


Spoken production involves the timely coordination of semantic, syntactic, and phonological properties of the words to be produced. In a word production task such as picture naming, recognition of the object induces activation of conceptual codes. Many models of spoken production make the assumption that a word's semantic and syntactic properties are represented in a “lemma” representation, and that semantically related lemmas are coactivated based on conceptual input. Activation then proceeds to a word form layer that represents a word's morphological and phonological properties (Dell, Reference Dell1986; Jescheniak & Levelt, Reference Jescheniak and Levelt1994; Levelt, Roelofs, & Meyer, Reference Levelt, Roelofs and Meyer1999; Roelofs, Reference Roelofs1992, Reference Roelofs1997).
A long-standing debate concerns the temporal coordination of, and interaction between, those information types, and especially how activation is transmitted from lexical nodes to phonological encoding. In the literature, researchers have proposed two opposite possibilities: serial and nonserial models. Serial discrete models (e.g., Levelt et al., Reference Levelt, Roelofs and Meyer1999) argue that for a given target word, only a single selected lemma spreads its activation to the phonological level, and semantic processing must be completed before phonological processing commences. By contrast, nonserial models such as cascaded models (e.g., Humphreys, Riddoch, & Quinlan, Reference Humphreys, Riddoch and Quinlan1988; Morsella & Miozzo, Reference Morsella and Miozzo2002) propose that multiple lexical–semantic candidates that are coactivated during retrieval of the target word transmit activation to the phonological level. An even stronger form of nonseriality is proposed by interactive models (e.g., Dell, Reference Dell1986) in which it is also assumed that transmission of activation between semantic and phonological processes is bidirectional, that is, word form encoding can influence lexical–semantic retrieval. Critically, in serial models, phonological activation is strictly restricted to the target word. By contrast, in nonserial models (both cascaded and interactive), phonological processing begins on the basis of early partial information provided by semantic processes, and any activated concepts and lemma nodes could transmit activation to their corresponding phonological nodes (in interactive models, activation also flows backward through the system). The present study investigates the possibility of multiple phonological activation differing across languages (in our case, English and Mandarin Chinese).
Findings from speech error studies have been taken to argue against a serial, and for an interactive, viewpoint (e.g., Dell, Reference Dell1986; Dell & Reich, Reference Dell and Reich1981). Recent findings from error-free spoken word production also argue against a strictly serial, and for a cascaded, processing mode. Much of this evidence is based on demonstrations of “multiple phonological activation”; that is, entries other than the target are activated at the phonological level. For instance, in the “picture–picture interference” task, two line drawings are superimposed in different colors, and speakers name a target picture based on color while attempting to ignore the distractor picture. Morsella and Miozzo (Reference Morsella and Miozzo2002) first demonstrated that when target and context picture were phonologically related (e.g., bed–bell), naming latencies were faster than when they were unrelated. The observation of phonological activation of context pictures has been replicated in English (Meyer & Damian, Reference Meyer and Damian2007) as well as in Spanish (Navarrete & Costa, Reference Navarrete and Costa2005) and Dutch (Roelofs, Reference Roelofs2008). This contradicts a central tenet of serial models of spoken word production (according to which phonological encoding should be restricted to the target only) and is in line with a cascaded view.
At the same time, cascading of activation from the semantic to the phonological level does appear to be restricted. In a variation of the task in which a single colored picture is presented, and speakers name either the object or the color, phonological facilitation is found when colors are named (and objects ignored) but not when objects are named (and colors ignored; e.g., Dumay & Damian, Reference Dumay and Damian2011; Kuipers & La Heij, Reference Kuipers and La Heij2009). This asymmetry suggests that cascading is limited to the “primary” dimension (i.e., the object name) but nontarget properties such as color (or size, as shown more recently by Roux, Bonin, & Kandel, Reference Roux, Bonin and Kandel2014) do not seem to be processed in a cascaded fashion. Hence, the evidence suggests a “limited cascadedness” view of spoken word production.
Independent of the debate as to whether or not cascadedness is restricted to particular target dimensions (see above), cascaded processing is itself probably quite subtle, such that cascading of nontarget properties is not detectable under all circumstances. This appears to be the case in the popular picture–word interference (PWI) task, in which participants are instructed to name target pictures while ignoring distractor words superimposed on the target. A semantic relationship between target picture and distractor (dog–cat) slows naming relative to an unrelated word, whereas a phonological relationship (cat–cap) speeds up latencies (Glaser & Düngelhoff, Reference Glaser and Düngelhoff1984; Schriefers, Meyer, & Levelt, Reference Schriefers, Meyer and Levelt1990; Starreveld & La Heij, Reference Starreveld and La Heij1995). The possibility of cascadedness of nontarget properties can be investigated by using “mediated” distractors, that is, words that are only indirectly related to the target, such as the target picture “dog” paired with a distractor “can,” which is phonologically related to the semantic target coordinate “cat.” If such mediated distractors were to influence target naming, this would imply that not only the target (in this case, “dog”) but also coactivated items (such as “cat”) underwent phonological processing. However, mediated distractors appear not to affect target naming latencies in PWI tasks (Damian, Reference Damian1998; Jescheniak, Hahne, Hoffmann, & Wagner, Reference Jescheniak, Hahne, Hoffmann and Wagner2006; but note that in the latter study, mediated effects were found in children) nor do mediated effects emerge in electrophysiological measures (Jescheniak, Hahne, & Schriefers, Reference Jescheniak, Hahne and Schriefers2003). This suggests that under typical circumstances, cascaded processing of nontarget properties might be too weak to exert a measurable effect. By contrast, mediated priming has been shown with pictures with near-synonymous names such as Schäfer-Hirte (both meaning “shepherd”; Jescheniak & Schriefers, Reference Jescheniak and Schriefers1998): when speakers named these pictures with the dominant name, then distractors that were phonologically related to the nondominant name caused interference (see Peterson & Savoy, Reference Peterson and Savoy1998, for related findings with regard to synonyms). In the case of objects with near-synonymous names, it appears that both alternatives are phonologically encoded (hence implying cascadedness), with the incorrect alternative being primed by the mediated distractor and hence causing interference.
Assuming that in spoken word production, cascading of activation from semantic to phonological levels is genuine yet subtle, one could surmise that mediated effects will emerge more clearly if the degree of semantic and/or phonological overlap within mediated target/distractor combinations is increased. As outlined above, this is arguably the case with target objects with near-synonymous names such as Schäfer-Hirte (Jescheniak & Schriefers, Reference Jescheniak and Schriefers1998) for which the two alternatives are semantically virtually identical. An alternative strategy might be to boost activation at the semantic level via presentation of two semantically related pictures. Oppermann, Jescheniak, Schriefers, and Görges (Reference Oppermann, Jescheniak, Schriefers and Görges2010) asked speakers to name, cued by color, one of two spatially separated pictures on a computer screen; in addition, a spoken distractor word was presented. Distractors that were phonologically related to the nontarget picture slowed down target naming latencies, but only when the two pictures were semantically related and not when they were unrelated. Accordingly, it is assumed that “there must be a semantics-sensitive mechanism that modulates the information flow in the conceptual-lexical system and that gates the amount of phonological activation” (see Roelofs, Reference Roelofs2008, p. 366).
