



1. Introduction
Disclaimer: Due to the nature of this work, some examples contain offensiveness, hate speech, and profanity. This doesn’t reflect the authors’ opinions by any means. We hope this work can help in detecting and preventing the spread of such harmful content.
Social media platforms provide a medium for individuals or a group to connect with the world and share their opinion (Intapong et al. Reference Intapong, Charoenpit, Achalakul and Ohkura2017), often with limited inhibitions. Taking the advantage of such liberation, social media users may use vulgar, pornographic, or hateful language. Such behavior can result in the spread of verbal hostility and can impact users’ psychological well-being (Gülaçtı Reference Gülaçtı2010; Waldron Reference Waldron2012).
In recent years, Twitter has become highly popular in the Arab region (Abdelali et al. Reference Abdelali, Mubarak, Samih, Hassan and Darwish2021b), with more than 27 million tweets per day (Alshehri et al. Reference Alshehri, El Moatez Billah Nagoudi and Abdul-Mageed2018). Many look to Twitter to express their views, ideas, and share their stories. While the importance of sharing these views and ideas is immense, the aforementioned societal problem of sharing malicious content also arises.
With the sheer volume of content on social media, manually filtering out malicious content while maintaining users’ right to freedom of expression is virtually impossible for the platform providers. The increased risk and effect of such hostility presence in social media has attracted many multidisciplinary researchers and motivated the need to automatically detect offensiveness of posts/comments and utilize the system to: (i) filter adult content (Cheng et al. Reference Cheng, Xing, Liu and Lv2014; Mubarak et al. Reference Mubarak, Hassan and Abdelali2021); (ii) quantify the intensity of polarization (Belcastro et al. Reference Belcastro, Cantini, Marozzo, Talia and Trunfio2020; Conover et al. Reference Conover, Ratkiewicz, Francisco, Gonçalves, Menczer and Flammini2011); (iii) classify trolls and propaganda accounts (Alhazbi Reference Alhazbi2020; Darwish et al. Reference Darwish, Alexandrov, Nakov and Mejova2017; Dimitrov et al. Reference Dimitrov, Ali, Shaar, Alam, Silvestri, Firooz, Nakov and Da San Martino2021a, Reference Dimitrov, Ali, Shaar, Alam, Silvestri, Firooz, Nakov and Da San Martinob); and (iv) identify hate speech and conflicts (Kiela et al. Reference Kiela, Firooz, Mohan, Goswami, Singh, Ringshia and Testuggine2020; Davidson et al. Reference Davidson, Warmsley, Macy and Weber2017; Ousidhoum et al. Reference Ousidhoum, Lin, Zhang, Song and Yeung2019; Chung et al. Reference Chung, Kuzmenko, Tekiroglu and Guerini2019).
Machine learning-based automation approaches require labeled datasets to distinguish malicious content from others. Constructing datasets, however, is not a straightforward process. In a randomly sampled collection of tweets, the percentage of malicious tweets is very small. Mubarak et al. (Reference Mubarak, Darwish and Magdy2017) report that only 1–2% of Arabic tweets are abusive. The percentage of hate speech is even smaller. This implies that to obtain a sizable dataset of malicious content, a massive number of tweets need to be labeled. To avoid this, existing approaches utilize heuristics to increase the percentage of malicious tweets before manually labeling them. Such heuristics include searching for specific language-dependent keywords or patterns.
In this paper, we present an automated emoji-based approach to collecting tweets that have a much higher percentage of malicious content, without having any language dependency. Emojis have quickly become an important part of our daily communication. They are used worldwide for conveying messages without any language or online platform barriers and have been referred to as a universal language (Mei Reference Mei2019; Dürscheid and Siever Reference Dürscheid and Siever2017). Hence, the extralinguistic information carried by the emojis can be instrumental in capturing offensive content, without being impacted by the lack of language-dependent knowledge, or any preferred linguistic patterns. Using emojis also resolves challenges posed by nonstandard spellings of offensive words.
To this end, we use emojis as anchors to collect tweets and manually annotate them for fine-grained abusive/offensive language categories—including hate speech, vulgar, and violent tweet content. We exploit the collected dataset for studying: (i) emoji usage in a different period of time; (ii) extraction of offensive words with different dialectal spellings and morphological variations; (iii) hate speech targets; (iv) linguistic content in vulgar and profanity words; and (v) exploring common patterns present in violent tweets.
Our comparative analysis shows that by using emojis as anchors, we end up with 35% offensive (OFF) tweets and 11% hate speech (HS) tweets, which is almost as double the approach used by Mubarak et al. (Reference Mubarak, Darwish and Magdy2017). Our experiments with various machine learning and deep learning classifiers show that the classifiers are able to learn effectively from the data. Further, we show that these classifiers are capable of generalizing well on two external datasets: (i) the OffensEval 2020 (SemEval, task 12) dataset (Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020) for Arabic offensive language identification, and (ii) the MPOLD dataset (Chowdhury et al. Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b)—a multi-platform dataset containing news comments annotated for offensiveness from Twitter, YouTube, and Facebook. This suggests that our method captures universal characteristics of offensive language on social media and can be used to collect larger datasets with less effort and linguistic knowledge support.
Therefore, the main contributions of the paper are as follows:
We present an emoji-based method to collect offensive and hate speech tweets. We show that using the method, we can collect a higher percentage of offensive and hate speech content compared to the existing methods. Moreover, we demonstrate that using this method we can collect a large number of offensive content in other languages such as Bengali.
We manually label the largest dataset for offensiveness, along with fine-grained hate speech types, vulgarity (profanity), and violence. This labeled data will be publicly released for the community.Footnote a
We perform an in-depth analysis of different properties of the dataset including common offensive words and hate speech targets. We show also that there are some cultural differences in using emojis in Arabic offensive tweets compared to English.
We build effective machine learning and deep learning-based classifiers to automatically tag offensive and hate speech with high accuracy. We show that our model perform well on external datasets collected from Twitter and also demonstrate the potential generalization capability of the designed model in different social media platforms—such as YouTube and Facebook.
We analyze common classification errors and provide some recommendations to enhance model explainability.
While our main focus, in this paper, is to create an Arabic offensive dataset, this method can easily be adapted for other languages and potentially other text classification tasks such as sentiment analysis or emotion detection.
The paper is structured as follows. In section 2, we discuss related work, focusing on the methods used by other researchers to collect datasets for offensive language. In section 3, we describe our data collection and annotation jobs. Section 4 contains an extensive analysis of the dataset. The analysis includes a study of offensive emojis, and how emoji usage changes in a different time period. We further analyze offensive words and hate speech targets found in our dataset. In Section 5, we train a set of machine learning and deep learning models for the classification of offensive language and hate speech. We manually analyze errors made by our models and also use Local Interpretable Model-Agnostic Explanations (LIME) explainability tool to interpret decisions made by our models. In this section, we also show that models trained on our data achieve good results on other datasets. Section 6 discusses ethics and the social impact of our work. Finally, in Section 7, we present a summary of our findings.
2. Related work
There has been a large amount of research in recent years to address and detect the growing use of “offensive languages” and hate speech in different social platforms (see Nakov et al. (Reference Nakov, Nayak, Dent, Bhatawdekar, Sarwar, Hardalov, Dinkov, Zlatkova, Bouchard and Augenstein2021) and Salminen et al. (Reference Salminen, Hopf, Chowdhury, Jung, Almerekhi and Jansen2020) for more details). Detecting offensive language has been the focus of many shared tasks such as OffensEval 2020 (Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020) for five languages and OSACT 2020 (Mubarak et al. Reference Mubarak, Darwish, Magdy, Elsayed and Al-Khalifa2020b) for Arabic. The best systems at the shared tasks (Alami et al. Reference Alami, Ouatik El Alaoui, Benlahbib and En-nahnahi2020; Hassan et al. Reference Hassan, Samih, Mubarak and Abdelali2020) utilized support vector machines (SVM) and fine-tuned transformer models. Hate speech has been less explored compared to offensive language. A dataset consisting of 5% hate speech was presented at OSACT 2020 shared task. The best system performed extensive preprocessing including normalizing emojis (translate their English description to Arabic) and dialectal Arabic (DA) to modern standard Arabic (MSA) conversion among others (Husain Reference Husain2020). ASAD (Hassan et al. Reference Hassan, Mubarak, Abdelali and Darwish2021a) is an online tool that utilizes the shared task datasets for offensiveness and hate speech detection in tweets along with other social media analysis components such as emotion (Hassan et al. Reference Hassan, Shaar and Darwish2021b) and spam detection (Mubarak et al. Reference Mubarak, Abdelali, Hassan and Darwish2020a).
To collect potentially offensive tweets, some studies use a list of seed offensive words and hashtags (e.g., Mubarak et al. Reference Mubarak, Darwish and Magdy2017). This approach has several drawbacks: (i) it is hard to maintain this list as offensive words are ever-evolving; (ii) Arabic dialects are widely used on social media and building such a list for different dialects is a challenging task that requires deep knowledge about cultures in many countries; and (iii) Arabic dialects have no standard writings. So, it is extremely difficult to list all possible surface forms and creative spellings for words in general including offensive words. Moreover, (iv) Arabic has a rich morphology (both derivational and inflectional), and a large number of affixes can be attached to words—for example ![]() (“wsyfElhA”—“and he will do it”)Footnote
b
—which makes string match for offensive words less optimal. Finally, (v) the offensiveness of many words is highly dependent on context, for example, the word
(“wsyfElhA”—“and he will do it”)Footnote
b
—which makes string match for offensive words less optimal. Finally, (v) the offensiveness of many words is highly dependent on context, for example, the word ![]() (“klb”—“dog”) can be used in offensive contexts such as
(“klb”—“dog”) can be used in offensive contexts such as ![]() (“hw klb”—“He is a dog”) and in clean contexts such as
(“hw klb”—“He is a dog”) and in clean contexts such as ![]() (“Endy klb”—“I have a dog”).
(“Endy klb”—“I have a dog”).
Table 1. Available Arabic datasets along with the annotation labels, data source and collection method, and percentage of offensive content.

