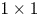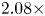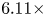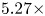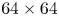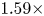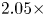Refine search
Actions for selected content:
1 results
Cross-layer knowledge distillation with KL divergence and offline ensemble for compressing deep neural network
-
- Journal:
- APSIPA Transactions on Signal and Information Processing / Volume 10 / 2021
- Published online by Cambridge University Press:
- 17 November 2021, e18
- Print publication:
- 2021
-
- Article
-
- You have access
- Open access
- HTML
- Export citation
-
Deep neural networks (DNN) have solved many tasks, including image classification, object detection, and semantic segmentation. However, when there are huge parameters and high level of computation associated with a DNN model, it becomes difficult to deploy on mobile devices. To address this difficulty, we propose an efficient compression method that can be split into three parts. First, we propose a cross-layer matrix to extract more features from the teacher's model. Second, we adopt Kullback Leibler (KL) Divergence in an offline environment to make the student model find a wider robust minimum. Finally, we propose the offline ensemble pre-trained teachers to teach a student model. To address dimension mismatch between teacher and student models, we adopt a $1\times 1$
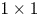 convolution and two-stage knowledge distillation to release this constraint. We conducted experiments with VGG and ResNet models, using the CIFAR-100 dataset. With VGG-11 as the teacher's model and VGG-6 as the student's model, experimental results showed that the Top-1 accuracy increased by 3.57% with a $2.08\times$
convolution and two-stage knowledge distillation to release this constraint. We conducted experiments with VGG and ResNet models, using the CIFAR-100 dataset. With VGG-11 as the teacher's model and VGG-6 as the student's model, experimental results showed that the Top-1 accuracy increased by 3.57% with a $2.08\times$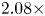 compression rate and 3.5x computation rate. With ResNet-32 as the teacher's model and ResNet-8 as the student's model, experimental results showed that Top-1 accuracy increased by 4.38% with a $6.11\times$
compression rate and 3.5x computation rate. With ResNet-32 as the teacher's model and ResNet-8 as the student's model, experimental results showed that Top-1 accuracy increased by 4.38% with a $6.11\times$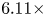 compression rate and $5.27\times$
compression rate and $5.27\times$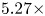 computation rate. In addition, we conducted experiments using the ImageNet$64\times 64$
computation rate. In addition, we conducted experiments using the ImageNet$64\times 64$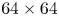 dataset. With MobileNet-16 as the teacher's model and MobileNet-9 as the student's model, experimental results showed that the Top-1 accuracy increased by 3.98% with a $1.59\times$
dataset. With MobileNet-16 as the teacher's model and MobileNet-9 as the student's model, experimental results showed that the Top-1 accuracy increased by 3.98% with a $1.59\times$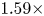 compression rate and $2.05\times$
compression rate and $2.05\times$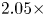 computation rate.
computation rate.