


The concept of nutrient requirements is central to the field of nutrition. Nutritional response kinetics refers to the basic shape of the curve describing the relationship between nutrient input levels (concentration or intake) and responses (growth, efficiency, metabolism, lactation, egg production, etc.). The particular choice of the mathematical response model to describe nutritional kinetics is, therefore, very important to nutritionists who need to estimate requirements of any organism. While some nutritionists consider that there should be a smooth transition from the ascending to the plateau portions of the response( Reference Morgan, Mercer and Flodin 1 – Reference Hua 4 ), the practical approaches are often to use multiple range tests, polynomials or the ‘broken-line’ spline model, to estimate the requirements for maximum performance, efficiency of nutrient utilisation, etc.( Reference Hua 4 – Reference Stephens, Payne and Ball 8 ). Just a very few examples of response models that have been described in this manner are weight gain v. nitrogen intake and isoleucine retention v. dietary casein level in rats, bone ash v. vitamin D level and blood clotting time v. vitamin K in chicks( Reference Morgan, Mercer and Flodin 1 ), whole body protein v. sulphur-containing amino acids in pigs( Reference Rakhshandeh, Htoo and Karrow 5 ), cataracts v. histidine levels( Reference Remø, Hevrøy and Olsvik 6 ) and energy metabolism v. arginine( Reference Andersen, Holen and Aksnes 7 ) in salmon diets, and the protein requirements of healthy pregnant women( Reference Stephens, Payne and Ball 8 ). In human nutrition, the practice has been to relate requirements or recommended allowances to clinical status, growth and body fluid composition. In agricultural animals and fish, a balance must be struck between feed costs and time to reach market weights and carcass composition( Reference Morgan, Mercer and Flodin 1 ). In crop production, a balance can be found using kinetic response models to maximise the difference between crop value and fertiliser costs.
To help nutritionists design more efficient nutritional experiments, we developed an Excel-based simulation program. The program, called the Nutritional Response Determination Optimization workbook (NuRDO.xls), simulates a series of experimental responses around a pre-selected ‘true’ model, which can be then used to estimate parameters and requirements. In particular, NuRDO can be used to simulate responses based on quadratic polynomials (QP, y=b 0+b 1 x+b 2 x 2), broken-line spline models with either linear (BLL, y=maximum if x>requirement, maximum+rate constant×(requirement–x) if x≤requirement) or quadratic (BLQ, y=maximum if x>requirement, maximum+rate constant×(requirement–x)2 if x≤requirement) ascending segments, or the saturation kinetics (SK, y=(intercept×rate constant+maximum×x kinetic order)/(rate constant+x kinetic order)) model( Reference Morgan, Mercer and Flodin 1 ) with parameters input by the user (Table 1; Fig. 1). For all models, y=response variable, x=nutrient level, b 0=intercept, b 1 and b 2=regression coefficients, while other variables are parameters.

Fig. 1 Example of Nutritional Response Determination Optimization (NuRDO) simulation of data from an experiment with eight nutrient levels between 5 and 15 with a maximum response of 100 and a rate constant of −10. The models fitted are the quadratic polynomial (QP, y=b
0+b
1
x+b
2
x
2), broken-line spline models with either linear (BLL, y=maximum if x>requirement, maximum+rate constant×(requirement–x) if x≤requirement) or quadratic (BLQ, y=maximum if x>requirement, maximum+rate constant×(requirement–x)2 if x≤requirement) ascending segments and the saturation kinetics (SK (intercept×rate constant+maximum×x
kinetic order)/(rate constant+x
kinetic order)). For all models, y=response variable, x=nutrient level, b
0=intercept, b
1 and b
2=regression coefficients, other variables are parameters. ![]() , Simulation;
, Simulation; ![]() , BLL;
, BLL; ![]() , BLQ;
, BLQ; ![]() , QP;
, QP; ![]() , SK.
, SK.
Table 1 Results of several models fitted to data simulated with various combinations of levels and replications per levelFootnote * (Standard errors and coefficients of determination)

