



Introduction
The coronavirus disease (COVID-19) pandemic is the global phenomenon which is shaping modern societies in the year 2020, a reason why the severe acute respiratory coronavirus 2 (SARS-CoV-2) has been named the once-in-a-century pathogen that scientists and global leaders had been worrying for [Reference Gates1]. Although some countries were able to reach suppression (≤5 cases per million per day, and ≥20 tests per case) of the epidemic by August 2020, most others had persistent detection of new cases, with varying degrees of transmission and testing rates [2]. Non-pharmacological interventions may facilitate a country reaching control of disease spread; these interventions include: early lockdowns combined with other measures (school and workplace closures, social distancing, travel restrictions and restrictions on mass gathering and public events), and use of facemasks [Reference Islam3–Reference Chu6]. However, strict quarantines have an important social and economic impact, and countries such as Mexico have not been able to endure prolonged quarantines, resulting in a sustained transmission and death toll. Novel strategies such as switching between closures and keeping communities open [Reference Cheong, Wen and Lai7], and regionalising closures in a timely manner [Reference Siegenfeld, Taleb and Bar-Yam8] could provide useful in limiting the impact of COVID-19 in complex countries such as Mexico.
Mexico has been one of the most affected countries by COVID-19; disparate differences in patient outcomes have been noted be related to inequalities [Reference Gutierrez and Bertozzi9]. Low and middle-income countries often suffer from inadequate healthcare due to the lack of equipment, poor organisation, and scarce qualified healthcare professionals. Thus, what works in high-income countries may not work in low-income countries [Reference Roder-DeWan10]. Therefore, there is a pressing need to develop accessible and simple tools to aid clinicians providing medical attention in the most unfavoured regions of Mexico.
Demographic and patient history risk factors for fatal outcomes in patients with COVID-19 have been characterised in large national cohorts [Reference Williamson11–Reference Gupta14], and broadly include: old age, sex (men), comorbidities, deprivation (a correlate of poverty) and belonging to certain ethnic groups. Other clinical, radiological and laboratory parameters at presentation have also been studied as risk factors for disease progression and death [Reference Gupta14, Reference Zhou15]. Several diagnostic and prognostic models have been developed to be used in patients with COVID-19 [Reference Wynants16]. However, most models include laboratory and radiographic variables which would be nearly impossible to collect in low-resource settings. Furthermore, these models have seldom been validated, are often inadequately reported or are overfitted due to a large predictor-to-outcome ratio [Reference Wynants16–Reference Hooli and King18], reasons that may limit their usefulness in real-world settings. Developing and validating models that only require demographic and patient history data, by using large national or multinational cohorts, may be a way to overcome these shortcomings to provide useful tools to clinicians in low-resource regions.
Therefore, we sought to develop and validate a multivariable prediction model of death in Mexican patients with COVID-19, by using demographic and patient history predictors.
Method
Study design
We conducted a national retrospective cohort study in two different sets of patients from the Mexican COVID-19 Epidemiological Surveillance Study [19] to develop and validate a multivariable prediction model of death in Mexican patients with COVID-19. Patient history variables were used as predictors of death as the outcome of interest. Blind assessment was not required since these are objective variables unlikely subjected to bias.
To develop the model, we included 264 026 patients studied between 28 February and 30 May 2020. All patients with a positive reverse transcription-polymerase chain reaction (RT-PCR) for SARS-CoV-2 were included to maximise the power and generalisability of results. Patients with incomplete data were excluded, whereas patients with the same demographic, clinical and follow-up variables were considered duplicated and only one entry was kept.
To validate the model, we included 592 160 patients studied between 1 June and 23 July 2020. Only patients with a positive RT-PCR for SARS-CoV-2 and complete unduplicated data were included to validate the model. We further performed simple random sampling of positive cases to increase statistical power in approximately 15% with respect to the sample used for developing the model.
