



Letters constitute the graphical representation of a language’s sounds, playing a pivotal role during word recognition and reading in alphabetic orthographies (see Grainger, Reference Grainger2018; Rayner et al., Reference Rayner, Pollatsek, Ashby and Clifton2012, for reviews). While some alphabets were purposely designed to capture all the nuances of their corresponding languages (e.g., Hangul script for Korean or Armenian alphabet for Armenian), most languages use a writing system from another language. The majority of European languages employ a slightly modified version of the Latin alphabet in which some letters are presented in their original form and others have an added mark (e.g., e vs. é; n vs. ñ). In the case of vowels, accent marks can be used to distinguish between otherwise homonymous words (e.g., mur <wall> vs. mûr <ripe> in French; té <tea> and te <you> in Spanish). However, they are more frequently used to modify a word’s phonological features, such as vowel quality (e.g., French: è→/ε/ vs. é→/e/), lexical stress (e.g., Spanish: América [aˈmeɾika] <America>), or vowel length (e.g., Czech: e → /ε/ vs. é → /εː/) (see Wells, Reference Wells2000). (Note that pronunciations are presented between square brackets and the English translations are presented between angle brackets.) Notably, accented vowels are considered variants of their non-accented counterparts in some languages (e.g., French, Spanish), but as different letters in others (e.g., Romanian, Polish, Finnish).Footnote 1
Towards a comprehensive model of letter/word recognition
Contemporary neurally inspired hierarchical models of letter and word recognition (e.g., Dehaene et al., Reference Dehaene, Cohen, Sigman and Vinckier2005; Grainger et al., Reference Grainger, Rey and Dufau2008; Schubert & McCloskey, Reference Schubert and McCloskey2013) assume that information from the visual features of letters gradually vanishes during letter/word recognition. This process implies increasingly complex layers of local contours, letter-shape detectors, abstract-letter detectors, local-bigram detectors, and word detectors (e.g., see Figure 1 in Dehaene et al., Reference Dehaene, Cohen, Sigman and Vinckier2005, for a graphical depiction). For instance, in the initial stages of processing, at a layer of case-specific detectors, the lowercase vowels e and e (but not the uppercase vowel E) would be processed similarly. Subsequently, at a layer of abstract letter detectors, the vowels e, e, and E would be processed alike (see Petit et al., Reference Petit, Midgley, Holcomb and Grainger2006, for electrophysiological evidence). These abstract letter units would be mapped onto local bigrams (e.g., TE, EN, or NT) and, finally, onto word units (e.g., TENT; see Dehaene et al., Reference Dehaene, Cohen, Sigman and Vinckier2005, Figure 1). Critically, none of these models has yet addressed how accented vowels are represented in the letter/word recognition system. A similar case applies to most computational models of visual word recognition (e.g., Adelman, Reference Adelman2011; Davis, Reference Davis2010; Grainger & Jacobs, Reference Grainger and Jacobs1996; Norris & Kinoshita, Reference Norris and Kinoshita2012; but see Ans et al., Reference Ans, Carbonnel and Valdois1998, for an exception). Bear in mind that these models were designed for English, which is the only major European language lacking accent marks (see Share, Reference Share2008, for discussion of the Anglocentric focus in word recognition research)—note that the Ans et al. (Reference Ans, Carbonnel and Valdois1998) model, which was created for French, assumes different abstract letter units for accented and non-accented vowels.
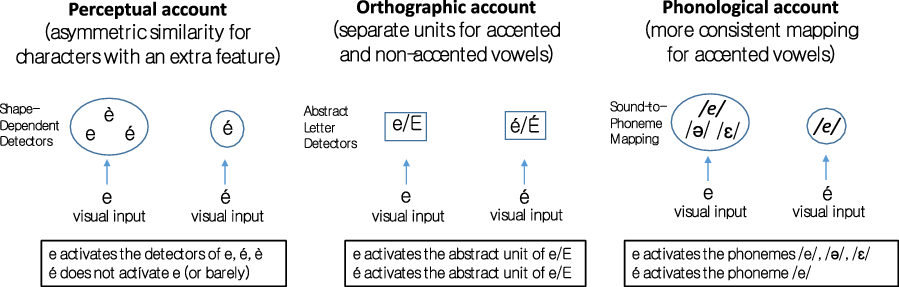
Figure 1. Illustration of the three accounts: perceptual account (left), orthographic account (center), and phonological account (right).
