


1 Introduction
Words and phrases may differ in the extent to which they are susceptible to expressive features such as intonational foregrounding and expressive morphology: their expressiveness. They may also differ in the degree to which they are integrated in the morphosyntactic structure of the utterance: their grammatical integration. In this paper we describe an inverse relation that appears to hold across widely varied languages, such that more expressiveness goes together with less grammatical integration, and vice versa. We study this relation closely in ideophones, vivid sensory words found in many of the world’s languages (Voeltz & Kilian-Hatz Reference Voeltz and Kilian-Hatz2001, Dingemanse Reference Dingemanse2012). The findings shed light on the more general question of how language users cope with the challenge of combining distinct modes of representation in one modality.
Ideophones are a good category to study expressiveness and grammatical integration because they exhibit a particularly clear interaction between the two. They are often cast as prototypically expressive words that are only borderline linguistic: special in terms of sound patterns, suprasegmentals, syntax, and semantics (e.g. Kunene Reference Kunene1965, Zwicky & Pullum Reference Zwicky, Pullum, Aske, Beery, Michaelis and Filip1987). On a seemingly contrasting view, they may have mildly interesting morphosyntax, but are overall well integrated into broader linguistic systems (e.g. Newman Reference Newman2001, Tsujimura & Deguchi Reference Tsujimura and Deguchi2007). We argue that these views can be unified in a typological-comparative approach that recognises that ideophones are often special words, set apart from other vocabulary in various ways, but that they can also enter into morphosyntactic constructions. We aim to explain why ideophones are typically expressive and free, and when they come to be more like ordinary words. We do this on the basis of descriptive data from a range of languages (Section 2), but most directly using corpus data from Japanese (Sections 3–5).
Japanese is well known for its extensive system of ideophones (Kita Reference Kita1997, Hamano Reference Hamano1998, Akita Reference Akita2009), vivid sensory words like
 $_{1}$
$_{1}$
 $_{1}$
C
$_{1}$
C
 $_{2}$
V
$_{2}$
V
 $_{2}$
-C
$_{2}$
-C
 $_{1}$
V
$_{1}$
V
 $_{1}$
C
$_{1}$
C
 $_{2}$
V
$_{2}$
V
 $_{2}$
) and suffixal templates (e.g. C
$_{2}$
) and suffixal templates (e.g. C
 $_{1}$
V
$_{1}$
V
 $_{1}$
C
$_{1}$
C
 $_{2}$
$_{2}$
 $_{2}$
ɾi). Akita (Reference Akita2009: 110) shows that these templates characterise 1643 out of 1652 items in a dictionary of Japanese ideophones. With a large and well-defined category of ideophones, Japanese is an excellent locus for a close study of expressiveness and grammatical integration.
$_{2}$
ɾi). Akita (Reference Akita2009: 110) shows that these templates characterise 1643 out of 1652 items in a dictionary of Japanese ideophones. With a large and well-defined category of ideophones, Japanese is an excellent locus for a close study of expressiveness and grammatical integration.
As a first illustration of the phenomenon, compare the examples in (1). (Here and in subsequent numbered examples, bold indicates the ideophone in focus, upward arrows ‘
 $\uparrow$
’ indicate intonational foregrounding, and vertical lines mark beginning and end of gesture g
$\uparrow$
’ indicate intonational foregrounding, and vertical lines mark beginning and end of gesture g
 $x$
; in the English translation, the text in italics translates the ideophone, and the text following g
$x$
; in the English translation, the text in italics translates the ideophone, and the text following g
 $x$
provides a verbal description of the gesture.)
$x$
provides a verbal description of the gesture.)

Both examples feature a disyllabic reduplicative ideophone: gatʃagatʃa ‘clattering noise’ and giɾigiɾi ‘barely’. However, they differ in expressiveness, with the ideophone in (1a) showing partial multiplication, vowel lengthening, and voiceless phonation, but the ideophone in (1b) showing none of these signs of expressiveness. The ideophones also differ in grammatical integration: in (1a), the ideophone occurs in a quotative construction and is syntactically optional, whereas in (1b), the ideophone occurs in a nominal construction integrated into the predicate. This is the inverse relation between expressiveness and grammatical integration which we will be exploring in this study. Tellingly, the more expressive ideophone in (1a) comes with an iconic gesture, while the one in (1b) does not; a factor we will be able to use in our analysis.
We ask two research questions:

We use multimodal corpus data to answer these questions. We collect all utterances in which ideophones occur and keep track of (a) expressiveness, as measured by three features of the speech signal: intonational foregrounding, phonational foregrounding, and expressive morphology; (b) grammatical integration, in terms of construction types ranking from more to less morphosyntactic integration; and (c) iconic gestures, as a measure independent from the speech signal that can shed light on the reason for the special behaviour of ideophones. To answer question (i), we test whether measures of expressiveness covary with degree of morphosyntactic integration. To answer question (ii), we look at the nature of the relation between expressiveness and grammatical integration, and consider additional evidence from gestures co-occurring with ideophones.
2 Expressiveness and grammatical integration
Ideophones are often characterised as ‘expressive’ words. What exactly this means varies somewhat by author: in the context of ideophones, it is used in connection with affective content (Samarin Reference Samarin1970, Baba Reference Baba2003, Potts Reference Potts2007), experiential semantics (Klamer Reference Klamer2002, Blench Reference Blench and Tourneux2013), and iconic form–meaning mappings (Diffloth Reference Diffloth and Thongkum1980, Kakehi Reference Kakehi1986, Tamori Reference Tamori1990). What unites these takes on expressiveness is that they can all be seen as pointing to the depictive nature of ideophones.
By ‘depictive’ we refer to one side of a well-known semiotic distinction between two modes of representation found in human communication: description and depiction (Clark & Gerrig Reference Clark and Gerrig1990).Footnote [2] These two modes of representation differ in how they map form and meaning, how they are built, and how they are typically interpreted (Table 1). A common shorthand for the distinction is ‘word’ versus ‘image’, reflecting a traditional view of language as a system of arbitrary words fully in the descriptive mode, with the depictive method of communication at best playing a secondary role in the gestures and bodily aspects of ‘paralanguage’. We argue that this traditional, exclusionary view may be profitably exchanged for a more inclusive account of the multiple semiotic resources that are available in everyday language use. Thus, where traditional accounts from Peirce (Reference Peirce1955) to Hockett (Reference Hockett1960) to Newmeyer (Reference Newmeyer1992) have tended to equate spoken words with the descriptive mode of representation, we will provide evidence and arguments that speech can also be depictive.
Table 1 Two modes of representation and their prototypical features.