Yet a different approach is to boost the magnitude of phonological activation via presentation of multiple distractor words. Abdel Rahman and Melinger (Reference Abdel Rahman and Melinger2008) superimposed two distractor words on a single target pictures, one of which sharing initial segments and the other sharing final segments with a word semantically related to the target. They found significant interference relative to an unrelated condition, consistent with the idea that when sufficiently primed, nontarget alternatives are phonologically activated. Most recently, Melinger and Abdel Rahman (Reference Melinger and Abdel Rahman2013) reported that activating a concept associatively related to a target picture via form-related distractor word pairs interfered with naming. For example, naming the target picture “pyramid” was slowed by the presence of the written distractors “camera” and “bagel” (form related to “camel,” an associate of “pyramid”), compared to an unrelated distractor combination. Overall, the evidence at present supports a theoretical framework in which activation transmission from semantic to phonological levels is cascaded.
WORD PRODUCTION IN WESTERN AND NON-WESTERN LANGUAGES
While, as reviewed above, an increasing body of evidence supports cascaded models, the extant research is largely based on Indo-European languages such as English, German, Spanish, and Dutch, and little attention has been paid to the possibility of a different phonological architecture in languages with nonalphabetic scripts. For instance, in the WEAVER model (Roelofs, Reference Roelofs1997) word form encoding includes parallel access to phonological segments as well as retrieval of suprasegmental information. The two types of information are subsequently sequentially merged and associated with syllables in an incremental fashion. However, this architecture might not be universal across languages, and it has recently been suggested (O'Seaghdha, Reference O'Seaghdha2015; O'Seaghdha, Chen, & Chen, Reference O'Seaghdha, Chen and Chen2010) that languages differ in the “proximate unit” of phonological encoding (i.e., the primary selectable unit below the word level). In Western languages, phonological segments constitute proximate units, and many priming effects demonstrated in experimental tasks (such as phonological facilitation in PWI tasks, e.g., Glaser & Düngelhoff, 1984; Schriefers et al., 1990) are based on segmental overlap. However, similar segmental manipulations in experiments conducted on Chinese individuals have resulted in null findings, and instead priming effects are observed with syllabic manipulations only (e.g., Chen, Chen, & Dell, Reference Chen, Chen and Dell2002; Chen, Lin, & Ferrand, Reference Chen, Lin and Ferrand2003; O'Seaghdha et al., Reference O'Seaghdha, Chen and Chen2010; Verdonschot, Nakayama, Zhang, Tamaoka, & Schiler, Reference Verdonschot, Nakayama, Zhang, Tamaoka and Schiller2013; You, Zhang, & Verdonschot, Reference You, Zhang and Verdonschot2012). This suggests that in non-Western languages such as Mandarin and Cantonese, syllables (rather than segments) constitute the proximate units. Roelofs (Reference Roelofs2015) recently provided a first attempt to computationally model such differences between languages concerning phonological encoding.
Potential differences between languages concerning the architecture of phonological encoding might have consequences for the issue of how activation is transmitted from the semantic to the phonological level. We have recently reported work that highlights such a difference. For instance, a possible strategy of tackling the serial versus nonserial issue is to apply additive-factors logic (Sternberg, Reference Sternberg1969) in a PWI experiment. By factorially crossing semantic and phonological overlap between targets and distractors, one can test for statistical additivity between the two variables. Additivity would be accounted for more easily with a serial model, whereas a statistical interaction would be more in line with a nonserial notion of lexical access. A substantial number of previous studies have demonstrated nonadditivity (i.e., a statistical interaction between semantic and phonological overlap) in such experiments, across various Western languages (e.g., English: Damian & Martin, Reference Damian and Martin1999; Taylor & Burke, Reference Taylor and Burke2002; Dutch: Starreveld & La Heij, Reference Starreveld and La Heij1995; French: Bonin & Fayol, Reference Bonin and Fayol2000), and this pattern is generally taken to support a nonserial notion. However, with Chinese materials and Mandarin speakers, we (Zhu, Damian, & Zhang, Reference Zhu, Zhang and Damian2016) found a strictly additive relation between semantic and (syllable-based) phonological relatedness. This pattern is more in line with a serial notion of lexical access, and underscores a potential important difference between Western and non-Western languages concerning phonological encoding.
Further evidence for this claim comes from studies based on electroencephalography (EEG), a method that allows to track access to representational stages before an overt response has commenced. Using a PWI task combined with EEG, Dell'Acqua et al. (Reference Dell'Acqua, Sessa, Peressotti, Mulatti, Navarrete and Grainger2010) found significant effects of semantic and phonological relatedness in the time window of 250–450 ms post–picture onset, with peak latencies of semantically related distractors (320 ms) coincided temporally with those of phonologically related distractors (321 ms). By contrast, with Chinese speakers, we (Zhu, Damian, & Zhang, Reference Zhu, Damian and Zhang2015) found a semantic effect in a time window of 250–450 ms, which was followed by a phonological effect in a much later time window, at 450–600 ms. Hence, EEG results from Mandarin speakers suggest a temporal dissociation between semantic and phonological stages in Chinese, that is, a serial/sequential pattern. Overall, these results lend some support to the possibility that phonological encoding might differ in important aspects between Western and non-Western languages such as Mandarin.
THE PRESENT STUDY
In the present study, we further tackled the issue of seriality versus cascadedness in spoken word production, as well as potential differences between Western and non-Western languages, with a novel approach. For our experiments, we reverted back to the use of “mediated” distractors in PWI tasks (distractors that are phonologically related to a semantic competitor of the target object), a manipulation that as summarized above typically results in null findings (e.g., Damian, Reference Damian1998) but under certain circumstances might render interference, namely, when semantic (e.g., Oppermann et al., Reference Oppermann, Jescheniak, Schriefers and Görges2010) or phonological (e.g., Abdel Rahman & Melinger, Reference Abdel Rahman and Melinger2008) activation is increased.
In our experiments we manipulated activation at the semantic level with a manipulation of “semantic blocking.” In this task, participants repeatedly name a small set of objects within an experimental block. Item sets within blocks are chosen such that they either belong to the same semantic category (“homogeneous” condition) or each picture comes from a different category (“heterogeneous”). The typical finding is that naming latencies are longer in the homogeneous than in the heterogeneous condition (Abdel Rahman & Melinger, Reference Abdel Rahman and Melinger2007; Aristei, Melinger, & Abdel Rahman, Reference Aristei, Melinger and Abdel Rahman2011; Belke, Meyer, & Damian, Reference Belke, Meyer and Damian2005; Damian & Als, Reference Damian and Als2005; Damian, Vigliocco, & Levelt, Reference Damian, Vigliocco and Levelt2001). Pictures in the same semantic category cause additional activation of the related concepts and their corresponding lexical items, which enhances the competition and delays lemma selection. However, the exact mechanism by which this effect occurs remains somewhat controversial. This issue is less important for our present purposes because regardless of what exactly causes the effect, it is safe to assume that in homogeneous contexts, targets and their semantic competitors are more highly activated than in heterogeneous contexts.