Clearly, a comprehensive model of letter and word recognition needs to specify 1) whether accented and non-accented vowels share or not their abstract letter units; and 2) whether this is dependent on the role of the accent marks in the language (e.g., vowel quality vs. lexical stress [or vowel length]). Several recent experiments have tackled these questions by combining Forster and Davis’ (Reference Forster and Davis1984) masked priming technique with an alphabetic decision task (“is the stimulus a letter?”; see Jacobs & Grainger, Reference Jacobs and Grainger1991). Chetail and Boursain (Reference Chetail and Boursain2019) conducted two parallel experiments with non-accented vowel targets in French. Their rationale was that if the vowels é and e activate the same orthographic units, they would be equally effective in priming the target E. Chetail and Boursain (Reference Chetail and Boursain2019) found shorter response times in an identity condition (e.g., prime e and target E) than in a visually similar condition with an added accent mark (e.g., é–E). Furthermore, response times in the visually similar condition were equivalent to those in a visually different condition where the prime was a consonant letter (e.g., r–E). Remarkably, the pattern of data was similar for cross-case visually similar and dissimilar letters (e.g., compare u–U vs. e–E), thereby suggesting that the priming effects occurred at an abstract level of processing (see also Gomez & Perea, Reference Gomez and Perea2020; Jacobs et al., Reference Jacobs, Grainger and Ferrand1995). Chetail and Boursain (Reference Chetail and Boursain2019) interpreted their findings as supporting the view that, at least in French, accented and non-accented vowels activate different abstract orthographic units. Of note, these findings can be easily captured by the multiple trace model proposed by Ans et al. (Reference Ans, Carbonnel and Valdois1998) in French, where each accented vowel has its own separate unit at the letter level (e.g., e, é, è, and ë are treated as distinct letters).
Are the representations of accented vowels in the letter/word recognition system shaped by language?
To examine the language-dependent vs. language-independent nature of this phenomenon, Perea et al. (Reference Perea, Fernández-López and Marcet2020) conducted a parallel experiment to Chetail and Boursain (Reference Chetail and Boursain2019) in Spanish. Unlike French, where accent marks indicate vowel quality, accented vowels in Spanish designate the stressed syllable with no change in vowel quality (e.g., both e and é correspond to the phoneme /e/). Notably, stressed syllables in Spanish may or may not have an accented vowel (e.g., compare sería [seˈɾia] <would be>, seria [ˈseɾja] <serious>, and serial [seˈɾjal] <serial>)—this depends on a specific set of rules (Real Academia Española, 2010). Thus, there are no a priori reasons to believe that accented and non-accented vowels in Spanish would activate separate orthographic representations (see Chetail & Boursain, Reference Chetail and Boursain2019). In their masked priming alphabetic decision experiment, Perea et al. (Reference Perea, Fernández-López and Marcet2020) included both accented and non-accented vowels as targets. For accented vowel targets, response times were virtually the same in the identity and visually similar conditions, which, in turn, were faster than in the visually different condition (e.g., é–É = e–É < a–É). This pattern favors the view that, in Spanish, accented and non-accented vowels share their abstract letter representations (see Marcet & Perea, Reference Marcet and Perea2021, for converging evidence during sentence reading).
For non-accented vowel targets, Perea et al. (Reference Perea, Fernández-López and Marcet2020) found an advantage of the identity condition (e–E) over the visually similar condition (é–E). While the advantage of e–E over é–E was half the size than in French (10 vs. 20 ms, respectively), one might argue that, if the vowels e and é had activated the same letter units, this difference should have been negligible in Spanish. To explain this effect, Perea et al. (Reference Perea, Fernández-López and Marcet2020) put forward a perceptual explanation in the spirit of the theories of asymmetric similarities in visual perception proposed by Treisman and Souther (Reference Treisman and Souther1985) and Tversky (Reference Tversky1977). The rationale is that a less salient object (e.g., the non-accented vowel e) is perceived as more similar to a more salient object (the accented vowel é [i.e., visually, the letter e with a mark]) than vice versa. In this vein, the differences in masked priming effects between accented vs. non-accented vowels in previous studies might simply reflect a relation of asymmetric similarity between two visual objects (Perea et al., Reference Perea, Baciero and Marcet2021a; see also Kinoshita et al., Reference Kinoshita, Yu, Verdonschot and Norris2021, for a similar reasoning). We must keep in mind that the initial encoding of letter identity during letter/word recognition is noisy (Bayesian Reader model: Norris & Kinoshita, Reference Norris and Kinoshita2012), and hence, masked primes may be confusable with other visually similar stimuli (e.g., 4→A in M4TERI4L; i→j in obiect; rn→m in docurnent; see Gutiérrez-Sigut et al., Reference Gutiérrez-Sigut, Marcet and Perea2019; Kinoshita et al., Reference Kinoshita, Robidoux, Mills and Norris2013; Marcet & Perea, Reference Marcet and Perea2017, Reference Marcet and Perea2018; Molinaro et al., Reference Molinaro, Duñabeitia, Marín-Gutiérrez and Carreiras2010). Critically, visual similarity effects are small/negligible for primes containing letters with diacritics (Marcet et al., Reference Marcet, Ghukasyan, Fernández-López and Perea2020; see also Kinoshita et al., Reference Kinoshita, Yu, Verdonschot and Norris2021; Perea et al., Reference Perea, Fernández-López and Marcet2020), thus suggesting that the salience of these marks makes these stimuli less confusable with their non-accented counterparts (i.e., e→é, but é↛e; see Perea et al., Reference Perea, Baciero and Marcet2021a, for discussion).
