


Impact Statement
In this work, we review the ways in which Machine Learning (ML) has been leveraged to make buildings smart and energy-efficient. In doing so, we touch upon traditional methods already in place and how ML-based solutions often match or outperform them. Our work aims to benefit ML researchers interested in how their expertise can be applied to the smart building sector, and smart building specialists—researchers whose primary interests are in energy efficiency, the quality of the indoor environment, the related occupant experience, advanced control methods, etc.—who wish to solve domain-specific problems using ML. Our work will equip researchers with a bird’s-eye view of the ML applications in Smart Buildings, enabling them to visualize the existing interdependencies among different subsystems, and design ML-based implementations for optimizing energy usage and occupant comfort.
1. Introduction
We spend 90% of our time every day in indoor environments, so buildings substantially influence our health, well-being, safety, and work and study performance. Also, the energy used in buildings to ensure individual safety and comfort is a leading contributor to climate change. It is estimated that in the United States, buildings (both residential and commercial) are responsible for approximately 40% of primary energy consumption, 73% of electrical use, and 40% of greenhouse gas emissions (U.S. Department of Energy—Energy Information Administration, Annual Energy Outlook, 2020). It is of utmost importance to improve building energy systems to optimize energy usage and thus limit the greenhouse gas emissions contributed by them, while, at the same time, ensuring an occupant-friendly environment to improve well-being and productivity. Energy use reductions while maintaining occupant comfort and productivity in buildings can be an environmentally sustainable, equitable, cost-effective, and scalable approach to reducing greenhouse gas emissions.
These requirements necessitate bringing to bear some of the latest sensing, computing, and control technologies into the built environment. It is expected that these technologies, appropriately integrated, will make the built environment responsive to occupant needs and environmental factors, delivering both superior occupant experience and unprecedented energy efficiency. In other words, the buildings will be “Smart”, which in this context refers to the union of “having buildings equipped with Internet-of-Things (IoT) devices and sensors to collect real-time data such as temperature, humidity, lighting levels, and air quality” as well as “having the infrastructure to harness the power of tools such as AI and machine learning (ML) to utilize data from buildings for energy efficiency and occupant comfort”.
Additionally, as computing has evolved, ML techniques are being shown to be complementary and, in many cases, superior to more classical approaches. The latter require accurate models describing the various aspects of the building and occupant behaviors, and such models are often inaccurate and very hard to build and maintain. As we will show in this paper, ML techniques often fill this gap.
The smart building ecosystem is illustrated in Figure 1. Occupants constitute the basic building block of the ecosystem. Being the consumers of the facilities that a building provides, occupants necessitate the regulation of the building systems to achieve the desired environment. The building comprises structures, devices, and systems in place to control and maintain the desired environment for the occupants, along with diagnostic systems to ensure robust operation. The building operation requires energy, which primarily comes in the form of electricity. The electrical energy is supplied to buildings via a power distribution system, where, with the advent of smart grids, buildings interact and exchange surplus energy and other ancillary services with the energy provider and with each other.
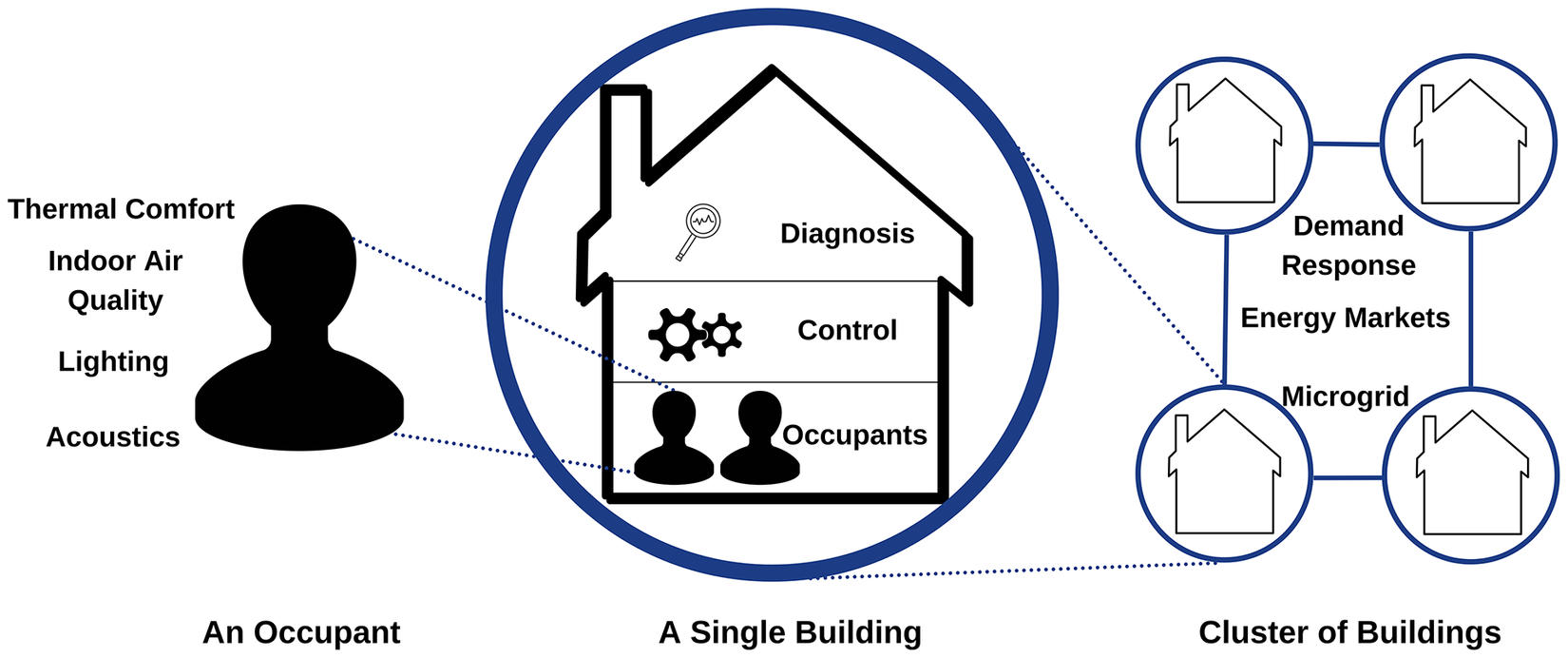
Figure 1. A taxonomy of the smart buildings illustrated at three levels: cluster of buildings, single building, and occupant.
In order to improve energy efficiency and occupant comfort, researchers and industry leaders have attempted to implement intelligent sensing, control, and automation approaches alongside techniques like incentive design and price adjustment to more effectively regulate energy usage. With the growth of IoT devices, and the great variety of user-to-device and device-to-device interactions, there is a need for integration and coordination of the related objectives and actions. Further, in order to derive insights from the vast amount of data in certain scenarios, and from the limited amount of data in others, ML applications are proliferating in smart buildings. These ML-driven insights can be used for downstream tasks such as forecasting, prediction, and control. In this work, we explore the growing application of ML in smart building systems, and examine how ML-based solutions often match or outperform more traditional methods.
1.1. Potential audience for this paper
Prior studies related to this paper (Rupp et al., Reference Rupp, Vásquez and Lamberts2015; Wang and Hong, Reference Wang and Hong2020; Zhang et al., Reference Zhang, Wen, Li, Chen, Ye, Fu and Livingood2021; Zhao et al., Reference Zhao, Lian and Lai2021) mainly focus on review studies in a subdomain. Another line of relevant prior studies include study of ML applications in smart buildings (Hong et al., Reference Hong, Wang, Luo and Zhang2020), from the viewpoint of an expert/researcher well aware of the dynamics of smart buildings. In this paper, we summarize and synthesize the research presented in these publications and provide a breadth-first view in the context of smart and energy-efficient buildings. Those who will benefit most from this summary are ML researchers interested in how their expertise can be applied to the smart building sector, and smart building specialists—researchers whose primary interests are in energy efficiency, the quality of the indoor environment and the related occupant experience, advanced control methods, occupancy modeling and monitoring, modeling and simulation, privacy, security, etc.—who wish to solve domain-specific problems using ML.
For literature search, we used the Google Scholar platform with keywords specific to various sections presented in this work, as it efficiently indexes and provides research studies at the intersection of multiple domains, which in our case is ML and smart buildings. Unlike many other search engines, we found the above platform be efficient in scoping literature from journals and conference proceedings, since the destination for many smart buildings research studies is journals, while in the case of ML, it is academic conferences.
2. Machine Learning
In this section, we briefly cover the fundamentals of some ML algorithms and methods that are commonly in practice in smart buildings. These ML algorithms can be commonly grouped under supervised, unsupervised, and reinforcement learning depending on the learning paradigm, i.e., the way a model gets trained on the available data. We briefly cover the functionalities of the above learning paradigms and various learning methods, while placing an emphasis on methods that we have found particularly useful in the context of optimizing the performance of the built environment, as detailed in the subsequent section.
2.1. Learning paradigms
2.1.1. Supervised ML
Supervised learning refers to a class of algorithms that learn using data points with known outcomes/labels. The model is trained using an appropriate learning algorithm (such as linear regression, random forests, or neural networks) that typically works through some optimization routine to minimize a loss or error function. The model is trained by feeding it input data as well as correct annotations, whenever available. If the output of the model is continuous, this process is called regression and if the output is discrete with finite classes, the process is called classification. Supervised learning has been implemented for substantial applications in real life, such as image classification/segmentation, natural language processing, time-series analysis. Since supervised learning requires annotated data, it faces a bottleneck when labeling is expensive or laborious.
2.1.2. Unsupervised ML
In contrast to supervised learning, unsupervised learning involves models/algorithms that look for patterns in an unlabeled dataset with minimal human supervision. Some unsupervised learning paradigms include clustering, which aims to group data into similar categories (clusters); dimensionality reduction, which aims to find a low-dimensional subspace that captures most of the variation in the data; and generative modeling, which aims to learn the data distribution in order to generate synthetic data.
2.1.3. Reinforcement learning (RL)
RL is a type of agent-based ML where a complex system is controlled through actions that optimize the system in some manner (Sutton and Barto, Reference Sutton and Barto2018). The actions (
 $ {a}_t $
) taken based on a probability distribution
$ {a}_t $
) taken based on a probability distribution
 $ {p}_{\pi } $
at a state (
$ {p}_{\pi } $
at a state (
 $ {s}_t $
) and time
$ {s}_t $
) and time
 $ t $
seek to optimize the expected sum of rewards
$ t $
seek to optimize the expected sum of rewards
 $ (r) $
based on a policy
$ (r) $
based on a policy
 $ (J) $
parameterized by
$ (J) $
parameterized by
 $ \theta $
; i.e.,
$ \theta $
; i.e.,
 $ J\left(\theta \right)={\sum}_{s_t,{a}_t\sim {p}_{\pi }}\left[r\left({s}_t,{a}_t\right)\right] $
.
$ J\left(\theta \right)={\sum}_{s_t,{a}_t\sim {p}_{\pi }}\left[r\left({s}_t,{a}_t\right)\right] $
.
RL is based on the Markov property of systems, where the evolution of system states is determined by the current state and the subsequent control sequence, and independent of the past states and past control inputs. Indeed, RL agents might be thought of as Markov decision processes (MDP) with neural nets serving as function approximators helping to decide which state transitions to attempt. RL is useful in when actions and environments are simple or data are plentiful. Early examples include backgammon (Tesauro, Reference Tesauro1994), the cart-pole problem, and Atari (Mnih et al., Reference Mnih, Kavukcuoglu, Silver, Graves, Antonoglou, Wierstra and Riedmiller2013). Recently, much work has been done to extend RL to broader uses.
RL architectures may be grouped in families with different learning methods; a simple one is policy gradient. Here, the controller is made up of a single function approximator that maps actions to states. The model is trained along the gradient of expected reward. One subfamily of policy gradient is the Actor-Critic that employs two function approximators; the actor estimates actions as in policy gradient, while the critic estimates the long-term value of the actions; these estimates contribute to the training of the actor network. An overview of the RL architecture taxonomy is provided in Figure 2.
