



1. Introduction
Social relationships are formed and maintained through individuals’ interpersonal actions (Borgatti & Halgin, Reference Borgatti and Halgin2011). These actions are often collected as relational events, i.e. sequences of directed interactions between individuals. A relational event, in general, consists of at least three elements (Stadtfeld & Block, Reference Stadtfeld and Block2017): a social actor who generates an event (the “sender”), a social actor who receives the event (the “receiver”), and the time at which the event takes place. Relational events occur in a variety of contexts, including interpersonal interactions (Stadtfeld & Block, Reference Stadtfeld and Block2017), online peer-production (Lerner & Lomi, Reference Lerner and Lomi2017), treaties between countries (Stadtfeld et al., Reference Stadtfeld, Hollway and Block2017a), classroom conversations (DuBois et al., Reference DuBois, Butts, McFarland and Smyth2013), animal behavior (Tranmer et al., Reference Tranmer, Marcum, Morton, Croft and de Kort2015; Patison et al., Reference Patison, Quintane, Swain, Robins and Pattison2015), online political discussion (Mulder & Leenders, Reference Mulder and Leenders2019), and capital transfer between banks (Zappa & Vu, Reference Zappa and Vu2021), among others.
Several statistical models for analyzing relational event data have been proposed (Butts, Reference Butts2008; Perry & Wolfe, Reference Perry and Wolfe2013; Stadtfeld, Reference Stadtfeld2012; Vu et al., Reference Vu, Asuncion, Hunter and Smyth2011a). These models enable the testing of hypotheses about how previous events, nodal attributes, dyadic attributes, and network structures explain the emergence of relational events through time. Among the models, Dynamic Network Actor Models (DyNAMs) investigate relational events as an actor-oriented decision process consisting of two decision levels (Stadtfeld & Block, Reference Stadtfeld and Block2017). The first level represents the time until an actor initiates the next relational event. The time between two consecutive events originated by the same actor is modeled as an exponential distribution with an actor-specific activity rate. The second level describes the choice of the receiver of the event. A conditional multinomial logit model determines the probability that an actor is chosen as a receiver.
Combinations of statistics and parameters define both the actor activity rate and the multinomial linear predictor. The statistics of the rates explain differences in actors’ activity due to their position in the network, their characteristics, or the sequence of previous events. The statistics of the multinomial logit model express preferences for various types of social structures, such as reciprocated dyads, transitive triads, or homophilous dyads. These preferences may vary depending on actors’ characteristics and their current position in the network. The parameters quantify the effect of the statistics in the evolution of the process. The DyNAM assumes that the parameters are constant over the actors and the context. Thus, heterogeneity between actors enters the model through statistics accounting for differences in actors’ attributes and structural positions that can be observed. In other words, the model assumes that actors with the same characteristics and network positions follow the same behavioral patterns. This homogeneity assumption, albeit statistically and computationally convenient, is difficult to justify in some empirical settings, e.g., in the presence of unobserved differences between actors or contexts. Such differences can lead to unobserved heterogeneity in actors’ activity or preferences beyond what the model specification could explain.
In this paper, we extend DyNAMs by including random-effects parameters that vary across actors or contexts and allow controlling for unknown sources of heterogeneity. The extension is rooted in the literature of multilevel and mixed-effects models (Gelman & Hill, Reference Gelman and Hill2006; Snijders & Bosker, Reference Snijders and Bosker2011; Raudenbush & Bryk, Reference Raudenbush and Bryk2002). Such models are commonly applied when the data presents a nested structure (e.g., students in classrooms and longitudinal measurement of subjects). The multilevel approach is suitable since we can think of the relational event sequence as a series of events nested within the sending actors or a pre-specified partition of the actors in groups. We follow a Bayesian approach to make inferences about the model parameters. The procedure uses Hamiltonian Chain Monte Carlo with the No-U-turn sampler (NUTS) as implemented in Stan (Hoffman & Gelman, Reference Hoffman and Gelman2014; Stan Development Team, 2022).
The model developed in this study is new in two regards. First, the model allows explaining actors’ (or groups’) deviation from the average tendency of a given network mechanism using actors’ covariates or monadic network statistics, thereby controlling for the differential agency of actors. Second, it introduces random effects to account for and test hypotheses on unobserved heterogeneity between actors for specific network statistics.
The article is organized as follows. Section 2 summarizes the literature on the relational event and random-effects network models. Section 3 presents the logic and the formulation of the standard DyNAM. The definition of the random-effects DyNAMs is described in Section 4. Sections 5 and 6 report information on the model estimation and selection. Section 7 illustrates the model by analyzing relational events among an online community of aspiring and professional digital and graphic designers. The paper concludes in Section 8 with a discussion.
2. Review of existing statistical network models
The DyNAM with random effects leans on two research lines: the Relational Event Model (REM) and network models that include random effects. Butts (Reference Butts2008) introduced the REM, a model inspired by event history analysis and agent-based modeling. This model assumes that all possible sender–receiver pairs are competing to initiate an event at each point in time. Under the assumption that the events occur following an inhomogeneous Poisson process and are independent conditional on the realized history of the process, it is possible to link the occurrence of the events with a rate function. This function depends on the information of the particular dyad and its position in the events’ network.
In contrast, the DyNAM uses ideas similar to the Stochastic Actor-Oriented Model (Snijders, Reference Snijders1996, Reference Snijders2001). It proposes a two-step decision process embedded in a continuous-time Markov chain. The first step describes the time until an actor initiates the next relational event and is modeled by an exponential distribution depending on the actor activity rate. The second determines the choice of the receiver of the event and is modeled by a multinomial probability distribution.
Variations describing the social interactions as the outcome of point processes have been presented by Perry and Wolfe (Reference Perry and Wolfe2013) and Vu et al. (Reference Vu, Asuncion, Hunter and Smyth2011a).
The inclusion of random effects in network models has been proposed in the literature for both cross-sectional and longitudinal network data. The
 $p_2$
model (Van Duijn et al., Reference Van Duijn, Snijders and Zijlstra2004), Exponential Random Graph Models with sender and receiver random effects (Box-Steffensmeier et al., Reference Box-Steffensmeier, Christenson and Morgan2018), and with random effects for a given network statistic (Thiemichen et al., Reference Thiemichen, Friel, Caimo and Kauermann2016) have been developed to account for actor heterogeneity in the analysis of cross-sectional data. Different work lines close to our proposal led to the extensions of the Stochastic Actor-Oriented Model and REM for longitudinal data. For the Stochastic Actor-Oriented Model, Schweinberger (Reference Schweinberger2007, chap. 4) and Schweinberger (Reference Schweinberger2020) proposed random effects to account for variations between actors and groups of actors, respectively. For the REM, DuBois et al. (Reference DuBois, Butts, McFarland and Smyth2013) studied multiple event sequences introducing random effects that vary across contexts.
$p_2$
model (Van Duijn et al., Reference Van Duijn, Snijders and Zijlstra2004), Exponential Random Graph Models with sender and receiver random effects (Box-Steffensmeier et al., Reference Box-Steffensmeier, Christenson and Morgan2018), and with random effects for a given network statistic (Thiemichen et al., Reference Thiemichen, Friel, Caimo and Kauermann2016) have been developed to account for actor heterogeneity in the analysis of cross-sectional data. Different work lines close to our proposal led to the extensions of the Stochastic Actor-Oriented Model and REM for longitudinal data. For the Stochastic Actor-Oriented Model, Schweinberger (Reference Schweinberger2007, chap. 4) and Schweinberger (Reference Schweinberger2020) proposed random effects to account for variations between actors and groups of actors, respectively. For the REM, DuBois et al. (Reference DuBois, Butts, McFarland and Smyth2013) studied multiple event sequences introducing random effects that vary across contexts.
