


Introduction
We live in an era of increasing worry that internet platforms like Facebook or Twitter, which mediate our online speech, are also fomenting hatred, spreading misinformation, and distorting political outcomes. The 2016 US presidential election, in particular, unleashed a torrent of concern about platform-borne harms. Policymakers around the world have called for laws requiring platforms to do more to combat illegal and even merely “harmful” content.
From the perspective of platforms themselves, these proposals have a lot in common. Regardless of their substantive mandates – to address content that is misleading, hateful, or violent, for example – they all require similar operational processes to comply. Platforms already have these processes in place to enforce current laws and their discretionary Community Guidelines. Any new efforts to regulate content online will likely build on existing systems, personnel, and tools – and inherit both their strengths and their weaknesses. That makes it important to understand those systems.
Reliable information about platforms’ content-removal systems was, for many years, hard to come by; but data and disclosures are steadily emerging as researchers focus on the topic and platforms ramp up their transparency efforts. This chapter reviews the current and likely future sources of information.
Some content takedowns are required by law, while others are performed voluntarily. Legal takedowns are shaped by intermediary liability laws, which tell platforms what responsibility they have for unlawful content posted by users. Platforms operating under legal frameworks like the US Digital Millennium Copyright Act (DMCA) or the EU’s eCommerce Directive typically meet their legal obligations using “notice-and-takedown” systems. Larger platforms invest heavily in these operations and sometimes supplement them with proactive efforts to identify and eliminate illegal material. However, the evidence we review suggests that platforms perform poorly at enforcing the law consistently at scale.
Platforms’ voluntary content removals are based on private rulesets: Community Guidelines. These private standards often prohibit a broad margin of lawful speech beyond that which actually violates the law. Community Guidelines may draw on platform operators’ own moral beliefs or social norms. They may also simply aim to shape the user experience for business purposes. A real estate listing site, for example, might exclude photos that do not show buildings and property. Most websites prohibit spam, pornography, and harassment for comparable reasons. Platforms can also use Community Guidelines to simplify their legal enforcement efforts and avoid conflict with governments, by simply prohibiting more speech than the law does. Governments, for their part, may avoid challenges under constitutions or human rights law if removal of legal content is attributed to private, rather than state, action (Angelopoulos et al. Reference Angelopolous, Brody and Hins2016). Therefore, as policymakers and the public have increasingly demanded that platforms remove content that is harmful or offensive, but not necessarily illegal, these discretionary rules have become ever more important.
New platform efforts to weed out prohibited content will, inevitably, have a lot in common with these existing systems. That is partly good news, because policymakers are not drafting on a blank slate. Lawyers, researchers, and platform employees have two decades of experience in the ways that content-removal systems work in practice. It is also, however, partly bad news. Evidence suggests that platforms do not do a great job as enforcers of speech rules. Even when they apply their own, self-defined Community Guidelines, the results often appear erratic. It is hard for independent researchers to quantify platforms’ accuracy in applying Community Guidelines standards, though, since the rules themselves are poorly understood and there is little reliable information about the specific text, images, videos, or other content removed.
Platforms’ performance under laws like US copyright law or German hate speech law can be easier to research, in part simply because the rules come from public law rather than platforms’ discretionary Community Guidelines. There is also somewhat more information available about how platforms apply legal rules and what specific content they take down. Footnote 1 This has allowed independent experts to assess the platforms’ removal practices – and document significant problems. Platforms that receive notices alleging illegality, and hence exposing them to legal risk, commonly err on the side of caution, removing even lawful information. Some simply take down any content identified in a complaint. This “over-removal” is a constant byproduct of notice-and-takedown systems. Platforms have removed information ranging from journalism and videos documenting police brutality in Ecuador (Reference VivancoVivanco 2014) to media coverage of fraud investigations in the United States (Reference CushingCushing 2017) to criticism of religious organizations (Reference GalperinGalperin 2008) to scientific reporting (Reference OranskyOransky 2013; Reference TimmerTimmer 2013).
Platforms historically have had little incentive to share detailed information about content removal with the public. Compiling records of evolving content takedown processes, which may use different tools and standards or be managed by different internal teams over time, is burdensome; and any disclosure, particularly one that admits error, can be used against platforms in court or in the press. Yet the longer-term benefits of greater transparency, for both society and platforms themselves, are becoming ever more evident. Without it, public debates about platform responsibility can become exercises in speculation. Laws passed without a practical foundation in platforms’ real-world operations and capabilities can be burdensome for the companies and their users, yet fail to achieve lawmakers’ legitimate goals.
Whether in recognition of this problem, or because of increasing pressure from civil society, academia, and other quarters, some platforms have provided substantially more public transparency in recent years. This chapter will review major sources of information released by platforms, as well as independent research concerning content takedown operations. We will begin in the section “Takedown and Intermediary Liability Laws” by very briefly reviewing intermediary liability law, which plays a central role in structuring platforms’ content-removal operations. One particularly robust academic study will serve to illustrate common platform takedown practices and research themes.
The section titled “Sources of Information,” which makes up the bulk of the chapter, provides a broader review of the current empirical literature and likely sources of future information. First, we discuss disclosures from platforms and other participants in content moderation, such as users and governments. Second, we discuss independent research from third parties such as academics and journalists, including data analysis, interviews, and surveys. Finally, before concluding the chapter, we will list specific questions and areas for future empirical research.
Debates about proposed new laws ranging from the EU’s Terrorist Content Regulation to Singapore’s “fake news” law should be informed by empirically grounded assessments of platforms’ capacity to comply and the potential unintended consequences of their compliance efforts. Without better information about platforms’ true strengths and weaknesses as speech regulators, we should not expect to see well-designed laws.
