


Introduction
Child speech is marked by considerable variability at the phonetic and phonological levels, and in many ways, deviates from adult speech patterns. At the phonetic level, differences in anatomy and motor control between children and adults have sizable influences on the phonetic output (e.g., Eguchi & Hirsch, Reference Eguchi and Hirsch1969; Koenig, Reference Koenig2000; Macken & Barton, Reference Macken and Barton1980; Smith & Kenney, Reference Smith and Kenney1998). At the phonological level, child word forms differ from those of adults with segmental and featural modifications. Processes including segment deletion, insertion, and metathesis are quite commonplace; subsegmental changes such as denasalization, vocalization, fronting, velarization, and stopping, among others, have also been attested (e.g., Barlow & Gierut, Reference Barlow and Gierut1999; Haelsig & Madison, Reference Haelsig and Madison1986; Smith, Reference Smith1973). Nevertheless, aspects of these levels and the interface between them may still resemble the mature grammar. In the present study, we investigate the extent to which child speech patterns parallel adult speech patterns with a focus on aspirated stop consonant voice onset time (VOT) in two- to five-year-old talkers of American English and Cantonese, and discuss the implications of these findings for the development of speech production representations.
VOT Production in English and Cantonese
Across languages, VOT is the primary correlate to the stop voicing contrast (Lisker & Abramson, Reference Lisker and Abramson1964). In word-initial position, American English and Cantonese have voiceless aspirated stops with long-lag VOT at three primary places of articulation. Phonologically, English aspirated stops are argued to be phonological surface segments of underlying /p t k/ which contrast with /b d g/.Footnote 1 Cantonese aspirated stops are argued to be phonological surface segments of underlying /ph th kh/ which contrast with /p t k/. In English, the phonetic places of articulation are bilabial, alveolar and velar, and in Cantonese, the places of articulation are bilabial, dental/alveolar, and velar. For simplicity, we refer to the three places as labial, coronal, and dorsal, and use the square-bracketed [ph th kh] to refer to the surface segments present in both languages. Previous studies have reported highly comparable VOT values between American English and Cantonese aspirated stops in adult speech, despite the fact that the two languages are otherwise typologically distinct (see Table 1).
Table 1. Previously reported VOT values in milliseconds from adult talkers of English and Cantonese. M refers to the mean, SD to the standard deviation, RM to the range of talker means, RSD to the range of talker standard deviations, and RI to the range of individual VOT values.

Empirical evidence suggests that most English- and Cantonese-speaking children acquire aspirated stops around two to three years of age (English: Barton, Reference Barton1976; Gilbert, Reference Gilbert1977; Macken & Barton, Reference Macken and Barton1980; Major, Reference Major1976; Kewley-Port & Preston, Reference Kewley-Port and Preston1974; Zlatin & Koenigsknecht, Reference Zlatin and Koenigsknecht1976; Cantonese: Stokes & To, Reference Stokes and To2002). Similar findings have also been reported for children of other languages with a voiceless aspirated stop series (e.g., Thai: Gandour, Petty, Dardarananda, Dechongkit, & Mukngoen, Reference Gandour, Petty, Dardarananda, Dechongkit and Mukngoen1986; Mandarin: Yang, Reference Yang2018). Child production of VOT in voiceless aspirated stops is, however, not immediately adult-like. Some studies report longer VOT values for children than adults, suggesting an ‘overshoot’ phase (Barton & Macken, Reference Barton and Macken1980; Gilbert, Reference Gilbert1977; Lee Oi Yee, Reference Lee Oi Yee1997; Millasseau, Bruggeman, Yuen, & Demuth, Reference Millasseau, Bruggeman, Yuen and Demuth2021), whereas others report shorter VOT values for children than adults (e.g., Kewley-Port & Preston, Reference Kewley-Port and Preston1974; Macken & Barton, Reference Macken and Barton1980; Zlatin & Koenigsknecht, Reference Zlatin and Koenigsknecht1976). Regardless of the relative direction, child VOT is consistently characterized by greater variability than adult productions (Barton & Macken, Reference Barton and Macken1980; Clumeck et al., Reference Clumeck, Barton, Macken and Huntington1981; Eguchi & Hirsch, Reference Eguchi and Hirsch1969; Koenig, Reference Koenig2000; Yang, Reference Yang2018; Zlatin & Koenigsknecht, Reference Zlatin and Koenigsknecht1976).
Increased variability in child VOT likely arises from underdeveloped laryngeal control, which refers to the management of glottal abduction degree, vocal fold tension, as well as transglottal pressure and flow (Koenig, Reference Koenig2000). Moreover, these skills may not fully mature until mid-adolescence (Koenig, Reference Koenig2000; Redford, Reference Redford2019; Smith & Zelaznik, Reference Smith and Zelaznik2004). Indeed, talker-specific VOT standard deviations of English aspirated stops are almost twice as large for five-year-old talkers than for adult talkers, and similar findings have been observed for Cantonese-learning children (see Table 2).Footnote 2
Table 2. Previously reported VOT values in milliseconds from child talkers of English and Cantonese. M refers to the mean, SD to the standard deviation, RM to the range of talker means, RSD to the range of talker standard deviations, and RI to the range of individual VOT values.

Structured VOT Variability
While VOT varies extensively across talkers, it is also highly structured among stop categories, at least in adult speech production. We discuss three primary types of structure observed in adult VOT – between-category VOT structure, within-category VOT structure, and “contextual” VOT structure – and present our proposed analysis and predictions for each type of structure with respect to child speech production. In particular, we investigate this structure in a large spoken corpus with 161 two- to five-year-olds in American English (81 talkers) and Cantonese (80 talkers). In children, VOT structure may need to develop over time as both the motor and linguistic systems mature. In this case, we would expect a lower degree of VOT structure in children than adults. Alternatively, children may already possess some mature phonetic representations despite limitations in motor control. In this case, we would expect a comparable degree of VOT structure in children as in adults.
Between-category VOT Structure
In many, if not all languages, the mean VOT of /p/ is lower than that of /k/, reflecting a consistent ordinal relationship (e.g., Cho & Ladefoged, Reference Cho and Ladefoged1999; Chodroff, Golden, & Wilson, Reference Chodroff, Golden and Wilson2019; Lisker & Abramson, Reference Lisker and Abramson1964). The mean VOT of /t/ is frequently intermediate to that of /p/ and /k/, though some variability in this ranking is not uncommon (e.g., Chodroff & Wilson, Reference Chodroff and Wilson2017; Docherty, Reference Docherty1992; Gandour et al., Reference Gandour, Petty, Dardarananda, Dechongkit and Mukngoen1986; Millasseau, Bruggeman, Yuen, & Demuth, Reference Millasseau, Bruggeman, Yuen and Demuth2019; Stuart-Smith, Sonderegger, Rathcke, & Macdonald, Reference Stuart-Smith, Sonderegger, Rathcke and Macdonald2015; Suomi, Reference Suomi1980). Moreover, language- and talker-specific mean VOTs are strongly correlated among stop categories with a shared laryngeal feature, particularly among aspirated stops. Across 68 languages, the correlation of language-specific mean VOTs between [ph] and [th] was 0.85, between [th] and [kh] 0.81, and between [th] and [kh] 0.82 (Chodroff et al., Reference Chodroff, Golden and Wilson2019). Among American English aspirated stops, correlations of talker-specific mean VOT exceeded 0.90 in isolated speech, 0.75 in connected speech, and 0.81 in spontaneous speech (Chodroff & Wilson, Reference Chodroff and Wilson2017). These findings indicate that in general, a talker with a long VOT for [ph] will also have a long VOT for both [th] and [kh], reflecting a consistent and strong linear relationship of VOT between differing places of articulation (e.g., Chodroff & Wilson, Reference Chodroff and Wilson2017; Koenig, Reference Koenig2000; Newman, Reference Newman2003; Theodore, Miller, & DeSteno, Reference Theodore, Miller and DeSteno2009; Zlatin, Reference Zlatin1974).