Importantly, the perceptual account put forward by Perea et al. (Reference Perea, Baciero and Marcet2021a) can readily accommodate the equivalent response times in the identity and visually similar conditions for accented targets (e.g., é–É = e–É; Spanish: Perea et al., Reference Perea, Fernández-López and Marcet2020; ä–Ä = a-Ä; Finnish: Perea et al., Reference Perea, Hyönä and Marcet2021b) and the advantage of the identity condition over the visually similar condition for non-accented targets (e.g., e–E < é–E) in Spanish (Perea et al., Reference Perea, Fernández-López and Marcet2020) and French (Chetail & Boursain, Reference Chetail and Boursain2019). Furthermore, as the locus of the asymmetric similarities in masked priming is at the very early stages of letter processing, they would occur for letters in all orthographies. Indeed, asymmetric similarities in masked priming have been reported with consonant letters (e.g., n→ñ, but ñ↛n; Marcet et al., Reference Marcet, Ghukasyan, Fernández-López and Perea2020) and Japanese kana characters (e.g., ![]() →
→![]() , but
, but ![]() ↛
↛![]() ; Kinoshita et al., Reference Kinoshita, Yu, Verdonschot and Norris2021).
; Kinoshita et al., Reference Kinoshita, Yu, Verdonschot and Norris2021).
Goals of the experiment
The present study was designed to disentangle between the perceptual and orthographic account of masked priming effects with accented and non-accented vowels. To that end, we conducted a masked priming alphabetic decision experiment in a language with a complex orthography-to-phonology mapping: Catalan. Although accent marks in Catalan may help distinguish among homonymous words (e.g., sí [si] <yes> vs. si [si] <if>), its more common function is to indicate both lexical stress (e.g., raó [rəˈo] <reason>) and vowel quality (e.g., è→/ε/, é→/e/, ò→/ɔ/, ó→/o/). Thus, Catalan language may provide a very stringent test to separate the predictions of the perceptual and orthographic accounts.
A key distinctive feature of Catalan, which is only shared by Portuguese among Romance languages, is that it has vowel reduction in unstressed syllables. The Catalan vowel system has seven or eight different phonemes depending on the dialect: /a/, /e/, /ε/, /i/, /o/, /ɔ/, /u/, and /ə/. In Eastern Catalan, it is composed of eight stressed vowels (/a ə ε e i ɔ o u/) and three/four unstressed vowels (depending on the dialect: /ə i u/ or /ə i o u/). Whether or not a vowel in a stressed syllable requires an accent mark is subject to a set of rules (Institut d’Estudis Catalans, 2016).Footnote 2 As a result, a non-accented vowel may form part of a stressed syllable (where there is no vowel reduction) or an unstressed syllable (where there is vowel reduction). In a stressed syllable, the non-accented vowel a corresponds to /a/ but, in an unstressed syllable, it is typically reduced to /ə/ (e.g., casa [ˈkazə] <house> vs. casal [kəˈzal] <manor house>). A more complex situation occurs for the non-accented vowels e and o. In a stressed syllable, depending on the specific word, the vowel e is pronounced /ε/ or /e/ (e.g., gerro [ˈʒεɾu] <pitcher>, dent [ˈdent] <tooth>) and the vowel o is pronounced /ɔ/ or /o/ (e.g., gros [ˈ ɾɔs] <big>; boca [ˈbokə] <mouth>). In an unstressed syllable, these letters typically correspond to /ə/ and /u/, respectively—note that the letter e may correspond to /ə/ or /e/ in Majorcan Catalan and the letter o is not reduced to /u/ in some dialects. Finally, neither the non-accented vowel i nor u is usually reduced. All and all, the orthography-to-phonology mapping in Catalan is transparent for accented vowels (i.e., they correspond to a stressed syllable), but it is intricate for non-accented vowels (see Pons, Reference Pons, Berns, Jacobs and Scheer2011, for a more detailed review of Catalan phonology). The participants in the experiment were all native speakers of Majorcan Catalan. Besides vowel reduction, Majorcan Catalan (in some areas) may also involve vowel harmony (see Llompart & Simonet, Reference Llompart and Simonet2017). Appendix A presents a brief depiction of vowel harmony in Majorcan Catalan (see Bibiloni, Reference Bibiloni2016; Pons, Reference Pons, Kan, Moore-Cantwell and Staubs2013, for a detailed description of vowels of Majorcan Catalan)—note that the presence/absence of vowel harmony does not modify the predictions of the experiment.
