


Project Talent (PT) is a U.S. national longitudinal study originally designed to identify characteristics in adolescence predictive of educational and occupational success. Participants include 377,000 individuals from 1200 schools, first assessed in 1960 while in secondary school (Grades 9–12). The students completed a 2-day assessment of cognitive abilities, aptitudes, vocational and leisure interests, personality and other individual and family characteristics (Flanagan, Reference Flanagan1962; Flanagan et al., Reference Flanagan, Dailey, Shaycoft, Gorham, Orr and Goldberg1960). Information on school and community characteristics was obtained from school staff and through linkage to 1960 Census data. Follow-up surveys were collected 1, 5 and 11 years after the students’ expected graduation from high school.
Our article in a prior Twin Research and Human Genetics (TRHG) special issue (Prescott, Achorn et al., Reference Prescott, Achorn, Kaiser, Mitchell, McArdle and Lapham2013) summarized the 1960 and subsequent data collections with the full PT sample, described the identification of twins and sibling sets within the sample, and described the methodology of our new data collection with twin families. In the present article, we report response rates in the 2014 collection, describe our method for assigning zygosity using survey responses and yearbook photographs, illustrate our twin–sib–classmate model using 1960 vocabulary scores and preview our 2019 data collection.
Project Talent Twin and Sibling 2014 Survey
In 2014, we conducted a 54-year follow-up of the PT twin sample, who were then aged 68–72 years. To increase statistical power, we also included the siblings of twins who had participated in the 1960 PT study, and thus called this the Project Talent Twin and Sibling (PTTS) Study. The goals of the study were to collect later-life health and psychosocial outcomes, assign zygosity and create a resource for future studies of aging. PTTS provides a unique opportunity to observe how differences in adolescence play out over later-life stages.
The initial PTTS sample included 5161 individuals from 2295 families. In the course of data collection, 62 families were found to contain nontwin sibling sets, and one triplet set was reclassified as a twin-pair plus sibling. The revised sample comprises 5003 individuals in 2233 families. These include 4447 twins (from 2224 pairs in 2220 families), 34 triplets (from 13 sets) and 522 of their nontwin siblings. As with any longitudinal study, the sample composition will continue to change. Additional twin-pairs from the 1960 sample have been identified, and we expect to identify more twins and siblings from a 2019 data collection with a larger sample of PT siblings and schoolmates.
Participant tracking and survey administration were conducted by the American Institutes for Research (AIR). Briefly, data collection consisted of an introductory letter followed by a mailed survey packet that included a cash incentive of $10. Individuals who did not respond initially were contacted over the course of 2 months with up to two reminder postcards, one or two additional survey packets, and up to 10 call attempts.
Table 1 details the individual-level survey response. Of the 5003 eligible individuals, 1104 (22.1%) were identified as deceased. Responses were received from 2493, a response rate of 63.9% among individuals known or presumed alive. Twins and triplets were slightly more likely than siblings of twins to return questionnaires, with a response of 64.6% compared to 58.1%.
Table 1. PTTS14 individual response status among twins and sibs of twins from PT 1960
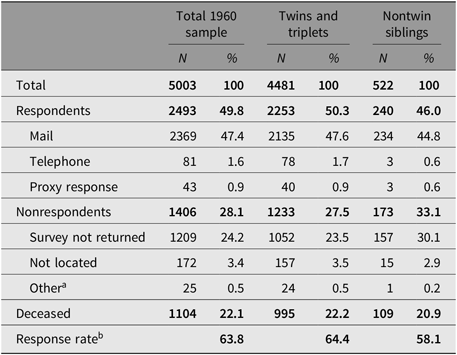
Note: Excludes 158 individuals identified as ineligible during data collection. Bold values used to indicate a higher-order category and associated Ns associated – of which the following lines are a sub-category.
a Includes 20 individuals incorrectly identified as deceased and 5 not mailed surveys due to procedural errors.
b (Respondent)/(Respondent + Nonrespondent).
The majority of returned surveys were completed by designated participants and returned via mail. For 43 participants who were incapacitated or deceased, a family member or caregiver completed sections of the survey designated for proxy response. Another 81 individuals completed an abbreviated version of the survey during follow-up telephone contacts to nonresponders.
The sample has 2233 family groups with twins or triplets. Surveys were returned by at least one family member in 1561 (69.9%) of families, providing reports on many individuals who were deceased or did not respond. For 813 families (36.4%), 2 or more individuals responded, allowing us to evaluate reliability of zygosity items, as well as reports of educational level and mortality of other family members. Within the 813, there are 723 families with complete pairs, representing 32.4% of total family groups and 51.7% of living pairs. A detailed listing of family-level response is provided in Supplement S1.
Evaluating Selection Effects
Our 2013 article evaluated the representativeness of the PT twin sample by comparing twins to other PT participants on a range of demographic measures from 1960. Twin families did not differ in socioeconomic status (SES), but as is typical of cohorts born before the widespread use of reproductive technology, twins were more likely than nontwins to come from large families and their parents tended to be older.
Other differences between the twins and the overall 1960 sample are attributable to the methods used to identify twin-pairs and to the PT sampling design. Briefly, siblings were linked within families based on the 1960 address, school attended and parent names. Twins were identified within sibships based on dates of birth. An individual was identified as a member of a twin-pair only if his/her cotwin attended the same school and was sampled into PT. In large urban high schools, a fraction of students rather than the entire school participated in the 1960 assessment. Consequently, twin-pairs were underascertained in metropolitan areas, and we did not identify twins whose cotwins were deceased or not in school (see Prescott, Achorn et al., Reference Prescott, Achorn, Kaiser, Mitchell, McArdle and Lapham2013 for details).
