



1. Introduction
The insurance distribution channel landscape has always been dominated by bancassurance, brokers, and agents, which accounts for over 90% of global annual premiums for both life and non-life products from 2013 to 2018 (McKinsey & Company, 2021). These channels dominated because they were able to reach customers effectively and promote the uptake of insurance. Banks have numerous touch points relating to customers’ savings, which is a natural gateway to offering wealth protection products while brokers and agents were able to reach individual customers effectively with bespoke advice.
However, the increasing penetration of global smartphone usage and the growing online presence of customers are starting to reshape how insurance is distributed. On any given day, a smartphone user interacts regularly with a number of mobile applications for various purposes (through different apps) including
-
Social media (Twitter, Facebook and TikTok)
-
Ride-hailing (Uber, Lyft, Grab, GoJek)
-
Food delivery (Deliveroo, foodpanda, DoorDash)
-
e-commerce (Amazon, Taobao, eBay, Shopee, Olist)
Customers’ interactions on such platforms greatly exceed what is humanly possible compared to traditional distribution channels, which remain heavily reliant on labour. Embedded insurance products aim to capitalise on this shift in distribution landscape by integrating or embedding relevant insurance propositions during a customers’ online purchase journey. Customers also build a rich and valuable source of data across these platforms that enables customised needs-based insurance offerings for individual profiles. Similar to how telematics has been utilised to profile drivers when assessing motor insurance pricing and risk classification (Weidner et al., Reference Weidner, Transchel and Weidner2016), this data could be leveraged to profile customer risk and recommend suitable products.
Traditional recommendation systems are already widely deployed to suggest videos, music and products on platforms such as YouTube, Spotify, and Amazon. These often involve identifying correlations within copious amount of collected user data (Sharma et al., Reference Sharma, Shaikh and Li2021). For example, Hussien et al. (Reference Hussien, Rahma and Abdulwahab2021) proposed a recommendation system based on likes, dislikes, views, product ratings, and past purchases to suggest computing products on an e-commerce platform. However, these traditional recommendation systems – although well developed and researched – have limited application for embedded insurance sales which happen incidentally to core products sold on e-commerce platforms.
The development of a needs-based insurance recommendation system is a relatively novel idea that remains largely unexplored. Spedicato and Savino (Reference Spedicato and Savino2022) applied an item-based collaborative filtering recommendation system for insurance marketing using customer data of a European insurance company. Similarly, Lesage et al. Reference Lesage, Deaconu, Lejay, Meira, Nichil and State(2020) proposed a recommendation system using XGBoost and an a priori algorithm for car insurance based on data from a leading car insurer in Luxembourg.
Although relevant, we note that both Spedicato and Savino (Reference Spedicato and Savino2022) and Lesage et al. Reference Lesage, Deaconu, Lejay, Meira, Nichil and State(2020) trained their recommendation systems on traditional insurer customer data containing policyholder demographic profiles (current policies, age, gender, etc.) and past insurance purchase history. Both further identified the lack of related insurance profiling data due to a small number of insurance products as a key driver contributing to the lacklustre application of traditional recommendation systems within insurance.
1.1. Our Contribution
We hope to address the above limitation identified by previous studies by introducing a framework to classify embedded insurance recommendation systems and proposing a novel needs-based collaborative filtering embedded insurance recommendation system. This approach is more relevant in an insurance context compared to a profile or item-based approach since users of e-commerce platforms do not actively search for or review embedded insurance purchases. The lack of specific user-generated data is therefore not a handicap to our proposed needs-based approach and differentiates this approach from other recommendation systems. We do this by considering the needs and risk profiles of customers via a proxy feature in a non-traditional insurance data set – a large e-commerce data set – and recommending related embedded insurance products.
In Section 2, we discuss embedded insurance in depth and share real-world examples of embedded insurance products. In Section 3, we elaborate on our framework to classify embedded insurance recommendation systems. In Section 4, we describe the details of the insurance products to be recommended. The remainder of this paper then focuses on our novel embedded insurance recommendation system starting with a summary of the data used in Section 5. Section 6 summarises the recommendation system and presents the results from the algorithm and some limitations, along with future research angles, before we conclude in Section 7.
2. What is Embedded Insurance?
Embedded insurance is the integration of insurance products within the purchase of third-party product or service as part of the customer’s purchase journey (Bosworth & Berkley, Reference Bosworth and Berkley2022). This way, customers have the option to purchase relevant or personalised insurance alongside products and services that matter to them, when it matters the most.
There are multiple benefits to embedded insurance. From insurers’ perspectives, embedded insurance creates the potential for lower cost distribution with greater outreach to more individuals. For third-party organisations such as ride-hailing firms, embedded insurance could improve customers’ value propositions and create new revenue streams in the form of commissions. For society, embedded insurance helps to narrow the protection gap, which is the difference between insured losses and uninsured losses.
The market opportunity for embedded insurance is immense. According to a report by InsTech London (2021), the embedded insurance market is expected to increase to $ 722 billion in gross written premiums by 2030. We further illustrate this potential by looking at a few real-world examples of embedded insurance implementation.
2.1. Social Media
Social media apps such as WeChat are embracing embedded insurance products. For example, customers can pay RMB 1 or USD 0.16 for cancer insurance coverage worth RMB 1000 when they use WeChat’s payment options. Customers can even opt to donate premiums to their connections within the WeChat network.
