



1. Introduction
Historians of political science traced the field’s history back to ancient Greek philosophers (Farr, Reference Farr1988), with a complicated kaleidoscope of diverse political thoughts, theories, schools, and approaches to study politics. Political science now carries wide and practical meaning in multiple areas of knowledge and skills. It became firmly associated with research-centered academic discipline of “social sciences” sometimes by the mid-twentieth century, achieving the more professionally defined and narrow meaning (Adcock Reference Adcock2014). Historians are still debating the exact origins of political science as a separate academic discipline (Adcock Reference Adcock2014: 216). Since Plato and Aristotle, the discipline has undergone extensive transformations.
As a result, the field itself and the different disciplines within it were often described as lacking integration and coherence (e.g., Goodin, Reference Goodin2009; Goodin & Klingemann, Reference Goodin and Klingemann1996; Heyse et al., Reference Heyse, Meyer, Mourey and Wijkström2003; Horak, Reference Horak2010), with frequent calls for more systematic and comprehensive depiction (e.g., Hydén et al., Reference Hydén, Immergut, Underdal, Ruin and Öhngren2002; Kouba et al., Reference Kouba, CíSAř and Navrátil2015). Goodin & Klingemann (Reference Goodin and Klingemann1996) point out that there are “lamentations and jeremiads about the fragmentation of political science” (Goodin & Klingemann, Reference Goodin and Klingemann1996: 99) and that there is a question about “how all the subspecialties sit together to form a coherent larger whole” (Goodin & Klingemann, Reference Goodin and Klingemann1996: 7). Given that previous research thought of fragmentation as a problem to be addressed, it appears that there is a need for a systematic evaluation of the composition of political science as a field.
Multiple previous attempts at introspection in the field of political science (e.g., Ricci, Reference Ricci1984; Parenti, Reference Parenti1983; Grant, Reference Grant2005) have revealed sharp internal divisions within (Garand, 2005). These divisions were attributed to naturally occurring subfields (e.g., Almond, Reference Almond1988; Smith, Reference Smith2002); separate intellectual camps (Almond, Reference Almond1988) or islands or communities (Shepsle, Reference Shepsle1990); organizational ties in the form of APSA memberships (Grant, Reference Grant2005); methodological approaches (Garand & Giles, Reference Garand and Giles2003); and many other scientific disputes that make the field of political science, as many scholars agree, rather fragmented (e.g., Underhill Reference Underhill2000; Udris Reference Udris2019).
Yet, there is a lot to be gained from understanding of developments in the field. Academic reasons for doing so, from research relevance (e.g., Stoker, Reference Stoker2015, Vecchi, Reference Vecchi2017) to epistemological and methodological considerations (e.g., Wolin, Reference Wolin and Richter2009; Benoit & Laver, Reference Benoit and Laver2012), have been amply discussed in the literature. In social sciences, however, the importance of coherent vision of the field is amplified by a vital position that social sciences occupy not only in academia but also in society and policy processes (Ceaser, Reference Ceaser1985). Political scientists, economists, and sociologists often take the roles of experts and consultants in applied research projects for governments and corporations (e.g., Petracca, Reference Petracca1989; Lake, Reference Lake1989). Therefore, the field’s fragmentation, which could lead to contradictive theories and explanations, may result in lower efficiency of proposed policies. Understanding the fragmentation, on the other hand, can help unify the practical approaches used by applied science.
The accumulation of knowledge about the social world and the efficiency of policymaking are dependent on the understanding of longstanding development of social science disciplines. As Fortunato et al. (Reference Fortunato, Bergstrom, Börner, Evans, Helbing, Milojević and Barabási2018) point out, research in the “science of science” domain could help identify “fundamental mechanisms responsible for scientific discovery” (Fortunato et al., Reference Fortunato, Bergstrom, Börner, Evans, Helbing, Milojević and Barabási2018: 1). Therefore, it is crucial not only for academics and historians of science but also for everybody to understand the past, present, and future of social sciences, in general, and political science in particular.
Garand (Reference Garand2005) has noted that perceptions of the field’s fragmentation, though noted by many, have not been subjected to systematic analysis. Partly, it was because very little systematic data were available, and Garand called previous attempts at examining the field “largely experiential, impressionistic, or anecdotal” (Garand, Reference Garand2005: 982). The literature mostly splits into two parts, each with its own limitations. One consists of comprehensive attempts to investigate the structure of the whole field but is based mostly on qualitative research methods. A good example of research output for this literature is handbooks (Goodin, Reference Goodin2009; Goodin & Klingemann, Reference Goodin and Klingemann1996). The second part consists of research papers that employ modern quantitative methodology, but applies it to limited subsets of political science, often just to one scientific journal from the field (e.g., Chi, Reference Chi2012; Adams et al., Reference Adams, Lind Infeld, Wikrent and Bintou Cisse2016).
Garand’s (Reference Garand2005) study was one of the first major comprehensive and systematic attempts at describing patterns in the fragmented discipline, focused on the patterns of evaluation of political science journals by scientists. Around the same time, bibliometric analysis, first introduced in the 1960s (Garfield, Reference Garfield1979), started to gain prominence and popularity as a tool for examining political science. Many have recognized the value of citation analysis as it provided the networks of scientific contacts between researchers (Lievrouw et al., Reference Lievrouw, Rogers, Lowe and Nadel1987). Since then, many studies attempted to evaluate the composition of political science using bibliometrics (e.g., Bjurström, Reference Bjurström2011; Dale & Goldfinch, Reference Dale and Goldfinch2005; Colman et al., Reference Colman, Dhillon and Coulthard1995; Chi, Reference Chi2012; Pehl, Reference Pehl2012). Again, the most notable limitation of these studies is the specificity of the context: analysis was done by subfield, country, region, etc.—not of the entire field of political science. Perhaps, it was because specific methodologies for analysis of the entire field were not yet fully developed, or that computational technologies were not sophisticated enough for such an undertaking, given the size of the field. Recently, an opportunity to examine an entire field presented itself with methodological advances in networks, applicable to bibliometric networks (e.g., Batagelj et al., Reference Batagelj, Ferligoj and Doreian2019; Batagelj, Reference Batagelj2020).
As a result, the call for a comprehensive examination of the field of political science can now be attempted to be answered by using bibliometric network approach. There are many questions to answer and many ways in which such research can be conducted—all of them, clearly, beyond the scope of one study. However, a good starting point appears to be the evaluation of the field from the standpoint of main scientific schools. Such an analysis can provide an overview of the structure of political science and its evolution over time, understanding how the scientific schools are formed and why they change.
The most recognized division of the field in political science is the partition by time periods. Almond (Reference Almond1996) defined at least three periods of political science development in the 20th century: “Chicago school” in 1920–1940; “behavioral political science” after the World War II; and “rational choice/methodological individualist approach.” However, historians of political science still argue about the number and length of such periods, and even what to call them: scientific traditions, schools, paradigms, scientific research programs, or approaches (Dryzek, Reference Dryzek1986; Ball, Reference Ball1976; Rodman, Reference Rodman1980; Beardsley, Reference Beardsley1974; Haas, Reference Haas1986). In this paper, we follow Adcock et al. (Reference Adcock, Bevir and Stimson2009) periodization, with three distinct periods. The first is the “old institutionalism” from late nineteenth century until into the interwar years. The second—behaviorism from the 1950s until the 1970s. The third and final—the “new institutionalism,” which became a new paradigm for a range of “cutting-edge research agendas” into the 1980s (Adcock et al., Reference Adcock, Bevir and Stimson2009: 259). Throughout the paper, we will refer to these periods as “paradigms” (Kuhn, Reference Kuhn1970) or scientific research programs (Lakatos, Reference Lakatos, Worrall and Currie1978) as they describe the change of the dominant theoretic and methodological approach, not a total abolition of a paradigm. Competing approaches continue to co-exist alongside the dominant.
Therefore, within this periodic division, research paradigms did not remain homogeneous. Postbehavioral stage is characterized by the crisis of behaviorism in the beginning, with a rise of diverse paradigms in political science (Farr & Seidelman, Reference Farr and Seidelman1993). Before the new institutionalism, there was a period of greater interest in the study of states and international regimes in 1975–1985—a “neostatism” (Adcock et al., Reference Adcock, Bevir and Stimson2009). The mid-1980s through the early 1990s were characterized by the expansion of new institutionalism with its plurality of research programs. Depending on the school, researchers recognize three or four major research programs within new institutionalism: rational choice theory, sociological institutionalism, historical institutionalism, and constructivism (also called discursive institutionalism, e.g., Wahlström & Sundberg, Reference Wahlström and Sundberg2018; Bell, Reference Bell2011) (Schmidt, Reference Schmidt2010).
The new approach to institutions within organizational sociology, and more importantly, the rational choice theory, which was an alternative to behaviorism since the 1980s, was introduced by March and Olsen (Reference March and Olsen1983). Historical institutionalism and constructivism emerged in the early 1990s as an alternative to rational choice (Adcock et al., Reference Adcock, Bevir and Stimson2009; Koelble, Reference Koelble1995, Hall & Taylor, Reference Hall and Taylor1996). Sociological institutionalism fully enters the field of political science in mid-1990s (Adcock et al., Reference Adcock, Bevir and Stimson2009). By the term “constructivism” historians of political science also mean an alternative to new institutionalism (Adcock et al., Reference Adcock, Bevir and Stimson2009), related to “interpretive turn” in political science (Blakely, Reference Blakely2013; Rhodes, Reference Rhodes2017).
The first objective of our study is to evaluate the presence, number, and change of paradigms or research programs in political science. Currently, there is some skepticism in the field related to this idea, the mere possibility to identify “a paradigm” within political science (e.g., Dryzek, Reference Dryzek1986; Ball, Reference Ball1976; Rodman, Reference Rodman1980; Beardsley, Reference Beardsley1974; Haas, Reference Haas1986). Some, especially older, studies argue that political science is in the pre-paradigm stage (Baum et al., Reference Baum, Griffiths, Matthews and Scherruble1976), so paradigms do not yet exist. Others state that political science is multiparadigmatic (e.g., Della Porta & Keating, Reference Della Porta and Keating2008), and paradigms within the field cannot be clearly separated from each other as they compete and interact with each other. However, in line with scholars who argue for the existence of paradigms, we test for their presence in this exploratory study. So, our first research question is focused on whether we can empirically identify paradigms in political science, quantify them, and evaluate their change. The time-series nature of the dataset allows to answer these questions.
Conventionally, there are several paradigms in political science: behaviorism (peaked in 1920–1960), rational choice theory (1980s), historical institutionalism and constructivism (1990s), and sociological institutionalism (mid-1990s) (Adcock et al., Reference Adcock, Bevir and Stimson2009). We also can evaluate the expansion of studies in the research programs of Marxism (Almond, Reference Almond1996; Farr & Seidelman, Reference Farr and Seidelman1993), neostatism, and computational political science (Lazer et al., Reference Lazer, Pentland, Adamic, Aral, Barabási, Brewer and Jebara2009; Weber et al., Reference Weber, Popescu and Pennacchiotti2013, Voinea, Reference Voinea2016; Wong et al., Reference Wong, Tan, Sen and Chiang2016). The latter is the emerging research program in political science, which returned the focus back to quantitative methods. It was the advent of new approaches such as data mining, machine learning, and other advanced methods of computational social sciences, which allowed for testing hypotheses not possible previously.
The second objective of this study is to identify the subdisciplines or topics within the field. Doing so may be useful for understanding the dynamics within the broad field. Goodin & Klingemann (Reference Goodin and Klingemann1996) proposed that the field of political science consists of ten subdisciplines: political theory, political institutions, law and politics, political behavior, contextual political analysis, comparative politics, international relations, political economy, public policy, and political methodology. While our study is mostly exploratory, it is certainly possible to see whether this proposition can withstand the scrutiny of an empirical exploration. Therefore, our second research question here is concerned with whether we can empirically identify ten subdisciplines listed above in political science, and if not—how many of them can be identified. To align the terminology of “subdisciplines” with the terminology of the bibliometric community, we will use words “clusters,” “islands,” and “topics” interchangeably.
To reach the study’s objectives, we use bibliometric network analysis with a dataset of articles from the Web of Science (WoS), published from 1946. Using writings-to-words and keywords co-occurrence networks’ analysis, we test the structure of the field computationally and measure the levels of its fragmentation. To achieve a better understanding of the paradigms’ dynamics and topic structure in political science, we analyzed words in different contexts: in time settings and with co-occurrence with other words.
