


1. Introduction
The common view on codeswitching – the use of two languages within the same conversation – has in previous decades evolved from something that “the ideal bilingual” should not fall prey to, at least not without a good external reason, “and certainly not within a single sentence” (Weinreich, Reference Weinreich1953, p.73), via “a communicative act, possibly a somewhat peculiar one but a communicative act nonetheless” (Luckmann, Reference Luckmann1983, p.97), to a phenomenon that “exemplifies the wonderful flexibility and creativity of language use [and] provides a unique testing ground for studying the cognitive mechanisms of bilingual language production” (Fricke & Kootstra, Reference Fricke and Kootstra2016, p.183). The present study employs this unique testing ground to investigate how the production of cognates affects subsequent language choice. It investigates so-called triggered codeswitching – codeswitching facilitated by the occurrence of cognates (words which are similar in form and meaning in two languages) – within the context of conversational dynamics.
Over the previous century, codeswitching has been studied from increasingly diverse angles, including grammatical, sociolinguistic, psycholinguistic, and neuroscientific perspectives. One thing that these diverse approaches have clearly shown is that codeswitching is regulated at multiple levels of processing. The grammatical study of codeswitching started with the early diary studies of Ronjat (Reference Ronjat1913) and Leopold (Reference Leopold1939–1949). This line of research has shown that grammatical considerations affect the shape that codeswitches take. Within this field, e.g., the linear grammatical approach has proposed that codeswitching must adhere to constraints based on syntactic equivalence between languages (Lehtinen, Reference Lehtinen1966; Sankoff & Poplack, Reference Sankoff and Poplack1981), the Universal Grammar approach has searched for universal government constraints on codeswitching (Di Sciullo, Muysken & Singh, Reference Di Sciullo, Muysken and Singh1986; Halmari, Reference Halmari1997; Muysken, Reference Muysken2000), while the Matrix Language approach has proposed different roles for the languages involved in codeswitching, with the Matrix Language providing the morpho-syntactic frame and more diverse morpho-syntactic elements than the Embedded Language (Myers-Scotton, Reference Myers-Scotton1997; Myers-Scotton & Jake, Reference Myers-Scotton and Jake2000). The sociolinguistic study of codeswitching, starting with the seminal work of Fishman (Reference Fishman1967) (cf. Blom & Gumperz, Reference Blom, Gumperz, Gumperz and Hymes1972; Gardner-Chloros, Reference Gardner-Chloros2009), has shown that social processes, including the construction of interactional meaning (Auer, Reference Auer1984, Reference Auer1998) and the indexing and negotiation of social group membership (Myers-Scotton, Reference Myers-Scotton1993a, Reference Myers-Scotton1993b), structure codeswitching.
In all those approaches, the level of analysis is the conversation or the sentence. The psycholinguistic and neurolinguistic disciplines, to the contrary, have predominantly focused on language switching in experimental tasks requiring single-word responses (e.g., Costa & Santesteban, Reference Costa and Santesteban2004; Hernandez, Reference Hernandez2009; Kleinman & Gollan, Reference Kleinman and Gollan2016), as opposed to codeswitching within or between sentences (so-called intra-sentential, and inter- or extra-sentential codeswitches, see e.g., Appel & Muysken, Reference Appel and Muysken1987; Poplack, Reference Poplack1980) produced in a conversational context. While there is no doubt that studies on language switching have yielded valuable insights in bilingual language production, it is important to note that there is necessarily a discrepancy between the requirements of single-word experiments and conversational language use. Differences are abundant, for example with respect to the process of sentence integration, speakers’ beliefs about what kind of speech output is expected, and task requirements and strategies. For example, Kleinman and Gollan (Reference Kleinman and Gollan2016) showed that whereas language switching studies generally show language switching costs (e.g., Broersma, Carter & Acheson, Reference Broersma, Carter and Acheson2016; Christoffels, Firk & Schiller, Reference Christoffels, Firk and Schiller2007; Costa & Santesteban, Reference Costa and Santesteban2004; Jackson, Swainson, Cunnington & Jackson, Reference Jackson, Swainson, Cunnington and Jackson2001; Meuter & Allport, Reference Meuter and Allport1999; Verhoef, Roelofs & Chwilla, Reference Verhoef, Roelofs and Chwilla2009, Reference Verhoef, Roelofs and Chwilla2010), which has been taken to reflect top-down language control, the occurrence of such costs is in fact task-driven. When participants based their decision to switch on the accessibility of the target word in both languages, rather than on other reasons such as participants’ prior decisions to switch or external incentives (including task cues), switching did not incur any costs (Kleinman & Gollan, Reference Kleinman and Gollan2016). This raises the question to what extent language control, which is common in language switching experiments, plays a role in codeswitching in everyday language use outside the laboratory.
Similarly, our own work on the relation between cognates and codeswitching on the one hand, and language switching on the other hand, has shown disparate results. In conversational contexts, the occurrence of cognates was found to facilitate codeswitching, suggesting that the production of cognates increases the activation of the non-selected language (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006; Broersma, Isurin, Bultena & De Bot, Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009). In language switching experiments, in contrast, inhibition was found during and after the production of cognatesFootnote 1, suggesting that the availability of two highly related response alternatives (i.e., the cognates’ representations in two languages) required increased cognitive control (Broersma et al., Reference Broersma, Carter and Acheson2016)Footnote 2. Structural priming studies have shown that cognates did lead to increased priming of syntactic structures between languages (Bernolet, Hartsuiker & Pickering, Reference Bernolet, Hartsuiker and Pickering2012), and of the position of codeswitches (Kootstra, Van Hell & Dijkstra, Reference Kootstra, Van Hell and Dijkstra2012), suggesting again that the role of cognates depends heavily on the nature of the experimental task.
According to Green and Wei's control process model of codeswitching (Reference Green and Wei2014), language task schemas that govern cognitive control processes (Green, Reference Green1986, Reference Green1998) cooperate in a codeswitching context, whereas in other contexts, presumably including most experiments, they compete. The specifics of the experimental context determine how they compete; in a single language context, control processes suppress output from the non-target language, whereas in a dual language context, language task schemas alternate.
The role of cognitive control is thus likely to be fundamentally different in experimentally-induced language switching than in spontaneous codeswitching in everyday language use. The present study therefore investigates codeswitching from a psycholinguistic perspective but with special attention to conversational dynamics. It assesses whether, in natural conversation, cognates can facilitate codeswitching by enhancing the activation of the non-selected language, as previously suggested (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009).
1.1. Triggered codeswitching
Previous studies have shown that cognates can play a role in the occurrence of codeswitching. The first observations about a relation between the two were made by Clyne, studying the language use of immigrant populations in Australia (Clyne, Reference Clyne1967, Reference Clyne1972, Reference Clyne1977, Reference Clyne1980, Reference Clyne2003). Clyne observed that cognates seemed to co-occur with codeswitches relatively often, in spontaneous speech of multilingual populations as diverse as German–, Croatian–, Dutch–, Vietnamese–, Italian–, and Spanish–English bilinguals, and Hungarian–German–English and Dutch–German–English trilinguals (Clyne, Reference Clyne2003). Statistical evidence for triggered codeswitching was first provided by Broersma and De Bot (Reference Broersma and De Bot2006), with a corpus-study of Moroccan Arabic–Dutch bilinguals’ conversational speech. Codeswitches occurred significantly more often directly after a cognate than expected by chance. This finding was replicated with Dutch–English (Broersma, Reference Broersma2009; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009) and Russian–English conversational speech (Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009). The diversity of these language combinations, with Moroccan Arabic–Dutch and Russian–English being unrelated languages with a small number of cognates, and Dutch–English both being West Germanic languages sharing many cognates, suggests that triggered codeswitching might be a common phenomenon in multilingual natural speech.