3. Dynamic Network Actor Models
Following the notation of Butts (Reference Butts2008) and Stadtfeld and Block (Reference Stadtfeld and Block2017), we represent an event as a tuple of the form
 $\omega = (i_\omega,\, j_\omega,\, t_\omega )$
, where
$\omega = (i_\omega,\, j_\omega,\, t_\omega )$
, where
 $i_\omega \in \mathcal{S}({t_\omega })$
denotes the event sender,
$i_\omega \in \mathcal{S}({t_\omega })$
denotes the event sender,
 $j_\omega \in \mathcal{R}({t_\omega })$
is the event receiver, and
$j_\omega \in \mathcal{R}({t_\omega })$
is the event receiver, and
 $t_\omega \in \mathbb{R}_{\geq 0}$
represents the time at which the event occurred. The sets
$t_\omega \in \mathbb{R}_{\geq 0}$
represents the time at which the event occurred. The sets
 $\mathcal{S}({t_\omega })$
and
$\mathcal{S}({t_\omega })$
and
 $\mathcal{R}({t_\omega })$
represent the collection of individuals, entities or agents that could potentially be the senders or receivers of an event at time
$\mathcal{R}({t_\omega })$
represent the collection of individuals, entities or agents that could potentially be the senders or receivers of an event at time
 $t_\omega$
. These sets can be disjoint
$t_\omega$
. These sets can be disjoint
 $(\mathcal{S}({t_\omega }) \cap \mathcal{R}({t_\omega }) = \emptyset )$
, as in the case of two-mode (bipartite) relational event data, or identical (
$(\mathcal{S}({t_\omega }) \cap \mathcal{R}({t_\omega }) = \emptyset )$
, as in the case of two-mode (bipartite) relational event data, or identical (
 $\mathcal{S}({t_\omega }) = \mathcal{R}({t_\omega })$
), as in the case of one-mode relational event data.
$\mathcal{S}({t_\omega }) = \mathcal{R}({t_\omega })$
), as in the case of one-mode relational event data.
A sequence of time-ordered relational events
 $\Omega = \{ \omega _1,\, \omega _2,\ldots,\, \omega _N\}$
is the focus of the model as the dependent variable. The process state
$\Omega = \{ \omega _1,\, \omega _2,\ldots,\, \omega _N\}$
is the focus of the model as the dependent variable. The process state
 ${\boldsymbol{{y}}}(t)$
is the explanatory variable in the model. It comprises all the relevant information of past events and attributes up to but not including
${\boldsymbol{{y}}}(t)$
is the explanatory variable in the model. It comprises all the relevant information of past events and attributes up to but not including
 $t_{\omega }$
. Formally, it is a multivariate system defined as
$t_{\omega }$
. Formally, it is a multivariate system defined as
 \begin{equation} {\boldsymbol{{y}}}(t) = (\boldsymbol{{x}}^{(1)}(t),\, \boldsymbol{{x}}^{(2)}(t),\, \ldots,\, \boldsymbol{{z}}^{(1)}(t),\, \boldsymbol{{z}}^{(2)}(t),\, \ldots,\, \mathcal{S}(t),\, \mathcal{R}(t) ) \quad t \lt t_{\omega } . \end{equation}
\begin{equation} {\boldsymbol{{y}}}(t) = (\boldsymbol{{x}}^{(1)}(t),\, \boldsymbol{{x}}^{(2)}(t),\, \ldots,\, \boldsymbol{{z}}^{(1)}(t),\, \boldsymbol{{z}}^{(2)}(t),\, \ldots,\, \mathcal{S}(t),\, \mathcal{R}(t) ) \quad t \lt t_{\omega } . \end{equation}
The elements
 $\boldsymbol{{x}}^{(.)}(t)$
are matrices representing the sequence of previous events, various types of networks, or relational data. The elements
$\boldsymbol{{x}}^{(.)}(t)$
are matrices representing the sequence of previous events, various types of networks, or relational data. The elements
 $\boldsymbol{{z}}^{(.)}(t)$
are nodal or global covariates that can be expressed as vectors or scalars. We omit the time indicator
$\boldsymbol{{z}}^{(.)}(t)$
are nodal or global covariates that can be expressed as vectors or scalars. We omit the time indicator
 $t$
when convenient, and denote vectors and matrices by bold case letters.
$t$
when convenient, and denote vectors and matrices by bold case letters.
DyNAMs (Stadtfeld & Block, Reference Stadtfeld and Block2017) assume that the observed sequence of relational events is the outcome of a continuous-time Markov process with two sub-steps modeling the changes in the network. The first step describes the time until an actor initiates the next relational event. The waiting time of an actor
 $i$
is modeled by an exponential distribution with rate parameter
$i$
is modeled by an exponential distribution with rate parameter
 $\tau _i$
that depends on a parameter vector
$\tau _i$
that depends on a parameter vector
 $\boldsymbol{\theta }$
, and an arbitrary set of real functions
$\boldsymbol{\theta }$
, and an arbitrary set of real functions
 $r_g$
evaluating the process state:
$r_g$
evaluating the process state:
 \begin{equation} \tau _i({\boldsymbol{{y}}};\, \boldsymbol{\theta }) = \exp \!\left (\theta _0 + \sum _g \theta _g\, r_g(i, {\boldsymbol{{y}}})\right ) . \end{equation}
\begin{equation} \tau _i({\boldsymbol{{y}}};\, \boldsymbol{\theta }) = \exp \!\left (\theta _0 + \sum _g \theta _g\, r_g(i, {\boldsymbol{{y}}})\right ) . \end{equation}
The functions
 $r_g$
, hereafter referred to as statistics, convey the idea that actors might exhibit a different rate due to their network position or covariates. The parameter
$r_g$
, hereafter referred to as statistics, convey the idea that actors might exhibit a different rate due to their network position or covariates. The parameter
 $\theta _g$
represents the effect of the statistic
$\theta _g$
represents the effect of the statistic
 $r_g$
in determining the rate. Positive values of the parameter indicate that the rate increases with the increase of
$r_g$
in determining the rate. Positive values of the parameter indicate that the rate increases with the increase of
 $r_g$
, thereby implying that actors with high values of
$r_g$
, thereby implying that actors with high values of
 $r_g$
are more likely to initiate events than actors with low values of
$r_g$
are more likely to initiate events than actors with low values of
 $r_g$
. Table 1 provides the pictorial representation of a few statistics
$r_g$
. Table 1 provides the pictorial representation of a few statistics
 $r_g$
along with the interpretation of the corresponding parameters
$r_g$
along with the interpretation of the corresponding parameters
 $\theta _g$
.
$\theta _g$
.
Table 1. Examples of statistics
 $r_g$
for the rate function
$r_g$
for the rate function
 $\tau _i$
in equation (2)
$\tau _i$
in equation (2)

The interpretation refers to positive values of
 $\theta _g$
. A similar interpretation holds for negative values of
$\theta _g$
. A similar interpretation holds for negative values of
 $\theta _g$
.
$\theta _g$
.