Next, we present our data and methodology in more detail, focusing on data collection, and creating the temporal writings-to-word networks and keywords co-occurrence network. Then, we provide the descriptive analysis of our networks and narrow the focus to temporal network analysis. Next, we present the analysis of keywords co-occurrence, discovering the topics within political science with link islands methodology (LIM). Finally, we perform a robustness check of the LIM with hierarchical cluster analysis (HCA). We conclude our paper with discussion and implications for the understanding of the field and further study.
2. Data and methodology
2.1. Data collection
In this paper, we follow the methodology of bibliometric analysis presented in detail by Maltseva & Batagelj (Reference Maltseva and Batagelj2020). We extract our initial dataset from the Web of Science (WoS) Core Collection database. WoS is known and trusted for its high indexing quality, and in some cases, better coverage of historical works (Harzing, Reference Harzing2013) than Google Scholar (Prins et al., Reference Prins, Costas, van Leeuwen and Wouters2016). Specifically in the field of political science, Bjurström (Reference Bjurström2011) also used it for bibliometric analysis. He noted that while journal articles allow analysis of large research fields and their dynamics, monographs (not all of which are indexed in WoS) often rely on these articles to make overarching conclusions. In other words, according to Bjurström (Reference Bjurström2011), analyzing articles provides the same benefit as analyzing monograph references. For bibliometric analysis, especially extracting field dynamics over time, and given its higher quality and trust that academic community places in it, WoS is a much more defendable and reproducible choice than other bibliometric databases.
WoS stores writing metadata information in fields with two-letter names and allows its users to run search queries using these fields. WoS fields relevant to this work are TI (title of the writing), ID (Keywords Plus, keywords assigned to writings by the WoS platform), and DE (keywords assigned to writings by their authors). In addition, WoS allows to use other pseudo-fields in its search queries. For example, using the field TS (topic) allows to simultaneously search the title, abstract, Keywords Plus, and author keywords of the writings for a specified scientific discipline. For example, using the WoS query “TS = (Political Science)” we return publications from 1946 to 2019Footnote 1 and the writings they cite within political science discipline. We retrieved 769,464 records, from which we removed news, reports, etc. As a result, the initial dataset contained 736,006 records of writings (articles and booksFootnote 2 ).
Next, we used WoS2Pajek (Batagelj, Reference Batagelj2017) to transform the initial dataset into the keyword network
 $WK$
(representing which writings used which words). The words were derived from the ID, DE, and TI fields of the WoS records, by process of lemmatization and stopwords removal. As a result, we produced network with sets of the following sizes: 3,824,982 writings, 111,258 words. Resulting network contains 676,603 writings with full descriptions and 3,148,379 cited-only writings (listed as cited by papers with full description). We received less writings with full description than records in the initial dataset because WoS2Pajek removes duplicates.
$WK$
(representing which writings used which words). The words were derived from the ID, DE, and TI fields of the WoS records, by process of lemmatization and stopwords removal. As a result, we produced network with sets of the following sizes: 3,824,982 writings, 111,258 words. Resulting network contains 676,603 writings with full descriptions and 3,148,379 cited-only writings (listed as cited by papers with full description). We received less writings with full description than records in the initial dataset because WoS2Pajek removes duplicates.
Next, we removed multiple links, which could happen as a by-product of keyword phrase entry (e.g., “soft power” and “hard power” key phrases would connect the word “power” to the article twice). Also, because the cited-only writings contain only partial information, we constructed reduced networks containing only writings with complete descriptions. The final sizes of these reduced networks (
 $WKr$
) were as follows: 676,603 writings and 111,258 words. This reduction is a well-known technique for bibliographic studies (Abouzid et al., Reference Abouzid, Anna and Marta2021), as it allows to lessen the computational complexity of further analysis.
$WKr$
) were as follows: 676,603 writings and 111,258 words. This reduction is a well-known technique for bibliographic studies (Abouzid et al., Reference Abouzid, Anna and Marta2021), as it allows to lessen the computational complexity of further analysis.
To prepare for the analysis of changes of popularity of different words over time, we removed writings that did not have information on the year they were published. We have also removed articles from 2019, not only because we collected data until July 2019 but also because there is a delay in indexing of articles in WoS, and not all articles from 2019 appear in the database even in 2020, as was suggested by other studies (Abouzid et al., Reference Abouzid, Anna and Marta2021; AlGhamdi et al., Reference AlGhamdi, Bret, Angel, Roland, Gwendolyn, Tuğrul and Daim2021) to improve the quality of the data. After this step, networks (
 $WKry$
) consisted of 671,699 writings and 111,258 words. As a final step, we removed words that were one character in size, contained numbers, or punctuation. We also removed anonymous writings (writings for which author names were not specified in WoS) and writings for which keywords and titles were not specified in WoS from the network
$WKry$
) consisted of 671,699 writings and 111,258 words. As a final step, we removed words that were one character in size, contained numbers, or punctuation. We also removed anonymous writings (writings for which author names were not specified in WoS) and writings for which keywords and titles were not specified in WoS from the network
 $WKry$
(Franceschini et al., Reference Franceschini, Maisano and Mastrogiacomo2016). These preparation steps are used in existing literature, as they allow to both remove writings with dubious contribution to the field and improve the interpretability of the results of the analysis (Lei & Liu, Reference Lei and Liu2019; Abouzid et al., Reference Abouzid, Anna and Marta2021). The resulting network (
$WKry$
(Franceschini et al., Reference Franceschini, Maisano and Mastrogiacomo2016). These preparation steps are used in existing literature, as they allow to both remove writings with dubious contribution to the field and improve the interpretability of the results of the analysis (Lei & Liu, Reference Lei and Liu2019; Abouzid et al., Reference Abouzid, Anna and Marta2021). The resulting network (
 $\textit{WKryx}$
) consisted of 651,358 writings and 106,373 words.
$\textit{WKryx}$
) consisted of 651,358 writings and 106,373 words.
For the analysis, we used two bimodal writings-to-words networks. The first was
 $WK$
described above. The second,
$WK$
described above. The second,
 $WK_{2}$
, was constructed only from keywords (ID and DE fields in WoS), without using titles (TI field in WoS).
$WK_{2}$
, was constructed only from keywords (ID and DE fields in WoS), without using titles (TI field in WoS).
Specific reason for doing so was that in 1990, WoS indexing policy has changed, and it started adding keywords (ID and DE fields, Figure 1). Using keywords only allows for a more accurate analysis than using titles also, as approach to generating titles for articles has changed in the last few decades. In the past, the titles were required to accurately reflect the content of the article (Zeller & Farmer, Reference Zeller and Farmer1999). Now authors have much more freedom, so titles are much more subject to individual choice and author’s creativity (Jixian & Jun, Reference Jixian and Jun2015). Since the second goal of our study was to identify subdisciplines, we did not want to clutter them unnecessarily with extra words from catchy titles.
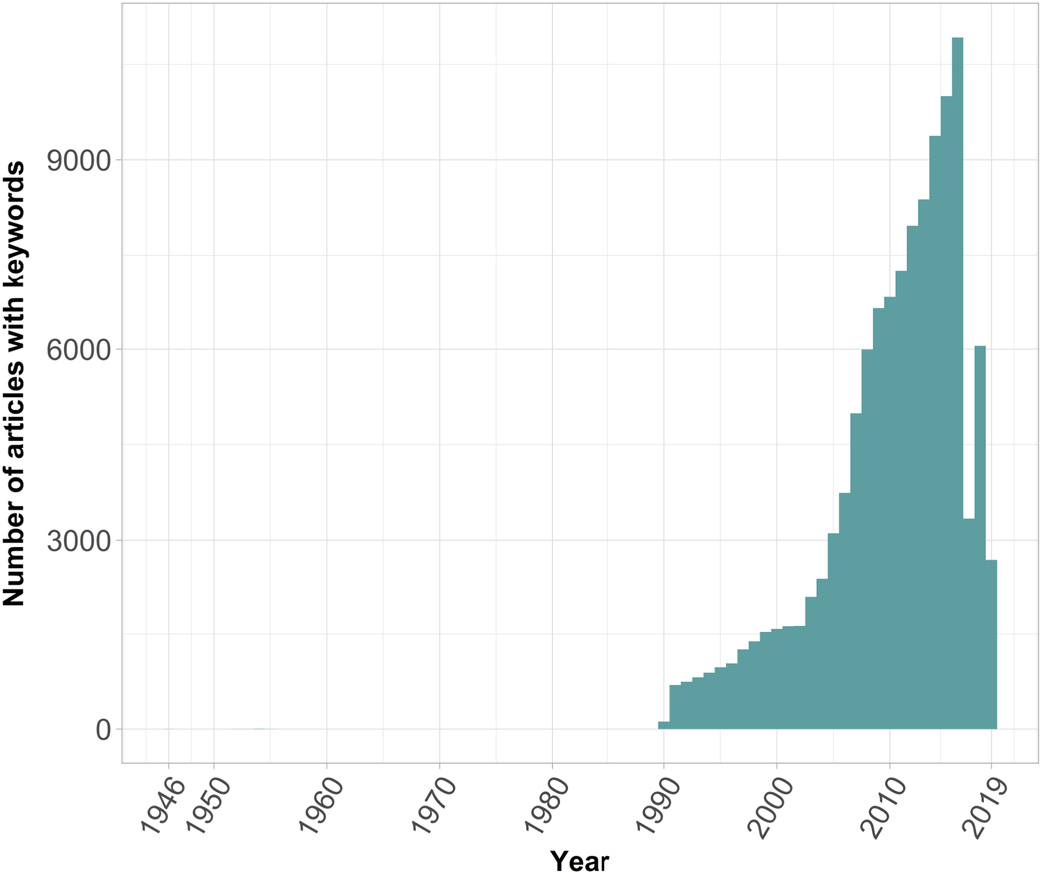
Figure 1. Number of articles with keywords per year.
Of course, there is an issue of keyword designation and their accuracy for describing the study. Journal practices differ with respect to keywords: some allow choices from a designated list; some allow authors to generate their own. There are other criticisms of keyword analysis, amply described in the literature, from linguistics (e.g., Egbert & Baker, Reference Egbert and Baker2016) to the discipline-specific studies, including political science (e.g., Pérez-Paredes, Reference Pérez-Paredes2019). However, there are studies that rebuff this argument by stating that “keywords reflect the changes in knowledge and interests in the discipline” (Yang, Reference Yang2019), which is precisely what we were set out to find out. Therefore, bibliometric analysis based on keywords only appears appropriate for our study purpose.
We then generated
 $WK_{2}r$
network, from which we removed all writings published before 1990. There were two reasons for doing so. First, it is a coincidence that WoS started using keywords (ID and DE fields) only since 1990. We had a choice of the starting year for our study and could have made a cut at a later year. However, modern political science is largely shaped by geopolitical events of late 1980s-early 1990s. As Lowi (Reference Lowi1992) pointed, out, “Regime changes throughout the world since 1989 ought to give us a clearer perspective on some new sciences of politics” (Lowi, Reference Lowi1992: 6). No matter the approach to studying political science, the field today is a reflection of research of most pressing political issues. Therefore, the subdisciplines within political science reflect these changes as well, so the year 1990 appears appropriate for the start of our exploration.
$WK_{2}r$
network, from which we removed all writings published before 1990. There were two reasons for doing so. First, it is a coincidence that WoS started using keywords (ID and DE fields) only since 1990. We had a choice of the starting year for our study and could have made a cut at a later year. However, modern political science is largely shaped by geopolitical events of late 1980s-early 1990s. As Lowi (Reference Lowi1992) pointed, out, “Regime changes throughout the world since 1989 ought to give us a clearer perspective on some new sciences of politics” (Lowi, Reference Lowi1992: 6). No matter the approach to studying political science, the field today is a reflection of research of most pressing political issues. Therefore, the subdisciplines within political science reflect these changes as well, so the year 1990 appears appropriate for the start of our exploration.
In addition to the adjustments described above for
 $\textit{WKryx}$
and applied to
$\textit{WKryx}$
and applied to
 $WK_{2}$
, we also removed misleading keywords (multiple words glued together, words containing numbers, abbreviations, names of chemical compounds, or non-English language words, for example “iii” or “aa”) by hand. This preprocessing step is widely used by bibliometric studies focused on keyword analysis (Rajasekharan et al., Reference Rajasekharan, Sankaran, Ramnarayan and Nandan Prabhu2021; Ye et al., Reference Ye, Jin, Zilong and Man2021; Yang et al., Reference Yang, Cui and Tong2021). Resulting network (
$WK_{2}$
, we also removed misleading keywords (multiple words glued together, words containing numbers, abbreviations, names of chemical compounds, or non-English language words, for example “iii” or “aa”) by hand. This preprocessing step is widely used by bibliometric studies focused on keyword analysis (Rajasekharan et al., Reference Rajasekharan, Sankaran, Ramnarayan and Nandan Prabhu2021; Ye et al., Reference Ye, Jin, Zilong and Man2021; Yang et al., Reference Yang, Cui and Tong2021). Resulting network (
 $WK_{2}ryx$
) consisted of 115,378 writings and 25,355 keywords.