Broersma and De Bot (Reference Broersma and De Bot2006) propose that the selection of a cognate from the mental lexicon might lead to a shift in the activation of the two languages that the cognate is connected to, boosting the activation of the least active language (i.e., the ‘non-selected’ language, Green, Reference Green1986). This is compatible with a common view, captured in the Subsystems Hypothesis (Paradis, Reference Paradis1987, Reference Paradis2004), that each one of a bilingual's languages forms a subset within a general (i.e., shared) system (cf. Green & Wei, Reference Green and Wei2014). Items are connected more strongly within than between languages, such that subsystems can function as separate unitsFootnote 3. For example, at the level of the mental lexicon, when a word is activated, this adds to the activation of all the words in the same language (Paradis, Reference Paradis, Coppens, Lebrun and Basso1998, Reference Paradis2004). This would make it possible for the selection of a cognate to affect the level of activation of all the words of the non-selected language at once.
The general consensus among psycholinguists is that, when bilinguals speak one language, lexical representations from both languages are activated (e.g., Abutalebi & Green, Reference Abutalebi and Green2007; Branzi, Martin, Abutalebi & Costa, Reference Branzi, Martin, Abutalebi and Costa2014; Costa & Caramazza, Reference Costa and Caramazza1999; Costa & Santesteban, Reference Costa and Santesteban2004, Reference Costa and Santesteban2006; De Bot, Reference De Bot1992; Finkbeiner, Gollan & Caramazza, Reference Finkbeiner, Gollan and Caramazza2006; Green, Reference Green1998; Green & Wei, Reference Green and Wei2014; Kroll, Bobb, Misra & Guo, Reference Kroll, Bobb, Misra and Guo2008; Kroll, Bobb & Wodniecka, Reference Kroll, Bobb and Wodniecka2006). When a speaker intends to produce a cognate, this thus entails the activation of the cognate's lemmas in both languages. As activation spreads from the cognate's two lemmas to the cognate's two word form representations, the overlapping parts of the word forms might receive activation from both lemmas; the similarity of the two word forms would thus enhance the activation of the cognate's two word form representations. Further, feedback loops from the phonological representations to the lemmas could also increase the activation of the cognate's two lemmas. It has been proposed that lemmas of words that share aspects of their form receive additional activation through such feedback loops (Bernolet et al., Reference Bernolet, Hartsuiker and Pickering2012; Declerck & Philipp, Reference Declerck and Philipp2015). Thus, the cognate's two lemmas would receive further activation from not one but two word forms, the activation of each of which was already enhanced. An additional or alternative explanation might be that cognates are more tightly connected at the conceptual level than non-cognates (De Groot & Nas, Reference De Groot and Nas1991; Van Hell & De Groot, Reference Van Hell and De Groot1998; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002), such that when one lemma of a cognate is activated, this activation might spread to the other lemma via the conceptual level, enhancing the activation of the language network of that lemma, thereby facilitating codeswitching (Broersma & De Bot, Reference Broersma and De Bot2006).
Similarly, overlap in meaning and form is generally held responsible for the processing advantages that have been found for cognates over non-cognates in a variety of experimental tasks, which include: faster picture naming for cognates than for non-cognates (Christoffels, De Groot & Kroll, Reference Christoffels, De Groot and Kroll2006; Christoffels et al., Reference Christoffels, Firk and Schiller2007; Costa, Caramazza & Sebastián-Gallés, Reference Costa, Caramazza and Sebastián-Gallés2000; Hoshino & Kroll, Reference Hoshino and Kroll2008; Verhoef et al., Reference Verhoef, Roelofs and Chwilla2009) and fewer tip-of-the-tongue experiences (Gollan & Acenas, Reference Gollan and Acenas2004), faster word recognition in visual lexical decision in L1 (Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002) and L2 (Dijkstra, Grainger & Van Heuven, Reference Dijkstra, Grainger and Van Heuven1999; Lemhöfer & Dijkstra, Reference Lemhöfer and Dijkstra2004), stronger between-language masked associative priming (De Groot & Nas, Reference De Groot and Nas1991) and repetition priming (De Groot & Nas, Reference De Groot and Nas1991; Gollan, Forster & Frost, Reference Gollan, Forster and Frost1997), faster production of associates within and between languages (Van Hell & De Groot, Reference Van Hell and De Groot1998; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002), faster translation for cognates than for non-cognates (Christoffels et al., Reference Christoffels, De Groot and Kroll2006; Kroll & Stewart, Reference Kroll and Stewart1994), and ERPs suggesting that cognates behave as higher-frequency words (Strijkers, Costa & Thierry, Reference Strijkers, Costa and Thierry2010), with ERP components associated with effects of lexical and phonological processing respectively (Christoffels et al., Reference Christoffels, Firk and Schiller2007; Strijkers et al., Reference Strijkers, Costa and Thierry2010). Note that some studies have reported the absence of cognate facilitation (Bultena, Dijkstra & Van Hell, Reference Bultena, Dijkstra and Van Hell2015; Costa et al., Reference Costa, Caramazza and Sebastián-Gallés2000; Ivanova & Costa, Reference Ivanova and Costa2008; Strijkers et al., Reference Strijkers, Costa and Thierry2010), or even cognate inhibition (Broersma et al., Reference Broersma, Carter and Acheson2016; Filippi, Karaminis & Thomas, Reference Filippi, Karaminis and Thomas2014; Li & Gollan, Reference Li and Gollan2018).
The lexical activation of a cognate would thus lead to the particularly strong activation of the cognate's lemmas and word forms in both languages. Whereas this might not noticeably affect the level of activation of the language that was already being spoken, the activation of the other language might be substantially enhanced. Note that for a speaker who finds herself in a setting where codeswitching is appropriate, both languages are likely to be highly activatedFootnote 4. In such settings, in which the social circumstances make codeswitching desirable and both languages are readily available to the speakers, the linguistic system has been described as being in a state of ‘self-organized criticality’ (De Bot, Broersma & Isurin, Reference De Bot, Broersma, Isurin, Isurin, Winford and De Bot2009; De Bot, Lowie & Verspoor, Reference De Bot, Lowie and Verspoor2007): in analogy to critical states in physics, following the Dynamic Systems Theory (Bak, Reference Bak1996), the linguistic system is said to be attracted to a state in which small events (such as the production of a cognate) are enough to lead to large changes (such as codeswitching). Thus, the small amount of additional lexical activation resulting from the selection of a cognate increases the likelihood of a switch into the other language (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006).
