
In this article we consider the estimation of the log-normalization constant associated to a class of continuous-time filtering models. In particular, we consider ensemble Kalman–Bucy filter estimates based upon several nonlinear Kalman–Bucy diffusions. Using new conditional bias results for the mean of the aforementioned methods, we analyze the empirical log-scale normalization constants in terms of their 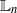 $\mathbb{L}_n$
-errors and
$\mathbb{L}_n$
-errors and 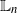 $\mathbb{L}_n$
-conditional bias. Depending on the type of nonlinear Kalman–Bucy diffusion, we show that these are bounded above by terms such as
$\mathbb{L}_n$
-conditional bias. Depending on the type of nonlinear Kalman–Bucy diffusion, we show that these are bounded above by terms such as 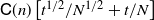 $\mathsf{C}(n)\left[t^{1/2}/N^{1/2} + t/N\right]$
or
$\mathsf{C}(n)\left[t^{1/2}/N^{1/2} + t/N\right]$
or 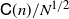 $\mathsf{C}(n)/N^{1/2}$
(
$\mathsf{C}(n)/N^{1/2}$
(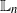 $\mathbb{L}_n$
-errors) and
$\mathbb{L}_n$
-errors) and 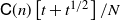 $\mathsf{C}(n)\left[t+t^{1/2}\right]/N$
or
$\mathsf{C}(n)\left[t+t^{1/2}\right]/N$
or 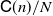 $\mathsf{C}(n)/N$
(
$\mathsf{C}(n)/N$
(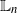 $\mathbb{L}_n$
-conditional bias), where t is the time horizon, N is the ensemble size, and
$\mathbb{L}_n$
-conditional bias), where t is the time horizon, N is the ensemble size, and 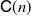 $\mathsf{C}(n)$
is a constant that depends only on n, not on N or t. Finally, we use these results for online static parameter estimation for the above filtering models and implement the methodology for both linear and nonlinear models.
$\mathsf{C}(n)$
is a constant that depends only on n, not on N or t. Finally, we use these results for online static parameter estimation for the above filtering models and implement the methodology for both linear and nonlinear models.
Flight delays may be decreased in a predictable way if the Weibull wind speed parameters of a runway, which are an important aspect of safety during the take-off and landing phases of aircraft, can be determined. One aim of this work is to determine the wind profile of Hasan Polatkan Airport (HPA) as a case study. Numerical methods for Weibull parameter determination perform better when the average wind speed estimation is the main objective. In this paper, a novel objective function that minimises the root-mean-square error by employing the cumulative distribution function is proposed based on the genetic algorithm and particle swarm optimisation. The results are compared with well-known numerical methods, such as maximum-likelihood estimation, the empirical method, the graphical method and the equivalent energy method, as well as the available objective function. Various statistical tests in the literature are applied, such as R2, Root-Mean-Square Error (RMSE) and 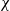 $\chi$2. In addition, the Mean Absolute Error (MAE) and total elapsed time calculated using the algorithms are compared. According to the results of the statistical tests, the proposed methods outperform others, achieving scores as high as 0.9789 and 0.9996 for the R2 test, as low as 0.0058 and 0.0057 for the RMSE test, 0.0036 and 0.0045 for the MAE test and 3.53 × 10−5 and 3.50 × 10−5 for the
$\chi$2. In addition, the Mean Absolute Error (MAE) and total elapsed time calculated using the algorithms are compared. According to the results of the statistical tests, the proposed methods outperform others, achieving scores as high as 0.9789 and 0.9996 for the R2 test, as low as 0.0058 and 0.0057 for the RMSE test, 0.0036 and 0.0045 for the MAE test and 3.53 × 10−5 and 3.50 × 10−5 for the 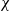 $\chi$2 test. In addition, the determination of the wind speed characteristics at HPA show that low wind speed characteristics and regimes throughout the year offer safer take-off and landing schedules for target aircraft. The principle aim of this paper is to help establish the correct orientation of new runways at HPA and maximise the capacity of the airport by minimising flight delays, which represent a significant impediment to air traffic flow.
$\chi$2 test. In addition, the determination of the wind speed characteristics at HPA show that low wind speed characteristics and regimes throughout the year offer safer take-off and landing schedules for target aircraft. The principle aim of this paper is to help establish the correct orientation of new runways at HPA and maximise the capacity of the airport by minimising flight delays, which represent a significant impediment to air traffic flow.

