

I. INTRODUCTION
A biometric system aims to verify the identity of an individual from their behavioral and/or biological characteristics [Reference Jain, Nandakumar and Ross1,Reference Hadid, Evans, Marcel and Fierrez2]. The body traits that can be used for biometric recognition are classified into anatomical and behavioral characteristics [Reference Jain, Ross and Pankanti3]. Anatomical traits include face [Reference Jain and Li4], fingerprint [Reference Maltoni, Maio, Jain and Prabhakar5], iris [Reference Daugman6], palmprint [Reference Connie, Teoh, Goh and Ngo7], hand geometry [Reference Sanchez-Reillo, Sanchez-Avila and Gonzalez-Marcos8], and ear shape [Reference Yan and Bowyer9]; while gait [Reference Yazdanpanah, Faez and Amirfattahi10], signature [Reference Nalwa11], and keystroke [Reference Monrose and Rubin12] dynamics are some of the behavioral characteristics [Reference Jain, Nandakumar and Nagar13]. Voice biometrics can be considered either as an anatomical or as a behavioral characteristics [Reference Jain, Ross and Pankanti3]. Robustness and security are two important factors as far as system deployment is concerned.
Speaker recognition usually refers to both speaker identification and speaker verification. A speaker identification system identifies who the speaker is, while an automatic speaker verification (ASV) system decides if an identity claim is true or false. The former is a multi-class classification problem, while the latter is a hypothesis test. A general ASV system is robust to zero-effort impostors, they are vulnerable to more sophisticated attacks. Such vulnerability represents one of the security concerns of ASV systems.
Spoofing involves an adversary (attacker) who masquerades as the target speaker to gain the access to a system [Reference Ergünay, Khoury, Lazaridis and Marcel14–Reference Evans16]. The spoofing attacks against an ASV system or biometric system in general are considered as a part of presentation attacks as per International Organization for Standardization (ISO) and International Electro-technical Commission (IEC) [Reference Koppell17]. As biometric information of a person can be easily obtained, spoofing attacks are inevitable [Reference Galbally, Marcel and Fierrez18]. Such spoofing attacks can happen to various biometric traits, such as fingerprints, iris, face, and voice patterns. Figure 1 shows some examples how the original biometric patterns can be spoofed with different techniques. In this paper, we are focusing only on the voice-based spoofing and anti-spoofing techniques for ASV system.

Fig. 1. Biometric identification along with spoofing techniques for fingerprint, iris, face, and voice. (Images are adapted from [19].)
The spoofed speech samples can be obtained through speech synthesis, voice conversion, or replay of recorded speech. Depending upon how the spoof samples are presented to ASV system the attacks are broadly classified into two categories, namely, direct attacks and indirect attacks. In direct attacks (also called as Physical Access (PA) attacks), the samples are applied as input to the ASV system through the sensor, i.e. at the microphone and transmission-level. In indirect attacks (also called as Logical Access (LA) attacks), the samples are involved by passing the sensor, i.e. ASV system software process, access during feature extraction, interfering with the models, and at the decision or score computation as shown in Fig. 2 [Reference Muckenhirn, Magimai-Doss and Marcel21].
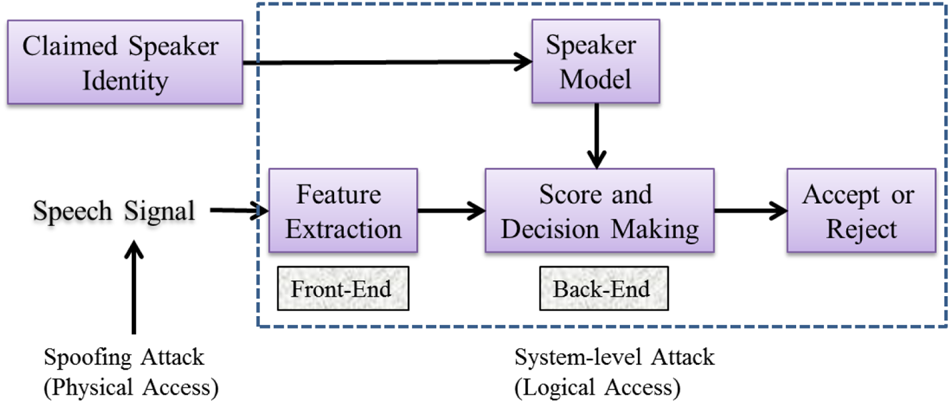
Fig. 2. Brief illustration of an Automatic Speaker Verification (ASV) system. After [Reference Wu, Evans, Kinnunen, Yamagishi, Alegre and Li20].
To objectively report the research progress, there is a need to provide a common dataset along with performance metric to evaluate the spoofing countermeasures. This was also discussed in the special session on spoofing and countermeasures for ASV held during INTERSPEECH 2013 [Reference Evans, Kinnunen and Yamagishi15]. This special session motivated the researchers to organize the first ASVspoof 2015 Challenge held in INTERSPEECH 2015 [Reference Wu, Kinnunen, Evans, Yamagishi, Hanilçi, Sahidullah and Sizov22]. The database released in this challenge contains two types of spoofing attacks, namely, synthetic speech (SS) and voice conversion (VC). As a follow-up, the second and third challenges were organized during INTERSPEECH 2017 and INTERSPEECH 2019, respectively [Reference Kinnunen, Sahidullah, Delgado, Todisco, Evans, Yamagishi and Lee24,Reference Kinnunen, Evans, Yamagishi, Lee, Sahidullah, Todisco and Delgado23]. The historical developments and key milestones of the ASVspoof initiative are illustrated in Fig. 3.