Why might adults be so consistent in their production of VOT across place of articulation? One explanation is that talkers have highly similar, or even identical, phonetic targets for the laryngeal realization of [ph], [th], and [kh]. This constraint on phonetic realization is referred to as target uniformity (Chodroff & Wilson, Reference Chodroff and Wilson2022), and it maximizes identity of phonetic targets (i.e., the motor or auditory goals for a speech sound) that correspond to a given distinctive feature value, such as [+spread glottis] (Chodroff & Wilson, Reference Chodroff and Wilson2017; see also Schwartz, Boë, & Abry, Reference Schwartz, Boë, Abry, Solé, Beddor and Ohala2007). For aspirated stop consonants, the phonetic targets corresponding to [+spread glottis] likely involve the glottal spreading gesture and its timing relative to the oral release. VOT would then be the measurable acoustic output of the phonetic target, and not the target itself. Theoretically, an individual could have a unique laryngeal phonetic target for each of [ph], [th], and [kh]. It is physically possible for a talker to specify [kh] with a phonetic target that has a shorter mean VOT than that for [ph], but across adult talkers, this rarely, if ever, happens. The posited uniformity constraint restricts such arbitrary variation in the phonetic target specification, and instead requires near identity across the laryngeal phonetic targets for [ph], [th], and [kh].
The extent to which such between-category VOT structure applies to child speech production has been scarcely investigated. Children’s developing motor systems do indeed result in greater VOT variability, but despite this immature laryngeal control, between-category VOT structure might also be present in child speech. Whalen, Levitt, and Goldstein (Reference Whalen, Levitt and Goldstein2007) found the expected VOT ranking in unaspirated stops produced by English- and French-babbling infants (9 and 12 months of age), but the infants had not yet acquired aspiration, which adds a layer of complexity to articulation. In addition, Koenig (Reference Koenig2000) found significant correlations of talker-specific VOT medians and maxima between [ph] and [th] across five-year-old and adult talkers (median VOT r = 0.78; maximal VOT r = 0.79, each p < 0.05), but the correlation across five-year-olds alone was not reported. To our knowledge, no study has yet investigated the linear relationship between aspirated stops across children younger than five.
To investigate between-category structure in children, we assess the linear and ordinal relationships between talker-specific mean VOTs of [th] and [kh]. A strong linear relationship suggests that the phonetic targets for the laryngeal realization of [th] and [kh] are not independent of each other, but rather yoked together – even with a developing motor system. The ordinal relationship is also reported for comparison with previous literature.
Within-category VOT Structure
In addition to between-category VOT structure, within-category VOT structure has been observed in the relationship between talker-specific means and standard deviations: adult talkers with longer VOTs typically also have a higher variance (Chodroff & Wilson, Reference Chodroff and Wilson2017). This relationship likely reflects a general motor principle which relates increased movement time to increased movement error (Schmidt, Zelaznik, Hawkins, Frank, & Quinn, Reference Schmidt, Zelaznik, Hawkins, Frank and Quinn1979; Turk & Shattuck-Hufnagel, Reference Turk and Shattuck-Hufnagel2014). It could be that children are so variable in speech production that no clear relationship emerges between the VOT mean and standard deviation. To investigate within-category structure, we examine the extent to which a talker’s mean VOT is correlated with its standard deviation within a stop category: a phonetic target that corresponds to a long VOT should also have a high standard deviation. A correlation here would suggest that the motor movement principle is present early in child speech production; a child aiming for phonetic targets with a more delayed voice onset will also have more variable realizations.
Contextual VOT Structure
VOT is subject to substantial variability both within and across talkers. VOT variability is structured by prosodic, environmental, and social factors (e.g., Cole, Choi, Kim, & Hasegawa-Johnson, Reference Cole, Choi, Kim, Hasegawa-Johnson, Solé, Recasens and Romero2003; Mielke & Nielsen, Reference Mielke and Nielsen2018; Yao, Reference Yao and Pak2009). VOT varies systematically by place of articulation (Fischer-Jørgensen, Reference Fischer-Jørgensen1954), following vowel quality (Klatt, Reference Klatt1975; Nearey & Rochet, Reference Nearey and Rochet1994), speaking rate (Miller, Green, & Reeves, Reference Miller, Green and Reeves1986; Theodore et al., Reference Theodore, Miller and DeSteno2009), prosodic domain (Cho & Keating, Reference Cho and Keating2009), lexical properties (e.g., Goldinger & Van Summers, Reference Goldinger and Van Summers1989; Yao, Reference Yao and Pak2009), age (e.g., Koenig, Reference Koenig2000; Stuart-Smith et al., Reference Stuart-Smith, Sonderegger, Rathcke and Macdonald2015), gender (e.g., Koenig, Reference Koenig2000; Swartz, Reference Swartz1992), and across talkers, particularly for aspirated stops. Some talkers have characteristically long VOTs, whereas others have characteristically short VOTs (Chodroff & Wilson, Reference Chodroff and Wilson2017; Docherty, Reference Docherty1992; Theodore et al., Reference Theodore, Miller and DeSteno2009). Among children, the influence of place of articulation is generally similar in direction to adult talkers (Zlatin & Koenigsknecht, Reference Zlatin and Koenigsknecht1976; Whalen et al., Reference Whalen, Levitt and Goldstein2007), but as far as we are aware, many other factors have not yet been explored.
To investigate contextual VOT structure, we assess the factors governing variability in VOT for word-initial, prevocalic [th] and [kh], including place of articulation, following vowel context, speaking rate, number of syllables, talker age, and talker gender. We expect these factors to have similar effects on VOT realization in children as in adults.
Present study
The present study investigates the degree to which two- to five-year-old children demonstrate adult-like VOT structure in the voiceless aspirated stop series of American English and Cantonese. Considerable evidence now supports the presence of VOT structure in adult speech within and between stop categories (Chodroff & Wilson, Reference Chodroff and Wilson2017, Reference Chodroff and Wilson2022; Chodroff et al., Reference Chodroff, Golden and Wilson2019; Hullebus, Tobin, & Gafos, Reference Hullebus, Tobin and Gafos2018; Johnson, Reference Johnson2021; Puggaard & Goldshtein, Reference Puggaard and Goldshtein2020; Tanner, Sonderegger, & Stuart-Smith, Reference Tanner, Sonderegger and Stuart-Smith2020).Footnote 3 Identifying the extent of this structure in child speech informs our understanding of the acquisition and cognitive representation of phonetic targets in language production: structure may reveal maturity in the representation despite relatively immature motor control.
The study repurposes American English and Cantonese speech data from the Paidologos Project on Cantonese, English, Greek, and Japanese child speech production (Edwards & Beckman, Reference Edwards and Beckman n.d.). American English and Cantonese were selected primarily based on data availability and because they each have a voiceless aspirated stop series; they are otherwise typologically distinct. For both American English and Cantonese, we investigate the extent of variability and structure in [th] and [kh] VOT as produced by two- to five-year-old talkers. Despite the presence of [ph] in both languages, we focus on [th] and [kh] as the Paidologos corpora included lingual consonants only. We examine the range of VOT means and standard deviations, followed by the structure of VOT along the three primary dimensions discussed above. For each analysis, we compare the child-specific values to corresponding adult values when available. For American English adults, we use the Chodroff and Wilson (Reference Chodroff and Wilson2017) adult VOT data from isolated speech for all analyses. For Cantonese, we use the Clumeck et al. (Reference Clumeck, Barton, Macken and Huntington1981) adult VOT data from isolated speech for comparison of VOT means and standard deviations. The observed patterns of variability shed light on the specification and structure of phonetic targets across speech sounds in child speech production.