Sources: TW (Twitter), Aljazeera (AJ), FB (Facebook), YT (YouTube).
Authors in Mubarak et al. (Reference Mubarak, Rashed, Darwish, Samih and Abdelali2020c) showed that offensive language exists in less than 2% of any random collection of tweets, and by considering a common pattern used in offensive communications, this ratio increases to 19% (5% are hate speech). This pattern is ![]() (“yA .. yA”—“O .. O .. ”) which is used mainly to direct the speech to a person or a group. This pattern is used across all dialects without any preference for topics or genres; however, it cannot be generalized to other languages.
(“yA .. yA”—“O .. O .. ”) which is used mainly to direct the speech to a person or a group. This pattern is used across all dialects without any preference for topics or genres; however, it cannot be generalized to other languages.
In the same research, authors observed that the most frequent personal attack on Arabic Twitter is to call a person an animal name (i.e., direct name-calling), and the most used animals are ![]() (“klb”—“dog”),
(“klb”—“dog”), ![]() (“HmAr”— “donkey”), and
(“HmAr”— “donkey”), and ![]() (“bhym”—“beast”) among others. In Chowdhury et al. (Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b), authors analyzed Arabic offensive language on Facebook, YouTube, and Twitter, and they showed that some emojis are widely used in offensive communications, including some animals (dog, pig, monkey, cow, etc.), some face emojis (anger, disgust, etc.), and others (shoe, etc.)
(“bhym”—“beast”) among others. In Chowdhury et al. (Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b), authors analyzed Arabic offensive language on Facebook, YouTube, and Twitter, and they showed that some emojis are widely used in offensive communications, including some animals (dog, pig, monkey, cow, etc.), some face emojis (anger, disgust, etc.), and others (shoe, etc.)
Unlike the aforementioned studies, we propose a generic method to collect offensive tweets regardless of their topics, genres, or dialects. We applied it to Arabic Twitter and obtained the largest dataset of tweets labeled for offensiveness (approx. 13K tweets) with 35% of the tweets labeled as offensive and 11% as hate speech. In this method, we simply use a list of emojis that commonly appear in offensive communications, including emojis that express anger, some animals, and inanimate things extracted from existing datasets of offensive tweets. We believe with small modifications to this list, considering cultural differences, the approach can be used for other languages as well to collect a large number of offensive tweets. Comparison with available Arabic datasets for offensive language and hate speech is shown in Table 1.
It is worth noting that authors in Wiegand and Ruppenhofer (Reference Wiegand and Ruppenhofer2021) used emojis to detect English abusive tweets. They used eight emojis based on correlations between concepts and abusive language as reported in the literature. These emojis (Figure 1) indicate violence and death, anger and disgust, dehumanization, and disrespect. Authors mentioned that the middle finger is the strongest emoji as it is universally regarded as a deeply offensive gesture, and they used it to collect distantly labeled training data. We will later highlight some differences between the usage of offensive emojis in Arabic and English.
3. Data
3.1 Data collection
We extracted common emojis that appear mostly in offensive communications from shared datasets in Zampieri et al. (Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020) and Chowdhury et al. (Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b) and obtained their emoji variations from https://emojipedia.org/. These emojis include some animals and symbols used for dehumanization and expressing disrespect, anger, or disgust. The complete list of emojis used for the data collection and their categories is given in Figure 2.

Figure 1. Emojis used in Wiegand and Ruppenhofer (Reference Wiegand and Ruppenhofer2021).