According to Green and Wei's control process model of codeswitching (Reference Green and Wei2014), in a codeswitching context, language task schemas cooperate rather than compete, enabling such changes in the activation of language networks and the occurrence of triggered codeswitching (Green & Wei, Reference Green and Wei2014). Following Muysken's (Reference Myers-Scotton and Jake2000) classification of codeswitches as insertions, alternations, and congruent lexicalizations, for the former two (which were predominant in Moroccan Arabic–Dutch (triggered) codeswitching, Broersma & De Bot, Reference Broersma and De Bot2006), the control process model of codeswitching proposes a coupled control mode in which two language task schemas take turns controlling language choice. For congruent lexicalization, also known as dense codeswitching between closely related languages (such as described for Dutch–English (triggered) codeswitching, Broersma, Reference Broersma2009; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009), the model proposes an open control mode in which language task schemas do not exercise top-down control on language choice. In both modes, codeswitches can be either intended, or an opportunistic response to a change in activation as a result of, for example, the occurrence of a cognate (Green & Wei, Reference Green and Wei2014).
The effect of the selection of a cognate on the activation of a language network is proposed to gradually diminish over time (Broersma & De Bot, Reference Broersma and De Bot2006). As the exact order in which words are selected from the mental lexicon cannot be determined in spontaneous speech, Broersma and De Bot (Reference Broersma and De Bot2006) propose to assess the effect of cognates on codeswitching at the clause level, under the assumption that words that end up in the same clause have likely been selected from the mental lexicon around the same time. Following Levelt (Reference Levelt1989), they adopt the basic clause (containing maximally one main verb) as unit of measurement. Codeswitching is then operationalized as either the use of two languages within the same clause, or the consecutive use of basic clauses in different languages. Note that though this definition is reminiscent of intra- and inter-sentential codeswitching, the unit of measurement is smaller.
The present study investigates whether the patterns of triggered codeswitching in spontaneous bilingual conversations conform to this scenario.
1.2. The present study
Using a large-scale corpus of Welsh–English spontaneous conversation, this study investigates whether triggered codeswitching is indeed the result of an increase in lexical activation of the non-selected language following the activation (and, in the cases that can be observed in overt speech, the selection) of a cognate. If such a change in language activation is what underlies triggered codeswitching, this should be visible in the patterns of co-occurrence of cognates and codeswitching in bilingual conversational speech.
First, this study aims to replicate the finding that cognates can facilitate codeswitching (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009), with a different language pair and with a much larger corpus than before. It tests the predictions of the adjusted triggering theory, as first proposed by Broersma and De Bot (Reference Broersma and De Bot2006). Contrary to the original triggering hypothesis (Clyne, Reference Clyne1967, Reference Clyne1972, Reference Clyne1977, Reference Clyne1980, Reference Clyne2003), which considered codeswitching as a linear (left-to-right) phenomenon at the level of the surface structure, the adjusted triggering theory is based on psycholinguistic processes, and has a greater predictive and explanatory value than the original triggering hypothesis (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006). The adjusted triggering theory predicts – and our first hypothesis therefore is – that clauses are more often codeswitched, either clause-internally (containing words from two languages) or -externally (being in a different language than the previous clause), when they do contain a cognate than when they do not. Previous studies that provide support for the theory included data from one to six speakers (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009). The present study analyses data from as many as 100 speakers, over 50 conversations, from the Welsh–English Siarad Corpus of spontaneous bilingual speech (Deuchar, Davies, Herring, Parafita Couto & Carter, Reference Deuchar, Davies, Herring, Parafita Couto, Carter, Thomas and Mennen2014; ESRC_Centre_for_Research_on_Bilingualism, n.d.). This is the first study of this magnitude to test the triggering theory.
It has been proposed that the state of the activation of a bilingual's two languages fluctuates under the influence of the situational context. The notion of the language mode describes those states as a continuum, with the monolingual mode, where one language is much more activated than the other, on one end, and the bilingual language mode, where both languages are highly activated, on the other end (Grosjean, Reference Grosjean1998; Soares & Grosjean, Reference Soares and Grosjean1984). Codeswitching is typically associated with a bilingual language mode. We propose that a bilingual language mode might also be characterized by an increased likelihood of producing cognates, as the ultimate bilingual words. Whenever speakers have a choice between a cognate and a non-cognate alternative, a bilingual language mode might bias them towards the cognate. Our second hypothesis is therefore that the proportion of cognates that a speaker uses throughout the conversation is related to codeswitching. We propose that the production of both cognates and codeswitches is more common for speakers in a bilingual language mode, suggesting a positive global relation between cognate density and codeswitching. It is thus predicted that speakers who produce more cognates during the conversation will overall codeswitch more than speakers who produce fewer cognates – that is, even in clauses where they do not produce any cognates.
Third, lexical activation is considered to be incremental (e.g., Levelt, Roelofs & Meyer, Reference Levelt, Roelofs and Meyer1999; Pitt & Samuel, Reference Pitt and Samuel2006). Thus, if triggered codeswitching is the result of an increase in activation of the non-selected language resulting from the selection of a cognate, the production of multiple cognates should increase the likelihood of codeswitching even more. Previous studies on triggered codeswitching assessed language pairs that differ widely in cognate density. In those datasets, between 3 and 71% of all the words were cognates (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009). In all datasets, there was a significant relation between the occurrence of cognates and codeswitches. The present study for the first time investigates whether the number of cognates within a clause affects the likelihood of codeswitching. It is predicted that a larger number of cognates within a clause will lead to a higher likelihood of clause-external codeswitching. (Note that no increased likelihood of clause-internal codeswitching is predicted, because a larger number of cognates implies a smaller number of non-cognates within the clause, effectively leaving less room for clause-internal codeswitching.)
Fourth, activation in the linguistic system is expected to gradually decay over time (e.g., Foygel & Dell, Reference Foygel and Dell2000; Paradis, Reference Paradis, Coppens, Lebrun and Basso1998, Reference Paradis2004), unless interference or inhibition bring it down (e.g., Abutalebi & Green, Reference Abutalebi and Green2007; Altmann & Gray, Reference Altmann and Gray2002; Green, Reference Green1998; Green & Wei, Reference Green and Wei2014). Once the activation of a language network has been increased, its activation is thus expected to remain high for some time. It is therefore predicted that codeswitching will be facilitated for some time after the production of a cognate, such that the production of a cognate in one clause facilitates codeswitching by the same speaker not only in the same clause, but also in the next one.
Fifth, as listening and speaking involve the same mental lexicon (e.g., Cutler, Reference Cutler2012; Levelt et al., Reference Levelt, Roelofs and Meyer1999; Liberman, Cooper, Shankweiler & Studdert-Kennedy, Reference Liberman, Cooper, Shankweiler and Studdert-Kennedy1967), hearing a cognate might affect the level of activation of language subsets in a similar way as producing one. Studies on syntactic priming show that perceived speech affects produced speech, both monolingually (Konopka & Meyer, Reference Konopka and Meyer2014; Pickering & Ferreira, Reference Pickering and Ferreira2008) and cross-linguistically (Hartsuiker & Bernolet, Reference Hartsuiker and Bernolet2017; Hartsuiker, Pickering & Veltkamp, Reference Hartsuiker, Pickering and Veltkamp2004; Kootstra & Doedens, Reference Kootstra and Doedens2016; Kootstra, Van Hell & Dijkstra, Reference Kootstra, Van Hell, Dijkstra, Isurin, Winford and De Bot2009; Loebell & Bock, Reference Loebell and Bock2003). The tendency to codeswitch (Fricke & Kootstra, Reference Fricke and Kootstra2016) and the word order in codeswitched utterances (Kootstra, Van Hell & Dijkstra, Reference Kootstra, Van Hell and Dijkstra2010) are also subject to between-speaker priming. Such inter-speaker priming tends to be weaker, however, than self-priming: Fricke and Kootstra (Reference Fricke and Kootstra2016) showed that speakers were more likely to codeswitch if the preceding utterance contained a codeswitch, when there was no speaker change in between; and also, but less so, when there was a speaker change. Similarly, Gries (Reference Gries2005) showed stronger self-priming than inter-speaker priming in monolingual speech. With respect to triggered codeswitching, in the Russian–English corpus, Broersma et al. (Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009) found no evidence that cognates uttered by one speaker facilitated codeswitching by another speaker. The present study, with a much larger corpus, re-investigates inter-speaker triggered codeswitching. It predicts that cognates produced by one interlocutor will not facilitate codeswitching by the other interlocutor to the same extent as self-produced cognates do, if at all.
