



1. Introduction
Assessing goodness of fit is an essential part of statistical modeling. Identifying systematic error and quantifying its size are important, because if a model does not fit well, parameter estimates may be considerably biased and, consequently, conclusions based on them may be erroneous (Browne and Cudeck, Reference Browne and Cudeck1992; Bollen, Reference Bollen1989).
As is well known, systematic errors are common in parsimonious statistical models in the social, educational, and behavioral sciences. Consequently, model fit is frequently evaluated using fit indices, which help to assess the size of systematic errors and to classify whether the fit may be considered as good, acceptable, or poor. Examples for commonly used fit indices are the Root-Mean-Square Error of Approximation (Steiger and Lind, Reference Steiger and Lind1980)and the Comparative Fit Index(CFI, Bentler, Reference Bentler1990).
Most fit indices are defined through test statistics, whereby the latter are frequently assumed to follow either a central or a noncentral
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution (Yuan, Reference Yuan2005). The assumption of a specific distribution is crucial for distinguishing between random (estimation) error and systematic (approximation) error (e.g., Steiger & Lind, Reference Steiger and Lind1980; Steiger et al., Reference Steiger, Shapiro and Browne1985). Specifically, estimation error is the random deviation of an estimate from its parameter, which depends on the specific sample. The approximation error is a fixed, nonstochastic quantity, which characterizes the systematic deviation between true parameters and their limiting approximation by the model.
-distribution (Yuan, Reference Yuan2005). The assumption of a specific distribution is crucial for distinguishing between random (estimation) error and systematic (approximation) error (e.g., Steiger & Lind, Reference Steiger and Lind1980; Steiger et al., Reference Steiger, Shapiro and Browne1985). Specifically, estimation error is the random deviation of an estimate from its parameter, which depends on the specific sample. The approximation error is a fixed, nonstochastic quantity, which characterizes the systematic deviation between true parameters and their limiting approximation by the model.
If there is no systematic error, that is, if the model fits the data exactly, test statistic T is assumed to asymptotically follow a central
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution, having an expected value equal to the model’s degrees of freedom (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
-distribution, having an expected value equal to the model’s degrees of freedom (
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 ). If there is systematic error, T is assumed to asymptotically follow a noncentral
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
). If there is systematic error, T is assumed to asymptotically follow a noncentral
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution, with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$E(T) = \text {df} + \lambda $$\end{document}
-distribution, with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$E(T) = \text {df} + \lambda $$\end{document}
 , in which
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
, in which
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 is the noncentrality parameter. Because of the additive contribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
is the noncentrality parameter. Because of the additive contribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 as well as the resulting increase by the latter in case of systematic error, the noncentrality parameter is a theoretically sound misfit quantity. A simple point estimate can be obtained as
as well as the resulting increase by the latter in case of systematic error, the noncentrality parameter is a theoretically sound misfit quantity. A simple point estimate can be obtained as

While the noncentrality parameter is well suited for quantifying systematic error, its specific value is complex to interpret. For making sense of it, the specific manner in which T is obtained needs to be taken into account. More specifically, it needs to be considered what determines the scaling of T and, therefore, the scaling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 .
.
In the context of covariance-structure models, T can be obtained using the normal theory maximum likelihood (ML) discrepancy (Jöreskog, Reference Jöreskog1969), or a (weighted) least-square discrepancy, that is

in which
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{{\hat{\sigma }}}$$\end{document}
 is a vector of model implied covariances,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{s}}$$\end{document}
is a vector of model implied covariances,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{s}}$$\end{document}
 is a vector of corresponding sample covariances, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
is a vector of corresponding sample covariances, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
 is a weight matrix.
is a weight matrix.
There are several candidates for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
 for which T (depending on distributional assumptions) asymptotically follows a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
for which T (depending on distributional assumptions) asymptotically follows a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution. Under normality assumptions, the generalized least squares (GLS) discrepancy can be used. It can be written as
-distribution. Under normality assumptions, the generalized least squares (GLS) discrepancy can be used. It can be written as

where
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{D}}$$\end{document}
 is a duplication matrix (e.g., Browne & Arminger, Reference Browne and Arminger1995) and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{S}}$$\end{document}
is a duplication matrix (e.g., Browne & Arminger, Reference Browne and Arminger1995) and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{S}}$$\end{document}
 is the variables’ covariance matrix. This discrepancy function has the same solution as the ML discrepancy, but a different minimum. If instead the inverted asymptotic variance-covariance-matrix of the elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{s}}$$\end{document}
is the variables’ covariance matrix. This discrepancy function has the same solution as the ML discrepancy, but a different minimum. If instead the inverted asymptotic variance-covariance-matrix of the elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{s}}$$\end{document}
 is inserted for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
is inserted for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
 , the asymptotically distribution free (ADF) discrepancy function is obtained (e.g., Browne, Reference Browne1982). Other candidates for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
, the asymptotically distribution free (ADF) discrepancy function is obtained (e.g., Browne, Reference Browne1982). Other candidates for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
 , such as the identity matrix, which is used for obtaining the unweighted least squares (ULS) discrepancy, do usually not yield an approximately
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
, such as the identity matrix, which is used for obtaining the unweighted least squares (ULS) discrepancy, do usually not yield an approximately
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distributed statistic.
-distributed statistic.
If an appropriate weighting is selected, then the expected contributions of deviations per
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 asymptotically follow mutually independent normal distributions having a variance of 1.0 and expectation
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _j$$\end{document}
asymptotically follow mutually independent normal distributions having a variance of 1.0 and expectation
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _j$$\end{document}
 , with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\cdots ,\text {df}$$\end{document}
, with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$j=1,\cdots ,\text {df}$$\end{document}
 . If there is no systematic difference between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{s}}$$\end{document}
. If there is no systematic difference between
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{s}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{{\hat{\sigma }}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{{\hat{\sigma }}}$$\end{document}
 , the expected values of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _j$$\end{document}
, the expected values of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _j$$\end{document}
 are 0.0. Accordingly, the square sum of expected values follows a central
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
are 0.0. Accordingly, the square sum of expected values follows a central
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution. In case of systematic error, that is, if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _j \ne 0.0$$\end{document}
-distribution. In case of systematic error, that is, if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _j \ne 0.0$$\end{document}
 , the square sum’s expected value is increased by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda = \sum _j \mu _j^2$$\end{document}
, the square sum’s expected value is increased by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda = \sum _j \mu _j^2$$\end{document}
 .
.
An important feature of this weighting is that specific values of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\mu _j$$\end{document}
 directly depend on the standardization of variances of random errors. In other words, the scaling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
directly depend on the standardization of variances of random errors. In other words, the scaling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 is determined by sampling properties. It follows that different
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
is determined by sampling properties. It follows that different
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 -values are obtained depending on sample size (which can be easily controlled for) as well as the estimators’ variances.
-values are obtained depending on sample size (which can be easily controlled for) as well as the estimators’ variances.
However, why should the size of nonstochastic quantity
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 depend on the expected variance of random errors? In fact, relying on such a scaling entails potential limitations. These limitations relate to the (i) interpretability and (ii) universality of using
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
depend on the expected variance of random errors? In fact, relying on such a scaling entails potential limitations. These limitations relate to the (i) interpretability and (ii) universality of using
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 for quantifying systematic error.
for quantifying systematic error.
For a simple illustration of the dependency between sampling properties and the size of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 , consider the following example. A model assumes a fixed correlation of zero, that is,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\sigma }}=0.0$$\end{document}
, consider the following example. A model assumes a fixed correlation of zero, that is,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\sigma }}=0.0$$\end{document}
 . The sample correlation’s expected value, however, is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$E(s)=0.1$$\end{document}
. The sample correlation’s expected value, however, is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$E(s)=0.1$$\end{document}
 . The specific value of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
. The specific value of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 (using Eq. (2)), depends on sample size n as well as the specific asymptotic variance of the sample estimate.
(using Eq. (2)), depends on sample size n as well as the specific asymptotic variance of the sample estimate.
Consider that n is either 1000 or 10, 000, and that either the variables’ product-moment correlations (pmc) or the tetrachoric correlations (tc) are analyzed.Footnote 1 The resulting estimates for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }}$$\end{document}
 are as follows: using pmc and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
are as follows: using pmc and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 , we obtain
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = 9.97$$\end{document}
, we obtain
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = 9.97$$\end{document}
 , and for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=10,000$$\end{document}
, and for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=10,000$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = 99.97$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = 99.97$$\end{document}
 . For tc we obtain
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = 4.11$$\end{document}
. For tc we obtain
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = 4.11$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = 41.09$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = 41.09$$\end{document}
 for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=10,000$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=10,000$$\end{document}
 respectively.
respectively.
As is well known, the impact of differing sample size on the noncentrality parameter can be readily accounted for, dividing it by n. The RMSEA, which gives the square root of the average noncentrality parameter per observation and degree of freedom, may be written as