The second step describes the choice of the receiver of the event. According to random utility theory, the choice of the receiver is modeled by a multinomial model having the form:
 \begin{equation} p(i \rightarrow j;\, {\boldsymbol{{y}}}, \boldsymbol{\beta }) = \frac{\exp \!\big (f(i, j, {\boldsymbol{{y}}}, \boldsymbol{\beta })\big )}{\sum _k \exp \!\big (f(i, k, {\boldsymbol{{y}}}, \boldsymbol{\beta })\big )},\ \forall j . \end{equation}
\begin{equation} p(i \rightarrow j;\, {\boldsymbol{{y}}}, \boldsymbol{\beta }) = \frac{\exp \!\big (f(i, j, {\boldsymbol{{y}}}, \boldsymbol{\beta })\big )}{\sum _k \exp \!\big (f(i, k, {\boldsymbol{{y}}}, \boldsymbol{\beta })\big )},\ \forall j . \end{equation}
In equation (3),
 $f(i, j, {\boldsymbol{{y}}},\boldsymbol{\beta })$
represents the systematic part of the utility function that actor
$f(i, j, {\boldsymbol{{y}}},\boldsymbol{\beta })$
represents the systematic part of the utility function that actor
 $i$
uses to evaluate all possible alters. The systematic component is a linear combination of real functions
$i$
uses to evaluate all possible alters. The systematic component is a linear combination of real functions
 $s_h$
, evaluating the process state in the presence of the event
$s_h$
, evaluating the process state in the presence of the event
 $i\rightarrow j$
and parameters
$i\rightarrow j$
and parameters
 $\beta _h$
:
$\beta _h$
:
 \begin{equation} f(i, j, {\boldsymbol{{y}}}, \boldsymbol{\beta }) = \sum _{h} \beta _h\, s_h(i,j,{\boldsymbol{{y}}}) . \end{equation}
\begin{equation} f(i, j, {\boldsymbol{{y}}}, \boldsymbol{\beta }) = \sum _{h} \beta _h\, s_h(i,j,{\boldsymbol{{y}}}) . \end{equation}
The functions
 $s_h$
are statistics expressing the sender preferences for actors having specific characteristics or embedded in particular social structures. The parameter
$s_h$
are statistics expressing the sender preferences for actors having specific characteristics or embedded in particular social structures. The parameter
 $\beta _h$
represents the effect of the statistic
$\beta _h$
represents the effect of the statistic
 $s_h$
in determining the receiver. Positive values of the parameter indicate that events to receiver
$s_h$
in determining the receiver. Positive values of the parameter indicate that events to receiver
 $j$
leading to high values of
$j$
leading to high values of
 $s_h$
are more likely than those to receiver
$s_h$
are more likely than those to receiver
 $k$
leading to low values of
$k$
leading to low values of
 $s_h$
. Table 2 shows the pictorial representation of the main statistics
$s_h$
. Table 2 shows the pictorial representation of the main statistics
 $s_h$
along with the interpretation of the corresponding parameters
$s_h$
along with the interpretation of the corresponding parameters
 $\beta _h$
.
$\beta _h$
.
Table 2. Examples of statistics
 $s_h$
for the systematic component
$s_h$
for the systematic component
 $f(i, j, {\boldsymbol{{y}}}, \boldsymbol{\beta })$
in equation (3).
$f(i, j, {\boldsymbol{{y}}}, \boldsymbol{\beta })$
in equation (3).

The interpretation refers to positive values of
 $\beta _h$
. A similar interpretation holds for negative values of
$\beta _h$
. A similar interpretation holds for negative values of
 $\beta _h$
.
$\beta _h$
.
The subprocesses describing the waiting time between events and the choice of the receiver are assumed to be conditionally independent, given the process state (Stadtfeld & Block, Reference Stadtfeld and Block2017). Thus, the vector of parameters
 $\boldsymbol{\theta }$
and
$\boldsymbol{\theta }$
and
 $\boldsymbol{\beta }$
can be obtained by performing estimation using the partial likelihoods of the submodels for the actor activity rates and the multinomial receiver choices, respectively. The R package goldfish (Stadtfeld & Hollway, Reference Stadtfeld and Hollway2022) provides the implementation of DyNAMs.
$\boldsymbol{\beta }$
can be obtained by performing estimation using the partial likelihoods of the submodels for the actor activity rates and the multinomial receiver choices, respectively. The R package goldfish (Stadtfeld & Hollway, Reference Stadtfeld and Hollway2022) provides the implementation of DyNAMs.
It must be noted that the assumption of separability in DyNAMs is analytically convenient, but also a reasonable representation of many social processes under study. It may not be tenable in situations where the timing of events depends on the choice of the receiver. We refer the readers to the papers of Stadtfeld and Block (Reference Stadtfeld and Block2017) and Stadtfeld et al. (Reference Stadtfeld, Hollway and Block2017b) for an extensive discussion on the assumption of separability.
4. Random effects in DyNAMs
The parameters
 $\theta _g$
and
$\theta _g$
and
 $\beta _h$
in equations (2) and (4), respectively, are assumed to be constant over the actors, thereby implying that the effect of the statistics is the same for all actors with the same characteristics and network positions. Here, we present the mathematical formulation of the random effects model for the second sub-step (the receiver’s choice) to relax the assumption that all actors have the same preferences for events leading to the formation of the statistics
$\beta _h$
in equations (2) and (4), respectively, are assumed to be constant over the actors, thereby implying that the effect of the statistics is the same for all actors with the same characteristics and network positions. Here, we present the mathematical formulation of the random effects model for the second sub-step (the receiver’s choice) to relax the assumption that all actors have the same preferences for events leading to the formation of the statistics
 $s_h$
. An analogous extension can be derived for the rate parameter
$s_h$
. An analogous extension can be derived for the rate parameter
 $\tau _i$
.
$\tau _i$
.
The derivation of the probability of choosing a receiver as a multinomial choice model under a random utility maximization is based on the assumptions of independence of irrelevant alternatives and the presence of additive disturbances distributed as a Type I extreme value distribution (McFadden, Reference McFadden and Zarembka1974; Luce & Suppes, Reference Luce, Suppes, Luce, Bush and Galanter1965). Additionally, the assumption that the random disturbances of the utility function are independent and identically distributed implies that the error term is a noise arising from unknown and unspecified sources after controlling for the covariates included in the model. Translating this into the framework of DyNAMs, this assumption implies that the receiver choices made from the same actor are independent after controlling for the state of the process through the statistics
 $s_h$
. However, consecutive choices made by the same actor present correlation even after controlling for covariates or could vary for the presence of random taste variations.
$s_h$
. However, consecutive choices made by the same actor present correlation even after controlling for covariates or could vary for the presence of random taste variations.
This problem has been recognized in the discrete choice modeling literature. McFadden and Train (Reference McFadden and Train2000) developed the random-coefficients logit model where the multinomial coefficients can vary over individuals and alternatives.
We use the same idea to extend the formulation of the utility function to include random effects in DyNAMs. The model specification follows the notation of Gelman and Hill (Reference Gelman and Hill2006). The utility function is split into two components as represented by the following equation
 \begin{equation} f(i, j, {\boldsymbol{{y}}},\boldsymbol{\beta },\boldsymbol{\alpha }) = \sum _{h} \beta _{h} \, s_h(i,j,{\boldsymbol{{y}}}) + \sum _{m} \alpha _{mi}\, s_m(i,\, j,\, {\boldsymbol{{y}}}) . \end{equation}
\begin{equation} f(i, j, {\boldsymbol{{y}}},\boldsymbol{\beta },\boldsymbol{\alpha }) = \sum _{h} \beta _{h} \, s_h(i,j,{\boldsymbol{{y}}}) + \sum _{m} \alpha _{mi}\, s_m(i,\, j,\, {\boldsymbol{{y}}}) . \end{equation}
The first component resembles equation (4) and represents the local configurations that are evaluated in the same way by all the actors as described by the fixed-effect coefficients
 $\beta _h$
. The second part introduces a new set of statistics
$\beta _h$
. The second part introduces a new set of statistics
 $s_m$
that depends on a set of random-effect coefficients
$s_m$
that depends on a set of random-effect coefficients
 $\alpha _{mi}$
for actor
$\alpha _{mi}$
for actor
 $i$
. The parameters
$i$
. The parameters
 $\alpha _{mi}$
are random slopes that allow the fixed effect part to vary over the actors. Formally,
$\alpha _{mi}$
are random slopes that allow the fixed effect part to vary over the actors. Formally,
 $\alpha _{mi}$
is defined as:
$\alpha _{mi}$
is defined as:
 \begin{align} \begin{split} \alpha _{mi} &= \gamma _{m0} + \sum _{n} \gamma _{mn} \, a_n(i,\, {\boldsymbol{{y}}}) + \eta _{mi} \\ \boldsymbol{\eta}_i &\sim MN(\boldsymbol{0}, \boldsymbol{\Sigma }) \nonumber \, . \end{split} \end{align}
\begin{align} \begin{split} \alpha _{mi} &= \gamma _{m0} + \sum _{n} \gamma _{mn} \, a_n(i,\, {\boldsymbol{{y}}}) + \eta _{mi} \\ \boldsymbol{\eta}_i &\sim MN(\boldsymbol{0}, \boldsymbol{\Sigma }) \nonumber \, . \end{split} \end{align}
The parameter
 $\gamma _{m0}$
represents the average importance of statistic
$\gamma _{m0}$
represents the average importance of statistic
 $s_m$
in the population when all real functions
$s_m$
in the population when all real functions
 $a_n$
take value zero. The second component
$a_n$
take value zero. The second component
 $\sum _{n} \gamma _{mn} \, a_n(i,\, {\boldsymbol{{y}}})$
controls for variations of the importance of statistic
$\sum _{n} \gamma _{mn} \, a_n(i,\, {\boldsymbol{{y}}})$
controls for variations of the importance of statistic
 $s_m$
that are explained by the real function
$s_m$
that are explained by the real function
 $a_n$
evaluating the process state. The functions
$a_n$
evaluating the process state. The functions
 $a_n$
can be nodal covariates or network statistics that reflect differences in the network position of the actors, similarly to the statistics
$a_n$
can be nodal covariates or network statistics that reflect differences in the network position of the actors, similarly to the statistics
 $r_g$
used in the waiting time formulation. It is worth mentioning that this second component is not considered in previous formulations of the random-coefficients logit model introduced in McFadden and Train (Reference McFadden and Train2000).
