




1. Introduction
We propose a cluster-based network model (CNM) from time-resolved snapshot data exemplified for a laminar mixing layer and an actuated turbulent boundary layer. The goal is purely data-driven reduced-order modelling trading the physical insights from first principles, e.g. the Galerkin method (see e.g. Holmes et al. Reference Holmes, Lumley, Berkooz and Rowley2012), with simplicity, robustness and closeness to the original data.
The mixing layer is an archetypical flow configuration associated with many academic and industrial applications. The flow is discussed virtually in any textbook of fluid mechanics. In the early stage, the laminar mixing layer gives rise to periodic, spatially growing Kelvin–Helmholtz vortices as described in stability theory (Michalke Reference Michalke1964), by vortex models (Hama Reference Hama1962) or by a proper orthogonal decomposition (POD) Galerkin model (Noack, Papas & Monkewitz Reference Noack, Papas and Monkewitz2005). At later stages, multiple vortex pairings induce the inverse cascade at lower wavenumbers and frequencies (Coats Reference Coats1997). In addition, three-dimensional instabilities enrich the coherent structures by rib vortices and spanwise waviness (see e.g. Liu Reference Liu1989). These mixing-layer structures may be seen in the near-field region of wakes and jets. Moreover, control of most shear flows, including bluff-body wakes and jets, is based on an effective manipulation of the mixing layer (Fiedler & Fernholz Reference Fiedler and Fernholz1990).
Another fundamental flow configuration is the turbulent boundary layer. Since Prandtl's (Reference Prandtl1904) discovery of the boundary layer theory, this flow is the cornerstone of practically every fluid and aerodynamic problem. In particular, skin-friction reduction through passive or active means has been the subject of research for many decades (Gad-el-Hak Reference Gad-el-Hak2000; Fan & Dong Reference Fan and Dong2016). Promising strategies include riblets (Walsh & Lindemann Reference Walsh and Lindemann1984), compliant surfaces (Luhar, Sharma & McKeon Reference Luhar, Sharma and McKeon2016), spanwise wall oscillations (Jung, Mangiavacchi & Akhavan Reference Jung, Mangiavacchi and Akhavan1992; Quadrio, Ricco & Viotti Reference Quadrio, Ricco and Viotti2009) and spanwise travelling waves with a Lorentz force (Du & Karniadakis Reference Du and Karniadakis2000) or wall-normal deflection (Klumpp, Meinke & Schröder Reference Klumpp, Meinke and Schröder2011; Albers et al. Reference Albers, Meysonnat, Fernex, Semann, Noack and Schröder2020). In this study, a spatio-temporal surface deformation with transverse travelling waves is chosen targeting aerodynamic applications. Thus, a drag reduction of 4.5 % was experimentally achieved for a turbulent boundary layer (Li et al. Reference Li, Jessen, Roggenkamp, Klaas, Silex, Schiek and Schröder2015). In a numerical partner study, the actuation parameters were improved, yielding 31 % drag reduction (Albers et al. Reference Albers, Meysonnat, Fernex, Semann, Noack and Schröder2020; Fernex et al. Reference Fernex, Semaan, Albers, Meysonnat, Schröder and Noack2020). The actuation was also applied over a wing section (Albers, Meysonnat & Schröder Reference Albers, Meysonnat and Schröder2019), where the pressure varies in the streamwise direction. Thus, the total drag was reduced by  $7.5\,\%$ accompanied by a slight lift increase.
$7.5\,\%$ accompanied by a slight lift increase.
For many decades, the mixing layer and the turbulent boundary layer have been long-standing benchmarks for reduced-order modelling. For the mixing layer, employed methods include input–output transfer functions (Sasaki et al. Reference Sasaki, Piantanida, Cavalieri and Jordan2017), parabolized stability equations (Sasaki et al. Reference Sasaki, Tissot, Cavalieri, Silvestre, Jordan and Biau2018), vortex filament models (Ashurst & Meiburg Reference Ashurst and Meiburg1988), POD models (Delville et al. Reference Delville, Ukeiley, Cordier, Bonnet and Glauser1999; Ukeiley et al. Reference Ukeiley, Cordier, Manceau, Delville, Bonnet and Glauser2001; Wei & Rowley Reference Wei and Rowley2009) and cluster-based reduced-order models (Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014). Already the laminar two-dimensional shear layer can give rise to multiple frequencies (Kasten et al. Reference Kasten, Reininghaus, Hotz, Hege, Noack, Daviller, Comte and Morzyński2016). The early stages of the convectively unstable and nearly linear dynamics of mixing layers and jets are well resolved by parabolized stability equations requiring little empirical input (Jordan & Colonius Reference Jordan and Colonius2013). After the three-dimensional transition, the accuracy of stability-based methods rapidly deteriorates or describes only a narrow frequency spectrum of the fluid dynamics. Stability methods combined with eddy-viscosity closure models may significantly extend the application range (Liu Reference Liu1989). Alternatively, data-driven grey-box models from snapshot data distilling the coherent-structure dynamics become an attractive avenue (Taira et al. Reference Taira, Brunton, Dawson, Rowley, Colonius, McKeon, Schmidt, Gordeyew, Theofilis and Ukeiley2018).
Since the pioneering POD model of Aubry et al. (Reference Aubry, Holmes, Lumley and Stone1988) for the unforced turbulent boundary layer, numerous advances of data-driven Galerkin models have been proposed. Podvin & Lumley (Reference Podvin and Lumley1998) proposed a low-dimensional model for the minimal channel flow unit for the purpose of physical understanding. Later, Podvin (Reference Podvin2009) has developed an accurate high-dimensional POD model for the wall region of a turbulent channel flow. The drag-reducing effect of compliant walls has been included in POD models by Lumley, Rempfer & Blossey (Reference Lumley, Rempfer and Blossey1999, p. 147).
The POD Galerkin methods arguably constitute the most popular and best-investigated data-driven grey-box modelling methods; POD Galerkin methods are intimately tied with the Navier–Stokes equations. While the kinematics, the modal expansion, is distilled from data, the temporal dynamics may be derived from first principles. Yet, the modal expansion encapsulates a convection dominated dynamics in an elliptic approach. This mismatch between the modelling approach and dynamics is the root cause of the fragility of data-driven Galerkin models (Noack Reference Noack2016). For the mixing layer, the lack of robustness is particularly pronounced as exhibited by modelled transients which are orders of magnitudes too large (Noack et al. Reference Noack, Papas and Monkewitz2005). Moreover, the time integration of the Galerkin model may easily lead to states far away from the training data, i.e. outside the region of model validity. This problem persists for other data-driven modal expansions, such as dynamic mode decomposition (Rowley et al. Reference Rowley, Mezić, Bagheri, Schlatter and Henningson2009; Schmid Reference Schmid2010).
This robustness challenge of elliptical approaches is avoided by cluster-based reduced-order models pioneered by Burkardt, Gunzburger & Lee (Reference Burkardt, Gunzburger and Lee2006). Here, the state is coarse-grained to a small number of centroids representative of the whole ensemble of snapshots. Hence, modelled states will be close to the training data by construction. The potential of an extrapolation, e.g. predicting larger fluctuation amplitudes, is traded for robustness, i.e. staying close to the snapshot data.
In the cluster-based Markov model (CMM) for the mixing layer (Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014; Li & Tan Reference Li and Tan2020), the temporal evolution is modelled as a probabilistic Markov model of the transition dynamics. The state vector of cluster probabilities may initially start in a single centroid but eventually diffuses to a fixed point representing the post-transient attractor. This fixed point is well reproduced by CMM. In addition, CMM has provided valuable physical insights for the mixing layer and Ahmed body wake (Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014), for the turbulent boundary layer (Ishar et al. Reference Ishar, Kaiser, Morzynski, Albers, Meysonnat, Schröder and Noack2019), for combustion related mixing (Cao et al. Reference Cao, Kaiser, Boreé, Noack, Thomas and Guilan2014) and for control design (Kaiser et al. Reference Kaiser, Noack, Spohn, Cattafesta and Morzyński2017; Nair et al. Reference Nair, Yeh, Kaiser, Noack, Brunton and Tiara2019).
A challenge for CMM is the temporal evolution: the state may quickly diffuse over the whole attractor, often within one typical time period. This study aims at a cluster-based network model (CNM) with improved dynamics resolution following Fernex et al. (Reference Fernex, Semann, Albers, Meysonnat, Schröder, Ishar, Kaiser and Noack2019). The dynamics is modelled by ‘constant velocity flights’ between the centroids as ‘airports’. The transition probabilities and times are consistent with the snapshot data. The dynamics is thus restricted to a sparse network of routes between the centroids. Network models are enjoying increasing popularity in all mathematical modelling fields including biology, sociology and the computer sciences. Network models have also been employed to explain vortex dynamics (Nair & Taira Reference Nair and Taira2015; Taira, Nair & Brunton Reference Taira, Nair and Brunton2016). Newman (Reference Newman2010) provides an excellent introduction to networks.
On the surface, the CNM, CMM and POD models look like similar data-driven reduced-order models from snapshot data. Yet, there are fundamental application differences which may be elucidated by an analogy to computational fluid mechanics. The traditional CMM might be compared with unsteady Reynolds-averaged Navier–Stokes simulations converging to the mean flow while resolving some dynamic features during the transient. In contrast, the proposed CNM mimics a large-eddy simulation designed to resolve unsteady coherent-structure dynamics. The applications of CNM are comparable with POD models. The POD model can be conceptualized as a data-driven version of the spectral method being routed in the traditional Galerkin methodology. In contrast, CNM is closer to a collocation method using the centroids as ‘lighthouses’ for the corresponding Voronoi cells.
The paper is organized as follows. Section 2 elaborates the methodology of the cluster-based network model. The limit-cycle dynamics and Lorenz attractor are employed as illustrating examples. Two flow configurations are chosen for the numerical analysis, an incompressible laminar mixing layer and a turbulent boundary layer. For the mixing layer (§ 3), the proposed CNM is benchmarked against the cluster-based Markov model. In § 4, CNM is performed for the three-dimensional actuated turbulent boundary layer featuring a more complex dynamics and § 5 summarizes this study and outlines future directions of research.
2. Cluster-based modelling
In this section, we propose a novel cluster-based reduced-order model (ROM) for the coherent structure dynamics starting at the time-resolved snapshots. In §§ 2.1 and 2.2 clustering and the cluster-based Markov model is recapitulated. Section 2.3 proposes a novel data-driven dynamic network resolving the transition dynamics between the clusters. In § 2.4, the time-discrete cluster-based ROM is enhanced for a continuous-time velocity prediction. The model validation includes the autocorrelation function of the flow as discussed in § 2.5. Figure 1 previews the methodology and will be explained later in the section. The relative advantages of CMM and CNM are illustrated for the Lorenz attractor in § 2.6.

Figure 1. Principle sketch of cluster-based modelling. The time-resolved snapshots are partitioned into a predetermined number of clusters represented by centroids in an unsupervised manner. Thereafter, each snapshot has a cluster affiliation  $k(t^m)$, being the index of the closest centroid. The cluster-based Markov model describes the evolution of the population of these clusters. The solution of CMM quickly converges against the asymptotic probability distribution. The proposed cluster-based network model resolves the dynamic transitions between the clusters by a deterministic–stochastic network.
$k(t^m)$, being the index of the closest centroid. The cluster-based Markov model describes the evolution of the population of these clusters. The solution of CMM quickly converges against the asymptotic probability distribution. The proposed cluster-based network model resolves the dynamic transitions between the clusters by a deterministic–stochastic network.
2.1. Clustering as coarse-graining
We consider velocity fields in a steady domain  $\varOmega$ which may be obtained from experiments or from numerical simulations. Starting point is an ensemble of
$\varOmega$ which may be obtained from experiments or from numerical simulations. Starting point is an ensemble of  $M$ statistically representative, time-resolved snapshots as employed for cluster-based models (Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014), Dynamic mode decomposition (DMD) (Rowley et al. Reference Rowley, Mezić, Bagheri, Schlatter and Henningson2009; Schmid Reference Schmid2010) or POD (see e.g. Holmes et al. Reference Holmes, Lumley, Berkooz and Rowley2012). The velocity field is equidistantly sampled with time step
$M$ statistically representative, time-resolved snapshots as employed for cluster-based models (Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014), Dynamic mode decomposition (DMD) (Rowley et al. Reference Rowley, Mezić, Bagheri, Schlatter and Henningson2009; Schmid Reference Schmid2010) or POD (see e.g. Holmes et al. Reference Holmes, Lumley, Berkooz and Rowley2012). The velocity field is equidistantly sampled with time step  $\Delta t$, i.e. the
$\Delta t$, i.e. the  $m$th instant reads
$m$th instant reads  $t^{m}=m \Delta t$. The corresponding snapshot velocity field is denoted by
$t^{m}=m \Delta t$. The corresponding snapshot velocity field is denoted by  $\boldsymbol {u}^{m}(\boldsymbol {x} ) :=\boldsymbol {u}(\boldsymbol {x}, t^{m})$,
$\boldsymbol {u}^{m}(\boldsymbol {x} ) :=\boldsymbol {u}(\boldsymbol {x}, t^{m})$,  $m=1,\ldots ,M$.
$m=1,\ldots ,M$.
Cluster analysis lumps similar objects into clusters as illustrated in figure 2. This lumping of data is performed in an unsupervised manner, i.e. no advance labelling or grouping of the data has been performed. In cluster-based models, the  $M$ snapshots
$M$ snapshots  $\boldsymbol {u}^{m} (\boldsymbol {x} )$ are coarse-grained into
$\boldsymbol {u}^{m} (\boldsymbol {x} )$ are coarse-grained into  $K$ clusters represented by the centroids
$K$ clusters represented by the centroids  $\boldsymbol {c}_k (\boldsymbol {x})$,
$\boldsymbol {c}_k (\boldsymbol {x})$,  $k=1,\ldots ,K$, using the unsupervised k-means++ algorithm (Steinhaus Reference Steinhaus1956; MacQueen Reference MacQueen1967; Lloyd Reference Lloyd1982). The centroids characterize the typical flow patterns of each cluster, also called modes in the ROM community. The corresponding cluster-affiliation function maps a velocity field
$k=1,\ldots ,K$, using the unsupervised k-means++ algorithm (Steinhaus Reference Steinhaus1956; MacQueen Reference MacQueen1967; Lloyd Reference Lloyd1982). The centroids characterize the typical flow patterns of each cluster, also called modes in the ROM community. The corresponding cluster-affiliation function maps a velocity field  $\boldsymbol {u}$ to the index of the closest centroid,
$\boldsymbol {u}$ to the index of the closest centroid,
 \begin{equation} k (\boldsymbol{u}) = \arg\min_i \Vert \boldsymbol{u} - \boldsymbol{c}_i \Vert_{\varOmega}, \end{equation}
\begin{equation} k (\boldsymbol{u}) = \arg\min_i \Vert \boldsymbol{u} - \boldsymbol{c}_i \Vert_{\varOmega}, \end{equation}
where  $\Vert \cdot \Vert _{\varOmega }$ denotes the standard Hilbert space norm in the domain
$\Vert \cdot \Vert _{\varOmega }$ denotes the standard Hilbert space norm in the domain  $\varOmega$ (see appendix A). This function defines cluster regions as Voronoi cells around the centroids
$\varOmega$ (see appendix A). This function defines cluster regions as Voronoi cells around the centroids
 \begin{equation} \mathcal{C}_i = \left \{ \boldsymbol{u} \in \mathcal{L}^2 ( \varOmega ) \colon k (\boldsymbol{u}) = i \right \}. \end{equation}
\begin{equation} \mathcal{C}_i = \left \{ \boldsymbol{u} \in \mathcal{L}^2 ( \varOmega ) \colon k (\boldsymbol{u}) = i \right \}. \end{equation}
This function can also be employed to map the snapshot index  $m$ to the representative cluster index
$m$ to the representative cluster index  $k(m) := k ( \boldsymbol {u}^m )$. Alternatively, the characteristic function
$k(m) := k ( \boldsymbol {u}^m )$. Alternatively, the characteristic function
 \begin{equation} \chi_i^m := \left\{\begin{array}{ll} 1, & \text{if} \ i=k(m), \\ 0, & \text{otherwise}, \end{array}\right. \end{equation}
\begin{equation} \chi_i^m := \left\{\begin{array}{ll} 1, & \text{if} \ i=k(m), \\ 0, & \text{otherwise}, \end{array}\right. \end{equation}
describes whether the  $m$th snapshot is affiliated with the
$m$th snapshot is affiliated with the  $l$th centroid. The latter two quantities are equivalent.
$l$th centroid. The latter two quantities are equivalent.

