
Kripke recently suggested viewing the intuitionistic continuum as an expansion in time of a definite classical continuum. We prove the classical consistency of a three-sorted intuitionistic formal system IC, simultaneously extending Kleene’s intuitionistic analysis I and a negative copy C° of the classically correct part of I, with an “end of time” axiom ET asserting that no choice sequence can be guaranteed not to be pointwise equal to a definite (classical or lawlike) sequence. “Not every sequence is pointwise equal to a definite sequence” is independent of IC. The proofs are by Crealizability interpretations based on classical ω-models 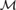 ${\cal M}$ =
${\cal M}$ = 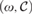 $\left( {\omega ,{\cal C}} \right)$ of C°.
$\left( {\omega ,{\cal C}} \right)$ of C°.