$r_g$
used in the waiting time formulation. It is worth mentioning that this second component is not considered in previous formulations of the random-coefficients logit model introduced in McFadden and Train (Reference McFadden and Train2000).
The third component
 $\eta _{mi}$
captures the variations from the mean population importance
$\eta _{mi}$
captures the variations from the mean population importance
 $\gamma _{m0}$
that is not explained by the actor’s statistics
$\gamma _{m0}$
that is not explained by the actor’s statistics
 $a_n$
. Here, we assume that when the number of random effects is larger than two, the
$a_n$
. Here, we assume that when the number of random effects is larger than two, the
 $\boldsymbol{\eta }_i$
has a multivariate normal distribution with mean vector
$\boldsymbol{\eta }_i$
has a multivariate normal distribution with mean vector
 $\boldsymbol{0}$
and variance–covariance matrix
$\boldsymbol{0}$
and variance–covariance matrix
 $\boldsymbol{\Sigma }$
. In the case of one random effect, this assumption reduces to a univariate normal distribution with mean
$\boldsymbol{\Sigma }$
. In the case of one random effect, this assumption reduces to a univariate normal distribution with mean
 $0$
and variance
$0$
and variance
 $\sigma ^2$
.
$\sigma ^2$
.
The formulation of the random-effects DyNAM presented above is quite flexible. The introduction of random effects controlling for unobserved heterogeneity in actors’ activity (i.e. in the rate function
 $\tau _i$
) is analogous to that in the receiver’s choice. Moreover, the use of random effects in DyNAM can be extended to model unobserved heterogeneity in data with different nested structures, in analogy with the modeling of multiple sequences introduced by DuBois et al. (Reference DuBois, Butts, McFarland and Smyth2013) for REMs. Compared to the model of DuBois et al. (Reference DuBois, Butts, McFarland and Smyth2013), the random-effects DyNAM is more general since it includes nodal covariates
$\tau _i$
) is analogous to that in the receiver’s choice. Moreover, the use of random effects in DyNAM can be extended to model unobserved heterogeneity in data with different nested structures, in analogy with the modeling of multiple sequences introduced by DuBois et al. (Reference DuBois, Butts, McFarland and Smyth2013) for REMs. Compared to the model of DuBois et al. (Reference DuBois, Butts, McFarland and Smyth2013), the random-effects DyNAM is more general since it includes nodal covariates
 $a_n$
in the definition of the random slopes.
$a_n$
in the definition of the random slopes.
The proposed model is implemented in the R package goldfish.latent available and hosted on GitHub https://github.com/snlab-ch/goldfish.latent .
5. Model estimation
The assumption that the subprocesses describing the waiting time between events and the choice of the receiver are conditionally independent, given the process state, holds in the presence of random effects. Thus, the vectors of parameters
 $\boldsymbol{\theta }$
,
$\boldsymbol{\theta }$
,
 $\boldsymbol{\beta }$
, and
$\boldsymbol{\beta }$
, and
 $\boldsymbol{\gamma }$
are estimated separately when only one of the submodels includes random effects. If the random effects appear in both submodels, the separability assumption does not hold anymore, and the parameters need to be estimated jointly.
$\boldsymbol{\gamma }$
are estimated separately when only one of the submodels includes random effects. If the random effects appear in both submodels, the separability assumption does not hold anymore, and the parameters need to be estimated jointly.
Here, we describe the estimation of a DyNAM with random effects in the receiver choice model only. The estimation of the parameter
 $\boldsymbol{\theta }$
is carried out over the partial likelihood as described at the end of Section 3.
$\boldsymbol{\theta }$
is carried out over the partial likelihood as described at the end of Section 3.
We follow a Bayesian approach to make inferences about the random-effect as well as the fixed-effect coefficients in the receiver choice submodel. The parameters are estimated using the Hamiltonian Monte Carlo (HMC) method (Neal, Reference Neal, Brooks, Gelman, Jones and Meng2011; Hoffman & Gelman, Reference Hoffman and Gelman2014) as implemented in the probabilistic programming language Stan (Stan Development Team, 2022). The HMC method and model parametrization we chose allows circumventing two issues that usually happen when estimating the parameters of mixed-effect models.
The first issue concerns the number of parameters to be estimated. It is well-known that inference for high-dimensional models is challenging. Typical Markov Chain Monte Carlo algorithms, like Gibbs or Metropolis sampling, tend to get stuck in local neighborhoods and poorly explore the space of the posterior distribution due to the use of inefficient random walks. It follows that sampling from the posterior distribution of mixed-effect models might be extremely time-consuming.
Algorithms based on the HMC have been developed to overcome this issue (Neal, Reference Neal, Brooks, Gelman, Jones and Meng2011). More specifically, the HMC method transforms the problem of sampling from a target distribution into the problem of simulating Hamiltonian dynamics by introducing an auxiliary variable scheme. In a nutshell, HMC explores the sample space simulating the evolution of a particle in a Hamiltonian system where the position and momentum of the particle are updated step by step. Empirical studies have proven that HMC algorithms perform much better than the Gibbs and Metropolis algorithms in high-dimensional scenarios. We refer the readers interested in the intuition behind the HMC method and the technical details to the papers of Betancourt (Reference Betancourt2017) and Neal (Reference Neal, Brooks, Gelman, Jones and Meng2011).
The second issue relates to the parametrization of the distribution for the random effects. As described in Betancourt and Girolami (Reference Betancourt and Girolami2015), small changes in the parameters of the random effects distributions might induce considerable changes in the density of the posterior distribution. If the data are sparse, the posterior distribution has the shape of a funnel with a quite narrow neck. A method to circumvent this pathology is to reparametrize the model with the help of auxiliary variables in such a way that the search space consists of independent variables. Papaspiliopoulos et al. (Reference Papaspiliopoulos, Roberts and Sköld2007) introduced the notion of scale noncentered parametrization for the mixed-effect model.