Accordingly, irrespective of sample size, RMSEA values based on product-moment correlations yield a value of roughly 0.1. However, for tc, which have larger variances, the RMSEA is 0.064. Note that widely accepted conventions consider RMSEA values smaller than 0.05 as indicating a good, values between 0.05 and 0.08 as an acceptable, and values larger than 0.10 as a poor model fit (e.g., Hu & Bentler, Reference Hu and Bentler1998). Thus, the fit of the tc-based model would be classified as acceptable and the fit of the pmc-based model as poor, although both models approximate the same structure.
Clearly, systematic variance differences between types of correlation coefficients are not accounted for by the RMSEA—nor by any other noncentrality parameter based fit index. This feature of fit indices, particularly their dependence on the variables’ level-of-measurement, has been reported by several authors (e.g., Maydeu-Olivares & Joe, Reference Maydeu-Olivares and Joe2014; Monroe & Cai, Reference Monroe and Cai2015; Xia & Yang, Reference Xia and Yang2018; Savalei, Reference Savalei2021). Specifically, previous research indicates that common fit indices, such as RMSEA, CFI and TLI (Tucker-Lewis Index), generally yield overly optimistic fit assessments when analyzing categorical as compared to metric variables.
Obviously, the source of the systematic difference in fit indices is the weighting of discrepancies, which depends on the variances of the respective type of estimate. Thus, any approach for resolving the outlined limitation would need to address the impact of the random-error-related weighting.
A previous approach that resolves one of the two limiting aspects of this weighting has been proposed by Savalei (Reference Savalei2021). While the general impact of random-error-related scaling is left unaltered, the difference in fit indices for metric and categorical data analyses is controlled for. Specifically, this adjustment rescales RMSEA-values pertaining to categorical data models in a way, that they approximate the expected value that would have been obtained analyzing metric data. This approach has the advantage that conventional cut-off criteria for the RMSEA can be used for categorical data as well. However, the scaling related attributes with respect to the interpretability of specific values are not addresses in this way.
Another approach, which is pursued in more detail in the following, aims to eliminate the impact of random-error-related scaling entirely. Fit indices that yield an unweighted discrepancy measure are already available. Examples are the standardized root-mean-square residual (SRMR, Jöreskog & Sörbom, Reference Jöreskog and Sörbom1988) and the correlation root-mean-squared residual (CRMR, Bollen, Reference Bollen1989). However, these measures do not distinguish between random and systematic error and, therefore, overestimate their population parameters. Fortunately, this limitation has been addressed by Maydeu-Olivares (Reference Maydeu-Olivares2017), who proposed an estimation approach for the population parameters of SRMR and CRMR. This proposal will be revisited below. A remaining limiting property of these indices, however, is that they merely address average discrepancies irrespective the model’s relative complexity.
The present article proposes a more general approach than the previous fit index adjustments. Specifically, it considers ways in which a “general-purpose” unweighted approximation error estimate can be obtained. Based on this estimate, different specific fit indices can be calculated. In contrast to Savalei (Reference Savalei2021), the new indices fully eliminate the random-error-related scaling, while similarly maintaining the equality of fit indices for metric and categorical data models. Consequently, by eliminating the specific scaling, individual fit index values have a comparably simple interpretation that can be directly linked to the size of covariance residuals. In contrast to the population estimates of SRMR and CRMR, as proposed by Maydeu-Olivares (Reference Maydeu-Olivares2017), fit indices that contain an unweighted approximation error offer more differentiated options for fit assessment. Particularly, such indices can (a) be implemented into fit indices that take the model’s complexity into account and (b) they can be used to assess absolute as well as relative fit. Specifically, absolute fit can be assessed by modifying the RMSEA with the new approximation error estimate, and relative fit can be considered by modifying the CFI.
2. Unweighted Approximation Error Estimate
The unweighted approximation error
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _\text {u}$$\end{document}
 can be defined as the sum of squared discrepancies due to approximation errors. It may be expressed as the population value of the unweighted least square (ULS) discrepancy, that is
can be defined as the sum of squared discrepancies due to approximation errors. It may be expressed as the population value of the unweighted least square (ULS) discrepancy, that is
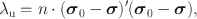
in which
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\sigma }_0$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\sigma }$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\sigma }$$\end{document}
 are the corresponding population covariances of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{s}}$$\end{document}
are the corresponding population covariances of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{s}}$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{{\hat{\sigma }}}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{{\hat{\sigma }}}$$\end{document}
 respectively. Note that the ULS discrepancy is merely a means to expressing the unweighted approximation error. It is not involved in model fitting, which can be performed by an entirely different function.
respectively. Note that the ULS discrepancy is merely a means to expressing the unweighted approximation error. It is not involved in model fitting, which can be performed by an entirely different function.
It is already known from other standardized fit indices, such as SRMR and CRMR, that it is only sensible to report a unit-weighted fit measure, if variables are scaled identically. Thus, the following considerations assume that a model’s correlation structure is used for calculating
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _\text {u}$$\end{document}
 . Consequently, the unweighted approximation error equals n-times the squared deviations between the true population correlations and their limiting approximation by the model. Note that, similar to SRMR and CRMR, model estimation does not necessarily need to be based on sample correlations.
. Consequently, the unweighted approximation error equals n-times the squared deviations between the true population correlations and their limiting approximation by the model. Note that, similar to SRMR and CRMR, model estimation does not necessarily need to be based on sample correlations.
Although
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _\text {u}$$\end{document}
 may be considered as a noncentrality parameter pertaining to the ULS discrepancy, it cannot be simply approximated using Eq. (1). Instead, there are two other general approaches in which a suitable estimate may be obtained. First, an adjusted estimate for the degrees of freedom
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
may be considered as a noncentrality parameter pertaining to the ULS discrepancy, it cannot be simply approximated using Eq. (1). Instead, there are two other general approaches in which a suitable estimate may be obtained. First, an adjusted estimate for the degrees of freedom
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 can be calculated, which can be inserted into (1). Second, a scaling constant that accounts for the relative amount of systematic error in relation to overall error can be used to rescale the ULS sample discrepancy.
can be calculated, which can be inserted into (1). Second, a scaling constant that accounts for the relative amount of systematic error in relation to overall error can be used to rescale the ULS sample discrepancy.
For implementing the first general approach, there are different options. For one, standard theory in connection with robust adjustments of test statistics based on oversimplified least-square estimation can be used as rationale (e.g., Muthen, Reference Muthén1997). Also, the upper mentioned approach of (Maydeu-Olivares, Reference Maydeu-Olivares2017) can be adapted. While both options are closely related, they have few distinct features.
Approach (1.1). In connection with ULS estimation, there are robust corrections available, which can be used for obtaining a model test statistic that approximates the expected value and variance of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution for the respective
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
-distribution for the respective
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 of the model ( e.g., Satorra, Reference Satorra1992). While this approach is commonly used for correcting model test statistics, it can also be used to approximate Eq. (4).
of the model ( e.g., Satorra, Reference Satorra1992). While this approach is commonly used for correcting model test statistics, it can also be used to approximate Eq. (4).
A mean-variance adjusted ULS test statistic (usually abbreviated as ULSMV) can be obtained based on an estimate of the correlation estimates’ covariance matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Gamma }$$\end{document}
 and the Jacobian matrix containing the derivatives of model implied correlations with respect to the model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Delta }$$\end{document}
and the Jacobian matrix containing the derivatives of model implied correlations with respect to the model parameters
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Delta }$$\end{document}
 . A more detailed description of these matrices in connection with robust adjustments can be found in Muthen (Reference Muthén1997).
. A more detailed description of these matrices in connection with robust adjustments can be found in Muthen (Reference Muthén1997).
For ULS, the adjusted test statistic is calculated as
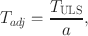
in which
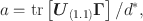
with