We have also evaluated selection due to mortality prior to 2014 (Bautista et al., Reference Bautista, McArdle, Achorn, Lapham and Prescott2015). The PTTS mortality rates are consistent with lifetable estimates for the U.S. population for individuals born 1942–1946 who survived into adolescence. For example, the median survival for a 15-year old in 1960 is estimated to be 72.3 years, but this varies by sex and race, with estimates of 76.2 for White females, 69.9 for White males and Black females and 63.2 for Black males (Arias et al., Reference Arias, Heron and Xu2017).
Sample Characteristics and Response Bias
Table 2 shows selected characteristics of the PTTS sample based on information collected in 1960 and 2014. These are just a few of the thousands of items collected on the sample, chosen to be descriptive and relevant to later-life health and cognition. We focus on effect sizes for characterizing group differences rather than tabling significance tests.
Table 2. Characteristics of PTTS sample
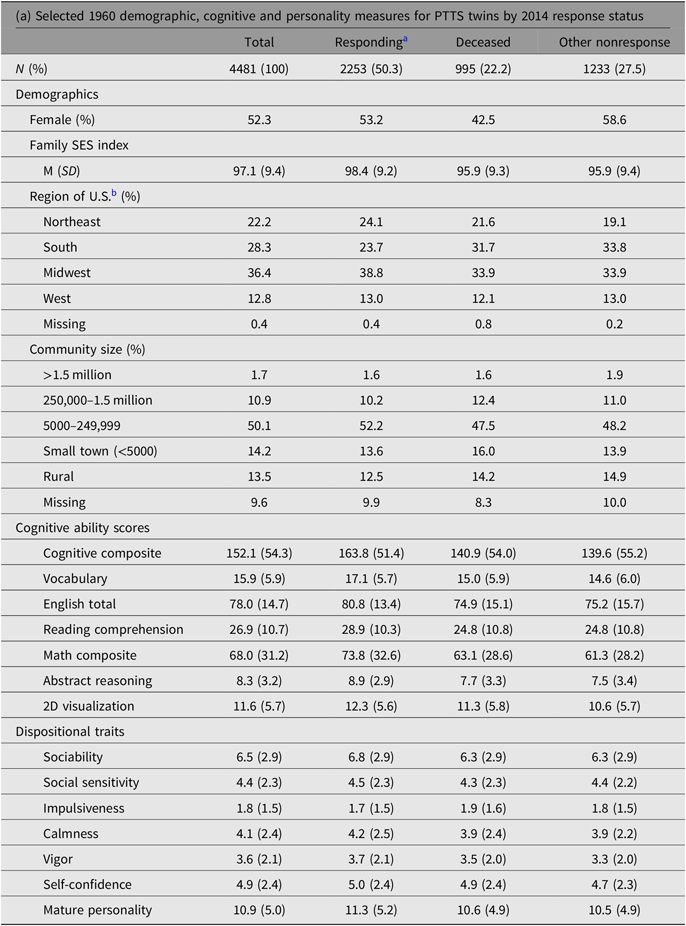
Note: Based on twins only, excludes siblings of twins. SES index has M = 97.7 and SD = 9.9 in full PT sample. Cognitive and Personality scores are raw scores out of total items.
a Includes 22 individuals for whom a proxy provided responses.
b Based on Census regions. Northeast = CT, DC, DE, MA, MD, ME, NH, NJ, NY, PA, RI, VT; South = AL, AR, FL, GA, KY, LA, MS, NC, SC, TN, VA, WV; Midwest = IA, IL, IN, KS, MI, MN, MO, ND, NE, OH, SD, WI; West = AK, AZ, CA, CO, HI, ID, MT, NC, NM, OK, OR, TX, WA, WY.
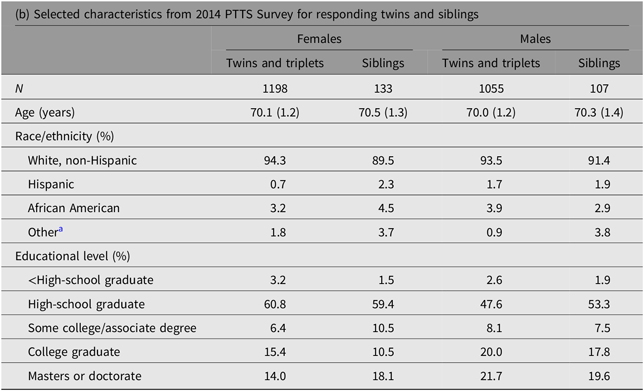
a Includes Native American, Asian, Pacific Islander.
Table 2a provides 1960 family and community characteristics, cognitive ability scores, and scores on dispositional traits for twins only, stratified by their participation status in 2014. Race and ethnicity are not included; this information was not collected in 1960 at the individual level, only aggregated by school. Overall, the PT sample was 94% White, consistent with the demographics of U.S. high-school students in 1960.
The twin sample is 52% female, and this varied somewhat by response category, with females accounting for 53% of respondents, 43% of the deceased and 59% of nonrespondents. This last figure is because females account for a higher proportion of individuals not tracked, often due to changing their last names since they last participated in PT.