Takedown and Intermediary Liability Laws
This section discusses intermediary liability laws, which form the legal backdrop for content-moderation discussions. As we explain, these laws determine when and how platforms are legally required to remove content. Following a brief legal analysis, we show how such laws operate in practice with the help of one particularly thorough study: “Notice and takedown in everyday practice” (Reference Urban, Karaganis and SchofieldUrban, Karaganis, and Schofield 2016).
Intermediary Liability Laws
Intermediary liability laws tell internet intermediaries such as ISPs, search engines, or social media companies what legal responsibility they have for their users’ speech. As a matter of black-letter law, they are typically separate from underlying substantive legal doctrines that define things like defamation or hate speech. Yet by prescribing when and how platforms must take action, intermediary liability laws strongly influence what speech actually gets taken down.
At a high level, intermediary liability laws must balance three, often competing goals. The legal details in national law typically reflect lawmakers’ judgment about how best to balance them. One goal is to prevent harm. Generally, the better job a law does of incentivizing platforms to take down illegal or otherwise harmful content, the more it will serve this goal. Another, often competing goal is to protect lawful online speech and information. A law that requires aggressive policing by platforms may run afoul of this goal, leading platforms to take down lawful and valuable speech in order to avoid legal risk. A third goal is to promote innovation. Early intermediary liability laws were conceived in part as means to protect nascent industries. Today, intermediary liability laws may profoundly affect competition between incumbent platforms and start-ups.
The balance of priorities between these three goals is a matter of national values and policy choices; but the question of what specific legal rules will, in practice, serve each goal is in part an empirical one, tied to the real-world practices of platforms responding to the law’s requirements and incentives.Footnote 2
Internationally, most intermediary laws share two basic elements. First, platforms are immune from legal claims arising from users’ unlawful speech as long as they do not get too involved in developing that speech. National laws diverge as to how “neutral” platforms must be to qualify for immunity and the degree of content moderation they can engage in without being exposed to liability. One relative outlier in this respect is the US Communications Decency Act (CDA), which grants platforms unusually broad immunities, even when they become aware of unlawful content, for the express purpose of encouraging them to moderate and weed out “objectionable” content.Footnote 3
Second, most intermediary liability laws give platforms obligations once they “know” about illegal content. In much of the world, platforms that learn about material like defamation or terrorist propaganda on their services must take down that content or face legal consequences. Laws vary substantially, however, in what counts as “knowledge.” Under some national rules, platforms can only be legally required to take down users’ speech if a court has adjudicated it unlawful.Footnote 4 Elsewhere, the law leaves platforms to decide for themselves what speech violates the law.
Within this framework, one important source of variation comes from the procedures that the law provides for platforms taking content down. The US Digital Millennium Copyright Act (DMCA) is one of the most procedurally detailed intermediary liability laws.Footnote 5 It spells out formal prerequisites for “notices” from rightsholders, steps for “counter-notice” by accused users, and other details including penalties for bad-faith notices against lawful speech. The Manila Principles, a set of model intermediary liability rules endorsed by civil society groups around the world and supported in the human rights literature, lists additional procedural protections – including public transparency requirements to illuminate errors, bias, or abuse in notice-and-takedown systems.Footnote 6
A rapidly developing intermediary liability policy debate concerns platforms’ potential obligations to proactively monitor or police users’ speech. Until recently, most countries’ laws built on the assumption that platforms could not, realistically, monitor user speech on an ongoing basis and accurately identify illegality. Important laws like the US DMCA and EU eCommerce Directive expressly disclaimed monitoring obligations,Footnote 7 making platforms responsible only for unlawful content they became aware of, usually through notice from third parties. Platforms’ voluntarily-developed filtering tools have since changed policymakers’ expectations, though the exact operation of those tools is poorly understood. One major new law, the EU’s Copyright Directive, effectively requires filtering.Footnote 8 Other proposals in areas like terrorist content are pending.Footnote 9 Critics ranging from technologists to three UN rapporteurs have raised serious concerns about filters (Reference Cannataci, Kaye and Ní AoláinCannataci et al. 2018; Reference O’Brian and MalcolmO’Brian and Malcolm 2018). As a 2019 letter from civil society organizations including European Digital Rights (EDRi), Article 19, and the American Civil Liberties Union (ACLU) put it, filters remain “untested and poorly understood technologies to restrict online expression,” with great potential to silence protected expression ranging from parody to human rights reporting, with resulting harm to “democratic values and individual human rights.”Footnote 10
Another emerging issue comes from both platforms’ and governments’ reliance on Community Guidelines instead of law as a basis for removing online content. Platforms’ discretionary rules often prohibit legal expression, and until recently it was generally assumed that platforms had extremely wide latitude to do so.Footnote 11 National constitutions and human rights laws protect internet users from state interference with their legal exercise of speech rights, but platforms are generally free to ban any speech they want; and, because Community Guidelines are privately defined and enforced, platforms’ decisions are generally not subject to review by courts.
In recent years, though, governments, particularly in Europe, have increasingly turned to platforms’ Community Guidelines as enforcement mechanisms. For example, both the European Commission’s Hate Speech Code of Conduct and Disinformation Code of Practice call on platforms to voluntarily prohibit specified content, often in reliance on Community Guidelines.Footnote 12 Law enforcement bodies including Europol, for their part, often use Community Guidelines or Terms of Service rather than law as a basis for asking platforms to take down content ( Europol 2016; Reference ChangChang 2018). Civil liberties organizations have decried these arrangements, saying they replace democratic lawmaking and courts with privatized and unaccountable systems (European Digital Rights 2016; see also Reference ChangChang 2018).