We combined the semantic blocking manipulation with the use of mediated (and other) distractors (note that Aristei et al., Reference Aristei, Melinger and Abdel Rahman2011, also used semantic blocking in conjunction with a PWI manipulation, but in their case, with semantically related distractor words). On each trial, a target picture was paired with one of three kinds of visual distractor words: unrelated, phonologically related, and mediated (i.e., phonologically related to a semantic competitor). See Figure 1 for a sketch of a “homogeneous” block with various distractors superimposed on target objects. In line with numerous previous findings in the PWI literature, we expected a facilitation effect from phonologically related distractors, and this effect should be of comparable magnitude in semantically heterogeneous and homogeneous contexts. The critical manipulation concerned the “mediated” distractors, which on any given trial were unrelated to the target word, but phonologically related to a semantic competitor. Based on existing findings (e.g., Damian, Reference Damian1998), we predicted that in semantically heterogeneous blocks, mediated distractors should not affect target naming latencies. By contrast, in semantically homogeneous blocks, targets as well as semantic competitors undergo heightened activation, and hence we predicted that here mediated distractors might slow down target naming latencies because distractors of this type will further prime an (already preactivated) potential competitor. We tested these predictions in Experiment 1 with English speakers.
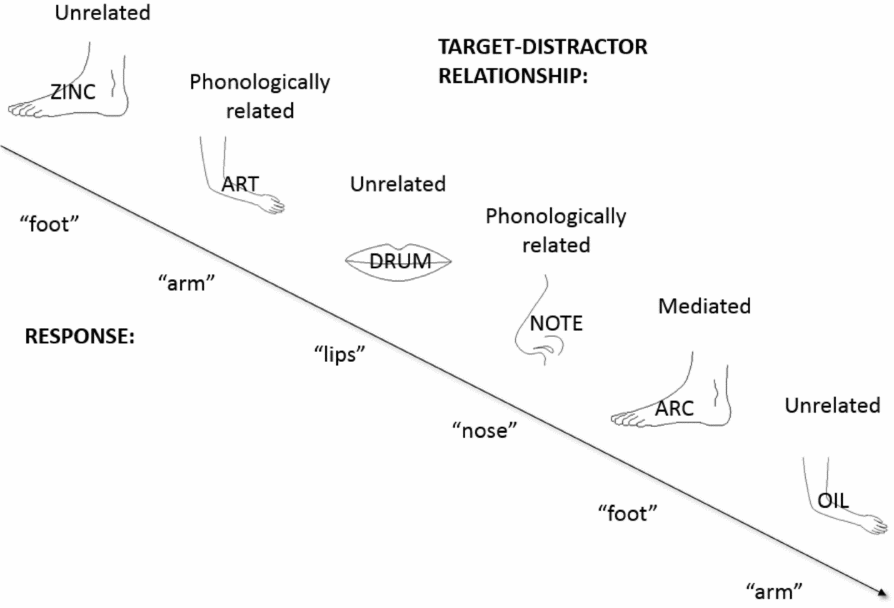
Figure 1. Picture–word interference task combined with semantic blocking: sample trials from a semantically homogeneous block (category: body parts) with unrelated, phonologicaistractor type in English. *p < .05; **p < .01; ***p < .001.
As highlighted in the previous section, there is preliminary support for the claim that phonological encoding in non-Western languages such as Mandarin might differ from Western languages. Specifically, Zhu et al. (Reference Zhu, Zhang and Damian2016) presented evidence for a more strictly serial notion of lexical access in Mandarin speakers, and Zhu et al. (Reference Zhu, Damian and Zhang2015) demonstrated that the time course of phonological encoding, as measured by EEG, differed from previous results obtained with Western speakers. A possible prediction from these findings is that the mediated effects that we predicted in Experiment 1, restricted to semantically homogeneous contexts, should generally be absent with Mandarin speakers. We tested this possibility in Experiment 2.
EXPERIMENT 1
Method
Participants
Twenty-four students (5 male; average age 21.4 years; range 18–31 years) from the University of Bristol were paid or received course credit for their participation. All were native English speakers and had normal or corrected-to-normal vision.
Materials and design
Sixteen black-and-white line pictures were selected from the standardized picture database of Snodgrass and Vanderwart (Reference Snodgrass and Vanderwart1980), including four objects in each of four semantic categories (body parts, furniture, tools, and vehicles). Objects were combined into sets of four in order to form four “homogeneous” and four “heterogeneous” sets: in “homogeneous” blocks, all four pictures were from the same semantic category, whereas in “heterogeneous” blocks, one picture came from each semantic category. All pictures had monosyllabic names.
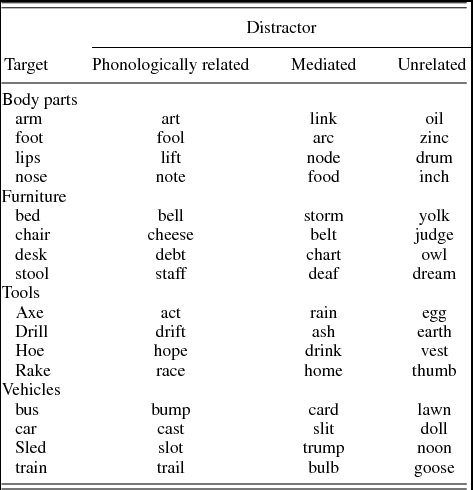
Each target picture was paired with three distractor words. A phonologically related word was chosen that shared one or more word-initial phonemes (58% segmental overlap on average) with the picture name (i.e., target: “train”; distractor: “trail”). A mediated word was chosen that shared one or more word-initial phonemes (54% shared segments on average) with a picture name from the same semantic category as the target (i.e., target: “train,” distractor: “bulb,” which is phonologically related to “bus”). An unrelated distractor word was selected that stood in no obvious relationship to the target (i.e., “goose” as a distractor). Distractors in each condition were statistically matched for length in phonemes and letters, and written frequency based on the normative information reported in the Neighborhood Watch program (Davis, Reference Davis2005). An additional four pictures were selected as practice items.
The experimental design included the variables semantic context (homogeneous and heterogeneous) and distractor type (phonologically related, mediated, and unrelated) as within-participants and within-items variables. Eight blocks that each contained four target pictures, presented repeatedly, were constructed. Within each block, each target was repeated 4 times under each distractor type. Therefore, each of the four targets occurred 12 times for a total 48 trials in each block. The order of items within one block was pseudorandomized for each participant with the constraint that a particular target and the first phoneme of a target name was never the same on consecutive trials. Four homogeneous blocks and four heterogeneous blocks were constructed, yielding a total of 384 trials. Homogeneous and heterogeneous blocks were presented in alternating orders, and the order of different block lists was counterbalanced according to a Latin square design.
We assessed the degree of semantic relatedness between semantic competitors of mediated distractors and target names, and the one between unrelated words and target names by 16 native English speakers (8 males, age from 19 to 26 years old) who did not take part in Experiment 1. Target picture names were paired with their corresponding semantic competitors of mediator distractor words and unrelated distractor words, respectively. The word pairs were presented in random order, and pictures from the same category were avoided in the consecutive trials. The word pairs were rated on a 5-point scale, with 5 indicating that word pairs were highly semantically related and 1 indicating that word pairs were semantically unrelated. The average degree of semantic relatedness was 1.74 (SD = 0.42) with a range of 1.25 to 2.69 between unrelated distractors and target names, and was 3.63 (SD = 0.45) with a range of 3.00 to 4.26 between semantic competitors and target names across subjects. A paired-sample t test indicated a significant difference between two semantic relatedness degrees, t (15) = 14.85, p < .001.