Fig. 3. The selected chronological progress in ASVspoof for voice biometrics. In INTERSPEECH 2013, a special session was organized and Spoofing and Anti-Spoofing (SAS) corpus of speech synthesis and voice conversion spoofing data was created. The first ASVspoof challenge was held in INTERSPEECH 2015. In 2016, the OCTAVE project started which focused on only replay spoofing data resulting in the second edition of ASVspoof challenge in INTERSPEECH 2017. The follow-up third ASVspoof 2019 challenge was on physical and LA attacks going to be held during INTERSPEECH 2019 [Reference Kinnunen, Evans, Yamagishi, Lee, Sahidullah, Todisco and Delgado23]. IS indicates INTERSPEECH.
We have seen a surge of research papers on spoofing detection in scientific conferences, such as APSIPA Annual Summit and Conference [Reference Kinnunen, Sahidullah, Delgado, Todisco, Evans, Yamagishi and Lee24], ICASSP, INTERSPEECH, and special issues in scientific journals, such as IEEE Transactions of Information Forensics special issues on Biometrics Spoofing and Countermeasures [Reference Evans, Li, Marcel and Ross25], IEEE Signal Processing Magazine special issue on Biometric Security and Privacy Protection [Reference Evans, Marcel, Ross and Teoh26], IEEE Journal on Selected Topics in Signal Processing special issue on Spoofing and Countermeasures for Automatic Speaker Verification [27], Special issue on Speaker and language characterization and recognition: voice modeling, conversion, synthesis, and ethical aspects [28], and Special issue on Advances in Automatic Speaker Verification Anti-spoofing [29]. This article provides an overview of the recent advances, and discusses the challenges.
A general discussion on biometrics and spoofing attacks was presented in [Reference Hadid, Evans, Marcel and Fierrez2]. The first survey paper on the ASVspoof challenge [Reference Wu, Evans, Kinnunen, Yamagishi, Alegre and Li20] discusses the past work and identifies priority research directions for the future [Reference Wu, Yamagishi, Kinnunen, Hanilçi, Sahidullah, Sizov, Evans and Todisco30] and presents the details of the dataset, protocols, and metrics of the ASVspoof 2015 challenge. It also provides a detailed analysis of the participating systems in the challenge.
A recent survey paper [Reference Patil and Kamble31] compares different countermeasures for both SS and replay detection. In particular, it discusses various classical representation learning approaches for SS and replay detection. This overview is an extension to [Reference Patil and Kamble31] that provides both historical and technological perspectives about the recent progress.
The organization of rest of the paper is as follows: The discussion of various spoofing attacks is presented in Section II. The discussion of different spoofing challenges and performance evaluation metrics are discussed in Section III. Furthermore, in Section IV and SectionV, we discussed different countermeasures approaches for synthetic and replay spoof speech detection (SSD) task. In this section, we represented the countermeasures in both classical and representation learning approaches for spoofing detection. The Section VI describes the limitation, technological challenges along with future research directions in spoofing research, and finally, we summarize the paper in Section VII.
II. ASV SYSTEM: SPOOFING ATTACKS
In the literature, the spoofing attacks are broadly classified into four types, namely, impersonation, SS, VC, and replay. Few of the spoofing algorithms used for spoofing attacks are shown in Fig. 4. The detailed description of each spoofing attack is discussed next.
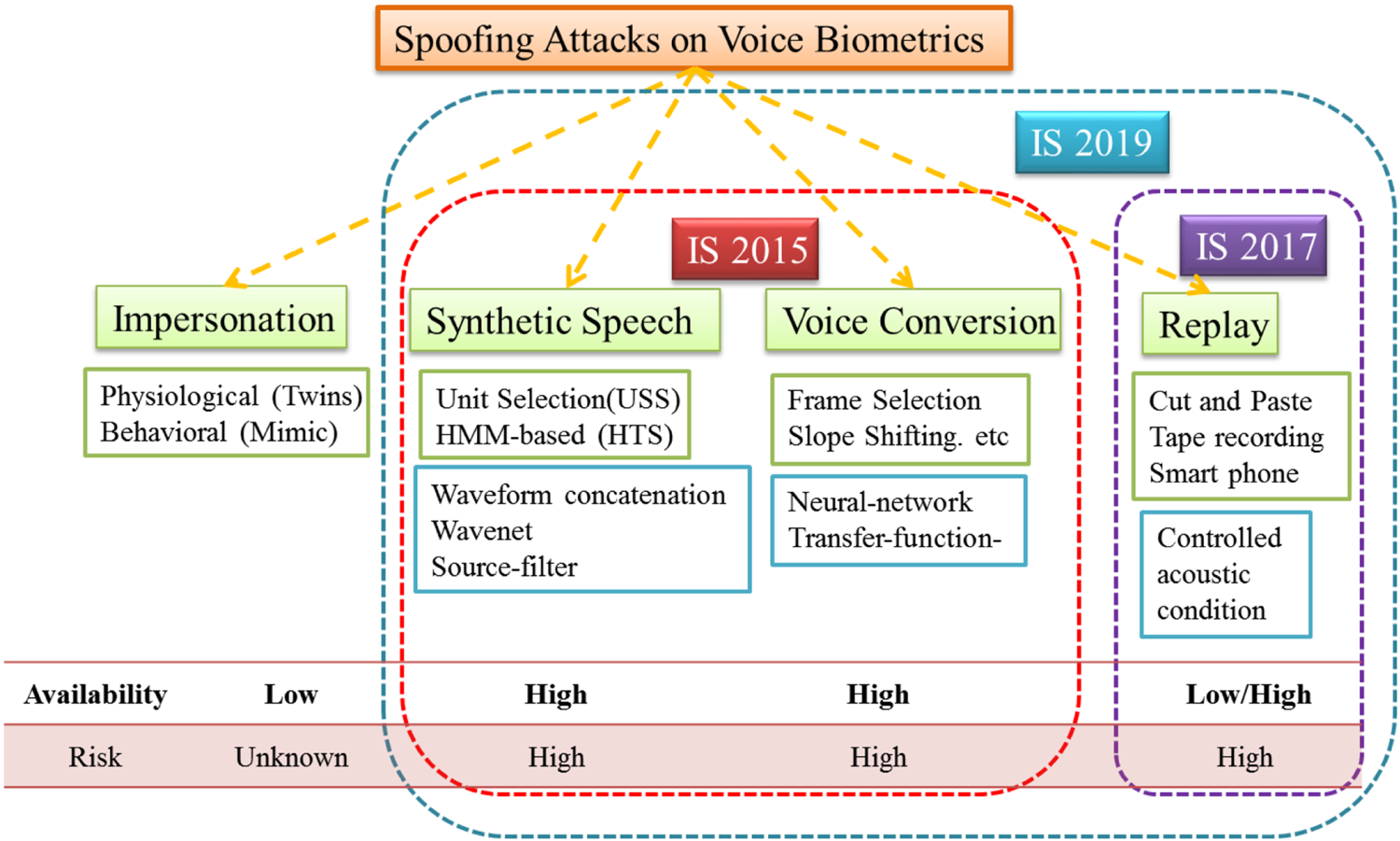
Fig. 4. Different spoofing attacks on voice biometrics along with their availability and risk factor. IS: INTERSPEECH. Adapted from [Reference Li, Patil and Kamble32].
A) Impersonation
Impersonation is defined as the process of producing the similar voice pattern and speech behavior of the target speaker's voice [Reference Markham33–Reference Hautamäki, Kinnunen, Hautamäki, Leino and Laukkanen35]. This can be done either by professional mimics/impersonator (by utilizing behavioral characteristics) or by twins (by utilizing physiological characteristics) [Reference Rosenberg36]. The impersonators do not require any technical background or machines to imitate the target speaker. The study in [Reference Lau, Tran and Wagner37] found that if the impostor is aware of the claimed speaker's voice and also carries similar voice pattern could crack the biometric system. For better imitation, the professional imitator tries to mimic the prosodic features of a target speaker [Reference Farrús, Wagner, Anguita and Hernando38]. Professional voice imitator intend to mimic the claimed speaker's prosody, accent, pronunciation, lexicon, and other high-level speaker traits. Such imitation may mislead human perception, however, it is less effective in attacking speaker verification systems because most speaker verification systems are based on spectral features to make decisions. Just like twins attacks, in impersonation attacks, the system is presented with natural human speech. A system to detect unnatural speech does not help. As it takes special training to impersonate someone's voice, impersonation attack is not considered as a common threat to speaker verification systems.