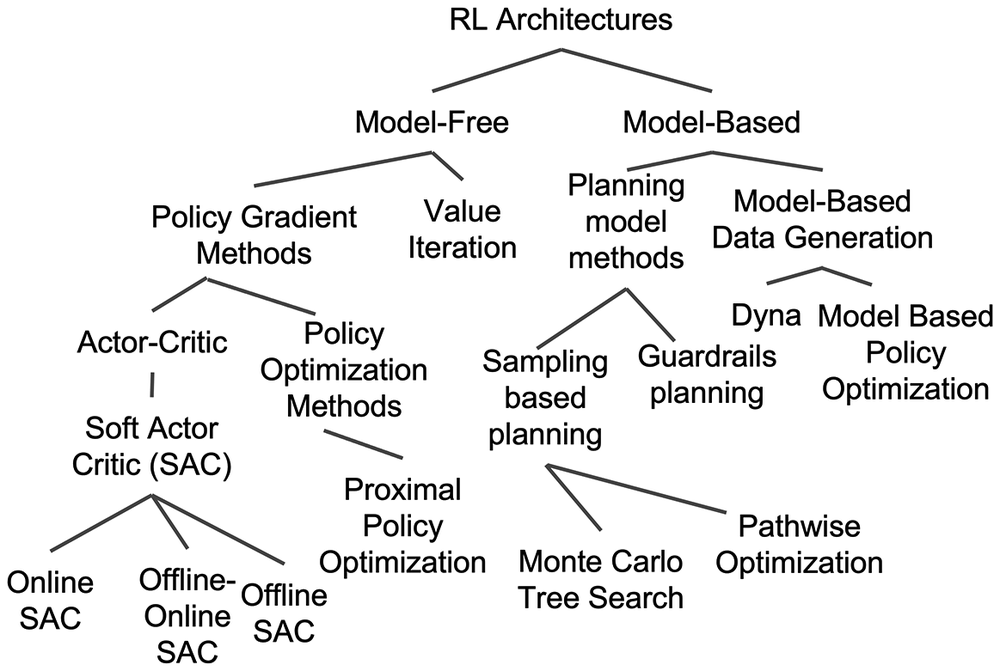
Figure 2. A taxonomy of reinforcement learning architectures.
We now discuss specific classes of algorithms that are commonly used in the smart building domain.
2.2. ML learning methods
2.2.1. Kernel-based methods
Kernel algorithms are designed for analyzing patterns in data from explicit feature vector representations provided to them. They work by projecting the onto hyperplanes that make the inference easier. Kernel methods can be used for supervised and unsupervised problems. A commonly used kernel-based method for classification is the support vector machine (SVM). Another common method in unsupervised settings is kernel principal component analysis (PCA), used for dimensionality reduction in order to facilitate clustering.
2.2.2. Ensemble methods
Ensemble methods combine multiple ML models to produce an optimal model. Common examples include tree-based algorithms such as decision tree, bagging (bootstrap aggregating), random forest, and gradient boosting.
2.2.3. Deep learning
Deep learning-based methods are usually deployed on extremely large datasets, and they use very complex artificial neural networks inspired by information processing in biological neurons for applications in supervised, semisupervised, or unsupervised settings. The neural network architecture depends on the nature of the available data. For example, convolutional neural networks typically analyze image data, while recurrent networks are usually applied to textual, natural language or time-series data.
2.2.4. Time-series forecasting methods
Time-series data comprise a sequence of data points indexed by time, such as stock prices, outdoor temperature, or electricity prices. Time-series analysis is used to extract statistical information about the data and potentially make predictions about future data points. Wide variety of methods can be used for time-series analysis and forecasting. Assuming future data have some relation with historically observed data, linear models such as moving average (MA), auto-regression (AR), and combinations of these can be used to forecast future data points. Some use cases are in stock price forecasting (Pai and Lin, Reference Pai and Lin2005) and in supply chain management (Aviv, Reference Aviv2003). Recurrent neural networks, and long short-term memory (LSTM) networks can also be used for time-series with more complex behaviors.
2.2.5. Physics-based ML
ML models have shown promising results in learning scientific problems that are yet to be well understood or where it is computationally infeasible with physics-based models. However, pure data-driven models often require very large datasets, offer limited extrapolation abilities, and are unable to provide physically consistent results or to offer intuition about the process they are modeling. On the other hand, pure physics-based models are often complex, include many uncertain parameters, and may be either too simplistic or too computationally intensive for the given application. This has led to the emergence of hybrid models that combine formal domain knowledge with ML. These hybrid models may compensate the weaknesses of pure physics-based models or pure data-driven models, and may be better able to both extrapolate and provide intuition about the process in question. Coupling physics knowledge with ML has been used in several areas, including medicine (Costabal et al., Reference Costabal, Yang, Perdikaris, Hurtado and Kuhl2020; Kissas et al., Reference Kissas, Yang, Hwuang, Witschey, Detre and Perdikaris2020), fluid mechanics (Cai et al., Reference Cai, Mao, Wang, Yin and Karniadakis2022), power systems (Misyris et al., Reference Misyris, Venzke and Chatzivasileiadis2020), manufacturing (Qi et al., Reference Qi, Chen, Li, Cheng and Li2019) etc. It has shown potential in better prediction accuracy using a smaller set of sample data and generalizability for out-of-sample scenarios.
2.2.6. Learning, dynamics, and control
Traditional control approaches such as system identification (Ljung, Reference Ljung1998) and adaptive control (Ioannou and Fidan, Reference Ioannou and Fidan2006) have similarities to supervised learning (Ljung et al., Reference Ljung, Andersson, Tiels and Schön2020) and RL (Matni et al., Reference Matni, Proutiere, Rantzer and Tu2019), respectively. While some system identification is implicit in all control approaches, as a part of how the model is formed, adaptive control never rose to the prominence of RL.
Several approaches to model-based RL use control-theoretic methods. Essentially, the problem is split into two parts: a dynamic model is learned from data, and the model is used to design a controller, with some variations, with model predictive control being a popular choice. Similarly, in traditional control applications, learned models are incorporated into modern control synthesis techniques, and standard methods of proving safety are adjusted to incorporate learned models. A learning-based approach that has proved to mesh particularly well with this approach uses Gaussian process models (Akametalu et al., Reference Akametalu, Fisac, Gillula, Kaynama, Zeilinger and Tomlin2014; Umlauft et al., Reference Umlauft, Lederer and Hirche2017; Wang et al., Reference Wang, Theodorou and Egerstedt2018; Devonport et al., Reference Devonport, Yin and Arcak2020, Reference Devonport, Yang, Ghaoui and Arcak2021b). Another point of contact is the use of statistical guarantees for controllers based on learned models. In RL, statistical guarantees of correctness such as regret bounds and probably approximately correct (PAC) bounds are used to ensure that optimal behavior is attained with high probability. By combining these statistical guarantees with control-theoretic techniques, they can also be used to ensure safety with high probability (Devonport and Arcak, Reference Devonport and Arcak2020; Devonport et al., Reference Devonport, Yang, El Ghaoui and Arcak2021a, Reference Devonport, Yang, Ghaoui and Arcak2021b). Since many learned models are statistical in nature, probabilistic bounds consistent with model accuracy have also been used extensively in recent years (Matni et al., Reference Matni, Proutiere, Rantzer and Tu2019).
3. Applications of ML in Smart Buildings
We organize the ML methods we have used in smart building applications by their targeted level of abstraction, namely at the level of occupants, single building, and a cluster of buildings as shown in Figure 3. Above applications directly or indirectly lead to enhancements in energy efficiency in buildings, while ensuring occupant comfort and productivity.
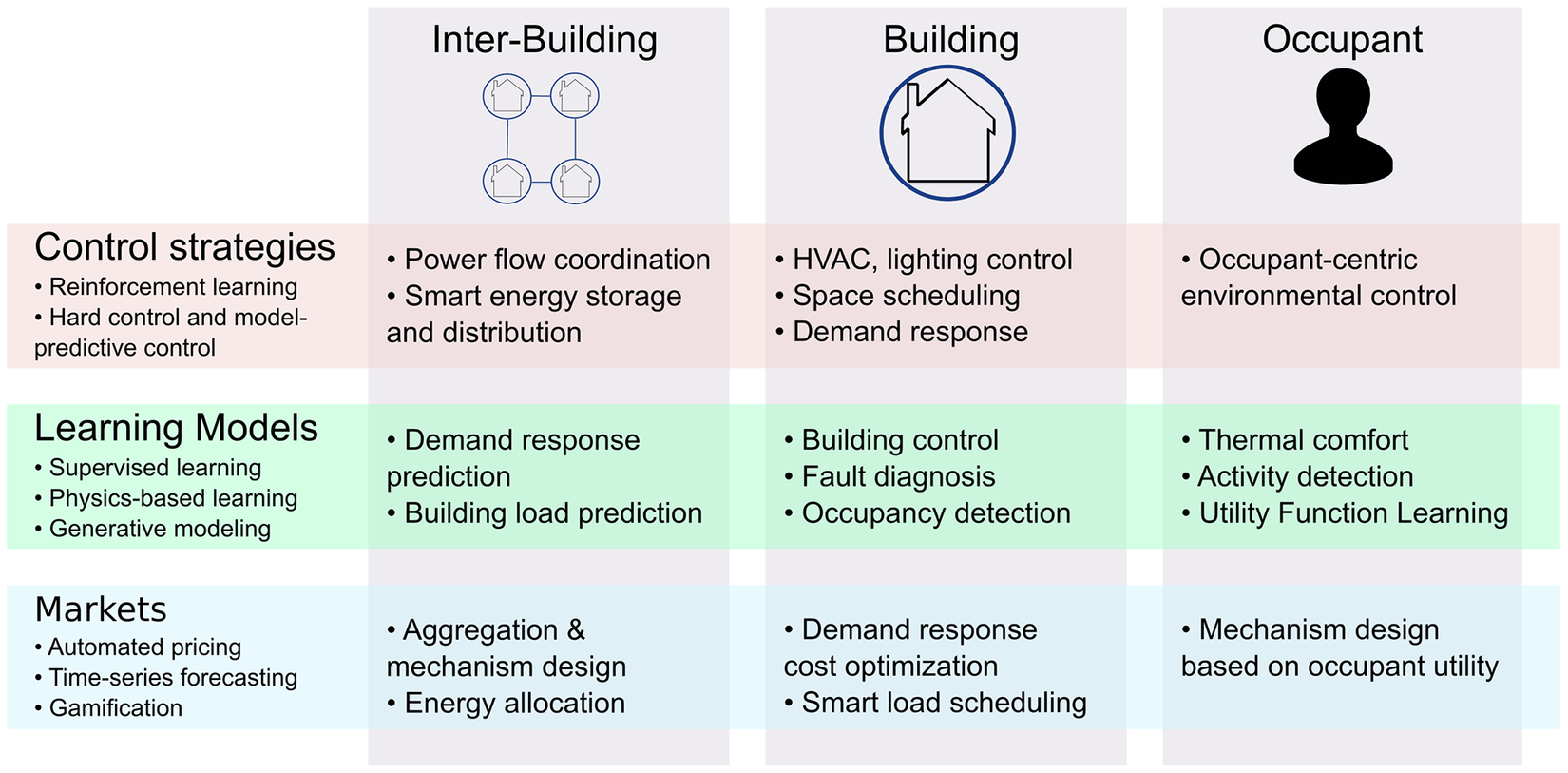
Figure 3. Illustration of various applications where machine learning methods can be deployed in smart buildings, grouped at the cluster of buildings level, the building level, and the occupant level.
3.1. Thermal comfort
The American Society of Heating, Refrigerating and Air-Conditioning Engineers (ASHRAE) defines thermal comfort as “the condition of the mind that expresses satisfaction with the thermal environment and is assessed by subjective evaluation” (Standard 55, 2020). We spend more than 90% of time in a day being within a built environment, where our health, well-being, performance, and energy consumption are linked to thermal comfort. However, studies show that only 40% of commercial building occupants are satisfied with their thermal environment (Graham et al., Reference Graham, Parkinson and Schiavon2021). Ensuring occupants’ thermal comfort involves understanding of the parameters that affect it, developing and using models to predict thermal comfort, and controlling heating, ventilation, and air-conditioning (HVAC) systems to achieve occupant satisfaction. ML has been applied to all of these sectors. In this section, we mainly cover thermal comfort understanding and prediction. In Section 3.4, we cover the control of the thermal environment in buildings. Thermal comfort of building occupants has been studied extensively. These models include traditional ones like the Predicted Mean Vote (PMV) and the adaptive thermal comfort models, as well as the more recent personal comfort models.
The most widely used thermal comfort model is the PMV, developed by Fanger (Reference Fanger1970) based on a set of experiments in controlled climate chambers. Fanger established a mathematical formula with six input parameters: air temperature, mean radiant temperature, relative humidity, air velocity, clothing insulation, and metabolic rate. The PMV model adopts a 7-point scale for its thermal sensation output, with values ranging from -3 to +3, and indicating cold, cool, slightly cool, neutral, slightly warm, warm, and hot, respectively. To gauge the level of dissatisfaction of individuals in a space where PMV has been computed, Fanger proposed a Predicted Percentage of Dissatisfied (PPD) model (Fanger, Reference Fanger1970), that establishes a quantitative prediction of the percentage of thermally dissatisfied occupants. To comply with ASHRAE 55 standards, the recommended range for PMV on the 7-point scale is between -0.5 and 0.5. The PMV model is designed with a uniform and steady-state conditioned environment and does not explicitly consider local discomfort, the nonuniformity of the space and dynamic thermal conditions (Zhao et al., Reference Zhao, Lian and Lai2021). It has also been developed with data from controlled climate chamber experiments, which are not necessarily transferable to the varying thermal environments that exist in buildings around the world (Cheung et al., Reference Cheung, Schiavon, Parkinson, Li and Brager2019). Experiments in real buildings showed that the PMV has a low prediction accuracy (around 33%), whereas the PPD is unreliable as a metric (Cheung et al., Reference Cheung, Schiavon, Parkinson, Li and Brager2019).