To foreshadow the argument, we will argue that ideophones typically are depictive representations in the verbal modality, and that recognising them as such explains certain widespread and otherwise unexpected regularities in the morphosyntactic typology of ideophones. To say that ideophones are depictions is to say that they are a form of mimesis rather than diegesis, that is they show rather than tell, they perform rather than merely inform. The proposal that ideophones are depictions is grounded in earlier work: they have been called vocal images (Westermann Reference Westermann and Boas1927), likened to gestures (Kunene Reference Kunene1965), and compared to cinematic imagery (Nuckolls Reference Nuckolls, Sherzer and Sammons2000). What we contribute in this study is novel evidence from a multimodal corpus of Japanese, which brings into sharper relief when and how the special semiotic status of ideophones has repercussions for their morphosyntactic realisation.
While the semiotic distinction between description and depiction will prove important later on, the primary observables we are concerned with are in the domain of prosody and morphosyntax. We define the expressiveness of linguistic signs as the degree to which they are foregrounded as distinct from other items, for instance by special intonational or phonational features. This is in line with the established use of ‘expressive’ as a term that contrasts with ‘plain’, ‘ordinary’ or ‘prosaic’ (Fudge Reference Fudge1970, Diffloth Reference Diffloth and Thongkum1980, Zwicky & Pullum Reference Zwicky, Pullum, Aske, Beery, Michaelis and Filip1987, Joseph Reference Joseph1994). A key notion here is foregrounding: ‘the use of the devices of the language in such a way that this use itself attracts attention’ (Havránek Reference Havránek and Garvin1964: 10). Foregrounding is a semiotic means that may be used for different communicative ends, from indicating noteworthiness (Bolinger Reference Bolinger1968) to expressing emotional content (Potts Reference Potts2007), to framing something as a depictive performance (Nuckolls Reference Nuckolls1996). The fact that foregrounding is a flexible semiotic means is one of the reasons that the term ‘expressiveness’ has come to mean different things for different authors. For instance, emotional language and ideophones may both be foregrounded, but for different reasons: emotion words to index a particular affective stance, ideophones to index a particular mode of representation. Here we provide evidence that expressive foregrounding in ideophones is associated with a depictive mode of representation.
Grammatical integration refers to the degree of integration in the morphosyntactic structure of the utterance. Grammatical integration can be measured in terms of linear position (peripheral items are less integrated), syntactic optionality (optional items are less integrated), and embedding in morphosyntactic structure (less deeply embedded items are less integrated). Across languages, the grammatical integration of ideophones tends to be low: they may be used alone as a complete utterance, and when they occur with a phrase they tend to appear at utterance edge in a loose appositional relation, where they may be grammatically optional (Watson Reference Watson2001). However, ideophones do in fact partake in sentential structure to varying degrees, and focusing only on their prototypically free, expressive side would lead us to miss a number of observations on their morphosyntactic typology.
2.1 Typological evidence
The central question of this paper is motivated by a typological pattern that is relatively well attested in ideophone languages, though evidence for it has not, as far as we know, been brought together in one place before. It is typical for grammatical descriptions of ideophone systems to note the expressiveness of ideophones and, independently, their relative syntactic independence. Yet when grammars go into more detail, there are often hints of a more complex relation between both.
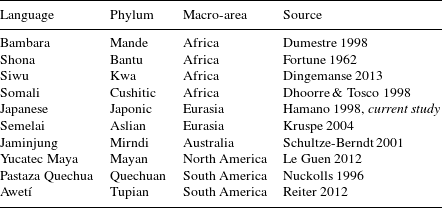
Table 2 lists ten languages from around the world for which grammatical descriptions provide some detail about these matters. In Bambara, a Mande language from Mali, ideophones normally occur at utterance edge, but ‘non-final position of the ideophone causes it to lose its high intonation and its status as expressive adverb’ (Dumestre Reference Dumestre1998: 327). In Shona, a Bantu language spoken in southern Africa, ideophones often show expressive features of pitch and lengthening, but these tend to disappear when the ideophone is incorporated in a verb or derived into a noun (Fortune Reference Fortune1962). In Siwu, ideophones that are more deeply integrated in the morphosyntax lose their expressive features (Dingemanse Reference Dingemanse2013). In Somali, a Cushitic language of Somalia, ideophones are a subclass of nouns, and their noun-like character appears to be linked to them being less expressive (Dhoorre & Tosco Reference Dhoorre and Tosco1998). In Semelai, an Aslian language of Malaysia, ideophones are ‘never syntactically integrated’ and ‘usually …distinguished by an intonation break’ from the surrounding material (Kruspe Reference Kruspe2004: 399). In Jaminjung of Northern Australia, ideophonic coverbs are often intonationally foregrounded, particularly when they function as semi-independent predicates and to a lesser extent when they are incorporated in canonical complex predicates (Schultze-Berndt Reference Schultze-Berndt2001). In Yucatec Maya of Mexico, when roots are instantiated as verbs, they are morphosyntactically integrated and combined with aspectual marking; but when instantiated as ideophones, the roots are characterised by syntactic independence, expressive morphology, and marked prosody (Le Guen Reference Le Guen2012). In Pastaza Quechua of Ecuador, ideophones are often syntactically displaced or isolated, in which case they are likely to be foregrounded intonationally, or they may occur in the unmarked preverbal position, in which case they are ‘minimally performative because they are relatively assimilated into the intonational contours of their respective utterances’ (Nuckolls Reference Nuckolls1996: 72). And finally, in Awetí, a Tupian language of Central Brazil, ideophones either occur as independent clauses or are embedded in a light verb construction. In the first case, they are ‘always prosodically marked’; in the second, ‘they may lose this feature and thus also their status as ideophones’ (Reiter Reference Reiter2012: 576).
Table 2 Ten languages of varied ancestry and geographical origins for which there is evidence of a relation between the expressiveness and grammatical integration of ideophones.
2.2 Proposals and predictions
The descriptions from the grammatical literature cited above all converge to suggest that some degree of expressiveness and syntactic freedom is the default case for ideophones, yet that things can also be turned around, with ideophones losing expressiveness when they are less syntactically free. Though these claims are suggestive, they are hampered by two problems: first, they are based on limited and in many cases unspecified data; second, they are unconnected observations without a unified explanation. What we aim to provide in this study is (i) an empirically grounded, quantitative investigation of the pattern in rich corpus data, and (ii) a unified account that explains the observations.
To structure the investigation, we note the following:

3 Current study: Japanese
Here we study expressiveness and grammatical integration using a corpus of Japanese. Corpus evidence is crucial for getting at expressive features of the speech signal, which would be hard to elicit and are best identified on the basis of recorded data available for repeated inspection. We use the NHK East Japan Great Earthquake Archives, one of the few available corpora of Japanese providing video as well as audio data of relatively informal, lively speech styles. All Japanese examples presented in this paper are taken from this corpus.
Previous work on Japanese has touched upon a link between expressiveness and grammatical integration. For instance, the syntactic embedding of ideophones has been linked to an ‘iconicity continuum’ (Hamano Reference Hamano1998) and syntactically independent ideophones were found in ‘emotive’ discourse (Baba Reference Baba2003). The current paper builds on this work, but goes significantly further by providing detailed corpus evidence and an empirically grounded explanation for the observed inverse relation.
3.1 Expressive features of ideophones in Japanese
Expressive features, as defined above, are those features that help foreground ideophones as special words. Here we focus on three such features: intonational foregrounding, phonational foregrounding, and expressive morphology.
Intonational foregrounding is one of the most common expressive features associated with ideophones cross-linguistically (Childs Reference Childs1994, Nuckolls Reference Nuckolls1996, Alpher Reference Alpher2001, Kruspe Reference Kruspe2004, among many others). In many languages, ideophones are often produced at a markedly higher or lower pitch range. Sometimes there is also an intonational pause separating the ideophone from surrounding material. In Japanese, the prosodic peak of an utterance often coincides with the ideophone, already pointing to its special foregrounded status (Kita Reference Kita1997: 395). Moreover, the pitch of the ideophone is often markedly distinct from the rest of the utterance. In (2) for instance, the ideophone ![]() ‘splash’ is produced in the upper part of the speaker’s pitch range and after it, the speaker returns to the normal pitch register used for speaking (Figure 1).
‘splash’ is produced in the upper part of the speaker’s pitch range and after it, the speaker returns to the normal pitch register used for speaking (Figure 1).
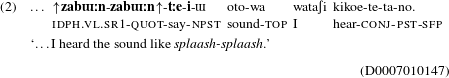

Figure 1 Waveform and pitch trace of (2), showing intonational foregrounding.
Phonational foregrounding is a term we introduce to capture the foregrounding of verbal material by means of marked departures from modal phonation. Though less frequently remarked upon than the intonational features of ideophones, special types of phonation such as breathy voice, growl, creaky voice, voicelessness, and whisper have been mentioned as a feature of ideophones across a range of languages (Childs Reference Childs1994, Ameka Reference Ameka2001, Mihas Reference Mihas2012). In the Japanese earthquake corpus, we find phonational foregrounding of ideophones in the form of breathy voice, creaky voice, stiff voice, falsetto, voicelessness, or whisper. In (2) above, the second iteration of ![]() is produced with tense phonation close to creaky voice, which also affects the pitch. In (3a),
is produced with tense phonation close to creaky voice, which also affects the pitch. In (3a), ![]() is pronounced as
is pronounced as ![]() with voiceless phonation. In (3b),
with voiceless phonation. In (3b), ![]() is pronounced as
is pronounced as ![]() with stiff voice, that is with the glottal opening narrower than normal.
with stiff voice, that is with the glottal opening narrower than normal.

Expressive morphology refers to special morphological processes applying commonly to ideophones and rarely to ordinary words, such as reduplication and lengthening (Zwicky & Pullum Reference Zwicky, Pullum, Aske, Beery, Michaelis and Filip1987).Footnote
[3]
Languages differ in the types of expressive morphology they make available. In Japanese, we find various types of stem repetition, partial multiplication, emphatic mora augmentation, vowel lengthening, and gemination (Hamano Reference Hamano1998, Nasu Reference Nasu2002, Akita Reference Akita2009). For instance, the ideophone don ‘bam’ can undergo various processes of expressive morphology, from vowel lengthening ![]() to partial multiplication (dododon) to stem repetition (don-don-don) (Akita Reference Akita2009: 36).
to partial multiplication (dododon) to stem repetition (don-don-don) (Akita Reference Akita2009: 36).
Example (4a) illustrates vowel lengthening of the ideophone ![]() ‘rapidly’, where the syllable is stretched around 300 ms longer than expected for normal speech (Figure 2). Two further examples of expressive morphology are in (4b), where
‘rapidly’, where the syllable is stretched around 300 ms longer than expected for normal speech (Figure 2). Two further examples of expressive morphology are in (4b), where ![]() ‘slow’ illustrates vowel lengthening and gat (-to) ‘rattling’ partial multiplication.Footnote
[4]
Finally, full repetition was illustrated in (2) above.
‘slow’ illustrates vowel lengthening and gat (-to) ‘rattling’ partial multiplication.Footnote
[4]
Finally, full repetition was illustrated in (2) above.


Figure 2 Waveform and pitch trace of (4a), showing expressive lengthening.

Intonational foregrounding, phonational foregrounding and expressive morphology are logically distinct, but they often occur together. Collectively, they contribute to the ‘performative foregrounding’ of ideophones (Nuckolls Reference Nuckolls1996): as we will see below, this foregrounding is done in the service of signalling a depictive mode of representation.
3.2 Morphosyntax of Japanese ideophones
The morphology and syntax of Japanese ideophones is a rich topic with a long history of research (Tamori Reference Tamori1984, Kita Reference Kita1997, Hamano Reference Hamano1998, Kageyama Reference Kageyama, Frellesvig, Shibatani and Smith2007, Toratani Reference Toratani2007, Akita Reference Akita2009, among many others). As illustrated in (5) below, Japanese ideophones are found in a range of morphosyntactic constructions (Tamori & Schourup Reference Tamori and Schourup1999, Akita Reference Akita2009, Toratani Reference Toratani, Hiraga, Herlofsky, Shinohara and Akita2015). For each construction, the number of tokens observed in the corpus is given in parentheses.