In speaker recognition, we aim to extract the unique speaker features from speech data. However, the speaker features become less unique between the twins [Reference Jain, Prabhakar and Pankanti39]. Generally, spectrographic analysis is used to identify the speaker's voice. In the case of identical twins, the same technique fails to perform [Reference Kersta and Colangelo40]. The study reported in [Reference Patil and Parhi41] states that the pattern of speech signals, pitch ( $F_0)$ contours, formant contours, and spectrograms for identical twin speakers are very similar, if not identical. Due to lack of uniqueness, the FAR increases for identical twins verification. Recently, the Voice ID service was launched by HSBC's phone banking business [42,43]. It failed to recognize true speaker [44]. Similar twins fraud was studied in other biometrics literature as well [Reference Jain, Prabhakar and Pankanti39]. The identical twins do have a similar spectrographic pattern, however, the speaker verification technology has seen a significant reduction in fraud, and has proven to be more secure than PINS, passwords, and memorable phrases. In twins attacks, the system is presented with natural human speech, a SS detection mechanism will not enhance the security of the system. To distinguish between the twins, further study on discriminative speaker features is required or more study in this direction is required as observed four decades earlier in [Reference Rosenberg36].
$F_0)$ contours, formant contours, and spectrograms for identical twin speakers are very similar, if not identical. Due to lack of uniqueness, the FAR increases for identical twins verification. Recently, the Voice ID service was launched by HSBC's phone banking business [42,43]. It failed to recognize true speaker [44]. Similar twins fraud was studied in other biometrics literature as well [Reference Jain, Prabhakar and Pankanti39]. The identical twins do have a similar spectrographic pattern, however, the speaker verification technology has seen a significant reduction in fraud, and has proven to be more secure than PINS, passwords, and memorable phrases. In twins attacks, the system is presented with natural human speech, a SS detection mechanism will not enhance the security of the system. To distinguish between the twins, further study on discriminative speaker features is required or more study in this direction is required as observed four decades earlier in [Reference Rosenberg36].
B) Synthetic speech
SS is also known as Text-To-Speech (TTS), which takes text as input and generate speech as output. It emulates a human vocal production system and represents a genuine threat. SS is now able to generate high-quality voice due to recent advances in unit selection [Reference Hunt and Black45], statistical parametric [Reference Zen, Tokuda and Black46], hybrid [Reference Qian, Soong and Yan47], and DNN-based TTS methods. Recently, deep learning-based techniques, such as Generative Adversarial Network (GAN) [Reference Saito, Takamichi and Saruwatari48], Tacotron [Reference Wang49], Wavenet [Reference van den Oord50], etc., are able to produce very natural sounding speech both in timbre and prosody. SS uses properties of a claimed speaker's voice characteristics and spectral cues of the natural speech. The spectral energy density of natural (Panel I) and synthetic (Panel II) speech signal are shown in Fig. 5. It is clearly observed that the distributions of spectral energies are very different between the natural speech and SS. The research on SS detection has been focused on how to detect the artifacts that exist in the SS samples. More technical description of algorithms are reported in [Reference Wu51,Reference De Leon, Pucher, Yamagishi, Hernaez and Saratxaga52].
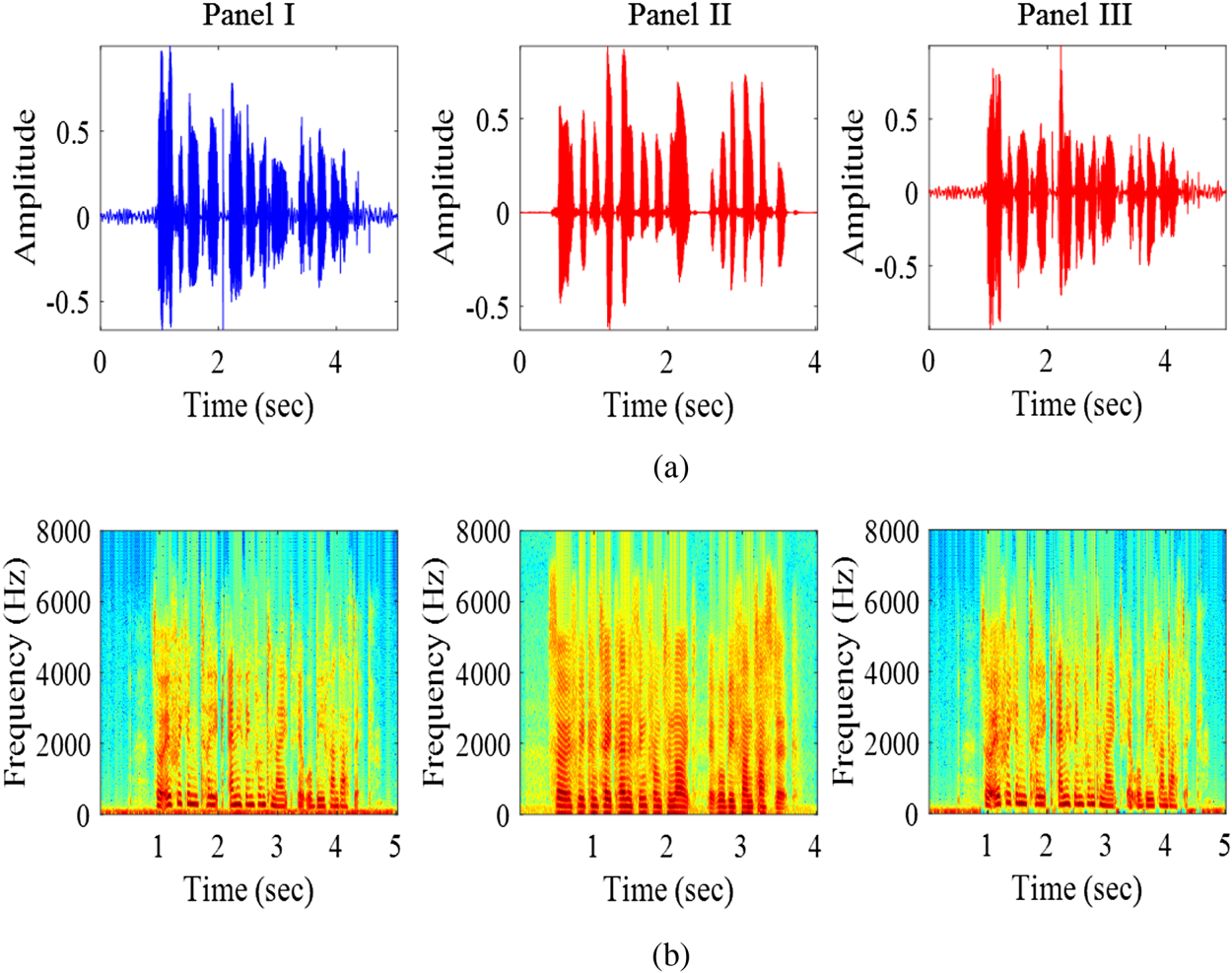
Fig. 5. Spectral energy densities of natural (Panel I), synthetic speech (Panel II), and voice converted speech (Panel III). (a) Time-domain speech signal, and (b) corresponding spectral energy density.
C) Voice conversion
VC is the process of converting the source speaker's voice to a sound similar to the target speaker's voice [Reference Lau, Wagner and Tran34,Reference Bonastre, Matrouf and Fredouille53,Reference Kinnunen, Wu, Lee, Sedlak, Chng and Li54]. VC deals with the information that relates to the segmental and suprasegmental features and keep the language content similar [Reference Wu and Li55]. Earlier studies include statistical techniques, such as Gaussian Mixture Model (GMM) [Reference Stylianou, Cappé and Moulines56], Hidden Markov Model (HMM) [Reference Kim, Lee and Oh57], unit selection [Reference Sundermann, Hoge, Bonafonte, Ney, Black and Narayanan58], principal component analysis (PCA) [Reference Wilde and Martinez59], and Non-negative matrix factorization (NMF) [Reference Zhang, Huang, Xie, Chng, Li and Dong60] for VC task. Recently, DNN [Reference Desai, Raghavendra, Yegnanarayana, Black and Prahallad61], Wavenet [Reference van den Oord50], and GAN [Reference Saito, Takamichi and Saruwatari48] represent a technology leap.
Studies also reported in the area of signal processing techniques, such as vector quantization [Reference Abe, Nakamura, Shikano and Kuwabara62] and frequency warping [Reference Erro and Moreno63]. The research on VC detection has also been focused on how to detect the artifacts arising from the VC process. One example of the converted speech is illustrated in Panel III of Fig. 5. More technical description of converted voices are reported in [Reference Wu51,Reference Wu and Li55].
D) Replay
One of the most accessible spoofing is replay attack. The attacker replays a pre-recorded voice from the target speaker to the system to gain access [Reference Lindberg and Blomberg64–Reference Villalba and Lleida66]. Such attack is meaningful only for text-dependent speaker verification systems. With high-quality record-replay audio device, the replayed speech is highly similar to the original speech, spectral content will change slightly due to device impulse response. Hence, replay is a serious adversary to text-dependent speaker verification system.
The genuine speech signal  $s[n]$ can be modeled as a convolution of glottal airflow,
$s[n]$ can be modeled as a convolution of glottal airflow,  $p[n]$ and vocal tract impulse response,
$p[n]$ and vocal tract impulse response,  $h[n]$ [Reference Quatieri67], i.e.
$h[n]$ [Reference Quatieri67], i.e.