Figure 2. Clustering exemplified in a two-dimensional state space. The snapshots  $\{\boldsymbol {u}^m\}_{m=1}^M$ are coarse-grained into three clusters. Each centroid
$\{\boldsymbol {u}^m\}_{m=1}^M$ are coarse-grained into three clusters. Each centroid  $\boldsymbol {c}_{k}, k=1, 2 ,3$, is the averaged field of all snapshots belonging to this cluster. Every centroid
$\boldsymbol {c}_{k}, k=1, 2 ,3$, is the averaged field of all snapshots belonging to this cluster. Every centroid  $\boldsymbol {c}_k$ is associated with a Voronoi cell
$\boldsymbol {c}_k$ is associated with a Voronoi cell  $\mathcal {C}_k$, i.e. a region in which the points are closer to
$\mathcal {C}_k$, i.e. a region in which the points are closer to  $\boldsymbol {c}_k$ than any other centroid. The cluster affiliation for a snapshot is the cluster index of the closest centroid which has been indicated by an arrow. By definition, the cluster affiliation is the index of the corresponding Voronoi cell.
$\boldsymbol {c}_k$ than any other centroid. The cluster affiliation for a snapshot is the cluster index of the closest centroid which has been indicated by an arrow. By definition, the cluster affiliation is the index of the corresponding Voronoi cell.
The performance of a set of centroids  $\{ \boldsymbol {c}_k \}_{k=1}^K$ with respect to a given set of snapshots
$\{ \boldsymbol {c}_k \}_{k=1}^K$ with respect to a given set of snapshots  $\{ \boldsymbol {u}^m \}_{m=1}^M$ is measured by the average variance of the snapshots with respect to their closest centroid. The corresponding inner-cluster variance reads
$\{ \boldsymbol {u}^m \}_{m=1}^M$ is measured by the average variance of the snapshots with respect to their closest centroid. The corresponding inner-cluster variance reads
 \begin{equation} J \left( \boldsymbol{c}_1,\ldots,\boldsymbol{c}_K \right ) = \frac{1}{M} \sum_{m=1}^{M} \left \Vert \boldsymbol{u}^{m}-\boldsymbol{c}_{k(m)} \right \Vert^2_{\varOmega} . \end{equation}
\begin{equation} J \left( \boldsymbol{c}_1,\ldots,\boldsymbol{c}_K \right ) = \frac{1}{M} \sum_{m=1}^{M} \left \Vert \boldsymbol{u}^{m}-\boldsymbol{c}_{k(m)} \right \Vert^2_{\varOmega} . \end{equation}
The optimal centroids  $\{ \boldsymbol {c}_k^{\star } \}_{k=1}^K$ minimize this inner-cluster variance:
$\{ \boldsymbol {c}_k^{\star } \}_{k=1}^K$ minimize this inner-cluster variance:
 \begin{equation} \left ( \boldsymbol{c}_1^{\star}, \ldots, \boldsymbol{c}_K^{\star} \right ) =\underset{\boldsymbol{c}_1,\ldots,\boldsymbol{c}_K}{\arg\min} J \left( \boldsymbol{c}_1,\ldots,\boldsymbol{c}_K \right ). \end{equation}
\begin{equation} \left ( \boldsymbol{c}_1^{\star}, \ldots, \boldsymbol{c}_K^{\star} \right ) =\underset{\boldsymbol{c}_1,\ldots,\boldsymbol{c}_K}{\arg\min} J \left( \boldsymbol{c}_1,\ldots,\boldsymbol{c}_K \right ). \end{equation}
The argument is indeterminate with respect to a re-ordering. For CMM, we chose the first cluster as the one with the highest population, i.e. the largest number of associated snapshots. The  $(k+1)$th cluster,
$(k+1)$th cluster,  $k>1$, has the largest transition probability from the
$k>1$, has the largest transition probability from the  $k$th one.
$k$th one.
The optimization problem (2.5) is solved by the k-means++ algorithm. The  $K$ centroids are initialized randomly and then iterated until convergence is reached or when the variance
$K$ centroids are initialized randomly and then iterated until convergence is reached or when the variance  $J$ is small enough; k-means++ repeats the clustering process 30 times and take the best set of centroids.
$J$ is small enough; k-means++ repeats the clustering process 30 times and take the best set of centroids.
The number of snapshots  $n_k$ in cluster
$n_k$ in cluster  $k$ is given by
$k$ is given by
 \begin{equation} n_k=\sum_{m=1}^{M} \chi_k^{m}. \end{equation}
\begin{equation} n_k=\sum_{m=1}^{M} \chi_k^{m}. \end{equation}The centroids are the mean velocity field of all snapshots in the corresponding cluster. In other words,
 \begin{equation} \boldsymbol{c}_k = \frac{1}{n_k} \sum_{\boldsymbol{u}^{m} \in \mathcal{C}_k} \boldsymbol{u}^{m}=\frac{1}{n_k} \sum_{m=1}^{M} \chi_k^{m} \boldsymbol{u}^{m}. \end{equation}
\begin{equation} \boldsymbol{c}_k = \frac{1}{n_k} \sum_{\boldsymbol{u}^{m} \in \mathcal{C}_k} \boldsymbol{u}^{m}=\frac{1}{n_k} \sum_{m=1}^{M} \chi_k^{m} \boldsymbol{u}^{m}. \end{equation}
In the following centroid visualizations, we accentuate the vortical structures by displaying the fluctuations  $\boldsymbol {c}_k - \bar {\boldsymbol {u}}$ around the snapshot mean
$\boldsymbol {c}_k - \bar {\boldsymbol {u}}$ around the snapshot mean  $\bar {\boldsymbol {u}}$ and not the full velocity field
$\bar {\boldsymbol {u}}$ and not the full velocity field  $\boldsymbol {c}_k$.
$\boldsymbol {c}_k$.
2.2. Cluster-based Markov model
We briefly recapitulate CMM by Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014) as our benchmark cluster-based reduced-order model. In CMM, the state variable is the cluster population  $\boldsymbol {p}=[ p_1,\ldots ,p_K ]^{\mathrm {T}}$, where
$\boldsymbol {p}=[ p_1,\ldots ,p_K ]^{\mathrm {T}}$, where  $p_i$ represents the probability of being in cluster
$p_i$ represents the probability of being in cluster  $i$ and the superscript
$i$ and the superscript  $\mathrm {T}$ denotes the transpose. The transition between clusters in a given time step
$\mathrm {T}$ denotes the transpose. The transition between clusters in a given time step  $\Delta t^c$ is described by the transition matrix
$\Delta t^c$ is described by the transition matrix  ${\boldsymbol{\mathsf{P}}} = (P_{ij}) \in \mathcal {R}^{K \times K}$. The superscript ‘
${\boldsymbol{\mathsf{P}}} = (P_{ij}) \in \mathcal {R}^{K \times K}$. The superscript ‘ $c$’ refers to cluster-based model. Here,
$c$’ refers to cluster-based model. Here,  $P_{ij}$ is the transition probability of moving from cluster
$P_{ij}$ is the transition probability of moving from cluster  $j$ to cluster
$j$ to cluster  $i$. Let
$i$. Let  $\boldsymbol {p}^l$ be the probability vector at time
$\boldsymbol {p}^l$ be the probability vector at time  $t^l = l \Delta t^c$, then the change in one time step is described by
$t^l = l \Delta t^c$, then the change in one time step is described by
 \begin{equation} \boldsymbol{p}^{l+1} = {\boldsymbol{\mathsf{P}}} \boldsymbol{p}^l. \end{equation}
\begin{equation} \boldsymbol{p}^{l+1} = {\boldsymbol{\mathsf{P}}} \boldsymbol{p}^l. \end{equation}
With increasing iterations, the iteration (2.8) converges to the asymptotic probability  $\boldsymbol {p}^{\infty } := \lim _{l\to \infty } \boldsymbol {p}^l$. In a typical case, (2.8) has a single fixed point
$\boldsymbol {p}^{\infty } := \lim _{l\to \infty } \boldsymbol {p}^l$. In a typical case, (2.8) has a single fixed point  $\boldsymbol {p}^{\infty }$. For completeness, a continuous form of Markov models with a new transition matrix
$\boldsymbol {p}^{\infty }$. For completeness, a continuous form of Markov models with a new transition matrix  ${{\boldsymbol{\mathsf{P}}}}^c$ is mentioned
${{\boldsymbol{\mathsf{P}}}}^c$ is mentioned
 \begin{equation} \frac{\textrm{d}\boldsymbol{p}}{\textrm{d}t}={\boldsymbol{\mathsf{P}}}^{c} \boldsymbol{p}. \end{equation}
\begin{equation} \frac{\textrm{d}\boldsymbol{p}}{\textrm{d}t}={\boldsymbol{\mathsf{P}}}^{c} \boldsymbol{p}. \end{equation}From the time-continuous form (2.9), the time-discrete one (2.8) can be derived. The opposite is not generally true. In the following, no continuous Markov models are employed.
A CMM of the time-resolved snapshots starts with cluster affiliation (2.1) which can also be considered function of time  $k(t)$. We refer to the original paper for the determination of
$k(t)$. We refer to the original paper for the determination of  $P_{ij}$ from
$P_{ij}$ from  $k(t)$. The time step
$k(t)$. The time step  $\Delta t^c$ is a critical design parameter for CMM. A good choice is a value where the transition from one cluster to the next is likely. If the time step is too small, the Markov model idles many times in each cluster for a stochastic number of times before transitioning to the next cluster. The model-based transition time may thus significantly deviate from the deterministic data-driven trajectories through the clusters. If the time step is too large, one may miss intermediate clusters. We choose
$\Delta t^c$ is a critical design parameter for CMM. A good choice is a value where the transition from one cluster to the next is likely. If the time step is too small, the Markov model idles many times in each cluster for a stochastic number of times before transitioning to the next cluster. The model-based transition time may thus significantly deviate from the deterministic data-driven trajectories through the clusters. If the time step is too large, one may miss intermediate clusters. We choose  $\Delta t^c= T/10$, where
$\Delta t^c= T/10$, where  $T$ is the characteristic period of the flow. On a circular limit cycle with uniform rotation, this value is optimal for
$T$ is the characteristic period of the flow. On a circular limit cycle with uniform rotation, this value is optimal for  $K=10$ clusters, enforcing the transition from one cluster to the next in each time step.
$K=10$ clusters, enforcing the transition from one cluster to the next in each time step.
In figure 3(a,c,e), the effect of the suboptimal time step is illustrated for the CMM of a uniform rotation  $u_1 = \cos ( 2{\rm \pi} t)$,
$u_1 = \cos ( 2{\rm \pi} t)$,  $u_2 = \sin (2 {\rm \pi}t)$. Here, four clusters and a time step
$u_2 = \sin (2 {\rm \pi}t)$. Here, four clusters and a time step  $\Delta t^c = 1/16$ are chosen. The probability of staying in the cluster during one time step is
$\Delta t^c = 1/16$ are chosen. The probability of staying in the cluster during one time step is  $P_{11}=P_{22}=P_{33}=P_{44}= 3/4$ and the transition probability to the next counter-clockwise neighbour is
$P_{11}=P_{22}=P_{33}=P_{44}= 3/4$ and the transition probability to the next counter-clockwise neighbour is  $P_{14}=P_{21}=P_{32}=P_{43}= 1/4$. Thus, the probability of staying in one cluster for
$P_{14}=P_{21}=P_{32}=P_{43}= 1/4$. Thus, the probability of staying in one cluster for  $l$ steps exponentially decays,
$l$ steps exponentially decays,  $P_{11}^l$. In contrast, the uniform rotation commands that the state is exactly three time steps in one cluster before it leaves in the fourth step. This example motivates the proposed cluster-based reduced-order model, foreshadowed in figure 3(b,d,f) and explained in the following section.
$P_{11}^l$. In contrast, the uniform rotation commands that the state is exactly three time steps in one cluster before it leaves in the fourth step. This example motivates the proposed cluster-based reduced-order model, foreshadowed in figure 3(b,d,f) and explained in the following section.

Figure 3. Introduction of cluster-based models for a limit-cycle example. The CMM and CNM are displayed in (a,c,e) and (b,d,f), respectively. The uniform rotation  $u_{1}=\cos (2{\rm \pi} t)$,
$u_{1}=\cos (2{\rm \pi} t)$,  $u_{2}=\sin (2{\rm \pi} t)$ in a two-dimensional plane is discretized by four centroids
$u_{2}=\sin (2{\rm \pi} t)$ in a two-dimensional plane is discretized by four centroids  $\boldsymbol {c}_{k}$,
$\boldsymbol {c}_{k}$,  $k=1,\ldots ,4$. (a) Phase portrait of CMM with time step
$k=1,\ldots ,4$. (a) Phase portrait of CMM with time step  $\Delta t=1/16$. The centroids are near the limit cycle (red dashed line). The state vector residing in centroid
$\Delta t=1/16$. The centroids are near the limit cycle (red dashed line). The state vector residing in centroid  $\boldsymbol {c}_{i}$ has the probability
$\boldsymbol {c}_{i}$ has the probability  $P_{ii}$ of staying in its state and
$P_{ii}$ of staying in its state and  $P_{ji}$ of transitioning to centroid
$P_{ji}$ of transitioning to centroid  $\boldsymbol {c}_{j}$ in the considered time step. (b) Phase portrait of the CNM. The state in centroid
$\boldsymbol {c}_{j}$ in the considered time step. (b) Phase portrait of the CNM. The state in centroid  $\boldsymbol {c}_{i}$ moves uniformly to its counter-clockwise neighbour taking a quarter period
$\boldsymbol {c}_{i}$ moves uniformly to its counter-clockwise neighbour taking a quarter period  $T_{14}=T_{21}=T_{32}=T_{43}=1/4$. Here,
$T_{14}=T_{21}=T_{32}=T_{43}=1/4$. Here,  $Q_{14}=Q_{21}=Q_{32}=Q_{43}=1$ and
$Q_{14}=Q_{21}=Q_{32}=Q_{43}=1$ and  $Q_{ij}=0$ otherwise. The estimated probability evolution starting in cluster
$Q_{ij}=0$ otherwise. The estimated probability evolution starting in cluster  $i=1$ at
$i=1$ at  $t=0$ is illustrated for CMM (c) and CNM (d). Panels (e) and (f) present the model-based evolution of the first coordinate
$t=0$ is illustrated for CMM (c) and CNM (d). Panels (e) and (f) present the model-based evolution of the first coordinate  $u_{1}$ for CMM and CNM, respectively. In (c–f), the solid black lines correspond to the uniform rotation and the dashed red line to the model.
$u_{1}$ for CMM and CNM, respectively. In (c–f), the solid black lines correspond to the uniform rotation and the dashed red line to the model.
2.3. Cluster-based network model
For CMM, the time step  $\Delta t^c$ is, as mentioned, an important design parameter. This design parameter can be avoided by the new proposed CNM. The key idea is to abandon the ‘stroboscopic’ view of CMM and focus on non-trivial transitions from cluster
$\Delta t^c$ is, as mentioned, an important design parameter. This design parameter can be avoided by the new proposed CNM. The key idea is to abandon the ‘stroboscopic’ view of CMM and focus on non-trivial transitions from cluster  $j$ to cluster
$j$ to cluster  $i$. These transitions are characterized by two parameters: the probability
$i$. These transitions are characterized by two parameters: the probability  $Q_{ij}$ and a time scale
$Q_{ij}$ and a time scale  $T_{ij}$. Evidently, no time step is needed for the description and the assumption of a constant transition time is found to be much more aligned with shear flow modes than assuming an exponential decay of residence time. Moreover, it could be relaxed by assuming a probability distribution of transition times.
$T_{ij}$. Evidently, no time step is needed for the description and the assumption of a constant transition time is found to be much more aligned with shear flow modes than assuming an exponential decay of residence time. Moreover, it could be relaxed by assuming a probability distribution of transition times.
In the following, the transition probability and transition time are inferred from the cluster affiliation function  $k(t)$. The continuous form is convenient for discussion. The time-discrete affiliation function
$k(t)$. The continuous form is convenient for discussion. The time-discrete affiliation function  $k(m)$ can be made continuous by taking the cluster of the snapshot which is closest in time:
$k(m)$ can be made continuous by taking the cluster of the snapshot which is closest in time:
 \begin{equation} k(t) = k \left ( \arg\min_m \left\vert t - t_m \right\vert \right). \end{equation}
\begin{equation} k(t) = k \left ( \arg\min_m \left\vert t - t_m \right\vert \right). \end{equation} The  $n$th transition time
$n$th transition time  $t_n$ of the cluster affiliation is recursively defined as the first discontinuity of
$t_n$ of the cluster affiliation is recursively defined as the first discontinuity of  $k(t)$ for
$k(t)$ for  $t>t_{n-1}$. Here,
$t>t_{n-1}$. Here,  $t_0 = 0$. The transition time
$t_0 = 0$. The transition time  $t_n$ satisfies
$t_n$ satisfies
 \begin{equation} k \left ( t_{n}-\varepsilon \right ) \neq k \left ( t_{n}+\varepsilon \right ) \end{equation}
\begin{equation} k \left ( t_{n}-\varepsilon \right ) \neq k \left ( t_{n}+\varepsilon \right ) \end{equation}
for any sufficiently small positive  $\varepsilon$. For
$\varepsilon$. For  $t \in ( t_n, t_{n+1} )$, the data-based trajectory is assumed to stay in cluster
$t \in ( t_n, t_{n+1} )$, the data-based trajectory is assumed to stay in cluster  $k$ at the averaged time
$k$ at the averaged time  $(t_{n+1}+t_n)/2$ (see figure 4). The residence time in this cluster is defined by
$(t_{n+1}+t_n)/2$ (see figure 4). The residence time in this cluster is defined by
 \begin{equation} \tau_{n} :=t_{n+1}-t_{n}. \end{equation}
\begin{equation} \tau_{n} :=t_{n+1}-t_{n}. \end{equation}
Let  $j$ and
$j$ and  $i$ be the indices of the clusters after
$i$ be the indices of the clusters after  $t_n$ and
$t_n$ and  $t_{n+1}$ respectively. Then the transition time from
$t_{n+1}$ respectively. Then the transition time from  $j$ to
$j$ to  $i$ is defined as half of the residence time of both clusters:
$i$ is defined as half of the residence time of both clusters:
 \begin{equation} \tau_{ij} := \frac{\tau_{n}+\tau_{n+1}}{2} = \frac{t_{n+2}-t_n}{2}. \end{equation}
\begin{equation} \tau_{ij} := \frac{\tau_{n}+\tau_{n+1}}{2} = \frac{t_{n+2}-t_n}{2}. \end{equation}
This definition may appear arbitrary but is the least-biased guess consistent with the available data. The sum of all residence times from a given data set add up to the total investigated time period  $T_0$.
$T_0$.