Figure 2. Categories of common offensive Emojis.
From a collection of 4.4M Arabic tweets between June 2016 and November 2017, we extracted all tweets having any of the aforementioned emojis. After removing duplicates, near duplicates, and very short tweets, we ended up with 12,698 tweets. We show later that tweets collected in another time period (in March 2021) still have high percentages of offensiveness and hate speech.
3.2 Annotation and quality control
We created an annotation job on Appen crowdsourcing platform to judge whether a tweet is offensive or not (Job1), and we invited annotators from all Arab countries.Footnote
c
Quality was assured using 200 questions that we manually obtained gold labels for (hidden test questions). Annotators should pass 80% of them to continue.Footnote
d
Each tweet was judged by 3 annotators and more than 190 annotators contributed to this job. Such a large number is needed for a subjective task like judging tweet offensiveness. Inter-Annotator Agreement (IAA) using Cohen’s kappa (
 $\kappa$
) value was 0.82, which indicates high-quality annotations (Landis and Koch Reference Landis and Koch1977).
$\kappa$
) value was 0.82, which indicates high-quality annotations (Landis and Koch Reference Landis and Koch1977).
Annotators fully agree (3 out of 3) in 65% of the tweets. For better quality, we hired and trained an expert linguist who is familiar with different dialects to carefully check all tweets having different opinions. This resulted in changing 18% of the labels (w.r.t to the previously assigned majority label) for the tweets.
3.3 Annotation of hate speech, profanity, and violence
We created another job on Appen with all the annotated offensive tweets from Job1 and asked annotators to detect the presence of hate speech. We defined hate speech as any content that contains offensive language targeting a group of people based on common characteristics, such as race/ethnicity/nationality, religion/belief, ideology, disability/disease, social class, and gender. We used job settings similar to Job1. Additionally, we asked annotators to judge whether the offensive tweets have profanity or vulgar words and whether they promote violence. Basic statistics and examples from different annotations are listed in Table 2.
Table 2. Statistics and examples from the annotated corpus (total of 12,698 tweets)

4. Analysis
We obtained a total of 582 different emojis in the final annotated data. Out of those, 122 emojis appear more than 20 times. In this section, we first report some observations seen in our data, followed by in-depth analysis of emoji in a different time period, linguistic characteristics associated with emojis along with targets of hate speech in these tweets.
4.1 Common offensive emojis
We report our observations about common emojis used to represent offensiveness below:
There are additional emojis, unique to our initial seed list, frequently used in the annotated offensive tweets. This class of emojis (see “New emojis” row in Figure 3) includes instances like spit/drops (65% of tweets having it was labeled as offensive) to hammer (18% offensive). This suggests a potential for enriching the initial emoji seed list and expanding the dataset in an iterative way.
Top offensive emojis are shown in Figure 3 (mostly animals). If a tweet has any of them, most likely it is labeled as offensive [pig (84% offensive) to middle finger (62%)]. Similar emojis appear in hate speech tweets with percentages range from 36% to 18%, respectively.
Top vulgar emojis are mostly used in tweets having adult content (e.g., adult ads).
For violence category, the most common emojis are knife, punch, and shoe in order.
4.2 Emojis usage in a different time period
We collected tweets from a different time period (in March 2021) to study the usage pattern of offensive emojis over time. For this, we selected six emojis from Figure 3 and their corresponding words to extract their tweets.Footnote e For each emoji and its corresponding word, we then randomly selected 200 tweets and asked an Arabic native speaker to judge the content for offensiveness.Footnote f
Our study suggests that some emojis (see Figure 4) and their corresponding words are widely used in offensive tweets during different periods of time. While the middle finger was reported as the strongest offensive emoji in English tweets (Wiegand and Ruppenhofer Reference Wiegand and Ruppenhofer2021), we found that there are more common offensive emojis that appear in our dataset of Arabic tweets such as pig (84%), shoe (77%), and dog (68%) (first in “Top offensive emojis” row in Figure 4). Tweets having middle finger emoji were tagged as offensive in 62% of the cases. We found annotation errors due to short context in some cases, but some users use the middle finger mistakenly instead of index fingerFootnote g as shown in Figure 5.

Figure 3. Categories of common offensive Emojis. Emojis in the same row are sorted based on percentage of offensive tweets (in descending order).
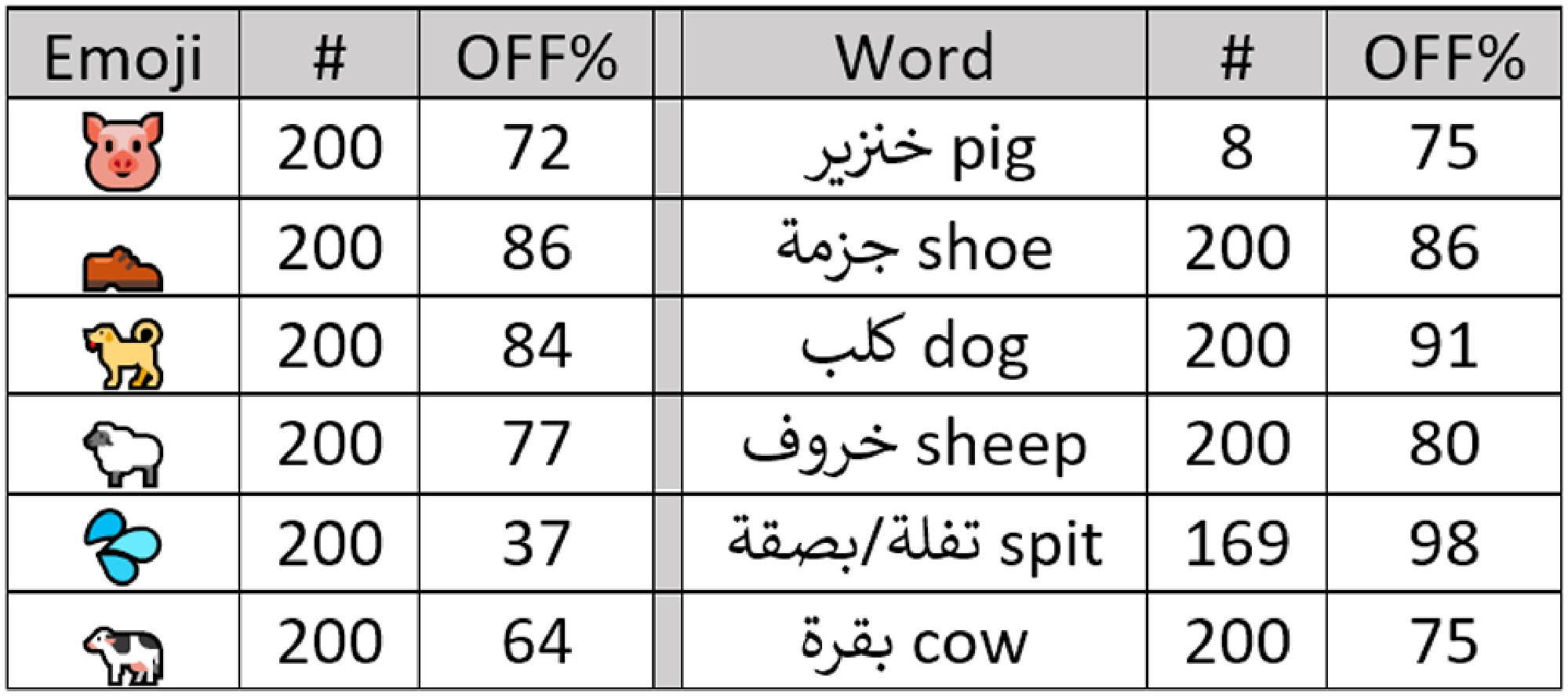
Figure 4. Percentage of offensive tweets for emojis and their corresponding words in samples from March 2021.
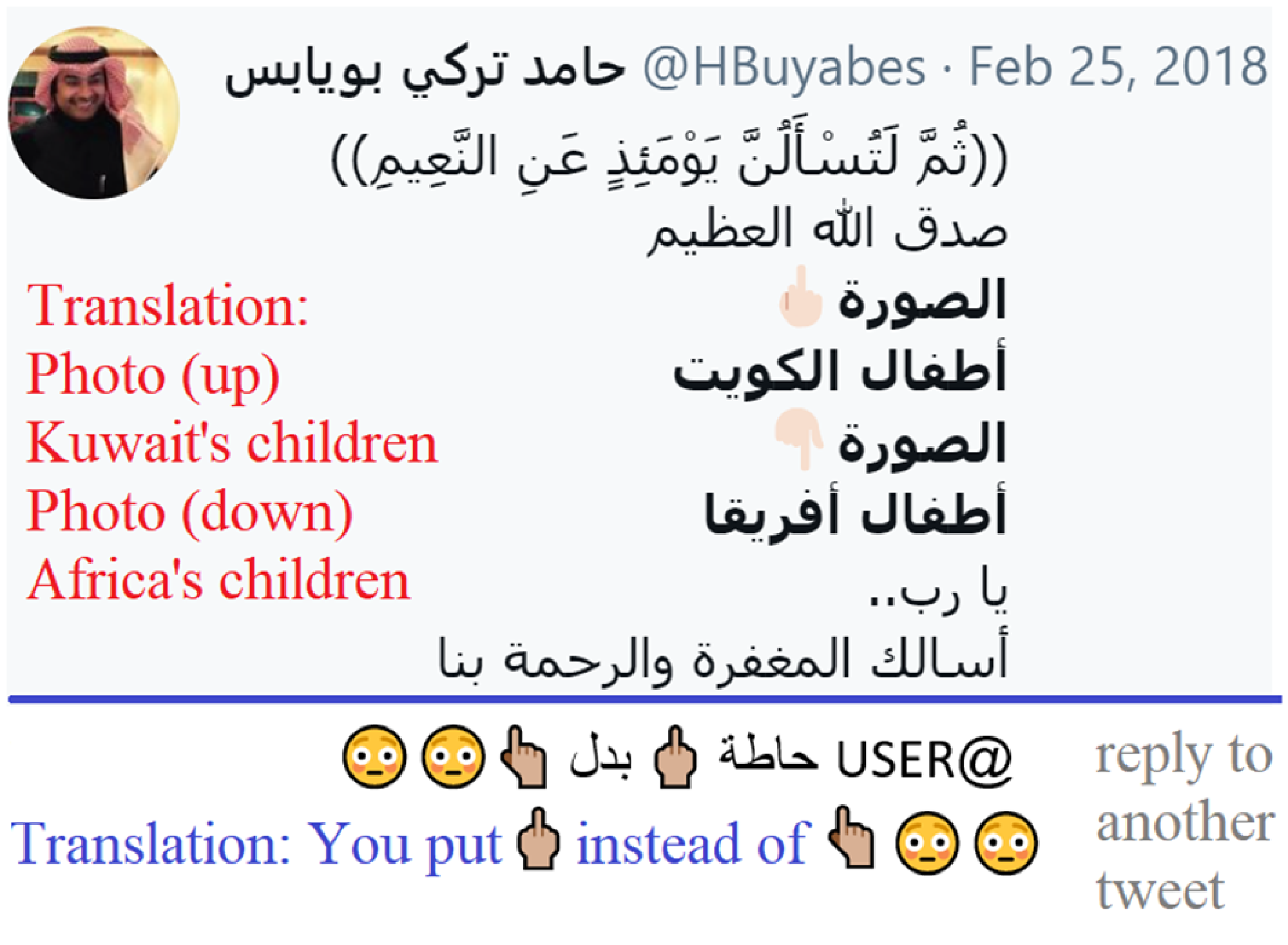
Figure 5. Wrong usage of middle finger emoji in Arabic tweets.
4.3 Emojis and linguistic usage
As observed in Donato and Paggio (Reference Donato and Paggio2017), emojis are often redundant and convey something already expressed verbally in tweets. Thus, offensive emojis may co-occur with many offensive words. As DA is widely used on Twitter, it’s very hard to list all variations of offensive dialectal words. Figure 6 shows an example where offensive emojis co-occurred with offensive dialectal words which confirms the aforementioned observation. It also shows how emojis are used to cover morphological variations such as number and gender.