QP, quadratic polynomial; SK, saturation kinetics model; reps, replicates.
* The CV between observations was 8 %; equally spaced levels between 5 and 15, for example for four levels=5·000, 8·333, 11·667, 15·000.
NuRDO can be used to evaluate the effects of experimental design choices on the expected confidence in requirements and/or other parameter estimates. The objectives of the studies reported here were to determine how standard errors of the estimates of nutritional requirements are affected by (1) the number of simulated experiments; (2) the number of nutrient levels and replicates (reps) per level; (3) the range of nutrient levels above and below the actual requirement; and (4) the variability of simulated responses (CV) and the shape of the ‘true’ response model (rate constant or RC).
The workbook should be most helpful in planning experiments to maximise the efficiency of resource use and to justify the number of experimental subjects required to achieve desired confidence in conclusions from experiments.
Methods
NuRDO is implemented as a Microsoft Excel workbook that allows the user to design a nutritional requirement experiment and simulate its outcomes (http://www.poultry.uga.edu/extension/PoultryNutrition.htm). First, the user selects the desired number of levels, replicates and the range of inputs. The workbook automatically generates a uniformly spaced grid of input levels. However, the generated levels can be adjusted, for example to cluster them around a suspected inflection point of the BLL or BLQ model. The user then selects the ‘true’ model from which the responses are simulated and calculates the corresponding model parameters. The available options are BLL, BLQ, QP and SK functional forms. Lastly, the user specifies the CV of simulated responses and the number of experiments to simulate. The workbook then generates a series of responses around the true model (with the random errors drawn from the normal distribution), fits up to four selected models (BLL, BLQ, QP and/or SK), and calculates and outputs the estimated parameters along with their standard errors and 95 % CI. The outputs are stored in the workbook and can be used for subsequent analysis.
se were calculated as square roots of the diagonal elements of the matrix:
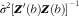 $\hat{\sigma }^{2} \left[ {{\mib{Z'}} \left( b \right){\mib{Z}} \left( b \right)} \right]^{{{\minus}1}} $
, where
$\hat{\sigma }^{2} \left[ {{\mib{Z'}} \left( b \right){\mib{Z}} \left( b \right)} \right]^{{{\minus}1}} $
, where
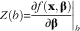 $Z(b){\equals}\left. {{{\partial f({\bf x},{\bf \bbeta })} \over {\partial {\bf \bbeta }}}} \right|_{b}$
;
$Z(b){\equals}\left. {{{\partial f({\bf x},{\bf \bbeta })} \over {\partial {\bf \bbeta }}}} \right|_{b}$
;
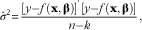 $\hat{\sigma }^{2} {\equals}{{\left[ {y{\minus}f({\bf x},{\bf \bbeta })} \right]^{\prime} \left[ {y{\minus}f({\bf x},{\bf \bbeta })} \right]} \over {n{\minus}k}},$
$\hat{\sigma }^{2} {\equals}{{\left[ {y{\minus}f({\bf x},{\bf \bbeta })} \right]^{\prime} \left[ {y{\minus}f({\bf x},{\bf \bbeta })} \right]} \over {n{\minus}k}},$
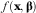 $f({\bf x},{\bf \bbeta })$
is the non-linear function parameters of which was estimated, x and y are the inputs and responses from a given experiment, respectively, n is the number of observations and k is the number of parameters. sd were calculated across different simulated experiments, that is: sd
$f({\bf x},{\bf \bbeta })$
is the non-linear function parameters of which was estimated, x and y are the inputs and responses from a given experiment, respectively, n is the number of observations and k is the number of parameters. sd were calculated across different simulated experiments, that is: sd
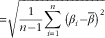 $${\equals}\sqrt {{1 \over {n{\minus}1}}\mathop{\sum}\limits_{i{\equals}1}^n {\left( {\beta _{i} {\minus}\bar{\beta }} \right)} ^{2} } $$
, where β
i
is the estimate of a specific parameter obtained from the simulated experiment i.
$${\equals}\sqrt {{1 \over {n{\minus}1}}\mathop{\sum}\limits_{i{\equals}1}^n {\left( {\beta _{i} {\minus}\bar{\beta }} \right)} ^{2} } $$
, where β
i
is the estimate of a specific parameter obtained from the simulated experiment i.
Linear regressions were fitted to R 2’s as functions of the total number of pens in the experiment.
Results
As the number of simulated experiments increased, the variation in the mean requirement decreased until thirty simulations were reached (Fig. 2). For the BLL model, increasing the size of the simulated experiment from sixteen to twenty-four pens decreased the se of the requirement estimate by about 19 % (Table 1; 0·46 v. 0·57), from twenty-four to forty-eight pens by about 28 % (0·33 v. 0·46) and from forty-eight to ninety-six pens by another 30 % (0·23 v. 0·33). se estimates were much higher (>100 %) for the BLQ models. Relative differences for the BLQ model were similar to the BLL model. R 2 values decreased as the number of pens (total variation) increased from sixteen to forty-eight for all models (BLL, P=0·039; BLQ, P=0·036; QP, P=0·025; SK, P=0·011). If the break-point was not central to the range studied (i.e. break-point of 12, Table 1), the se decreased for the BLL model, but increased for the BLQ model. R 2 values increased for all four models when the break point was not in the centre of the range studied. The combination of nutrient levels and number of replications per level made little difference in the precision of the requirement estimates; in this example eight levels of six reps each and sixteen levels of three reps each gave very similar results with se of 0·27 (to two decimal places).