On the other hand, the replay speech signal,  $r[n]$ can be modeled as the convolution of the genuine speech signal
$r[n]$ can be modeled as the convolution of the genuine speech signal  $s[n]$, and the impulse response,
$s[n]$, and the impulse response,  $\eta [n]$ of the intermediate devices (playback and recording device) along with propagating environment and additive noise,
$\eta [n]$ of the intermediate devices (playback and recording device) along with propagating environment and additive noise,  $N[n]$ of [Reference Alegre, Janicki and Evans68] and is given by:
$N[n]$ of [Reference Alegre, Janicki and Evans68] and is given by:

where the  $\eta [n]$ is the extra convolved components which is a combination of impulse responses of recording device
$\eta [n]$ is the extra convolved components which is a combination of impulse responses of recording device  $ h_{mic}[n]$, recording environment
$ h_{mic}[n]$, recording environment  $a[n]$, playback device (multimedia speaker)
$a[n]$, playback device (multimedia speaker)  $h_{spk}[n]$, and playback environment
$h_{spk}[n]$, and playback environment  $b[n]$ [Reference Alegre, Janicki and Evans68].
$b[n]$ [Reference Alegre, Janicki and Evans68].

In replayed speech detection, we hope to detect the presence of the channel and noise distortion to the original speech signal [Reference Janicki, Alegre and Evans69]. The speech signal recorded with the playback device contains the convolutional and additive distortions from the intermediate device and background [Reference Alegre, Janicki and Evans68]. An important part in the detection of replay attack is the process of feature representation. To obtain the discriminative information between natural and replayed speech signal, one should focus on the spectral characteristics that represent the information of the intermediate devices [Reference Rafi, Murty and Nayak70]. Figure 6 shows the spectrographic analysis of natural speech and replay speech signal taken from the ASVspoof 2017 Challenge database [Reference Kinnunen, Sahidullah, Delgado, Todisco, Evans, Yamagishi and Lee24]. The Panel I of Fig. 6 shows the natural speech signal with the corresponding spectrogram of the natural speech signal for the utterance, “Actions speak louder than words”, and similarly Panel II is for the replayed speech signal. It can be observed from Fig. 6 that there is a difference in temporal as well as in spectral representation between Panel I (natural) and Panel II (replay) speech signal due to the channel and noise distortion as shown in equation (2).

Fig. 6. Spectral energy densities of natural (Panel I) and replay speech (Panel II). (a) Time-domain speech signal, and (b) spectral energy density.
III. DATABASES AND PERFORMANCE EVALUATION METRICS
The early studies of spoofing attacks used different speech and speaker recognition databases, such as YOHO, NIST, and WSJ. The databases used for anti-spoofing studies are reported in Table 1. Since 2015, the research community has released multiple evaluation databases, that include SAS, ASVspoof 2015, ASVspoof 2017, ASVspoof 2019 challenge, AVspoof, RedDots Replayed databases. The AVspoof database introduces replay spoofing attacks along with SS and VC spoofing attacks. It was designed to simulate the attacks via LA and PA. This database was used in the BTAS 2016 Challenge [Reference Ergünay, Khoury, Lazaridis and Marcel14,Reference Korshunov76]. RedDots [Reference Kinnunen77] database is developed originally for text-dependent ASV research that was re-developed from replay attacks. This database is derived from the original RedDots database under various recording and playback conditions. However, standard impersonation database is not yet available publicly, the study reported in [Reference Campbell79] used the YOHO database that was designed for ASV system. In this paper, we focus on the description of ASVspoof challenge datasets. Next, we will discuss about challenge databases in details.
Table 1. Various corpus on spoofing attacks to ASV system.

A) ASVspoof 2015 challenge
The ASVspoof 2015 Challenge database was the first major release for spoofing and countermeasures research [Reference Wu, Evans, Kinnunen, Yamagishi, Alegre and Li20]. The database consists of natural and spoofed speech, which is generated via speech synthesis and VC, for LA attacks. There are no remarkable channel or background noise effects. The database is divided into three subsets, namely, training, development, and evaluation. The evaluation subset consists of known and unknown attacks. They include the same five algorithms used to generate the development dataset and hence, called as known (S1-S5) attacks. In addition, other spoofing algorithms are included in unknown (S6-S10), attacks which were used directly in the test data. The number of speakers in the database is reported in Table 2. The detailed description of the database can be found in [Reference Wu, Kinnunen, Evans, Yamagishi, Hanilçi, Sahidullah and Sizov22,Reference Wu51,Reference Wu, Evans, Kinnunen, Yamagishi, Alegre and Li20]
Table 2. A summary of ASVspoof 2015 Challenge database [Reference Wu, Kinnunen, Evans, Yamagishi, Hanilçi, Sahidullah and Sizov22].

B) AVspoof database
AVspoof database introduces replay spoofing attacks along with synthetic speech and VC spoofing attacks. It was designed to simulate the attacks via LA and PA. This database was used in the BTAS 2016 Challenge [Reference Ergünay, Khoury, Lazaridis and Marcel14,Reference Korshunov76]. The statistics of the database are summarized in Table 3. This database reports a comprehensive variety of presentation attacks including attacks when a genuine data is played back to an ASV system using laptop speakers, high-quality speakers, and two mobile phones. SS attacks, such as speech synthesis and VC replayed with laptop speakers, are also included [Reference Korshunov76]. The “unknown” attacks were introduced in the test set to make the competition more challenging [Reference Korshunov76]. The organizers of the challenge provided a baseline system which is based on the open source Bob toolbox [Reference Korshunov76]. The baseline system consists of simple spectrogram-based ratio as features and logistic regression as a pattern classifier [Reference Korshunov76].
Table 3. A summary of AVspoof Database [Reference Ergünay, Khoury, Lazaridis and Marcel14].

PA, Physical Access; LA, Logical Access
C) ASVspoof 2017 challenge
The ASVspoof 2017 Challenge database was built on the RedDots corpus [Reference Lee80], and its replayed speech [Reference Kinnunen77], which is therefore a replay database, and the speech is text-dependent. The number of speakers in training, development, and evaluation subset with corresponding number of genuine and spoofed utterances are summarized in Table 4. The detailed description of the database can be found in [Reference Kinnunen, Sahidullah, Delgado, Todisco, Evans, Yamagishi and Lee24,Reference Delgado81].
Table 4. A summary of ASVspoof 2017 Challenge version 2.0 [Reference Kinnunen, Sahidullah, Delgado, Todisco, Evans, Yamagishi and Lee24,Reference Delgado81].

There were some anomalies in the original ASVspoof 2017 database. The problem was fixed in the ASVspoof 2017 Version 2.0 release [Reference Delgado81]. Along with the corrected data, more detailed description of recording and playback devices as well as acoustic environments was also reported.
D) ASVspoof 2019 challenge
The ASVspoof 2019 challenge is an extension of the previously held two challenges which focuses on countermeasures for all the three major attack types, namely, SS, VC, and replay. In this particular challenge database, there are two sub-challenges, namely, LA and PA. The statistics of the database are summarized in Table 5 [82]. The training dataset includes genuine and spoofed speech from 20 speakers (eight male and 12 female). The spoof speech signals are generated using one of the two VC and four speech synthesis algorithms. The data conditions for earlier ASVspoof 2017 challenge were created in an uncontrolled setup, and hence, this condition made the results challenging to analyze the signal due to varying additive and convolutive noise. This uncontrolled condition was taken care in the present challenge by creating a simulated and controlled acoustic environment conditions. Unlike previous challenge editions, ASVspoof 2019 adopts a recently-proposed Tandem Detection Cost Function (t-DCF) as the primary performance metric along with % EER [Reference Kinnunen83].
Table 5. The summary of ASVspoof 2019 Challenge database [82].

E) ReMASC
The ReMASC (Realistic Replay Attack Microphone Array Speech Corpus) is the first publicly available database that is designed specifically for the protection of voice-controlled systems (VCSs) against various replay attacks in various conditions and environments [Reference Gong, Yang, Huber, MacKnight and Poellabauer84]. The ASVspoof 2019 challenge consists of simulated data for clear theoretical analysis of audio spoofing attacks in physical environments, however, it brings a simulation-to-reality gap. Recent increase for the VCSs depends on voice input as the primary user–machine interaction modality such as, intelligent personal assistants (e.g. Amazon Echo, Samsung Bixby, and Google Home) allow users to control their smart home appliances and complete many other tasks with ease. The VCSs also began to be used in vehicles to allow drivers to control their cars' navigation systems and other vehicle services. The number of speakers and the environment conditions are summarized in Table 6.
Table 6. Data volume of the ReMASC corpus (*indicates incomplete data due to recording device crashes).

F) Performance evaluation metrics
For effective comparison between algorithms, we need both the standard databases and common evaluation metrics. Given a test speech sample, four possible decisions can be made in SSD, which are summarized in Table 7, where a False Acceptance Rate (FAR) and a False Rejection Rate (FRR) represent two types of classification errors. FAR and FRR are also called as false alarm and miss detection, respectively [Reference Bimbot85]. A system's performance can also be described by an Equal Error Rate (EER) at which the FAR (false alarm) and FRR (miss detect) equals [Reference Bimbot85,Reference Evans, Kinnunen and Yamagishi15].
Table 7. Decision of four possible outcomes in the ASV system [Reference Wu, Evans, Kinnunen, Yamagishi, Alegre and Li20].