Family SES was indexed by a weighted composite of nine items (variable P808 in the PT databank, Wise et al., Reference Wise, McLaughlin and Steel1979) assessing maternal and paternal educational levels, paternal occupation, type of residence and household possessions such as appliances, automobiles and luxury goods. On average, respondents in 2014 had 1960 family SES about 0.3 standard deviations higher than twins who were deceased or did not respond, F (3,4477) = 39.4, p < .0001.
The most marked group differences are for cognitive abilities scores, for which the mean scores for respondents are 0.2–0.5 SD higher than those of the deceased and nonresponding groups. The dispositional trait scales were developed for PT; their relation to contemporary Big 5 dimensions has been studied in another sample (Pozzebon et al., Reference Pozzebon, Damian, Hill, Lin, Lapham and Roberts2013). The association between scores on these measures and the 2014 response status was small, with all group differences ≤ 0.2 SDs.
Table 2b shows demographic characteristics of twin and sibling respondents to the 2014 survey, including age, race/ethnicity and achieved education. The mean age was 70 years (range 66–74), 53.4% of respondents were female and 93.6% identified as White, non-Hispanic. Twins and siblings of twins were similar for all variables. Males and females were similar except for educational attainment, with 41.3% of males attaining at least a college degree compared to 29.4% of females.
Zygosity Assignment in PTTS
As perusal of the TRHG special issues attest, the number of twin registries is increasing and will likely continue to expand with greater availability of databases covering national and regional populations (e.g., Lakhani et al., Reference Lakhani, Tierney, Manrai, Yang, Visscher and Patel2019). Our experience assigning zygosity in PT is relevant to other samples that identify twins from population databases and include individuals who are not individually assessed. We thus provide considerable detail on the process and supporting validity information. We were guided by empirical studies (Prescott, Reference Prescott, McArdle and Ritschard2014; Wu et al., Reference Wu, Page and Snieder2010) as well as our extensive experience with other datasets of adult twins.
Sources of information used for zygosity classification include items on physical resemblance collected in the 2014 survey and photographs obtained from high-school yearbooks. We considered using adolescent height and weight, as reported in the 1960 PT survey, but the responses to these items were coded in broad categories (of 3 inches and 15 lb., respectively). Analysis of height and weight distributions in a sample of adolescent twin-pairs aged 15–18 with known zygosity indicated that these categories could not be used to reliably assign zygosity (J. Harris, personal communication, 2014).
Survey Items and Zygosity Algorithm
Physical resemblance questions on the PTTS14 survey included standard items on being confused for each other as children, whether the pair was ‘alike as two peas in a pod’, height and weight of each twin at age 20, and the respondent’s opinion of the pair’s zygosity. Two open-ended items asked the reason for their opinion and for comments pertinent to physical resemblance. All zygosity items were asked of members of same-sex twin-pairs and of siblings about their twin siblings. Triplets were telephoned to obtain information about each same-sex pairing.
As detailed in Supplement S2, responses to survey items were coded into an algorithm adapted from that described by Nichols and Bilbro (Reference Nichols and Bilbro1966). The algorithm was applied separately to item responses provided by each reporter (twin or sibling) about the pair and yielded an assignment of monozygotic (MZ), dizygotic (DZ) or indeterminate.
Agreement for the algorithm assignment was high across all types of reporters. Chance-corrected agreement was K = 0.75 for 521 twin–cotwin pairs and K = 0.80 for 156 twin-sibling pairs. Agreement did not differ appreciably based on the sex of the twin-pair (see Supplement S3). We considered this strong evidence for the validity of the algorithm and believe that it justifies assigning zygosity based on the responses of a single twin or sibling of twins.
Photographs
Searches were conducted to locate yearbooks from the years 1959 to 1963 for all schools that participated in PT in 1960. Yearbooks were obtained through internet searches, libraries, schools, eBay, historical societies and PT participants. In addition, photos of twins and triplets were extracted from yearbooks available on the classmates.com website. As of this writing, we have photos of 748 (47.4%) of the same-sex pairs.
Yearbook photos vary in quality, size and clarity and are nearly all in black and white. About 10% were too small or indistinct to be useful for zygosity. If photos from multiple years were available, we prioritized those from later years — senior photos are often larger and DZ twins diverge more with age.
In a prior presentation, we reported preliminary results from applying feature detection software to identify twin-pairs from digitized photographs of 40 adolescent twins with zygosity assigned by blood markers (Prescott, Xu et al., Reference Prescott, Xu, Achorn, Lapham, Mitchell, Kaiser and Biederman2013). The algorithm had high accuracy identifying which individuals were cotwins of each other, but further study found no difference from chance in assigning pair zygosity. We believe that the successful cotwin identification was due to twins within a pair being photographed under the same conditions (e.g., lighting, background). More sophisticated facial detection algorithms may be suitable for zygosity assignment but would require photos taken under controlled conditions.
Scanned photos of twins in a pair were viewed side by side on a computer screen. Ratings were blinded to survey responses and other information about the twins. Prior to viewing, a research assistant removed names and other captions. Identical pairs often have first names that rhyme (e.g., Ronald and Donald, Karen and Sharon), and we did not want this information to influence zygosity ratings. For each pair of photos, two to five raters independently assigned a score on a 5-point scale (definitely MZ, probably MZ, uncertain, probably DZ and definitely DZ), and then ratings were compared in real time. When ratings differed, consensus was reached through further examination and discussion.