and

From the adjusted test statistic
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_{adj}$$\end{document}
 and degrees of freedom
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d^*$$\end{document}
and degrees of freedom
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$d^*$$\end{document}
 a noncentrality parameter estimate can be obtained by inserting these values into Eq. (1). The unweighted discrepancy function can then be obtained by rescaling the value using a. Simplifying the resulting expression yields
a noncentrality parameter estimate can be obtained by inserting these values into Eq. (1). The unweighted discrepancy function can then be obtained by rescaling the value using a. Simplifying the resulting expression yields

Approach (1.2). Another unweighted approximation error estimate can be obtained based on a minor reformulation of the approach of Maydeu-Olivares (Reference Maydeu-Olivares2017), which was originally designed to approximate the population value of SRMR and CRMR. Specifically, the noncentrality parameter estimate can be calculated as
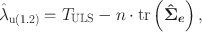
in which
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{{\hat{\Sigma }}_e}$$\end{document}
 is the variance-covariance matrix of the (correlation) residuals, that is
is the variance-covariance matrix of the (correlation) residuals, that is

with
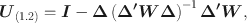
in which
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
 is the weight matrix of the GLS discrepancy function and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Gamma }$$\end{document}
is the weight matrix of the GLS discrepancy function and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Gamma }$$\end{document}
 as well as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Delta }$$\end{document}
as well as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Delta }$$\end{document}
 are defined as above.
are defined as above.
Clearly, approaches (1.1) and (1.2) are closely related. The central difference is that approach (1.2) additionally includes
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
 . While this is important for estimating the correlations’ variance-covariance matrix, the immediate impact for obtaining an appropriate estimate of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _\text {u}$$\end{document}
. While this is important for estimating the correlations’ variance-covariance matrix, the immediate impact for obtaining an appropriate estimate of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _\text {u}$$\end{document}
 is not obvious.
is not obvious.
Approaches (1.1) and (1.2) solely depend on (i) the sample correlation, (ii) an estimation of their variance-covariance matrix, and (iii) the parameter estimates of a model. The specific discrepancy function used for fitting the model’s parameter estimates is only relevant for (iii). However, because of the equivalence between ML and GLS, approach (1.2) might be particularly suited in connection with ML parameter estimates.
Approach (2). The second approach is based on the assumption that (i) sources of random and systematic error are independent and that (ii) the test statistic’s expected value results from the additive contribution of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda $$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 . If both assumptions are satisfied, then the corresponding test statistic asymptotically follows a (non-)central
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
. If both assumptions are satisfied, then the corresponding test statistic asymptotically follows a (non-)central
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution. It then follows that the relative proportion of variances attributed to systematic error in relation to the total error can be expressed as
-distribution. It then follows that the relative proportion of variances attributed to systematic error in relation to the total error can be expressed as
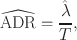
which is henceforth referred to as Approximation Discrepancy Ratio (ADR). The ML discrepancy function is a viable candidate for calculating ADR, because it yields a close approximation of the noncentral
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution under various misspecification scenarios (e.g., Curranet al., Reference Curran, Bollen, Paxton, Kirby and Chen2002). However, while any discrepancy function yielding the above properties is suited for obtaining T, in practice, the specific choice might have a considerable impact on the results, because of their notable performance differences (e.g., Olsson et al., Reference Olsson, Foss and Breivik2004; Shi & Maydeu-Olivares, Reference Shi and Maydeu-Olivares2020)
-distribution under various misspecification scenarios (e.g., Curranet al., Reference Curran, Bollen, Paxton, Kirby and Chen2002). However, while any discrepancy function yielding the above properties is suited for obtaining T, in practice, the specific choice might have a considerable impact on the results, because of their notable performance differences (e.g., Olsson et al., Reference Olsson, Foss and Breivik2004; Shi & Maydeu-Olivares, Reference Shi and Maydeu-Olivares2020)
The result of (8) can then be used to weigh test statistic
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_\text {ULS}$$\end{document}
 , that is
, that is

which yields the proportion of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_\text {ULS}$$\end{document}
 that is attributed to systematic error. It is important to notice, that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_\text {ULS}$$\end{document}
that is attributed to systematic error. It is important to notice, that
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_\text {ULS}$$\end{document}
 and T (used in the calculation of ADR) originate from different discrepancy functions. In this way, the desired scaling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_\text {ULS}$$\end{document}
and T (used in the calculation of ADR) originate from different discrepancy functions. In this way, the desired scaling of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$T_\text {ULS}$$\end{document}
 is combined with an appropriate measure of the relative contribution of systematic error. It is easy to see that, if the same discrepancy function would be used for both quantities, the trivial result
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = {\hat{\lambda }}/T \cdot T$$\end{document}
is combined with an appropriate measure of the relative contribution of systematic error. It is easy to see that, if the same discrepancy function would be used for both quantities, the trivial result
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }} = {\hat{\lambda }}/T \cdot T$$\end{document}
 would be obtained.
would be obtained.
The second approach has the advantage that it is (a) computationally rather simple and (b) that the result of any discrepancy function can be used without requiring any specific adaption, as long as the corresponding distributional assumptions are satisfied. However, the inclusion of the results of a second discrepancy function make this approach conceptually more complex and it is difficult to say under which conditions the upper mentioned assumptions are met.
Considering property (b), approach (2) is similarly applicable to metric as well as categorical data. In order to apply approaches (1.1) and (1.2) to categorical data models (for instance based on the variables’ polychoric correlations), matrices
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Gamma }$$\end{document}
 ,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Delta }$$\end{document}
,
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Delta }$$\end{document}
 , and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
, and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{W}}$$\end{document}
 need to be selected accordingly.
need to be selected accordingly.
Another interesting feature of approach (2) is that it can be calculated retrospectively without having the original data, as long as the model fit test statistic as well as the square sum of correlation residuals are available. The size of the latter may also be inferred from the CRMR.
Although approaches (1) and (2) proceed differently, there is one direct connection. If approach (2) is used in connection with ULSMV estimation, its yields the same result as approach (1.1).
New Fit Indices
Based on the unweighted approximation error, new fit indices can be calculated by substituting the noncentrality parameter in their well-established counterparts. An unweighted Root-Mean-Square Error of Approximation RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 can be calculated analogous to equation (3), yielding
can be calculated analogous to equation (3), yielding