As the numbers of tokens suggest, five types of constructions are particularly common: Quotative, Collocational, ‘say’-verbal (noun-modifying), ‘do’-verbal, and Nominal (the latter two subsumed under the label ‘Predicative’). These five types make available the two hierarchies for the degree of morphosyntactic integration of ideophones presented in (6). We describe the morphosyntactic basis for these rankings in the next section.

3.2.1 Predicate integration hierarchy
The predicate integration hierarchy comprises four productive constructions that constitute a VP (accounting for 90% of ideophone tokens in the corpus): Quotative, Collocational, ‘do’-verbal, and Nominal, the latter two united in being predicative. Ideophones in these constructions are integrated into the predicate to different degrees, as measured by obligatoriness and syntactic position.
The Quotative construction consists of an ideophone and the quotative particle -to or its colloquial counterpart -te. In the Quotative construction, ideophones are both syntactically and semantically separated from their host predicates (Toratani Reference Toratani, Vance and Jones2006, Reference Toratani2007; Akita & Usuki Reference Akita and Usuki2016). They are not syntactically obligatory elements; in (7) bakibaki-to ‘with a cracking sound’, ![]() ‘glancing’ and
‘glancing’ and ![]() ‘swelling up’ can be left out without affecting the grammaticality.
‘swelling up’ can be left out without affecting the grammaticality.

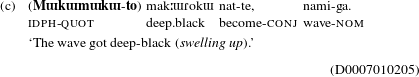
Quotative ideophones frequently occur in preverbal (e.g. bakibaki-to ‘with a cracking sound’ preceding ![]() ‘break’ in (7a)) and non-preverbal positions (e.g.
‘break’ in (7a)) and non-preverbal positions (e.g. ![]() ‘glancing’ occurring away from mi- ‘look’ in (7b)). They collocate with a wide variety of predicates, as illustrated by
‘glancing’ occurring away from mi- ‘look’ in (7b)). They collocate with a wide variety of predicates, as illustrated by ![]() ‘swelling up’ in (7c), whose host predicate
‘swelling up’ in (7c), whose host predicate ![]() ‘get deep-black’ is not directly predictable from its movement meaning. All these phenomena confirm the low integration of Quotative ideophones with the predicate.
‘get deep-black’ is not directly predictable from its movement meaning. All these phenomena confirm the low integration of Quotative ideophones with the predicate.
The Collocational construction has the ideophone appearing in close association with a verb, without a quotative marker. As illustrated in (8), ideophones in this construction appear to be omissible and may appear in different sentential positions; ![]() ‘clearly’ in (8a) occurs preverbally, whereas
‘clearly’ in (8a) occurs preverbally, whereas ![]() ‘walking gingerly’ in (8b) occurs away from the predicate it modifies (
‘walking gingerly’ in (8b) occurs away from the predicate it modifies (![]() ‘get down’).
‘get down’).

However, ideophones in Collocational constructions form a tight unit with their host predicates (Akita & Usuki Reference Akita and Usuki2016), exhibiting a strong preference for preverbal occurrence and tending to have a close collocational relation with particular verbs. Working with a corpus of novels, Toratani (Reference Toratani, Vance and Jones2006) reports that 81% of ideophones in Collocational constructions were found in the preverbal position, whereas only 48% of Quotative ideophones were preverbal. Moreover, the Collocational construction is far less likely than the Quotative construction to allow atypical collocations, such as (7c) above (![]() ‘get deep-black swelling up’). These syntactic and collocational facts are signs that ideophones occurring in the Collocational construction are more morphosyntactically integrated than in the Quotative construction.
‘get deep-black swelling up’). These syntactic and collocational facts are signs that ideophones occurring in the Collocational construction are more morphosyntactically integrated than in the Quotative construction.
The two Predicative constructions – ‘do’-verbal and Nominal – are more tightly integrated with the predicate. The ‘do’-verbal construction consists of an ideophone and the dummy verb su- ‘do’ (Tsujimura Reference Tsujimura, Fried and Boas2005, Kageyama Reference Kageyama, Frellesvig, Shibatani and Smith2007), and the Nominal construction consists of an ideophone and a copula (Kita Reference Kita1997, Toratani Reference Toratani, Hiraga, Herlofsky, Shinohara and Akita2015). These ideophonic constructions are not syntactically optional, as illustrated in (9) and (10).


These data are the basis for the predicate integration hierarchy for Japanese ideophones in (6a). The Quotative construction is least integrated in that it is syntactically optional and freely occurs in different sentential positions. The Collocational construction is more integrated into the predicate in terms of its positional and collocational preference. The ‘do’-verbal and the Nominal constructions are part of the predicate and constitute the indispensable part of a sentence. This three-way hierarchy allows us to examine the inverse relation between grammatical integration and expressiveness in a gradual fashion for the majority of ideophone tokens in the corpus.
3.2.2 The optionality hierarchy
A second, simpler way of measuring morphosyntactic integration is by syntactic optionality only, a measure that can be applied to all ideophones in the corpus regardless of construction type.Footnote [6] Given this criterion, the ideophonic constructions in Japanese can be divided into two groups, as in (11).

The constructions in (11a) are syntactically obligatory, as they constitute predicate complexes. In contrast, the constructions in (11b) are syntactically optional, as they either stand alone or modify predicates or nouns as additional elements. We assume that obligatory elements are more deeply grammatically integrated into the sentence structure than optional elements. This simple dichotomy can be used in addition to the three-way predicate integration hierarchy to investigate the relation between grammatical integration and expressiveness.
3.3 Gesture
So far we have considered only speech, distinguishing expressive features and construction types to be tracked for each ideophone token in our corpus of Japanese narratives. Yet language use is fundamentally multimodal, and utterances often combine speech and gesture. Gesture provides an additional source of evidence that may help elucidate the mechanism underlying the interaction we observe. Gestures come in many types (Kendon Reference Kendon2004), but given our focus on depiction, we will primarily be interested in iconic gestures: manual movements whose shape depicts aspects of meaning by means of perceptual analogies. Consider the following examples from the corpus:


Figure 3 (Colour online) Gesture 1 from (12), accompanying baːn ‘incoming wave’.