$WK_{2}ryx$
) consisted of 115,378 writings and 25,355 keywords.
2.2. Temporal writings-to-words networks
Using the
 $\textit{WKryx}$
network as our starting point, we created a collection of 73 networks
$\textit{WKryx}$
network as our starting point, we created a collection of 73 networks
 $\textit{WKins}$
, each containing a full set of words as one mode and the writings only from a given year (from the period 1946–2018) as the second mode. To construct temporal networks, we applied temporal quantities approach (Batagelj & Maltseva, Reference Batagelj and Maltseva2020; Batagelj & Praprotnik, Reference Batagelj and Praprotnik2016) to the
$\textit{WKins}$
, each containing a full set of words as one mode and the writings only from a given year (from the period 1946–2018) as the second mode. To construct temporal networks, we applied temporal quantities approach (Batagelj & Maltseva, Reference Batagelj and Maltseva2020; Batagelj & Praprotnik, Reference Batagelj and Praprotnik2016) to the
 $\textit{WKryx}$
network, using Python libraries Nets and TQ (Batagelj, Reference Batagelj2014). We used temporal writings-to-words networks (
$\textit{WKryx}$
network, using Python libraries Nets and TQ (Batagelj, Reference Batagelj2014). We used temporal writings-to-words networks (
 $\textit{WKins}$
) for further temporal analysis of paradigms change in political science. In Table 1S of the Supplementary Materials, we provide a detailed step-by-step network transformation from the
$\textit{WKins}$
) for further temporal analysis of paradigms change in political science. In Table 1S of the Supplementary Materials, we provide a detailed step-by-step network transformation from the
 $WK$
network to
$WK$
network to
 $\textit{WKins}$
network with explanation of the steps and the purpose.
$\textit{WKins}$
network with explanation of the steps and the purpose.
2.3. Keywords co-occurrence network
To build keywords co-occurrence network, we used
 $WK_{2}ryx$
, since, as noted above, keywords (without words from titles) more precisely determine the subdisciplines or topics in political science. Keywords co-occurrence network
$WK_{2}ryx$
, since, as noted above, keywords (without words from titles) more precisely determine the subdisciplines or topics in political science. Keywords co-occurrence network
 $\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
is a result of multiplication of normalized reduced transposed writings-to-keywords network (
$\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
is a result of multiplication of normalized reduced transposed writings-to-keywords network (
 $nWK^{\prime}_{2}ryx$
) by itself.
$nWK^{\prime}_{2}ryx$
) by itself.
 \begin{equation*} \mathit{nK}\mathit{'}\mathit{K}\mathit{'}=nW{K^{\prime}_{2}}ryx^{T}*nWK^{\prime}_{2}ryx \end{equation*}
\begin{equation*} \mathit{nK}\mathit{'}\mathit{K}\mathit{'}=nW{K^{\prime}_{2}}ryx^{T}*nWK^{\prime}_{2}ryx \end{equation*}
Such approach to creating the keyword co-occurrence network can have some drawbacks. One of them is overrating the contribution of writings with very large number of keywords. To deal with such cases, we used the fractional approach (Batagelj & Cerinšek, Reference Batagelj and Cerinšek2013; Gauffriau et al., Reference Gauffriau, Larsen, Maye, Roulin-Perriard and von Ins2007), which normalizes each article’s input to the resulting network to be equal to 1. It is called “penalization” and was implemented to reduce the influence of writings that included a large number of keywords. With too many keywords, the importance score (indegree) of an individual word becomes lower. This means that scores of words that are typically used together with a large number of other words (e.g., the word “review” or “handbook,” which are used in writings describing broad areas and topics) will be affected by this procedure the most.
In a regular network, the outdegree is equal to the number of keywords in the writing, and the indegree is equal to the number of writings in which the same keywords are used. The normalization creates the network where the weight of each arc is divided by the sum of weights of all arcs having the same initial node as this arc (the outdegree of a node):
 \begin{equation*} nWK_{2}ryx\left[w,k\right]=\frac{WK_{2}ryx\left[w,k\right]}{\max\!\left(1,\text{outdegree}(w)\right)} \end{equation*}
\begin{equation*} nWK_{2}ryx\left[w,k\right]=\frac{WK_{2}ryx\left[w,k\right]}{\max\!\left(1,\text{outdegree}(w)\right)} \end{equation*}
where w is a writing and k is a keyword. Here, the contribution of each writing is set to be equal to 1. Note that this procedure assumes that all keywords are equally important.
The
 $nWK_{2}ryx$
network was reduced to the
$nWK_{2}ryx$
network was reduced to the
 $nWK^{\prime}_{2}ryx$
network by removing keywords with weighted indegree less than 1 from the
$nWK^{\prime}_{2}ryx$
network by removing keywords with weighted indegree less than 1 from the
 $nWK_{2}ryx$
. Indegree of less than 1 meant that none of the keywords carried substantive meaning. Retention of such articles carried no substantive weight but increased the computational complexity for construction of the keyword co-occurrence network. Keywords with weighted indegree substantially less than 1 were either not related to political science (e.g., “mycobacterium,” “veggie”) or contained combination of letters that were, perhaps, some uncommon abbreviations (“pla,” “chp”). Removing such keywords did not alter the meaning but simplified the analysis. Keyword co-occurrence network reduction is a common practice in bibliographic studies aimed at reducing the computational complexity of the analysis, although typically, studies use arbitrary threshold, such as keeping only top 10% of the studies’ entities (Kim et al., Reference Kim, Seojin, Fei and Yongjun2020).
$nWK_{2}ryx$
. Indegree of less than 1 meant that none of the keywords carried substantive meaning. Retention of such articles carried no substantive weight but increased the computational complexity for construction of the keyword co-occurrence network. Keywords with weighted indegree substantially less than 1 were either not related to political science (e.g., “mycobacterium,” “veggie”) or contained combination of letters that were, perhaps, some uncommon abbreviations (“pla,” “chp”). Removing such keywords did not alter the meaning but simplified the analysis. Keyword co-occurrence network reduction is a common practice in bibliographic studies aimed at reducing the computational complexity of the analysis, although typically, studies use arbitrary threshold, such as keeping only top 10% of the studies’ entities (Kim et al., Reference Kim, Seojin, Fei and Yongjun2020).
The minimum and maximum indegrees for the
 $nW\mathrm{K}_{2}ryx$
networks were 0.012 (for words “debreu” and “evolutionarily”) and 2,078.093 (for the word “policy”). The number of words that were retained in the network
$nW\mathrm{K}_{2}ryx$
networks were 0.012 (for words “debreu” and “evolutionarily”) and 2,078.093 (for the word “policy”). The number of words that were retained in the network
 $nWK^{\prime}_{2}ryx$
was 5,564, the number of words that fell below the threshold of 1 and were removed was 19,791. For further analysis, we normalized the WKryx network using the same normalization technique. The minimum and maximum indegrees for the
$nWK^{\prime}_{2}ryx$
was 5,564, the number of words that fell below the threshold of 1 and were removed was 19,791. For further analysis, we normalized the WKryx network using the same normalization technique. The minimum and maximum indegrees for the
 $\textit{nWKryx}$
networks were 0.004 (for a group of German words and the word “chlorinate”) and 6,945.407 (for the word “politics”). We used keywords co-occurrence network (
$\textit{nWKryx}$
networks were 0.004 (for a group of German words and the word “chlorinate”) and 6,945.407 (for the word “politics”). We used keywords co-occurrence network (
 $\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
), consisting of 5,564 keywords, for topics’ discovery in political science using island methods (Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014). Summary statistics for all these networks is presented in Table 1; please also see Table 2S in Supplementary materials for step-by-step description of the network transformation process.
$\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
), consisting of 5,564 keywords, for topics’ discovery in political science using island methods (Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014). Summary statistics for all these networks is presented in Table 1; please also see Table 2S in Supplementary materials for step-by-step description of the network transformation process.
Table 1. Descriptive statistics of the analyzed networks

3. Seventy-year evolution of paradigms in political science: Temporal writings-to-words networks’ analysis
3.1. Descriptive network analysis
The distribution of the number of analyzed words in complete network,
 $\textit{WKryx}$
, containing words derived from author and platform keywords (ID and DE fields) and writing titles (TI field in WoS), is presented in Figure 2. As is apparent from the figure, most studies contain 2–6 describing words. After about 10 descriptive words, the number of articles containing them goes sharply down.
$\textit{WKryx}$
, containing words derived from author and platform keywords (ID and DE fields) and writing titles (TI field in WoS), is presented in Figure 2. As is apparent from the figure, most studies contain 2–6 describing words. After about 10 descriptive words, the number of articles containing them goes sharply down.

Figure 2. Logarithmic plots with distributions of the number of words per writings.
Figure 3 shows the distribution of the number of words used in all writings in the
 $\textit{WKryx}$
network. As is apparent from the graph, a large number of words are mentioned only once (50,550), twice (14,036), or three times (7,401). The usage of these words is episodic. There are also words which are used extensively, constructing the core concepts of the field.
$\textit{WKryx}$
network. As is apparent from the graph, a large number of words are mentioned only once (50,550), twice (14,036), or three times (7,401). The usage of these words is episodic. There are also words which are used extensively, constructing the core concepts of the field.

Figure 3. Logarithmic plots with distributions of the unique combinations of all words used in all writings.
The most frequent words are presented in Table 3S of Supplementary Materials. Not surprisingly, the words “political” and “politics” are the most frequently used words (54,302 and 50,946, respectively). The result that these words are used most frequently is certainly expected, since we studied political science writings, but it also demonstrates the validity of the resulting datasets.
As a check for the fractional approach to network normalization, which was used in the same manner for all of the networks, we compared top words in the normalized network (
 $\textit{nWKryx}$
) with top words of the non-normalized network (
$\textit{nWKryx}$
) with top words of the non-normalized network (
 $\textit{WKryx}$
). The network was normalized to remedy the effect of writings with a large number of words on the analysis, similar to a TF-IDF approach to text analysis. We did not find many differences. One the one hand, words “peace,” “life,” “reply,” “future,” “French,” “Russia” (bold in Table 3S) which are present in the top-60 of the normalized network, are absent from the top of non-normalized network. It means that these were the words that were “penalized” the least—in other words, they are used for designation of more narrow topics. Given the meaning of these words, it is not surprising and appears to be accurate.
$\textit{WKryx}$
). The network was normalized to remedy the effect of writings with a large number of words on the analysis, similar to a TF-IDF approach to text analysis. We did not find many differences. One the one hand, words “peace,” “life,” “reply,” “future,” “French,” “Russia” (bold in Table 3S) which are present in the top-60 of the normalized network, are absent from the top of non-normalized network. It means that these were the words that were “penalized” the least—in other words, they are used for designation of more narrow topics. Given the meaning of these words, it is not surprising and appears to be accurate.
On the other hand, words “model,” “governance,” “civil,” “democratic,” “institution,” and “community” (underlined in Table 3S) are present in the top-60 of the non-normalized network but are absent in the normalized. These words are penalized the most, which means they are used for designation of wider topics. Such logic also appears to be accurate, given the meaning of these words.
3.2. Temporal network analysis
To test our first assumption about paradigm changes in political science, we use temporal network analysis. This method allows us to trace the longitudinal development of behaviorism, new institutionalism, and constructivism paradigms. Moreover, we can also attempt to find dynamics in development of smaller traditions of Marxism, neostatism, and computational political science.
For temporal network analysis, we used writings-to-words networks created for each year from 1946 to 2018 (
 $\textit{WKins}$
). Figure 4 presents temporal distributions of the number of all words used in political science writings by year. These are not unique words—they are all words used by all writings during the year.
$\textit{WKins}$
). Figure 4 presents temporal distributions of the number of all words used in political science writings by year. These are not unique words—they are all words used by all writings during the year.