Critically, the existence of vowel reduction in unstressed Catalan vowels allowed us to test not only the feasibility of the orthographic and perceptual accounts but also an ortho-phonological account. The basic idea of this latter account is that a non-accented vowel in Catalan (e.g., e) may have a more variable grapheme-to-phoneme mapping than an accented vowel (e.g., é; e→/ε/, /e/, or /ə/, whereas é→/e/) so that the latter would provide a more stable phonological code than for former. As in the French and Spanish experiments discussed above, we employed a masked priming alphabetic decision task—this allowed us to compare the findings in Catalan with the findings in these other languages. The design of the Experiment was parallel to that of Perea et al. (Reference Perea, Fernández-López and Marcet2020), except that we added a novel control condition (o–E for the unrelated prime ó–E; ó–É for the unrelated prime o–É). This way, we had a full 2 × 2 × 2 factorial experimental design: 1) the prime and target shared the base letter or not (e.g., related: e–E or é–E vs. unrelated: o–E or ó–E); 2) the target was accented or not (e.g., E vs. É); and 3) the prime was accented or not (e.g., e vs. é; o vs. ó).
Predictions from the perceptual, orthographic, and phonological accounts
A perceptual account based on asymmetric similarities would predict that, for related pairs, a non-accented vowel (i.e., the less salient object) is more perceptually similar to its accented counterpart (i.e., the most salient object) than vice versa (Perea et al., Reference Perea, Baciero and Marcet2021a; see also Kinoshita et al., Reference Kinoshita, Yu, Verdonschot and Norris2021, for an analogous argument). Thus, a masked prime consisting of a non-accented vowel (e.g., e) would initially generate a percept similar to its corresponding accented vowel (e.g., é). The net effect would be faster response times in the identity condition than in the visually similar condition (e.g., e–E < é–E). In contrast, masked primes with an accented vowel (i.e., a salient feature; e.g., é) would be less likely to be confusable with their corresponding non-accented vowel (e.g., e). As a result, there would be (if anything) a negligible advantage of the identity vs. visually similar pairs for accented targets (e.g., é–É ≈ e–É) (see left panel of Figure 1). Concerning unrelated prime–target pairs, neither accented nor non-accented primes would be perceptually close to the target stimuli, and, hence, this account would not predict any differences (e.g., ó–É = o–É and ó–E = o–E).
An orthographic account (Chetail & Boursain, Reference Chetail and Boursain2019) assumes that, in languages where accent marks may indicate vowel quality (e.g., French, Catalan), accented and non-accented vowels (e.g., e and é) activate separate orthographic units (see middle panel of Figure 1). As a result, for related pairs, this account would predict faster responses in the identity condition than in the visually similar condition for non-accented targets (e.g., e–E < é–E) and for accented targets (e.g., é–É < e–É)—note that this latter prediction differs from the perceptual account. Concerning the unrelated prime–target pairs, accented and non-accented primes would activate different orthographic units than the target (e.g., ó–E vs. o–E; ó–É vs. o–É), and, hence, ó–E would behave like o–E, and ó–É would behave as o–É.
Finally, we discuss a third, ortho-phonological explanation based on the activation of phonological codes (see Ziegler et al., Reference Ziegler, Ferrand, Jacobs, Rey and Grainger2000, for evidence of phonological effects when primes and targets share the same name; see also Posner & Mitchell, Reference Posner and Mitchell1967, for early evidence).Footnote 3 Because of vowel reduction in Catalan, accented vowels (e.g., é) may provide a more stable phonological code (e.g., é → /e/) than non-accented vowels (e.g., e → /e/, /ə/, or /ε/). Thus, for an accented target (e.g., É), an identity prime (e.g., é) would provide not only the same orthographic code but also a more stable phonological code than the visually similar prime (e.g., e; i.e., é–É < e–É)—note that this prediction is different from that of perceptual and orthographic accounts. In contrast, for a non-accented target (e.g., E), the visually similar prime (e.g., é) would provide a more stable phonological code than the identity prime (e.g., e). Given that the orthographic codes might benefit e–E more than é–E, the net priming effect would depend on the interplay between the two codes (see right panel of Figure 1). Concerning unrelated prime–target pairs, accented primes could delay target processing. The reason is that an accented vowel prime would provide a more stable (mismatching) phonological code than that provided by a non-accented vowel (e.g., é-O slower than e-O).
Method
Participants
The participants were 48 students (37 female) with normal/corrected vision and no history of reading problems from the Universitat de les Illes Balears (mean age: 21.5 years old; range: 20–25), thus resulting in more than 2,600 observations per priming condition (i.e., following Brysbaert and Stevens’ (Reference Brysbaert and Stevens2018) recommendation). All participants were native speakers of Majorcan Catalan, and their teaching language was Catalan in primary and secondary education; furthermore, all participants reported that Catalan was their dominant language, being their primary language in social settings. Given that participants also mastered the other official language in the Balearic Islands, Spanish, there may be some effects of diversity in linguistic experiences in this sample (e.g., classes at the university level for these participants were taught in Catalan or Spanish interchangeably, depending on the class instructor). Participants signed a consent form before beginning the Experiment and received a small monetary compensation (3€) for their time. The Ethics Committee of the Universitat de València approved this experiment.