For the random-effects DyNAM, the scale noncentered parametrization is obtained by factorizing the variance–covariance matrix
 $\boldsymbol\Sigma$
using the Cholesky factorization. The factorization represents the random effects as a transformation of a set of independent normal standard variables:
$\boldsymbol\Sigma$
using the Cholesky factorization. The factorization represents the random effects as a transformation of a set of independent normal standard variables:
 \begin{align*} \alpha _{mi} &= \gamma _{m0} + \sum _{n} \gamma _{mn} \, a_n(i,\, {\boldsymbol{{y}}}) + \tilde{\eta }_{mi} \boldsymbol{\Lambda } \\ \boldsymbol{\Sigma } &= \boldsymbol{\Lambda } \boldsymbol{\Lambda }^t \\ \tilde{\boldsymbol{\eta}}_i &\sim MN(\boldsymbol{0}, {\boldsymbol{{I}}}) \end{align*}
\begin{align*} \alpha _{mi} &= \gamma _{m0} + \sum _{n} \gamma _{mn} \, a_n(i,\, {\boldsymbol{{y}}}) + \tilde{\eta }_{mi} \boldsymbol{\Lambda } \\ \boldsymbol{\Sigma } &= \boldsymbol{\Lambda } \boldsymbol{\Lambda }^t \\ \tilde{\boldsymbol{\eta}}_i &\sim MN(\boldsymbol{0}, {\boldsymbol{{I}}}) \end{align*}
with
 $\boldsymbol{\Lambda }$
a lower triangular matrix with real and non-negative diagonal values.
$\boldsymbol{\Lambda }$
a lower triangular matrix with real and non-negative diagonal values.
We implemented the estimation procedure based on the HMC method with the scale noncentered transformation using Stan (Stan Development Team, 2022). Based on our experience, we recommend to use an inverse Gamma distribution
 $\Gamma ^{-1}(1, 1)$
for the variance
$\Gamma ^{-1}(1, 1)$
for the variance
 $\sigma ^2$
when the model includes only one random effect, and the inverse Wishart distribution
$\sigma ^2$
when the model includes only one random effect, and the inverse Wishart distribution
 $\textit{Inv-Wishart}_{M}({\boldsymbol{{I}}})$
distribution with
$\textit{Inv-Wishart}_{M}({\boldsymbol{{I}}})$
distribution with
 $M\gt 1$
random effects for the variance–covariance matrix
$M\gt 1$
random effects for the variance–covariance matrix
 $\boldsymbol{\Sigma }$
(Gelman & Hill, Reference Gelman and Hill2006). We also suggest to use a weakly informative normal distribution (e.g.,
$\boldsymbol{\Sigma }$
(Gelman & Hill, Reference Gelman and Hill2006). We also suggest to use a weakly informative normal distribution (e.g.,
 $N(0, 4)$
) for the parameters
$N(0, 4)$
) for the parameters
 $\theta _g,\, \beta _h, \, \gamma _{mn}$
.
$\theta _g,\, \beta _h, \, \gamma _{mn}$
.
6. Model comparison
The application of the random-effects DyNAM requires the specification of the fixed and random effects included in the model. Statistics based on information criteria are crucial to support researchers in choosing which statistics have random effects. This complements the model specification process based on theory-driven arguments.
Drawing on the literature on the random effects model, we suggest using the Deviance Information Criteria (DIC), Widely Available Information Criteria (WAIC or Watanabe-Akaike Information Criteria), and Leave-One-Out Cross-Validation criteria with Pareto-Smoothed Importance Sampling (LOO-PSIS) (Vehtari et al., Reference Vehtari, Gelman and Gabry2017). The information criteria mentioned above aim to estimate the expected out-of-sample error using a bias-corrected adjustment of within-sample error (Gelman et al., Reference Gelman, Hwang and Vehtari2014). In the context of DyNAMs, the expected out-of-sample error is the prediction error for a relational event with a model that uses all events in the sequence except the one considered for prediction to estimate the parameters. A brute force approach would require re-estimating the model for each event in the sequence. Each information criterion uses a different bias-correction adjustment to get around the requirement of re-estimation using a model estimated with the complete event sequence as an input. Interested readers can refer to Vehtari et al. (Reference Vehtari, Gelman and Gabry2017) and Gelman et al. (Reference Gelman, Hwang and Vehtari2014) for a detailed description.
Two versions of the information criteria listed above have been computed using either the conditional or marginal version of the likelihood depending on the focus wished for the information criteria. The choice between the two depends on the specific application and whether the model should be predictive for events sent by actors presented in the data or events sent by new actors. The conditional likelihood predicts for senders presented in the data and thus incorporates the random coefficients in the analysis. The marginal likelihood predicts for new senders and thus integrates the random coefficients out as in, e.g., adaptive quadrature approximation using the MCMC samples proposed by Merkle et al. (Reference Merkle, Furr and Rabe-Hesketh2019). For random-effects DyNAMs, we suggest using the marginalized criteria because the comparison focuses on the variability explained by including random effects rather than the particular values taken by them.
7. Application to dynamics on an online community
Online social media platforms represent a rich source for the study of relational events (Lerner & Lomi, Reference Lerner and Lomi2017; Mulder & Leenders, Reference Mulder and Leenders2019). A large body of research has focused on the most prominent sites like Twitter, Facebook, Reddit, and Instagram to study the propagation of information (Bakshy et al., Reference Bakshy, Messing and Adamic2015), content generation (Bhattacharya et al., Reference Bhattacharya, Phan, Bai and Airoldi2019), and political position (Hemphill et al., Reference Hemphill, Otterbacher and Shapiro2013), among others topics. Social media niche sites represent a better scenario to study social phenomenon in-depth, beyond the analyses on actors centrality, as demonstrated in studies of virality (Hemsley & Kelly, Reference Hemsley and Kelly2019) and professional development (Marlow & Dabbish, Reference Marlow and Dabbish2014). In the latter, a social niche site is an online platform that caters to a specific audience (e.g., designers, academics, or knitters).
We investigated the dynamics of an online community for aspiring and professional digital and graphic designers called Dribbble.com. Footnote 1 The website was founded in 2009 and is a social network site to share and get feedback on user-made work (Scolere, Reference Scolere2019). Dribbble uses an invite-only membership system for new users and has a specific daily and monthly rate limit on the number of post images. As a consequence, the work posted on the platform has a high standard, and users develop a sense of belonging to an elite community (Wachs et al., Reference Wachs, Hannák, Vörös and Daróczy2017). Users label the pieces of work with one or more tags describing the content and characteristics of the image.
Users can interact in different ways on the platform: they can follow other users, and like and comment on the work of other users. Time-stamped information on these interactions was collected using the platform API service.
After describing the data set, we illustrate how to apply the random-effects DyNAM to analyze the Dribble data. In particular, we outline the model specification and perform model selection using information criteria.
7.1 Description of the data set
We analyzed the sequence of like events that took place from 2015-03-10 to 2015-03-13 among the users. We chose a week in March (only the weekdays, Tuesday to Friday) to avoid the effects of seasonal and cyclic behavior observed in the data. The sequence of likes displayed a yearly seasonal cycle, with a peak in January and a decline in the last trimester of the year. The four days reflect the activity of a typical week during 2015, a year after the initial consolidation period of the platform (2009–2013), and before a second growth period that happened in 2016. We excluded from the data set the users belonging to a team as those might be employees of design companies who potentially interact with each other differently than nonaffiliated users.
We focused on published design pieces that use the tag “UI” (User Interface), the most frequent tag used throughout data collection. The subset allowed us to study the behavior of users working in similar design areas. We considered all the users who posted at least one new image, or were part of at least three like events or two follow events either as sender or receiver during the days considered for the analysis. We ended up with a data set with 1,080 users, 4,671 like events, 992 follow events, and 297 newly published design pieces.