Figure 4. Sketch of times and periods employed in the cluster-based network model;  $\times$ marks the centre of the cluster residence time, while
$\times$ marks the centre of the cluster residence time, while  $\bullet$ denotes the transition between clusters.
$\bullet$ denotes the transition between clusters.
The direct transition probability  $Q_{ij}$ and transition time
$Q_{ij}$ and transition time  $T_{ij}$ can be inferred from the data. Then,
$T_{ij}$ can be inferred from the data. Then,
 \begin{equation} Q_{ij}=\frac{n_{ij}} {n_{j}},\quad i,j=1,\ldots,K, \end{equation}
\begin{equation} Q_{ij}=\frac{n_{ij}} {n_{j}},\quad i,j=1,\ldots,K, \end{equation}
where  $n_{ij}$ is the number of transitions from
$n_{ij}$ is the number of transitions from  $\boldsymbol {c}_{j}$ to
$\boldsymbol {c}_{j}$ to  $\boldsymbol {c}_{i}$ and
$\boldsymbol {c}_{i}$ and  $n_j$ the number of transitions departing from
$n_j$ the number of transitions departing from  $\boldsymbol {c}_{j}$ regardless of the destination point
$\boldsymbol {c}_{j}$ regardless of the destination point
 \begin{equation} n_j=\sum_{i=1}^K n_{i j},\quad i,j=1,\ldots,K. \end{equation}
\begin{equation} n_j=\sum_{i=1}^K n_{i j},\quad i,j=1,\ldots,K. \end{equation}
We emphasize that  $n_{ii}=0$ for
$n_{ii}=0$ for  $i=1,\ldots ,K$ by very definition of a direct transition. The direct transition matrix (DTM)
$i=1,\ldots ,K$ by very definition of a direct transition. The direct transition matrix (DTM)  ${\boldsymbol{\mathsf{Q}}} = (Q_{ij} ) \in \mathcal {R}^{K \times K}$ lumps these probabilities into a single entity.
${\boldsymbol{\mathsf{Q}}} = (Q_{ij} ) \in \mathcal {R}^{K \times K}$ lumps these probabilities into a single entity.
Similarly, the direct transition time  $T_{ij}$ from cluster
$T_{ij}$ from cluster  $j$ to cluster
$j$ to cluster  $i$ is taken to be the average of all values. This average is symbolically denoted by
$i$ is taken to be the average of all values. This average is symbolically denoted by
 \begin{equation} T_{i j}= \langle \tau_{ij} \rangle. \end{equation}
\begin{equation} T_{i j}= \langle \tau_{ij} \rangle. \end{equation}
These values are lumped into the matrix  ${\boldsymbol{\mathsf{T}}} = (T_{ij} ) \in \mathcal {R}^{K \times K}$.
${\boldsymbol{\mathsf{T}}} = (T_{ij} ) \in \mathcal {R}^{K \times K}$.
It should be noted that a given trajectory may repeatedly pass through the same clusters (Voronoi cells) with different residence and transition times. With enough data, this variability may be incorporated into the model. Our goal is to compare the Markov model with the most simple network model where constant (averaged) transition times are assumed.
The CNM predicts the asymptotic cluster probability  $p^{\infty }_i$ in cluster
$p^{\infty }_i$ in cluster  $i$. Let
$i$. Let  $[0,T_0]$ be a sufficiently long time horizon simulated by the model. Then, the probability of staying in cluster
$[0,T_0]$ be a sufficiently long time horizon simulated by the model. Then, the probability of staying in cluster  $i$ is the cumulative residence time normalized by the simulation time
$i$ is the cumulative residence time normalized by the simulation time
 \begin{equation} p^{\infty}_i= \frac{\sum \tau_i}{T_0}. \end{equation}
\begin{equation} p^{\infty}_i= \frac{\sum \tau_i}{T_0}. \end{equation} We return to the introductory example depicted in figure 3. The CNM is seen to accurately describe the uniform rotation (figure 3f) and correctly yields the asymptotic cluster probability  $p_i^{\infty } =1/4$,
$p_i^{\infty } =1/4$,  $i=1,\ldots ,4$. In contrast, the prediction horizon of the CMM is limited to approximately one period. After this time, the initial condition is forgotten and the asymptotic distribution is reached – rendering CMM unsuitable for dynamic prediction. However, CMM predicts the asymptotic state faster than the CNM. For this particular example, the CMM could be made equivalent to the CNM by choosing
$i=1,\ldots ,4$. In contrast, the prediction horizon of the CMM is limited to approximately one period. After this time, the initial condition is forgotten and the asymptotic distribution is reached – rendering CMM unsuitable for dynamic prediction. However, CMM predicts the asymptotic state faster than the CNM. For this particular example, the CMM could be made equivalent to the CNM by choosing  $\Delta t^c=1/4$. However, the Markov model will inevitably diffuse the state with a range of cluster transition times, e.g. for non-uniform rotation or more complex dynamics.
$\Delta t^c=1/4$. However, the Markov model will inevitably diffuse the state with a range of cluster transition times, e.g. for non-uniform rotation or more complex dynamics.
2.4. Velocity fields associated with the cluster-based reduced-order models
The CMM describes the cluster population
 \begin{equation} \boldsymbol{p}=\left[ p_{1},\ldots,p_{K} \right]^{\textrm{T}} \end{equation}
\begin{equation} \boldsymbol{p}=\left[ p_{1},\ldots,p_{K} \right]^{\textrm{T}} \end{equation}
at discrete times  $t=l \Delta t^c$. In the following, this population is considered to be continuous in time, e.g. by using linear or higher-order interpolation. The corresponding velocity field
$t=l \Delta t^c$. In the following, this population is considered to be continuous in time, e.g. by using linear or higher-order interpolation. The corresponding velocity field  $\boldsymbol u(\boldsymbol x ,t)$ at time
$\boldsymbol u(\boldsymbol x ,t)$ at time  $t$ is defined as the expectation value,
$t$ is defined as the expectation value,
 \begin{equation} \boldsymbol u(\boldsymbol x ,t) =\sum_{i=1}^{K} p_{i}(t) \boldsymbol c_{i}(\boldsymbol x), \end{equation}
\begin{equation} \boldsymbol u(\boldsymbol x ,t) =\sum_{i=1}^{K} p_{i}(t) \boldsymbol c_{i}(\boldsymbol x), \end{equation}
where  $\boldsymbol c_{i}$ is the
$\boldsymbol c_{i}$ is the  $i$th centroid.
$i$th centroid.
The CNM is based on centroid visits at discrete times. The clusters  $k_0, k_1, k_2, \ldots$ are visited at times
$k_0, k_1, k_2, \ldots$ are visited at times
 \begin{equation} t_0=0, \quad t_1=T_{k_1 k_0}, \quad t_2= t_1 + T_{k_2 k_1}, \ldots \end{equation}
\begin{equation} t_0=0, \quad t_1=T_{k_1 k_0}, \quad t_2= t_1 + T_{k_2 k_1}, \ldots \end{equation}
consistent with the direct transition matrix  $(Q_{ij})$ and the transition times
$(Q_{ij})$ and the transition times  $T_{ij}$. A uniform motion is assumed between these visits. In other words, for
$T_{ij}$. A uniform motion is assumed between these visits. In other words, for  $t \in [t_n,t_{n+1}]$ the velocity field reads
$t \in [t_n,t_{n+1}]$ the velocity field reads
 \begin{equation} \boldsymbol{u}(\boldsymbol{x},t) = \alpha_{n} (t) \boldsymbol{c}_{k_n} (\boldsymbol{x}) + \left [ 1-\alpha_n(t) \right ] \boldsymbol{c}_{k_{n+1}} (\boldsymbol{x}), \quad \alpha_n = \frac{t_{n+1}-t}{t_{n+1}-t_n} . \end{equation}
\begin{equation} \boldsymbol{u}(\boldsymbol{x},t) = \alpha_{n} (t) \boldsymbol{c}_{k_n} (\boldsymbol{x}) + \left [ 1-\alpha_n(t) \right ] \boldsymbol{c}_{k_{n+1}} (\boldsymbol{x}), \quad \alpha_n = \frac{t_{n+1}-t}{t_{n+1}-t_n} . \end{equation}We note that a smoother motion may be achieved with splines.
The actual flow computations are based on a lossless POD, as elaborated in appendix A. The interpolations are performed with the mode amplitudes  $\boldsymbol {a}= [ a_1,\ldots ,a_N ]^{\textrm {T}}$ before being transcribed into velocity fields via the POD expansion.
$\boldsymbol {a}= [ a_1,\ldots ,a_N ]^{\textrm {T}}$ before being transcribed into velocity fields via the POD expansion.
Figure 5 compares the classical CMM with stroboscopic temporal prediction of discrete states and the proposed CNM with time-continuous uniform motion on a network of routes between two centroids. In the top row, the possible states are illustrated. In case of the CMM, the states (2.19), denoted by red dots, quickly converge to the mean flow, like Reynolds-averaged Navier–Stokes simulations. The CNM-predicted state (2.21) moves on the directed network, marked by red arrows, and is reminiscent of large-eddy simulations. As displayed in the middle row, the CMM is discrete in time while the CNM dynamics is time continuous with cluster visits after pre-specified transition times  $T_{jk}$. The bottom row shows another difference: CMM describes averages over all centroids while the CNM only allows for linear interpolations between two neighbouring centroids. This interpolation is consistent with the purpose of accurately resolving evolving coherent structures. Averaging over many centroids acts like a low-pass filter mitigating the fluctuation level and thus underresolving the coherent structures.
$T_{jk}$. The bottom row shows another difference: CMM describes averages over all centroids while the CNM only allows for linear interpolations between two neighbouring centroids. This interpolation is consistent with the purpose of accurately resolving evolving coherent structures. Averaging over many centroids acts like a low-pass filter mitigating the fluctuation level and thus underresolving the coherent structures.

Figure 5. Comparison of the CMM and CNM. For reasons of simplicity, an example with four centroids  $i$,
$i$,  $j$,
$j$,  $k$ and
$k$ and  $l$ is shown. The CNM exemplifies the evolution of the weight of centroid
$l$ is shown. The CNM exemplifies the evolution of the weight of centroid  $k$. For the CMM, the transition from cluster
$k$. For the CMM, the transition from cluster  $k$ to
$k$ to  $j$ is shown. The predicted state (2.21) is determined by the weights
$j$ is shown. The predicted state (2.21) is determined by the weights  $w_k(t) = \alpha (t)$ and
$w_k(t) = \alpha (t)$ and  $w_j = 1-\alpha (t)$,
$w_j = 1-\alpha (t)$,  $\alpha =(t_{n+1}-t)/T_{jk}$ in the time interval
$\alpha =(t_{n+1}-t)/T_{jk}$ in the time interval  $[ t_n,t_{n+1} ]$. For details, see text.
$[ t_n,t_{n+1} ]$. For details, see text.
2.5. Validation of the cluster-based reduced-order models
Following Protas, Noack & Östh (Reference Protas, Noack and Östh2015), the cluster-based model is validated based on the computed and predicted autocorrelation function of the velocity field. The unbiased autocorrelation function reads
 \begin{equation} R(\tau) :=\frac{1}{T-\tau} \int_{\tau}^{\textrm{T}} \int_{\varOmega} \boldsymbol{u}(\boldsymbol{x}, t-\tau) \boldsymbol{\cdot} \boldsymbol{u}(\boldsymbol{x}, t)\,\textrm{d}\boldsymbol{x}\,\textrm{d}t, \quad \tau \in[0, T). \end{equation}
\begin{equation} R(\tau) :=\frac{1}{T-\tau} \int_{\tau}^{\textrm{T}} \int_{\varOmega} \boldsymbol{u}(\boldsymbol{x}, t-\tau) \boldsymbol{\cdot} \boldsymbol{u}(\boldsymbol{x}, t)\,\textrm{d}\boldsymbol{x}\,\textrm{d}t, \quad \tau \in[0, T). \end{equation}
This function reveals the turbulent fluctuation level  $R(0)$ and the frequency spectrum. Moreover, the problem of comparing two trajectories with finite dynamic prediction horizons due to the increasing phase mismatch is avoided (Pastoor et al. Reference Pastoor, King, Noack, King and Tadmor2005).
$R(0)$ and the frequency spectrum. Moreover, the problem of comparing two trajectories with finite dynamic prediction horizons due to the increasing phase mismatch is avoided (Pastoor et al. Reference Pastoor, King, Noack, King and Tadmor2005).
In case of the CNM, the modelled autocorrelation function  $\hat {R}$ is based on the modelled velocity field (2.21). In case of the CMM, the time integration quickly leads to the average flow and is not indicative of the range of possible initial conditions. Hence,
$\hat {R}$ is based on the modelled velocity field (2.21). In case of the CMM, the time integration quickly leads to the average flow and is not indicative of the range of possible initial conditions. Hence,  $K$ trajectories are considered starting with
$K$ trajectories are considered starting with  $p_k=1$ for each cluster
$p_k=1$ for each cluster  $k$, or, equivalently,
$k$, or, equivalently,  $\boldsymbol {p}^{\circ k} (t=0)= [ \delta _{1k}, \ldots , \delta _{Kk} ]^{\mathrm {T}}$. These cluster-specific autocorrelation functions are weighted with the cluster probability
$\boldsymbol {p}^{\circ k} (t=0)= [ \delta _{1k}, \ldots , \delta _{Kk} ]^{\mathrm {T}}$. These cluster-specific autocorrelation functions are weighted with the cluster probability  $p_i^{\infty }$
$p_i^{\infty }$
 \begin{equation} \hat{R} (\tau) :=\sum_{k=1}^K p_i^{\infty} \int_{0}^T \int_{\varOmega} \boldsymbol{u}^{\circ k} (\boldsymbol{x}, t) \boldsymbol{\cdot} \boldsymbol{u}^{\circ k} (\boldsymbol{x}, t+\tau ) \,\textrm{d}\boldsymbol{x}\,\textrm{d}t, \quad \tau \in[0, T), \end{equation}
\begin{equation} \hat{R} (\tau) :=\sum_{k=1}^K p_i^{\infty} \int_{0}^T \int_{\varOmega} \boldsymbol{u}^{\circ k} (\boldsymbol{x}, t) \boldsymbol{\cdot} \boldsymbol{u}^{\circ k} (\boldsymbol{x}, t+\tau ) \,\textrm{d}\boldsymbol{x}\,\textrm{d}t, \quad \tau \in[0, T), \end{equation}
where  $\boldsymbol {u}^{\circ k}$ denotes the CMM-predicted velocity field starting in cluster
$\boldsymbol {u}^{\circ k}$ denotes the CMM-predicted velocity field starting in cluster  $k$.
$k$.
2.6. Lorenz system as an illustrating example
Following the original CMM paper by Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014), the CNM is illustrated for the celebrated Lorenz (Reference Lorenz1963) system, arguably the first demonstration of a chaotic dynamics in low-dimensional dynamics. The Lorenz system is a three-dimensional autonomous system of nonlinear ordinary differential equations. The derivation was inspired by a Galerkin model of Rayleigh–Bénard convection, but typically selected parameters clearly exceed the range of model validity (Sparrow Reference Sparrow1982). The system features non-periodic, deterministic, dissipative dynamics associated with exponential divergence and convergence to a fractal strange attractor. The three coupled nonlinear differential equations read
 \begin{gather} \frac{\mathrm{d} x}{\mathrm{d} t} =\sigma(y-x), \end{gather}
\begin{gather} \frac{\mathrm{d} x}{\mathrm{d} t} =\sigma(y-x), \end{gather} \begin{gather}\frac{\mathrm{d} y}{\mathrm{d} t} =x(r-z)-y, \end{gather}
\begin{gather}\frac{\mathrm{d} y}{\mathrm{d} t} =x(r-z)-y, \end{gather} \begin{gather}\frac{\mathrm{d} z}{\mathrm{d} t} =x y-b z, \end{gather}
\begin{gather}\frac{\mathrm{d} z}{\mathrm{d} t} =x y-b z, \end{gather}
with the system parameters  $\sigma =10$,
$\sigma =10$,  $b=8/3$ and
$b=8/3$ and  $r=28$. For these parameters, there are three unstable fixed points at
$r=28$. For these parameters, there are three unstable fixed points at  $(0,0,0)$ and
$(0,0,0)$ and  $(\pm \sqrt {72},\pm \sqrt {72},27)$, denoted by
$(\pm \sqrt {72},\pm \sqrt {72},27)$, denoted by  $F^+$ and
$F^+$ and  $F^-$, respectively. The attractor of the Lorenz system resembles two butterfly wings around
$F^-$, respectively. The attractor of the Lorenz system resembles two butterfly wings around  $F^+$ and
$F^+$ and  $F^-$ in phase space. The trajectory typically oscillates for several periods with increasing amplitude around a fixed point (
$F^-$ in phase space. The trajectory typically oscillates for several periods with increasing amplitude around a fixed point ( $F^+$ or
$F^+$ or  $F^-$) before it moves to the other wing. The number of revolutions made on either side varies unpredictably from one cycle to the next.
$F^-$) before it moves to the other wing. The number of revolutions made on either side varies unpredictably from one cycle to the next.
The Lorenz equations (2.24) are solved employing an explicit fourth-order Runge–Kutta scheme with an initial condition on the attractor. The time-resolved snapshot data  $\boldsymbol {x}(t_{m})$ with
$\boldsymbol {x}(t_{m})$ with  $\boldsymbol x=[x,y,z]^{\textrm {T}}$ are collected at a sampling time step
$\boldsymbol x=[x,y,z]^{\textrm {T}}$ are collected at a sampling time step  $\Delta t=0.005$ corresponding roughly to one thousandth of a typical oscillation period. The k-means++ algorithm partitions
$\Delta t=0.005$ corresponding roughly to one thousandth of a typical oscillation period. The k-means++ algorithm partitions  $M=1\,000\,000$ snapshots into
$M=1\,000\,000$ snapshots into  $K=10$ clusters. Figure 6(a) displays a phase portrait of the corresponding clusters. The snapshots associated with one cluster are highlighted by the same colour. The
$K=10$ clusters. Figure 6(a) displays a phase portrait of the corresponding clusters. The snapshots associated with one cluster are highlighted by the same colour. The  $10$ clusters feature three different subsets: the transition clusters
$10$ clusters feature three different subsets: the transition clusters  $k=1,2$ between two butterfly wings, the
$k=1,2$ between two butterfly wings, the  $F^-$ wing related cluster
$F^-$ wing related cluster  $k=3,4,5,6$ and clusters
$k=3,4,5,6$ and clusters  $k=7,8,9,10$ associated with the
$k=7,8,9,10$ associated with the  $F^+$ wing. The wing-related cluster groups represent approximately
$F^+$ wing. The wing-related cluster groups represent approximately  $90^{\circ }$ phase bins and do not resolve the amplitude. Evidently, the 10 clusters are coarse representations of the state.
$90^{\circ }$ phase bins and do not resolve the amplitude. Evidently, the 10 clusters are coarse representations of the state.

Figure 6. Cluster-based network model for the Lorenz attractor. (a) Cluster partitioning: the centroids are displayed as coloured solid circles. A trajectory is illustrated by a black curve. The dots on this trajectory are coloured according to their cluster affiliation. The clusters  $k=3,4,5,6$ oscillate around the fixed point
$k=3,4,5,6$ oscillate around the fixed point  $F^-$ and clusters
$F^-$ and clusters  $k=7,8,9,10$ around
$k=7,8,9,10$ around  $F^+$. The clusters
$F^+$. The clusters  $k=1,2$ connect both ‘ears’ of the Lorenz attractor. (b) The trajectory of the CNM (red dashed line). The centroids represent the network nodes and edges represent possible transitions. Here, trajectory of CNM is obtained by a spline interpolation through the visited centroids.
$k=1,2$ connect both ‘ears’ of the Lorenz attractor. (b) The trajectory of the CNM (red dashed line). The centroids represent the network nodes and edges represent possible transitions. Here, trajectory of CNM is obtained by a spline interpolation through the visited centroids.
In the following, the dynamics is resolved by the network model of § 2.3. The  $10$ centroids are considered as nodes in the network. The transition between these centroids define directed edges characterized by direct transition matrix
$10$ centroids are considered as nodes in the network. The transition between these centroids define directed edges characterized by direct transition matrix  ${\boldsymbol{\mathsf{Q}}}$ and the flight times
${\boldsymbol{\mathsf{Q}}}$ and the flight times  ${\boldsymbol{\mathsf{T}}}$. The connectivity is described by the adjacency matrix
${\boldsymbol{\mathsf{T}}}$. The connectivity is described by the adjacency matrix  $H({\boldsymbol{\mathsf{Q}}})$ where
$H({\boldsymbol{\mathsf{Q}}})$ where  $H$ denotes the Heaviside function: non-vanishing elements of
$H$ denotes the Heaviside function: non-vanishing elements of  ${\boldsymbol{\mathsf{Q}}}$ are replaced by unity (Newman Reference Newman2010). Figure 7, displays the DTM
${\boldsymbol{\mathsf{Q}}}$ are replaced by unity (Newman Reference Newman2010). Figure 7, displays the DTM  ${\boldsymbol{\mathsf{Q}}}$ (figure 7a) and associated transition time matrix
${\boldsymbol{\mathsf{Q}}}$ (figure 7a) and associated transition time matrix  ${\boldsymbol{\mathsf{T}}}$ (figure 7b). The matrices reveal three distinct cluster groups consistent with the phase diagram of figure 6. Clusters
${\boldsymbol{\mathsf{T}}}$ (figure 7b). The matrices reveal three distinct cluster groups consistent with the phase diagram of figure 6. Clusters  $1$ and
$1$ and  $2$ allow transitions to
$2$ allow transitions to  $3$ and
$3$ and  $10$, i.e. the
$10$, i.e. the  $F^-$ and
$F^-$ and  $F^+$ wing, respectively, and have been called flipper clusters by Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014). The cluster transition sequence
$F^+$ wing, respectively, and have been called flipper clusters by Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014). The cluster transition sequence  $3 \to 4 \to 5 \to 6 \to 1 \to 2 \to 3$ is the dominant cyclic group associated with the
$3 \to 4 \to 5 \to 6 \to 1 \to 2 \to 3$ is the dominant cyclic group associated with the  $F^-$ wing. Another cyclic group skips cluster
$F^-$ wing. Another cyclic group skips cluster  $2$:
$2$:  $3 \to 4 \to 5 \to 6 \to 1 \to 3$. A cyclic group through the
$3 \to 4 \to 5 \to 6 \to 1 \to 3$. A cyclic group through the  $F^+$ wing reads
$F^+$ wing reads  $10 \to 9 \to 8 \to 7 \to 1 \to 10$. A longer sequence includes the second cluster:
$10 \to 9 \to 8 \to 7 \to 1 \to 10$. A longer sequence includes the second cluster:  $10 \to 9 \to 8 \to 7 \to 1 \to 2 \to 10$. The transition times in the wing centroids are noticeably smaller than the passage through the flipper clusters.
$10 \to 9 \to 8 \to 7 \to 1 \to 2 \to 10$. The transition times in the wing centroids are noticeably smaller than the passage through the flipper clusters.