Photo raters were project investigators who were trained on photos of twin-pairs with zygosity assignments of definitely MZ or definitely DZ based on survey responses. Raters were instructed to compare the photos based on the entire gestalt then to compare facial features (nose, ears, brow line, and chin) and proportions (e.g., face shape, length-to-width ratio, and interocular distance). We disregarded characteristics that could be altered (hair color and texture, eyebrow shape) and considered the potential impact of differences between twins in facial expression, head angle and body weight. Eye color was difficult to distinguish in photographs and was informative for rating zygosity only for pairs whose eye colors were markedly different. In general, photos of males were easier to evaluate because a large proportion of females had hair covering their ears and foreheads. Apprehending the gestalt was often improved by rotating the photos and viewing them upside down.
Final Classification Process
The final stage in determining zygosity was to combine the photo ratings, algorithmic assignments and responses to other 2014 survey items relevant to zygosity. In general, algorithmic assignments took priority over photo ratings. When there were disagreements among algorithmic assignments based on different raters, priority was given to twin reports over sibling reports. We also considered which items contributed and the strength of the algorithm classification (see Supplement S2).
All responses to open-ended items were read to determine their relevance for interpreting other information. For example, algorithm assignment as DZ on the basis of a ‘rarely or never confused’ response was disregarded if one twin was reported to have a distinguishing physical feature (e.g., a prominent facial scar) and other responses and evidence were consistent with the pair being MZ. A respondent’s opinion that the pair was MZ was disregarded if the reason provided was unrelated to physical similarity (e.g., similar personalities, the delivery physician saying the pair was identical).
Algorithm assignments were checked for consistency with other survey information, particularly twins’ opinion and the peas-in-a-pod item. Pairs with rater disagreements, having inconsistencies with other survey items, and with one or more algorithm assignments of Indeterminate were assigned for hand review. Across the sample, hand review was conducted for 139 twin-pairs where zygosity was inconsistent between the algorithm and other sources. Given the greater complexity of assigning zygosity for triplets, all triplet sets received hand review.
Details of the sources of information used for zygosity assignment and how they were combined into the final zygosity are provided in Supplements S4 and S5. Briefly, for 521 same-sex twin-pairs with both twins responding to zygosity items, photo ratings were included in the decision-making only if algorithm assignments were inconsistent or inconclusive. For 282 pairs with photos and (1) one twin responding, (2) one twin plus sibling(s) responding, or (3) neither twin but one or more responding sibling(s), the photo ratings agreed with the algorithmic zygosity for 231 (82%). Among the remaining 51 pairs, zygosity assignment was made for 28 pairs and 23 were classified as Unknown. For 233 pairs with photos but no zygosity survey information, photo ratings were used to assign zygosity for 213 pairs (91%) and 20 were classified as Unknown.
Finally, a seven-level certainty rating from Highly Likely MZ to Highly Likely DZ was assigned for the zygosity classification of each pair. There were several hundred combinations of information sources and quality so we present only a summary here. (Details of decision rules for assigning certainty are available from the authors.) A highly likely rating was assigned for pairs with agreement of the algorithmic assignments for two or more respondents in a family or agreement of a single respondent’s algorithmic assignment with the photo rating. Pairs with less information or inconsistent information that eventually received a zygosity classification received a probable rating. Pairs with some inconsistent or minimal information were called possible. The distinction between certainty levels is mostly useful for sensitivity tests to evaluate the accuracy of the zygosity classification. For the purposes of data analysis, pairs in the highly likely and probable categories are combined to create the MZ and DZ groups, and pairs in the possible categories are treated as missing.
Table 3 displays the distribution of the final zygosity assignments by pair sex, separately for all 2253 twin-pairs in the 1960 PT dataset and for the 745 complete pairs responding to the 2014 survey. Summing across the Probably and Highly Likely categories, the 1960 sample includes 588 MZ pairs (341 MZ female (MZF) and 247 MZ male (MZM)); 690 same-sex DZ pairs (353 DZ female (DZF) and 337 DZ male (DZM)); 656 opposite-sex DZ (OSDZ) pairs, and 319 pairs with Unknown or Possible zygosity. The higher proportion of females than males is consistent with the overall gender distribution in PT (with males having higher mortality and being more likely to drop out of high school than females). Having fewer MZM than DZM pairs is unexpected, given the similar incidence of MZ and DZ twin births for this cohort (i.e., predominantly White and born before assisted reproduction). This pattern is not likely due to a bias in ascertainment. Because twins were ascertained pairwise in 1960, a participant whose cotwin was not assessed would not be identified as a member of a twin-pair. This means that any genetically based mechanism contributing to underascertainment (e.g., death, school dropout) would be expected to increase (not decrease) the MZ–DZ ratio. The ratio of same-sex to OSDZ pairs (690–656) is consistent with the overall gender ratio and suggests that there is not a strong bias in ascertainment associated with being male. Most of the pairs classified as Unknown had no family members participating in 2014 and either had no information or had photographs only. A process that produced pair concordance for nonparticipation in 2014 among MZ more than DZ pairs would produce a pattern of more MZ than DZ pairs being classified as Unknown.