Apparatus
Stimuli were presented via an IBM-compatible computer on a 17-inch monitor using DMDX 3.0 (Forster & Forster, Reference Forster and Forster2003). Pictures were standardized to a size of approximately 6 × 6 cm and displayed at the center of the screen. Distractor words were presented in 22-point Times New Roman font, centrally superimposed on the target pictures. Naming latencies were measured from target onset using a digital voice key.
Procedure
Participants were tested individually in a soundproof room. They were seated approximately 60 cm from a computer screen. Participants were asked to familiarize themselves with the experimental stimuli by viewing each target for 3000 ms with the correct name printed underneath. Then, participants were instructed to name individual target pictures as fast and accurately as possible while attempting to ignore superimposed distractor words. In a subsequent practice block, four additional pictures paired with unrelated distractor words were presented twice. Then, eight experimental blocks of 48 trials each were carried out.
Each trial involved the following sequence: A fixation point (*) was presented in the middle of the screen for 500 ms, followed by a blank screen for 500 ms. Then, the target picture and distractor word were presented simultaneously on the screen. Target pictures and distractor words disappeared when participants initiated a voice response. An intertrial interval of 1500 ms was included in each trial. The experiment took about 40 min in total.
Results of Experiment 1
Data from incorrect responses and other responses caused by microphone errors (3.4%), naming latencies longer than 2000 ms or shorter than 200 ms (0.3%), and those deviating by more than 3 SD from a participant's mean (1.28%) were removed from the response time analyses. Furthermore, it is well known from previous studies that the effect of semantic context differs between first presentation of an object within a block and all subsequent presentations, with either little or no effect on first presentation (e.g., Aristei et al., Reference Aristei, Melinger and Abdel Rahman2011; Belke et al., Reference Belke, Meyer and Damian2005; Damian & Als, Reference Damian and Als2005), or a facilitatory effect (e.g., Abdel Rahman & Melinger, Reference Abdel Rahman and Melinger2007). Because this pattern is of little interest to the purpose of our current study, we removed data from the first presentation of an object paired with each kind of distractor within each block.Footnote 1 Error rates were low (overall 1.6%) and thus were not analyzed further.
Figure 2 presents mean picture naming latencies and standard errors by semantic context and distractor type. As expected, a sizable semantic blocking effect is visible, as well as priming from phonologically related distractors. Mediated distractors have no effect in the semantically heterogeneous context, but generate numerical interference in the homogeneous context.
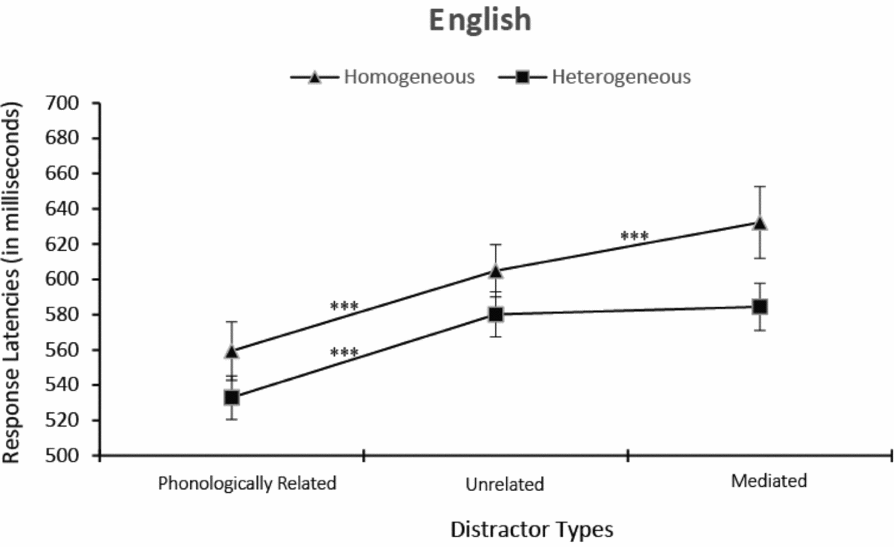
Figure 2. Mean pictures naming latencies and standard errors dependent on semantic context and distractor type in English. *p < .05; **p<.01; ***p<.001.
Analyses of variance (ANOVAs) were conducted on the response latencies, with participants (F 1) or items (F 2) as random factors and semantic context and distractor type as within-participants and within-items variables. A significant effect of semantic context was found, F 1 (1, 23) = 27.07, MSE = 1,445, p < .001, ηp2 = 0.54; F 2 (1, 15) = 20.62, MSE = 1,330, p < .001, ηp2 = 0.58, and a significant effect of distractor type, F 1 (2, 46) = 104.9, MSE = 479, p < .001, ηp2 = 0.82; F 2 (2, 30) = 56.96, MSE = 597, p < .001, ηp2 = 0.79. The interaction between semantic context and distractor type was significant, F 1 (2, 46) = 3.86, MSE = 519, p < .05, ηp2 = 0.14; F 2 (2, 30) = 9.61, MSE = 136, p < .001, ηp2 = 0.39.
In order to assess the effects of phonological and mediated overlap separately, as well as to explore potential interactions with the semantic context manipulation, we conducted two additional analyses in which the unrelated condition and one of the two related conditions (phonologically or mediated) was included whereas the other related condition was removed. First, ANOVAs with semantic context (homogeneous vs. heterogeneous) and phonological relatedness (related vs. unrelated) as within-participants and within-items factors revealed a significant effect of semantic context, F 1 (1, 23) = 13.43, MSE = 1,164, p < .001, ηp2 = 0.37; F 2 (1, 15) = 11.01, MSE = 1,015, p < .01, ηp2 = 0.42, a significant effect of distractor type, F 1 (1, 23) = 126.74, MSE = 407, p < .001, ηp2 = 0.85; F 2 (1, 15) = 57.19, MSE = 616, p < .001, ηp2 = 0.79, but no interaction between semantic context and phonological relatedness, F 1 (1, 23) < 1, MSE = 207, p > .1; F 2 (1, 15) < 1, MSE = 181, p > .1. Planned t tests for the phonological facilitation in the homogeneous context (M diff = –45 ms) were significant, t 1 (23) = –7.59, p < .001; t 2 (15) = –5.37, p < .001, and so were t tests for phonological facilitation in the heterogeneous context (M diff = –47 ms), t 1 (23) = –12.07, p < .001; t 2 (15) = –9.5, p < .001. Hence, we found the expected phonological facilitation, and this effect was independent of semantic context.