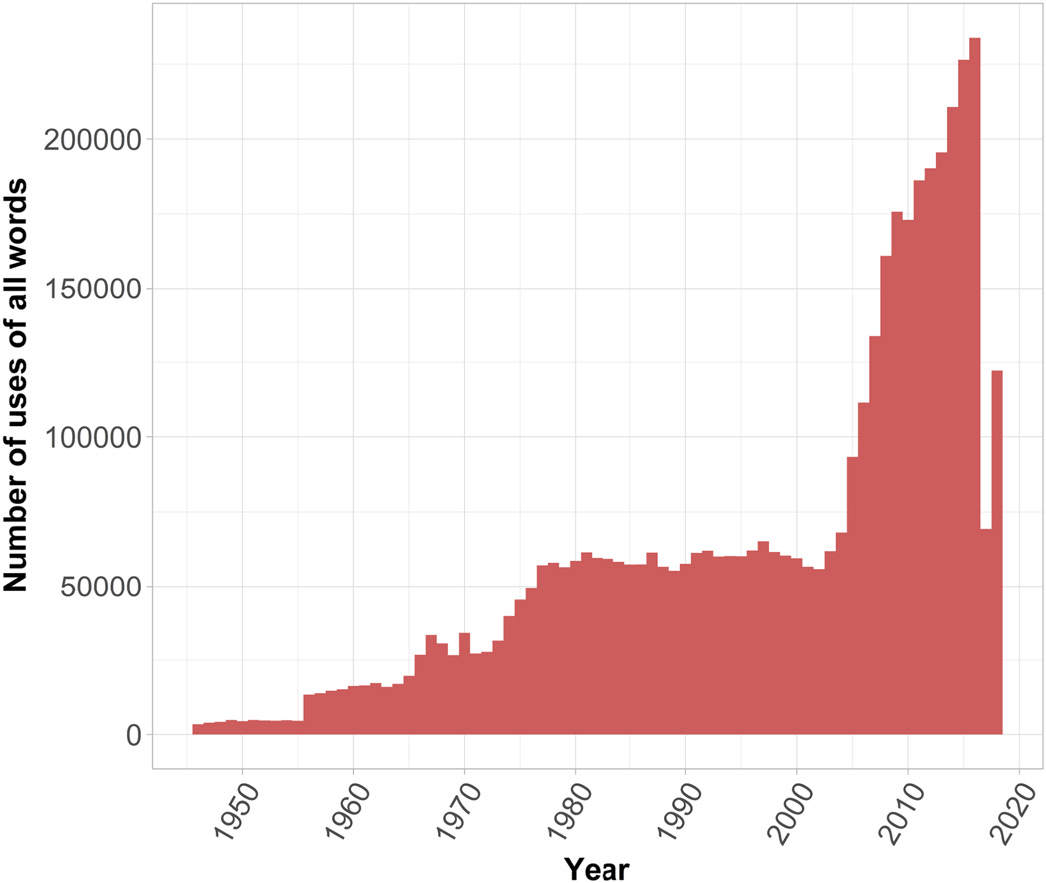
Figure 4. WKins: distribution based on words and writings.
The overall trend, of course, demonstrates a significant growth of the number of words used—from 3,415 in 1946 to a peak of over 233,818 in 2016 (the drop in the numbers in 2017–2018 is due to delay in indexing). This growing trend is easily explained by the growth of political science discipline and the subdisciplines within it, as well as the growth in the absolute number of journals. In the decade prior to mid-1990s alone, over a hundred new journals were launched (Almond, Reference Almond1996). This appears to be a part of overall process that of development of the field of political science. This includes, but is not limited to, more articles being published, more journals becoming active, more topics coming into the view of political scientists. What is interesting, however, is that this growth is not even—it occurs in spurts. Such spurts occurred in mid-1960s and mid-1970s, continuing into the 2000s, coinciding with known changes in scientific debates.
The first spurt coincides with growth in behaviorism after the WWII. Then, the end of 1960s—beginning of 1970s is a well-known period of debates around behaviorism and questions about its capacity to explain political phenomena (Farr & Seidelman, Reference Farr and Seidelman1993). Some scholars even spoke about the paradigm shift and the end of “normal science” in political studies (Ball, Reference Ball1976; Beardsley, Reference Beardsley1974). The substantial increase (almost double) from mid-1970s until 1980s corresponds to the rise of rational choice theory tradition. The spurt around the 1980s–1990s is contemporaneous with the two new versions of new institutionalism—sociological and historical. Finally, around mid-2000s, we see the increase in constructivism, the expansion of advanced computational social sciences methods, and the possible establishment of a multi-paradigm approach to political science, first spoken about Ball (Reference Ball1987) and Haas (Reference Haas1986). Even if this timeline is not exact, the evidence of a pattern consisting of periods of relative “calm” interleaved with periods of explosive growth in the discipline development is clear.
A more detailed analysis of words for each specific paradigm allows to narrow down these periods more precisely. We calculated the proportion of the number of appearances of each word to the most frequent word for each year based on the
 $\textit{WKins}$
network (Batagelj & Praprotnik, Reference Batagelj and Praprotnik2016). This proportion normalizes the importance of a certain word over time from 0 to 100%. The proportions for the words associated with each paradigm of political science over time are presented in the Figures 5 and 6.
$\textit{WKins}$
network (Batagelj & Praprotnik, Reference Batagelj and Praprotnik2016). This proportion normalizes the importance of a certain word over time from 0 to 100%. The proportions for the words associated with each paradigm of political science over time are presented in the Figures 5 and 6.

Figure 5. Distribution of proportion of keywords indicating paradigms (part 1).
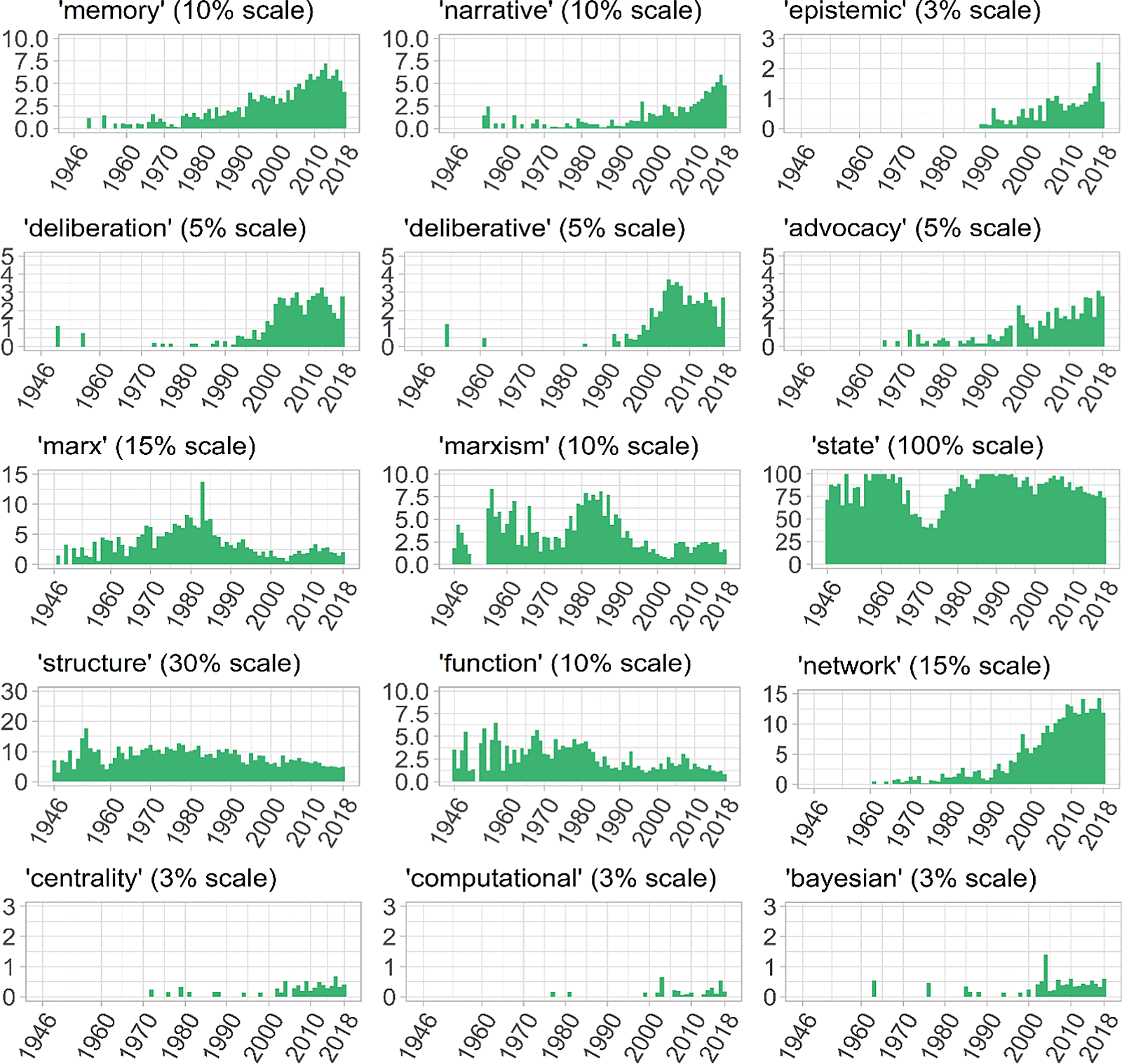
Figure 6. Distribution of proportion of keywords indicating paradigms (part 2).
For the first paradigm, behaviorism, the most indicative are the words “behavior,” “behavioral,” and “psychology” (Adcock et al., Reference Adcock, Bevir and Stimson2009). If the use of the word “behavior” is stable over time, then the usage distribution of the words “behavioral” and “psychology” is more interesting (see the first line of Figure 5). From 1946 until the mid-1950s, there is a peak of the use of the word “psychology,” closely related to behaviorism (Adcock et al., Reference Adcock, Bevir and Stimson2009). Another less pronounced and shorter peak of the word is apparent after the mid-1960s, when the literature was full of debates about the crisis of behaviorism. After that time, with exception of some barely noticeable peaks, the popularity of this word steadily declines. We see a similar pattern in the dynamics of the word “behavioral” with a more pronounced increase by mid-1960s and almost complete drop of interest to the term by 1980s, when the dominance of the alternative traditions of new institutionalism is firmly established.
The youngest approach within new institutional tradition is rational choice theory started to grow in 1970s. We test its dynamics using such word markers as “rational” and “choice,” which are obvious; “game” (as in “game theory”) is a synonym for this research program (Figure 5, second line) (Goodin & Klingemann, Reference Goodin and Klingemann1996; Hall & Taylor, Reference Hall and Taylor1996). Indeed, if we look at the first two words alone, the advent of this tradition occurs at the end of 1970s. However, the word “game” reaches its first prolonged peak of popularity in 1970. In 1980s, at the time of new institutionalism establishment, the growth of all three words reaches a near-plateau, with a sharp increase again in the 1990s. The end of 1990s—beginning of 2000s—sees the highest popularity of this paradigm. Perhaps, this is because popular in the U.S. approaches became popular elsewhere with a bit of a delay. Nonetheless, from the mid-2000s, the popularity of rational choice theory is declining.
We started testing new institutionalism as a whole paradigm with words “institutionalism,” “institutional,” “institution.” All three words show very similar dynamics of growth in usage from 1990s (Figure 5, line 5), indicating the advent and the growing dominance of this latest new paradigm. We further distinguish two other approaches within it: sociological institutionalism and historical institutionalism—based on their differences in the definition of “institution” and approach to institutional change (Schmidt, Reference Schmidt2010).
We tested sociological institutionalism development using such words as “sociological,” “cultural,” “norm,” “rule,” and “frame,” historical institutionalism—using words “historical,” “history,” “culture,” “path,” “dependency,” “critical,” and “juncture.” We observed interesting dynamics for words “norm,” “rule,” and “frame” for sociological institutionalism, and “culture,” “path,” and “juncture” for historical (Schmidt, Reference Schmidt2010).
Apparently, historical institutionalism started to develop earlier than sociological institutionalism. The word “culture” starts its long-term growth approximately in mid-1970s, reaches its first peak in second part of 1980s, then continues its growth in the 1990s, and reaches the maximum around the 2000s. It somewhat loses its popularity in recent years, but remains significant in the literature, which means that this paradigm continues its dominance in political science. The word “path” follows approximately the same trajectory. The word “juncture” is a much less pronounced, with an advent in the 1990s and continued use in the 2000s (Figure 5, line 3) (Schmidt, Reference Schmidt2010).
Judging by the dynamics of the words “norm,” “frame,” and “rule,” the stable long-term growth of the sociological institutionalism paradigm started in the mid-1990s and continues this path (Figure 5, line 4). An interesting dynamic is observed with the word “frame”: it came to use much later than the other two words, but then sharply increased in popularity and remains popular until now (Schmidt, Reference Schmidt2010).
For constructivism or “discursive institutionalism,” we used the distinguishing framework proposed by Schmidt (Reference Schmidt2010). Following her rationale, we tested the following markers of constructivism: “constructivism,” “construct,” “ideas,” “ideational,” “discourses,” “discursive,” “communication,” “communicative,” “memory,” “narrative,” “epistemic,” “deliberation,” “deliberative,” “advocacy,” “interpretation,” “interpretive.” They all share similar patterns—the start of growth in the 1990s and proliferation in the 2000s (Figure 5, lines 6,7; and Figure 6, lines 1,2).