American English
American English: Methods
The analysis employed the English portion of the Paidologos Corpus, which contains isolated speech produced by 81 children (40 female) aged 2;0 to 5;11, and time-aligned transcripts (Edwards & Beckman, Reference Edwards and Beckman n.d.). There were approximately 10 male and 10 female talkers per age (two-year-olds: 9 F, 11 M; three-year-olds: 10 F, 10 M; four-year-olds: 10 F, 11 M; five-year-olds: 11 F, 9 M). Within each age group, approximately half were considered “young” (Y: less than 6 months to the year) and half “old” (O: more than 6 months to the year; two-year-olds: 8 Y, 12 O; three-year-olds: 10 Y, 10 O; four-year-olds: 13 Y, 8 O; five-year-olds: 11 Y, 9 O). All participants came from middle socioeconomic status families, were typically developing, and had normal hearing (Edwards & Beckman, Reference Edwards and Beckman n.d.). Each child completed a picture-naming task with stimuli consisting of an image and a corresponding sound file. Children were instructed to repeat the word; repeat responses were elicited if the response was different from the prompted word or if the tester thought the target sequence would be impossible to transcribe for any reason. The decision to employ the imitation paradigm was to ensure all participants had the same stimulus presentation. Audible productions, including repetitions, were retained in the recording and transcribed by native-speaker trained phoneticians. All recordings were made in quiet rooms at one or more preschools in central Ohio (Edwards & Beckman, Reference Edwards and Beckman2008a, Reference Edwards and Beckman2008b).
All stimuli began with /t k s/ and preceded the broad vowel categories of /i e a o u/; these consonants and vowels are present in the four languages investigated in the original corpus (Edwards & Beckman, Reference Edwards and Beckman2008a). For our current analysis, we examined only those tokens beginning with [th] or [kh]. There were 29 unique words: 14 beginning with [th] and 15 beginning with [kh]. These consonants preceded the vowels [i ɪ eɪ ɛ ʌ ɑ ɔ oʊ ʊ u], and were loosely balanced across the five broad vowel categories (Edwards & Beckman, Reference Edwards and Beckman2008b). The stimulus list of words beginning with aspirated stops can be found in the Appendix.
The transcript for each recording was aligned to the audio with the Penn Forced Aligner (Yuan & Liberman, Reference Yuan and Liberman2008). Word-initial stop boundaries were extended by 40 ms in each direction to create an interval of analysis for AutoVOT, an automatic VOT aligner that aims to identify the locations of the stop release and onset of voicing (Keshet, Sonderegger, & Knowles, Reference Keshet, Sonderegger and Knowles2014). All stop boundaries were manually corrected to align with the stop release, marked by the transient in the waveform, and the onset of voicing in the following vowel, marked by the start of periodicity in the waveform or the presence of the voice bar in the spectrogram. We retained all intended stop consonant productions for which the child produced an identifiable obstruent in initial position; this included a few repetitions for certain words. An identifiable obstruent was defined by the presence of aperiodicity, indicative of frication, in the waveform. Speaking rate was measured as the duration of the vowel immediately following the stop consonant (see also Theodore et al., Reference Theodore, Miller and DeSteno2009). Vowel offsets were also manually corrected for this estimation.
In total, there were 2,226 word-initial, prevocalic stops for analysis: the two-year-olds produced 580 tokens (per-child range: 24 to 39), the three-year-olds 526 tokens (per-child range: 14 to 31), the four-year-olds 580 tokens (per-child range: 17 to 30), and the five-year-olds 540 tokens (per-child range: 12 to 33). The median number of tokens per child was 13 for [th] (range: 5 to 16) and 15 for [kh] (range: 7 to 22).
American English: Results
The VOT means and standard deviations for [th] and [kh] for each age group are reported in Tables 3 and 4, along with the range of talker-specific means and standard deviations. The range of VOT means for [th] and [kh] overlapped considerably with corresponding adult means reported in Chodroff and Wilson (Reference Chodroff and Wilson2017). A handful of tokens were produced with short-lag VOT; however, all talker-specific mean VOTs were well within the long-lag VOT range (> 35 ms). Moreover, only about 4% of VOT tokens were less than 35 ms, and these were produced at an approximately equal rate across age groups (two: 21 tokens, three: 22, four: 27, five: 24).
Table 3. American English talker-specific means and standard deviations (SD) of [th] VOT in milliseconds presented for each age group and overall. The grand mean, SD, and range of talker means are taken over the distribution of talker-specific VOT means. The mean talker SD and range of talker SDs are taken over the distribution of talker-specific VOT standard deviations. Adult values calculated from the Chodroff and Wilson (Reference Chodroff and Wilson2017) isolated speech data are reproduced here for comparison.

Table 4. American English talker-specific means and standard deviations (SD) of [kh] VOT in milliseconds presented for each age group and overall. The grand mean, SD, and range of talker means are taken over the distribution of talker-specific VOT means. The mean talker SD and range of talker SDs are taken over the distribution of talker-specific VOT standard deviations. Adult values calculated from the Chodroff and Wilson (Reference Chodroff and Wilson2017) isolated speech data are reported here for comparison.

While the mean VOTs were similar between children and adults, children had considerably larger standard deviations relative to adults. Across children, the maximum talker-specific standard deviation was 64 ms for [th] and 93 ms for [kh]; both stops had sizable ranges of talker-specific standard deviations. In contrast, adult stop-specific standard deviations were typically between 10 and 30 ms for word-initial aspirated stops in isolated speech (Chodroff & Wilson, Reference Chodroff and Wilson2017).
With respect to between-category structure, talker-specific mean VOTs were highly correlated between [th] and [kh] across two- to five-year-olds (see Table 5 and Figure 1). The correlation was slightly lower than the adult VOT correlation for [th] and [kh] in isolated speech reported in Chodroff and Wilson (Reference Chodroff and Wilson2017; r = 0.98), but still strong at r = 0.80. A moderate to strong and significant correlation was also observed within each age group. With respect to the ordinal relationship, 58% of children had a [th] VOT mean slightly longer than their respective [kh] VOT mean. A simple linear regression model predicting a child-specific VOT mean for [kh] from the corresponding VOT mean for [th] revealed that, at overall lower [th] VOT values, [kh] was more likely to be greater than [th]; but, as the VOT for [th] increased, the distance between [th] and [kh] decreased until the ranking ultimately reversed (β0 = 23.70, β1 = 0.71, each p < 0.001).
Table 5. Correlations between American English talker-specific means for [th] and [kh] along with 95% bootstrapped confidence intervals. Adult data calculated from the Chodroff and Wilson (Reference Chodroff and Wilson2017) isolated speech study are reported here for comparison. ** reflects p < 0.001.


Figure 1. Variation and covariation of VOT means (ms) across American English child talkers at a) age two, b) age three, c) age four, and d) age five. Each ellipsis is centered on the paired talker-specific means for [th] and [kh], and the diameter reflects the stop-specific standard deviation, scaled by 0.5. Marginal histograms show variation in talker means. The dashed line reflects the line of equality, the solid line the best-fit linear regression line, and the gray shading the local confidence interval around the best-fit linear regression line.
