


The human metabolome is influenced by genetic, transcriptional and post-transcriptional factors as well as by the gut microbiome and environmental factors like diet and other lifestyle determinants( Reference Nicholson 1 , Reference Beger, Dunn and Schmidt 2 ). It is well known that individuals show large differences in their nutrient requirements and responses to diet and medication according to their metabolic characteristics( Reference Beger, Dunn and Schmidt 2 – Reference Holmes, Wilson and Nicholson 5 ). Specific dietary recommendations or drug treatments for disease states should thus be tailored to optimise the benefit to the individual. Equally important, specific treatments should not be provided to individuals with only a minor response or a lack of positive response to the intervention. The concept of personalisation is supposed to be more effective with respect to individual benefit:risk ratio and health-care costs than currently used general dietary recommendations and standard treatments for chronic disease( Reference de Roos 3 – Reference Livingstone, Celis-Morales and Navas-Carretero 8 ).
Such efforts have led to the concept of metabotyping or metabolic phenotyping, which describes the categorisation of individuals based on their metabolic or phenotypic characteristics into more homogeneous subgroups, the so-called metabotypes or metabolic phenotypes. This concept implies that individuals within a subgroup show a high metabolic similarity and those in different subgroups show a high dissimilarity. Metabotyping could, thus, allow the identification of subpopulations or specific patient groups responding differently to a defined dietary or medical intervention, promising better nutritional and medical treatment at the metabotype group level( Reference O’Donovan, Walsh and Gibney 6 , Reference Morris, O’Grada and Ryan 9 – Reference Brennan 13 ).
The metabotyping approach has been used widely in healthy animals( Reference Pontoizeau, Fearnside and Navratil 14 , Reference Gavaghan, Holmes and Lenz 15 ) as well as in rodent models of disease for testing drug effects( Reference Clayton, Lindon and Cloarec 16 , Reference Holmes, Nicholls and Lindon 17 ). On this basis, it was possible to separate strain-specific metabolic phenotypes or strain subtypes based on the plasma, urine or faecal metabolic profiles, thereby finding diagnostic and prognostic biomarker differences between groups( Reference Pontoizeau, Fearnside and Navratil 14 – Reference Yang, Liu and Zheng 26 ). Strain subtypes could be established by sex( Reference Gavaghan McKee, Wilson and Nicholson 19 , Reference Garcia-Perez, Villasenor and Wijeyesekera 23 – Reference Plumb, Granger and Stumpf 25 ), age( Reference Calvani, Brasili and Praticò 22 ), diet( Reference Fearnside, Dumas and Rothwell 20 , Reference Yang, Liu and Zheng 26 ) or diurnal time of sample collection( Reference Gavaghan, Wilson and Nicholson 18 , Reference Bollard, Holmes and Lindon 21 , Reference Plumb, Granger and Stumpf 25 ).
Further, several human studies have been conducted to define specific metabotypes, but these studies used a variety of methods and inconsistent definitions, indicating that the term ‘metabotype’ is often used with quite a different meaning. In reviews on personalised nutrition, O’Donovan et al.( Reference O’Donovan, Walsh and Gibney 6 ) and Brennan( Reference Brennan 13 ) proposed the concept of metabotyping and provided examples of articles using the metabotyping approach.
The aim of this paper was to review the existing literature on metabotyping in human studies, to show its application in targeted nutrition and, thus, to provide recommendations for future studies in this field.
Methods
A comprehensive literature search was performed using PubMed, Google and Google Scholar up to May 2016. However, this is not a strictly systematic review as described, for example, by the Cochrane Collaboration( Reference JPT and Green 27 ) because of many open questions. The first search strategy addressed the definition of metabotypes in healthy individuals or population-based samples to find evidence for differences in metabolism and corresponding subgroups. The second search was conducted on the definition of metabotypes in patients with chronic diet-related metabolic diseases (obesity, metabolic syndrome, diabetes, dyslipidaemia, hyperlipidaemia, hyperuricemia, gout and hypertension) for diagnosing or establishing metabolically homogeneous patient subgroups.
