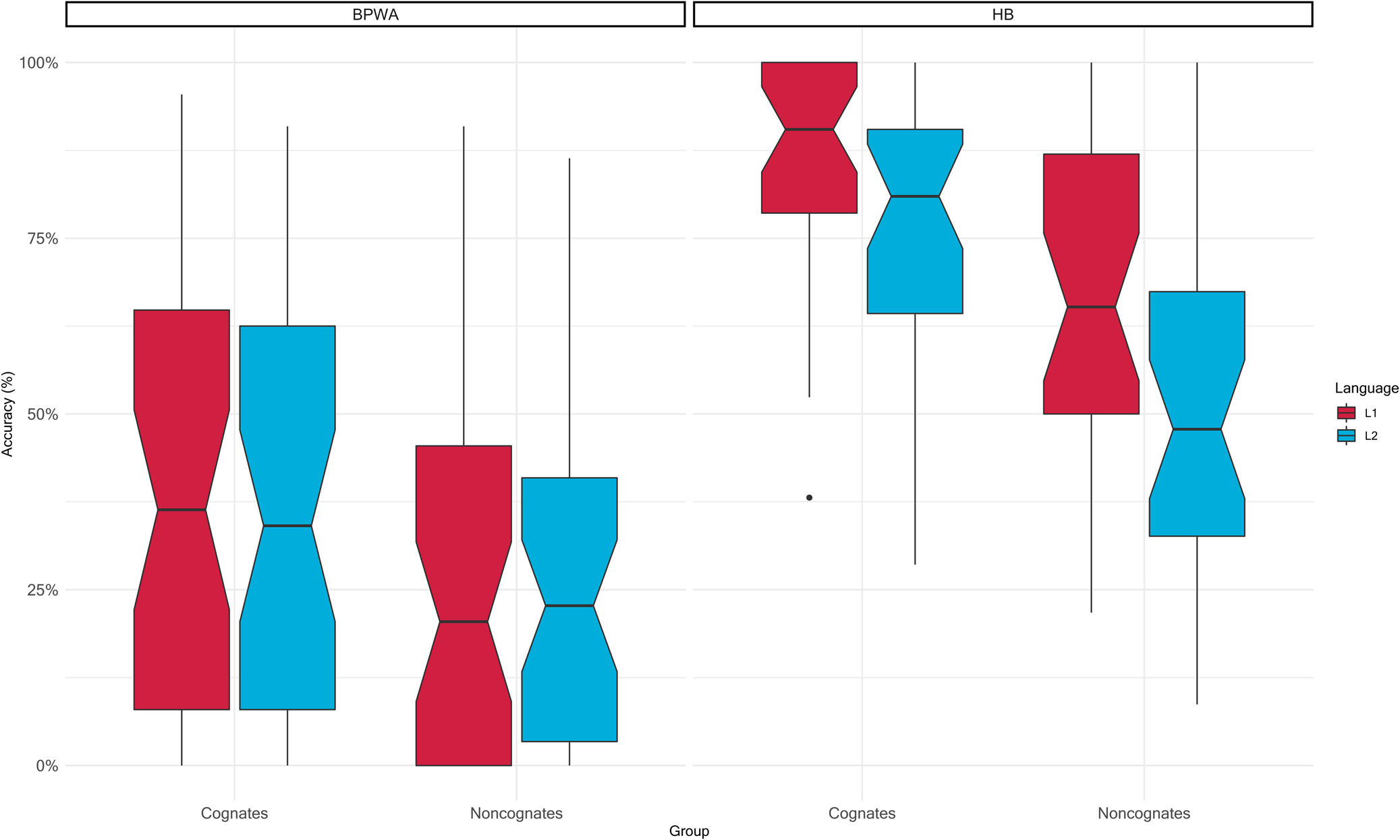
Figure 1. Naming accuracy of BPWA and HB for cognate and noncognate items in L1 and L2 on the Boston Naming Test. Cognates were named with greater accuracy than noncognates by BPWA (on the left), and HB (on the right). HB appear to demonstrate greater facilitation in both L1 (red) and L2 (blue) when naming cognates relative to noncognates as compared to BPWA.
The horizontal line in each box represents the median while the notches in each box represent its 95% confidence interval. Vertical lines extending above and below represent maximum and minimum ranges. Points beyond the vertical lines represent outliers.