Five hypotheses are thus investigated concerning: 1) the occurrence of triggered codeswitching, 2) effects of cognate density, 3) incremental build-up of triggered codeswitching, 4) the scope of triggered codeswitching, and 5) inter-speaker dynamics of triggered codeswitching.
2. Method
2.1. The Siarad Corpus
The Siarad Corpus (ESRC_Centre_for_Research_on_Bilingualism, n.d.) is a large Welsh–English corpus, consisting of forty hours of spontaneous speech by fluent bilinguals in informal conversations between friends or family members. It contains 447,507 words from 151 speakers across 69 conversations of approximately 30 minutes each (Deuchar et al., Reference Deuchar, Davies, Herring, Parafita Couto, Carter, Thomas and Mennen2014). CHAT transcriptions (MacWhinney, Reference MacWhinney2000) are provided, and language tags indicating Welsh, English and cognate words.
Across the Siarad Corpus, 81% of the clauses (with a finite verb) are monolingual and 19% are mixed. Welsh is used more than English in all conversations, providing between 51-93% (average: 84%) of the words, and forming the base language in 95% of the monolingual and 100% of the mixed-language clauses (Carter, Deuchar, Davies & Parafita Couto, Reference Carter, Deuchar, Davies and Parafita Couto2011). Hence, the large majority of codeswitches consist of English insertions into clauses where Welsh is the base language. 71% are single-word and 29% are multi-word insertions, most typically nouns and adjectives and sometimes adverbs (Deuchar, Donnelly & Piercy, Reference Deuchar, Donnelly, Piercy, Durham and Morris2016). The nature of the codeswitches in the Siarad corpus is considered to be representative of the community's language use (Davies, Reference Davies2010). The following examples (from the ‘Davies1’ conversation) both have Welsh as the base language and contain English insertions (underlined); further, (1) contains one cognate and (2) four cognates (in bold).
(1) mam yn mynd (y)n stressed.
mum getting stressed
(2) a o'n i fel shower quick supper straight i practice.
and I was like quick shower, supper, straight to practice
For the present study, as the small proportion of clauses with English as the base language precludes a reliable comparison of Welsh and English as the base language, we chose to collapse over the two languages in all analyses. To facilitate statistical analyses, only conversations between two people were selected, yielding 50 conversations from a total of 100 speakers. Transcription tiers were glossed with a newly developed automated method called the Bangor Autoglosser (Carter, Broersma & Donnelly, Reference Carter, Broersma, Donnelly, De la Fuente, Valenzuela and Sanz2016; Carter, Broersma, Donnelly & Konopka, Reference Carter, Broersma, Donnelly and Konopka2017; Donnelly & Deuchar, Reference Donnelly and Deuchar2011). Complex clauses were split into simple clauses with the newly developed Bangor Automated Clause-Splitter (Carter et al., Reference Carter, Broersma, Donnelly, De la Fuente, Valenzuela and Sanz2016; Carter et al., Reference Carter, Broersma, Donnelly and Konopka2017), yielding 64,521 clauses. For each clause, the base language was determined as the language of the finite verb. Note that the unit of measurement is thus somewhat different from earlier studies of triggered codeswitching that used basic rather than simple clauses (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009). The Siarad corpus provides this information to enable application of the Matrix Language Frame Model (Myers-Scotton, Reference Myers-Scotton1997; Myers-Scotton & Jake, Reference Myers-Scotton and Jake2000). Whereas that model does not play a role in the present study, we nevertheless chose to adopt simple clauses as the unit of measurement, and finite verbs as indicators of the base language, because of the availability of this information in the corpus.
2.2. Variables
The data required for the analyses were obtained as follows. To assess clause-internal codeswitching, only clauses containing two or more words were included in the analyses (removing the one-word clauses: 8,062/64,521 = 12%). For each of the remaining 56,459 clauses, it was assessed whether it contained a clause-internal codeswitch. Clauses were considered to contain an internal codeswitch when they contained both uniquely Welsh and uniquely English words (disregarding any words with ambiguous language identity, i.e., cognates).
For each clause (including the single-word clauses), it was assessed whether it contained a clause-external codeswitch. Clause-external codeswitching was assessed with a backward method and a forward method. Clauses were considered to contain an external codeswitch when the language of the finite verb differed from that of the previous clause (backward method) or of the following clause (forward method). (Note that a single clause could thus contain both an internal and an external codeswitch.) Analyses (and figures) only include clauses that were preceded by a clause that did not contain any cognates for the backward method, and that were followed by a clause that did not contain any cognates for the forward method, to avoid uncontrolled cognate effects from those adjacent clauses. For the backward method, the first clause of each conversation served as the reference and was excluded from the analysis, whereas for the forward method, the last clause of each conversation served as the reference and was excluded from analysis.
For each word, it was assessed whether it was a cognate or not. Words were considered as cognates when they were marked as such in the Siarad corpus (based on whether or not they occur in specified published dictionaries, Deuchar et al., Reference Deuchar, Davies, Herring, Parafita Couto, Carter, Thomas and Mennen2014), or when they occurred on a list of Welsh verbs borrowed from English and assimilated into Welsh to a greater or lesser extent (Stammers & Deuchar, Reference Stammers and Deuchar2012), or on a list of other cognates manually compiled for this studyFootnote 5.
Two variables addressed the characteristics of the cognates. Presence of Cognates was a binary variable (yes/no) indicating whether a clause contained any cognates or not. Number of Cognates provided the total number of cognates in the clause if larger than zero.
For each clause, the control variable Clause Length indicated the total number of words in the clause. Speaker Change indicated whether or not a clause was the last clause in a speech turn and thus, when assessing clause-external codeswitching with the forward method, whether two clauses were produced by one single or two different speakers.
For each speaker, the Proportion of Cognates per Speaker provided the proportion of cognates (i.e., the total number of cognates divided by the total number of words) over the entire conversation for the individual speaker.
2.3. Statistical analyses
The data were analyzed in R (version 3.3.2) (R Development Core Team, 2009) with logit mixed models (Jaeger, Reference Jaeger2008) (lme4 version 1.1-13). These analyses allow for simultaneous modeling of effects at the level of conversations and individual speakers (in this dataset, speakers were nested within conversations), and allow for testing of variability associated with each predictor at the level of both conversations and speakers with the inclusion of random slopes (e.g., the effect of a predictor may differ across speakers, and random slopes for this predictor capture this variability). They are also particularly well suited for analysis of datasets with unequal numbers of observations at each level of the predictor of interest. Overall, these models provide a more sensitive test of the influence of each predictor on the target behavior than analyses of variance, particularly for binary response variables, or other parametric and non-parametric tests (i.e., tests that require aggregation of data at the level of either “participants” or “items”).