Different combinations of the following keywords were used to search for studies that performed metabotyping in healthy subjects or in population-based samples: ‘metabotype’, ‘metabolic phenotype’, ‘metabolomic phenotype’, ‘molecular phenotype’, ‘clinical phenotype’, ‘biochemical phenotype’, ‘metabolic profile’, ‘metabolomic profile’, ‘metabolic pattern’, ‘nutritional phenotype’, ‘nutritype’, ‘metabolome’, ‘metabolomics’, ‘metabolism’ or ‘metabolic response’ and ‘cluster’, ‘pattern’, ‘subgroup’, ‘subtype’, ‘cluster analysis’ or ‘principal component analysis’. In addition, an extended search was conducted on this topic including information on underlying causes for differences in metabolism between individuals, namely with regard to genetics, epigenetics, transcriptomics or the microbiome( Reference Holmes, Wilson and Nicholson 5 ). To this end, the search terms ‘genetics’, ‘genotype’, ‘SNP’, ‘epigenetics’, ‘transcriptomics’, ‘gut microbiota’ or ‘enterotype’ were added to the search strategy mentioned above.
The literature search concerning the definition of metabotypes in patients was restricted to frequent chronic metabolic diseases with a strong relation to diet. This selection was based on the worldwide growing prevalence of diet-related metabolic diseases such as obesity and type 2 diabetes, on the one hand, and on the fact that, besides tailored medical treatments, targeted dietary intervention could also have an important effect on diet-related diseases, on the other( 28 ). Thus, in addition to the keywords mentioned above concerning the definition of metabotypes in healthy subjects or population-based samples, the following search terms referring to common metabolic diseases were included in the search strategy: ‘obesity’, ‘adiposity’, ‘metabolic syndrome’, ‘diabetes’, ‘dyslipidaemia’, ‘hyperlipidaemia’, ‘hyperuricemia’, ‘gout’ or ‘hypertension’. Again, extended searches with keywords addressing underlying causes of metabolic differences were performed.
Relevant articles were selected by first checking titles and abstracts and subsequently the full text of the search results in accordance with the inclusion criteria. Additional studies were identified through supplementary screening of the reference lists of all articles analysed.
The following inclusion and exclusion criteria were used in the literature search: original research articles in English language on human studies, which established homogeneous groups of individuals using statistical analyses based on metabolic data from the body fluids blood and urine. Studies using exclusively other information like genetic, epigenetic, transcriptomic, microbiome, anthropometric or lifestyle data for group establishment were excluded, except in combination with metabolic and/or metabolomics data. In addition, studies in which metabotyping was based only on the combination of simple cut-off points of metabolic variables instead of on statistical analyses, as in the definition of the metabolic syndrome, were not included in this review. In general, all types of study designs were accepted and there were no restrictions on sample size. However, the study populations were limited to healthy subjects or population-based samples in the first search and – for the definition of patient subgroups – to individuals affected by common chronic metabolic diseases in the second search. Extreme or rare chronic diet-related metabolic diseases were not included.
Results
In total, thirty-four articles met the inclusion criteria, of which twenty-five articles were related to the definition of metabotypes in healthy subjects or population-based samples, and nine articles were related to the definition of patient subgroups with common metabolic diseases revealed by metabotyping.
Definition of metabotypes in healthy subjects or population-based samples
Tables 1 and 2 summarise the key features of the twenty-five articles identified according to the definition of metabotypes in healthy subjects or population-based samples. Table 1 gives an overview of twenty articles defining metabotypes based on fasting data. Table 2 shows an additional five articles defining metabotypes on the basis of metabolic response data for different dietary interventions. Both tables present the respective study objectives, designs and samples, the variables for clustering and their preprocessing, the clustering methods used and their validation as well as the main findings. With the exception of four articles( Reference Wilcox, Wyszynski and Panhuysen 36 , Reference Micciolo 41 , Reference Baumgartner, Siervogel and Roche 42 , Reference Ventura, Loken and Birch 45 ), the studies were published within the past decade. The studies were conducted mainly, but not exclusively, in Europe and the USA, either with population-based samples or random samples of healthy individuals. The sample size of the studies varied considerably from twenty to up to 3000 participants. Also, the age range of the study populations differed across the studies with a main focus on adults. Regarding sex, two studies investigated only men( Reference Bouwman, Vogels and Wopereis 51 , Reference Chua, Shui and Lee 52 ), five studies only women( Reference Zubair, Kuzawa and McDade 34 , Reference Tzeng, Chang and Chang 38 , Reference Ventura, Loken and Birch 45 , Reference Moazzami, Shrestha and Morrison 47 , Reference Krishnan, Newman and Hembrooke 49 ) and all other studies included both sexes.