Materials
The target letters were the five vowel letters of Catalan, both in their non-accented and accented forms (non-accented: A, E, I, O, U; accented: À, È, É, Í, Ò, Ó, Ó). For each non-accented target letter, we created four lowercase primes: 1) the same as the target (e.g., e–E); 2) the same base letter as the target except for the addition of a diacritical mark (e.g., é–E); 3) a different vowel (u–E); and 4) a different vowel with an accent mark (ú–E). The priming conditions for the accented target letters were parallel to that of the unaccented target letters (e.g., é–É, e–É, ú–É, u–É). We employed 40-pt Courier New to present the stimuli. To act as foils in the alphabetical decision task, we selected five artificial letters in uppercase from the Courier New analog of the BACS database (Vidal et al., Reference Vidal, Content and Chetail2017)—these were presented either in the original unaccented form or in accented form (e.g., ![]() ,
, ![]() ). The accented forms of each non-letter were created with the TypeLight font editor (CR8 Software Solutions Ltd, 2020). Each target non-letter was preceded by a prime that was parallel to those of the target letters (e.g., non-accented target: a-
). The accented forms of each non-letter were created with the TypeLight font editor (CR8 Software Solutions Ltd, 2020). Each target non-letter was preceded by a prime that was parallel to those of the target letters (e.g., non-accented target: a-![]() , à-
, à-![]() , o-
, o-![]() , ò-
, ò-![]() ; accented target: a-
; accented target: a-![]() , à-
, à-![]() , o-
, o-![]() , ò-
, ò-![]() ). The experimental list was composed of 448 trials (224 letter trials and 224 non-letter trials), preceded by a brief practice of 20 trials. The list of letters and non-letters, together with all the prime-target combinations, is presented in Appendix B.
). The experimental list was composed of 448 trials (224 letter trials and 224 non-letter trials), preceded by a brief practice of 20 trials. The list of letters and non-letters, together with all the prime-target combinations, is presented in Appendix B.
Procedure
The Experiment was conducted in a quiet lab using Windows computers equipped with DMDX (Forster & Forster, Reference Forster and Forster2003). We used the same setup in the masked priming alphabetical decision task as that employed by Chetail and Boursain (Reference Chetail and Boursain2019) and Perea et al. (Reference Perea, Fernández-López and Marcet2020): pattern mask (500 ms), prime (50 ms), and target—until response or 2-sec timeout. The stimuli were presented in random order, written in black on a white background. Participants were told that they would be presented with a stimulus that could be a real letter or not; they had to press the “green” button (M key) on a computer keyboard if the stimulus was a letter and the “red” button (Z key) if it was not. This decision had to be made as quick as possible, but trying to keep a high accuracy level. The duration of the session was around 25 min.
Results
For the latency analyses, we removed the incorrect responses and the response times shorter than 200 ms (3 observations). Failure to respond before the 2-sec deadline was coded as an incorrect response (8 observations). Table 1 presents the mean response times and accuracy in each experimental condition.
Table 1. Average response times (in ms) and accuracy for each of the conditions in the experiment

Note: For the non-letters, the mean RTs and accuracy were 528 ms and .952, respectively.
For the statistical analyses on the letter targets, we employed generalized linear mixed-effects models in R (R Core Team, 2020) with the lmer package (Bates et al., Reference Bates, Machler, Balker and Wolker2015) with separate analyses of the latency and accuracy data. The p values were obtained with the lmerTest package (Kuznetsova, Brockhoff, & Christensen, Reference Kuznetsova, Brockhoff and Christensen2017). The three fixed factors in the models were Type of target (non-accented, accented), Type of Prime (non-accented, accented), and rime-target relation (same base letter [related]; different base letter [unrelated]). The levels of the three factors were centered at zero and coded as −0.5 and 0.5. For the latency data, we employed the Gamma distribution to avoid the use of non-linear transformations of the response times (see Marcet et al., Reference Marcet, Ghukasyan, Fernández-López and Perea2020; Yang & Lupker, Reference Yang and Lupker2019). For the accuracy data, we employed the binomial distribution. We chose the most complex random-effect model structure that successfully converged (see Barr, Levy, Scheepers, & Tily, Reference Barr, Levy, Scheepers and Tily2013)—the models are presented in Appendix C. Pairwise comparisons after an interaction were conducted with the emmeans package (Lenth et al., Reference Lenth, Singmann, Love, Buerkner and Herve2020) using the Tukey HSD correction.
Response time data
The coefficients of the model are presented in Table 2. The analyses of the latency data showed faster response times to the targets when preceded by a related prime than when preceded by an unrelated prime (e.g., é–É faster than ó–É; b = 7.57, SE = 2.11, t = 3.58, p < .001) and faster response times to non-accented than accented targets (b = 20.54, SE = 2.21, t = 9.31, p < .001). The main effect of Type of Prime did not approach significance (b = 0.88, SE = 2.41, t = 0.34, p = .74). Critically, these effects were modulated not only by significant two-way interactions but also by a significant three-way interaction (b = 16.56, SE = 3.29, t = 5.04, p < .001). To inspect the three-way interaction, the effects of prime type and target type for related and unrelated pairs were examined separately. This choice was fully in line with the Experiment’s hypotheses (i.e., for related pairs: do identity and visually similar primes behave differently? For unrelated pairs, do primes with an accent mark slow down target processing?).