A Case Study: Notice and Takedown in Everyday Practice
By far the most thorough analysis of intermediary liability compliance operations is “Notice and takedown in everyday practice” (Reference Urban, Karaganis and SchofieldUrban et al. 2016). To produce it, researchers reviewed takedown notices affecting some 4,000 individual webpage URLs in Google’s web search and image search products and interviewed platform operators, rightsholders, and other participants in the notice-and-takedown ecosystem. Although focused on copyright (the area for which the richest public dataset is available), its thorough analysis documents trends and issues with close analogs for content removal under other laws. Many of its lessons, particularly those relating to automation and large-scale operations, are relevant to removal under Community Guidelines as well.
One of the study’s most important findings is the divergence between the operations and capabilities of mega-platforms like Google and other, more modest internet intermediaries (Reference Urban, Karaganis and SchofieldUrban et al. 2016, pp. 28–29, 73–74). Smaller or more traditional companies generally employed teams of three or fewer people for this function and carried out substantive individual review of each notice (Reference Urban, Karaganis and SchofieldUrban et al. 2016, pp. 29, 36). Many described “opting to take down content even when they are uncertain about the strength of the underlying claim” in order to avoid exposure to liability (Reference Urban, Karaganis and SchofieldUrban et al. 2016, p. 41). They also reported notifiers’ “deliberate gaming” of the takedown process, “including to harass competitors, to resolve personal disputes, to silence a critic, or to threaten the [platform]” (Reference Urban, Karaganis and SchofieldUrban et al. 2016, p. 40).
The picture for larger players was very different. The difference began with scale: In contrast to the dozens or hundreds of notices received by smaller operations, Google received more than 108 million removal notices for web search during the study’s six-month period (Reference Urban, Karaganis and SchofieldUrban et al. 2016, pp. 29, 77). Both large-scale notifiers and platforms relied heavily on automation. Rightsholders and their outsourced vendors automated the notification process, for example by using search queries to identify lists of URLs (Reference Urban, Karaganis and SchofieldUrban et al. 2016, p. 92). The resulting “robonotices” sometimes included errors, like a request from the musician Usher to take down a film version of Edgar Allan Poe’s Fall of the House of Usher (Reference Urban, Karaganis and SchofieldUrban et al. 2016, pp. 90–91).
Platforms reported automatically accepting many such automated requests, in particular from “trusted” sources. As a result, some provided no human review at all for the majority of automated notices they received (Reference Urban, Karaganis and SchofieldUrban et al. 2016, p. 29). Some also proactively policed content, using “measures such as ex-ante filtering systems, hash-matching based ‘staydown’ systems, [and] direct back-end takedown privileges for trusted rightsholders” (Reference Urban, Karaganis and SchofieldUrban et al. 2016, p. 29).
In their quantitative analysis, Urban and colleagues documented considerable error in DMCA operations. Among notices submitted to Google web search, for example, they found questionable legal claims in 28 percent (Reference Urban, Karaganis and SchofieldUrban et al. 2016, p. 88). Some 4.2 percent – which extrapolates to 4.5 million requests across the six-month dataset – seemed to be simple errors, requesting removal of material that did not relate to the notifier’s legal claim (Reference Urban, Karaganis and SchofieldUrban et al. 2016, p. 88). Among notices submitted to Google’s image search product, the figure was 38 percent (Reference Urban, Karaganis and SchofieldUrban et al. 2016, pp. 98–99). Fully 70 percent of image search notices were called into serious doubt if calculations included one individual’s barrage of improper takedown demands (Reference Urban, Karaganis and SchofieldUrban et al. 2016, pp. 98–99).Footnote 13
Platforms interviewed for the Urban study also reported a low rate of DMCA counter-notices from users challenging erroneous takedowns. Many platforms received no counter-notices at all (Reference Urban, Karaganis and SchofieldUrban et al. 2016, p. 44). This finding is consistent with figures released by the Motion Picture Association of America in 2013, showing a 0.000032 percent rate of counter-notices to DMCA removal requests filed by member companies; only 8 counter-notices were identified for 25,235,151 notified URLs (Reference BoydenBoyden 2013). Platform transparency reports, similarly, typically report counter-notice rates of well below 1 percent for copyright claims (Reference Bridy and KellerBridy and Keller 2016). Given the widespread documentation of over-removal, these figures suggest that wrongful removals are going unchallenged.
Sources of Information
This section reviews numerous sources of empirical information, both from platforms and other participants involved in content takedown and from independent researchers. Some, including major platform transparency reports, are published on regular schedules and should be fruitful sources of future information.
Disclosures by Platforms and Other Participants in Content Takedown
Platforms reveal information about content moderation in manifold ways. These include (1) periodic transparency reports; (2) primary source information shared with academic research archives such as Harvard’s Lumen Database; (3) notices to affected individuals about takedown decisions; and (4) incidental public statements and other disclosures about specific content issues. Increasingly, (5) governments also require platforms to perform public filings about content moderation, and some also publish data about their own involvement in takedown procedures. (6) Third-party audits also reveal information about takedown practices, as do (7) leaked information from platforms.
Transparency Reports
Many platforms publish periodic transparency reports, which typically disclose aggregate data about requests for content removal. An index of transparency reports maintained by the civil society organization Access Now lists reports from more than seventy companies,Footnote 14 including Google,Footnote 15 Facebook,Footnote 16 Twitter,Footnote 17 Amazon,Footnote 18 Tumblr,Footnote 19 Medium,Footnote 20 Reddit,Footnote 21 Github,Footnote 22 and WordPress.Footnote 23 These can provide important quantitative overviews of the big picture – or at least part of it. They typically aggregate data about removal requests, along with the platform’s rate of compliance. They may also disclose the frequency with which users accused of wrongdoing choose to appeal or challenge platforms’ decisions. Transparency reports have historically focused on legal removal requests. In 2018, however, Facebook,Footnote 24 Twitter,Footnote 25 and YouTubeFootnote 26 all published their first Community Guidelines enforcement reports.