Fig. 2 Influence of number of Nutritional Response Determination Optimization simulations on the precision of requirement estimation. There were ten requirement estimates with five to eighty simulations each. Each point represents one requirement estimate. ![]() , Broken-line quadratic model;
, Broken-line quadratic model; ![]() , broken-line linear model.
, broken-line linear model.
The influence of range of nutrient levels simulated was dependent on the experimental replication (Table 2). As the range of simulated nutrient levels decreased, R 2 values decreased and when the range was too small, the models would not converge and thus produced no se estimates. With forty-eight total observations there was little difference in se estimates for the BLL model but for the BLQ model, the estimated se increased as the simulated interval decreased.
Table 2 Results of several models fitted to data simulated with various ranges of data above and below the simulated nutritional requirement or ‘break point’Footnote * (Standard errors and coefficients of determination)

QP, quadratic polynomial; SK, saturation kinetics model; reps, replicates; FC, Excel failed to converge on a solution for that data.
* Equally spaced levels between low and high, for example four equally spaced levels between 5 and 15=5·000, 8·333, 11·667, 15·000.
As the CV of the simulated responses increased, the requirement estimates became less precise (Fig. 3 and 4), although there seems to be little difference above CV levels of 6 % for either the BLL or BLQ models. The more important factor is the RC, the slope of the ascending portion of the response (Table 3). If the angle between the segments in the BLL model is relatively small, the requirement estimate is more precise. As the angle becomes greater (−20 v. −2), the increase in se is much greater with higher CV.

Fig. 3 Effect of the CV of the experimental unit on the precision of requirement estimation. Each point represents one requirement estimate from thirty simulations. ![]() , Broken-line quadratic model;
, Broken-line quadratic model; ![]() , broken-line linear model.
, broken-line linear model.

Fig. 4 Example of Nutritional Response Determination Optimization simulations with different rate constants (RC) and different observation to observation CV. ![]() , Simulations CV=4 %;
, Simulations CV=4 %; ![]() , RC=−4;
, RC=−4; ![]() , RC=−12;
, RC=−12; ![]() , simulations CV=10 %.
, simulations CV=10 %.
Table 3 Results of several models fitted to data simulated with different rate constants and two coefficients of variationFootnote * (Standard errors and coefficients of determination)