We also examined the dynamics of other, smaller, research programs in political science, not all of which are accepted by historians of science as paradigms, but nonetheless, remain important anchors in political science. It appears that the peak of interest to “Marx” and “Marxism,” which some consider as a separate approach in political science (Bowman, Reference Bowman2007), was reached in the 1980s (Figure 6, line 3).
Neostatism (Adcock et al., Reference Adcock, Bevir and Stimson2009; Nettl, Reference Nettl1968) as a separate paradigm is not so clearly defined as other traditions, because the word “state” is very popular in political science in general. However, the other words that we tested—“statism,” “stateness,” “statehood,” “etatism”—are not. It seems that the end of 1970s was marked by a rapid growth of the usage of the word “state,” with a decade of dominance of this word from the mid-1980s to the mid-1990s (Figure 6, line 3). This is evidence for the argument that neostatism was an alternative to new institutionalism after the crisis of behaviorism. Another alternative to behaviorism, which is not so popular now, was structural functional approach (Varshney, Reference Varshney1978; Groth, Reference Groth1970; Mitchell, Reference Mitchell1958). The usage of the base words for this approach—“structure” and “function”—grew in the 1960s, peaked in the 1970s, and declined in the 1980–1990s (Figure 6, line 4).
Words indicative of computational political science (Lazer et al., Reference Lazer, Pentland, Adamic, Aral, Barabási, Brewer and Jebara2009; Weber et al., Reference Weber, Popescu and Pennacchiotti2013, Voinea, Reference Voinea2016; Wong et al., Reference Wong, Tan, Sen and Chiang2016)—“computational,” “centrality,” “mixed,” “machine,” “Bayesian”—are not yet popular, relatively speaking, in political science yet (Figure 6, lines 6,7). One exception may be the word “network.” However, this word has a much wider meaning: it relates not only to “network analysis” but also to other areas of political science, not necessarily studied with statistical network-analytic methods. The word “network” can also indicate formation of networks in public policy—policy networks; it could be related to a special management type—network governance. Nonetheless, judging by the use of other related words in the aggregate, we can conclude that computational social sciences are gaining popularity. While the trend is optimistic, this paradigm is still in its infancy in political science. An implicit indication is the fact that the literature is using the phrase “computational social science” as opposed to “computational political science” (Lazer et al., Reference Lazer, Pentland, Adamic, Aral, Barabási, Brewer and Jebara2009; Weber et al., Reference Weber, Popescu and Pennacchiotti2013, Voinea, Reference Voinea2016; Wong et al., Reference Wong, Tan, Sen and Chiang2016).
4. Keywords co-occurrence network analysis: Topic discovery in political science
We next turn to the second objective our study: a finer examination of the paradigms for the discovery of more narrow topics or subdisciplines. For this purpose, we use the
 $nWK^{\prime}_{2}ryx$
and
$nWK^{\prime}_{2}ryx$
and
 $nK'K'$
networks.
$nK'K'$
networks.
4.1. Descriptive network analysis
Figure 7(a) shows the distribution of the number of keywords per writing in the
 $nWK_{2}ryx$
network. Figure 7(b) presents the same information for the
$nWK_{2}ryx$
network. Figure 7(b) presents the same information for the
 $nWK^{\prime}_{2}ryx$
network. Overall, most articles use from one to ten keywords. After ten, the number of articles using a higher number of keywords starts to decline sharply.
$nWK^{\prime}_{2}ryx$
network. Overall, most articles use from one to ten keywords. After ten, the number of articles using a higher number of keywords starts to decline sharply.
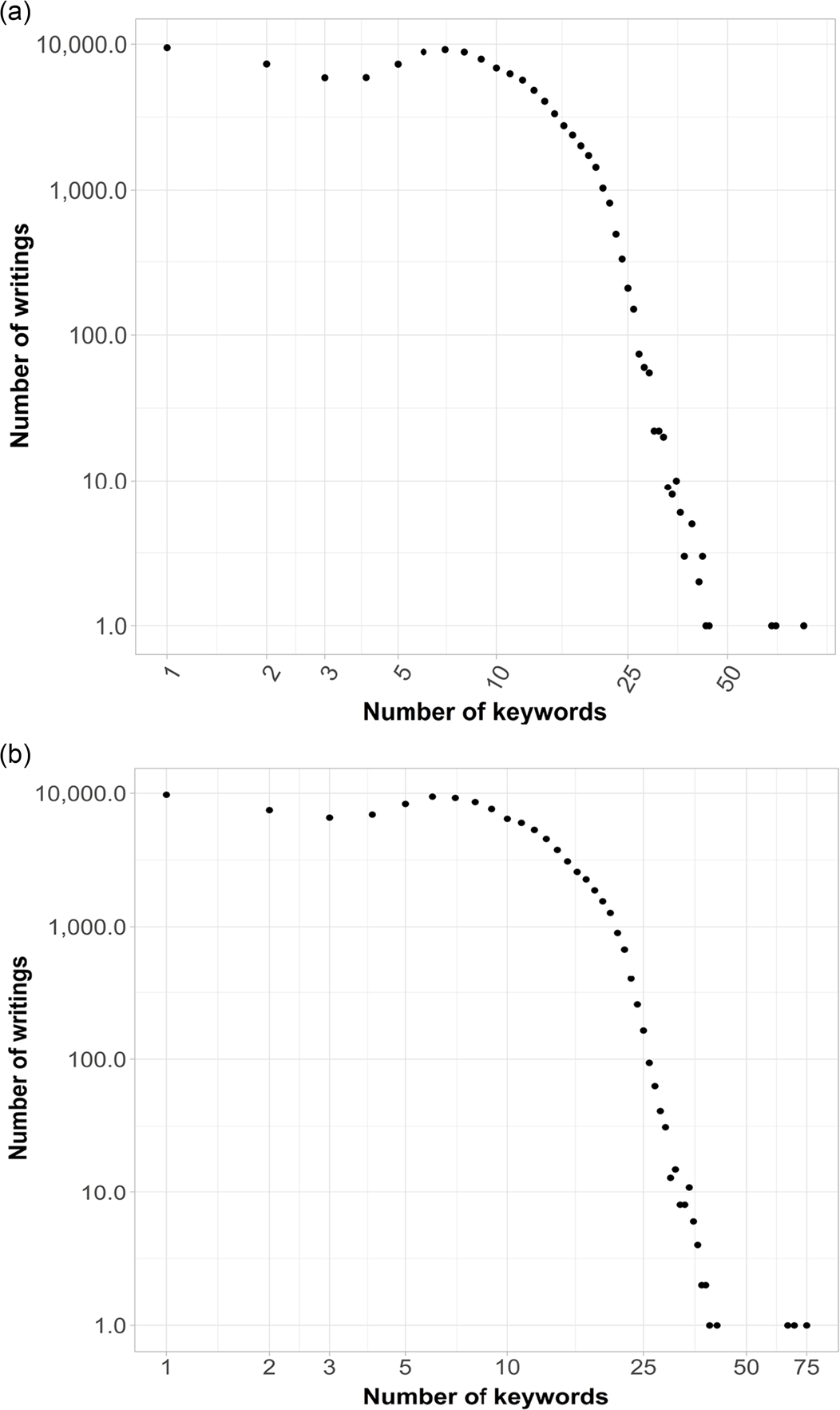
Figure 7. (a) Logarithmic plots with distributions of the number of keywords per writing (nWK
2
ryx). (b) Logarithmic plots with distributions of the number of keywords per writing (nW
 $K^{\prime}_{2}$
ryx).
$K^{\prime}_{2}$
ryx).
Figure 8(a) and (b) show distribution of unique keywords used by writings. Figure 8(a) shows distribution of all keywords used, from the nWK 2 ryx network. This plot demonstrates that there are keyword combinations very large in size, used by a small number of writings. For example, there is a combination of 10,000 keywords used only by one writing.
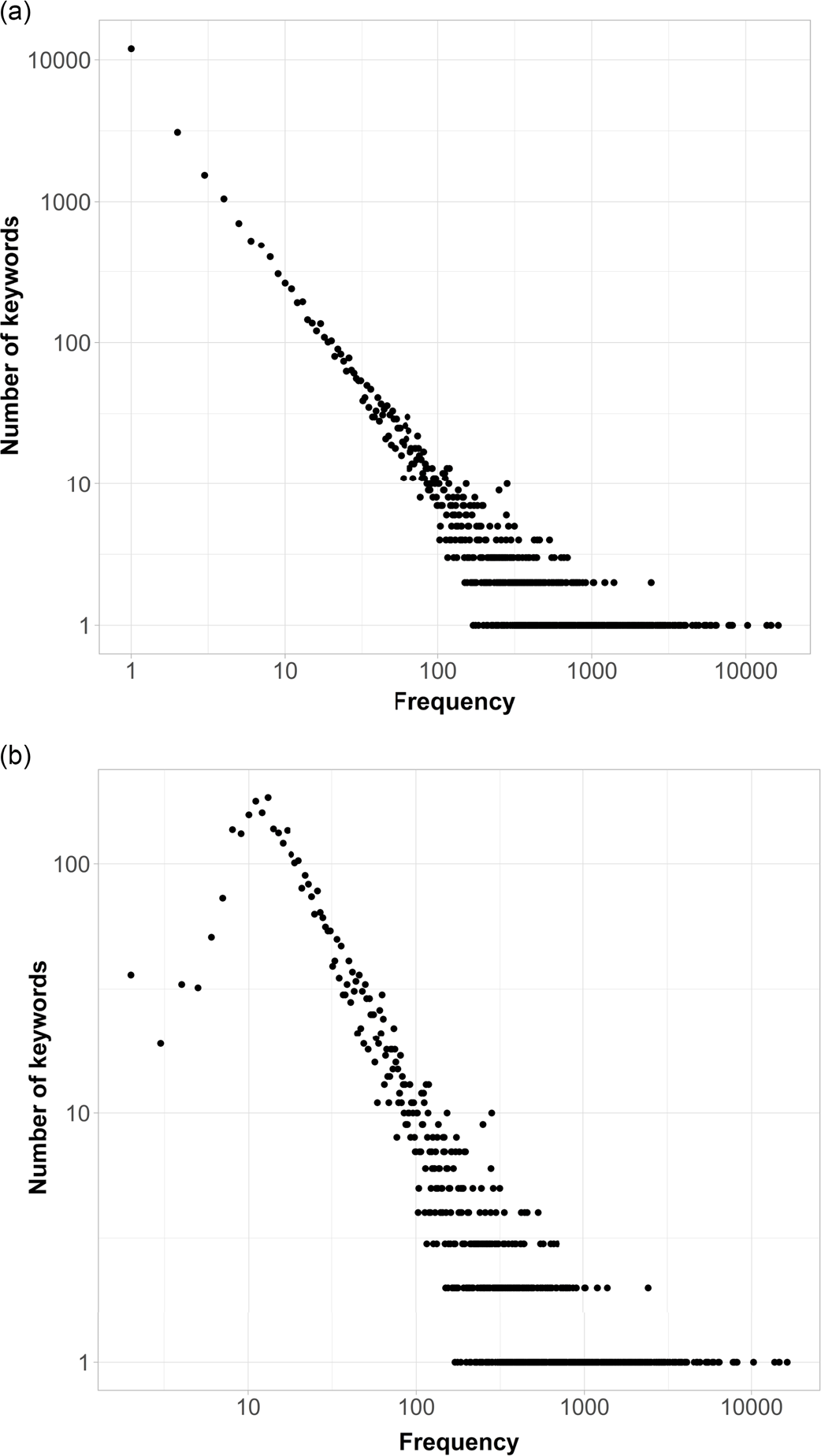
Figure 8. (a) Logarithmic plots with distributions of the number of unique combinations of all keywords used in all writings (nWK
2
ryx). (b) Logarithmic plots with distributions of unique combinations of keywords after removal of misleading keywords, used in all writings (nW
 $K^{\prime}_{2}$
ryx).
$K^{\prime}_{2}$
ryx).
Figure 8(b) shows distribution of keywords from nWK’
2
ryx network, created after removal of misleading keywords, and thus describing the field more accurately. The major difference with Figure 8(a) is observed for the range of 10–100 keywords. There are many combinations of 10–100 keywords in the full network that are used by close to 100 writings. However, some of these combinations, apparently, do not carry a lot of meaning: after misleading keywords are removed, there are six keyword combinations left within the 10–100 range that are used by less than ten writings. Otherwise, the distribution of keywords in nW
 $K^{\prime}_{2}$
ryx network peaks at 184 individual keyword combinations that are mentioned in 13 writings. Another 160 combinations are used by 12 writings each; 178—by 11 writings each, etc.