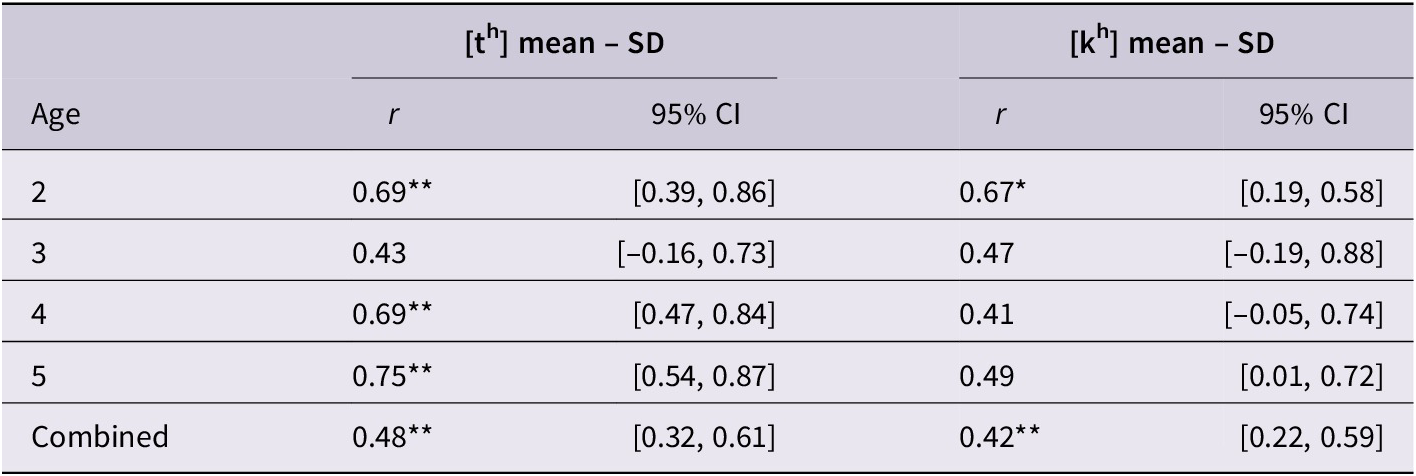
Additional within-category structure was also observed: talker-specific VOT means and standard deviations were moderately correlated within each stop category, though not all correlations reached significance (Table 6). Overall, the within-category correlations across children parallel adult VOT correlations which were also moderate in magnitude ([th]: r = 0.53, [kh]: r = 0.43; Chodroff & Wilson, Reference Chodroff and Wilson2017).
Table 6. Correlations of American English talker-specific means and corresponding standard deviations (SD) along with 95% bootstrapped confidence intervals. Adult values from the Chodroff and Wilson (Reference Chodroff and Wilson2017) isolated speech data are reported here for comparison. * reflects p < 0.01. ** reflects p < 0.001.

Variation in individual VOT values was analyzed with a linear mixed-effects model with fixed effects of place of articulation, speaking rate, number of syllables, following vowel height, following vowel tenseness, age, gender, the interaction between height and tenseness, and the full interactions between speaking rate, number of syllables, and age. The model also included a random by-child intercept and slope for place of articulation. All fixed effects were weighted effect coded in the following manner: place of articulation (coronal = 1, dorsal = –0.85), number of syllables (one = 1, two = –1.23), vowel height (high [i ɪ u ʊ] = 1, non-high [eɪ ɛ ʌ oʊ ɔ ɑ] = –0.54), vowel tenseness (tense [i eɪ ʌ u oʊ ɔ ɑ] = 1, lax [ɪ ɛ ʊ] = –2.95), and age (age2: two = 1, five = –1.07; age3: three = 1, five = –0.97; age4: four = 1, five = –1.07), and gender (female = 1, male = –1). Weighted effect coding is similar to sum coding but corrects for unbalanced data in the estimation of effects (Nieuwenhuis, te Grotenhuis, & Pelzer, Reference Nieuwenhuis, te Grotenhuis and Pelzer2017; te Grotenhuis, Pelzer, Eisinga, Nieuwenhuis, Schmidt-Catran, & Konig, Reference te Grotenhuis, Pelzer, Eisinga, Nieuwenhuis, Schmidt-Catran and Konig2017). As described above, speaking rate was measured as the following vowel duration, and was centered on the mean (174 ms) to facilitate model interpretation.
The model revealed significant effects of number of syllables, vowel height, vowel tenseness, age, as well as significant interactions between vowel height and tenseness, and speaking rate and age. VOTs in monosyllabic words were significantly longer than those in disyllabic words (syllables: β = 7.25, t = 4.72). Significantly longer VOTs were also observed before high vowels (height: β = 8.20, t = 4.27), before tense vowels (tenseness: β = 2.75, t = 2.98), and particularly before high, tense vowels: VOTs preceding high tense vowels ([i u]) were slightly longer than those preceding non-high tense vowels ([eɪ ʌ oʊ ɔ a]) (height × tenseness: β = 3.36, t = 3.20). The VOT of two-year-olds was significantly longer than average, by almost 13 ms (age2: β = 13.28, t = 3.24); this was further modulated by a small, but significant interaction with speaking rate, in which VOT increased by about 5 ms for each 100 ms increase in vowel duration (rate × age2: β = 0.05, t = 2.79). The VOT of four-year-olds was significantly shorter than average by approximately 10 ms (age4: β = –9.75, t = –2.36); the VOT of three-year-olds did not significantly differ from the mean (age3: β = –1.81, t = –0.43).
The main effects of place of articulation, speaking rate, and gender did not significantly influence VOT (place: β = –2.44, t = –1.79; rate: β = 0.02, t = 1.79; gender: β = 0.42, t = 0.18). The interactions between speaking rate and the three- or four-year-old age groups, number of syllables and each age group, and the three-way interactions between speaking rate, number of syllables, and each age group all failed to reach significance (rate × age3: β = –0.02, t = –0.99; rate × age4: β = 09.91, t = –0.46; syllables × age2: β = 0.51, t = 0.32; syllables × age3: β = –1.63, t = –0.96; syllables × age4: β = 1.22, t = 0.67; rate × syllables × age2: β = –0.02, t = –1.40; rate × syllables × age3: β = 0.02, t = 1.02; rate × syllables × age4: β = 0.03, t = 1.41).
American English: Discussion
Among American English children, considerable variation and structure emerged in the VOT of [th] and [kh]. The range of child VOT means for [th] and [kh] did not differ substantially from the corresponding ranges of adult VOT means in isolated speech (Chodroff & Wilson, Reference Chodroff and Wilson2017). Consistent with previous studies, child VOT standard deviations were much higher than adult VOT standard deviations for both [th] and [kh] (see also Koenig, Reference Koenig2000). Notably, the child VOT standard deviations reported here were on average two times larger than the corresponding adult VOT standard deviations reported in Chodroff and Wilson (Reference Chodroff and Wilson2017). Moderate correlations were observed between the VOT mean and standard deviation, indicating increased variability with longer VOT targets.
With regards to between-category structure, a strong correlation of talker-specific mean VOT between [th] and [kh] was observed for each age group (r = 0.73 to r = 0.82). Though these correlations are not as high as the corresponding correlations in adult isolated speech (r = 0.95), they are comparable to figures in adult connected speech (r = 0.77). The highly predictable relationship between [th] and [kh] VOT indicates that American English-learning children clearly represent the structured relationship between the laryngeal targets of [th] and [kh].
Beyond the linear relationship, between-category structure can also be assessed with the ordinal (rank) relationship of VOT. For just over half of the children, the VOT mean for [th] exceeded that of [kh], though statistically, the difference in VOT between [th] and [kh] was negligible and not significant. This corresponds to previous findings of adult American English speech where 46% of adult talkers also produced a marginally longer VOT mean for [th] than [kh] (Chodroff & Wilson, Reference Chodroff and Wilson2017; see also Docherty, Reference Docherty1992; Stuart-Smith et al., Reference Stuart-Smith, Sonderegger, Rathcke and Macdonald2015; Yao, Reference Yao and Pak2009). This inconsistency in rank somewhat contrasts with the broader generalization that VOT increases with more posterior places of articulation (Cho & Ladefoged, Reference Cho and Ladefoged1999); however, the linear relationship was still highly predictable: at lower VOT values, [th] was more likely to be shorter than [kh], and as the overall VOT increased, the VOT mean for [th] was likely to surpass that of [kh].
