



1. Introduction
How does candidate order on the ballot affect voting behavior and election results? Ballot order effects have important implications for ballot design, candidate selection, and intra-party competition in American and comparative politics (Ho and Imai Reference Ho and Imai2008; Marcinkiewicz and Stegmaier Reference Marcinkiewicz and Stegmaier2015; Ortega Villodres Reference Ortega Villodres2008). Previous research suggests that candidates in the first and last positions tend to receive more votes than other candidates (Alvarez, Sinclair, and Hasen Reference Alvarez, Sinclair and Hasen2006), focusing on first-past-the-post (Ho and Imai Reference Ho and Imai2008) and party-list proportional representation (Gulzar, Robinson, and Ruiz Reference Gulzar, Robinson and Ruiz2022).
In this study, I extend the analysis of ballot order effects to electoral systems with ordinal ballots, where voters rank candidates. These systems include ranked-choice voting (RCV), instant-runoff elections or alternative vote, single-transferable vote, and Borda count (Reilly Reference Reilly2001; Santucci Reference Santucci2021). Here, I focus on elections with grid-style ballots. Although several studies examine ballot order effects under some of these systems, unfortunately, these analyses are limited to voters’ first-choice votes (Curtice and Marsh Reference Curtice and Marsh2014; King and Leigh Reference King and Leigh2009; Marcinkiewicz and Stegmaier Reference Marcinkiewicz and Stegmaier2015; Orr Reference Orr2002; Ortega Villodres Reference Ortega Villodres2008). In contrast, I seek to propose an approach to study ballot order effects on people’s entire candidate rankings.
This letter makes several contributions. First, I discuss two types of ballot order effects, including “position effects”—voters vote for specific candidates because of their ballot positions—and “pattern ranking”—voters rank candidates geometrically given their grid-style ballots. Next, I discuss experimental designs for identifying and estimating these effects. Finally, I illustrate the proposed methods by using survey and natural experiments based on actual RCV elections in 2022. I find that while voters seem less susceptible to specific ballot positions, ballot design can still impact voters via pattern ranking—even when candidate order is fully randomized.
This work has several implications for ballot design, survey research, and ranking data analysis. First, it shows that pattern ranking may affect electoral outcomes in RCV and other systems. With fixed ballot order, as in many RCV elections in the United States, pattern ranking may be the most consequential. Experts have suggested that ballot order randomization may solve the problem.Footnote 1 However, this letter demonstrates that pattern ranking may still affect electoral results even when ballot order is fully randomized, which is often considered the best but practically challenging solution.Footnote 2 Consequently, it may be worth considering an alternative solution to ballot order effects, which does not depend on randomization or rotation, when voters rank candidates.
Second, similar effects may impact all survey research using ranking questions. When a subset of respondents offer ranking responses based on geometric patterns and not their underlying preferences, collected data cannot be used to study people’s attitudes and behaviors without caution. Thus, future research must investigate the statistical consequences of pattern ranking for survey research. Atsusaka and Kim (Reference Atsusaka and Kim2024), for example, examine how pattern ranking leads to measurement errors in ranking questions and propose design-based methods to address the problem.
Finally, ranking data allow researchers to study diverse quantities of interest while targeting many different substantive questions. However, this flexibility also implies that analyzing ranking data can be prone to arbitrary analysis and presentation (Atsusaka Reference Atsusaka2023). Thus, future research must investigate how to leverage ranking data while avoiding selective inference.
2. Framework and Quantities of Interest
Consider an experiment where subjects are exposed to a grid-style ballot with a particular candidate order. Figure 1, for example, displays a grid-style ranking ballot based on the 2022 U.S. Senate election in Alaska.Footnote
3
In this experiment, the treatment is the order in which candidates appear on the ballot (e.g., Chesbro
 $\rightarrow $
Kelley
$\rightarrow $
Kelley
 $\rightarrow $
Murkowski
$\rightarrow $
Murkowski
 $\rightarrow $
Tshibaka). The outcome in this experiment is a ranking that subjects assign to the list of candidates, such as (2, 1, 3, 4). I consider two effects: position effects and pattern ranking.
$\rightarrow $
Tshibaka). The outcome in this experiment is a ranking that subjects assign to the list of candidates, such as (2, 1, 3, 4). I consider two effects: position effects and pattern ranking.