Table 1 Definition of metabotypes based on metabolic data in the fasting state

IDL, intermediate-density lipoprotein; hs-CRP, high-sensitivity C-reactive protein; GLM, general linear model; HOMA-IR, homoeostasis model assessment of insulin resistance; OSC-PLS-DA, orthogonal signal-correction partial least squares discriminant analysis; BP, blood pressure; HOMA2-S, homoeostasis model assessment of insulin sensitivity; PCA, principal component analysis; AIC, Akaike information criterion; BIC, Bayesian information criterion.
Table 2 Definition of metabotypes based on metabolic response data to interventions

oGTT, oral glucose-tolerance test; GLM, general linear model; hs-CRP, high-sensitivity C-reactive protein; HOMA-IR, homoeostasis model assessment of insulin resistance; PCA, principal component analysis; PLS-DA, partial least squares discriminant analysis.
For the identification of metabotypes, different numbers of clustering variables were used. Besides the use of full 1H NMR spectra or metabolomics data in some studies( Reference Vázquez-Fresno, Llorach and Perera 32 , Reference Moazzami, Shrestha and Morrison 47 , Reference Qureshi, Wagenknecht and Watkins 48 , Reference Bouwman, Vogels and Wopereis 51 , Reference Chua, Shui and Lee 52 ), all other studies used selected metabolites for clustering similar components of the metabolic syndrome( Reference Huang, Mori and Burke 43 , Reference Ventura, Loken and Birch 45 ) or cardiovascular risk factors( Reference Wilcox, Wyszynski and Panhuysen 36 , Reference Wilcox, Li and Sun 37 , Reference Baumgartner, Siervogel and Roche 42 ). The type of the cluster variables differed between the studies using blood or urine metabolites, diverse metabolite classes or specifically selected individual metabolite subclasses like lipoproteins or fatty acids and those using fasting metabolites (Table 1) or metabolic responses to dietary interventions (Table 2). According to the number and type of the selected clustering variables, the definitions of metabotypes differed considerably; they ranged between general fasting metabotypes, more specific fasting parameter subgroups like plasma lipoprotein( Reference van Bochove, van Schalkwijk and Parnell 29 , Reference Frazier-Wood, Glasser and Garvey 33 ) or fatty acid clusters( Reference Li, Brennan and McNulty 39 ) and response groups to defined meal challenges or dietary interventions. However, in most studies, at least some standard clinical markers such as glucose, TAG and cholesterol were included. Besides metabolic data, the inclusion of additional phenotypic factors for the definition of metabotypes was implemented in some studies: for example, the consideration of anthropometric parameters like BMI or waist circumference( Reference Vázquez-Fresno, Llorach and Perera 32 , Reference Wilcox, Wyszynski and Panhuysen 36 – Reference Tzeng, Chang and Chang 38 , Reference Micciolo 41 , Reference Huang, Mori and Burke 43 – Reference Ventura, Loken and Birch 45 ) and blood pressure( Reference Zubair, Kuzawa and McDade 34 – Reference Tzeng, Chang and Chang 38 , Reference Bermúdez, Rojas and Salazar 40 – Reference Huang, Mori and Burke 43 , Reference Ventura, Loken and Birch 45 , Reference Bucci, Legnani and Armentano 46 ). However, only the study by Bouwman et al.( Reference Bouwman, Vogels and Wopereis 51 ) also assessed some underlying causes for differences in metabolism between subpopulations in the clustering process using transcriptomics data.