Source of data
Data are collected and regularly updated by the Mexican Secretariat of Health and are available in the Open Data platform of the Federal Government of Mexico [20]. A historical repository of individual datasets starting on 12 April 2020 is available through the General Directorate of Epidemiology [21]. Patients who met criteria of suspected COVID-19 case and were subsequently tested for SARS-CoV-2 were included in the study, starting on late February 2020 when the first suspected cases arrived in Mexico. Two diagnostic strategies are outlined in the National COVID-19 Epidemiological Surveillance Plan [19]: (1) testing of 10% of ambulatory patients with mild symptoms of respiratory disease and 100% of patients with respiratory distress at evaluation in one of the 475 monitoring units of viral respiratory disease (USMER, for its acronym in Spanish) which are strategically distributed to be representative of the Mexican population, and (2) testing 100% of patients who meet diagnostic criteria of Severe Acute Respiratory Infection (defined as shortness of breath, temperature ≥38 °C, cough and ≥1 of the following: chest pain, tachypnoea, or acute respiratory distress syndrome) who seek medical attention in non-USMER units.
Healthcare professionals collecting a diagnostic specimen are required to fill out a format containing demographic and patient history variables. Follow-up of all suspected COVID-19 cases is registered by accredited hospital epidemiologists (inpatients) and the responsible healthcare professional of every Local Health Jurisdiction (ambulatory patients), who ultimately upload data to the Respiratory Diseases Epidemiological Surveillance System. Results of diagnostic RT-PCR for SARS-CoV-2 are directly uploaded by the diagnostic facility; accreditation of diagnostic procedures by the Mexican Institute of Diagnostics and Epidemiological Reference is required to upload results. Reporting of deaths is obligatory and must be done in less than 48 h after occurrence. One caveat to this reporting method is that patients who are tested more than once in different jurisdictions may be duplicated. No variables that could lead to identification of patients are provided in datasets. Thus, the only way to eliminate duplications is through matching of cases with equal demographic and clinical variables. Specific information of treatments is not released.
Variables provided in the datasets are: origin (USMER, non-USMER), healthcare provider, state, birthplace, place of residency, nationality, indigenous language speaker, migratory status, type of medical attention (hospitalisation/ambulatory), admission date, symptom onset date, invasive mechanical ventilation (intubation (yes/no)), admission to intensive care unit (ICU) (yes/no), pneumonia (yes/no), date of death, contact with confirmed COVID-19 cases (yes/no), SARS-CoV-2 RT-PCR result (positive, negative, or pending), age, sex and current pregnancy, and the following comorbidities (yes/no): diabetes, hypertension, obesity, cardiovascular disease (CVD), chronic kidney disease (CKD), immunosuppression, asthma, chronic obstructive pulmonary disease (COPD) and smoking.
Statistical analysis
Descriptive data were calculated and are provided as frequencies, percentages or mean with standard deviation (s.d.). Characteristics of patients in the model development and validation cohorts were compared through Student's t-test or χ 2. A Cox regression model was applied to predict the risk of death. The risk of death was assessed through univariate analysis of the following variables: age, sex, current pregnancy, diabetes, COPD, asthma, immunosuppression, hypertension, CVD, obesity, CKD, smoking and time from symptom onset to medical attention. Age and time from symptom onset to medical attention were included in the model as quantitative variables, whereas the rest of the variables were modelled as dummy variables. Risk factors associated with death which were statistically significant (P < 0.05) were included to develop the multivariate regression model. All variables with a level of significance P < 0.1 were considered in the Cox regression model by using the Enter method. Variables that kept a level of significance P < 0.05 were used in the final model, which was evaluated through Harrell's C-statistic to determine its discrimination of death.