2.2. Ride-hailing
Grab, a ride-hailing giant in Southeast Asia, has embedded several types of insurance products in its ecosystem. One example includes Ride Cover micro-insurance, which covers accidents that may occur during customers’ ride-hailing journeys. The product also pays out vouchers to compensate customers in the event that the ride is delayed by more than 10 minutes after the estimated arrival time.
2.3. Food Delivery
Deliveroo, an online food delivery platform, has launched accident insurance aimed at covering food delivery riders. The insurance offers security to riders in the event of an injury, to provide them greater peace of mind while on the road.
2.4. E-commerce
On the e-commerce side, shipping returns insurance products are embedded in Alibaba’s Tmall marketplace products and are offered to small businesses for $ 0.50 or less. This kind of insurance is offered by ZhongAn, an online-only insurer in China that covers the cost of shipping fees incurred when returns are made by buyers to sellers for reasons such as change of mind or damaged itemsFootnote 1 . This kind of insurance has helped to foster buyer trust in Tmall’s platform as it offers peace of mind, contributing to higher volumes of transactions.
2.5. Insurance on Credit Card Purchase
OP cooperative bankFootnote 2 , one of the largest banks in Finland, provides product protection insurance for card purchases made by owner-customers anywhere in the world using the credit or debit feature of the bank’s credit cards. In this manner, insurance is embedded during the purchase journey with the use of the bank’s card and covers loss caused by damage to or theft of products after a certain period following the purchase date as per their terms and conditions.
3. Embedded Insurance Recommendation System
There are three main types of traditional recommendation systems, namely, content-based filtering, collaborative filtering and hybrid filtering. Content-based filtering technique entails constructing a profile of both the active users based on their actions (likes, dislikes, views, past purchases etc.) and matching the same against similar profiles (brand, usage, item category, price etc.) of unseen products (Bogers & Van den Bosch, Reference Bogers and Van den Bosch2009) constructed based on item description. Collaborative filtering, on the other hand, provides recommendation to a user based on what majority of other similar users liked or purchased (Breese et al., Reference Breese, Heckerman and Carl Kadie2013). One clear challenge to this technique is the requirement to have a considerably large user base in order to generate reliable recommendations. Finally, hybrid filtering blends both content-based and collaborative filtering into a single approach.
Unlike traditional recommendation systems, however, embedded insurance recommendation systems do not have the luxury of buyer-provided behavioural inputs as noted by Lesage et al. (Reference Lesage, Deaconu, Lejay, Meira, Nichil and State2020). Buyers are unlikely to provide as detailed a review of a motor insurance product as they would for a pair of shoes or fashion accessories. The volume of embedded insurance sales data available to assess insurance suitability is also limited, although this is expected to change with the uptick in volume of embedded insurance.
Hence, it is necessary to leverage non-insurance-related data to assess and provide insurance recommendations. This is done by augmenting the existing catalogue of traditional recommendation systems with two novel systems targeted for embedded insurance – product-based filtering and needs-based collaborative filtering, as shown in Figure 1.
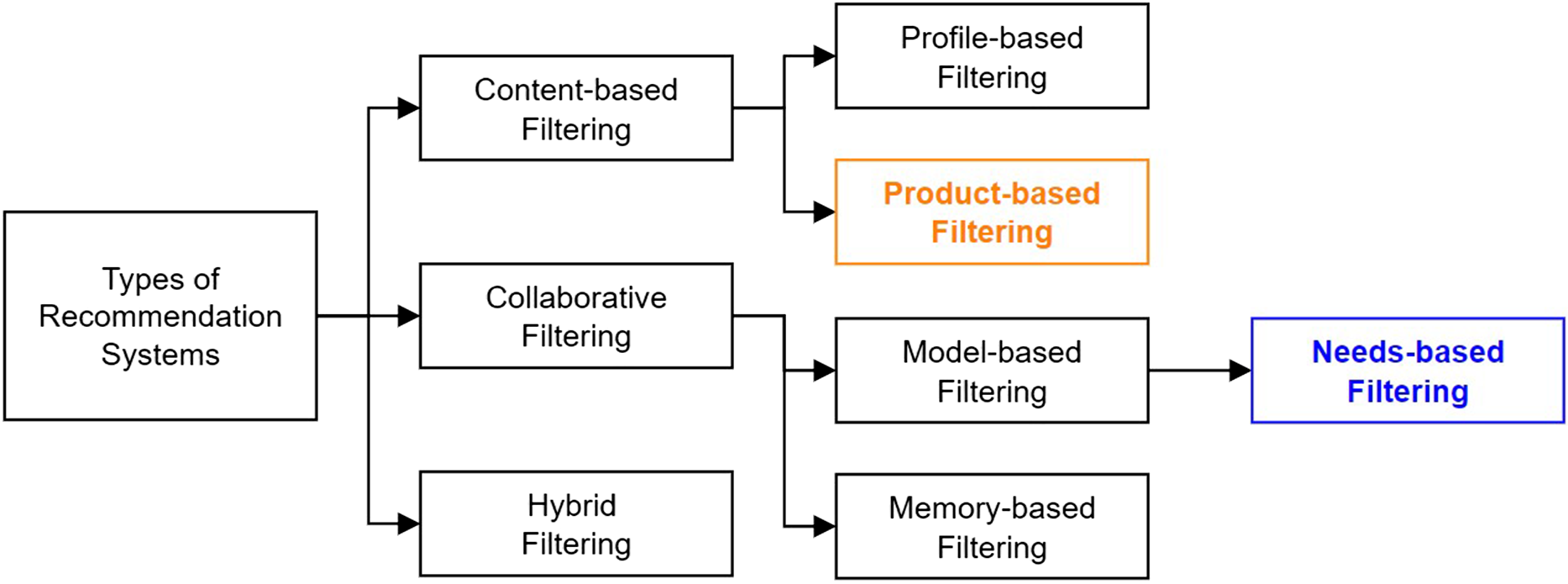
Figure 1. Types of recommendation systems with two new additions (in blue and orange) relevant for embedded insurance.