For correlation structure models, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 yields the average absolute correlation residual due to approximation error per
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
yields the average absolute correlation residual due to approximation error per
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 . For instance, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.05$$\end{document}
. For instance, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.05$$\end{document}
 denotes that the average absolute correlation residual per
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
denotes that the average absolute correlation residual per
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 due to systematic error is 0.05. Clearly, this interpretation is rather simple and intuitive as compared to that of the original RMSEA, for which the scaling of the noncentrality parameter needs to be considered.
due to systematic error is 0.05. Clearly, this interpretation is rather simple and intuitive as compared to that of the original RMSEA, for which the scaling of the noncentrality parameter needs to be considered.
In order to obtain an asymptotically unbiased estimate for the population value of equation (10), minor adjustments are required. For approaches (1.1) and (1.2) a correction constant can be obtained as follows, which is derived using Taylor expansions of moments of functions of random variables, which is outlined in more detail for approach (2).
For approach (1.2) Maydeu-Olivares (Reference Maydeu-Olivares2017) has given the following adjustment. For a simplified notation, let
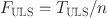
Then, the estimate of Eq. (10) based on approach (1.2) is

in which k is the correction constant, that is

with

The same approach can be used for approach (1.1), replacing
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{{\hat{\Sigma }}_e}$$\end{document}
 with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{-1} \text {tr}\left[ {\varvec{U}}_{(1.1)} \varvec{\Gamma } \right] $$\end{document}
with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n^{-1} \text {tr}\left[ {\varvec{U}}_{(1.1)} \varvec{\Gamma } \right] $$\end{document}
 .
.
For approach (2), a bias corrected RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 estimate can be obtained using
estimate can be obtained using

with
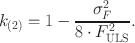
The correction factor as well as standard errors of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$f(F_\text {ULS}) = \text {RMSEA}_{u(2)}$$\end{document}
 can also be estimated using the Delta method (e.g., Wolter, Reference Wolter1985). Specifically, expected value and variance are
can also be estimated using the Delta method (e.g., Wolter, Reference Wolter1985). Specifically, expected value and variance are

and
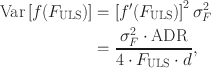
given that

and
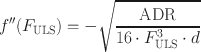
RMSEA values are commonly reported together with their
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 confidence interval. Assuming that the sampling distribution of the indices approximately follows a normal distribution in large samples, the interval may be calculated as
confidence interval. Assuming that the sampling distribution of the indices approximately follows a normal distribution in large samples, the interval may be calculated as
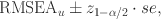
in which se is the asymptotic standard error of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$RMSEA_u$$\end{document}
 .
.
For approach (1.2), the asymptotic standard error proposed by Maydeu-Olivares (Reference Maydeu-Olivares2017) can be used with one minor modification, replacing the number of nonredundant covariances/correlation with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\text {df}$$\end{document}
 . This yields
. This yields

For approach (2), a similar approach can be used. Carrying the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$1/k_{(2)}$$\end{document}
 scaling forward, the asymptotic standard error is otherwise identical to the square root of expression of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\textrm{Var}\left[ f(F_\text {ULS})\right] $$\end{document}
scaling forward, the asymptotic standard error is otherwise identical to the square root of expression of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\textrm{Var}\left[ f(F_\text {ULS})\right] $$\end{document}
 , given above, yielding
, given above, yielding
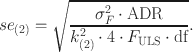
An unweighted version of the Comparative Fit Index (CFI) can be obtained in a similar manner. The CFI considers the relation between the noncentrality parameter of the fitted model to that of a less complex base model (usually an independence model). Again, the noncentrality parameter is replaced by
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }}_\text {u}$$\end{document}
 . Specifically, the CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
. Specifically, the CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 may be written as
may be written as

in which
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\hat{\lambda }}_{B \cdot \text {u}}$$\end{document}
 is the unweighted approximation error estimate for the base model. Because estimates of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _\text {u}$$\end{document}
is the unweighted approximation error estimate for the base model. Because estimates of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _\text {u}$$\end{document}
 are not systematically biased, no additional adjustments are required.
are not systematically biased, no additional adjustments are required.
The interpretation of CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 may also be considered as somewhat simpler than that pertaining to the original CFI. Specifically, CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
may also be considered as somewhat simpler than that pertaining to the original CFI. Specifically, CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 expresses the size of systematic error variance of the base model relative to that of the fitted model. For instance, CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u = 0.90$$\end{document}
expresses the size of systematic error variance of the base model relative to that of the fitted model. For instance, CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u = 0.90$$\end{document}
 denotes that the squared correlation residuals of a specific model are
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
denotes that the squared correlation residuals of a specific model are
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 smaller than those of the baseline model.
smaller than those of the baseline model.
The present considerations are restricted to RMSEA and CFI, because they are prototypical indices which include a noncentrality parameter estimate in their original formulation. Other relative fit indices that use a similar expression as the CFI, such as the Tucker-Lewis Index (TLI) or Normed Fit Index (NFI), lack this property and are, therefore, not suitable for the current purpose.
While specific values of RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 have a simple interpretation that can be directly connected to the absolute or squared correlation residuals, it is not obvious which values might indicate a good, acceptable or poor fit. There are two option for identifying suitable cutoff values for the new indices. First, by expert consensus based on empirical examples, which is the approach with which cutoff values for most fit indices have been established (e.g., Hu & Bentler, Reference Hu and Bentler1998). Second, by comparing established and new indices. If they are in a relatively simple relation, this may provide sufficient information to establish suitable cutoffs. While the first approach is beyond the scope of this article, the second approach will be pursued in the next section using simulation studies.
have a simple interpretation that can be directly connected to the absolute or squared correlation residuals, it is not obvious which values might indicate a good, acceptable or poor fit. There are two option for identifying suitable cutoff values for the new indices. First, by expert consensus based on empirical examples, which is the approach with which cutoff values for most fit indices have been established (e.g., Hu & Bentler, Reference Hu and Bentler1998). Second, by comparing established and new indices. If they are in a relatively simple relation, this may provide sufficient information to establish suitable cutoffs. While the first approach is beyond the scope of this article, the second approach will be pursued in the next section using simulation studies.
To assist with the calculation of the new indices, the supplementary materials to this article contain a data example (’example_data.txt’) as well as the corresponding R-code (’R_example.pdf’) for calculating RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 based on approaches (1.1), (1.2), and (2). The data is metric and contains 4 variables and 1000 cases. The corresponding analysis assumes one latent variable. The R-code can be also used for evaluating other data sets and models. For more information, see the instructions in the materials.
based on approaches (1.1), (1.2), and (2). The data is metric and contains 4 variables and 1000 cases. The corresponding analysis assumes one latent variable. The R-code can be also used for evaluating other data sets and models. For more information, see the instructions in the materials.
Simulation Study
For investigating the properties of the new indices, a simulation study was conducted considering a set of varying confirmatory factor model structures. These simulations pursue the goals to demonstrate (i) that accurate estimates of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\lambda _\text {u}$$\end{document}
 can be obtained in finite samples, (ii) that fit indices based on the new measure yield identical values for models based on metric and dichotomous variables for identical model structures, and (iii) to identify suitable cutoff values for RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
can be obtained in finite samples, (ii) that fit indices based on the new measure yield identical values for models based on metric and dichotomous variables for identical model structures, and (iii) to identify suitable cutoff values for RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 by comparing them to their noncentrality-parameter-based counterparts.
by comparing them to their noncentrality-parameter-based counterparts.
Method
Data were generated based on population correlation matrices
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Sigma }_0$$\end{document}
 for a given q-factorial model structure. These matrices were calculated from predefined
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p \times q$$\end{document}
for a given q-factorial model structure. These matrices were calculated from predefined
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p \times q$$\end{document}
 matrices of item loadings
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{K}}$$\end{document}
matrices of item loadings
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$${\varvec{K}}$$\end{document}
 , a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q \times q$$\end{document}
, a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q \times q$$\end{document}
 matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Phi }$$\end{document}
matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Phi }$$\end{document}
 of factor inter-correlations, and a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p \times p$$\end{document}
of factor inter-correlations, and a
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p \times p$$\end{document}
 diagonal matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Psi }$$\end{document}
diagonal matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Psi }$$\end{document}
 of residuals, that is
of residuals, that is