A scoring system was developed in accordance with the model proposed by Sullivan et al. [Reference Sullivan, Massaro and D'Agostino22]. Each risk factor was organised into categories and the reference value was determined as follows. Age was entered into the Cox regression model as a continuous variable and further categorised into 10 sets of years (<20, 20–29, 30–39, 40–49, 50–59, 60–69, 70–79, 80–89, 90–99 and >90); the midpoint between the nine values of each category was set as the reference value (Wij). The reference for age as a risk factor (Wi REF) was set in the 20–29 years category since this group had the lowest mortality in a previous study performed in Mexican patients with COVID-19 [Reference Kammar-García12]. For the rest of risk factors, the absence of comorbidities and being woman (sex) were set as the reference values. Each Wi REF was subtracted from Wij and multiplied by the regression coefficient (βi) of the risk factor to determine units of regression of distancing for every risk factor in the reference category βi(Wij − Wi REF). A constant B, defined as the constant increase in units of risk for each 5-year increase, was obtained by multiplying βi × 5. Values for B were 0.25 in this study. Scores for each category were obtained with the equation βi(Wij − Wi REF)/B. For every point in the risk score, the estimated risk of death (p) was calculated with the Cox proportional hazards regression analysis:
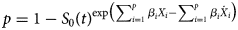
where S 0(t) is the average survival according to mean values of every risk factor; $\sum\nolimits_{i = 1}^p {\beta _iX_i}$ is substituted with each value of the risk score, times the B constant, plus the reference age value according to the βi of age and $\sum\nolimits_{i = 1}^p {\beta _i{\dot{X}}_i}$
is substituted with each value of the risk score, times the B constant, plus the reference age value according to the βi of age and $\sum\nolimits_{i = 1}^p {\beta _i{\dot{X}}_i}$ is the sum of every βi times the proportion or mean value of every risk factor.
is the sum of every βi times the proportion or mean value of every risk factor.
To validate the model, we calculated the risk score for every patient and applied the Cox proportional hazards regression analysis. Estimated risks were obtained from both the scoring system and the observed risk in the regression analysis. The values obtained for patients in the validation cohort were distributed in percentiles (1–99) to determine the scoring categories. The estimated and observed risks were compared in each scoring category (percentiles 25, 50, 75 and 99).
The Kaplan–Meier analysis was performed to determine survival in each category of the scoring system, and a Cox regression analysis, to determine increases in the death risk for each category.
The association between the risk score and the probability of other adverse events (hospitalisation, invasive mechanical ventilation, pneumonia and admission to ICU) were also studied. The frequencies of each adverse event for every category in the scoring system were quantified and a binomial logistic regression analysis was performed to determine the risk of each adverse event according to the risk score; logarithms of the odds ratios (ORs) were graphed to establish the scoring value at which risk for every adverse event is increased.
All statistical analyses were performed using SPSS software v.21 and R statistical software v.3.6.2; figures were created in GraphPad Prism v.6. A value of P < 0.05 was used to establish statistical significance.
Results
Out of 264 026 patients in the model development cohort, 84 627 had a positive RT-PCR for SARS-CoV-2, 140 553 were negative and 38 846 had pending results. After exclusion of patients with incomplete data and duplicated registries, 83 779 patients with a positive test were included to develop the model. Among the 592 160 patients in the model validation cohort, 256 488 patients had a positive result, 253 447 were negative and 82 225 had unreported results. After excluding duplicated and incomplete registries, and random sampling of positive cases, 100 000 patients were included to validate the model. Descriptive values of demographic characteristics, patient history and outcomes of patients (survivors and non-survivors) in both cohorts are provided in Table 1.
Table 1. Demographic characteristics, patient history data and outcomes in the model development and validation cohorts

Data are presented as mean values (s.d.), unless otherwise specified.
a Statistical significance with respect to survivors.
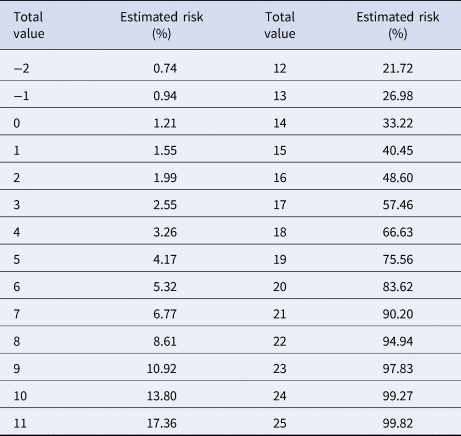
Variables included in the Cox regression model are presented in Table 2. Eight risk factors were included in the model (age, sex, diabetes, COPD, immunosuppression, hypertension, obesity and CKD); the only quantitative variable was age. Age, diabetes and CKD were associated with the greatest increases in death. The predictive model has a discrimination of 0.8 (95% confidence interval (CI) 0.796–0.804) and an average survival of 0.903 with the mean values for every risk factor. The patient history COVID-19 (PH-Covid19) scoring system assigns a score to every risk factor ultimately included in the predictive model (Table 3); the sum of scores for all risk factors included ranges from −2 to 25 points. Predicted probabilities of death in patients with a positive test for SARS-CoV-2 for every possible total value in the scoring system range from 0.74% to 99.82% (Table 4).