3.1. Product-Based Filtering
Product-based (or service-based) filtering is the simplest form of embedded insurance recommendation system. It works similarly to its parent content-based filtering by considering the profile of the item or services that buyers are purchasing and then recommending a relevant insurance product. This filtering is performed without considering the user’s profile.
A simple example is the offering of Rider Cover by Grab when a ride-hailing user is about to embark on a new journey. The insurance product is relevant to the service that will be used, regardless of the profile of the user. Other e-commerce examples include the offering of electronics damage protection with purchase of a mobile phone, product liability insurance when purchasing milk powders, and general damage protection for generic items such as bags.
The description and category of product or service consumed indicates a plausible type of embedded insurance product that can be recommended during a customer’s journey. On an e-commerce platform, this is usually deployed simplistically by manually mapping a specific embedded insurance product to different items with a similar profile.
However, a key drawback of product-based filtering is the lack of dynamism. A buyer purchasing a second screen protector for a second or third time would not require two or more cracked screen protection policies if already bought. Product-based filtering, however, would continue recommending the same embedded insurance product without considering this fact.
3.2. Needs-based Collaborative Filtering
Our proposed needs-based collaborative filtering overcomes this limitation of product-based filtering by considering the needs of the customer and operates comparably with item-based and user-based filtering. Rather than comparing similarities between user and item profile, this method identifies clusters of similarities in risk profiles across the population using machine learning algorithms.
In an e-commerce context, if a buyer A of an online product encountered a risk event during the order life cycle from order created to order completed and another buyer B encountered the same risk event on the same purchase, buyers A and B have the same embedded insurance needs. More specifically, certain orders could face a higher risk of lateness or non-delivery than others, depending on seller and buyer location, while other fragile orders may be damaged during shipment.
Each of these individual risks therefore present a need for embedded insurance, which can be assessed by considering the probability of such risks actually occurring from past purchases. This is analogous to user-based filtering, with a key difference being profiling of user needs instead of user profiles. E-commerce firms often capture data related to delivery timings, payment types, review scores, and open-ended reviews. Such non-traditional insurance data can shed light on insurance needs that have greater affinity for buyers compared to product-based filtering.
4. Selected Embedded Insurance Products
To demonstrate our proposed needs-based collaborative filtering approach, we have selected three embedded insurance products, namely, bills protection insurance, late delivery insurance, and product protection insurance. These products were selected based on the types of risks that could reasonably be deduced from the Olist data, as explained in Section 5. The types of risk covered also span different parts of a buyer’s purchase journey on an e-commerce platform, as shown in Figure 2.

Figure 2. Buyer’s purchase journey on an e-commerce platform and relevant insurance.
4.1. Bills Protection Insurance
A buyer who prefers paying for purchases via credit card instalments could face cashflow issues due to unfortunate circumstances. This creates a need for bills protection insurance, which is a product that covers buyers’ outstanding bills payments in the event of loss of income due to accident or death.
Our aim is to train a supervised learning K-nearest neighbour algorithm that predicts the probability of a buyer using a credit card as the main mode of payment with a high instalment period. This algorithm will be trained on historical purchase data and applied on future new purchases. The embedded bills insurance can then be offered to buyers with a high predicted probability of using a credit card, even before that payment option is selected.
Buyers can therefore feel more assured of meeting their bill payments even in unforeseen events, further driving up sales on Olist.
4.2. Late Delivery Insurance
Delivery expectations have evolved over the past few years. Due to intense competition within the e-commerce space, customers increasingly expect fast and predictable deliveries. This leads to a need for late delivery insurance, which offers a payout to customers when their goods arrive after the expected delivery timeframe.
We intend to identify potential late delivery insurance customers by training an algorithm to predict whether an order will be delivered on time. This will be applied to future transactions, and this insurance product will be recommended to relevant customers.
This insurance product could be an effective way to retain customers within the Olist ecosystem, as it can be used to ease customer dissatisfaction around late deliveries.
4.3. Product Protection Insurance
With the growing competition among sellers on online platforms, sellers are required to offer different value-added services such as product protection plans that can increase the likelihood of a consumer’s intention to buy and help build customer loyalty towards the brand by providing assurance that a product is reliable and will work as intended after acceptance of delivery. This will also give customers peace of mind from the moment they purchase a product and can provide them with a high-quality e-commerce experience.
We used review score and text mining techniques on customer reviews and then performed sentiment analysis. For each purchase with a customer review, we attempted to predict if it corresponds to a “good” review, i.e. the customer is satisfied with the purchase, or to a “bad” one, which would mean that the customer is not satisfied. We trained our algorithm using the available customer reviews from past data, the results of which will be used to recommend product protection insurance for future transactions to people buying products online with negative sentiment.