$K^{\prime}_{2}$
ryx network peaks at 184 individual keyword combinations that are mentioned in 13 writings. Another 160 combinations are used by 12 writings each; 178—by 11 writings each, etc.
Creating a network without misleading keywords allowed us to focus on keywords that are indicative of their respective topics or are used extensively, constructing the core concepts of the field. Later analysis will show that with reduced network we have managed to identify both keywords that specify the core concepts of political science as well as keywords that represent individual subfields, this speaks for the validity of the data used in the analysis.
An exploratory analysis showed that in the keywords co-occurrence network (
 $\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
), the most frequent keywords which are used together with other keywords are “political,” “state,” “politics,” “policy,” “social,” “public,” “democracy” and “power” (Table 4S, supplementary materials). Comparative analysis of two sets of keywords: those used in the largest number of articles and those used most frequently with other keywords, allows to separate keywords into generic and specific. While the construction of the networks used for this comparison may have impacted the scores themselves, it is the relative importance of different keywords that we consider for this analysis. For this purpose, Table 4S contains top-60 keywords from two networks: the keywords co-occurrence network (
$\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
), the most frequent keywords which are used together with other keywords are “political,” “state,” “politics,” “policy,” “social,” “public,” “democracy” and “power” (Table 4S, supplementary materials). Comparative analysis of two sets of keywords: those used in the largest number of articles and those used most frequently with other keywords, allows to separate keywords into generic and specific. While the construction of the networks used for this comparison may have impacted the scores themselves, it is the relative importance of different keywords that we consider for this analysis. For this purpose, Table 4S contains top-60 keywords from two networks: the keywords co-occurrence network (
 $\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
) and writings-to-keywords network (
$\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
) and writings-to-keywords network (
 $nWK^{\prime}_{2}ryx$
).
$nWK^{\prime}_{2}ryx$
).
The keywords that are underlined in Table 4S—“human,” “justice,” “community,” “American,” “decision,” “strategy,” “culture” and “new”—are present in a relatively small number of articles, but are connected with a large number of other keywords. These are the generic keywords, meaning that by these keywords alone, it is not possible to understand the topic of the article. To place the meaning correctly, other, more specific, keywords are required. These keywords can delineate wider topics and be used in different contexts and areas. For example, the keyword “community” may indicate a methodological topic—“community detection” in networks, but may also be related to coalition formation in public policy—“policy communities,” or to a special policy instrument—“community building.”
Keywords that are bolded in Table 4S—“representation,” “competition,” “integration,” “voting,” “trade,” “electoral,” “EU” and “growth”—are present in a relatively large number of articles, but they are connected to a smaller number of keywords. Most likely, this means that they are more specific. The topic of the article is understood from these keywords without additional explanations. These keywords can delineate finer topics and be used in narrow contexts and areas. For example, the keyword “EU” indicates a specific region of the world and the socioeconomic union of countries within it. As another example, the keyword “growth” also has a rather narrow meaning of “economic growth” in political science. Overall, again, this is a confirmation of the data validity.
4.2. Cluster network analysis: Link islands method
We next use cluster network analysis to test our second assumption that political science consists of ten subdisciplines or topics: political theory, political institutions, law and politics, political behavior, contextual political analysis, comparative politics, international relations, political economy, public policy, and political methodology. We do so by using the link islands method (Nooy et al., Reference Nooy, Mrvar and Batagelj2018; Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014), selected because it is now widely used in scientific networks and has been shown to accurately detect scientific schools in many different disciplines (Doreian et al., Reference Doreian, Batagelj and Ferligoj2020). “Island” is defined (Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014) as a maximal connected subgraph, with values of edges between the nodes of the subgraph higher than the values of edges between the subgraph and the rest of the network. An important property of islands is that they “identify locally important subnetworks at different levels. Therefore, they can be used to detect emerging groups of phenomena” (Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014: 55). It allows to isolate not only large clusters but also smaller islands—in this case, “coherent well-connected” (Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014: 54) subdisciplines in political science. This is exactly what we need to grasp the meaning in the fragmented and separated subfields in this discipline.
To determine the number of cuts that would allow us to delineate ten islands—the theoretical number of subdisciplines in political science—we analyzed the plots of changes in the number of islands against the maximum cut sizes [Figure 9(a) and (b)]. We selected the minimum cut based on the distribution of the number of keywords per writing. As stated before, the majority of writings contain between 1 and 10 keywords; therefore, for the minimum cut, we took 2, 3, 5, and 10 keywords. (We did not use one keyword because the minimum number of keywords required to specify a topic is two.)

Figure 9. (a) Plots of changes in the number of islands against the maximum cut sizes (complete network
 $nK'K'$
). (b) Plots of changes in the number of islands against the maximum cut sizes (Main island (5,000 nodes) of the first cut of the network
$nK'K'$
). (b) Plots of changes in the number of islands against the maximum cut sizes (Main island (5,000 nodes) of the first cut of the network
 $nK'K'$
).
$nK'K'$
).
In order to achieve the theoretically specified number of islands (ten), we need a minimum cut of 2 and maximum cuts in the range of 5,000–5,066 keywords; or minimum cut of 3 and maximum cuts in the range of 3,035–3,284 keywords. Cuts 5 and 10 do not provide us an opportunity to receive 10 islands (Figure 9a). In bibliometric studies, thresholds of 2 or 3 keywords are typically used when analyzing keyword co-occurrence networks are often used (Schodl et al., Reference Schodl, Klein and Winckler2017; Maltseva & Batagelj, Reference Maltseva and Batagelj2020; Žnidaršič et al., Reference Žnidaršič, Maltseva, Brezavšček, Maletič and Baggia2021).
Therefore, the sizes of our subnetworks ranged from 2 to 5,000 nodes, allowing us to cluster our keywords co-occurrence network (
 $\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
) into 10 islands. The main island contains 5,000 nodes; other smaller islands contain two keywords each (Table 5S, Supplementary Materials).
$\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
) into 10 islands. The main island contains 5,000 nodes; other smaller islands contain two keywords each (Table 5S, Supplementary Materials).
These smaller islands represent narrow, borderline topics in political science, perhaps crossing into other disciplines. They can be described as follows: politics of Latin American countries (“partido, nacional”), including the presidency of Juan Manuel Santos in Colombia (“manuel, juan”); knowledge economy and developing society-academia partnerships (“triple, helix”); art and political science (“avant, garde”); lobbying and interest representation in governing bodies (“revolve, door”); human rights issues in liberal economies (“faire, laissez”); nuclear weapons proliferation issues (“uranium, enrichment”); studies of human emotions and their connections to policy (“gesture, imitation”); anarchy studies and public choice (“maghribi, trader”).
The main island of about 5,000 keywords, which we have obtained from the first cut, is too large to be analyzed in its entirety and is likely to contain the core topics and subdisciplines of political science. Therefore, using the island methodology (Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014) we partition it again. To achieve theoretically relevant ten islands, we can partition this main island of the first partition using 2 as minimum cut and any number in a range from 4,796 to 4,808 as a maximum cut. Alternatively, we can choose 3 as a minimum cut and a number in the range from 3,035 to 3,284 for a maximum cut. Cuts 5 and 10 again do not provide us an opportunity to obtain ten islands (Figure 9b). In order to achieve the theoretically specified number of islands (ten), we need a minimum cut of 3 and maximum cuts in the range of 3,035–3,284 keywords.
The sizes of the subnetworks we obtained ranged from 3 to 3,100 nodes, allowing us to cluster the main island of the keywords co-occurrence network (
 $\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
) into 10 islands. The main island contains 3,100 nodes; other islands contain 3–4 keywords each (Table 6S, supplementary materials).
$\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
) into 10 islands. The main island contains 3,100 nodes; other islands contain 3–4 keywords each (Table 6S, supplementary materials).
These smaller islands represent narrow, almost borderline topics in political science, perhaps crossing into other disciplines. They can be described as follows: genetically modified organisms and their consequences for policy (“genetically, modify, organism”); drones and political consequences of their use (“aerial, unmanned, vehicle”); political philosophy of Gilles Deleuze and its application to political research (“deleuze, gille, guattari”); neuroscience and politics (“cortex, neuroscience, prefrontal”); conflicts and fate of African states (e.g., Côte d’Ivoire) (“cote, divoire, ivoire”); pandemics (HIV/AIDS, SARS, and their consequences) (“immunodeficiency, october, sar, virus”); conflict in Nagorny Karabach and surrounding regions (“armenia, azerbaijan, karabakh, o Nagorno”); introductions to special issues and volumes and analysis of editors’ and writers’ political identities, including written productions (“editor, introduction, writer”); information cascade theory and its applications to the study of new media, new protests, policy diffusion, etc. (“cascade, fad, informational”).
Despite the wide variety of topics, two partitions with main islands (5,000 and 3,100 nodes) have similar nine smaller islands. They contain smaller islands with relatively new topics, small number of writings’ citations, and small number of writings in general. These topics are new for political science, but quite likely, very promising for future expansive research. This is because they borderline other disciplines, such as sociology, neuroscience, medicine, engineering, philosophy, psychology, philology, area studies, economics etc.—meaning, they are interdisciplinary or cross-disciplinary. As calls for interdisciplinary research are becoming more urgent in social sciences, these new, but already developing fields have the potential for quickly answering such calls (Goodin, Reference Goodin2009).
The main island of 3,100 keywords we have obtained from the second cut is also large and, similar to the first cut, likely to contain a mixture of topics. Therefore, we repeat the partitioning procedure again (Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014), reapplying the same island methodology to the main island of 3,100 nodes with limits from three to 300 keywords in an island. The resulting partition consists of 18 islands (Table 6, supplementary materials). The first 17 islands are small, consisting of 3–5 keywords, with another big island of 300 nodes. They can be grouped into four categories associated with four subdisciplines: public policy, political theory, international relations, and political methodology (Table 7S).
The largest group are the topics related to public policy issues. It includes citizen safety and protection from fatal accidents fires, natural disasters, (“crowd, fatality, traffic”); motivated reasoning, skepticism, and belief systems of politicians and citizens (“motivate, reasoning, skepticism”); politics of equal opportunity and tolerance (“fetal, pain, sympathy”); collective political trauma and trauma policy (“disorder, posttraumatic, stress”); sport policy (“football, professional, sport, team”); indigenous people, youth policy, and what unites them—minority rights, transitional justice, and other related theories (“indigenous, people, young”); analysis of financial and other markets in periods of growth and decline (“automobile, boom, bust”); codes, standards, and regulations (“code, conduct, operational”).
The second group are the studies related to theory testing. Not all the theories are popular in political science, and the studies are often dedicated to their applicability to the field. These are the theories of collectivism and individualism (“collectivism, individualism, methodological”); equity theories and the works of Amartya Sen (“amartya, entitlement, sen”); Tullock’s rent-seeking game and its applications (“efficient, rent, seek”); and the Condorcet jury theorem and its applications to politics (“condorcet, jury, theorem”).
The third group are topics loosely related to international relations. It includes China and its trade policies (“belt, road, silk”); colonialism and its consequences (“colonialism, Japanese, settler”); problems related to natural resources and the tragedy of commons—resource curse, conflicts, and wars (“curse, natural, resource”). The final group is the group of methodological studies. It includes the black box of causal inference in politics (“causal, inference, mechanism”) and problems with survey methodology—nonresponse bias, etc. (“exchange, rate, response, survey, telephone”).
The main island of the third cut or partitions represented in Figure 10. We argue that this island represents the core topics in political science or the “the canon that practicing political scientists need to master in order to have mastered the discipline” (Goodin, Reference Goodin2009: 29).