All continuous predictors were mean-centered and categorical predictors were coded with Helmert contrast codes: e.g., for binary predictors, one level of the predictor was assigned a -.5 weight and the other a .5 weight (the weights were then adjusted for different numbers of observations within each level).
The tables list beta coefficients (in log-odds space) and associated z values. The intercepts in all models show the base probability of speakers producing (clause-internal or -external) codeswitches. Coefficients for all fixed effects show the log odds of each predictor influencing production of codeswitches; for clarity, coefficients are transformed from log odds to odds ratios in the text below. Odds ratios are easier to interpret than log odds, and indicate whether codeswitching was more likely to occur as a function of a given predictor or not. For example, in Table 1a, the intercept of −2.31, which equals an odds ratio of .10, shows that the odds of producing clauses with clause-internal codeswitches are only .10 higher than clauses without clause-internal codeswitches; the coefficient for the predictor Presence of Cognates of .50, which equals an odds ratio of 1.65, shows that the odds of producing a clause-external codeswitch are 1.65 times higher if a cognate is present.
Table 1. Two models predicting the production of a) clause-internal codeswitches, and b) clause-external codeswitches in the same clause (backward method). In all tables: (s) refers to the inclusion of random slopes; coefficients are given in log odds, but are reported in the text as odds ratios (for main effects); * = p < .05 (including smaller p values), † = p < .10.

For all analyses, we first fit full models, including all three-way interactions among the predictors and the maximal random structure. Models were simplified by removing random slopes iteratively in cases of non-convergence (Barr, Levy, Scheepers & Tily, Reference Barr, Levy, Scheepers and Tily2013).
3. Results
In order to test the five hypotheses, the analyses examined the effect of cognates on the occurrence of either clause-internal or clause-external codeswitches. Each model also included the Proportion of Cognates per Speaker (except the model on the Number of Cognates, see 3.3).
3.1. The occurrence of triggered codeswitching
The first hypothesis was that clauses that contained one or more cognates were more often codeswitched, either clause-internally or clause-externally, than clauses that did not contain a cognate. Figure 1a and 1b shows that, as predicted, there were more clause-internal and clause-external codeswitches in clauses containing one or more cognates than in clauses without any cognates.
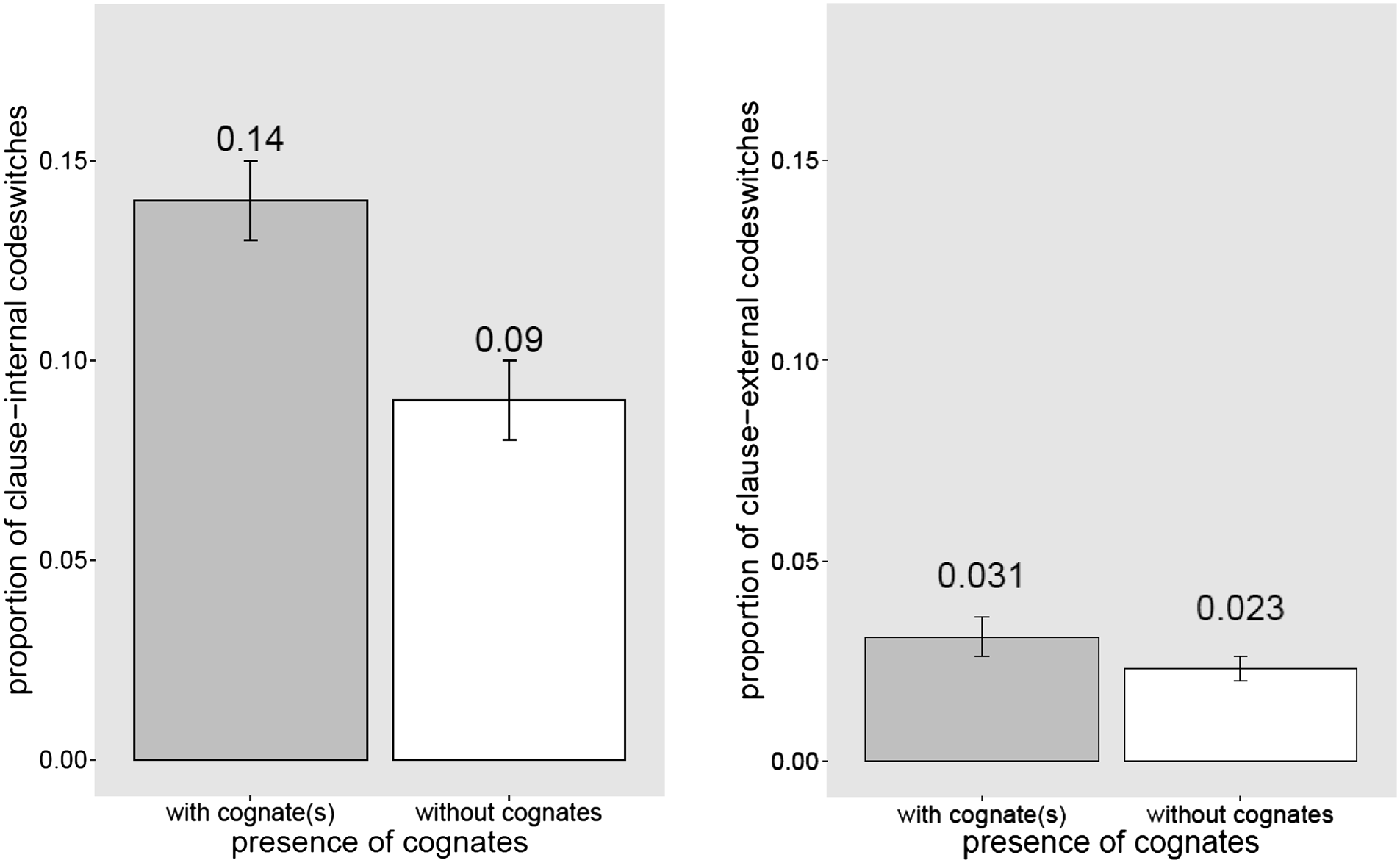
Fig. 1. Proportion of codeswitches in clauses with and without cognate(s). (a): clause-internal codeswitches; (b) clause-external codeswitches in the same clause (backward method). All figures show by-participant means; error bars are standard errors.
Two models evaluated the effect of the Presence of Cognates in the clause on the occurrence of codeswitching in the same clause, the first for clause-internal codeswitching (Table 1a) and the second for clause-external codeswitching (Table 1b). Clause-external codeswitching was assessed in a backward manner (comparing the language of each clause with that of the previous clause). Each model also included the variable Proportion of Cognates per Speaker, which will be discussed in 3.2.
The models showed a reliable effect of the Presence of Cognates on clause-internal codeswitching and on clause-external codeswitching (Table 1); the odds of speakers producing a clause-internal codeswitch in clauses containing cognates were 1.65 times higher than in the absence of a cognate, and the odds of speakers producing a clause-external codeswitch were 1.34 times higher in clauses containing cognates. Note that the effect of the Presence of Cognates on the same speaker's codeswitching is replicated in all the following analyses.