5. Data and Feature Engineering
In this section, we discuss the data used and the pre-processing performed. For our work, we have used the publicly available Brazilian e-commerce data published by Olist on Kaggle Footnote 3 with nine separate databases.
In Section 5.1, we introduce an overview of the data. Our analysis is performed at individual order level using distinct information from each of the nine databases. Sections 5.2 to 5.4 discuss our approach to extracting and processing key information that would be used to train our proposed embedded insurance recommendation system.
5.1. Overall Data Structure
This data contains nine separate databases with information on 99,441 unique individual orders made from 2016 to 2018 on the online e-commerce platform Olist. Each of these nine Olist databases contains specific information relevant to our insurance recommendation system. This is explained in detail in Table 1.
Table 1. Details of Olist database
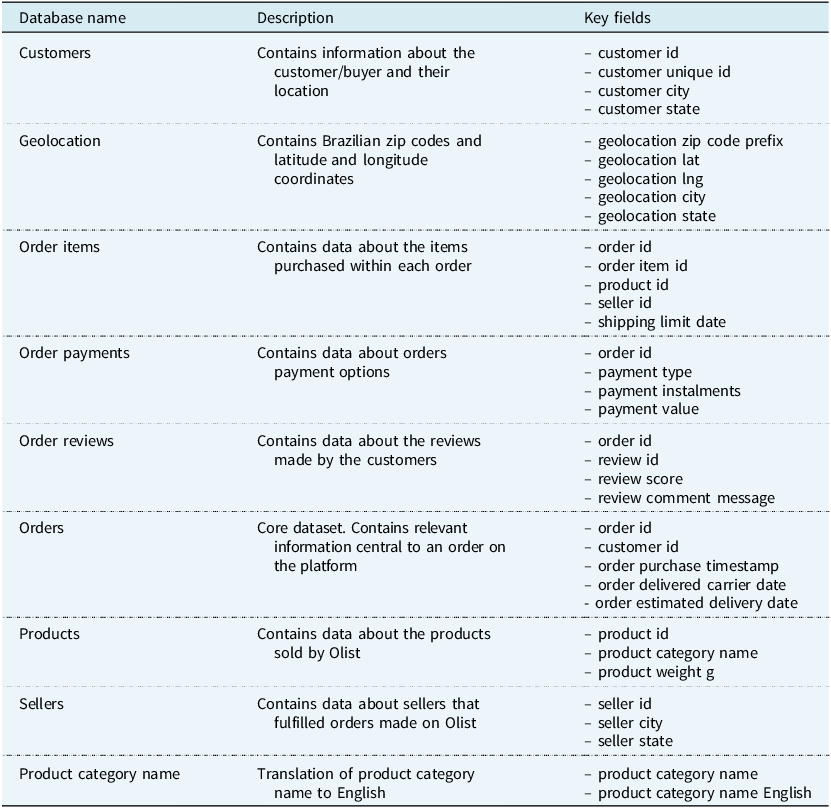
Only selected fields are shown.
The presence of critical order-level information such as order status, order value, freight price, geolocation data of sellers and buyers, product reviews and product attributes allows us to analyse insurance needs and recommend insurance products for each individual buyer.
5.2. Payment Data
To assess the need for bills protection insurance, we relied mainly on the order payments, order items, and products database that contains payment-related information. payment type indicates that 76% of payments were made using a credit card while the remaining payments were transacted using BoletoFootnote 4 , voucher, or debit card. The field payment instalments further indicates the number of credit instalments the payment was split into, with two or more credit instalments representing 40% of total transactions.
Owing to the lack of credit risk indicators such as total outstanding loans, credit default histories, and loan-to-asset ratios, we relied on a proxy indicator to determine the bills protection insurance needs of a buyer. We hypothesise that the need for bills protection insurance would be heavily influenced by the number of credit instalments used by the buyer on checkout. This is known as the selected risk proxy for this product. Two or more instalments indicates a stronger buyer affinity to purchase bills protection insurance.
A number of predictor variables such as payment value, item category, buyer location and number of items in an order were then selected to predict the probability a buyer opting to transact with two or more credit instalments and hence the probability of needing bills protection insurance.
5.3. Orders Data
We relied primarily on the orders, customers and sellers database to predict the need for late delivery insurance. The field order estimated delivered date represents the estimated date on which the order will be delivered to the customer, while order delivered customer date indicates the actual delivery date. Based on this information, we are able to determine whether each order is delivered on time.
Figure 3 shows proportion of deliveries in each month that were late. February to March 2018 had the highest percentage of late deliveries due to the truck driver strike in Brazil. On average, there is a higher percentage of late deliveries during the months October to March, which is the typical rainy season in Brazil. Based on our observations, late deliveries are likely to be strongly correlated with purchase month. In order to incorporate the element of seasonality in our model, we have not made any adjustments to normalise the data across different months.