Figure 4 (Colour online) Gesture 1 from (13), accompanying zorozoroːt ‘one after another in line’.
In example (12) above, the ideophone ![]() is produced with intonational foregrounding and expressive lengthening and occurs in the noun-modifying ‘say’-verbal construction. It comes time-aligned with an iconic gesture depicting the movement of the enormous wave of water approaching (Figure 3). In example (13), the ideophone
is produced with intonational foregrounding and expressive lengthening and occurs in the noun-modifying ‘say’-verbal construction. It comes time-aligned with an iconic gesture depicting the movement of the enormous wave of water approaching (Figure 3). In example (13), the ideophone ![]() ‘one after another in line’ is likewise produced with intonational foregrounding and expressive morphology and occurs in the Quotative construction. It comes time-aligned with an iconic gesture, in which the movement of both arms depicts the ‘one after another in line’ meaning evoked by the ideophone (Figure 4).
‘one after another in line’ is likewise produced with intonational foregrounding and expressive morphology and occurs in the Quotative construction. It comes time-aligned with an iconic gesture, in which the movement of both arms depicts the ‘one after another in line’ meaning evoked by the ideophone (Figure 4).
The relation between ideophones and iconic gestures is not exclusive: iconic gestures may co-occur with other elements as well, as with the verb in (12). However, earlier work has shown that ideophones are much more likely to co-occur with iconic gestures than verbs are: in a Japanese corpus of cartoon retellings, as many as 94% of ideophones co-occurred with an iconic gesture, whereas this held for only 40% of verbs in a matched sample from the same corpus (Kita Reference Kita1997; see also Son Reference Son2010). This shows that there is a privileged relation between ideophones and iconic gestures, probably reflecting their shared nature as depictions of sensory imagery (Kunene Reference Kunene1965).
Gestures occurring with ideophones are closely related to them in two key ways: (i) they coincide temporally, with gesture and ideophone starting around the same time and gestures being repeated if ideophones are repeated; and (ii) the information they reveal is closely related to the meaning of the ideophone, with the visual iconicity of manual gestures joining the vocal iconicity of ideophonic speech (Nuckolls Reference Nuckolls, Sherzer and Sammons2000). Studies of co-speech gesture often assume that speech and gesture play complementary roles, with speech supplying the relatively abstract verbal content and iconic gestures supplying more imagistic, gradient representations (McNeill Reference McNeill1992; Özyürek Reference Özyürek2014; Goldin-Meadow, published online 1 July 2016; Kelly, Reference Kellyin press). But when it comes to ideophones, speech and gesture are not loosely aligned and complementary, but tightly coupled and alike in mode of representation: they perform the same role of depicting sensory imagery, albeit in different modalities and therefore also with different affordances for iconicity (Dingemanse Reference Dingemanse2013).
All this implies that we can use evidence from co-occurring iconic gestures to shed light on the mechanism underlying the relation between expressiveness and integration investigated here. Essentially, iconic gesture enables us to link expressiveness and grammatical integration to the distinction between descriptive and depictive modes of representation. If ideophones are at their most expressive and least integrated when they are most like depictions of sensory imagery, then they should be especially likely to come together with gestures in exactly those conditions.
4 Materials and method
The NHK East Japan Great Earthquake Archives corpus consists of the videos and transcripts of 214 interviews with victims and rescuers in the great earthquake which hit East Japan on 11 March 2011.Footnote [7] The length of the interviews ranges from about five to fifteen minutes, and the whole database contains 10,657 utterances. The recordings usually start with edited summary, followed by a free-form narrative; we consider only ideophones in the narratives. Within the narratives, we find 692 ideophone tokens (203 types).
We coded all 692 ideophone tokens in the corpus for construction type and syntactic optionality, as well as for the occurrence of intonational foregrounding, phonational foregrounding, and expressive morphology. Additionally, we coded the ideophones for co-occurring gestures. There were 549 cases in our data where the speaker of the ideophone is visible in the frame. In 284 of these (52%), the ideophone occurred with a time-aligned gesture. Of these gestures, 94% were iconic, 4% were pointing gestures, and a handful were mixed or beat-like movements (see Kendon Reference Kendon2004 for a discussion of these categories). This confirms the strong association between ideophones and iconic gestures found in earlier work (Kita Reference Kita1997, Dingemanse Reference Dingemanse2013).
Whereas measures of expressive morphology and syntactic integration are unambiguous – based on well-defined rules of ideophonic morphophonology and morphosyntax (Hamano Reference Hamano1998, Akita Reference Akita2009) – assessing the presence or absence of intonational foregrounding, phonational foregrounding, and iconic gestures can be more subjective. To ensure coding reliability, 10% of the data (70 cases) were also coded by an independent coder. Concordance rates and Cohen’s
 $\unicode[STIX]{x1D705}$
show that coding reliability is good to very good (Table 3). Measures like Cohen’s
$\unicode[STIX]{x1D705}$
show that coding reliability is good to very good (Table 3). Measures like Cohen’s
 $\unicode[STIX]{x1D705}$
assume equiprobability and penalise skewed data values – the ‘high agreement, low consistency’ paradox (Feinstein & Cicchetti Reference Feinstein and Cicchetti1990). For intonational foregrounding, our interpretation of the
$\unicode[STIX]{x1D705}$
assume equiprobability and penalise skewed data values – the ‘high agreement, low consistency’ paradox (Feinstein & Cicchetti Reference Feinstein and Cicchetti1990). For intonational foregrounding, our interpretation of the
 $\unicode[STIX]{x1D705}$
value is ‘good’ because the two values of intonational foregrounding (yes and no) are not equiprobable in our data while the concordance rate is still 74.29%.
$\unicode[STIX]{x1D705}$
value is ‘good’ because the two values of intonational foregrounding (yes and no) are not equiprobable in our data while the concordance rate is still 74.29%.
Table 3 Coding reliability.