Factor loadings were chosen in a way that population correlation matrix
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Sigma }_0$$\end{document}
 yielded a predefined ULS-discrepancy from the best approximating correlation matrix implied by the model. Specifically, loadings were chosen in a way that the true approximation discrepancies yielded predefined target values for each of the simulation settings. This was achieved by numerical optimization, iteratively optimizing the population model discrepancy with respect to the fit indices’ target values based on the model parameters using the Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm as implemented in the optim-procedure in R. Two target value settings were considered: (i) RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.05$$\end{document}
yielded a predefined ULS-discrepancy from the best approximating correlation matrix implied by the model. Specifically, loadings were chosen in a way that the true approximation discrepancies yielded predefined target values for each of the simulation settings. This was achieved by numerical optimization, iteratively optimizing the population model discrepancy with respect to the fit indices’ target values based on the model parameters using the Broyden–Fletcher–Goldfarb–Shanno (BFGS) algorithm as implemented in the optim-procedure in R. Two target value settings were considered: (i) RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.05$$\end{document}
 ; CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.95$$\end{document}
; CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.95$$\end{document}
 and (ii) RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.05$$\end{document}
and (ii) RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.05$$\end{document}
 ; CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
; CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
 .
.
The source of systematic error was the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
 latent variable, which, in addition to the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q-1$$\end{document}
latent variable, which, in addition to the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q-1$$\end{document}
 latent variables, was considered for generating the data, whereas the analysis model only considered the structure of the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q-1$$\end{document}
latent variables, was considered for generating the data, whereas the analysis model only considered the structure of the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q-1$$\end{document}
 latent variables. For introducing additional variability to the way in which systematic misfit was generated, two different types of loading patterns were used for the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
latent variables. For introducing additional variability to the way in which systematic misfit was generated, two different types of loading patterns were used for the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
 latent variable.
latent variable.
For the first type, the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
 latent variable had loadings on the first and last indicator pertaining to each of the prior
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*=q-1$$\end{document}
latent variable had loadings on the first and last indicator pertaining to each of the prior
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*=q-1$$\end{document}
 latent variables. For instance, for a three-factorial model structure with overall
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=8$$\end{document}
latent variables. For instance, for a three-factorial model structure with overall
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=8$$\end{document}
 variables, the loading matrix would be
variables, the loading matrix would be
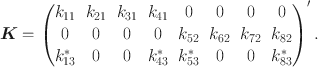
For the second type, the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
 latent variable had positive loadings on the first half of the indicators pertaining to each of the prior
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
latent variable had positive loadings on the first half of the indicators pertaining to each of the prior
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
 latent variables, and negative loadings on the second half. Consequently, the three-factorial structure with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=8$$\end{document}
latent variables, and negative loadings on the second half. Consequently, the three-factorial structure with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=8$$\end{document}
 variables would be
variables would be

The two loading patterns are henceforth referred to as misfit type I and misfit type II.
For the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
 latent variables, loadings adhered to a simple structure, that is, each variable had loadings on one latent variable only. For simplicity, loadings on the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
latent variables, loadings adhered to a simple structure, that is, each variable had loadings on one latent variable only. For simplicity, loadings on the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
 latent variables had identical loadings k. Similarly, loadings on the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
latent variables had identical loadings k. Similarly, loadings on the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
 latent variable had identical values
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k^*$$\end{document}
latent variable had identical values
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k^*$$\end{document}
 . Correlations between the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
. Correlations between the first
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
 factors were set to 0.3 by default. The
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
factors were set to 0.3 by default. The
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^{th}$$\end{document}
 latent variable was assumed independent from the remaining
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q-1$$\end{document}
latent variable was assumed independent from the remaining
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q-1$$\end{document}
 latent variables.
latent variables.
Altogether, 56 model settings were considered. In addition to misfit type and target values for RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 , the number of variables p, the number of latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
, the number of variables p, the number of latent variables
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*$$\end{document}
 , and sample size n were varied. Specifically, the combinations of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=8$$\end{document}
, and sample size n were varied. Specifically, the combinations of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=8$$\end{document}
 , 12, and 18 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*=1$$\end{document}
, 12, and 18 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*=1$$\end{document}
 , 2 and 3 were considered, omitting the combinations of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*=1$$\end{document}
, 2 and 3 were considered, omitting the combinations of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*=1$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=18$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=18$$\end{document}
 as well as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*=3$$\end{document}
as well as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^*=3$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=8$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p=8$$\end{document}
 . Sample sizes were
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=250$$\end{document}
. Sample sizes were
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=250$$\end{document}
 and 1000. The specific values for k and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k^*$$\end{document}
and 1000. The specific values for k and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$k^*$$\end{document}
 for the different model settings, rounded to three decimal places, are given in Table 1.
for the different model settings, rounded to three decimal places, are given in Table 1.
Table 1. True loadings for the population models for the different model settings.

For each of the 56 settings, 1000 data sets were sampled from a multivariate normal distribution based on corresponding correlation matrices
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Sigma }_0$$\end{document}
 . These correlation matrices were then analyzed using confirmatory factor analyses based on ML and ULSMV estimation. For comparing fit indices between metric and dichotomous variables, additional dichotomized data sets were generated from the existing data by splitting metric variables at their mean. The dichotomized data were analyzed based on their tetrachoric correlation matrices using ULSMV.Footnote 2
. These correlation matrices were then analyzed using confirmatory factor analyses based on ML and ULSMV estimation. For comparing fit indices between metric and dichotomous variables, additional dichotomized data sets were generated from the existing data by splitting metric variables at their mean. The dichotomized data were analyzed based on their tetrachoric correlation matrices using ULSMV.Footnote 2
For the analyses based on ML estimation, all approximation error estimates were calculated using approach (1.1), (1.2), and (2). For the ULSMV analyses, only approaches (1.1) and (1.2) were included, because of the equivalence of (1.1) and (2) under this specific condition. Finally, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 based on the different approaches, as well as their noncentrality-parameter-based counterparts were calculated for each model and averaged within simulation settings.
based on the different approaches, as well as their noncentrality-parameter-based counterparts were calculated for each model and averaged within simulation settings.
Results
Results pertaining to models using ML and ULSMV estimation are presented separately. First, the results of metric data analyses with ML estimation are considered. Tables 2 and 3 give RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 estimates as well as the coverage probabilities of the corresponding
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
estimates as well as the coverage probabilities of the corresponding
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 -confidence intervals based on the different approaches for misfit type I and II respectively. Clearly, the average estimates of RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
-confidence intervals based on the different approaches for misfit type I and II respectively. Clearly, the average estimates of RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 are very close to their target values of 0.05 irrespective of the estimation approach. This holds true across all simulation settings, implying that the unweighted approximation error estimate performs well if calculated based on multivariate normal indicators and the ML test statistic. For sample sizes of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
are very close to their target values of 0.05 irrespective of the estimation approach. This holds true across all simulation settings, implying that the unweighted approximation error estimate performs well if calculated based on multivariate normal indicators and the ML test statistic. For sample sizes of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 deviations of the average estimate from the target value are seldom larger than
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pm 0.001$$\end{document}
deviations of the average estimate from the target value are seldom larger than
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pm 0.001$$\end{document}
 .
.
While neither type of misfit, nor the complexity of the model appears to have a distinct impact on the accuracy of average values, approach (2) has a tendency to overestimate the true RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 value in conditions in which the true CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
value in conditions in which the true CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 value is 0.99. These are also the conditions, in which average loadings are distinctly higher than for CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.95$$\end{document}
value is 0.99. These are also the conditions, in which average loadings are distinctly higher than for CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.95$$\end{document}
 (see also Table 1). In such conditions, in which reproduced correlations are large, absolute deviations between sample and model implied correlations are more strongly weighted by typical discrepancy functions. Accordingly, because ADR-estimates are obtained based on the ML discrepancy function, this might have caused this slight overestimation.
(see also Table 1). In such conditions, in which reproduced correlations are large, absolute deviations between sample and model implied correlations are more strongly weighted by typical discrepancy functions. Accordingly, because ADR-estimates are obtained based on the ML discrepancy function, this might have caused this slight overestimation.
Comparing values of the original RMSEA, it becomes obvious that they do not directly compare to RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 . For more complex models, as well as higher loadings, typical RMSEA values clearly exceed RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
. For more complex models, as well as higher loadings, typical RMSEA values clearly exceed RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 values. Particularly, in simulation settings with CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
values. Particularly, in simulation settings with CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
 , this trend can be observed. The reason for this is obvious. Because the elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Sigma }_0$$\end{document}
, this trend can be observed. The reason for this is obvious. Because the elements of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\varvec{\Sigma }_0$$\end{document}
 are comparably more extreme than in these settings, standard errors are smaller, and the scaling of the corresponding (weighted) discrepancy is relatively increased. Thus, the noncentrality parameter as well as the RMSEA are increased accordingly.
are comparably more extreme than in these settings, standard errors are smaller, and the scaling of the corresponding (weighted) discrepancy is relatively increased. Thus, the noncentrality parameter as well as the RMSEA are increased accordingly.
Table 2. Average RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and RMSEA values as well as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
and RMSEA values as well as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 -CI coverages of ML confirmatory factor models based on 1000 replications per cell. (Misfit Type I).
-CI coverages of ML confirmatory factor models based on 1000 replications per cell. (Misfit Type I).