Table 2. Estimates of the generalized linear mixed-effect model of the latency data

For related pairs, we found faster response times to accented than non-accented targets (b = 18.07, SE = 3.20, t = 5.65, p < .001) and no signs of an effect of prime type (|t| < 1, p = .93). More importantly, the interaction between Type of target and Type of Prime was significant (b = −19.53, SE = 43.91, t = −5.00, p < .001). This interaction reflected faster response times in the identity than in the visually similar condition for accented pairs (é–É faster than e–É; 21 ms, p < .001), but not for non-accented pairs (e–E = é–E, less than 1 ms, p > .90).
For unrelated pairs, we found faster responses to non-accented than to accented targets (b = 11.32, SE = 3.12, t = 3.63, p < .001) and faster responses to the targets when preceded by a non-accented prime than when preceded by an accented prime (e.g., o–E [o–É] < ó–E [ó–É]; b = 10.27, SE = 4.31, t = 2.39, p = .017). The interaction between the two factors did not approach significance (|t| < 1, p = .46).
Accuracy data
As can be seen in Table 1, accuracy was very high and approximately similar across conditions (range: .96–.97). None of the effects approached significance (all ps > .10).
To supplement the above analyses and visualize the dissociation of the masked priming effects in the identity vs. visually similar conditions for accented and non-accented targets, we employed delta plots (see De Jong et al., Reference De Jong, Liang and Lauber1994; Ridderinkhof, Reference Ridderinkhof, Prinz and Hommel2002). Delta plots represent the difference between the distributions of response times of the two conditions (i.e., visually different and identity conditions) quantile by quantile. We created two delta plots, one for non-accented targets and another for accented targets (see Figure 2). An effect in the intercept (i.e., the leading edge of the response time distribution) is typically interpreted as due to an encoding stage. In contrast, an effect in the slope reflects an accumulation of evidence in the decision (see Gomez, Reference Gomez and Adelman2012).

Figure 2. Delta plots: Difference between the visually different condition and the identity condition as a function of response time for accented targets (left panel) and non-accented targets (right panel). Each dot represents the mean response time at a specific quantile, all of them with equal number of observations (i.e., Vincentiles; see Jiang et al. Reference Jiang, Rouder and Speckman2004).
For non-accented targets, the delta plot shows intercepts and slopes close to zero (i.e., the response distribution of the identity and visually similar conditions are remarkably alike), thus mimicking the null effect from the linear mixed-effects analyses. In contrast, for accented targets, the delta plot has an intercept below zero and a positive slope (see Gomez et al., Reference Gomez, Perea and Ratcliff2013, for a similar dissociation in masked priming lexical decision for non-word targets). This means that 1) in the leading edge of the response time distributions (i.e., the .1 quantile), there is disadvantage of the identity condition (e.g., é–É) relative to the visually similar condition (e.g., e–É), and 2) this initial disadvantage turns into an advantage of the identity condition in the higher quantiles (i.e., “yes” decisions are more difficult for e–É than for é–É). Thus, this quantile-based descriptive technique offers converging evidence to the results obtained through linear mixed-effects models and provides some insights on the nature of the priming effects.
To sum up, for related pairs, we found faster responses to accented targets when preceded by an identity prime than when preceded by a visually similar prime (e.g., é–É faster than e–É), whereas for non-accented targets, both identity and visually similar primes behaved similarly (e.g., e–E = é–E). In addition, for unrelated pairs, we found faster responses when the prime did not contain an accent mark (e.g., o–E [o–É] faster than ó–E [ó–É]).
Discussion
The issue of how accented and non-accented vowels are represented in the letter/word recognition system is essential to implement a general model of visual word recognition in Latin-based orthographies (see Chetail & Boursain, Reference Chetail and Boursain2019; Domínguez & Cuetos, Reference Domínguez and Cuetos2018; Perea et al., Reference Perea, Fernández-López and Marcet2020, in press). Here we conducted a masked priming alphabetic decision experiment with accented vs. non-accented vowels in Catalan (i.e., a phonological complex language) to adjudicate between the perceptually based account proposed by Perea et al. (Reference Perea, Fernández-López and Marcet2020) (e→E, but é↛e) and the orthographic account proposed by Chetail and Boursain (Reference Chetail and Boursain2019) (é↛e and e↛é), while also considering a third, ortho-phonological account (é→é and e↛é). The main finding of the present experiment was that the identity condition produced faster response times than the visually similar condition for accented targets (e.g., é–É < e–É), but not for non-accented targets (e.g., e–E = é–E). In addition, for unrelated pairs, response times were slower when the prime contained an accented prime, regardless of whether the target had an accented vowel or not (e.g., o–E [o–É] < ó–E [ó–É]). We now proceed to consider the implications of these findings.