Figure 7. Cluster-based network model of the Lorenz attractor. (a) Direct transition matrix  $(Q_{ij})$. (b) Transition time
$(Q_{ij})$. (b) Transition time  $(T_{ij})$.
$(T_{ij})$.
Figure 8 compares the asymptotic population  $\boldsymbol {p}^{\infty }$ predicted by CNM with the population from a long-term simulation. The CNM statistics are based on
$\boldsymbol {p}^{\infty }$ predicted by CNM with the population from a long-term simulation. The CNM statistics are based on  $20\,000$ transitions while the integration of the Lorenz equations is performed over 5000 time units. Both statistics correspond to the roughly 800 periods found to be sufficient for an accurate statistics. The relative error of the CNM is no more than approximately 10 %. This error does not decrease with much larger integration times, but is linked to the coarse-graining of the state to Voronoi cells around the centroids. The assumed constant transition time
$20\,000$ transitions while the integration of the Lorenz equations is performed over 5000 time units. Both statistics correspond to the roughly 800 periods found to be sufficient for an accurate statistics. The relative error of the CNM is no more than approximately 10 %. This error does not decrease with much larger integration times, but is linked to the coarse-graining of the state to Voronoi cells around the centroids. The assumed constant transition time  $\tau _{ij}$ for all trajectories from cluster
$\tau _{ij}$ for all trajectories from cluster  $j$ to cluster
$j$ to cluster  $i$ is a crude assumption. In fact, the transition times can vary by a large factor and can thus give rise to significant systematic errors. A more accurate transition model may, for instance, include earlier transitions for a more realistic representation of the trajectory. Intriguingly, the CMM has an error of only 0.5 % which is one order of magnitude lower. Due to the stroboscopic monitoring of the CMM states, no estimates of the transition times are required and one source of systematic errors is excluded by construction.
$i$ is a crude assumption. In fact, the transition times can vary by a large factor and can thus give rise to significant systematic errors. A more accurate transition model may, for instance, include earlier transitions for a more realistic representation of the trajectory. Intriguingly, the CMM has an error of only 0.5 % which is one order of magnitude lower. Due to the stroboscopic monitoring of the CMM states, no estimates of the transition times are required and one source of systematic errors is excluded by construction.

Figure 8. Cluster probability distribution of the Lorenz system (solid rectangles) and the corresponding cluster-based network model (open rectangles). The model results are based on  $20\,000$ transitions.
$20\,000$ transitions.
A distinguishing feature of the CNM is the resolution of the temporal dynamics illustrated in figure 9. The evolution of the model-based trajectory is hardly distinguishable from the one obtained by numerical integration. Smoothness of the CNM trajectory has been achieved by splines connecting the states between two consecutive centroid visits. Yet, the oscillatory amplitude growth in both wings cannot be resolved with this low cluster-based resolution. The CNM can only follow the simulations for a short time period, as nearby trajectories exponentially diverge with Lyapunov exponent 2.16 (Wolf et al. Reference Wolf, Swift, Swinney and Vastano1985) and the initial separation in each cluster is already large. Yet, the fluctuation amplitude, frequency content and bi-modality are well reproduced. A CNM with  $K=100$ clusters yields more realistic dynamics but require orders of magnitude more simulation data. At the least-order extreme, a CNM with two or three clusters only coarsely resolves the transitions between both ears of the Lorenz attractor, not the growing oscillations in each ear.
$K=100$ clusters yields more realistic dynamics but require orders of magnitude more simulation data. At the least-order extreme, a CNM with two or three clusters only coarsely resolves the transitions between both ears of the Lorenz attractor, not the growing oscillations in each ear.

Figure 9. Evolution of the Lorenz system  $x$,
$x$,  $y$,
$y$,  $z$,
$z$,  $t\in [0,20]$ from integrating the dynamical system (black solid line) and from the prediction of the cluster-based network model (red dashed line).
$t\in [0,20]$ from integrating the dynamical system (black solid line) and from the prediction of the cluster-based network model (red dashed line).
Finally, the autocorrelation of the simulation (black solid curve) and the CNM (red dashed curve) are presented for aggregate comparison in figure 10. CNM roughly reproduces the fast oscillatory decay of the autocorrelation function in the first five periods.

Figure 10. Autocorrelation function of the Lorenz system (black solid line) and the cluster-based network model (red dashed line).
3. Cluster-based reduced-order modelling of the mixing layer
In this section, the cluster-based models are applied to a two-dimensional incompressible mixing layer with Kelvin–Helmholtz vortices undergoing vortex pairing. The flow configuration of the mixing layer and the employed direct Navier–Stokes solver is presented in § 3.1. In § 3.2, the dominant flow features of the mixing layer are presented. Then (§ 3.3), the snapshots of incompressible mixing layer are coarse-grained into centroids. Following Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014), a cluster-based Markov model (CMM, § 3.4) is developed as a benchmark for the proposed network model (CNM, § 3.5).
3.1. Flow configuration and direct numerical simulation
The two-dimensional incompressible mixing layer and a velocity ratio of  $3:1$ is considered as the test plant in this paper. The velocity ratio is a common choice in the literature (Comte, Silvestrini & Bégou Reference Comte, Silvestrini and Bégou1998; Noack et al. Reference Noack, Papas and Monkewitz2005; Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014). The high- and low-speed streams have velocities
$3:1$ is considered as the test plant in this paper. The velocity ratio is a common choice in the literature (Comte, Silvestrini & Bégou Reference Comte, Silvestrini and Bégou1998; Noack et al. Reference Noack, Papas and Monkewitz2005; Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014). The high- and low-speed streams have velocities  $U_1$ and
$U_1$ and  $U_2$, respectively. The convection velocity
$U_2$, respectively. The convection velocity  $U_c$ of coherent structure is well approximated by the average velocity (Monkewitz Reference Monkewitz1988)
$U_c$ of coherent structure is well approximated by the average velocity (Monkewitz Reference Monkewitz1988)
 \begin{equation} U_{c}=\frac{U_{1}+U_{2}}{2}. \end{equation}
\begin{equation} U_{c}=\frac{U_{1}+U_{2}}{2}. \end{equation}
The initial vorticity thickness is denoted by  $\delta _0$. The Newtonian fluid is characterized by the density
$\delta _0$. The Newtonian fluid is characterized by the density  $\rho$ and kinematic viscosity
$\rho$ and kinematic viscosity  $\nu$. The flow characteristics are described by the Reynolds number based on the convection velocity
$\nu$. The flow characteristics are described by the Reynolds number based on the convection velocity  $Re = U_c \delta _0 / \nu$ and velocity ratio. In the sequel, all quantities are assumed to be non-dimensionalized with the initial vorticity thickness
$Re = U_c \delta _0 / \nu$ and velocity ratio. In the sequel, all quantities are assumed to be non-dimensionalized with the initial vorticity thickness  $\delta _0$, the high-speed velocity
$\delta _0$, the high-speed velocity  $U_1$ and the density
$U_1$ and the density  $\rho$. The Reynolds number is set to 200.
$\rho$. The Reynolds number is set to 200.
The flow is described in a Cartesian coordinate system  $(x,y)$ with the origin at the maximum gradient location of the inlet profile. The
$(x,y)$ with the origin at the maximum gradient location of the inlet profile. The  $x$-axis points in the streamwise direction and the
$x$-axis points in the streamwise direction and the  $y$-axis points in the direction of the high-speed stream. The velocity components in the
$y$-axis points in the direction of the high-speed stream. The velocity components in the  $x$- and
$x$- and  $y$-directions are denoted by
$y$-directions are denoted by  $u$ and
$u$ and  $v$, respectively.
$v$, respectively.
Figure 11 illustrates the rectangular computational domain
 \begin{equation} \varOmega : = \{ ( x , y ) \in \mathcal{R}^2 : 0 \leq x \leq 80 \wedge \vert y \vert \leq 15 \} \end{equation}
\begin{equation} \varOmega : = \{ ( x , y ) \in \mathcal{R}^2 : 0 \leq x \leq 80 \wedge \vert y \vert \leq 15 \} \end{equation}
with 10 237 nodes and 2248 triangular elements. The location vector is denoted by  $\boldsymbol {x}=(x,y)$. Similarly, the velocity vector is denoted by
$\boldsymbol {x}=(x,y)$. Similarly, the velocity vector is denoted by  $\boldsymbol {u}=(u,v)$. The inlet velocity profile reads
$\boldsymbol {u}=(u,v)$. The inlet velocity profile reads
 \begin{equation} u=2+\tanh \left( \frac{2y}{\delta_{0}} \right), \quad v=0, \quad \text{where} \ \delta_{0}=1. \end{equation}
\begin{equation} u=2+\tanh \left( \frac{2y}{\delta_{0}} \right), \quad v=0, \quad \text{where} \ \delta_{0}=1. \end{equation}
The Kelvin–Helmholtz vortices are triggered at the inlet by a stochastic perturbation of the  $u$-component for
$u$-component for  $y \in [-2,2]$ with a standard deviation of
$y \in [-2,2]$ with a standard deviation of  $0.01 U_c$.
$0.01 U_c$.

Figure 11. Numerical simulation sketch of incompressible mixing layer. An unperturbed tanh velocity profile  $u(y) =2+\tanh (2y)$ is patched in the inlet of a rectangular domain. Time-averaged streamwise velocity profiles separated by
$u(y) =2+\tanh (2y)$ is patched in the inlet of a rectangular domain. Time-averaged streamwise velocity profiles separated by  $\Delta x$=10 are visualized by blue lines. The red dashed curves mark the mixing-layer thickness. We chose the 90 % thickness of the profile starting with the average velocity, i.e.
$\Delta x$=10 are visualized by blue lines. The red dashed curves mark the mixing-layer thickness. We chose the 90 % thickness of the profile starting with the average velocity, i.e.  $u=2.9$ and
$u=2.9$ and  $u=1.1$.
$u=1.1$.
The streamwise extent of the domain is 80. This corresponds to a downwash time of 40 given the convection velocity of 2. This is the minimum time for the transient time as all initial interior vortices will leave the domain. A simulation over 400 convective units corresponds to 10 downwash times. This period is found to be sufficient for a good statistics of the mean value and fluctuation level. One simulation yields  $M=10\,000$ velocity snapshots
$M=10\,000$ velocity snapshots  $\boldsymbol {u}^{m}(\boldsymbol {x})=\boldsymbol {u}(\boldsymbol {x},t^m)$, where the sampling times
$\boldsymbol {u}^{m}(\boldsymbol {x})=\boldsymbol {u}(\boldsymbol {x},t^m)$, where the sampling times  $t^m = 0.04\ \textrm {m}$ start with
$t^m = 0.04\ \textrm {m}$ start with  $t=0$ in the converged post-transient phase. The sampling frequency
$t=0$ in the converged post-transient phase. The sampling frequency  $25$ is two orders of magnitude larger than the dominant shear-layer frequency of
$25$ is two orders of magnitude larger than the dominant shear-layer frequency of  $f=0.1075$ in the most active downstream region.
$f=0.1075$ in the most active downstream region.
An in-house direct numerical simulation solver was employed to simulate the incompressible mixing layer. This solver is based on the finite-element method with third-order Taylor–Hood elements and implicit third-order time integration. The solver has been used for numerous configurations, like the cylinder wake (Noack et al. Reference Noack, Stankiewicz, Morzyński and Schmid2016), the mixing layer (Shaqarin, Noack & Morzyński Reference Shaqarin, Noack and Morzyński2018) and the fluidic pinball (Ishar et al. Reference Ishar, Kaiser, Morzynski, Albers, Meysonnat, Schröder and Noack2019), to name only a few.
3.2. Flow features
The incompressible mixing layer exhibits two typical behaviours. First, the initial dynamics is characterized by the roll-up of vorticity originating from the Kelvin–Helmholtz (K–H) instability (see figure 12b i). Second, these vortices pair further downstream, as can be seen at the outlet region of figure 12(b ii). This vortex pairing contributes to the mixing layer growth. The location of vortex pairing may change significantly in time. Upstream (downstream) vortex pairing is associated with high (low) fluctuation energy.

Figure 12. Mixing-layer simulation. (a) Energy fluctuation over time with the maximum marked by a blue square and minimum by a red square. (b) Vorticity fields associated with the maximum and minimum fluctuation energies. The minimum (b i) corresponds to a K–H vortex at  $t=167.60$, The maximum (b ii) features vortex pairing at
$t=167.60$, The maximum (b ii) features vortex pairing at  $t=195.92$. The curves represent the isolines of vorticity. Higher values corresponds to darker green areas.
$t=195.92$. The curves represent the isolines of vorticity. Higher values corresponds to darker green areas.
The time-averaged velocity field in figure 11 shows the mixing layer growth. The velocity thickness is visualized by a red dashed line and is defined as the distance between transverse locations where the mean streamwise velocity was equal to  $U_{1}-0.05 \Delta U$ and
$U_{1}-0.05 \Delta U$ and  $U_{2}+0.05 \Delta U$. The mixing-layer thickness increases significantly between
$U_{2}+0.05 \Delta U$. The mixing-layer thickness increases significantly between  $x=30$ and
$x=30$ and  $x=60$. Here, vortex pairing leads to this thickness increase.
$x=60$. Here, vortex pairing leads to this thickness increase.
The temporal dynamics may be inferred from the evolution of the fluctuation energy in figure 12(a). The fluctuations indicate narrow bandwidth oscillatory behaviour. More refined insights may be gained from the correlation function between the flows at time  $t$ and
$t$ and  $t^{\prime }$,
$t^{\prime }$,
 \begin{equation} C(t,t^{\prime}) = \int_{\varOmega} \boldsymbol{u}^{\prime} \left ( \boldsymbol{x},t \right ) \boldsymbol{\cdot} \boldsymbol{u}^{\prime} \left ( \boldsymbol{x},t^{\prime} \right )\, \textrm{d}\boldsymbol{x}. \end{equation}
\begin{equation} C(t,t^{\prime}) = \int_{\varOmega} \boldsymbol{u}^{\prime} \left ( \boldsymbol{x},t \right ) \boldsymbol{\cdot} \boldsymbol{u}^{\prime} \left ( \boldsymbol{x},t^{\prime} \right )\, \textrm{d}\boldsymbol{x}. \end{equation} Figure 13 illustrates the autocorrelation matrix for  $t,t^{\prime } \in [0,400]$. The fluctuation energy of figure 12(a) is quantified in the diagonal,
$t,t^{\prime } \in [0,400]$. The fluctuation energy of figure 12(a) is quantified in the diagonal,  $\mathcal {K}(t) = C(t,t)/2$. The wavy pattern indicates oscillatory coherent structures. The changes from pure periodicity are caused by vortex pairing at a large range of streamwise locations.
$\mathcal {K}(t) = C(t,t)/2$. The wavy pattern indicates oscillatory coherent structures. The changes from pure periodicity are caused by vortex pairing at a large range of streamwise locations.

Figure 13. Autocorrelation matrix (3.4) of the mixing layer for  $t ,t^{\prime } \in [0,400]$. The value is presented in the colour bar. The plot is based on 401 snapshots collected at uniform time steps
$t ,t^{\prime } \in [0,400]$. The value is presented in the colour bar. The plot is based on 401 snapshots collected at uniform time steps  $\Delta t=1$.
$\Delta t=1$.
3.3. Clustering
Both considered reduced-order models are based on the direct numerical simulation of the two-dimensional incompressible mixing layer described in § 3.1;  $M=10\,000$ velocity field snapshots of the post-transient phase are sampled with a time step
$M=10\,000$ velocity field snapshots of the post-transient phase are sampled with a time step  $\Delta t = 0.04$.
$\Delta t = 0.04$.
The computational load of clustering is significantly reduced by an effectively lossless POD compression detailed in appendix A. In fact, all operations are performed on the POD amplitude vector  $\boldsymbol {a}= [a_{1},a_{2},\ldots ,a_{N}]^{\textrm {T}}$ instead of the snapshots.
$\boldsymbol {a}= [a_{1},a_{2},\ldots ,a_{N}]^{\textrm {T}}$ instead of the snapshots.
The  $M$ snapshots are clustered with the k-means++ algorithm into
$M$ snapshots are clustered with the k-means++ algorithm into  $K=10$ centroids. This number is small enough to allow for the physical interpretation of all centroids and all transitions but large enough for a meaningful reduced-order model. Figure 14 illustrates the transverse velocity fluctuation of the centroids. The first six centroids show the streamwise convection of K–H vortices, while the next four centroids resolve a vortex pairing (VP) event. In centroid
$K=10$ centroids. This number is small enough to allow for the physical interpretation of all centroids and all transitions but large enough for a meaningful reduced-order model. Figure 14 illustrates the transverse velocity fluctuation of the centroids. The first six centroids show the streamwise convection of K–H vortices, while the next four centroids resolve a vortex pairing (VP) event. In centroid  $7$, two vortices merge at the beginning of the vortex chain. In the following three centroids, the merging is completed and leads to a large vortex. Note that the VP centroids
$7$, two vortices merge at the beginning of the vortex chain. In the following three centroids, the merging is completed and leads to a large vortex. Note that the VP centroids  $k=7,8,9,10$ have pronounced vortices at a similar position as the K–H centroids
$k=7,8,9,10$ have pronounced vortices at a similar position as the K–H centroids  $k=4,5,6$, respectively. The structures of the K–H and VP centroids are noticeably different. The main vortices of the K–H centroids are elliptical and the major axis is rotated in clockwise direction, i.e. the upper part of the vortices follow the faster stream. In contrast, the main elliptical vortices of VP centroids are rotated in mathematically positive direction, i.e. the upper part of these vortices move upstream with respect to their centre.
$k=4,5,6$, respectively. The structures of the K–H and VP centroids are noticeably different. The main vortices of the K–H centroids are elliptical and the major axis is rotated in clockwise direction, i.e. the upper part of the vortices follow the faster stream. In contrast, the main elliptical vortices of VP centroids are rotated in mathematically positive direction, i.e. the upper part of these vortices move upstream with respect to their centre.