CV=sd/mean; QP, quadratic polynomial; SK, saturation kinetics model; reps, replicates.
* Eight equally spaced levels between 5 and 15.
Discussion
In planning experiments, it is most helpful for nutritionists to know the expected variation and the shape of the response from historical data; plus they need to have some expectation of the acceptable variation in the requirement estimate. With this basic information, the nutritionist can decide if they have sufficient resources and then how to best allocate the resources to meet their goals. In the past, nutritionists had to make an educated guess on the best way to design their experiments. The NuRDO workbook uses Excel to take at least some of the guesswork out of the process of experimental design. Note that the results from NuRDO simulations will never be exactly the same because they are based on random draws from normal distributions (the same as real experiments have individuals randomly chosen from some greater population). However, with enough simulated experiments, the mean results of multiple simulations should be very similar up to any desired number of decimal places.
The three factors having the largest impact on accuracy of requirement estimates are the CV of the subjects, RC and interval (nutrient levels) to study. If the RC is small and there is a very gradual transition from ascending portion of the response to the plateau portion, it will be difficult to get a precise estimate of the requirement in question regardless of the number of levels and replicates used. This is a result of the requirement estimate being made for the population and not any particular individual(s). The influence of the RC is not just a matter of scaling that can be manipulated in graphing the data. The slope of the regression line is the critical factor and it is represented by the RC in the model used to estimate the se of the requirement. There is little that can be done to alter the RC. Like the K m in enzyme kinetics, RC is a property of the system being studied.
On the other hand, the variation between individuals, or the CV, can often be changed to help increase experimental precision. The most common method of decreasing the CV is to choose uniform individuals to study. It is important that conclusions drawn from limited populations are not extrapolated to other populations. Regressions with only individuals near the mean weight, for instance, may not be normally distributed (a transformation may be necessary) and the results may only apply to similar individuals. Choosing one sex or the other, one strain or the other, etc. may be quite useful if it is remembered that the results may only be applicable to the sub-population from which they were derived.
Choosing the appropriate range of nutrient levels to study is an area where NuRDO may be particularly helpful. If there are no preliminary or historical data then the range to be studied should be particularly wide to include all possible outcomes. Once there is preliminary or historical data to base experiments on, then NuRDO can be helpful in making sure the range studied is not too narrow. If there is too much concentration near the requirement, then the R 2 may be low and the model may even fail to converge on an se estimate. While it seems intuitive that replication should be concentrated near the break-point, it is not necessarily helpful if the range studied is narrowed, or if the RC is small.
There are two aspects of NuRDO simulations that are critical for accurate predictions: model fitting and random observation distribution. The model fitting method implemented in Excel by NuRDO gives the same result as SAS( Reference Vedenov and Pesti 9 , 10 ). Non-linear equations are fitted by iterative methods, trial and error, until a given tolerance is reached to find the coefficients minimising the model sum of squares. While no method is perfect, the method implemented by NuRDO gives the same results as one of the most accepted statistical analytical packages available.
The second potential source of error in NuRDO simulations is in Excel’s ability to randomly choose observations belonging the specified distribution (means and standard deviations). By their very nature when random numbers are involved the results are not perfectly reproducible (especially obvious with small sample sizes). Still, if enough simulations are obtained, the means and standard deviations should closely approach those specified. When one million simulations were made from populations specified to have a mean of 100 and sd of 10, means ranged from 99·9781 to 100·0186 and sd ranged from 9·9846 to 10·0277 (n 10). The overall mean was 99·9976 for 0·0024 % error (n 107). The overall sd was 9·9997 for 0·0265 % error (n 107).
Therefore, the errors inherent in NuRDO’s implementation are much smaller than the experimental error in means and standard errors in typical nutrition experiments (Tables 1–3). Experimental error should not be expected to cause noticeable differences in model parameter estimates. The key to using NuRDO efficiently is to have a good estimate of expected variation under the experimental conditions being simulated, and to perform enough simulations that the coefficient estimates have acceptable variation for the intended use of the experimental results.
The NuRDO workbook was designed to help nutritionists to design experiments using several common models that all may accurately describe nutrition response kinetics under particular circumstances( Reference Pesti, Vedenov and Cason 11 ). The comparisons made in Tables 1–3 and Fig. 1–4 are mainly based on the BLL and BLQ models, as they are the ones that feature requirement estimates with standard errors. The standard errors of the requirements are direct indications of the precision that may be expected from an actual experiment. Of course, that is if the experiments that are actually performed have subject to subject variation and RC similar to past observations. NuRDO could be used in a similar fashion to estimate the precision in estimating the R max or K m for the SK model( Reference Morgan, Mercer and Flodin 1 ) or the nutrient concentration giving the maximum response in the QP model. We implemented NuRDO with four commonly used nutritional response models assuming that there is no model appropriate for all situations and researchers should further adapt it to other situations as they deem appropriate. Nutritional kinetics have been studied in a wide variety of species including humans rats, mice chicks and fish( Reference Morgan, Mercer and Flodin 1 – Reference Stephens, Payne and Ball 8 ). The models should be appropriate for all organisms since enzyme catalysed reactions are common processes of all living things. The NuRDO workbook was developed with four common response models, but is easily adaptable to simulate data from practically any other response model considered more appropriate for any organism.
Acknowledgements
This research was funded by Georgia Agricultural Experiment Station and Hatch project TEX0-1-9258.
The authors’ contributions are as follows: G. M. P., D. V. and R. A. A. designed the workbook; D. V. programmed the workbook; G. M. P. conducted the simulations and wrote the manuscript with input from all authors; G. M. P. had primary responsibility for the final content. R. W. formatted the manuscript; all authors read and approved the final version of the manuscript.
The authors have no financial or personal conflicts of interest to declare.