Transparency reports have major limitations. The aggregated data in transparency reports only shows the platforms’ own assessments, and not the merits of the underlying cases. That means researchers cannot evaluate the accuracy of takedown decisions or spot any trends of inconsistent enforcement. Also, most transparency reports only cover particular categories of takedowns – often only those initiated by governments or copyright-holders. This leaves open questions about platforms’ responses to legal allegations brought by individuals under, say, French defamation law or Brazilian privacy law.
Transparency reports also vary widely in the ways they classify data, making apples-to-apples comparisons between companies difficult. In particular, reports that track how many notices a company received cannot fruitfully be compared to reports tracking how many items of content they were asked to remove, since one notice may list any number of items.
Transparency reports also vary greatly in detail. Take, for instance, the aforementioned Community Guideline reports. YouTube’s report documents the number of channels and videos removed for eleven different types of standards violations (e.g., spam, nudity, promotion of violence and extremism) (Google 2018a). It also specifies how these videos were detected, whether through automated flagging, individual trusted flaggers, users, NGOs, or government agencies. Facebook’s report is even more detailed; it also registers how often users appealed against removal decisions and how often content was later restored (either proactively by Facebook or following a user appeal) (Facebook 2018b). In addition to this numerical reporting, Facebook provides details about operations. Its expected staff of more than 20,000 people are working on content moderation, including native speakers of more than 50 languages and teams working around the clock. Separately, Facebook has published a detailed public version of its Community Standards (Facebook 2018b) and a guide to understanding the figures from the report (Facebook 2018). Twitter’s report, on the other hand, is significantly less detailed. It only documents the number of unique accounts reported and actioned for six different categories of violations, without specifying appeal or reinstatement rates or reporting mechanisms other than those from known government entities (Twitter 2018).
One important external assessment of company transparency reports’ strengths and weaknesses can be found in the Electronic Frontier Foundation’s periodic Who Has Your Back report (Reference GebhartGebhart 2018). Another can be found in the Ranking Digital Rights Corporate Accountability Index, which rates technology companies on numerous measures relating to transparency and protection of users’ free expression and privacy rights.Footnote 27 The Open Technology Institute’s Transparency Reporting Toolkit also provides a valuable comparison of existing reports and recommendations for improved practices (Open Technology Institute 2018). It draws on the widely endorsed Santa Clara Principles, which call for “numbers, notice, and appeal” as essential elements in platforms’ content-removal operations.Footnote 28
Primary Source Information Shared by Platforms
For researchers to draw their own conclusions about platforms’ content-removal practices, they need to know what content was actually removed. To date, the best source for such information has been the Lumen database (“Lumen”), an archive hosted at Harvard’s Berkman Klein Center.
Lumen archives legal takedown notices from any platform – or sender – that chooses to share them. Senders’ personal information, and occasionally – as in the case of child abuse content – content location URLs are redacted, but researchers can otherwise review the entire communication. At last check, the database held some 9.3 million notices, targeting approximately 3.35 billion URLs.Footnote 29 The majority comes from Google; other contributors include Twitter, WordPress, the Internet Archive, Kickstarter, Reddit, and Vimeo. Because the notices identify material that is often still available at the listed URL, researchers can look at the specific content alleged to be illegal and assess whether a platform made the right decision. The Lumen database has enabled extensive academic research.Footnote 30
Demands for other forms of “primary source” transparency are increasing. An important recent proposal from the French government, for example, calls for transparency sufficient for auditors to review specific takedown decisions.Footnote 31 Similarly, proposed amendments to the German Network Enforcement Law (Netzwerkdurschsetzungsgesetz, or NetzDG) – discussed in further detail in the section titled “Public Filings and Other Government Disclosures” – also call for the auditing of content moderation practices and the creation of a public “clearing house” to adjudicate user complaints about wrongful removals (German Parliament 2018). Such independent oversight mechanisms, if they proved operationally and economically feasible, might also allow more detailed third-party research into the substance of content-moderation decisions.
Notice to Affected Individuals
Platforms also provide potentially useful information to individuals affected by takedown requests. In particular, they may (1) respond to a person who requested removal, letting them know if the request was honored; (2) notify the user whose content was taken down; or (3) “tombstone” missing material, putting up a notice for users who are trying to visit a missing page or find information. YouTube’s “this video is not available” notices are perhaps the most visually familiar example for many internet users.
Information gleaned from notices in individual cases often drives news cycles about particularly controversial decisions. It cannot show researchers the big picture, but it can play an important role in surfacing errors, by putting information in the hands of the people most likely to care and take action.
Issue-Specific Platform Disclosures
For high-profile content-moderation issues, platforms are increasingly issuing in-depth public statements to explain their policies. Some offer detailed information on platforms’ assessment of individual cases, which is typically lacking from aggregate transparency reports.
An important example is the terrorist attack on Christchurch of March 15, 2019. Video footage of the attack was livestreamed on Facebook and spread virally to several other websites. Facebook ultimately issued two public announcements describing their efforts to remove this graphic footage. They provide detailed timelines of events, starting with the first livestream, as well as data on how often it was subsequently viewed, shared, re-uploaded, and ultimately removed.Footnote 32 In its response to the Christchurch incident, Facebook also took the unprecedented step of inviting a legal academic, Kate Klonick, to sit with response teams. Klonick later published her observations (Reference KlonickKlonick 2019).
Facebook also issued several statements regarding its efforts to remove “coordinated inauthentic behavior,” to protect elections in, for example, Ukraine,Footnote 33 Israel,Footnote 34 India, and PakistanFootnote 35 and targeting fake accounts originating from RussiaFootnote 36 and Iran.Footnote 37 These posts explain how the platform identifies inauthentic behavior, what patterns it has found, and what removal decisions it made including examples as well as aggregate data.