Table 2. Risk factors associated with death in Mexican patients with a positive diagnostic test for SARS-CoV-2 (model development cohort)

HR, hazard ratio; 95% CI: 95% confidence interval; COPD, chronic obstructive pulmonary disease; CKD, chronic kidney disease.
Table 3. PH-Covid19 risk score to predict death in patients with COVID-19
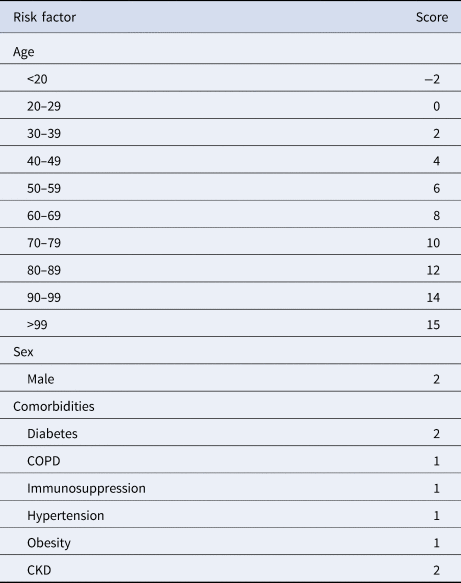
COPD, chronic obstructive pulmonary disease; CKD, chronic kidney disease.
Range of values: −2 to 25.
Reference categories for included variables: age (20–29 years), sex (woman), diabetes (no diabetes), COPD (no COPD), immunosuppression (no immunosuppression), hypertension (no hypertension), obesity (no obesity), CKD (no CKD).
Table 4. Estimated risk of death according to every possible score in the PH-Covid19 score, in Mexican patients with a positive test for SARS-CoV-2
Baseline characteristics and outcomes of patients in the validation cohort were statistically significantly different from those in the model development cohort, except for time from symptom onset to medical attention (Table 1). Results of the Cox regression model applied to the validation cohort are provided in Supplementary Table S1. Calculated scores in the validation cohort reflected the following distribution according to percentiles: −2 to 2 points, percentile 1 to 25; 3 to 5 points, percentile 25–50; 6 to 8 points, percentile 51 to 75 and 9 to 15 points, percentile 76 to 99. Patients >99 percentile were considered as extreme values. Estimated risks and the observed risks of death obtained from the Cox proportional hazard regression analysis, in relation to the scores in each percentile, are presented in Figure 1. The estimated and observed risks were similar for every group (−2 to 2 points, 3 to 5 points, 6 to 8 points, and 9 to 15 points) and were strongly correlated (r = 0.98, R 2 = 0.96, P < 0.0001).

Fig. 1. Estimated and observed risks of death in Mexican patients with a positive test for SARS-CoV-2, according to categories derived from the PH-Covid19 scoring system. Data are presented as mean and 95% CIs.
In the survival comparison between the groups (−2 to 2 points, 3 to 5 points, 6 to 8 points, and 9 to 15 points) generated after the percentile distribution (Fig. 2), survival was lower with increasing scores; survival in the −2 to 2 points group was 99.6%; in the 3 to 5 points group, 98.6%; in the 6 to 8 points group, 95.7%, and in the 9 to 15 points group, 84.3%. Groups were compared against the −2 to 2 points group (P < 0.0001 for all comparisons). In the Cox regression analysis, increased risk of death occurred in patients in the 3 to 5 points group (hazard ratio (HR): 3.54, 95% CI 2.85–4.39), 6 to 8 points group (HR: 10.67, 95% CI 8.78–12.98), 9 to 15 points group (HR: 41.9, 95% CI 34.7–50.7) and >15 points group (HR: 87.6, 95% CI 70.1–109.5) compared with the −2 to 2 points group (reference category).

