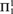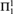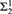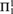Refine search
Actions for selected content:
28 results
INTROENUMERABILITY, AUTOREDUCIBILITY, AND RANDOMNESS
- Part of
-
- Journal:
- The Journal of Symbolic Logic , First View
- Published online by Cambridge University Press:
- 12 December 2023, pp. 1-9
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
We define
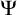 $\Psi $-autoreducible sets given an autoreduction procedure
$\Psi $-autoreducible sets given an autoreduction procedure 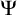 $\Psi $. Then, we show that for any
$\Psi $. Then, we show that for any 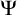 $\Psi $, a measurable class of
$\Psi $, a measurable class of 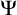 $\Psi $-autoreducible sets has measure zero. Using this, we show that classes of cototal, uniformly introenumerable, introenumerable, and hyper-cototal enumeration degrees all have measure zero.
$\Psi $-autoreducible sets has measure zero. Using this, we show that classes of cototal, uniformly introenumerable, introenumerable, and hyper-cototal enumeration degrees all have measure zero.By analyzing the arithmetical complexity of the classes of cototal sets and cototal enumeration degrees, we show that weakly 2-random sets cannot be cototal and weakly 3-random sets cannot be of cototal enumeration degree. Then, we see that this result is optimal by showing that there exists a 1-random cototal set and a 2-random set of cototal enumeration degree. For uniformly introenumerable degrees and introenumerable degrees, we utilize
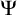 $\Psi $-autoreducibility again to show the optimal result that no weakly 3-random sets can have introenumerable enumeration degree. We also show that no 1-random set can be introenumerable.
$\Psi $-autoreducibility again to show the optimal result that no weakly 3-random sets can have introenumerable enumeration degree. We also show that no 1-random set can be introenumerable.
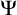
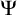
UNIVERSAL CODING AND PREDICTION ON ERGODIC RANDOM POINTS
- Part of
-
- Journal:
- Bulletin of Symbolic Logic / Volume 28 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 02 May 2022, pp. 387-412
- Print publication:
- September 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
SOME QUESTIONS OF UNIFORMITY IN ALGORITHMIC RANDOMNESS
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 86 / Issue 4 / December 2021
- Published online by Cambridge University Press:
- 12 August 2021, pp. 1612-1631
- Print publication:
- December 2021
-
- Article
- Export citation
-
The
 $\Omega $ numbers—the halting probabilities of universal prefix-free machines—are known to be exactly the Martin-Löf random left-c.e. reals. We show that one cannot uniformly produce, from a Martin-Löf random left-c.e. real
$\Omega $ numbers—the halting probabilities of universal prefix-free machines—are known to be exactly the Martin-Löf random left-c.e. reals. We show that one cannot uniformly produce, from a Martin-Löf random left-c.e. real 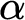 $\alpha $, a universal prefix-free machine U whose halting probability is
$\alpha $, a universal prefix-free machine U whose halting probability is 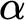 $\alpha $. We also answer a question of Barmpalias and Lewis-Pye by showing that given a left-c.e. real
$\alpha $. We also answer a question of Barmpalias and Lewis-Pye by showing that given a left-c.e. real 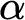 $\alpha $, one cannot uniformly produce a left-c.e. real
$\alpha $, one cannot uniformly produce a left-c.e. real 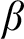 $\beta $ such that
$\beta $ such that 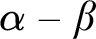 $\alpha - \beta $ is neither left-c.e. nor right-c.e.
$\alpha - \beta $ is neither left-c.e. nor right-c.e.

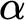
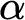
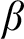
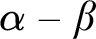
A NOTE ON THE LEARNING-THEORETIC CHARACTERIZATIONS OF RANDOMNESS AND CONVERGENCE
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 15 / Issue 3 / September 2022
- Published online by Cambridge University Press:
- 22 March 2021, pp. 807-822
- Print publication:
- September 2022
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
INFINITE STRINGS AND THEIR LARGE SCALE PROPERTIES
- Part of
-
- Journal:
- The Journal of Symbolic Logic / Volume 87 / Issue 2 / June 2022
- Published online by Cambridge University Press:
- 30 October 2020, pp. 585-625
- Print publication:
- June 2022
-
- Article
- Export citation
-
The aim of this paper is to shed light on our understanding of large scale properties of infinite strings. We say that one string
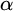 $\alpha $ has weaker large scale geometry than that of
$\alpha $ has weaker large scale geometry than that of 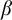 $\beta $ if there is color preserving bi-Lipschitz map from
$\beta $ if there is color preserving bi-Lipschitz map from 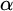 $\alpha $ into
$\alpha $ into 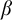 $\beta $ with small distortion. This definition allows us to define a partially ordered set of large scale geometries on the classes of all infinite strings. This partial order compares large scale geometries of infinite strings. As such, it presents an algebraic tool for classification of global patterns. We study properties of this partial order. We prove, for instance, that this partial order has a greatest element and also possess infinite chains and antichains. We also investigate the sets of large scale geometries of strings accepted by finite state machines such as Büchi automata. We provide an algorithm that describes large scale geometries of strings accepted by Büchi automata. This connects the work with the complexity theory. We also prove that the quasi-isometry problem is a
$\beta $ with small distortion. This definition allows us to define a partially ordered set of large scale geometries on the classes of all infinite strings. This partial order compares large scale geometries of infinite strings. As such, it presents an algebraic tool for classification of global patterns. We study properties of this partial order. We prove, for instance, that this partial order has a greatest element and also possess infinite chains and antichains. We also investigate the sets of large scale geometries of strings accepted by finite state machines such as Büchi automata. We provide an algorithm that describes large scale geometries of strings accepted by Büchi automata. This connects the work with the complexity theory. We also prove that the quasi-isometry problem is a 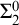 $\Sigma _2^0$-complete set, thus providing a bridge with computability theory. Finally, we build algebraic structures that are invariants of large scale geometries. We invoke asymptotic cones, a key concept in geometric group theory, defined via model-theoretic notion of ultra-product. Partly, we study asymptotic cones of algorithmically random strings, thus connecting the topic with algorithmic randomness.