Within a given stop category, the phonetic targets for overall VOT might also account for the corresponding variance, thus reflecting VOT structure within a stop category. Indeed, moderate to strong correlations were observed between talker-specific VOT means and standard deviations for both [th] and [kh].
Contextual VOT variation partially paralleled adult speech patterns. Speaking rate (as an interaction with age), number of syllables, and the following vowel (high, tense vowels in particular) significantly accounted for variation in child VOT. These factors also influenced VOT in adult speech, but at times only in the connected speech style as opposed to the isolated speech style. Specifically, a following [i] or [u] corresponded to a significantly longer VOT in adult connected speech, mirroring the significant height by tenseness interaction in child VOT, but this influence was not observed in isolated speech (Chodroff & Wilson, Reference Chodroff and Wilson2017). Nevertheless, speaking rate and number of syllables (only tested in connected speech) had significant influences on adult VOT production.
Overall age differences were also observed: relative to average, two-year-olds had significantly longer VOTs, whereas four-year-olds had shorter VOTs. The longer VOTs observed for the two-year-olds partially reflected a stronger influence of speaking rate and number of syllables on VOT for their age group, but these enhanced effects could not entirely account for the duration. This could reflect a general overshoot phase of VOT production (Macken & Barton, Reference Macken and Barton1980), or simply a bias in the sample. It is worth noting that in the isolated speech style, some adult mean VOTs were just as long as the mean VOTs from two-year-olds. The long VOT values found here may not be so atypical for any age, at least in this isolated speech style.
Cantonese
In the following section, we investigate variability and systematicity in the VOT of [th] and [kh] across 80 two- to five-year old Cantonese talkers. Cantonese parallels American English in having voiceless aspirated stops in word-initial position. While the underlying featural representation of these stops could differ between languages, the same laryngeal feature is argued to be present for each Cantonese aspirated stop (i.e., [+spread glottis], [-voice], or even [“X”], where X can refer to any shared feature). Based on the shared featural representation, we expect Cantonese-learning children to parallel their American English-learning peers in VOT production.
Cantonese nevertheless does differ from English along many phonological dimensions, most notably by having an expanded inventory of aspirated consonants. In addition to the simple aspiration contrasts (/ph th kh/ vs /p t k/), Cantonese has an aspiration contrast on the alveolar affricate (/͡tsh/ vs ͡ts/) and labialized velar voiceless stop (/kwh/ vs /kw/). As these do not occur in English and given their increased articulatory complexity (e.g., affrication and labialization), we leave the realization of these stops to future research; nonetheless, the larger inventory could impact the acquisition trajectory or structural relationships between places of articulation.
Cantonese: Methods
This analysis employed the Cantonese portion of the Paidologos Corpus (Edwards & Beckman, n.d.). The corpus contents and collection procedure mirrored that of the English portion, but was based at the Chinese University of Hong Kong. 80 talkers, aged two to five, were recorded in quiet rooms in one or more nurseries in Hong Kong. 10 male and 10 female talkers were recruited for each age year. For children aged two to four, half of the children were young for the age group (e.g., 2;0 to 2;5) and half were old for the age group (e.g., 2;6 to 2;11). For children in the five-year-old group, 15 were “young” for the group, and 5 were “old”. All participants came from middle socioeconomic status families, were typically developing, and had normal hearing (Edwards & Beckman, n.d.). Participants were asked to complete a picture naming task in which an image and prerecorded audio stimulus were presented to the child. The child’s production and any subsequent repetitions were recorded. As in the English methods, all stimuli began with /t k s/ and preceded the broad vowel categories of /i e a o u/. For Cantonese, the initial consonants were [t th ͡ts ͡tsh s k kh kw kwh]. For comparison with English, we analyzed words beginning with [th] and [kh]. There were 27 unique words: 12 beginning with [th] and 15 beginning with [kh]. These consonants were followed by the vowels [iː iːu ɪ ɛː ei a aːi ɐu ɔː ɔːi ʊ uːy]; as for English, the stimuli were loosely balanced across the five broad vowel categories (Edwards & Beckman, Reference Edwards and Beckman2008a, Reference Edwards and Beckman2008b). A full list of the words and initial syllable transcriptions can be found in the Appendix.
To obtain VOT measurements, boundaries of word-initial stop consonants were submitted to AutoVOT, which automatically identified the stop release and onset of voicing (Keshet et al., Reference Keshet, Sonderegger and Knowles2014). All stop boundaries were manually corrected to align with the burst release and the onset of voicing, using the same acoustic landmarks noted in the American English study. Any instance in which the child did not produce the intended stop-initial prompt was excluded from analysis.
In addition to manual refinement of the VOT boundaries, syllable boundaries were also marked. Since it was difficult to identify a clear boundary before a nasal, we used the syllable rhyme duration (vowel and following consonant, if present) as a proxy for speaking rate instead of the following vowel duration.
In total, there were 2,017 word-initial, prevocalic stops for analysis: the two-year-olds produced 495 tokens (per-child range: 21 to 27), the three-year-olds 516 tokens (per-child range: 24 to 29), the four-year-olds 512 tokens (per-child range: 16 to 30), and the five-year-olds 494 tokens (per-child range: 11 to 29). The median number of tokens per child was 12 for [th] (range: 3 to 14) and 15 for [kh] (range: 7 to 17).
Cantonese: Results
As shown in Tables 7 and 8, stop-specific means and standard deviations ranged considerably across talkers. The means were comparable to previously reported adult VOT means from isolated speech which range from approximately 70 to 90 ms for [th] and [kh] (Clumeck et al., Reference Clumeck, Barton, Macken and Huntington1981; Lee Oi Yee, Reference Lee Oi Yee1997; Lisker & Abramson, Reference Lisker and Abramson1964). Nevertheless, several children under the age of 5 still produced short-lag VOTs for the intended long-lag stops. Specifically, seven VOT means from five unique child talkers were well within the short-lag range (< 35 ms; three two-year-olds, one three-year-old, and one four-year-old), and approximately 10% of VOT tokens were less than 35 ms. The rate of short-lag VOT production decreased with age (two: 89 tokens, three: 73, four: 35, five: 7).
Table 7. Cantonese means and standard deviations (SD) of [th] VOT in milliseconds presented for each age group and overall. The grand mean, SD, and range of talker means are taken over the distribution of talker-specific VOT means. The mean talker SD and range of talker SDs are taken over the distribution of talker-specific VOT standard deviations. Adult values come from Clumeck et al. (Reference Clumeck, Barton, Macken and Huntington1981) and are reported here for comparison.

Table 8. Cantonese talker-specific means and standard deviations (SD) of [kh] VOT in milliseconds presented for each age group and overall. The grand mean, SD, and range of talker means are taken over the distribution of talker-specific VOT means. The mean talker SD and range of talker SDs are taken over the distribution of talker-specific VOT standard deviations. Adult values come from Clumeck et al. (Reference Clumeck, Barton, Macken and Huntington1981) and are reported here for comparison.

As in English, VOT variation was highly structured between [th] and [kh]: talker-specific means VOTs were strongly correlated between [th] and [kh] across two- to five-year old talkers (see Table 9 and Figure 2). A simple linear regression revealed that the difference between [th] and [kh] VOT means decreased with overall higher VOT values (β0 = 15.45, β1 = 0.89, each p < 0.01). The ordinal relationship between [th] and [kh] VOT means conformed to the expected generalization in which VOT increases with more posterior places of articulation for 73% of Cantonese-learning children. As shown in Table 10, talker-specific child means and standard deviations were moderately correlated within each of the stop categories, though as before, not all correlations reached significance.
Table 9. Correlations between Cantonese talker-specific means for [th] and [kh] along with 95% bootstrapped confidence intervals. * reflects p < 0.01; ** reflects p < 0.001.