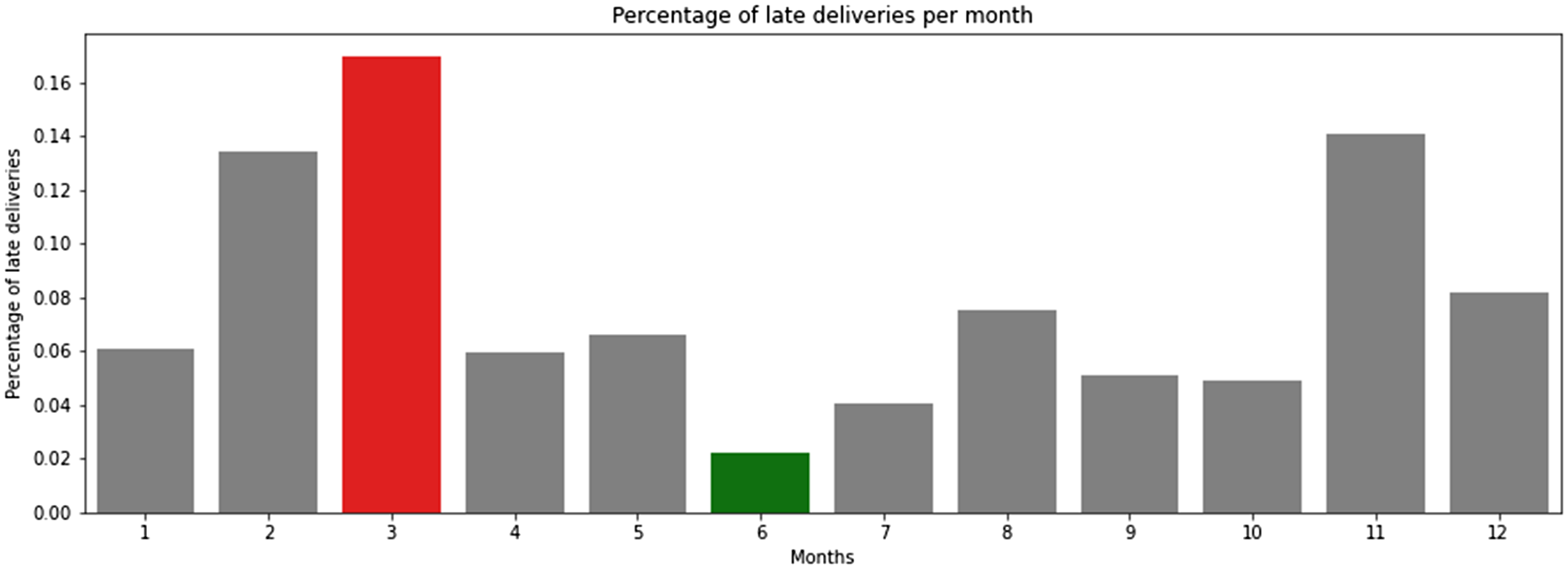
Figure 3. Late deliveries as a percentage of total orders for Olist in Brazil (red=highest, green=lowest).
In order to train the model, we set up an indicator feature to show if an order is delivered on time. This is used as the risk proxy for late delivery insurance. Various features such as customer zip code, seller zip code, total order value, and purchase month are then selected to predict the probability that an order will be delivered late and whether the customer will require late delivery insurance.
5.4. Review Data
To study product protection, we used fields review comment message and review score, which have customer reviews and scores of various products purchased. As the reviews are in Portuguese, we first translated them to English using the Googletrans Python library, which implemented the Google Translate API.
We used review score as a proxy for product sentiment to train the model. The review scores in the Olist data are categorised on an overall rating score of 1 to 5, with 1 being the lowest in terms of product satisfaction and 5 being the highest. For the training data, we split the data and created the column “sentiment” so that review scores set as 1, 2, and 3 are labelled as -1 (negative sentiment) and those rated as 4 or 5 as +1 (positive sentiment).
Each customer review is composed of feedback on the buyer’s experience of the product. We also manually annotated the sentiment as negative or positive according to the translated customer reviews, and these sentiments were used in the test data to assess model accuracy.
Next, to prepare the review text for sentiment analysis, we cleansed the text by applying lowercase transformation, tokenisation (split the text into individual words), and lemmatisation (transform every word into its root form, e.g. “rooms” will become “room”). We also removed punctuation, words that contain numbers, stop words (like “the,” “a,” “this” etc.), empty tokens, and words with a single letter. We then assigned a tag to every word to define if it corresponds to a noun, a verb, etc., using part-of-speech tagging.
5.5. Train and Test Dataset
After applying feature engineering steps, we used 32,781 unique individual orders and their corresponding features as training and 8,196 (or the remaining 20%) unique individual orders as test data. This subset of training and test data was selected as each data point contains overlapping features suitable to train all three models mentioned in Section 6. Once the models were trained, we reapplied the model to the entire 99,224 orders to recommend the most relevant embedded insurance product.
6. Methodology and Results
An overview of our proposed needs-based collaborative filtering recommendation system is presented in Figure 4. It comprises three main steps: data extraction and feature engineering, model training and model aggregation. Data extraction and feature engineering have been covered in Section 5 and we will cover the training of supervised learning models and model aggregation in Sections 6.1.1 to . For a statistical overview of recommendation systems, we direct readers to Spedicato and Savino (Reference Spedicato and Savino2022) for a more general discussion.