For a particular ASV system, the detection scores are computed with a false alarm and miss rate, denoted respectively, as  $P_\mathrm {fa}(\theta )$ and
$P_\mathrm {fa}(\theta )$ and  $P_\mathrm {miss}(\theta )$ at decision threshold θ, and are given as follows:
$P_\mathrm {miss}(\theta )$ at decision threshold θ, and are given as follows:


where  $P_\mathrm {fa}(\theta )$ and
$P_\mathrm {fa}(\theta )$ and  $P_\mathrm {miss}(\theta )$ are monotonically decreasing and increasing functions of θ. The EER corresponds to the threshold
$P_\mathrm {miss}(\theta )$ are monotonically decreasing and increasing functions of θ. The EER corresponds to the threshold  $\theta _{EER}$ at which the two detection error rates coincide, i.e.
$\theta _{EER}$ at which the two detection error rates coincide, i.e.

Impostor trials corresponding to a score higher than the threshold will be misclassified as genuine trials, whereas genuine trials with a score lower than the threshold will be misclassified as impostor trials. Since the two errors are inversely related, it is often desirable to illustrate the performance as a function of the threshold θ. One such measure is the Half Total Error Rate (HTER) [Reference Korshunov76]:

Performance can also be illustrated graphically with Detection-Error Trade-off (DET) curve [Reference Martin86]. The DET curve illustrates the behavior of a system for different decision threshold, θ, that also allows us to observe a trade-off between the FAR and the FRR.
The Detection Cost Function (DCF) is defined in terms of the cost of miss and false alarms along with the prior probability for the target speaker hypothesis. The standard DCF is designed for the assessment of a single ASV system whereas t-DCF metric combines the assessment of ASV system and the spoofing countermeasures [Reference Kinnunen83]. One of the initial attempts in this direction was reported for the spoof detection task for professional mimics [Reference Patil, Dutta and Basu87]. The t-DCF metric was used in ASVspoof 2019 evaluation [Reference Kinnunen83].
IV. COUNTERMEASURES FOR SYNTHETIC SPOOFING ATTACKS
We now give an overview of system construction for anti-spoofing against SS that includes synthesized and converted voices. The ASVspoof 2015 Challenge provided a common platform to study the effectiveness of countermeasures. Similar to other pattern classification system, a traditional spoof detection system consists of two parts, namely, feature extraction and pattern classifier as shown in Fig. 7. We will discuss the traditional approach and the end-to-end approach in more detail in this section.

Fig. 7. Spoofing detection framework.
1) Traditional approaches
There have been several early studies on finding features that reflect the artifacts in the SS. For example, one study considers that the pitch ( $F_0$) pattern of SS is more rigid than that of natural speech in [Reference Leon, Stewart and Yamagishi88], temporal structure of SS is different from that of natural speech [Reference Wu, Xiao, Chng and Li89], and SS contains phase distortions [Reference De Leon, Hernaez, Saratxaga, Pucher and Yamagishi90]. However, these features were observed on ad hoc databases, and moreover, they were not evaluated using a common performance evaluation metric. Hence, there was a need to develop a shared task for SS detection, that motivated the ASVspoof 2015 Challenge [Reference Wu, Evans, Kinnunen, Yamagishi, Alegre and Li20,Reference Wu, Kinnunen, Evans, Yamagishi, Hanilçi, Sahidullah and Sizov22].
$F_0$) pattern of SS is more rigid than that of natural speech in [Reference Leon, Stewart and Yamagishi88], temporal structure of SS is different from that of natural speech [Reference Wu, Xiao, Chng and Li89], and SS contains phase distortions [Reference De Leon, Hernaez, Saratxaga, Pucher and Yamagishi90]. However, these features were observed on ad hoc databases, and moreover, they were not evaluated using a common performance evaluation metric. Hence, there was a need to develop a shared task for SS detection, that motivated the ASVspoof 2015 Challenge [Reference Wu, Evans, Kinnunen, Yamagishi, Alegre and Li20,Reference Wu, Kinnunen, Evans, Yamagishi, Hanilçi, Sahidullah and Sizov22].
In ASVspoof 2015 Challenge, it was observed that the efforts on better features were more effective than the complex classifiers [Reference Kamble and Patil91]. Furthermore, long-term features are more effective than short-term features that are derived from short-term windows. The Constant-Q Cepstral Coefficients (CQCC) [Reference Todisco, Delgado and Evans92], and Cochlear Filter Cepstral Coefficients Instantaneous Frequency (CFCCIF) [Reference Patel and Patil93] offer state-of-the-art performance on ASVspoof 2015 database. The CFCCIF feature extraction, which is described by Speech Research Lab DA-IICT in Fig. 8, represents the best performance in ASVspoof 2015.

Fig. 8. Block diagram of the CFCCIF feature extraction process. After [Reference Patel and Patil93].
The CQCC features are extracted with the constant-Q transform (CQT), a perceptually-inspired alternative to Fourier-based approaches for time-frequency analysis. The CQCC features found to be generalized across three different databases (i.e. ASVspoof 2015 Challenge, AVspoof, and RedDots replayed database) and it delivered the state-of-the-art performance in each case [Reference Todisco, Delgado and Evans94].
Other effective features include high-dimensional magnitude-based features, and phase-based features as reported in a comparative study [Reference Xiao, Tian, Du, Xu, Chng and Li95]. The magnitude-based features include Log Magnitude Spectrum, and Residual Log Magnitude Spectrum; the phase-based features include Group Delay Function, Modified Group Delay Function, Baseband Phase Difference, Pitch Synchronous Phase, Instantaneous Frequency Derivative in Fig. 9.

Fig. 9. Demonstration of eight different types of features is shown for a natural utterance D15_1000931 from the development set of ASVspoof 2015 challenge dataset. For each feature type, only the low half of the FFT frequency bins are shown. Adapted from [Reference Xiao, Tian, Du, Xu, Chng and Li95].
The features extracted using subband processing were also explored, such as Linear Frequency Cepstral Coefficients (LFCC) [Reference Sahidullah, Kinnunen and Hanilçi96], Energy Separation Algorithm-Instantaneous Frequency Cepstral Coefficients (ESA-IFCC) [Reference Kamble and Patil91], and Constant-Q Statistics-plus-Principal Information Coefficient (CQSPIC) [Reference Yang, You and He97]. The basic motivation behind subband processing is that artifacts of SS manifest differently in different subbands. Temporal features, such as instantaneous frequency and envelop, are sensitive to those artifacts. Another technique for subband processing is to perform a two-level scattering decomposition through a wavelet filterbank to derive a scalogram as shown in Fig. 10 [Reference Sriskandaraja, Sethu, Ambikairajah and Li98].