Before grouping individuals into metabotypes, diverse preprocessing steps were applied in the studies analysed to the cluster variables such as outlier exclusion, log-transformation of skewed data, dimension reduction (e.g. by multiple-correspondence analysis) and standardisation (e.g. range-scaling or z-standardisation). Different unsupervised learning methods were used in the studies to define relatively homogeneous metabolic groups of individuals. These included k-means cluster analysis, hierarchical clustering and combinations of the two, principal component analysis (PCA), latent class analysis( Reference Frazier-Wood, Glasser and Garvey 33 ) and mixed-model clustering( Reference Morris, O’Grada and Ryan 9 , Reference Ventura, Loken and Birch 45 ). Then, supervised learning methods, such as partial least squares regression as well as statistical tests like the t test and ANOVA, were used to find discriminatory variables between the established groups. Clustering indices, cross-validation procedures, repetitions with different cluster seeds and cluster numbers as well as different clustering methods were applied to validate the clustering results. Biologically meaningful metabotypes, which were differentiated using discriminatory variables, also confirmed the clustering results. Using the clustering methods, different numbers of metabotypes were found, ranging between two and eight groups. Some studies identified subgroups of individuals with differential response to nutritional interventions; others only described differences between the subgroups, mainly in the fasting state.
The following two studies are examples for the establishment of metabotypes using metabolite profiles obtained in the fasting state and the subsequent investigation of differences in response to dietary interventions between the subgroups. O’Sullivan et al.( Reference O’Sullivan, Gibney and Connor 30 ) described metabotypes in an Irish intervention study with 135 healthy individuals aged 18–63 years. After z-standardisation, thirteen blood 1H NMR biochemical markers of the metabolic syndrome and serum vitamin-D levels were used in a k-means cluster analysis. Five distinct biologically meaningful clusters were found. Among these, one group with lower serum vitamin-D levels and higher levels of adipokines showed a positive response to vitamin-D supplementation on parameters of the metabolic syndrome. The stability of the cluster result was verified using a 5-fold cross-validation method. Second, Vázquez-Fresno et al.( Reference Vázquez-Fresno, Llorach and Perera 32 ) investigated fifty-seven subjects at a high cardiovascular risk aged ≥55 years in a randomised and controlled cross-over study. k-Means cluster analysis revealed four well-differentiated and biologically meaningful clusters using sixty-nine blood and urine 1H NMR biochemical markers and anthropometric variables identifying red wine polyphenol-responsive metabotypes. In addition to cross-validation, cluster indices like Dunn analysis and Figure of Merit analysis were used.
An example for the definition of metabotypes based on metabolic response data to a dietary intervention is the Irish Metabolic Challenge (MECHE) study, which included 116 participants aged 18–60 years( Reference Morris, O’Grada and Ryan 9 ). Mixed-model clustering of blood glucose curves revealed four distinct metabotypes with different responses to an oral glucose-tolerance test, of which one group was identified as a high-risk phenotype. The stability of the differentiated clusters was confirmed by another intervention, an oral lipid-tolerance test. Wang et al.( Reference Wang, Edwards and Clevidence 50 ) described metabotypes in a dietary intervention with carotenoid-rich beverages in a cross-over design based on twenty-three healthy subjects in the USA. In each carotenoid arm, the responses to all plasma carotenoids were analysed individually. k-Means cluster analysis revealed five distinct subgroups with different temporal responses. Subsequently, strong and weak responders to individual dietary carotenoids were identified. The different responses were induced by genetic variants of the carotenoid-metabolising enzyme β-carotene 15,15’-monooxygenase 1.