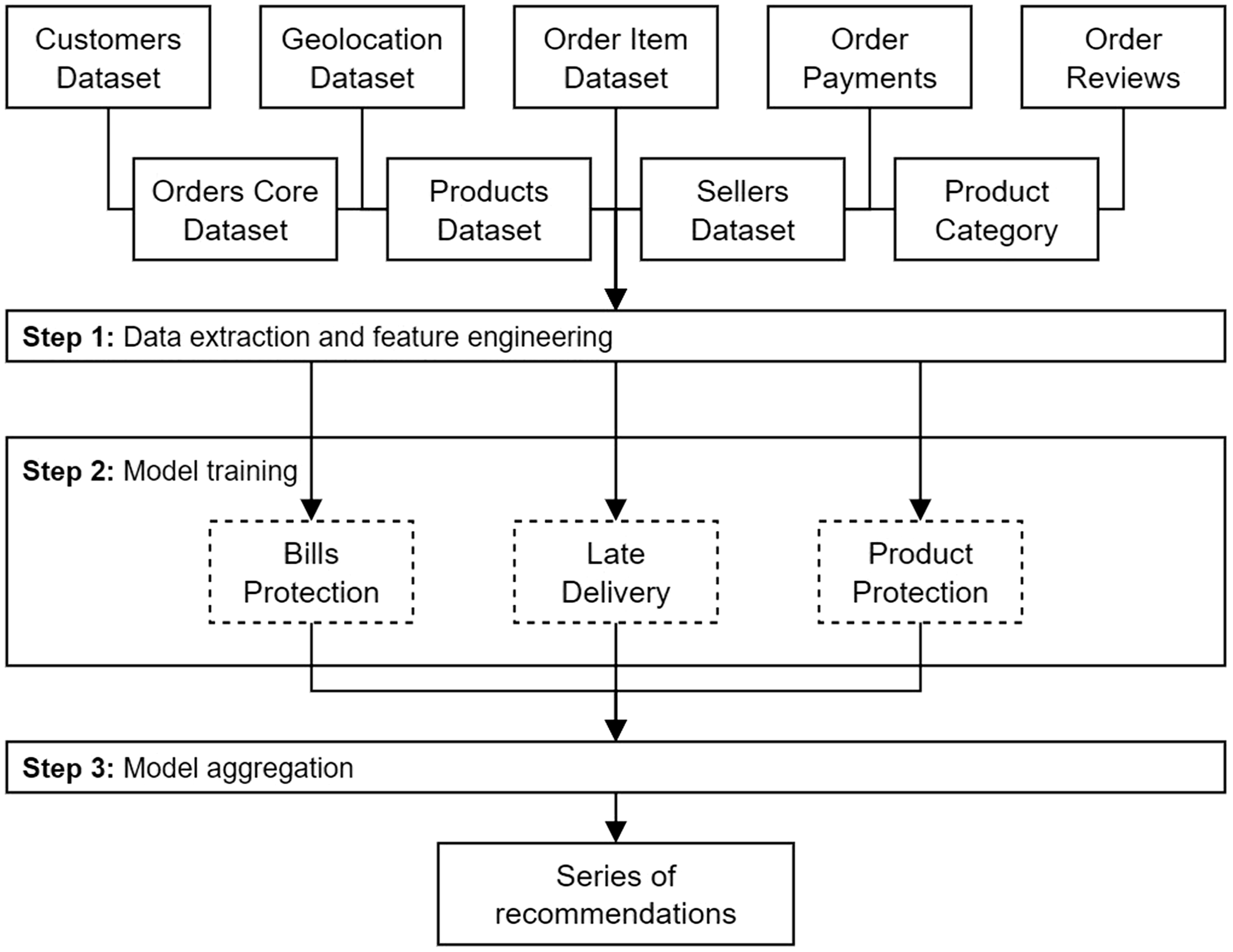
Figure 4. Overview of proposed needs-based collaborative filtering recommendation system.
6.1. Individual Model Training
The main objective of this step is to train supervised learning models to estimate how probable specific insurance needs of users on Olist arise. Similar to how user-based and item-based filtering work by matching the closest matching users and items to provide recommendations, the models trained in this step cluster users’ insurance needs to the closest matching needs that other users faced, using supervised learning algorithms such as random forests and support vector machines (SVMs). In-depth discussion of these algorithms is beyond the scope of this paper.
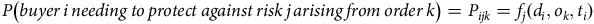 $$P\left( {buyer\,i\,needing{\rm{ }}\,to\,{\rm{ }}protect\,{\rm{ }}against\,{\rm{ }}risk\,j\,arising\,{\rm{ }}from\,{\rm{ }}order\,{\rm{ }}k} \right) = {P_{ijk}} = {f_j}\left( {{d_i},{o_k},{t_i}} \right)$$
$$P\left( {buyer\,i\,needing{\rm{ }}\,to\,{\rm{ }}protect\,{\rm{ }}against\,{\rm{ }}risk\,j\,arising\,{\rm{ }}from\,{\rm{ }}order\,{\rm{ }}k} \right) = {P_{ijk}} = {f_j}\left( {{d_i},{o_k},{t_i}} \right)$$
Adopting the mathematical formulation proposed by Spedicato and Savino (Reference Spedicato and Savino2022), let the probability density function P ij represent the likelihood of a buyer i on an e-commerce platform encountering the selected risk event j for a specific order k. We further assume that P ij depends on multiple risk variables such as demographics of the buyer d i , order-level details o k , and the timing t i , each described as follows:
-
The demographic features of a buyer include their age, gender, geographical location, time spent on the e-commerce site, and past purchase history. Second-order features could be deduced from purchase history, including parenthood status, hobbies, and interest. Given the anonymisation of the data performed by Olist, the use of this risk variable is limited to geographical location in our paper.