Figure 1 Example of grid-style ordinal ballot.
2.1. Position Effects
First, I consider the causal effect of candidate
 $j \ (=1,\ldots ,J)$
shown in a specific position
$j \ (=1,\ldots ,J)$
shown in a specific position
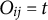 $O_{ij}=t$
(treated) as opposed to another position
$O_{ij}=t$
(treated) as opposed to another position
 $O_{ij}=t^{*}$
(control) for voter
$O_{ij}=t^{*}$
(control) for voter
 $i \ (=1,\ldots ,n)$
. To define quantities of interest, I rely on the potential-outcomes framework for ranking data considered in Atsusaka (Reference Atsusaka2023).
$i \ (=1,\ldots ,n)$
. To define quantities of interest, I rely on the potential-outcomes framework for ranking data considered in Atsusaka (Reference Atsusaka2023).
Let voter i’s potential rankings be
 $\textbf {Y}_{i}(O_{ij}=t)$
and
$\textbf {Y}_{i}(O_{ij}=t)$
and
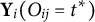 $\textbf {Y}_{i}(O_{ij}=t^{*})$
, respectively (e.g.,
$\textbf {Y}_{i}(O_{ij}=t^{*})$
, respectively (e.g.,
 $\textbf {Y}_{i}(O_{ij}=t)=(1,4,2,3)$
). Let
$\textbf {Y}_{i}(O_{ij}=t)=(1,4,2,3)$
). Let
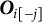 $\boldsymbol {O}_{i[-j]}$
be the ordering (position) of the other
$\boldsymbol {O}_{i[-j]}$
be the ordering (position) of the other
 $J-1$
candidates. Finally, let
$J-1$
candidates. Finally, let
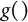 $g()$
be a summary function that maps rankings into scalar values.
$g()$
be a summary function that maps rankings into scalar values.
One causal quantity of interest is the average treatment effect of position t for candidate j on voters’ rankings with respect to counterfactual position
 $t^{*}$
and the order of the remaining candidates
$t^{*}$
and the order of the remaining candidates
 $\boldsymbol {o}$
. I call it the conditional position effect:
$\boldsymbol {o}$
. I call it the conditional position effect:

While various summary functions can be used, the following application focuses on two functions for
 $g()$
: (1) the marginal rank of candidate j (e.g., candidate A was ranked third) and (2) the indicator function that denotes whether candidate j was ranked or not (e.g., candidate B was not ranked).Footnote
4
Thus, I study the position effects on the average rank of each candidate and the probability that each candidate is selected, both of which are useful quantities in elections with ordinal ballots.
$g()$
: (1) the marginal rank of candidate j (e.g., candidate A was ranked third) and (2) the indicator function that denotes whether candidate j was ranked or not (e.g., candidate B was not ranked).Footnote
4
Thus, I study the position effects on the average rank of each candidate and the probability that each candidate is selected, both of which are useful quantities in elections with ordinal ballots.
In many applications, however, researchers may wish to study the overall effect of position t for candidate j on voters’ rankings averaged over all possible counterfactual position
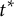 $t^{*}$
and all possible ordering of the remaining candidates
$t^{*}$
and all possible ordering of the remaining candidates
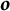 $\boldsymbol {o}$
. I call it the average position effect of position t:
$\boldsymbol {o}$
. I call it the average position effect of position t:

The average position effect is the probability-weighted average of all possible conditional position effects.Footnote
5
Appendix A of the Supplementary Material shows that researchers can identify and estimate the average position effect by fully randomizing ballot orders. Here, one challenge is that the number of comparisons proliferates as the number of candidates increases. For example, with 10 candidates and a given treatment position t (e.g., t = 1) for a target candidate, researchers need to consider 9 counterfactual control positions
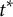 $t^{*}$
(e.g.,
$t^{*}$
(e.g.,
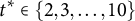 $t^{*} \in \{2, 3, \ldots,10\}$
) and
$t^{*} \in \{2, 3, \ldots,10\}$
) and
 $9!$
ways to permute the other nine candidates. Accordingly, researchers need at least
$9!$
ways to permute the other nine candidates. Accordingly, researchers need at least
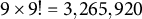 $9 \times 9! = 3,265,920$
control units to estimate the above effect.
$9 \times 9! = 3,265,920$
control units to estimate the above effect.
To resolve this issue, Appendix A of the Supplementary Material shows that analysts can estimate the average position effect with considerably fewer control units by making two additional assumptions. Researchers can estimate the average position effect on candidate ranks, for example, for each position-candidate pair by regressing each candidate’s rank (or any function of it) on a dummy variable denoting a specific ballot position.
2.2. Pattern Ranking
Pattern ranking refers to when voters provide ranked ballots by following specific geometric patterns independent of their preferences. A special case of pattern ranking—(1, 2, …, J)—has been known as “donkey voting” (Orr Reference Orr2002; Reilly Reference Reilly2001, 158). Figure 2 visualizes that pattern ranking generalizes the idea of donkey voting by accommodating many more geometric patterns, including what I call diagonal vote (Panel A, no angle), zigzag vote (Panel B, two or more major angles), and dogleg vote (Panel C, one major angle).