First, our data rule out a perceptually based explanation of the priming effects based on the asymmetric similarities between a more salient (i.e., accented vowel) and a less salient (non-accented vowel) visual object. Perea et al. (Reference Perea, Baciero and Marcet2021a) proposed that, in the initial moments of letter processing, the less salient object (i.e., the non-accented vowel) would be highly confusable with its more salient counterpart (i.e., the accented vowel) but not the other way around (i.e., e→E, but é↛e). Thus, for accented targets, one would have expected similar response times to é–É and e–É and faster response times to e–E than é–E (i.e., the same pattern as in Spanish; see Perea et al., Reference Perea, Fernández-López and Marcet2020). However, neither the accented nor the non-accented targets in Catalan showed this pattern (i.e., we found é–É < e–É and e–E = é–E). The very different pattern of priming effects for Catalan and Spanish strongly suggests that the characteristics of the language shape the processing of accented vs. non-accented vowels beyond visual saliency. Therefore, the present findings pose some limits to the universality of the hypothesis of asymmetric similarities.
Moreover, the present findings also pose problems for an orthographic account that assumes that non-accented and accented vowels (e.g., e and é) activate different abstract letter units in a phonologically complex language (Chetail & Boursain, Reference Chetail and Boursain2019). As non-accented and accented vowels would activate different orthographic units during letter identification, this account predicted an equivalent advantage of the identity condition over the visually similar condition for both accented and non-accented targets (e.g., é–É < e–É and e–E < é–E). We did find this advantage for accented targets, but there were no signs of such an advantage for non-accented targets (i.e., the difference was less than 1 ms; see also Figure 2)—note that the parallel experiments in French and Spanish did show this advantage for non-accented targets. The lack of an advantage of e–E over é–E suggests that there are other (non-orthographic) codes at play in the masked priming alphabetic decision task with vowels in Catalan.
Thus, neither the perceptual account nor the orthographic account can capture the pattern of data of the present Experiment. In the Introduction, we discussed a complementary explanation to the orthographic account: An alphabetic decision task with vowels would involve the activation of both orthographic codes and phonological codes—this idea is analogous to the word recognition literature in which both types of codes are activated from the masked primes (e.g., see Ferrand & Grainger, Reference Ferrand and Grainger1992; Grainger & Ferrand, Reference Grainger and Ferrand1994). Importantly, although orthographic and phonological codes of vowels go hand in hand in Spanish (e.g., e→/e/ and é→/e/), this is not the case in Catalan. As stated earlier, Catalan has a consistent grapheme-to-phoneme mapping for accented vowels (e.g., é→/e/) and a convoluted grapheme-to-phoneme mapping for non-accented vowels (e.g., e → /e/, /ə/, /ε/). As a result, phonological codes in Catalan are very stable for an accented vowel, but quite variable for a non-accented vowel. This may have modulated the obtained priming effects. Keep in mind that identity prime–target pairs for an accented target (e.g., é–É) may have benefited from the activation of orthographic/phonological codes. In contrast, the visually similar prime–target pairs (e.g., e–É) would share neither the phonological codes nor the orthographic codes. Thus, this ortho-phonological account can readily accommodate the sizeable advantage of é–É over e–É. As the delta plot showed (left panel of Figure 1), this effect grew larger as a function of response speed. This pattern is consistent with the view that the information accumulated to make a “yes” decision for visually similar pairs like e–É is slower than that of identity pairs (e.g., é–É) because it involves conflicting orthographic and phonological codes. The net result is a lower “quality of information” for e–É than for é–É (see Gomez, Reference Gomez and Adelman2012). What about non-accented targets? In this case, the identity prime would share the orthographic codes with the target (e.g., e–E), but the phonological code from the prime may not be stable; in turn, the visually similar prime would provide a stable phonological code for the target, but it would not share the orthographic codes (e.g., é–E). In the present experiment, this interplay resulted in an overall null priming effect (e–E ≈ é–E; see right panel of Figure 1). In sum, a combination of orthographic and phonological codes for accented and non-accented vowels provides a reasonably good account of the present findings with related pairs in Catalan. Furthermore, as shown below, this account can also capture the results obtained with unrelated pairs.
A novel feature of the present Experiment is that we also tested whether an accented prime affected target processing for unrelated prime–target pairs (ó–É vs. o–É; ó–E vs. é–E). We found faster responses for targets preceded by non-accented prime than when preceded by an accented prime.Footnote 4 This difference was remarkably similar for accented and non-accented targets, so it was not due to the salience of the accent mark for non-accented targets. This pattern cannot be easily accommodated by perceptually based or orthographic accounts: For these accounts, there is no reason why a target vowel (e.g., E) would be differentially affected by an unrelated accented or a non-accented prime (e.g., the prime o vs. the prime ó). Importantly, this difference can be readily explained by the ortho-phonological account. In Catalan, an accented prime provides a more stable phonological code (e.g., ó→/o/) than a non-accented prime. Thus, the disadvantage of pairs like ó–É when compared to o–É can be related to a mismatch due to the orthographic and phonological codes activated by the accented primes and the ones activated by the target stimulus, hence slowing down target processing.