With the booming development of ML techniques and their versatile applications, researchers have attempted to develop data-driven approaches using ML to predict thermal comfort. Often, the Fanger’s features, alone or with additional relevant real and synthetic features, are fed into a data-driven model to learn the connections between the features and the thermal preference labels (Kim et al., Reference Kim, Zhou, Schiavon, Raftery and Brager2018; Liu et al., Reference Liu, Schiavon, Das, Jin and Spanos2019). The model is later leveraged to predict the same given raw features. Because the models are trained to learn directly from the data, and not from a rule that was established using prior experiments, they perform better as compared to PMV.
Kernel-based approaches have been widely used for thermal sensation/preference prediction. The list of kernel-based methods popular for thermal comfort prediction includes SVM (Chaudhuri et al., Reference Chaudhuri, Zhai, Soh, Li and Xie2018; Alsaleem et al., Reference Alsaleem, Tesfay, Rafaie, Sinkar, Besarla and Arunasalam2020; Chai et al., Reference Chai, Wang, Zhai and Yang2020; Liu et al., Reference Liu, Nie, Liu, Liu and Lai2020; Zhou et al., Reference Zhou, Xu, Zhang, Niu, Luo, Zhou and Zhang2020), K-nearest neighbors (KNN) (Liu et al., Reference Liu, Schiavon, Das, Jin and Spanos2019; Lu et al., Reference Lu, Wang, Lin and Hameen2019; Pigliautile et al., Reference Pigliautile, Casaccia, Morresi, Arnesano, Pisello and Revel2020; Lee and Ham, Reference Lee and Ham2021; Cheung et al., Reference Cheung, Graham and Schiavon2022), and ensemble learning algorithms, such as random forest (RF) (Kim et al., Reference Kim, Schiavon and Brager2018; Liu et al., Reference Liu, Schiavon, Das, Jin and Spanos2019) and AdaBoost (Ab). Recently, feed-forward neural networks (Zhai and Soh, Reference Zhai and Soh2017; Lu et al., Reference Liu, Schiavon, Das, Jin and Spanos2019; Das et al., Reference Das, Schiavon and Spanos2021), and time-series based networks (Chennapragada et al., Reference Chennapragada, Periyakoil, Das and Spanos2022) have surpassed state-of-the-art kernel-based models in thermal comfort prediction.
Traditional thermal comfort models, as described above, are developed based on aggregated data from a large population. So, rather than predicting the thermal comfort of individuals, they were designed to predict the average thermal comfort of a population, when all its members are exposed to the same environment. This naturally misses the inevitable and sometimes significant differences in how different individuals respond to the same thermal environment. A new approach to thermal comfort modeling that uses personal comfort models instead of the average response of a large population, can be applied to any building thermal control system (Kim et al., Reference Karg and Lucia2018). Personal thermal comfort can adapt to the available input variables, such as environmental variables (Cheung et al., Reference Cheung, Schiavon, Gall, Jin and Nazaroff2017), occupant behaviors (Kim et al., Reference Kim, Zhou, Schiavon, Raftery and Brager2018), and physiological signals (Liu et al., Reference Liu, Schiavon, Das, Jin and Spanos2019). Several experiments have been conducted over the years for population groups varying in terms of environmental and personal conditions. ML algorithms ranging from kernel-based methods to neural network-based methods have been proposed as the predictor. For instance, Liu et al. (Reference Liu, Schiavon, Das, Jin and Spanos2019) conducted an experiment to collect physiological signals (skin temperature, heart rate) of 14 subjects (6 female and 8 male adults) and environmental parameters (air temperature, relative humidity) for 2–4 weeks (at least 20 h per day). They developed ML-based predictors of thermal preference for each individual, using synthetic features derived from the above raw features (e.g., mean heart rate over last 5-min from the survey response time) as the input with RF being the best predictor. A data-driven method with indoor environment was applied to classify occupant’s personal thermal preference with temperature and humidity sensors (Laftchiev and Nikovski, Reference Laftchiev and Nikovski2016). Authors in Sim et al. (Reference Sim, Yoon and Cho2018) developed personal thermal sensation models based on watch-type sweat rate sensors. Among all the ML methods, kernel-based algorithms are still the most commonly used ones. However, other ML approaches are also becoming popular in modeling the complex interactions that exist between the features without much feature engineering, e.g., time-series prediction (Somu et al., Reference Somu, Sriram, Kowli and Ramamritham2021), artificial neural networks (Das et al., Reference Das, Tran, Singh, Yue, Tison, Sangiovanni-Vincentelli and Spanos2021), etc. Better approaches for modeling tabular data in smart buildings, with a focus on thermal comfort datasets are provided in Das and Spanos (Reference Das and Spanos2022a).
Although several studies show high prediction accuracy of thermal comfort with various ML methods, there are still several challenges ahead. A common challenge in designing ML-based thermal comfort predictors is the issue of class imbalance in data. Almost all of the thermal comfort datasets (Ličina et al., Reference Ličina, Cheung, Zhang, De Dear, Parkinson, Arens, Chun, Schiavon, Luo and Brager2018; Liu et al., Reference Liu, Schiavon, Das, Jin and Spanos2019) are inherently class-imbalanced, i.e., they have more data belonging to “Prefer No-Change” than “Prefer Warmer” and “Prefer Cooler” thermal preference classes. Researchers have tackled this issue by using weighed loss functions for ML models. A related challenge is the overall lack of sufficient amount of data (Liu et al., Reference Liu, Schiavon, Das, Jin and Spanos2019). Collecting large amounts of data as required by ML models from humans via real-world experiments is expensive and cumbersome. Generating synthetic data to augment the training dataset is one of the approaches that has been proposed for tackling the above challenges. Synthetic data generation can be done using classical methods such as SMOTE (Chawla et al., Reference Chawla, Bowyer, Hall and Kegelmeyer2002; Quintana et al., Reference Quintana, Schiavon, Tham and Miller2020) or using advanced neural network-based generative models (Quintana et al., Reference Quintana, Schiavon, Tham and Miller2020; Das et al., Reference Das, Tran, Singh, Yue, Tison, Sangiovanni-Vincentelli and Spanos2021; Yoshikawa et al., Reference Yoshikawa, Uchiyama and Higashino2021; Das and Spanos, Reference Das and Spanos2022b).
Another challenge is domain discrepancy. Thermal comfort, as per PMV, is dependent on six major parameters as described in the beginning of the section or, as per the adaptive thermal comfort model, is dependent on the outside temperature. However, it also varies from person to person, across climatic regions and economic conditions. A literature review of personal comfort models concluded that there is a lack of diversity in terms of building types, climates zone, and participants that are considered in existing thermal comfort studies (Martins et al., Reference Martins, Soebarto and Williamson2022). Under such domain discrepancy, models developed in one environment, when used in another target environment may lead to low accuracy or misleading predictions. Also, thermal comfort modeling in general depends largely on self-reporting, which is inherently unreliable. To deal with the data/label insufficiency challenge, domain adaptation methods have been proposed to adapt ML models from one domain to another. Das et al. (Reference Das, Tran, Singh, Yue, Tison, Sangiovanni-Vincentelli and Spanos2021) propose a transfer learning framework, using Adversarial Domain Adaptation (ADA) to develop personal thermal comfort predictors for target occupants in an unsupervised manner. Gao et al. (Reference Gao, Shao, Rahaman, Zhai, David and Salim2021) propose a transfer learning-based multilayer perceptron model for domain adaptation across cities.
In summary, ML models have proven to improve thermal comfort prediction accuracy and they allow a wider and more flexible range of input parameters. They can adapt to the available data streams, and they improve their performance over time. While there are still challenges, there are also many future research opportunities, as listed in Section 5.
3.2. Occupancy and activity sensing
Occupancy and activity sensing are key aspects for the observability of a human-in-the-loop building control system. Traditionally, building operation methods that include occupancy as one of their parameters, such as starting heating/cooling from early morning until late in the evening during weekdays assuming maximum occupancy during working hours often have static schedules set for the occupancy, which is far from realistic. Also, how much a building will be occupied depends on several other factors, such as weather, building type, and holiday schedule. Such static policies may lead to a significant waste in energy consumption, because the heating/cooling and ventilation levels are set with no regard for the actual occupancy level. Activity sensing also helps to provide personalized, context-aware services in buildings, thus enhancing overall satisfaction in buildings while creating a safety net for adverse events such as falls in elderly homes (Petroşanu et al., Reference Petroşanu, Caruţaşu, Caruţaşu and Pirjan2019).
Occupancy sensing can be performed using both intrusive and nonintrusive methods. Intrusive methods require the occupants to carry an electronic device whose signature is followed by a central server to infer occupancy/positioning (Lee et al., Reference Lee, Chon, Kim, Ha and Cha2013; Filippoupolitis et al., Reference Filippoupolitis, Oliff and Loukas2016; Zou et al., Reference Zou, Jiang, Luo, Zhu, Lu and Xie2016, Reference Zou, Zhou, Jiang, Chien, Xie and Spanos2018a, Reference Zou, Zhou, Yang and Spanos2018b). However, requiring occupants to constantly carry a device is not reliable. This problem gets magnified for the case of elderly population. Hence, nonintrusive methods for occupancy sensing are getting popular. In nonintrusive method, occupancy/activity is detected from data collected from various sensing modalities, and some ground truth during controlled experiments. Machine learning-based methods are very effective for nonintrusive occupancy sensing, allowing for the data-driven construction of a model to map sensor data into an estimate of occupancy.
Nonintrusive methods for occupancy sensing can be divided according to the sensing modalities they employ. A common choice is video feeds from cameras installed in rooms. Regular cameras have not found significant usage because of their privacy issue; infrared sensors or thermal cameras have rather been the choice for occupancy detection. For example, Kraft et al. (Reference Kraft, Aszkowski, Pieczyński and Fularz2021) use a U-Net-like convolutional neural network on thermal images to infer occupancy. Other studies employing similar ML methods on depth cameras are Brackney et al., Reference Brackney, Florita, Swindler, Polese and Brunemann2012; Diraco et al., Reference Diraco, Leone and Siciliano2015; and Zhao et al., Reference Zhao, Tu and Chang2019. But, in general, cameras have other issues such as poor illumination conditions and occlusion. A recent body of work focuses on occupancy and activity detection from Wi-Fi signals (Zou et al., Reference Zou, Das, Yang, Zhou and Spanos2019), because of its ubiquitous presence, and better privacy guarantees. Zou et al. (Reference Zou, Zhou, Yang, Gu, Xie and Spanos2017, Reference Zou, Zhou, Yang and Spanos2018c) use Channel State Information (CSI) data collected from Wi-Fi sensors (a transmitter and a receiver) and measuring the shape similarity between adjacent time-series CSI curves to infer the occupancy. They improve the detection mechanism in Zou et al. (Reference Zou, Yang, Das, Liu, Zhou and Spanos2019) by using convolutional neural networks on the CSI heatmaps to detect human gestures. Another modality that is used to detect occupancy is CO2 data in a room. A number of studies (Rahman and Han, Reference Rahman and Han2017; Zuraimi et al., Reference Zuraimi, Pantazaras, Chaturvedi, Yang, Tham and Lee2017; Arendt et al., Reference Arendt, Johansen, Jørgensen, Kjærgaard, Mattera, Sangogboye, Schwee and Veje2018; Wei et al., Reference Wei, Tien, Chow, Wu and Calautit2022) employ ML methods to map the CO
 $ {}_2 $
concentration and occupancy. Finally, studies such as Zou et al. (Reference Zou, Zhou, Yang, Liu, Das and Spanos2019) propose sensor fusion, where data from multiple sensing modalities, i.e., RGB camera, and Wi-Fi, are used in tandem to come up with a robust activity detection mechanism.
$ {}_2 $
concentration and occupancy. Finally, studies such as Zou et al. (Reference Zou, Zhou, Yang, Liu, Das and Spanos2019) propose sensor fusion, where data from multiple sensing modalities, i.e., RGB camera, and Wi-Fi, are used in tandem to come up with a robust activity detection mechanism.
Many of the sensors used for occupancy and activity detection are spatial in nature, i.e., their data are specific to the design of the spatial environment that they are deployed in. Hence, ML algorithms designed for one environment fails to perform optimally for new environments. Hence, transfer learning methods have been proposed in the literature to adapt ML models across domains and sensor choices. Zou et al. (Reference Zou, Das, Yang, Zhou and Spanos2019) adapt an ML model to detect gestures using Wi-Fi CSI data between two rooms in a building. Such applications involving transfer learning between domains has been explored in the application of occupancy and activity sensing in several other literature studies (e.g., Pan et al., Reference Pan, Zheng, Yang and Hu2008; Khalil et al., Reference Khalil, McGough, Pourmirza, Pazhoohesh and Walker2021; Li et al., Reference Li, Cui, Khan, Raza, Piechocki, Doufexi and Farnham2021; Dridi et al., Reference Dridi, Amayri and Bouguila2022; Omeragic et al., Reference Omeragic, Orhan, Uzunovic and Golubovic2023). Pinto et al. (Reference Pinto, Wang, Roy, Hong and Capozzoli2022) delve further into a review of transfer learning application in smart buildings.