Fig. 2. Kaplan–Meier survival curves in Mexican patients with a positive test for SARS-CoV-2, according to categories derived from the PH-Covid19 scoring system. Dashed lines represent 95% CIs.
In accordance with this, risk categories were derived from the scoring system: low (−2 to 2 points), medium-low (3 to 5 points), medium (6 to 8 points), medium-high (9 to 15 points), and high (>15 points).
The prevalence for every adverse event in each category of the scoring system are provided in Figure 3; results of the logistic regression analysis to determine the risk of adverse events for each risk category in the PH-Covid19 scoring system are given in Supplementary Table S2. Tendencies of risk increment for each adverse event with augmenting scores (Supplementary Fig. S1) reflect that risk for any adverse event starts at a value of 5 points.

Fig. 3. Prevalence of adverse events in Mexican patients with a positive test for SARS-CoV-2, according to categories derived from the PH-Covid19 scoring system.
Discussion
We have developed and validated the PH-Covid19 score, a multivariable prediction model of death in Mexican patients with COVID-19, by using different datasets from the Mexican COVID-19 Epidemiological Surveillance Study. This scoring system has been created to aid clinicians working under resource-strained conditions to early stratify patients with COVID-19 according to their risk of fatal outcomes, without the need to perform laboratory or imaging studies.
Sex (men), which increases 2 points in our score, was correlated with death in our study and others [Reference Williamson11, Reference Kammar-García12, Reference Gupta14, Reference Zhou15, Reference Docherty23]. Similar to other studies, we found that older age is the main risk factor for dying from COVID-19, with every 10-year increase associated with the largest increases in the HR [Reference Williamson11, Reference Gupta14, Reference Docherty23]. In a recent prospective validation study of prognostic models for COVID-19, none of the models that predicted mortality in patients with COVID-19 were better than age alone to predict in-hospital mortality [Reference Gupta24]. This may be explained by the fact that many models for COVID-19 have failed to account for the large increases in mortality risk due to increasing ages. In the PH-Covid19 scoring system, 10-year increases add 2 points, starting from 30 years, whereas being <20 years subtracts 2 points.
Diabetes and CKD resulted in 2-point increases in the score. Other studies had similar findings to ours [Reference Kammar-García12, Reference Guan13, Reference Zhou15, Reference Docherty23]; one study found an uncertain increased risk attributable to diabetes (HR: 1.14, 95% CI 0.91–1.43) in critically-ill patients [Reference Gupta14]; in another study, uncontrolled diabetes further increased the risk (HR: 1.95, 95% CI 1.83–2.08) with respect to controlled diabetes (HR: 1.31, 95% CI 1.24–1.37), whereas CKD stages 4–5 caused a greater increase (HR: 2.52, 95% CI 2.33–2.72) compared to CKD stages 3a–3b (HR: 2.52, 95% CI 2.33–2.72) [Reference Williamson11]. Obesity had the third strongest association with death, resulting in a 1-point increase in our scoring system; other studies have had similar findings [Reference Kammar-García12, Reference Docherty23]. Adjusted risk of death by obesity occurred with gradual increases in higher obesity classes [Reference Williamson11] and no evident or clear risk was identified in another study for class I and II obesity, whereas class III obesity was significantly correlated with death [Reference Gupta14]. This last study, however, included only patients admitted to ICUs who had a high prevalence of comorbidities, which are independent risk factors for ICU admission [Reference Kammar-García12].
Hypertension was a risk factor for death similar to other studies [Reference Kammar-García12, Reference Guan13], and resulted in a 1-point increase in the scoring system. In one large study, risk of death for hypertension adjusted by all covariates apparently reduced the risk (HR: 0.89, 95% CI 0.85–0.93), likely reflecting an artificial reduction of risk driven by diabetes and obesity since age and sex adjusted risk increased the risk (HR: 1.09, 95% CI 1.05–1.14) [Reference Williamson11]. COPD also increased 1 point in our model, being also associated with death in other studies [Reference Williamson11–Reference Guan13, Reference Docherty23].