Cloudflare, a web infrastructure company, published a particularly influential blog post about content moderation in the aftermath of the Charlottesville riots of August 11, 2018. It explained why the company had decided to terminate its services to The Daily Stormer, a white supremacist website. The author, CEO Matthew Prince, was remarkably self-critical and highlighted the “the risks of a company like Cloudflare getting into content policing” (Cloudflare 2017).
Perhaps the most in-depth example of issue-specific reporting is Google’s report on Three Years of the Right to Be Forgotten (Google 2018b). This document is unique in the degree of detail it provides about the company’s internal process in assessing individual removal requests. It provides anonymized examples of individual cases, such as one request to remove search results for “an interview [the notifier] conducted after surviving a terrorist attack” and another for “a news article about [the notifier’s] acquittal for domestic violence on the grounds that no medical report was presented to the judge confirming the victim’s injuries” (Google 2018b, p. 10; Google took down both). The report lists several specific factors and classifications Google uses to resolve requests. One factor, for example, is the identity of the “requesting entity.” Google classifies the requesting entity for each item of disputed online content using the six categories in Table 10.1 (Google 2018b, p. 5). Based on these granular criteria, Google generates aggregate numbers and statistical analysis.
Table 10.1 Breakdown of all requested URLs after January 2016 by the categories of requesting entities
| Requesting entity | Requested URLs | Breakdown | Delisting rate |
|---|---|---|---|
| Private individual | 858,852 | 84.5% | 44.7% |
| Minor | 55,140 | 5.4% | 78.0% |
| Nongovernmental public figure | 41,213 | 4.1% | 35.5% |
| Government official or politician | 33,937 | 3.3% | 11.7% |
| Corporate entity | 22,739 | 2.2% | 0.0% |
| Deceased person | 4,402 | 0.4% | 27.2% |
Note. Private individuals make up the bulk of requests.
The report is also valuable because it illustrates concretely how a platform might break down complex claims into standardized elements or checkboxes for rapid, large-scale processing. Independent researchers could review these elements to assess, for example, how adequate they seem as an alternative to judicial review of parties’ competing privacy and free expression rights. They could also use the reported factors and elements as a concrete, debatable starting point in discussing what information platform employees should reasonably track and report about each takedown decision.
Public Filings and Other Government Disclosures
Valuable information about platform operations sometimes surfaces to the public through court or other public filings.Footnote 38 Documents made public in the Viacom v. YouTube case, for example, made headlines for their revelations about both parties to the suit (Reference AndersonAnderson 2010; YouTube 2010). Information disclosed in response to consultations by governments or transnational bodies has appeared in publications including a 2012 European Commission staff report (European Commission 2012) and reports from the office of the UN Free Expression Rapporteur (Reference KayeKaye 2017).
More recently, large platforms including Facebook, YouTube, and Twitter have published important reports as part of their compliance with Germany’s NetzDG law.Footnote 39 That law is best known for its unusually strict content-removal rules, but it also imposes unprecedented public reporting requirements. Platforms’ biannual reports include information such as staffing numbers, wellness resources available to staff, operational processes, the number of consultations with external legal counsel, and turnaround time for responding to notices, broken down by the specific legal violation alleged. While researchers have no independent means of assessing accuracy of the platforms’ legal determinations, the reports are rich in other statistics and operational detail.
For example, in the second half of 2018, YouTube received NetzDG notices identifying more than 250,000 items. The most reported category was Hate Speech or Political Extremism (83,000 plus complaints), followed by Defamation or Insults (51,000 plus) and Sexual Content (36,000 plus). In response, YouTube removed 54,644 items, with takedown rates varying per content category (Google 2018c). The report also shows whether notices were submitted by users vs. German government agencies.
As Figure 10.1 from the report shows, YouTube also relied heavily on Community Guidelines. Nonetheless, it looked to German law to resolve the legal status of more than 10,000 items.
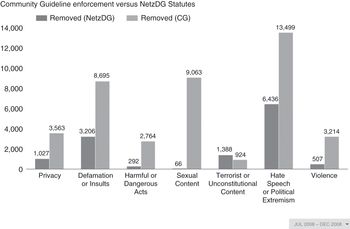
Facebook’s NetzDG reports paint a very different picture. In the same period, they reportedly received only 500 NetzDG complaints, involving 1,048 items of content – only a fraction of what YouTube and other major platforms received (Facebook 2018b). This is likely because their NetzDG complaint form was less visible on their website compared to YouTube or Twitter. Yet Facebook’s Community Guideline removals in the same period numbered in the millions and were not included in the NetzDG report. On July 2, 2019, Germany’s Federal Office of Justice fined Facebook €2 million for incomplete reporting, claiming that, because it was unclear which complaints based on Community Guidelines had in fact identified unlawful material, “the number of received complaints about unlawful content is incomplete,” and the reports therefore created a “distorted picture” (Bundesamt für Justiz 2019). This raises the question whether NetzDG also requires platforms to assess and report on the lawfulness of content decisions that are not referred to them under the NetzDG framework.
The European Commission also persuaded Twitter, Google, and Facebook to publish monthly compliance reports in the run-up to the EU elections of May 2019, as part of the Code of Practice on Disinformation (European Commission 2018b). These reports describe a range of activity related to disinformation, including media literacy and fact-checking efforts but also certain forms of content moderation. Importantly, these are some of the few reports to discuss the enforcement of advertising standards, including procedural information on the approval, review, and transparency mechanisms for political advertising as well as quantitative data on advertising activity and removal decisions. In May 2019, for instance, Google detected 16,690 EU-based Google accounts in violation of its misrepresentation policies, and Twitter removed 1,418 ads in violation of their Unacceptable Business Practices Policy (which prohibits, e.g., misleading content) (Google 2019; Twitter 2019). Finally, the US House Intelligence Committee has also published important datasets, obtained from Facebook, about Russian political advertising during the 2016 US presidential elections (US House of Representatives 2019).