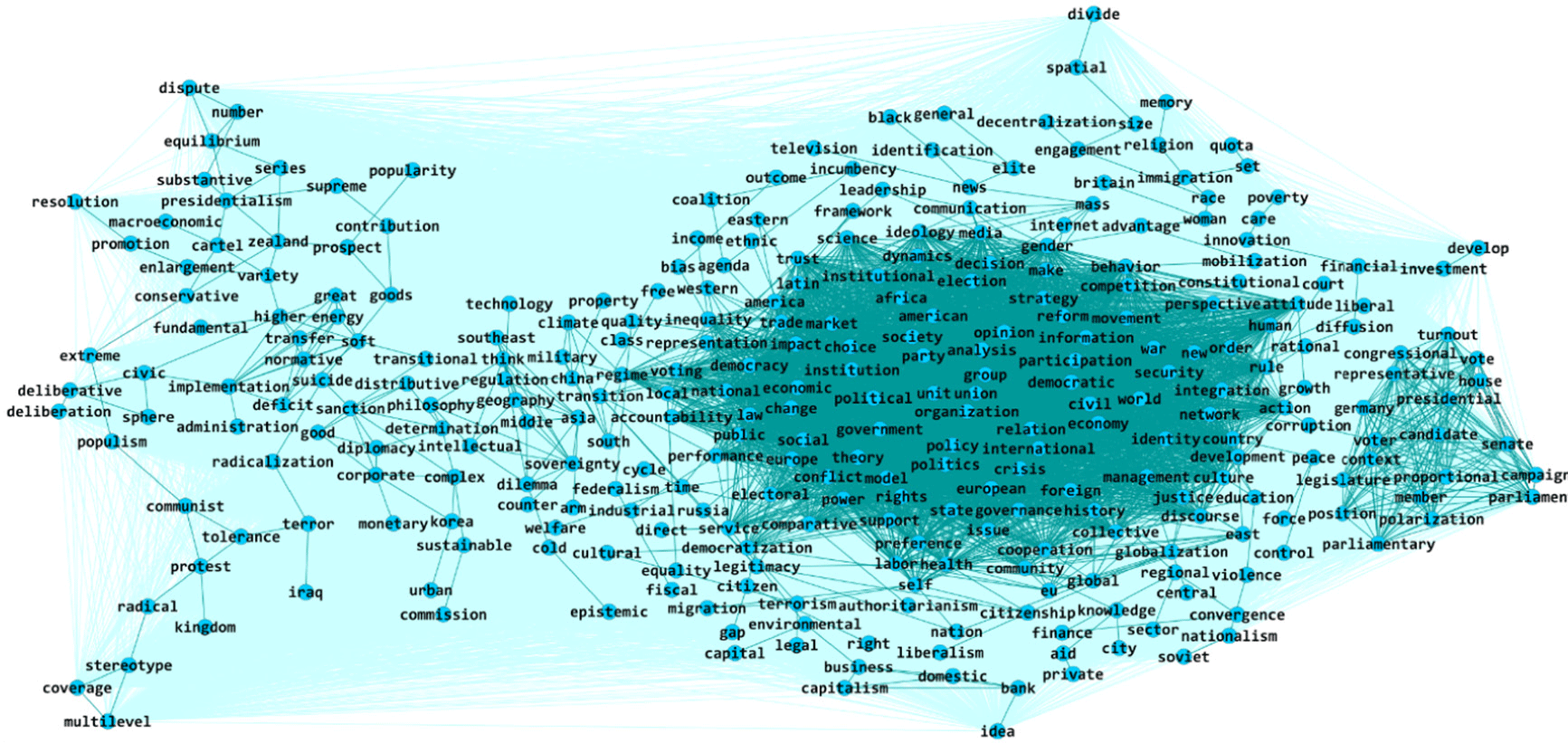
Figure 10. Main island of
 $nK'K'$
network: “the canon of political science”.
$nK'K'$
network: “the canon of political science”.
To have the opportunity to examine this island with more accuracy, following the same procedure of Batagelj et al. (Reference Batagelj, Doreian, Ferligoj and Kejzar2014), we again partitioned the islands with cuts of 2,5. This allowed us to isolate 31 islands. The topics of islands corresponded most closely to the current state of affairs in the field of political science, because they represent the nine of the coveted ten subdisciplines. They are shown in Table 8S of Supplementary Materials.
“Public policy,” again, seems to be the topic leader, taking into consideration the number of topics that were algorithmically extracted as the most connected by keywords related to this discipline. Public policy is comprised of seven islands out of 31. Each island is a separate topic in the public policy subfield: civic and higher education (with keywords “civic, education, higher”); health care policy (“care, health”); socioeconomic and political inequality (“income, inequality”); issues of decision-making on individual, collective and state levels—the topic more related to public administration at the intersection of decision sciences (“decision, make”); local governance problems (“government, local”); global environmental policy and challenges including climate change (“change, climate”); issues of gender policy and discrimination (“gender, woman”).
“International relations,” “political economy,” and “political behavior” are the next two subdisciplines that are related with several islands, four in each case. International relations are represented by its namesake main island (“international, law, relation”). There is also a large island representing an important topic for this subdiscipline—writings related to the analysis of conflict resolution, wars, topics of peace and security (“civil, conflict, peace, society, war”). Another island is related to the issues of transitional and international justice and law (“court, justice, supreme, transitional”). The last island can also be attributed to the “law and politics” subdiscipline, because it contains writings related to national courts and justice. The issues of international self-determination, annexes, and secessions, are also important on agenda of contemporary international relations (“determination, self”).
“Political economy” is represented by an island about financial crises (“crisis, financial”); economic growth and development (“development, economic, growth”); the study of the markets, including labor markets and the issues related to labor migration (“labor, market”). In addition, there is an island related to the cyclicality of economic development and related political cycles (“business, cycle”).
“Political behavior” is represented by an island related to collective action (“action, collective”) and social movements (“movement, social”). It also contains a more traditional subtopics of electoral behavior (“turnout, voter”), and public opinion studies (“opinion, public”).
The already mentioned subdiscipline of “law and politics” is also represented by the writings about relationships between national and international laws and the issues of priority of one over the other (“court, justice, supreme, transitional”). It is also related to no less important topic of human rights (“human, rights”). Both are separate islands.
The subdiscipline of “political institutions” is traditionally related to the study of institutes of democracy, related institutes of elections and multiple parties, and also economic institutes, often serving as the foundation of the subdiscipline. The keywords that represent this island “democracy, economy, election, party, political.”
Two subdisciplines—“contextual political analysis” and “comparative politics”—do not have their separate islands. More likely, they share topics with each other, studying them from different angles. One such topic is regional studies, related to writings about specific world regions, such as Eastern Europe (“eastern, Europe”); South Africa (“Africa, south”); Middle East and Southeast Asia (“Asia, east, middle, southeast”); European Union (“European, integration, union”), Latin America (“America, Latin”). They also share a common topic of country development (“country, develop”). Each subdiscipline claims its own methodological approach to the study of political phenomena. However, the literature also contains writings about the difficulties related to establishing the identity of each discipline.
Two other subdisciplines—“political methodology” and “political theory”—are not well-represented by extracted islands. However, some islands extracted during the third cut could be attributed to each of them (Table 7S). Among the islands of the fourth cut, “political methodology” also contains a topic of longitudinal analysis (“series, time”), which is quite popular and relevant for the study of political processes. From the third cut, we also know that this subdiscipline is represented by writings related to survey methodology, methods of causal inference modeling, and causal mechanism detection.
For “political theory,” we did not find any islands in the fourth partition, but they were present in the third one. However, almost all islands of the fourth cut contained purely theoretical papers. It is interesting to note that previous bibliometric studies found this subdiscipline to be less integrated in political science (Goodin, Reference Goodin2009). It is also possible that we did not find a separate island for “political theory” because theory scholars, for the most part, prefer to publish books. Also, it is possible that there is a difference between theoretical topics and theory-oriented scholars. The scholars are less integrated with other scientists, while the topics, on the contrary, are more integrated and related to other studies that test them empirically.
Finally, there are three islands that are somewhat problematic—they cannot be related to any one subdiscipline. The first island is the island that contains studies on “new” topics, but also New Zealand (“new, Zealand”). The second is related to politics and news (“media, news”). The third is related to the problems of foreign policy, state policy, and politics (“foreign, policy, politics, state, unit”). If the first island is more logical but less relevant, the other two are quite interesting. “Political communications” appears to be a legitimate subdiscipline, though Goodin (Reference Goodin2009) does not identify it with the main ten—only as a smaller subdiscipline, more prominent historically. It is recognized, however, by some other scholars of political science and media studies (e.g., Graber & Smith, Reference Graber and Smith2005). The final island is a very interesting collection of writings on the intersection of at least two subdisciplines—“international relations” and “public policy”—and perhaps, even contains a third—“political institutions.”
Altogether, we have extracted 66 islands, which is substantially more than ten theoretically hypothesized subdisciplines. Relying on a team of subject matter experts, led by a professor with over twenty years of work in the field of political science, we qualitatively interpreted them for their correspondence with the ten theoretical subdisciplines. However, we were not always able to do so: not all islands could be clearly assigned to one and only one subdiscipline. It appears that ten theoretical subdisciplines are not distinctive; they are, more likely, formed by groups of islands or clusters—not the exclusive topics. Therefore, a much more important conclusion of this study is that the field of political science can be described by a clear core-periphery structure, which we have observed repeatedly over several cuts across topics.
4.3. Cluster network analysis robustness check with HCA
To test the robustness of our conclusions, we implement the HCA method as an alternative to the LIM. Specifically, we wanted to see if we would again obtain the core-periphery structure of the topics, and whether we would find more than ten subdisciplines. HCA is a method that has been widely used in bibliometric studies to analyze keyword co-occurrence networks along with the link islands method (Sun et al., Reference Sun, Tang, Ye, Zhang, Wen and Zhang2014; Bhuyan et al., Reference Bhuyan, Sanguri and Sharma2021; Lee et al., Reference Lee, Choi and Kim2010; Yang & Ning, Reference Yang and Ning2021). In implementation of the HCA approach, we used the same restriction on the number of clusters that we have received from cuts of LIM method and followed the procedure of further clustering of the largest island obtained by each partition (a total of four times). Table 9S of the Supplementary Materials describes the partitions obtained by LIM and HCA.
Following this approach, we first converted the normalized keywords co-occurrence network
 $\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
to a dissimilarity matrix using the cosine distance measure. The use of the cosine measure allowed us to group the keywords based on the similarity of contexts in which they were used (Maldonado-Guerra & Emms, Reference Maldonado-Guerra and Emms2011; Zhiqiang et al., Reference Zhiqiang, Werimin and Zhenhua2009). The use of this measure was suggested by previous bibliometric studies (Bhuyan et al., Reference Bhuyan, Sanguri and Sharma2021) focused on keyword co-occurrence analysis.
$\mathit{nK}\mathit{'}\mathit{K}\mathit{'}$
to a dissimilarity matrix using the cosine distance measure. The use of the cosine measure allowed us to group the keywords based on the similarity of contexts in which they were used (Maldonado-Guerra & Emms, Reference Maldonado-Guerra and Emms2011; Zhiqiang et al., Reference Zhiqiang, Werimin and Zhenhua2009). The use of this measure was suggested by previous bibliometric studies (Bhuyan et al., Reference Bhuyan, Sanguri and Sharma2021) focused on keyword co-occurrence analysis.
Then, we have applied the HCA procedure using complete linkage as the agglomeration method. This method searches for tight, compact clusters, which allows the discovered topics to be more interpretable (Sileshi & Gamback, Reference Sileshi and Gamback2009).
To evaluate the results received by applying the LIM, we partitioned the network
 $nK'K'$
into 10 clusters using the HCA. In the first partition, the size of the largest cluster was 5,521 keywords, which is comparable with the largest island of 5,000 keywords received in the first LIM partition. In the HCA partition, the sizes of other clusters were much smaller (from 1 to 11 keywords). This finding is also comparable to the first LIM partition, where the sizes of all smaller islands were equal to two (Figure 11, Table 9S in Supplementary Materials). Therefore, we can conclude that in first partitions by two different methods we obtained the core-periphery network structure.
$nK'K'$
into 10 clusters using the HCA. In the first partition, the size of the largest cluster was 5,521 keywords, which is comparable with the largest island of 5,000 keywords received in the first LIM partition. In the HCA partition, the sizes of other clusters were much smaller (from 1 to 11 keywords). This finding is also comparable to the first LIM partition, where the sizes of all smaller islands were equal to two (Figure 11, Table 9S in Supplementary Materials). Therefore, we can conclude that in first partitions by two different methods we obtained the core-periphery network structure.

Figure 11. Comparison of partitions obtained with link island method and hierarchical clustering.
In line with the LIM, we further split the largest HCA cluster of the first partition (5,521 keywords) into ten clusters. Resulting HCA partition had a large cluster of 5,395 keywords, and several clusters consisted of 43 keywords or less (see Table 9S). In the second partition of LIM, the largest partition was 3,100 nodes; the sizes of other islands ranged from three to four keywords. Again, this structure of partitions we received from both methods (one giant cluster and several much smaller ones) points to the presence of a core-periphery structure within the network.
Again, following the LIM, we further split the largest cluster of the second HCA partition (5,395 keywords). For the third partition, we aimed to adjust the number of clusters in such a way that that the size of the smallest cluster was at least three. In the third partition of LIM, the network was separated into 18 islands, with 300-word largest island, and smaller islands ranging from three to five keywords. In the third HCA partition, the network was also separated into 18 clusters, with the largest cluster of size 5,054 and smaller clusters with four to 41 keywords (Figure 11, Table 9S). Therefore, we can again conclude that the network
 $nK'K'$
has a core-periphery structure. Also, applying both methods—LIM and HCA—at this stage, when we do not limit the number of output clusters with ten, we received more than ten clusters. The HCA, as an alternative method, confirms our finding of existence of more than ten subdisciplines or topics in political science.