5 Findings
We hypothesised that the degree of expressiveness of ideophones is inversely related to their grammatical integration. On this hypothesis, the more integrated an ideophone is, the less expressive features it should show. If the hypothesis is false, the degree of expressiveness of ideophones should bear no relation to their grammatical behaviour.
5.1 Descriptive statistics and correlations
Of the 692 ideophone tokens, 625 can be categorised as Quotative (389), Collocational (155) or Predicative (81), confirming that ideophones on the whole tend towards grammatical independence. However, here we are interested in how ideophones behave across the cline of grammatical integration, so we track expressive features for each of the three morphosyntactic contexts.
Figure 5 shows the presence and absence of expressive features across the Predicate integration hierarchy, Quotative < Collocational < Predicative in the order of increasing integration. The distribution is as predicted by the main hypothesis: a disproportionate amount of ideophones with expressive features occur in the Quotative construction, less so in the Collocational construction, and least of all in Predicative constructions. The three measures of expressiveness all pattern in broadly similar ways, though intonational foregrounding is most frequently attested and phonational foregrounding is much less frequent overall.
Statistical tests confirm the distributional evidence shown in Figure 5: morphosyntactic integration is negatively correlated with intonational foregrounding (Pearson’s
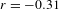 $r=-0.31$
,
$r=-0.31$
,
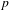 $p$
< .0001), expressive morphology (
$p$
< .0001), expressive morphology (
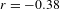 $r=-0.38$
,
$r=-0.38$
,
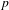 $p$
< .0001), and phonational foregrounding (
$p$
< .0001), and phonational foregrounding (
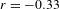 $r=-0.33$
,
$r=-0.33$
,
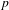 $p$
< .0001), all
$p$
< .0001), all
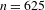 $n=625$
, all
$n=625$
, all
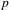 $p$
-values Bonferroni-corrected for multiple comparisons. In short, there is an inverse relation between each of the individual expressive features and the degree of morphosyntactic integration of ideophones.
$p$
-values Bonferroni-corrected for multiple comparisons. In short, there is an inverse relation between each of the individual expressive features and the degree of morphosyntactic integration of ideophones.

Figure 5 Expressive features of ideophones by morphosyntactic integration (
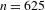 $n=625$
).
$n=625$
).
As each of the expressive features can occur on their own, they are logically independent. Despite this, they are highly correlated with each other, as expected on the hypothesis that they are all indexes of the depictive mode of representation. We see positive correlations between intonational foregrounding and expressive morphology (
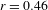 $r=0.46$
,
$r=0.46$
,
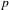 $p$
< .0001), intonational and phonational foregrounding (
$p$
< .0001), intonational and phonational foregrounding (
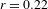 $r=0.22$
,
$r=0.22$
,
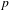 $p$
< .0001), phonational foregrounding and expressive morphology (
$p$
< .0001), phonational foregrounding and expressive morphology (
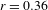 $r=0.36$
,
$r=0.36$
,
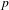 $p$
< .0001), all
$p$
< .0001), all
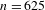 $n=625$
, all
$n=625$
, all
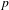 $p$
-values Bonferroni-corrected for multiple comparisons.
$p$
-values Bonferroni-corrected for multiple comparisons.
To further study the relation between expressiveness and grammatical integration, we compute a cumulative measure of expressiveness ranging from 0 (no expressive feature) to 3 (three expressive features). Figure 6 shows the grammatical integration and cumulative expressiveness for ideophone tokens in the corpus. Ideophone tokens with the highest degree of expressiveness are found almost exclusively in the Quotative construction; ideophone tokens with two or one expressive feature are found predominantly in the Quotative and Collocational constructions. In contrast, the majority of ideophones in Predicative constructions show no expressive features at all.
The skewness of the distribution is borne out in a statistical test, which finds a strong negative correlation between cumulative expressiveness and morphosyntactic integration (Spearman’s
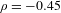 $\unicode[STIX]{x1D70C}=-0.45$
,
$\unicode[STIX]{x1D70C}=-0.45$
,
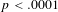 $p<.0001$
,
$p<.0001$
,
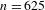 $n=625$
). We use a Spearman ranked correlation here instead of Pearson’s rho because the comparison is now between two ordinal variables (0 < 1 < 2 < 3 for cumulative expressiveness; Quotative < Collocational < Predicative for grammatical integration). There are no differences in significance when running a Pearson correlation.
$n=625$
). We use a Spearman ranked correlation here instead of Pearson’s rho because the comparison is now between two ordinal variables (0 < 1 < 2 < 3 for cumulative expressiveness; Quotative < Collocational < Predicative for grammatical integration). There are no differences in significance when running a Pearson correlation.