Platforms also disclose takedown information to the European Commission for inclusion in the Commission’s reporting on the Hate Speech Code of Conduct (European Commission 2016, 2017). Under the Code of Conduct, expert organizations notify participating platforms about content the organizations have identified as illegal hate speech. Platforms complied with 28 percent of such notices in the Commission’s first review and 59 percent in its second – a development billed by the Commission as “important progress.” Yet the figures represent only notifiers’ and platforms’ rate of agreement about what content should come down; and, while the Code of Conduct refers to “illegal” hate speech, platforms (and perhaps also notifiers) presumably actually assess notices under their Community Guidelines. Without independent access to notices and affected content, we cannot know what standards either side is applying, how consistently and accurately those standards are enforced, or how they relate to any country’s laws.Footnote 40
Some related but more modest disclosures come from governments themselves, sometimes in conjunction with platforms. A 2016 report from Europol, for example, discusses terrorist content referred by its Internet Referral Unit (IRU) to platforms for takedown (Europol 2016). As of then, the IRU had referred 9,787 items to 70 different platforms. Its success rate was greater than 90 percent. Because IRUs seek removal under platforms’ Community Guidelines, however, this figure reflects only success in predicting platforms’ applications of those rules – or convincing platforms to adopt law enforcement agents’ interpretation. Independent researchers have no means of ascertaining what portion of referred or removed content violates any laws.
Some European states also operate their own IRUs at the national level. Their operations have been criticized for a lack of transparency, but occasional disclosures have occurred. The UK’s Counter-Terrorist Information Referral Unit (CTIRU) published data on its website on December 2016 claiming that it was instigating the removal of more than 2,000 pieces of content per week and was on course to have removed more than 250,000 pieces of content in total by the end of the year (UK Metropolitan Police 2016). The CTIRU has also published information in Parliamentary HearingsFootnote 41 and in response to Freedom of Information requests submitted by University College Dublin law professor T. J. Reference McIntyre and EdwardsMcIntyre (2018).
More government reporting about their involvement in content moderation may one day be required by law. The EU Parliament’s draft of the Terrorist Content Regulation, for example, includes detailed requirements for transparency about law enforcement referrals to platforms.Footnote 42
Audits
Published reports from independent auditors represent a small but likely growing category of disclosure. The Global Network Initiative has published reports of privacy and content-removal practices going back to 2013 for companies including Facebook, Google, LinkedIn, Microsoft, and Yahoo, for example. The reports, which draw on internal but nonprivileged information shared by the companies, include general assessments and case studies.Footnote 43 Other one-off independent audits have become a common response to tech industry scandals and may produce relevant information going forward.Footnote 44
A Human Rights Audit of the Internet Watch Foundation (“IWF Audit”) report provides insights into an important non-platform participant in content takedowns (Reference MacDonaldMacDonald 2014).Footnote 45 The UK’s Internet Watch Foundation (IWF) is a private, nonprofit organization that works with police, companies, and the public to identify child sexual abuse material online. It then conveys lists of URLs to intermediaries to be blocked. The IWF Audit, prepared at IWF’s request by an outside human rights expert, details the group’s internal operations and suggests improved processes for, among other things, appeals and difficult legal judgment calls. This report is unique among empirical research – and important to developments well beyond child protection – in its focus on the interplay of state and private action. For example, it discusses the role that IWF as a private organization plays in speeding takedown requests initiated by police – requests that would otherwise require additional judicial process (Reference MacDonaldMacDonald 2014, p. 5).
Leaked Information
In addition to their publicly available Community Guidelines, platforms also issue more detailed rules and instructions for their content-moderation staff. These documents are confidential, but they have been leaked to the press on several occasions. They shed some light on the way that platforms’ general principles are enforced in practice; in order to instruct their moderators at scale, platforms are often forced to reduce complex speech issues to simplified rules of thumb.
For instance, Facebook instruction manuals leaked to The Guardian told content moderators that the phrase “Someone should shoot Trump” was a credible threat of violence, whereas “Let’s beat up fat kids” was not (Reference HopkinsHopkins 2017). In documents leaked to the Süddeutsche Zeitung, Facebook instructed moderators to treat people as public figures, with fewer privacy protections, as long as they “were mentioned in news reports five times or more in the past two years” (Reference Krause and GraseggerKrause and Grasegger 2016). Gawker’s 2012 leaks alleged that Facebook contractors were instructed to “escalate” to Facebook employees any “maps of Kurdistan,” “burning Turkish flag(s),” and “All attacks on Ataturk (visual and text)” – suggesting that Facebook made concessions to public pressure from Turkey (Reference ChenChen 2012). More recently, the New York Times has also published similar documents (Reference FisherFisher 2018).
Independent Research
A growing and important body of information about platforms’ takedown practices comes from outside researchers. Some (1) analyze data released by platforms, while others (2) perform surveys and interviews with platform staff and other participants in the takedown ecosystem.Footnote 46 (3) Others have run their own tests and experiments with platform services and associated software.
Analysis of Data Disclosed by Platforms
As mentioned in the section on “Primary Source Information Shared by Platforms,” researchers using the Lumen database can do an important thing most others cannot: review the content that platforms actually removed. A handful of Lumen-based reports, like Notice and Takedown, take this approach (Reference Urban, Karaganis and SchofieldUrban et al. 2016). Most concern copyright, since the bulk of the data Lumen holds relates to the US DMCA.Footnote 47
One recent exception came from law professor Eugene Volokh, who discovered that numerous claimants had falsified court orders and used them to convince Google to take content out of its search results (Reference Volokh and LevyVolokh and Levy 2016). Volokh’s detective work, which involved hiring an actual detective, turned on clues like the dates and official stamp numbers that appeared on the putative court documents – details that were only available because Lumen gives researchers access to exact copies.