Results from our validation did not provide different patient history predictors which could enhance the performance of our model. Thus, model updating was not required. The robustness of the model is reflected in the standard errors and CIs that imply an adequate estimation of population parameters. Furthermore, standard error of the regression coefficient indicates the dispersion of this statistic for the studied population, and the CIs calculated for every risk factor allow us to interpret that the estimations of HRs are precise. Similarly, comparisons of predicted and observed risks for every score groups are not different since their CIs overlap. Survival analyses show that even though survival rates for contiguous risk categories are close to each other, their CIs are equally close to each estimated survival probability, thereby supporting a robust estimation of survival according to risk categories in our study.
Some of our findings raise concerns regarding quality and access to healthcare in Mexico. 10.3–13.5% of patients who died in our cohorts did not receive in-hospital care at any moment of the disease, only 15.5–18.3% of patients were admitted to an ICU before dying and only 21.3–28.1% of patients who died were intubated; conversely, intubation in survivors was unusually low (0.8–1.3%). In other studies of hospitalised-only patients, 53–72% of non-survivors were admitted to an ICU and 51–59% received invasive mechanical ventilation [Reference Zhou15, Reference Richardson25, Reference Yang26]. Observed mortality in COVID-19 patients under 60 years is lower when access to healthcare is not a limitation [Reference Karagiannidis27]; non-survivors in our cohorts were younger (mean age 60–61.4 years) than those in other studies (67–80 years) [Reference Gupta14, Reference Zhou15, Reference Docherty23, Reference Wu28].
Patients diagnosed with pneumonia in both cohorts were 12.8–21% among survivors and 77.4–87.5% of non-survivors. These numbers are low compared to the prevalence of chest computed tomography-scan abnormalities which occur in 67.3–70.8% of asymptomatic/pre-symptomatic patients [Reference Hu29, Reference Wang30], 95.5% of patients with mild COVID-19 [Reference Liang31] and 98% of all COVID-19 patients included in a meta-analysis [Reference Awulachew32]. Chest X-ray, on the other hand, may be normal in up to 63% of patients with early COVID-19 pneumonia [Reference Cleverley, Piper and Jones33]. Nonetheless, the low proportion of pneumonia in non-survivors suggests non-optimal diagnosis of pneumonia may be occurring in Mexico. The lack of an operational definition may have contributed since clinicians could have defined pneumonia differently based on clinical and/or radiographical findings. Other possibilities should be explored, including knowledge of Mexican clinicians on how to diagnose pneumonia and access to radiological studies during the pandemic in low-resource settings.
One recent model developed in a large cohort of in-hospital patients from a large cohort in the UK accurately predicts in-hospital death (area under the curve (AUC): 0.79, 95% CI 0.78–0.79) [Reference Knight34]. However, the 4C mortality score may be limited due to not accounting for the large increases in risk of death for every 10-year age category. This scoring system is easy to use, however, it requires input of two laboratory values (C-reactive protein and urea) which may limit its use in low-resource contexts and, differently to ours, its use is limited to in-hospital patients.
Three prognostic COVID-19 models have been developed in Mexican patients. The LOW-HARM model [Reference Soto-Mota35] is a 100-point scoring system calculated by inputting patient history and laboratory values, in which 65 points was set as the cut-off value to predict death (AUC: 0.80, 95% CI 0.77–0.84), similar to the PH-Covid19 scoring system (AUC: 0.80, 95% CI 0.796–0.804) which advantageously only requires patient history predictors. Another scoring system uses age (cut-off 65 years), comorbidities and pneumonia to predict death [Reference Bello-Chavolla36]. This model was accurate at predicting death and other adverse events but has the limitation of not accounting for the large increases in risk for every 10-year category or similar. Also, the model by Bello-Chavolla et al. was developed using one dataset of the Mexican Epidemiological Surveillance Study, which unfortunately had no operational definition for pneumonia as discussed earlier. A third model was developed and validated to predict the risk of admission to ICU; the ABC-GOALS model was developed in three versions: clinical, clinical + laboratory and clinical + laboratory + imaging predictors [Reference Mejía-Vilet37].
In one systematic review of existing prediction models for diagnosis and prognosis of COVID-19, the use of any of the reviewed models was discouraged since, out of 91 diagnostic and 50 prognostic models, all were at high risk of bias due to methodological constraints and poor reporting [Reference Wynants16]. Predictive models of death (eight) often excluded patients that had not developed the outcome of interest, did not account for censorship, inadequately reported discrimination and calibration of the model, and had a high risk of bias according to PROBAST evaluation, despite authors claiming good global performances of their models. We have addressed these concerns in our development and validation of the PH-Covid19 scoring system.