Figure 14. The cluster centroids  $\boldsymbol {c}_{k}$,
$\boldsymbol {c}_{k}$,  $k=1, \ldots , 10$, of the mixing layer. The transverse velocity fluctuation is depicted with contour lines. Red and blue regions mark positive and negative values.
$k=1, \ldots , 10$, of the mixing layer. The transverse velocity fluctuation is depicted with contour lines. Red and blue regions mark positive and negative values.
The centroids represent characteristic stages in the mixing-layer dynamics as can be elucidated in a proximity map. This map reflects the configuration matrix  ${\boldsymbol{\mathsf{D}}} = (D_{ij}) \in $
${\boldsymbol{\mathsf{D}}} = (D_{ij}) \in $  $\mathcal {R}^{K \times K}$ comprising the distance between two centroids
$\mathcal {R}^{K \times K}$ comprising the distance between two centroids
 \begin{equation} D_{i j}^{c} :=\left\|\boldsymbol{c}_{i}-\boldsymbol{c}_{j}\right\|_{\varOmega},\quad i,j=1,2,\ldots,K. \end{equation}
\begin{equation} D_{i j}^{c} :=\left\|\boldsymbol{c}_{i}-\boldsymbol{c}_{j}\right\|_{\varOmega},\quad i,j=1,2,\ldots,K. \end{equation}
Following Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014), the proximity map is used to represent the configuration matrix  ${\boldsymbol{\mathsf{D}}}$ in a two-dimensional feature space
${\boldsymbol{\mathsf{D}}}$ in a two-dimensional feature space  $\boldsymbol {\gamma } \in \mathcal {R}^2$ optimally preserving the relative distances. The proximity map employs classical multidimensional scaling (Mardia, Kent & Bibby Reference Mardia, Kent and Bibby1979). Figure 15(a) displays centroids close to a circle which is characteristic of vortex shedding.
$\boldsymbol {\gamma } \in \mathcal {R}^2$ optimally preserving the relative distances. The proximity map employs classical multidimensional scaling (Mardia, Kent & Bibby Reference Mardia, Kent and Bibby1979). Figure 15(a) displays centroids close to a circle which is characteristic of vortex shedding.

Figure 15. Cluster-based Markov model of the mixing layer. (a) Proximity map of centroids. Each centroid is marked by a solid coloured circle. The colour denotes the relative energy content (see colour bar on top). Unity corresponds to the average value. (b) Transition matrix. The probability value is displayed by the background colour and the radius of the corresponding circle.
3.4. Markov model
The temporal mixing-layer evolution is characterized by the cluster transition matrix  ${\boldsymbol{\mathsf{P}}}$ illustrated in figure 15(b);
${\boldsymbol{\mathsf{P}}}$ illustrated in figure 15(b);  $P_{ij}$ represents the probability of moving from cluster
$P_{ij}$ represents the probability of moving from cluster  $j$ to
$j$ to  $i$ in one forward time step. Here, we choose a time step
$i$ in one forward time step. Here, we choose a time step  $\Delta t^c=T/10=1$ where the
$\Delta t^c=T/10=1$ where the  $T=10$ is the dominant period of the evolved mixing layer.
$T=10$ is the dominant period of the evolved mixing layer.
The cluster transition matrix reveals two cyclic groups. The first group  $1 \to 2 \to 3 \to 4 \to 5 \to 6 \to 7 \to 1$ is consistent with the convection process of the K–H vortex shedding observed in the centroid visualization. This periodic process corresponds to a nearly uniform clockwise rotation in the proximity map. The second cyclic group
$1 \to 2 \to 3 \to 4 \to 5 \to 6 \to 7 \to 1$ is consistent with the convection process of the K–H vortex shedding observed in the centroid visualization. This periodic process corresponds to a nearly uniform clockwise rotation in the proximity map. The second cyclic group  $8 \to 9 \to 10 \to 7 \to 1 \to 2\to 8$ comprises VP centroids
$8 \to 9 \to 10 \to 7 \to 1 \to 2\to 8$ comprises VP centroids  $k=8,9,10$ and shares two centroids with the K–H regime. This dynamics also leads to a nearly uniform clockwise rotation in the feature space. There are also transitions from the VP to K–H regime, e.g.
$k=8,9,10$ and shares two centroids with the K–H regime. This dynamics also leads to a nearly uniform clockwise rotation in the feature space. There are also transitions from the VP to K–H regime, e.g.  $8 \to 4$,
$8 \to 4$,  $9 \to 5$,
$9 \to 5$,  $10 \to 6$ and
$10 \to 6$ and  $10 \to 7$ and in the opposite direction. All these transitions are between similar centroids of both groups. From the cluster index the orientation of the main elliptical vortices can be inferred. For
$10 \to 7$ and in the opposite direction. All these transitions are between similar centroids of both groups. From the cluster index the orientation of the main elliptical vortices can be inferred. For  $k \le 6$ (
$k \le 6$ ( $k\ge 7$), the upper part of the vortices are displaced in (against) the direction of the flow with respect to their centres.
$k\ge 7$), the upper part of the vortices are displaced in (against) the direction of the flow with respect to their centres.
The evolution of the cluster population vector  $\boldsymbol {p}^l$ at
$\boldsymbol {p}^l$ at  $t=l \Delta t^c$ is investigated by iterating equation (2.8). Figure 16 compares the probability distribution of DNS data and the model-based asymptotic vector
$t=l \Delta t^c$ is investigated by iterating equation (2.8). Figure 16 compares the probability distribution of DNS data and the model-based asymptotic vector  $\boldsymbol {p}^{\infty }$. The agreement is astonishingly good for such a low-order model. The probability vector converges quickly to a unique, stationary probability distribution near
$\boldsymbol {p}^{\infty }$. The agreement is astonishingly good for such a low-order model. The probability vector converges quickly to a unique, stationary probability distribution near  $t=20$.
$t=20$.

Figure 16. Cluster probability distribution of the mixing layer from the DNS data and the cluster-based Markov model. Solid rectangles denote the probability  $q_{k}$ from the DNS data. Open rectangles represent asymptotic values from the CMM after
$q_{k}$ from the DNS data. Open rectangles represent asymptotic values from the CMM after  $l=35$ iterations.
$l=35$ iterations.
In figure 17, the dynamics of CMM is illustrated for the first cluster probability  $p_1$ and the first POD mode amplitude
$p_1$ and the first POD mode amplitude  $a_1$ inferred from the flow state (2.19). Starting point is direct numerical simulation starting at
$a_1$ inferred from the flow state (2.19). Starting point is direct numerical simulation starting at  $t=0$ close to the first cluster
$t=0$ close to the first cluster  $\boldsymbol {c}_1$ which corresponds to the probability vector
$\boldsymbol {c}_1$ which corresponds to the probability vector  $\boldsymbol {p}=[1,0,0,0,0,0,0,0,0,0]^{\textrm {T}}$. The probability and POD mode amplitude of CMM show a convergence after around
$\boldsymbol {p}=[1,0,0,0,0,0,0,0,0,0]^{\textrm {T}}$. The probability and POD mode amplitude of CMM show a convergence after around  $l=35$ iterations or, equivalently,
$l=35$ iterations or, equivalently,  $t\approx 35$. The solid horizon line denotes
$t\approx 35$. The solid horizon line denotes  $q_1$, i.e. the population of the first cluster from DNS data. The POD mode amplitude
$q_1$, i.e. the population of the first cluster from DNS data. The POD mode amplitude  $a_1$ performs three strongly damped oscillations before vanishing.
$a_1$ performs three strongly damped oscillations before vanishing.

Figure 17. Dynamics of the mixing layer from DNS and the cluster-based Markov model.  $(a)$ Probability evolution for DNS (black solid line) and for CMM (red dashed line). The probability of the first cluster
$(a)$ Probability evolution for DNS (black solid line) and for CMM (red dashed line). The probability of the first cluster  $p_{1}$ quickly converges to
$p_{1}$ quickly converges to  $p^{\infty }_i$ around
$p^{\infty }_i$ around  $t=35$. The corresponding DNS value is
$t=35$. The corresponding DNS value is  $0.1325$ and is represented by a horizontal line.
$0.1325$ and is represented by a horizontal line.  $(b)$ The evolution of the first POD mode amplitude
$(b)$ The evolution of the first POD mode amplitude  $a_{1}$ for DNS (black solid line) and CMM (red dashed line).
$a_{1}$ for DNS (black solid line) and CMM (red dashed line).  $(c)$ The autocorrelation function for DNS (black solid line) and for CMM (red dashed line).
$(c)$ The autocorrelation function for DNS (black solid line) and for CMM (red dashed line).
Figure 17(c) shows an oscillating quickly decaying autocorrelation function of CMM which is consistent with the observations for  $a_1$ and
$a_1$ and  $p_1$. In contrast, the autocorrelation function associated with the DNS keeps oscillating around with an amplitude around 50 % of the average fluctuation level. This level indicates that half of the fluctuation energy resides in repeating oscillatory flow structures while the other half is of non-repeating stochastic nature.
$p_1$. In contrast, the autocorrelation function associated with the DNS keeps oscillating around with an amplitude around 50 % of the average fluctuation level. This level indicates that half of the fluctuation energy resides in repeating oscillatory flow structures while the other half is of non-repeating stochastic nature.
3.5. Network model
In this section, a CNM is developed using the same snapshot data and same centroids. Starting point for the dynamic network is the cluster-affiliation function  $k(t)$. Following § 2.3, the direct cluster transition matrix
$k(t)$. Following § 2.3, the direct cluster transition matrix  ${\boldsymbol{\mathsf{Q}}}$ with associated average transition times
${\boldsymbol{\mathsf{Q}}}$ with associated average transition times  ${\boldsymbol{\mathsf{T}}}$ are derived. Figure 18 illustrates both matrices. These matrices have the almost same structure as the Markov model except for the diagonal elements which are vanishing by design. In other words,
${\boldsymbol{\mathsf{T}}}$ are derived. Figure 18 illustrates both matrices. These matrices have the almost same structure as the Markov model except for the diagonal elements which are vanishing by design. In other words,
 \begin{gather} Q_{ii}=T_{ii}=0, \quad \forall i \in \{1,\ldots,K\} , \end{gather}
\begin{gather} Q_{ii}=T_{ii}=0, \quad \forall i \in \{1,\ldots,K\} , \end{gather} \begin{gather}H[P_{ij}]=H[Q_{ij}]= H[T_{ij}], \quad \forall i, j \in \{1,\ldots,K\} \wedge i \not = j , \end{gather}
\begin{gather}H[P_{ij}]=H[Q_{ij}]= H[T_{ij}], \quad \forall i, j \in \{1,\ldots,K\} \wedge i \not = j , \end{gather}
with  $H$ being again the Heaviside function. Vanishing diagonal elements (3.6a) arise from the requirement of non-trivial transitions. Theoretically, the trajectory may terminate in a cluster, like in a stable fixed point of a linear dynamical system. This case is not compatible with the goal to model a well-resolved non-trivial attractor and shall be ignored in this study. Equation (3.6b) requires a sufficiently small time step of the CMM. Otherwise, the stroboscopic view on the trajectory may miss a crossing of an intermediate cluster. This happens with the transition from
$H$ being again the Heaviside function. Vanishing diagonal elements (3.6a) arise from the requirement of non-trivial transitions. Theoretically, the trajectory may terminate in a cluster, like in a stable fixed point of a linear dynamical system. This case is not compatible with the goal to model a well-resolved non-trivial attractor and shall be ignored in this study. Equation (3.6b) requires a sufficiently small time step of the CMM. Otherwise, the stroboscopic view on the trajectory may miss a crossing of an intermediate cluster. This happens with the transition from  $1 \to 2 \to 3$ in one CMM time step
$1 \to 2 \to 3$ in one CMM time step  $\Delta t^c$. Hence,
$\Delta t^c$. Hence,  $P_{31} \not = 0$ while
$P_{31} \not = 0$ while  $Q_{31} = 0$. However, this is a rare event, as indicated by the small value of
$Q_{31} = 0$. However, this is a rare event, as indicated by the small value of  $P_{31}$.
$P_{31}$.

Figure 18. Dynamics of the cluster-based network model for the mixing layer. (a) Direct transition matrix. (b) Averaged transition time. The non-vanishing values are denoted by the circle radius and the colour code from the bottom caption.
An inspection of  ${\boldsymbol{\mathsf{T}}}$ reveals that the transition time between K–H and VP centroids is relatively small. This is consistent with the closeness of the corresponding centroids in the proximity map (figure 15a). An exception is the transition between K–H centroid 2 to VP centroid 8 which are well separated in the proximity map. Intriguingly, the transitions within the K–H and VP regimes are also strongly correlated with the distances depicted in the proximity map. For instance, the smallest (largest) inner-regime transition from centroid
${\boldsymbol{\mathsf{T}}}$ reveals that the transition time between K–H and VP centroids is relatively small. This is consistent with the closeness of the corresponding centroids in the proximity map (figure 15a). An exception is the transition between K–H centroid 2 to VP centroid 8 which are well separated in the proximity map. Intriguingly, the transitions within the K–H and VP regimes are also strongly correlated with the distances depicted in the proximity map. For instance, the smallest (largest) inner-regime transition from centroid  $6$ to
$6$ to  $7$ (
$7$ ( $8$ to
$8$ to  $9$) is associated with a small (large) distance in the proximity map. The physical interpretation of the cycle-to-cycle variations of the CMM persist for CNM.
$9$) is associated with a small (large) distance in the proximity map. The physical interpretation of the cycle-to-cycle variations of the CMM persist for CNM.
In the following, the temporal dynamics of CNM is investigated based on the identified centroids  $\boldsymbol {c}_{k}$, the description of their connectivity DTM
$\boldsymbol {c}_{k}$, the description of their connectivity DTM  ${\boldsymbol{\mathsf{Q}}}$ and their flight times
${\boldsymbol{\mathsf{Q}}}$ and their flight times  ${\boldsymbol{\mathsf{T}}}$. Like a POD model, CNM is a grey-box model resolving the temporal dynamics and the associated coherent structures. We choose cluster
${\boldsymbol{\mathsf{T}}}$. Like a POD model, CNM is a grey-box model resolving the temporal dynamics and the associated coherent structures. We choose cluster  $k=1$ as initial condition for DNS and for the CNM and integrate over
$k=1$ as initial condition for DNS and for the CNM and integrate over  $l=20\,000$ transitions. In figure 19, the asymptotic cluster population
$l=20\,000$ transitions. In figure 19, the asymptotic cluster population  $\boldsymbol {p}^{\infty }$ from (2.17) is compared with
$\boldsymbol {p}^{\infty }$ from (2.17) is compared with  $\boldsymbol {q}$ from the DNS. The discrepancies of few per cent seem expectable and tolerable for a 10-cluster model. This difference is not cured by increasing the amount of transition data in CNM. Intriguingly, the probability distribution of the CMM displayed in figure 16 is significantly more accurate. This behaviour can be linked to the simple transition time estimate which employs one single average value for a large range of observed transition times. We have developed more refined and more accurate transition time estimates leading to much better agreements of the cluster probability distributions. The price is increased complexity of the CNM which we deemed not helpful for our first publication.
$\boldsymbol {q}$ from the DNS. The discrepancies of few per cent seem expectable and tolerable for a 10-cluster model. This difference is not cured by increasing the amount of transition data in CNM. Intriguingly, the probability distribution of the CMM displayed in figure 16 is significantly more accurate. This behaviour can be linked to the simple transition time estimate which employs one single average value for a large range of observed transition times. We have developed more refined and more accurate transition time estimates leading to much better agreements of the cluster probability distributions. The price is increased complexity of the CNM which we deemed not helpful for our first publication.

Figure 19. Cluster probability distribution of the mixing layer from DNS (solid rectangles) and cluster-based network model (open rectangles). The modelled values are obtained from simulating  $20\,000$ clusters transitions.
$20\,000$ clusters transitions.
Figure 20 shows the evolution of the first two POD mode amplitudes (red dashed curve). The CNM tracks well the amplitude and phase of the DNS over  $100$ time units. As for the Lorenz system, the temporal evolution is smoothed by a spline and does not use the non-smooth uniform motion between two consecutive centroid visits.
$100$ time units. As for the Lorenz system, the temporal evolution is smoothed by a spline and does not use the non-smooth uniform motion between two consecutive centroid visits.

Figure 20. Evolution of mode amplitudes  $a_{1}$,
$a_{1}$, 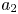 $a_{2}$ for the mixing layer
$a_{2}$ for the mixing layer  $t\in [0,100]$. The curves correspond to DNS (black solid line) and the cluster-based network model (red dashed line).
$t\in [0,100]$. The curves correspond to DNS (black solid line) and the cluster-based network model (red dashed line).
Figure 21 compares the autocorrelation function of the CNM and the DNS. We intentionally do not normalize this function to reveal the resolved fluctuation level at vanishing time delay. As expected, the model-based fluctuation level is significantly lower than the DNS value. This difference is quantified by the unresolved inner-cluster variance. Intriguingly, CNM and DNS functions become already similar after half a period. The asymptotic fluctuation level represents coherent structures which are well resolved by the chosen centroids and serve as coarse-grained recurrence points of the DNS. Due to the dominant oscillatory dynamics, the autocorrelation does not vanish with increasing time. The good reproduction autocorrelation function is a posteriori justification for the chosen cluster number.

Figure 21. Autocorrelation function of the mixing layer for DNS (black solid line) and cluster-based network model (red dashed line).
4. Cluster-based network modelling of the actuated turbulent boundary layer
In this section, the cluster-based network modelling is implemented on a three-dimensional actuated turbulent boundary layer. First (§ 4.1), the flow configuration and the large-eddy simulation is described. The clustering results, which follow the same coarse-graining approach as for the shear layer, are presented in § 4.2. A cluster-based network model is developed and assessed in § 4.3.
4.1. Flow configuration and large-eddy simulation
In this section, the actuated turbulent boundary layer configuration for skin-friction reduction is detailed. In particular, the actuation mechanism is presented, and the numerical set-up is described. For more details, the reader is referred to Albers et al. (Reference Albers, Meysonnat and Schröder2019) and Fernex et al. (Reference Fernex, Semaan, Albers, Meysonnat, Schröder and Noack2020). The fluid flow is described in a Cartesian frame of reference where the streamwise, wall-normal and spanwise coordinates are denoted by  $\boldsymbol {x} = (x,y,z)$ and the velocity components by
$\boldsymbol {x} = (x,y,z)$ and the velocity components by  $\boldsymbol {u} = (u,v,w)$. The Mach number is set to Ma
$\boldsymbol {u} = (u,v,w)$. The Mach number is set to Ma  $= 0.1$ corresponding to a nearly incompressible flow. An illustration of the rectangular physical domain is shown in figure 22. A momentum thickness of
$= 0.1$ corresponding to a nearly incompressible flow. An illustration of the rectangular physical domain is shown in figure 22. A momentum thickness of  $\theta = 1$ at
$\theta = 1$ at  $x_0$ is achieved such that the momentum thickness based Reynolds number is
$x_0$ is achieved such that the momentum thickness based Reynolds number is  $Re_{\theta } = 1000$ at
$Re_{\theta } = 1000$ at  $x_0$. The domain length and height in the streamwise and wall-normal directions are
$x_0$. The domain length and height in the streamwise and wall-normal directions are  $L_x = 190\,\theta$ and
$L_x = 190\,\theta$ and  $L_y = 105\,\theta$. In the spanwise direction, different domain widths
$L_y = 105\,\theta$. In the spanwise direction, different domain widths  $L_z \in [21.65\,\theta , 108.25\,\theta ]$ are used to simulate different actuation wavelengths.
$L_z \in [21.65\,\theta , 108.25\,\theta ]$ are used to simulate different actuation wavelengths.