To summarize, ML methods have been proposed to map the relation between data from sensors, and occupancy/activity. Once trained, these models can then be deployed to predict the occupancy which then gets fed to building control mechanisms (Esrafilian-Najafabadi and Haghighat, Reference Esrafilian-Najafabadi and Haghighat2021).
3.3. Building design and modeling
Building information modeling (BIM) was introduced in the 1970s when Eastman (Reference Eastman1975) proposed the idea of migrating from hand-drawn building design toward automation and digitization. Early building modeling focused on the computational representation of geometry, which is also known as 3D modeling. Later, a set of new tools focusing on the building performances were developed, including Building Design Advisor (BDA) (Papamichael et al., Reference Papamichael, LaPorta and Chauvet1997), Ecotect (Roberts and Marsh, Reference Roberts and Marsh2001), EnergyPlus (Crawley et al., Reference Crawley, Lawrie, Winkelmann, Buhl, Huang, Pedersen, Strand, Liesen, Fisher and Witte2001), ESP-r (Strachan et al., 2008), DEST (Yan et al., Reference Yan, Xia, Tang, Song, Zhang and Jiang2008), and Modelica (Fritzson and Engelson, Reference Fritzson and Engelson1998). They focused on thermal, energy, lighting, and air quality aspects. They provided feedback and “what-if" analyses. With the emergence of IoT, data have become more easily accessible, which has helped support building simulation tools and allowed development of ML models. The development of building models over the past decades is summarized in Figure 4.

Figure 4. Evolution of building modeling.
The goal of building modeling is to support the design, construction, and operation of buildings. Early building modeling was mostly used during the design phase, and was not usually maintained or updated after the building was constructed. In recent years, the digital twins (DT) concept (Grieves and Vickers, Reference Grieves and Vickers2017) has emerged for physical systems where a virtual “twin" is developed that mirror the actual physical system. DT can monitor a building’s condition in real-time and plays an important role in control applications, fault diagnosis, and prognosis. The following sections describe the intersection between ML and building modeling. It is separated into 5 parts: models, design automation, DT, applications, and challenges.
3.3.1 Models
There are three types of building models: white box, black box, and gray box, as illustrated in Figure 5.

Figure 5. Three types of building models.
3.3.1.1. White box model
The “white box” or “first principles” approach models the building system with detailed physics-based equations. Building components and subsystems are modeled in a detailed manner to predict their behaviors. Common Building Performance Simulation (BPS) tools for physics-based modeling are Modelica (Fritzson and Engelson, Reference Fritzson and Engelson1998), EnergyPlus (Crawley et al., Reference Crawley, Lawrie, Winkelmann, Buhl, Huang, Pedersen, Strand, Liesen, Fisher and Witte2001), TRNSYS (U. o. W.-M, 1975), and ESP-r (Strachan et al., 2008). Though a white box model can capture the building dynamics well, it requires a lot of information from the physical building and may suffer from high uncertainties.
3.3.1.2. Black box model
A black box model, also known as a data-driven or ML model, is a modeling approach that constructs a model directly from data without knowledge of the system physics. With the emergence of IoT, sensor measurements are continuously collected at various locations in a building to reflect current operations, which provides an opportunity to build data-driven models. For example, building load prediction using black box models is an important aspect of improving building energy performance. Its applications include control optimization, fault diagnosis, and demand side management (Zhang et al., Reference Zhang, Wen, Li, Chen, Ye, Fu and Livingood2021). The common ML methodologies for building load prediction are ANN, SVM, Gaussian-based regressions, and clustering (Seyedzadeh et al., Reference Seyedzadeh, Rahimian, Glesk and Roper2018). The drawbacks of black box models include the need for a large amount of data and the fact that the accuracy of the model is highly dependent on the data quality. Another drawback is their fragility, which occurs when they give results that are not physically possible and may not perform reliably in conditions that have not been seen before. In addition, black box models lack interpretability and may have a high computational cost.
3.3.1.3. Gray box model
Gray box modeling is a modeling approach that simplifies the physical equations to simulate the behavior of a building and it combines them with ML techniques. By doing that, it aims to reduce the system complexity while maintaining prediction accuracy. An example of such a model is using thermal networks to model buildings (Bacher and Madsen, Reference Bacher and Madsen2011), which is a common approach in building modeling. Thermal networks model dynamics of a building through resistor and capacitor (RC) circuits, and the parameters are identified with measurements from the real system. Studies show that the gray box model works well in building control applications (Širokỳ et al., Reference Širokỳ, Oldewurtel, Cigler and Prívara2011; Oldewurtel et al., Reference Oldewurtel, Parisio, Jones, Gyalistras, Gwerder, Stauch, Lehmann and Morari2012a) and grid integration. However, the design of the thermal network is still ambiguous. The best selection of the number of resistors and capacitors for the model is unclear. Bacher and Madsen (Reference Bacher and Madsen2011) analyzed the model selections and found that the 3R3C model is the minimal best fit model for a 120 m2 building located in Denmark. However, it is inconclusive if all buildings of similar size and use can be modeled with 3R3C with the same accuracy.
Lin et al. (Reference Lin, Tang and Spanos2021) build a building model based on information available to minimize the number of uncertain parameters by combining physics-based equations with a neural network. Other researchers (Daw et al., Reference Daw, Karpatne, Watkins, Read and Kumar2017; Robinson et al., Reference Robinson, Pawar, Rasheed and San2022) explored physics-based ML for modeling lake temperature and other dynamical systems. However, there are limited studies in physics-based ML for building modeling.
The definition of gray box models is still ambiguous, where it can refer to a resistor–capacitor network or a hybrid model that utilizes both first principal equations and data-driven methods. While gray box models have shown success in several applications, they are not systematically defined or thoroughly analyzed.
3.3.2. Design automation
Buildings are complex systems. Among their objectives is to provide comfortable and safe conditions to people. Building performance is affected by people’s behavior (Hong et al., Reference Hong, Yan, D’Oca and Chen2017). Developing a model of a building with these complexities is often time-consuming and costly. Though white box models are widely used in simulation-based studies, gray and black box model are more commonly used in experimental studies of real buildings (Zhan and Chong, Reference Zhan and Chong2021). As a result, building design automation is an active area of research to help in developing fast and accurate building models.
Currently, automated design of buildings mostly involves the development of 3D building models. Most of the 3D models are built with Revit/AutoCAD based on site measurements or estimations during the design phase. Sometimes, researchers collect building measurements through LiDAR or airborne stereo imagery to construct 3D building models (Haala and Kada, Reference Haala and Kada2010), which can automatically be imported to BIM or building simulation tools. However, this approach only captures the building at a geometrical level and cannot represent the operational level of buildings. Jia et al. (Reference Jia, Jin, Jin, Zhou, Konstantakopoulos, Zou, Kim, Li, Gu and Arghandeh2018) proposed a platform-based design to reduce redundancy in hardware and software usage in building applications. The design performance is optimized by exploring the design space.
The emergence of building design libraries such as Modelica Building Library (Wetter et al., Reference Wetter, Zuo, Nouidui and Pang2014) opens up opportunities for platform-based design automation of buildings. However, automated building modeling that captures building dynamics is underdeveloped, and most modeling methods still require human intervention.
3.3.3. Digital twins
The AIAA and AIA (American Institute of Aeronautics and Astronautics, 2022) recently published a position paper that defines a digital twin as “A set of virtual information constructs that mimics the structure, context and behavior of an individual/unique physical asset, or a group of physical assets, is dynamically updated with data from its physical twin throughout its life cycle and informs decisions that realize value.” The same definition can be applied to buildings, specifically how a physics-based model evolves over the course of its lifecycle as information or data about the building becomes available, i.e., as the building goes from the design phase (as designed) to the construction and commissioning phase (as built) to the postoccupancy phase (“as operated”). For buildings, forward BPS tools such as EnergyPlus (Crawley et al., Reference Crawley, Lawrie, Winkelmann, Buhl, Huang, Pedersen, Strand, Liesen, Fisher and Witte2001), TRNSYS (U. o. W.-M, 1975), ESP-r (Strachan et al., Reference Strachan, Kokogiannakis and Macdonald2008), and Modelica (Fritzson and Engelson, Reference Fritzson and Engelson1998) are usually used to estimate the energy use of the building and its subsystems. Over the past decade, ML has been increasingly applied to BPS, fueled in part by the emergence of the IoT and the need for computationally tractable predictions.
ML has been used during the design stage to augment generative design and parametric simulations. Deep generative algorithms such as Generative Adversarial Networks (GANs) (Huang and Zheng, Reference Huang and Zheng2018; Nauata et al., Reference Nauata, Chang, Cheng, Mori and Furukawa2020) have been proposed for generating diverse but realistic architectural floorplans that are known to be a time-consuming iterative process. The automated generation of architectural floorplans can be coupled with BPS tools to systematically explore architectural layouts that optimize building energy efficiency (Gan et al., Reference Gan, Wong, Tse, Cheng, Lo and Chan2019).
Metamodeling, defined as the practice of using a model to describe another model as an instance (Allemang et al., Reference Allemang, Hendler and Gandon2011), is another aspect where ML has been extensively applied to BPS throughout the building lifecycle. Given the complex interaction between different building systems and subsystems, design optimization during early design typically requires exploring high-dimensional design space. Consequently, ML has been used to create metamodels that can be used for optimization and uncertainty analysis (Eisenhower et al., Reference Eisenhower, O’Neill, Narayanan, Fonoberov and Mezić2012; Bre et al., Reference Bre, Roman and Fachinotti2020). Although most studies predict energy consumption and thermal comfort, metamodels have also been proposed for the emulation outputs such as natural ventilation and daylighting to support the modeling of passive design strategies (Chen et al., Reference Chen, Yang and Sun2017). A comparison of different metamodeling techniques can be found in Østergård et al. (Reference Østergård, Jensen and Maagaard2018).
Moving from design to postoccupancy, model calibration is often undertaken to improve the model’s credibility by reducing the discrepancies between simulation predictions and actual observations. Metamodeling using ML is often used to emulate simulation predictions to alleviate the high computation costs (Coakley et al., Reference Coakley, Raftery and Keane2014). Particularly, metamodeling is almost always applied in Bayesian calibration that is computationally intractable because of the need to perform many model evaluations (Chong et al., Reference Chong, Gu and Jia2021). More recently, Bayesian optimization and meta-learning through deep probabilistic neural networks have been proposed to reduce the number of simulations required for model calibration significantly, avoiding the need for metamodels altogether (Chakrabarty et al., Reference Chakrabarty, Maddalena, Qiao and Laughman2021; Zhan et al., Reference Zhan, Wichern, Laughman, Chong and Chakrabarty2022).
BPS has also been applied to enhance the use of deep RL (DRL) based building controls. For instance, BPS can be used to develop building test cases for the comparison and benchmarking of DRL algorithms (Blum et al., Reference Blum, Arroyo, Huang, Drgoňa, Jorissen, Walnum, Chen, Benne, Vrabie and Wetter2021). The deployment of DRL in real-world building controls can be challenging because of the need for large amounts of training data before achieving acceptable performance (Botvinick et al., Reference Botvinick, Ritter, Wang, Kurth-Nelson, Blundell and Hassabis2019). Consequently, the exploration during online training can lead to undesirable building operations when the algorithm performs suboptimally. To enhance the practical applications of DRL, BPS has been used as an emulator to pretrain a DRL agent offline. For instance, Zhang et al. (Reference Zhang, Chong, Pan, Zhang and Lam2019) used an automatically calibrated EnergyPlus model for the offline training of an A3C (Asynchronous Advantage Actor-Critic) algorithm that is subsequently deployed in a radiant heating system. It was also shown that a DRL trained offline could achieve similar near-optimal results as model predictive control (Brandi et al., Reference Brandi, Fiorentini and Capozzoli2022). However, pretraining a DRL agent using a model contradicts the advantages of DRL being “model-free” because BPS models can be time-consuming to develop. Therefore, further research could usefully explore the use of simpler and a lower level of detail models for the offline training of DRL agents for building controls.
3.3.4. Applications: Design, control, and fault diagnosis
The main applications for building modeling are facilitating design choice, testing control algorithms, and detecting faults in a system. BPS is used in the design phase of buildings to provide feedback in energy consumption, and greenhouse gas emissions and to guide design choices (Clarke, Reference Clarke2007; Hensen and Lamberts, Reference Hensen and Lamberts2012). Additionally, the development of a robust control system often requires a detailed understanding of system dynamics. Building modeling can provide dynamic feedback to test various control algorithms, which will be discussed in more detail in the next section. Fault detection also plays a crucial part in reducing maintenance costs and increasing the energy efficiency of building operations (Dong et al., Reference Dong, O’Neill and Li2014). However, faults in an actual building do not occur frequently, and it is hard to collect fault data for analysis. Data sets for fault diagnosis are usually created through testbed experiments or simulations. BPS can provide “what-if" analysis to assist in fault modeling and creating meaningful datasets.