Table 3. Aphasia severity and repetition scores per Western-Aphasia Battery, and comparison of bilingual persons with aphasia and healthy bilinguals on their L1 and L2 naming accuracy of cognates and noncognates on the Boston Naming Test

WAB-R Repetition reflects participant scores (out of 100) on the repetition subtest. Accuracy reflects the average percentage of correct naming responses on a selected subset of cognates and noncognates of the BNT. Cohen's d values reflect the effect size of the cognate facilitation effect.
L1 = first-acquired language; L2 = second-acquired language; BPWA = bilingual persons with aphasia; HB = healthy bilinguals; WAB-R = Western Aphasia Battery-Revised; AQ = Aphasia Quotient; BNT = Boston Naming Test.
Table 4. Comparing naming performance between healthy bilinguals and bilingual persons with aphasia in the Boston Naming Test

Parameter estimates, standard errors, z-values, and p-values of fixed-effect terms in the statistical model comparing naming performance between healthy bilinguals and bilingual persons with aphasia. All statistically significant results are marked in bold. p-values were estimated using the ‘lmerTest’ package in R (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). *p < .05; **p < .01; ***p < .001.
BPWA = bilingual persons with aphasia; HB = healthy bilinguals; SE = standard error.
3.2. Cognate facilitation in naming performance for HB and BPWA
To address question (ii), we first compared accuracies on cognate and noncognate items in L1 and L2 within groups and computed effect sizes for cognate versus noncognate naming. Next, regarding group-level comparisons in cognate facilitation effect, a two-way ANOVA was used to examine differences in cognate facilitation by group (HB/BPWA) and language (L1/L2).
First, we found that HB L1 (t(30) = 8.397, p < .001) and L2 (t(30) = 9.578, p < .001) cognate performance was superior to L1 and L2 noncognate performance, respectively. Likewise, BPWA L1 (t(39) = -5.523, p < .001) and L2 (t(39) = 5.296, p < .001) cognate performance was superior to L1 and L2 noncognate performance, respectively. Next, effect size calculations showed medium effect sizes on cognate facilitation effect for both L1 (d = .578) and L2 (d = .577) in HB, and small effect sizes on cognate facilitation effect for both L1 (d = .246) and L2 (d = .208) in BPWA. See Table 4 for more detail.
Results of the two-way ANOVA revealed a significant main effect of group [F(1, 138) = 34.213, p < .001], but no significant effects of language [F(1, 138) = .077, p = .780] nor of the group × language interaction [F(1, 138) = 1.365, p = .244], suggesting relatively balanced facilitation between languages in each group. Post-hoc comparisons revealed that cognate facilitation was significantly superior for HB versus BPWA (p < .001). Overall, both groups showed statistical evidence of a cognate facilitation effect, but the effect was stronger for HB, noted via effect size and in direct between-group comparisons. Again, there was no within-group difference in facilitation between languages.
3.3. Predictors of naming accuracy in L1 and L2 in HB and BPWA
Healthy bilinguals
To address question (iii) with respect to HB in L1, we fit a model consisting of lexical frequency, phoneme/grapheme overlap, all bilingual language experience components for HB, and all two-way interactions between these variables, to L1 naming accuracy. Stepwise selection revealed a model showing significant positive effects of phoneme/grapheme overlap (β = 1.356, SE = .417, z-value = 4.713, p < .001), in addition to a phoneme/grapheme overlap × L2 Ability/Use/Exposure interaction (β = .397, SE = .090, z-value = 4.372, p < .001). Regarding the latter, as words in L1 more greatly resembled their translation pairs in L2, and, simultaneously, as individuals increased in their L2 Background/Confidence, the likelihood of a correct response in L1 increased. Conversely, L2 Background/Confidence (β = −.750, SE = .311, z-value = −2.411, p = .015) and an L2 Background/Confidence × L2 Ability/Use/Exposure interaction (β = −.782, SE = .370, z-value = −2.112, p = .034) showed significant negative effects, suggesting that significant bilingual language experience in L2 decreased the likelihood of an accurate response in L1 (see Figure 2A-B for visualization of significant interactions). L2 Ability/Use/Exposure independently showed a small, positive effect, but was not significant (β = .422, SE = .312, z-value = 1.354, p = .175).