3.2. Effects of cognate density
The second hypothesis was that speakers who produced more cognates during the conversation overall would codeswitch more than speakers who produced fewer cognates (even in clauses where they did not produce cognates). Indeed, as Figure 2 shows, speakers who produced more cognates during the conversation had a higher likelihood of codeswitching, both for clause-internal codeswitches (Figure 2a) and for clause-external codeswitches (determined in a backward manner) (Figure 2b).

Fig. 2. Proportion of codeswitches as a function of Proportion of Cognates per Speaker, with fitted regression lines and the 95% confidence region. (a) clause-internal codeswitches; (b) clause-external codeswitches in the same clause (backward method).
The two models described above showed reliable effects of the Proportion of Cognates per Speaker on clause-internal and clause-external codeswitching (Table 1a and 1b), confirming that the likelihood of producing codeswitches was positively related to the Proportion of Cognates per Speaker. Note that the effect of Proportion of Cognates per Speaker on codeswitching is replicated in all the following analyses.
The proportions of cognates throughout the conversation are strongly correlated for the speaker dyads (r = .63). This supports the notion that the use of cognates might reflect the language mode a speaker is in. As conversational partners are likely to be in a similar language mode, they might thus align their use of cognates.
3.3. Incremental build-up of triggered codeswitching
The third hypothesis was that a larger number of cognates within a clause would lead to a higher likelihood of clause-external codeswitching. In line with this prediction, as Figure 3 shows, among all the clauses that contained one or more cognates, there were more clause-external codeswitches in clauses that contained more cognates. The number of clauses with more than three cognates was fairly small, such that the relatively low proportion of codeswitching in those clauses must be interpreted with caution. (Here, clauses preceded by clauses containing cognates were not excluded from the analysis, as the effect of cognates within the same clause was expected to be stronger than that of cognates in the previous clause.)

Fig. 3. Proportion of codeswitches as a function of the Number of Cognates in the clause if larger than 0: clause-external codeswitches in the same clause (backward method). The number of cases over which proportions were calculated is included in parentheses.
An analysis was performed using the Number of Cognates in the clause if larger than zero as a continuous predictor, examining its effect on clause-external codeswitching determined in the backward manner. Clause Length was included to assess whether any effect on codeswitching followed from the absolute number of cognates, or rather from the number of cognates relative to the total number of words in the clause. Due to the inclusion of Clause Length, Proportion of Cognates per Speaker could not be included in the model (as models with both predictors failed to converge).
As Table 2 shows, there was a significant effect of the Number of Cognates, with more clause-external codeswitches in clauses that contained more cognates; the odds of speakers producing a codeswitch increased by 1.26 with each additional cognate. Thus, as predicted, there was a positive relation between the number of cognates in the clause and clause-external codeswitching in the same clause. This was an effect of the relative rather than the absolute number of cognates in the clause, as shown by the significant interaction between Number of Cognates and Clause Length. In addition there was a main effect of Clause Length (with more clause-external codeswitches in shorter clauses).
Table 2. Model predicting the production of clause-external codeswitches in the same clause (backward method) for pairs of clauses produced by a single speaker; includes only clauses where the Number of Cognates is larger than zero.

Finally, recall that the Number of Cognates was not expected to affect clause-internal codeswitching in the same way as clause-external codeswitching, as a larger Number of Cognates leaves relatively less room for non-cognates within a clause and thus for clause-internal codeswitching. Indeed, an analogous analysis for clause-internal codeswitching showed a negative relation between Number of Cognates and codeswitching, and a positive relation between Clause Length and codeswitching, with longer clauses containing more clause-internal codeswitches (see Appendix).
3.4. The scope of triggered codeswitching
The fourth hypothesis was that, as activation decays gradually, the production of a cognate in one clause would still facilitate codeswitching in the same speaker's next clause. In order to investigate this, clause-external codeswitching was assessed in a forward manner (comparing the language of each clause with that of the next clause), limiting the analysis to those cases where both clauses were produced by a single speaker. This analysis enabled us to investigate what the effect was of the characteristics of one clause (i.e., whether or not it contained a cognate) on the clause-external codeswitching in the next clause. Figure 4 shows that, as predicted, clauses with cognates were more often followed by external codeswitches in the next clause than clauses that did not contain any cognates; i.e., there were more clause-external codeswitches in clauses after clauses containing cognates than after clauses without any cognates.

Fig. 4. Proportion of codeswitches following on clauses with and without cognate(s): clause-external codeswitches in the next clause (forward method) for pairs of clauses produced by a single speaker.
A model was fit to evaluate the effect of the Presence of Cognates in the clause on the occurrence of clause-external codeswitches in the next clause by the same speaker. There was indeed a reliable effect of the Presence of Cognates (Table 3); the odds of speakers producing a clause-external codeswitch after clauses containing cognates were 1.68 times higher than after clauses not containing any cognates. Thus, the triggering effect of cognates extends beyond the clause they are part of. Second, there was again a significant effect of the Proportion of Cognates per Speaker, showing that speakers who produced more cognates during the conversation had a higher likelihood of codeswitching.
Table 3. Model predicting the production of clause-external codeswitches in the next clause (forward method) for pairs of clauses produced by a single speaker.

3.5. Inter-speaker dynamics of triggered codeswitching
The fifth hypothesis was that cognates that were produced by the interlocutor would not facilitate codeswitching as much as self-produced cognates, if at all. Thus, the Presence of Cognates in one clause was predicted to affect clause-external codeswitching in the following clause less when the two clauses were produced by two different speakers (i.e., when there was a Speaker Change in between) than when they were produced by a single speaker. In order to investigate this, an analysis was done similar to the previous one, but now including only those cases where the two clauses were produced by two different speakers; next, a comparison was made between those cases where the two clauses were produced by a single versus two different speakers.
First, Table 4 shows that in the event of a speaker change, clauses with cognates were equally often followed by external codeswitches in the next clause as clauses without any cognates. Thus, the triggering effect which was found to extend beyond the clause that the cognates were part of for the same speaker (see 3.4) does not extend to the next speaker.
Table 4. Model predicting the production of clause-external codeswitches in the next clause (forward method) for pairs of clauses produced by two different speakers.

There was also a significant positive effect of the next speaker's Proportion of Cognates per Speaker on that same speaker's codeswitching, confirming the global effect of cognate density on codeswitching.
Next, the model with the variable Speaker Change (Table 5) showed a significant interaction between Presence of Cognates and Speaker Change, confirming that the effect of Presence of Cognates on codeswitching depended on whether the cognates were self-produced or produced by the interlocutor.
Table 5. Model predicting the production of clause-external codeswitches in the next clause (forward method), with the variable Speaker Change.

In addition, there was a main effect of Speaker Change, with more clause-external codeswitching in the first clause of a new speech turn than in clauses within a speech turn (the odds of producing a codeswitch were 1.52 times higher in the first clause of a new speech turn). Further, as in the previous analyses, there was a main effect of Presence of Cognates, as well as a main effect of the Proportion of Cognates per Speaker (here in some cases reflecting the value of the same speaker and in other cases the – strongly correlated – value of the other speaker), showing a positive global effect of cognate density. There was also a significant interaction between Speaker change and Proportion of Cognates per Speaker, and a significant three-way interaction among Presence of Cognates, Speaker Change, and Proportion of Cognates per Speaker.