3.3.5. Challenges
There are two main challenges in building modeling. First, there is a gap between building models during the design and the operation phases. Moreover, no standard connections are established between BIM and BPS tools, which results in unavoidable human effort to recreate the model for operation after the design phase. Though some established geometrical models can be exported to the BPS software, there are limitations in software compatibility and set up requirements. Second, there is no systematic approach to model selection. Limited studies have explored whether a certain type of model (white, black, or gray box model) is better for a specific application. Developing a level of abstraction of building modeling may benefit the development of a better model selection process for various applications. We anticipate that techniques from machine learning, such as neural architecture search and physics-based ML, can be used here to improve building modeling.
3.4. Building control
A critical application of a building model is the design of control systems for the building subsystems. These are typically “local models” that capture only aspects of the building that are pertinent to low-level control, such as a physical model heat and ventilation in a collection of rooms near a target temperature. However, a large-scale model is still important for controller design, as it is necessary to understand how the subsystems of a building interact. For the purposes of this review, the most important subsystem in terms of complexity of control and size of energy demand is arguably the HVAC system, so we will focus our attention there. However, we do want to note that HVAC is by no means the only control problem that has received focus; other building control systems enjoy active work and engaged communities, including lighting (Lee and Selkowitz, Reference Lee and Selkowitz1994; Panjaitan and Hartoyo, Reference Panjaitan and Hartoyo2011; ul Haq et al., Reference ul Haq, Hassan, Abdullah, Rahman, Abdullah, Hussin and Said2014; Wagiman et al., Reference Wagiman, Abdullah, Hassan and Radzi2019), window control (Psomas et al., Reference Psomas, Fiorentini, Kokogiannakis and Heiselberg2017; Yoon et al., Reference Yoon, Piette, Han, Wu and Malkawi2020), electric vehicle charging (Kontou et al., Reference Kontou, Yin and Ge2017; Turker and Bacha, Reference Turker and Bacha2018; Al-Ogaili et al., Reference Al-Ogaili, Hashim, Rahmat, Ramasamy, Marsadek, Faisal and Hannan2019), and domestic water heating (Passenberg et al., Reference Passenberg, Meyer, Feldmaier and Shen2016; Wanjiru et al., Reference Wanjiru, Sichilalu and Xia2017; Starke et al., Reference Starke, Munk, Zandi, Kuruganti, Buckberry, Hall and Leverette2020).
Controlling the HVAC system of a building can be, and for many decades has been, accomplished by classical control techniques. Here, the control objective simply being to keep temperatures somewhat close to a setpoint or within a deadband. Two simple controller types have proven to achieve this goal for HVAC systems: (1) threshold-based “bang-bang” controllers (2) and PID controllers. Bang-bang control applies the greatest allowable heating or cooling when the measured temperature leaves a certain band around the target temperature, but otherwise remains inactive. PID controllers use a linear feedback strategy, which decides a control action using a linear function of previous measurements. PID denotes a “proportional-integral-derivative” function formed as the sum of the current measurement (the proportional component) and approximations of the time derivative and integral of the temperature. These simple control policies even achieve optimality in certain cases: for example, the bang-bang strategies are optimal for minimizing the total time that the HVAC system is active, and PID controllers can be tuned to minimize the sensitivity of the controller to exogenous disturbances. However, if we ask for a strategy that is optimal with respect to delivering thermal comfort, or to account for energy load profiles throughout the day, predictively preheat and cool, or try to minimize other metrics such as carbon emissions, these simple control strategies no longer suffice.
The optimal operation of HVAC systems with respect to cost, emissions, comfort, or a combination therein is a multistep optimization problem due to the thermal capacity of buildings and the nonlinear operation of the HVAC system. Specifically, the dynamics of building thermal behavior is a slow-moving process and subject to time delays. This enables the precooling or preheating of buildings (e.g., storing the cooling energy in building mass). Besides, the operation efficiency of HVAC system is nonlinear with respect to supplied air. For example, the amount of energy required to maintain a constant temperature in a zone is a product of supplied zone air flow rates and the difference of the indoor temperature and the supplied temperature. The fan power of air handling unit (AHU) is cubic with respect to the total supplied air. In addition, the operation of HVAC system suffers from time-varying disturbances, such as the outdoor weather variations (i.e., radiation, temperature, humidity, etc.) and the occupancy changes.
HVAC system operation has raised extensive concerns in recent decades due to the continued increase of energy consumption of buildings and the high priority to save building energy consumption. Fortunately, the related work is plentiful and rapid progress has been achieved in this area. Existing studies can be broadly categorized by model architecture into: (1) Model Predictive Control (MPC) and (2) RL. On top of that, the combination of ML with MPC is developed with the objective to explore the benefits of the classic MPC controllers and the powerful approximation and characterization capabilities of ML tools.
MPC can be used to turn a standard ML algorithm for supervised learning into a model-based RL strategy for optimal control. The key idea is that MPC can be decomposed into two functional components: a state transition model and an optimizer. The ML half of the reaction is responsible for learning a state-space dynamical model– the goal is essentially to learn an application-specific digital twin. The predictive model may be application-agnostic (e.g., a general neural net) or leverage some degree of model knowledge as in the physics-informed model used in Nghiem et al. (Reference Nghiem, Drgoňa, Jones, Nagy, Schwan, Dey, Chakrabarty, Cairano, Paulson, Carron, Zeilinger, Cortez and Vrabie2023).
In the following sections, we review the existing studies in ML and building control under three categories.
3.4.1. Model predictive control
MPC takes a large step toward improving these aims by incorporating optimization directly into the control policy. We wish to frame briefly our section on MPC: although it would not be considered a classic case of ML, we find it helpful to thoroughly embed the motivations behind its development and active use into our understanding of the learning-based methods to follow. Thus, we will spend significant time describing it.
The key idea of MPC is to predict the value of the objective function in the future using an auxiliary dynamical model of the building’s behavior and to select a control action that optimizes the predicted reward. Generally, if the dynamics model is
 $ f $
, the action
$ f $
, the action
 $ u $
, the state
$ u $
, the state
 $ x $
, the objective
$ x $
, the objective
 $ y $
, and the current timestep
$ y $
, and the current timestep
 $ t $
, then MPC solves:
$ t $
, then MPC solves:
 $$ {\displaystyle \begin{array}{ll}\underset{u}{\hskip0.6em \mathrm{argmin}}& \sum \limits_{\tau =t}^{t+T}-y\left(x,u\right)\\ {}\mathrm{subject}\ \mathrm{to}:& x\left(\tau +1\right)=f\left(x\left(\tau \right),u\left(\tau \right)\right);\tau =t,\dots, T-1\\ {}& x\left(t+T\right)=0;\tau =t,\dots, T-1\\ {}& x\left(\tau \right)\in \mathcal{X};\tau =t,\dots, T-1\\ {}& u\left(\tau \right)\in \mathcal{U};\tau =t,\dots, T-1\\ {}& \end{array}} $$
$$ {\displaystyle \begin{array}{ll}\underset{u}{\hskip0.6em \mathrm{argmin}}& \sum \limits_{\tau =t}^{t+T}-y\left(x,u\right)\\ {}\mathrm{subject}\ \mathrm{to}:& x\left(\tau +1\right)=f\left(x\left(\tau \right),u\left(\tau \right)\right);\tau =t,\dots, T-1\\ {}& x\left(t+T\right)=0;\tau =t,\dots, T-1\\ {}& x\left(\tau \right)\in \mathcal{X};\tau =t,\dots, T-1\\ {}& u\left(\tau \right)\in \mathcal{U};\tau =t,\dots, T-1\\ {}& \end{array}} $$
The condition
 $ x\left(\tau \right)\mathcal{X} $
is a state-space constraint, which can be used to ensure safety by attempting to keep the state vector in a region of the state space that is known a priori not to be dangerous.
$ x\left(\tau \right)\mathcal{X} $
is a state-space constraint, which can be used to ensure safety by attempting to keep the state vector in a region of the state space that is known a priori not to be dangerous.
For a given state
 $ x $
, (3.1) computes a sequence of
$ x $
, (3.1) computes a sequence of
 $ T $
control actions in order to minimize the predicted reward. While the building control policy could use all
$ T $
control actions in order to minimize the predicted reward. While the building control policy could use all
 $ T $
actions, so that (3.1) need only be solved every
$ T $
actions, so that (3.1) need only be solved every
 $ T $
time steps, to do so would force the controller to ignore what is happening in the outside world for those time steps. Since the control model used in (3.1) can never be fully accurate, and since dynamical prediction errors compound very quickly, what happens during those time steps is likely very different from what the controller predicts in (3.1). Moreover, the controller would be effectively blind to unanticipated dangers while executing the sequence: by the time
$ T $
time steps, to do so would force the controller to ignore what is happening in the outside world for those time steps. Since the control model used in (3.1) can never be fully accurate, and since dynamical prediction errors compound very quickly, what happens during those time steps is likely very different from what the controller predicts in (3.1). Moreover, the controller would be effectively blind to unanticipated dangers while executing the sequence: by the time
 $ T $
time steps are up, it may be too late to bring the system back to safety.
$ T $
time steps are up, it may be too late to bring the system back to safety.
Thus, the second key idea of MPC is to resist the temptation to use the full input sequence: an MPC controller solves (3.1) at each time step, and applies only the first computed input. Using only the first control action is how MPC mitigates potential dangers while retaining optimal behavior.
MPC has been widely used to achieve anticipatory control of HVAC system for energy saving while ensuring human comfort (Drgoňa et al., Reference Drgoňa, Arroyo, Figueroa, Blum, Arendt, Kim, Ollé, Oravec, Wetter, Vrabie and Helsen2020). MPC-based control methods require the solving of a multistep optimization problem so as to achieve the control sequence. The control output at the current stage is exerted and this process is repeated with the evolving of time. MPC-based control methods are online control methods that rely on the dynamic predictions of system disturbance. For HVAC control, several critical issues are related to the development of MPC-based controller: modeling complexity, modeling accuracy, and prediction accuracy. MPC-based controllers have been popular with HVAC control (see (Oldewurtel et al., Reference Oldewurtel, Parisio, Jones, Gyalistras, Gwerder, Stauch, Lehmann and Morari2012b; Afram and Janabi-Sharifi, Reference Afram and Janabi-Sharifi2014; Drgoňa et al., Reference Drgoňa, Arroyo, Figueroa, Blum, Arendt, Kim, Ollé, Oravec, Wetter, Vrabie and Helsen2020; Kathirgamanathan et al., Reference Kathirgamanathan, De Rosa, Mangina and Finn2021) for a comprehensive review).The MPC controllers generally use either physics-based models (also known as “analytical first principle” or “forward models”) or data-driven models (also known as “black box” or “inverse models”) to predict system output.
MPC-based controllers have many advantages over rule-based or PID controllers. Since the energy saving and human comfort targets may be directly expressed in the MPC’s objective and constraints and the time-varying disturbances are directly considered, MPC shows superior performance in energy efficiency and in ensuring human comfort. In addition, MPC-based controllers are robust to the time-varying disturbance, quick transient response to the environment changes, and consistent performance under a wide range of varying operating conditions.