$\Sigma _2^0$-complete set, thus providing a bridge with computability theory. Finally, we build algebraic structures that are invariants of large scale geometries. We invoke asymptotic cones, a key concept in geometric group theory, defined via model-theoretic notion of ultra-product. Partly, we study asymptotic cones of algorithmically random strings, thus connecting the topic with algorithmic randomness.
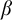
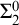
8 - Higher randomness
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 232-300
-
- Chapter
- Export citation
1 - Key developments in algorithmic randomness
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 1-39
-
- Chapter
- Export citation
6 - Aspects of Chaitin’s Omega
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 175-205
-
- Chapter
- Export citation
3 - Algorithmic randomness and constructive/computable measure theory
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 58-114
-
- Chapter
- Export citation
7 - Biased algorithmic randomness
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 206-231
-
- Chapter
- Export citation
2 - Algorithmic randomness in ergodic theory
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 40-57
-
- Chapter
- Export citation
5 - Relativization in randomness
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 134-174
-
- Chapter
- Export citation
4 - Algorithmic randomness and layerwise computability
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 115-133
-
- Chapter
- Export citation
9 - Resource bounded randomness and its applications
-
-
- Book:
- Algorithmic Randomness
- Published online:
- 07 May 2020
- Print publication:
- 07 May 2020, pp 301-348
-
- Chapter
- Export citation
A LEARNING-THEORETIC CHARACTERISATION OF MARTIN-LÖF RANDOMNESS AND SCHNORR RANDOMNESS
- Part of
-
- Journal:
- The Review of Symbolic Logic / Volume 14 / Issue 2 / June 2021
- Published online by Cambridge University Press:
- 04 November 2019, pp. 531-549
- Print publication:
- June 2021
-
- Article
- Export citation
RANK AND RANDOMNESS
-
- Journal:
- The Journal of Symbolic Logic / Volume 84 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 19 September 2019, pp. 1527-1543
- Print publication:
- December 2019
-
- Article
- Export citation
-
We show that for each computable ordinal
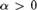 $\alpha> 0$ it is possible to find in each Martin-Löf random
$\alpha> 0$ it is possible to find in each Martin-Löf random 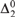 ${\rm{\Delta }}_2^0 $ degree a sequence R of Cantor-Bendixson rank α, while ensuring that the sequences that inductively witness R’s rank are all Martin-Löf random with respect to a single countably supported and computable measure. This is a strengthening for random degrees of a recent result of Downey, Wu, and Yang, and can be understood as a randomized version of it.
${\rm{\Delta }}_2^0 $ degree a sequence R of Cantor-Bendixson rank α, while ensuring that the sequences that inductively witness R’s rank are all Martin-Löf random with respect to a single countably supported and computable measure. This is a strengthening for random degrees of a recent result of Downey, Wu, and Yang, and can be understood as a randomized version of it.
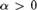
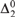
RANDOMNESS NOTIONS AND REVERSE MATHEMATICS
-
- Journal:
- The Journal of Symbolic Logic / Volume 85 / Issue 1 / March 2020
- Published online by Cambridge University Press:
- 09 September 2019, pp. 271-299
- Print publication:
- March 2020
-
- Article
- Export citation
-
We investigate the strength of a randomness notion
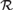 ${\cal R}$ as a set-existence principle in second-order arithmetic: for each Z there is an X that is
${\cal R}$ as a set-existence principle in second-order arithmetic: for each Z there is an X that is 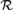 ${\cal R}$-random relative to Z. We show that the equivalence between 2-randomness and being infinitely often C-incompressible is provable in
${\cal R}$-random relative to Z. We show that the equivalence between 2-randomness and being infinitely often C-incompressible is provable in 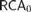 $RC{A_0}$. We verify that
$RC{A_0}$. We verify that 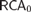 $RC{A_0}$ proves the basic implications among randomness notions: 2-random
$RC{A_0}$ proves the basic implications among randomness notions: 2-random 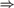 $\Rightarrow$ weakly 2-random
$\Rightarrow$ weakly 2-random 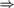 $\Rightarrow$ Martin-Löf random
$\Rightarrow$ Martin-Löf random 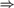 $\Rightarrow$ computably random
$\Rightarrow$ computably random 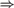 $\Rightarrow$ Schnorr random. Also, over
$\Rightarrow$ Schnorr random. Also, over 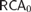 $RC{A_0}$ the existence of computable randoms is equivalent to the existence of Schnorr randoms. We show that the existence of balanced randoms is equivalent to the existence of Martin-Löf randoms, and we describe a sense in which this result is nearly optimal.