Figure 2. Panels A-B depict interactions between (A) L2 Ability/Use/Exposure and phoneme/grapheme overlap and (B) L2 Ability/Use/Exposure and L2 Background/Confidence from the L1 HB model. Panels C-D depict interactions between (C) L2 Ability/Use and lexical frequency and (D) phoneme/grapheme overlap and L1 Confidence/Family Proficiency from the L1 BPWA model. All variables are centered. The x-axis represents the component at a standard deviation (SD) between -3 and +2 (A-B) or the component and phoneme/grapheme overlap at a SD between -2 or -1 and +2 (C-D). The y-axis represents predicted L1 naming accuracy in percentages for HB (A-B) and BPWA (C-D). In all panels, the red line indicates the variable at -1 SD, the blue line indicates the variable at the mean, and the green line indicates the variable at +1 SD. In (A), when words show little phoneme/grapheme overlap (red), probability of an accurate response is minimally moderated by greater L2 Ability/Use/Exposure, while when words show high phoneme/grapheme overlap (green), greater L2 Ability/Use/Exposure results in an increase in probability of an accurate response. In (B), benefit of a high L2 Background/Confidence (green) diminishes as participants increase their L2 Ability/Use/Exposure, while those with a low L2 Background/Confidence (red) are benefitted from an increase in their L2 Background/Confidence. In (C), as Ability/Use in L2 increases, the comparative benefit of frequency decreases. In (D), as phoneme/grapheme overlap increases, the predicted disparity in performance across individuals with low, mean, and high Confidence/Family Proficiency in L1 decreases.
Likewise, for HB in L2, we fit a model consisting of lexical frequency, phoneme/grapheme overlap, all bilingual language experience components for HB, and all two-way interactions between these variables, to L2 naming accuracy. Stepwise selection revealed a model showing significant positive effects of phoneme/grapheme overlap (β = .762, SE = .225, z-value = 3.380, p < .001) and lexical frequency (β = 1.047, SE = .230, z-value = 4.545, p < .001) independently, suggesting that words whose translation pairs show greater overlap in form and meaning and, separately, more commonly occurring words, were likelier to be accurately named. Next, L2 Background/Confidence (β = .825, SE = .288, z-value = 2.863, p = .004) and L2 Ability/Use/Exposure (β = .868, SE = .286, z-value = 3.037, p = .002) showed significant and positive effects, independently, suggesting that greater bilingual language experience in L2 is associated with higher likelihood of an accurate response in L2. See Supplementary Table 3 for a table of both L1 and L2 HB models.
In summary, for HB L1 naming accuracy, higher phoneme/grapheme overlap between words and their translation pairs was beneficial, including when it was paired with high L2 Ability/Use/Exposure. Detrimental effects to L1 naming were noted when L2 Background/Confidence was high and when both aforementioned L2 components interacted. In contrast, for HB L2 naming accuracy, higher phoneme/grapheme overlap, higher lexical frequency, and higher factor scores on both L2 components, independently, were beneficial.
Bilingual persons with aphasia
To address question (iii) with respect to BPWA in L1, we fit a model consisting of BPWA L1 WAB-R AQ, in addition to lexical frequency, phoneme/grapheme overlap, all bilingual language experience components for BPWA, and all two-way interactions between these variables, to L1 naming accuracy. Stepwise selection revealed a model showing significant positive effects of L1 WAB-R AQ (p < .001), lexical frequency (p < .001), and L1 Confidence/Family Proficiency (p = .011), independently. Less overall language impairment in L1, more common stimuli, and greater L1 Confidence/Family Proficiency, separately, were associated with an increased likelihood of an accurate response in L1. Next, the model revealed significant negative interactions between lexical frequency × L2 Ability/Use (p = .034) and phoneme/grapheme overlap × L1 Confidence/Family Proficiency (p = .049). That is, as L2 Ability/Use increased, the benefit of a stimuli's higher lexical frequency decreased. Further, as overlap increased, the disparity in performance between individuals with low, mean, and high L1 Confidence/Family Proficiency diminished (see Figure 2C-D for visualization). L2 Ability/Use showed a small, negative effect, but it was not significant (p = .213). Notably, phoneme/grapheme overlap was included in the selected model and showed a small positive effect, but it was not significant (p = .420).
Similarly, for BPWA in L2, we fit a model consisting of BPWA L2 WAB-R AQ, in addition to, lexical frequency, phoneme/grapheme overlap, all bilingual language experience components for BPWA, and all two-way interactions between these variables, to L2 naming accuracy. Stepwise selection revealed a model showing significant positive effects of L2 WAB-R AQ (p < .001), lexical frequency (p < .001), and L2 Ability/Use (p = .009), independently. Similar to the L1 BPWA model, less overall language impairment in L2, more common stimuli, and greater L2 Ability/Use, showed an association with an increased likelihood of an accurate response in L2. While L1 Confidence/Family Proficiency (p = .716), phoneme/grapheme overlap (p = .06), and an interaction between L1 Confidence/Family Proficiency × phoneme/grapheme overlap (p = .05) are included, all three predictors are not significant (all p values ≥ .050). See Table 5 for further details on both L1 and L2 models.