However, MPC’s advantages are achieved at the cost of frequently solving comprehensive optimization problems online. The intrinsic problem related to the HVAC control is nonlinear and nonconvex. This leads to the high online computation cost. Many efforts have been made to address the computational challenges. One solution is to restrict attention to linear models of the form
 $ x\left(t+1\right)=A(t)x+B(t)u $
, where
$ x\left(t+1\right)=A(t)x+B(t)u $
, where
 $ A(t) $
and
$ A(t) $
and
 $ B(t) $
are matrix functions whose values may be time-dependent but not state-dependent. This model simplification, in conjunction with a quadratic objective, reduces (3.1) to a quadratic program, a convex problem that even embedded devices can solve quickly. However, a simpler model will necessarily lead to predictions of lower accuracy, and thereby worse performance. If we do not wish to simplify the model, an alternative is to develop explicit MPC controllers (Drgoňa et al., Reference Drgoňa, Kvasnica, Klaučo and Fikar2013; Klaučo and Kvasnica, Reference Klaučo and Kvasnica2014; Parisio et al., Reference Parisio, Fabietti, Molinari, Varagnolo and Johansson2014). The key idea is to drive some close-form solution for the MPC problem and then identify the parameterized control outputs online. To achieve the objective, simplified or approximated linear models for HVAC control are generally used. The benefit of explicit MPC is that it can be implemented on simple hardware and yields low online computation cost. Another line of work to address the computation burden is to develop distributed solvers. When MPC-based controllers are applied to large-scale commercial buildings, we require to solve large-scale optimization problem that couples the control of the HVAC system supplying multiple zones or rooms. Centralized methods tend to suffer from the high computation cost and are not scalable. Many studies have made effort to develop distributed MPC controllers (Radhakrishnan et al., Reference Radhakrishnan, Su, Su and Poolla2016, Reference Radhakrishnan, Srinivasan, Su and Poolla2017; Zhang et al., Reference Zhang, Shi, Yan, Malkawi and Li2017; Yang et al., Reference Yang, Zhao, Li and Zomaya2020, Reference Yang, Srinivasan, Hu and Spanos2021). The major challenge to develop distributed MPC controllers for HVAC system is to handling the couplings across the multiple zones, including the thermal couplings (i.e., heat transfer), the composite objective (i.e., the fan power is quadratic with respect to the total zone mass flow rates), and operating constraints). The optimization problem related to multizone HVAC system is a nonlinear and nonconvex optimization problem subject to nonlinear couplings (nonlinear and nonconvex). The existing distributed solution methods cannot be directly applied to solve such a class of problems. To overcome the challenges and enable the decomposition of the problem, (Zhang et al., Reference Zhang, Shi, Yan, Malkawi and Li2017; Yang et al., Reference Yang, Zhao, Li and Zomaya2020, Reference Yang, Srinivasan, Hu and Spanos2021) has explored the convex relaxation technique to solve such problem. Particularly, Yang et al. (Reference Yang, Zhao, Li and Zomaya2020, Reference Yang, Srinivasan, Hu and Spanos2021) have applied the well-known alternating direction method of multipliers (ADMM) to solve the resulting relaxed problems, which have nonconvex objectives but subject to linear couplings. The superior performance both in energy saving and computation efficiency have been demonstrated via simulations. Slightly different, Radhakrishnan et al. (Reference Radhakrishnan, Su, Su and Poolla2016, Reference Radhakrishnan, Srinivasan, Su and Poolla2017) have explored the decomposition of the problem with respect to the zone controller via hierarchical optimization and relaxation. Particularly, these works have relied on predictions to predict the thermal couplings across the zones. Besides, the objective components are optimized in two steps. These studies have comprehensively discussed the challenges to develop distributed control methods for large-scale commercial buildings due to the problem complexity.
$ B(t) $
are matrix functions whose values may be time-dependent but not state-dependent. This model simplification, in conjunction with a quadratic objective, reduces (3.1) to a quadratic program, a convex problem that even embedded devices can solve quickly. However, a simpler model will necessarily lead to predictions of lower accuracy, and thereby worse performance. If we do not wish to simplify the model, an alternative is to develop explicit MPC controllers (Drgoňa et al., Reference Drgoňa, Kvasnica, Klaučo and Fikar2013; Klaučo and Kvasnica, Reference Klaučo and Kvasnica2014; Parisio et al., Reference Parisio, Fabietti, Molinari, Varagnolo and Johansson2014). The key idea is to drive some close-form solution for the MPC problem and then identify the parameterized control outputs online. To achieve the objective, simplified or approximated linear models for HVAC control are generally used. The benefit of explicit MPC is that it can be implemented on simple hardware and yields low online computation cost. Another line of work to address the computation burden is to develop distributed solvers. When MPC-based controllers are applied to large-scale commercial buildings, we require to solve large-scale optimization problem that couples the control of the HVAC system supplying multiple zones or rooms. Centralized methods tend to suffer from the high computation cost and are not scalable. Many studies have made effort to develop distributed MPC controllers (Radhakrishnan et al., Reference Radhakrishnan, Su, Su and Poolla2016, Reference Radhakrishnan, Srinivasan, Su and Poolla2017; Zhang et al., Reference Zhang, Shi, Yan, Malkawi and Li2017; Yang et al., Reference Yang, Zhao, Li and Zomaya2020, Reference Yang, Srinivasan, Hu and Spanos2021). The major challenge to develop distributed MPC controllers for HVAC system is to handling the couplings across the multiple zones, including the thermal couplings (i.e., heat transfer), the composite objective (i.e., the fan power is quadratic with respect to the total zone mass flow rates), and operating constraints). The optimization problem related to multizone HVAC system is a nonlinear and nonconvex optimization problem subject to nonlinear couplings (nonlinear and nonconvex). The existing distributed solution methods cannot be directly applied to solve such a class of problems. To overcome the challenges and enable the decomposition of the problem, (Zhang et al., Reference Zhang, Shi, Yan, Malkawi and Li2017; Yang et al., Reference Yang, Zhao, Li and Zomaya2020, Reference Yang, Srinivasan, Hu and Spanos2021) has explored the convex relaxation technique to solve such problem. Particularly, Yang et al. (Reference Yang, Zhao, Li and Zomaya2020, Reference Yang, Srinivasan, Hu and Spanos2021) have applied the well-known alternating direction method of multipliers (ADMM) to solve the resulting relaxed problems, which have nonconvex objectives but subject to linear couplings. The superior performance both in energy saving and computation efficiency have been demonstrated via simulations. Slightly different, Radhakrishnan et al. (Reference Radhakrishnan, Su, Su and Poolla2016, Reference Radhakrishnan, Srinivasan, Su and Poolla2017) have explored the decomposition of the problem with respect to the zone controller via hierarchical optimization and relaxation. Particularly, these works have relied on predictions to predict the thermal couplings across the zones. Besides, the objective components are optimized in two steps. These studies have comprehensively discussed the challenges to develop distributed control methods for large-scale commercial buildings due to the problem complexity.
3.4.2. Reinforcement learning
Time-varying and uncertain parameters such as the weather variations and occupancy represent one major challenge for HVAC control. MPC controllers have relied on short-term dynamic predictions to address such problems but at the cost of high online computation burden and an accurate model to predict the system state evolution. These are the two main obstacles for the wide deployment of MPC controllers in practice. As one main branch of ML, RL explores to optimize the operation of system through the interaction with environment as long as the performance can be observed and quantified.
RL being one of the mainstream tools for multistage decision making under uncertainties (Sutton and Barto, Reference Sutton and Barto2018) makes it well suited for HVAC control. Indeed, RL has been widely used for advanced control of HVAC systems considering the uncertainties and multistage problem features (Sun et al., Reference Sun, Luh, Jia, Jiang, Wang and Song2012, Reference Sun, Luh, Jia and Yan2015; Yang et al., Reference Yang, Hu and Spanos2021). RL can enable efficient online computation by learning the control policies offline. Specifically, by learning the control policies offline, the online implementation of RL only requires to search the table to identify the mapping from the state space to the action space.
However, the obstacle to effective implementation of RL is that the learning may be computationally intensive or intractable when state and action space are large, either in terms of dimensionality (number of observations) or enumeration of action space (continuous vs. categorical.) To overcome the challenges, DRL has been popular in this domain. DRL proposes to combine the approximation and characterization capabilities of deep neural networks with RL techniques. Specially, deep neural networks are used to characterize the state or state action value functions. The benefits of DRL include reducing the quantity of data required for training and reducing the memory required to store the policy for online implementation. The proliferation of smart meters has boosted the development of DRL-based HVAC controllers for smart buildings. We direct the readers to (Han et al., Reference Han, May, Zhang, Wang, Pan, Yan, Jin and Xu2019; Mason and Grijalva, Reference Mason and Grijalva2019; Wang and Hong, Reference Wang and Hong2020; Yang et al., Reference Yang, Hu and Spanos2020; Yu et al., Reference Yu, Qin, Zhang, Shen, Jiang and Guan2021). As an earlier work, Wei et al. (Reference Wei, Wang and Zhu2017) has explored deep Q-network-based RL for single zone HVAC control. A Q-network is trained to approximate the state-value functions to overcome the computation burden related to the large state space. Yu et al. (Reference Yu, Xie, Xie, Zou, Zhang, Sun, Zhang, Zhang and Jiang2019) has explored the application of Deep Deterministic Policy Gradients (DDPG) (Lillicrap et al., Reference Lillicrap, Hunt, Pritzel, Heess, Erez, Tassa, Silver and Wierstra2015) for the management of building energy system including an HVAC system. The benefit of DDPG is that it can enable the decision making on the continuous state and action space so as to improve the control accuracy. While most of the existing works have focus on the control of HVAC system for single zone or single room, several recent works have explored the development of distributed RL for multizone commercial buildings (Yu et al., Reference Yu, Sun, Xu, Shen, Yue, Jiang and Guan2020; Hanumaiah and Genc, Reference Hanumaiah and Genc2021). For example, Yu et al. (Reference Yu, Sun, Xu, Shen, Yue, Jiang and Guan2020) studied the application of multiagent actor-attention-critic RL (Iqbal and Sha, Reference Iqbal and Sha2019) for multizone HVAC control considering both thermal comfort and indoor air quality.
One major advantage of RL-based HVAC controllers over MPC is that it does not depend on explicit and accurate models, as in classical RL methods, a model of the environment may only ever be implicitly encoded in the inner layers of the policy or value prediction. In this way, RL methods alleviate the burden on the engineer for articulating an accurate model of the environment. It also allows for environment adaptation, i.e., flexibility to an environment that changes over time. The RL agent would just shift the value prediction it makes from actions over time.
RL methods are generally offline tools and require a rich set of data to compute the optimal control policies for a wide range of possible operation conditions. Moreover, the existing RL models including DRLs are still suffering from the computation intensity and scalability issues. Classical RL works best in cases where failure, at least at first, is relatively cheap. However, numerous studies elucidate ways that RL can be modified to reduce variability and increase safety. Arnold et al use Surprise Minimizing RL, a type of RL that rewards the agent for achieving states closer to those seen before, in optimizing building demand response (Arnold et al., Reference Arnold, Srivastava, Spangher, Agwan and Spanos2021). Augmenting RL with a system simulation is important, as almost always a large part of the training can take place in a simulation environment which can use a rules-based heuristic as a starting point, and use exogenous parameters to create a distribution of unique systems to train on (i.e., domain randomization). Finn firmly established the field of meta-learning in RL, arguing that a technique like model agnostic meta-learning can train in the different simulations to approximate a starting distribution for policy network weight initializations (Finn et al., Reference Finn, Abbeel and Levine2017). Jang et al. studies offline learning through offline-online RL (Jang et al., Reference Jang, Spangher, Khattar, Agwan and Spanos2021) and Model Agnostic Meta Learning (MAML) (Jang et al., Reference Jang, Spangher, Srivistava, Khattar, Agwan, Nadarajah and Spanos2021) to get RL agents “hit the ground ready” using offline datasets and simulations.
3.4.3. Learning-based MPC
From the above literature, we note that MPC and RL tools both have pros and cons for HVAC control. MPC-based controllers can yield superior performance both in energy saving and ensuring human comfort due to the capability to incorporate the dynamic predictions regarding the disturbances. However, this is achieved at the cost of high online computation burden. Moreover, MPC-based controllers generally suffer from the modeling complexity. For example, the more elaborate thermal comfort model, such as the PMV is hard to be incorporated in the MPC-based control due the challenge to solve the optimization problem (Xu et al., Reference Xu, Hu, Spanos and Schiavon2017). In contrast, RL-based models can accommodate the modeling complexities but require a huge amount of data to ensure the consistence of performance under uncertainties. The current research trends have been the combination of MPC and RL so as to enjoy both of their pros. The researches are mainly in the following two aspects. One is to use ML to mimic the control policies output by MPC controllers. Specifically, the control of MPC controllers can be regarded as the parameterized policy with respect to the disturbance. To reduce the online computation burden and enable the deployment of MPC controller on simple hardware, the characterization capacity of ML, such as deep neutral networks can be leverage to train parameterized control policies. This can yield control policies of high energy-saving performance and human comfort with MPC at lower online implementation cost. For example, Drgoňa et al. (Reference Drgoňa, Picard, Kvasnica and Helsen2018) proposed an approximate MPC where deep time delay neural networks (TDNN) and regression tree-based regression models are used to mimic the control policy of MPC controller. Simulation results show that the approximate MPC only incurs a slight performance loss (3%) but reduces the online computation burden by a factor of 7. Later, a real-time implementation of the approximate MPC is developed and demonstrated in Drgoňa et al. (Reference Drgona, Helsen and Vrabie2019) in an office building located in Hasselt, Belgium. Similarly, Karg and Lucia (Reference Karg and Lucia2018) proposed to use deep learning networks to learn the control policies of MPC controller to enable low-cost implementation. Using ML tools to learn the control policies of MPC controllers can be regarded as the extension of the explicit MPC discussed above. When the problem is simple and the closed-form solution is available, the implementation of explicit MPC only requires to compute the parameters of the parameterized policy and therefore the online implementation only requires low online computation cost. By leveraging ML tools, we are able to achieve the same objective by training the parameterized policies using deep neural networks when the problem is complex and the explicit closed-form solution is not accessible. Another line of work to combine ML with MPC is to use ML to establish the models for some complex components with building or HVAC system. We direct the readers to Afram et al. (Reference Afram, Janabi-Sharifi, Fung and Raahemifar2017) for a comprehensive review. For example, neural networks can be trained to efficiently predict PMV (Ferreira et al., Reference Ferreira, Ruano, Silva and Conceicao2012; Ku et al., Reference Ku, Liaw, Tsai and Liu2014) for a MPC controller. Since neural networks are generally characterized by nonlinear functions, the nonlinear solvers, such as genetic algorithms and particle swarm algorithms are often used to solve the resulting optimization problem. Compared with the original PMV models, neural network approximation can enable more efficient evaluation of the PMV index without requiring any iterations.