Figure 6. Emojis co-occur with dialectal and morphological variations.
4.4 Offensive words
To partially solve spelling mistakes in the collected tweets, we normalized some letters which are commonly used interchangeably by mistake, namely letters ![]() to letters
to letters ![]() in order. We calculated the valence score for normalized words in offensive and clean tweets as described in Conover et al. (Reference Conover, Ratkiewicz, Francisco, Gonçalves, Menczer and Flammini2011). The score helps determine the distinctiveness of a given word in a specific class in reference to other classes. Given
in order. We calculated the valence score for normalized words in offensive and clean tweets as described in Conover et al. (Reference Conover, Ratkiewicz, Francisco, Gonçalves, Menczer and Flammini2011). The score helps determine the distinctiveness of a given word in a specific class in reference to other classes. Given
 $N(t,\text{off})$
and
$N(t,\text{off})$
and
 $N(t,\text{cln})$
, which are the frequency of the term
$N(t,\text{cln})$
, which are the frequency of the term
 $t$
in offensive tweets (
$t$
in offensive tweets (
 $\text{off}$
) and clean tweets (
$\text{off}$
) and clean tweets (
 $\text{cln}$
) in order, valence score is computed as:
$\text{cln}$
) in order, valence score is computed as:
 \begin{equation} \large V(t) = 2* \frac{\frac{N(t, \text{off})}{N(\text{off})}}{\frac{N(t, \text{off})}{N(\text{off})} + \frac{N(t, \text{cln})}{N(\text{cln})}} - 1 \end{equation}
\begin{equation} \large V(t) = 2* \frac{\frac{N(t, \text{off})}{N(\text{off})}}{\frac{N(t, \text{off})}{N(\text{off})} + \frac{N(t, \text{cln})}{N(\text{cln})}} - 1 \end{equation}
where
 $N(\text{off})$
and
$N(\text{off})$
and
 $N(\text{cln})$
are the total number of occurrences of all words in offensive (
$N(\text{cln})$
are the total number of occurrences of all words in offensive (
 $\text{off}$
) and clean (
$\text{off}$
) and clean (
 $\text{cln}$
) tweets, respectively.
$\text{cln}$
) tweets, respectively.
Figure 7 shows the top words with the highest valance score in offensive tweets.Footnote
h
In addition to some animal words (e.g., dog and sheep), the list contains many dialectal words that are widely used in offensive communications such as ![]() (“zq, xrA, zbAlh”—shit, and garbage) and some adult ads words such as
(“zq, xrA, zbAlh”—shit, and garbage) and some adult ads words such as ![]() (“sks, dywv”— sex, and cuckold). This proves the efficiency of starting with offensive emojis to collect related offensive words without any preference for dialect or genre. All lists of extracted words with their valence scores will be made publicly available.
(“sks, dywv”— sex, and cuckold). This proves the efficiency of starting with offensive emojis to collect related offensive words without any preference for dialect or genre. All lists of extracted words with their valence scores will be made publicly available.