Est.: RMSEA estimate and CIC:
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 -confidence interval coverage pertaining to the respective approach; Orig. Est.: unadjusted RMSEA.
-confidence interval coverage pertaining to the respective approach; Orig. Est.: unadjusted RMSEA.
The coverage probabilities of the
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 -confidence interval (CIC) are adequate. Particularly, if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
-confidence interval (CIC) are adequate. Particularly, if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 , results are close to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
, results are close to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 . For smaller sample sizes, CICs remain somewhat below their target. Also, confidence intervals coverages pertaining to approaches (1.1) and (1.2) are somewhat closer to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
. For smaller sample sizes, CICs remain somewhat below their target. Also, confidence intervals coverages pertaining to approaches (1.1) and (1.2) are somewhat closer to
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 than those of approach (2). For bias type II and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
than those of approach (2). For bias type II and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
 , all confidence intervals are somewhat too wide for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
, all confidence intervals are somewhat too wide for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 , irrespective of the condition.
, irrespective of the condition.
Table 3. Average RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and RMSEA values as well as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
and RMSEA values as well as
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 -CI coverages of ML confirmatory factor models based on 1000 replications per cell. (Misfit Type II).
-CI coverages of ML confirmatory factor models based on 1000 replications per cell. (Misfit Type II).

Est.: RMSEA estimate and CIC:
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 -confidence interval coverage pertaining to the respective approach; Orig. Est.: unadjusted RMSEA.
-confidence interval coverage pertaining to the respective approach; Orig. Est.: unadjusted RMSEA.
Table 4 gives the CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 estimates based on the different approaches for the metric data analyses with ML estimation. Similar to the RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
estimates based on the different approaches for the metric data analyses with ML estimation. Similar to the RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 estimates, values are consistently close to their target value.
estimates, values are consistently close to their target value.
Table 4. Average CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI values of ML confirmatory factor models based on 1000 replications per cell.
and CFI values of ML confirmatory factor models based on 1000 replications per cell.
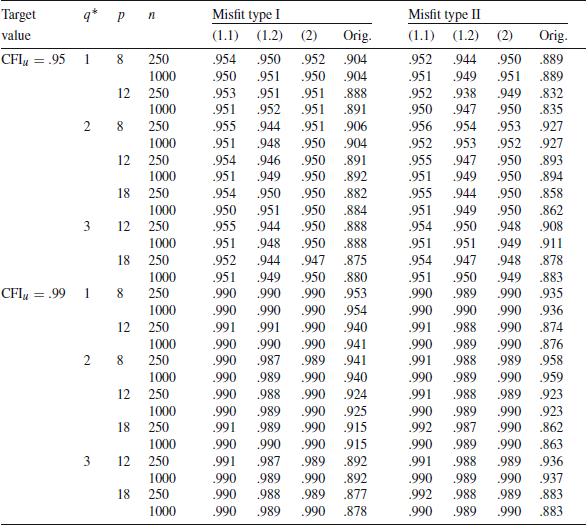
Orig.: unadjusted CFI.
Comparing the original CFI with CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 , the former is continuously smaller. For settings in which CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
, the former is continuously smaller. For settings in which CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
 , this difference in size increases as the number of latent variables is increased, whereby CFI-values become consistently smaller with increasing model complexity. This difference is also likely connected to the different average correlation sizes within the respective conditions.
, this difference in size increases as the number of latent variables is increased, whereby CFI-values become consistently smaller with increasing model complexity. This difference is also likely connected to the different average correlation sizes within the respective conditions.
Despite the difference in average value, the corresponding unweighted and noncentrality-parameter-based indices measure very similar aspects of misspecification. This can be verified by the substantial correlations between RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and RMSEA (mean
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ = 0.918$$\end{document}
and RMSEA (mean
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ = 0.918$$\end{document}
 ; range
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ = 0.598: 0.991$$\end{document}
; range
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ = 0.598: 0.991$$\end{document}
 ) as well as those between CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
) as well as those between CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI (mean
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ = 0.913$$\end{document}
and CFI (mean
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ = 0.913$$\end{document}
 ; range
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ = 0.553: 0.989$$\end{document}
; range
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$ = 0.553: 0.989$$\end{document}
 ) within the individual simulation conditions. Note that all indices within conditions have the same target values and, therefore, decreased estimate variances lead to smaller correlations if the sample is large and the model has many parameters.
) within the individual simulation conditions. Note that all indices within conditions have the same target values and, therefore, decreased estimate variances lead to smaller correlations if the sample is large and the model has many parameters.
Second, the simulation results pertaining to the ULSMV analyses for metric as well as dichotomous variables are considered. The underlying model structures were fully identical for the two variable types respectively. Adjustments were performed using approach (1.1) and (1.2).
Tables 5 and 6 give RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and RMSEA for the ULSMV analyses for each of the data settings separated for misfit type I and II respectively. Results pertaining to CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and RMSEA for the ULSMV analyses for each of the data settings separated for misfit type I and II respectively. Results pertaining to CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI are contained in Table 7.
and CFI are contained in Table 7.
Table 5. Average RMSEAu and RMSEA values as well as 90%-CI coverages of ULSMV confirmatory factor models based on 1000 replications per cell. (Misfit Type I).