Definition of patient subgroups with metabolic diseases by metabotyping
Table 3 presents nine publications that were selected during the literature search on the definition of metabotypes in patients with chronic diet-related metabolic diseases for diagnosing or establishing metabolically homogeneous patient subgroups. All articles were published within the last 10 years and, again, a majority of the studies were performed in Europe and the USA with differences in study design, sample size (between fifty and 50 000 participants) and the age range of adults. Both sexes were considered in all studies. The articles describe the diagnosis and subgrouping of patients affected by diabetes, obesity, the metabolic syndrome or dyslipidaemia. Here, again, the definitions of patient subgroups varied according to the use of different numbers of metabolic clustering variables. In addition, the types of clustering variables differed, often depending on the particular disease investigated. For example, Mäkinen et al.( Reference Mäkinen, Soininen and Forsblom 60 ) used a full blood serum 1H NMR spectrum for the subgrouping of patients with type 1 diabetes. In contrast, Arguelles et al.( Reference Arguelles, Llabre and Sacco 58 ) tried to identify subgroups of the metabolic syndrome using only components of this syndrome (waist circumference, systolic and diastolic blood pressure, HDL, TAG, fasting glucose and medication use) for the clustering procedure. Few studies used additional variables such as anthropometry( Reference Schader 54 , Reference Frei, Lessa Bde and Nogueira 57 , Reference Arguelles, Llabre and Sacco 58 ) or medication use( Reference Arguelles, Llabre and Sacco 58 , Reference Kim, Oh and Pieczkiewicz 59 ) along with the metabolic information in the clustering process. As a result, the studies identified different patient subgroups depending on the metabolic data assessed. After the application of various preprocessing steps to the cluster variables as described above, clustering methods like k-means cluster analysis, hierarchical clustering and combinations of the two, topological analysis( Reference Li, Cheng and Glicksberg 55 ), latent class analysis( Reference Arguelles, Llabre and Sacco 58 ) and self-organising maps( Reference Mäkinen, Soininen and Forsblom 60 ) were applied. Discriminatory variables between the resulting disease subgroups were again identified using test statistics. Moreover, biological meaning, clustering indices, cross-validation procedures, repetitions with different cluster seeds and cluster numbers as well as different clustering algorithms were applied to validate the clustering results. Different numbers of disease subgroups were formed, mainly two to four groups.
Table 3 Definition of patient subgroups with metabolic diseases by metabotyping

HOMA-IR, homoeostasis model assessment of insulin resistance; GWAS, genome-wide association study; MESA, Multi-Ethnic Study of Atherosclerosis; SHARe, SNP Health Association Resource; BP, blood pressure; GLP-1, glucagon-like peptide-1; GIP, glucose-dependent insulinotropic polypeptide; AIC, Akaike information criterion; BIC, Bayesian information criterion; ABIC, sample size-adjusted BIC; PCA, principal component analysis.
An example for the establishment of type 2 diabetes subgroups is the study by Schader( Reference Schader 54 ) using three studies in the USA with a total of 832 patients with type 2 diabetes aged 30–84 years. Applying k-means cluster analysis with ten standardised metabolic and anthropometric characteristics assessed before the diagnosis of type 2 diabetes, two subgroups of the disease were found. Despite the stability of the clustering results, measured using the Calinski method and twenty-five repetitions of the clustering method, and strong differentiation of individuals based on discriminatory variables, no statistically significant difference was found between the genetic risk factors among the subgroups. In a smaller sample size of ninety-six patients with type 2 diabetes, Amato et al.( Reference Amato, Pizzolanti and Torregrossa 56 ) used three fasting incretins in a two-step cluster analysis to identify two subgroups of this disease.
Discussion
This review analysed the literature on metabotyping of individuals in metabolic and nutrition research. In total, thirty-four studies were included in this analysis covering a wide range of populations and using various clustering variables and statistical methods to identify different numbers of metabotypes. Consequently, it is difficult to draw meaningful conclusions regarding the establishment of metabotypes based on these rather heterogeneous studies using different approaches in metabotyping. However, this paper includes all available human studies using metabotyping in healthy subjects, population-based samples and patients with chronic metabolic diseases, and thereby represents the current state of knowledge.
Differences in study populations
We found a considerable variation in metabotypes across the countries in which the studies were performed, and this could be due to different genetic characteristics, environmental influences (like dietary and cultural behaviour), risk factors and disease rates( Reference Holmes, Wilson and Nicholson 5 , Reference Holmes, Loo and Stamler 62 – Reference Dumas, Maibaum and Teague 64 ). This variation was seen to be particularly large between Western countries and East Asian countries, whereas metabotypes across different Western countries displayed substantial overlapping( Reference Holmes, Loo and Stamler 62 , Reference Dumas, Maibaum and Teague 64 ). As most studies we review here were conducted in Western populations in Europe and the USA, the defined metabotypes seem to be transferable and comparable between these studies. However, there is a lack of data as to whether these metabotypes can be transferred to other ethnic populations.