Reporting and Interviews with Participants in Takedown Processes
Other researchers have carried out the painstaking work of tracking global developments and seeking out and interviewing individual participants. Rebecca McKinnon laid important groundwork for this in her 2012 book Consent of the Networked (Reference MacKinnonMacKinnon 2012). The Notice and Takedown report, discussed in the section titled “A Case Study: Notice and Takedown in Everyday Practice,” builds on interviews and extensively documents the self-reported behaviors of copyright owners, platforms, and other players in the notice-and-takedown ecosystem (Reference Urban, Karaganis and SchofieldUrban et al. 2016, pp. 10–13, 116–117).
Noteworthy contributions relating to Community Guidelines enforcement include Kate Klonick’s article “The new governors: The people, rules, and processes governing online speech,” for which the author reviewed public reporting to date on the topic and interviewed early platform content moderators to understand the growth of their rules. Facebook, for example, started with vague rules, remembered by one employee as “Feel bad? Take it down” (Reference KlonickKlonick 2018). Tarleton Gillespie explored content moderation at length in a 2018 book (Reference GillespieGillespie 2018). Other researchers have reported on platforms’ publicly documented removal rules (Reference Venturini, Louzada, Maciel, Zingales, Stylianou and BelliVenturini et al. 2016; Reference York, Faris, Deibert and HeacockYork et al. 2018).
Reporters like Julia Angwin have experimented with platform content toleration, documenting things like anti-Semitic ad targeting terms on Facebook (Reference Angwin, Varner and TobinAngwin, Varner, and Tobin 2017). Academics and civil society advocates affiliated with Onlinecensorship.org have used crowdsourcing to gather and quantify users’ reports of experiences with platform takedowns (Anderson, Carlson et al. 2016; Anderson, Stender et al. 2016), including apparent disparate impact on vulnerable and minority groups (Reference York and GulloYork and Gullo 2018). Documentarians have produced at least two films about the on-the-ground experience of individual frontline content moderators working in places like India or the Philippines for vendors under contract with US-based platforms.Footnote 48 Daniel Kreiss and Shannon McGregor have performed in-depth interviews with Facebook and Google’s advertising staff, in order to study how company standards around political advertising are developed and enforced (Reference Kreiss and McGregorKreiss and McGregor 2019); and academics including Sarah Roberts have analyzed more closely the role – and vulnerability – of this global workforce (Reference RobertsRoberts 2019).
Academics also engage with platform employees at conferences and other discussion events, such as the Content Moderation at Scale (or “COMO”) series initiated by Professor Eric Goldman of Santa Clara University.Footnote 49
Independent Trials and Experiments
Because platforms’ content-removal decisions are taken behind closed doors, some researchers have been creative in nosing out useful information. European researchers in the early 2000s, for example, experimented with posting famous out-of-copyright literature – John Stuart Mill’s On Liberty in one case (Reference Ahlert, Marsden and YungAhlert, Marsden, and Yung 2004) and an essay by the nineteenth-century Dutch satirist Multatuli in another (Reference LeydenLeyden 2004) – and then submitting copyright infringement notices to see if intermediaries would take them down. Most intermediaries complied. More recently, the researcher Rishabh Dara sent a wide array of content-removal requests to intermediaries in India and tracked their responses in detail (Reference DaraDara 2011). There, too, platforms generally erred on the side of caution. Dara’s research is relatively unique in its focus on non-copyright claims. For example, by invoking a law against advocacy of gambling, he caused a news site to take down user comments concerning a proposed change in Indian gambling law (2011, p. 15).Footnote 50 University of Haifa researchers Mayaan Perel and Niva Elkin-Koren did similar research in Israel to assess the use of algorithms in copyright takedown processes – a method they call “black box tinkering” (Reference Perel and Elkin-KorenPerel and Elkin-Koren 2017).
Independent research may be particularly relevant for the study of algorithmic content filtering systems, which have become increasingly central to legal debates and large platforms’ moderation practices. Reliance on these technologies concerns civil rights activists, since they perform poorly in decisions that require nuanced assessments of context.Footnote 51 Distinguishing terrorist propaganda from journalist commentary on terrorism, for instance, or distinguishing content piracy from parody or other fair uses, is difficult to automate.
In a 2018 report, the Center for Democracy and Technology reviewed commercially available text-based filters and found an accuracy rate in the 70–80 percent range (Center for Democracy and Technology 2017). Filters performed particularly poorly in assessing jokes or sarcasm or in languages not spoken by their developers (Center for Democracy and Technology 2017, pp. 14, 19). A 2017 report by Princeton Computer Science professor Nick Feamster and Evan Engstrom of the start-up–advocacy group Engine provides greater technical detail, analyzing one of the few open-source (and hence publicly reviewable) filtering tools, Echoprint (Reference Engstrom and FeamsterEngstrom and Feamster 2017). The authors found a 1–2 percent error rate in simple duplicate matching, including both false positive and false negatives.
Under a broader view of content moderation, platforms also shape discourse through the design of their ranking and recommender algorithms, such as Facebook’s News Feed and YouTube’s Recommended videos (Reference KellerKeller 2019b). A growing body of literature in computer science and communications science seeks to ascertain the operation and effects of these complex systems.Footnote 52 The design of these algorithms is currently unregulated, but several governments have recently proposed to do so.Footnote 53 Most of these initiatives also explicitly demand greater transparency in algorithmic recommendations.Footnote 54
Consequences of Platform Content Removal
Most empirical research on platform content takedowns focuses on removal decisions themselves. Research on more complex questions about how removals affect individual users or society at large is generally harder to come by.