Fig. 10. Block diagram of two-level scattering decomposition. Adapted from [Reference Sriskandaraja, Sethu, Ambikairajah and Li98].
2) Representation learning approaches
The representation learning approaches work either in the form of feature learning or as a pattern classifier. With feature learning, it was observed that the use of DNN for representation learning followed by GMM or SVM classifier was more successful than using DNN as a classifier. The hidden layer representation obtained from DNN was used as features (called as spoofing vectors or s-vectors), and Mahalanobis distance for classification [Reference Chen, Qian, Dinkel, Chen and Yu99]. The CNN and RNN classifiers were explored along with three features, namely, Teager Energy Operator (TEO) Critical Band Autocorrelation Envelope (TEO-CB-Auto-Env), Perceptual Minimum Variance Distortionless Response (PMVDR), and raw spectrograms [Reference Zhang, Yu and Hansen100].
In [Reference Qian, Chen and Yu101], feature learning is followed by LDA and GMM classifiers. The frame-level and sequence-level features were extracted using DNN and RNN, respectively, resulted in 0% EER for all the attack types from S1 to S9, and 1.1% EER on all the averaged conditions [Reference Qian, Chen and Yu101]. Bottleneck features extracted from the DNN hidden layers were also used with GMM classifier in [Reference Alam, Kenny, Gupta and Stafylakis102]. In [Reference Sailor, Kamble and Patil103], the Convolutional Restricted Boltzmann Machine (ConvRBM) is used for auditory filterbank learning that performed better than traditionally handcrafted filterbanks. The study [Reference Sailor, Kamble and Patil103] shows that ConvRBM learns better low-frequency subband filters on ASVspoof 2015 dataset than on TIMIT. Supervised auditory filterbank learning using DNN was also studied in [Reference Yu, Tan, Zhang, Ma and Guo104]. The first- and second-order Long-Term Spectral Statistics (LTSS) were used for synthetic SSD task along with various classifiers with DNN outperforming others. [Reference Muckenhirn, Korshunov, Magimai-Doss and Marcel105].
Recently, end-to-end DNN approaches have emerged for various speech and audio processing applications [Reference Zhang, Cummins and Schuller106], [Reference Heittola, çakır and Virtanen107]. The goal of the end-to-end DNN is to learn acoustic representation from the raw speech and audio signals as well as perform classification task in a DNN network [Reference Tokozume and Harada108], [Reference Chiu109]. For synthetic SSD task, Convolutional Neural Network (CNN) was used for feature learning from raw speech signals and binary classification task [Reference Muckenhirn, Magimai-Doss and Marcel110]. Along with CNN layers, Long-Short Term Memory (LSTM) layers were used in an architecture called Convolutional LSTM DNN (CLDNN) trained directly on raw speech signals [Reference Dinkel, Chen, Qian and Yu111,Reference Dinkel, Qian and Yu112].While CLDNN achieves 0% EER, it has not worked well for S10 set. The end-to-end DNN approach represents a new direction of anti-spoofing study.
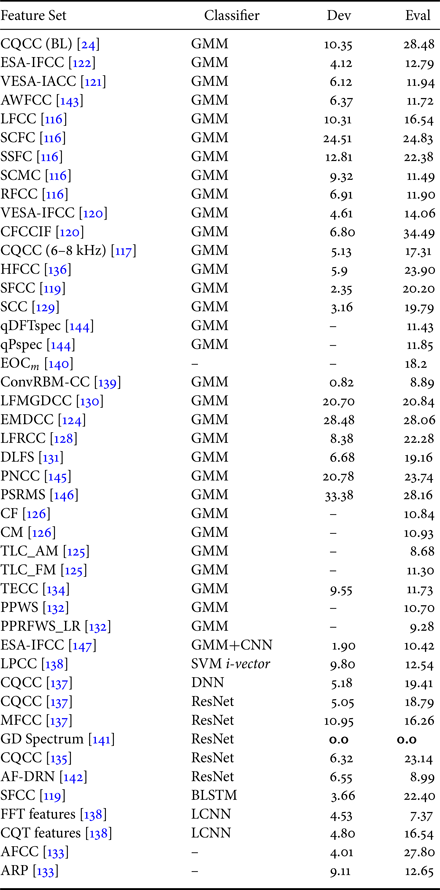
In ASVspoof 2015 Challenge, the systems in [Reference Xiao, Tian, Du, Xu, Chng and Li95,Reference Villalba, Miguel, Ortega and Lleida113] use DNN as the classifiers. In [Reference Yu, Tan, Ma, Martin and Guo114], a DNN classifier with novel human log-likelihoods (HLL) scoring method was proposed that performed significantly better and achieved an average EER of all the attack types to 0.04%. It was shown in [Reference Yu, Tan, Ma, Martin and Guo114] that HLL scoring method is more suitable for the SSD task than the classical LLR scoring method, especially when the spoofed speech is very similar to the human speech [Reference Yu, Tan, Ma, Martin and Guo114]. The output softmax layer consists of neurons representing spoofing and human (natural) speech labels. According to the literature, the system performances on ASVspoof 2015 Challenge database are summarized in Table 8, with the system of CQCC feature set, and DNN-HLL classifier representing the best performance.
Table 8. Comparison of results (in % EER) on ASVspoof 2015 Challenge Database.

V. COUNTERMEASURES FOR REPLAY SPOOFING ATTACKS
We now give an overview of system construction for anti-spoofing against replay attacks.
1) Acoustic features
The use of high-fidelity recording devices represents a serious threat, therefore countermeasures were proposed to guard against such attack. The spectral peak mapping method was proposed as a countermeasure to detect the replay attack on a remote telephone interaction [Reference Shang and Stevenson115]. Replay attacks with far-field recordings were addressed in [Reference Villalba and Lleida66].
The ASVspoof 2017 Challenge paid a special attention to replay speech detection. The baseline system with CQCC features and GMM classifier were provided by the organizers as it performs well in the earlier evaluation [Reference Kinnunen, Sahidullah, Delgado, Todisco, Evans, Yamagishi and Lee24]. The acoustic features, such as Rectangular Filter Cepstral Coefficients (RFCC), Subband Spectral Centroid Magnitude Coefficients (SCMC), Subband Spectral Centroid Frequency Coefficients (SCFC), Subband Spectral Flux Coefficients (SSFC) studied. It is found that the SCMC followed by feature normalization method outperforms other acoustic features [Reference Font, Espín and Cano116]. With the analysis on Inverse Mel Frequency Cepstral Coefficients (IMFCC), Linear Prediction Cepstral Coefficients (LPCC), and LP residual features, it is found that high-frequency regions have more discriminative information than the other frequency regions [Reference Witkowski, Kacprzak, Zelasko, Kowalczyk and Gałka117]. The effect of mean and variance normalization of CQCC feature set with Support Vector Machines (SVM) classifier was studied in [Reference Delgado81,Reference Wang, Xiao and Zhu118]. One of the approaches used Single Frequency Filtering (SFF) and found the importance of high-resolution temporal features [Reference Alluri, Achanta, Kadiri, Gangashetty and Vuppala119].
The short-time AM-FM features set obtained using Energy Separation Algorithm (ESA) were studied in [Reference Patil, Kamble, Patel and Soni120,Reference Kamble and Patil121] as shown in Fig. 11. The features were also developed with subband filter analysis using CFCCIF [Reference Patil, Kamble, Patel and Soni120], IFCC [Reference Jelil, Das, Prasanna and Sinha123], Empirical Mode Decomposition Cepstral Coefficients (EMDCC) [Reference Tapkir and Patil124], transmission line cochlear model [Reference Gunendradasan, Irtza, Ambikairajah and Epps125], auditory inspired spatial differentiation filterbank [Reference Wickramasinghe, Ambikairajah, Epps, Sethu and Li126], and ESA-IF-based feature estimation using Cochlear filter in [Reference Patil, Rajul, Sai and Patil127]. Excitation source-based features were studied in [Reference Tak and Patil128], wavelet-based features in [Reference Sriskandaraja, Suthokumar, Sethu and Ambikairajah129], and phase-based features in [Reference Srinivas and Patil130]. The concept of feature switching at the decision-level, along with information from the non-voiced segments were studied in [Reference Saranya, Padmanabhan and Murthy131].

Fig 11. Schematic block diagram of short-time instantaneous amplitude and frequency modulation (AM-FM) feature set. After [Reference Kamble, Tak and Patil122].
The study in [Reference Suthokumar, Sriskandaraja, Sethu, Wijenayake and Ambikairajah132] shows that some phonemes carry more replay artifacts than others, therefore consequently judicious use of phoneme-specific models can improve replay detection. The analysis of full-frequency bands with F-ratio and multi-channel feature extraction using attention-based adaptive-filters (AAF) is studied in [Reference Liu, Wang, Dang, Nakagawa, Guan and Li133]. The analysis of replay speech signal using reverberation concept and Teager energy profile is studied in [Reference Kamble and Patil134].
2) Representation of learning approaches
The three key observations from ASVspoof 2017 Challenge are the use of spectral information in the higher frequency regions, feature normalization, and representation learning approach. It was shown that many representation learning-based approaches did well in the ASVspoof 2017 Challenge.
First, we describe the representation learning approaches used in ASVspoof 2017 Challenge. End-to-end replay spoofing detection was proposed using deep residual network (ResNet) and raw spectrograms of speech signals [Reference Cai, Cai, Liu, Li and Li135]. It was also shown that data augmentation in DNN significantly improves the performance [Reference Cai, Cai, Liu, Li and Li135]. In one of the approaches, DNN was trained to discriminate between the various channel conditions available in the ASVSpoof 2017 Challenge database, namely, recording, playback, and session conditions [Reference Nagarsheth, Khoury, Patil and Garland136]. In [Reference Nagarsheth, Khoury, Patil and Garland136], the DNN features were learned from CQCC and HFCC features followed by an SVM classifier. The model fusion strategies using ResNet, GMM, and DNN were also explored and found to perform better compared to individual systems [Reference Chen, Xie, Zhang and Xu137]. In particular, the ASVspoof 2017 Challenge winner system used CNN and RNN for representation learning from STFT spectrograms followed by a GMM classifier [Reference Lavrentyeva, Novoselov, Malykh, Kozlov, Kudashev and Shchemelinin138].
The use of ConvRBM to learn auditory filterbank followed by the AM-FM demodulation using ESA for the replay SSD task was studied in [Reference Sailor, Kamble and Patil139]. The ConvRBM learns subband filters that represent high-frequency information in a much better way when used with pre-emphasized speech signals as shown in Fig. 12. Combining representation learning and signal processing techniques there is significant improvement of 0.82 and 8.89% EER on the development and evaluation set. A novel algorithm called NeuroEvolution of Augmenting Topologies (NEAT) was used in an end-to-end anti-spoofing network [Reference Valenti, Delgado, Todisco, Evans and Pilati140]. The NEAT framework also introduces a new fitness function for DNN that results in better generalization than the baseline system and improves the relative performance by 22% on the ASVspoof 2017 database [Reference Valenti, Delgado, Todisco, Evans and Pilati140].

