Let  $k\geqslant 1$
be a natural number and
$k\geqslant 1$
be a natural number and 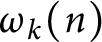 $\omega _k(n)$
denote the number of distinct prime factors of a natural number n with multiplicity k. We estimate the first and second moments of the functions
$\omega _k(n)$
denote the number of distinct prime factors of a natural number n with multiplicity k. We estimate the first and second moments of the functions 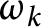 $\omega _k$
with
$\omega _k$
with 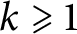 $k\geqslant 1$
. Moreover, we prove that the function
$k\geqslant 1$
. Moreover, we prove that the function 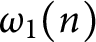 $\omega _1(n)$
has normal order
$\omega _1(n)$
has normal order 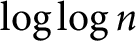 $\log \log n$
and the function
$\log \log n$
and the function 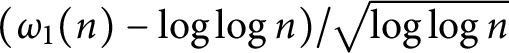 $(\omega _1(n)-\log \log n)/\sqrt {\log \log n}$
has a normal distribution. Finally, we prove that the functions
$(\omega _1(n)-\log \log n)/\sqrt {\log \log n}$
has a normal distribution. Finally, we prove that the functions 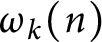 $\omega _k(n)$
with
$\omega _k(n)$
with 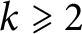 $k\geqslant 2$
do not have normal order
$k\geqslant 2$
do not have normal order 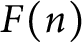 $F(n)$
for any nondecreasing nonnegative function F.
$F(n)$
for any nondecreasing nonnegative function F.
This paper presents new Gaussian approximations for the cumulative distribution function P(Aλ ≤ s) of a Poisson random variable Aλ with mean λ. Using an integral transformation, we first bring the Poisson distribution into quasi-Gaussian form, which permits evaluation in terms of the normal distribution function Φ. The quasi-Gaussian form contains an implicitly defined function y, which is closely related to the Lambert W-function. A detailed analysis of y leads to a powerful asymptotic expansion and sharp bounds on P(Aλ ≤ s). The results for P(Aλ ≤ s) differ from most classical results related to the central limit theorem in that the leading term Φ(β), with 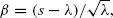 is replaced by Φ(α), where α is a simple function of s that converges to β as s tends to ∞. Changing β into α turns out to increase precision for small and moderately large values of s. The results for P(Aλ ≤ s) lead to similar results related to the Erlang B formula. The asymptotic expansion for Erlang's B is shown to give rise to accurate approximations; the obtained bounds seem to be the sharpest in the literature thus far.
is replaced by Φ(α), where α is a simple function of s that converges to β as s tends to ∞. Changing β into α turns out to increase precision for small and moderately large values of s. The results for P(Aλ ≤ s) lead to similar results related to the Erlang B formula. The asymptotic expansion for Erlang's B is shown to give rise to accurate approximations; the obtained bounds seem to be the sharpest in the literature thus far.
Let F be a probability distribution function with density f. We assume that (a) F has finite moments of any integer positive order and (b) the classical problem of moments for F has a nonunique solution (F is M-indeterminate). Our goal is to describe a 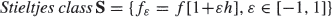 , where h is a ‘small' perturbation function. Such a class S consists of different distributions Fε (fε is the density of Fε) all sharing the same moments as those of F, thus illustrating the nonuniqueness of F, and of any Fε, in terms of the moments. Power transformations of distributions such as the normal, log-normal and exponential are considered and for them Stieltjes classes written explicitly. We define a characteristic of S called an index of dissimilarity and calculate its value in some cases. A new Stieltjes class involving a power of the normal distribution is presented. An open question about the inverse Gaussian distribution is formulated. Related topics are briefly discussed.
, where h is a ‘small' perturbation function. Such a class S consists of different distributions Fε (fε is the density of Fε) all sharing the same moments as those of F, thus illustrating the nonuniqueness of F, and of any Fε, in terms of the moments. Power transformations of distributions such as the normal, log-normal and exponential are considered and for them Stieltjes classes written explicitly. We define a characteristic of S called an index of dissimilarity and calculate its value in some cases. A new Stieltjes class involving a power of the normal distribution is presented. An open question about the inverse Gaussian distribution is formulated. Related topics are briefly discussed.