Figure 6 Cumulative expressiveness and morphosyntactic integration for ideophones in the corpus (
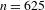 $n=625$
), showing that higher expressiveness correlates with lower integration.
$n=625$
), showing that higher expressiveness correlates with lower integration.
5.2 Linear mixed effects modelling
As we work with corpus data, the number of cases in each condition is not balanced, and there are multiple possible dependencies between observations: some utterances in the corpus feature multiple ideophones, and some utterances are produced by the same speaker, so not all observations are independent and they may be affected by individual differences in expressive speech. We use mixed effects modelling (Bates, Mächler, Bolker & Walker Reference Bates, Mächler, Bolker and Walker2015) in R (R Core Team 2015) to find out whether cumulative expressiveness remains a significant predictor of morphosyntactic integration when we control for these dependencies.
We constructed a mixed effects model of morphosyntactic integration as a function of expressiveness. The fixed effect factor is expressiveness. We include utterance as a random effect and allow expressiveness to vary with random slope by narrative (each narrative has a unique narrator, so this is a proxy for individual differences). The model achieves a fit that is significantly better than a null model with no fixed effect (
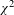 $\unicode[STIX]{x1D712}^{2}$
(1) = 91.33,
$\unicode[STIX]{x1D712}^{2}$
(1) = 91.33,
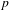 $p$
< .0001, log likelihood difference = 45.66). Thus, mixed effects modelling confirms that higher expressiveness is related to lower grammatical integration even when we control for dependencies and imbalances in the corpus data. If we make the simplifying assumption that the distance between categories is the same at every scale point, we can interpret the model estimate as telling us that every step up in expressiveness makes it 29% more likely that an ideophone is realised with lower grammatical integration.
$p$
< .0001, log likelihood difference = 45.66). Thus, mixed effects modelling confirms that higher expressiveness is related to lower grammatical integration even when we control for dependencies and imbalances in the corpus data. If we make the simplifying assumption that the distance between categories is the same at every scale point, we can interpret the model estimate as telling us that every step up in expressiveness makes it 29% more likely that an ideophone is realised with lower grammatical integration.
So far we have focused on grammatical integration as measured by the predicate integration hierarchy, our most fine-grained view of the phenomenon. The results are strongly similar for integration measured in terms of syntactic optionality. There is a strong correlation between cumulative expressiveness and syntactic optionality (Spearman’s
 $\unicode[STIX]{x1D70C}$
= 0.27,
$\unicode[STIX]{x1D70C}$
= 0.27,
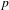 $p$
< .0001,
$p$
< .0001,
 $n$
= 692). A mixed effects model testing how cumulative expressiveness affects optionality (with the same random effects structure as above) achieves a fit that is significantly better than a null model with no fixed effect (
$n$
= 692). A mixed effects model testing how cumulative expressiveness affects optionality (with the same random effects structure as above) achieves a fit that is significantly better than a null model with no fixed effect (
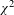 $\unicode[STIX]{x1D712}^{2}$
(1) = 32.31,
$\unicode[STIX]{x1D712}^{2}$
(1) = 32.31,
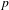 $p$
< .0001, log likelihood difference = 16.15). So higher cumulative expressiveness is consistently correlated with lower grammatical integration whichever measure of integration we use.
$p$
< .0001, log likelihood difference = 16.15). So higher cumulative expressiveness is consistently correlated with lower grammatical integration whichever measure of integration we use.
The results provide a detailed view of the relative expressiveness of ideophones across morphosyntactic contexts. The three expressive features pattern in the same way: they are most common in the most free construction types and least common (in fact mostly absent) in the least free ones. Correlational evidence and mixed effects modelling converge to confirm the main hypothesis that expressiveness is inversely related to morphosyntactic integration.
5.3 Evidence from gesture
So far, all our measures have been from the speech signal and its morphosyntactic structure. As we have argued above, evidence from gesture may serve to elucidate the underlying mechanism: if expressive features are indicative of the depictive mode of representation, this should be reflected in the patterning of iconic gestures, which also inhabit this mode of representation. So we expect iconic gestures to be particularly common when ideophones are at their most expressive.
Like Figure 6 above, Figure 7 below shows all ideophones according to the predication hierarchy, but now coded to show the co-occurrence of iconic gestures (which are observed for 242 tokens). Gestures accompanying ideophones are most abundant in the Quotative construction (58% of visible tokens), less so in the Collocational construction (41%), and least in the Predicative constructions (18%). There is also a clear relation to cumulative expressiveness: gestures are most abundant for ideophones with three expressive features (85% of visible tokens), less so for tokens with two expressive features (72%), less again for one expressive feature (48%), and least of all for ideophones without expressive features (only 12%). A statistical test confirms that there is a strong negative correlation between the occurrence of gesture and morphosyntactic integration (Pearson’s
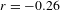 $r=-0.26$
,
$r=-0.26$
,
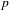 $p$
< .0001,
$p$
< .0001,
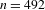 $n=492$
), and a strong positive correlation between gesture and cumulative expressiveness (Pearson’s
$n=492$
), and a strong positive correlation between gesture and cumulative expressiveness (Pearson’s
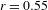 $r=0.55$
,
$r=0.55$
,
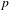 $p$
< .0001,
$p$
< .0001,
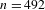 $n=492$
, all
$n=492$
, all
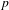 $p$
’s Bonferroni-corrected).
$p$
’s Bonferroni-corrected).
In sum, co-occurring gestures are a strong predictor of the morphosyntactic integration of ideophones, and are highly correlated with expressive features of the speech signal. This confirms the main hypothesis and supports the proposed mechanism by showing that the inverse relation between expressiveness and grammatical integration is directly connected to the depictive nature of ideophones.

Figure 7 Gesture, expressiveness and integration for ideophones in the corpus (
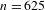 $n=625$
), showing gestures (
$n=625$
), showing gestures (
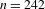 $n=242$
) tend to co-occur with ideophones when they are most expressive and least integrated.
$n=242$
) tend to co-occur with ideophones when they are most expressive and least integrated.
6 Discussion
Our results accomplish three things: (i) they provide empirical grounding for the relation between expressiveness and grammatical integration; (ii) they provide a more detailed view of the interaction, teasing apart three clearly defined expressive features and showing for each of them how they vary across three morphosyntactic contexts; and (iii) they use evidence from gesture to link the inverse relation between expressiveness and integration more directly to the depictive nature of ideophones. We are now in a position to move from observation to explanation.
6.1 Explanation
Why do expressiveness and morphosyntactic freedom go together so naturally in ideophones? Conversely, why do ideophones tend to lose their expressiveness when they are more deeply integrated in the utterance? Both expressiveness and a lack of morphosyntactic integration are often cited as typical features of ideophones, so to cite their co-occurrence as explaining the relation would border on tautology. Instead we propose that the expressive and free nature of ideophones has to do with a fundamental difference in mode of representation: they are depictions as opposed to descriptions.
The interaction between expressiveness and grammatical integration reflects the encounter of two partly incommensurable methods of communication: the discrete, arbitrary, descriptive system represented by ordinary words, and the gradient, iconic, depictive system embodied by ideophones. These two methods place different requirements on the material use of speech: in description, discrete segments like phonemes and morphemes are combined, integrated and linearised into ordinary utterances; in depiction, speech is used in a more gradient way to suggest meaning by means of iconic form–meaning mappings. Yet both are inevitably part of the same single linearly unfolding speech stream, which leads to a challenge akin to the linearisation problem in psycholinguistics (Levelt Reference Levelt1981).
We propose this challenge is met by the relation between expressiveness and syntactic independence we see in ideophones. The expressive features foreground the ideophone, drawing attention to the word as a performance and inviting listeners to imagine what it is like to perceive what it depicts. This performance requires a ‘stage’ where the vivid depiction of sensory imagery in speech is the rule rather than the exception. This is why ideophones thrive when they are free, and why they behave more like plain words when bound within morphosyntax. In the words of Daniel Kunene,