Fig 12. The ConvRBM subband filters in temporal-domain (a) without, and (b) with pre-emphasis, respectively. After [Reference Sailor, Kamble and Patil139].
A novel visual attention mechanism is employed in deep ResNet architecture using the group delay features (GD spectrum) that resulted in EER of 0% on both the development and evaluation sets, respectively [Reference Tom, Jain and Dey141]. In [Reference Lai, Abad, Richmond, Yamagishi, Dehak and King142] attention-based filtering is used that enhances the feature representation in both time and frequency-domains and used ResNet-based classifier. Class activation maps (CAM) using global average pooling (GAP) utilizes the implicit attention mechanism present in CNN. Hence, representation learning approaches are very promising directions for the replay SSD compared to the synthetic SSD task. According to the literature, the system performances on ASVspoof 2017 Challenge dataset are summarized in Table 9.
Table 9. Comparison of results (in % EER) on ASVspoof 2017 Challenge Database.
BL, baseline
VI. LIMITATIONS AND TECHNOLOGICAL CHALLENGES
In this section, we hope to discuss some topics that are worthy of further inquiry and possible future direction.
(i) Logical and Physical Access: The PA is the actual spoofing where the speech is played back through a microphone into the ASV system. However, the ASVspoof database gave special attention to LA attacks. For such attacks, it is assumed that the spoofed samples are directly injected into the system through a software-based process [Reference Muckenhirn, Magimai-Doss and Marcel21]. Hence, PA attacks are more realistic than the logical access attacks, where the attacker plays back a recorded utterance to the system. This utterance can be either obtained from the real speaker or can be forged using VC or synthetic speech (SS) algorithms. This motivates the study on PA attacks and evaluation database development.
(ii) Diversity of Spoofing Attacks: The ASVspoof 2015 Challenge database consists of only VC and synthetic speech spoofing algorithms. This database consists of variation of seven VC spoofing techniques and only three synthetic speech techniques. It is noted that ASVspoof 2017 Challenge database focuses only on replay spoof. While ASVspoof 2015 and 2017 database includes SS, VC, and replay spoofing techniques, the spoofing voice database is not developed using the latest neural voice generation techniques.
(iii) Performance of Joint Protocol with ASV Systems: The current studies of countermeasures and ASV systems are carried out separately. What user would like to have is a secure and accurate ASV system. However, a more robust ASV system to noise and channel variations may become less secure against spoofing attacks. As there is no guarantee of having a better performing countermeasure that provides lower EER and also reliable for the ASV system performance. Hence, with the progress made in the research of spoofing detection, evaluation metrics must evolve to reflect the joint protocol system performance.
(iv) Liveness Detection: The use of high-quality recording loudspeaker or playback device to record/playback the speech signal, in this process the quality of signal captured becomes indistinguishable from live human voice. This high-quality device makes the speech signal impossible to detect that depends on the acoustic cues. This gives rise to investigate further on the liveness detection of human voice.
(v) Signal Degradation Conditions: Current publicly available spoofing databases are developed in clean conditions. However, the recent replay database was recorded under various acoustic environmental conditions. For ASVspoof 2015 Challenge database, the noisy database was developed by adding various noises at different Signal-to-Noise Ratio (SNR) levels. Further investigations are required as to how the diversity of different noise types affects the SSD performance. In addition, the study is required to observe the effect on SSD when the additive noise is added manually, and when the noise is added naturally via the acoustic environment. For example, a study was done for a replay database under different background, microphone, etc. [Reference Delgado81]. Hence, the countermeasures must be developed that it should be robust to signal degradation conditions as well.
(vi) Robustness in ASV implies Vulnerability: In practice, we would like ASV system to be robust against variations, such as microphone and transmission channel, intersession, acoustic noise, speaker aging, etc. A robust ASV system may become vulnerable to various spoofing attacks as it tries to nullify these effects and normalize the spoofing speech toward the natural speech. Thus, robustness and anti-spoofing security should be addressed separately. It is worth to study how features, classifiers, and systems are designed to be both robust and secure.
(vii) Lack of Exploiting Excitation Source Information: Less amount of work is done in using excitation source assuming that the Glottal Closure Instants (GCI) are having sharp impulse-like nature for voiced speech. The spectrum of the glottal source (Glottal Flow Waveform (GFW)) for voiced speech is expected to have harmonic structure in the frequency-domain. Thus, any deviation from the degradation in the harmonic structure could capture the signature of spoof speech [Reference Tak and Patil128]. To the best of authors' knowledge, there is no study reported in analyzing this particular aspect. We believe several source information, such as Linear Prediction (LP) residual, Teager Energy Operator (TEO) profile and its Variable length (VTEO) profile, etc., could be explored in the framework of recent study reported in [Reference Tak and Patil128].
(viii) Exploring Phase-based Features: It is important to note that phase-based features (either time-domain analytic or frequency-domain) could capture a different kind of information in spoofed speech depending upon the type of spoof. For example, in USS system, when the speech sound units are picked up by optimizing the target cost, in the synthesized voice, it will have linear phase mismatches (since these units are recorded in different sessions) [Reference Stylianou148]. On the other hand, for replay speech, the impulse response of the acoustic environment (say room) gets convolved with the natural speech. The impulse response of an acoustic system (in this case room) is infinite in duration, i.e. Infinite Impulse Response (IIR) in nature (due to infinite transmissions and reflections). Thus, the non-linear phase in frequency-domain of this acoustic system is added to the phase of natural speech. In addition, corresponding effects of this non-linear phase could be observed in temporal-domain, such as non-integer delay in frequency components. There have been many studies in phase features in SS detection. Phase study remains a research topic that is worth more investigations.
(ix) Comparison of Human versus Machine-learning: It is of great interest to know whether human perception is important in identifying spoofing, and hence, humans can achieve better performance than automatic approaches in detecting spoofing attacks. There was a benchmark study comparing automatic systems against human performance on a speaker verification and SS spoofing detection tasks (SS and voice conversion spoofs) [Reference Wu149]. It was observed that human listeners detect spoofing less well than most of the automatic approaches except USS speech [Reference Wu149]. In a similar study, it was found that both the humans and machines have difficulties in spoofing detection when narrowband speech signals were used (8 kHz sampling frequency) [Reference Wester, Wu and Yamagishi150]. Hence, for telephone line speech signals, it is more challenging to do SSD due to the lower available bandwidth up to 4 kHz. It may be of great interest to study human performance for replay SSD task.
(x) Robustness to High-Quality Speech Synthesizers: Recently, many representation learning-based high-quality speech synthesis techniques were proposed that achieved significantly better naturalness. The Wavenet [Reference van den Oord50], GAN [Reference Saito, Takamichi and Saruwatari48], and other end-to-end speech synthesis architectures [Reference Wang, Lorenzo-Trueba, Takaki, Juvela and Yamagishi151] produce high-quality synthesized speech. It is also shown that low-quality publicly available database can be used to produce high-quality spoof data using GAN-based speech enhancement [Reference Lorenzo-Trueba, Fang, Wang, Echizen, Yamagishi and Kinnunen152]. Such high-quality SS and VC techniques may further increase the difficulties in synthetic SSD. This technique could be used to generate spoof speech database in the next edition of ASVspoof challenge [Reference Kinnunen, Evans, Yamagishi, Lee, Sahidullah, Todisco and Delgado23].
VII. SUMMARY AND CONCLUSIONS