All and all, the present experiment suggests that, when applied to Catalan, neurally inspired models of letter and word recognition should include different arrays of abstract letter detectors for non-accented and accented vowels. Similarly, when implementing computational models of visual word recognition (e.g., using the EasyNet platform, see Adelman et al., Reference Adelman, Gubian and Davis2018), accented and non-accented vowels should be given different units at the letter level. Importantly, in other languages such as Spanish (where accent marks do not indicate vowel quality), it may be more parsimonious to assume that accented and non-accented vowels share their abstract orthographic units (see Marcet & Perea, Reference Marcet and Perea2021, for discussion). Keep in mind that while accent marks on a vowel in Spanish have a prosodic role during word recognition (i.e., the stressed syllable), non-accented vowels may also correspond to a stressed syllable (e.g., boca [ˈboka] <mouth> vs. bocal [boˈkal] <jug>).
In sum, the present Experiment favors the view that accented and non-accented vowels are represented differently in a language with complex grapheme-to-phoneme mappings, Catalan. At the same time, our findings pose limits to the universality of asymmetric similarities between salient (accented) and non-salient (non-accented) letters, at least in tasks that involve orthographic/phonological codes that may override the initial impact of visual salience (see left panel of Figure 2). Instead, our findings favor the view that there is a rapid activation of orthographic and phonological codes for accented and non-accented vowels. More research should examine the interplay between orthographic and phonological codes of accented vs. non-accented letters (vowels vs. consonants) using languages with various phoneme-to-grapheme mappings and with techniques that allow the tracking of the time course of priming effects (e.g., event-related potentials, see Massol et al., Reference Massol, Grainger, Midgley and Holcomb2012; Petit et al., Reference Petit, Midgley, Holcomb and Grainger2006).
Acknowledgments
This paper was funded by Grant GV/2020/074 from Valencian Government to AM, and Grant PSI2017-86210-P from the Spanish Ministry of Science and Innovation to MP.
Conflict of interest
The authors declare that they have no conflict of interest.
Appendix A. Vowel harmony scenarios in Majorcan Catalan
Besides vowel reduction, three different vowel harmony scenarios can occur in Majorcan Catalan, which tend to be marginal and affect a subset of the lexicon:
-
1. [ə] → [o] where mid vowel /o/ in stressed position may spread the feature “back” to the vowel /ə/ in pretonic position. Thus, the words genoll <knee> and meló <melon> would be pronounced as [ʤoˈnoʎ] and [moˈlo]—the common pronunciations would be [ʤəˈnoʎ/ and [məˈlo].
-
2. [ə] → [o] in the masculine gender allomorph which is inserted to prevent final clusters. For instance, bronze <bronze>, cogombre <cucumber>, and cotxe <car> are pronounced [ˈbɾónzo], [koˈɣombɾo], and [ˈkoʧo] instead of [ˈbɾoónzə], [koˈɣombɾə], and [ˈkoʧə].
-
3. [ə] → [i] The palatal consonants in onset position may spread the feature “palatal” to the following vowel. This way, the words gegant <giant>, geniva <gingiva>, lleixiu <bleach>, and xebró <beam> can be pronounced [ʤiˈɣant], [ʤiˈniva], [ʎijˈʃiw] and [ʧiˈbɾo]—the common pronunciation would be [ʤəˈɣant], [ʤəˈniva], [ʎəjˈʃiw], and [ʧəˈbɾo].
Appendix B. Letters and non-letters in the experiment
Prime-target combinations in the Experiment—the procedure was analogous to that used by Chetail and Boursain (Reference Chetail and Boursain2019).

Appendix C. Generalized linear mixed-effects models in the experiment
Overall analyses (RT data)
Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) [“glmerMod”]
Family: Gamma (identity)
Formula: RT ∼ same * primetype * targettype + (1 + primetype * targettype | subject) + (1 + primetype | item)
Data: mallorcaRT
Control: glmerControl(optimizer = “bobyqa,” optCtrl = list(maxfun = 2e+05))
Related pairs
Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) [“glmerMod”]
Family: Gamma (identity)
Formula: RT ∼ primetype * targettype + (1 + primetype | subject) + (1 + targettype | item)
Data: subset(mallorcaRT, same == −0.5)
Control: glmerControl(optimizer = “bobyqa,” optCtrl = list(maxfun = 2e+05))
Unrelated pairs
Generalized linear mixed model fit by maximum likelihood (Laplace Approximation) [“glmerMod”]
Family: Gamma (identity)
Formula: RT ∼ primetype * targettype + (1 + primetype | subject) + (1 + primetype | item)
Data: subset(mallorcaRT, same == 0.5)
Control: glmerControl(optimizer = “bobyqa,” optCtrl = list(maxfun = 2e+05))





 Open access
Open access