Table 3. Zygosity assignments of PTTS twin and triplet sets
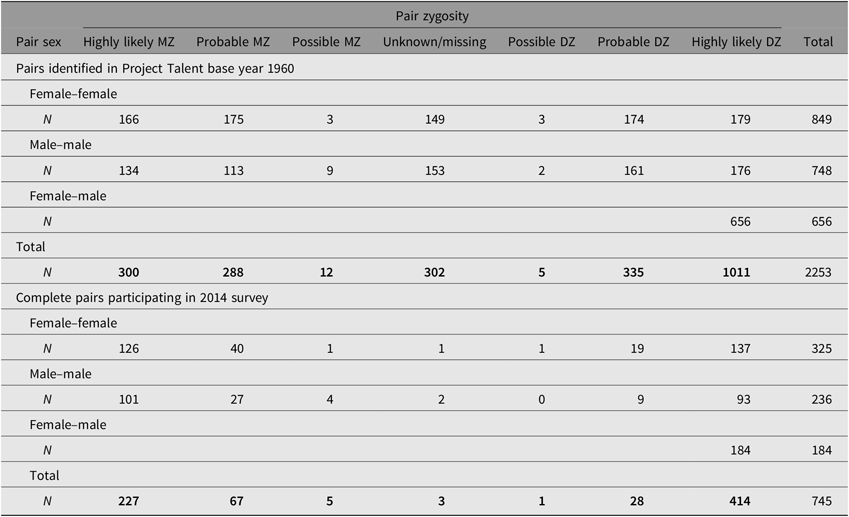
Note: Zygosity is a pair-level (not individual level, or family level) variable and Ns refer to pairs. Triplet sets contribute 34 pairs: 8 triplet sets contribute 3 pairs each and 5 triplet sets contribute 2 pairs each.
As can be seen in the lower portion of Table 3, all but nine of the twin-pairs who both responded were assigned a Highly Likely or Probable certainly level. As the survey was the source of the zygosity algorithm, this is not surprising. The proportion of pairs with both twins returning 2014 surveys follows the typical pattern seen in adult twin studies, with higher pairwise participation from MZ and DZ female pairs (MZF = 48.7%; MZM = 51.8%; DZF = 44.2%; DZM = 30.3%, OSDZ = 28.0%).
Other Siblings in PT
In addition to the 5003 twins, triplets and their siblings in PTTS, another 83,423 PT respondents came from families with two or more nontwin siblings participating in 1960. As shown in Table 4, combining the samples yields a total of 49,599 pairs of individuals available for analysis. We refer to this as the Sibs sample. A small portion of these individuals have been identified as cousins and half- or step-siblings, but the large majority is believed to be full siblings. Any unidentified half-siblings are not likely to create much bias. In general population samples, nonpaternity is much lower than once believed (Larmuseau et al., Reference Larmuseau, Matthijs and Wenseleers2016). The small age difference between siblings in PT families (1–3 years) means the proportion with different fathers is likely to be even lower.
Table 4. Twin, triplet and sibling pairs in Project Talent by sex and zygosity
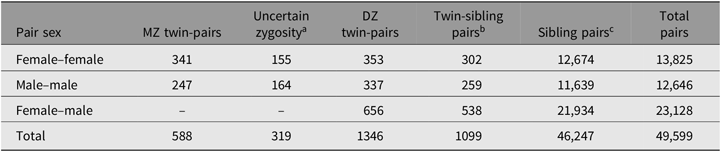
MZ = monozygotic, DZ = dizygotic.
Note: Based on 88,477 individuals from 42,723 families in 1960 Project Talent base year sample. Ns are all possible pairs: families with three individuals contribute three pairs, four individuals contribute six pairs, and so on.
a Includes Possible and Unknown categories (see Table 3).
b Twin-sibling pairs include families with two sets of twins.
c Sibling pairs are nontwins.
Using the GIFTS Model to Isolate Environmental Effects
To our knowledge, the PTTS design is unique among the existing twin studies in its inclusion of a large number of siblings from nontwin families and the level of information from and about schools. Using this design, variation in a measured trait can be partitioned into five components: additive genetic (G), individual-specific environment and error (I), environments shared by siblings within a family (F), environmental effects specific to twin-pairs (T) and environmental effects due to sharing the same school (or other neighborhood/community factors, S). The model can be further expanded to include sex-specific effects of each component.
Unrelated individuals attending the same schools can be compared with twins and their siblings to estimate extrafamilial environmental effects that contribute to similarity of the twins. This is an important issue, as what is often referred to as ‘family environment’ in a standard twin design actually reflects all environmental sources of resemblance between siblings, including schools, neighborhoods, shared peers, and between-family effects arising from social class, religion, ethnicity and other macrolevel influences.
Including schoolmates increases the power to detect school-level effects separately from family effects, and it adjusts for potential selection bias associated with the family sample. The school-level data are also useful for identifying to what degree lower similarity of nontwin siblings compared to twins is due to the effects of age or offspring spacing.
Because families are nested within schools, the F and S components are not fully distinct. They are latent variables, estimated based on design effects, and do not permit attributions to specific causal processes. However, partitioning variation into these sources provides evidence that can rule out some mechanisms. The 1960 PT assessment includes many school-level measures that can be used to better distinguish these sources of variation.
Other standard twin model assumptions apply to the model, including additivity and independence of the different sources of variance, negligible assortative mating and equal environments of MZ and DZ twin-pairs. The validity of these assumptions can be evaluated using measured indices of parental characteristics, participants’ reports of their neighborhood, school variables on educational quality, and census and principal measures of community characteristics, population density and geographical region.