-
Order-level details include seller shop name, seller location, item category (such as electronics, home & living and automotive), payment mode (credit card, Boleto, voucher), order review ratings, and delivery information. Depending on the selected risk event, a different combination of order-level variables was used to model P ij .
-
As described by Spedicato and Savino (Reference Spedicato and Savino2022), timing is the undetectable random component of the model. This could include a natural catastrophe typhoon event resulting in the damage of all orders in-delivery or an economic recession leading to higher need for bills protection type insurance.
The objective of each supervised learning model introduced in Section 6 is therefore to learn P ij based on the selected order-level details. The key metric chosen to assess model performance is accuracy. Each model described is assessed on how well it is able to predict the selected risk proxy on an unseen test data set. Accuracy is selected as each of these binary classification models are trained to identify whether the selected risk proxy occurred or did not occur. Table 2 shows the training and test accuracy for each model.
Table 2. Model accuracy of individual models

6.1.1. Bills protection insurance
The need for bills protection insurance is proxied by the number of credit instalments used by the buyer on checkout. In the model, this is represented as a binary target variable, where 0 represents one instalment or other forms of payment, and 1 represents 2 or more credit instalments. We applied standard scaling to the payment value and one-hot encoding to buyers’ location and item categories, which are categorical variables. While standard scaling transforms data to have a zero mean and unit variance, one-hot encoding enables the conversion of categorical data into numerical data.
We trained a simple random forest model with 100 trees and a maximum depth of 15 using entropy as the loss function. We obtained these hyperparameters after performing a grid search comprising 384 combinations of hyperparameters.
The model achieved 69% and 68% accuracy on the training and test data respectively. Examination of the feature importance of each of the inputs to the random forest model suggested that payment_value is the most important feature. This is expected as buyers are naturally more inclined to pay by instalments for more expensive orders.
6.1.2. Late delivery insurance
To predict the need for late delivery insurance, we selected a binary target variable where 0 indicates that an order was not delivered on time, while 1 indicates that an order was delivered on time. This binary variable was computed by comparing order delivered_customer date with order_estimated_delivery_date.
We then trained a random forest classifier model using default parameters. Based on this model, we evaluated the feature importance of the model features. The results show that the feature shipped_on_time is the least important with a score of 0.037, while seller_zip_code prefix is the most important with a score of 0.345. We maintained the feature shipped_on_time as the model accuracy decreased when this feature was removed.
It is evident from Figure 3 that the proportion of late delivered orders is much lower than orders delivered on time. This created an imbalanced data set resulting in low recall and low F1 scores. We then applied the synthetic minority oversampling technique (SMOTE) to oversample the minority “False” class. The re-trained random forest model based on oversampled data achieved 100% and 87% accuracy on the training and test data respectively compared to 78% and 71% without oversampling.
6.1.3. Product protection insurance
The selected target variable is the sentiment of the buyer’s review text with −1 representing negative sentiment and +1 positive sentiment. This is a proxy that represents the usability and satisfaction of the buyer towards the purchased product. We applied term frequency-inverse document frequency (TF–IDF) (Das & Chakraborty, Reference Das and Chakraborty2018) to extract features from the cleansed text data.
Since we have converted text into features, we can apply any classification model to our training data. While extracting the features, we set ngram_range as (2,3) and ran four machine learning models namely decision tree, random forest, naive Bayes, and SVM. Next, we ran all models again with default ngram_range setting, i.e. (1,1), and attained the maximum accuracy with SVM. The selected SVM model achieved 95% and 90% accuracy on the training and test data respectively.
Owing to limited data fields available to use for this study, we have used proxies as mentioned in earlier sections to predict the sentiments. Additional information such as details on return-related data could have given us further insights to incorporate in the analysis. The translation of customer reviews to English further complicated the sentiment analysis and not every time mentioned the exact detailed reason for the return. We therefore assumed that negative sentiment would contribute to the need for product protection and most of the returns requested would be because of faulty or inferior-quality product. In the following sections, while explaining model aggregations, we would explain further how taking into account seller-product aggregator could help us support this assumption.
6.2 Combined Needs-Based Recommendation System
Although each individual model mentioned from Sections 6.1.1 to 6.1.3 is able to predict the insurance needs of a buyer on Olist and therefore recommend the appropriate product, we assume that only one embedded insurance will eventually be recommended during the buyer’s purchase journey. This is a reasonable assumption given the limited screen real estate to promote more than one embedded insurance on an e-commerce mobile application.
Hence, we propose a model aggregation algorithm that recommends the most appropriate needs-based embedded insurance based on each individual model. We started off with a simple aggregator based on Equation (2) where j 1, j 2 and j 3 refer to selected risk events relating to bills insurance, late delivery and product protection.