One possible exception is the growing body of research on online influence and the distortion of democratic political processes. Areas of empirical inquiry include “fake news,” Russian electoral interference, bot-based message amplification, and political bias in platforms’ content-moderation policies. Current and likely future work in this area is comparatively robust and is discussed throughout this volume. A promising source for future research is Facebook’s Social Science One project with the Social Science Research Council, which will provide some access to anonymized user data for independent research on “the effects of social media on democracy and elections.”Footnote 55
Another relevant issue is the charge, increasingly raised in the United States, Germany, and elsewhere, that major California-based platforms are biased against political conservatives. Individual takedown decisions often drive news coverage or social media concern about this possibility. To meaningfully assess the claim, however, researchers would need far more information about overall takedown patterns. Even with that data, researchers may continue to disagree on what qualifies as legitimate political speech and which speakers fall into the category of “conservatives.” For example, commentators have disagreed on the appropriate classification of the American Nazi Party (Reference HananiaHanania 2019; Reference GravesGraves 2019).
Beyond election-related topics, empirical research on the broader impact of platform takedown decisions is rare. One particularly pressing question concerns the connection between online speech and offline violence. Observers around the world have pointed to social media as a causal factor in violence in areas from Myanmar to Libya (Reference Walsh and ZwayWalsh and Zway 2018; Reference McLaughlinMcLaughlin 2018). A 2018 study from Germany, claiming to quantify Facebook’s impact on physical assaults against immigrants, drew both headlines and condemnation of its methodology (Reference FisherTaub and Fisher 2018; Reference MasnickMasnick 2018).
Research on terrorism, radicalization, and recruitment is comparatively advanced, but experts are divided on the true role of online materials. A 2017 review of literature to date, for example, cited divergent opinions but some movement toward “consensus that the internet alone is not generally a cause of radicalisation, but can act as a facilitator and catalyser of an individual’s trajectory towards violent political acts” (Reference Meleagrou-Hitchens and KaderbhaiMeleagrou-Hitchens and Kaderbhai 2017, pp. 19, 39; Reference KellerKeller 2018).
Other researchers have cited data suggesting that open platforms, which permit public visibility and counter-speech, may be less conducive to real-world violence than more isolated internet echo chambers (Reference BeneschBenesch 2014; Reference MungerMunger 2017).Footnote 56 A related empirical question concerns online speech and public participation by members of vulnerable or minority groups. Many thinkers express concern, for example, that toleration for lawful but offensive or threatening speech on platforms like Twitter effectively diminishes the public presence of ethnic minorities, women, and other frequently attacked groups (Reference WestWest 2017). Civil rights organizations have also charged platforms with disproportionately silencing members of minority groups.Footnote 57 Questions about disparate impact or bias in takedown operations are all but impossible to truly answer, however, in the absence of representative datasets revealing individual content-removal decisions.
Other consequences of platform takedown operations may affect any user. Individuals who are locked out of their accounts with major platforms like Facebook or Google, for example, may find themselves unable to access other online services that depend on the same login information. Those who depend on hosting services to maintain their writing or art may find their own sole copies deleted (Reference MacdonaldMacdonald 2016); and several studies suggest that internet users who believe their speech is being monitored curtail their writing and research (Reference Marthews and TuckerMarthews and Tucker 2017, Pen America 2013, Reference PenneyPenney 2016).
Empirical Questions About Platform Content Takedowns
The empirical research summarized in this chapter answers some important questions about platform content takedowns and illuminates others. Key considerations that should inform policy decisions are listed here. Current and future research addressing these questions will improve both our understanding and public decision-making on questions involving platforms and online speech.
Accuracy rates in identifying prohibited material
◦ In notices from third parties generally
◦ In notices from expert or “trusted” third parties
◦ In flags generated by automated tools
◦ In platform decision-making
Areas of higher or lower accuracy
◦ For different claims (such as defamation or copyright)
◦ For different kinds of content (such as images vs. text; English language vs. Hindi; news articles vs. poems)
◦ For different kinds of notifiers (such as “trusted experts”)
Success rates of mechanisms designed to prevent over-removal
◦ Legal obligations or penalties for notifiers
◦ Legal obligations or penalties for platforms
◦ Counter-notice by users accused of posting unlawful content
◦ Audits by platforms
◦ Audits by third parties
◦ Public transparency
Costs
◦ Economic or other costs to platforms
◦ Economic or other costs to third parties when platforms under-remove (prohibited content persists on platforms)
◦ Economic or other costs to third parties when platforms over-remove (when platforms take down lawful or permitted content)
Filters
◦ Accuracy in identifying duplicates
◦ Accuracy in classifying never-before-seen content
◦ Ability to discern or assess when the same item of content appears in a new context (such as news reporting)
◦ Relative accuracy for different kinds of prohibited content (such as nudity vs. support of terrorism)
◦ Relative accuracy for different kinds of files or media (such as text vs. MP3)
◦ Effectiveness of human review by platform employees to correct filtering errors
◦ Cost, including implementation and maintenance costs for platforms that license third-party filtering technology
◦ Impact on subsequent technical development (such as locking in particular technical designs)
Community Guidelines
◦ Rules enforced
◦ Processes, including appeal
◦ Accuracy and cost of enforcement
◦ Governments’ role in setting Community Guidelines
◦ Governments’ role in specific content-removal decisions
Consequences of removal, over-removal, and under-removal
Conclusion
Public understanding of platforms’ content-removal operations, even among specialized researchers, has long been limited. This information vacuum leaves policymakers poorly equipped to respond to concerns about platforms, online speech, and democracy. A growing body of independent research and company disclosures, however, is beginning to remedy the situation. Through improved public transparency by platforms, and thoughtful inquiry and evaluation by independent experts, we may move toward new insights and sounder public policy decisions.



 Open access
Open access