Figure 2 Examples of pattern ranking.
Appendix B of the Supplementary Material shows that when (1) ballot order is randomized and (2) no voter performs pattern ranking, raw responses (recorded rankings with respect to given candidate orders) follow a uniform distribution regardless of people’s underlying preference. Thus, deviation from uniformity can be treated as potential evidence for pattern ranking. More formally, researchers can apply Pearson’s
 $\chi ^2$
test to this problem with test statistic:
$\chi ^2$
test to this problem with test statistic:
 $$\begin{align} \chi^2 = \sum_{r=1}^{J!}\frac{\big( N\widehat{p}_{r} - N\frac{1}{J!} \big)^2}{N\frac{1}{J!}}, \end{align}$$
$$\begin{align} \chi^2 = \sum_{r=1}^{J!}\frac{\big( N\widehat{p}_{r} - N\frac{1}{J!} \big)^2}{N\frac{1}{J!}}, \end{align}$$
where
 $\widehat {p}_{r}$
is the observed proportion of recorded ranking
$\widehat {p}_{r}$
is the observed proportion of recorded ranking
 $r \ (=1,\ldots ,J!)$
,
$r \ (=1,\ldots ,J!)$
,
 $\frac {1}{J!}$
is the expected proportion of the same ranking under the null, and N is the number of observations. Here, one limitation is that applying the test to ranking data with more than five or six items becomes challenging. I leave future research to address the limitation.
$\frac {1}{J!}$
is the expected proportion of the same ranking under the null, and N is the number of observations. Here, one limitation is that applying the test to ranking data with more than five or six items becomes challenging. I leave future research to address the limitation.
3. Application I: Survey Experiments in Congressional and Mayoral RCV Elections
To illustrate the framework, I performed survey experiments via Lucid Marketplace from October 10 to November 7, 2022, before the Oakland mayoral election, the U.S. House of Representatives election in Alaska, and the U.S. Senate election in Alaska.Footnote 6 I used survey experiments because they allowed me to fully randomize ballot orders. This section examines ballot (item) order effects in the context of surveys. Thus, its results may directly apply to all ranking questions beyond RCV. In contrast, the next section seeks to offer more realistic estimates of ballot order effects in actual elections.

Figure 3 Average position effects. Note: Blue = positive, red = negative, gray = nonsignificant.
The survey presented a list of actual candidates to randomly sampled respondents from Oakland (
 $n=258$
) and Alaska (
$n=258$
) and Alaska (
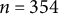 $n=354$
), respectively. The survey asked all respondents two questions. In “forced ranking” questions, which are used to study position effects on average ranks and pattern ranking, respondents must rank all candidates. In “optional ranking” questions, which are leveraged to identify position effects on candidate selection and pattern ranking, they could rank up to three candidates in Oakland and four candidates in Alaska, reflecting their election laws. The order of the two questions was randomized.Footnote
7
Appendix C of the Supplementary Material summarizes the survey design.
$n=354$
), respectively. The survey asked all respondents two questions. In “forced ranking” questions, which are used to study position effects on average ranks and pattern ranking, respondents must rank all candidates. In “optional ranking” questions, which are leveraged to identify position effects on candidate selection and pattern ranking, they could rank up to three candidates in Oakland and four candidates in Alaska, reflecting their election laws. The order of the two questions was randomized.Footnote
7
Appendix C of the Supplementary Material summarizes the survey design.
3.1. Position Effects
Figure 3 visualizes the average position effects on average ranks (upper panels) and candidate selection probabilities (lower panels) for all candidate-position combinations in the three elections. The blue (red) results represent positive (negative) effects, denoting higher (lower) average ranks and selection probabilities, while the gray results suggest nonsignificance.
I find that about 91% (240/264) of the average position effects are statistically insignificant. Although some effects are statistically significant, I find almost no consistent pattern among them. Indeed, 5% of all effects can be significant purely by chance. The results are conservative in the sense that we should observe less significant effects (stronger evidence) if I correct statistical inference for multiple comparisons. The result suggests that respondents were hardly susceptible to average position effects in the experiments.
3.2. Pattern Ranking
Panel A of Figure 4 plots the empirical distributions of all recorded rankings in the U.S. House (left) and U.S. Senate (right) races in Alaska. The panel shows the results from the forced (filled) and optional (non-filled) ranking questions. There are 4! = 24 different ways to rank, and each recorded ranking (given a particular candidate order) should be selected with probability 1/24 = 0.042 without pattern ranking. In Panel B, I visualize all 24 rankings, which are categorized into either the diagonal vote (solid line), zigzag vote (dashed line), or dogleg vote (dotted line).Footnote 8
Panel A shows nonuniform distributions of recorded rankings, implying the presence of pattern ranking. Some geometric patterns, notably (1, 2, 3, 4), are selected significantly more often than others. This means that although some of the ballots reflect people’s genuine preferences, many of them may be based solely on a diagonal line. Pearson’s
 $\chi ^2$
test rejects the null hypothesis that each of the four distributions is uniform at the
$\chi ^2$
test rejects the null hypothesis that each of the four distributions is uniform at the
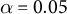 $\alpha = 0.05$
level. Moreover, in Tables F1 and F2 in the Supplementary Material, I find that the dogleg vote is more prevalent than the zigzag vote in almost all cases.
$\alpha = 0.05$
level. Moreover, in Tables F1 and F2 in the Supplementary Material, I find that the dogleg vote is more prevalent than the zigzag vote in almost all cases.
Panel B of Figure 4 provides additional evidence for pattern ranking—31% and 37% of respondents offered the same recorded ranking across the two questions, even though only 3% (House) and 1.6% (Senate) of respondents saw the same candidate order. Namely, many people selected the same geometric pattern even though they were exposed to different orders of candidates. While it requires additional information to estimate the proportion of pattern rankers (Atsusaka and Kim Reference Atsusaka and Kim2024), the results offer partial evidence for pattern ranking.
4. Application II: A Natural Experiment from Alaskan RCV Elections
Finally, I present an alternative strategy to study pattern ranking. In Alaska’s federal and gubernatorial races, candidates are alphabetically ordered in the first state house district and rotated in subsequent districts.Footnote 9 For example, consider four candidates: A, B, C, and D. Then, District 1 has ballot order {A, B, C, D}, District 2 {B, C, D, A}, District 3 {C, D, A, B}, and District 4 {D, A, B, C}. This rotation continues until District 40.