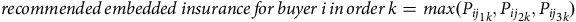 $$recommended\,{\rm{ }}embedded\,{\rm{ }}insurance\,{\rm{ }}for\,{\rm{ }}buyer\,{\rm{ }}i\,{\rm{ }}in\,{\rm{ }}order\,{\rm{ }}k = max({P_{ij}}_{1k},{P_{ij}}_{2k},{P_{ij}}_{3k})$$
$$recommended\,{\rm{ }}embedded\,{\rm{ }}insurance\,{\rm{ }}for\,{\rm{ }}buyer\,{\rm{ }}i\,{\rm{ }}in\,{\rm{ }}order\,{\rm{ }}k = max({P_{ij}}_{1k},{P_{ij}}_{2k},{P_{ij}}_{3k})$$
This simple aggregator essentially recommends the embedded insurance with the highest probability predicted by each of the three models for that specific order. However, a key limitation of this model is the reliance on features that are not available at the point of order creation by an Olist buyer. This includes the review comments for that order that could only be obtained after the order is completed and the estimated delivery time. Even if these features were available at the point of order creation, the need for the e-commerce application to be fast and responsive means that any computation time needs to be minimised. Hence, applying “live” features as model inputs during order checkout is likely to be practically infeasible without slowing down user experience.
To overcome these limitations, we further propose a seller-product-based aggregation algorithm. This is represented by Equation (3):
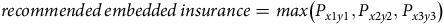 $$recommended\,{\rm{ }}embedded\,{\rm{ }}insurance = max\left( {{P_{x1y1}},{P_{x2y2}},{P_{x3y3}}} \right)$$
$$recommended\,{\rm{ }}embedded\,{\rm{ }}insurance = max\left( {{P_{x1y1}},{P_{x2y2}},{P_{x3y3}}} \right)$$
where P xlyl is the weighted average of P ijk arising from a specific seller x and specific product category y. The selected weight is w l .
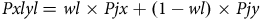 $$Pxlyl{\rm{ }} = wl{\rm{ }} \times Pjx{\rm{ }} + \left( {1 - wl} \right) \times Pjy$$
$$Pxlyl{\rm{ }} = wl{\rm{ }} \times Pjx{\rm{ }} + \left( {1 - wl} \right) \times Pjy$$
P jx is therefore the average probability across all k orders of risk j occurring whenever a buyer purchases an order from seller x. Similarly, P jy is the average probability across all k orders of risk j occurring whenever a buyer purchases an order from an item category y. This is represented by Equations (5) and (6):
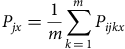 $${P_{jx}} = {{1}\over{m}}\sum\limits_{k \, = \, 1}^m {{P_{ijkx}}} $$
$${P_{jx}} = {{1}\over{m}}\sum\limits_{k \, = \, 1}^m {{P_{ijkx}}} $$
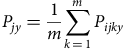 $${P_{jy}} = {{1}\over{m}}\sum\limits_{k \,=\,1}^m {{P_{ijky}}} $$
$${P_{jy}} = {{1}\over{m}}\sum\limits_{k \,=\,1}^m {{P_{ijky}}} $$
Seller-product-based aggregation can speed up computation time at the front-end because only three key variables namely seller, item category, and selected weight w l are required. Certain specific risks are also better represented by the seller and/or product components. For example, a specific seller may be more prone to selling inferior-quality products or buyers may be more inclined to pay by instalments for specific item categories. These features are often too large to be represented categorically in the model, but their importance should not be ignored. Additional components can also be considered in aggregate, such as averaging across the type of couriers used or the location of sellers/buyers.
6.3. Results
Table 3 shows the number of embedded insurance products recommended for the entire data set of 99,000 orders based on both the simple and seller-product aggregator. It is reasonable that bills insurance is the most recommended product followed by product protection and late delivery.
Table 3. Number of orders recommended with each embedded insurance for simple versus seller-product aggregator

This is because in the presence of adverse conditions leading to increasingly bad reviews or late deliveries, e-commerce platforms will often take action to correct for these risk scenarios. These actions include improving logistics network, reducing traffic to sellers with bad reviews or outright banning poor sellers. Naturally, these actions would lead to a lower need for embedded insurance covering these risks.
The seller-product aggregator resulted in higher recommendations for bills insurance. This could potentially be due to the more balanced predictions leading to higher seller and product averages. However, a key limitation of our study is the inability to test this recommendation system with real-world feedback of embedded insurance purchases. This prevented the optimisation of key variables in the seller-product aggregator. For example, a weighted average approach could have been taken in Equations 5 and 6, which account for the value or weight of the order. The parameters w 1 and w 2 could similarly be tuned to give more weight to seller or product dimensions.
7. Conclusion
In this paper, we presented a novel needs-based embedded insurance recommendation system specifically for e-commerce platforms. This recommendation system addresses traditional established recommendation systems’ limited application in the context of insurance products due to the lack of user-generated insurance purchase information by focusing on user’s needs.
For our study, we selected the public Olist database, which contains order-level information of orders made on the Brazilian e-commerce platform. This distinguishes our work from previous studies that relied on customer dataset from traditional insurers.
We applied common machine learning algorithms to identify three different insurance needs namely bills protection insurance, late delivery insurance, and product protection insurance of an e-commerce user during their purchase journey. The accuracy of these models was measured against risk proxies identified in the data. Through this process, we have shown that it is possible to recommend insurance products based on non-traditional data by linking relevant features to the underlying risk signature.
However, a key limitation is the ability to test this algorithm with purchase patterns of real-world buyers to create a feedback loop to optimise the aggregation model. This would be a future research topic for interested industry practitioners.








 Open access
Open access