Second, ANOVAs with semantic context (homogeneous or heterogeneous) and mediated relatedness (related vs. unrelated) as within-participants and within-items factors revealed a significant effect of semantic context, F 1 (1, 23) = 28.03, MSE = 1,124, p < .001, ηp2 = 0.55; F 2 (1, 15) = 24.97, MSE = 887, p < .001, ηp2 = 0.63, as well a significant effect of distractor type, F 1 (1, 23) = 16.06, MSE = 377, p < .001, ηp2 = 0.41; F 2 (1, 15) = 8.14, MSE = 491, p < .05, ηp2 = 0.35. A significant interaction of semantic context and distractor type was obtained, F 1 (1, 23) = 6.44, MSE = 503, p < .05, ηp2 = 0.22; F 2 (1, 15) = 30.21, MSE = 68, p < .001, ηp2 = 0.67. Planned t tests for the mediated effect in the homogeneous context (M diff = –27 ms) were significant, t 1 (23) = 3.82, p < .00; t 2 (15) = 4.82, p < .001, but t tests for the mediated effect in the heterogeneous context (M diff = 4 ms) were not, t 1 (23) = 0.92, p = .37; t 2 (15) = 0.72, p = .48. Hence, mediated distractors had an effect only in a semantically homogeneous context.
To evaluate the effect size of the phonological and the mediated effect, we calculated their Cohen d for the homogeneous and heterogeneous conditions separately. For the phonological effect, Cohen d was 0.76 (heterogeneous) and 0.60 (homogeneous). For the mediated effect, Cohen d was 0.06 (heterogeneous) and 0.31 (homogeneous).
Discussion of Experiment 1
The main findings of Experiment 1 were as follows. First, in line with numerous recent studies (e.g., Abdel Rahman & Melinger, Reference Abdel Rahman and Melinger2007; Aristei et al., Reference Aristei, Melinger and Abdel Rahman2011; Belke et al., Reference Belke, Meyer and Damian2005; Damian et al., Reference Damian, Vigliocco and Levelt2001), a semantic context effect was observed: pictures were named more slowly in semantic homogeneous than in heterogeneous blocks. This effect likely arises from boosted semantic activation among response items when named in the homogeneous, compared to the heterogeneous, context. Second, we found a facilitation effect from phonologically related distractors, a finding that is again predicted by numerous existent studies (e.g., Damian & Martin, Reference Damian and Martin1999; Schriefers et al., 1990; Starreveld & La Heij, 1995) and shows that English speakers benefit from segment-sized (i.e., subsyllabic) phonological overlap between distractor and target. Third and most important, we found an interfering effect of mediated distractors, but this effect was present only in a semantically homogeneous, but not in a heterogeneous context. This finding demonstrates multiple phonological activation (i.e., phonological activation of a nontarget lexical entry) but only when targets and competitors are already preactivated via the semantic context in which they occur. Hence, the results add to the evidence suggesting that activation transmission to the phonological level is restricted. The combination of PWI with semantic blocking provides a task that is sensitive to otherwise relatively weak multiple phonological activation.
Experiment 2 used the same experimental manipulation, but now with Chinese materials and native Mandarin speakers. The semantic context effect, as well as the facilitatory effect of phonologically related distractors, should be similar across languages. However, based on previous results (e.g., Zhu et al., Reference Zhu, Damian and Zhang2015, Reference Zhu, Zhang and Damian2016), we predicted that the mediated effect that emerged in the first experiment, but only under a semantically homogeneous context, should be absent in the second experiment.
EXPERIMENT 2
Method
Participants
Twenty undergraduate students (10 male; average age 21.4 years; range 19–25 years) from Beijing Forest University and China Agricultural University were paid for their participation. All were native Mandarin Chinese speakers and had normal or corrected-to-normal vision.
Materials and design
Twenty-five black-and -white line pictures were selected from a standardized picture database in Chinese (Zhang & Yang, Reference Zhang and Yang2003), including five objects from each of five semantic categories (animals, body parts, clothing, fruits, and tools). All pictures had disyllabic names. The objects were combined into sets of five in order to form five homogeneous and five heterogeneous blocks, with the latter ones including one item in each semantic category.
Each target picture was paired with three disyllabic distractor words. A phonologically related word was chosen that shared the first syllable but not the tone with the picture name (i.e., target: 袋鼠, /dai4shu3/, kangaroo; distractor: 歹徒, /dai3tu2/, gangster). A mediated word was chosen that shared the first syllable but not the tone with the first character of a picture name from the same semantic category as the target (i.e., target “kangaroo,” distractor: 席子, /xi2zi5/, “mat,” which is phonologically related to 犀牛, /xi1niu2/, “rhinoceros”). An unrelated word was selected that stood in no obvious relationship to the target (i.e., 枕头 /zhen3tou2/, pillow). Distractors in each condition were statistically matched for number of strokes and written frequency based on normative information reported in the database of the Chinese Lexicon (Chinese Linguistic Data Consortium, 2003). An additional two drawings were selected as practice items.
The experimental design included the variables semantic context (homogeneous and heterogeneous) and distractor type (phonologically related, mediated, and unrelated) as within-participants and within-items variables. Ten blocks that each contained five pictures were constructed. Within each block, each target was repeated 4 times in each distractor type. Therefore, each of the five targets occurred 12 times for a total 60 trials in each block. The order of items within one block was pseudorandomized for each participant with the constraint that a particular target and the first phoneme of a target name was never the same on consecutive trials. Five homogeneous blocks and five heterogeneous blocks were constructed, yielding a total of 600 trials. Homogeneous and heterogeneous blocks were presented in alternating orders, and the order of different block lists was counterbalanced according to a Latin square design.
We also assessed the degree of semantic relatedness between semantic competitors of mediated distractors and target names, and the one between unrelated words and target names by 16 native Chinese speakers (4 males, age from 18 to 45 years old) who did not take part in the Experiment 2. An identical rating procedure as the one in English was used. The average degree of semantic relatedness was 1.61 (SD = 0.42) with a range of 1.00 to 2.64 between unrelated distractors and target names, and was 3.75 (SD = 0.52) with a range of 3.08 to 4.68 between semantic competitors and target names across subjects. A paired-sample t test indicated a significant difference between two semantic relatedness degrees, t (15) = 15.25, p < .001. For semantic competitors of the mediator distractor words, an independent-sample t test indicated there was no significant difference between English and Chinese speakers, t (30) = –0.73, p = .47, reflecting that the degree of semantic relatedness between target names and semantic competitors were similar in English and Chinese.
Apparatus
The experiment was performed using E-Prime Professional Software (Version 1.1; Psychology Software Tools). Pictures were standardized to a size of approximately 6 × 6 cm and displayed at the center of the screen. Distractor words were presented in 30-point Song font, centrally superimposed on the target pictures. Naming latencies were measured from target onset using a digital voice key, connected with the computer via a PST serial response box.
Procedure
The procedure was identical to Experiment 1, with the exception that 10 experimental blocks of 60 trials each were presented. The experiment took about 60 min in total per participant.
Results of Experiment 2
Data from incorrect responses (0.9%), and other responses such as mouth clicks (0.6%), naming latencies longer than 2000 ms or shorter than 200 ms (0.008%), and those deviating by more than 3 SD from a participant's mean (1.51%) were removed from all analyses. As in Experiment 1, data of the first presentation of an object paired with three different kinds of distractors within each block were removed from the analysis. Error rates were low (overall <1%) and thus were not analyzed further.