Comparing metabotypes between different age ranges may be hampered by the physiological ageing process itself, which is characterised by marked changes in metabolism or metabolic flexibility( Reference Chaleckis, Murakami and Takada 65 ). However, it was shown in some studies that the plasma metabotypes (metabolite profiles) of individuals remain relatively stable over a few years( Reference Bernini, Bertini and Luchinat 66 , Reference Yousri, Kastenmüller and Gieger 67 ) and only large differences in age seem to be relevant. As many metabolites differ between men and women – for example, steroid hormones or branched chain amino acids( Reference Holmes, Loo and Stamler 62 , Reference Krumsiek, Mittelstrass and Do 68 , Reference Kochhar, Jacobs and Ramadan 69 ) – studies need to consider sex differences. This could be achieved by the exclusion of these sex-specific variables from the clustering process or by separate analyses for men and women.
Differences in variables used for clustering
The use of diverse types and numbers of clustering variables does not allow a reasonable comparison of the metabotypes identified in different studies. At present, the debate on the most important criteria and variables to be used for the definition of a biologically meaningful metabotype remains open. Equally important, the aim of metabotype definition has to be defined a priori. In 2000, Gavaghan et al.( Reference Gavaghan, Holmes and Lenz 15 ) defined a metabotype as ‘a probabilistic multiparametric description of an organism in a given physiological state based on analysis of its cell types, biofluids or tissues’. Later, metabotyping was described in several studies as the ‘process of grouping similar individuals based on their metabolic or phenotypic characteristics( Reference O’Donovan, Walsh and Gibney 6 , Reference Morris, O’Grada and Ryan 9 – Reference Brennan 13 ). These wide and general definitions of metabotypes allow the inclusion of all studies establishing subgroups based on (1) healthy or sick people (thus also in the diagnosis or subgrouping of patients), (2) the fasting state or response to interventions, (3) a few or a variety of metabolites and (4) specifically selected single metabolite subclasses like lipoproteins, diverse metabolite subclasses or the addition of other variables like underlying causes for differences in metabolism – for example, genetic, epigenetic or gut microbiome information.
The selection of variables plays an important role in the identification and separation of metabotypes. Grouping of individuals based on a few variables or single specific metabolite classes provides a restricted definition of metabotypes, as only a small part of human metabolism is taken into account. However, for the establishment of plasma lipoprotein clusters in the studies by van Bochove et al.( Reference van Bochove, van Schalkwijk and Parnell 29 ) and Frazier-Wood et al.( Reference Frazier-Wood, Glasser and Garvey 33 ), or of plasma fatty acid patterns in the study by Li et al.( Reference Li, Brennan and McNulty 39 ), restriction to the respective lipid variables seemed to be sufficient for subclassification. Likewise, Wang et al.( Reference Wang, Edwards and Clevidence 50 ) considered only the plasma carotenoid levels after a dietary intervention with carotenoids. The same was the case in the study by Morris et al.( Reference Morris, O’Grada and Ryan 9 ) considering only blood glucose levels, measured at several points in time, to identify groups with differential glucose responses to an oral glucose-tolerance test. This is of course in accordance with the current clinical practice for classification of type 2 diabetes based on the plasma kinetics of glucose. In diagnosing or subgrouping patients, the restriction of variables to disease-related parameters could also be sufficient for subclassification. For example, Arguelles et al.( Reference Arguelles, Llabre and Sacco 58 ) established subgroups of the metabolic syndrome patients based on the standard criteria for disease description, namely waist circumference, systolic and diastolic blood pressure, HDL, TAG, fasting glucose and medication use. The grouping in other studies using plasma fatty acids for the description of the metabolic syndrome( Reference Zák, Burda and Vecka 53 ) and fasting incretins for the subgrouping of diabetes( Reference Amato, Pizzolanti and Torregrossa 56 ) could be probably refined by the consideration of additional disease-related variables.