Table 5. Predictors of L1 and L2 naming accuracy in bilingual persons with aphasia in the Boston Naming Test
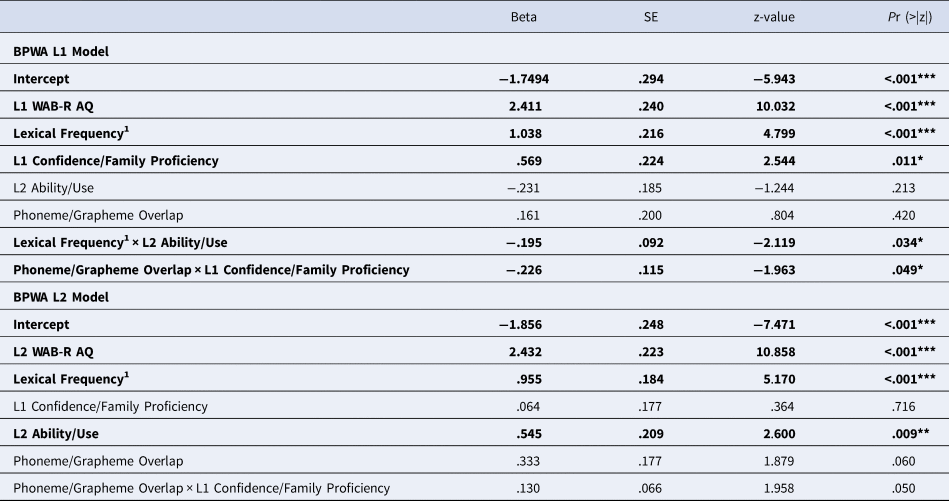
Parameter estimates, (standard errors), z-values, and p-values of fixed-effect terms in the statistical models of L1 and L2 naming accuracy for bilingual persons with aphasia. All statistically significant results are marked in bold. p-values were estimated using the ‘lmerTest’ package in R (Kuznetsova et al., Reference Kuznetsova, Brockhoff and Christensen2017). *p < .05; **p < .01; ***p < .001.
L1 = first-acquired language; L2 = second-acquired language; BPWA = bilingual persons with aphasia; WAB-R = Western Aphasia Battery – Revised; AQ = Aphasia Quotient; SE = standard error. 1Log-transformed.
In summary, for BPWA L1 naming, higher (i) lexical frequency, (ii) L1 WAB-R AQ scores, and (iii) factor scores in L1 Confidence/Family Proficiency were beneficial. Detrimental effects to L1 naming were apparent when lexical frequency interacted with L2 Ability/Use, with greater L2 Ability/Use diminishing the benefit of lexical frequency. We also found detrimental effects when phoneme/grapheme overlap interacted with L1 Confidence/Family Proficiency, with greater overlap resulting in a comparative decrease in benefit of high L1 Confidence/Family Proficiency. In contrast, for BPWA L2 naming accuracy, only higher (i) lexical frequency, (ii) L2 WAB-R AQ scores, and (iii) factor scores on L2 Ability/Use were beneficial.
3.4. Predictors of the cognate facilitation effect in BPWA and HB
Healthy bilinguals
Finally, to address question (iv) regarding factors influencing overall cognate facilitation effect, for HB, we fit a multiple linear regression model consisting of all two-way interactions between HB bilingual language experience components to by-participant cognate facilitation (i.e., individual overall accuracy on cognate items minus noncognate items). Stepwise selection resulted in a significant model (R2 = .35, F(5, 1358) = 153.50, p < .001), with a significant intercept (β = .257, SE = .004, t-value = 55.689, p < .001) and significant, positive effects of L1 Ability/Background/Confidence (β = .068, SE = .008, t-value = 8.399, p < .001) and L2 Background/Confidence (β = .088, SE = .005, t-value = 17.195, p < .001), independently. This indicates that both greater L1 Ability/Background/Confidence and L2 Background/Confidence resulted in a greater overall cognate facilitation effect. Next, the model showed two positive, significant interactions: L1 Ability/Background/Confidence × L2 Background/Confidence (β = .068, SE = .006, t-value = 10.432, p < .001) and L2 Background/Confidence × L2 Ability/Use/Exposure (β = .103, SE = .006, t-value = 15.764, p < .001). This indicates that pairing both (i) high L1 Ability/Background/Confidence and (ii) high L2 Ability/Use/Exposure with high L2 Background/Confidence results in significantly greater facilitation when naming cognates versus noncognates overall (see Figure 3B-C). L2 Ability/Use/Exposure was included but did not reach significance (β = .011, SE = .006, t-value = 1.697, p = .090).