For any point in time
 $t$
, we defined the sender set (
$t$
, we defined the sender set (
 $\mathcal{S}({t})$
) as the collection of users that created an account in the platform before time
$\mathcal{S}({t})$
) as the collection of users that created an account in the platform before time
 $t$
and the receiver set (
$t$
and the receiver set (
 $\mathcal{R}({t})$
) as the subset of users in
$\mathcal{R}({t})$
) as the subset of users in
 $\mathcal{S}({t})$
that posted a shot before time
$\mathcal{S}({t})$
that posted a shot before time
 $t$
. The process state is defined as
$t$
. The process state is defined as
 \begin{equation*}{\boldsymbol{{y}}}(t) = (\boldsymbol{{x}}^{(\textit {l})}(t),\, \boldsymbol{{x}}^{(\textit {f})}(t),\, \mathcal {S}(t),\, \mathcal {R}(t))\end{equation*}
\begin{equation*}{\boldsymbol{{y}}}(t) = (\boldsymbol{{x}}^{(\textit {l})}(t),\, \boldsymbol{{x}}^{(\textit {f})}(t),\, \mathcal {S}(t),\, \mathcal {R}(t))\end{equation*}
where
 $\boldsymbol{{x}}^{(\textit{l})}(t)$
is the binary network of the past like events and, similarly,
$\boldsymbol{{x}}^{(\textit{l})}(t)$
is the binary network of the past like events and, similarly,
 $\boldsymbol{{x}}^{(\textit{f})}(t)$
the binary network of past follow events between users.
$\boldsymbol{{x}}^{(\textit{f})}(t)$
the binary network of past follow events between users.
7.2 Model specification
As an illustration, we use different specifications of the DyNAM choice submodel including both random and fixed effects. All the models have the same fixed-effects specification, and differ in the specification of the random effects.
The fixed-effect specification includes the following statistics:
 \begin{align} s_{1}(i,j,{\boldsymbol{{y}}}) &= x^{(\textit{l})}_{ij}\nonumber \\ s_{2}(i,j,{\boldsymbol{{y}}}) &= x^{(\textit{l})}_{ji}\nonumber \\ s_{3}(i,j,{\boldsymbol{{y}}}) &= x^{(\textit{f})}_{ij} \nonumber \\ s_{4}(i,j,{\boldsymbol{{y}}}) &= x^{(\textit{f})}_{ji} . \end{align}
\begin{align} s_{1}(i,j,{\boldsymbol{{y}}}) &= x^{(\textit{l})}_{ij}\nonumber \\ s_{2}(i,j,{\boldsymbol{{y}}}) &= x^{(\textit{l})}_{ji}\nonumber \\ s_{3}(i,j,{\boldsymbol{{y}}}) &= x^{(\textit{f})}_{ij} \nonumber \\ s_{4}(i,j,{\boldsymbol{{y}}}) &= x^{(\textit{f})}_{ji} . \end{align}
The statistic
 $s_{1}$
takes value 1 if user
$s_{1}$
takes value 1 if user
 $i$
liked a piece of work posted by user
$i$
liked a piece of work posted by user
 $j$
in the past, 0 otherwise. This inertia effect plays the role of the “intercept” in the model and captures the elemental behavior of updating existing ties. The statistic
$j$
in the past, 0 otherwise. This inertia effect plays the role of the “intercept” in the model and captures the elemental behavior of updating existing ties. The statistic
 $s_{2}$
captures the tendency to reciprocate previous likes of other users. Thus, the statistics
$s_{2}$
captures the tendency to reciprocate previous likes of other users. Thus, the statistics
 $s_{1}$
and
$s_{1}$
and
 $s_{2}$
model the dependence of like events on previous like events. The statistic
$s_{2}$
model the dependence of like events on previous like events. The statistic
 $s_{3}$
represents the tendency of actors to like the pieces of work posted by users followed on the platform. Similarly, the statistic
$s_{3}$
represents the tendency of actors to like the pieces of work posted by users followed on the platform. Similarly, the statistic
 $s_4$
expresses the tendency to reciprocate follow events by likes events. These effects model the dependence of like events on previous follow events, an expected behavior in online social platforms beyond the essential endogenous process generated by the likes events.
$s_4$
expresses the tendency to reciprocate follow events by likes events. These effects model the dependence of like events on previous follow events, an expected behavior in online social platforms beyond the essential endogenous process generated by the likes events.
Table 3. Model specifications used to analyze the like relational events. Model (1) is a standard DyNAM. Models (2) to (4) are DyNAMs with random effects.

We included random coefficients for the inertia effect as this is considered a baseline effect in the receiver choice model of DyNAMs. The simplest random-effects specification includes only the parameter
 $\gamma _{10}$
. The resulting model (Model (2) in Table 3) assesses how much variation of the random inertia coefficients is present in the analyzed event sequence. To explain part of the variability of the random effects using actors’ characteristics, we subsequently added the following statistics:
$\gamma _{10}$
. The resulting model (Model (2) in Table 3) assesses how much variation of the random inertia coefficients is present in the analyzed event sequence. To explain part of the variability of the random effects using actors’ characteristics, we subsequently added the following statistics:
 \begin{align} a_{1}(i,{\boldsymbol{{y}}}) &= \log \!\Big ( \sum _j x^{(\textit{l})}_{ij}(t_0) + 1 \Big ) \nonumber \\ a_{2}(i,{\boldsymbol{{y}}}) &= t_0 - t_{i_c} . \end{align}
\begin{align} a_{1}(i,{\boldsymbol{{y}}}) &= \log \!\Big ( \sum _j x^{(\textit{l})}_{ij}(t_0) + 1 \Big ) \nonumber \\ a_{2}(i,{\boldsymbol{{y}}}) &= t_0 - t_{i_c} . \end{align}
The statistic
 $a_1$
is the out-degree activity of the actors at time
$a_1$
is the out-degree activity of the actors at time
 $t_0$
, the initial time of the analyzed event sequence that corresponds to 2015-03-10. We used the logarithm of the out-degree because of the heavy-tailed and skewed distribution of the statistic. The log transformation reduces the effect of the highly active users on the parameter size. The statistic
$t_0$
, the initial time of the analyzed event sequence that corresponds to 2015-03-10. We used the logarithm of the out-degree because of the heavy-tailed and skewed distribution of the statistic. The log transformation reduces the effect of the highly active users on the parameter size. The statistic
 $a_2$
is the lifetime in years of a user’s account measured at time
$a_2$
is the lifetime in years of a user’s account measured at time
 $t_0$
. The term
$t_0$
. The term
 $t_{i_c}$
is the time at which the user
$t_{i_c}$
is the time at which the user
 $i$
created the account in the platform, which predates
$i$
created the account in the platform, which predates
 $t_0$
, the beginning of the analyzed period, in each case.
$t_0$
, the beginning of the analyzed period, in each case.
To facilitate the interpretation and the numerical stability of the HMC, we standardized the statistics
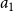 $a_1$
and
$a_1$
and
 $a_2$
by subtracting their mean and dividing by their standard error. This transformation helps to keep a general set of priors for the
$a_2$
by subtracting their mean and dividing by their standard error. This transformation helps to keep a general set of priors for the
 $a_n$
coefficients where the parameters are scale-free. In other cases, the prior should consider the scale of the data in a sensitive way to avoid having a strongly informed prior that might heavily influence the posterior distribution. The inclusion of the statistics
$a_n$
coefficients where the parameters are scale-free. In other cases, the prior should consider the scale of the data in a sensitive way to avoid having a strongly informed prior that might heavily influence the posterior distribution. The inclusion of the statistics
 $a_1$
and
$a_1$
and
 $a_2$
one at the time led to Models (3) and (4) in Table 3.
$a_2$
one at the time led to Models (3) and (4) in Table 3.