4. Discussion
4.1. The five hypotheses
This study tested the adjusted triggering theory (Broersma & De Bot, Reference Broersma and De Bot2006), which states that triggered codeswitching is the result of an increase in lexical activation of the non-selected language following the lexical selection of a cognate. Using a large corpus of bilingual conversational speech, five hypotheses were tested. Patterns of co-occurrence of cognates and codeswitches were examined and found to be compatible with all five hypotheses, thus providing evidence in favor of the adjusted triggering theory.
First, this study set out to test the predictions of the adjusted triggering theory (Broersma & De Bot, Reference Broersma and De Bot2006), that clauses that contain a cognate are more often codeswitched, either clause-internally or -externally, than clauses that do not contain a cognate. Confirming the hypothesis, there was a very consistent effect of Presence of Cognates on codeswitching: in all analyses, there were more codeswitches in clauses containing cognates than in clauses without any cognates. In the Presence of Cognates there were significantly more clause-internal and -external codeswitches than in their absence. These findings confirm the results from earlier tests of the adjusted triggering theory (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009), with a different language pair and, importantly, with a much larger corpus than previously used.
The second hypothesis was that there would be a positive global relation between a speaker's cognate density and codeswitching. The proportion of cognates that a speaker used throughout the conversation was predicted to be positively related to codeswitching, such that speakers who produced more cognates during the conversation would overall (i.e., even in clauses where they did not produce any cognates) codeswitch more than speakers who produced fewer cognates. Confirming the hypothesis, there were consistent effects of the Proportion of Cognates per Speaker on codeswitching in all analyses. Speakers who produced more cognates overall had a higher chance to produce both clause-internal and clause-external codeswitches. Thus, as predicted, speakers who produced more cognates tended to codeswitch more than speakers who produced fewer cognates, in line with our proposal that both the production of cognates and of codeswitches is more common for speakers in a more strongly bilingual language mode (Grosjean, Reference Grosjean1998; Soares & Grosjean, Reference Soares and Grosjean1984). The strong correlation between the proportions of cognates throughout the conversation for conversational partners further shows that conversational partners are aligned in this respect.
The third hypothesis, that a larger number of cognates within a clause would increase the likelihood of the clause being externally codeswitched, was also confirmed. The Number of Cognates affected clause-external codeswitches, with a larger number of cognates in the clause being associated with a higher proportion of clause-external codeswitches by the same speaker. (For clause-internal codeswitching, a larger number of cognates within a clause was not predicted to be related to an increased likelihood of codeswitching, because a larger number of cognates implies a relatively smaller number of non-cognates within the clause, such that there is less opportunity for clause-internal codeswitching. Indeed, the Number of Cognates in fact even decreased the likelihood of clause-internal codeswitching; see Appendix.) The confirmation of the third hypothesis is in line with the common view that lexical activation is incremental in nature (e.g., Levelt et al., Reference Levelt, Roelofs and Meyer1999; Pitt & Samuel, Reference Pitt and Samuel2006).
The fourth hypothesis was that codeswitching would be facilitated for some time after the production of a cognate, such that the production of a cognate in one clause would facilitate codeswitching not only in the same clause, but also in the next clause from the same speaker. Confirming the hypothesis, clauses that contained cognates were more often followed by external codeswitches in the next clause than clauses that did not contain any cognates. This shows that the effect of cognates extended beyond the clause that they were part of. This finding is in line with the common view that activation in the linguistic (and non-linguistic) system, including that of a language network, is retained for some time, and decays over time only gradually (e.g., Foygel & Dell, Reference Foygel and Dell2000; Green & Wei, Reference Green and Wei2014; Paradis, Reference Paradis, Coppens, Lebrun and Basso1998, Reference Paradis2004).
The fifth hypothesis was that cognates produced by one interlocutor would not facilitate codeswitching by the other interlocutor to the same extent as self-produced cognates did. To this end, it was assessed whether there was an effect of cognates produced by one speaker on the clause-external codeswitches produced by the other speaker in the next clause. The results showed that the Presence of Cognates in clauses produced by one speaker did not predict the likelihood of clause-external codeswitches in the following clause by the other speaker. Comparing cases with and without speaker change, a significant interaction between Presence of Cognates and Speaker Change confirmed the differential effect of cognates on codeswitching when the cognates were self-produced versus when they were produced by the conversational partner. The results thus confirm and extend those from Broersma et al. (Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009), who also found no evidence that cognates from one speaker facilitated codeswitching by the other speaker. Syntactic priming studies have shown that the perception of sentences affects consecutive production (both within and across languages, and in codeswitching, e.g, Fricke & Kootstra, Reference Fricke and Kootstra2016; Hartsuiker & Bernolet, Reference Hartsuiker and Bernolet2017; Loebell & Bock, Reference Loebell and Bock2003; Pickering & Ferreira, Reference Pickering and Ferreira2008). Studies that directly compared self-priming to inter-speaker priming have shown that such priming tends to be stronger when both utterances are produced by a single speaker than when they are produced by two different speakers (Fricke & Kootstra, Reference Fricke and Kootstra2016; Gries, Reference Gries2005). The present findings provide further evidence that self-priming is stronger than between-speaker priming – the latter of which here in fact being non-existent.
4.2. Cognitive mechanisms underlying triggered codeswitching
This study has found corroborating evidence that the production of cognates is related to the occurrence of codeswitching. It has been proposed that this is the result of a shift in the activation levels of the speaker's two languages (Broersma & De Bot, Reference Broersma and De Bot2006). The lexical activation and selection of a cognate is proposed to cause a particularly strong activation of the cognate's lemmas as well as word form representations, not only in the intended language but also in the non-selected language. This activation of the translation equivalent in the non-selected language is proposed to be stronger for cognate than for non-cognate target wordsFootnote 6. Several mechanisms might contribute to this, all as a result of the cognates’ overlap in word form and meaning. First, as lexical representations from both languages are believed to be activated when bilinguals speak (e.g., Abutalebi & Green, Reference Abutalebi and Green2007; Branzi et al., Reference Branzi, Martin, Abutalebi and Costa2014; Costa & Caramazza, Reference Costa and Caramazza1999; Costa & Santesteban, Reference Costa and Santesteban2004, Reference Costa and Santesteban2006; De Bot, Reference De Bot1992; Finkbeiner et al., Reference Finkbeiner, Gollan and Caramazza2006; Green, Reference Green1998; Green & Wei, Reference Green and Wei2014; Kroll et al., Reference Kroll, Bobb, Misra and Guo2008; Kroll et al., Reference Kroll, Bobb and Wodniecka2006), producing a cognate (like any other word) involves activating the cognate's lemmas in both languages. The cognate's form overlap might then enhance the activation of the two word form representations because, as both lemmas send activation to the corresponding word form, the overlapping parts of the word forms might receive activation from both lemmas. Second, it has been proposed that feedback loops from the word forms to the lemmas further increase the activation of the two lemmas (Bernolet et al., Reference Bernolet, Hartsuiker and Pickering2012; Declerck & Philipp, Reference Declerck and Philipp2015), as the cognate's lemmas receive activation from two rather than one word form representations, the activation of which was already enhanced. Third, as the conceptual representations of cognate pairs might be particularly closely connected (De Groot & Nas, Reference De Groot and Nas1991; Van Hell & De Groot, Reference Van Hell and De Groot1998; Van Hell & Dijkstra, Reference Van Hell and Dijkstra2002), the activation of a cognate's lemma in one language might spread to the other lemma via the concept level (Broersma & De Bot, Reference Broersma and De Bot2006). Thus, the selection of a cognate in one language would enhance the activation of the cognate's lemma and form representation in the other language particularly strongly. As languages are commonly assumed to function as subsystems in a shared system (Green & Wei, Reference Green and Wei2014; Paradis, Reference Paradis1987, Reference Paradis2004), the selection of a cognate could thus boost the activation of the non-selected language as a whole, which has been proposed to increase the likelihood of switching to that language after the production of a cognate (Broersma & De Bot, Reference Broersma and De Bot2006).