Est.: RMSEA estimate and CIC:
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 -confidence interval coverage pertaining to the respective approach; Orig. Est.: unadjusted RMSEA.
-confidence interval coverage pertaining to the respective approach; Orig. Est.: unadjusted RMSEA.
Similar to the ML analyses, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 consistently approach their respective target values of 0.05 and 0.95/0.99 across conditions. This holds equally true for metric as well as dichotomous data. Although there are descriptive differences between approaches (1.1) and (1.2.) within singular condition, there are no notable differences in average performance.
consistently approach their respective target values of 0.05 and 0.95/0.99 across conditions. This holds equally true for metric as well as dichotomous data. Although there are descriptive differences between approaches (1.1) and (1.2.) within singular condition, there are no notable differences in average performance.
If the sample size is
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 , deviations from the true values only rarely exceed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pm 0.001$$\end{document}
, deviations from the true values only rarely exceed
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pm 0.001$$\end{document}
 for metric data and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pm 0.002$$\end{document}
for metric data and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\pm 0.002$$\end{document}
 for dichotomous data. However, if the sample size is small and if many factors are modeled based on comparably few variables, fit indices have a notable bias. In these cases, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
for dichotomous data. However, if the sample size is small and if many factors are modeled based on comparably few variables, fit indices have a notable bias. In these cases, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 values are underestimated and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
values are underestimated and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 values are overestimated. Specifically, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
values are overestimated. Specifically, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 underestimated its target value by up to 0.010 points and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
underestimated its target value by up to 0.010 points and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 are increased by up to 0.013 points if the target value is 0.95 and 0.003 points if the target value is 0.99. Interestingly, these effects do not differ in strength between metric and dichotomous data analyses.
are increased by up to 0.013 points if the target value is 0.95 and 0.003 points if the target value is 0.99. Interestingly, these effects do not differ in strength between metric and dichotomous data analyses.
The deviations from the target value in small samples do most likely not result from a specific property of the new fit indices. This may be inferred from the strong differences of the original RMSEA and CFI between different sample sizes within otherwise identical conditions, which are similar in size to the target value deviations for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=250$$\end{document}
 .
.
While there are no strong differences between metric and dichotomous data models with respect to average value of the new indices, differences between confidence interval coverages are more pronounced. Coverages pertaining to the metric data models are reasonably close to their target of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 . For
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=250$$\end{document}
. For
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=250$$\end{document}
 there are some individual conditions (misfit type II, p=18, CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
there are some individual conditions (misfit type II, p=18, CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u=0.99$$\end{document}
 ) in which CIC pertaining to approach (1.2) are very poor. This may be explained in part by the biased estimates in the respective conditions.
) in which CIC pertaining to approach (1.2) are very poor. This may be explained in part by the biased estimates in the respective conditions.
The CIC pertaining to the dichotomous data models perform reasonably well for approach (1.2) if
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 . However, confidence intervals pertaining to approach (1.1) and, even more notable, CICs in samples with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=250$$\end{document}
. However, confidence intervals pertaining to approach (1.1) and, even more notable, CICs in samples with
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=250$$\end{document}
 are too small across conditions. Again, part of this can be attributed the moderate estimation bias in small samples. Nevertheless, reliable RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
are too small across conditions. Again, part of this can be attributed the moderate estimation bias in small samples. Nevertheless, reliable RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 confidence intervals for dichotomous data models are only obtained using approach (1.2) in larger samples.
confidence intervals for dichotomous data models are only obtained using approach (1.2) in larger samples.
Table 6. Average RMSEAu and RMSEA values as well as 90%-CI coverages of ULSMV confirmatory factor models based on 1000 replications per cell. (Misfit Type II).
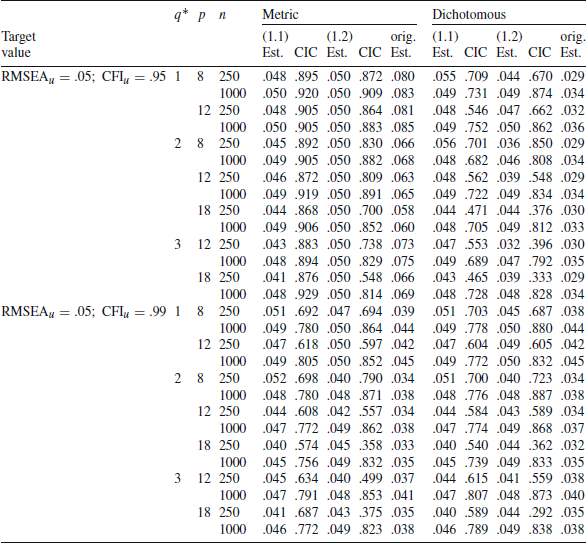
Est.: RMSEA estimate and CIC:
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$90\%$$\end{document}
 -confidence interval coverage pertaining to the respective approach; Orig. Est.: unadjusted RMSEA.
-confidence interval coverage pertaining to the respective approach; Orig. Est.: unadjusted RMSEA.
Because dichotomous data were obtained directly from the metric data within single replications of the simulation study, correlations of fit indices based on the two types of data can be considered. Specifically, the average correlation between fit indices for metric and dichotomous data models was 0.999 for RMESA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 across conditions and adjustment approaches. Thus, not only do they approach the same target value, they are also similarly sensitive to the respective discrepancies.
across conditions and adjustment approaches. Thus, not only do they approach the same target value, they are also similarly sensitive to the respective discrepancies.
As was expected, conventional noncentrality-parameter-based fit indices differ strongly between metric and dichotomous data. Specifically, RMSEA values for models based on dichotomous indicators are consistently smaller (by at least 0.020 points) than those obtained from metric variable models, which matches previous results of Monroe and Cai (Reference Monroe and Cai2015) and Xia and Yang (Reference Xia and Yang2018). Also, CFI values from dichotomous data models are continuously larger than those obtained from metric data models. Thus, despite the identical model structures, fit assessments based on different variable types would lead to different conclusions using conventional fit indices. Interestingly, while RMSEA and CFI differ between metric and dichotomous data, they are virtually identical for analyses based on ML and ULSMV within corresponding conditions.
Table 7. Average CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI values of ULSMV confirmatory factor models based on 1000 replications per cell.
and CFI values of ULSMV confirmatory factor models based on 1000 replications per cell.