Figure 22. Overview of the physical domain of the actuated turbulent boundary layer flow, where  $L_x, L_y,$ and
$L_x, L_y,$ and  $L_z$ are the domain dimensions in the Cartesian directions,
$L_z$ are the domain dimensions in the Cartesian directions,  $\lambda$ is the wavelength of the spanwise travelling wave and
$\lambda$ is the wavelength of the spanwise travelling wave and  $x_0$ marks the actuation onset. The shaded red surface
$x_0$ marks the actuation onset. The shaded red surface  $A_{surf}$ marks the integration area of the wall-shear stress
$A_{surf}$ marks the integration area of the wall-shear stress  $\tau _w$.
$\tau _w$.
At the domain inlet, a synthetic turbulence generation method is applied to generate a natural turbulent boundary layer flow after a transition length of 2–4 boundary layer thicknesses (Roidl, Meinke & Schröder Reference Roidl, Meinke and Schröder2013). Characteristic boundary conditions are used at the domain exit and a no-slip wall boundary condition is enforced at the lower domain boundary for the unactuated and actuated wall.
The actuation is performed by a transverse travelling wave on the surface. The corresponding wall motion is prescribed by the space- and time-dependent function
 \begin{equation} y_{{wall}}^+(z^+,t^+) = A^+ \cos\left( \frac{2{\rm \pi}}{\lambda^+}z^+ - \frac{2{\rm \pi}}{T^+}t^+ \right), \end{equation}
\begin{equation} y_{{wall}}^+(z^+,t^+) = A^+ \cos\left( \frac{2{\rm \pi}}{\lambda^+}z^+ - \frac{2{\rm \pi}}{T^+}t^+ \right), \end{equation}
in the interval  $-5 \leq x/\theta \leq 140$. The quantities
$-5 \leq x/\theta \leq 140$. The quantities  $\lambda ^+$,
$\lambda ^+$,  $T^+$ and
$T^+$ and  $A^+$ denote the wavelength, period and amplitude in inner coordinates, i.e. the parameters are scaled by the viscosity
$A^+$ denote the wavelength, period and amplitude in inner coordinates, i.e. the parameters are scaled by the viscosity  $\nu$ and the friction velocity of the unactuated reference case
$\nu$ and the friction velocity of the unactuated reference case  $u^n_{\tau }$. In the area just upstream and downstream of the wave actuation region, a spatial transition is used from a flat plate to an actuated plate and vice versa (Albers et al. Reference Albers, Meysonnat and Schröder2019). In total, 38 actuation configurations with wavelength
$u^n_{\tau }$. In the area just upstream and downstream of the wave actuation region, a spatial transition is used from a flat plate to an actuated plate and vice versa (Albers et al. Reference Albers, Meysonnat and Schröder2019). In total, 38 actuation configurations with wavelength  $\lambda ^+ \in [200,500,3000]$, period
$\lambda ^+ \in [200,500,3000]$, period  $T^+ \in [20,120]$ and amplitude
$T^+ \in [20,120]$ and amplitude  $A^+ \in [10,78]$ are simulated. In the current study, we model one test case with
$A^+ \in [10,78]$ are simulated. In the current study, we model one test case with  $\lambda ^+=1000$,
$\lambda ^+=1000$,  $T^+=120$ and
$T^+=120$ and  $A^+ =40$ which yields the largest drag reduction of 3 % found at that wavelength. These actuation parameters correspond to case N36 in table 3 of Ishar et al. (Reference Ishar, Kaiser, Morzynski, Albers, Meysonnat, Schröder and Noack2019) and in table 2 of Albers et al. (Reference Albers, Meysonnat, Fernex, Semann, Noack and Schröder2020).
$A^+ =40$ which yields the largest drag reduction of 3 % found at that wavelength. These actuation parameters correspond to case N36 in table 3 of Ishar et al. (Reference Ishar, Kaiser, Morzynski, Albers, Meysonnat, Schröder and Noack2019) and in table 2 of Albers et al. (Reference Albers, Meysonnat, Fernex, Semann, Noack and Schröder2020).
The physical domain is discretized by a structured block-type mesh with a resolution of  $\Delta x^+ = 12.0$ in the streamwise and
$\Delta x^+ = 12.0$ in the streamwise and  $\Delta z^+ = 4.0$ in the spanwise direction. In the wall-normal direction, a resolution of
$\Delta z^+ = 4.0$ in the spanwise direction. In the wall-normal direction, a resolution of  $\Delta _y^+|_{{wall}} = 1.0$ at the wall is used with gradual coarsening away from the wall. Depending on the domain width, the meshes consist of 24–120 million cells.
$\Delta _y^+|_{{wall}} = 1.0$ at the wall is used with gradual coarsening away from the wall. Depending on the domain width, the meshes consist of 24–120 million cells.
The actuated flat plate turbulent boundary layer flow is governed by the unsteady compressible Navier–Stokes equations in the arbitrary Lagrangian–Eulerian formulation for time-dependent domains. A second-order accurate finite-volume approximation of the governing equations is used in which the convective fluxes are computed by the advection upstream splitting method (AUSM) and time integration is performed via a 5-stage Runge–Kutta scheme. The smallest dissipative scales are implicitly modelled through the numerical dissipation of the AUSM scheme. This monotonically integrated large-eddy simulation approach (Boris et al. Reference Boris, Grinstein, Oran and Kolbe1992) is capable of accurately capturing all physics of the resolved scales (Meinke et al. Reference Meinke, Schröder, Krause and Rister2002).
The actuated simulations are initialized by the solution from the unactuated reference case and the temporal transition from the flat plate to the actuated wall is initiated. When a converged state of the friction drag is obtained, statistics are collected for  $t U_{\infty } / \theta = 1250$ convective times.
$t U_{\infty } / \theta = 1250$ convective times.
The actuation effects on the near-wall flow features are illustrated in figure 23, which shows contours of the streamwise velocity fluctuation of a reference natural (figure 23a) and the actuated case (figure 23b). The intensity of the near-wall streaks, which are known to contribute to skin friction, are observed to diminish with the actuation.

Figure 23. Contours of the random streamwise velocity fluctuations in the near-wall region of (a) a non-actuated reference case and (b) the actuated case. The actuation diminishes the near-wall streak intensity. The surface deformation is indicated at the bottom.
4.2. Clustering
Similar to the mixing layer, the clustering of the actuated boundary layer large-eddy simulation (LES) snapshots is performed using a lossless POD compression. Again, this compression dramatically reduces the computational load of clustering. Here, we perform the POD and the clustering on all 38 test cases simultaneously. Employing this enlarged set of POD modes yields a richer, and thus more accurate, dynamical representation of the individual test cases and allows for a direct comparison of different actuations (Ishar et al. Reference Ishar, Kaiser, Morzynski, Albers, Meysonnat, Schröder and Noack2019). Concatenating all configurations results in  $M=15\,873$ snapshots sampled at
$M=15\,873$ snapshots sampled at  $\Delta t = 0.94$ time units.
$\Delta t = 0.94$ time units.
Following Ishar et al. (Reference Ishar, Kaiser, Morzynski, Albers, Meysonnat, Schröder and Noack2019), the  $M$ snapshots are clustered with the k-means++ algorithm into 50 centroids, corresponding to
$M$ snapshots are clustered with the k-means++ algorithm into 50 centroids, corresponding to  $K=10$ centroids populated by the investigated actuation. It is worth noting that increasing
$K=10$ centroids populated by the investigated actuation. It is worth noting that increasing  $K$ significantly, say
$K$ significantly, say  $K=100$, uncovers centroids with smaller length scale features associated with broadband turbulence of the boundary layer. In this study, we purposely choose to focus on the main energy-containing dynamics and thus limit the number of centroids to
$K=100$, uncovers centroids with smaller length scale features associated with broadband turbulence of the boundary layer. In this study, we purposely choose to focus on the main energy-containing dynamics and thus limit the number of centroids to  $K=10$. Figure 24 presents four centroid distributions of the test case with
$K=10$. Figure 24 presents four centroid distributions of the test case with  $\lambda ^+=1000$,
$\lambda ^+=1000$,  $T^+ =120$ and
$T^+ =120$ and  $A^+ =40$. As the figure shows, the centroids have similar spatial distributions and are phase shifted with respect to one another. Such behaviour is consistent with a limit-cycle dynamics, indicating partial lock-on of the boundary layer dynamics to the periodic surface actuation. This lock-on phenomenon is sometimes associated with aerodynamic gains or losses depending on the targeted flow instability. It is synonymous with synchronization, and has been repeatedly investigated for drag reduction problems (Barros et al. Reference Barros, Borée, Noack and Spohn2016; Taira & Nakao Reference Taira and Nakao2018; Herrmann et al. Reference Herrmann, Philipp, Richard and Brunton2020). Similar to these studies, a lower actuation threshold with sufficient authority is required to synchronize the flow.
$A^+ =40$. As the figure shows, the centroids have similar spatial distributions and are phase shifted with respect to one another. Such behaviour is consistent with a limit-cycle dynamics, indicating partial lock-on of the boundary layer dynamics to the periodic surface actuation. This lock-on phenomenon is sometimes associated with aerodynamic gains or losses depending on the targeted flow instability. It is synonymous with synchronization, and has been repeatedly investigated for drag reduction problems (Barros et al. Reference Barros, Borée, Noack and Spohn2016; Taira & Nakao Reference Taira and Nakao2018; Herrmann et al. Reference Herrmann, Philipp, Richard and Brunton2020). Similar to these studies, a lower actuation threshold with sufficient authority is required to synchronize the flow.

Figure 24. The cluster centroids  $\boldsymbol {c}_{k}, k= 2, 4, 9, 10$ of the actuated boundary layer. The cluster numbers are denoted in the state space of figure 25. The iso-surfaces correspond to constant wall-normal velocity of
$\boldsymbol {c}_{k}, k= 2, 4, 9, 10$ of the actuated boundary layer. The cluster numbers are denoted in the state space of figure 25. The iso-surfaces correspond to constant wall-normal velocity of  $V^+={\pm }0.04$. Red and blue regions mark positive and negative values.
$V^+={\pm }0.04$. Red and blue regions mark positive and negative values.
The dynamics is well represented in the state space illustrated in figure 25, which is spanned by the first three POD mode coefficients. The cluster centroids are displayed as black solid circles and their indices are labelled. The snapshots are coloured according to their cluster affiliation. Similar to the shear layer, the dynamics of the actuated boundary layer appears to be driven by two physical phenomena: a cyclic behaviour synchronized with the surface actuation, and a quasi-stochastic component that forces the limit cycle to experience cycle-to-cycle variations (Cao et al. Reference Cao, Kaiser, Boreé, Noack, Thomas and Guilan2014). The latter phenomenon is associated with broadband turbulence of the boundary layer.

Figure 25. The state space is spanned by the first three mode coefficients of the lossless proper orthogonal decomposition of the LES data. The cluster centroids are displayed as black solid circles and the snapshots are coloured according to their cluster affiliation.
4.3. Network model
The CNM is generated based on the direct transition matrix and the averaged transition time matrix, which are illustrated in figure 26. We reiterate the vanishing diagonal elements of both matrices, i.e.  $Q_{ii}=T_{ii}=0$, which are a result of enforcing non-trivial transitions. The direct transition matrix (cf. figure 26a) shows both the dominant transition probability of subsequent centroids being associated with the limit-cycle behaviour, and the wandering dynamics from the remaining transitions. The transition time matrix between the centroids (cf. figure 26b) reflects the same behaviour, and exhibits a quasi-constant transition time for limit-cycle ‘flight times’ and diverse transition times for the wandering effect.
$Q_{ii}=T_{ii}=0$, which are a result of enforcing non-trivial transitions. The direct transition matrix (cf. figure 26a) shows both the dominant transition probability of subsequent centroids being associated with the limit-cycle behaviour, and the wandering dynamics from the remaining transitions. The transition time matrix between the centroids (cf. figure 26b) reflects the same behaviour, and exhibits a quasi-constant transition time for limit-cycle ‘flight times’ and diverse transition times for the wandering effect.

Figure 26. Dynamics of the cluster-based network model for the actuated boundary layer. (a) Direct transition matrix. (b) Averaged transition time. The non-vanishing values of the matrix elements are proportional to the circle radius and can be inferred from the colour code from the bottom caption.
Figure 27 compares the probability distribution of LES data and the model-based asymptotic vector  $\boldsymbol {p}^{\infty }$. Again, we choose cluster
$\boldsymbol {p}^{\infty }$. Again, we choose cluster  $k = 1$ as the initial condition for LES and for the CNM and integrate over
$k = 1$ as the initial condition for LES and for the CNM and integrate over  $l = 106$ transitions, which corresponds to a similar time range as that of the snapshots. The agreement between the two distributions is good.
$l = 106$ transitions, which corresponds to a similar time range as that of the snapshots. The agreement between the two distributions is good.

Figure 27. Probability distribution of the actuated boundary layer from large-eddy simulation (solid rectangle) and cluster-based network model (open rectangle). The CNM values are obtained from simulating  $l=106$ cluster transitions.
$l=106$ cluster transitions.
The model performance is assessed against the reference LES results. Figure 28 shows the evolution of the first four POD mode amplitudes (red dashed curve). The dominance of the first two POD modes compared to the subsequent modes is expected for the current quasi-synchronous actuated flow. Similar to the previously presented results, the temporal evolution is smoothed with a spline. As the figure shows, CNM agrees very well with the amplitude and phase of the LES reference data over the entire approximately  $400$ time units.
$400$ time units.

Figure 28. Evolution of mode amplitudes  $a_{1}$–
$a_{1}$– $a_{4}$ for the actuated boundary layer
$a_{4}$ for the actuated boundary layer  $t\in [0,400]$. The curves correspond to LES (black solid line) and cluster-based network model (red dashed line).
$t\in [0,400]$. The curves correspond to LES (black solid line) and cluster-based network model (red dashed line).
The agreement between the model and the reference data is further corroborated by comparing the autocorrelation function. Figure 29 displays the autocorrelation function of the CNM and the LES. As with the mixing layer, the model-based fluctuation level at vanishing time delay is lower than the LES value but becomes similar to oscillation level for an arbitrary larger time horizon. This large representation error at  $\tau =0$ relates to the unresolved inner-cluster variance. Yet, the centroids adequately resolve the periodic flow response of the flow to the periodic surface actuation.
$\tau =0$ relates to the unresolved inner-cluster variance. Yet, the centroids adequately resolve the periodic flow response of the flow to the periodic surface actuation.