GIFTS Model Applied to 1960 Vocabulary Scores
We selected vocabulary (Vocab) from the 1960 PT cognitive scales to illustrate the GIFTS (genetics, individual, family, twin, and school) model. Knowledge of word meanings is acquired through reading, social interaction and formal teaching, so it seemed likely to be influenced by genetic as well as community-level, family-level and individual-specific environmental factors. Initial estimates from twin correlations supported this and also indicated a small sex difference in scores.
Sample
The analyses reported here draw from three groups of individuals: twins, siblings of twins and other full siblings attending the same schools as the twins and siblings. Overall, 5.1% of individuals were missing Vocab or had invalid cognitive data (based on the PT credibility index, R101, Wise et al., Reference Wise, McLaughlin and Steel1979). Individuals with valid Vocab scores were included regardless of the data status of their siblings. For simplicity, we excluded relatives other than twins and full siblings (N < 50) as well as twins with unknown zygosity, and siblings of these twins. The analyses are based on 3744 twins, 483 siblings of twins and 76,128 siblings from other families.
Measures
The Vocab scale (variable R172 in the PT databank, Wise et al., Reference Wise, McLaughlin and Steel1979) includes 30 items from the general information section of the Student Information Blank. The measure was intended to ‘give some indication of the relative size of the student’s general vocabulary’ (Wise et al., Reference Wise, McLaughlin and Steel1979, p. A-2). Observed scores ranged from 0 to 30.
Analysis method
Variance component models were estimated using the HPMIXED procedure in SAS (SAS Institute, 2012), a version of PROC MIXED for analyzing large datasets. The approach is an extension of that described previously for estimating genetic and environmental variance component models for twin data (McArdle, Reference McArdle2006; McArdle & Prescott, Reference McArdle and Prescott2005; Prescott, McArdle, Achorn et al., Reference Prescott, McArdle, Achorn, Kaiser and Lapham2012). The current application extends our earlier logic to include other types of relatives and multiple types of shared environments (same schools, same families, same twinship). A detailed treatment of the model specification and validating simulations is available elsewhere (Prescott et al., Reference Prescott, Walters and McArdle2019). Here, we focus on illustrating the estimation of the GIFTS model in PT data.
The analysis sample was successively broadened to illustrate the value of including the other types of relationships for estimating environmental effects. We first used twin and triplet sets to fit the standard three component model, referred to here as GIF, for additive genetics, individual and family. Next, siblings of twins were included to allow estimation of the twin component (GIFT model). The third set of analyses included the Sibs data to estimate the full GIFTS model.
Results
Vocab scores of the twins (M = 16.5, SD = 5.7) and sibs of twins (M = 16.7, SD = 5.8) are somewhat lower in average and less variable than in the Sibs group (M = 17.3, SD = 5.9). Resemblance for Vocab scores was calculated for five groups varying in genetic and environmental relatedness using SAS HPMIXED. After adjusting the scores for sex and age, intraclass correlations were MZ twins r = .82, DZ twins r = .59, twin-sibling r = .55, other siblings r = .52 and unrelated schoolmates r = .26.
Twins only
The estimated proportions of variance based on the standard twin model using the Twin Only data are 49% genetic, 21% individual and 30% family. Additional models testing for sex differences yielded little evidence of sex-specific genetic and environmental variance (dLL < 1.0 for all models). The power to detect sex differences would be increased greatly by including same- and opposite-sex sibling pairs, but given the long run time and lack of evidence in twins, we did not run sex differences models in the larger samples.
Table 5 summarizes the model-fitting results and variance component estimates from a series of models fit to each of the three analysis sets. Relative model fit is indexed by differences in log-likelihood of nested models. Sex (coded as male = 1, female = 0) and age (coded in years and months, centered around 16 years) were included as covariates in all models.
Table 5. GIFTS model results for 1960 vocabulary scores estimated from different family groupings
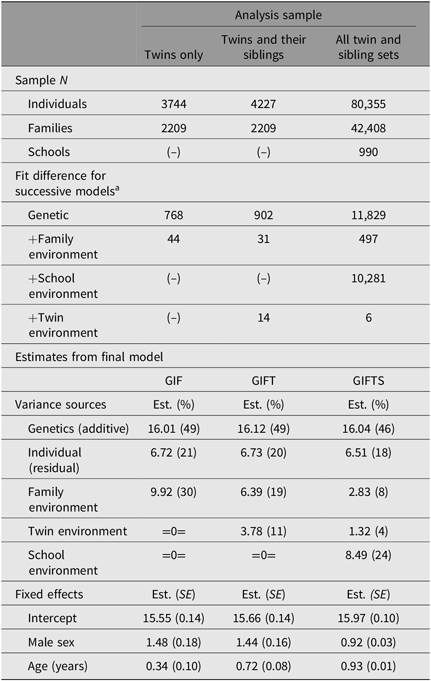
Note: (–) indicates that parameter is not identified in this subgroup; the corresponding variance estimate is fixed to zero (=0=). Residual includes individual environment and random error. All models include fixed effects of sex (coded as male = 1, female = 0) and age (centered at 16). Baseline model includes residual and fixed effects. Fits of baseline models in each sample: Twin only = 23,628; Twins + their sibs = 26,711; All sibs = 509,404, Sibs + 25% = 924,319. Percentages may not sum to 100 due to rounding.
a Difference in −2LL relative to model in previous row.