3.4.4. Summary
Though MPC and RL are two main tools for HVAC control, there has not been significant implementation of them in buildings, where the primary controllers have been PID and rule-based ones. There are still many practical issues required to be addressed to enable the deployment of MPC and RL-based methods. Challenges related to classic MPC controllers include the development of models that can properly trade off the modeling complexity and accuracy. In addition, the performance of MPC-based controllers is closely related to the prediction accuracy of disturbance and the prediction horizon. Last but not the least, MPC-based controllers suffer from the high online computation cost and the implementation requires advanced micro-controllers. In contrast, RL-based controllers are free from the establishment of models and can enable efficient and low-cost implementation but requires enormous data to train the agent. Moreover, RL-based controllers cannot incorporate the possibly available dynamic predictions to enhance the performance. That is why most of the existing RL-based controllers are not comparable with MPC-based controllers in terms of energy-saving performance. Another critical issue related to MPC controller is that the safely cannot be ensured. Since the agent is trained on limited data, RL-based controller may draw the system to any possible state which may be prohibitive in practice. Combining ML with MPC-based controllers seems a promising solution as it can enjoy both the pros of ML and MPC. However, how well the control policies can be learned and how the network should be designed remain to be investigated. The operation of HVAC system is expected to provide a comfortable indoor environment for the occupants.
3.4.5. Mechanism design
Compliance is the ability for people, in aggregate, to follow guidelines or recommendations. In any system that seeks to influence human behavior, lack of compliance is generally a large problem. Energy systems are no different: an empirical study of demand response found that noncompliance weakened the overall effect of the programs (Cappers et al., Reference Cappers, Goldman and Kathan2010).
Gamification of systems, i.e., the adding of an additional layer of intrinsic motivation to a core program, may be an important tool to boost compliance. The additional layer of motivation may come in the form of engagement-derived pleasure (i.e., interesting and exciting gameplay), competition (i.e., equally matched competitors), or social status (i.e., badges, ranks, and advancement). Hamari et al., Reference Hamari, Koivisto and Sarsa2014 rightly note the explosion in interest in gamification, from gamification around code learning to gamification around energy demand reduction and perform an extensive review of its efficacy, finding that generally gamification provides positive results. Figure 6 provides a visualization of the gamification pipeline and the purpose it serves.
Figure 6. An example of a system in which gamification can be part of a control strategy.
There are some examples of gamifying office-related energy systems in the literature. Although not extensively, ML algorithms have been utilized in the gamification process to improve some individual components of the game. In one example, a game called “NTU Social Game” has been formulated around reductions in energy in a residential dormitory. Here, players compete against each other to have the lowest energy, and accrue points depending on how much less energy they consume. Prizes are not simply doled out according to whoever has the highest energy reductions; instead, players are entered into a prize pool if they are among the top third performing participants. A small number of prizes are allocated randomly among the winning pool as per the Vickrey Clarke Groves (VCG) auction mechanism. A design like this is shown to boost user engagement and directive compliance (Konstantakopoulos et al., Reference Konstantakopoulos, Barkan, He, Veeravalli, Liu and Spanos2019a, Reference Konstantakopoulos, Das, Barkan, He, Veeravalli, Liu, Manasawala, Lin and Spanos2019b). The NTU Social Game has been used for energy reduction and to test different visualizations on player outcome (Spangher et al., Reference Spangher, Tawade, Devonport and Spanos2019). It has also been used to conduct segmentation analysis of players into low, medium, and high energy-efficient groups for intelligent incentive planning (Das et al., Reference Das, Konstantakopoulos, Manasawala, Veeravalli, Liu and Spanos2019, Reference Das, Konstantakopoulos, Manasawala, Veeravalli, Liu and Spanos2020). The authors use a hybrid approach of supervised classification and unsupervised clustering, to create the characteristic clusters that satisfy the energy efficiency level. They also have incorporated explainability in the model by combining both the ML approaches.
An extension of this work, “OfficeLearn”, considers prices that are distributed across a day. Here, a building controller sets energy prices throughout the day, and players compete with each other on having the lowest cost of energy throughout the day. As before, the top performing individuals are entered into a prize pool and selected based on a VCG auction mechanism (Spangher et al., Reference Spangher, Gokul, Khattar, Palakapilly, Tawade, Bouyamourn, Devonport and Spanos2020). This paper presents an OpenAI gym environment for testing demand response with occupant level building dynamics, useful for standardizing RL algorithms implemented for the same purpose.
Other examples of energy-based games exist. In one game called “energy chickens”, competitors save energy from smart appliances for the health of virtual chickens; depending on how healthy the chickens are, they will generate probabilistically more or less eggs (Orland et al., Reference Orland, Ram, Lang, Houser, Kling and Coccia2014). In another game, “Energy Battle”, players in simulations of identical residential homes strive to reduce energy and players compete one to one without a VCG mechanism (Geelen et al., Reference Geelen, Keyson, Boess and Brezet2012). In a third game, “EnerGAware”, players also compete in a building simulation in which players, who are virtual cats, decide how to operate a house’s appliances with greater energy efficiency while not reducing any overall functions (Casals et al., Reference Casals, Gangolells, Macarulla, Forcada, Fuertes and Jones2020). The use of ML in energy social games, although not prominent before, is showing signs of increase, and is adequately justified since ML can have a profound use in coordinating multiagent systems such as a game.
3.5. Integration of buildings with power grids, microgrids, and energy markets
So far, we have discussed how modeling and control methods can be used to improve occupant comfort and increase the energy efficiency of buildings. However, buildings do not function in isolation and their operation can actually have significant impacts on other energy systems. The energy utilized in buildings come from power grids, and recently, from renewable sources installed at the local building/community level as well. In order to mitigate climate change, buildings must maximize their energy consumption from clean sources.
One way that buildings can achieve the above is by providing load flexibility to facilitate clean energy sources such as wind and solar that have variable generation and cannot be controlled at will to meet electricity demand, a mechanism commonly called demand response (DR). By making their electricity consumption flexible, buildings can adapt to variable generation curves and enable greater amounts of clean generation on the power grid. Buildings can capitalize on their load flexibility using two methods: by participating directly in DR programs run by utilities or by forming aggregations and participating in broader energy markets.
Another way that smart buildings can mitigate carbon emissions is by investing in local clean generation resources (like solar). Smart buildings are often equipped with distributed energy resources (DERs) such as rooftop solar, backup batteries, and electric vehicles (and chargers) to reduce demand charges or optimize grid consumption. If these resources are associated with a single building, they may not be fully utilized. Therefore, buildings should function as prosumers, i.e., use their electricity production capability to provide services to other buildings or to the power grid. Doing so can increase the utilization of clean energy sources, and incentivize additional investment in DERs thus reducing the reliance on grid-wide CO2 emission. In the following parts, we will discuss DR in further details, and how ML plays a role in achieving the same. We will also cover on the prosumer nature of buildings.
3.5.1. Demand response
We start off by discussing how individual buildings can use their load flexibility as DR resources. DR is a broad term for a variety of methods used to module electricity demand. These can include load response to time-varying electricity rates, financial incentives, or direct control of loads (like appliances and air-conditioning) by utilities.
3.5.1.1. DR sources and timescales
There are two primary sources of flexible loads in smart buildings: lighting and the HVAC system (Watson et al., Reference Watson, Kiliccote, Motegi and Piette2006). Modifying energy consumption for either of these has a direct impact on the building occupants, as covered in the thermal comfort section (Section 3.1). Lighting control is a great DR resource since it does not have a rebound effect, i.e., curtailing lighting load during a DR event does not cause a spike after the DR period ends.
Flexible load can be modulated over timescales ranging from a few seconds to a few hours (Alstone et al., Reference Alstone, Potter, Piette, Schwartz, Berger, Dunn, Smith, Sohn, Aghajanzadeh and Stensson2017). For example, smart buildings can shift load by preheating or precooling their indoor spaces, and can shed load altogether by reducing their lighting levels. They can also modulate their instantaneous load by adjusting fan speeds, and respond to high-frequency regulation signals in electricity markets.
3.5.1.2. DR program mechanisms
The two most common types of DR schemes are time-of-use (ToU) rates and curtailment contracts. Time-based rates aim to shape the energy consumption curve by driving long-term behavioral change and energy efficiency investments (Alstone et al., Reference Alstone, Potter, Piette, Schwartz, Berger, Dunn, Smith, Sohn, Aghajanzadeh and Stensson2017). Utilities also run DR programs to procure short-term load curtailment, e.g., in situations when the electricity price spikes and it is too expensive to procure additional generation. These programs are typically structured as contracts where the buildings promise to curtail their energy consumption by a certain amount when called upon to do so, and the utility pays an incentive upfront based on the curtailment size. If the building is unable to curtail its consumption by that amount, it has to pay a penalty to the utility proportional to the shortfall. Readers are encouraged to refer to Albadi and El-Saadany (Reference Albadi and El-Saadany2007) for an overview of common DR mechanisms.
3.5.1.3. ML for forecasting loads and baselines
Buildings procure energy from utilities, who buy it from generators through long-term contracts or in wholesale energy markets. Energy consumption is variable, and utilities employ many ML methods to forecast electricity consumption accurately. Authors in Federal Energy Regulatory Commission (2020) provide an overview of the functioning of electricity markets. The electricity consumption forecasts are usually made for the aggregate load, and individual building loads are not as important for utilities. However, there are a couple of use cases for load forecasting at the building level.
First, in order to implement DR programs and incentivize loads to modulate their energy consumption, it is important to estimate the counterfactual energy consumption: what would the load have consumed without an incentive/intervention? This is considered as the baseline, and needs to be developed at the load level, i.e., building level. There are a number of ML methods used for developing baselines. Deb et al. (Reference Deb, Zhang, Yang, Lee and Shah2017) conduct a review of time-series models for forecasting building energy consumption. They found that a variety of ML models have been used for this purpose: classical time-series methods such as ARIMA, SVM regression for short-term and long-term forecasts, as well as neural network-based methods. Jazaeri et al. (Reference Jazaeri, Alpcan, Gordon, Brandao, Hoban and Seeling2016) compare different methods for computing baselines, such as regression, neural networks, polynomial interpolation, and classical methods (X of last Y days) used by utilities. They find that the ML methods emerge as the state-of-the-art for most of the cases.
A second use case of forecasting load at the building level is peak shaving, where buildings aim to forecast and then reduce their peak energy consumption in order to reduce the demand charges that they have to pay as a part of their electricity bill. Xu et al. (Reference Xu, Wang and Tang2019) develop a probabilistic forecasting methodology to predict the time of occurrence of magnitude of the peak load, where they quantify the probabilistic occurrence and magnitude of the peak load. Kim et al. (Reference Kim, Son and Kim2019) use a variety of time-series methods to forecast the peak load demand of institutional buildings, with a dataset of buildings in South Korea.
3.5.1.4. ML for estimating DR capability
Once the baseline energy consumption is estimated, the utility/system operator can compare it with the actual consumption to determine the impact of the DR program, and in turn determine payments and penalties. However, most energy consumption by buildings is variable, and depends on occupancy and weather conditions. Additionally, the impact of load reduction measures such as reducing lighting and changing temperature setpoints are difficult to estimate ahead of time since the amount of energy curtailed will depend on the building state before the intervention. Some work has been done to quantify the effect of DR actions, e.g., Nghiem and Jones (Reference Nghiem and Jones2017) develop a Gaussian process model of how buildings respond to DR signals. In DR contracts, there might be a penalty associated with curtailment shortfall, and accurately estimating curtailment capability becomes an important task. Mathieu et al. (Reference Mathieu, Price, Kiliccote and Piette2011) use linear regression to develop models for estimating DR capability using time-of-week and outdoor air temperature buckets. It is important to have such DR capability estimates over longer time horizons, and Jung et al. (Reference Jung, Krishna, Temple and Yau2014) develop a look-up table approach to predict future DR capability. They relate power consumption data to parameters such as time-of-day, day-of-week, occupancy, and outdoor temperatures and determine the load flexibility at a point when the forecast value of these parameters is available.
3.5.2. DR aggregations
Load flexibility can be procured through utility programs as discussed previously, and also through direct market participation by loads. There has been a move in recent years to allow loads to submit bids for load reduction into wholesale electricity markets, and treat those bids similar to generation bids. Federal regulations, specifically Federal Energy Regulatory Commission (FERC) Order 2222 in the United States have mandated that distributed resources be allowed to participate in wholesale markets. The state of California has instituted a market mechanism called DR auction mechanism to allow loads to submit bids as ‘negative generation’. However, the magnitude of load flexibility provided by individual buildings is often too small for them to participate directly in electricity markets. This is where aggregations can play a role: aggregators can bundle the load modulation capability of multiple buildings and use the aggregate capacity to submit bids to electricity markets. DR can also be coupled with other resources like generation and storage, and form a part of a virtual power plant.