Figure 2. Variation and covariation of VOT means (ms) across Cantonese child talkers at a) age two, b) age three, c) age four, and d) age five. Each ellipsis is centered on the paired talker-specific means for [th] and [kh], and the diameter reflects the stop-specific standard deviation, scaled by 0.5. Marginal histograms show variation in talker means. The dashed line reflects the line of equality, the solid line the best-fit linear regression line, and the gray shading the local confidence interval around the best-fit linear regression line.
Table 10. Correlations of Cantonese talker-specific means and corresponding standard deviations (SD) along with 95% bootstrapped confidence intervals. * reflects p < 0.01; ** reflects p < 0.001.
A linear mixed-effects regression was used to assess factors governing variability in VOT. Categorical predictors were weighted effect coded (te Grotenhuis et al., Reference te Grotenhuis, Pelzer, Eisinga, Nieuwenhuis, Schmidt-Catran and Konig2017) and continuous variables were centered on their respective means. The model included fixed effects of place of articulation (coronal = 1, dorsal = –0.80), speaking rate (mean: 233 ms), number of syllables (two = 1, three = –2.01), following vowel height (high [iː iːu ɪ u uːy ʊ] = 1, non-high [ɛː ei a aːi ɐu ɔː ɔːy] = –1.07), following vowel tenseness (tense [iː iːu ɛː ei a aːi ɐu ɔː ɔːy u uːy] = 1, lax [ɪ ʊ] = –4.42), age (age2: two = 1, five = –1.00; age3: three = 1, five = -1.04; age4: four = 1, five = –1.04), and gender (female = 1, male = –0.97). All interactions between speaking rate, number of syllables, and age were also included.Footnote 4 The random effect structure included an intercept and slope for place of articulation by participant and an intercept for item. Speaking rate was approximated using the syllable rhyme duration (duration of the following vowel and coda nasal consonant if present).
The model revealed significant effects of place of articulation, number of syllables, vowel height, and vowel tenseness. Coronal stops were shorter than dorsal stops by approximately 6 ms (place: β = –3.08, t = –3.49). The number of syllables in the word significantly modulated the initial VOT: VOT in disyllabic words was approximately 4 ms longer than VOT in trisyllabic words (syllables: β = 2.02, t = 3.41). VOT preceding high vowels was also significantly longer than VOT preceding non-high vowels, by about 10 ms (height: β = 5.17, t = 5.88). VOT preceding tense vowels was also significantly longer than preceding lax vowels (tenseness: β = 2.81, t = 6.50).
Main effects of speaking rate, age and gender failed to reach significance. Though trending in the expected direction, speaking rate did not significantly influence VOT (rate: β = 0.02, t = 1.92). Much of the VOT variation that could be related to speaking rate was accounted for by the number of syllables in the word. Comparable VOT values were also found across two- to five-year-olds (age2: β = –6.93, t = –1.60; age3: β = –6.70, t = –1.57; age4: β = 0.98, t = 0.23) and between male and female talkers (gender: β = –0.73, t = –0.29). All two- and three-way interactions between speaking rate, number of syllables, and age were also not significant (rate × syllables: β = 0.00, t = –0.61; rate × age2: β = 0.01, t = 0.51; rate × age3: β = –0.01, t = –0.36; rate × age4: β = –0.01, t = –0.44; syllables × age2: β = –0.33, t = –0.32; syllables × age3: β = –0.33, t = –0.33; syllables × age4: β = 0.29, t = 0.27; rate × syllables × age2: β = 0.02, t = 1.64; rate × syllables × age3: β = 0.00, t = –0.36; rate × syllables × age4: β = 0.00, t = –0.27).
Cantonese: Discussion
The average child VOT means did not differ considerably from previously reported adult values that were around 70 to 90 ms for aspirated stop categories (Clumeck et al., Reference Clumeck, Barton, Macken and Huntington1981; Lee Oi Yee, Reference Lee Oi Yee1997; Lisker & Abramson, Reference Lisker and Abramson1964); however, considerable individual variability was observed. Several two- and three-year-old talkers had not yet acquired consistent long-lag VOT; stop-specific means for eight of the talkers were below 50 ms (four two-year-olds, three three-year-olds, one four-year-old). All but one talker above the age of four had average VOTs well within the long-lag VOT range (e.g., ≥ 50 ms). Consistent with previous child VOT studies, the standard deviations of Cantonese children were slightly higher than the corresponding standard deviations of adult talkers (e.g., Koenig, Reference Koenig2000). Clumeck et al. (Reference Clumeck, Barton, Macken and Huntington1981) observed adult standard deviations of approximately 21 and 22 ms for [th] and [kh], whereas the average child standard deviation in the present study was 27 and 28 ms for these same categories. In addition, the talker-specific child means and standard deviations were moderately and significantly correlated with one another.
With respect to between-category VOT structure, strong correlations of talker-specific mean VOT were observed between [th] and [kh] for each age group. Cantonese children clearly represent the structured relationship between stop VOTs and reliably produce this relationship between stop categories. Moreover, the expected ordinal relationship in VOT between [th] and [kh] was also observed for most Cantonese-learning children, and the difference between them was significant. Overall shorter VOT values also corresponded to a slightly greater VOT difference between the two places of articulation. Within-category VOT structure was observed in the moderate to strong correlations between VOT means and standard deviations for both [th] and [kh]. Finally, contextual influences of place of articulation, number of syllables and following vowel context also significantly influenced VOT in Cantonese child speech: [kh] had a longer VOT than [th], and longer VOTs were observed in words with fewer syllables. In addition, longer VOTs were observed before high or tense vowels. In contrast to American English, no effect of age or speaking rate (as approximated by rhyme duration) was observed.
General Discussion
The present study identified considerable VOT variability in aspirated stops produced by American English and Cantonese two- to five-year-old talkers. Consistent with previous studies, the within-category standard deviations of child talkers were larger than those of adult talkers, but in contrast, child VOT means were very similar to corresponding adult VOT means in each language. Although a repetition approach was used to collect these materials, the increased variability in child speech relative to adult speech importantly indicates that children were not merely reproducing the exact form of the adult prompt. Moreover, child VOT production was still highly structured: between stop categories, strong correlations of VOT means were identified across talkers of each age group and in each language. Within each stop category, child-specific means and corresponding standard deviations were mostly positively correlated with one another. Child VOT variability was also structured by many of the same contextual factors implicated in adult speech production. These findings indicate that American English and Cantonese children represent VOT structure among aspirated stops to a reasonably high degree and in a manner comparable to adult speech. These findings have implications for the representation of subsegmental detail, its relation to the constraint of uniformity on phonetic realization, as well as active debates in language acquisition regarding innate or emergent representations.
Representation of Subsegmental Detail and Uniformity
The present study highlights clear similarities in the phonological and phonetic representation of aspirated stop consonants between children and adults. Across talkers, the correlation between [th] and [kh] VOT means was strong, and within a talker, the difference between [th] and [kh] means was generally small. Moreover, most child VOT means were well within the adult VOT range, suggesting comparable phonetic targets — at least in the average. Critical to note is the fact that children observe this structure, despite having underdeveloped motor and specifically laryngeal control (Goffman & Smith, Reference Goffman and Smith1999; Green, Moore, Higashikawa, & Steeve, Reference Green, Moore and Steeve2000; Koenig, Reference Koenig2000). This developing laryngeal control is naturally reflected in the substantially larger standard deviations of VOT relative to adults. That is, the physical instantiation of stop VOT is more variable in children than adults.