Figure 7. Offensive words (including vulgar words).
For intrinsic evaluation, we manually revised these top offensive words, and we found that 71% of them appear dominantly in offensive communications and can be considered as correct offensive words. However, the remaining 29% are not necessarily offensive and can appear in many clean contexts. This includes named entities such as ![]() (“AyrAn, bwtyn, AlHwvy, b$Ar”—Iran, Putin, Houthi, Bashar) in addition to some words that were concentrated by chance in our offensive tweets. Examples of such words are
(“AyrAn, bwtyn, AlHwvy, b$Ar”—Iran, Putin, Houthi, Bashar) in addition to some words that were concentrated by chance in our offensive tweets. Examples of such words are ![]() (“*l, bldk, *kwr”— humiliation, your country, males).
(“*l, bldk, *kwr”— humiliation, your country, males).
Table 3. Common targets in hate speech tweets

4.5 Hate speech targets
We used the aforementioned valence score formula to extract common words appear in all hate speech tweets. Then, we manually filtered and grouped them to extract common targets for hate speech. These targets include women, countries, groups, and political parties as listed in Table 3.
4.5.1 Religious hate speech targets
Detecting religious hate speech in Arabic was the main focus of Albadi et al. (Reference Albadi, Kurdi and Mishra2018). Authors mentioned that Arabic is the official language in 6 of the 11 countries with the highest Social Hostilities Index.Footnote i They found that 33% of all hateful tweets targeted against Jews followed by Shia and Christians. We analyzed hateful tweets in our dataset, and we found similar results where Jews are the main target of religious prejudice with 39% of all hateful tweets followed by Muslims, Christians, and Shia. Figure 8 shows the distribution of hate speech tweets for different religious groups.
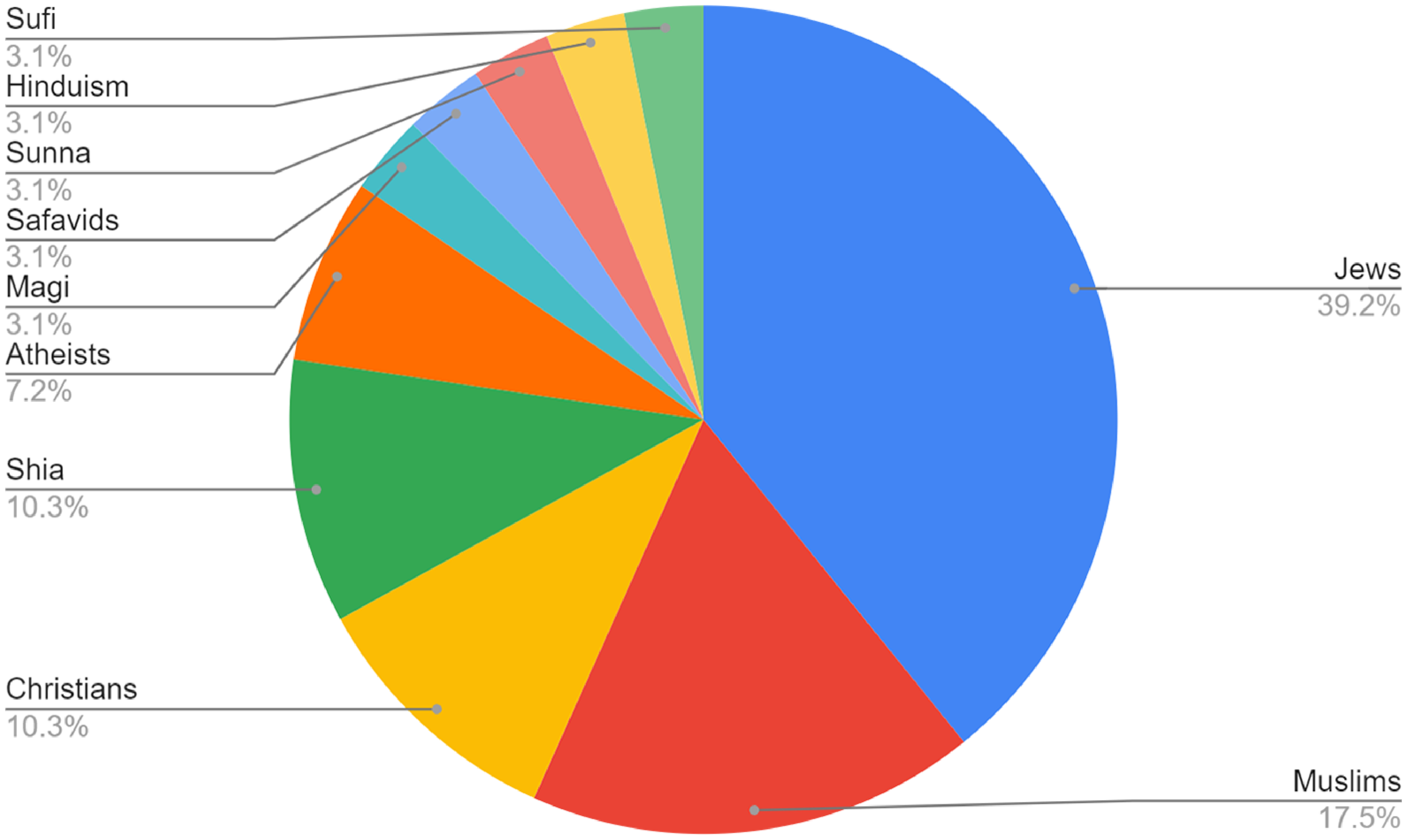
Figure 8. Hate speech% for different religious groups.
4.6 Vulgar and profanity words
We observe that vulgar words include genitals, sexual actions, and references in addition to words used in adult ads. They are mainly written in DA, and the most common words are shown in Figure 7.
4.7 Violence tweets
As violence tweets are rare (0.7% in our collection), we manually analyzed them all to extract common patterns. These patterns are summarized in Table 4. First, we define ¡head¿ for head and neck, and ¡body¿ for body parts including ¡head¿ that can be used as objects for many violence verbs, for example, I will stab [him/his neck]. For future work, we plan to extend this list using synonyms and related words from dictionaries/BERT models. Then, we extract tweets having any of these verbs and targets after applying some morphological expansions.
Table 4. Common patterns in violence tweets
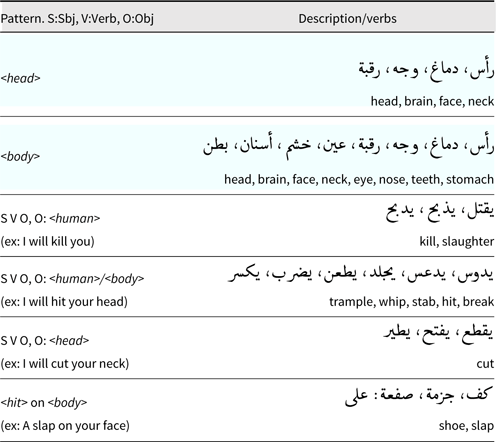