Table 3 shows the considered model specifications for the utility of the receiver choice. Model (1) is the model without random effects and is the baseline model against which the random-effects DyNAM are compared. Model (2) adds random coefficients for the inertia effect to Model (1). Models (3) and (4) further add the statistics
 $a_1$
and
$a_1$
and
 $a_2$
, respectively, in
$a_2$
, respectively, in
 $\alpha _{1i}$
to explain part of the variability of the random coefficients of the inertia statistic. It is worth mentioning that the substitution of
$\alpha _{1i}$
to explain part of the variability of the random coefficients of the inertia statistic. It is worth mentioning that the substitution of
 $\alpha _{1i}$
in the utility formula
$\alpha _{1i}$
in the utility formula
 $f(i, j, {\boldsymbol{{y}}},\boldsymbol{\beta },\boldsymbol{\alpha })$
for Models (3) and (4) yields to a representation where the corresponding
$f(i, j, {\boldsymbol{{y}}},\boldsymbol{\beta },\boldsymbol{\alpha })$
for Models (3) and (4) yields to a representation where the corresponding
 $a_n$
statistics is part of an interaction with the
$a_n$
statistics is part of an interaction with the
 $s_1$
statistic. This formulation is used in the implementation of the models.
$s_1$
statistic. This formulation is used in the implementation of the models.
7.3 Results
The data were prepossessed using the R package goldfish (Stadtfeld & Hollway, Reference Stadtfeld and Hollway2022) that allows computing the change statistics for each event for the model formulation described in Section 7.2. We used an inverse Gamma
 $\Gamma ^{-1}(1, 1)$
as a prior distribution for the random-effects variance
$\Gamma ^{-1}(1, 1)$
as a prior distribution for the random-effects variance
 $\sigma ^2$
and place a
$\sigma ^2$
and place a
 $N(0, 4)$
prior on each
$N(0, 4)$
prior on each
 $\beta _h, \, \gamma _{1n}$
parameter for the estimation.
$\beta _h, \, \gamma _{1n}$
parameter for the estimation.
We checked the convergence of the HMC algorithm using diagnostic plots (e.g., trace plots) and statistics (e.g., rank normalized split-
 $\hat{R}$
statistic, effective sample size) as described in Vehtari et al. (Reference Vehtari, Gelman, Simpson, Carpenter and Bürkner2021).
$\hat{R}$
statistic, effective sample size) as described in Vehtari et al. (Reference Vehtari, Gelman, Simpson, Carpenter and Bürkner2021).
Figure 1 and Table 4 report the results obtained from 1,250 draws each from 8 chain of the posterior distribution.Footnote 2

Figure 1. Credibility intervals and posterior means for the parameters of the models defined in Table 3. The white dot with the thick border represents the posterior mean. The horizontal lines show the 50% (thick line) and 90% credibility intervals (thin line).
Table 4. Summary statistics of the posterior distribution, mean, standard deviation (SD) and credibility interval (CI) for the models defined in Table 3.

Figure 1 shows the central 50% and 90% credibility intervals and the means of the posterior distribution for the coefficients in Models (1) to (4). The white dot with the thick border represents the posterior mean. The horizontal lines show the 50% (thick line) and 90% (thin line) credibility intervals indicating the admissible range of coefficients values compatible with the data. The central 50% credible interval is defined by the first and third quantiles, while the central 90% credibility interval by the percentile 5% and 95% of the posterior distribution. The different colours indicate the estimates of the quantities described above for each of the Models (1) to (4).
Comparisons among the estimates suggest that the fixed effect coefficients, except the one for the inertia statistic, do not differ significantly across the four models. This result is expected since the model specifications presented in Table 3 introduce random effects and actors covariates to explain the variability of the inertia coefficient.
The inertia coefficient in Model (1) has a mean posterior of
 $1.73$
. In the actor-specific random effects Model (2), the average inertia coefficient has a mean posterior of
$1.73$
. In the actor-specific random effects Model (2), the average inertia coefficient has a mean posterior of
 $2.18$
, portraying an increase with respect to the fixed effect in Model (1). The average inertia value increases further to
$2.18$
, portraying an increase with respect to the fixed effect in Model (1). The average inertia value increases further to
 $2.49$
when the model accounts for the out-degree activity of the users [Model (3)], but remains the same when the lifetime of an account is considered [Model (4)].
$2.49$
when the model accounts for the out-degree activity of the users [Model (3)], but remains the same when the lifetime of an account is considered [Model (4)].
Similar results are observed for the estimates of the posterior mean of the variance of the random effects
 $\sigma ^2$
. The value of
$\sigma ^2$
. The value of
 $\sigma ^2$
in Model (2) is
$\sigma ^2$
in Model (2) is
 $1.29$
. The introduction of the log-outdegree [Model (3)] leads to a posterior mean of
$1.29$
. The introduction of the log-outdegree [Model (3)] leads to a posterior mean of
 $0.82$
and reduces the unexplained variance of the inertia effect by 36% (
$0.82$
and reduces the unexplained variance of the inertia effect by 36% (
 $=\!(1.29-0.82)/1.29\cdot 100$
). No significant reduction is noted when controlling for the lifetime of an account in Model (4) (
$=\!(1.29-0.82)/1.29\cdot 100$
). No significant reduction is noted when controlling for the lifetime of an account in Model (4) (
 $\sigma ^2 = 1.28$
).
$\sigma ^2 = 1.28$
).
Figure 2 shows the posterior mean (white dot), the central 50% (dark grey), and 90% (light grey) credible intervals for each random coefficient
 $\eta _{1i}$
describing the unexplained variance of the inertia effect for each user. In the plots, the users are displayed according to the increasing value of the posterior mean in Model (2).
$\eta _{1i}$
describing the unexplained variance of the inertia effect for each user. In the plots, the users are displayed according to the increasing value of the posterior mean in Model (2).

Figure 2. Credibility intervals for random effects
 $\eta _{1i}$
by actors for the Models (2) to (4) described in Table 3.
$\eta _{1i}$
by actors for the Models (2) to (4) described in Table 3.
Figure 2 indicates that the unexplained variability decreases from Model (2) to Model (3), as suggested by the smaller posterior means and ranges of the credibility intervals. No differences are observed when comparing Model (4) to Model (2). This result aligns with the observations above.
We also note that there are differences in the length of the credibility intervals among the users. The analyzed data are unbalanced since users did not engage in the same number of events. For users with a few events, large credibility intervals are obtained, and the coefficient
 $\eta _{1i}$
shrinks towards the global average tendency. In contrast, short credibility intervals and large deviations
$\eta _{1i}$
shrinks towards the global average tendency. In contrast, short credibility intervals and large deviations
 $\eta _{1i}$
from zero are observed for actors engaged in a considerable number of events. This is a common finding in multilevel models (Gelman & Hill, Reference Gelman and Hill2006; Snijders & Bosker, Reference Snijders and Bosker2011).
$\eta _{1i}$
from zero are observed for actors engaged in a considerable number of events. This is a common finding in multilevel models (Gelman & Hill, Reference Gelman and Hill2006; Snijders & Bosker, Reference Snijders and Bosker2011).
We conclude this section by formally comparing Models (1) to (4) based on the marginalized criteria introduced in Section 6 and illustrating the interpretations of the coefficients of the selected model. Table 5 shows the values of the information criteria for the four models. The models with the random effects have a better fit than the standard DyNAM [Model (1)], as suggested by the lower values of the criteria. In particular, the specification in Model (3) is the most adequate, as suggested by the inference of the posterior means and credibility intervals presented in the previous line.