Figure 3. Panel A depicts the relationship between L2 Western Aphasia Battery-Revised Aphasia Quotient (WAB-R AQ) and overall cognate facilitation effect in BPWA. Panels B-C depict interactions between (B) L1 Ability/Background /Confidence and L2 Background/Confidence, and (C) L2 Ability/Use/Exposure and L2 Background/Confidence for overall cognate facilitation in HB. All variables are centered. The x-axis represents (A) L2 WAB-R AQ at a standard deviation (SD) between −2 and +1, or (B-C) the component at a SD between −3 and +1. The y-axis represents overall cognate facilitation effect (accuracy on cognate items minus accuracy on noncognate items) in percentages. In (A), L2 WAB-R AQ show a relatively linear relationship with overall cognate facilitation effect in BPWA. In both (B-C) the red line indicates the variable at −1 SD, the blue line indicates the variable at the mean, and the green line indicates the variable at +1 SD. In both (B-C), there is a synergistic effect of increasing L2 Background/Confidence along levels of L1 Ability/Background/Confidence in (B), and L2 Ability/Use/Exposure in (C).
Bilingual persons with aphasia
Correspondingly, for BPWA, we fit a multiple linear regression model consisting of both L1 and L2 WAB-R AQ and all two-way interactions between BPWA bilingual language experience components to by-participant cognate facilitation. Stepwise selection resulted in a significant model (R2 = .52, F(1, 38) = 43.88, p < .001) with a significant intercept (β = .106, SE = .011, t-value = 9.637, p < .001), retaining only the significant, positive effect of L2 WAB-R AQ (β = .073, SE = .011, t-value = 6.624, p < .001). This indicates that as overall language impairment in L2 decreases, facilitation effects when naming cognates increase (see Figure 3A).
In summary, in HB, cognate facilitation was explained by several dimensions of bilingual language experience in both L1 and L2, including two synergistic interactions across languages and within languages (e.g., L1 × L2; L2 × L2). In all cases, higher factor scores in all components, including in interactions, resulted in greater cognate facilitation. In BPWA, the majority (R2 = .52) of cognate facilitation was explained solely by L2 WAB-R AQ, with higher L2 WAB-R AQ scores coinciding with greater cognate facilitation effect.
4. Discussion
The purpose of this study was to examine the naming performance of BPWA on the Boston Naming Test in terms of their naming accuracy for cognates and noncognates in L1 and L2 and cognate facilitation (i.e., naming accuracy on cognate items minus noncognate items). To this end, we assessed their naming performance and their cognate facilitation effects relative to a group of HB. We also examined the influence of bilingual language experience within each group's L1 and L2 on naming accuracy and on cognate facilitation overall. The BNT is one of the most common assessment measures of lexical access in picture naming, often used for diagnosis of language dysfunction in clinical neuropsychology (Hall et al., Reference Hall, O'Carroll, Frith, Johnstone, Owens, Lawrie, McIntosh and Sharpe2010). Importantly, the BNT is frequently employed with BPWA, yet it includes many cognate items between the English and Spanish versions (Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007) that can influence naming performance across these two languages.
Our analyses found that relative to HB, BPWA were (i) outperformed in overall naming accuracy, (ii) showed lower naming accuracies on cognate items as compared to noncognate items, and (iii) exhibited a smaller cognate facilitation effect irrespective of language. Further, we found that L1 and L2 naming performance in both groups was associated with lexical frequency, L1 and L2 language experience, and additionally, by L1 and L2 language impairment for BPWA. While the groups were similar in these respects, strikingly, they differed in benefit drawn from phoneme/grapheme overlap (see Figure 1). We also found a significant association between bilingual language experience and the extent of cognate facilitation shown on L1 and L2 naming performance in HB, with greater factor scores on all components retained by the model resulting in greater cognate facilitation. Meanwhile, greater cognate facilitation in BPWA was only associated with lower L2 language impairment. We discuss the results and implications of these findings below.