Figure 29. Autocorrelation function of the actuated turbulent boundary layer for LES (black solid line) and cluster-based network model (red dashed line).
5. Conclusions
In the present study, we propose a new data-driven methodology for modelling nonlinear dynamical systems. We trade compatibility with first principles, as with a POD-based Galerkin model, with the simplicity and robustness of the modelling. Point of departure is the cluster-based Markov model (Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014) for time-resolved snapshot data. The snapshots are coarse-grained into a few representative centroids. The temporal evolution of the state is conceptualized as a straight constant velocity movement from one centroid to the next. The average flight time and the transition probabilities are inferred from the data. Thus, the dynamics is modelled by a deterministic–stochastic network model with the centroids as nodes, the straight trajectory segments as edges, the transition time as parameters of the edges and the transition probability characterizing the nodes.
The resulting cluster-based network model has several desirable features: (i) The methodology is simple and automatable. (ii) The off-line computational load is only slightly larger than a snapshot-based POD. After the computation of the POD, the clustering and network model requires a tiny fraction of the computational operation. If the CNM is computed with original flow data without POD compression, the computational costs are orders of magnitudes larger, as elaborated in appendix A. (iii) The CNM has the same recurrence properties as the original data: if one cluster is visited multiple times in the data, it will also be a recurrence point of the CNM. (iv) Long-term integration will never lead to a divergence – unlike POD models. (v) The framework is very flexible allowing us, for instance, to incorporate multiple operating conditions.
The simplicity and robustness have a price. On the kinematic side, the vanilla version of CNM does not have the possibility of extrapolating the data, e.g. resolving oscillations at higher amplitudes not contained in the data. On the dynamic side, we lose the relationship to first principles: the network model is purely inferred from the snapshot data, without links to the Navier–Stokes equations. In particular, cluster-based models are not natural frameworks for dynamic instabilities, as the notion of exponential growth and nonlinear saturation is intimately tied to Galerkin flow expansions. Subsequent generalizations need to overcome these restrictions.
Cluster-based network modelling is applied to the Lorenz attractor. A k-means++ algorithm yields 10 centroids from a long time-resolved solution. Four centroids represent each ear of the attractor and two, the switching area. Despite the coarseness of the presentation, the temporal dynamics mimics well the oscillations in each ear and the switching between both ears. The agreement is mirrored by the similarity between the autocorrelation functions of the simulation and the CNM. Statistically, the cluster population is predicted with acceptable accuracy. The CNM dramatically outperforms the cluster-based Markov model (Kaiser et al. Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014) in terms of predicting the temporal evolution. In contrast, CMM is more accurate for the cluster population. The error source of the CNM can be traced back to the chosen simple model of transition times.
Two demonstrations of CNM are performed with a laminar two-dimensional mixing layer and with a periodically actuated turbulent boundary layer. The mixing layer features K–H vortices and occasional vortex pairing. The cycle-to-cycle variations are clearly distilled by the centroids and the proximity map shows the possible transitions. The transition probabilities and times are quantified in the CNM model parameters. The actuated turbulent boundary layer exhibits partial lock-on with a superimposed stochastic meandering. For both applications, the snapshots are coarse-grained into 10 centroids. For the mixing layer, one group of centroids can be associated with K–H vortices and a second group to vortex pairing – similar to Kaiser et al. (Reference Kaiser, Noack, Cordier, Spohn, Segond, Abel, Daviller, Östh, Krajnović and Niven2014). In contrast, the centroid affiliations for the actuated turbulent boundary layer are less categorizable. The dominant periodic dynamics is superimposed with quasi-stochastic transitions associated with broadband turbulence. The CNM well resolves the temporal evolution of the main flow dynamics, the fluctuation level, the autocorrelation function and the cluster population. A noteworthy observation relates to the autocorrelation function. For vanishing time delay, this function displays the average representation which is significant both for the mixing layer and wall turbulence. Yet, the function is surprisingly well represented by the CNM after one characteristic period. This behaviour corroborates that the dominant periodic dynamics is well resolved by the CNM with 10 centroids and the local interpolation between them.
The CNM is found to have a distinct advantage over the departure point, CMM, namely the much longer prediction horizon as evidenced by the autocorrelation function. POD and DMD models may describe the same flow with a similar number of modes (Protas et al. Reference Protas, Noack and Östh2015). We emphasize that the construction of the CNM could be fully automated in a software package. In contrast, data-driven nonlinear Galerkin models may be designed as insightful least-order representations with interpretable modes. Moreover, the Galerkin dynamics may reveal the interplay between linear and nonlinear terms, as beautifully displayed in mean-field theory (Stuart Reference Stuart1971), self-consistent models (Mantič-Lugo, Arratia & Gallaire Reference Mantič-Lugo, Arratia and Gallaire2014), resolvent operator approaches (Gomez et al. Reference Gomez, Blackburn, Rudman, Sharma and McKeon2016), finite-time thermodynamics (Noack et al. Reference Noack, Schlegel, Ahlborn, Mutschke, Morzyński, Comte and Tadmor2008) and criteria for boundedness (Schlegel & Noack Reference Schlegel and Noack2015). Yet, a functional model requires the careful choice of flow data, potentially shift and other non-standard modes, subscale closure models and calibration techniques. Thus, cluster-based and POD based models have different niche applications.
CNM opens a novel automatable avenue for nonlinear dynamical modelling. Moreover, CNM provides a framework for estimation and model-based control. This extension is elaborated in appendix C and complements model-free cluster-based control for open-loop actuation (Kaiser et al. Reference Kaiser, Noack, Spohn, Cattafesta and Morzyński2017) and for feedback laws (Nair et al. Reference Nair, Yeh, Kaiser, Noack, Brunton and Tiara2019). The authors actively pursue this direction.
Acknowledgements
H.L. appreciates the Graduate Student Research Innovation Project of Hunan Province (grant no. CX2018B027). He gratefully acknowledges the support of the China Scholarship Council (CSC) (no. CSC201803170267) during his study in Technische Universität Berlin and the excellent working conditions of the Hermann-Föttinger-Institute. D.F., B.R.N. and R.S. would like to thank the German science foundation (DFG) grant number SE 2504/2-1 for supporting this work. In addition, B.R.N. thanks the French National Research Agency (ANR-17-ASTR-0022 grant ‘FlowCon’), and the Bernd Noack Cybernetics Foundation for additional support. J.T. acknowledges the funding from the National Natural Science Foundation of China (no. 91441121). M.M. acknowledges partial funding from the Polish Ministry of Science and Higher Education (MNiSW) under the grant no. 05/54/DSPB/6492. We are particularly indebted to M. Albers and W. Schröder for initiating our fruitful collaborative adventure on skin-friction reduction and for providing the employed LES data of the actuated boundary layer. We have highly profited from stimulating discussions with S. Brunton, G. Y. C. Maceda, N. Deng, A. Ehlert, E. Kaiser, M. Lennie, F. Lusseyran, C. N. Nayeri, L. Pastur, C. O. Paschereit and K. Taira. Last but not least, we thank the referees for important and insightful suggestions which have inspired new included investigations. The graphical abstract has been prepared by Q. (Kiki) Lin.
Declaration of interests
The authors report no conflict of interest.
Appendix A. Data compression for clustering
Clustering is a computationally expensive process based on a large number of area/volume integrals for the distance between snapshots and centroids. Let  $M$ and
$M$ and  $K$ be the number of snapshots and clusters, respectively, then a single k-means iteration requires the computation of
$K$ be the number of snapshots and clusters, respectively, then a single k-means iteration requires the computation of  $K \times M$ integrals. Let
$K \times M$ integrals. Let  $I$ be the number of k-means iterations and
$I$ be the number of k-means iterations and  $L$ be the number of repetitions then the total number of integrals is
$L$ be the number of repetitions then the total number of integrals is  $L \times I \times K \times M$. Typical values are
$L \times I \times K \times M$. Typical values are  $K\sim 10$,
$K\sim 10$,  $I \sim 10 K$ and
$I \sim 10 K$ and  $L \sim 100$.
$L \sim 100$.
The computational load can be significantly reduced by pre-processing the snapshot data with a lossless POD. The most expensive step of a typical snapshot POD is the computation of the correlation matrix with  $M \times (M+1)/2$ area/volume integrals. Thus, the integral for the distance between two velocity fields transforms into the Euclidean norm with
$M \times (M+1)/2$ area/volume integrals. Thus, the integral for the distance between two velocity fields transforms into the Euclidean norm with  $(M-1)$-dimensional vectors of POD mode amplitudes. The computational saving reads
$(M-1)$-dimensional vectors of POD mode amplitudes. The computational saving reads
 \begin{equation} \frac{M \times (M+1)/2}{L \times I \times K \times M} = \frac{M+1}{2 L \times I \times K}. \end{equation}
\begin{equation} \frac{M \times (M+1)/2}{L \times I \times K \times M} = \frac{M+1}{2 L \times I \times K}. \end{equation}With typical values, the savings are one or two orders of magnitudes.
For completeness and self-consistency, the snapshot POD algorithm is described. POD is performed with the whole computational domain  $\varOmega$. The inner product between two velocity fields
$\varOmega$. The inner product between two velocity fields  $\boldsymbol {v}(\boldsymbol {x})$,
$\boldsymbol {v}(\boldsymbol {x})$,  $\boldsymbol {w}(\boldsymbol {x})$ in the square-integrable Hilbert space
$\boldsymbol {w}(\boldsymbol {x})$ in the square-integrable Hilbert space  ${\mathcal {L}}^2 (\varOmega )$ reads
${\mathcal {L}}^2 (\varOmega )$ reads
 \begin{equation} \left( \boldsymbol{v} , \boldsymbol{w} \right)_{\varOmega} = \int_{\varOmega} \,\textrm{d} \boldsymbol{x} \boldsymbol{v} ( \boldsymbol{x} ) \boldsymbol{\cdot} \boldsymbol{w} ( \boldsymbol{x} ). \end{equation}
\begin{equation} \left( \boldsymbol{v} , \boldsymbol{w} \right)_{\varOmega} = \int_{\varOmega} \,\textrm{d} \boldsymbol{x} \boldsymbol{v} ( \boldsymbol{x} ) \boldsymbol{\cdot} \boldsymbol{w} ( \boldsymbol{x} ). \end{equation}The corresponding norm is given by
 \begin{equation} \left \Vert \boldsymbol{v} \right \Vert_{\varOmega} = \sqrt{ \left ( \boldsymbol{v}, \boldsymbol{v} \right )_{\varOmega} }. \end{equation}
\begin{equation} \left \Vert \boldsymbol{v} \right \Vert_{\varOmega} = \sqrt{ \left ( \boldsymbol{v}, \boldsymbol{v} \right )_{\varOmega} }. \end{equation}
The distance  $D$ between two velocity fields is based on this norm,
$D$ between two velocity fields is based on this norm,
 \begin{equation} D( \boldsymbol{v}, \boldsymbol{w} ) = \left \Vert \boldsymbol{v} - \boldsymbol{w} \right \Vert_{\varOmega}. \end{equation}
\begin{equation} D( \boldsymbol{v}, \boldsymbol{w} ) = \left \Vert \boldsymbol{v} - \boldsymbol{w} \right \Vert_{\varOmega}. \end{equation} The inner product (A 2) uniquely defines the snapshot POD (see e.g. Holmes et al. Reference Holmes, Lumley, Berkooz and Rowley2012). The  $m$th snapshot is represented by
$m$th snapshot is represented by
 \begin{equation} \boldsymbol{u}^{m}(\boldsymbol{x}) :=\boldsymbol{u}_0 (\boldsymbol{x})+ \sum_{i=1}^{M-1} a_i^m \boldsymbol{u}_{i}( \boldsymbol{x}), \end{equation}
\begin{equation} \boldsymbol{u}^{m}(\boldsymbol{x}) :=\boldsymbol{u}_0 (\boldsymbol{x})+ \sum_{i=1}^{M-1} a_i^m \boldsymbol{u}_{i}( \boldsymbol{x}), \end{equation}
where  $\boldsymbol {u}_0$ denotes the mean flow,
$\boldsymbol {u}_0$ denotes the mean flow,  $\boldsymbol {u}_i$ the
$\boldsymbol {u}_i$ the  $i$th POD mode and
$i$th POD mode and  $a_i^m$ the POD mode amplitude corresponding to the
$a_i^m$ the POD mode amplitude corresponding to the  $m$th snapshot. It may be noted that the maximal number of POD modes is
$m$th snapshot. It may be noted that the maximal number of POD modes is  $M-1$, e.g. two snapshots define a one-dimensional line, not a plane.
$M-1$, e.g. two snapshots define a one-dimensional line, not a plane.
Let  $\boldsymbol {v}=\boldsymbol {u}_0 + \sum _{i=1}^{M-1} b_i \boldsymbol {u}_i$ and
$\boldsymbol {v}=\boldsymbol {u}_0 + \sum _{i=1}^{M-1} b_i \boldsymbol {u}_i$ and  $\boldsymbol {w}=\boldsymbol {u}_0 + \sum _{i=1}^{M-1} c_i \boldsymbol {u}_i$ be two velocity field representations, e.g. a snapshot and a centroid. Then, their distance is given by
$\boldsymbol {w}=\boldsymbol {u}_0 + \sum _{i=1}^{M-1} c_i \boldsymbol {u}_i$ be two velocity field representations, e.g. a snapshot and a centroid. Then, their distance is given by
 \begin{equation} D( \boldsymbol{v}, \boldsymbol{w} )_{\varOmega} = \sqrt{\sum_{i=1}^{M-1} \left (b_i -c_i \right )^2}. \end{equation}
\begin{equation} D( \boldsymbol{v}, \boldsymbol{w} )_{\varOmega} = \sqrt{\sum_{i=1}^{M-1} \left (b_i -c_i \right )^2}. \end{equation}Evidently, (A 6) is much quicker to compute than (A 4) assuming the typical case that the number of grid points is much larger than the number of snapshots.
Appendix B. On the optimal number of clusters
We investigate the prediction error of a CNM with direct transition matrix  ${\boldsymbol{\mathsf{Q}}}$ and transition time matrix
${\boldsymbol{\mathsf{Q}}}$ and transition time matrix  ${\boldsymbol{\mathsf{T}}}$ for
${\boldsymbol{\mathsf{T}}}$ for  $K$ clusters from
$K$ clusters from  $M$ snapshot data. The number of clusters
$M$ snapshot data. The number of clusters  $K$ significantly influences the prediction error of the CNM. Coarse clustering (small
$K$ significantly influences the prediction error of the CNM. Coarse clustering (small  $K$) means that the direct transition matrix
$K$) means that the direct transition matrix  $\boldsymbol {Q}$ can be inferred from a lot of transition data and is hence relatively accurate. Yet, the snapshots in each cluster have a large representation error. In contrast, a finely resolving clustering (large
$\boldsymbol {Q}$ can be inferred from a lot of transition data and is hence relatively accurate. Yet, the snapshots in each cluster have a large representation error. In contrast, a finely resolving clustering (large  $K$) implies a more accurate representation of the true state. Yet, the transition matrix is larger and the error of the estimated transition probability increases. The extremes are
$K$) implies a more accurate representation of the true state. Yet, the transition matrix is larger and the error of the estimated transition probability increases. The extremes are  $K=1$ cluster with large representation error and
$K=1$ cluster with large representation error and  $K=M$ with vanishing representation error, but large error of the transition matrix for new data. We can expect a sweet spot with optimal prediction error based on good representation error and an accurate estimate of the transition matrix.
$K=M$ with vanishing representation error, but large error of the transition matrix for new data. We can expect a sweet spot with optimal prediction error based on good representation error and an accurate estimate of the transition matrix.
In the following, we define the performance measure for the CNM. The starting point is the error between the model and true state  $\delta \boldsymbol {u}(t)=\boldsymbol {u}^{\circ }(t)-\boldsymbol {u}^{\bullet }(t)$. The modelling error for a specified number of clusters
$\delta \boldsymbol {u}(t)=\boldsymbol {u}^{\circ }(t)-\boldsymbol {u}^{\bullet }(t)$. The modelling error for a specified number of clusters  $K$ is defined as average error for all available snapshots with prediction horizon
$K$ is defined as average error for all available snapshots with prediction horizon  $\tau$ starting from the most accurate initial condition
$\tau$ starting from the most accurate initial condition  $\boldsymbol {u}^{\circ }(0) \approx \boldsymbol {u}^{\bullet }(0)$. The true initial state is taken from the snapshot data
$\boldsymbol {u}^{\circ }(0) \approx \boldsymbol {u}^{\bullet }(0)$. The true initial state is taken from the snapshot data  $\boldsymbol {u}^m$, while the modelled initial state is the closest centroid
$\boldsymbol {u}^m$, while the modelled initial state is the closest centroid  $\boldsymbol {c}_{k^m}$. The resulting error reads
$\boldsymbol {c}_{k^m}$. The resulting error reads
 \begin{equation} C(\tau):=\overline{\left\|\boldsymbol{u}^{\circ}(t+\tau)-\boldsymbol{u}^{\bullet}(t+\tau)\right\|^{2}}_{\varOmega}. \end{equation}
\begin{equation} C(\tau):=\overline{\left\|\boldsymbol{u}^{\circ}(t+\tau)-\boldsymbol{u}^{\bullet}(t+\tau)\right\|^{2}}_{\varOmega}. \end{equation}
The overbar denotes the average over the prediction errors for all available snapshots  $\boldsymbol {u}^{\bullet }(t)$ with data horizon until
$\boldsymbol {u}^{\bullet }(t)$ with data horizon until  $t+ \tau$;
$t+ \tau$;  $C(0)$ corresponds to the representation error where the true state
$C(0)$ corresponds to the representation error where the true state  $\boldsymbol {u}^{\bullet }(t)$ is estimated by the modelled state
$\boldsymbol {u}^{\bullet }(t)$ is estimated by the modelled state  $\boldsymbol {u}^{\circ }(t)$ as accurately as possible;
$\boldsymbol {u}^{\circ }(t)$ as accurately as possible;  $C(\tau )$ is the prediction error after time
$C(\tau )$ is the prediction error after time  $\tau$.
$\tau$.
Figure 30 illustrates the temporal evolution of prediction error for  $\tau \le 50$, roughly corresponding to five Kelvin–Helmholtz shedding periods. This error expectedly increases with growing prediction horizon
$\tau \le 50$, roughly corresponding to five Kelvin–Helmholtz shedding periods. This error expectedly increases with growing prediction horizon  $\tau$ for all investigated numbers of clusters
$\tau$ for all investigated numbers of clusters  $K=10,20,50, 100$. There is no uniformly superior prediction error for any number of clusters. Small (large)
$K=10,20,50, 100$. There is no uniformly superior prediction error for any number of clusters. Small (large)  $K$ correspond to large (small) representation and prediction error for a small time horizon. However, the more inaccurate transition matrix leads to larger prediction errors in the long run. The CNM with
$K$ correspond to large (small) representation and prediction error for a small time horizon. However, the more inaccurate transition matrix leads to larger prediction errors in the long run. The CNM with  $K=10$ leads to the smallest prediction error for
$K=10$ leads to the smallest prediction error for  $\tau \in [12.5,50]$ in comparison to all other investigated models. Hence, we conclude that
$\tau \in [12.5,50]$ in comparison to all other investigated models. Hence, we conclude that  $K=10$ is a good choice for the cluster number for a prediction horizon with one to several shedding periods.
$K=10$ is a good choice for the cluster number for a prediction horizon with one to several shedding periods.