These findings are also consistent with a constraint of target uniformity on phonetic realization: strong VOT covariation among aspirated stops should arise due to underlying uniformity in the mapping from the laryngeal feature (e.g., [+spread glottis]) to the corresponding phonetic target across segments, regardless of the place of articulation (Chodroff & Wilson, Reference Chodroff and Wilson2017, Reference Chodroff and Wilson2022; Keating, Reference Keating, Solé, Recasens and Romero2003). Overall, the phonological representation of aspirated stops appears to be comparable to that of adult talkers with a common feature yoking [th] and [kh] together. In child speech production, as in adult speech production, the representation of a given segment is not as an independent entity, but rather as a member of a natural class, connected by a shared subsegmental representation. Moreover, the phonetic representation of the laryngeal feature, where the abstract phonetic target is approximated by the average VOT, is also very adult-like for most two- to five-year-olds.
Variation in Uniformity
As a constraint on phonetic realization, target uniformity minimizes deviations in the phonetic targets that correspond to a distinctive feature value across relevant segments. Though the correlations between VOT means were overall strong, the strength of the relationship did differ by language. The VOT correlations in American English were slightly weaker than those in Cantonese, and the ranking between [th] and [kh] VOTs was less consistent in English than in Cantonese. The Cantonese ranking followed the expected ordinal relationship based on universal patterns ([th] < [kh]). Interestingly, while the American English ranking was more variable across children, the same pattern was observed across American English-speaking adults. Specifically, the VOT of [th] was frequently longer than that of [kh], especially at overall long VOT values.
One possible explanation for this difference in ranking could be a weaker [kh] occlusion in English than in Cantonese. The duration necessary for sufficient intraoral pressure would end up being longer, giving rise to a slightly shorter VOT for [kh] than might otherwise be expected. Evidence for a weak stop occlusion could be the presence of a multiple burst release or frication in the release, which is indeed relatively common in dorsal stop productions (Lavoie, Reference Lavoie2001; Olive, Greenwood, & Coleman, Reference Olive, Greenwood and Coleman1993).
In a post-hoc analysis, the stop productions from the five-year old talkers were labeled for a single burst release or a multiple burst release. A logistic mixed-effects regression revealed that, contrary to expectation, Cantonese stops were significantly more likely to have a multiple burst release than English stops (
 $ \beta $
= 0.37, p < 0.01), and conforming to expectation, [kh] was more likely to be produced with a multiple burst release in both languages (
$ \beta $
= 0.37, p < 0.01), and conforming to expectation, [kh] was more likely to be produced with a multiple burst release in both languages (
 $ \beta $
= 0.41, p < 0.001). No interaction was observed between language and stop category on the release type (single or multiple;
$ \beta $
= 0.41, p < 0.001). No interaction was observed between language and stop category on the release type (single or multiple;
 $ \beta $
= –0.02, p = 0.80). Based on impression of the audio and waveform, aspirated stops in Cantonese child speech were overall more likely to be fricated than those in English. This line of investigation was therefore inconclusive with respect to the VOT ranking.
$ \beta $
= –0.02, p = 0.80). Based on impression of the audio and waveform, aspirated stops in Cantonese child speech were overall more likely to be fricated than those in English. This line of investigation was therefore inconclusive with respect to the VOT ranking.
Alternatively, it may be that target uniformity has a weaker influence in American English than in Cantonese. This is not to say that uniformity has no influence: the expected deviation from the VOT values for [th] and [kh] given uniformity of articulatorily-specified targets is very small, and the correlations are still strong. The unexpected but relatively consistent VOT ranking in American English could instead be accounted for by a broader constraint of “pattern” uniformity, in which talkers maintain consistent differences between phonetic targets of related speech sounds (Chodroff & Wilson, Reference Chodroff and Wilson2022).
Development of Subsegmental Representation
The current findings strongly suggest a subsegmental representation of a laryngeal feature in speech production in talkers as young as two years of age: some feature must tie the productions of e.g., [th] and [kh] together. Barring the evident variability in laryngeal control, the observed between-category VOT structure between stop categories is already robust at an early age. Nevertheless, for the given isolated speech style, the adult correlational structure between [th] and [kh] is still tighter (r = 0.95). This difference between children and adults could be due to one of the following scenarios: 1) children have a detailed cognitive representation of the relationship, but struggle in the articulation, or 2) children are still developing the cognitive representation of the relationship and also struggle in the articulation. Regardless, the subsegmental representation between [th] and [kh] is already apparent. In light of this, however, is this representation innate or does it emerge from the perception of ambient speech data?
It is well-established that perceptual sensitivity to phonetic detail, especially VOT, emerges at a very young age. By one month of age, infants demonstrate the capacity to discriminate between voiced and voiceless stop consonants along the VOT continuum (Aslin, Jusczyk, & Pisoni, Reference Aslin, Jusczyk, Pisoni and Damon1998; Eimas, Siqueland, Jusczyk, & Vigorito, Reference Eimas, Siqueland, Jusczyk and Vigorito1971; McMurray & Aslin, Reference McMurray and Aslin2005). At eight months, infants show sensitivity to within-category VOT variation (McMurray & Aslin, Reference McMurray and Aslin2005), and at one year, sensitivity to mispronunciations of familiar words involving the laryngeal feature (Swingley & Aslin, Reference Swingley and Aslin2000). Finally, five- and seven-year-old children display adult-like identification and discrimination of stop consonants (Wolf, Reference Wolf1973). These findings show that children are highly attuned to VOT variation and its relevance to the voicing feature at a young age.
Given sensitivity to VOT variation for stop voicing discrimination, children may also be attuned to VOT systematicity among stops with a shared laryngeal feature. A child could reasonably acquire a rich representation of VOT and its laryngeal representation for speech production directly from ambient data and very early on (e.g., PRIMIR: Werker & Curtin, Reference Werker and Curtin2005). How exactly such perceptual input relates to production representations, however, is complicated. If information is indeed “coupled” between the perceptual and production representations, children could mimic these perceptual representations in speech production (McMurray & Farris-Trimble, Reference McMurray and Farris-Trimble2012; Redford, Reference Redford2019; Schwartz, Basirat, Ménard, & Sato, Reference Schwartz, Basirat, Ménard and Sato2012).
However, one important caveat needs to be raised for an emergent representation: a child would need to recognize that VOT must be calibrated by talker. If the child tracked the [th] VOTs from talker A and the [kh] VOTs from talker B, consistency in the between-category structure would be unlikely to arise given the considerable cross-talker variability in overall VOT values. Social sensitivity to the source of the content has indeed been proposed for handling multi-talker input for child speech perception, so such talker-specific tracking of VOT is not improbable (Tripp, Feldman, & Idsardi, Reference Tripp, Feldman and Idsardi2021). Indeed, how multi-talker input might affect any emergent representations of this feature is open for debate. In perception, infant word learning frequently improves with multi-talker input or highly variable input from a single talker along multiple acoustic dimensions (e.g., Bulgarelli & Bergelson, Reference Bulgarelli and Bergelson2022; Galle, Apfelbaum, & McMurray, Reference Galle, Apfelbaum and McMurray2015; Rost & McMurray, Reference Rost and McMurray2009, Reference Rost and McMurray2010; cf. Quam, Knight, & Gerken, Reference Quam, Knight and Gerken2017). In production, multi-talker input also improves production accuracy and speed in four-year-olds, whereas single talker input does not (Richtsmaier, Gerken, Goffman, & Hogan, Reference Richtsmeier, Gerken, Goffman and Hogan2009).