Figure 4 Suggestive evidence for pattern ranking.

Figure 5 Analysis of donkey voting (U.S. Senate election in Alaska). Note: Numbers index treated districts. Horizontal lines are control average values.
This “alphabetization-rotation” procedure may give us a unique chance to analyze RCV in Alaska as a natural experiment. Here, districts are the units of analysis. The outcome is the proportion of voters providing a particular candidate ranking.Footnote 10 The binary treatment denotes whether voters see a given ballot order or not.
Suppose that a target outcome is the proportion of candidate ranking (B, C, D, A). Suppose also that researchers wish to study the prevalence of donkey voting. Then, Districts 2, 6, …, 38 become “treated” districts, where performing donkey voting is the same as casting ranked ballot (B, C, D, A), while others are “control” districts. How many voters provided the target candidate ranking per donkey voting? One possible identification strategy is to compare the outcomes between the treated and control districts. The key assumption is that the proportion of voters who prefer (B, C, D, A) is comparable across the treatment status. Then, the difference in the proportions can be solely attributable to donkey voting.
Figure 5 illustrates this idea by plotting control and treated (with district numbers) districts with respect to four candidate ranking profiles in the 2022 U.S. Senate election. The horizontal lines represent the average values for the control districts. The graph illustrates that the treated districts, on average, have higher proportions than the control districts. I find that about 0.6%–3% of actual ballots may be attributable to donkey voting. Appendix F of the Supplementary Material presents similar results for the 2022 U.S. House and Alaska gubernatorial elections, providing suggestive evidence that donkey voting may be consistently present in actual RCV elections. Of course, this remains a demonstrative analysis, and future research must scrutinize the validity of the identification strategy and its applications to position effects and other forms of pattern ranking.
5. Limitations and Future Research
One notable limitation of this study is that the above analyses require voters’ full rankings, except for the analysis of position effects on candidate selection. To analyze pattern ranking, for example, this work only examined respondents (in Figure 4) and voters (in Figure 5) who ranked four candidates. This is an important limitation because, in many contests, voters may rank a single or at least not all candidates. Thus, it is critical that future research extend the proposed methods to partially ranked data. Potential extensions include the partial identification of position effects, where we may leverage principal stratification and extreme value bounds, and the analysis of “partial pattern ranking,” where we focus on three or four digits in people’s entire candidate rankings. Despite this and other limitations (Appendix H of the Supplementary Material), this letter makes several contributions to the study of ballot order effects when voters rank candidates.
Acknowledgements
This study was approved by the Institutional Review Board (IRB) at Dartmouth College (Study ID: STUDY00032593). For valuable feedback, the author thanks Gustavo Diaz, Seo-young Silvia Kim, Randy Stevenson, Agustín Vallejo, and two anonymous reviewers. The author also thanks Jordan Holbrook for his excellent research assistance for this study. This work was previously circulated as “Analyzing Ballot Order Effects in Ranked-Choice Voting.”
Data Availability Statement
Replication materials can be found on the Political Analysis Harvard Dataverse for Atsusaka (Reference Atsusaka2024) at https://doi.org/10.7910/DVN/AJXRCV.
Supplementary Material
For supplementary material accompanying this paper, please visit https://doi.org/10.1017/pan.2024.9.












 Open access
Open access