3.5.2.1. Value proposition of aggregations
Aggregations can add value beyond simply providing a means of market participation, by spreading the risk of shortfall of curtailment capability. Burger et al. (Reference Burger, Chaves-Avila, Batlle and Perez-Arriaga2016) discuss the value of aggregators in electricity systems, and identify that apart from opportunistic and transitory value, aggregations also provide fundamental value, e.g., through economies of scale, that is independent of market or regulatory context. Since the load curtailment capability of buildings is variable, and each building faces a risk of having to pay penalties if it curtails less power than it promised to. However, different buildings will have different variability in their load curtailment capability, and aggregations can capitalize on this uncorrelatedness to minimize the penalty risk for all the participants (Agwan et al., Reference Agwan, Poolla and Spanos2021). Optimizing the complementary nature of buildings can significantly increase the marginal value of forming an aggregation.
3.5.2.2. Optimizing market bids
Once an aggregation is formed, it can optimize its bid in electricity markets using price forecasts and predictions of the available curtailment capacity. A variety of time-series methods are used by commercial entities that participate in these markets, and improving on these methods is an active area of research in both academia and industry as it can directly lead to higher revenues. Shinde and Amelin (Reference Shinde and Amelin2019) conduct a review of electricity price forecasting methods. Brusaferri et al. (Reference Brusaferri, Matteucci, Portolani and Vitali2019) develop probabilistic forecasting methods for electricity prices using Bayesian deep learning methods, as opposed to commonly used point forecasts.
3.5.3. Prosumers and local energy markets
So far, we covered how buildings can use their load flexibility to provide services to the power grid, both individually and through aggregations. Additionally, buildings can directly consume energy from onsite clean resources. Smart buildings are often equipped with a variety of generation and storage resources such as rooftop solar, battery backups, and electric vehicle chargers, which can be used to reduce demand charges or optimize grid consumption. They can profit from these resources by supplying energy back to the grid, i.e., functioning as prosumers. A prosumer is an entity that is capable of energy production as well as consumption through the presence of local generation and energy storage devices.
3.5.3.1. Value proposition of prosumers
Investing in local energy resources is not always a profitable proposition: buildings have to invest in over-capacity generation to meet peak loads, and storage might only be used for peak shaving on a few days in a month or a few hours in a day. If these resources can be shared across multiple users, their utilization levels can increase which can further incentivize investment in clean energy sources. One way to facilitate such sharing is through local energy markets, where prosumers can trade energy with each other before procuring the aggregate balance from an outside source, such as the utility (Agwan, Reference Agwan2020).
3.5.3.2. Organization of local energy markets
There are two main challenges that come up while organizing local energy markets: selecting prosumers to form a market, and then managing the trades within the market. ML methods are used in tackling both of these.
First, we consider the problem of setting up a local energy market, and the methods used to address this challenge. Saad et al. (Reference Saad, Han and Poor2011) use coalitional game theory to optimally aggregate prosumers in a cooperative microgrid. Wu et al. (Reference Wu, Ma, Huang, Fu and Balducci2020) uses a mixed-integer linear programming to discuss the optimal sizing of energy resources in a microgrid. In the study by Quashie et al. (Reference Quashie, Marnay, Bouffard and Joós2018), the microgrid resource planning problem is cast as the upper level of a bilevel program which aims to optimize investment costs along with system reliability. Research in this area mainly focuses on optimizing resource investments, and the problem of evaluating a new prosumer using numerical metrics is not as widely studied. While forming a local energy market, it is valuable to select participants that complement each other’s net load curves. For example, a building that has a net load at a certain time would benefit from being in a market with a net generator at that time. The complementarity of market participants is essentially a measure of how well the electricity generation and demand curves match up. There have been game theoretic approaches to evaluating complementary participants, and the authors in Agwan et al. (Reference Agwan, Spangher, Arnold, Srivastava, Poolla and Spanos2021) have developed a complementarity metric that uses net generation and load curves to evaluate the marginal value of adding new participants to the local energy markets.
Once a market has been set up, we need to facilitate energy trades between participants. This can be achieved by soliciting demand and supply bids from participants, and then settling the market. However, it may be an onerous task for buildings to generate such bids for a market. An alternative to this approach is to set a price for energy and then settle all trades at those prices. A number of previous studies develop price-based controls: Kim and Giannakis (Reference Kim and Giannakis2016) develop a price to minimize load variation, and Liu et al. (Reference Liu, Yu, Wang, Li, Ma and Lei2017) develop a price based on supply-demand ratio to incentivize energy sharing.
While this price can be set in an iterative manner using a variety of distributed optimization techniques, it might be preferable to set it in a one-shot manner to avoid the time lag of back-and-forth communications. This method has been investigated in the literature, e.g., Jia et al. (Reference Jia, Zhao and Tong2013) develop an online learning method to dynamically price electricity for retail consumers. They try to learn the response function of a number of price-sensitive consumers who modify their HVAC load to optimize their consumption. Agwan et al. (Reference Agwan, Spanos and Poolla2021) approach this problem using RL, and develop a controller that can set day ahead electricity prices for a local market with a variety of prosumers.
In summary, ML can aid in predicting the energy load of buildings, enable DR schemes via load flexibility, and can accelerate the energy market set up with buildings as prosumers.
4. Limitations of ML in the Context of Smart Buildings
Although ML techniques have proliferated successfully across many fields, the lack of success of ML in some applications bears note. There are some notable applications where ML does not work well such as safety critical applications, data-poor applications; we describe the fundamental barriers to success in these domains. Arguably, most of these barriers also exist when ML is employed in smart buildings.
4.1. 51/49 vs. 99/01 problems
Does the area of interest require 51% and 49% failure of the control algorithm in its trials, or does it require 99% success and 1% failure? Examples of the former may include stock investing, product recommendation, efficient allocation of computational tasks, and image classification. Examples of the latter may include medical decisions, decisions in autonomous driving vehicles etc.
In smart buildings, the applications fall into both the above categories, and it often becomes harder for ML algorithms to achieve 99/01 performance without jeopardizing robustness and safety. Advancements in ML that may help to address 99/01 problems in buildings are safety-guarantees in ML, robust worst case minimizing RL, proper explainability, etc.
4.2. Data availability
Does the domain provide rich, reliable, and accurate data? The shining examples of ML success often occur in domains where this is the case: RL techniques started to shine when Atari game simulators were developed and could be run millions of times, image ML began to flourish when large image datasets were provided and standardized, and natural language processing began to bear fruit when datasets like the entirety of Wikipedia could be processed and trained on. Most recently, large language models (LLMs) have captured public interest with their performance, largely based on their training on an incredibly large corpus of written materials. In contrast, building energy datasets are not nearly as large, rich, or diverse, and so many of the techniques that work well in different domains may not translate well into the built environment (Ličina et al., Reference Ličina, Cheung, Zhang, De Dear, Parkinson, Arens, Chun, Schiavon, Luo and Brager2018; Fierro et al., Reference Fierro, Pritoni, AbdelBaky, Lengyel, Leyden, Prakash, Gupta, Raftery, Peffer and Thomson2019; Miller et al., Reference Miller, Kathirgamanathan, Picchetti, Arjunan, Park, Nagy, Raftery, Hobson, Shi and Meggers2020; Dong et al., Reference Dong, Liu, Mu, Jiang, Pandey, Hong, Olesen, Lawrence, O’Neil and Andrews2022). A fruitful area of work may include preparing and standardizing large datasets for ease of energy research. Also, given that each building is unique, techniques such as domain transfer learning may be leveraged to enhance the utility of building-specific datasets. Also, advancements in RL that can work well in data-poor regimes may include generative models, regularized and sparse models, etc.
4.3. Pathway to physical implementation
Does the domain have a physical interface that can use the output of ML models? Oftentimes, we may put a lot of work into making a prediction model accurate, but a building from the 1970s might not have the physical infrastructure to house the model, respond to its predictions, or reliably provide state information. A smart appliance may be limited in its scope and effect. To this extent, building operating systems (OS) are newer developments that seek to unify buildings into one software control scheme. Another important function of building OSes should be to provide to the outside world an API that does not need to be aware of inner complexities of the building but can provide certain data about the building (aggregate energy usage) and receive certain grid information like price and state. A third important function of the building OS is to provide unified controls. To this extent, ML research in controls is inherently closer to many of the applications that a building may need.
4.4. Computational cost
Researchers need to be aware of the tradeoff between energy saved via efficient building operations, and the carbon emissions from the compute used to achieve the above. Machine learning is notoriously compute-heavy, and some ML models can require large amounts of energy for training and deployment. The information technology sector is responsible for 2–3% of global greenhouse gas emissions, and the benefits of applying ML in buildings to reduce emissions should be compared to the emissions caused by these models themselves, whether in training or in deployment. Further analysis of these emissions can be found in Kaack et al. (Reference Kaack, Donti, Strubell, Kamiya, Creutzig and Rolnick2022).
5. Conclusion and Future Work
During the life cycle of a building including the design, construction, operation and maintenance, retrofitting, and disposal, there are many factors that contribute toward a building’s energy consumption, efficiency, and embodied carbon. In this paper, we primarily evaluated improving energy efficiency in buildings via ML during design, operation, and maintenance stage. From the well-being of an individual, to building’s occupants, to the building operations and maintenance, and finally to the electric grid impact and energy market economic response, we discussed all the different facets of the smart building ecosystem.
While ML shows promising results in facilitating the energy improvement of building operation and maintenance, there are still several challenges and works to alleviate them ahead. The foremost challenge of all ML approaches is the time and effort to collect reliable data. ML models require a great amount of data, and the quality and the selection of the data greatly affects the quality of the output model. In thermal comfort modeling, data are even harder to come by as it uses intrusive methods that require occupants’ input. Additionally, thermal comfort data are inherently class-imbalanced, which may result in ill-conditioned models. In building modeling, realistic data such as occupancy, temperature settings, and schedules are crucial, and without them, the outcomes of models may be inaccurate or have a high level of uncertainty. Furthermore, the realistic data required may be completely dependent on the application in which the data are needed. Although many researchers have been collecting this realistic data, there is no consistency between companies or research entities. As such, utilizing the collected data across many applications is time-consuming and ultimately infeasible. A potential solution for the above data issue is to develop a standard for collecting and storing building data, potentially as a public data repository from which crowd-sourced data can be posted and requested. An example of a data standard that could suffice is the BRICK schema (Balaji et al., Reference Balaji, Bhattacharya, Fierro, Gao, Gluck, Hong, Johansen, Koh, Ploennigs and Agarwal2018), which is a metadata schema that represents buildings’ sensor information and the relationships between them. Gray box models developed on the data along with building physics can be the ultimate goal. Synthetic data-generation methods are also being proposed as a solution to the data insufficiency problem (Das and Spanos, Reference Das and Spanos2022b).
Generalization is another open challenge for building applications. Firstly, thermal physiology and expectations vary significantly between human occupants. If all occupants’ thermal comfort models need to be individually trained, it will be computationally expensive. As a result, the need for more generalized models that can represent all occupants arises. Secondly, as all buildings are inherently different in design and operation, models, and control strategies from one building are difficult to apply to other buildings. Hence, transfer learning and domain adaptation are some open areas of research that help create more generalized building models.
Finally, thermal comfort models, building models, control algorithms, and grid applications exist on different platforms and do not have a standard interface through which they can all be used. Developing a standardized platform for each application and a standardize interface protocol for the above information can benefit the research communities, as the application of the above techniques are correlated.
As data become more widely available through IoT and ML becomes more computationally feasible, more and more success can be achieved in enhancing occupant comfort and building energy performance. In the future, ML could provide resiliency in the built environment and assist in optimizing occupants’ satisfaction, energy use and cost.
Author contribution
All the authors conceptualized the project. H.P.D. coordinated the ideation, analysis, and writing effort, and other project administration efforts. H.P.D., Y-W.L., U.A., L.S., A.D., Y.Y., J.D., and A.C. were responsible for all formal analysis, investigation, and writing of the original draft. S.S. and C.J.S. supervised the project, and were responsible for reviewing and editing of the paper.
Competing interest
The authors declare none.
Data availability statement
Review papers used in this study are available publicly.
Ethics statement
The research meets all ethical guidelines, including adherence to the legal requirements of the study country.
Funding statement
This research is funded by the Republic of Singapore’s National Research Foundation through a grant to the Berkeley Education Alliance for Research in Singapore (BEARS) for the Singapore-Berkeley Building Efficiency and Sustainability in the Tropics (SinBerBEST) Program. BEARS has been established by the University of California, Berkeley as a center for intellectual excellence in research and education in Singapore.







 Open access
Open access