



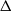
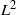
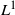
Crossref Citations
This article has been cited by the following publications. This list is generated based on data provided by Crossref.
Gagnon, Philippe
and
Maire, Florian
2024.
An asymptotic Peskun ordering and its application to lifted samplers.
Bernoulli,
Vol. 30,
Issue. 3,