Figure 9. Total percentage of offensive tweets in a sample of 50 tweets for each emoji in Bengali tweets.
4.8 Is emojis a universal anchor?
The typical approach to crawl data from social media, especially from Twitter, is heavily dependent on task-specific keywords. Preparing such keyword-specific anchors needs significant knowledge of the language usage. However, using emojis to collect the data removes the initial language dependency and inherited bias from the keyword-search space.
In this section, we study the efficacy of emojis to collect offensive tweets for other languages. We utilize the proposed pipelines for Bengali (a low-resource language)Footnote j and analyzed the percentage of offensive tweets obtained using the method. Moreover, we also include analysis of English tweets to indicate how offensive communication and emoji usage are still culture-dependent if not language.
For Bengali, we collected 200 tweets in August 2021 for five emojis (a total of 1K tweets) from the different groups listed in Figure 2. From these 200, we randomly selected 50 tweets per emoji (a total of 250 tweets) and a Bengali native speaker annotated them for offensiveness. We noticed that
 $\approx 34\%$
of all the annotated tweets are offensive. We observed that tweets with “middle finger” had the most frequent (
$\approx 34\%$
of all the annotated tweets are offensive. We observed that tweets with “middle finger” had the most frequent (
 $50\%$
of tweets) number of offensive content, followed by “pile of poo” emoji (32% of tweets). The detailed distribution is in Figure 9 with examples in Figure 10. We plan to use this method to collect and annotate offensive tweets for other low-resource languages such as Hindi,Footnote
k
in addition to Bengali. We keep this as a potential future work.
$50\%$
of tweets) number of offensive content, followed by “pile of poo” emoji (32% of tweets). The detailed distribution is in Figure 9 with examples in Figure 10. We plan to use this method to collect and annotate offensive tweets for other low-resource languages such as Hindi,Footnote
k
in addition to Bengali. We keep this as a potential future work.

Figure 10. Examples of (non-)offensive tweets in Bengali collected using emojis.
As the usage of emojis for offensive content in English is well studied, we only collected English tweets having the top Arabic offensive emojis (pig and shoe) in April 2021. We collected more than 8,000 tweets per each, and we randomly selected and annotated 200 tweets for each emoji. We noticed that less than 5% of those tweets are offensive. Often, pig emoji appears in contexts about food while shoe emoji appears in tweets talking about fashion and clothes. Examples are shown in Figure 11.

Figure 11. English examples of pig and shoe emojis (topics of common usages and offensive contexts are shown).
This suggests that while some emojis are widely used in offensive communications in a particular culture, they might be used completely in different ways in other languages or cultures. Thus, it’s important to keep these differences in mind when collecting data using emojis from different cultures.
5. Experiments and results
In this section, we describe the details of machine learning algorithms—SVM and transformers, used to test the performance of the dataset followed by the experimental setup. We then present our classification results for in-domain model testing along with in-detailed classification error analysis and model prediction explainability. Furthermore, we evaluated the model’s generalization capability across different datasets and various social media platforms.
5.1 Classification models
In order to design the automated classification system, we fine-tuned the state-of-the-art monolingual (Arabic) pretrained transformer architectures—AraBERT (Antoun et al. Reference Antoun, Baly and Hajj2020) and QARiB (Abdelali et al. Reference Abdelali, Hassan, Mubarak, Darwish and Samih2021a). Furthermore, we compared the performance of the monolingual transformers with two multilingual BERT: mBERT (Devlin et al. Reference Devlin, Chang, Lee and Toutanova2019) and XLM-RoBERTa (Conneau et al. Reference Conneau, Khandelwal, Goyal, Chaudhary, Wenzek, Guzmán, Grave, Ott, Zettlemoyer and Stoyanov2019). As a baseline, we use an SVM (Platt Reference Platt1998) classifier due to its reputation as a universal learner and for its ability to learn independently of the dimensionality of the feature space and the class distribution of the training dataset.
5.1.1 Support vector machines (SVM)
We used word n-gram and character n-gram vectors weighted by term frequency-inverse document frequency (tf-idf) as features to SVM. We experimented with character n-grams (
 $n=[2,5]$
) and word n-gram (
$n=[2,5]$
) and word n-gram (
 $n=[1,3]$
) individually and also a combination of them using the linear kernel with default parameters of SVM classifier (
$n=[1,3]$
) individually and also a combination of them using the linear kernel with default parameters of SVM classifier (
 $C=1.0$
).
$C=1.0$
).
5.1.2 Transformer models
We fine-tuned the mono and multilingual transformer models on our training data. For the monolingual task, both the transformers—AraBERT and QARiB—are of identical architecture with variation in the pretraining data. AraBERT is trained on Arabic Wikipedia, whereas QARiB is trained on Twitter data and Arabic Gigaword, thus encapsulating formal and informal writing styles in each transformers.
As for the multilingual models, we fine-tuned mBERT, trained on Wikipedia articles for 104 languages including Arabic using the case-sensitive base model. In addition, we also fine-tuned XLM-RoBERTa—trained on a large dataset with 100 languages using cleaned CommonCrawl data.
5.2 Experimental data and setup
5.2.1 Data split
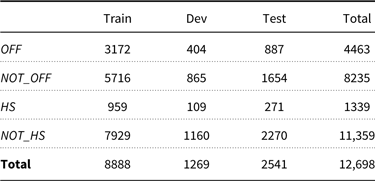
We trained the classifiers using 70% of the data and validated with 10%. We used the rest (20% of the data) for testing the system performance. Detailed data distribution of offensive and hate speech tweets are given in Table 5.
Table 5. Distribution of offensive and hate speech data
5.2.2 Evaluation measures
We evaluated the dataset using macro-averaged precision, recall, and F1-measure, in addition to the accuracy.
5.2.3 Offensive/hate speech classifiers
For the respective downstream tasks, we fine-tuned the aforementioned BERT models by adding a dense layer that outputs class probabilities. We use a learning rate of
 $8e-5$
with a batch size of
$8e-5$
with a batch size of
 $64$
and
$64$
and
 $3$
epochs. For the fine-tuning, we restricted the maximum input length to 47 tokens (99th percentile in the training dataset), with no extra preprocessing of the data.
$3$
epochs. For the fine-tuning, we restricted the maximum input length to 47 tokens (99th percentile in the training dataset), with no extra preprocessing of the data.
5.3 Results
From the reported results, presented in Table 6 and Table 7, we observe the monolingual models significantly outperform the multilingual models. This observation is in-aligned with previous studies (Polignano et al. Reference Polignano, Basile, de Gemmis, Semeraro and Basile2019; Chowdhury et al. Reference Chowdhury, Abdelali, Darwish, Soon-Gyo, Salminen and Jansen2020a).
Table 6. Macro-averaged (P)recision, (R)ecall, and F1 for offensive language classification. Best results are highlighted in bold.
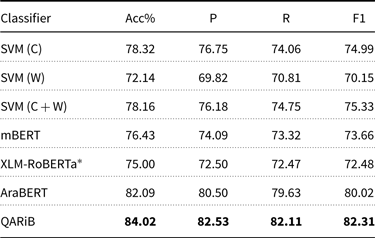
*Results obtained with different learning rate (2e-5) instead of 8e-5. C: character n-grams W: words n-grams.
Table 7. Macro-averaged (P)recision, (R)ecall, and F1 for hate speech classification. Best results are highlighted in bold.