Table 5. Information Criteria (IC), expected log pointwise predictive density (elpd) and effective number of parameters (p) with their standard error (SE) for the Models in Table 3

Concerning the parameter interpretation of Model (3), the significant values of the fixed parameters in Table 4 can be interpreted as follows. The positive parameter for the reciprocity effect in the likes network (
 $\beta _2$
) suggests a tendency to choose a receiver that liked the sender’s artwork in the past. Similarly, the positive parameter for the tie effect in the following network (
$\beta _2$
) suggests a tendency to choose a receiver that liked the sender’s artwork in the past. Similarly, the positive parameter for the tie effect in the following network (
 $\beta _3$
) indicates that there is evidence that users tend to like pieces of work posted by users they follow on the platform. In addition, the positive parameter for the reciprocity effect in the following network (
$\beta _3$
) indicates that there is evidence that users tend to like pieces of work posted by users they follow on the platform. In addition, the positive parameter for the reciprocity effect in the following network (
 $\beta _4$
) suggests a preference for receivers who followed the sender on the platform. For the random effects related to the inertia, the value of the average inertia coefficient (
$\beta _4$
) suggests a preference for receivers who followed the sender on the platform. For the random effects related to the inertia, the value of the average inertia coefficient (
 $\gamma _{10}$
) is positive and significant, indicating a tendency to choose a receiver that the sender had liked artwork pieces in the past. Additionally, for the models with random effects, the negative value of the parameter related to the logarithm of the outdegree (
$\gamma _{10}$
) is positive and significant, indicating a tendency to choose a receiver that the sender had liked artwork pieces in the past. Additionally, for the models with random effects, the negative value of the parameter related to the logarithm of the outdegree (
 $\gamma _{11} \lt 0$
) indicates that low-active users are more likely to send likes events to the same receiver than more active users. Finally, the positive value of the inertia random effect variance
$\gamma _{11} \lt 0$
) indicates that low-active users are more likely to send likes events to the same receiver than more active users. Finally, the positive value of the inertia random effect variance
 $\sigma ^2$
suggests users differ in their tendency to send like events to the same receiver. The interpretation of the parameters is conditional on a particular user initiating a like event at a certain point in time, as modeled by the rate submodel.
$\sigma ^2$
suggests users differ in their tendency to send like events to the same receiver. The interpretation of the parameters is conditional on a particular user initiating a like event at a certain point in time, as modeled by the rate submodel.
8. Conclusion
In this paper, we proposed an extension of the DyNAMs and developed a practical and appropriate implementation of parameter estimation for this model. Random-effects DyNAM draw on the literature on multilevel models and include random effects to control for actor or context unobserved heterogeneity in relational event data.
The model formulation includes monadic network statics or actors’ covariates to explain part of the unobserved variability of a given network mechanism. Consequently, this new formulation has the advantage of providing a more precise estimation of the individual variations from the mean population importance parameters, especially for actors that send a few events (Gelman & Hill, Reference Gelman and Hill2006). Furthermore, the coefficients related to the monadic actors’ covariates allow making inferences regarding the strength and direction in which actors deviate from the average tendency of the network mechanism by every unit of change in the given covariate. This is an advantage compared to the related model of DuBois et al. (Reference DuBois, Butts, McFarland and Smyth2013).
We have described the random-effects DyNAMs for the multinomial choice model that determines the receiver of the events. However, the framework is flexible. It can be generalized to include random effects in the model specification for the actors’ activity rate in an analogous way. Similarly, the model can be extended to analyze multiple sequences of events or more complex relational data. The proposed estimation method can be applied when the random effects are only used in one of the submodels. In that case, the separability assumption holds. If the random effects appear in both submodels, the parameters must be estimated jointly to consider the natural correlation between the random effects from the same actor in the different submodels. The development of the joint estimation of the parameters is the subject of future work.
A Bayesian estimation procedure based on HMC algorithms has been developed and implemented to estimate the parameters of the models. Compared to the more traditional Gibbs and Metropolis-Hastings algorithms, the HMC methods are more efficient and allow the exploration of the space of the posterior distribution more quickly. The current implementation applied to the empirical example, which represents a middle-size data set, took 17 hours to generate the draws of the posterior distribution for Model (2) and 9 hours for Model (3), where the model includes a monadic covariate to explain the variability. Models were run on a quad-core Intel Xeon E3-1585Lv5 processor (3.0–3.7 GHz). However, an additional limitation refers to the computation time scalability for large datasets, which represents an issue for the application of the model extension. A possible solution is to exploit the sparsity of the event network. The sparsity induces incremental updates of the statistics to a few actors. Our model extension could use additional strategies proposed to reduce the computation time considering the network event’s sparsity (Vu et al., Reference Vu, Asuncion, Hunter and Smyth2011b; Perry & Wolfe, Reference Perry and Wolfe2013). A second alternative is using nested case-control sampling to reduce the data set size as proposed by Vu et al. (Reference Vu, Lomi, Mascia and Pallotti2017) and Lerner and Lomi (Reference Lerner and Lomi2020) for REM.
A natural progression of this work is extending the modeling framework to scenarios where the events sequence generative process display seasonal or cyclic behaviors. Some strategies have been developed for REMs that require prior knowledge either of the regular intervals that produce the seasonality (Amati et al., Reference Amati, Lomi and Mascia2019) or the time window size where variations happen (Mulder & Leenders, Reference Mulder and Leenders2019). Those strategies can also be implemented using the random-effects DyNAM introduced here, allowing empirical studies in scenarios where the data presents seasonal or cyclic behaviors without restricting the analysis to a subset of the data. Formulation of a DyNAM directly modeling temporal trends is the object of ongoing research.
Applications of the proposed extension required that researchers specify which statistics should be included in the model using random effects. Snijders and Bosker (Reference Snijders and Bosker2011, sec. 6.4) discussed this issue for multilevel models offering a digested compendium of possible problems and guidelines to follow during the model specification. Snijders and Bosker described the role of the substantive theory and the statistical considerations in the model specification. Regarding the substantive theory, it is advisable to include random effects for statistics that relate to hypotheses on unobserved heterogeneity or are plausible from subject-matter knowledge. For the statistical considerations, in the absence of prior knowledge, researchers in the absence of prior knowledge, researchers may follow a data-driven approach to select the network statistics to have random effects. In general, it is not advisable to include all statistics as random effects because the model would induce long computation times and might fail to converge. Limiting the number of random effects to a few may be necessary so that the model describes the event sequence satisfactorily but without unnecessary complications.
We illustrated the application of the random-effects DyNAM by analyzing relational events among the users of an online community of aspiring and professional digital and graphic designers. Based on the argument that users might behave differently on the platform, we focused on the inertia effect describing the repetition of events between the same sender and receiver. This is a baseline effect in the receiver choice model of DyNAMs. The analysis indicates that there are indeed differences between users. Part of the inertia variability can be explained by the users’ activity, with a lower likelihood of active users repeating events than less active users, but not by the lifetime of the users’ account.
We used a subset of the dataset where known cyclic and seasonal patterns identified after an exploratory data analysis are considered. Consequently, the model results illustrate the model’s applicability rather than a formal empirical study. Hence, the findings reflect the dynamics of the likes events during the analyzed week for users working in a similar design area. It is possible that popular tags may have similar event dynamics to the ones found here, considering that the dataset used the most frequent tag. The behavior might differ for tags used for niche communities of designers working in specified trends of art or types of designs.
The application shows that the model could be of particular value in social media contexts, where often large data sets can be collected while little is known about user characteristics. However, we believe that the new random-effects DyNAM could be fruitfully applied in a variety of relational event studies where behavioral heterogeneity between individuals can be expected.
Data availability
The data we used for the illustration are not publicly available. They were collected by Prof. Johannes Wachs (Vienna University of Economics and Business) who was kind enough to shared them with us.
Acknowledgements
We thank the anonymous reviewers and the editor Prof. Tom A.B. Snijders for their careful reading and constructive comments. We also like to thank the members of the Social Networks Lab at ETH Zürich, attendees to Duisterbelt, and Prof. Marijtje van Duijn (University of Groningen) for feedback on the model definition and specification. We are also grateful to Prof. Johannes Wachs (Vienna University of Economics and Business) for sharing the data for the illustration of the model.
Funding statement
This research has received funding from The Swiss National Science Foundation (grants no. 10001A_169965, 10DL17_183008, and P2EZP1_188022).
Competing interests
None.















 Open access
Open access