4.1. Comparing HB and BPWA in L1 and L2 naming accuracy of cognates and noncognates, and cognate facilitation
Regarding questions (i) and (ii), as hypothesized, BPWA were outperformed by HB in both L1 and L2 naming and in cognate facilitation, though overall, both groups named cognates with higher accuracy than noncognates. Contrary to our hypothesis, despite both groups profiling as L1-dominant, neither BPWA nor HB showed within-group differences in facilitation effect by language. While this may contradict what our literature review would suggest regarding HB, i.e., cognate facilitation should more greatly benefit the nondominant language, we highlight that HB L2 Daily Use was significantly greater than L1 Daily Use, possibly resulting in performance that more closely resembles a balanced bilingual (i.e., similar facilitation effects for both languages; Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007).
Regarding BPWA, in Roberts and Deslauriers (Reference Roberts and Deslauriers1999), BPWA named both L1 and L2 cognates correctly with relatively high accuracy and showed stronger cognate facilitation in L2, while BPWA in this study named L1 and L2 cognates with relatively low accuracy and showed limited cognate facilitation in either language. Several differences may account for this discrepancy. For example, all patients reported by Roberts and Deslauriers (Reference Roberts and Deslauriers1999) had confirmed receipt of anywhere between 1 and >12 months of language therapy primarily in L1, whereas the BPWA in this study received language therapy primarily in L2 or did not receive language therapy at all. Furthermore, the Roberts and Deslauriers (Reference Roberts and Deslauriers1999) study only included patients with mild to moderate aphasia and who did not show symptoms of dysarthria or apraxia. In contrast, this study did not exclude participants due to severity or speech and language comorbidities, which may suggest that severity of impairment plays a role in whether substantial cognate facilitation emerges in BPWA (see Table 3 for comparative data).
Importantly, our study demonstrates a dissociation in cognate facilitation effect by modality within BPWA. Van der Linden et al. (Reference Van der Linden, Verreyt, De Letter, Hemelsoet, Mariën, Santens, Stevens, Szmalec and Duyck2018) reported cognate facilitation effects on a receptive lexical decision task in BPWA. Critically, the magnitude of cognate facilitation on RT for BPWA with differential language impairment surpassed that of their HB group, and magnitude of effect for item accuracy was not different between groups. Our data, based on a speech production task, e.g., picture naming, suggests the opposite trend: BPWA and HB differed in cognate facilitation, and BPWA clearly drew less benefit from cognate items. It appears that aphasia, in impacting lexical access mechanisms, sufficiently dissociates comprehension and production processes that have previously been found to be relatively symmetric cross-modally in cognate performance (Christoffels et al., Reference Christoffels, de Groot and Kroll2006). Through the lens of population encoding (Nadeau, Reference Nadeau2019), ABI which results in aphasia often focally damages the integrity of linguistic knowledge, including, but not limited to, semantic and phonologic sequence knowledge, which then attenuates the benefit of the shared knowledge pertaining to cognates between both languages. This results in worse performance than would be expected for cognates in BPWA.
4.2. Predictors of L1 naming in HB and BPWA
Regarding question (iii) and concerning L1, as hypothesized for HB, we found that L1 naming accuracy was positively influenced by phoneme/grapheme overlap and an interaction between phoneme/grapheme overlap and L2 language experience, i.e., L2 Ability/Use/Exposure. A closer examination of Figure 2A helps situate the results. Little to no phoneme/grapheme overlap demonstrates no benefit to L1 naming in individuals with strong L2 language experience, as lack of phoneme/grapheme overlap would imply the individual is relying entirely on L1 faculties. However, for words that show moderate to high phoneme/grapheme overlap, the greater the individual's L2 language experience, the more benefit they can derive on L1 naming as they are able to advantageously coactivate word forms through spreading activation from shared semantic features, leading to facilitation through convergence at the target lexical-semantic node. As Nadeau (Reference Nadeau2019) suggests, cognate effects arise through activation of – unlike BPWA – intact, overlapping L1 and L2 semantic-phonologic knowledge, and more entrenched knowledge between both language systems should lead to greater facilitation effects.
Finally, we speculated that high L2 language experience may represent individuals with shifted dominance, therefore weakening L1 naming performance. Accordingly, individuals with high L2 language experience, e.g., increased L2 Background/Confidence, showed diminished L1 naming accuracy.
In contrast, partially in line with our hypothesis for BPWA, L1 WAB-R AQ scores, lexical frequency, and L1 language experience, i.e., L1 Confidence/Family Proficiency, suggested higher naming accuracies in L1. Moreover, while we did not anticipate a significant and negative interaction between lexical frequency and L2 Ability/Use, this result paralleled our prediction relating to L2 language experience and phoneme/grapheme overlap (Section 1.5; language experience in the nontarget language would moderate the effect of overlap). More specifically, this result reproduced the lexical frequency effect often found in HB, but in BPWA, i.e., increased language proficiency reduces the typically robust, positive effect of higher lexical frequency on the increased likelihood of word recognition (Diependaele et al., Reference Diependaele, Lemhöfer and Brysbaert2013).