Figure 30. The prediction error  $C(\tau )$ over time with selected number of clusters
$C(\tau )$ over time with selected number of clusters  $K=1$,
$K=1$,  $10$,
$10$,  $20$,
$20$,  $50$,
$50$,  $100$.
$100$.
We refrain from fine-tuning the optimal number of clusters as this number is a function of the prediction horizon  $\tau$. For
$\tau$. For  $\tau =0$, a CNM with
$\tau =0$, a CNM with  $K=M$ reduces the representation error to zero, at least for the training data. For
$K=M$ reduces the representation error to zero, at least for the training data. For  $\tau =\infty$, the trivial CNM with
$\tau =\infty$, the trivial CNM with  $K=1$ yielding the mean flow outperforms all other models roughly by a factor 2. The average error between model and data can easily be shown to be larger than the average distance of the data to the mean. Let us consider the data
$K=1$ yielding the mean flow outperforms all other models roughly by a factor 2. The average error between model and data can easily be shown to be larger than the average distance of the data to the mean. Let us consider the data  $u^{\bullet }=\cos t$ and model
$u^{\bullet }=\cos t$ and model  $u^{\circ } = \cos 1.05 t$ with small frequency difference, i.e. increasing phase error. Then,
$u^{\circ } = \cos 1.05 t$ with small frequency difference, i.e. increasing phase error. Then,  $\overline { ( u^{\bullet }-u^{\circ } )^2} = 1$ but
$\overline { ( u^{\bullet }-u^{\circ } )^2} = 1$ but  $\overline {( u^{\circ } - 0 )^2 } = 1/2$. On average,
$\overline {( u^{\circ } - 0 )^2 } = 1/2$. On average,  $u^{\circ }$ stays closer to the mean
$u^{\circ }$ stays closer to the mean  $0$ than to another harmonics which is occasionally out of phase.
$0$ than to another harmonics which is occasionally out of phase.
Finally, we remark that the number of clusters  $K$ plays a similar role in cluster-based models than the number of POD modes
$K$ plays a similar role in cluster-based models than the number of POD modes  $N$ in Galerkin models. Human interpretability is easier for a low-dimensional flow representation while the accuracy increases with the model order. For instance, for periodic dynamics, the phase resolution of each centroid is approximately
$N$ in Galerkin models. Human interpretability is easier for a low-dimensional flow representation while the accuracy increases with the model order. For instance, for periodic dynamics, the phase resolution of each centroid is approximately  $360^{\circ }/K$. However, there is a noticeable difference in robustness between CNM and POD models. POD models tend to become more fragile with increasing state-space dimension, as every new degree of freedom comes with many new coefficients and potential error amplifiers. In contrast, the robustness of cluster-based model does not suffer from increasing dimension. A second difference relates to the modes. Increasing the number of POD modes does not affect the lower-order modes by design. In contrast, all centroids change as
$360^{\circ }/K$. However, there is a noticeable difference in robustness between CNM and POD models. POD models tend to become more fragile with increasing state-space dimension, as every new degree of freedom comes with many new coefficients and potential error amplifiers. In contrast, the robustness of cluster-based model does not suffer from increasing dimension. A second difference relates to the modes. Increasing the number of POD modes does not affect the lower-order modes by design. In contrast, all centroids change as  $K$ is just increased by
$K$ is just increased by  $1$. Similarly, all intervals of a one-dimensional finite-element discretization change as the number of elements increase by one.
$1$. Similarly, all intervals of a one-dimensional finite-element discretization change as the number of elements increase by one.
Appendix C. POD versus cluster-based network modelling
The POD models and CNM belong to the family of data-driven dynamic grey-box models which resolve the evolution of coherent structures. Dynamic POD modelling was pioneered by Aubry et al. (Reference Aubry, Holmes, Lumley and Stone1988) and has enjoyed over three decades of rapid development on coherent-structure descriptions, dynamical systems, estimation and control. In contrast, networks have been recently introduced to reduced-order modelling of fluid flows (Nair & Taira Reference Nair and Taira2015; Taira et al. Reference Taira, Nair and Brunton2016). In this section, we compare POD models and CNM with respect to kinematics (appendix C.1), dynamics (appendix C.2), estimation (appendix C.3) and control (appendix C.4) – foreshadowing promising future opportunities of CNM.
C.1. Kinematics
Starting point of most data-driven grey-box models are  $M$ flow snapshots
$M$ flow snapshots  $\{ \boldsymbol {u} (\boldsymbol {x}) \}_{m=1}^M$ typically resolving first and second statistical moments. Like the dynamic mode decomposition (Rowley et al. Reference Rowley, Mezić, Bagheri, Schlatter and Henningson2009; Schmid Reference Schmid2010), the snapshots are assumed to resolve the coherent-structure evolution in time so that the temporal dynamics can be identified. The POD expands the fluctuations around the mean flow
$\{ \boldsymbol {u} (\boldsymbol {x}) \}_{m=1}^M$ typically resolving first and second statistical moments. Like the dynamic mode decomposition (Rowley et al. Reference Rowley, Mezić, Bagheri, Schlatter and Henningson2009; Schmid Reference Schmid2010), the snapshots are assumed to resolve the coherent-structure evolution in time so that the temporal dynamics can be identified. The POD expands the fluctuations around the mean flow  $\boldsymbol {u}_0$ into a given number
$\boldsymbol {u}_0$ into a given number  $N$ of orthonormal modes
$N$ of orthonormal modes  $\boldsymbol {u}_i$:
$\boldsymbol {u}_i$:
 \begin{equation} \boldsymbol{u} (\boldsymbol{x}, t) = \boldsymbol{u}_0 (\boldsymbol{x}) + \sum_{i=1}^N a_i(t) \boldsymbol{u}_i (\boldsymbol{x}) + \boldsymbol{\epsilon} (\boldsymbol{x},t). \end{equation}
\begin{equation} \boldsymbol{u} (\boldsymbol{x}, t) = \boldsymbol{u}_0 (\boldsymbol{x}) + \sum_{i=1}^N a_i(t) \boldsymbol{u}_i (\boldsymbol{x}) + \boldsymbol{\epsilon} (\boldsymbol{x},t). \end{equation}
By design, this expansion minimizes the averaged representation error  $\sum _{m=1}^M \Vert \boldsymbol {\epsilon }^{m} \Vert ^2_{\varOmega }/M$ with respect to all Galerkin expansions of
$\sum _{m=1}^M \Vert \boldsymbol {\epsilon }^{m} \Vert ^2_{\varOmega }/M$ with respect to all Galerkin expansions of  $N$ modes. The POD modes are linear combinations of the fluctuations
$N$ modes. The POD modes are linear combinations of the fluctuations  $\boldsymbol {u}^m-\boldsymbol {u}_0$.
$\boldsymbol {u}^m-\boldsymbol {u}_0$.
Clustering coarse-grains the snapshot data to a given number  $K$ of centroids
$K$ of centroids  $\{ \boldsymbol {c}_k \}_{k=1}^K$. Each snapshots with index
$\{ \boldsymbol {c}_k \}_{k=1}^K$. Each snapshots with index  $m$ belongs to the closest centroid
$m$ belongs to the closest centroid  $k_m$. The centroids are requested to minimize the averaged representation error
$k_m$. The centroids are requested to minimize the averaged representation error  $\Vert \boldsymbol {u}^m - \boldsymbol {c}_{k^m} \Vert ^2$. Similar to POD modes, centroids are linear combinations of the snapshots.
$\Vert \boldsymbol {u}^m - \boldsymbol {c}_{k^m} \Vert ^2$. Similar to POD modes, centroids are linear combinations of the snapshots.
The representation error of centroids can be further reduced by allowing for interpolations:
 \begin{equation} \boldsymbol{u} (\boldsymbol{x}, t) = \sum_{k=1}^K w_k(t) \boldsymbol{c}_k (\boldsymbol{x}), \quad \sum_{k=1}^K w_k(t) = 1, \quad \forall k \colon w_k(t) \ge 0. \end{equation}
\begin{equation} \boldsymbol{u} (\boldsymbol{x}, t) = \sum_{k=1}^K w_k(t) \boldsymbol{c}_k (\boldsymbol{x}), \quad \sum_{k=1}^K w_k(t) = 1, \quad \forall k \colon w_k(t) \ge 0. \end{equation}
In case of the Markov model, the weights are the evolving probabilities  $w_k(t) = p_k(t)$ and make the expansion (C 2) converge to the mean flow. In case of the network model, the weights characterize ‘flights’ with uniform velocity between two centroids, say from
$w_k(t) = p_k(t)$ and make the expansion (C 2) converge to the mean flow. In case of the network model, the weights characterize ‘flights’ with uniform velocity between two centroids, say from  $k$ to
$k$ to  $j$, and typically re-visit all centroids in finite time. The Markov model might be compared with unsteady Reynolds-averaged Navier–Stokes equations converging to the mean flow while the network model is reminiscent of the large-eddy simulations.
$j$, and typically re-visit all centroids in finite time. The Markov model might be compared with unsteady Reynolds-averaged Navier–Stokes equations converging to the mean flow while the network model is reminiscent of the large-eddy simulations.
We emphasize that (C 1) and (C 2) look similar but have quite different ranges of applications. The POD expansion is based on the superposition of modes with arbitrary mode amplitudes  $a_i$. Neither the mean flow nor the POD modes are realizable states. POD could be considered a data-driven analogue of the Fourier expansion. In contrast, the cluster-based expansion is only meant to describe a local interpolation for CNM. The centroids are coarse-grained approximations of realizable states. The centroids may be conceptualized as collocation points for a finite-element inspired ansatz and the associated Voronoi cells serve as finite elements. As a corollary, POD expansions can describe new states which are far from the snapshot database, because the mode amplitudes are not confined. In contrast, cluster-based expansions are bound to stay close to the training data by the non-negativity
$a_i$. Neither the mean flow nor the POD modes are realizable states. POD could be considered a data-driven analogue of the Fourier expansion. In contrast, the cluster-based expansion is only meant to describe a local interpolation for CNM. The centroids are coarse-grained approximations of realizable states. The centroids may be conceptualized as collocation points for a finite-element inspired ansatz and the associated Voronoi cells serve as finite elements. As a corollary, POD expansions can describe new states which are far from the snapshot database, because the mode amplitudes are not confined. In contrast, cluster-based expansions are bound to stay close to the training data by the non-negativity  $w_k \ge 0$ and the normalization constraint
$w_k \ge 0$ and the normalization constraint  $\sum _{k=1}^K w_k = 1$. By construction, global POD expansions have lower representation error as cluster-based expansions with the same number of modes. Some POD modes of simple dynamics may have a physical meaning as they resolve instability modes or harmonics. Typically, however, POD modes comprise a mix of frequencies and are difficult to interpret. In contrast, all centroids are human-interpretable coarse-grained flows which are representative for a certain state-space region. Summarizing, the choice between POD and clustering strongly depends on the intended applications.
$\sum _{k=1}^K w_k = 1$. By construction, global POD expansions have lower representation error as cluster-based expansions with the same number of modes. Some POD modes of simple dynamics may have a physical meaning as they resolve instability modes or harmonics. Typically, however, POD modes comprise a mix of frequencies and are difficult to interpret. In contrast, all centroids are human-interpretable coarse-grained flows which are representative for a certain state-space region. Summarizing, the choice between POD and clustering strongly depends on the intended applications.
C.2. Dynamics
The temporal evolution of the incompressible viscous flow can be derived from the Galerkin expansion and the Navier–Stokes equations (Fletcher Reference Fletcher1984) for steady domains with stationary boundary conditions. The resulting Galerkin system for the mode amplitude vector  $\boldsymbol {a}= [ a_1, a_2, \ldots , a_N ]^{\mathrm {T}}$ is the autonomous system
$\boldsymbol {a}= [ a_1, a_2, \ldots , a_N ]^{\mathrm {T}}$ is the autonomous system
 \begin{equation} \frac{\textrm{d}\boldsymbol{a}}{\textrm{d}t} = \boldsymbol{f} ( \boldsymbol{a} ). \end{equation}
\begin{equation} \frac{\textrm{d}\boldsymbol{a}}{\textrm{d}t} = \boldsymbol{f} ( \boldsymbol{a} ). \end{equation}For turbulent flows, only a fraction of the fluctuation energy is resolved by the POD modes and the effect of the remaining unresolved fluctuations must be accounted for. Myriad of subgrid turbulence models and calibration techniques have been proposed and the identification of a robust realistic dynamical system constitutes a challenge. Even the basic physical requirement of a globally bounded dynamics is often not met (Schlegel & Noack Reference Schlegel and Noack2015).
CNM might be conceptualized as flights between airports (centroids) from a discrete network of routes with destination probabilities (transition matrix) and flight times (transition times). In CNM, the chosen ‘destination’  $j$ from ‘airport’
$j$ from ‘airport’  $k$ at time
$k$ at time  $t^m$ from centroid
$t^m$ from centroid  $k$ at time
$k$ at time  $t^m$ to centroid
$t^m$ to centroid  $j$ during
$j$ during  $t^{m+1} = t^m + T_{jk}$ is described by
$t^{m+1} = t^m + T_{jk}$ is described by
 \begin{gather} j = \text{realization according to}\ Q_{jk} ,\end{gather}
\begin{gather} j = \text{realization according to}\ Q_{jk} ,\end{gather} \begin{gather}\boldsymbol{u} (\boldsymbol{x}, t) = w_k(t) \boldsymbol{c}_k( \boldsymbol{x} ) + w_j(t) \boldsymbol{c}_j( \boldsymbol{x} ), \end{gather}
\begin{gather}\boldsymbol{u} (\boldsymbol{x}, t) = w_k(t) \boldsymbol{c}_k( \boldsymbol{x} ) + w_j(t) \boldsymbol{c}_j( \boldsymbol{x} ), \end{gather} \begin{gather}w_j(t) = (t-t^m)/T_{jk}, \quad w_k(t) = 1-w_j(t). \end{gather}
\begin{gather}w_j(t) = (t-t^m)/T_{jk}, \quad w_k(t) = 1-w_j(t). \end{gather}
At time  $t^{m+1}$, a similar decision on the next destination is made, and so on. The CNM (C 4) describes a deterministic–stochastic dynamics in contrast to the deterministic (C 3).
$t^{m+1}$, a similar decision on the next destination is made, and so on. The CNM (C 4) describes a deterministic–stochastic dynamics in contrast to the deterministic (C 3).
In contrast to POD models, the CNM (C 4) contains no design parameter beyond the number of clusters and is fully automated. Moreover, the dynamics is robust and cannot diverge, unlike POD models. The price is the confinement to the neighbourhood of the training data. Again, the decision in favour of the POD model or CNM strongly depends on the goal. The POD models may allow deeper dynamics insights; CNM is much simpler and much more robust by design.
C.3. Estimation
In most experiments, only few signals, denoted by the vector  $\boldsymbol {s}(t)$, can be recorded. Let
$\boldsymbol {s}(t)$, can be recorded. Let  $\boldsymbol {u}^m ( \boldsymbol {x}, t^m), m=1,\ldots , M$, be the snapshots associated with the sensor readings
$\boldsymbol {u}^m ( \boldsymbol {x}, t^m), m=1,\ldots , M$, be the snapshots associated with the sensor readings  $\boldsymbol {s}^m = \boldsymbol {s} (t^m)$. The easiest realization of the estimator
$\boldsymbol {s}^m = \boldsymbol {s} (t^m)$. The easiest realization of the estimator
 \begin{equation} \hat{\boldsymbol{u}} (\boldsymbol{x},t) = \boldsymbol{G} \left ( \boldsymbol{x}, \boldsymbol{s}(t) \right ) \end{equation}
\begin{equation} \hat{\boldsymbol{u}} (\boldsymbol{x},t) = \boldsymbol{G} \left ( \boldsymbol{x}, \boldsymbol{s}(t) \right ) \end{equation}
for sensor reading  $\boldsymbol {s}$ is to find the closed sensor data
$\boldsymbol {s}$ is to find the closed sensor data  $\boldsymbol {s}^m$ from the data base and to take the corresponding snapshot
$\boldsymbol {s}^m$ from the data base and to take the corresponding snapshot  $\boldsymbol {u}^m$ as an estimator. This simplistic 1-nearest neighbour estimator can be refined in numerous ways. An interpolation with
$\boldsymbol {u}^m$ as an estimator. This simplistic 1-nearest neighbour estimator can be refined in numerous ways. An interpolation with  $K$ data points can be performed with a
$K$ data points can be performed with a  $K$-nearest neighbour approach (Loiseau, Noack & Brunton Reference Loiseau, Noack and Brunton2018). The sensor signals may be lifted to a feature space without dynamic false neighbours, for instance with time-delay coordinates (Loiseau et al. Reference Loiseau, Noack and Brunton2018). Or the structure of
$K$-nearest neighbour approach (Loiseau, Noack & Brunton Reference Loiseau, Noack and Brunton2018). The sensor signals may be lifted to a feature space without dynamic false neighbours, for instance with time-delay coordinates (Loiseau et al. Reference Loiseau, Noack and Brunton2018). Or the structure of  $\boldsymbol {G}$ may be pre-assumed as in linear stochastic estimation.
$\boldsymbol {G}$ may be pre-assumed as in linear stochastic estimation.
The estimated flow field is canonically transcribed into POD mode amplitudes  $\hat {\boldsymbol {a}}$ and permissible centroid weights
$\hat {\boldsymbol {a}}$ and permissible centroid weights  $\hat {\boldsymbol {w}}=[ \hat {w}_1,\hat {w}_2,\ldots , \hat {w}_N ]^{\mathrm {T}}$. Summarizing, the estimation can easily be realized as add-ons in POD models and CNM. For completeness, we mention the possibility of dynamic observers exploiting the dynamical system.
$\hat {\boldsymbol {w}}=[ \hat {w}_1,\hat {w}_2,\ldots , \hat {w}_N ]^{\mathrm {T}}$. Summarizing, the estimation can easily be realized as add-ons in POD models and CNM. For completeness, we mention the possibility of dynamic observers exploiting the dynamical system.
C.4. Control
The POD models may be enriched with a forcing term. In a simple case, like a volume force, the forcing term is additive and linear in the actuation command  $\boldsymbol {b} = [ b_1, b_2, \ldots , b_{N_b} ]^{\textrm {T}}$ with the gain matrix
$\boldsymbol {b} = [ b_1, b_2, \ldots , b_{N_b} ]^{\textrm {T}}$ with the gain matrix  $\boldsymbol {B}$:
$\boldsymbol {B}$:
 \begin{equation} \frac{\textrm{d}\boldsymbol{a}}{\textrm{d}t} = \boldsymbol{f} ( \boldsymbol{a} ) + \boldsymbol{B} \boldsymbol{b}. \end{equation}
\begin{equation} \frac{\textrm{d}\boldsymbol{a}}{\textrm{d}t} = \boldsymbol{f} ( \boldsymbol{a} ) + \boldsymbol{B} \boldsymbol{b}. \end{equation}From here on, stabilizing control laws may be derived from linearizations or other strategies (Brunton & Noack Reference Brunton and Noack2015).
The control design for CNM is more complex. The actuation command  $\boldsymbol {b}$ affects the dynamics (C 4) via changed transition probabilities
$\boldsymbol {b}$ affects the dynamics (C 4) via changed transition probabilities  ${\boldsymbol{\mathsf{Q}}} (\boldsymbol {b})$ and changed transition times
${\boldsymbol{\mathsf{Q}}} (\boldsymbol {b})$ and changed transition times  ${\boldsymbol{\mathsf{T}}} (\boldsymbol {b})$. In a simple case, this dependency may be linearized:
${\boldsymbol{\mathsf{T}}} (\boldsymbol {b})$. In a simple case, this dependency may be linearized:
 \begin{equation} {\boldsymbol{\mathsf{Q}}} = {\boldsymbol{\mathsf{Q}}}_0 + \sum_{l=1}^{N_b} b_l {\boldsymbol{\mathsf{Q}}}_l, \quad {\boldsymbol{\mathsf{T}}} = {\boldsymbol{\mathsf{T}}}_0 + \sum_{l=1}^{N_b} b_l {\boldsymbol{\mathsf{T}}}_l. \end{equation}
\begin{equation} {\boldsymbol{\mathsf{Q}}} = {\boldsymbol{\mathsf{Q}}}_0 + \sum_{l=1}^{N_b} b_l {\boldsymbol{\mathsf{Q}}}_l, \quad {\boldsymbol{\mathsf{T}}} = {\boldsymbol{\mathsf{T}}}_0 + \sum_{l=1}^{N_b} b_l {\boldsymbol{\mathsf{T}}}_l. \end{equation}
Here, the subscript ‘ $0$’ corresponds to the unforced state, while the subscript ‘
$0$’ corresponds to the unforced state, while the subscript ‘ $l$’ denotes changes caused by the actuation command
$l$’ denotes changes caused by the actuation command  $b_l$. The matrices may be identified from actuated flow data. After, the forced CNM (C 4)–(C 7) is identified, a regression solver can be employed to optimize the control law with respect to a cost function. Genetic programming has proven to be a powerful method for this method in dozens of turbulence control experiments (Noack Reference Noack, Zhou, Kimura, Peng, Lucey and Hung2019).
$b_l$. The matrices may be identified from actuated flow data. After, the forced CNM (C 4)–(C 7) is identified, a regression solver can be employed to optimize the control law with respect to a cost function. Genetic programming has proven to be a powerful method for this method in dozens of turbulence control experiments (Noack Reference Noack, Zhou, Kimura, Peng, Lucey and Hung2019).
We remark that the deterministic–stochastic network dynamics rules out ‘simple’ control design based on local linearizations, but requires the numerical solution of a non-convect nonlinear optimization problem. Thus, the computational cost of this approach is significantly larger than the model-based linear control. Yet, cluster-based network model may enable nonlinear infinite-horizon control at a fraction of the computational cost of linear optimal control using the Navier–Stokes equations. The authors actively pursue this novel avenue of cluster-based network control for turbulence. Nair et al. (Reference Nair, Yeh, Kaiser, Noack, Brunton and Tiara2019) and Kaiser et al. (Reference Kaiser, Noack, Spohn, Cattafesta and Morzyński2017) present a model-free cluster-based control as a prelude to these efforts.
























































































































 Open access
Open access