$nK'K'$
has a core-periphery structure. Also, applying both methods—LIM and HCA—at this stage, when we do not limit the number of output clusters with ten, we received more than ten clusters. The HCA, as an alternative method, confirms our finding of existence of more than ten subdisciplines or topics in political science.
Following the final step of LIM, we once again extracted the largest cluster of 5,054 nodes from the third HCA partition. With the fourth partition of LIM, we generated islands from two to five keywords in size. We reproduce this with HCA, creating a partition with clusters of size two to five, by adjusting the number of clusters. With the LIM, we have obtained 31 islands; with HCA, we have found 75 clusters, with their sizes ranging from 1 to 548 keywords. Even though the number of HCA clusters was much larger than with the LIM, we again supported our main theses that political science is represented by much greater number of subdisciplines than ten.
However, these findings also point at an important difference between the link island method and hierarchical clustering. The LIM not only allows for discovery of small, dense, cohesive subgroups within the network, but also automatically identifies keywords that do not belong to any cohesive topic. Such keywords are removed from further analysis by being assigned to the zeroth island which is not interpreted, leaving remaining subgroups to be more meaningful. In contrast, the HCA method, which is requiring that all keywords in the analysis need to be assigned to a cluster, gives rise to large, hard to interpret collections of keywords (e.g., larger than 500 keywords in partition 4). In HCA, keywords that do not form cohesive topics are still added to the generated clusters, thus sharply decreasing their interpretability.
The first three rounds of clustering with both methods show a very similar pattern of a single giant cluster or island combined with several much smaller clusters or islands. This pattern suggests that the normalized keyword co-occurrence network has a core-periphery structure, with both methods peeling outer layers of the core of the network during each round of clustering. Both HCA and LIM confirm the main findings of the previous section that there are more than ten subdisciplines of political science and that the network
 $nK'K'$
has a core-periphery structure.
$nK'K'$
has a core-periphery structure.
5. Discussion
This study had two major objectives. The first objective was to evaluate the presence, number, and change of paradigms or research programs in political science; the second—to identify the subdisciplines or topics within the field. Using a Web of Science (WoS) Core Collection dataset of all writings in political science field from 1946, we used the LIM (Batagelj et al., Reference Batagelj, Doreian, Ferligoj and Kejzar2014) and HCA (Sun et al., Reference Sun, Tang, Ye, Zhang, Wen and Zhang2014; Bhuyan et al., Reference Bhuyan, Sanguri and Sharma2021; Lee et al., Reference Lee, Choi and Kim2010; Yang & Ning, Reference Yang and Ning2021) methods for extracting related papers. To the best of our knowledge, this study was the first comprehensive bibliometric study in the field of political science, not limited by subfield, region, or some other narrowing criterion.
The study was mostly exploratory, though we relied on two assumptions to anchor our exploration: the most recognized division of the field by time periods and presence of ten subdisciplines. Our results indicate that despite some skepticism surrounding the possibility of extracting paradigms in political science, it is possible, in principle, to do so. We have found the evidence of existing in the literature, but contested, periodization of two paradigms. The first is behavioral studies from at least 1946 (the beginning of the study; actual advent of this approach happened, perhaps, much earlier) until the 1970s. The second is the new institutionalism paradigm from 1980s until now. This was the first contribution of our study.
Another contribution of our study was that we have uncovered the dynamics of research programs inside the new institutionalism paradigm. The rational choice theory, one of the research programs within this paradigm, appeared in the 1970s, but most likely was experiencing a decline by the 2000s. Historical institutionalism, which reached its peak in the 1980s, continued to develop well into the 1990s and 2000s, unlike rational choice. The latest research program within this paradigm, sociological institutionalism, appeared in the 1990s and is also still on the rise. Overall, new institutionalism, first associated with rational choice, continues its dominance due to the last two research programs. Constructivism, which some call the fourth research program inside the new institutionalism, does exist somewhat separately from the other three, but also started to rise in the 1990s and continues to develop to present times.
To check yet another widely accepted notion of the field’s development—that the field is multiparadigmatic—we examined the presence of smaller paradigms, such as Marxism, neostatism, and computational social sciences. We also observe the presence of new institutionalism and other paradigms. In other words, multiple paradigms in the field do exist.
We also confirmed the presence of subdisciplines within the field, though their number is not limited to ten major, as outlined by Goodin (Reference Goodin2009). Altogether, there are 66 topics, though quite a few of them are combined inside a major island or cluster, the “canon of political science.” From the original ten that we’ve looked for, some subdisciplines, indeed, are more dominant, some are more clearly delineated while others are fuzzy. There are also some that are, probably, on the rise as the generators of new “hot” topics and methods and could form new subdisciplines in the future. Overall, however, it is reasonable to conclude that “subdiscipline” is a construct: subdisciplines do not exist in isolation, their borders are not clearly defined, and they often intersect with each other. We have also identified the “borderline,” or interdisciplinary subfields, which cross over many other fields of science. This was the third contribution of our study.
Another important contribution that logically flows from this idea is that despite the pronounced fragmentation, political science is being integrated—but not only by scientists, as Goodin (Reference Goodin2009) suggested. His ideas were centered around the premise that with too much fragmentation inside the field, we need “integrators”—scientists who could keep track of the field’s development and provide the direction for a more coherent approach to research, applicable to many diverse subdisciplines. Our results show that such “integrators” are not necessary: the field is being “held together” by paradigms, and across all paradigms—by the “canon of political science.” As paradigms develop, the dominant paradigm may be replaced by another. Previously dominant paradigms do not disappear from the agenda, they continue to remain a part of the field, but to a lesser degree. Paradigms develop over time, but at any given time, there is one dominant paradigm. This dominant paradigm becomes the integrator of the political science field.
The same applies to the “canon” or the core of political science, formed by ten subdisciplines. They remain more or less unchanged, but this does not preclude formation of new subdisciplines on the periphery, or transfer of the new subdisciplines to the “core.” However, the core-periphery structure of political science does not change and keeps the field from separating into separate fields. So, in essence, fragmentation exists on the periphery of a solid, integrated foundation, formed by “canon” of political science. Perhaps, this conclusion warrants further study.
Temporal analysis indicated that political science is a developing, evolving field, where many studies are dedicated to specific events happening in the society. There are waves and periods of dominance of certain paradigms or research programs, and future studies could examine, in detail, what causes a certain paradigm or research program to appear.
There were some interesting results obtained with temporal analysis, which did not immediately fit inside the study’s main objectives: some interesting words did not form separate islands yet were obviously present across multiple topics. The first was the word “American,” with very interesting dynamics. It dominated until about mid-1950s, then continued a slow decline to present times. This means that the political science was mostly American right after the WWII, but slowly internationalized and expanded to other parts of the world. The word “democracy” also had an interesting dynamic, with a sharp increase in interest in the 1990s that continues until now. These two waves form two important topics in political science—“American politics” and “democracy studies.” However, we did not find such islands in contrast with, for example, European politics. It appears that words “American” and “democracy” are so popular that they are connected to too many other words. They are the keywords of the wider context, creating their own discourse in political science: everything in the field starts with American and democracy. This is very clear in Figure 10, where these two words are clearly present in the busiest center of the network.
Our final contribution is to network science methodology: we validated the use of link island methodology with the HCA, widely used for evaluation of large weighted networks (including bibliometric). We have replicated the LIM procedure with HCA and obtained the same general results: the presence of a core-periphery structure within the political science keyword network (in the first three partitions) and the presence of more than ten topics in the field. Moreover, we have verified that LIM provides for more interpretable results by removal of keywords that do not belong to any cohesive topic. Unlike LIM, HCA does not have that ability and forces such keywords to remain a part of the analysis. Therefore, LIM allows for a more meaningful interpretation of the obtained islands.
6. Limitations and future work
This study is not without limitations. The first limitation is the use of the WoS database for our study. Of course, like any database, it contains errors and omissions. It also limits the scope of the study simply because it does not include all writings in the field of political science. To its defense, WoS provides important indexing services that are much more reliable than those of Google Scholar, for example, which is much more inclusive. There are standardized fields that contain the necessary data, important article metadata, and many other benefits of using WoS over collecting data manually—a rather daunting task for the project of this size.
Moreover, we have found that multiple studies were conducted that have examined WoS, Scopus, Google Scholar, and other bibliometric databases with each other. For example, the time-series study by Harzing & Alakangas (Reference Harzing and Alakangas2016) showed that all three databases “provide sufficient stability of coverage to be used for more detailed cross-disciplinary comparisons.” The study showed that despite differences, the overall coverage of the disciplines is relatively consistent in all databases. A field-specific study by Falagas et al. (Reference Falagas, Pitsouni, Malietzis and Pappas2008), which also included PubMed in the analysis, noted some differences in coverage, but most importantly, criticized Google Scholar for some errors, omissions, and other “inadequacies” (p. 342). Of course, there is an issue of multiple predatory journals that flood the net with “worthless” publications (Sharma & Verma, Reference Sharma and Verma2018), which should not be representative of any science. Despite all the defenses of WoS as a database, however, we do realize that some of the important writings could be missing from our analysis, making it, at best, incomplete.
The second limitation of our study is the way in which we considered and treated words and keywords. First, we treated author-generated keywords equally with WoS-generated keywords. It is possible that author-generated keywords might have more weight. More important is the fact that we treat title words the same as keywords (e.g., for longitudinal analysis). As we have stated in the method section, we created two networks—one without titles—precisely because titles might not be very representative of the paper topic. However, for examining the development of topics over time, title words remain and are given equal weight with keywords. Presently, we do not have a way to evaluate this possible difference in weights, so we leave it for future studies.
The third limitation, also related to our treatment of words, is the way we’ve reduced key phrases and titles to single words to build networks of co-occurrences. We also removed duplicates connecting words to writings (as would be the case with “soft power” and “hard power” key phrases that connect the word “power” to the writing). There is a valid concern that doing so might remove some of the richness that composite keywords provide and might lead to misinterpretation of the words that have different meaning based on context. This could also affect the way that word combinations represent subdisciplines. We realize that this could be one of the reasons for the “fuzziness” in the island definitions that we have observed. It could also be the reason why some of the more common words in the field ended up together as opposed to specific areas where they belong. While we certainly realize this limitation, we think that for this first exploratory study our approach was sufficient for our goal. Moreover, we used the islands methodology that isolate the words that are more often connected to each other and remove the keywords that do not belong to any topic, segregating the fields based on word combinations that separate them. In other words, LIM allows to obtain the phrases through connected keywords in co-occurrence networks. Nonetheless, we suggest that future studies extend this methodology to include composite key phrases to examine the field to a finer extent.
The fourth limitation is the starting year of our study, which was the year 1990. Despite two compelling reasons for doing so—inclusion of keywords in WoS articles and geopolitical events after the end of Cold War, which shaped the modern political science, inclusion of early writings could have altered our results. We do not believe that the main findings of our study—presence of a core-periphery structure and more than ten subdisciplines in the field—would have changed by such inclusion. If anything, we expect our results would have been only more confirmed, given the lower number of topics in the field in earlier years. However, this is a good starting point for further exploration.
Overall, this study lays an important ground for further research. It was the first study to examine the entire field of political science, and it showed that such exploration is not only possible, but also quite meaningful, with new and interesting insights. The most obvious extensions of this study are further examination of temporal networks, exploration of co-evolution of topics in academia and in practice and the role that academics play in influencing politics and society in general. More work should be done on establishing the boundaries of the integrated core—the “canon of political science”—and the fragmented periphery that forms that diverse subdisciplines.
Specific suggestions for future studies also include projections of what could be the “fields of the future.”Footnote 3 Temporal network analysis could be extended to anticipate upcoming changes in the field. Moreover, a finer analysis could be done on a smaller sample of journals to see whether the same islands emerge there or if there is a different pattern of topics that are indicative of certain journal editor preferences. Perhaps, some journals are responsible for the peripheral groups, while others are developing the main core. Even on a finer scale, it would be interesting to see if publishing articles in certain topical fields would lead to tenure and promotion or if certain subjects would dominate the agenda in graduate schools, preparing future scholars to work on specific topics. In other words, the “science of science” (Fortunato et al., Reference Fortunato, Bergstrom, Börner, Evans, Helbing, Milojević and Barabási2018) in political science field has a lot of promise.
Competing interests
None.
Supplementary materials
For supplementary material for this article, please visit http://doi.org/10.1017/nws.2022.39




















 Open access
Open access