The contribution of the present study has been to put this explanation of ideophone morphosyntax on firm empirical footing. We first tested the relation between expressive features of the speech signal and morphosyntactic freedom and found an inverse relation: more expressiveness goes together with less integration. We then tested whether freedom and expressive features are signs of the depictive nature of ideophones using a measure distinct from the speech signal: gesture. We found that the expressive features of spoken ideophones strongly correlate with the iconic gestures coming with them, strengthening the case for the analysis of ideophones as depictive performances when at their most expressive and free.
Although the primary data in this study have come from Japanese, we have brought together preliminary evidence for strongly similar patterns in a wide range of unrelated languages (Table 2). These descriptive facts of ideophone typology receive a unified explanation in the conceptual framework outlined here.
6.2 Predictions
Besides explaining a good number of empirical observations, our account generates testable predictions in the areas of language typology, language processing, and language change.
With regard to language typology, our account predicts the absence of languages in which highly integrated ideophones tend to be more expressive than loosely integrated ideophones. Such languages would falsify the account in its current formulation. Instead we expect that ideophones in any language will show the same inverse relation between expressiveness and grammatical integration. Relatedly, our account predicts that features of expressiveness and measures of morphosyntactic integration of ideophones may differ as a function of the typological profile of languages. For instance, some languages may allow ideophones to occur on their own, others may always require the presence of some grammatical marker, and yet others may feature ideophones that are even more bound, and each of these will have consequences for the (relative) expressiveness of ideophones in that context. Further, our results provide the first quantitative evidence of phonational foregrounding and predict this is likely more widespread than reported so far.
The regularities we have described here provide people with a set of heuristics that can guide the production and interpretation of verbal material. From this follows a prediction that ideophones produced with more expressive features should invite more iconic interpretations. Indeed, recent experimental work shows that prosody (including intonation and duration) is an important contributor to sound-symbolic effects (Nygaard, Herold & Namy Reference Nygaard, Herold and Namy2009, Dingemanse, Schuerman, Reinisch, Tufvesson & Mitterer Reference Dingemanse, Schuerman, Reinisch, Tufvesson and Mitterer2016). Another prediction is that newly created ideophones, which may be based on new or existing verbal material, should be maximally expressive and minimally integrated in order to be recognised as depictions rather than descriptions. Both predictions can be experimentally tested and point to promising directions for future research on ideophones and vocal iconicity.
Further predictions arise in the domain of language change. If new ideophones must be maximally expressive, it follows that less expressive ideophones are likely older and more conventionalised. So the inverse relation between expressiveness and grammatical integration provides a pathway for deideophonisation. Over time, ideophones may assimilate to ordinary vocabulary. Our account predicts that this assimilation will manifest itself as a gradual loss of expressiveness and a gradual increase in morphosyntactic integration. Known processes of reduction and conventionalisation (Bybee Reference Bybee2007) suggest that this is especially likely to occur with more frequently used ideophones. The overall picture that emerges is one of ideophone inventories as in a state of flux, with expressiveness and grammatical integration pulling in different directions.
6.3 Generalisations
The inverse relation between expressiveness and grammatical integration is not limited to ideophones. It applies to any situation in which language users combine descriptive and depictive content.
Take quotations. These can fruitfully be analysed as depictions or ‘demonstrations’ (Clark & Gerrig Reference Clark and Gerrig1990, Davidson Reference Davidson2015) in which speakers attempt to depict selected aspects of some original (speech) behaviour. Like ideophones, quotations come in a range of construction types that differ in their morphosyntactic integration (De Vries Reference De Vries2008, Güldemann Reference Güldemann2008). There is also evidence that this difference goes along with prosodic cues akin to the expressive features we have discussed for ideophones; for instance, in direct quotation (but not indirect quotation), the quoted speech tends to be set off prosodically from the surrounding material by means of pauses and intonational foregrounding (Güldemann Reference Güldemann2008: 222–223). Furthermore, direct quotations often include manual gestures and other visual signals that help signal the depictive mode of representation (Sidnell Reference Sidnell2006). The picture proves to be exactly parallel: the more expressive features a quotation shows, the more likely it is to be morphosyntactically free; and both freedom and expressiveness are signs of its status as a depiction.
Ideophones and verbal quotations are special in being vocal depictions occurring within the linearly unfolding stream of speech. The inverse relation between expressiveness and integration directly follows from this fact: within the confines of the modality of speech, the main way to differentiate depiction from description is to exploit the temporal and material properties of the speech stream. This is why depictions in speech often occur at utterance edge, clearly distinguished from the adjacent descriptive material.
Speech is of course only one aspect of the rich reality of face-to-face interaction, which often combines different articulators and semiotic resources into composite utterances (Slama-Cazacu Reference Slama-Cazacu, McCormack and Wurm1976, Enfield Reference Enfield2009). From this perspective, the relation between expressiveness and integration captures a more fundamental fact about the production and interpretation of composite utterances in communication. If we use different modes of representation together, there must be cues or meta-communicative signals (Bateson Reference Bateson1955) that enable language users to distinguish these modes and parse and interpret the material accordingly. Sometimes such cues may be given by the fact that the semiotic resources are materially distinct and used according to their most natural affordances. This is what gives rise to default inferences linking manual gesture to depiction and speech to description (Goldin-Meadow, published online 1 July 2016). When this is not the case, cues must be realised in material aspects of the signals. In this study we have investigated various expressive features of speech: modifications of the signal that serve to cue a distinction in mode of representation. In other modalities we can expect analogous modifications or semiotic resources to serve as meta-communicative signals. For example, shifts in gaze patterns and body posture can play a similar role in demarcating depictions in multimodal discourse (Sidnell Reference Sidnell2006) and in the phenomenon of role shift in sign language (Davidson Reference Davidson2015).
We have focused here on ideophones as they provide a particularly clear view of the inverse relation between expressiveness and grammatical integration. Exclamations and interjections form another of group of linguistic signs combining high expressiveness and low integration. These signs are primarily indexical (Kockelman Reference Kockelman2010) as opposed to depictive or descriptive. Therefore, their expressiveness and grammatical freedom across languages may be explained by a generalised version of our account: it is a way to meet the challenge of combining distinct modes of representation in a linear speech signal.
7 Conclusions
Descriptions of ideophones have often been torn between casting them as extralinguistic exotics or stressing their integration in linguistic systems. Here we have shown how these seemingly contrastive views can be reconciled in a more comprehensive view of the morphosyntactic typology of ideophones – and how in the process we can shed light on a more general aspect of human language. Intonational foregrounding, phonational foregrounding, and expressive morphology commonly accompany ideophones across languages. They are not merely incidental features correlating with ideophone use, but serve the semiotic function of foregrounding some stretch of the speech signal as a depiction as opposed to a description.
The inverse relation between expressiveness and grammatical integration we have described here shows how people may exploit material features of the speech signal to conjoin and contrast different modes of representation. Too often, the distinction between description and depiction has been used as a demarcation line separating word from image and language from paralanguage. Here we have shown that it runs through much of our everyday language use, and that we can only begin to understand language in all of its aspects when we consider description and depiction together.