Notably and in contrast to HB, phoneme/grapheme overlap was not associated with L1 naming accuracy in BPWA; however, an increase in phoneme/grapheme overlap was associated with a decrease in the benefit of L1 language experience on L1 naming. Figure 2D clarifies this relationship: higher phoneme/grapheme overlap appears to benefit BPWA with low L1 Confidence/Family Proficiency, which aligns with the understanding that overlapping form and meaning is beneficial to the weaker language in naming (Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007; Robinson Anthony & Blumenfeld, Reference Robinson Anthony and Blumenfeld2019; Rosselli et al., Reference Rosselli, Ardila, Jurado and Salvatierra2014). Comparatively, for BPWA with high L1 language experience, e.g., L1 Confidence/Proficiency, higher phoneme/grapheme overlap is less useful, indicating that cognate status is less beneficial to the stronger language in naming (Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007; Rosselli et al., Reference Rosselli, Ardila, Jurado and Salvatierra2014).
4.3. Predictors of L2 naming in HB and BPWA
Regarding question (iii) and concerning L2, as predicted for HB, we found that phoneme/grapheme overlap, lexical frequency, and L2 language experience, i.e., L2 Background/Confidence, and L2 Ability/Use/Exposure, all positively contributed toward overall higher naming accuracies. Increasing phoneme/grapheme overlap and lexical frequency improves L2 naming accuracy, and rich language experience in the target language additionally exhibits positive effects.
Conversely, as predicted for BPWA, we found that L2 WAB-R AQ scores, lexical frequency, and L2 language experience suggested higher naming accuracies in L2. Notably, again, phoneme/grapheme overlap was not associated with a benefit to naming accuracy in L2 for BPWA. Likewise, a positive phoneme/grapheme overlap × L1 Confidence/Family Proficiency interaction only approached significance. Similar to L1 for BPWA, impairment of lexical access mechanisms (i.e., aphasia) depresses spreading activation from semantic nodes in L1 to L2 and vice versa. Therefore, convergence of activation perhaps does not occur, or activation does not meet a sufficient threshold to instantiate the target lexical-semantic representation for verbal output (Dijkstra et al., Reference Dijkstra, Wahl, Buytenhuijs, Halem, Al-Jibouri, Korte and Rekké2019; Harnish, Reference Harnish2018; Silkes et al., Reference Silkes, Baker and Love2020; Silkes & Rogers, Reference Silkes and Rogers2012).
Overall, these findings affirm that for HB, cognate status is robustly beneficial to naming in the nondominant language because it allows individuals to capitalize on coactivation of the target word and its translation pair given their overlapping features, the latter being firmly established in the dominant language. Thus, access to the target word when naming in the nondominant language is partly facilitated by the entrenched representation in the dominant language. However, when already naming in the dominant language, cognate status results in a far smaller benefit, as bilinguals are directly accessing the most established word representation. For BPWA, these processes are only weakly instantiated due to ABI, resulting in no apparent influence of L2 language experience toward the benefit of cognate status.
4.4. Predictors of cognate facilitation on L1 and L2 picture naming in HB and BPWA
Regarding question (iv), as predicted in HB, cognate facilitation was driven by a broad set of bilingual language experiences. The model showed significant, positive effects of L1 and L2 language experience independently, and interactions between both L1 and L2 language experience and separate L2 language experience components. Richer language experience in either language, and particularly, rich language experience in both languages (e.g., Gollan et al., Reference Gollan, Fennema-Notestine, Montoya and Jernigan2007), resulted in cognate facilitation effects in picture naming.
Contrastingly, partly in line with our hypotheses, in BPWA, L2 WAB-R AQ scores were the sole predictor of cognate facilitation, explaining 52% of the variance. First, it is often the case that L1 is more firmly established than L2 pre-ABI (Mehotcheva & Köpke, Reference Mehotcheva and Köpke2019). Second, L2 WAB-R AQ serves as a measure of L2 function in BPWA, and indeed L2 WAB-R AQ was lower than L1 WAB-R AQ in our group of BPWA. Thus, it seems plausible to have expected the more impaired language post-ABI to be primarily responsible for explaining cognate facilitation effects, as facilitation is often contingent on the ability to bidirectionally propagate activation between language systems or overlapping representations. Finally, as our literature review suggests, it is often in the weaker language that cognate facilitation emerges most strongly. For BPWA, if the weaker language is also the most damaged, then cognate facilitation effects may be greatly suppressed.