One strength of our model is that it was developed and validated in cohorts including both ambulatory and hospitalised patients, whereas most other prognostic models for COVID-19 have been developed in hospitalised-only patients.
Another strength of our study is that we were able to perform a type 3 analysis according to TRIPOD by using individual datasets to develop and validate our model; this design allows for external validation of the performance of a model [Reference Moons38]. It is worth highlighting that sample sizes in both cohorts include thousands of patients, which adds robustness to our model.
One limitation of our study is that certain diseases (cancer, haematological malignancies and neurologic diseases) and specific states of a disease (obesity class, former or current smoker and control of diabetes, hypertension and asthma) which increase the risk of dying from COVID-19 [Reference Williamson11] were not studied since they are not provided in the datasets. Furthermore, we were not able to study other social determinants and population factors which could be having an important impact in patient outcomes [Reference Mathur39, Reference Cheong and Jones40]. However, our model accounts for the main risk factors associated with death in patients with COVID-19, and not requiring inputting specific disease states makes it easier to be used by clinicians while minimising the risk of not having enough data to use the score with precision. Another limitation is that the epidemiological surveillance strategy in Mexico allows testing of only 10% of ambulatory patients. Furthermore, the operational definition of suspected COVID-19 case used in Mexico until 24 August 2020 had a low sensitivity (58.2%), but a high specificity (63.7%) compared to that used by the CDC (85.8% and 25.8%, respectively) [41]. Altogether, this means that our cohorts may include very few patients with asymptomatic COVID-19 and fewer patients with mild COVID-19 compared to other national datasets with higher testing rates. Since it was not possible to determine the exact number of patients with mild disease in our cohorts, we can only indirectly suggest that mild-disease patients could comprise around 71.5% and 84.4% of patients according to the fraction of non-hospitalised patients who survived, a number high enough to permit the use of this score in patients with mild-to-severe COVID-19.
Future models that could outperform ours in low-resource settings should account for the large increases in risk due to age, evaluate more comorbidities and disease states, avoid difficult-to-obtain laboratory and imaging parameters and evaluate the impact of social determinants of mortality in COVID-19. Also, it would be ideal for these models to come from large national or multinational cohorts including both ambulatory and hospitalised patients, similar to that of the OpenSAFELY study [Reference Williamson42].
The PH-Covid19 score was created to be used in limited-resource settings where access to laboratory and imaging studies may be restricted. In places where this is not a limitation and for patients who are likely to have already been admitted to hospital (critical patients), other prognostic models may have a better performance than ours. However, clinicians should consider that most models have not been validated before deciding to use any COVID-19 diagnostic or prognostic model.
The PH-Covid19 score uses patient history predictors which are frequently known at the first contact with a patient, or can be interrogated rapidly, to predict death in patients with COVID-19. This score was developed and validated in Mexican patients to be used in low-resource settings where obtaining laboratory and radiographic studies may not be immediately possible. This score will aid clinicians to stratify patients with COVID-19 at risk of fatal outcomes to use healthcare resources more efficiently.
Supplementary material
The supplementary material for this article can be found at https://doi.org/10.1017/S0950268820002903
Acknowledgements
J.M.-G. would like to thank ‘Dirección General de Calidad y Educación en Salud’ for supporting his participation in ‘Programa Nacional de Servicio Social en Investigación en Salud’.
Financial support
This research did not receive any specific grant from funding agencies in the public, commercial or not-for-profit sectors.
Conflict of interest
None.
Ethical standards
This paper is a retrospective study of an open-source dataset of patients in Mexico. The Ministry of Health of Mexico approved the recollection of information.
Data availability statement
The data that support the findings of this study are openly available in Historical COVID-19 Datasets of the Directorate General of Epidemiology of Mexico at https://www.gob.mx/salud/documentos/datos-abiertos-bases-historicas-direccion-general-de-epidemiologia [21].










 Open access
Open access