Figure 3 presents mean picture naming latencies and standard errors by semantic context and distractor type. As in the first experiment, the expected semantic blocking effect, as well as facilitation from phonologically related distractors, is visible. By contrast, mediated distractors appear to have little or no effect, and this is the case both in the semantically homogeneous and the heterogeneous contexts.
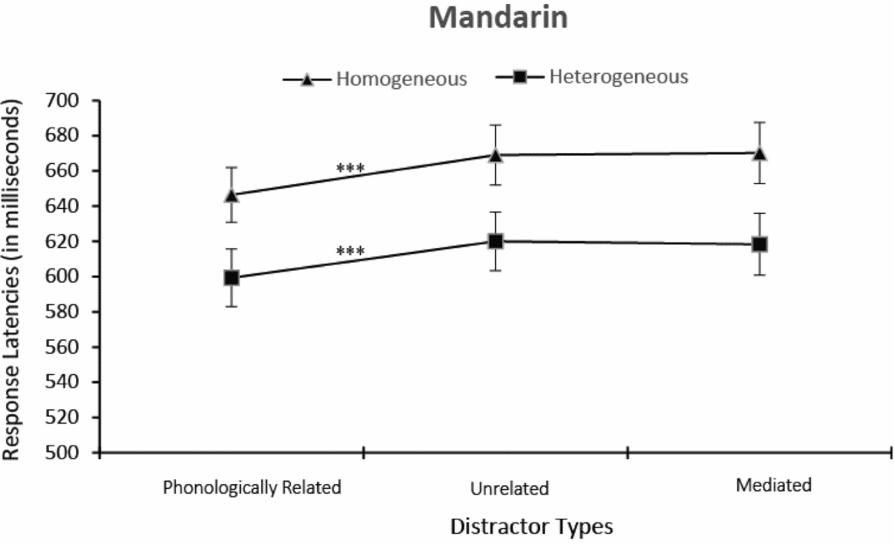
Figure 3. Mean pictures naming latencies and standard errors dependent on semantic context and distractor type in Mandarin. *p < .05; **p < .01; ***p < .001.
ANOVAs were conducted on the response latency means, with participants (F1) or items (F2) as random factors and semantic context and distractor type as within-participants and within-items variables. A significant effect of sSemantic context was found, F 1 (1, 19) = 78.87, MSE = 924, p < .001, ηp2 = 0.81; F 2 (1, 24) = 70.40, MSE = 1321, p < .001, ηp2 = 0.75, as well a significant effect of distractor type, F 1 (2, 38) = 29.62, MSE = 209, p < .001, ηp2 = 0.61; F 2 (2, 48) = 28.64, MSE = 276, p < .001, ηp2 = 0.54. No interaction was found between these two variables, F 1 (2, 38) = 0.39, p = .68; F 2 (2, 48) = 0.57, p = .57. Because the absence of this interaction contrasts with the results from the first experiment, and in order to establish the likelihood of the null hypothesis being true, we further conducted a Bayesian analysis with the method suggested by Rouder, Morey, Speckman, and Province (Reference Rouder, Morey, Speckman and Province2012) using JASP software (Love et al., Reference Love, Selker, Marsman, Jamil, Dropmann, Verhagen and Wagenmakers2015). The results revealed that the model with only the two main effects was superior to the full model including the interaction, with a Bayes factor of BF 10 = 5.36, which implies that the null hypothesis is more than five times more likely than the alternative hypothesis. According to the classification suggested by Jeffreys (1961), this constitutes “substantial” evidence for the null hypothesis (i.e., the finding of no interaction is true).
In order to assess the effects of phonological and mediated overlap separately, planned t tests analogous to those conducted in the first experiment were carried out. These showed that the phonological facilitation effect in the semantically homogeneous context (M diff = –23 ms) was significant, t 1 (19) = –5.18, p < .001; t 2 (24) = –5.40, p < .001, as was the effect in the semantically heterogeneous context (M diff = –21 ms), t 1 (19) = –5.04, p < .001; t 2 (24) = –7.86, p < .001. By contrast, mediated distractors had no effect under the semantically homogeneous context (M diff = 1 ms), t 1 (19) = 0.42, p = .68; t 2 (24) = 0.41, p = .68, nor under the semantically heterogeneous context (M diff = –2 ms), t 1 (19) = –0.34, p = .74; t 2 (24) = –0.20, p = .84. To further support the null finding concerning the effects of mediated distractors, we conducted Bayesian analysis using JASP software as mentioned above. Using the Jeffreys–Zellner–Siow Bayes-factor paired-sample t test (Rouder, Speckman, Sun, Morey, & Iverson, Reference Rouder, Speckman, Sun, Morey and Iverson2009), our result showed a Bayes factor BF 10 of 3.99 for the mediated effect in homogeneous blocks, and 4.08 for heterogeneous blocks, suggesting that the null hypothesis is approximately four times more likely than the alternative hypothesis. Again, the results provide substantial support for the null hypothesis over the alternative.
To evaluate the effect size of the phonological and the mediated effect, we calculated their Cohen d for the homogeneous and heterogeneous conditions separately. For the phonological effect, Cohen d was 0.28 (heterogeneous) and 0.31 (homogeneous). For the mediated effect, Cohen d was 0.02 (heterogeneous) and 0.01 (homogeneous).
Discussion of Experiment 2
The results of Experiment 1, with English speakers, had suggested multiple phonological activation, as indicated by an interfering impact of mediated distractors that was restricted to a semantically homogeneous context. The goal of Experiment 2 was to determine whether this was also the case with Mandarin speakers. The results showed the expected semantic context effect (we are not aware of previous studies that had used semantic blocking in Chinese, but prima facie this effect should be independent of response language) as well as phonological facilitation from related distractors (Wong & Chen, Reference Wong and Chen2008; Zhang, Chen, Weekes, & Yang, Reference Zhang, Chen, Weekes and Yang2009; Zhang & Yang, Reference Zhang and Yang2005; Zhao, La Heij, & Schiller, Reference Zhao, La Heij and Schiller2012). However, no mediated effect was found, a finding that clearly diverges from the results of the first experiment with English speakers. Although semantic activation was boosted when objects were named in a context of other items belonging to the same category (hence giving rise to the semantic blocking effect), mediated distractors that were phonologically related to one of the semantic alternatives showed no effect. The absence of a mediated effect in Mandarin cannot be attributed to insensitivity of the task we used since we obtained mediated effects in Experiment 1 (subtle differences in design and materials between the two experiments will be discussed in detail below). Hence, we argue that the discrepancy between the results obtained from English and Mandarin speakers concerning mediated effect arises from differences with regard to phonological encoding.
GENERAL DISCUSSION
In the experiments reported here, we revisited the issue of information transmission from semantic to phonological levels in spoken word production. Combining the semantic blocking paradigm with a picture–word interference manipulation, the critical question was whether “mediated” distractors (words that are phonologically related to a semantic competitor of the target object) exert an effect on target naming latencies. If so, the results could lend further support to the claim that information transmission in spoken production is “cascaded” (e.g., Kuipers & La Heij, Reference Kuipers and La Heij2009; Morsella & Miozzo, Reference Morsella and Miozzo2002; Navarrete & Costa, Reference Navarrete and Costa2005) and at least under some circumstances involves the activation of multiple phonological entries. In Experiment 1, we used English speakers and materials, and (besides the expected effects of semantic context and phonologically related distractors), we found mediated priming, but only in the semantically homogeneous, and not in the heterogeneous, context. In Experiment 2, we used Chinese materials and native Mandarin speakers in a design that was otherwise largely analogous to the first study. Again, we found semantic context effects and facilitation from phonologically related distractors. Critically, however, mediated priming was found under neither the semantically homogeneous nor the heterogeneous context.