*Results obtained with different learning rate (2e-5) instead of 8e-5. C: character n-grams W: words n-grams.
Comparing the monolingual models, for offensive classification, we observe that mixed trained model—QARiB, outperforms AraBERT by a margin of 2.3%. Contrary to that, in hate classification, we noticed AraBERT—trained with formal text—performs the best. However, the performance difference is very small (
 $0.1\%$
) and can be attributed to the randomness mentioned in Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019).
$0.1\%$
) and can be attributed to the randomness mentioned in Devlin et al. (Reference Devlin, Chang, Lee and Toutanova2019).
5.3.1 Error analysis
We analyzed the classification errors of our best classifier for offensive language detection. Common cases are listed in Table 8. We found similar errors in hate speech detection, and the main difference is that the target of the offense is a group of people as opposed to individuals.
From Table 8, we noticed most of the confusion occurs due to lack of context in the input, implicit offensive instances, misunderstanding of grammatical constructs like negation, bias toward some animals, and the presence of sarcasm. Moreover, we also noticed some classification errors due to human annotation errors—which is common given the complexity of the annotation task itself and its dependence on individual perspectives.
Table 8. Common error types in offense detection. Classes: FP (false-positives) and FN (false-negatives)

5.3.2 Model prediction explainability
We use LIME (Ribeiro et al. Reference Ribeiro, Singh and Guestrin2016) to interpret our best classifier. LIME is a model-agnostic method that perturbs the input text and gives weight to words based on how the model’s predictions change.
We analyzed a sample of false-positive and false-negative examples from the output of LIME and our best classifier. We found much confusion in the model decisions while considering the words as offensive or clean. We summarize common errors in the examples shown in Figure 12 and recommend the following for better explainability results: (i) ignore Twitter-specific symbols and symbols used for formatting (e.g., RT (Retweet), user mentions, links, <LF> (newline)), for example, replace mentions with @USER, links with URL, <LF> with space. (ii) As emojis are not recognized by LIME, replace them with their meanings, for example, middle_finger. (iii) Remove repeated letters that are commonly found in tweets and used for emphasis, for example, convert ![]() (“xlllAS”—“enooough”) to
(“xlllAS”—“enooough”) to ![]() (“xlAS”“enough”). (iv) We noticed confusion in interpreting words’ contribution toward classifying (non-)offensiveness. However, such confusion is understandable given the limited resource that is used to learn discriminating linguistic information. In the future, we plan to explore the use of more balanced large data, collected from diverse sources. It’s worth mentioning that those errors are not necessarily LIME errors as we have errors due to model predictions (F1 is 82.31).
(“xlAS”“enough”). (iv) We noticed confusion in interpreting words’ contribution toward classifying (non-)offensiveness. However, such confusion is understandable given the limited resource that is used to learn discriminating linguistic information. In the future, we plan to explore the use of more balanced large data, collected from diverse sources. It’s worth mentioning that those errors are not necessarily LIME errors as we have errors due to model predictions (F1 is 82.31).
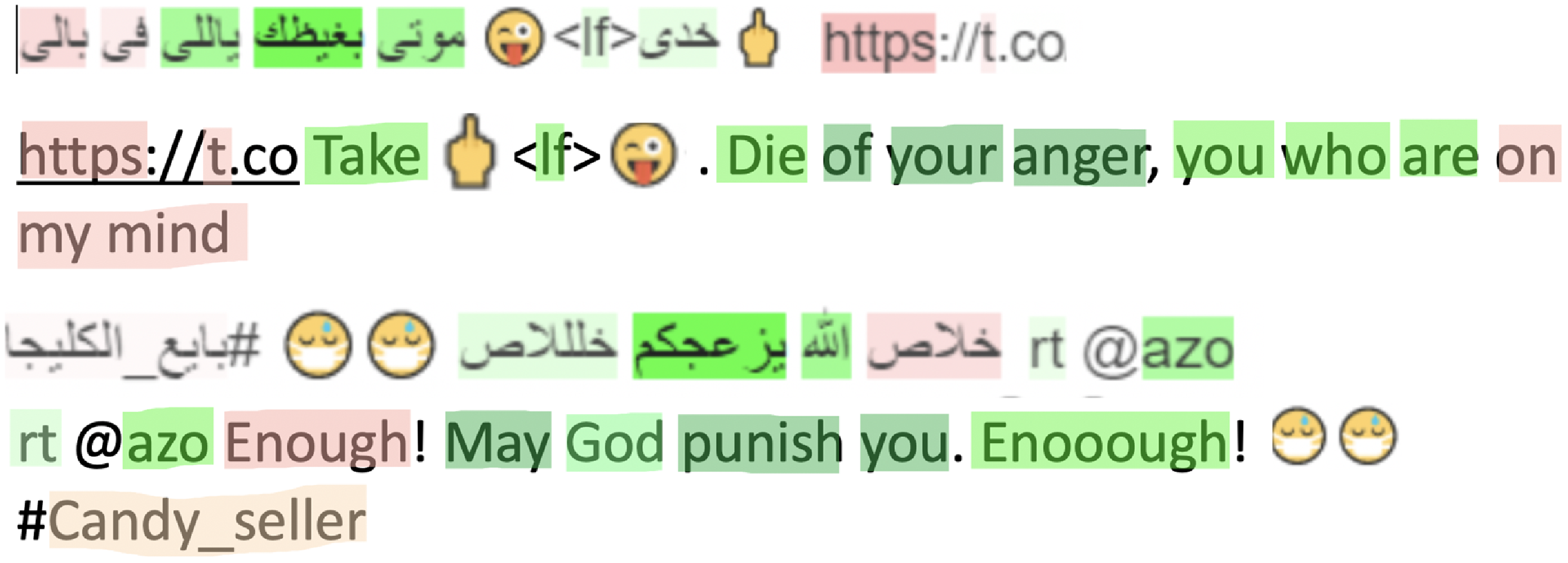
Figure 12. Examples of explainability errors. Green-colored words contribute to classification as offensive, while red-colored words contribute to classification as a non-offensive class. Rough translations are provided.
5.4 Generalization capability of models
Our proposed method of collecting an offensive language dataset relies on emojis. While this method yields a higher percentage of offensive content compared to existing methods, it’s crucial that models trained on our dataset perform well not only on our test set but also on external datasets. Achieving such generalization can help us to assert with confidence that our method captures characteristics of offensive language that are universal, and not specific to our dataset only.
In addition, assessing the generalization of the model to other social media platforms such as Facebook and YouTube can indicate the universal usage of emoji and also the effectiveness of harnessing the extralinguistic information present in emojis for offensive tasks.
5.4.1 Generalization to other Twitter data
To ascertain the generalization capability to other Twitter data, we evaluate our best performing model (QARiB, fine-tuned on our offensive training data) on the official test set of SemEval 2020 task 12 (OffensEval 2020, Arabic data) Zampieri et al. (Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020) data. For comparison, we also fine-tune QARiB on SemEval training data and evaluate on our dataset. Further, we fine-tune QARiB on the combination of the two datasets and evaluate the test sets separately.
The SemEval data contains 8000 tweets for training and 2000 tweets for testing. The tweets are manually annotated for offensiveness. To have a higher percentage of offensive tweets, only tweets that contained “yA” in the text were considered. “yA” is commonly used in Arabic offensive language (Zampieri et al. Reference Zampieri, Nakov, Rosenthal, Atanasova, Karadzhov, Mubarak, Derczynski, Pitenis and Çöltekin2020). Twenty percent of the data are tagged as offensive.
From Table 9, we can see that QARiB, fine-tuned on our data, achieves F1 score of 85.21 on the SemEval test set. However, when fine-tuned on SemEval data but tested on our data, QARiB achieves F1 score of 72.26. This suggests that models trained on our dataset capture characteristics of SemEval data reasonably well while also having more variety compared to SemEval data. It’s worth mentioning that combining the two datasets yield F1 score of 91.57 on SemEval dataset, which is an increase of 1.40 from the highest ranked system (Alami et al. Reference Alami, Ouatik El Alaoui, Benlahbib and En-nahnahi2020) at SemEval that achieved F1 score of 90.17 on the same test set.
Table 9. Performance comparison of QARiB, fine-tuned on our dataset (EMOJI-OFF), SemEval dataset and combination of the two datasets
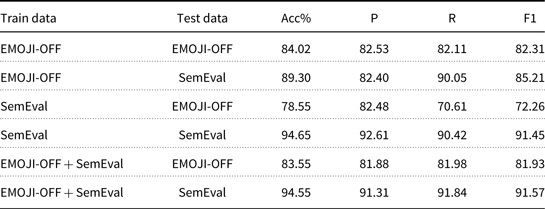
Table 10. Performance on multi-platform data. MPOLD-TW/YT/FB refers to Twitter, YouTube, and Facebook portions of MPOLD dataset, respectively. The MPOLD-TW/YT/FB columns contain numbers reported in Chowdhury et al. (Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b). The EMOJI-OFF column represents QARIB fine-tuned on our data. All numbers are macro-averaged F1.
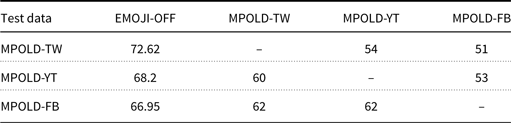
5.4.2 Generalization to multi-platform data