Orig.: unadjusted CFI.
Deriving cutoff values for RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 by comparing them to their traditional counterparts is only possible to a limited extent, because of their non-constant relation across simulation conditions. Particularly if the target value of CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
by comparing them to their traditional counterparts is only possible to a limited extent, because of their non-constant relation across simulation conditions. Particularly if the target value of CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 is 0.99, this non-constant relation is most pronounced. Nevertheless, because RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
is 0.99, this non-constant relation is most pronounced. Nevertheless, because RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 does not differ strongly from the RMSEA, although the former yields somewhat smaller values, similar cutoff conventions, as suggested by Hu and Bentler (Reference Hu and Bentler1999), may be viable. For CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
does not differ strongly from the RMSEA, although the former yields somewhat smaller values, similar cutoff conventions, as suggested by Hu and Bentler (Reference Hu and Bentler1999), may be viable. For CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 , which always exceeds the CFI, a value of 0.99 may relate sufficiently to an CFI value of 0.95. However, it may be more advisable to refine cutoff criteria based on empirical experience, similar to the initial determination of cutoffs pertaining to RMSEA and CFI, rather than to restrict to relying on an analogy that only partly applies.
, which always exceeds the CFI, a value of 0.99 may relate sufficiently to an CFI value of 0.95. However, it may be more advisable to refine cutoff criteria based on empirical experience, similar to the initial determination of cutoffs pertaining to RMSEA and CFI, rather than to restrict to relying on an analogy that only partly applies.
Another perspective for identifying a suitable cut-off value may be to simulate metric data with predefined target values for the original RMSEA and CFI. In this way, cut-off values for the new indices can be specifically linked to their established counterparts. A table containing the expected values of the new fit indices based on target values on RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$=0.05$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$=0.05$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$=0.05$$\end{document}
 (for present simulation conditions) is contained in the supplementary materials of this article.
(for present simulation conditions) is contained in the supplementary materials of this article.
Discussion
In the present article, unweighted approximation error estimates have been developed to resolve the scaling related limitations of noncentrality-parameter-based fit assessments. These unweighted estimates were inserted as replacements of conventional noncentrality parameter estimates in the established fit indices RMSEA and CFI. As was demonstrated, the modified indices have a simple interpretation with respect to correlation residuals due to systematic error. In addition, the new indices yield identical values for latent variable models based on metric and dichotomous variables. Clearly, these two properties make them viable alternatives or additions to their established counterparts. Moreover, the impact of different discrepancy functions on typical fit index values, which has recently been reported by Shi and Maydeu-Olivares (Reference Shi and Maydeu-Olivares2020), does not affect the new indices, because any scaling information specific to parameter estimation is eliminated.
The finite sample performance of the new fit indices was evaluated using simulation studies. Metric data was analyzed using ML and ULSMV, whereas analyses of dichotomous data were only performed using ULSMV. Of course other estimators could have been used for model fitting. For instance, it would have been similarly viable to analyze categorical data with ML or any other least square discrepancy. In future studies it might be interesting to investigate a more comprehensive selection of model estimation approaches.
For all simulation settings, the new fit indices (i) closely and consistently approached their target values and (ii) yielded virtually identical values for metric and dichotomous variables. For metric data models in combination with ML estimation, the match between fit index estimate and target value may be considered as completely satisfactory to recommend them for empirical applications already for sample size of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=250$$\end{document}
 . When using ULSMV, the small sample performance was limited in some conditions. However, for a sample size of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
. When using ULSMV, the small sample performance was limited in some conditions. However, for a sample size of
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 , fit index estimates were similarly accurate on average for analyses based on metric as well as dichotomous data.
, fit index estimates were similarly accurate on average for analyses based on metric as well as dichotomous data.
Comparing the different approaches for obtaining a point estimate of the unweighted approximation error, there were only marginal and mostly nonsystematic differences. In conditions with ML estimation, approaches (1.1) and (2) had a slight tendency to overestimate and approach (1.2) to underestimate the indices. For ULSMV estimation with dichotomous data, estimates based on approach (1.1) were on average (but not across all conditions) slightly more accurate. Overall, for obtaining a point estimate, all approach may be considered as equally suited.
With respect to confidence interval coverage, analyses based on metric data yielded satisfactory results, with some exceptions. Particularly ML estimation in combination with fit indices based on approaches (1.1) and (1.2) worked generally well, whereas confidence intervals for approach (2) were slightly too narrow on average. For ULSMV analyses with metric data, approaches (1.1) and (1.2) work comparably well. However, for misfit type II and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$q^* \ge 2$$\end{document}
 and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p \ge 12$$\end{document}
and
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$p \ge 12$$\end{document}
 there was a surprising decline in CIC.
there was a surprising decline in CIC.
For dichotomous data analyses, confidence intervals were uniformly too narrow. While for
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$n=1000$$\end{document}
 the impact may be considered as moderate to small, for smaller samples and complex models, coverages were poor. In such cases it might be advisable to consider implementing a bootstrapping approach (e.g., Zhang & Savalei, Reference Zhang and Savalei2016).
the impact may be considered as moderate to small, for smaller samples and complex models, coverages were poor. In such cases it might be advisable to consider implementing a bootstrapping approach (e.g., Zhang & Savalei, Reference Zhang and Savalei2016).
Clearly, while the indices as well as CIC appear to consistently approach their target values, there is some bias in small samples in combination with complex analyses. However, this is not specific to the new indices, which can be concluded from the identical deviations of RMSEA and CFI depending on sample size. In addition, similar results pertaining to CIC are also typical (e.g., Savalei, Reference Savalei2021; Zhang & Savalei, Reference Zhang and Savalei2016).
The partially worse performance of fit indices in connection with ULSMV estimation is not entirely unexpected. One reason for this might be the limited adherence of the ULSMV test statistic to a noncentral
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$\chi ^2$$\end{document}
 -distribution under misspecification. In general, least-square based discrepancy functions have shown to perform slightly worse under some conditions than ML (e.g., Olsson et al. Reference Olsson, Foss and Breivik2004). Also, the ULSMV-adjustment might have limitations under some aspects of model misspecification, because it is based on theorems of Box (Reference Box1954) on the sum of least squares, which assume deviations to have expectations of zero. However, for now these considerations are mere conjectures.
-distribution under misspecification. In general, least-square based discrepancy functions have shown to perform slightly worse under some conditions than ML (e.g., Olsson et al. Reference Olsson, Foss and Breivik2004). Also, the ULSMV-adjustment might have limitations under some aspects of model misspecification, because it is based on theorems of Box (Reference Box1954) on the sum of least squares, which assume deviations to have expectations of zero. However, for now these considerations are mere conjectures.
For the established, noncentrality-parameter-based versions of RMSEA and CFI, results of Monroe and Cai (Reference Monroe and Cai2015) and Xia and Yang (Reference Xia and Yang2018) were replicated, demonstrating that these fit indices yield different conclusions depending on the variables’ level-of-measurement for identical model structures. Specifically, RMSEA and CFI based on dichotomous data models continuously suggested a better model fit than those pertaining to metric data models. Thus, the universality of cutoff values pertaining to conventional fit indices is questionable.
Because of the different scaling, RMSEA and RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 as well as CFI and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
as well as CFI and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 yielded different values on average as well as across simulation study conditions. Because the conventional noncentrality parameter weighs the same absolute residuals more strongly for comparably larger correlations, the RMSEA becomes larger relative to RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
yielded different values on average as well as across simulation study conditions. Because the conventional noncentrality parameter weighs the same absolute residuals more strongly for comparably larger correlations, the RMSEA becomes larger relative to RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 as the average correlation size increases. Whether this property may be considered as an advantage or disadvantage is not obvious. While from the perspective of random deviations, identical absolute differences in larger parameters are more meaningful, this does not necessarily mean that the same perspective is sensible for considering systematic deviations.
as the average correlation size increases. Whether this property may be considered as an advantage or disadvantage is not obvious. While from the perspective of random deviations, identical absolute differences in larger parameters are more meaningful, this does not necessarily mean that the same perspective is sensible for considering systematic deviations.
With respect to sensitivity to detect misfit, the consistently large correlations between RMSEA and CFI with the corresponding new indices RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 suggest that the latter differentiate similarly well. Consequently, it appears natural that discriminability results of previous large-scale fit index comparisons (e.g., Hu & Bentler, Reference Hu and Bentler1998; Reference Hu and Bentler1999) should similarly apply to RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
suggest that the latter differentiate similarly well. Consequently, it appears natural that discriminability results of previous large-scale fit index comparisons (e.g., Hu & Bentler, Reference Hu and Bentler1998; Reference Hu and Bentler1999) should similarly apply to RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 .
.
Although the primary objective of the present article is the introduction of the unweighted approximation error estimate as a suitable basis for fit index development, rather than a comprehensive evaluation of new fit indices, potential cutoff values for RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
and CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 may already be considered. While comparing the new and the original indices did not provide a simple rationale which cutoff values should be preferred, at least some conclusions may be drawn. As was outlined at the end of the results section, a sensible cutoff value for RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
may already be considered. While comparing the new and the original indices did not provide a simple rationale which cutoff values should be preferred, at least some conclusions may be drawn. As was outlined at the end of the results section, a sensible cutoff value for RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 might be similar to that of the original RMSEA, that is, 0.05 for models with a good fit. For CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
might be similar to that of the original RMSEA, that is, 0.05 for models with a good fit. For CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 a cutoff value of 0.99 appears recommendable, because of its match to a CFI of 0.95 for models with smaller numbers of variables. However, the results also suggest that it might be useful to consider both new indices simultaneously. Specifically, while in case of CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u = 0.95$$\end{document}
a cutoff value of 0.99 appears recommendable, because of its match to a CFI of 0.95 for models with smaller numbers of variables. However, the results also suggest that it might be useful to consider both new indices simultaneously. Specifically, while in case of CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u = 0.95$$\end{document}
 , RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u = 0,05$$\end{document}
, RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u = 0,05$$\end{document}
 appears to have a close relation to a similarly sized RMSEA, a slightly decreased RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
appears to have a close relation to a similarly sized RMSEA, a slightly decreased RMSEA
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u$$\end{document}
 -value would be expected in cases of CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u = 0.99$$\end{document}
-value would be expected in cases of CFI
\documentclass[12pt]{minimal}
\usepackage{amsmath}
\usepackage{wasysym}
\usepackage{amsfonts}
\usepackage{amssymb}
\usepackage{amsbsy}
\usepackage{mathrsfs}
\usepackage{upgreek}
\setlength{\oddsidemargin}{-69pt}
\begin{document}$$_u = 0.99$$\end{document}
 .
.
While, I consider the present cutoff recommendations as sufficient for now, they need to be considered as preliminary. Because the new indices are intended as measures in their own right, having their own specific interpretations, more extensive evaluations, such as those conducted by Hu and Bentler (Reference Hu and Bentler1998) and Hu and Bentler (Reference Hu and Bentler1999), would certainly be a sensible (or even necessary) pursuit of future research.
















 Open access
Open access