Twins and siblings of twins
Adding the 483 siblings of twins to the analysis sample allows estimation of the GIFT model, with twin-specific environment. The variance estimates for the genetic and individual sources are virtually the same as in the twin sample GIF model (49% and 20%, respectively), but now the family environment is partitioned into 19% shared by all siblings in a family and 11% specific to twin-pairs. Examining the fixed effects shows that including nontwin siblings yields larger age effects. Here, the predicted score is 0.72 points higher per year of age, twice the size of the effect obtained with twins alone (0.34 per year). This reflects the fact that age effects in twin models are confounded with between-family effects, whereas in twin/sib data, age is both a between- and within-family variable.
All siblings
Using the dataset of twins and all siblings (N = 80,355) allows estimation of the full GIFTS model. Now, instead of the family component estimated as 30% for vocabulary knowledge, the largest component is the school effect of 24%, with another 8% family and 4% twin-pair-specific. This large school effect indicates that vocabulary knowledge, at least by adolescence, is not coming directly from parents or the home environment, but originates from a larger scale process — such as the neighborhood or school they choose.
Figure 1 shows the variance component estimates in raw units based on each of the three analysis samples. As noted previously, the score variance among the Sibs sample is somewhat larger than that in the twin families — reflecting the greater variation in the full sample — which includes small parochial and other schools that did not have twin-pairs. The raw estimates for genetic and individual variance are the same as estimated for the Twin sample, but the larger total variance means the percentages are slightly smaller (46% vs. 49% and 18% vs. 20%).
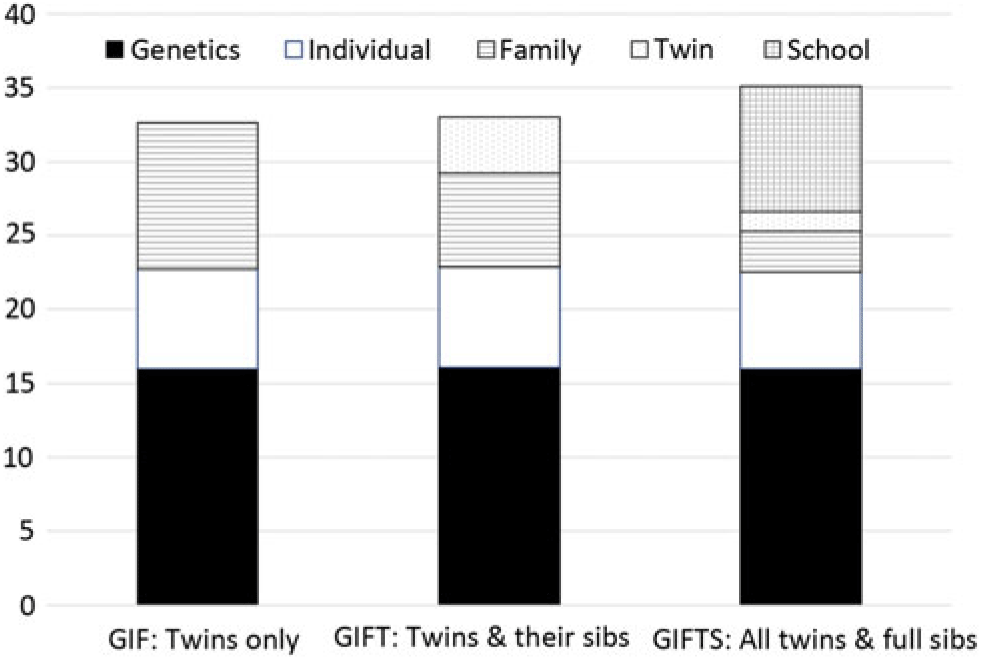
Fig. 1. GIFTS model estimates for sources of variation in 1960 vocabulary scores based on twins, siblings and schoolmates in Project Talent.
These results also inform the interpretation of the twin-specific effect obtained previously. The estimate of 11% obtained from the twin/sibling GIFT model might tempt one to speculate about intrauterine effects (e.g., Bütikofer et al., Reference Bütikofer, Figlio, Karbownik, Kuzawa and Salvanes2019). Its reduction to 4% after accounting for school effects, however, suggests that vocabulary scores are influenced by grade-specific curriculum and other learning experiences shared within twin-pairs but not shared with their siblings.
Research with the PTTS Study
The wealth of data available from and about PT twins and siblings can address a wide variety of questions on human development and aging. Research conducted with the 2014 PTTS data includes analyses of family SES effects on educational attainment (Arpawong, Zavala et al., Reference Arpawong, Zavala, Gatz, Gruenewald and Prescott2018) and later-life health (Gruenewald et al., Reference Gruenewald, Robinette and Arpawong2015; Prescott, Arpawong et al., Reference Prescott, Arpawong and Gruenewald2015), adolescent antecedents of later-life cognitive engagement (Arpawong, Gruenewald et al., Reference Arpawong, Gruenewald and Prescott2018), and genetic and environmental effects on educational attainment (Arpawong et al., Reference Arpawong, Walters, Gatz, Gruenewald, McArdle, Lapham and Prescott2017), occupational complexity (Zavala et al., Reference Zavala, Arpawong, Gruenewald and Prescott2018) and subjective aging (Zavala et al., Reference Zavala, Arpawong and Prescott2019).