Alternatively, the representations necessary for systematic laryngeal realization could be innate or arise from an innate general pressure for representational economy in cognition (e.g., Maddieson, Reference Maddieson1995; Schwartz et al., Reference Schwartz, Boë, Abry, Solé, Beddor and Ohala2007). Re-use of the laryngeal gesture and laryngeal-oral timing relationship across places of articulation would be economical in representation (e.g., Smith & Zelaznik, Reference Smith and Zelaznik2004). However, while target uniformity is related to a general principle of economy, it does not require perfect re-use of phonetic targets across speech sounds (Chodroff & Wilson, Reference Chodroff and Wilson2022). In fact, the VOT patterns suggest the laryngeal phonetic targets might differ slightly between places of articulation. Regardless, the constraint enforces a high degree of similarity across speech sounds in the phonetic targets corresponding to the shared distinctive feature.Footnote 5 Such a pressure for economical representations could be argued to arise from a general, but innate bias in cognition.
Indeed, English- and French-learning infants at 6, 9, and 12 months of age demonstrate a reasonably consistent ordinal VOT relationship in babbled unaspirated stops (Whalen et al., Reference Whalen, Levitt and Goldstein2007). Such an ordinal relationship is expected if children are indeed attempting similar laryngeal targets across stop place of articulation. Whereas development of a uniform set of laryngeal phonetic targets might suggest that the between-category relationships strengthen over time, we instead observe a stable relationship across age groups.
Regardless of the representational origins, these findings indicate an early and strong presence of the subsegmental relationship between [th] and [kh] in speech production, pointing towards an early or even innate constraint on phonetic realization. By the age of two, children have developed not only a fine-grained perceptual representation of the laryngeal contrast in stop consonants, but also, a rich production representation of the laryngeal feature for voiceless aspirated stops.
Conclusion
Overall, child VOT production was more variable than adult VOT production, but the means and overall VOT structure were highly comparable. All three forms of structure indicate a rather mature representation of phonetic detail in child speech production. Of note is the strong between-category VOT correlations that are consistent with universal patterns of VOT (Chodroff et al., Reference Chodroff, Golden and Wilson2019). The highly predictable linear relationship of VOT may reflect a constraint of target uniformity on phonetic realization, in which the phonetic targets corresponding to the laryngeal feature of both [t h] and [k h] are yoked together and highly similar. This structure reveals that children represent phonetic detail that is below the level of a word (e.g., Vihman, Reference Vihman2017). Overall these findings shed light on our understanding of phonetic representations in child speech.
Future studies should extend this analysis of phonetic systematicity and variation to additional segments, phonetic dimensions, and languages in child speech production. For example, structured phonetic variation has been observed across adult talkers in the F1 of vowels with a shared height, such as mid vowels, [e] and [o] (e.g., Schwartz & Ménard, Reference Schwartz and Ménard2019; Oushiro, Reference Oushiro, Calhoun, Escudero, Tabain and Warren2019; Salesky, Chodroff, Pimentel, Wiesner, Cotterell, Black, & Eisner, Reference Salesky, Chodroff, Pimentel, Wiesner, Cotterell, Black and Eisner2019; Watt, Reference Watt2000), and in spectral properties of sibilant fricatives with a shared place of articulation (e.g., Salesky et al., Reference Salesky, Chodroff, Pimentel, Wiesner, Cotterell, Black and Eisner2019; Chodroff & Wilson, Reference Chodroff and Wilson2022). It remains to be seen whether such structure is also observed in other segments and phonetic dimensions across child talkers.
Acknowledgments
We gratefully acknowledge Colin Wilson for early discussion and contributions related to this work. Many thanks to Alessandra Golden for help in processing the English VOT data, as well as Justin Lo and Adas Li for help with Cantonese transliteration and translation. We are also grateful to Emily Atkinson and Marilyn Vihman for helpful discussion and feedback, and to Mara Breen for coordinating remote research opportunities for Mt. Holyoke College undergraduate students. Finally, we thank the Mt. Holyoke’s Lynk Summer Funding Program for financially supporting the third author for work on this project.
Data and Analysis Scripts
The data and analysis scripts for this study are available on OSF at https://osf.io/hmz27/?view_only=99fb3db9e267440791248c4b63b3e47a.
Appendix
Table 11. Stimulus list of English words beginning with aspirated stops.
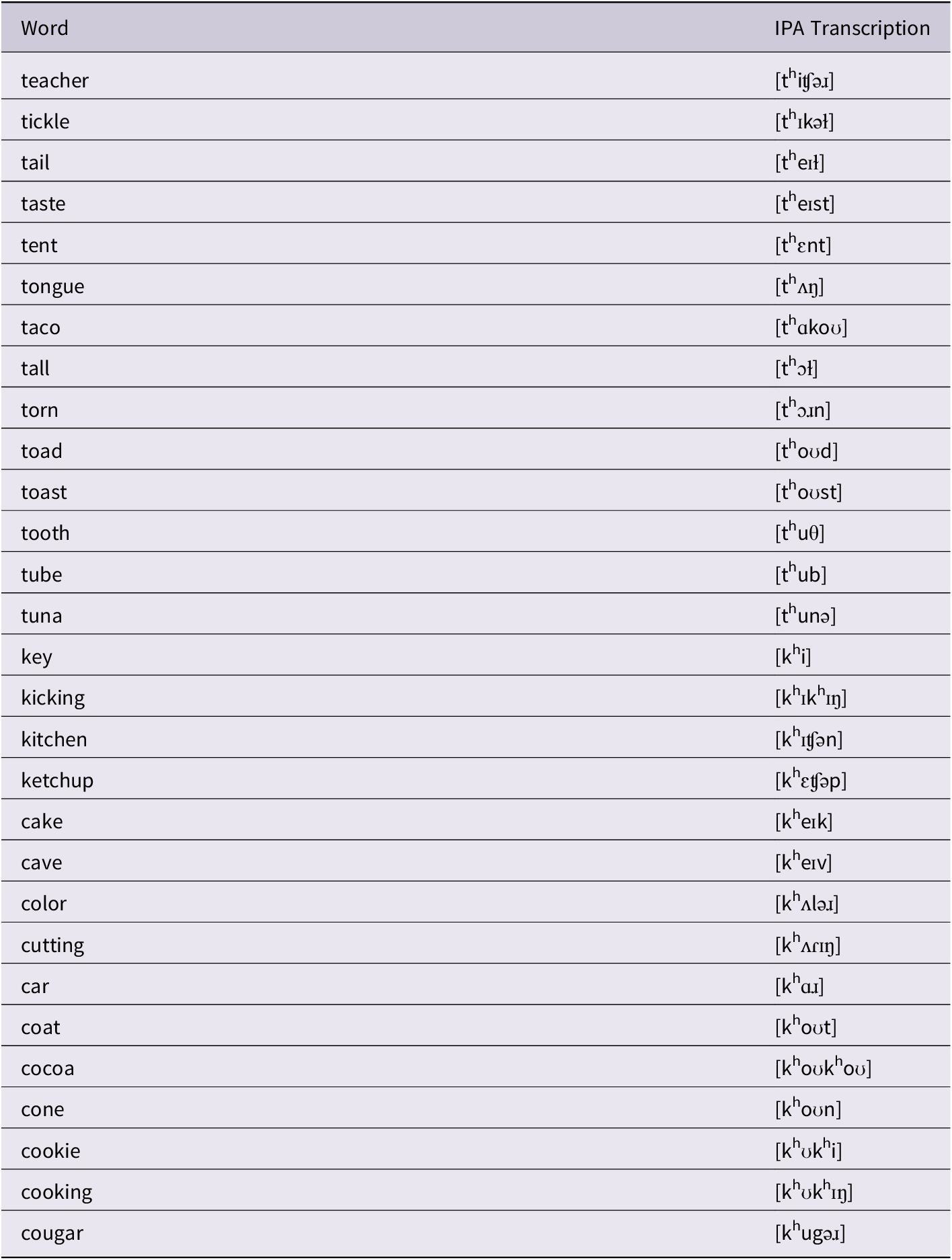
Table 12. Stimulus list of Cantonese words beginning with simple aspirated stops.
















 Open access
Open access