The English results are generally in line with those from previous studies conducted on speakers of Western languages. As summarized above, there is accumulating evidence for a “cascaded” view of lexical access in speaking: it is principally possible for nontarget lexical entries to cascade activation to the phonological level, but cascadedness is generally so subtle that it cannot be detected in all tasks and circumstances. Hence, for instance, mediated distractors in PWI tasks (words that are phonologically related to a semantic competitor of the target object) show no effect on target naming under usual circumstances (e.g., Damian, Reference Damian1998). Only when either semantic or phonological activation is boosted relative to a “standard” case (e.g., when two semantically related pictures are presented, as in Oppermann et al., Reference Oppermann, Jescheniak, Schriefers and Görges2010, or when a single picture is paired with two phonologically related distractors, as in Abdel Rahman & Melinger, Reference Abdel Rahman and Melinger2008) do mediated distractors show an effect. This is in line with our findings from English speakers: mediated distractors had no effect in semantically heterogeneous blocks, but they generated interference when presented in semantically homogeneous blocks in which semantic activation of targets and competitors is presumably increased.
The results from Mandarin speakers are perhaps more surprising. In a largely analogous experiment, the expected semantic blocking and phonological facilitation effects were found. This is reassuring as there is no obvious reason why these effects should be affected by target language. However, no mediated effects were found in this experiment. At face value, the absence of mediated effects might be interpreted as evidence for serial information transmission in Mandarin. If so, our results would suggest a fundamental difference between the target languages with regard to phonological encoding: weak cascadedness in English, but strictly serial transmission in Mandarin.
We highlight the fact that the absence of a mediated effect in spoken Mandarin is fully compatible with two sets of results that we recently reported: Zhu et al. (Reference Zhu, Zhang and Damian2016) factorially crossed semantic and phonological relatedness in a PWI task with Mandarin speakers, and in contrast to numerous previous findings from speakers of Western languages, the two types of relatedness exerted a strictly additive relationship in Mandarin. Based on additive factors logic, this can be interpreted as indicating serial/discrete information transmission between semantic and phonological levels. Zhu et al. (Reference Zhu, Damian and Zhang2015) provided further evidence for a serial model via EEG and showed that with Mandarin speakers, semantic and phonological stages emerged in sequential corresponding time windows, which conflicts with comparable EEG studies conducted on speakers of Western languages where both stages appeared largely at the same time. Both sets of results are in line with the absence of a mediated effect in our present Experiment 2, and point toward a serial transmission mode in Mandarin spoken word production.
Is it possible that the difference observed in the mediated condition between English and Chinese arose at the conceptual level? Perhaps speakers of the two languages exhibit differences in which they mentally represent the semantic categories that we used (tools, furniture, body parts, etc.), and the presence or absence of a mediated effect hinges on the underlying conceptual representations. However, studies on such semantic categories have suggested strong similarity across languages (e.g., Bowerman, 1973; Brown, 1973; Slobin, 1970, 1973), and accordingly, the chosen categories and exemplars in our experiments successfully evoked the semantic blocking effect numerously reported before, and in both languages. The semantic effect in our task was numerically more pronounced in Chinese than in English, which should render it more likely that mediated effects should be observed in the former compared to the latter language. However, instead, we found mediated effects only in English but not in Chinese. This makes a conceptual origin of the differences in the mediated condition unlikely.Footnote 2
It is acknowledged that there are subtle differences in materials and manipulations across the two studies that might hamper a clear interpretation of the results. These are as follows: in Experiment 1, we used four semantic categories with four examples each; in Experiment 2, there were five categories with five exemplars. This variation is unlikely to make a difference and is within the limits of the existing literature (e.g., Damian et al., Reference Damian, Vigliocco and Levelt2001, used a 5 × 5 design, whereas Damian & Als, Reference Damian and Als2005, used 4 × 4). Due to the difference in categories/exemplars between the two experiments, but given the identical repetition of targets within each block (12), this resulted in 384 trials per participant in the first experiment, but 600 trials in the second. It is unlikely that the overall length of the experiments would have influenced the results (e.g., Maess, Friederici, Damian, Meyer, & Levelt, Reference Maess, Friederici, Damian, Meyer and Levelt2002, reported a semantic blocking experiment with a total of 1,200 trials).
In addition, form overlap in our study was manipulated in terms of both orthography and phonology for the English stimuli, but exclusively in terms of phonology for the Chinese stimuli.Footnote 3 This discrepancy arose from constraints on stimulus selection; ideally, one would use either English distractors that are only phonologically but not orthographically related or Chinese distractors that share orthographic properties such as the first character with the target. Unfortunately, both strategies are difficult to implement: in alphabetic languages such as English, sound and spelling are necessarily confounded, so it is difficult or impossible to find word pairs that are phonologically but not orthographically related. In Chinese, if a distractor and a target share the first orthographic character, semantic associations between the two are unavoidable. One could also consider repeating our two experiments with spoken, rather than written, distractors, but again this is problematic as due to the prevalent homophony in Mandarin, isolated spoken words are often difficult to disambiguate. Considering these potential factors, the different findings in English and Chinese should be interpreted cautiously and need to be investigated further.
A further variation that is difficult to avoid is that in the English experiment, targets and distractors were monosyllabic, whereas in Chinese they were disyllabic. This arises from the statistics of the target languages: within the constraints of the semantic blocking paradigm, it would be difficult to identify adequate disyllabic targets in English, or monosyllabic targets in Chinese. In addition, phonological overlap was segmental in the English experiment, but syllabic in Chinese. Again, this inconsistency cannot be avoided: because targets are monosyllabic in English, phonological overlap is necessarily subsyllabic and segmental. In Mandarin, by contrast, subsyllabic segmental overlap in PWI tasks results in little or no priming (e.g., Wong & Chen, Reference Wong and Chen2008, Reference Wong and Chen2009); hence, we had to define overlap syllabically (here, in terms of the initial syllable overlapping between target and distractor). It is worth highlighting that the relative degree of phonological overlap between target and distractor was comparable across the two experiments: average segmental overlap was 54% in Experiment 1 (see Materials section), and syllabic overlap was 50% in Experiment 2 (one out of two syllables was shared between disyllabic targets and distractors).