There is no consensus yet on a uniform use of the term ‘metabotype’, thus it is subjectively applied, usually based on the respective study objectives. In this review, the definitions of metabotypes differed considerably; they ranged between general fasting metabotypes, more specific fasting parameter subgroups like plasma lipoprotein( Reference van Bochove, van Schalkwijk and Parnell 29 , Reference Frazier-Wood, Glasser and Garvey 33 ) or fatty acid clusters( Reference Li, Brennan and McNulty 39 ) and response groups to defined meal challenges or dietary interventions according to the number and type of the selected clustering variables. Although an accepted definition of metabotype seems attractive, there is also the view that there is no need for a strict metabotype definition. On the one hand, it may be argued that a metabotype has by its nature a wide definition and should not be restricted. On the other hand, a better comparability of studies could be achieved using a stricter definition. Even if a strict general definition appears implausible or unrealistic, more precise sub-definitions of metabotypes could be developed, for example for lipid and carbohydrate (glucose) metabolism. Thus, metabolic variables restricted to specific metabolic pathways like to those of lipoproteins may be sufficient depending on the respective study objective.
However, it is assumed that the inclusion of various metabolites originating from different pathways as well as additional information from anthropometry or that obtained by including genetics, epigenetics or the gut microbiome in the process of metabotyping provides a more precise characterisation of individuals and, thus, the establishment of more refined and generally valid metabotypes( Reference Bartel, Krumsiek and Theis 70 ). This can be achieved through the use of ‘-omics’ data such as metabolomics, genomics and epigenomics, where research is growing rapidly( Reference Beger, Dunn and Schmidt 2 , Reference Valdes, Glass and Spector 71 , Reference Kurland, Accili and Burant 72 ). Thus, it may be wise to suggest a stricter definition of generally valid metabotypes in healthy subjects or population-based samples by at least the use of variables originating from different metabolic pathways, preferably the use of targeted or untargeted metabolomics data.
Further, there is no agreement as to whether the definition of metabotypes should be based on fasting data (see Table 1) or rather on metabolic response data to interventions (see Table 2), for which we identified only five studies that met the inclusion criteria. An argument for the use of metabolic response data to interventions is the increase of variation between individuals as some metabolic differences are only visible through challenges and would remain undetected using fasting blood values( Reference Krug, Kastenmüller and Stückler 73 ). However, the establishment of metabotypes by means of fasting data allows extensive measurements of larger study populations and is thus more feasible in the general population. It is important to note that intra-individual variations of metabolite concentrations may also occur because of diurnal time, stress, latent diseases as well as by measurement and storage conditions of the samples( Reference Holmes, Wilson and Nicholson 5 , Reference Dumas, Maibaum and Teague 64 , Reference Rezzi, Martin and Alonso 74 , Reference Ghini, Saccenti and Tenori 75 ). However, these differences were shown to be smaller than inter-individual differences, suggesting that individual metabotypes are relatively robust( Reference Assfalg, Bertini and Colangiuli 76 ).
Differences in statistical analyses
As a variety of statistical methods are available for the establishment of metabotypes(
Reference Bartel, Krumsiek and Theis
70
), there is an on-going discussion on which statistical methods should be used to obtain the best spread between subgroups. The preprocessing of variables is especially dependent on the structure of the variables and the requirements of the subsequent clustering methods. Thus, the implementation of outlier exclusion and data transformation has to be decided individually. If the number of clustering variables exceeds one per ten observations, application of data-reduction analyses like PCA or multiple-correspondence analysis must be considered to avoid over adjustment(
Reference Jain, Duin and Mao
77
). In many studies included in this review, standardisation has been applied to the cluster variables to avoid bias from different scales and units in the grouping analysis(
Reference Everitt, Landau and Leese
78
,
Reference Kaufman and Rousseeuw
79
). The most commonly used method is z-standardisation
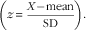 $$\left( {z{\,\equals\,}{{X{\minus}{\rm mean}} \over {{\rm SD}}}} \right).$$
$$\left( {z{\,\equals\,}{{X{\minus}{\rm mean}} \over {{\rm SD}}}} \right).$$
Concerning the different clustering methods( Reference Everitt, Landau and Leese 78 – Reference Bacher, Pöge and Wenzig 82 ), k-means cluster analysis and hierarchical cluster analysis were applied most commonly. Each clustering method has its own advantages and disadvantages and must be selected depending on the characteristics of the respective data set (e.g. depending on the scale level or the sample size). k-Means cluster analysis seems to be more suitable for large data sets than hierarchical clustering. However, the number of clusters has to be specified in advance for k-means cluster analysis, whereas hierarchical clustering does not need the number of clusters to be determined( Reference Bacher, Pöge and Wenzig 82 ). In addition, there are novel clustering techniques available in the field of bioinformatics, for example the so-called machine learning methods( Reference Dua and Chowriappa 83 ).