The present study, as well as previous studies on triggered codeswitching (Broersma, Reference Broersma2009; Broersma & De Bot, Reference Broersma and De Bot2006; Broersma et al., Reference Broersma, Isurin, Bultena, De Bot, Isurin, Winford and De Bot2009; Clyne, Reference Clyne1967, Reference Clyne1972, Reference Clyne1977, Reference Clyne1980, Reference Clyne2003), has provided evidence that there is a relation between the production of cognates and the occurrence of codeswitching. The results however cannot unambiguously uncover the direction or causality of the relation. It is possible for example that, contrary to what we have proposed, codeswitching in fact enhances the production of cognates. This seems a less likely interpretation, however, as word choice is first and foremost bound by the message a speaker wants to convey and, for most concepts, speakers do not have a choice between a cognate and a non-cognate alternative. Whereas there is certainly some room to choose cognates over non-cognates, this alone seems too limited to explain the reported patterns of co-occurrence.
It is also possible that a shared underlying source contributes to the production of both cognates and codeswitches. In line with this, we have proposed that a more strongly bilingual language mode would stimulate the production of cognates as well as codeswitches. The results confirm that speakers who produced more cognates throughout the conversation (i.e., with a higher cognate density) also produced more codeswitches throughout. This positive global relation thus conforms to the notion that a more strongly bilingual language mode (Grosjean, Reference Grosjean1998; Soares & Grosjean, Reference Soares and Grosjean1984) contributes to the production not only of codeswitches, but also, as we have proposed, of cognates. Further, we found that speaker dyads produced highly similar proportions of cognates within a conversation, suggesting that conversational partners have aligned language modes. An interesting perspective on this comes from Dynamic Systems Theory (Bak, Reference Bak1996), proposing that linguistic systems are attracted to a critical state, where small events can lead to big and unpredictable changes (De Bot et al., Reference De Bot, Broersma, Isurin, Isurin, Winford and De Bot2009; De Bot et al., Reference De Bot, Lowie and Verspoor2007). In bilingual settings like the ones studied here, speakers might codeswitch and use the (limited) room they have in choosing cognates over non-cognates to attain such a critical state. Both cognates and codeswitches might thus be tools for the achievement of ‘self-organized criticality’.
Whereas language mode and self-organized criticality might thus explain the positive global relation between cognate density and codeswitching, it cannot explain the local relation between specific cognates and codeswitches in the same or in the next clause. We therefore believe that the most convincing interpretation of the reported pattern of co-occurrence of specific cognates and codeswitches is the account described above, in which the lexical selection of cognates enhances the activation of the non-selected language, thereby facilitating a switch to that language. We thus argue that the relation is causal, with cognates facilitating codeswitches. The two accounts are not mutually exclusive and can each explain different aspects of triggered codeswitching.
The local relation between cognates and codeswitches in the same or the next clause – that is, triggered codeswitching proper – can be further understood in terms of Green and Wei's control process model of codeswitching (Reference Green and Wei2014). It proposes that insertional and alternational codeswitches as found in the Siarad corpus (with the large majority of codeswitches consisting of English insertions into clauses where Welsh is the base language) are produced in a coupled control mode where control of language choice passes from one language task schema to the other. In addition to codeswitches that are planned at a higher level, this control mode also allows for codeswitches that result from a change in language activation because of, for example, the selection of a cognate (Green & Wei, Reference Green and Wei2014).
4.3. Conclusions
This study has provided further evidence that the production of cognates can facilitate codeswitching. It has further specified and tested the proposed psycholinguistic account for triggered codeswitching, which entails that the lexical selection of a cognate can lead to a shift in the activation of two language subsets, enhancing the activation of the least active language, resulting in an increased likelihood of codeswitching (as first proposed by Broersma and de Bot, Reference Broersma and De Bot2006). This account was connected with current insights in lexical processing from which five hypotheses were derived, and tested against a large-scale corpus of bilingual speech.
Assessing the regularities of triggered codeswitching in the corpus, it was found that: 1) there were more clause-internal and clause-external codeswitches in clauses containing cognates than in clauses without cognates; 2) speakers who produced more cognates throughout the conversation codeswitched more than speakers who produced fewer cognates, suggesting a global effect of the language mode they were in (Grosjean, Reference Grosjean1998; Soares & Grosjean, Reference Soares and Grosjean1984); 3) a larger number of cognates in a clause increased the likelihood of clause-external codeswitching, in line with the common idea that activation is incremental (e.g., Levelt et al., Reference Levelt, Roelofs and Meyer1999; Pitt & Samuel, Reference Pitt and Samuel2006); 4) codeswitching was still facilitated for some time after the production of a cognate, in line with the notion that activation in the linguistic system decays gradually (e.g., Foygel & Dell, Reference Foygel and Dell2000; Green & Wei, Reference Green and Wei2014; Paradis, Reference Paradis, Coppens, Lebrun and Basso1998, Reference Paradis2004); and 5) hearing rather than producing a cognate had no facilitatory effect on codeswitching, reminiscent of findings of syntactic priming being stronger within than across speakers (Fricke & Kootstra, Reference Fricke and Kootstra2016; Gries, Reference Gries2005).
The confirmation of the five hypotheses corroborates the validity of the proposed cognitive account of triggered codeswitching, and further clarifies the relation between the lexical activation of cognates and the realization of codeswitches, in accord with current insights in lexical processing. Finally, this study complements previous psycholinguistic work on language switching, which has predominantly entailed single-word experimental tasks, by investigating the processes of language choice within the context of conversational dynamics.
Acknowledgements
This research was supported by a Small Research Grant from the British Academy awarded to the first and second authors. Writing was supported by a Vidi grant from the Netherlands Organisation for Scientific Research (NWO), awarded to the first author. We gratefully acknowledge the support of the Max Planck Institute for Psycholinguistics and the Bangor Bilingualism Centre. We also want to express our gratitude to our reviewers, whose insightful comments and creative suggestions have greatly contributed to the improvement of this paper; we have enjoyed the exchange!
Appendix
Model predicting the production of clause-internal codeswitches, including only clauses where the Number of Cognates is larger than 0. (s) refers to the inclusion of random slopes. Coefficients are given in log odds, but are reported in the text as odds ratios (for main effects). * = p < .05 (including smaller p values); † = p < .10.











 Open access
Open access