$RC{A_0}$ the existence of computable randoms is equivalent to the existence of Schnorr randoms. We show that the existence of balanced randoms is equivalent to the existence of Martin-Löf randoms, and we describe a sense in which this result is nearly optimal.
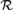
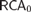
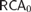
GENERICITY AND RANDOMNESS WITH ITTMS
-
- Journal:
- The Journal of Symbolic Logic / Volume 84 / Issue 4 / December 2019
- Published online by Cambridge University Press:
- 09 September 2019, pp. 1670-1710
- Print publication:
- December 2019
-
- Article
- Export citation
ON THE INTERPLAY BETWEEN EFFECTIVE NOTIONS OF RANDOMNESS AND GENERICITY
-
- Journal:
- The Journal of Symbolic Logic / Volume 84 / Issue 1 / March 2019
- Published online by Cambridge University Press:
- 30 January 2019, pp. 393-407
- Print publication:
- March 2019
-
- Article
- Export citation
-
In this paper, we study the power and limitations of computing effectively generic sequences using effectively random oracles. Previously, it was known that every 2-random sequence computes a 1-generic sequence (as shown by Kautz) and every 2-random sequence forms a minimal pair in the Turing degrees with every 2-generic sequence (as shown by Nies, Stephan, and Terwijn). We strengthen these results by showing that every Demuth random sequence computes a 1-generic sequence and that every Demuth random sequence forms a minimal pair with every pb-generic sequence (where pb-genericity is an effective notion of genericity that is strictly between 1-genericity and 2-genericity). Moreover, we prove that for every comeager
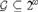 ${\cal G} \subseteq {2^\omega }$, there is some weakly 2-random sequence X that computes some
${\cal G} \subseteq {2^\omega }$, there is some weakly 2-random sequence X that computes some 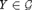 $Y \in {\cal G}$, a result that allows us to provide a fairly complete classification as to how various notions of effective randomness interact in the Turing degrees with various notions of effective genericity.
$Y \in {\cal G}$, a result that allows us to provide a fairly complete classification as to how various notions of effective randomness interact in the Turing degrees with various notions of effective genericity.
RANDOMNESS VIA INFINITE COMPUTATION AND EFFECTIVE DESCRIPTIVE SET THEORY
-
- Journal:
- The Journal of Symbolic Logic / Volume 83 / Issue 2 / June 2018
- Published online by Cambridge University Press:
- 01 August 2018, pp. 766-789
- Print publication:
- June 2018
-
- Article
- Export citation
-
We study randomness beyond
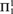 ${\rm{\Pi }}_1^1$-randomness and its Martin-Löf type variant, which was introduced in [16] and further studied in [3]. Here we focus on a class strictly between
${\rm{\Pi }}_1^1$-randomness and its Martin-Löf type variant, which was introduced in [16] and further studied in [3]. Here we focus on a class strictly between 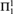 ${\rm{\Pi }}_1^1$ and
${\rm{\Pi }}_1^1$ and 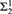 ${\rm{\Sigma }}_2^1$ that is given by the infinite time Turing machines (ITTMs) introduced by Hamkins and Kidder. The main results show that the randomness notions associated with this class have several desirable properties, which resemble those of classical random notions such as Martin-Löf randomness and randomness notions defined via effective descriptive set theory such as
${\rm{\Sigma }}_2^1$ that is given by the infinite time Turing machines (ITTMs) introduced by Hamkins and Kidder. The main results show that the randomness notions associated with this class have several desirable properties, which resemble those of classical random notions such as Martin-Löf randomness and randomness notions defined via effective descriptive set theory such as 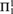 ${\rm{\Pi }}_1^1$-randomness. For instance, mutual randoms do not share information and a version of van Lambalgen’s theorem holds.
${\rm{\Pi }}_1^1$-randomness. For instance, mutual randoms do not share information and a version of van Lambalgen’s theorem holds.Towards these results, we prove the following analogue to a theorem of Sacks. If a real is infinite time Turing computable relative to all reals in some given set of reals with positive Lebesgue measure, then it is already infinite time Turing computable. As a technical tool towards this result, we prove facts of independent interest about random forcing over increasing unions of admissible sets, which allow efficient proofs of some classical results about hyperarithmetic sets.