Having established generalization capability of our model to external Twitter data, we are interested in assessing how much our model can generalize to other social media platforms such as Facebook and YouTube. This is a challenging task as content on these platforms can differ greatly from each other. For example, Twitter imposes a tweet length limit of 280 characters. There is no such limitation on Facebook or YouTube comments. The audience is also different on different platforms. Because of these differences, users write in different styles across the different platforms. Moreover, as Chowdhury et al. (Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b) point out, the percentage of offensive content is much higher on Twitter compared to YouTube or Facebook.
To assess our model performance on other platform content, we evaluate the MPOLD dataset (Chowdhury et al. Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b) using our best model (EMOJI-OFF). The MPOLD dataset is a multi-platform dataset that contains 4,000 Arabic news comments from Twitter (1624), YouTube (1592), and Facebook (784). These comments are manually tagged for offensiveness. Out of the 4,000 comments, 675 (16.88%) were tagged as offensive.
We report our cross-domain model performance in Table 10. For better comparison, we present the cross-domain results reported by Chowdhury et al. (Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b). From Table 10, we can see that QARiB, fine-tuned on our data, achieves F1 scores of 68.2 and 66.95 on the YouTube and Facebook portions of MPOLD dataset, respectively. While these numbers are lower than that we saw earlier in Table 9 (as expected), they are still considerably higher than the cross-domain numbers reported in Chowdhury et al. (Reference Chowdhury, Mubarak, Abdelali, Jung, Jansen and Salminen2020b), which are 0.60 and 0.62 for YouTube and Facebook test sets, respectively. This suggests that models trained on our data have the potential of generalizing to content on other platforms.
5.4.3 Generalization to datasets without emoji
In order to assess how well our model performs on datasets without emoji, first, we removed all emojis from our dataset and fine-tuned our best model, QARiB. We evaluated this model on our test data and SemEval data (both with emojis removed). We did not notice any significant difference in performance as the model obtained F1 score of 85.03 on SemEval test set and F1 score of 83.05 on our test set, both of which are comparable to the numbers reported in Table 9. In the second experiment, we retained the emojis in our training set but excluded all tweets from the SemEval test set that contain emojis. Our model achieved F1 score of 83.94 in this setting. This again suggests that models trained on our data are not reliant on emojis and can generalize to datasets without emojis.
6. Ethics and social impact
After showcasing the effectiveness of using emojis for data collection and design, here we discuss the social impacts and ethical concerns surrounding the newly released data.
6.1 User privacy
The dataset was collected using the Twitter API. For privacy, we anonymized the dataset by removing usernames and other sensitive user identifiers. However, in the future, if any concern is raised for a particular content, we will comply with legitimate concerns by removing the affected tweets from the corpus. Furthermore, to keep privacy and datasets integrity, we are providing tweets by text, not the corresponding tweet ids.
6.2 Biases
Any biases found in the dataset are unintentional, and we do not intend to do harm to any group or individual. The bias in our data, for example, toward a particular group, is unintentional and is a true representation of the Twitter space during the period of our collection and according to our generic proposed method. Emojis used as seeds to create the collection are extracted automatically from publicly available datasets without any bias in our selection. The collection was obtained over a span of 18 months to have a good diversity of tweets written by many authors.
As for the assigned annotation labels, we follow a well-defined schema and available information to perceive final labels for offensiveness, hate speech, and vulgarity. The labels are not a reflection of our opinion. Test questions used for quality control were selected to cover different annotation classes proportionally to their distributions in the collected tweets.
Although more than 190 workers have participated in the annotation process (with at least 80% success ratio for 200 test questions), this doesn’t guarantee perfect quality of annotation. As noted in Mubarak and Darwish (Reference Mubarak and Darwish2014), Arabic Twitter is dominated by tweets from Gulf countries (Saudi Arabia, Kuwait, etc.) while Appen (previously CrowdFlower/Figure8) crowdsourcing platform has
 $\approx 30\%$
of annotators from Egypt (the most Arabic populated country) (Mubarak and Darwish Reference Mubarak and Darwish2016). This may lead to misunderstanding (and incorrect labeling) of the portion of tweets, especially when they are written in dialects that are not understood by annotators. Moreover, almost three-quarters of Arab annotators on Appen are males which may lead to hidden biases in data annotation.
$\approx 30\%$
of annotators from Egypt (the most Arabic populated country) (Mubarak and Darwish Reference Mubarak and Darwish2016). This may lead to misunderstanding (and incorrect labeling) of the portion of tweets, especially when they are written in dialects that are not understood by annotators. Moreover, almost three-quarters of Arab annotators on Appen are males which may lead to hidden biases in data annotation.
6.3 Potential misuse
We urge the research community to be aware that our dataset can be used to misuse like any other social media data. If such misuse is noticed, human moderation is encouraged in order to ensure this does not occur.
7. Conclusion
The automation of detecting offensiveness (including hate speech) is limited by the availability of large balanced manually annotated datasets. To overcome such lacking, we propose a generic language-, topic- and genre-independent approach to collect a large percentage of Arabic offensive and hate speech data. We utilize the extralinguistic information embedded in the emojis to collect a large number of offensive tweets. We manually annotated the Arabic dataset for different layers of information, including offensiveness, followed by fine-grained hate speech, vulgar, and violence content annotation. Furthermore, we benchmark the dataset for detecting offensive content and hate speech using different transformer architectures and performed in-depth analysis for temporal changes, linguistic usage, and target audience. We also studied specific patterns in violence tweets. We demonstrate that the transformer model trained on our data achieves strong results on an external Twitter dataset. Further, the model outperforms previous models in literature when tested on multi-platform data that contains offensive comments from Twitter, YouTube, and Facebook. This is the largest Arabic dataset for multilevel offensive language detection annotated with fine-grained hate speech, vulgar, and violence labels. We publicly release the dataset for the research community.
Competing interests
The authors declare none.























 Open access
Open access