4.5. Limitations, clinical implications, and future directions
Several issues remain unresolved in the study of picture naming performance of BPWA on cognates. First, although we used a global measure of L1 and L2 language impairment (i.e., WAB-R AQ scores), which reflects performance on tasks relating to auditory and visual comprehension, content/meaning and fluency in speech, reading, writing, naming, and repetition, it is a unitary measure. Future studies should examine, and control for, language performance on non-production-based modalities – given that cognate facilitation effects are cross-modal (e.g., Frances et al., Reference Frances, Navarra-Barindelli and Martin2021), and these effects are likely dissociated in the presence of ABI; as we have found in comparing results on naming versus visual word recognition/comprehension (Van der Linden et al., Reference Van der Linden, Verreyt, De Letter, Hemelsoet, Mariën, Santens, Stevens, Szmalec and Duyck2018).
Although we controlled for lexical frequency in our analyses, the cognate and noncognate items in the BNT are not originally matched for lexical frequency. As Blumenfeld et al. (Reference Blumenfeld, Bobb and Marian2016) advise, given complex interactions between phoneme/grapheme overlap, lexical frequency, and language proficiency, future studies examining these effects in both HB and BPWA should control for and probe these imbalances by using, for example, both low and high frequency cognates, while also considering formal metrics of bilingual language experience as we have done here.
It is also worth considering that the cognate stimuli from the BNT show only modest phoneme/grapheme overlap and do not contain any perfect cognates. Frances et al. (Reference Frances, Navarra-Barindelli and Martin2021) argue that perfect cognates may hold special status, demonstrating larger facilitation effects on lexical decision performance, such that identical cognates outperform even high overlap words. Therefore, it is difficult to generalize our findings on BNT items to perfect cognates and it is strongly recommended that future studies examine the cognate facilitation effect across the full phoneme/grapheme overlap spectrum with larger word sets.
Finally, some clinical implications may be drawn from these results. Clinicians testing Spanish–English BPWA using the BNT may consider ignoring the stop criterion (i.e., cease the assessment upon six consecutive inaccurate responses). These and previous results suggest that the latter half of the assessment does not steadily increase in difficultly as intended in the original BNT English monolingual version due to inclusion of cognates (Kohnert et al., Reference Kohnert, Hernandez and Bates1998). The examination of cognate naming in BPWA may provide insight into the relative intactness of the mechanisms mediating access to and from L1-to-L2 and vice versa. Clinicians may further consider integrating qualitative or quantitative assessments of bilingual language experience to better contextualize BPWA performance on the BNT, e.g., poor overall naming performance in the nondominant language except on cognates, especially when extensive clinical assessments across languages are limited.
5. Conclusion
In summary, the present study compared the presence and magnitude of cognate facilitation effects during picture naming in BPWA relative to HB in both groups’ L1 and L2, accounting for the extent of phonetic and orthographic overlap between stimuli and their translation pairs, as well as individual-level bilingual language experience. Our findings suggest that while the bilingual experiential influences on picture naming in BPWA are similar to those observed in HB in both L1 and L2, overall, the benefit derived from cognate status in naming in this clinical population is intensely attenuated secondary to damage to lexical access mechanisms. Furthermore, while overall cognate facilitation effect is associated with rich language experience in both languages in HB, for BPWA, only the severity of L2 language impairment showed an association, explaining over half of the variance in performance. We propose that more detailed assessments and extensive analysis of lexical access of cognates in bilingual aphasia can provide additional insights to the structure and preservation of healthy and damaged bilingual lexicons.
Supplementary Material
supplementary material for this article can be found at http://doi.org/10.1017/S1366728923000251
Acknowledgements
The authors thank the individuals who participated in this study. We also thank members of the Aphasia Research Laboratory for their helpful comments throughout the development of this manuscript. Finally, we thank all three peer reviewers for their thoughtful comments and insight. This work was supported by the National Institutes of Health/National Institute on Deafness and Other Communication Disorders through grant T32DC013017 awarded to Manuel J. Marte and grant U01DC014922 awarded to Swathi Kiran and Risto Mikkulainen. Claudia Peñaloza is supported by the Juan de la Cierva-Incorporación Program (IJC2018-037818) funded by Ministerio de Ciencia e Innovación, Agencia Estatal de Investigación MCIN/AEI 10.13039/501100011033.
Competing interests
The authors declare none.










 Open access
Open access