We have used data from 1960 to evaluate alternative factor structures of cognitive abilities (McArdle, Reference McArdle2011; Prescott et al., Reference Prescott, McArdle, Lapham and Plotts2011), develop the family/classmate model (Prescott, McArdle, Achorn et al., Reference Prescott, McArdle, Achorn, Kaiser and Lapham2012), test the basis for sex differences in male-advantaged aspects of cognition (Prescott, McArdle, Berenbaum et al., Reference Prescott, McArdle, Berenbaum and Lapham2012) and estimate interactions of family SES with heritability of cognition (Prescott et al. Reference Prescott, McArdle, Achorn, Kaiser and Lapham2014). Methodologically focused work includes using family data to improve participant tracking (Achorn et al., Reference Achorn, Prescott, Battle, Kaiser, Lapham and Rebok2015), data mining approaches for identifying predictors of nonresponse (Bautista et al., Reference Bautista, McArdle, Achorn, Lapham and Prescott2015), validation of zygosity assignment (Prescott, Achorn et al., Reference Prescott, Achorn, Bautista, Cortez, McArdle and Lapham2015) and evaluating adaptive versions of several cognitive measures used in 1960 for use in new data collections (Prescott et al., Reference Prescott, Kadlec, Walters and McArdle2016).
Much of this research was presented at conferences as work in progress due to incomplete zygosity assignments. Zygosity assignment for twin-pairs in PTTS was completed in 2019, enabling biometric analysis of the 2014 and earlier twin and sibling data.
Future Directions
In September 2016, we received funding from the U.S. National Institutes of Health (NIH) to conduct a further follow-up of the PTTS sample, along with approximately 15,000 other PT participants who had not been contacted since the 1970s. About 10,000 are nontwin siblings, and another 5000 attended the same schools as the twins and siblings. There is an oversample of racial and ethnic minority participants as well as students from families with low SES in 1960. These groups comprise the Project Talent Aging Study (PTAS).
The overall goal of PTAS is to identify earlier life antecedents of later-life cognitive decline and dementia. Data collection includes a mailed survey booklet covering demographics, current health and activities, a brief telephone cognitive assessment and a more detailed web-based assessment with health history, family background, health behaviors, and self-administered cognitive measures, including several visuo-spatial and reasoning measures originally administered in PT 1960 and administered in adaptive format (Prescott et al., Reference Prescott, Kadlec, Walters and McArdle2016). Individuals unable to access the web were sent a tablet computer containing the same content. Data collection was completed in May 2019 and data processing is underway.
PTTS established the twin and sibling sample and assigned zygosity. PTAS adds a large number of outcome variables. Several administrative linkages of PT participants are in progress, including matching to health outcomes through MedRIC (www.medric.info) and to the U.S. National Death Index (www.cdc.gov/nchs/ndi/index.htm) for mortality and cause of death (Chapman et al., Reference Chapman, Huang, Horner, Peters, Sempeles, Roberts and Lapham2019).
Together, these PT follow-up data collections create a resource that is distinguished from other aging cohorts by the wealth of variables available from adolescence, including multiple dimensions of cognitive abilities, the genetically informative design, and the ability to distinguish among different levels of environmental influence. Drawing from the population-representative 1960 sample allows sample representativeness and selection effects to be evaluated. In addition to its focus on cognitive outcomes, PTAS includes measures of health and wellbeing that can address many other questions about early-life antecedents of later-life outcomes.
Throughout its 60-year history, PT has contributed to a broad array of research on adult development. Our selection of measures has been guided by the goal of harmonizing with other U.S. aging cohorts and other twin studies of aging (e.g., Finkel, Reference Finkel2018; Pedersen et al., Reference Pedersen, Gatz, Finch, Finkel, Butler, Dahl Aslan and Whitfield2019). We have joined with AIR in continuing this tradition by archiving more recent new data collections. PTTS 2014 and earlier datasets are available from AIR to qualified researchers (see Acknowledgments).We welcome inquiries from researchers interested in collaborating on analyses of the PT twin and sibling data.
Supplementary material
To view supplementary material for this article, please visit https://doi.org/10.1017/thg.2019.117
Data
Access to the 1960 PT data is available through Inter-university Consortium for Political and Social Research at https://www.icpsr.umich.edu/icpsrweb/NACDA/studies/33341. Data, documentation and copies of measures for the 1960 PT, 1-, 5- and 11-year follow-up studies, and 2014 PTTS data collection are available from AIR through a restricted data use agreement. For more information, contact AIR at ProjectTalentSTudy@air.org or 1-866-770-6077.
Acknowledgments
The authors are grateful to the PT participants, and the many collaborators past and present who contributed their effort and expertise to this project. Special thanks for their contributions to PTTS are due to Jonathan King, Jack McArdle, Gwen Fisher, Sheri Berenbaum, Irv Gottesman, Kelly Kadlec, Jennifer Harris, Randy Bautista and George Rebok. Finally, the authors are grateful to the AIR for supplementing NIH funding and to the AIR staff without whom this study would not have been possible: Susan J. Lapham, Kelly Peters, Deanna Achorn, Ashley Kaiser, Danielle Battle, and Lindsey Mitchell.
Financial support
PTTS development was supported by NIH grant R01 AG043656 and research development funds from the AIR. The PTAS was supported by NIH grants R01-AG056163 (Principal Investigators: C. Prescott & S. Lapham) and RF1-AG056164 (Principal Investigators: J. Manly & S. Lapham).
Conflict of interest
None.
Ethical standards
The authors assert that all procedures contributing to this work comply with the ethical standards of the relevant national and institutional committees on human experimentation and with the Helsinki Declaration of 1975, as revised in 2008.