This article provided an overview of the SSD task. We reviewed different countermeasure approaches for synthetic and replay detection, in particular, classical and representation learning approaches. The study also reported various technological challenges involved during spoofing detection and also discussed various spoofing databases with their limitations. The article also discusses the recent advances in the spoofing area for ASV task.
A significant amount of research has been carried out to assess the vulnerability of ASV systems to different spoofing attacks. It is especially challenging to recreate real attacking conditions during the development of various spoofing database. Under particular controlled conditions, different spoofing attacks are developed, as they are unfeasible to collect a database with all different possibilities that are available in the market. The performance metric is usually distributed into train, development, and test set, where these individual sets have almost similar examples of spoofs in all the sets. However, real-world scenario for ASV represents an open set evaluation without having any constraints on the spoofs used to attack given ASV system.
In the current spoofing context described in this article and lessons learned in more than 10 years of spoofing research, there are still few open questions that need to be answered. They are: What are the future challenges that arise further in voice biometric spoofing? What are the issues which are yet to be looked into and need to be explored further? Where do we go from here?
Presently, one of the most urgent needs is to define a clear methodology to assess the spoofing attacks. This is not a straightforward issue, as many new variables are involved during the development of spoofing algorithms. Another observation is that there does not exist superior anti-spoofing technique that performs uniformly along all the spoofs. Approaching only with one countermeasure will depend on the nature of the attack scenario and data acquisition conditions. Hence, there should be another complementary countermeasure followed by fusion approaches to develop high-performance countermeasure over different spoofing data. In addition, practical considerations should not be left out. As technology progresses, new techniques continue to emerge in the form of hardware devices and signal processing methods. Hence, it is important to keep a track of such technological progress, since this advancement could be the key to develop a novel and efficient countermeasure.
Finally, though a significant amount of work is now being reported in the field of spoofing detection, different methodologies and attacks have also evolved that became more and more sophisticated. As a consequence, yet there are many big challenges that are to be faced to protect against spoofing attacks, hopefully, that will be lead in the upcoming years with a new generation of more secure voice biometric systems.
ACKNOWLEDGMENTS
Authors would like to thank the authorities of DA-IICT Gandhinagar, India and NUS Singapore for their support to carry out this research work. First author would like to thank the University Grants Commission (UGC), New Delhi, India for providing Rajiv Gandhi National Fellowship (RGNF) for her doctoral studies.
Madhu R. Kamble is a Ph.D. student at DA-IICT, Gandhinagar. She did her M. Tech. degree from Cummins College of Engineering, Pune, Maharashtra, India in 2015 in Signal Processing specialization and the B.Tech degree from P.V.P.I.T, Budhgaon, Sangli, Maharashtra in 2012. She has been awarded with Rajiv Gandhi National Fellowship (RGNF) for her doctoral research studies. Her research interest is in voice biometrics, in particular, analysis of spoofing attacks and development of countermeasures. Recently, she offered a tutorial jointly with Prof. Patil on the same topic in IEEE-WIE Conference, at AISSM's Pune in Dec 2016. She was the co-instructor for a tutorial in Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA-ASC), Kuala Lumpur, Malaysia, 2017. She is a research intern at Samsung Research Institute, Bangalore (SRI-B), India during May-Nov 2019. She is a student member of ISCA, student member of IEEE, IEEE Signal Processing Society, and APSIPA. She is a reviewer for Computer, Speech and Language and Nerocomputing Journal, Elsevier. She received ISCA and IEEE SPS student travel grant to present her papers during INTERSPEECH, 2017 and ICASSP 2019.
Hardik B. Sailor is a Post Doctoral researcher in the University of Sheffield, UK. He completed his Ph.D. degree in 2018 at DA-IICT, Gandhinagar, India. He received the B.E. degree from Government Engg. College (GEC), Surat in 2010. In 2013, he received the M.Tech. degree from DA-IICT, Gandhinagar. He was also a project staff member of MeitY, Govt. of India sponsored consortium project, “Automatic Speech Recognition for Agricultural Commodities Phase-II”, (April 2016–March 2018). At DA-IICT, he was a project staff member of MeitY, Govt. of India sponsored project on, “Development of Text-to-Speech (TTS) Synthesis Systems for Indian languages Phase-II”, from May 2012 to March 2016. His research area includes representation learning, auditory processing, Automatic Speech Recognition (ASR), and sound classification. His main research is focused on developing representation learning to model the auditory processing. He has published 25 research papers in top conferences and peer-reviewed journals. He is a student member of IEEE, IEEE Signal Processing Society, and International Speech Communication Association (ISCA). He is a reviewer for IEEE/ACM Transactions in Audio, Speech, and Language Processing, IEEE Signal Processing Letters, and Applied Acoustics, Elsevier. Recently, he received ISCA student travel grant 650 euros to present his three co-authored papers during INTERSPEECH 2018.
Hemant A. Patil received the B.E. degree from the North Maharashtra University, Jalgaon, India, in 1999, the M.E. degree from Swami Ramanand Teerth Marathwada University, Nanded, India, in 2000, and the Ph.D. degree from the Indian Institute of Technology, Kharagpur, India, in 2006. He is currently a Professor at Dhirubhai Ambani Institute of Information and Communication Technology, Gandhinagar, India. He has coedited a book with Dr. A. Neustein (Editor-in-Chief, IJST, Springer) on Forensic Speaker Recognition: Law Enforcement and Counter-Terrorism (New York, NY, USA: Springer). He served as PI/Co-PI for three MeitY and two DST sponsored projects. Prof. Patil was a chair of satellite workshop committee during INTERSPEECH, 2018, Hyderabad, India. He is selected as APSIPA Distinguished Lecturer (DL) for 2018–2019 and delivered 21 APSIPA DLs in three countries, namely, India, Canada, and China. Recently, he is elected as ISCA DL for 2020–2021. He is an affiliate member of the IEEE SLTC and a member of the IEEE Signal Processing Society, the IEEE Circuits and Systems Society (Awards), and the International Speech Communication Association (ISCA).
Haizhou Li (M'91-SM'01-F'14) received the B.Sc., M.Sc., and Ph.D degrees in electrical and electronic engineering from South China University of Technology, Guangzhou, China, in 1984, 1987, and 1990, respectively. He is currently a Professor with the Department of Electrical and Computer Engineering, National University of Singapore (NUS), Singapore. He is also a Conjoint Professor at the University of New South Wales, Kensington, NSW, Australia. Prior to joining NUS, he taught in the University of Hong Kong (1988–1990) and South China University of Technology (1990–1994). He was a Visiting Professor with CRIN in France (1994–1995), Research Manager with the Apple-ISS Research Centre (1996–1998), Research Director with Lernout & Hauspie Asia Pacific (1999–2001), Vice President with InfoTalk Corp. Ltd. (2001–2003), and the Principal Scientist and Department Head of Human Language Technology with the Institute for Infocomm Research, Singapore (2003–2016). His research interests include automatic speech recognition, speaker and language recognition, and natural language processing. He is currently the Editor-in-Chief for the IEEE/ACM TRANSACTIONS ON AUDIO, SPEECH, AND LANGUAGE PROCESSING (2015–2018), a Member of the Editorial Board of Computer Speech and Language (2012–2018). He was an elected Member of IEEE Speech and Language Processing Technical Committee (2013–2015), the President of the International Speech Communication Association (2015–2017), the President of Asia Pacific Signal and Information Processing Association (2015–2016), and the President of Asian Federation of Natural Language Processing (2017–2018). He was the General Chair of ACL 2012 and INTERSPEECH 2014. He was the recipient of the National Infocomm Award 2002 and the Presidents Technology Award 2013 in Singapore. He was named one of the two Nokia Visiting Professors in 2009 by the Nokia Foundation.






















 Open access
Open access