What are the theoretical implications of the current findings with regard to models of phonological encoding across languages? Due to the sparsity of available results on word production in non-Western languages, theoretical accounts of the results from our experiments are necessarily speculative. Figure 4 shows a rough processing sketch of word form encoding across the two target languages, loosely adapted from Roelofs (Reference Roelofs2015) and O'Seaghdha (Reference O'Seaghdha2015). “Proximate units,” defined as the primary selectable unit below the word level by O'Seaghdha, Dell, and Schwartz (Reference O'Seaghdha, Chen and Chen2010), are highlighted. Note that the Mandarin model contains a segmental layer, despite the fact that behavioral experiments that manipulated segmental overlap have tended to result in null findings (e.g., Chen et al., Reference Chen, Chen and Dell2002; Wong & Chen, Reference Wong and Chen2008, Reference Wong and Chen2009; see also Verdonschot et al., Reference Verdonschot, Kiyama, Tamaoka, Kinoshita, La Heij and Schiller2011, for results from Japanese). Segments nevertheless probably contribute to phonological encoding because segmentally based speech errors are found in spoken Chinese (e.g., Chen, Reference Chen1993); note also that Qu, Damian, and Kazanina (Reference Qu, Damian and Kazanina2012; see also Yu, Mo, & Mo, Reference Yu, Mo and Mo2014) presented EEG evidence for the presence of segmental effects in Mandarin speakers despite behavioral null findings, which further warrants inclusion of such a segmental layer in the model.
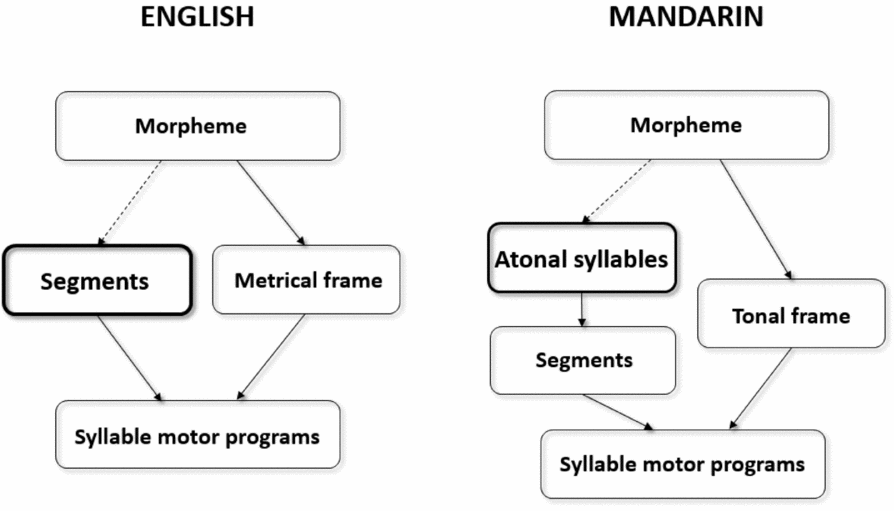
Figure 4. Sketch of phonological encoding in English and Mandarin. Proximate unites are highlighted.
Given that phonological overlap in our experiments was defined at the proximate unit level (i.e., segmental in English but based on atonal syllables in Mandarin), there is no obvious reason why information transmission from morpheme to proximate unit level should be cascaded in English, but serial in Mandarin. Nevertheless, this is what our results suggest. Hence, processing along the critical pathway (shown in dotted lines in Figure 4) could fundamentally differ between languages. This account is admittedly post hoc, and it is not obvious why this should be the case. Perhaps this is because in Western languages, relatively few segments combine to form a potentially unlimited number of lexical items, whereas in Mandarin, the number of syllables is much larger and so a discrete activation makes sense for syllables whereas the process is more continuous for segments.
In all three relevant sets of results (Zhu et al., Reference Zhu, Damian and Zhang2015, Reference Zhu, Zhang and Damian2016; and the current findings), phonological overlap was defined in terms of overlapping atonal syllables (e.g., the target “cherry,” /ying1tao2/ was paired with the distractor “profit,” /ying2li4/). Given that in PWI tasks, segmental overlap in (Cantonese) Chinese by itself does not generate priming (Wong & Chen, Reference Wong and Chen2008, Reference Wong and Chen2009), we attributed the phonological facilitation in our Experiment 2 to the “proximate unit” layer of atonal syllables. Is it possible that this assumption is incorrect, and phonological facilitation perhaps took place at the level of the tonally specified syllable? If so, this could explain the statistical additivity between semantic interference and phonological facilitation reported in Zhu et al. (Reference Zhu, Zhang and Damian2016), as well as the relatively late time window under which phonological effects appeared in the EEG results reported by Zhu et al. (Reference Zhu, Damian and Zhang2015). Such an account would have to explain why the coactivation of similar (but tonally mismatching) syllables generates behavioral priming. Under the assumption that segments and tonal syllables are bidirectionally connected, perhaps the activation of the distractor syllable /ying2/ could prime, via shared segments, the target syllable /ying1/.
Although this scenario is not impossible, we believe that similar effects would then be predicted for Western languages as well: for example, if both the target object “cat” and a phonologically related distractor “cap” activate their corresponding syllables and activation is shared between them via segmental overlap, then we should also find syllabic priming in English and other Western languages. However, this is not the case (e.g., Schiller, Reference Schiller1998, Reference Schiller2000; Schiller, Costa, & Colomé, Reference Schiller, Costa and Colomé2002), nor does the prediction agree with EEG studies of spoken word production (see above) that have shown a “late” time window of phonological effects only in Mandarin, but not in Western languages. Furthermore, it is interesting to note that the WEAVER model of word form encoding (Levelt et al., Reference Levelt, Roelofs and Meyer1999; Roelofs, Reference Roelofs1997) stipulates that access to syllable program nodes is competitive. Hence, the prediction from this framework is that coactivation of similar syllables should hinder, rather than facilitate, access to the correct target syllable. This clearly conflicts with the fact that phonological overlap in PWI generally results in facilitation.
Clearly, further research is required to resolve this issue, and we acknowledge the need for alternative approaches concerning how the phonological properties of a target language could affect semantic-to-phonological transmission. Especially, other phonological properties such as neighborhood density (Peramunage, Blumstein, Myers, Goldrick, & Baese-Berk, Reference Peramunage, Blumstein, Myers, Goldrick and Baese-Berk2011), the role of the relatively low number of atonal syllables and unique properties of tones in Chinese (Roelofs, Reference Roelofs2015), need to be investigated directly in the future.
To summarize, the results of the present study suggest that in English spoken word production, nontarget lexical entries can under certain circumstances activate their corresponding phonological properties, supporting a notion of lexical access in which information transmission from semantic to phonological layers is cascaded. This pattern dovetails with a rising number of findings from various tasks and conducted with speakers of Western languages. By contrast, in Mandarin word production, no such evidence for cascadedness was found, and information transmission appeared more strictly serial. This discrepancy highlights potential fundamental differences in phonological encoding across target languages. The combination of semantic blocking and picture–word interference used here and previously (Aristei et al., Reference Aristei, Melinger and Abdel Rahman2011) offers new possibilities for investigating the underlying mechanisms of spoken word production.
APPENDIX A
Table A.1. Materials used in Experiment 1
APPENDIX B
Table B.1. Materials used in Experiment 2

ACKNOWLEDGMENTS
This research was supported by the National Natural Science Foundation of China under Grant 31471074, and the Key Project of the Beijing Social Science Foundation under grant 16YYA006 (to Q.Z.).
SUPPLEMENTARY MATERIAL
To view supplementary material for this article, please visit https://doi.org/10.1017/S0142716418000024