The selection of validation criteria like statistical tests and clustering indices is also dependent on the structure of the data. The reproducibility of metabotypes should be tested in a validation data set to confirm the results and to prove their generalisability.
Differences in the main findings
The aim of most studies was to examine metabolic differences between the established metabotypes and to test associations with certain diseases. However, the application of metabotypes, especially the development of targeted interventions for responsive subgroups, is rather limited in the literature. In addition, intervention by supplementation may increase serum levels in all subgroups but with possibly either larger effects in some subgroups or attainment of a threshold concentration considered to be within the normal range. Thus, responsiveness to an intervention does not necessarily mean benefit and, therefore, outcome parameters also need to be properly defined to evaluate the benefit of interventions, which so far has been rare in previous studies. Only few studies investigated the responsiveness of the established metabotypes to dietary interventions with regard to a specific disease. O’Sullivan et al.( Reference O’Sullivan, Gibney and Connor 30 ) identified a subgroup with a positive response to vitamin D supplementation concerning the metabolic syndrome; Vázquez-Fresno et al.( Reference Vázquez-Fresno, Llorach and Perera 32 ) detected a subgroup of patients at cardiovascular risk responsive to red wine polyphenols; and Moazzami et al.( Reference Moazzami, Shrestha and Morrison 47 ) identified individuals with reduced insulin sensitivity after consumption of bread. There is only one study that developed tailored dietary recommendations for subgroups using a decision-tree approach( Reference O’Donovan, Walsh and Nugent 31 ). Until now, the established metabotypes have not been transferred to larger populations for specific, tailored interventions.
Conclusion
In conclusion, this literature review shows that metabotyping can help identify metabolically similar subpopulations or patient subgroups responding differently to defined nutritional interventions. Consequently, better tailored and, thus, more precise dietary recommendations than generalised advice may be provided to whole populations at a metabotype group level. The aim of future studies should be the refinement of the definition of generally valid metabotypes in large samples, especially with a possibly more precise phenotype description of individuals based on different ‘-omics’ data, particularly metabolomics data. Another aim should be the development of stricter definitions of specific metabotypes for metabolic pathways. The metabotypes should then be tested for differential reactions to diverse dietary factors with regard to properly defined outcome parameters. On the basis of such results, populations can be better stratified in order to provide effective tailored prevention and intervention programs. The implementation of these recommendations in populations may become a future task. Finally, individual health benefits may be improved and the rising costs in the health-care system originating from obesity and other diet-related metabolic diseases may be better controlled.
Acknowledgements
This study was supported by the enable Cluster and is catalogued by the enable Steering Committee as enable 001 (http://enable-cluster.de). This work was funded by a grant from the German Ministry for Education and Research (BMBF) FK 01EA1409E.
Contributions of authors were as follows: A. R. conceived the review, conducted the literature search and wrote the paper; C. G. provided advice regarding the literature search and revised the paper; H. H. provided advice regarding the literature search and revised the paper; H. D. provided advice regarding the literature search and revised the paper; J. L. conceived the review, provided advice regarding the literature search and revised the paper. All authors have read and approved the final manuscript.
None of the authors has any conflicts of interest to declare.



